【源码预备】Calcite基础知识与概念:关系代数概念、查询优化、sql关键字执行顺序以及calcite基础概念
文章目录
- 一. 关系代数的基本知识
- 二. 查询优化
- 三. SQL语句的解析顺序
- 1. FROM
- 2. WHERE
- 3. GROUP BY
- 4. HAVING
- 5. SELECT
- 四. Apache Calcite中的基本概念
- 1. Adapter
- 2. Calcite中的关系表达式
- 2.1. 关系表达式例子
- 2.2. 源码底层结构
- 3. Calcite的优化规则
- 4. Calcite的Trait--算子物理属性
- 5. Calcite的Calling Convention(调用约定)
- 6. Calcite内建算子
本文主要描述:Calcite 相关的基础性内容。
- 关系代数基础概念
- 查询优化简单介绍
- sql关键字解析顺序
- calcite基础概念
上篇了解了【源码分析】 Calcite 处理流程详解:calcite架构、处理流程以及就一个运行示例进行源码分析之后,我们对calcite有了一定的认知,但有些细节还未说明,所以本篇讨论对 Calcite 相关的基础性内容进行说明。希望通过本篇能够对Calcite的原理细节有一个更加清晰的了解。
一. 关系代数的基本知识
在学习Apache Calcite的一些基本概念之前,首先要弄懂关系表达式,并且要知道SQL与关系表达式的关系,因为Calcite的最核心的概念就是关系表达式。
关系代数是关系型数据库操作的理论基础,关系代数支持并、差、笛卡尔积、投影和选择等基本运算。关系代数也是 Calcite 的核心,任何一个查询都可以表示成由关系运算符组成的树。
在 Calcite 中,它会先将 SQL 转换成关系表达式(relational expression),然后通过规则匹配(rules match)进行相应的优化,优化会有一个成本(cost)模型为参考。
关系代数相关内容,简单总结如下:

二. 查询优化
查询优化主要是围绕着 等价交换 的原则做相应的转换,相关文章
数据库查询优化入门: 代数与物理优化基础;
三. SQL语句的解析顺序
一个sql语句是按照如下的顺序解析的:
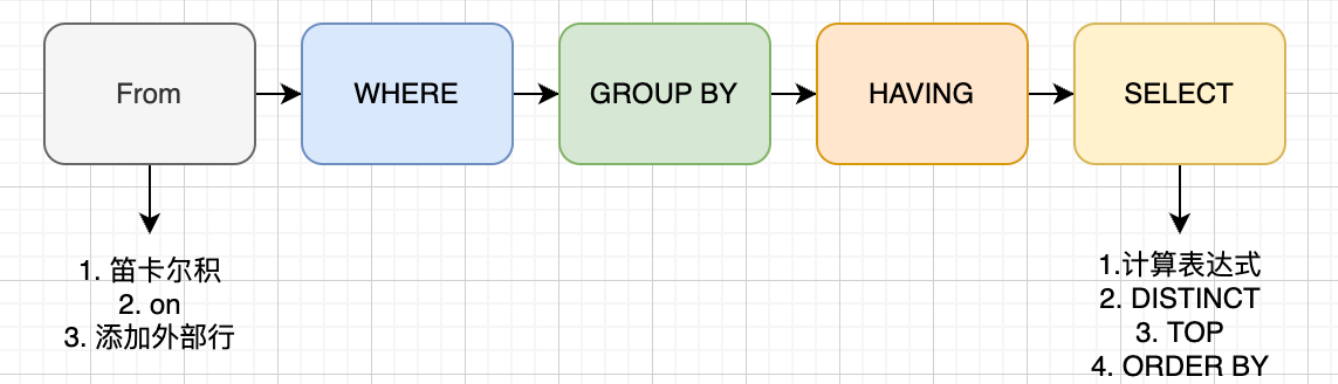
1. FROM
FROM后面的表标识了这条语句要查询的数据源。和一些子句如,(1-J1)笛卡尔积,(1-J2)ON过滤,(1-J3)添加外部列,所要应用的对象。FROM过程之后会生成一个虚拟表VT1。
- (1-J1)笛卡尔积 这个步骤会计算两个相关联表的笛卡尔积(CROSS JOIN) ,生成虚拟表VT1-J1。
- (1-J2)ON过滤 这个步骤基于虚拟表VT1-J1这一个虚拟表进行过滤,过滤出所有满足ON 谓词条件的列,生成虚拟表VT1-J2。
- (1-J3)添加外部行 如果使用了外连接,保留表中的不符合ON条件的列也会被加入到VT1-J2中,作为外部行,生成虚拟表VT1-J3。
2. WHERE
对VT1过程中生成的临时表进行过滤,满足where子句的列被插入到VT2表中。
3. GROUP BY
这个子句会把VT2中生成的表按照GROUP BY中的列进行分组。生成VT3表。
4. HAVING
这个子句对VT3表中的不同的组进行过滤,满足HAVING条件的子句被加入到VT4表中。
5. SELECT
这个子句对SELECT子句中的元素进行处理,生成VT5表。
- (5-1)计算表达式 计算SELECT 子句中的表达式,生成VT5-1
- (5-2) DISTINCT 寻找VT5-1中的重复列,并删掉,生成VT5-2
- (5-3) TOP 从ORDER BY子句定义的结果中,筛选出符合条件的列。生成VT5-3表
- ORDER BY 从VT5-3中的表中,根据ORDER BY 子句的条件对结果进行排序,生成VC6表。
四. Apache Calcite中的基本概念
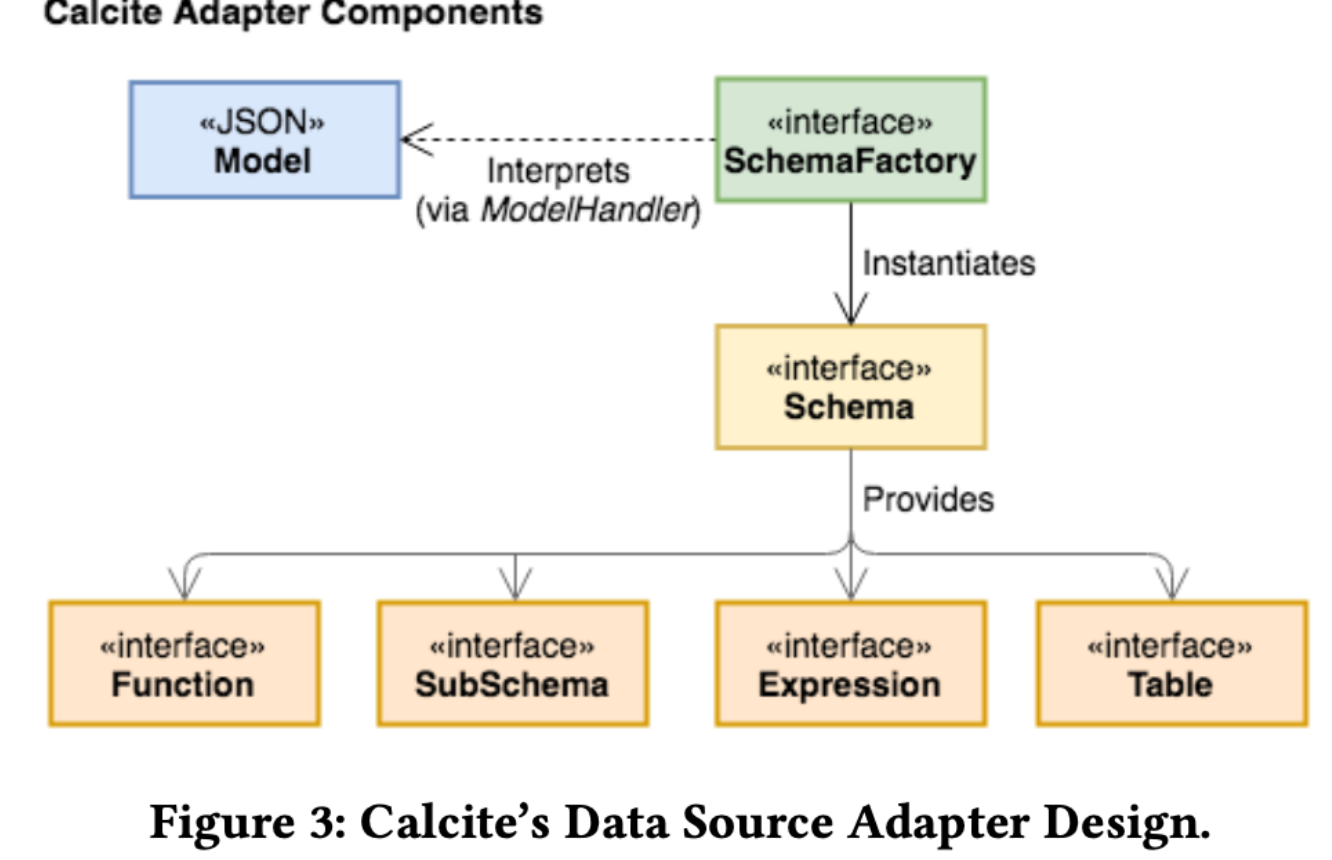
1. Adapter
在Calcite的架构中,Adapter的概念使Calcite知道如何去访问不同的数据源。一个数据源的Adapter对应有一个model,一个schema,一个schema Factory。
model定义了数据源的物理属性,比如下面的JDBC Adapter的model:
{"defaultSchema": "db1","schemas": [{"factory": "org.apache.calcite.adapter.jdbc.JdbcSchema$Factory","name": "db1","operand": {"jdbcDriver": "com.mysql.cj.jdbc.Driver","jdbcPassword": "changeme","jdbcUrl": "jdbc:mysql://localhost:3306/test","jdbcUser": "root"},"type": "custom"}],"version": "1.0"
}
schema定义了数据的格式和层次。schema factory可以解析model来创建schema。
2. Calcite中的关系表达式
