kettle的基本介绍和使用
1、 kettle概述
1.1 什么是kettle
Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
1.2 Kettle核心知识点
1.2.1 Kettle工程存储方式
- 以XML形式存储
- 以资源库方式存储(数据库资源库和文件资源库)
1.2.2 Kettle的两种设计
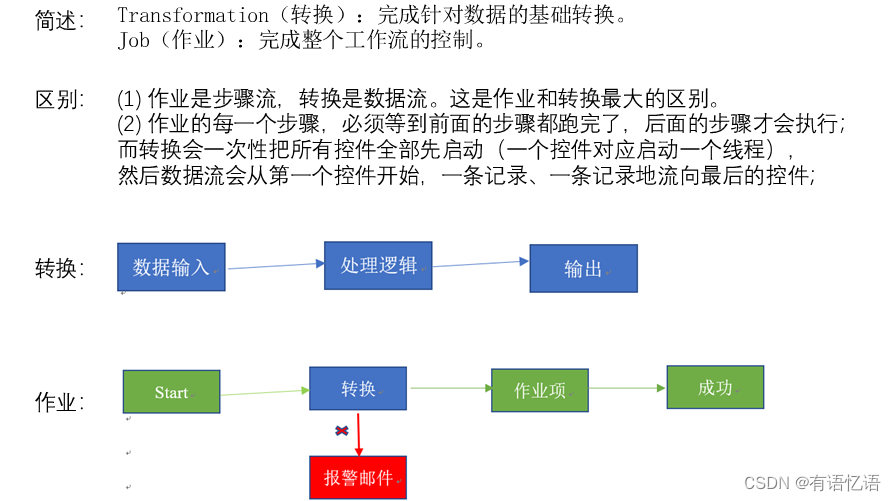
1.2.3 Kettle的组成

