Spark 中 BroadCast 导致的内存溢出(SparkFatalException)
背景
本文基于
Spark 3.1.1
open-jdk-1.8.0.352
目前在排查 Spark 任务的时候,遇到了一个很奇怪的问题,在此记录一下。
现象描述
一个 Spark Application, Driver端的内存为 5GB,一直以来都是能正常调度运行,突然有一天,报错了:
Caused by: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute, tree:
Exchange hashpartitioning(user_lable_id#530L, 500), ENSURE_REQUIREMENTS, [id=#1564]
+- *(16) Project [xxx]+- *(16) BroadcastHashJoin ...+- *(14) ColumnarToRow+- FileScan parquet xxxat org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:56)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.doExecute(ShuffleExchangeExec.scala:169)at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)at org.apache.spark.sql.execution.InputAdapter.inputRDD(WholeStageCodegenExec.scala:525)at org.apache.spark.sql.execution.InputRDDCodegen.inputRDDs(WholeStageCodegenExec.scala:453)at org.apache.spark.sql.execution.InputRDDCodegen.inputRDDs$(WholeStageCodegenExec.scala:452)at org.apache.spark.sql.execution.InputAdapter.inputRDDs(WholeStageCodegenExec.scala:496)at org.apache.spark.sql.execution.SortExec.inputRDDs(SortExec.scala:132)at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:746)at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)at org.apache.spark.sql.execution.InputAdapter.doExecute(WholeStageCodegenExec.scala:511)at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)at org.apache.spark.sql.execution.joins.SortMergeJoinExec.inputRDDs(SortMergeJoinExec.scala:378)at org.apache.spark.sql.execution.ProjectExec.inputRDDs(basicPhysicalOperators.scala:50)at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:746)at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD$lzycompute(ShuffleExchangeExec.scala:123)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD(ShuffleExchangeExec.scala:123)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.shuffleDependency$lzycompute(ShuffleExchangeExec.scala:157)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.shuffleDependency(ShuffleExchangeExec.scala:155)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.$anonfun$doExecute$1(ShuffleExchangeExec.scala:172)at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)... 291 more
Caused by: java.util.concurrent.ExecutionException: org.apache.spark.util.SparkFatalExceptionat java.util.concurrent.FutureTask.report(FutureTask.java:122)at java.util.concurrent.FutureTask.get(FutureTask.java:206)at org.apache.spark.sql.execution.exchange.BroadcastExchangeExec.doExecuteBroadcast(BroadcastExchangeExec.scala:199)at org.apache.spark.sql.execution.InputAdapter.doExecuteBroadcast(WholeStageCodegenExec.scala:515)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeBroadcast$1(SparkPlan.scala:193)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.SparkPlan.executeBroadcast(SparkPlan.scala:189)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.prepareBroadcast(BroadcastHashJoinExec.scala:203)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.prepareRelation(BroadcastHashJoinExec.scala:217)at org.apache.spark.sql.execution.joins.HashJoin.codegenOuter(HashJoin.scala:497)at org.apache.spark.sql.execution.joins.HashJoin.codegenOuter$(HashJoin.scala:496)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.codegenOuter(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.joins.HashJoin.doConsume(HashJoin.scala:352)at org.apache.spark.sql.execution.joins.HashJoin.doConsume$(HashJoin.scala:349)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.doConsume(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.CodegenSupport.consume(WholeStageCodegenExec.scala:194)at org.apache.spark.sql.execution.CodegenSupport.consume$(WholeStageCodegenExec.scala:149)at org.apache.spark.sql.execution.ProjectExec.consume(basicPhysicalOperators.scala:41)at org.apache.spark.sql.execution.ProjectExec.doConsume(basicPhysicalOperators.scala:87)at org.apache.spark.sql.execution.CodegenSupport.consume(WholeStageCodegenExec.scala:194)at org.apache.spark.sql.execution.CodegenSupport.consume$(WholeStageCodegenExec.scala:149)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.consume(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.joins.HashJoin.codegenOuter(HashJoin.scala:542)at org.apache.spark.sql.execution.joins.HashJoin.codegenOuter$(HashJoin.scala:496)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.codegenOuter(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.joins.HashJoin.doConsume(HashJoin.scala:352)at