numpy库的一些常用函数
文章目录
- 广播(broadcast)
- 迭代数组
- 数组运算
- 修改数组的形状
- 修改数组维度
- 连接数组
- 分割数组
- 数组元素的添加与删除
- Numpy算术函数
- Numpy 统计函数
- Numpy排序、条件筛选函数
- 条件筛选
import numpy as np
a=np.arange(15).reshape(3,5)
a
array([[ 0, 1, 2, 3, 4],[ 5, 6, 7, 8, 9],[10, 11, 12, 13, 14]])
a.shape
(3, 5)
a.ndim
2
a.dtype.name
'int64'
a.itemsize
8
a.size
15
type(a)
numpy.ndarray
b=np.array([6,7,8])
b
array([6, 7, 8])
b=np.array([(1.2,2,3),(4,5,6)])
b.ndim
2
b.shape
(2, 3)
b
array([[1.2, 2. , 3. ],[4. , 5. , 6. ]])
np.zeros((3,4))
array([[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]])
np.ones((2,3,4),dtype=np.int64)
array([[[1, 1, 1, 1],[1, 1, 1, 1],[1, 1, 1, 1]],[[1, 1, 1, 1],[1, 1, 1, 1],[1, 1, 1, 1]]])
from numpy import pi
np.linspace(0,2,9)
array([0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75, 2. ])
print(np.arange(10000))
[ 0 1 2 ... 9997 9998 9999]
- 与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行
A=np.array([[1,1],[0,1]])
B=np.array([[2,0],[3,4]])
A*B
array([[2, 0],[0, 4]])
A@B
array([[5, 4],[3, 4]])
A.dot(B)
array([[5, 4],[3, 4]])
a=np.random.random((2,3))
a
array([[0.78801026, 0.48701335, 0.03912818],[0.36542642, 0.99769419, 0.75786037]])
a.sum()
3.435132775123305
a.min()
0.03912818216471092
a.max()
0.9976941879734568
- numpy.array可以指定沿着对应的轴进行应用操作,通过axis参数指定,axis=0位按照列进行计算,axis=1为按照行进行计算,cumsum函数是按照指定的轴的方向进行累加
b=np.arange(12).reshape(3,4)
b
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
b.sum(axis=0)
array([12, 15, 18, 21])
b.sum(axis=1)
array([ 6, 22, 38])
b.cumsum(axis=1)
array([[ 0, 1, 3, 6],[ 4, 9, 15, 22],[ 8, 17, 27, 38]])
b.cumsum(axis=0)
array([[ 0, 1, 2, 3],[ 4, 6, 8, 10],[12, 15, 18, 21]])
- NumPy提供熟悉的数学函数,例如sin,cos和exp。在NumPy中,这些被称为“通函数”(ufunc)。在NumPy中,这些函数在数组上按元素进行运算,产生一个数组作为输出。
a=np.arange(10)**3
a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
#从位置0开始,步长为2替换1000
a[:6:2]=-1000
a
array([-1000, 1, -1000, 27, -1000, 125, 216, 343, 512,729])
a=a[::-1]
a
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1,-1000])
a**(1/3.)
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_63544/3446105811.py:1: RuntimeWarning: invalid value encountered in powera**(1/3.)array([ 9., 8., 7., 6., 5., nan, 3., nan, 1., nan])
- hstack和ystack,数组的水平堆叠和垂直堆叠
a1= np.array([1,2,3])
a2=np.array([4,5,6])
result_vstack=np.vstack((a1,a2))
result_vstack
array([[1, 2, 3],[4, 5, 6]])
result_hstack=np.hstack((a1,a2))
result_hstack
array([1, 2, 3, 4, 5, 6])
- NumPy提供比常规Python序列更多的索引功能。除了通过整数和切片进行索引之外,正如我们之前看到的,数组可以由整数数组和布尔数组索引。
a=np.arange(12)**2
a
array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121])
i=np.array([1,3,5,7])
a[i]
array([ 1, 9, 25, 49])
j=np.array([[3,4],[9,7]])
a[j]
array([[ 9, 16],[81, 49]])
palette = np.array( [ [0,0,0], # black[255,0,0], # red[0,255,0], # green[0,0,255], # blue[255,255,255] ] )
image=np.array([[0,1,2,0],[0,3,4,0]])
palette[image]
array([[[ 0, 0, 0],[255, 0, 0],[ 0, 255, 0],[ 0, 0, 0]],[[ 0, 0, 0],[ 0, 0, 255],[255, 255, 255],[ 0, 0, 0]]])
#为多个维度提供索引。每个维度的索引数组必须具有相同的形状。
a = np.arange(12).reshape(3,4)
a
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
i = np.array( [ [0,1], [1,2] ] )
j = np.array( [ [2,1], [3,3] ] )
a[i,j]
array([[ 2, 5],[ 7, 11]])
a[:,j]
array([[[ 2, 1],[ 3, 3]],[[ 6, 5],[ 7, 7]],[[10, 9],[11, 11]]])
#也可以按顺序(比如列表)放入i,j使用列表进行索引
l=[i,j]
a[l]
/var/folders/cr/2fpn8__12377w89ml3mv5ksw0000gn/T/ipykernel_63544/3994289241.py:3: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.a[l]array([[ 2, 5],[ 7, 11]])
- 使用数组索引的另一个常见用法是搜索与时间相关的系列的最大值
time = np.linspace(20, 145, 5)
data = np.sin(np.arange(20)).reshape(5,4)
print(time)
print(data)
[ 20. 51.25 82.5 113.75 145. ]
[[ 0. 0.84147098 0.90929743 0.14112001][-0.7568025 -0.95892427 -0.2794155 0.6569866 ][ 0.98935825 0.41211849 -0.54402111 -0.99999021][-0.53657292 0.42016704 0.99060736 0.65028784][-0.28790332 -0.96139749 -0.75098725 0.14987721]]
#记录每一列的最大值的索引位置
ind = data.argmax(axis=0)
ind
array([2, 0, 3, 1])
time_max=time[ind]
data_max=data[ind,range(data.shape[1])]
print(time_max)
print(data_max)
[ 82.5 20. 113.75 51.25]
[0.98935825 0.84147098 0.99060736 0.6569866 ]
- 当我们使用(整数)索引数组索引数组时,我们提供了要选择的索引列表。使用布尔索引,方法是不同的; 我们明确地选择我们想要的数组中的哪些项目以及我们不需要的项目。人们可以想到的最自然的布尔索引方法是使用与原始数组具有 相同形状的 布尔数组:
