大数据平台小结
搭建大数据平台
启动流程
1、启动Nginx服务(在bdp-web-mysql服务中)
cd /usr/local/nginx/# 启动Nginx
./sbin/nginx# 查看端口是否存在
netstat -tunlp|grep 20001
2、启动zookeeper(在bdp-executor-realtime123)
cd /app/bdp/apache-zookeeper-3.5.8-bin/bin# 启动
./zkServer.sh start# 查看状态
./zkServer.sh status
3、开启实时同步微服务(在bdp-executor-realtime123)
cd /app/bdp/bdp-realtime
sh bin/start.sh
tail -200f logs/bdp-realtime.log4、启动confluent服务(在bdp-executor-realtime123)
cd /app/bdp/confluent-6.2.0
# 重载系统服务
systemctl daemon-reload# 使用系统服务启动服务
systemctl start zookeeper
systemctl start kafka
systemctl start kafka-connect必须依次启动zookeeper、kafka、kafka-connect,可用jps命令查看服务是否启动,下面是服务名与进程名对照。启动confluent服务的命令如上,然后启动bdp-server/executor/realtime的命令如下
cd /app/bdp/bdp-server
sh bin/start.sh
tail -200f logs/bdp-server.log服务名 | 进程名 |
zookeeper | QuorumPeerMain |
kafka | Kafka |
kafka-connect | ConnectDistributed |
确保jps命令存在上面三个进程名即可,代表安装成功。
刚开始只是照着文档都配置了一遍,然后登录进去后,测试了连接数据源后就以为成功了,后面再去操作的时候都不知道怎么跑起来,这里记录一下。同时还是改一下反手关掉虚拟机的毛病,挂起就可。
平台熟悉
各个服务的作用
应用名 | 信息 |
bdp-server | 服务端:大数据平台的大脑,掌控所有的任务启停,任务调度,微服务调用,元数据操作。(最多部署两个) |
bdp-executor | 执行器:任务执行器,负责任务执行与调度。(可部署多个) |
bdp-realtime | 实时同步微服务:对实时同步组件的管理。(仅可部署一个) |
bdp-web | 前端:大数据平台的入口,用户的操作页面。 |
bdp_db | 元数据库:存放大数据平台的元数据。 |
confluent | 实时同步组件:实时同步任务、物理删除任务的运行。(可部署多个) |
这里记录这个表主要是需要了解一下各个服务的作用
大数据平台涉及到的技术
confluent组件中包含了zookeeper(微服务调用)、kafka、kafka-connect(实时同步组件)
大数据监控平台是采用Grafana、Prometheus、node-exporter实现的,可对所有服务器的硬件资源进行监控,方便运维和及时了解平台运行情况。
Grafana用来展现监控数据,各种图表
Prometheus用来收集存储监控数据
node-exporter用来采集服务器各个指标值
这里列出的技术点都是我不熟悉的或者了解不深的,后期需要系统学习一下
Linux命令收集
# 查看子网掩码
ip route show
# 查看进程
ps -ef|grep node_exporter
# 查看端口
netstat -tunlp|grep node_exporter
#查看软件商是否存在
rpm -qa|grep mariadb
# 查看CPU核数
cat /proc/cpuinfo| grep "processor"| wc -l
#查看内存大小
free -h
# 查看磁盘信息
df -h# 关闭防火墙
systemctl stop firewalld.service
# 禁用防火墙开机自启
systemctl disable firewalld.service
# 检查防火墙状态
systemctl status firewalld.service# 临时生效,但重启服务器后失效(禁用selinux)
setenforce 0
# 永久生效,但需要重启服务器(禁用selinux)
vim /etc/selinux/config
# 调整为disabled(禁用selinux)
SELINUX=disabled#修改磁盘io调度
grubby --update-kernel=ALL --args="elevator=deadline"
#禁用透明页
grubby --update-kernel=ALL --args="transparent_hugepage=never"#对象删除
cd /etc/systemd/logind.conf
# 修改配置,取消注释,调整为no,保存退出
RemoveIPC=no
# 重启服务,使修改生效
systemctl restart systemd-logind# 修改机器名