在 Calcite 中,关系表达式通常以树形结构的形式表示。树的根节点是查询的最外层操作符,例如 SELECT、FROM、WHERE 等,每个操作符都有其对应的子节点,子节点可以是另一个关系表达式或者具体的数据源(where: 由adapter实现?)。
2.1. 关系表达式例子
如下 SQL 查询及其关系表达式
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE c.state = 'CA';LogicalProject(order_id=[$0], order_date=[$1], customer_id=[$2], order_total=[$3])LogicalFilter(condition=[=($5, 'CA')])LogicalJoin(condition=[=($2, $6)], joinType=[inner])EnumerableTableScan(table=[[MY_DB, ORDERS]])EnumerableTableScan(table=[[MY_DB, CUSTOMERS]])说明
- 每个节点代表一个操作符,例如 LogicalProject 代表 SELECT 操作,LogicalFilter 代表 WHERE 操作,LogicalJoin 代表 JOIN 操作。
- 节点的顺序和嵌套结构代表了查询的**执行顺序(从下往上看)**和逻辑关系。
- 节点参数:包括操作符参数和子节点引用。例如 LogicalProject 的参数是输出的列,子节点是它所操作的关系表达式。
理解关系表达式对于理解 Calcite 的查询优化和执行过程非常重要。
2.2. 源码底层结构
转换为关系表达式的基本逻辑
在calcite中,当一个sql字符串被解析为SqlNode结构的AST树(抽象语法树)后,并不能直接被Calcite的优化器优化。还需要通过SqlToRelConverter将SqlNode结构转换成为RelNode结构组成的树。
关系表达式算子接口与实现
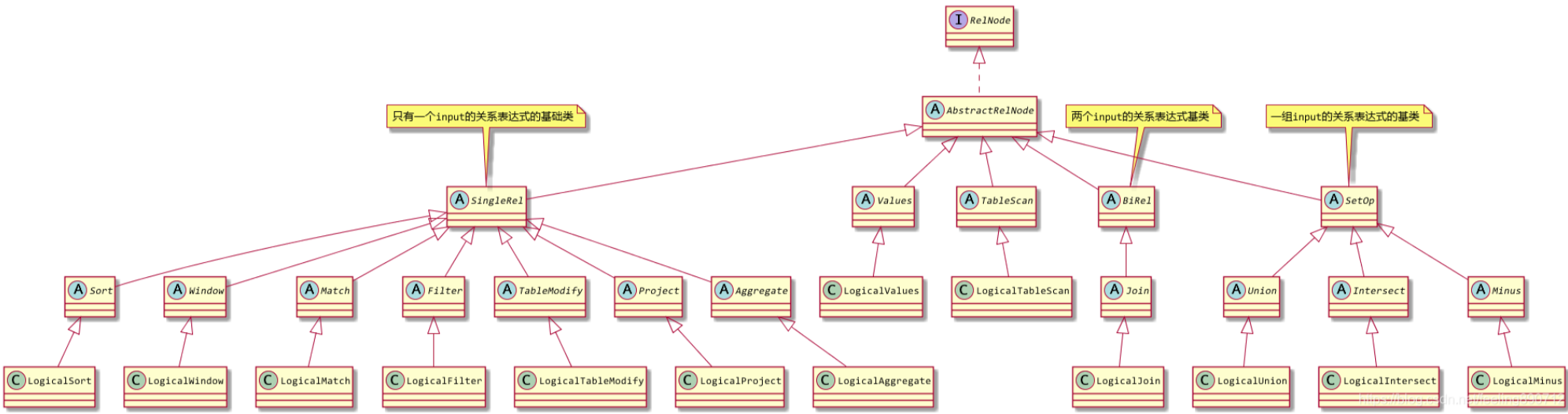
如上图所示,Calcite所有的关系表达式算子都需要实现RelNode接口。其中Calcite的核心算子有:TableScan, TableModify, Values, Project, Filter, Aggregate, Join, Sort, Union, Intersect, Minus, Window 与Match。
通过这些类的名字比较容易理解它们与SQL的对应关系,比如TableModify对应SQL中的INSERT、UPDATE、CREATE操作,Minus对应SQL中的EXCEPT操作,Window对应流处理的window概念等。
Calcite中的这些核心算子都有对应的纯逻辑子类LogicalXXX,SqlToRelConverter将SqlNode转换出来的RelNode树中,每个节点都是这些LogicalXXX子类组成的。它们并不能生成可执行的执行计划,只是用于表示SQL对应的关系表达式结构。
Adapter 对接实现
与Calcite对接的后端执行引擎的Adapter都会实现这些算子的可执行的实现。比如Cassandra adpter会有CassandraProject 在Calcite中逻辑算子转换成后端引擎实现的对应算子是在Calcite Planner(优化器)对RelNode树执行优化时候根据优化Rule将逻辑算子替换成对应的实际算子。