a = np.arange(12).reshape(3,4)
b = a > 4
b
array([[False, False, False, False],[False, True, True, True],[ True, True, True, True]])
#将a数组中大于4的部分打印出来
a[b]
array([ 5, 6, 7, 8, 9, 10, 11])
- 使用布尔值进行索引的第二种方法更类似于整数索引; 对于数组的每个维度,我们给出一个1D布尔数组,选择我们想要的切片,请注意,1D布尔数组的长度必须与要切片的尺寸(或轴)的长度一致。在前面的例子中,b1具有长度为3(的数目 的行 中a),和 b2(长度4)适合于索引的第二轴线(列) a。
a = np.arange(12).reshape(3,4)a
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
b1 = np.array([False,True,True])
b2 = np.array([True,False,True,False])
a[b1,:]
array([[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
a[:,b2]
array([[ 0, 2],[ 4, 6],[ 8, 10]])
a[b1,b2]
array([ 4, 10])
- ix_函数可用于组合不同的向量,以便获得每个n-uplet的结果。例如,如果要计算从每个向量a,b和c中取得的所有三元组的所有a + b * c:
a = np.array([2,3,4,5])
b = np.array([8,5,4])
c = np.array([5,4,6,8,3])
ax,bx,cx = np.ix_(a,b,c)
ax.shape, bx.shape, cx.shape
((4, 1, 1), (1, 3, 1), (1, 1, 5))
result = ax+bx*cx
result
array([[[42, 34, 50, 66, 26],[27, 22, 32, 42, 17],[22, 18, 26, 34, 14]],[[43, 35, 51, 67, 27],[28, 23, 33, 43, 18],[23, 19, 27, 35, 15]],[[44, 36, 52, 68, 28],[29, 24, 34, 44, 19],[24, 20, 28, 36, 16]],[[45, 37, 53, 69, 29],[30, 25, 35, 45, 20],[25, 21, 29, 37, 17]]])
d=np.dtype(int)
np.issubdtype(d,np.floating)
False
np.power(100,8,dtype=np.int64)
10000000000000000
np.power(100,8,dtype=np.int32)
1874919424
from io import BytesIO
data="\n".join(str(i) for i in range(10)).encode('utf-8')
np.genfromtxt(BytesIO(data),skip_header=3,skip_footer=5)
array([3., 4.])
d="1 2 3 \n 4 5 6".encode('utf-8')
np.genfromtxt(BytesIO(d),usecols=(0,-1))
array([[1., 3.],[4., 6.]])
x=np.arange(10)
x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
x.shape=(2,5)
x[0][0]
0
y=np.arange(35).reshape(5,7)
y
array([[ 0, 1, 2, 3, 4, 5, 6],[ 7, 8, 9, 10, 11, 12, 13],[14, 15, 16, 17, 18, 19, 20],[21, 22, 23, 24, 25, 26, 27],[28, 29, 30, 31, 32, 33, 34]])
y[1:5:2,::3]
array([[ 7, 10, 13],[21, 24, 27]])
#实践中广播的一个例子:
x=np.arange(4)
xx=x.reshape(4,1)
y=np.ones(5)
z=np.ones((3,4))
xx
array([[0],[1],[2],[3]])
x
array([0, 1, 2, 3])
y
array([1., 1., 1., 1., 1.])
xx+y
array([[1., 1., 1., 1., 1.],[2., 2., 2., 2., 2.],[3., 3., 3., 3., 3.],[4., 4., 4., 4., 4.]])
z
array([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]])
x+z
array([[1., 2., 3., 4.],[1., 2., 3., 4.],[1., 2., 3., 4.]])
data=np.arange(20).reshape(4,5)
data
array([[ 0, 1, 2, 3, 4],[ 5, 6, 7, 8, 9],[10, 11, 12, 13, 14],[15, 16, 17, 18, 19]])
a=np.arange(10)
#slice是分割函数,从索引2开始到索引7停止,步长为2
s=slice(2,8,2)
a[s]
array([2, 4, 6])
广播(broadcast)
广播的规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
- 输出数组的形状是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
简单理解:对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
- 数组拥有相同形状。
- 当前维度的值相等。
- 当前维度的值有一个是 1。
若条件不满足,抛出 “ValueError: frames are not aligned” 异常。
a=np.array([[0,0,0],[10,10,10],[20,20,20],[30,30,30]])
b=np.array([1,2,3])
a+b
array([[ 1, 2, 3],[11, 12, 13],[21, 22, 23],[31, 32, 33]])
迭代数组
-
NumPy 迭代器对象 numpy.nditer 提供了一种灵活访问一个或者多个数组元素的方式。
-
迭代器最基本的任务的可以完成对数组元素的访问。
-
接下来我们使用 arange() 函数创建一个 2X3 数组,并使用 nditer 对它进行迭代。
a=np.arange(6).reshape(2,3)
print(a)
print('使用nditer 迭代输出元素:')
for x in np.nditer(a):print(x,end=",")
[[0 1 2][3 4 5]]
使用nditer 迭代输出元素:
0,1,2,3,4,5,
-
以上实例不是使用标准 C 或者 Fortran 顺序,选择的顺序是和数组内存布局一致的,这样做是为了提升访问的效率,默认是行序优先(row-major order,或者说是 C-order)。
-
这反映了默认情况下只需访问每个元素,而无需考虑其特定顺序。我们可以通过迭代上述数组的转置来看到这一点,并与以 C 顺序访问数组转置的 copy 方式做对比,如下实例:
a=np.arange(6).reshape(2,3)
for x in np.nditer(a.T):print(x,end=",")
print('\n')
for x in np.nditer(a.T.copy(order='C')):print(x,end=",")
0,1,2,3,4,5,0,3,1,4,2,5,
-
从上述例子可以看出,a 和 a.T 的遍历顺序是一样的,也就是他们在内存中的存储顺序也是一样的,但是 a.T.copy(order = ‘C’) 的遍历结果是不同的,那是因为它和前两种的存储方式是不一样的,默认是按行访问。
-
for x in np.nditer(a, order=‘F’):Fortran order,即是列序优先;
-
for x in np.nditer(a.T, order=‘C’):C order,即是行序优先;
-
nditer 对象有另一个可选参数 op_flags。 默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值的修改,必须指定 readwrite 或者 writeonly 的模式。
import numpy as npa = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:')
print (a)
print ('\n')
for x in np.nditer(a, op_flags=['readwrite']): x[...]=2*x
print ('修改后的数组是:')
print (a)
原始数组是:
[[ 0 5 10 15][20 25 30 35][40 45 50 55]] 修改后的数组是:
[[ 0 10 20 30][ 40 50 60 70][ 80 90 100 110]]
数组运算