org.apache.spark.sql.execution.joins.HashJoin.doConsume$(HashJoin.scala:349)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.doConsume(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.CodegenSupport.consume(WholeStageCodegenExec.scala:194)at org.apache.spark.sql.execution.CodegenSupport.consume$(WholeStageCodegenExec.scala:149)at org.apache.spark.sql.execution.ProjectExec.consume(basicPhysicalOperators.scala:41)at org.apache.spark.sql.execution.ProjectExec.doConsume(basicPhysicalOperators.scala:87)at org.apache.spark.sql.execution.CodegenSupport.consume(WholeStageCodegenExec.scala:194)at org.apache.spark.sql.execution.CodegenSupport.consume$(WholeStageCodegenExec.scala:149)at org.apache.spark.sql.execution.InputAdapter.consume(WholeStageCodegenExec.scala:496)at org.apache.spark.sql.execution.InputRDDCodegen.doProduce(WholeStageCodegenExec.scala:483)at org.apache.spark.sql.execution.InputRDDCodegen.doProduce$(WholeStageCodegenExec.scala:456)at org.apache.spark.sql.execution.InputAdapter.doProduce(WholeStageCodegenExec.scala:496)at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.InputAdapter.produce(WholeStageCodegenExec.scala:496)at org.apache.spark.sql.execution.ProjectExec.doProduce(basicPhysicalOperators.scala:54)at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.ProjectExec.produce(basicPhysicalOperators.scala:41)at org.apache.spark.sql.execution.joins.HashJoin.doProduce(HashJoin.scala:346)at org.apache.spark.sql.execution.joins.HashJoin.doProduce$(HashJoin.scala:345)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.doProduce(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.produce(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.ProjectExec.doProduce(basicPhysicalOperators.scala:54)at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.ProjectExec.produce(basicPhysicalOperators.scala:41)at org.apache.spark.sql.execution.joins.HashJoin.doProduce(HashJoin.scala:346)at org.apache.spark.sql.execution.joins.HashJoin.doProduce$(HashJoin.scala:345)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.doProduce(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.joins.BroadcastHashJoinExec.produce(BroadcastHashJoinExec.scala:40)at org.apache.spark.sql.execution.ProjectExec.doProduce(basicPhysicalOperators.scala:54)at org.apache.spark.sql.execution.CodegenSupport.$anonfun$produce$1(WholeStageCodegenExec.scala:95)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.CodegenSupport.produce(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.CodegenSupport.produce$(WholeStageCodegenExec.scala:90)at org.apache.spark.sql.execution.ProjectExec.produce(basicPhysicalOperators.scala:41)at org.apache.spark.sql.execution.WholeStageCodegenExec.doCodeGen(WholeStageCodegenExec.scala:655)at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:718)at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD$lzycompute(ShuffleExchangeExec.scala:123)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.inputRDD(ShuffleExchangeExec.scala:123)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.shuffleDependency$lzycompute(ShuffleExchangeExec.scala:157)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.shuffleDependency(ShuffleExchangeExec.scala:155)at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.$anonfun$doExecute$1(ShuffleExchangeExec.scala:172)at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)... 328 more
Caused by: org.apache.spark.util.SparkFatalExceptionat org.apache.spark.sql.execution.exchange.BroadcastExchangeExec.$anonfun$relationFuture$1(BroadcastExchangeExec.scala:173)at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withThreadLocalCaptured$1(SQLExecution.scala:190)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:750)
注意:处于安全考虑,本文隐藏了具体的物理执行计划
对于一个在大数据行业摸爬滚打了多年的老手来说,第一眼肯定是跟着堆栈信息进行排查,
理所当然的就是会找到BroadcastExchangeExec这个类,但是就算把代码全看一遍也不会有所发现。
蓦然回首
这个问题折腾了我大约2个小时,错误发生的上下文都看了不止十遍了,还是没找到一丝头绪,可能是上帝的旨意,在离错误不到50行的地方,刚好是一个页面的距离,发现了以下错误:
53.024: [Full GC (Ergonomics) [PSYoungGen: 802227K->698101K(1191424K)] [ParOldGen: 3085945K->3085781K(3495424K)] 3888173K->3783883K(4686848K), [Metaspace: 135862K->135862K(1185792K)], 0.9651630 secs] [Times: user=25.51 sys=0.39, real=0.96 secs]
53.990: [Full GC (Allocation Failure) [PSYoungGen: 698101K->698047K(1191424K)] [ParOldGen: 3085781K->3079721K(3495424K)] 3783883K->3777769K(4686848K), [Metaspace: 135862K->134900K(1185792K)], 0.6236139 secs] [Times: user=14.05 sys=0.28, real=0.63 secs]
java.lang.OutOfMemoryError: Java heap space
Dumping heap to panda_dump ...