1.3 kettle特点

2、 kettle安装部署和使用
2.1 kettle安装地址
官网地址
https://community.hitachivantara.com/docs/DOC-1009855
下载地址
https://sourceforge.net/projects/pentaho/files/Data%20Integration/
2.2 Windows下安装使用
2.2.1 概述
在实际企业开发中,都是在本地环境下进行kettle的job和Transformation开发的,可以在本地运行,也可以连接远程机器运行
2.2.2 安装
- 安装jdk
- 下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
- 双击Spoon.bat,启动图形化界面工具,就可以直接使用了
2.2.3 案例
- 案例一 把stu1的数据按id同步到stu2,stu2有相同id则更新数据
(1)在mysql中创建两张表
mysql> create database kettle;
mysql> use kettle;
mysql> create table stu1(id int,name varchar(20),age int);
mysql> create table stu2(id int,name varchar(20));
(2)往两张表中插入一些数据
mysql> insert into stu1 values(1001,‘zhangsan’,20),(1002,‘lisi’,18), (1003,‘wangwu’,23);
mysql> insert into stu2 values(1001,‘wukong’);
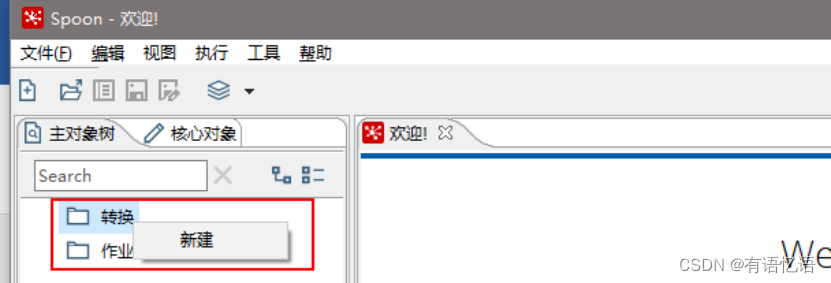
(3)在kettle中新建转换
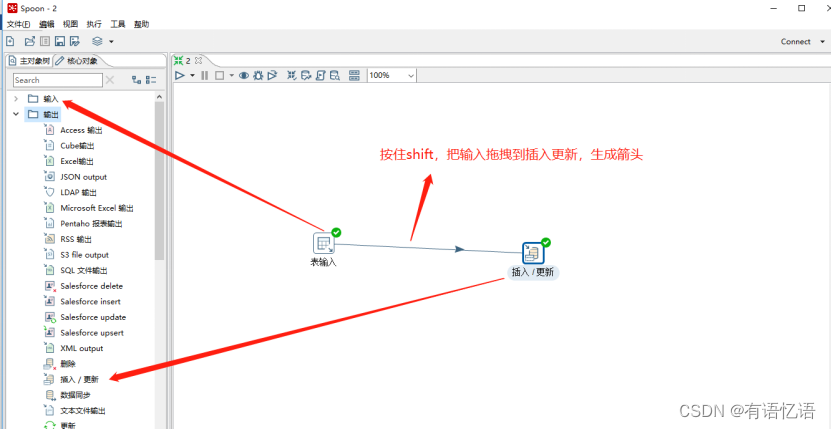
(4)分别在输入和输出中拉出表输入和插入/更新
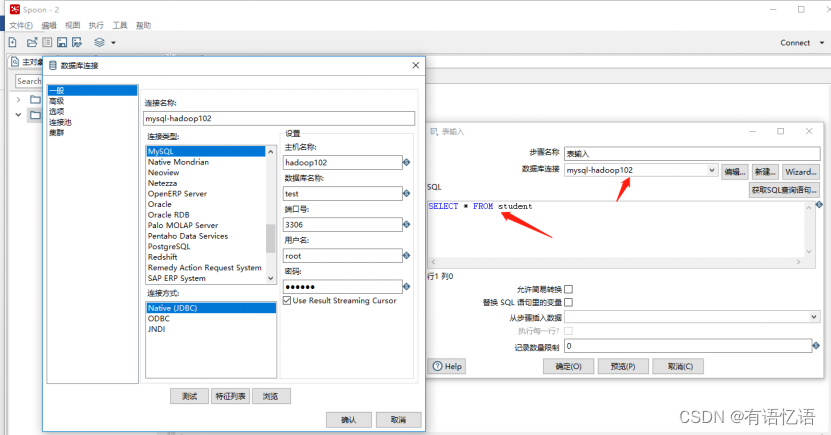
(5)双击表输入对象,填写相关配置,测试是否成功
(6)双击 更新/插入对象,填写相关配置
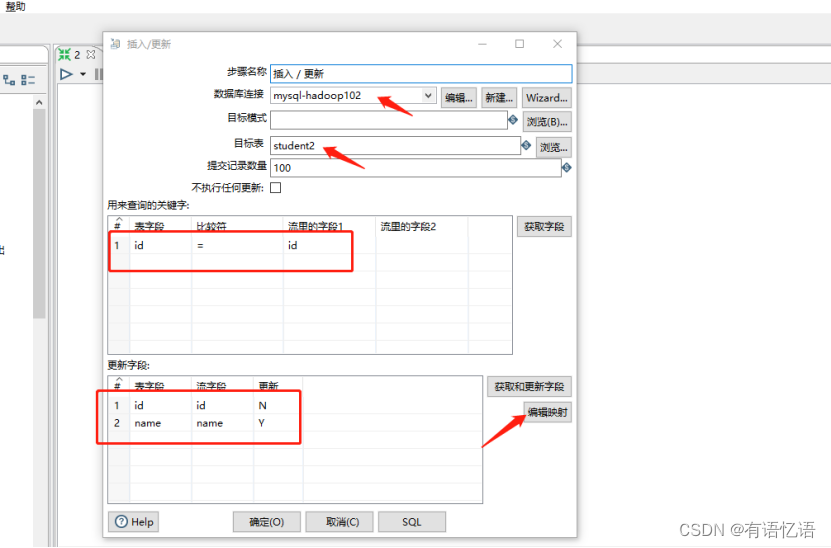
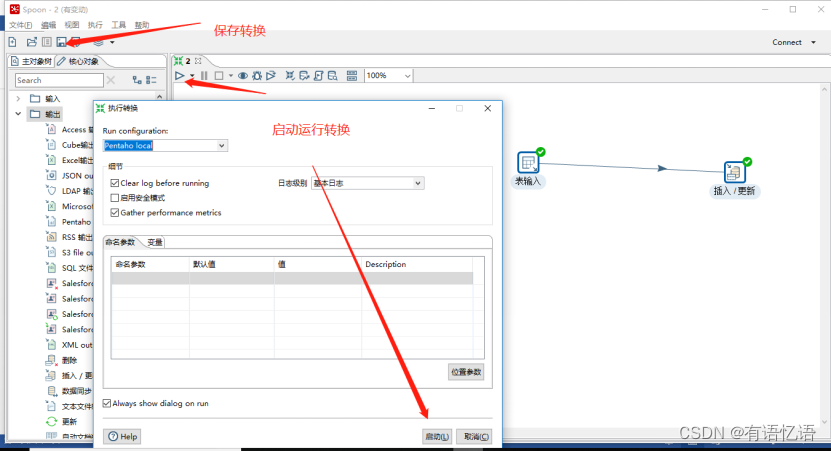
(7)保存转换,启动运行,去mysql表查看结果
注意:如果需要连接mysql数据库,需要要先将mysql的连接驱动包复制到kettle的根目录下的lib目录中,否则会报错找不到驱动。
- 案例2:使用作业执行上述转换,并且额外在表student2中添加一条数据
(1)新建一个作业
(2) 按图示拉取组件
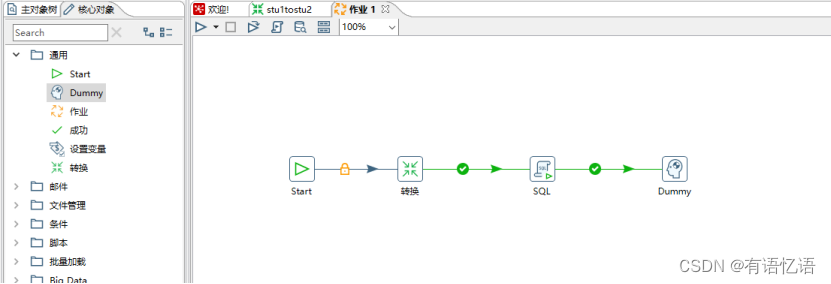
(3)双击Start编辑Start
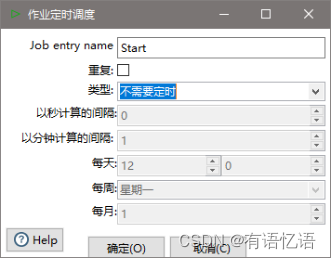
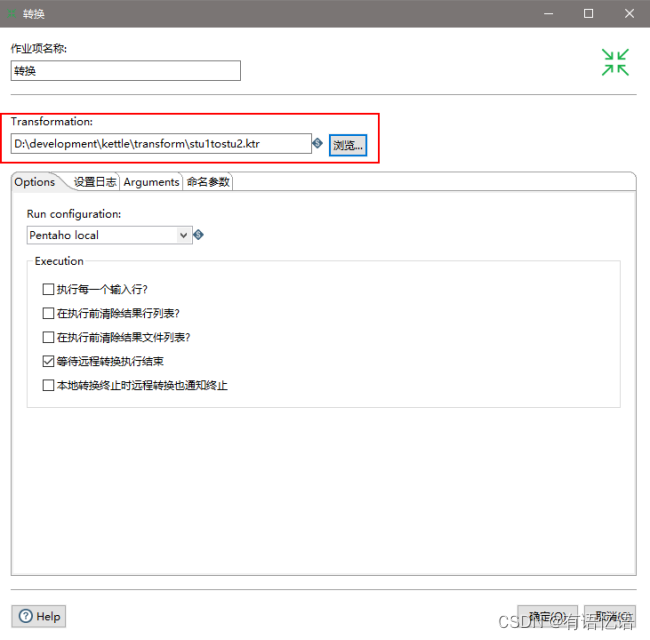
(4)双击转换,选择案例1保存的文件