修改数组的形状
| 函数 | 描述 |
|---|---|
| reshape | 不改变数据的条件下修改形状 |
| flat | 数组元素迭代器 |
| flatten | 返回一份数组拷贝,对拷贝所做的修改不会影响原始数组 |
| ravel | 返回展开数组 |
a=np.arange(9).reshape(3,3)
print('原始数组:')
for row in a:print(row)
#对数组中的每个元素进行处理,使用flat属性,是数组迭代器
print('迭代后的数组:')
for el in a.flat:print(el)
原始数组:
[0 1 2]
[3 4 5]
[6 7 8]
迭代后的数组:
0
1
2
3
4
5
6
7
8
a=np.arange(9).reshape(3,3)
print('原始数组')
print(a)
print('\n')
print('展开的数组:')
print(a.flatten())
print('\n')
print('按照F风格(列)展开的数组:')
print(a.flatten(order='F'))
原始数组
[[0 1 2][3 4 5][6 7 8]]
展开的数组:
[0 1 2 3 4 5 6 7 8]
按照F风格(列)展开的数组:
[0 3 6 1 4 7 2 5 8]
-
numpy.ravel() 展平的数组元素,顺序通常是"C风格",返回的是数组视图(view,有点类似 C/C++引用reference的意味),修改会影响原始数组。
-
该函数接收两个参数:
-
numpy.ravel(a, order=‘C’) [order:‘C’ – 按行,‘F’ – 按列,‘A’ – 原顺序,‘K’ – 元素在内存中的出现顺序。]
a=np.arange(9).reshape(3,3)
print('原始数组')
print(a)
print('\n')
print ('调用 ravel 函数之后:')
print (a.ravel())
print ('\n')
print ('以 F 风格顺序调用 ravel 函数之后:')
print (a.ravel(order = 'F'))
原始数组
[[0 1 2][3 4 5][6 7 8]]
调用 ravel 函数之后:
[0 1 2 3 4 5 6 7 8]
以 F 风格顺序调用 ravel 函数之后:
[0 3 6 1 4 7 2 5 8]
| 函数 | 描述 |
|---|---|
| transpose | 对换数组的维度 |
| ndarray.T | 和 self.transpose() 相同 |
| rollaxis | 向后滚动指定的轴 |
| swapaxes | 对换数组的两个轴 |
修改数组维度
| 函数 | 描述 |
|---|---|
| broadcast | 产生模仿广播的对象 |
| broadcast_to | 将数组广播到新形状 |
| expand_dims | 扩展数组的形状 |
| squeeze | 从数组的形状中删除一维条目 |
连接数组
| 函数 | 描述 |
|---|---|
| concatenate | 连接沿现有轴的数组序列 |
| stack | 沿着新的轴加入一系列数组 |
| hstack | 水平堆叠序列中的数组(列方向) |
| vstack | 竖直堆叠序列中的数组(行方向) |
分割数组
| 函数 | 描述 |
|---|---|
| split | 将一个数组分割为多个子数组 |
| hsplit | 将一个数组水平分割为多个子数组(按列) |
| vsplit | 将一个数组垂直分割为多个子数组(按行) |
数组元素的添加与删除
| 函数 | 描述 |
|---|---|
| resize | 返回指定形状的新数组 |
| append | 将值添加到数组末尾 |
| insert | 沿指定轴将值插入到指定下标之前 |
| delete | 删掉某个轴的子数组,并返回删除后的新数组 |
| unique | 查找数组内的唯一元素 |
a = np.array([[1,2],[3,4]])print ('第一个数组:')
print (a)
print ('\n')
b = np.array([[5,6],[7,8]])print ('第二个数组:')
print (b)
print ('\n')
# 两个数组的维度相同print ('沿轴 0 连接两个数组:')
print (np.concatenate((a,b)))
print ('\n')print ('沿轴 1 连接两个数组:')
print (np.concatenate((a,b),axis = 1))
第一个数组:
[[1 2][3 4]]
第二个数组:
[[5 6][7 8]]
沿轴 0 连接两个数组:
[[1 2][3 4][5 6][7 8]]
沿轴 1 连接两个数组:
[[1 2 5 6][3 4 7 8]]
a = np.array([[1,2],[3,4]])
print ('第一个数组:')
print (a)
print ('\n')
b = np.array([[5,6],[7,8]])print ('第二个数组:')
print (b)
print ('\n')print ('沿轴 0 堆叠两个数组:')
print (np.stack((a,b),0))
print ('\n')print ('沿轴 1 堆叠两个数组:')
print (np.stack((a,b),1))
第一个数组:
[[1 2][3 4]]
第二个数组:
[[5 6][7 8]]
沿轴 0 堆叠两个数组:
[[[1 2][3 4]][[5 6][7 8]]]
沿轴 1 堆叠两个数组:
[[[1 2][5 6]][[3 4][7 8]]]
a = np.array([[1,2,3],[4,5,6]])print ('第一个数组:')
print (a)
print ('\n')print ('第一个数组的形状:')
print (a.shape)
print ('\n')
b = np.resize(a, (3,2))print ('第二个数组:')
print (b)
print ('\n')print ('第二个数组的形状:')
print (b.shape)
print ('\n')
# 要注意 a 的第一行在 b 中重复出现,因为尺寸变大了print ('修改第二个数组的大小:')
b = np.resize(a,(3,3))
print (b)
第一个数组:
[[1 2 3][4 5 6]]第一个数组的形状:
(2, 3)第二个数组:
[[1 2][3 4][5 6]]第二个数组的形状:
(3, 2)修改第二个数组的大小:
[[1 2 3][4 5 6][1 2 3]]
# numpy.append 函数在数组的末尾添加值。 追加操作会分配整个数组,并把原来的数组复制到新数组中。 此外,输入数组的维度必须匹配否则将生成ValueError。
# append 函数返回的始终是一个一维数组。
import numpy as npa = np.array([[1,2,3],[4,5,6]])print ('第一个数组:')
print (a)
print ('\n')print ('向数组添加元素:')
print (np.append(a, [7,8,9]))
print ('\n')print ('沿轴 0 添加元素:')
print (np.append(a, [[7,8,9]],axis = 0))
print ('\n')print ('沿轴 1 添加元素:')
print (np.append(a, [[5,5,5],[7,8,9]],axis = 1))
第一个数组:
[[1 2 3][4 5 6]] 向数组添加元素:
[1 2 3 4 5 6 7 8 9]沿轴 0 添加元素:
[[1 2 3][4 5 6][7 8 9]]沿轴 1 添加元素:
[[1 2 3 5 5 5][4 5 6 7 8 9]]
#numpy.insert 函数在给定索引之前,沿给定轴在输入数组中插入值。
#如果值的类型转换为要插入,则它与输入数组不同。 插入没有原地的,函数会返回一个新数组。 此外,如果未提供轴,则输入数组会被展开。a = np.array([[1,2],[3,4],[5,6]])print ('第一个数组:')
print (a)
print ('\n')print ('未传递 Axis 参数。 在删除之前输入数组会被展开。')
print (np.insert(a,3,[11,12]))
print ('\n')
print ('传递了 Axis 参数。 会广播值数组来配输入数组。')print ('沿轴 0 广播:')
print (np.insert(a,1,[11],axis = 0))
print ('\n')print ('沿轴 1 广播:')
print (np.insert(a,1,11,axis = 1))
第一个数组:
[[1 2][3 4][5 6]]未传递 Axis 参数。 在删除之前输入数组会被展开。
[ 1 2 3 11 12 4 5 6] 传递了 Axis 参数。 会广播值数组来配输入数组。
沿轴 0 广播:
[[ 1 2][11 11][ 3 4][ 5 6]]沿轴 1 广播:
[[ 1 11 2][ 3 11 4][ 5 11 6]]
# numpy.delete 函数返回从输入数组中删除指定子数组的新数组。 与 insert() 函数的情况一样,如果未提供轴参数,则输入数组将展开。
import numpy as npa = np.arange(12).reshape(3,4)print ('第一个数组:')
