【深度学习】cv领域中各种loss损失介绍
文章目录
- 前言
- 一、均方误差
- 二、交叉熵损失
- 三、二元交叉熵损失
- 四、Smooth L1 Loss
- 五、IOU系列的loss
前言
损失函数是度量模型的预测输出与真实标签之间的差异或误差,在深度学习算法中起着重要作用。具体作用:
1、目标优化:损失函数是优化算法的目标函数,通过最小化损失函数,模型的参数可以使得预测值接近真实值。训练过程的目标就是找到使损失函数最小化的参数。
2、模型评估:损失函数也可用于评估模型的性能。
3、指导学习过程:通过损失函数,模型可以学习如何调整权重和偏置以最小化预测实际标签之间的差异。这是通过梯度下降等优化算法来实现,这些算法使用损失函数的梯度来指导参数的更新。
深度学习损失函数在训练和评估深度学习模型中发挥关键作用,直接影响模型的性能和泛化能力。选择合适的损失函数是深度学习模型设计中的一个重要决策。
一、均方误差
均方误差(Mean Squared Error,MSE)是一种用于回归问题的损失函数,它度量模型的预测值与实际标签之间的平方差的平均值。通常用在具有连续输出的回归问题中使用,结合梯度下降等优化算法,最小化模型的预测误差。
优点:由于平方的存在,能对大误差给予更大的惩罚。缺点:对离群值(异常值)非常敏感,单个异常值可能对整体损失较大影响。
在pytroch的API:参考文档
torch.nn.MSELoss(reduction=‘mean’)
reduction (str, optional) – Specifies the reduction to apply to the output: ‘none’ | ‘mean’ | ‘sum’. ‘none’: no reduction will be applied, ‘mean’: the sum of the output will be divided by the number of elements in the output, ‘sum’: the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction. Default: ‘mean’
代码示例:
import torch
import torch.nn as nntorch.random.manual_seed(0)if __name__ == '__main__':mse = nn.MSELoss(reduction='sum')inputs = torch.randn(3, 5, requires_grad=True)outputs = torch.randn(3, 5)loss = mse(inputs, outputs)
在cv中,常用在以下几个领域:
- 图像配准(模板匹配):MSE用于衡量两个图像之间的差异。通过比较配准后的图像与目标之间的像素,评估二者之间的差异。
- 回归任务:在图像属性预测等任务中,MSE是一种常见的损失函数。
- 目标检测:在目标检测中,当模型需要回归目标边界框的坐标时,MSE度量预测框与真实框之间的位置差异。如yolov1等。
- 自监督学习:生成的目标通常是通过对原始数据应用某种变换而获得的。MSE可以用于度量模型生成的结果与变换后的原始数据之间的差异。
- 生成对抗网络(GAN): 在 GAN 中,生成器的输出与真实图像之间的差异通常可以通过 MSE 来度量。然而,对抗性损失(例如二元交叉熵)通常更为常见,因为它更好地促使生成器生成逼真的图像。
二、交叉熵损失
CrossEntropyLoss(交叉熵损失)是在多分类问题中常用的损失函数,用于衡量模型输出的概率分布与真实标签的差异。
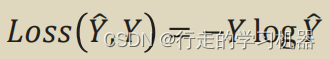
Y代表真实值, Y-head表示预测值
交叉熵损失通过比较模型对每个类别的预测概率与真实标签的概率分布,惩罚模型对正确类别的不确定性越大的情况。在优化过程中,模型的目标是最小化交叉熵损失,以使得模型对每个样本的预测更接近真实的标签分布。参考文档
在PyTorch等深度学习框架中,CrossEntropyLoss通常与Softmax激活函数结合使用。Softmax函数能够将模型的原始输出转换成表示概率分布的形式,而CrossEntropyLoss则基于这些概率计算损失。
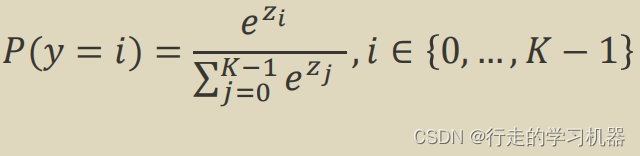
代码示例:
import torch
import torch.nn as nn# Example of target with class indices
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
output = loss(input, target)
output.backward()
# Example of target with class probabilities
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5).softmax(dim=1)
output = loss(input, target)
output.backward()
在cv领域,交叉熵损失常用在图像多分类的场景中。
三、二元交叉熵损失
BCELoss是交叉熵损失在二分类问题上的一个特例。在深度学习中,会使用二元交叉熵损失函数来衡量二分类模型的性能。与一般的交叉熵损失相比,二元交叉熵只涉及两个类别,因此简化了损失函数的形式。优化算法(如梯度下降)通过最小化BCELoss来调整模型参数,使得模型在二分类任务中更准确。
表达式如下:
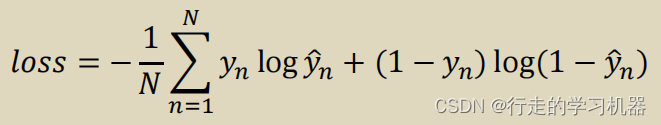
在pytorch的API:
torch.nn.BCELoss(weight=None, reduction=‘mean’)
reduction (str, optional) – Specifies the reduction to apply to the output: ‘none’ | ‘mean’ | ‘sum’. ‘none’: no reduction will be applied, ‘mean’: the sum of the output will be divided by the number of elements in the output, ‘sum’: the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction. Default: ‘mean’
在PyTorch等深度学习框架中,BCELoss通常与Sigmoid激活函数一起使用,因为Sigmoid函数可以将模型输出映射到[0, 1]范围内的概率值。这两者的结合通常用于最后一层的模型输出。
代码示例:
import torch
import torch.nn as nnm = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, 2, requires_grad=True)
target = torch.rand(3, 2, requires_grad=False)
output = loss(m(input), target)
output.backward()
四、Smooth L1 Loss
Smooth L1 Loss,也称为 Huber Loss,是一种损失函数,通常用于回归问题。它的特点是相对于均方误差(MSE),在预测接近目标值时损失函数的增长更缓慢,这使得它对离群值(outliers)更加鲁棒。

