21 Nacos客户端本地缓存及故障转移
Nacos客户端本地缓存及故障转移
在Nacos本地缓存的时候有的时候必然会出现一些故障,这些故障就需要进行处理,涉及到的核心类为ServiceInfoHolder和FailoverReactor。

本地缓存有两方面,第一方面是从注册中心获得实例信息会缓存在内存当中,也就是通过Map的形式承载,这样查询操作都方便。第二方面便是通过磁盘文件的形式定时缓存起来,以备不时之需。
故障转移也分两方面,第一方面是故障转移的开关是通过文件来标记的;第二方面是当开启故障转移之后,当发生故障时,可以从故障转移备份的文件中来获得服务实例信息。
ServiceInfoHolder功能概述
ServiceInfoHolder类,顾名思义,服务信息的持有者。每次客户端从注册中心获取新的服务信息时都会调用该类,其中processServiceInfo方法来进行本地化处理,包括更新缓存服务、发布事件、更新本地文件等。

除了这些核心功能以外,该类在实例化的时候,还做了本地缓存目录初始化、故障转移初始化等操作,下面我们来分析。
ServiceInfo的本地内存缓存
ServiceInfo,注册服务的信息,其中包含了服务名称、分组名称、集群信息、实例列表信息,上次更新时间等,所以我们由此得出客户端从服务端注册中心获得到的信息在本地都以ServiceInfo作为承载者。
而ServiceInfoHolder类又持有了ServiceInfo,通过一个ConcurrentMap来储存.
// ServiceInfoHolder
private final ConcurrentMap<String, ServiceInfo> serviceInfoMap;
这就是Nacos客户端对服务端获取到的注册信息的第一层缓存,并且之前的课程中我们分析processServiceInfo方法时,我们已经看到,当服务信息变更时会第一时间更新ServiceInfoMap中的信息.
public ServiceInfo processServiceInfo(ServiceInfo serviceInfo) {....//缓存服务信息serviceInfoMap.put(serviceInfo.getKey(), serviceInfo);// 判断注册的实例信息是否更改boolean changed = isChangedServiceInfo(oldService, serviceInfo);if (StringUtils.isBlank(serviceInfo.getJsonFromServer())) {serviceInfo.setJsonFromServer(JacksonUtils.toJson(serviceInfo));}....return serviceInfo;
}
serviceInfoMap的使用就是这样,当变动实例向其中put最新数据即可。当使用实例时,根据key进行get操作即可。
serviceInfoMap在ServiceInfoHolder的构造方法中进行初始化,默认创建一个空的ConcurrentMap。但当配置了启动时从缓存文件读取信息时,则会从本地缓存进行加载。
public ServiceInfoHolder(String namespace, Properties properties) {initCacheDir(namespace, properties);// 启动时是否从缓存目录读取信息,默认false。if (isLoadCacheAtStart(properties)) {this.serviceInfoMap = new ConcurrentHashMap<String, ServiceInfo>(DiskCache.read(this.cacheDir));} else {this.serviceInfoMap = new ConcurrentHashMap<String, ServiceInfo>(16);}this.failoverReactor = new FailoverReactor(this, cacheDir);this.pushEmptyProtection = isPushEmptyProtect(properties);
}
这里我们要注意一下,涉及到了本地缓存目录,在我们上节课的学习中我们知道,processServiceInfo方法中,当服务实例变更时,会看到通过DiskCache#write方法向该目录写入ServiceInfo信息。
public ServiceInfo processServiceInfo(ServiceInfo serviceInfo) {.....// 服务实例已变更if (changed) {NAMING_LOGGER.info("current ips:({}) service: {} -> {}", serviceInfo.ipCount(), serviceInfo.getKey(),JacksonUtils.toJson(serviceInfo.getHosts()));// 添加实例变更事件InstancesChangeEvent,订阅者NotifyCenter.publishEvent(new InstancesChangeEvent(serviceInfo.getName(), serviceInfo.getGroupName(),serviceInfo.getClusters(), serviceInfo.getHosts()));// 记录Service本地文件DiskCache.write(serviceInfo, cacheDir);}return serviceInfo;
}
本地缓存目录
本地缓存目录cacheDir是ServiceInfoHolder的一个属性,用于指定本地缓存的根目录和故障转移的根目录。

