kafka KRaft 集群搭建
kafka KRaft集群安装
包下载
https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgz
kafka集群构建好后的数据目录结构
[root@localhost data]# tree /data/kafka
/data/kafka
├── kafka-1 # 节点1源码目录
├── kafka-2 # 节点2源码目录
├── kafka-3 # 节点3源码目录
└── kafkadata # kafka数据存放目录├── kafkadata1 # 节点1数据存放目录├── kafkadata2 # 节点2数据存放目录└── kafkadata3 # 节点3数据存放目录
更改kafka配置文件
kafka节点1配置文件
[root@localhost kraft]# cat cat /data/kafka/kafka-1/config/kraft/server.properties |grep -Ev "#|^$"
# 表示kafka的KRaft模式
process.roles=broker,controller
# 集群节点的标记
node.id=1
# 参与集群投票节点
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
# 定义监听地址
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
inter.broker.listener.name=PLAINTEXT
# 对外宣告地址
advertised.listeners=PLAINTEXT://localhost:19092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kraft-combined-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
kafka节点2配置文件
[root@localhost kafka]# cat /data/kafka/kafka-2/config/kraft/server.properties |grep -Ev "#|^$"
process.roles=broker,controller
node.id=2
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:29092,CONTROLLER://:29093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://localhost:29092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafkadata/kafkadata2
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
kafka节点3配置文件
[root@localhost kafka]# cat /data/kafka/kafka-3/config/kraft/server.properties |grep -Ev "#|^$"
process.roles=broker,controller
node.id=3
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:39092,CONTROLLER://:39093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://localhost:39092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafkadata/kafkadata3
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
获取集群uuid
[root@localhost kafka]# /data/kafka/kafka-1/bin/kafka-storage.sh random-uuid
fzSBf0PjTRi3zNH_0Abc-g
格式化kafka数据存储目录
/data/kafka/kafka-1/bin/kafka-storage.sh format -t fzSBf0PjTRi3zNH_0Abc-g -c /data/kafka/kafka-1/config/kraft/server.properties
/data/kafka/kafka-2/bin/kafka-storage.sh format -t fzSBf0PjTRi3zNH_0Abc-g -c /data/kafka/kafka-2/config/kraft/server.properties
/data/kafka/kafka-3/bin/kafka-storage.sh format -t fzSBf0PjTRi3zNH_0Abc-g -c /data/kafka/kafka-3/config/kraft/server.properties
启动kafka
nohup /data/kafka/kafka-1/bin/kafka-server-start.sh /data/kafka/kafka-1/config/kraft/server.properties >> /data/kafka/kafkadata/kafka-1.log &
nohup /data/kafka/kafka-2/bin/kafka-server-start.sh /data/kafka/kafka-2/config/kraft/server.properties >> /data/kafka/kafkadata/kafka-2.log &
nohup /data/kafka/kafka-3/bin/kafka-server-start.sh /data/kafka/kafka-3/config/kraft/server.properties >> /data/kafka/kafkadata/kafka-3.log &
创建主题,3个分区,3个副本
/data/kafka/kafka-3/bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:39092 --replication-factor 3 --partitions 3
列出主题,查看主题是否创建
/data/kafka/kafka-3/bin/kafka-topics.sh --list --bootstrap-server localhost:39092
生产消息
/data/kafka/kafka-3/bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:39092
消费消息
/data/kafka/kafka-3/bin/kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server localhost:39092
检查集群脚本状态
/data/kafka/kafka-3/bin/kafka-broker-api-versions.sh --bootstrap-server localhost:39092
集群的性能测试
生产者性能测试
/data/kafka/kafka-3/bin/kafka-producer-perf-test.sh --topic test-topic --num-records 50000 --record-size 1000 --throughput -1 --producer-props bootstrap.servers=localhost:39092
消费者性能测试
/data/kafka/kafka-3/bin/kafka-consumer-perf-test.sh --topic test-topic --bootstrap-server localhost:39092 --fetch-size 1048576 --messages 50000 --threads 1
相关文章:

kafka KRaft 集群搭建
kafka KRaft集群安装 包下载 https://downloads.apache.org/kafka/3.6.1/kafka_2.13-3.6.1.tgzkafka集群构建好后的数据目录结构 [rootlocalhost data]# tree /data/kafka /data/kafka ├── kafka-1 # 节点1源码目录 ├── kafka-2 # 节点2源码目录 ├── kafka-3 # 节点…...

oracle角色管理
常用角色 CONNECT,RESOURCE,DBA,EXP_FULL_DATABASE,IMP_FULL_DATABASE 1角色可以自定义,语法与创建用户一样 CREATE role role1 IDENTIFIED by 123; 2授权权限给角色 --自定义角色 CREATE role role1 IDENTIFIED by 123; --授权权限给角色 GRANT create view, …...
)
汽车信息安全--芯片厂、OEM安全启动汇总(2)
目录 1.STM32 X-CUBE-SBSFU 2.小米澎湃OS安全启动 3.小结 在汽车信息安全--芯片厂、OEM安全启动汇总-CSDN博客,我们描述了芯驰E3的安全启动机制,接下来我们继续看其他芯片、OEM等安全启动机制。 1.STM32 X-CUBE-SBSFU 该产品全称Secure Boot and Secure...