beta一般等于1。
优点:
- 鲁棒性:Smooth L1 Loss相对于均方误差(MSE)对离群值更具鲁棒性。这使得它在处理包含噪声或异常值的数据时表现更好,尤其在回归任务中,其中存在离群值的可能性较大。
- 平滑性: 在 (|x| < 1) 的情况下,Smooth L1 Loss使用平方项,使得损失在预测接近目标值时增长缓慢。这种平滑性有助于训练过程的稳定性。
- 对于大误差的抑制效果: 对于大误差,Smooth L1 Loss的增长速率较慢,相对于MSE,它在对大误差的处理上更加温和。
缺点: - 对小误差不敏感: 对于小误差,Smooth L1 Loss的损失增长速率较快,这可能使得在某些情况下对小误差不够敏感。这也可能导致模型对于较小的误差调整得过于激烈。
- 非唯一性: 对于某些相同的误差,Smooth L1 Loss可能有多个最小值。这使得损失函数的形状在某些情况下变得复杂,可能对优化过程产生一定的影响。
在pytorch中的API:
torch.nn.SmoothL1Loss(reduction=‘mean’, beta=1.0)
在cv领域中,smooth L1 loss常用来代替MSE,用于边界框回归,相比较MSE,smooth L1 loss更抗干扰。
五、IOU系列的loss
IOU Loss用于衡量目标检测模型性能的损失函数。用于监督模型在生成边界框预测时与真实边界框之间的重叠程度。
总共有四种IOU相关的Loss:IOU Loss、GIOU Loss、DIOU Loss、CIOU Loss
(1)IOU Loss:衡量预测框与真实框的IOU的大小,IOU越大,损失越少。
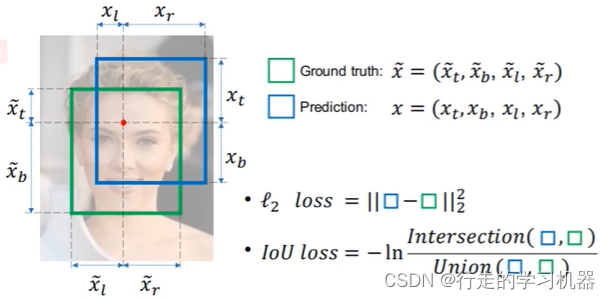
优点:能够更好反应重合程度,具有尺度不变性;
缺点:当二者不相交时,Loss为0,导致损失没办法继续传播。
(2)、GIOU Loss
GIOULoss针对IOULoss的缺点,引入了Ac和u,改善了部分IOULoss的缺陷。
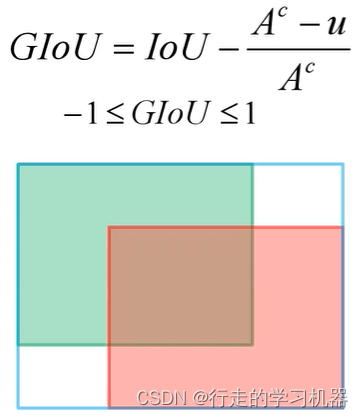
Ac表示蓝色矩形框的面积,u表示预测框与真实框的并集。
GIOULoss表达式:
GIOU Loss = 1 - GIOU
缺点是:两个边界框在同一水平线上时(Ac等于u),退化成IOU。收敛慢,收敛精度低。
(3)DIOU Loss
DIOU Loss在IOU的基础上,考虑了预测框与边界框中心的距离及最大矩形框的对角线距离。
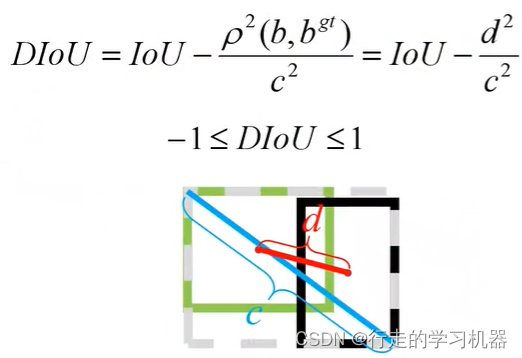
DIOULoss = 1 - DIou
DIOULoss极大加快了收敛速度和收敛精度。
(4)CIOU Loss
CIOU Loss在DIOU Loss的基础上,还考虑长宽比。