hostnamectl set-hostname 机器名
# 修改后切换用户,查看机器名是否修改正确
su
# 修改host文件
vim /etc/hosts
# 将服务器机器名增加至hosts文件中,之后保存退出即可
192.168.181.144 bdp-server #服务器免密
ssh-keygen -t rsa
#将公钥内容写入到authorized_keys文件中
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys
#将本地公钥复制到远程服务器
ssh-copy-id -i 机器名# 重新加载服务配置
systemctl daemon-reload
# 启动服务
systemctl start ntpd
# 服务开机自启
systemctl enable ntpd
# 查看服务状态
systemctl status ntpd
# 使用系统服务停止服务
systemctl stop zookeeper# 解压
rpm -ivh jdk-8u241-linux-x64.rpm
tar -zxvf prometheus-2.17.2.linux-amd64.tar.gz
unzip nginx.zip#启动bdp-server/executor/realtime
cd /app/bdp/bdp-server
sh bin/start.sh
tail -200f logs/bdp-server.log我把文档里觉得有用常用的Linux命令集合在一起,方便我后期多加熟悉和练习,少复制多敲!!!
遇到的bug
bug1
报错信息
zookeeper服务起不来
报错原因
由于电脑配置有限,只开启了五台服务器,所以把bdp-executor和bdp-realtime放在一起,共开三台虚拟机,每一台服务器配置了bdp-executor和bdp-realtime,后面zookeeper服务起不来,最后发现是confluent里面zookeeper和bdp-executor里的zookeeper冲突了
解决办法
最后解决办法是bdp-executor的zookeeper不用了,bdp-executor和bdp-realtime都用confluent里面zookeeper
bug2
报错信息
zookeeper启动后秒挂,反正就是跑步起来,检查配置文件也没有问题
报错原因
由于在配置kafka的时候broker.id=1使用的是XShell的批量修改,导致三个集群的kafka都是broker.id=1,然后我启动了,启动后报错,检查发现配置文件错误,然后又修改了配置文件,改成了正确的配置,但是由于启动了kafka,所以这些错误的配置文件就注册到了zookeeper和kafka的缓存里,
后面虽然修改成正确的配置文件 ,但是由于已经注册到了zookeeper和kafka的缓存里,导致zookeeper里的配置和后面修改后的新的配置不同,zookeeper就挂掉了
解决办法
删掉zookeeper里注册的信息和kafka的本地缓存,然后重启即可
bug3
报错信息
org.pentaho.di.core.exception.KettleException:
org.pentaho.di.core.exception.KettleDatabaseException:
Couldn't execute SQL: LOAD DATA LOCAL INFILE '/tmp/9efa05b987b846728da85793a6dc131d' INTO TABLE `temp_2aeadf472f5cc5a1` 报错原因
权限不足
解决办法
show GLOBAL VARIABLES like 'local_infile';
set GLOBAL local_infile='off';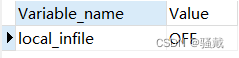
把local_infile改成off即可
bug4
报错信息
在测试批数据同步配置的时候发现运行后就卡在那里,没有继续执行,直接跳到最后断开日志,然后卡死
报错原因
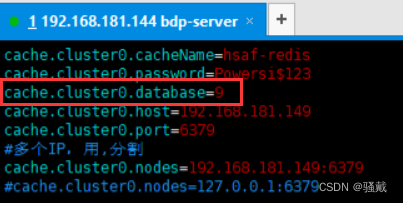
在bdp-server的conf/config/cache/cache.properties配置中,缓存配置中的下面标出的这一行配置要和bdp-executor-realtime123这三个的缓存配置要保持一致,这里我都设置为9
解决办法
把bdp-server和bdp-executor-realtime123的cache.properties中的cache.cluster0.database都改成9,保证一致即可
bug5
报错信息
在测试实时数据同步上线的时候报错,报错一大堆,上线失败
报错原因
数据库的时区和系统的时区不一致导致的
解决办法
在本地的数据库中执行set global time_zone='+8:00'来修改mysql全局时区为北京时间,也就是我们所在的东8区
bug6
报错信息
某次打开虚拟机的时候,发现输入ip a后没有en33的ip,简单来说就是ip不见了,但是之前明明存在,突然消失
报错原因
可能是隐藏或者IPADDR配置项失效
解决办法