Heap dump file created [3938522340 bytes in 5.708 secs]
真是 众人寻他千百度,蓦然回首, 没想到是 OOM 问题。
结论
在查找错误的时候,还是得在错误的上下文中多翻几页。
相关文章:
)
Spark 中 BroadCast 导致的内存溢出(SparkFatalException)
背景 本文基于 Spark 3.1.1 open-jdk-1.8.0.352目前在排查 Spark 任务的时候,遇到了一个很奇怪的问题,在此记录一下。 现象描述 一个 Spark Application, Driver端的内存为 5GB,一直以来都是能正常调度运行,突然有一天,报…...
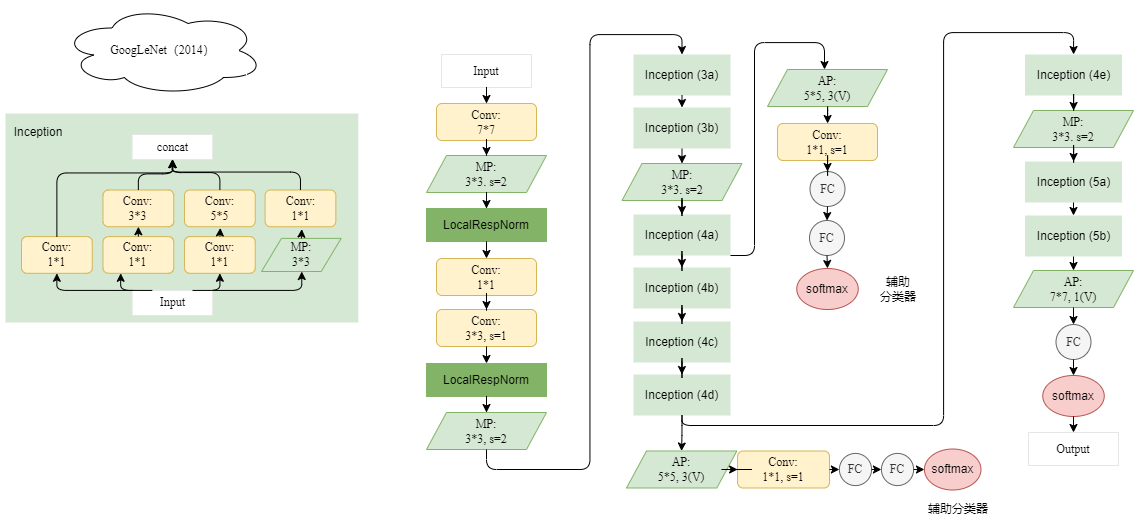
深度学习经典算法详细模型图
很早绘制的一些模型图,当时放在CSDN的草稿里,今天发现了,把它分享出来吧,还能更清晰的帮助理解! 1.AlexNet(2012) 2. VGGNet(2014) 3. SqueezeNet(2016) 4. GoogleNet(2014)...
03、Kafka ------ CMAK(Kafka 图形界面管理工具) 下载、安装、启动
目录 CMAK(Kafka 图形界面管理工具)下载安装启动打开 cmak 图形界面 CMAK(Kafka 图形界面管理工具) Kafka本身并没有提供Web管理工具,而是推荐使用bin目录下各种工具命令来管理Kafka, 这些工具命令其实用起…...