相关文章:
【深度学习】cv领域中各种loss损失介绍
文章目录 前言一、均方误差二、交叉熵损失三、二元交叉熵损失四、Smooth L1 Loss五、IOU系列的loss 前言 损失函数是度量模型的预测输出与真实标签之间的差异或误差,在深度学习算法中起着重要作用。具体作用: 1、目标优化:损失函数是优化算法…...

2024年,为什么学网络安全找不到工作?这才是重要原因!
为什么网络安全人才缺口那么大,但很多人还是找不到工作?其实大家都忽略了1个重点,那就是不清楚企业在招什么样的人。 我花了2天的时间统计了主流招聘网站的岗位信息,发现了一个惊人的真相,那就是企业都喜欢招这3种人&a…...
很有用!小企业如何从零开始制作产品手册?
对于初创公司和小企业来说,创造一份高效、吸引人的产品手册可能不是特别简单,特别是当资源和预算有限的时候。然而,一份良好的产品手册可以帮助你传达你的品牌故事,展示你的产品,甚至可以帮助你提高销售额,…...

基于OpenCV的图像缩放
基础概念 缩放是将图像的尺寸变小或变大的过程,即减少或增加原图像数据的像素个数,或者说通过增加或删除像素点来改变图像的尺寸; 基本原理:将分辨率(图片尺寸)为(w,h)的图像,缩放后其图像分辨…...

基于长短期神经网络LSTM的测量误差预测
目录 背影 摘要 代码和数据下载:基于长短期神经网络LSTM的测量误差预测(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/download/abc991835105/88714812 LSTM的基本定义 LSTM实现的步骤 基于长短期神经网络LSTM的测量误差预测 结果分析 展望 参考论文 背影 …...
`package.json`也可以有注释了
众所周知,JSON文件是不支持注释的,除了JSON5/JSONC之外,我们在开发项目特别是前端项目时,大量会用到JSON文件,特别是在编写package.json中的scripts时,由于缺少注释,当有大量的命令脚本时,就有了…...