识别所有网络接口
sudo dhclient ens33
查看ip地址
sudo ifconfig ens33
最后输入ip a即可bug7
报错信息
在bug6的操作后发现ip地址变了,不是我之前的那个ip
报错原因
linux默认是自动获取ip,所以在每次重启虚拟机的时候IP地址都会换,可能是IP地址由DHCP自动分配
解决办法
#修改配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33

修改配置文件的 BOOTPROTO为static(表示使用静态ip),然后下面追加指定的ip地址,然后使用 service network restart或者systemct restart network刷新网络,这里可能还会报错
Restarting network (via systemctl): Job for network.service failed because the control process exited with error code.
See "systemctl status network.service" and "journalctl -xe" for details. 使用systemctl status network.service命令查看错误详情
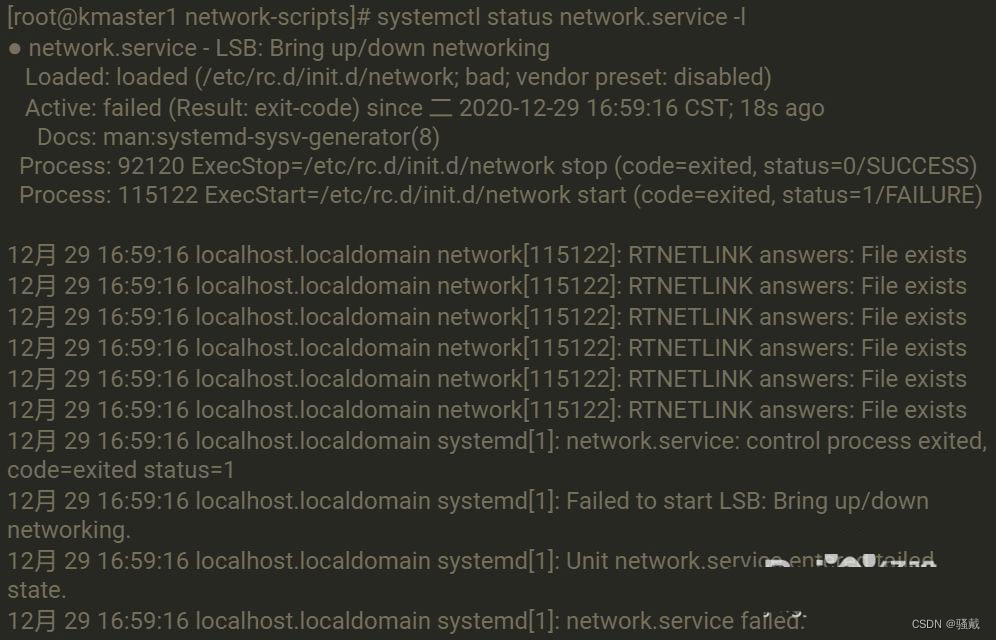
出现这种报错一般是和 NetworkManager 服务冲突导致的(network和NetworkManager一起工作时就会出现冲突),直接关闭 NetworkManger 服务就好了, service NetworkManager stop,并且禁止开机启动 systemctl disable NetworkManager(一定要记得关闭自启动,不然下次开机后又是老样子)
NetworkManager 的相关命令:
查看运行状态:systemctl status NetworkManager
启动:systemctl start NetworkManager
重启:systemctl restart NetworkManager
关闭:systemctl stop NetworkManager
查看是否开机启动:systemctl is-enabled NetworkManager
开机启动:systemctl enable NetworkManager
禁止开机启动:systemctl disable NetworkManager部署文档存在的错误
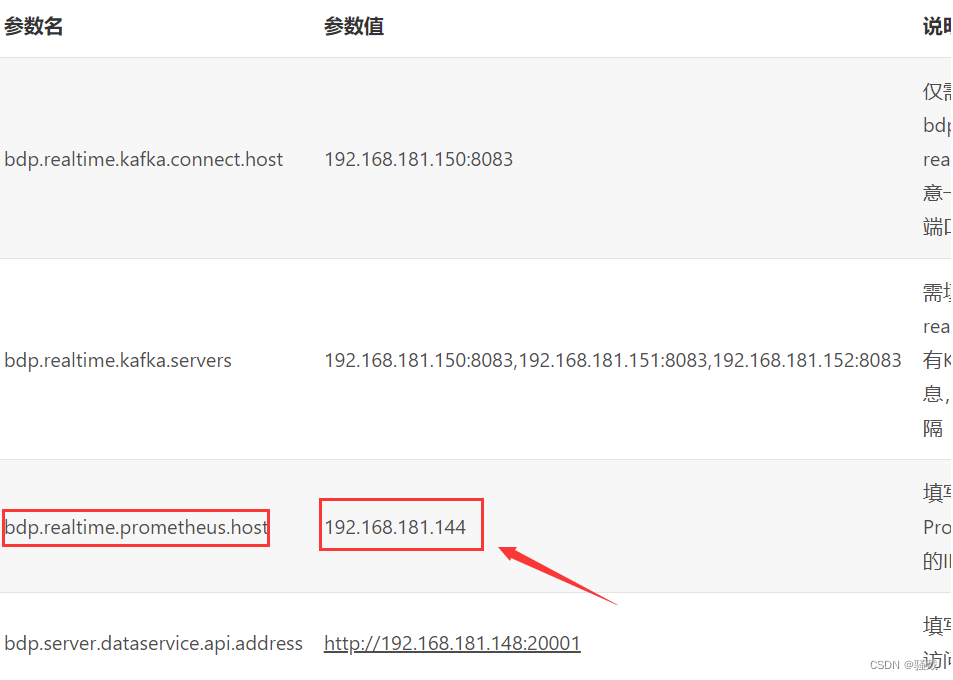
在初始化mysql的时候,需要修改表bdp_sys_para的值,如下图prometheus的参数值错了,应该是192.168.181.148(已经和峰少说过)