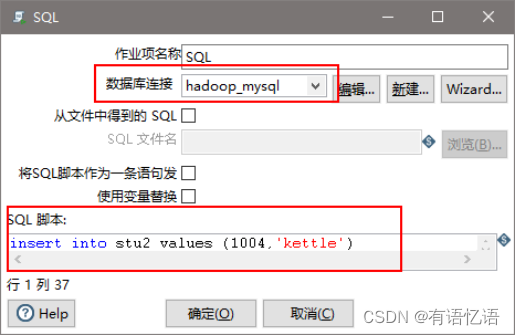
(5)双击SQL,编辑SQL语句
(6)保存执行
3)案例3:将hive表的数据输出到hdfs
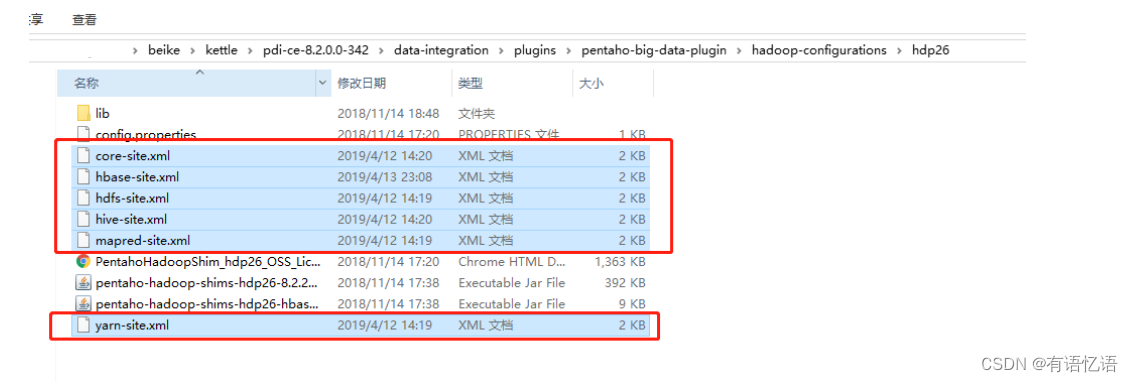
(1)因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
(2)启动hdfs,yarn,hbase集群的所有进程,启动hiveserver2服务
[ybb@hadoop102 ~]$ /opt/module/hadoop-2.7.2/sbin/start-all.sh
开启HBase前启动Zookeeper
[ybb@hadoop102 ~]$ /opt/module/hbase-1.3.1/bin/start-hbase.sh
[ybb@hadoop102 ~]$ /opt/module/hive/bin/hiveserver2
(3)进入beeline,查看10000端口开启情况
[ybb@hadoop102 ~]$ /opt/module/hive/bin/beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://hadoop102:10000(回车)
Connecting to jdbc:hive2://hadoop102:10000
Enter username for jdbc:hive2://hadoop102:10000: ybb(输入ybb)
Enter password for jdbc:hive2://hadoop102:10000:(直接回车)
Connected to: Apache Hive (version 1.2.1)
Driver: Hive JDBC (version 1.2.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop102:10000>(到了这里说明成功开启10000端口)
(4)创建两张表dept和emp
CREATE TABLE dept(deptno int, dname string,loc string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
(5)插入数据
insert into dept values(10,'accounting','NEW YORK'),(20,'RESEARCH','DALLAS'),(30,'SALES','CHICAGO'),(40,'OPERATIONS','BOSTON');insert into emp values
(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),
(7499,'ALLEN','SALESMAN',7698,'1980-12-17',1600,300,30),
(7521,'WARD','SALESMAN',7698,'1980-12-17',1250,500,30),