数学之何为数学
数学是什么 数学是绝大多数人学得最多的一门功课,但对于“数学是什么?”这一看来很普通的问题,却很难一下子给出一个使公众满意的回答。按照恩格斯的说法,数学是以现实世界的空间形式和数量关系为研究对象的。尽管人们现在对空间…...

docker容器内,将django项目数据库改为postgresql
容器为ubuntu20.04版本,新建了一套django项目,使用的默认sqllit3,换为postgresql,容器里安装postgresql方法 步骤1: 安装PostgreSQL数据库 # 打开一个bash会话在你的容器中 docker exec -it <container_id_or_name> bash#…...
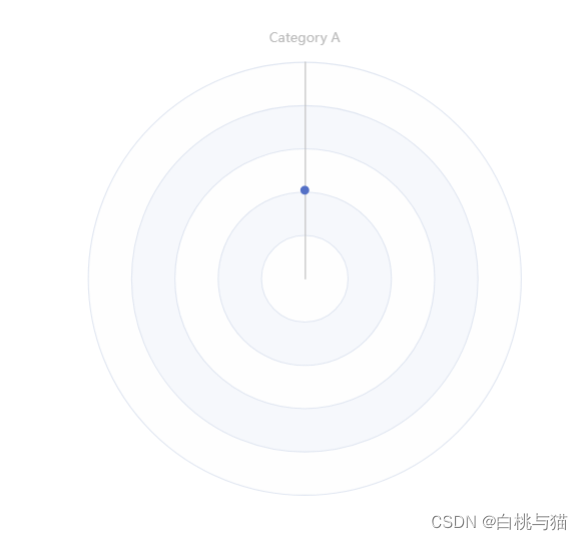
【echarts】雷达图参数详细介绍
1. 详细示例 var option {tooltip: {trigger: item},radar: {startAngle: 90,//第一个指示器轴的角度,默认90indicator: [// 指示器{ name: Category A, max: 220 },// name:指示器名称{ name: Category B, max: 200 },// max:指示器的最大值,可选&…...