复习python从入门到实践——函数function
复习python从入门到实践——函数function 函数是特别难的,大家一定要好好学、好好复习、反复巩固。函数没学好,会为后面造成很大困扰。 教科书中函数举例会稍微有点复杂。在此章复习中,我将整理出容易疏漏和混淆的知识点,并用最简…...
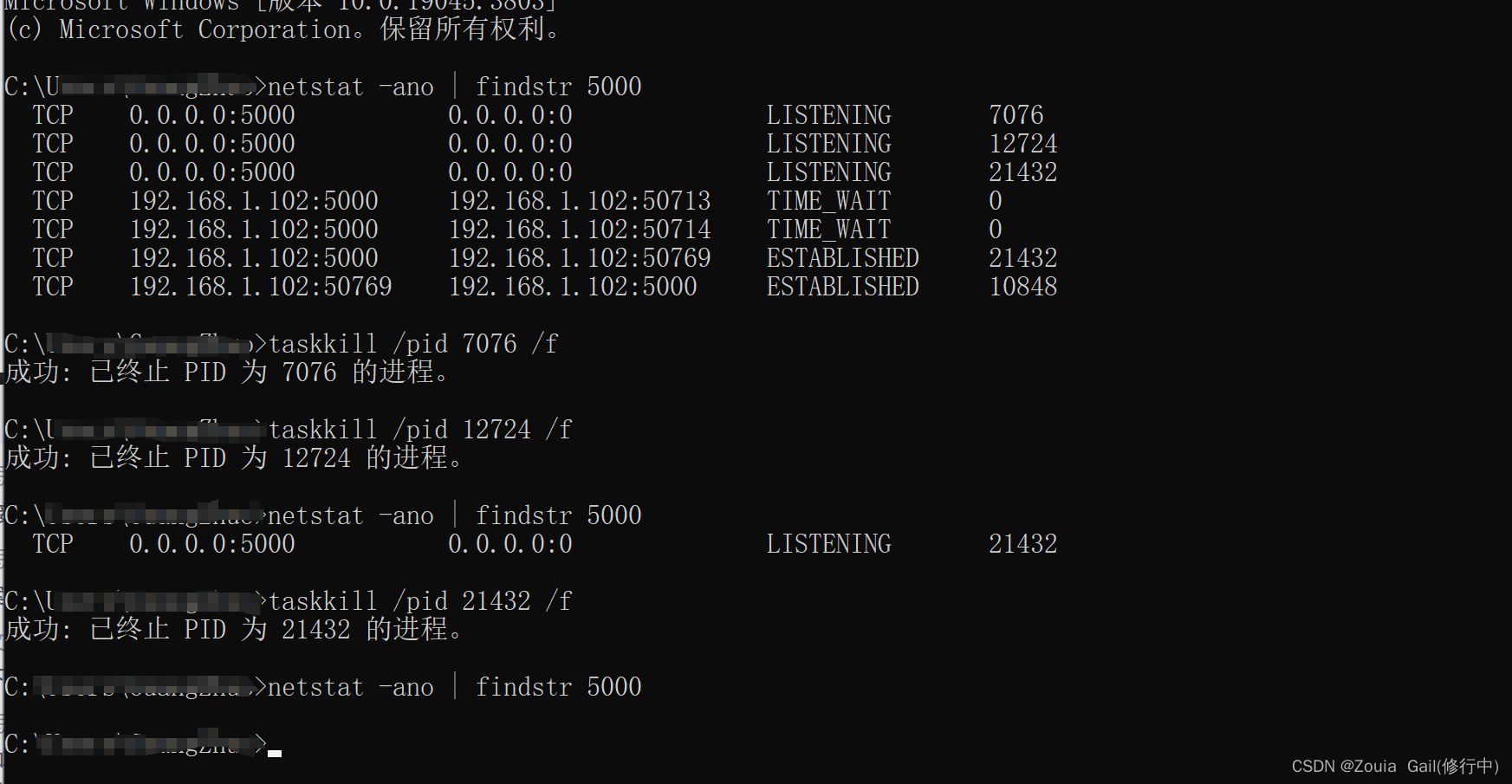
【Internal Server Error】pycharm解决关闭flask端口依然占用问题
Internal Server Error The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application. 起因: 我们在运行flask后,断开服务依然保持运行࿰…...