(7566,'JONES','MANAGER',7839,'1980-12-17',2975,NULL,20);
(6)按下图建立流程图
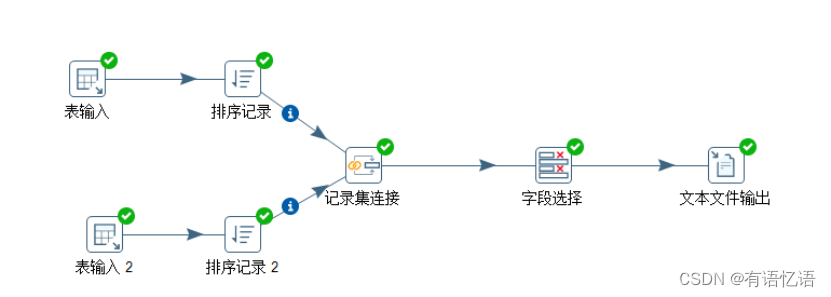
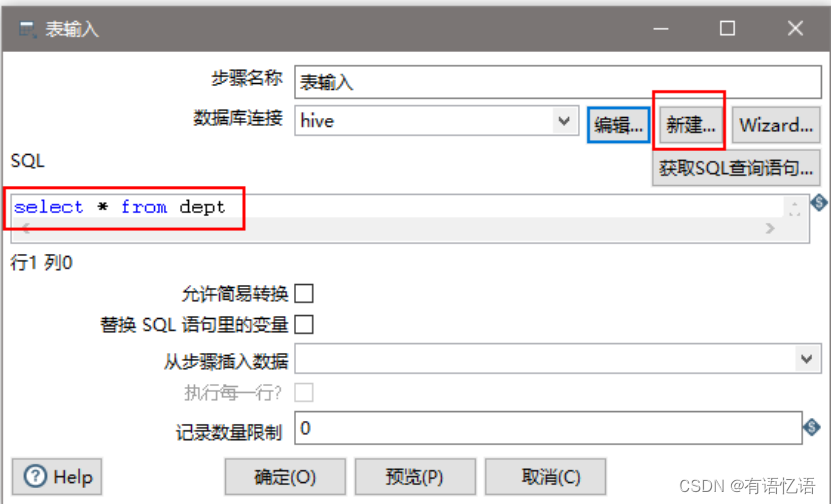
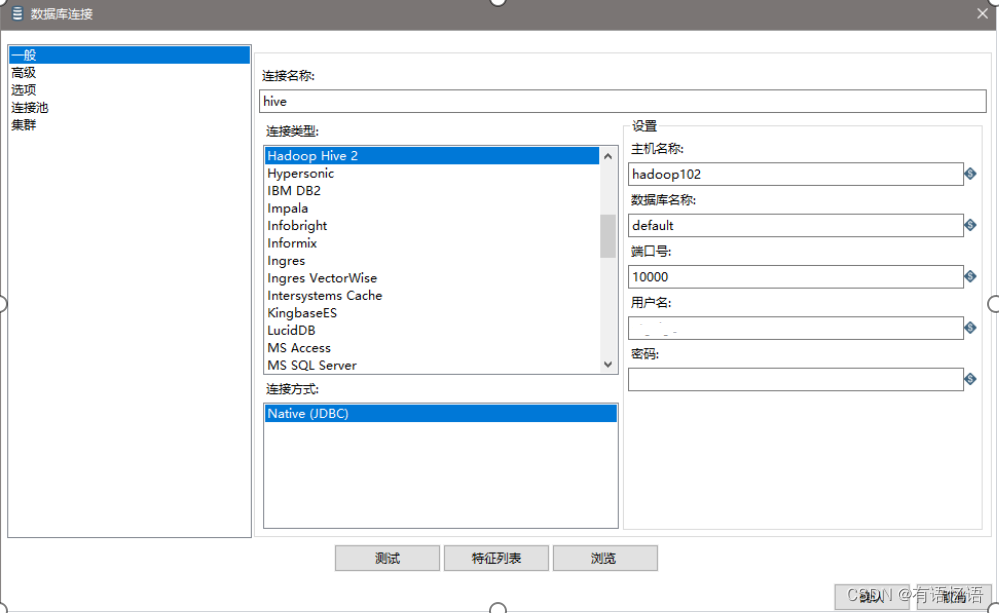
(7)设置表输入,连接hive
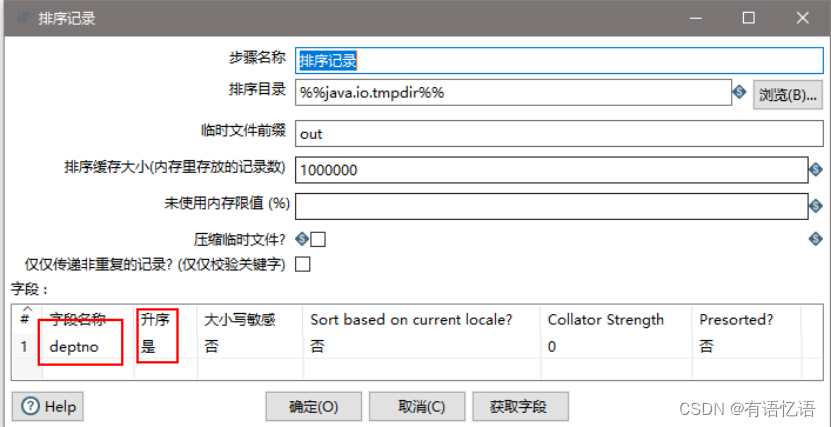
(8)设置排序属性
(9)设置连接属性
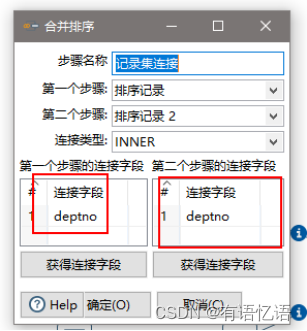
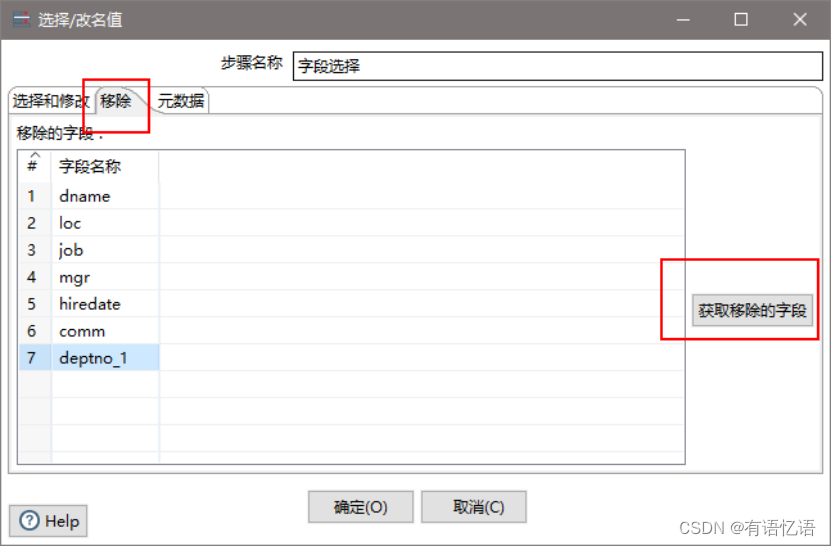
(10)设置字段选择
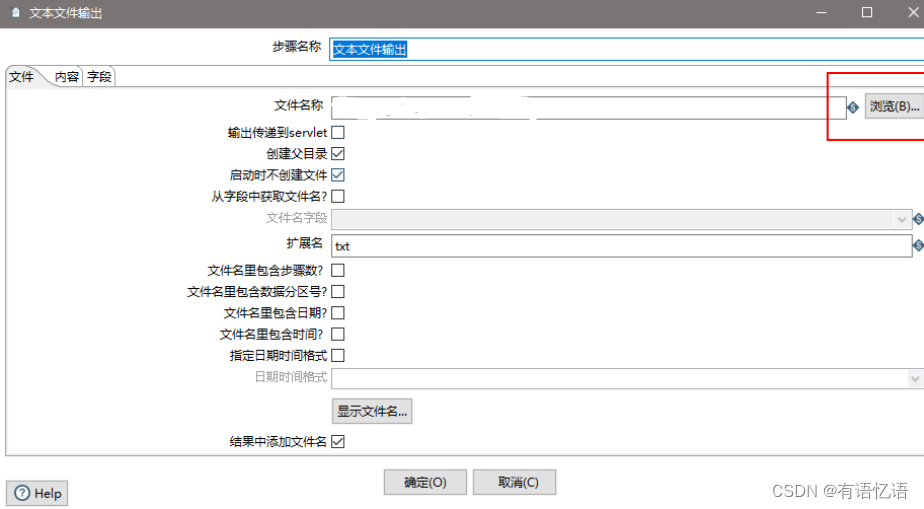
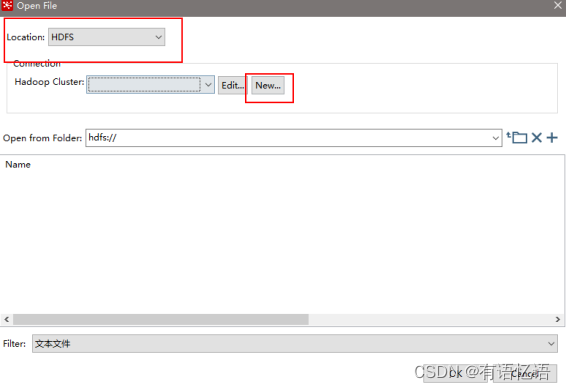
(11)设置文件输出
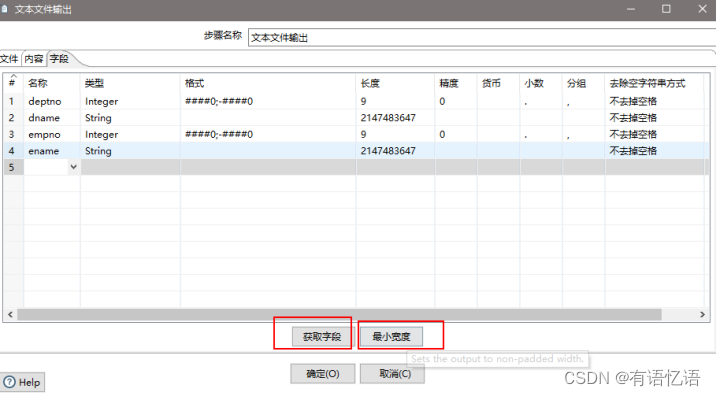
(12)保存并运行查看hdfs
2.3 创建资源库
2.3.1 数据库资源库
数据库资源库是将作业和转换相关的信息存储在数据库中,执行的时候直接去数据库读取信息,很容易跨平台使用
1)点击右上角connect,选择Other Resporitory
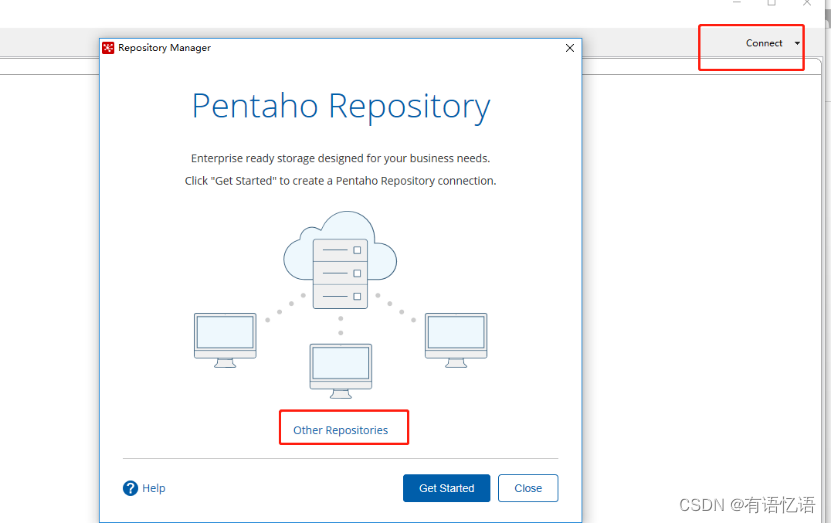
2) 选择Database Repository
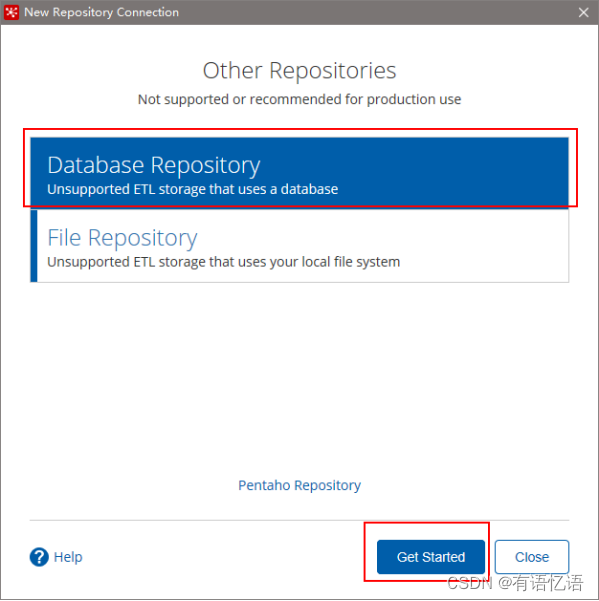
3) 建立新连接
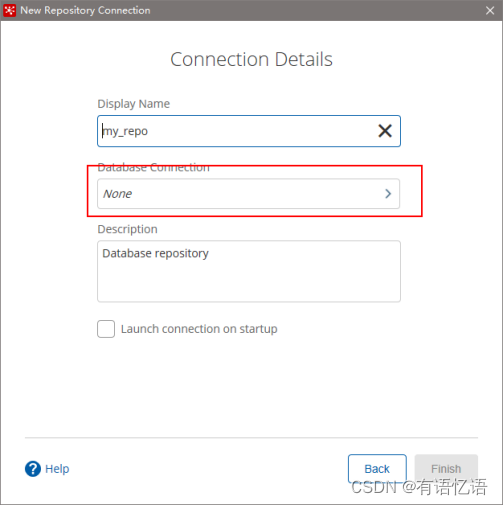
4) 填好之后,点击finish,会在指定的库中创建很多表,至此数据库资源库创建完成
5) 连接资源库
默认账号密码为admin
6) 将之前做过的转换导入资源库
(1)选择从xml文件导入
(2)随便选择一个转换
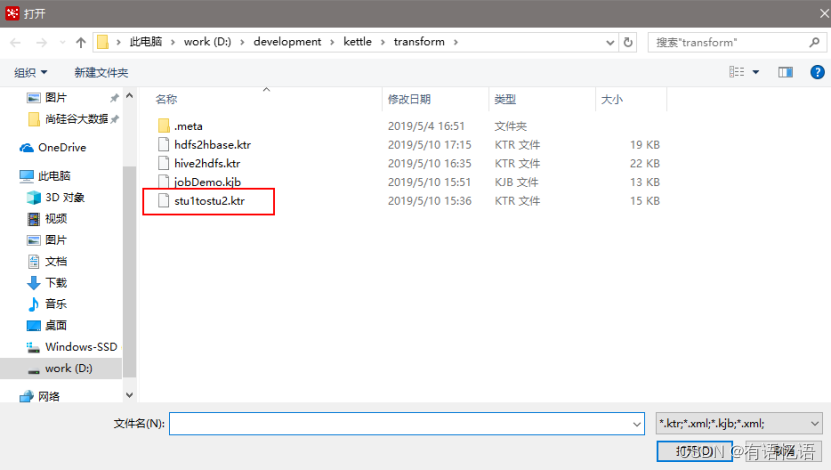
(3)点击保存,选择存储位置及文件名
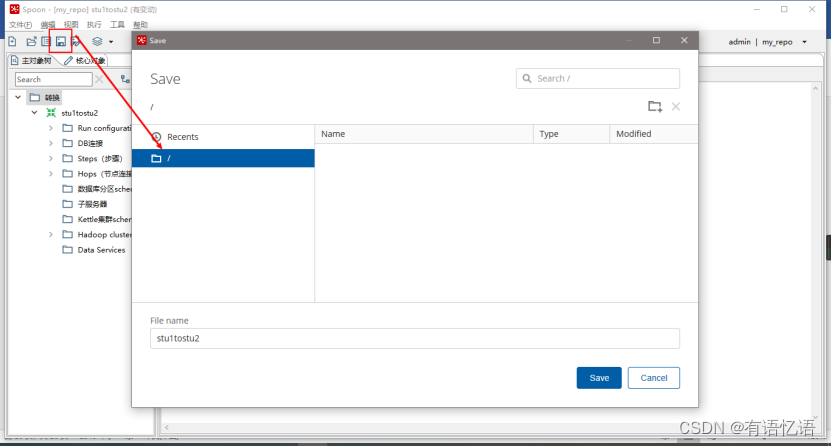
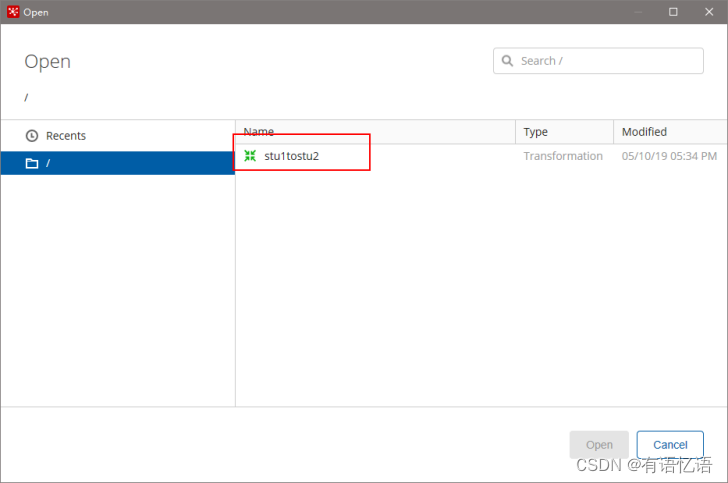
(4)打开资源库查看保存结果
2.3.2 文件资源库
将作业和转换相关的信息存储在指定的目录中,其实和XML的方式一样
创建方式跟创建数据库资源库步骤类似,只是不需要用户密码就可以访问,跨
平台使用比较麻烦
1)选择connect
2)点击add后点击Other Repositories
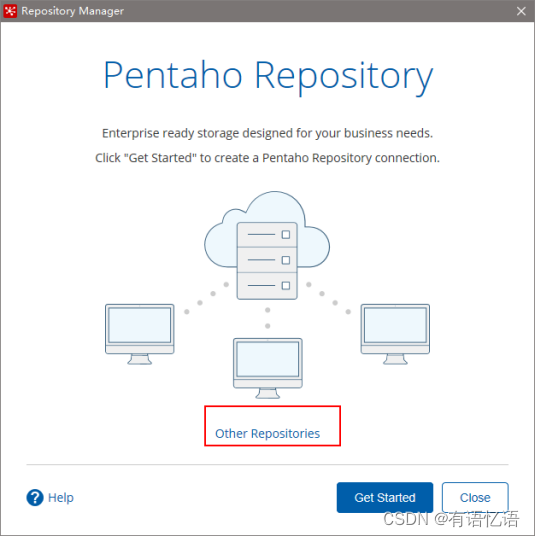
3)选择File Repository
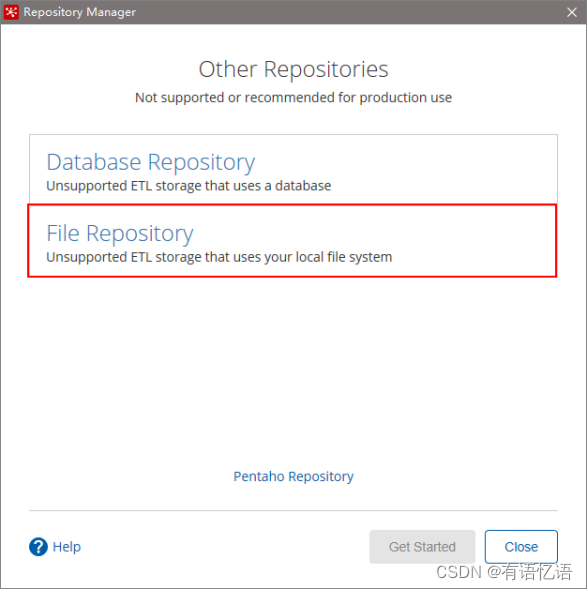
4)填写信息
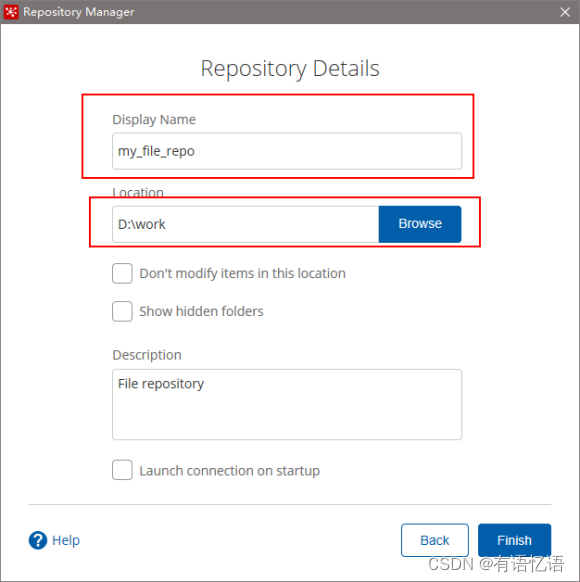
2.4 Linux下安装使用
2.4.1 单机
1)jdk安装
2)安装包上传到服务器,解压