总结
本次搭建大数据平台,发现自己的Linux命令有很多都不熟练,然后意识到Linux对于学大数据的人来说的重要性,因为大数据集群都是搭建在Linux上,而Linux的命令是灵魂,所以多敲少复制!
在搭建的过程中,遇到了很多的bug和错误,发现自己再处理这些错误的时候第一反应就是复制到百度上一顿乱搜,这是老毛病,后面需要慢慢的培养自己遇到问题先思考-->看日志-->百度-->找峰少或者严胜救援
知道如何搭建大数据平台,了解大数据平台的组件、大数据平台的组成部分及其作用等等,更加熟悉了大数据平台的功能,意识到自己的不足之处,技术栈的缺乏,专业能力的不足,还有很大的提升空间!
相关文章:
大数据平台小结
搭建大数据平台启动流程1、启动Nginx服务(在bdp-web-mysql服务中)cd /usr/local/nginx/# 启动Nginx ./sbin/nginx# 查看端口是否存在 netstat -tunlp|grep 200012、启动zookeeper(在bdp-executor-realtime123)cd /app/bdp/apache-…...

力扣-139单词拆分
力扣-139单词拆分 1、题目 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 示例 1: 输入: s "…...

图机器学习-图神经网络
图神经网络 前面讲了图机器学习的一些传统方法,现在正式进入到课程的核心部分:图神经网络。 Design of GNN 那么图神经网络和我们之前接触的一些深度神经网络有什么不同呢? 对于别的类型的神经网络,往往我们都是处理一些类似网…...