torch.nn.functional.interpolate与torchvision.transforms.Resize方法对张量图像Resize应用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、非张量数据使用torch方法resize(transforms.Resize)二、张量数据使用torch方法resize(torch.nn.functional.interpolate) 前言 要使用 PyTorch 对张量进行…...
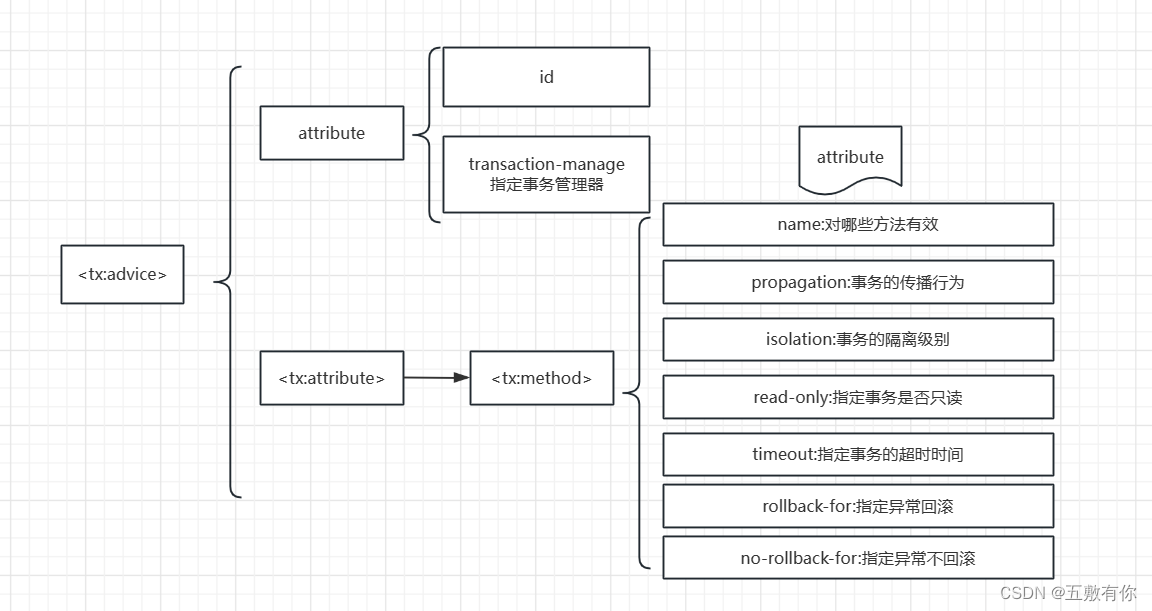
【Spring】Spring的事务管理
前言: package com.aqiuo.service.impl;import com.aqiuo.dao.AccountMapper; import com.aqiuo.pojo.Account; import com.aqiuo.service.AccountService; import org.springframework.jdbc.core.JdbcTemplate;import java.sql.Connection; import java.sql.SQLEx…...
配置cendos 安装docker 配置阿里云国内加速
由于我安装的cendos是镜像版。已经被配置好了。所以只需要更新相关配置信息即可。 输入 yum update自动更新所有配置 更新完成后输入 yum list docker-ce --showduplicates | sort -r 自动查询所有可用的docker版本 输入 yum install docker-ce docker-ce-cli container…...
【深度学习:Domain Adversarial Neural Networks (DANN) 】领域对抗神经网络简介
【深度学习:Domain Adversarial Neural Networks】领域对抗神经网络简介 前言领域对抗神经网络DANN 模型架构DANN 训练流程DANN示例 GPT示例 前言 领域适应(DA)指的是当不同数据集的输入分布发生变化(这种变化通常被称为共变量变…...