print (a)
print ('\n')print ('未传递 Axis 参数。 在插入之前输入数组会被展开。')
print (np.delete(a,5))
print ('\n')print ('删除第二列:')
print (np.delete(a,1,axis = 1))
print ('\n')print ('包含从数组中删除的替代值的切片:')
a = np.array([1,2,3,4,5,6,7,8,9,10])
print (np.delete(a, np.s_[::2]))
第一个数组:
[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]]未传递 Axis 参数。 在插入之前输入数组会被展开。
[ 0 1 2 3 4 6 7 8 9 10 11] 删除第二列:
[[ 0 2 3][ 4 6 7][ 8 10 11]]包含从数组中删除的替代值的切片:
[ 2 4 6 8 10]
#numpy.unique 函数用于去除数组中的重复元素。
#numpy.unique(arr, return_index, return_inverse, return_counts)
#arr:输入数组,如果不是一维数组则会展开
#return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储
#return_inverse:如果为true,返回旧列表元素在新列表中的位置(下标),并以列表形式储
#return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数
a = np.array([5,2,6,2,7,5,6,8,2,9])print ('第一个数组:')
print (a)
print ('\n')print ('第一个数组的去重值:')
u = np.unique(a)
print (u)
print ('\n')print ('去重数组的索引数组:')
u,indices = np.unique(a, return_index = True)
print (indices)
print ('\n')print ('我们可以看到每个和原数组下标对应的数值:')
print (a)
print ('\n')print ('去重数组的下标:')
u,indices = np.unique(a,return_inverse = True)
print (u)
print ('\n')print ('下标为:')
print (indices)
print ('\n')print ('使用下标重构原数组:')
print (u[indices])
print ('\n')print ('返回去重元素的重复数量:')
u,indices = np.unique(a,return_counts = True)
print (u)
print (indices)
第一个数组:
[5 2 6 2 7 5 6 8 2 9] 第一个数组的去重值:
[2 5 6 7 8 9]去重数组的索引数组:
[1 0 2 4 7 9]我们可以看到每个和原数组下标对应的数值:
[5 2 6 2 7 5 6 8 2 9]去重数组的下标:
[2 5 6 7 8 9]下标为:
[1 0 2 0 3 1 2 4 0 5]使用下标重构原数组:
[5 2 6 2 7 5 6 8 2 9]返回去重元素的重复数量:
[2 5 6 7 8 9]
[3 2 2 1 1 1]
Numpy算术函数
- NumPy 算术函数包含简单的加减乘除: add(),subtract(),multiply() 和 divide()。
- 需要注意的是数组必须具有相同的形状或符合数组广播规则。
- numpy.reciprocal() 函数返回参数逐元素的倒数。如 1/4 倒数为 4/1
- numpy.power() 函数将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂。
- numpy.mod() 计算输入数组中相应元素的相除后的余数。 函数 numpy.remainder() 也产生相同的结果。
import numpy as np a = np.arange(9, dtype = np.float_).reshape(3,3)
print ('第一个数组:')
print (a)
print ('\n')
print ('第二个数组:')
b = np.array([10,10,10])
print (b)
print ('\n')
print ('两个数组相加:')
print (np.add(a,b))
print ('\n')
print ('两个数组相减:')
print (np.subtract(a,b))
print ('\n')
print ('两个数组相乘:')
print (np.multiply(a,b))
print ('\n')
print ('两个数组相除:')
print (np.divide(a,b))
第一个数组:
[[0. 1. 2.][3. 4. 5.][6. 7. 8.]] 第二个数组:
[10 10 10] 两个数组相加:
[[10. 11. 12.][13. 14. 15.][16. 17. 18.]]两个数组相减:
[[-10. -9. -8.][ -7. -6. -5.][ -4. -3. -2.]] 两个数组相乘:
[[ 0. 10. 20.][30. 40. 50.][60. 70. 80.]] 两个数组相除:
[[0. 0.1 0.2][0.3 0.4 0.5][0.6 0.7 0.8]]
Numpy 统计函数
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。
numpy.amin() 和 numpy.amax()numpy.amin() 用于计算数组中的元素沿指定轴的最小值。
numpy.ptp() 函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。
numpy.amin(a, axis=None, out=None, keepdims=<no value>, initial=<no value>, where=<no value>)numpy.median() 函数用于计算数组 a 中元素的中位数(中值)
numpy.percentile() 百分位数是统计中使用的度量,表示小于这个值的观察值的百分比。 函数numpy.percentile()接受以下参数。
numpy.average() 函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。
np.std 计算标准差
np.var 计算方差
参数说明:
a: 输入的数组,可以是一个NumPy数组或类似数组的对象。
axis: 可选参数,用于指定在哪个轴上计算最小值。如果不提供此参数,则返回整个数组的最小值。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。
out: 可选参数,用于指定结果的存储位置。
keepdims: 可选参数,如果为True,将保持结果数组的维度数目与输入数组相同。如果为False(默认值),则会去除计算后维度为1的轴。
initial: 可选参数,用于指定一个初始值,然后在数组的元素上计算最小值。
where: 可选参数,一个布尔数组,用于指定仅考虑满足条件的元素。
numpy.percentile()
参数说明:
a: 输入数组q: 要计算的百分位数,在 0 ~ 100 之间
axis: 沿着它计算百分位数的轴
numpy.median() numpy.median(a, axis=None, out=None, overwrite_input=False, keepdims=<no value>)参数说明:
a: 输入的数组,可以是一个 NumPy 数组或类似数组的对象。axis: 可选参数,用于指定在哪个轴上计算中位数。如果不提供此参数,则计算整个数组的中位数。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。
out: 可选参数,用于指定结果的存储位置。
overwrite_input: 可选参数,如果为True,则允许在计算中使用输入数组的内存。这可能会在某些情况下提高性能,但可能会修改输入数组的内容。
keepdims: 可选参数,如果为True,将保持结果数组的维度数目与输入数组相同。如果为False(默认值),则会去除计算后维度为1的轴。
numpy.average() numpy.average(a, axis=None, weights=None, returned=False)
该函数可以接受一个轴参数。 如果没有指定轴,则数组会被展开。加权平均值即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。
考虑数组[1,2,3,4]和相应的权重[4,3,2,1],通过将相应元素的乘积相加,并将和除以权重的和,来计算加权平均值。
参数说明:a: 输入的数组,可以是一个 NumPy 数组或类似数组的对象。
axis: 可选参数,用于指定在哪个轴上计算加权平均值。如果不提供此参数,则计算整个数组的加权平均值。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。
