了解一下InternLM2
-
大模型的出现和发展得益于增长的数据量、计算能力的提升以及算法优化等因素。这些模型在各种任务中展现出惊人的性能,比如自然语言处理、计算机视觉、语音识别等。这种模型通常采用深度神经网络结构,如
Transformer、BERT、GPT( Generative Pre-trained Transformer )等。大模型的优势在于其能够捕捉和理解数据中更为复杂、抽象的特征和关系。通过大规模参数的学习,它们可以提高在各种任务上的泛化能力,并在未经过大量特定领域数据训练的情况下实现较好的表现。然而,大模型也面临着一些挑战,比如巨大的计算资源需求、高昂的训练成本、对大规模数据的依赖以及模型的可解释性等问题。因此,大模型的应用和发展也需要在性能、成本和道德等多个方面进行权衡和考量。InternLM-7B 包含了一个拥有 70 亿参数的基础模型和一个为实际场景量身定制的对话模型。该模型具有以下特点:1,利用数万亿的高质量 token 进行训练,建立了一个强大的知识库;2.支持 8k token 的上下文窗口长度,使得输入序列更长并增强了推理能力。基于InternLM训练框架,上海人工智能实验室已经发布了两个开源的预训练模型:InternLM-7B和InternLM-20B。 -
InternLM是一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。通过单一的代码库,它支持在拥有数千个GPU的大型集群上进行预训练,并在单个GPU上进行微调,同时实现了卓越的性能优化。在1024个GPU上训练时,InternLM可以实现近90%的加速效率。基于InternLM训练框架,上海人工智能实验室已经发布了两个开源的预训练模型:InternLM-7B和InternLM-20B。Lagent是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。通过Lagent框架可以更好的发挥InternLM的全部性能。 -
7B demo 的训练配置文件样例如下:
-
JOB_NAME = "7b_train" SEQ_LEN = 2048 HIDDEN_SIZE = 4096 NUM_ATTENTION_HEAD = 32 MLP_RATIO = 8 / 3 NUM_LAYER = 32 VOCAB_SIZE = 103168 MODEL_ONLY_FOLDER = "local:llm_ckpts/xxxx" # Ckpt folder format: # fs: 'local:/mnt/nfs/XXX' SAVE_CKPT_FOLDER = "local:llm_ckpts" LOAD_CKPT_FOLDER = "local:llm_ckpts/49" # boto3 Ckpt folder format: # import os # BOTO3_IP = os.environ["BOTO3_IP"] # boto3 bucket endpoint # SAVE_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm" # LOAD_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm/snapshot/1/" CHECKPOINT_EVERY = 50 ckpt = dict(enable_save_ckpt=False, # enable ckpt save.save_ckpt_folder=SAVE_CKPT_FOLDER, # Path to save training ckpt.# load_ckpt_folder=LOAD_CKPT_FOLDER, # Ckpt path to resume training(load weights and scheduler/context states).# load_model_only_folder=MODEL_ONLY_FOLDER, # Path to initialize with given model weights.load_optimizer=True, # Wheter to load optimizer states when continuing training.checkpoint_every=CHECKPOINT_EVERY,async_upload=True, # async ckpt upload. (only work for boto3 ckpt)async_upload_tmp_folder="/dev/shm/internlm_tmp_ckpt/", # path for temporarily files during asynchronous upload.snapshot_ckpt_folder="/".join([SAVE_CKPT_FOLDER, "snapshot"]), # directory for snapshot ckpt storage path.oss_snapshot_freq=int(CHECKPOINT_EVERY / 2), # snapshot ckpt save frequency. ) TRAIN_FOLDER = "/path/to/dataset" VALID_FOLDER = "/path/to/dataset" data = dict(seq_len=SEQ_LEN,# micro_num means the number of micro_batch contained in one gradient updatemicro_num=4,# packed_length = micro_bsz * SEQ_LENmicro_bsz=2,# defaults to the value of micro_numvalid_micro_num=4,# defaults to 0, means disable evaluatevalid_every=50,pack_sample_into_one=False,total_steps=50000,skip_batches="",rampup_batch_size="",# Datasets with less than 50 rows will be discardedmin_length=50,# train_folder=TRAIN_FOLDER,# valid_folder=VALID_FOLDER, ) grad_scaler = dict(fp16=dict(# the initial loss scale, defaults to 2**16initial_scale=2**16,# the minimum loss scale, defaults to Nonemin_scale=1,# the number of steps to increase loss scale when no overflow occursgrowth_interval=1000,),# the multiplication factor for increasing loss scale, defaults to 2growth_factor=2,# the multiplication factor for decreasing loss scale, defaults to 0.5backoff_factor=0.5,# the maximum loss scale, defaults to Nonemax_scale=2**24,# the number of overflows before decreasing loss scale, defaults to 