在ServiceInfoHolder的构造方法中,初始化并且生成缓存目录

这个initCacheDir就不用了细看了,就是生成缓存目录的操作,默认路径:${user.home}/nacos/naming/public,也可以自定义,通过System.setProperty(“JM.SNAPSHOT.PATH”)自定义.
这里初始化完目录之后,故障转移信息也存储在该目录下。
private void initCacheDir(String namespace, Properties properties) {String jmSnapshotPath = System.getProperty(JM_SNAPSHOT_PATH_PROPERTY);String namingCacheRegistryDir = "";if (properties.getProperty(PropertyKeyConst.NAMING_CACHE_REGISTRY_DIR) != null) {namingCacheRegistryDir = File.separator + properties.getProperty(PropertyKeyConst.NAMING_CACHE_REGISTRY_DIR);}if (!StringUtils.isBlank(jmSnapshotPath)) {cacheDir = jmSnapshotPath + File.separator + FILE_PATH_NACOS + namingCacheRegistryDir+ File.separator + FILE_PATH_NAMING + File.separator + namespace;} else {cacheDir = System.getProperty(USER_HOME_PROPERTY) + File.separator + FILE_PATH_NACOS + namingCacheRegistryDir+ File.separator + FILE_PATH_NAMING + File.separator + namespace;}
}
故障转移
在ServiceInfoHolder的构造方法中,还会初始化一个FailoverReactor类,同样是ServiceInfoHolder的成员变量。FailoverReactor的作用便是用来处理故障转移的。