注意:1. 把mysql驱动拷贝到lib目录下
2. 将本地用户家目录下的隐藏目录C:\Users\自己用户名.kettle,整个上传到linux的家目录/home/ybb/下
3)运行数据库资源库中的转换:
[ybb@hadoop102 data-integration]$./pan.sh -rep=my_repo -user=admin -pass=admin -trans=stu1tostu2 -dir=/
参数说明:
-rep 资源库名称
-user 资源库用户名
-pass 资源库密码
-trans 要启动的转换名称
-dir 目录(不要忘了前缀 /)
4)运行资源库里的作业:
记得把作业里的转换变成资源库中的资源
[ybb@hadoop102 data-integration]$./kitchen.sh -rep=repo1 -user=admin -pass=admin -job=jobDemo1 -logfile=./logs/log.txt -dir=/
参数说明:
-rep - 资源库名
-user - 资源库用户名
-pass – 资源库密码
-job – job名
-dir – job路径
-logfile – 日志目录
2.4.2 集群模式
- 准备三台服务器,hadoop102作为Kettle主服务器,服务器端口号为8080,hadoop103和hadoop104作为两个子服务器,端口号分别为8081和8082。
- 安装部署jdk
- hadoop完全分布式环境搭建,并启动进程(因为要使用hdfs)
- 上传解压kettle的安装包
- 进到/opt/module/data-integration/pwd目录,修改配置文件
修改主服务器配置文件carte-config-master-8080.xml
<slaveserver><name>master</name><hostname>hadoop102</hostname><port>8080</port><master>Y</master><username>cluster</username><password>cluster</password></slaveserver>修改从服务器配置文件carte-config-8081.xml<masters><slaveserver><name>master</name><hostname>hadoop102</hostname><port>8080</port><username>cluster</username><password>cluster</password><master>Y</master></slaveserver></masters><report_to_masters>Y</report_to_masters><slaveserver><name>slave1</name><hostname>hadoop103</hostname><port>8081</port><username>cluster</username><password>cluster</password><master>N</master></slaveserver>