这里的adapter与flink的connector设计上是什么关系?
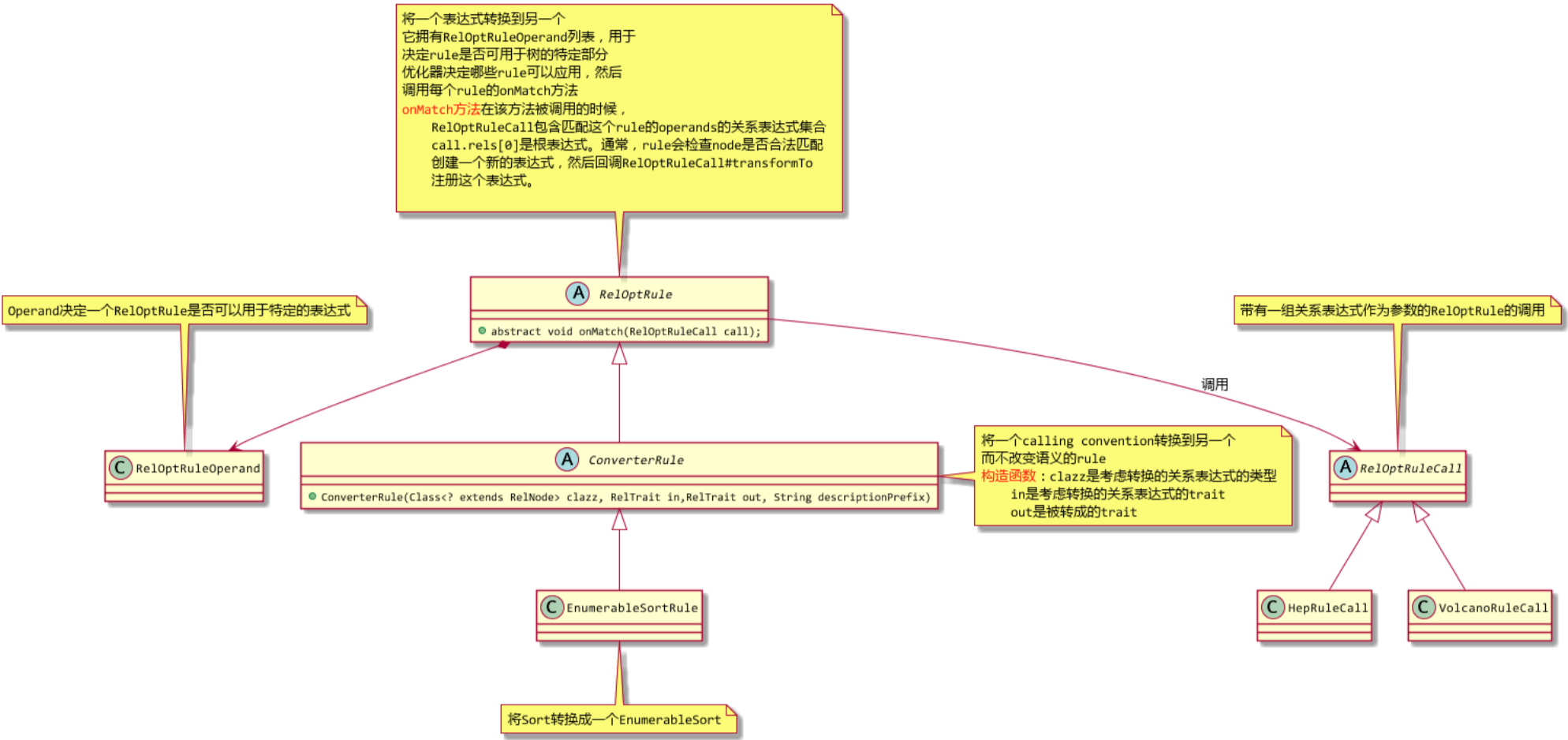
3. Calcite的优化规则
Calcite的优化器规则可以将一个关系表达式转换成等价的关系表达式,而这些优化器规则的基类都是RelOptRule。如下图的EnumerableSortRule可以将LogicalSort逻辑算子转换成Calcite内建的可执行的算子EnumerableSort。
package org.apache.calcite.adapter.enumerable;class EnumerableSortRule extends ConverterRule {EnumerableSortRule() {super(Sort.class, Convention.NONE, EnumerableConvention.INSTANCE,"EnumerableSortRule");}public RelNode convert(RelNode rel) {final Sort sort = (Sort) rel;if (sort.offset != null || sort.fetch != null) {return null;}final RelNode input = sort.getInput();return EnumerableSort.create(convert(input,input.getTraitSet().replace(EnumerableConvention.INSTANCE)),sort.getCollation(),null,null);}
}
Sort.class在优化器运行时匹配这条规则,然后优化器调用convert将原来的Sort算子转换为EnumerableSort算子。比如,LogicalSort在优化器优化时会匹配到这条规则,EnumerableSort就会替代LogicalSort。
除了上面的转换规则以外,Calcite已经实现了许多规则可以注册到优化器中,在优化时调用,比如filter、project等算子下推的优化规则等。目前Calcite已经实现了两种优化器引擎:基于代价优化的class VolcanoPlanner和基于经验的优化class HepPlanner。
4. Calcite的Trait–算子物理属性
在Calcite中没有使用不同的对象代表逻辑和物理算子,而是使用trait来表示一个算子的物理属性。
Calcite中使用接口RelTrait来代表一个关系表达式节点的物理属性,使用RelTraitDef来表示Reltrait的class。
RelTrait与RelTraitDef的关系就像java中对象与Class的关系一样,每个对象都有Class。
对于物理的关系表达式算子会有一些物理属性,这些物理属性都会用RelTrait来表示。
比如每个算子都有Calling Convention这一Reltrait。比如上图中Sort算子还会有一个物理属性RelCollation,因为Sort算子会对表的一些字段进行排序,RelCollation这一物理属性就会记录这个Sort算子要排序的字段索引、排序方向,null值怎么排序等信息。