public ServiceInfoHolder(String namespace, Properties properties) {....// this为ServiceHolder当前对象,这里可以立即为两者相互持有对方的引用this.failoverReactor = new FailoverReactor(this, cacheDir);.....
}
我们来看一下FailoverReactor的构造方法,FailoverReactor的构造方法基本上把它的功能都展示出来了:
1. 持有ServiceInfoHolder的引用
2. 拼接故障目录:${user.home}/nacos/naming/public/failover,其中public也有可能是其他的自定义命名空间
3. 初始化executorService(执行者服务)
4. init方法:通过executorService开启多个定时任务执行
public FailoverReactor(ServiceInfoHolder serviceInfoHolder, String cacheDir) {// 持有ServiceInfoHolder的引用this.serviceInfoHolder = serviceInfoHolder;// 拼接故障目录:${user.home}/nacos/naming/public/failoverthis.failoverDir = cacheDir + FAILOVER_DIR;// 初始化executorServicethis.executorService = new ScheduledThreadPoolExecutor(1, new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);// 守护线程模式运行thread.setDaemon(true);thread.setName("com.alibaba.nacos.naming.failover");return thread;}});// 其他初始化操作,通过executorService开启多个定时任务执行this.init();
}
init方法执行
在这个方法中开启了三个定时任务,这三个任务其实都是FailoverReactor的内部类:
1. 初始化立即执行,执行间隔5秒,执行任务SwitchRefresher
2. 初始化延迟30分钟执行,执行间隔24小时,执行任务DiskFileWriter
3. 初始化立即执行,执行间隔10秒,执行核心操作为DiskFileWriter
public void init() {// 初始化立即执行,执行间隔5秒,执行任务SwitchRefresherexecutorService.scheduleWithFixedDelay(new SwitchRefresher(), 0L, 5000L, TimeUnit.MILLISECONDS);// 初始化延迟30分钟执行,执行间隔24小时,执行任务DiskFileWriterexecutorService.scheduleWithFixedDelay(new DiskFileWriter(), 30, DAY_PERIOD_MINUTES, TimeUnit.MINUTES);// backup file on startup if failover directory is empty.// 如果故障目录为空,启动时立即执行,立即备份文件// 初始化立即执行,执行间隔10秒,执行核心操作为DiskFileWriterexecutorService.schedule(new Runnable() {@Overridepublic void run() {try {File cacheDir = new File(failoverDir);if (!cacheDir.exists() && !cacheDir.mkdirs()) {throw new IllegalStateException("failed to create cache dir: " + failoverDir);}File[] files = cacheDir.listFiles();if (files == null || files.length <= 0) {new DiskFileWriter().run();}} catch (Throwable e) {NAMING_LOGGER.error("[NA] failed to backup file on startup.", e);}}}, 10000L, TimeUnit.MILLISECONDS);
}
这里我们先看DiskFileWriter,这里的逻辑不难,就是获取ServiceInfo中缓存的ServiceInfo,判断是否满足写入磁盘,如果条件满足,就将其写入拼接的故障目录,因为后两个定时任务执行的都是DiskFileWriter,但是第三个定时任务是有前置判断的,只要文件不存在就会立即执行把文件写入到本地磁盘中。
class DiskFileWriter extends TimerTask {@Overridepublic void run() {Map<String, ServiceInfo> map = serviceInfoHolder.getServiceInfoMap();for (Map.Entry<String, ServiceInfo> entry : map.entrySet()) {ServiceInfo serviceInfo = entry.getValue();if (StringUtils.equals(serviceInfo.getKey(), UtilAndComs.ALL_IPS) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.ENV_LIST_KEY) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.ENV_CONFIGS) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.VIP_CLIENT_FILE) || StringUtils.equals(serviceInfo.getName(), UtilAndComs.ALL_HOSTS)) {continue;}// 将缓存写入磁盘DiskCache.write(serviceInfo, failoverDir);}}
}
接下来,我们再来看第一个定时任务SwitchRefresher的核心实现,具体逻辑如下:
1. 如果故障转移文件不存在,则直接返回(文件开关)
2. 比较文件修改时间,如果已经修改,则获取故障转移文件中的内容。
3. 故障转移文件中存储了0和1标识。0表示关闭,1表示开启。
4. 当为开启状态时,执行线程FailoverFileReader。
class SwitchRefresher implements Runnable {long lastModifiedMillis = 0L;@Overridepublic void run() {try {File switchFile = new File(failoverDir + UtilAndComs.FAILOVER_SWITCH);// 文件不存在则退出if (!switchFile.exists()) {switchParams.put(FAILOVER_MODE_PARAM, Boolean.FALSE.toString());NAMING_LOGGER.debug("failover switch is not found, {}", switchFile.getName());return;}long modified = switchFile.lastModified();if (lastModifiedMillis < modified) {lastModifiedMillis = modified;// 获取故障转移文件内容String failover = ConcurrentDiskUtil.getFileContent(failoverDir + UtilAndComs.FAILOVER_SWITCH,Charset.defaultCharset().toString());if (!StringUtils.isEmpty(failover)) {String[] lines = failover.split(DiskCache.getLineSeparator());for (String line : lines) {String line1 = line.trim();// 1 表示开启故障转移模式if (IS_FAILOVER_MODE.equals(line1)) {switchParams.put(FAILOVER_MODE_PARAM, Boolean.TRUE.toString());NAMING_LOGGER.info("failover-mode is on");new FailoverFileReader().run();// 0 表示关闭故障转移模式} else if (NO_FAILOVER_MODE.equals(line1)) {switchParams.put(FAILOVER_MODE_PARAM, Boolean.FALSE.toString());NAMING_LOGGER.info("failover-mode is off");}}} else {switchParams.put(FAILOVER_MODE_PARAM, Boolean.FALSE.toString());}}} catch (Throwable e) {NAMING_LOGGER.error("[NA] failed to read failover switch.", e);}}
}
FailoverFileReader
顾名思义,故障转移文件读取,基本操作就是读取failover目录存储的备份服务信息文件内容,然后转换成ServiceInfo,并且将所有的ServiceInfo储存在FailoverReactor的ServiceMap属性中。
流程如下:
1. 读取failover目录下的所有文件,进行遍历处理
2. 如果文件不存在跳过
3. 如果文件是故障转移开关标志文件跳过
4. 读取文件中的备份内容,转换为ServiceInfo对象
5. 将ServiceInfo对象放入到domMap中
6. 最后判断domMap不为空,赋值给serviceMap
class FailoverFileReader implements Runnable {@Overridepublic void run() {Map<String, ServiceInfo> domMap = new HashMap<String, ServiceInfo>(16);BufferedReader reader = null;try {File cacheDir = new File(failoverDir);if (!cacheDir.exists() && !cacheDir.mkdirs()) {throw new IllegalStateException("failed to create cache dir: " + failoverDir);}File[] files = cacheDir.listFiles();if (files == null) {return;}for (File file : files) {if (!file.isFile()) {continue;}// 如果是故障转移标志文件,则跳过if (file.getName().equals(UtilAndComs.FAILOVER_SWITCH)) {continue;}ServiceInfo dom = new ServiceInfo(file.getName());try {String dataString = ConcurrentDiskUtil.getFileContent(file, Charset.defaultCharset().toString());reader = new BufferedReader(new StringReader(dataString));String json;if ((json = reader.readLine()) != null) {try {dom = JacksonUtils.toObj(json, ServiceInfo.class);} catch (Exception e) {NAMING_LOGGER.error("[NA] error while parsing cached dom : {}", json, e);}}} catch (Exception e) {NAMING_LOGGER.error("[NA] failed to read cache for dom: {}", file.getName(), e);} finally {try {if (reader != null) {reader.close();}} catch (Exception e) {//ignore}}if (!CollectionUtils.isEmpty(dom.getHosts())) {domMap.put(dom.getKey(), dom);}}} catch (Exception e) {NAMING_LOGGER.error("[NA] failed to read cache file", e);}// 读入缓存if (domMap.size() > 0) {serviceMap = domMap;}}
}
但是这里还有一个问题就是serviceMap是哪里用到的,这个其实是我们之前读取实例时候用到的getServiceInfo方法。
其实这里就是一旦开启故障转移就会先调用failoverReactor.getService方法,此方法便是从serviceMap中获取ServiceInfo
public ServiceInfo getService(String key) {ServiceInfo serviceInfo = serviceMap.get(key);if (serviceInfo == null) {serviceInfo = new ServiceInfo();serviceInfo.setName(key);}return serviceInfo;
}
调用serviceMap方法getServiceInfo方法就在ServiceInfoHolder中
// ServiceInfoHolder
public ServiceInfo getServiceInfo(final String serviceName, final String groupName, final String clusters) {NAMING_LOGGER.debug("failover-mode: {}", failoverReactor.isFailoverSwitch());String groupedServiceName = NamingUtils.getGroupedName(serviceName, groupName);String key = ServiceInfo.getKey(groupedServiceName, clusters);if (failoverReactor.isFailoverSwitch()) {return failoverReactor.getService(key);}return serviceInfoMap.get(key);
}
相关文章:
21 Nacos客户端本地缓存及故障转移
Nacos客户端本地缓存及故障转移 在Nacos本地缓存的时候有的时候必然会出现一些故障,这些故障就需要进行处理,涉及到的核心类为ServiceInfoHolder和FailoverReactor。 本地缓存有两方面,第一方面是从注册中心获得实例信息会缓存在内存当中&a…...