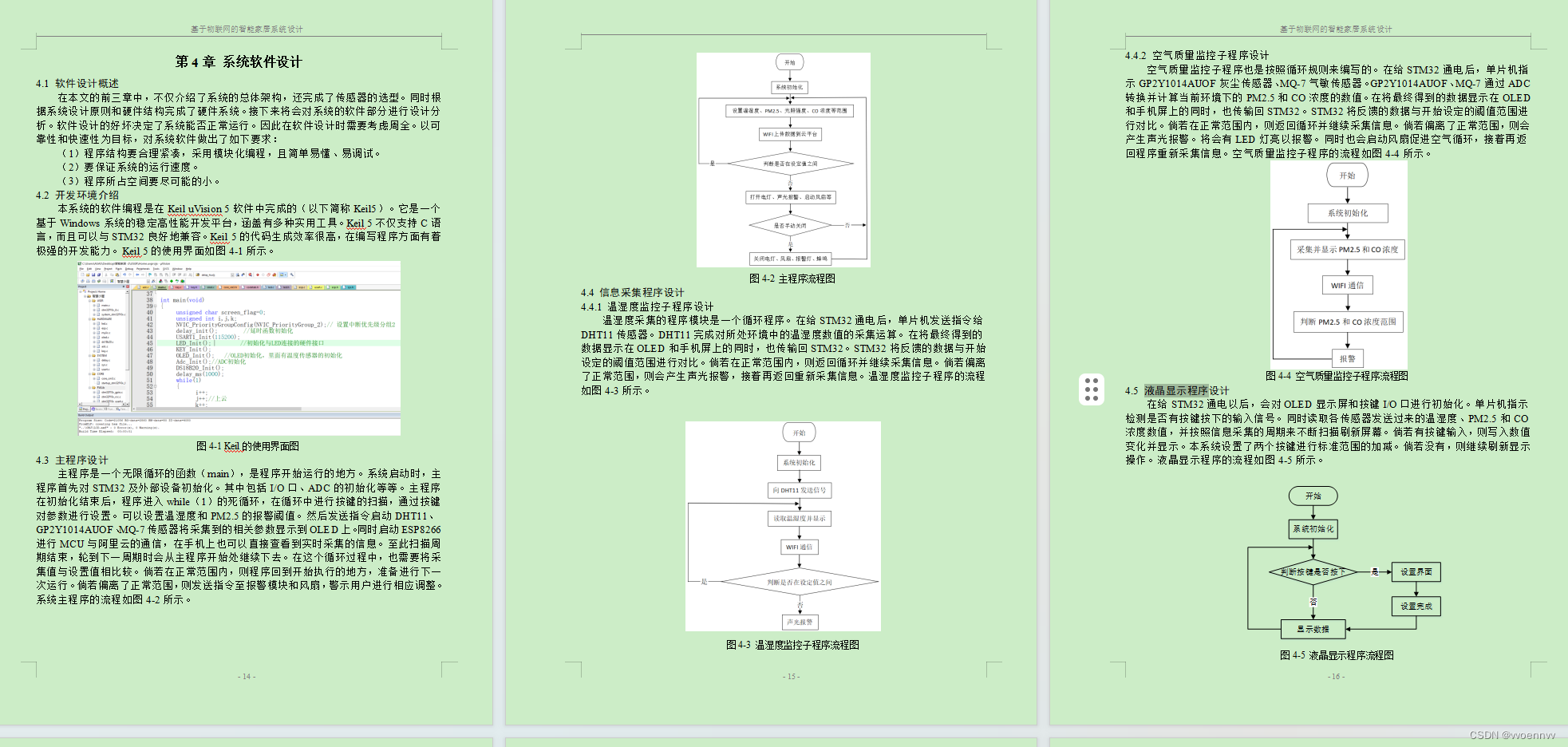
STM32 ESP8266 物联网智能温室大棚 (附源码 PCB 原理图 设计文档)
资料下载: https://download.csdn.net/download/vvoennvv/88680924 一、概述 本系统以STM32F103C8T6单片机为主控芯片,采用相关传感器构建系统硬件电路。其中使用DHT11温湿度传感器对温度和湿度的采集,MQ-7一氧化碳传感器检测CO浓度,GP2Y101…...