5. Calcite的Calling Convention(调用约定)
Calling Convention在Calcite中使用接口Convention表示,Convention接口是RelTrait的直接口,所以是一个算子的属性。
Calling Convention可以理解为一个特定数据引擎协议,拥有相同Convention的算子可以认为都是同一个数据引擎的算子可以相互连接起来。比如JDBC的算子JDBCXXX都有JdbcConvention,Calcite的内建Enumerable算子EnumerableXXX都有EnumerableConvention。
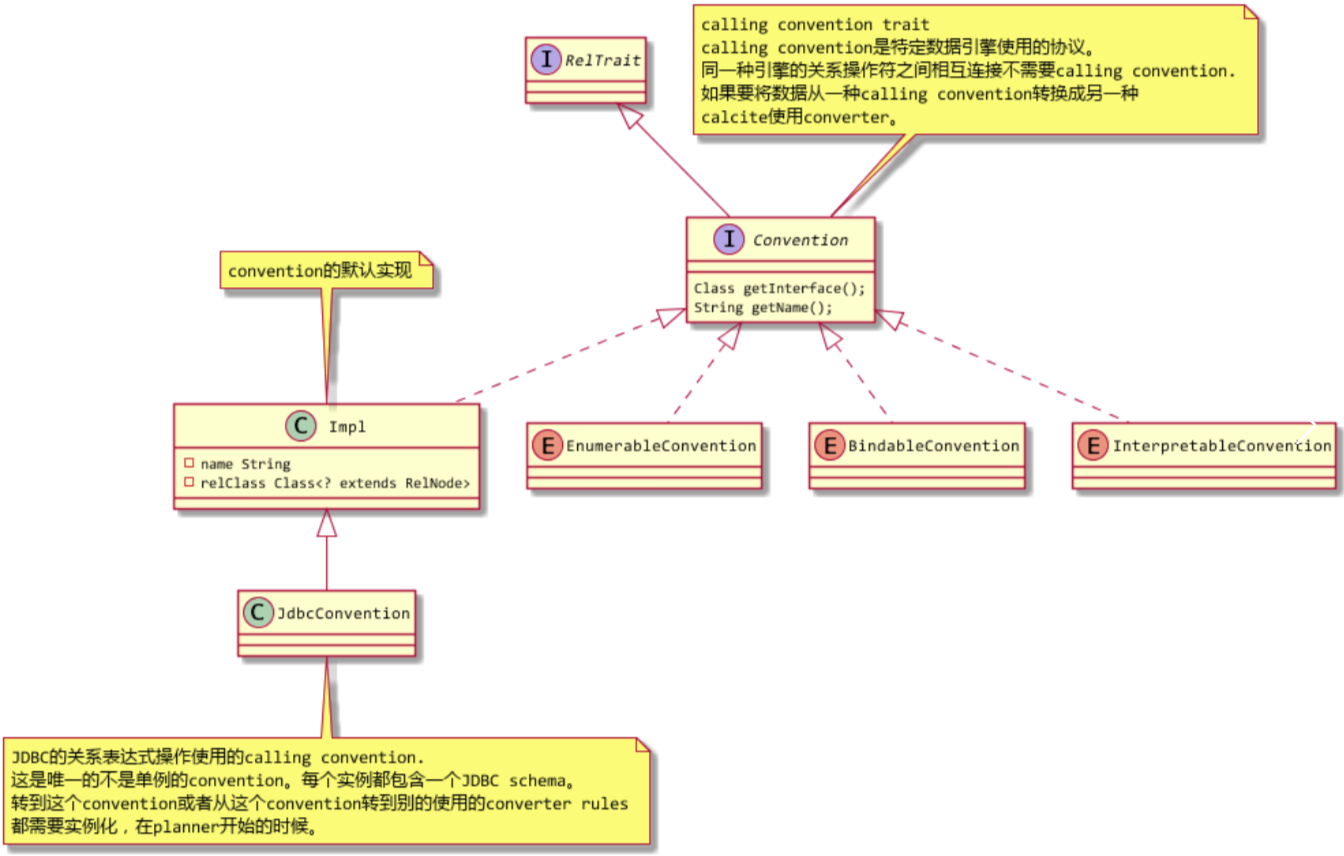
上图中,Jdbc算子可以通过JdbcConvention获得对应数据库的SqlDialect和JdbcSchema等数据,这样可以生成对应数据库的sql,获得数据库的连接池与数据库交互实现算子的逻辑。
join场景
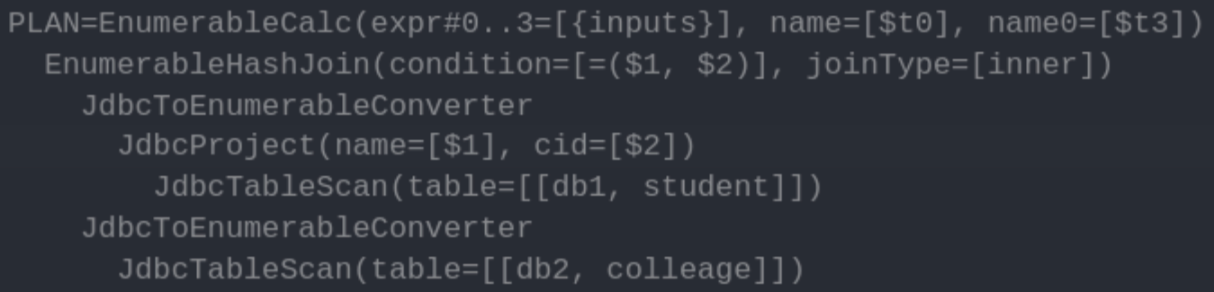
如果数据要从一个Calling Convention的算子到另一个Calling Convention算子的时候,比如使用Calcite进行跨库join的场景。需要接口Converter的子类作为两种算子之间的桥梁将两种算子连接起来。
比如上面的执行计划,要将Enumerable的算子与Jdbc的算子连接起来,中间就要使用JdbcToEnumerableConverter作为桥梁。
6. Calcite内建算子
如果一个Adapter没有实现所有的核心关系表达式算子,Calcite也能生成完整的执行计划,完成整个数据处理过程。这是因为Calcite内建了EnumerableConvention作为Calling Convention的Enumerable算子,实现了所有核心的关系表达式算子,比如EnumerableFilter,EnumerableSrt,EnumerableHashJoin等。
Enumerable算子效率不高
使用Enumerable算子效率不高,而且都是在内存中处理的。比如EnumerableHashJoin算子join两个表都是在内存中处理表的所有数据,数据量一大就会造成内存溢出。如果实现一个数据引擎的Adapter,能提供对应算子的处理能力就应该实现这个算子,将工作推到后端的数据引擎中处理,避免回退到使用Enumerable算子。
参考:
https://blog.csdn.net/feeling890712/article/details/106333425
相关文章:
【源码预备】Calcite基础知识与概念:关系代数概念、查询优化、sql关键字执行顺序以及calcite基础概念
文章目录 一. 关系代数的基本知识二. 查询优化三. SQL语句的解析顺序1. FROM2. WHERE3. GROUP BY4. HAVING5. SELECT 四. Apache Calcite中的基本概念1. Adapter2. Calcite中的关系表达式2.1. 关系表达式例子2.2. 源码底层结构 3. Calcite的优化规则4. Calcite的Trait--算子物理…...