遍历读取文件夹下的所有文件
遍历读取文件夹下的所有文件 例如,读取文件夹下,子文件夹的所有的jpg文件: import glob path "./database/20230302/night/*/*.jpg"#设置自己的文件夹路径以及文件 image_files glob.glob(path, recursiveTrue)for image_file …...
nexus安装与入门
安装 nexus-3.31.1-01-unix.tar.gz 链接:https://pan.baidu.com/s/1YrJMwpGxmu8N2d7XMl6fSg 提取码:kfeh 上传到服务器,解压 tar -zvxf nexus-3.31.1-01-unix.tar.gz进入bin目录,启动 ./nexus start查看状态 ./nexus status默…...
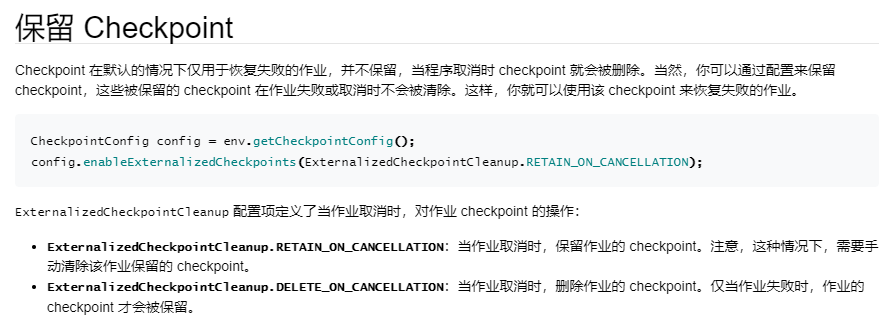
Flink SQL Checkpoint 学习总结
前言 学习总结Flink SQL Checkpoint的使用,主要目的是为了验证Flink SQL流式任务挂掉后,重启时还可以继续从上次的运行状态恢复。 验证方式 Flink SQL流式增量读取Hudi表然后sink MySQL表,任务启动后处于running状态,先查看sin…...
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书 一、竞赛时间 总计:360分钟 竞赛阶段竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 A模块 A-1 登录安全加固 180分钟 200分 A-2 本地安全策略配置 A-3 流量完整性保护 A-4 事件监控 …...

