Clip:学习笔记
Clip
文章目录
- Clip
- 前言
- 一、原理
- 1.1 摘要
- 1.2 引言
- 1.3 方法
- 1.4 实验
- 1.4.1 zero-shot Transfer
- 1.4.2 PROMPT ENGINEERING AND ENSEMBLING
- 1.5 局限性
- 二、总结
前言
阅读论文:
Learning Transferable Visual Models From Natural Language Supervision
CLIP 论文逐段精读【论文精读】
Github:
https://openai.com/research/clip
https://github.com/OpenAI/CLIP
知乎:
如何评价OpenAI最新的工作CLIP:连接文本和图像,zero shot效果堪比ResNet50?
OpenAI发布CLIP模型快一年了,盘点那些CLIP相关让人印象深刻的工作
一、原理
原理:
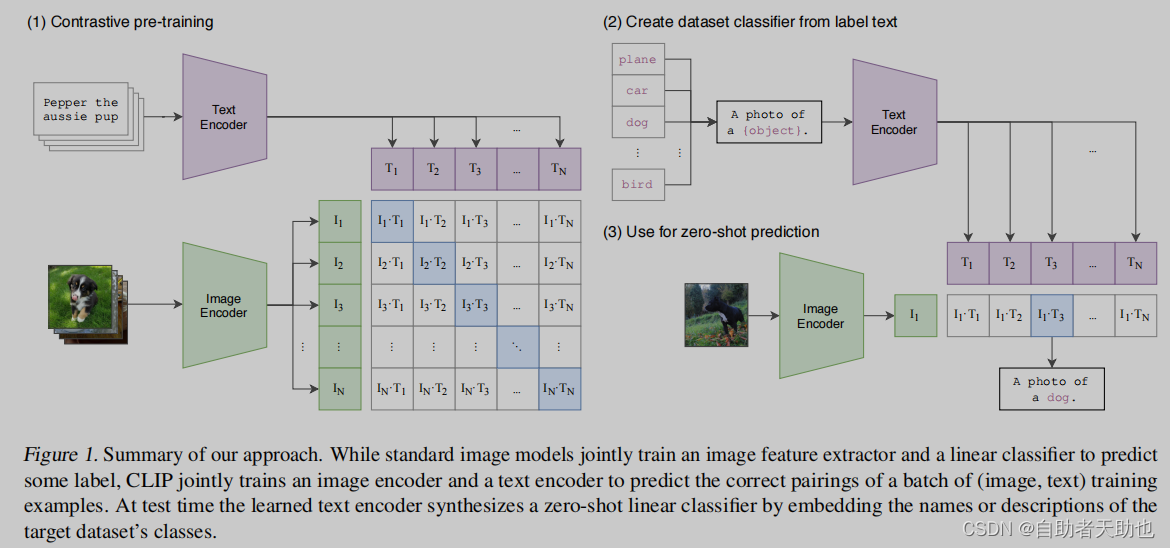
一个batch中,image encoder (可以是resnet,也可以是visual transformers)对应 text encoder 在矩阵中进行对比学习,蓝色对角线上的是正例样本,其余的都是负样本。推理的时候如何做到不需要imagenet的监督学习,就可以做到监督信号的呢?那是构造了prompt template, 原本的linear的1000个类,构造成 a photo of a [object label]经过text encoder(pretrain的 encoder),得到的向量和 image 经过 image encoder的向量进行求cosine similarity.
- 针对prompt template的构造还有 prompt engineering和prompt ensmble两种方法
- 比对学习需要大量的图片文本的数据集,openai收集了4亿对的数据集进行预训练
效果:迁移学习能力非常强,zeroshot在视觉数据集上效果很好,尤其是ImageNet上的效果,摆脱了categorical label的限制
The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on
https://openai.com/research/clip

和NLP的结合,CLIP学出来的视觉特征和语言描述的某些物体产生强烈的联系
有趣的应用:
styleCLIP
text 2 修改图片
CLIPDraw
text 2 简笔画的生成,抽象主义的
物体监测分割
open-vocabulary detector
视频检索clifs
1.1 摘要
imagenet 1000 类
CIFAR 10
CIFAR 100
目标监测
coco 80
语义分割
city scapes 19
视频
Kineitcs 400
想法
Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision.
对应的任务设计成:
We demonstrate that the simple pre-training task of redicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet.