2hysteresis=2, ) hybrid_zero_optimizer = dict(# Enable low_level_optimzer overlap_communicationoverlap_sync_grad=True,overlap_sync_param=True,# bucket size for nccl communication paramsreduce_bucket_size=512 * 1024 * 1024,# grad clippingclip_grad_norm=1.0, ) loss = dict(label_smoothing=0, ) adam = dict(lr=1e-4,adam_beta1=0.9,adam_beta2=0.95,adam_beta2_c=0,adam_eps=1e-8,weight_decay=0.01, )lr_scheduler = dict(total_steps=data["total_steps"],init_steps=0, # optimizer_warmup_stepwarmup_ratio=0.01,eta_min=1e-5,last_epoch=-1, )beta2_scheduler = dict(init_beta2=adam["adam_beta2"],c=adam["adam_beta2_c"],cur_iter=-1, )model = dict(checkpoint=False, # The proportion of layers for activation aheckpointing, the optional value are True/False/[0-1]num_attention_heads=NUM_ATTENTION_HEAD,embed_split_hidden=True,vocab_size=VOCAB_SIZE,embed_grad_scale=1,parallel_output=True,hidden_size=HIDDEN_SIZE,num_layers=NUM_LAYER,mlp_ratio=MLP_RATIO,apply_post_layer_norm=False,dtype="torch.float16", # Support: "torch.float16", "torch.half", "torch.bfloat16", "torch.float32", "torch.tf32"norm_type="rmsnorm",layer_norm_epsilon=1e-5,use_flash_attn=True,num_chunks=1, # if num_chunks > 1, interleaved pipeline scheduler is used. ) """ zero1 parallel:1. if zero1 <= 0, The size of the zero process group is equal to the size of the dp process group,so parameters will be divided within the range of dp.2. if zero1 == 1, zero is not used, and all dp groups retain the full amount of model parameters.3. zero1 > 1 and zero1 <= dp world size, the world size of zero is a subset of dp world size.For smaller models, it is usually a better choice to split the parameters within nodes with a setting <= 8. pipeline parallel (dict):1. size: int, the size of pipeline parallel.2. interleaved_overlap: bool, enable/disable communication overlap when using interleaved pipeline scheduler. tensor parallel: tensor parallel size, usually the number of GPUs per node. """ parallel = dict(zero1=8,pipeline=dict(size=1, interleaved_overlap=True),sequence_parallel=False, )cudnn_deterministic = False cudnn_benchmark = False
-
-
30B demo 训练配置文件样例如下:
-
JOB_NAME = "30b_train" SEQ_LEN = 2048 HIDDEN_SIZE = 6144 NUM_ATTENTION_HEAD = 48 MLP_RATIO = 8 / 3 NUM_LAYER = 60 VOCAB_SIZE = 103168 MODEL_ONLY_FOLDER = "local:llm_ckpts/xxxx" # Ckpt folder format: # fs: 'local:/mnt/nfs/XXX' SAVE_CKPT_FOLDER = "local:llm_ckpts" LOAD_CKPT_FOLDER = "local:llm_ckpts/49" # boto3 Ckpt folder format: # import os # BOTO3_IP = os.environ["BOTO3_IP"] # boto3 bucket endpoint # SAVE_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm" # LOAD_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm/snapshot/1/" CHECKPOINT_EVERY = 50 ckpt = dict(enable_save_ckpt=False, # enable ckpt save.save_ckpt_folder=SAVE_CKPT_FOLDER, # Path to save training ckpt.# load_ckpt_folder=LOAD_CKPT_FOLDER, # Ckpt path to resume training(load weights and scheduler/context states).