HarmonyOS 开发基础(五)Button
HarmonyOS 开发基础(五)Button Entry Component struct Index {build() {Row() {Column() {// Button:ArkUI 的基础组件 按钮组件// label 参数:文字型按钮Button(我是按钮)// width:属性方法,设置组件的宽…...
带前后端H5即时通讯聊天系统源码
带有前后端的H5即时通讯聊天系统源码。该源码是一个开源的即时通信demo,需要前后端配合使用。它的主要目的是为了促进学习和交流,并为大家提供开发即时通讯功能的思路。尽管该源码提供了许多功能,但仍需要进行自行开发。该项目最初的开发初衷…...
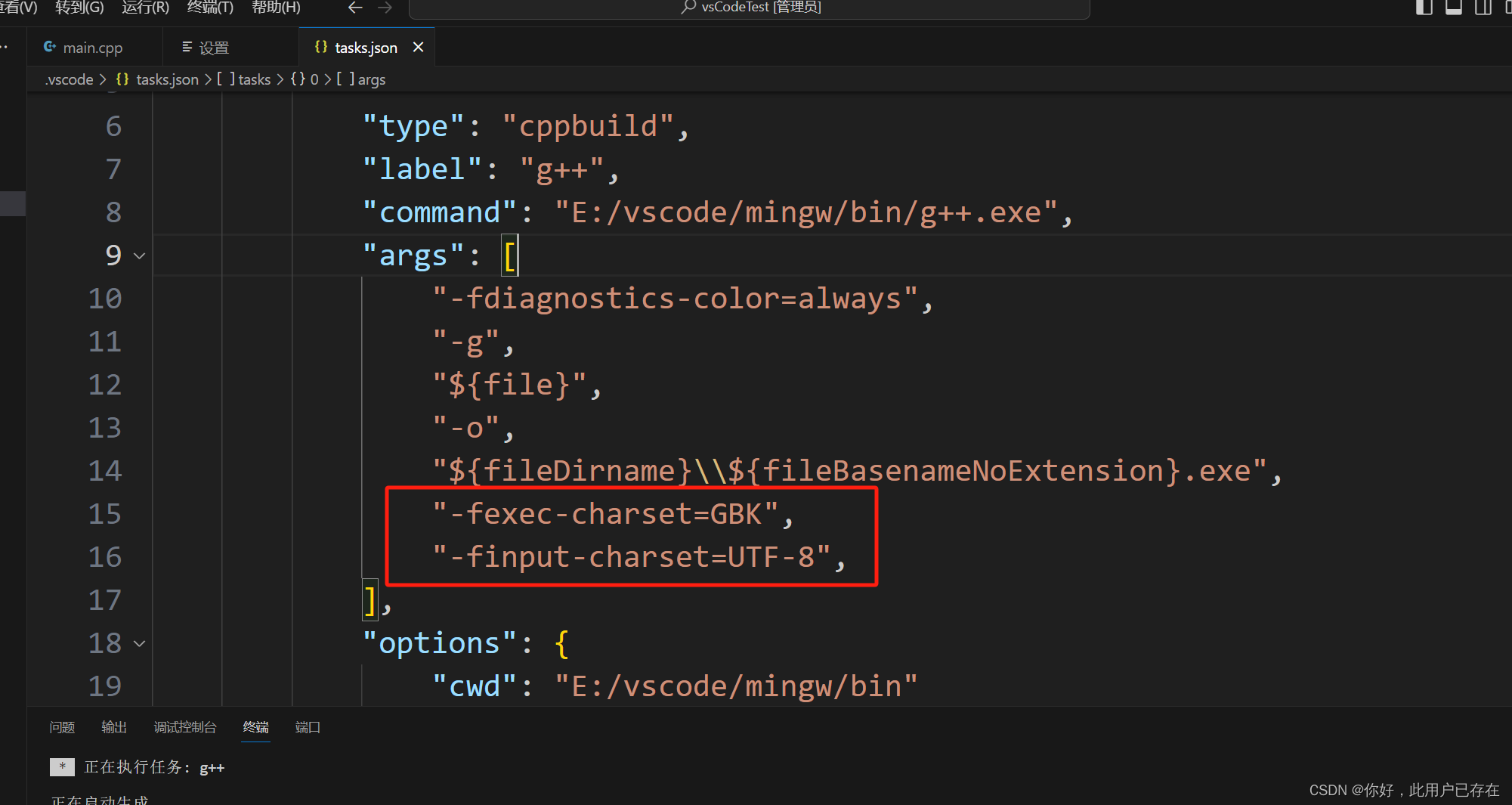
vsCode输出控制台中文乱码解决
在tasks.json里的args中添加 "-fexec-charsetGBK", // 处理mingw中文编码问题 "-finput-charsetUTF-8",// 处理mingw中文编码问题...
「服务器」4.新手小白如何安装服务器环境-宝塔
刚开始初始化好的服务器,使用了阿里云客户端,看着网络脚本乱装,后来决定宝塔环境发现有重复的环境,遂决定重新初始化一下,然后重头干起。 重置服务器 将服务器关闭运行状态后,点击重新初始化云盘即可重新初…...