实验
在30个不同的CV datasets上做测试,迁移的效果非常好
开源的代码只有推理的部分,并没有预训练的部分
1.2 引言
The development of “text-to-text” as a standardized input-output interface (McCann et al., 2018;Radford et al., 2019; Raffel et al., 2019) has enabled task-agnostic architectures to zero-shot transfer to downstream datasets removing the need for specialized output heads or dataset specific customization
核心在于预训练的架构和下游任务无关,这样就不需要监督信号学习一个和下游任务相关的分类头。
NLP的那套预训练的方法:
These results suggest that the aggregate supervision accessible to modern pre-training methods within web-scale collections of text surpasses that of high-quality crowd-labeled NLP datasets
这个方法是很有效的,希望用到CV的相关任务中来。
作者从1999年的相关论文讨论到2021年
主要跟2017年的Learning visual n-grams from web data
有了transformer、完形填空自监督的学习信号后,有了VirTex\ICMLM\Con-VIRT,基于transformer做的后面的一些工作是想把一些弱的监督信号用起来:
Instead, more narrowly scoped but well-targeted uses of weak supervision have improved performance. Mahajan et al. (2018) showed
that predicting ImageNet-related hashtags on Instagram images is an effective pre-training task. When fine-tuned to ImageNet these pre-trained models increased accuracy by over 5% and improved the overall state of the art at the time. Kolesnikov et al. (2019) and Dosovitskiy et al. (2020) have also demonstrated large gains on a broader set of transfer benchmarks by pre-training models to predict the classes of the noisily labeled JFT-300M dataset.
好处是弱的监督信号的数据集大,因此,作者认为,使用gold-labels是很有限的,反而希望用上,那些取之不尽用之不竭的文本,即使用上了在模型层面还是很有局限性,主要是用静态的softmax作为分类头,缺乏zero-shot的能力。
Both works carefully design, and in the process limit, their supervision to 1000 and 18291 classes respectively. Natural language is able to express, and therefore supervise, a much wider set of visual concepts through its generality. Both approaches also use static softmax classifiers to perform prediction and lack a mechanism for dynamic outputs. This severely curtails their flexibility and limits their “zero-shot” capabilities.
之前的工作不行,主要是数据集的规模和模型的规模都要上去。accelerator years,所以作者团队先从数据集开始入手,收集了4对的文本图片对。模型层面从:resnet\efficient net\vision transformer(VIT Large),就提出了CLIP。单单视觉上的模型就用了8个,最大和最小的模型容量差了100倍。
作者怒刷30个数据集,看泛化性和迁移的效果。在做zero-shot之前呢,作者去看了linear-probe,为了进一步提供模型的学习能力,直接把主干网络冻住,训练最后一层的分类头,发现全方面碾压之前的方法。
1.3 方法
用上了deep contextual representations, like bert,就能利用上abundant source of supervision,
总结下来说:文本监督信号,帮助训练一个视觉模型,是很有潜力,前提是数据集量够大,目前能用的数据集:MS-COCO\Visual Genome,好归好,但是数据量太少了,JFT300M有3亿个样本、Instagram 有3.5billion。YFCC100标注质量太差了,有人去清晰了下,只身下15M了。
NLP那边的数据集来说和GPT2差不多的级别,CV和JFT300m还多了一个亿。WIT数据集。
之前训练的模型也还只是在1000类别上就已经如此的耗时了,更不用说是开放点视觉概念任务上了。作者提出:
In the course of our efforts, we found training efficiency was key to successfully scaling natural language supervision and we selected our
final pre-training method based on this metric
训练的效率视乎是训练自然语言监督信号的核心。
- step1, similar to VirTex , jointly trained an image CNN and text transformer from scratch to predict the caption of an image, 结果:很慢
- contrastive objectives can learn better representations than their equivalent predictive objective 比对学习目标比预测型的目标更加好学
- 不仅如此,推理的速度更加快,快了4倍
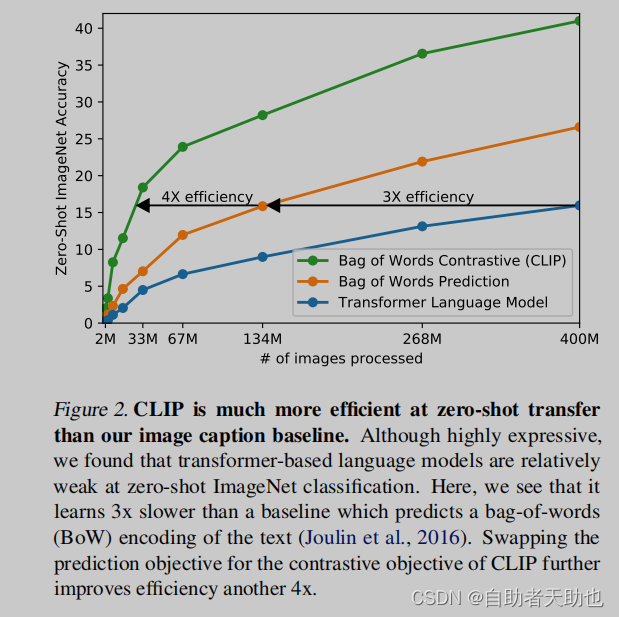
橙色是将文本变成全局的特征,而不是逐字逐句的特征,再把约束放宽,推理速度又更近一步。 - 伪代码
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images [8, 224, 224, 3]
# T[n, l] - minibatch of aligned texts [8,512]
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)# symmetric loss function
# SimCLR 到 BYOL, 一直到最新的MOCO V3 DINO这些工作都是用对称式的目标函数
labels = np.arange(n) 对角线上的元素
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2Figure 3. Numpy-like pseudocode for the core of an implementation of CLIP.