# load_model_only_folder=MODEL_ONLY_FOLDER, # Path to initialize with given model weights.load_optimizer=True, # Wheter to load optimizer states when continuing training.checkpoint_every=CHECKPOINT_EVERY,async_upload=True, # async ckpt upload. (only work for boto3 ckpt)async_upload_tmp_folder="/dev/shm/internlm_tmp_ckpt/", # path for temporarily files during asynchronous upload.snapshot_ckpt_folder="/".join([SAVE_CKPT_FOLDER, "snapshot"]), # directory for snapshot ckpt storage path.oss_snapshot_freq=int(CHECKPOINT_EVERY / 2), # snapshot ckpt save frequency. ) TRAIN_FOLDER = "/path/to/dataset" VALID_FOLDER = "/path/to/dataset" data = dict(seq_len=SEQ_LEN,# micro_num means the number of micro_batch contained in one gradient updatemicro_num=4,# packed_length = micro_bsz * SEQ_LENmicro_bsz=2,# defaults to the value of micro_numvalid_micro_num=4,# defaults to 0, means disable evaluatevalid_every=50,pack_sample_into_one=False,total_steps=50000,skip_batches="",rampup_batch_size="",# Datasets with less than 50 rows will be discardedmin_length=50,# train_folder=TRAIN_FOLDER,# valid_folder=VALID_FOLDER, ) grad_scaler = dict(fp16=dict(# the initial loss scale, defaults to 2**16initial_scale=2**16,# the minimum loss scale, defaults to Nonemin_scale=1,# the number of steps to increase loss scale when no overflow occursgrowth_interval=1000,),# the multiplication factor for increasing loss scale, defaults to 2growth_factor=2,# the multiplication factor for decreasing loss scale, defaults to 0.5backoff_factor=0.5,# the maximum loss scale, defaults to Nonemax_scale=2**24,# the number of overflows before decreasing loss scale, defaults to 2hysteresis=2, ) hybrid_zero_optimizer = dict(# Enable low_level_optimzer overlap_communicationoverlap_sync_grad=True,overlap_sync_param=True,# bucket size for nccl communication paramsreduce_bucket_size=512 * 1024 * 1024,# grad clippingclip_grad_norm=1.0, ) loss = dict(label_smoothing=0, ) adam = dict(lr=1e-4,adam_beta1=0.9,adam_beta2=0.95,adam_beta2_c=0,adam_eps=1e-8,weight_decay=0.01, )lr_scheduler = dict(total_steps=data["total_steps"],init_steps=0, # optimizer_warmup_stepwarmup_ratio=0.01,eta_min=1e-5,last_epoch=-1, ) beta2_scheduler = dict(init_beta2=adam["adam_beta2"],c=adam["adam_beta2_c"],cur_iter=-1, )model = dict(checkpoint=False, # The proportion of layers for activation aheckpointing, the optional value are True/False/[0-1]num_attention_heads=NUM_ATTENTION_HEAD,embed_split_hidden=True,vocab_size=VOCAB_SIZE,embed_grad_scale=1,parallel_output=True,hidden_size=HIDDEN_SIZE,num_layers=NUM_LAYER,mlp_ratio=MLP_RATIO,apply_post_layer_norm=False,dtype="torch.float16", # Support: "torch.float16", "torch.half", "torch.bfloat16", "torch.float32", "torch.tf32"norm_type="rmsnorm",layer_norm_epsilon=1e-5,use_flash_attn=True,num_chunks=1, # if num_chunks > 1, interleaved pipeline scheduler is used. ) """ zero1 parallel:1. if zero1 <= 0, The size of the zero process group is equal to the size of the dp process group,so parameters will be divided within the range of dp.2. if zero1 == 1, zero is not used, and all dp groups retain the full amount of model parameters.3. zero1 > 1 and zero1 <= dp world size, the world size of zero is a subset of dp world size.For smaller models, it is usually a better choice to split the parameters within nodes with a setting <= 8. pipeline parallel (dict):1. size: int, the size of pipeline parallel.2. interleaved_overlap: bool, enable/disable communication overlap when using interleaved pipeline scheduler. tensor parallel: tensor parallel size, usually the number of GPUs per node. """ parallel = dict(zero1=-1,tensor=4,pipeline=dict(size=1, interleaved_overlap=True),sequence_parallel=False, ) cudnn_deterministic = False cudnn_benchmark = False
-
30B Demo — InternLM 0.2.0 文档
相关文章:

了解一下InternLM2
大模型的出现和发展得益于增长的数据量、计算能力的提升以及算法优化等因素。这些模型在各种任务中展现出惊人的性能,比如自然语言处理、计算机视觉、语音识别等。这种模型通常采用深度神经网络结构,如 Transformer、BERT、GPT( Generative P…...

关于使用统一服务器,vscode和网页版jupyter notebook的交互问题
autodl 查看虚拟环境 在antodl上租借了一个服务器,通过在网页上运行jupyter notebook和在vscode中运行,发现环境都默认的是miniconda3。 conda info --envs 当然环境中所有的包都是一样的。 要查看当前虚拟环境中安装的所有包,可以使用以…...

Linux22.04系统安装显卡驱动,cuda,cudnn流程
1. 安装显卡驱动 ubuntu-drivers deices显示所有适配显卡的驱动型号,recommended为推荐安装 安装 sudo apt install nvidia-driver-440重启 sudo reboot验证 nvidia-smi2. 安装cuda 在 CUDA Toolkit 的下载页面选择系统版本和安装方式,下载并运行…...

【常考简答题】操作系统
目录 1、什么是进程 2、创建进程步骤 3、什么是死锁 4、死锁四个必要条件 5、什么是内存管理 6、内存管理功能 7、进程的三个基本状态转化图 8、操作系统为什么引入线程 9、什么是对换技术,好处是什么 10、DMA直接存取控制工作方式流程图 11、什么是假脱…...
Large Language Models Paper 分享
论文1: ChatGPTs One-year Anniversary: Are Open-Source Large Language Models Catching up? 简介 2022年11月,OpenAI发布了ChatGPT,这一事件在AI社区甚至全世界引起了轰动。首次,一个基于应用的AI聊天机器人能够提供有帮助、…...
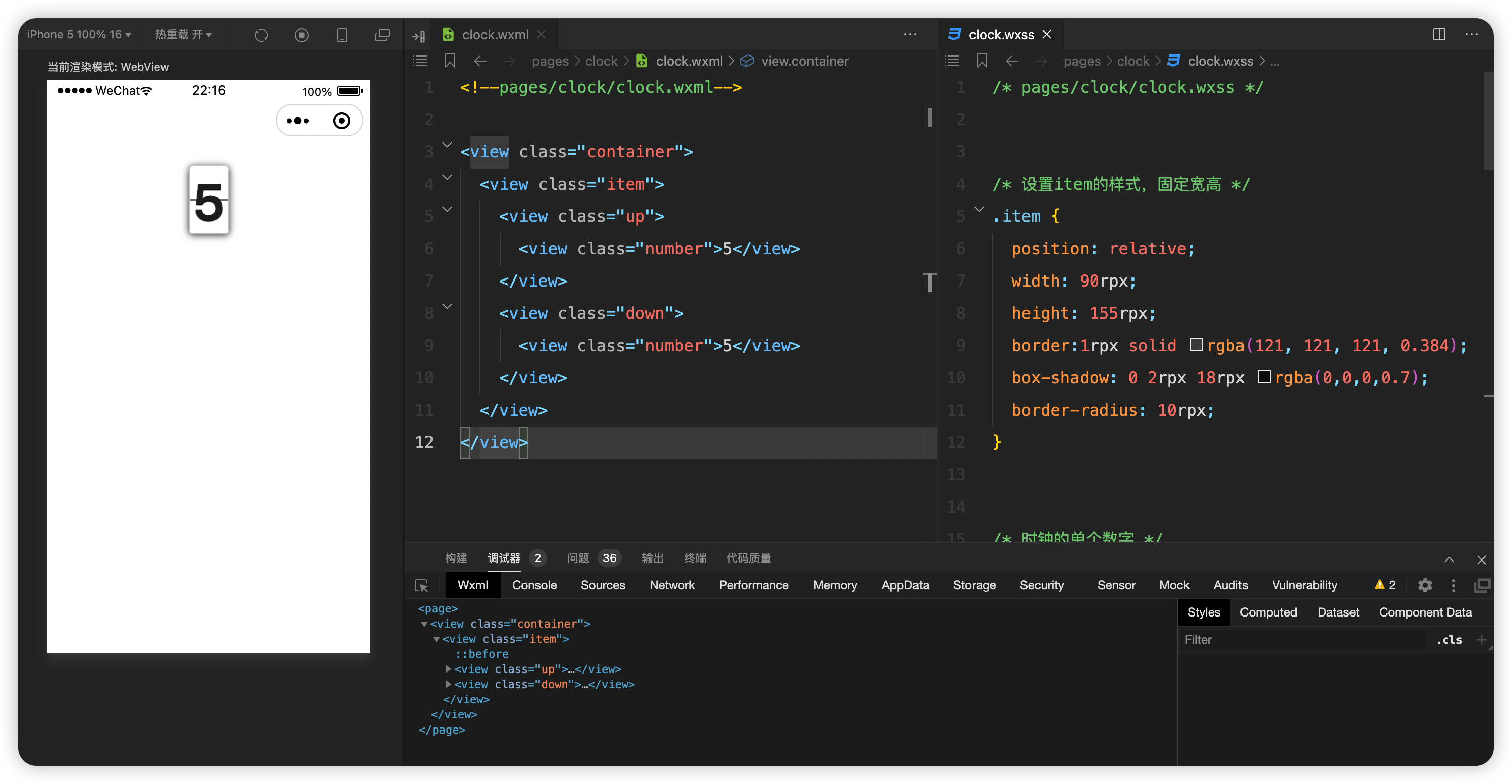
微信小程序实战-01翻页时钟-1
文章目录 前言需求分析功能设计界面设计界面结构设计界面样式设计 逻辑设计 单页功能实现运行结果 前言 我经常在手机上用的一款app有一个功能是翻页时钟,基于之前学习的小程序相关的基础内容,我打算在微信小程序中也设计一个翻页时钟功能,J…...