【Java 设计模式】23 种设计模式
文章目录 设计模式是什么计算机行业里的设计模式创建型模式(共 5 种)结构型模式(共 7 种)行为型模式(共 11 种) 总结 设计模式是什么 “每一个模式描述了一个在我们周围不断重复发生的问题,以及…...

ElasticSearch深度分页解决方案
一、前言 ElasticSearch是一个基于Lucene的搜索引擎,它支持复杂的全文搜索和实时数据分析。在实际应用中,我们经常需要对大量数据进行分页查询,但是传统的分页方式在处理大量数据时会遇到性能瓶颈。本文将介绍ElasticSearch分页工作原理、深…...

nginx下upstream模块详解
目录 一:介绍 二:特性介绍 一:介绍 Nginx的upstream模块用于定义后端服务器组,以及与这些服务器进行通信的方式。它是Nginx负载均衡功能的核心部分,允许将请求转发到多个后端服务器,并平衡负载。 在upst…...
基于ssm的双减后初小教育课外学习生活活动平台的设计与实现论文
双减后初小教育课外学习生活活动平台的设计与实现 摘 要 当下,正处于信息化的时代,许多行业顺应时代的变化,结合使用计算机技术向数字化、信息化建设迈进。以前学校对于课外学习活动信息的管理和控制,采用人工登记的方式保存相关…...
wblogic中间件配置数据源
配置数据源 1.服务-数据源-配置-新建 2.单机选一般数据源 3.选择源名称、jndi名称、数据库类型 4.选择驱动 5.下一步 6.输入连接串信息 参考: 格式二:jdbc:oracle:thin:<host>:<port>:<SID> 数据库名称配置的sid 7.测试配置ÿ…...
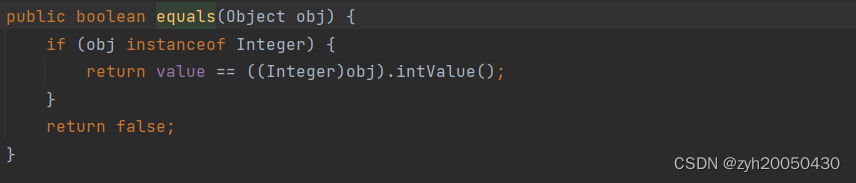
Java数据结构之装箱拆箱
装箱和拆箱 也叫装包拆包,装包是把那八种基本数据类型转换为它的包装类,拆包则相反 上面这俩种方式都是装包,下面是它的字节码文件 用到了Integer的ValueOf方法: 就是返回了一个Integer类的对象,把它的value属性设置成…...
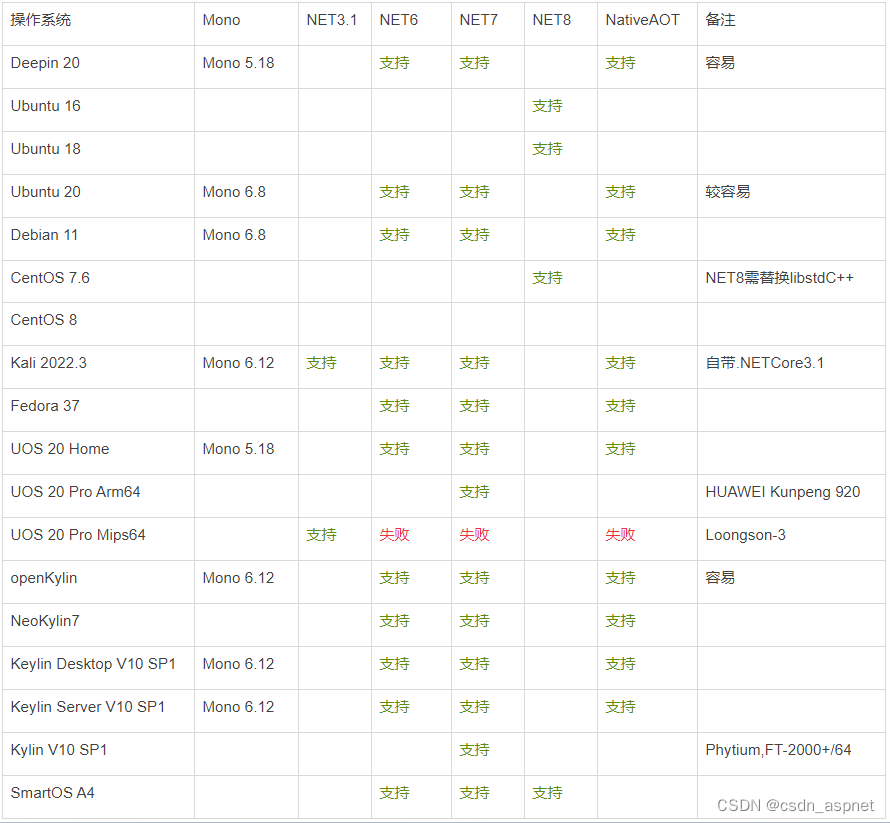
各版本 操作系统 对 .NET Framework 与 .NET Core 支持
有两种类型的受支持版本:长期支持 (LTS) 版本和标准期限支持 (STS) 版本。 所有版本的质量都是一样的。 唯一的区别是支持的时间长短。 LTS 版本可获得为期三年的免费支持和补丁。 STS 版本可获得 18 个月的免费支持和修补程序。 有关详细信息,请参阅 .N…...