训练细节:
- 数据集太大,不会导致over-fitting的问题
- 从头预训练没有加载imagesnet权重和文本的权重
- 也没有用非线性层的映射,在表示层和比对的embedding映射空间,这里只用了linear层
- 移除了只采样图片文本的一个句子的功能
- 简化了图片数据增强的功能,只采用裁剪这种方式
- 对于比对学习中temperature parameter参数只是设置为可以学习的标量
- 视觉部分,模型可以选择ResNET(还稍微做了一些修改) ,也可以选择visual transformers(VIT), 文本部分只是使用的transformers
. As a base size we use a 63M-parameter 12-layer 512-wide model with 8 attention heads.
- BPE\49152词表、76的最大长度
- 并在模型的宽度和深度做了一些简单的尝试
- 5个resnet(50-101-50x4-50x16-50x64), 3个vit(32-16-14)
- 模型训练的是32epochs,Adam优化器
- 权重衰减、not gains, not biases
- cosine schedule的lr
- 只在resnet50做了grid searches 一个epoches,
- 32768的batch_size, 天啊
- 混精度训练、 gradient checkpointing、 half-precision Adam statistics、half-precision stochastically rounded text encoder weights
- 相似度的计算也是放在不同的GPU上
题外话:openai热衷于GPT
GPT系列、DALL-E、Image gpt 和 openai codex
1.4 实验
1.4.1 zero-shot Transfer
Our focus on studying zero-shot transfer as an evaluation of task learning is inspired by work demonstrating task learning in the field of NLP
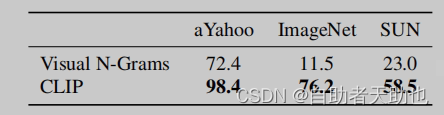
作者的核心就是使用一张图片,分别问1000个句子,之后做一个softmax, 就可以进行相对应的zero-shot了。
大幅度提升了效果
1.4.2 PROMPT ENGINEERING AND ENSEMBLING
主要的问题是词语的多义性,polysemy
When the name of a class is the only information provided to CLIP’s text encoder it is unable to differentiate which word sense is meant due to the lack of context
论文提出模板式:
A photo of a {label} to be a good default that helps specify the text is about the content of the image
如果知道更多信息,那效果会更好
For example on Oxford-IIIT Pets, using “A photo of a {label}, a type of pet.” to help provide context worked well. Likewise, on Food101 specifying a type of food and on FGVC Aircraft a type of aircraft helped too.