BigDecimal的性能问题
BigDecimal 是 Java 中用于精确计算的数字类,它可以处理任意精度的小数运算。由于其精确性和灵活性,BigDecimal 在某些场景下可能会带来性能问题。 BigDecimal的性能问题 BigDecimal的性能问题主要源于以下几点: 内存占用:BigDec…...
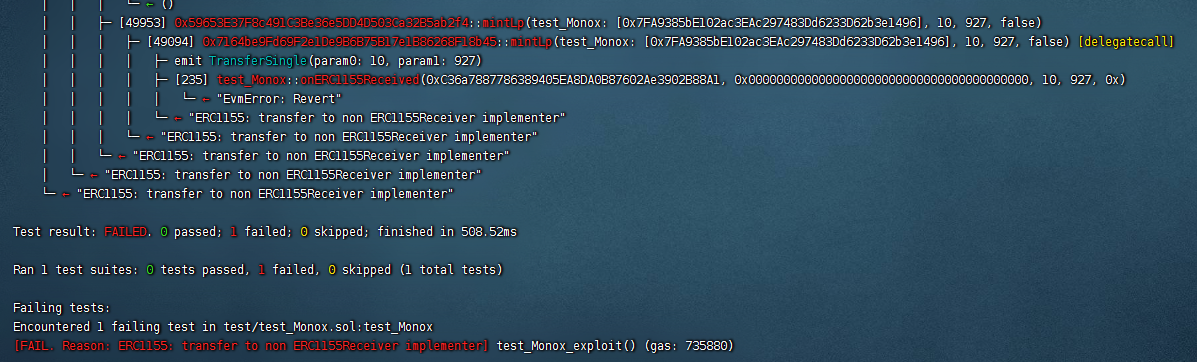
Defi安全-Monox攻击事件Foundry复现
其它相关内容可见个人主页 Mono攻击事件的介绍见:Defi安全–Monox攻击事件分析–phalconetherscan 1. 前情提要和思路介绍 Monox使用单边池模型,创建的是代币-vCash交易对,添加流动性时,只需添加代币,即可进行任意代…...
大二上总结和寒假计划
👂 Start Again - Connor Price/Chloe Sagum - 单曲 - 网易云音乐 👂 年年 - 徐秉龙 - 单曲 - 网易云音乐 目录 🌼前言 👊成长 (1)情感 (2)运动 (3)穿搭…...

使用 pdfh5 实现 pdf 预览功能
1. 安装 npm install pdfh5 2. 使用 html部分: <div id"showPdf" style"width: 100%;"></div> js部分: <script> //合同展示组件 import Pdfh5 from pdfh5 //合同组件样式 import pdfh5/css/pdfh5.css expo…...

HttpRunner辅助函数debugtalk.py
辅助函数debugtalk.py Httprunner框架中,使用yaml或json文件进行用例描述,无法做一些复杂操作,如保存一些数据跨文件调用,或者实现一些复杂逻辑判断等,为了解决这个问题,引入了debugtalk.py辅助函数来进行一…...