MyBatis中主键回填的两种实现方式
主键回填其实是一个非常常见的需求,特别是在数据添加的过程中,我们经常需要添加完数据之后,需要获取刚刚添加的数据 id,无论是 Jdbc 还是各种各样的数据库框架都对此提供了相关的支持,本文我就来和和大家分享下数据库主…...

Windows11如何打开ie浏览器
目录1.背景:2.方法一:在 edge 中配置使用 ie 模式3.方法二:通过 Internet 选项 打开1.背景: 昨天电脑自动从win10升级为win11了,突然发现电脑找不到ie浏览器了,打开全都是直接跳转到 edge 浏览器࿰…...

Linux:进程间通信
目录 进程间通信目的 进程间通信分类 管道 System V IPC POSIX IPC 什么是管道 站在文件描述符角度-深度理解管道 管道使用 管道通信的四种情况 管道通信的特点 进程池管理 命名管道 创建一个命名管道 命名管道的打开规则 命名管道通信实例 匿名管道与命名管道的…...

【java】将LAC改造成Elasticsearch分词插件
目录 为什么要将LAC改造成ES插件? 怎么将LAC改造成ES插件? 确认LAC java接口能work 搭建ES插件开发调试环境 编写插件 生成插件 安装、运行插件 linux版本的动态链接库生成 总结 参考文档 为什么要将LAC改造成ES插件? ES是著名的非…...
)
TPM 2.0实例探索3 —— LUKS磁盘加密(5)
接前文:TPM 2.0实例探索3 —— LUKS磁盘加密(4) 本文大部分内容参考: Code Sample: Protecting secret data and keys using Intel Platform... 二、LUKS磁盘加密实例 4. 将密码存储于TPM的PCR 现在将TPM非易失性存储器中保护…...
mybatisplus复习(黑马)
学习目标能够基于MyBatisPlus完成标准Dao开发能够掌握MyBatisPlus的条件查询能够掌握MyBatisPlus的字段映射与表名映射能够掌握id生成策略控制能够理解代码生成器的相关配置一、MyBatisPlus简介MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工…...