Golang 线程安全与 sync.Map
前言 线程安全通常是指在并发环境下,共享资源的访问被适当地管理,以防止竞争条件(race conditions)导致的数据不一致 Go语言中的线程安全可以通过多种方式实现 实现方式 互斥锁(Mutexes) Go的sync包提供…...

1.2 Hadoop概述
小肥柴的Hadoop之旅 1.2 Hadoop概述 目录1.2 Hadoop概述1.2.1 回归问题1.2.2 Google的三篇论文1.2.3 Hadoop的诞生过程1.2.4 Hadoop特点简介 参考文献和资料 ) 目录 1.2 Hadoop概述 1.2.1 回归问题 通过前一篇帖子的介绍,特别是问题思考部分的说明,我…...

Adams许可管理安全控制策略
随着全球信息化的快速发展,信息安全和许可管理问题日益凸显。在这场无形的挑战中,Adams许可管理安全控制策略以其卓越的性能和可靠性,引领着解决这类问题的新潮流。 Adams许可管理安全控制策略是一种全方位、多层次的安全控制方案࿰…...

无人地磅系统|内蒙古中兴首创无人地磅和远程高效管理的突破
走进标杆企业,感受名企力量,探寻学习优秀企业领先之道。 本期要跟砼行们推介的标杆企业是内蒙古赤峰市砼行业的龙头企业:赤峰中兴首创混凝土搅拌有限责任公司(以下简称为中兴首创)。 中兴首创成立于2011年初ÿ…...

【SpringCloud】7、Spring Cloud Gateway限流配置
1、限流介绍 Spring Cloud Gateway 的限流配置主要涉及到令牌桶算法的实现。令牌桶算法可以对某一时间窗口内的请求数进行限制,保持系统的可用性和稳定性,防止因流量暴增而导致的系统运行缓慢或宕机。 在 Spring Cloud Gateway 中,官方提供了 RequestRateLimiterGatewayFi…...
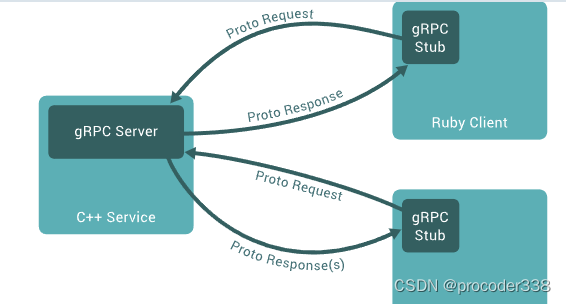
【gRPC学习】使用go学习gRPC
个人博客:Sekyoro的博客小屋 个人网站:Proanimer的个人网站 RPC是远程调用,而google实现了grpc比较方便地实现了远程调用,gRPC是一个现代的开源远程过程调用(RPC)框架 概念介绍 在gRPC中,客户端应用程序可以直接调用另一台计算机上的服务器应用程序上的方法&#…...
C语言中常用的字符串函数(strlen、sizeof、sscanf、sprintf、strcpy)
C语言中常用的字符串函数 文章目录 C语言中常用的字符串函数1 strlen函数2 sizeof函数2.1 sizeof介绍2.2 sizeof用法 3 sscanf函数3.1 sscanf介绍3.2 sscanf用法3.3 sscanf高级用法 4 sprintf函数4.1 背景4.2 sprintf用法 5 strcpy函数5.1 strcpy介绍5.1 strcpy用法 1 strlen函…...