配置Airbyte资源限制
资源限制有三种不同的级别配置:Instance-wide - 应用到Airbyte实例创建的Sync Job的所有容器上。Connector-specific - 应用到Airbyte实例创建的Sync Job的所有指定类型连接器的容器上Connection-specific - 应用到Airbyte实例创建的Sync Job的所有指定管道的容器上…...
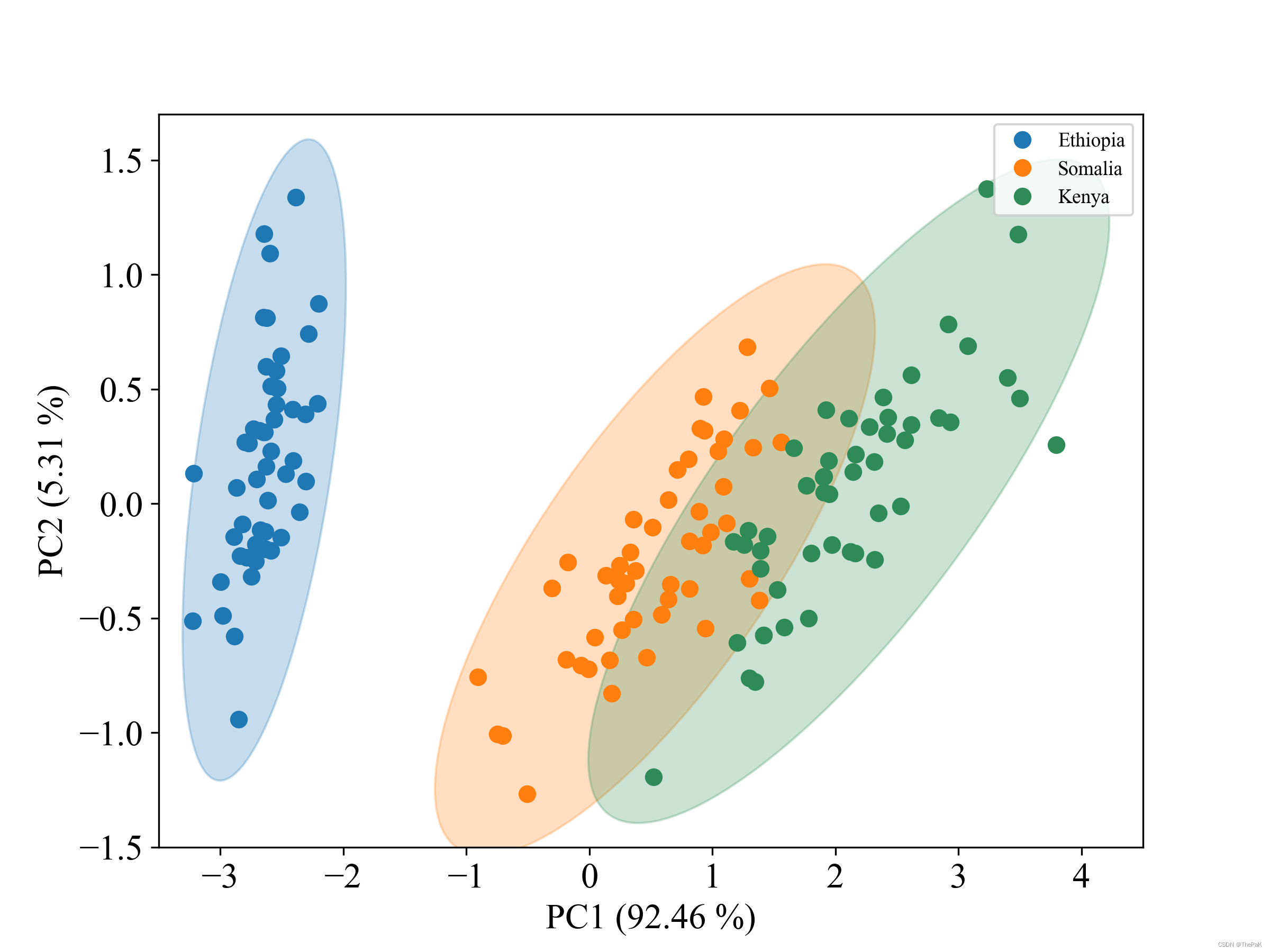
python实现PCA降维画分类散点图并标出95%的置信区间
此代码以数据集鸢尾花为例,对其使用PCA降维后,绘制了三个类别的样本点和对应的置信圆(即椭圆)。先放效果图。 下面是完整代码: from matplotlib.patches import Ellipsedef plot_point_cov(points, nstd3, axNone, **…...