【数据聚类|深度聚类】Deep Comprehensive Correlation Mining for Image Clustering(DCCM)论文研读
Abstract 翻译 最近出现的深度无监督方法使我们能够联合学习表示和对未标记数据进行聚类。这些深度聚类方法主要关注样本之间的相关性,例如选择高精度对来逐步调整特征表示,而忽略了其他有用的相关性。本文提出了一种新的聚类框架,称为深度全面相关挖掘(DCCM),从三个方面…...

CE认证机构有哪些机构?
CE认证机构有哪些机构? 所有出口欧盟的产品都需要办理CE证明,而电子电器以及玩具是强制性要做CE认证。很多人以为只有办理欧盟NB公告机构的CE认证才可以被承认,实际上并不是。那么,除了NB公告上的机构,还有哪些认证机…...
解决方法)
MYSQL5.7:Access denied for user ‘root‘@‘localhost‘ (using password:YES)解决方法
一、打开MySQL目录下的my.ini文件,在文件的[mysqld]下面添加一行 skip-grant-tables,保存并关闭文件;skip-grant-tables :跳过密码登录,登录时无需密码。my.ini :一般在和bin同目录下,如果没有的话可自己创…...

单目运算符、双目运算符、三目运算符
单目运算符是什么 单目运算符是指运算所需变量为一个的运算符 又叫一元运算符,其中有逻辑非运算符:!、按位取 反运算符:~、自增自减运算符:,-等。 逻辑非运算符【!】、按位取反运算符【~】、 自…...
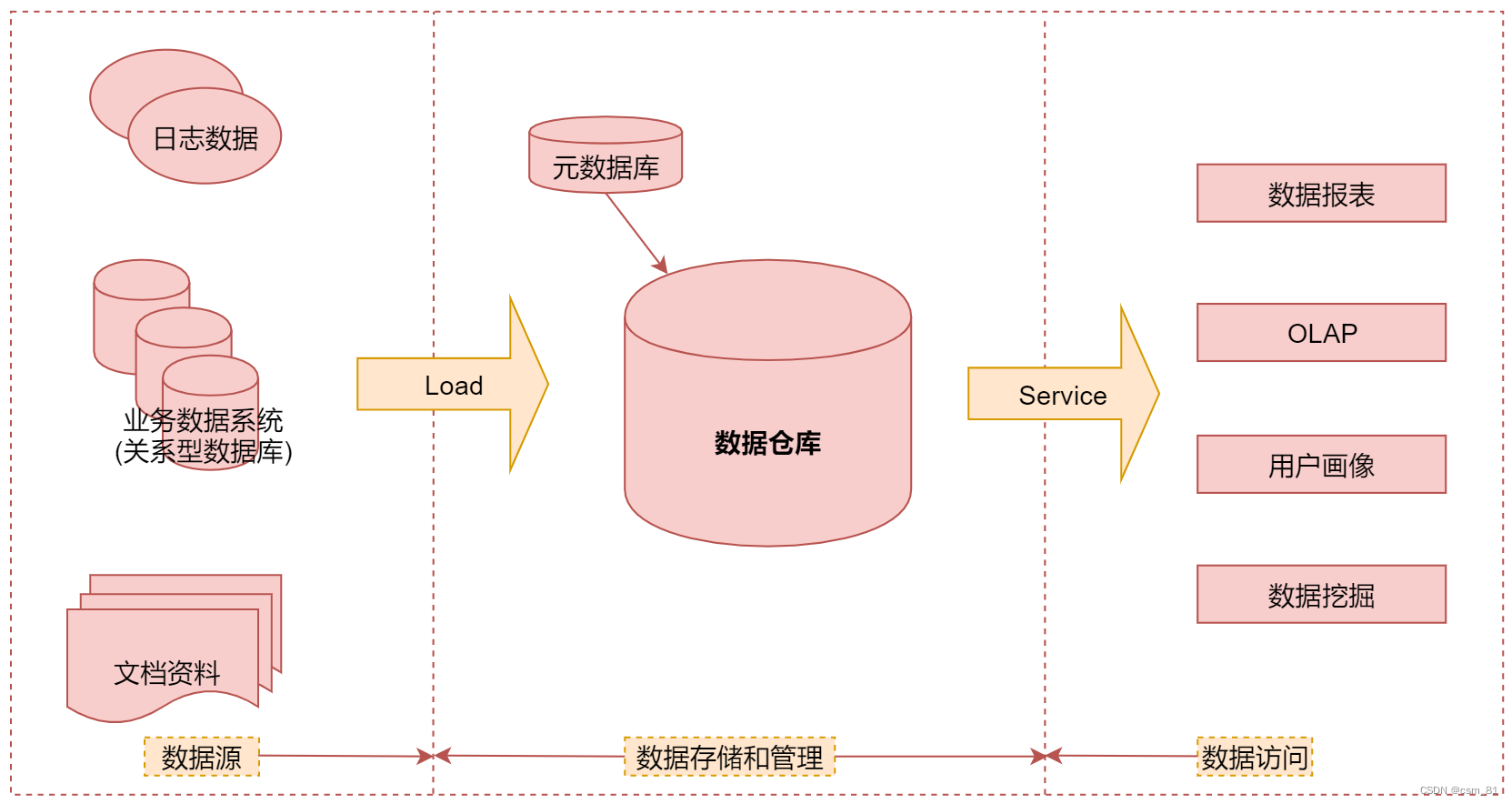
离线数据仓库项目搭建——准备篇
文章目录(一)什么是数据仓库(二)数据仓库基础知识(三)数据仓库建模方式(1)星行模型(2)雪花模型(3)星型模型 VS 雪花模型(四…...
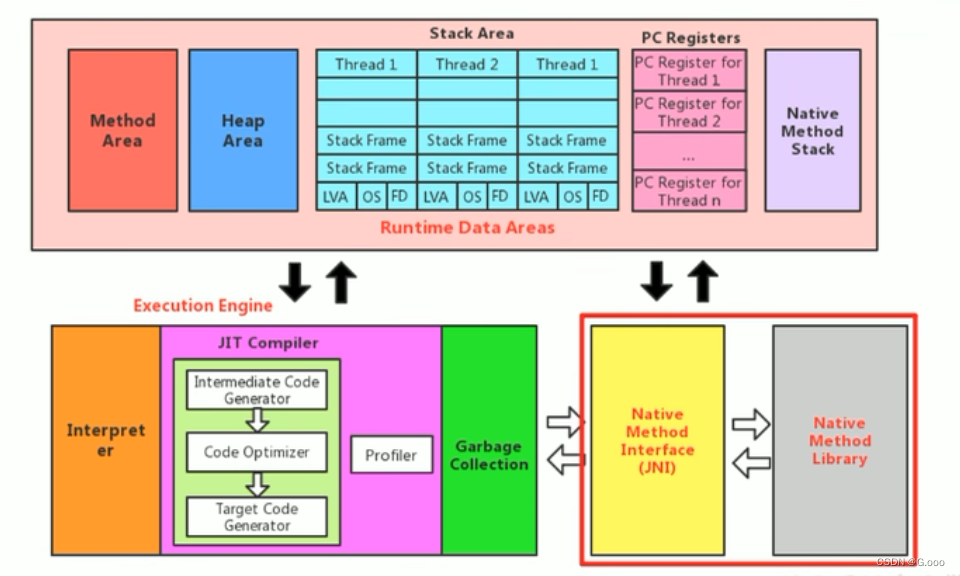
十七、本地方法接口的理解
什么是本地方法? 1.简单来讲,一个Ntive method 就是一个Java调用非Java代码的接口.一个Native Method 是这样一个Java方法:该方法的实现由非Java语言实现,比如C,这个特征并非Java所特有,很多其他的编程语言都由这一机制,比如在C中…...
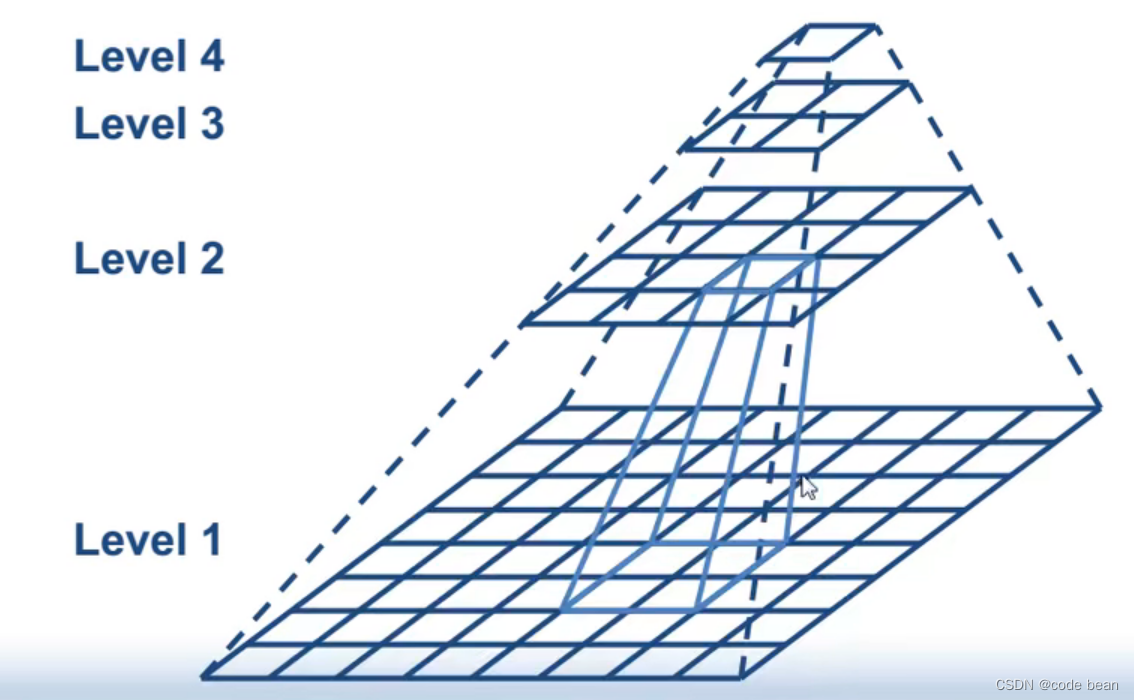
【halcon】模板匹配参数之金字塔级数
背景 今天,在使用模板匹配的时候,突然程序卡死,CPU直接飙到100%。最后排查发现是模板匹配其中一个参数 NumLevels 导致的: NumLevels: The number of pyramid levels used during the search is determined with numLevels. If n…...