网络安全试题进阶——附答案
选择题 什么是CSRF攻击的全称? A. Cross-Site Request ForgeryB. Cross-Site ScriptingC. Credential Sniffing and Retrieval ForceD. Cyber Security and Risk Framework 哪种安全攻击利用用户的社交工程,诱使他们点击似乎是合法链接的恶意链接&#x…...
二刷Laravel 教程(构建页面)总结Ⅰ
L01 Laravel 教程 - Web 开发实战入门 ( Laravel 9.x ) 一、功能 1.会话控制(登录、退出、记住我) 2.用户功能(注册、用户激活、密码重设、邮件发送、个人中心、用户列表、用户删除) 3.静态页面(首页、关于、帮助&am…...
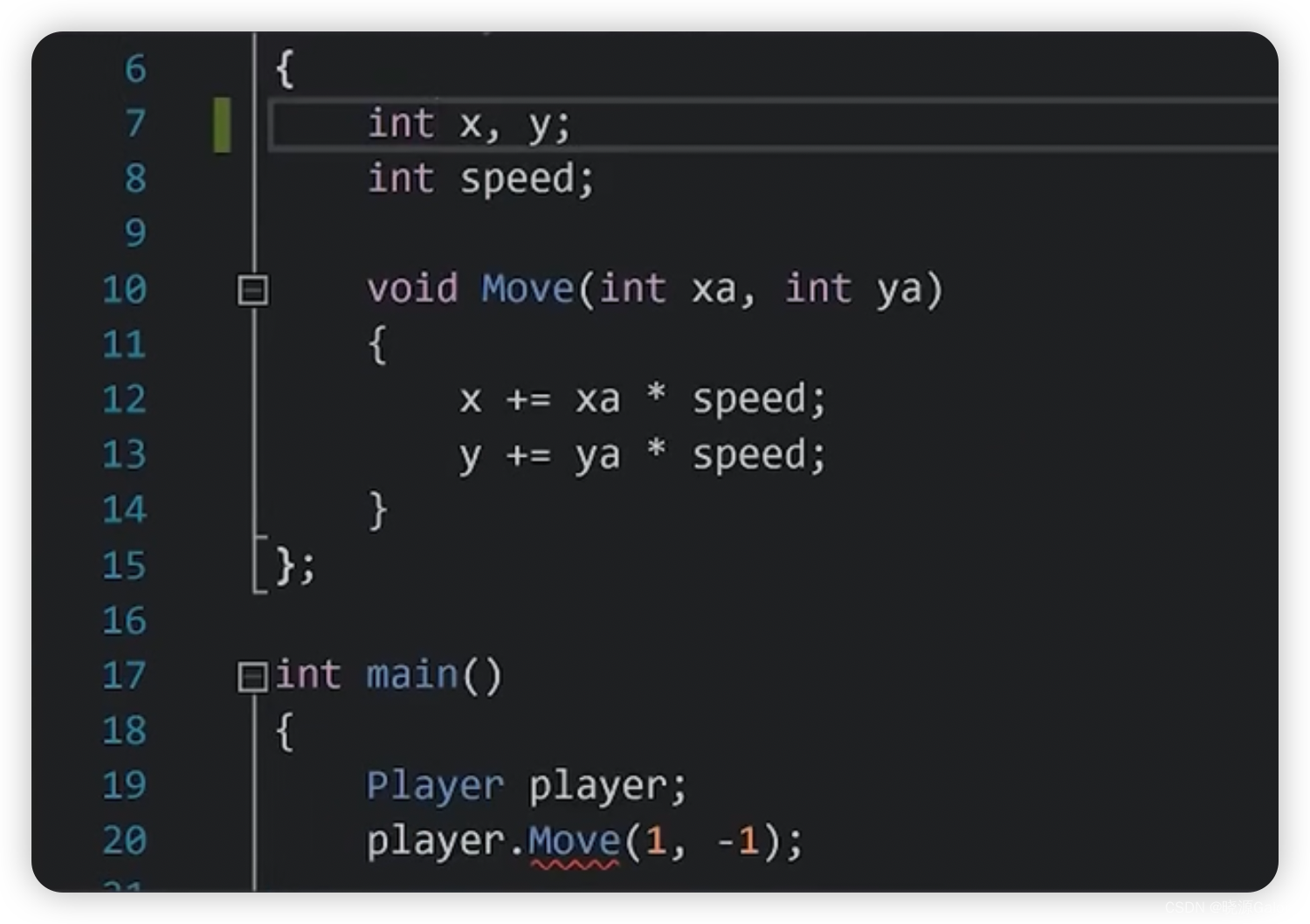
C++|19.C++类与结构体对比
类和结构体 类和结构体本质上并没有太大区别。 但两者在默认上有所区别。 类默认成员变量是私有的,而结构体默认成员变量是公有的。 也就是说,对于一个类来说,会默认使用private去保护其内部成员变量使得无法直接访问到其内部的变量。 同时从…...