修改从配置文件carte-config-8082.xml
<masters><slaveserver><name>master</name><hostname>hadoop102</hostname><port>8080</port><username>cluster</username><password>cluster</password><master>Y</master></slaveserver></masters><report_to_masters>Y</report_to_masters><slaveserver><name>slave2</name><hostname>hadoop104</hostname><port>8082</port><username>cluster</username><password>cluster</password><master>N</master></slaveserver>
-
分发整个kettle的安装目录,xsync data-integration
-
启动相关进程,在hadoop102,hadoop103,hadoop104上执行
[ybb@hadoop102 data-integration] . / c a r t e . s h h a d o o p 1028080 [ y b b @ h a d o o p 103 d a t a − i n t e g r a t i o n ] ./carte.sh hadoop102 8080 [ybb@hadoop103 data-integration] ./carte.shhadoop1028080[ybb@hadoop103data−integration]./carte.sh hadoop103 8081
[ybb@hadoop104 data-integration]$./carte.sh hadoop104 8082 -
访问web页面
http://hadoop102:8080 -
案例:读取hive中的emp表,根据id进行排序,并将结果输出到hdfs上
注意:因为涉及到hive和hbase的读写,需要修改相关配置文件。
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
(1) 创建转换,编辑步骤,填好相关配置
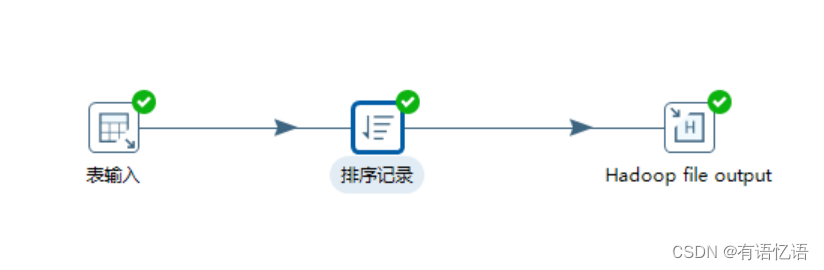
(2) 创建子服务器,填写相关配置,跟集群上的配置相同
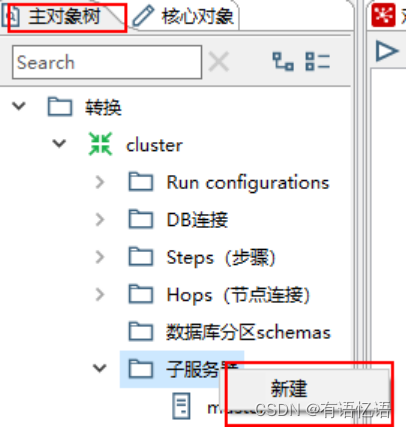
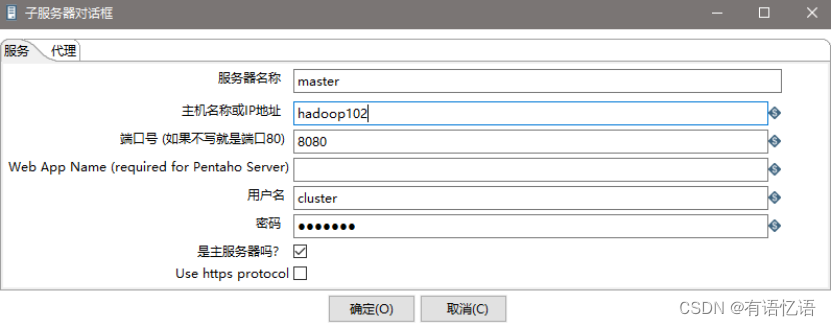
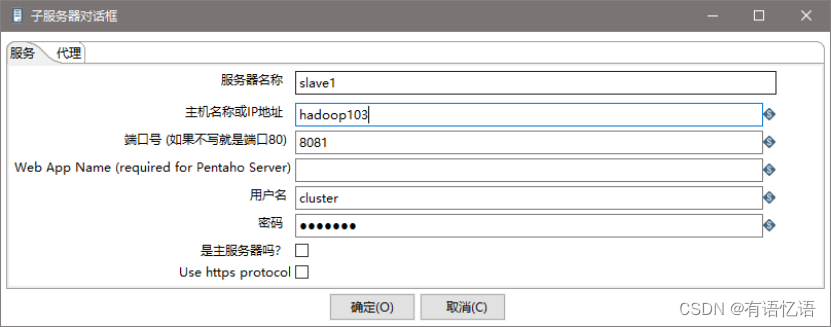
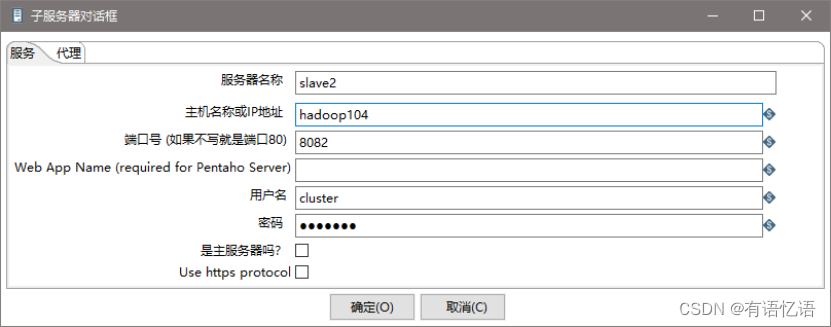
(3) 创建集群schema,选中上一步的几个服务器
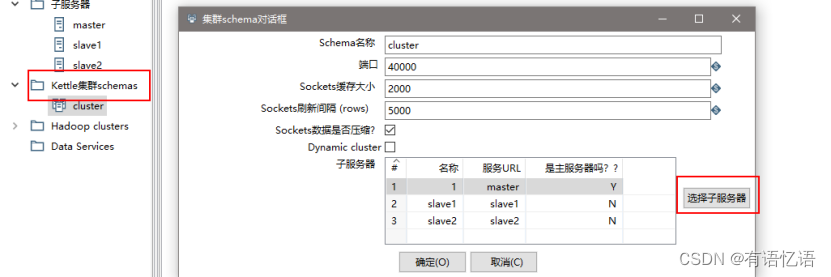
(4) 对于要在集群上执行的步骤,右键选择集群,选中上一步创建的集群schema