【DevOps-08-1】Harbor镜像仓库介绍和安装
一、简要描述 Harbor介绍Harbor安装 下载离线安装包把下载的离线安装包上传到服务器,并且解压修改Harbor配置文件启动Harbor登录Harbor管理后台Harbor管理后台首页二、Harbor介绍 前面在部署项目时,我们主要采用Jenkins推送jar包到指定服务器,再通过脚本命令让目标服务器对当…...
第八节 vue3新特性
系列文章目录 目录 系列文章目录 前言 操作方法 总结 前言 vue3与vue2的区别及特性。 具体信息 页面不用跟标签包裹cs...
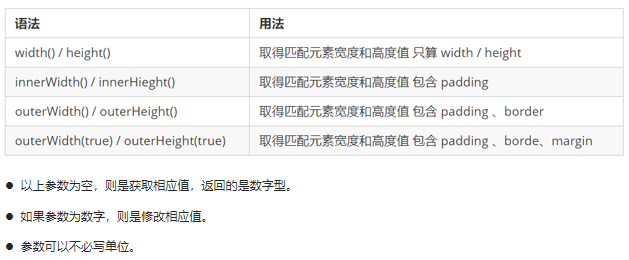
Web前端-jQuery
文章目录 jQuery1.1 jQuery 介绍1.1.1 JavaScript 库1.1.2 jQuery的概念1.1.3 jQuery的优点 1.2 jQuery 的基本使用1.2.1 jQuery 的下载1.2.2 jQuery快速入门1.2.3 jQuery入口函数1.2.4 jQuery中的顶级对象$1.2.5 jQuery 对象和 DOM 对象1.2.6. jQuery 对象和 DOM 对象转换 1.3…...

Leetcod面试经典150题刷题记录 —— 二叉搜索树篇
Leetcod面试经典150题刷题记录-系列Leetcod面试经典150题刷题记录——数组 / 字符串篇Leetcod面试经典150题刷题记录 —— 双指针篇Leetcod面试经典150题刷题记录 —— 矩阵篇Leetcod面试经典150题刷题记录 —— 滑动窗口篇Leetcod面试经典150题刷题记录 —— 哈希表篇Leetcod面…...
【大数据进阶第三阶段之ClickHouse学习笔记】ClickHouse的简介和使用
1、ClickHouse简介 ClickHouse是一种列式数据库管理系统(DBMS),专门用于高性能数据分析和数据仓库应用。它是一个开源的数据库系统,最初由俄罗斯搜索引擎公司Yandex开发,用于满足大规模数据分析和报告的需求。 开源地址…...
Linux下Redis6下载、安装和配置教程-2024年1月5日
Linux下Redis6下载、安装和配置教程-2024年1月5日 一、下载二、安装三、启动四、设置开机自启五、Redis的客户端1.Redis命令行客户端2.windows上的图形化桌面客户端 一、下载 1.Redis的官方下载:https://redis.io/download/ 2.网盘下载: 链接ÿ…...
Java后端开发——Ajax、jQuery和JSON
Java后端开发——Ajax、jQuery和JSON 概述 Ajax全称是Asynchronous Javascript and XML,即异步的JavaScript和 XML。Ajax是一种Web应用技术,该技术是在JavaScript、DOM、服务器配合下,实现浏览器向服务器发送异步请求。 Ajax异步请求方式不…...
ssm基于Vue的戏剧推广网站论文
摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统戏剧推广信息管理难度大,容错率低,…...

安卓adb
目录 如何开启 ADB 注意事项 如何使用 ADB ADB 能干什么 ADB(Android Debug Bridge)是一个多功能命令工具,它可以允许你与 Android 设备进行通信。它提供了多种设备权限,包括安装和调试应用,以及访问设备上未通过…...