jupyter lab安装和配置
jupyter lab 安装和配置 一、jupyter lab安装并配置 安装jupyterlab pip install jupyterlab启动 Jupyter lab默认会打开实验环境的,也可以自己在浏览器地址栏输入127.0.0.1:8888/lab 汉化 pip install jupyterlab-language-pack-zh-CN刷新一下网页࿰…...

用Docker搭建yolov5开发环境
拉取镜像 sudo docker pull pytorch/pytorch:latest 创建容器 sudo docker run -it -d --gpus "device0" pytorch/pytorch bash 查看所有容器 sudo docker ps -a 查看运行中的容器 sudo docker ps 进入容器 docker start -i 容器ID 将依赖包全都导入到requiremen…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

LabVIEW双光子成像系统技术
双光子成像技术的核心特性 双光子成像通过双低能量光子协同激发机制,展现出显著的技术优势: 深层组织穿透能力:适用于活体组织深度成像 高分辨率观测性能:满足微观结构的精细研究需求 低光毒性特点:减少对样本的损伤…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...
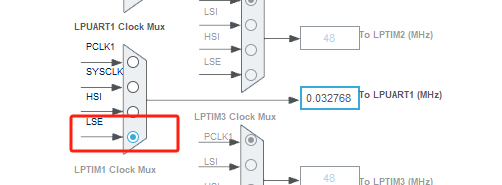
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...