(5) 创建Run Configuration,选择集群模式,直接运行
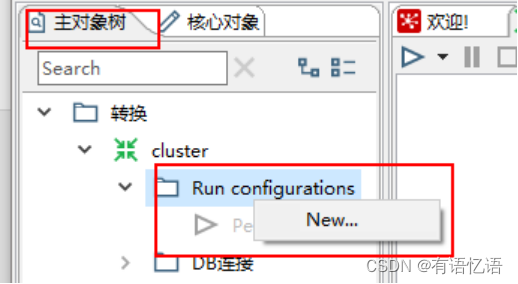
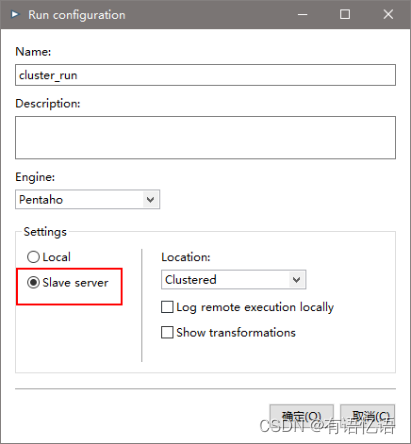
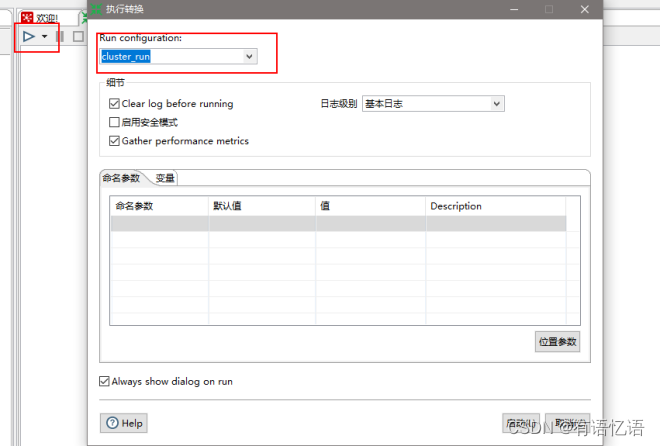
3、 调优
1、调整JVM大小进行性能优化,修改Kettle根目录下的Spoon脚本。