作者用了80个提示模板
https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb
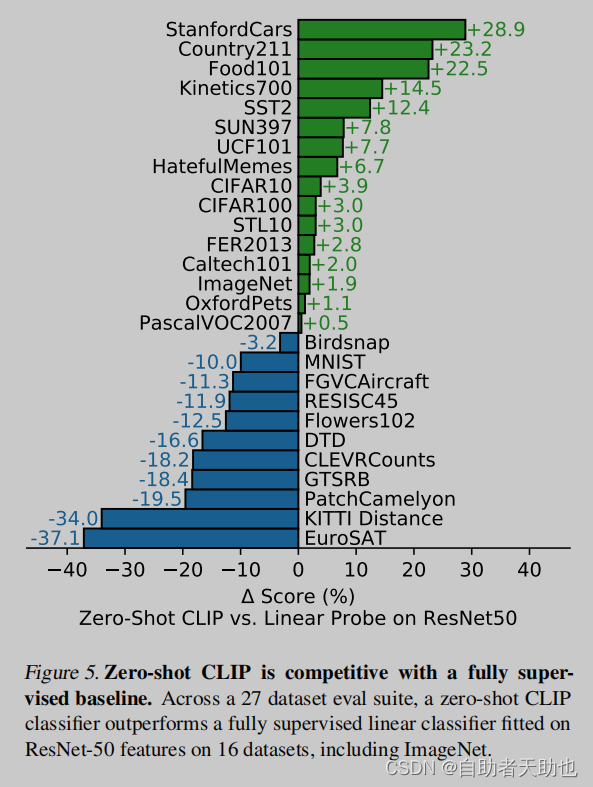
再做了27个数据集的实验:
- clip的zero-shot,以及linear probe就是冻住主干,只训练最后一层的linear层
- linear probe是基线版本,绿色是优于probe的,蓝色是低的
- 物品的分类效果会更加好,更难的数据集,纹理、物体的计数会更加抽象,会更难
- 难的任务,可能需要few shot
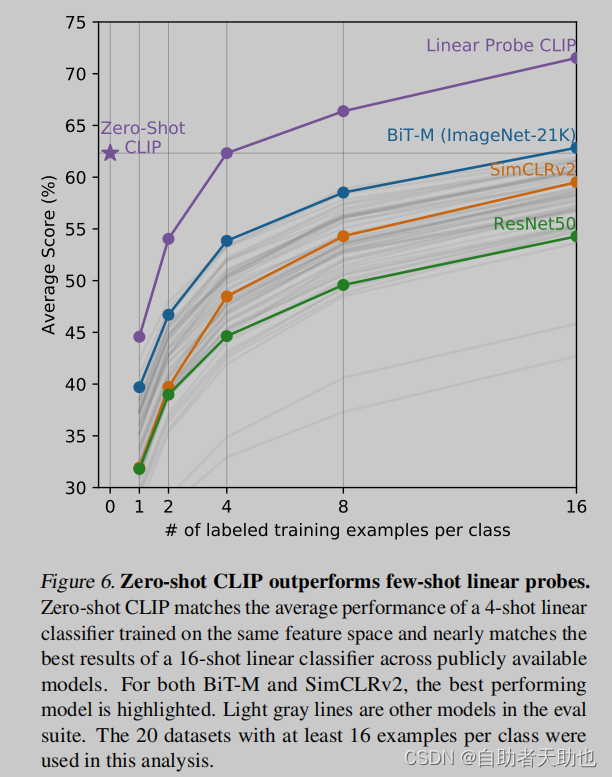
- few shot的实验也做了,横坐标是每个label使用的样本,纵坐标是20个数据集中的平均准确率,同时都是用的linear probe,clip冻住的是图片的encoder,
- bit是专门为迁移学习所做的,当时最好的迁移学习的模型,很强的baseline