Mysql高级之索引结构详解
Mysql的索引详解1.索引定义2.索引结构2.1数据结构分析2.1.1熟知的数据结构2.1.2分析为什么这么多的数据结构不全适用于索引结构2.2Hash结构2.3B tree结构3.索引分类3.1聚集索引(聚簇索引)3.2非聚集索引(稀疏索引)3.3联合索引3.4主…...
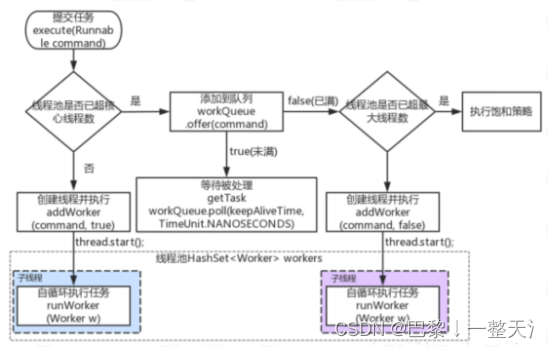
【线程-J.U.C】
Lock J.U.C最核心组件,Lock接口出现之前,多线程的并发安全只能由synchronized处理,但java5之后,Lock的出现可以解决synchronized的短板,更加灵活。 Lock本质上是一个接口,定义了释放锁(unlock&…...
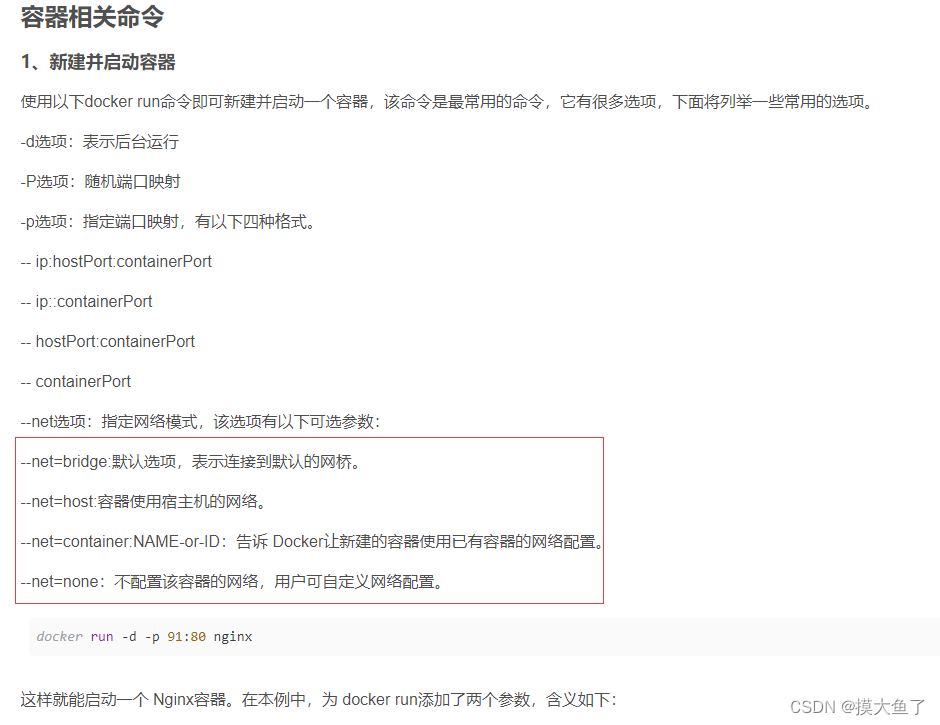
docker布署spring boot jar包项目
目录docker 安装创建目录制作镜像启动容器查看日志docker 安装 Docker安装、详解与部署 创建目录 服务器中创建一个目录,存放项目jar包和Dockerfile 文件 mkdir /目录位置创建目录后创建Dockerfile文件,上传jar包到同一目录下 创建dockerfile vim Doc…...

极简Vue3教程--Pinia状态管理
Pinia(发音为/piːnjʌ/,如英语中的“peenya”)是最接近pia(西班牙语中的菠萝)的词;Pinia开始于大概2019年,最初是作为一个实验为Vue重新设计状态管理,让它用起来像组合式API&#x…...

常用的map转bean互转方法
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 常用的map转bean互转方法一、hutool工具类二、fastjson工具类三、beanutils_BeanUtils工具类 不太好用四、cglib BeanMap工具类 不太好用五、reflect 反射来玩 不太好玩六、I…...