weights: 可选参数,用于指定对应数据点的权重。如果不提供权重数组,则默认为等权重。
returned: 可选参数,如果为True,将同时返回加权平均值和权重总和。
a = np.array([[3,7,5],[8,4,3],[2,4,9]])
print ('我们的数组是:')
print (a)
print ('\n')
print ('调用 amin() 函数:')
print (np.amin(a,1))
print ('\n')
print ('再次调用 amin() 函数:')
print (np.amin(a,0))
print ('\n')
print ('调用 amax() 函数:')
print (np.amax(a))
print ('\n')
print ('再次调用 amax() 函数:')
print (np.amax(a, axis = 0))
我们的数组是:
[[3 7 5][8 4 3][2 4 9]]调用 amin() 函数:
[3 3 2] 再次调用 amin() 函数:
[2 4 3] 调用 amax() 函数:
9再次调用 amax() 函数:
[8 7 9]
Numpy排序、条件筛选函数
NumPy 提供了多种排序的方法。 这些排序函数实现不同的排序算法,每个排序算法的特征在于执行速度,最坏情况性能,所需的工作空间和算法的稳定性。
numpy.sort() 函数返回输入数组的排序副本。函数格式如下:
numpy.sort(a, axis, kind, order)
参数说明:a: 要排序的数组
axis: 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序, axis=0 按列排序,axis=1 按行排序
kind: 默认为’quicksort’(快速排序)
order: 如果数组包含字段,则是要排序的字段
numpy.argsort() 函数返回的是数组值从小到大的索引值。
numpy.lexsort()
- numpy.lexsort() 用于对多个序列进行排序。把它想象成对电子表格进行排序,每一列代表一个序列,排序时优先照顾靠后的列。
- 这里举一个应用场景:小升初考试,重点班录取学生按照总成绩录取。在总成绩相同时,数学成绩高的优先录取,在总成绩和数学成绩都相同时,按照英语成绩录取…… 这里,总成绩排在电子表格的最后一列,数学成绩在倒数第二列,英语成绩在倒数第三列。
| 函数 | 描述 |
|---|---|
| msort(a) | 数组按第一个轴排序,返回排序后的数组副本。np.msort(a) 相等于 np.sort(a, axis=0) |
| sort_complex(a) | 对复数按照先实部后虚部的顺序进行排序。 |
| partition(a, kth[, axis, kind, order]) | 指定一个数,对数组进行分区 |
| argpartition(a, kth[, axis, kind, order]) | 可以通过关键字 kind 指定算法沿着指定轴对数组进行分区 |
条件筛选
numpy.argmax() 和 numpy.argmin()函数分别沿给定轴返回最大和最小元素的索引。
numpy.where() 函数返回输入数组中满足给定条件的元素的索引。
numpy.extract() 函数根据某个条件从数组中抽取元素,返回满条件的元素。
a = np.array([[3,7],[9,1]])
print ('我们的数组是:')
print (a)
print ('\n')
print ('调用 sort() 函数:')
print (np.sort(a))
print ('\n')
print ('按列排序:')
print (np.sort(a, axis = 0))
print ('\n')
# 在 sort 函数中排序字段
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)
print ('我们的数组是:')
print (a)
print ('\n')
print ('按 name 排序:')
print (np.sort(a, order = 'name'))
我们的数组是:
[[3 7][9 1]]调用 sort() 函数:
[[3 7][1 9]] 按列排序:
[[3 1][9 7]] 我们的数组是:
[(b'raju', 21) (b'anil', 25) (b'ravi', 17) (b'amar', 27)] 按 name 排序:
[(b'amar', 27) (b'anil', 25) (b'raju', 21) (b'ravi', 17)]
x = np.array([3, 1, 2])
print ('我们的数组是:')
print (x)
print ('\n')
print ('对 x 调用 argsort() 函数:')
y = np.argsort(x)
print (y)
print ('\n')
print ('以排序后的顺序重构原数组:')
print (x[y])
print ('\n')
print ('使用循环重构原数组:')
for i in y: print (x[i], end=" ")
我们的数组是:
[3 1 2] 对 x 调用 argsort() 函数:
[1 2 0]以排序后的顺序重构原数组:
[1 2 3] 使用循环重构原数组:
1 2 3
nm = ('raju','anil','ravi','amar')
dv = ('f.y.', 's.y.', 's.y.', 'f.y.')
ind = np.lexsort((dv,nm))
print ('调用 lexsort() 函数:')
print (ind)
print ('\n')
print ('使用这个索引来获取排序后的数据:')
print ([nm[i] + ", " + dv[i] for i in ind])
调用 lexsort() 函数:
[3 1 0 2] 使用这个索引来获取排序后的数据:
['amar, f.y.', 'anil, s.y.', 'raju, f.y.', 'ravi, s.y.']
a = np.array([[30,40,70],[80,20,10],[50,90,60]])
print ('我们的数组是:')
print (a)
print ('\n')
print ('调用 argmax() 函数:')
print (np.argmax(a))
print ('\n')
print ('展开数组:')
print (a.flatten())
print ('\n')
print ('沿轴 0 的最大值索引:')
maxindex = np.argmax(a, axis = 0)
print (maxindex)
print ('\n')
print ('沿轴 1 的最大值索引:')
maxindex = np.argmax(a, axis = 1)
print (maxindex)
print ('\n')
print ('调用 argmin() 函数:')
minindex = np.argmin(a)
print (minindex)
print ('\n')
print ('展开数组中的最小值:')
print (a.flatten()[minindex])
print ('\n')
print ('沿轴 0 的最小值索引:')
minindex = np.argmin(a, axis = 0)
print (minindex)
print ('\n')
print ('沿轴 1 的最小值索引:')
minindex = np.argmin(a, axis = 1)
print (minindex)
我们的数组是:
[[30 40 70][80 20 10][50 90 60]] 调用 argmax() 函数:
7展开数组:
[30 40 70 80 20 10 50 90 60] 沿轴 0 的最大值索引:
[1 2 0] 沿轴 1 的最大值索引:
[2 0 1]调用 argmin() 函数:
5 展开数组中的最小值:
10 沿轴 0 的最小值索引:
[0 1 1]沿轴 1 的最小值索引:
[0 2 0]
x = np.arange(9.).reshape(3, 3)
print ('我们的数组是:')
print (x)
print ( '大于 3 的元素的索引:')
y = np.where(x > 3)
print (y)
print ('使用这些索引来获取满足条件的元素:')
print (x[y])
我们的数组是:
[[0. 1. 2.][3. 4. 5.][6. 7. 8.]]
大于 3 的元素的索引:
(array([1, 1, 2, 2, 2]), array([1, 2, 0, 1, 2]))
使用这些索引来获取满足条件的元素:
[4. 5. 6. 7. 8.]
x = np.arange(9.).reshape(3, 3)
print ('我们的数组是:')
print (x)
# 定义条件, 选择偶数元素
condition = np.mod(x,2) == 0
print ('按元素的条件值:')
print (condition)
print ('使用条件提取元素:')
print (np.extract(condition, x))
我们的数组是:
[[0. 1. 2.][3. 4. 5.][6. 7. 8.]]
按元素的条件值:
[[ True False True][False True False][ True False True]]
使用条件提取元素:
[0. 2. 4. 6. 8.]
相关文章:

numpy库的一些常用函数
文章目录 广播(broadcast)迭代数组数组运算修改数组的形状 修改数组维度连接数组分割数组数组元素的添加与删除Numpy算术函数Numpy 统计函数Numpy排序、条件筛选函数条件筛选 import numpy as np anp.arange(15).reshape(3,5)aarray([[ 0, 1, 2, 3, …...

成员变量与局部变量的区别?
如果你现在需要准备面试,可以关注我的公众号:”Tom聊架构“,回复暗号:”578“,领取一份我整理的50W字面试宝典,可以帮助你提高80%的面试通过率,价值很高!! 语法形式&…...

ES6---判断对象是否为{}
介绍 使用es6语法判断一个对象是否为{} 示例 使用ES6的Object.keys()方法,返回值是对象中属性名组成的数组 let obj {}let keys Object.keys(obj) if(keys.length){alert(对象不为{}) }else{alert(对象为{}) }代码地址 https://gitee.com/u.uu.com/js-test/b…...
高性能、可扩展、分布式对象存储系统MinIO的介绍、部署步骤以及代码示例
详细介绍 MinIO 是一款流行的开源对象存储系统,设计上兼容 Amazon S3 API,主要用于私有云和边缘计算场景。它提供了高性能、高可用性以及易于管理的对象存储服务。以下是 MinIO 的详细介绍及优缺点: 架构与特性: 开源与跨平台&am…...