参数参考:
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xms1024m:设置JVM促使内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
2、 调整提交(Commit)记录数大小进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000
3、尽量使用数据库连接池;
4、尽量提高批处理的commit size;
5、尽量使用缓存,缓存尽量大一些(主要是文本文件和数据流);
6、Kettle是Java做的,尽量用大一点的内存参数启动Kettle;
7、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
8、插入大量数据的时候尽量把索引删掉;
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
10、能使用truncate table的时候,就不要使用deleteall row这种类似sql合理的分区,如果删除操作是基于某一个分区的,就不要使用delete row这种方式(不管是deletesql还是delete步骤),直接把分区drop掉,再重新创建;
11、尽量缩小输入的数据集的大小(增量更新也是为了这个目的);
12、尽量使用数据库原生的方式装载文本文件(Oracle的sqlloader, mysql的bulk loader步骤)。
相关文章:
kettle的基本介绍和使用
1、 kettle概述 1.1 什么是kettle Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。 1.2 Kettle核心知识点 1.2.1 Kettle工程存储方式 以XML形式存储以资源库方式存储…...

数据结构第2章 栈和队列
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 本篇笔记整理:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 0、思维导图栈和队列1、栈1)特点2࿰…...

Axure鲜花商城网站原型图,网上花店订花O2O本地生活电商平台
作品概况 页面数量:共 30 页 兼容软件:仅支持Axure RP 9/10,非程序软件无源代码 应用领域:鲜花网、花店网站、本地生活电商 作品特色 本作品为「鲜花购物商城」网站模板,高保真高交互,属于O2O本地生活电…...
【docker】centos 使用 Nexus Repository 搭建私有仓库
Nexus Repository 是一种流行的软件仓库管理工具,它可以帮助您搭建私有仓库,以便在内部网络或私有云环境中存储、管理和分发各种软件包和组件。 它常被用于搭建Maven的镜像仓库。本文演示如何用Nexus Repository搭建docker 私有仓库。 使用Nexus Repos…...
RabbitMQ(八)消息的序列化
目录 一、为什么需要消息序列化?二、常用的消息序列化方式1)Java原生序列化(默认)2)JSON格式3)Protobuf 格式4)Avro 格式5)MessagePack 格式 三、总结 RabbitMQ 是一个强大的消息中间…...

23款奔驰GLC260L升级原厂540全景影像 安装效果分享
嗨 今天给大家介绍一台奔驰GLC260L升级原厂360全景影像 新款GLC升级原厂360全景影像 也只需要安装前面 左右三个摄像头 后面的那个还是正常用的,不过不一样的是 升级完成之后会有多了个功能 那就是新款透明底盘,星骏汇小许Xjh15863 左右两边只需要更换后…...

【CSS】文字描边的三种实现方式
目录 1. 可行的几种方式1.1. text-shadow 描边代码优缺点 1.2. text-stroke 描边实现优缺点 1.3. svg 描边实现优缺点 总结 1. 可行的几种方式 text-shadow–webkit-text-strokesvg 1.1. text-shadow 描边 MDN text-shadow 代码 <div class"text stroke">…...

【事务】事务传播级别
Spring事务定义了7种传播机制: PROPAGATION_REQUIRED:默认的Spring事物传播级别,若当前存在事务,则加入该事务,若不存在事务,则新建一个事务。 PAOPAGATION_REQUIRE_NEW:若当前没有事务&#x…...
Android WiFi 连接
Android WiFi 连接 1、设置中WiFi显示2、WiFi 连接流程2.1 获取PrimaryClientModeManager2.2 ClientModeImpl状态机ConnectableState2.3 ISupplicantStaNetworkCallback 回调监听 3、 简要时序图4、原生低层驱动5、关键日志 1、设置中WiFi显示 Android WiFi基础概览 packages/a…...

PLC与上位机PN通讯时,如何防止连接失败?
连接西门子PLC时失败,或者连接不上PLC,你可能需要做以下几点设置才可以。 一般来说每个PLC都有自己的IP地址,如果你的地址与PLC的地址冲突也就是地址重复是连接不上PLC的,如果地址没有冲突,但是不是在一个网段上也会导…...

LDD学习笔记 -- Linux错误码
LDD学习笔记 -- Linux错误码 EACCES(Permission Denied) 13EEXIST(File Exits) 17EINVAL(Invalid Argument) 22ENOENT(No Such File or Directory)ENOMEM(Out of Memory)EIO(Input/Output Error) 5ENOSPC(No space Left on Device)ENOTTY(Not a Typewrite)EPIPE(Broken Pipe)EI…...
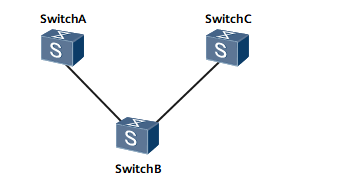
华为交换机入门(六):VLAN的配置
VLAN(Virtual Local Area Network)即虚拟局域网,是将一个物理的LAN在逻辑上划分成多个广播域的通信技术。VLAN内的主机间可以直接通信,而VLAN间不能直接互通,从而将广播报文限制在一个VLAN内。 VLAN 主要用来解决如何…...

登录验证
目录 会话技术 Cookie Session JWT JWT生成 JWT校验 会话技术 会话 打开浏览器,访问web服务器的资源,会话建立,直到有一方断开连接,会话结束。在一次会话中可以包含多次请求与响应 会话跟踪 一种维护浏览器的方法 服务器需要…...

利用Podman构建基于Fission env/builder的镜像
镜像准备 构建Dockerfile fission的基础环境包括两种:env 以及 builder。如果仅基于code构建function(i.e., 只创建deployachive),仅构建env即可;但如果需要构建sourcearchive,则需要同时创建env和builde…...

php加减乘除函数
目录 第一部分:简单示例 1、加法 2、减法 3、乘法 4、除法 第二部分:官方文档 1、加法 2、减法 3、乘法 4、除法 第一部分:简单示例 1、加法 $result bcadd(1.2, 1.4, 2); echo $result;//2.60 2、减法 $result bcsub(1.6, 1.…...
来校验参数)
Go语言学习记录——用正则表达式(regexp包)来校验参数
前言 最近坐毕设ing,简单的一个管理系统。 其中对于用户注册、登录功能,需要进行一些参数校验。 因为之前使用过,因此这里计划使用正则表达式进行校验。但是之前的使用也仅限于使用,因此这次专门进行一次学习,并做此记…...

公司办公电脑文件防泄密系统
电脑文件防泄密系统是一种用于保护企业机密文件的软件系统,它采用一系列的安全技术手段,如数据加密、访问控制、审计跟踪等,来确保企业机密文件不被非法获取、窃取或泄漏。这种系统通常适用于企业、政府机构等需要对重要文件进行保密的机构。…...
手把手带你死磕ORBSLAM3源代码(三十四)Tracking.cc MonocularInitialization编辑
目录 一.前言 二.代码 2.1完整代码 2.2 单目视觉跟踪初始化 一.前言 这段代码是一个名为MonocularInitialization的函数,它属于Tracking类。从函数名称和代码内容来看,这个函数主要用于单目视觉跟踪的初始化过程。以下是代码的详细解读: 首先,函数检查一个名为m...

STL标准库与泛型编程(侯捷)笔记3
STL标准库与泛型编程(侯捷) 本文是学习笔记,仅供个人学习使用。如有侵权,请联系删除。 参考链接 Youbute: 侯捷-STL标准库与泛型编程 B站: 侯捷 - STL Github:STL源码剖析中源码 https://github.com/SilverMaple/STLSourceCo…...

Iceberg: 列式读取Parquet数据
通过Spark读取Parquet文件的基本流程 SQL > Spark解析SQL生成逻辑计划树 LogicalPlan > Spark创建扫描表/读取数据的逻辑计划结点 DataSourceV2ScanRelation > Spark优化逻辑计划树,生成物理计划树 SparkPlan > Spark根据不同的属性,将逻辑…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...