Docker安装MySql详细步骤
1、新建挂载目录 首先进入安装mysql的目录,没有就自行创建 mkdir -p /usr/local/docker/mysql-docker cd /usr/local/docker/mysql-docker 接着挂载目录 # 选择自己的软件安装目录,新建挂载文件目录 mkdir -p data logs mysql-files conf # 赋予权限…...

【微服务合集】
文章目录 MyBatisPlusMyBatisPlus 注解WrapperMybatisPlus批量插入(saveBatch)MyBatisPlus 分页插件 DockerDockerfileDocker网络Docker部署项目 黑马微服务文档尚硅谷SpringBoot2尚硅谷SpringBoot3 MyBatisPlus MyBatisPlus 注解 TableName TableId TableField MyBatisPlu…...

Hadoop之mapreduce参数大全-2
25.指定在Reduce任务在shuffle阶段的fetch操作中重试的超时时间 mapreduce.reduce.shuffle.fetch.retry.timeout-ms是Apache Hadoop MapReduce任务配置中的一个属性,用于指定在Reduce任务在shuffle阶段的fetch操作中重试的超时时间(以毫秒为单位&#x…...
)
目标检测YOLO实战应用案例100讲-基于图像增强的鸟类目标检测(续)
目录 SRGAN网络模型改进研究 3.1 SRGAN超分辨率模型 3.1.1 SRGAN网络结构 3.1.2 SRGAN的损失函数...