oracle重启数据库lsnrctl重启监听
oracle重启数据库lsnrctl重启监听 su到oracle用户下,命令 su - oracle切换需要启动的数据库实例: export ORACLE_SIDorcl进入Sqlplus控制台,命令: sqlplus /nolog以系统管理员登录,命令: connect / as sysdba如果是…...
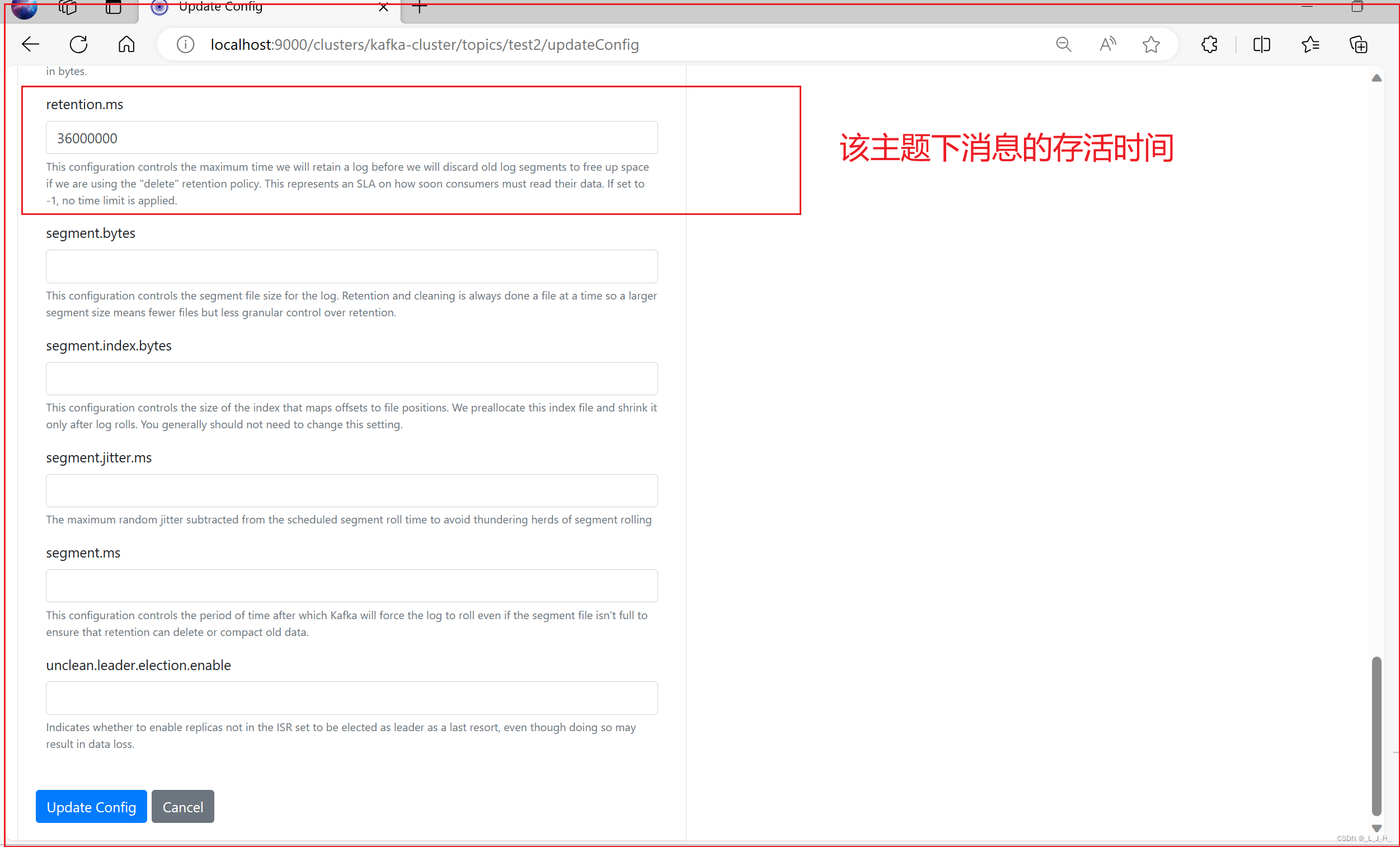
08、Kafka ------ 消息存储相关的配置-->消息过期时间设置、查看主题下的消息存活时间等配置
目录 消息存储相关的配置★ 消息的存储介绍★ 消息过期时间及处理方式演示:log.cleanup.policy 属性配置 ★ 修改指定主题的消息保存时间演示:将 test2 主题下的消息的保存时间设为10个小时1、先查看test2主题下的配置2、然后设置消息的保存时间3、然后再…...
JAVA基础学习笔记-day15-File类与IO流
JAVA基础学习笔记-day15-File类与IO流 1. java.io.File类的使用1.1 概述1.2 构造器1.3 常用方法1、获取文件和目录基本信息2、列出目录的下一级3、File类的重命名功能4、判断功能的方法5、创建、删除功能 2. IO流原理及流的分类2.1 Java IO原理2.2 流的分类2.3 流的API 3. 节点…...