2.4G收发一体芯片NRF24L01P跟国产软硬件兼容 SI24R1对比
超低功耗高性能 2.4GHz GFSK 无线收发器芯片Si24R1,软硬件兼容NRF24L01P. Si24R1 是一颗工作在 2.4GHz ISM 频段,专为低功耗无线场合设计,集成嵌入式ARQ 基带协议引擎的无线收发器芯片。工作频率范围为 2400MHz-2525MHz,共有 126个…...
——单一职责原则、开放-关闭原则)
设计模式之七大原则(一)——单一职责原则、开放-关闭原则
目录一、设计模式的目的二、设计模式的七大原则1.单一职责原则2.开放-关闭原则一、设计模式的目的 设计模式的目的是为了提高代码重用性、可读性、可扩展性、可靠性,使得程序呈现出高内聚、低耦合的特性。 代码重用性(相同功能的代码,不用多…...
)
C++ set、unordered_set、multiset它们之间的区别与一些使用方法(不断更新)
set、unordered_set、multiset是什么?以及它们之间的区别 首先,它们三个都是C标准库提供的关联容器中的一种。只不过set、multiset容器是有序的,而unordered_set容器是无序的 std::set 是 C 标准库中的一个容器,其存储的元素按设…...
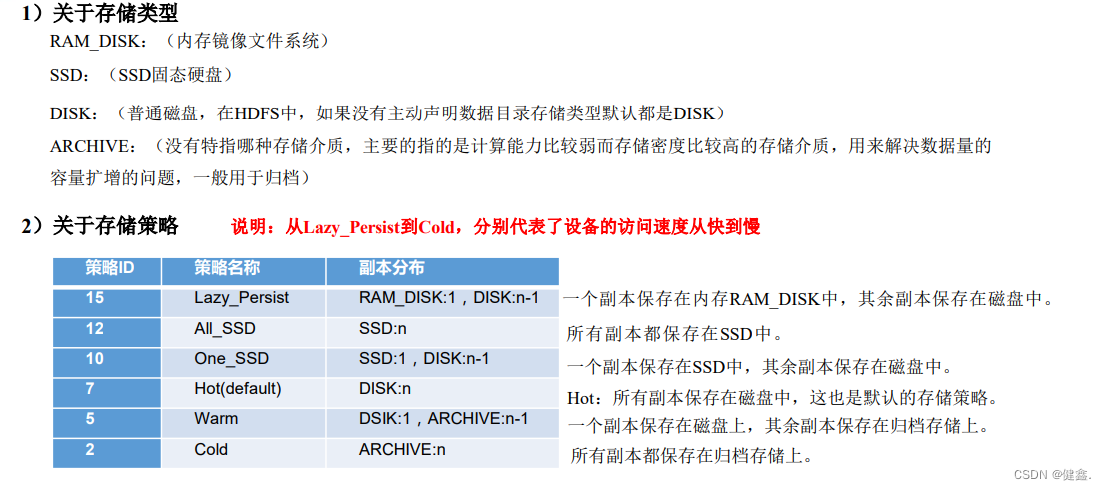
hadoop调优
hadoop调优 1 HDFS核心参数 1.1 NameNode内存生产配置 1.1.1 NameNode内存计算 每个文件块大概占用150byte,如果一台服务器128G,能存储的文件块如下 128 (G)* 1024(MB) * 1024(KB) * 1024(Byte) / 150 Byte 9.1 亿 1.1.2 Hadoop2.x 在Hadoop2.x中…...
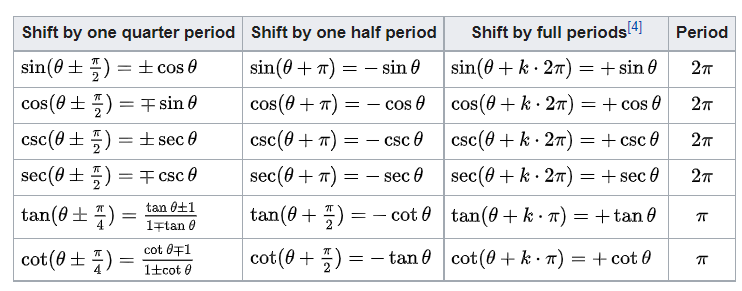
EM@三角函数诱导公式
文章目录诱导公式单位圆坐标和三角函数记忆口诀符号看象限奇变偶不变例常用诱导公式🎈常用部分(5对)倒数关系六种三角函数间的转换关系小结ReflectionsShifts and periodicity诱导公式 诱导公式 - 维基百科,自由的百科全书 (wikipedia.org) 单位圆坐标…...

是不是只能学IT互联网技术才有发展前途?
当然不是,三百六十行,行行出状元。 但我们需要认清一个现实是,我们正处于一个信息爆炸的时代,掌握紧跟潮流的技术,才可以让我们更自信地面对每天的生活,才有多余的精力、财力来享受生活。“人生在世&#…...

Linux 进程:exit和_exit的辨析
目录1.接口与函数2.缓冲区3.exit 与 _exit(1)_exit(2)exit这里来认识exit函数和 _exit接口 ,它们的作用是类似的,都是在调用后退出程序,可以在程序的任何地方调用。 1.接口与函数 exit函数和_exit接口,一个函数,一个…...
智能电子标签——商超版价签
2.1英寸TFT黑白电子价签 ★ 快速变价,高效运营 ★ 市场实用,布局物联网未来 ★ 更好客户体验 ★ 降低系统成本,具备竞争力 ★ 2.1英寸黑白红电子价签 ★ 电池低能耗,常规使用三年 ★ 穿透力强不慣障碍 ★ 2.4G载波&#x…...
计算机网络自检
1 计网体系结构 因特网结构: 计网三个组成成分: 工作方式-其中2个部分: 功能-两个子网: 5个XAN分别是: 传输技术,两者的主要区别: 4种基本网络拓扑结构: 3种交换技术: 协…...