【数位dp】【动态规划】C++算法:233.数字 1 的个数
作者推荐 【动态规划】C算法312 戳气球 本文涉及的基础知识点 动态规划 数位dp LeetCode:233数字 1 的个数 给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。 示例 1: 输入:n 13 输出:6 示例 2ÿ…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...
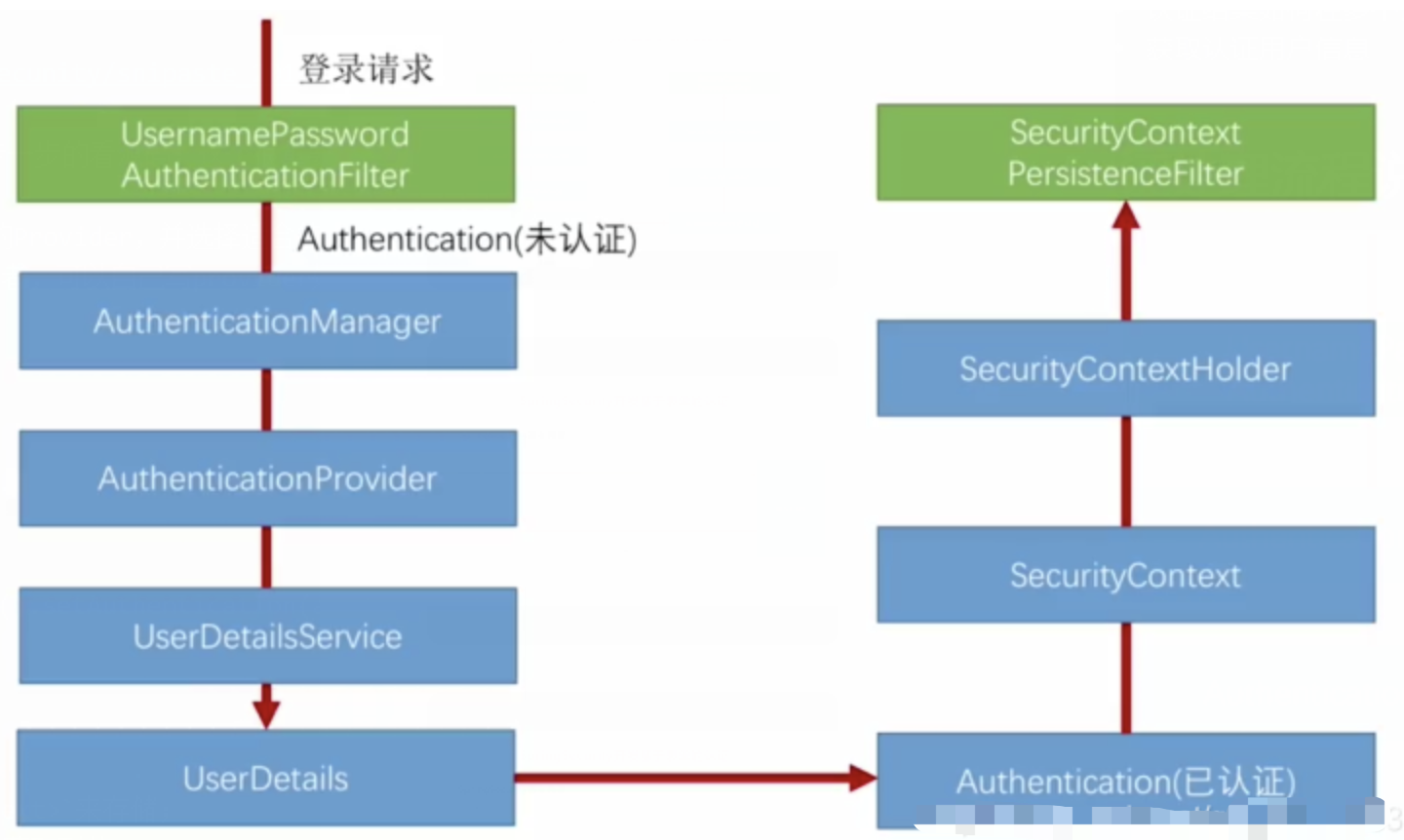
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...