PC端扫描小程序二维码登录
1、获取二维码地址,通过请求微信开发者文档中的服务端获取无限制小程序二维码URL #controller层 import org.apache.commons.codec.binary.Base64;/*** 获取小程序二维码*/PassTokenGetMapping("/getQrCode")public AjaxResult getQrCode(BlogUserDto bl…...
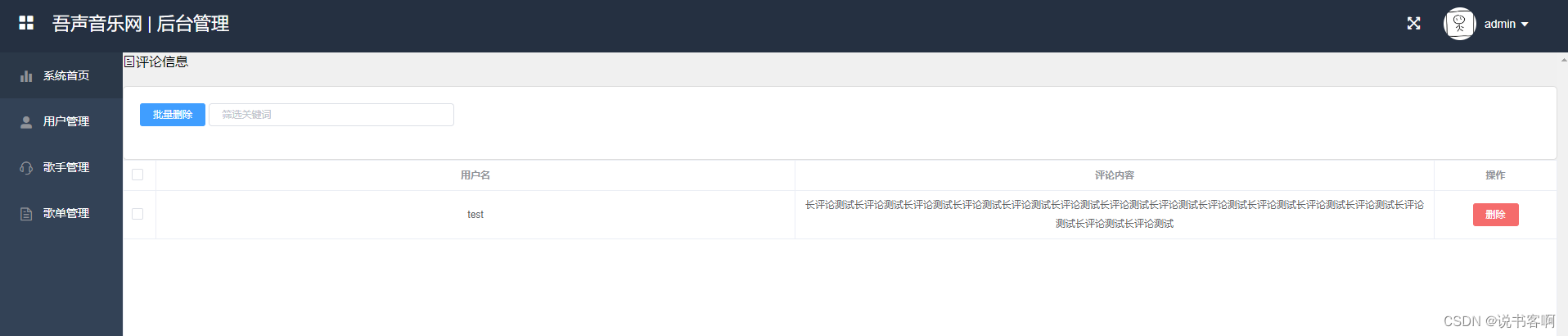
计算机毕业设计 | SpringBoot+vue移动端音乐网站 音乐播放器(附源码)
1,项目背景 随着计算机技术的发展,网络技术对我们生活和工作显得越来越重要,特别是现在信息高度发达的今天,人们对最新信息的需求和发布迫切的需要及时性。为了满足不同人们对网络需求,各种特色,各种主题的…...

Flutter 中的 Stream:异步编程的利器
在Flutter中,异步编程是非常重要的一部分,特别是在处理用户输入、网络请求或其他涉及时间的操作时。Flutter提供了一种强大的工具,称为Stream,用于简化异步编程的过程。 什么是 Stream? Stream是一种用于处理异步数据…...

2023 波卡年度报告选读:Polkadot SDK 与开发者社区
原文:https://dashboards.data.paritytech.io/reports/2023/index.html#section6 编译:OneBlock 编者注:Parity 数据团队发布的 2023 年 Polkadot 年度数据报告,对推动生态系统的关键数据进行了深入分析。报告全文较长ÿ…...
:探究变量与数据类型的内存占用)
深入了解Go语言中的unsafe.Sizeof():探究变量与数据类型的内存占用
当涉及到在 Go 语言中确定变量或数据类型所占用的内存空间大小时,unsafe 包中的 Sizeof() 函数成为了一个强有力的工具。它可以用来获取变量或数据类型所占用的字节数,但需要注意的是,它不考虑内存对齐和填充的情况。因此,在使用 …...

安卓上使用免费的地图OpenStreetMap
前一段使用了微信的地图,非常的好用。但是存在的问题是海外无法使用,出国就不能用了; 其实国内三家:百度,高德,微信都是一样的问题,当涉及到商业使用的时候需要付费; 国外除了谷歌…...
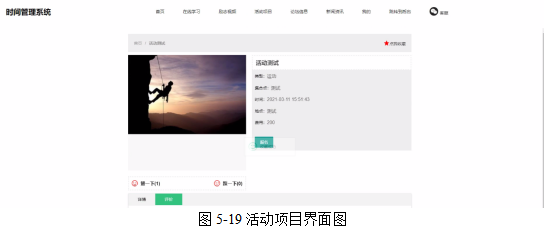
基于Java SSM框架实现时间管理系统项目【项目源码+论文说明】
基于java的SSM框架实现时间管理系统演示 摘要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势;对于时间管理系统当然也不能排除在外,随着网络技术的不断成熟,带动了时间管理…...
Mac安装upx及不同os计算md5值
Mac安装upx 最近需要将exe文件打包到pod内部,为了减少包占用磁盘空间,需要借用upx对windows exe文件进行压缩。 1 概念:压缩工具 UPX 全称是 “Ultimate Packer for eXecutables”,是一个免费、开源、编写、可扩展、高性能的可执行…...