DC真实数据都有哪些?Filecoin为DC数据存储的解决方案又是什么?
对于生活在数字时代的我们而言,数据或许就和平日呼吸的空气一样,已经不需要我们再去思考其概念。我们的日常生活中无时无刻都有数据的身影,日常的购物消费、出行、学习、记录,当我们每天生活有数字化加持的小区里,工作…...

嵌入式系统C与C++混合编程实践指南
嵌入式系统中的C与C混合编程实践指南1. 混合编程的核心挑战与解决方案1.1 混合编程的典型问题场景在嵌入式系统开发中,经常出现底层驱动使用C语言编写(追求稳定性),而业务逻辑层采用C实现(利用面向对象特性便于扩展&am…...

重构信息洪流:Folo让你重新掌控数字生活的开源利器
重构信息洪流:Folo让你重新掌控数字生活的开源利器 【免费下载链接】follow [WIP] Next generation information browser 项目地址: https://gitcode.com/GitHub_Trending/fol/follow 每天打开手机,你是否需要在12个APP间切换才能读完所有重要内容…...

【差分隐私核心参数权威指南】:ε、δ、敏感度如何精准配置?20年实战经验总结的5大避坑法则
第一章:差分隐私核心参数的数学本质与哲学内涵差分隐私并非一种具体算法,而是一套形式化约束框架,其力量源于对“隐私损失”这一抽象概念的可量化建模。其中,ε(epsilon)与δ(delta)…...

3.19 PowerBI进阶指南-利用ArcGIS地图实现精准地理位置可视化
1. 为什么需要ArcGIS地图可视化? 如果你经常用PowerBI做数据分析,肯定遇到过这样的尴尬:当你想在地图上展示销售网点分布、物流配送路线或者区域业绩对比时,PowerBI自带的Azure Maps居然无法显示中国地图。这个问题困扰了很多国内…...

Coze-Loop在金融风控中的应用:实时交易监测系统
Coze-Loop在金融风控中的应用:实时交易监测系统 1. 引言 想象一下这样的场景:一家大型银行的交易系统每秒处理着成千上万笔交易,突然出现了一笔异常大额转账,收款账户来自高风险地区。传统的风控系统可能需要几分钟才能识别这个…...
)
【车辆控制】基于H∞控制器与鲁棒线性二次调节器RLQR的铰接式重型车辆的稳健路径跟踪控制研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
|线路+站点分离|SHP格式|覆盖所有开通城市)
2025年全国地铁线路与站点矢量数据(高德地图源)|线路+站点分离|SHP格式|覆盖所有开通城市
🔍 数据简介 本数据集基于高德地图2025年1月最新公开数据提取,完整覆盖中国大陆所有已开通城市轨道交通的城市包含: 地铁/轻轨/市域铁路/有轨电车等所有轨道交通车型运营中、试运行线路 数据严格按线路(Line) 与 站点&…...

Kettle转换里SQL步骤优先级太高?手把手教你用‘阻塞数据’控件实现‘先删后插’
Kettle转换中SQL步骤优先级问题深度解析:如何精准控制"先删后插"流程 在ETL开发领域,Kettle(现称Pentaho Data Integration)因其可视化操作和强大功能成为众多数据工程师的首选工具。然而,当开发者从简单的数…...

pyLDAvis终极指南:如何用交互式可视化轻松理解主题模型
pyLDAvis终极指南:如何用交互式可视化轻松理解主题模型 【免费下载链接】pyLDAvis Python library for interactive topic model visualization. Port of the R LDAvis package. 项目地址: https://gitcode.com/gh_mirrors/py/pyLDAvis 你是否曾面对一个训练…...

像素幻梦部署案例:中小企业低成本搭建像素艺术AI内容生产平台
像素幻梦部署案例:中小企业低成本搭建像素艺术AI内容生产平台 1. 项目背景与价值 在数字内容创作领域,像素艺术因其独特的复古美感和广泛的适用性,成为游戏开发、社交媒体、品牌营销等领域的热门选择。然而传统像素艺术创作需要专业的美术功…...