域名解析服务器:连接你与互联网的桥梁
域名解析服务器:连接你与互联网的桥梁 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨一个网络世界中至关重要却鲜为人知的角…...

理论物理在天线设计和射频电路设计中的应用
理论物理的基本原理可以应用于电路中的电磁场分析和电磁波传播问题,例如天线设计和射频电路设计。通过应用麦克斯韦方程组和电磁波传播理论,可以优化电路的性能,提高天线的辐射效率和射频电路的传输效率。麦克斯韦方程组是描述电磁场行为的基…...

MySql01:初识
1.mysql数据库2.配置环境变量3. 列的类型和属性,索引,注释3.1 类型3.2 属性3.3 主键(主键索引)3.4 注释 4.结构化查询语句分类:5.列类型--表列类型设置 1.mysql数据库 数据库: 数据仓库,存储数据,以前我…...

Python——运算符
num 1 num 1 print("num1:", num) num - 1 print("num-1:", num) num * 4 print("num*4:", num) num / 4 print("num/4:", num) num 3 num % 2 print("num%2:", num) num ** 2 print("num**2:", num) 运行结果…...

赋能软件开发:生成式AI在优化编程工作流中的应用与前景
随着人工智能(AI)技术的快速发展,特别是生成式AI模型如GPT-3/4的出现,软件开发行业正经历一场变革,这些模型通过提供代码生成、自动化测试和错误检测等功能,极大地提高了开发效率和软件质量。 本文旨在深入…...
达5.5%)
准分子消光炉市场预测:2025-2031年复合年增长率(CAGR)达5.5%
在工业表面处理领域,准分子消光炉作为一种依托准分子紫外(UV)光(典型波长172nm)的专用工业系统,正凭借其低温可控、精准改性的技术特性,重塑高端材料处理市场格局。据恒州诚思(YH Re…...

128. 如何在 RKE2 或 K3s 集群中更改容器日志级别
Procedure 程序The containerd log level can be set to one of the following values: trace, debug, info, warn, error, fatal or panic. In RKE2 and K3s clusters the log level is not explicitly set by default, and so containerd defaults to info level logging. D…...

从模型下载到API服务:手把手教你用MS-Swift+VLLM部署Qwen2.5-VL,打造自己的图像理解服务
从模型下载到API服务:手把手教你用MS-SwiftVLLM部署Qwen2.5-VL,打造自己的图像理解服务 在人工智能技术快速发展的今天,多模态大模型正逐渐成为理解和处理图像、文本等复杂数据的关键工具。Qwen2.5-VL作为一款强大的视觉语言模型,…...

亚马逊,TEMU平台针对电动泵美国站的UL778标准
UL778是电动泵的安全标准,主要用于规范在日常使用场景下的潜水或非潜水电泵的安全性能,确保产品在北美市场的准入合规 。一、适用产品范围以下类型的电泵通常适用于UL778标准:潜水泵:电机可完全浸入水中运行的泵。非潜水…...

算法岗正在分化:谁在做模型谁在做应用
你这个问题,我先给个结论,一个可能会让你有点意外但绝对是现实的结论:你遇到的情况,不是特例,而是正在迅速成为行业的主流和新常态。你实习干的活,很有可能就是未来几年大多数“AI工程师”或者“算法工程师…...

5步构建家庭网络广告拦截系统:从规则部署到性能优化
5步构建家庭网络广告拦截系统:从规则部署到性能优化 【免费下载链接】AdGuardHomeRules 高达百万级规则!由我原创&整理的 AdGuardHomeRules ADH广告拦截过滤规则!打造全网最强最全规则集 项目地址: https://gitcode.com/gh_mirrors/ad/…...

Windows HEIC缩略图终极指南:免费解决iPhone照片预览问题
Windows HEIC缩略图终极指南:免费解决iPhone照片预览问题 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 你是否曾将…...

手把手教你:在无外网服务器上用Docker离线搭建Jitsi-Meet视频会议系统
无外网环境下的Jitsi-Meet容器化部署实战指南 在金融、军工等对网络安全要求极高的行业,或是某些特殊的生产环境中,服务器往往被部署在完全隔离的内网中。这种环境下,传统的在线安装方式完全失效,而视频会议系统又是现代企业协作的…...
)
保姆级教程:用Keil5同时开发51单片机和STM32(C51+MDK环境配置)
嵌入式开发双环境实战:Keil5高效配置C51与MDK开发平台 在嵌入式开发领域,51单片机和STM32系列因其各自优势长期占据重要地位。许多工程师在日常工作中需要同时处理这两种架构的项目,频繁切换开发环境不仅降低效率,还容易导致开发…...
)
Docker数据迁移到新磁盘的5个常见坑及解决方案(附详细步骤)
Docker数据迁移到新磁盘的5个常见坑及解决方案(附详细步骤) 当你发现服务器上的Docker容器运行越来越慢,或者频繁出现"no space left on device"的错误时,数据迁移就成了迫在眉睫的任务。作为一名经历过数十次Docker迁移…...