WPF ComboBox限制输入长度
在WPF中,你可以通过两种方式来限制ComboBox的输入长度: 使用PreviewTextInput事件:你可以在这个事件的处理程序中检查输入文本的长度,如果超过最大长度则阻止输入。 <ComboBox PreviewTextInput"ComboBox_PreviewTextIn…...

windows配置网络IP地址的方法
在Windows系统中配置网络IP地址,可以按照以下步骤进行: 打开“控制面板”,选择“网络和Internet”选项。在“网络和Internet”窗口中,单击“网络和共享中心”选项。在“网络和共享中心”窗口中,单击“更改适配器设置”…...

windows配置电脑网络IP的方法
通过控制面板配置IP地址: 打开控制面板: 可以通过在开始菜单中搜索“控制面板”来打开控制面板。选择“网络和Internet”或“网络和共享中心”: 在控制面板中,根据 Windows 版本不同,选中对应的选项进入网络设置。点击…...

MySQL,原子性rename
RENAME TABLE old_table TO backup_table, new_table TO old_table;...

FPGA之按键消抖
目录 1.原理 2.代码 2.1 key_filter.v 2.2 tb_key_filter.v 1.原理 按键分为自锁式按键和机械按键,图左边为自锁式按键 上图为RS触发器硬件消抖,当按键的个数比较多时常常使用软件消抖。硬件消抖会使用额外的器件占用电路板上的空间。 思路就是使用延…...

国内知名的技术平台
1、csdn,中文最大的技术交流平台 2、iteye,程序员的交流平台,归属csdn 3、cnblogs,这个也不错 4、简书也不错...

C#操作注册表
说明 今天用C#开发了一个简单的服务,需要设置成为自启动,网上有很多方法,放到启动运行等,但是今天想介绍一个,通过修改注册表实现,同时介绍一下操作注册表。 private void TestReg(){//仅对当前用户有效 H…...

Unity中BRP下的深度图
文章目录 前言一、在Shader中使用1、在使用深度图前申明2、在片元着色器中 二、在C#脚本中开启摄像机深度图三、最终效果 前言 在之前的文章中,我们实现了URP下的深度图使用。 Unity中URP下使用屏幕坐标采样深度图 在这篇文章中,我们来看一下BRP下深度…...

物联网的感知层、网络层与应用层分享
物联网的概念在很早以前就已经被提出,20世纪末期在美国召开的移动计算和网络国际会议就已经提出了物联网(Internet of Things)这个概念。 最先提出这个概念的是MIT Auto-ID中心的Ashton教授,他在研究RFID技术时,便提出了结合物品编码、互联网…...

kafka KRaft 集群搭建
kafka KRaft集群安装 包下载 https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgzkafka集群构建好后的数据目录结构 [rootlocalhost data]# tree /data/kafka /data/kafka ├── kafka-1 # 节点1源码目录 ├── kafka-2 # 节点2源码目录 ├── kafka-3 # 节点…...

oracle角色管理
常用角色 CONNECT,RESOURCE,DBA,EXP_FULL_DATABASE,IMP_FULL_DATABASE 1角色可以自定义,语法与创建用户一样 CREATE role role1 IDENTIFIED by 123; 2授权权限给角色 --自定义角色 CREATE role role1 IDENTIFIED by 123; --授权权限给角色 GRANT create view, …...
)
汽车信息安全--芯片厂、OEM安全启动汇总(2)
目录 1.STM32 X-CUBE-SBSFU 2.小米澎湃OS安全启动 3.小结 在汽车信息安全--芯片厂、OEM安全启动汇总-CSDN博客,我们描述了芯驰E3的安全启动机制,接下来我们继续看其他芯片、OEM等安全启动机制。 1.STM32 X-CUBE-SBSFU 该产品全称Secure Boot and Secure...

HarmonyOS 开发基础(五)Button
HarmonyOS 开发基础(五)Button Entry Component struct Index {build() {Row() {Column() {// Button:ArkUI 的基础组件 按钮组件// label 参数:文字型按钮Button(我是按钮)// width:属性方法,设置组件的宽…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

Python Einops库:深度学习中的张量操作革命
Einops(爱因斯坦操作库)就像给张量操作戴上了一副"语义眼镜"——让你用人类能理解的方式告诉计算机如何操作多维数组。这个基于爱因斯坦求和约定的库,用类似自然语言的表达式替代了晦涩的API调用,彻底改变了深度学习工程…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...