MYSQL分表容量预估:简明指南
随着数据量的日益增长,分表技术成为优化mysql数据库性能的重要策略。本文介绍一种简明有效的预估分表容量大小的方法,帮助开发者和数据库管理员进行有效的资源规划。 背景 在处理大规模数据时,为了优化性能和管理便利,常常采用分…...
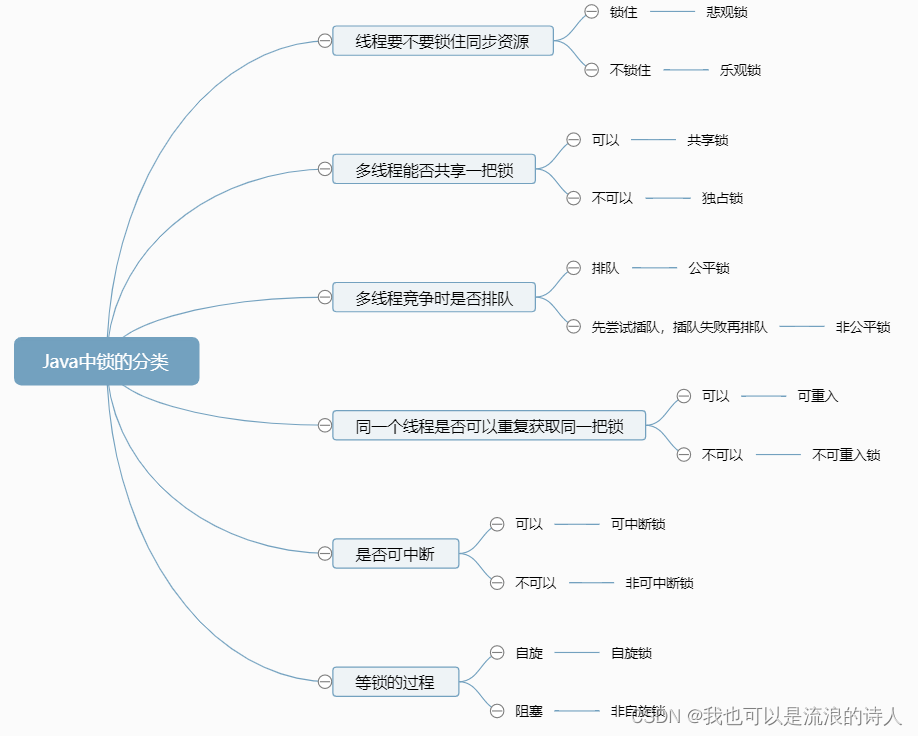
面试宝典进阶之Java线程面试题
T1、【初级】线程和进程有什么区别? (1)线程是CPU调度的最小单位,进程是计算分配资源的最小单位。 (2)一个进程至少要有一个线程。 (3)进程之间的内存是隔离的,而同一个…...
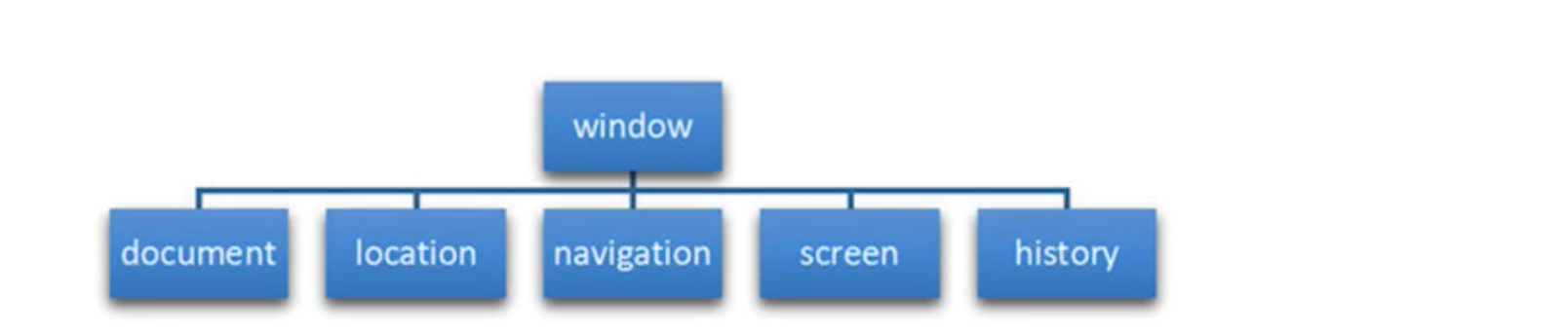
BOM简介
1.1 常用的键盘事件 1.1.1 键盘事件 键盘事件触发条件onkeydown按键被按下时触发onkeypress按键被按下时触发onkeyup按键被松开时触发 注意:addEventListener事件不需要加on <script>//1. keydown 按键按下的时候触发,按任意键都触发,也可以识…...

Java中的集合框架
概念与作用 集合概念 现实生活中:很多事物凑在一起 数学中的集合:具有共同属性的事物的总体 java中的集合类:是一种工具类,就像是容器,储存任意数量的具有共同属性的对象 在编程时,常常需要集中存放多个…...

Rustdesk打开Win10 下客户端下面服务不会自启,显示服务未运行
环境: Rustdesk1.19 问题描述: Rustdesk打开Win10 下客户端下面服务不会自启,显示服务未运行 解决方案: 1.查看源代码 pub async fn start_all() {crate::hbbs_http::sync::start();let mut nat_tested = false;check_zombie()...

【SPDK】【NoF】使用SPDK部署NVMe over TCP
SPDK NVMe over Fabrics Target是一个用户空间应用程序,通过以太网,Infiniband或光纤通道等结构呈现块设备,SPDK目前支持RDMA和TCP传输。 本文将在已经编译好SPDK的基础上演示如何使用SPDK搭建NVMe over TCP,前提是您已经将一块NVMe硬盘挂载…...

Spring boot 3 集成rocketmq-spring-boot-starter解决版本不一致问题
安装RocketMQ根据上篇文章使用Docker安装RocketMQ并启动之后,有个隐患详情见下文 Spring Boot集成 <dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.2…...
--获取某度热榜)
python爬虫实战(6)--获取某度热榜
1. 项目描述 需要用到的类库 pip install requests pip install beautifulsoup4 pip install pandas pip install openpyxl然后,我们来编写python脚本,并引入需要的库: import requests from bs4 import BeautifulSoup import pandas as p…...

十三、K8S之亲和性
亲和性 一、概念 在K8S中,亲和性(Affinity)用来定义Pod与节点关系的概念,亲和性通过指定标签选择器和拓扑域约束来决定 Pod 应该调度到哪些节点上。与污点相反,它主要是尽量往某节点靠。 亲和性是 Kubernetes 中非常…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...