Apache Camel笔记
Apache Camel笔记 1. Apache Camel概念 Apache Camel是一个轻量级的应用集成开发框架,专注于简化集成应用的开发。它基于Enterprise Integration Patterns(企业集成模式,简称EIP)的设计理念,提供了灵活的路由和中介机制…...

CSDN定制的奖品谁不想要?
各位大佬,在下真的缺一个喝水的杯子!!! 2023年即将画上句号,在这一年的技术征途上,CSDN始终陪伴在我身边,为我提供了丰富的知识资源、实用的技术文章和友好的交流平台。当我得知自己有幸获得CS…...

橄榄油行业分析:预计2029年将达到298亿美元
橄榄油是全世界公认高端食用油。橄榄油要以油橄榄树的果实为主要原料制得的植物油脂。橄榄油是世界上四大食用草本植物植物油脂之一,每年产量在260~300万吨级之间,占全球橄榄油生产量18900万吨级的1.5%上下。以其带有不饱和脂肪、角鲨烯、花青…...
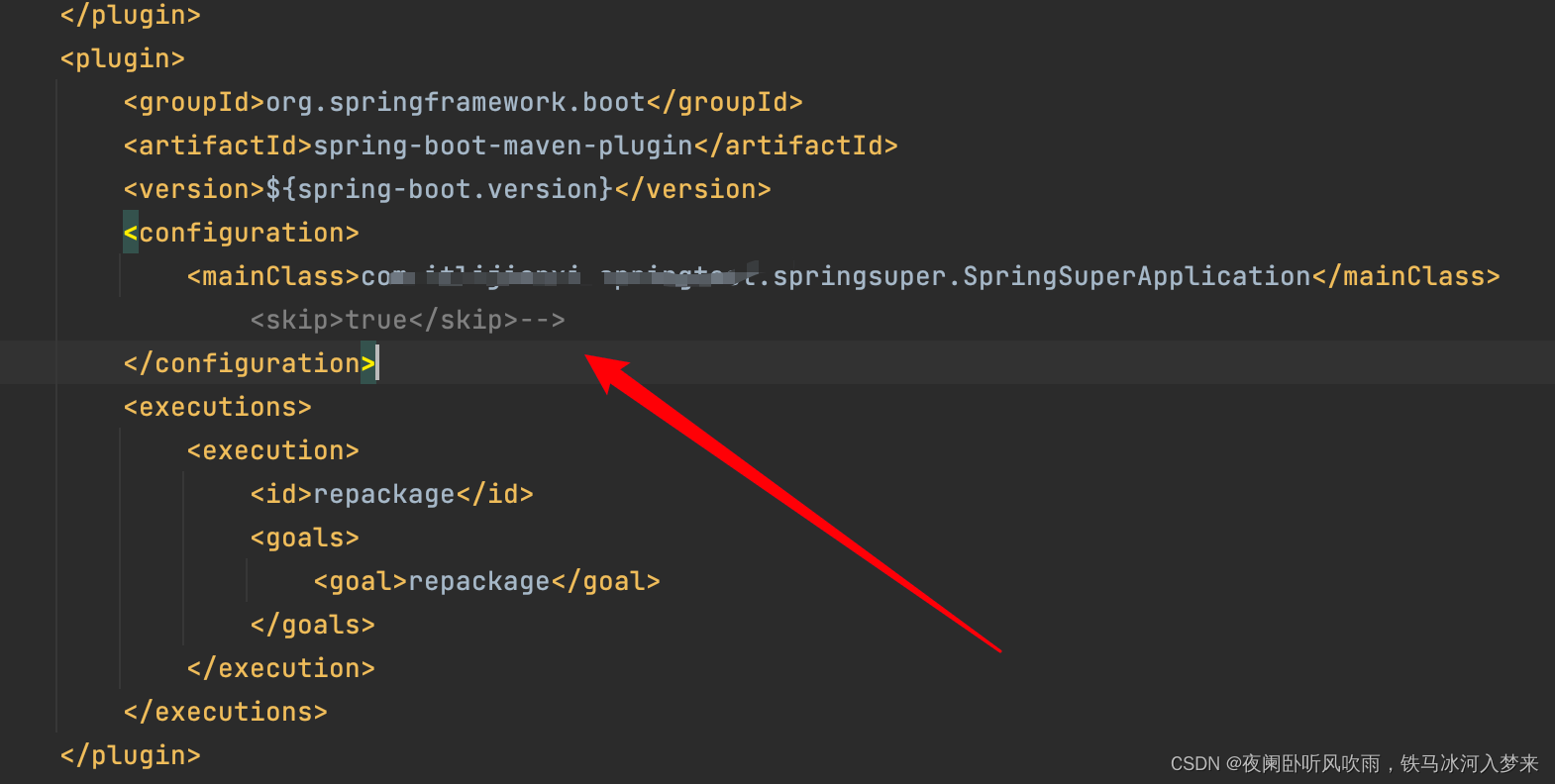
Maven 工程 java -jar 时提示 xxx-SNAPSHOT.jar 中没有主清单属性
Maven 工程 java -jar 时提示 xxx-SNAPSHOT.jar 中没有主清单属性 将skip属性注释掉或者改为false 如果为true,则工程找不到主启动类...

2. Mybatis 中SQL 执行原理
这里有两种方式,一种为常用的 Spring 依赖注入 Mapper 的方式。另一种为直接使用 SqlSessionTemplate 执行 Sql 的方式。 Spring 依赖注入 Mapper 的方式 Mapper 接口注入 SpringIOC 容器 Spring 容器在扫描 BeanDefinition 阶段会扫描 Mapper 接口类,…...

平衡合规与发展天平, 激发数据要素价值
数字经济大潮汹涌,为了应对复杂的外部环境,培育企业内生竞争力,企业需要摆脱贪大求快的增长模式,转向依靠合规与发展的双轮驱动。 数字经济的核心在于数据。重视数据作为生产要素的战略意义,积极建设数据要素流通交易…...

JAVA毕业设计118—基于Java+Springboot的宠物寄养管理系统(源代码+数据库)
毕设所有选题: https://blog.csdn.net/2303_76227485/article/details/131104075 基于JavaSpringboot的宠物寄养管理系统(源代码数据库)118 一、系统介绍 本系统分为管理员、用户两种角色 1、用户: 登陆、注册、密码修改、宠物寄养、寄养订单、宠物…...

oracle 19c容器数据库数据加载和传输-----SQL*Loader(一)
目录 数据加载 (一)控制文件加载 1.创建用户执行sqlldr 2.创建文本文件和控制文件 3.查看表数据 4.查看log文件 (二)快捷方式加载 1.system用户执行 2.查看表数据 3.查看log文件 外部表 数据加载和传输的工具࿱…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...