Qt/C++编写视频监控系统82-自定义音柱显示
一、前言 通过音柱控件实时展示当前播放的声音产生的振幅的大小,得益于音频播放组件内置了音频振幅的计算,可以动态开启和关闭,开启后会对发送过来的要播放的声音数据,进行运算得到当前这个音频数据的振幅,类似于分贝…...
)
大模型插件开发已进入“VSCode 2026语法纪元”:你还在用旧版Extension API?3个必迁API变更清单(含兼容性迁移脚本)
更多请点击: https://intelliparadigm.com 第一章:VSCode 2026大模型插件开发概览 随着大语言模型能力持续演进,VSCode 2026 版本原生强化了对 LLM 插件的底层支持,包括统一的 aiExtensionHost 运行时、跨模型推理抽象层&#…...

M9A:重返未来1999终极自动化助手完整指南,三步实现游戏日常全托管
M9A:重返未来1999终极自动化助手完整指南,三步实现游戏日常全托管 【免费下载链接】M9A 重返未来:1999 小助手 | Assistant For Reverse: 1999 项目地址: https://gitcode.com/gh_mirrors/m9/M9A 你是否厌倦了《重返未来:1…...

长期使用Taotoken服务后对其API稳定性和故障切换机制的体会
长期使用Taotoken服务后对其API稳定性和故障切换机制的体会 1. 视频项目中的高频调用实践 在最近一个视频内容生成项目中,我们团队需要频繁调用大模型API进行脚本润色、分镜描述生成和字幕校对。项目周期紧张时,日均API调用量达到数千次。Taotoken的统…...

AMD迷你PC游戏性能优化:内存与操作系统影响解析
1. 迷你PC游戏性能测试:操作系统与内存的影响解析最近在折腾一台基于AMD平台的迷你PC时,我发现了一个有趣的现象:这台配置了16GB内存、运行Manjaro Linux的"伪Steam Deck",在切换到Windows 11后性能明显下降。更奇怪的是…...

LinkSwift网盘直链下载助手:9大平台高效免费下载完整指南
LinkSwift网盘直链下载助手:9大平台高效免费下载完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

Cloudflare Workers部署Gemini OpenAI网关:统一接口调用AI模型
1. 项目概述:在Cloudflare Workers上搭建你的专属Gemini OpenAI网关 如果你和我一样,既眼馋Google Gemini 2.5系列模型强大的推理能力和超长上下文,又习惯了OpenAI API那种简洁统一的调用方式,那么你肯定也想过:要是能…...

为 Ubuntu 上的 OpenClaw Agent 工作流配置 Taotoken 作为模型供应商
为 Ubuntu 上的 OpenClaw Agent 工作流配置 Taotoken 作为模型供应商 1. 准备工作 在开始配置之前,请确保您的 Ubuntu 系统已安装 Node.js 16 或更高版本。这是运行 OpenClaw 和 Taotoken CLI 工具的基础环境。您可以通过以下命令检查 Node.js 版本: …...

ClawRecipes:基于文件优先与菜谱驱动的AI团队协作脚手架
1. 项目概述:ClawRecipes,一个为AI团队协作而生的“脚手架”工具如果你正在使用OpenClaw,并且已经厌倦了在聊天界面里手动协调多个AI助手、来回传递文件、或者为每个新项目重复搭建相同的工作目录结构,那么ClawRecipes可能就是你在…...
)
Win10/11学汇编不求人:手把手教你用DosBox+Debug搭建复古调试环境(附debug命令速查表)
Win10/11学汇编不求人:手把手教你用DosBoxDebug搭建复古调试环境 在64位Windows系统普及的今天,学习汇编语言时最令人头疼的莫过于找不到合适的调试工具。许多高校计算机组成原理课程仍在使用经典的debug.exe,但这个工具早已从现代Windows系统…...

Docker容器化RouterOS部署指南:从原理到实战应用
1. 项目概述与核心价值最近在折腾家庭网络和边缘计算环境,一个绕不开的需求就是需要一个稳定、可编程、且资源占用极低的网络核心。无论是想搭建一个软路由,还是需要一个轻量级的网络测试沙盒,又或者是在云服务器上模拟复杂的网络拓扑&#x…...