- 1,2,4的fewshot效果还没有多模态的zero-shot好,说明文本的监督信号确实强
zeroshot\few shot都做完了,接下来如果直接使用全量的监督信号的数据进行实验会如何
方法有两种:
1、linear probe
2、finetune
作者只用第一种方式,减少预训练对数据的影响,看预训练的好坏。finetune太多参数可以调,这样就不好比对效果。
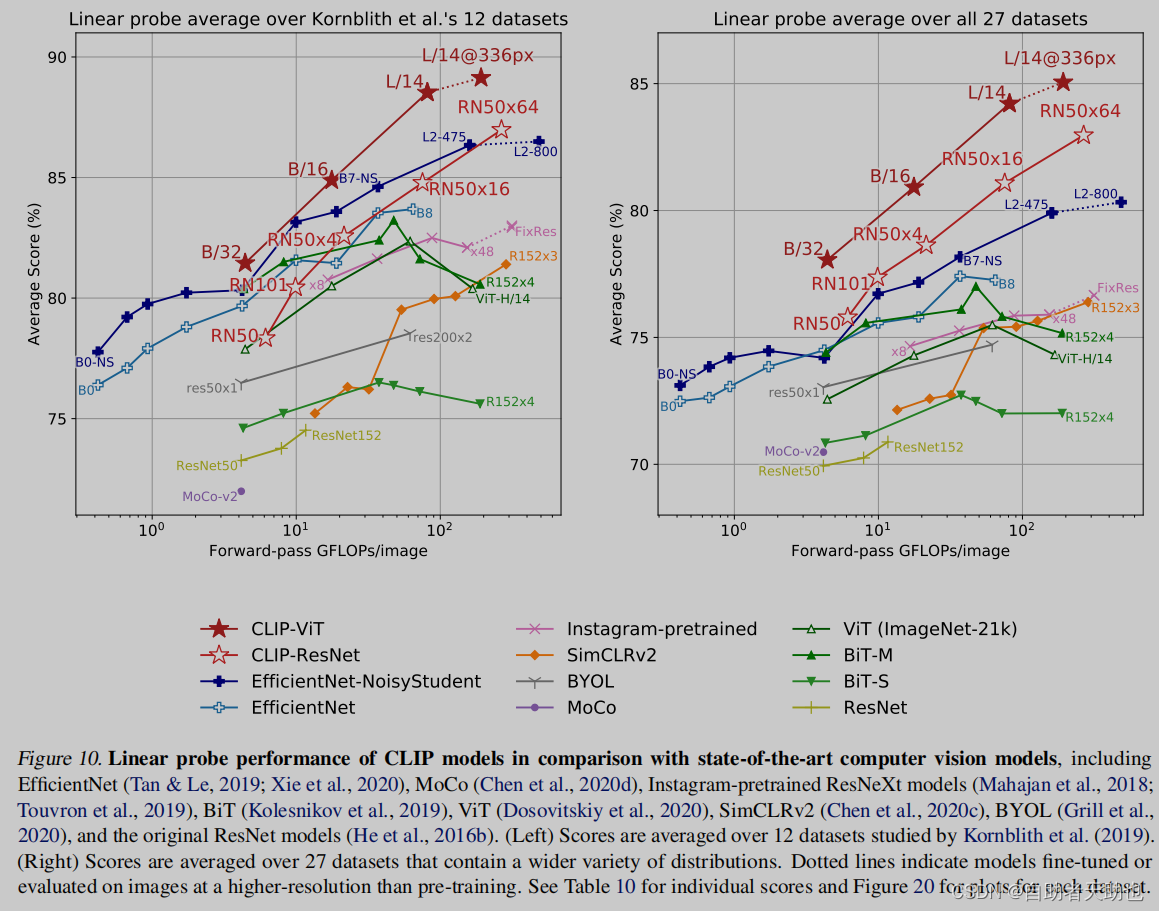
横坐标是一张图经过的参数量,纵坐标是准确率
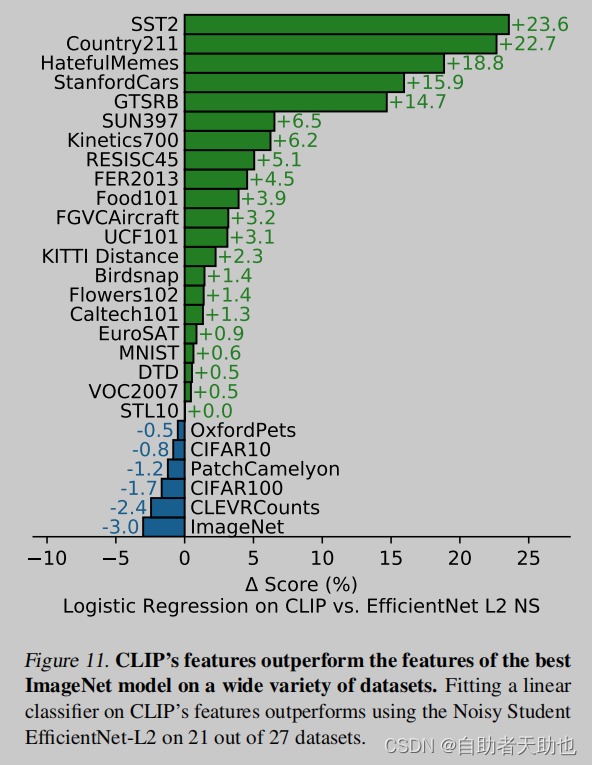
作者再把clip和efficientnet做对比
Fitting a linear classifier on CLIP’s features outperforms using the Noisy Student
EfficientNet-L2 on 21 out of 27 datasets.
冻住主干网络,只训分类头,全量的数据。
当数据有偏移的时候,模型表现如何:
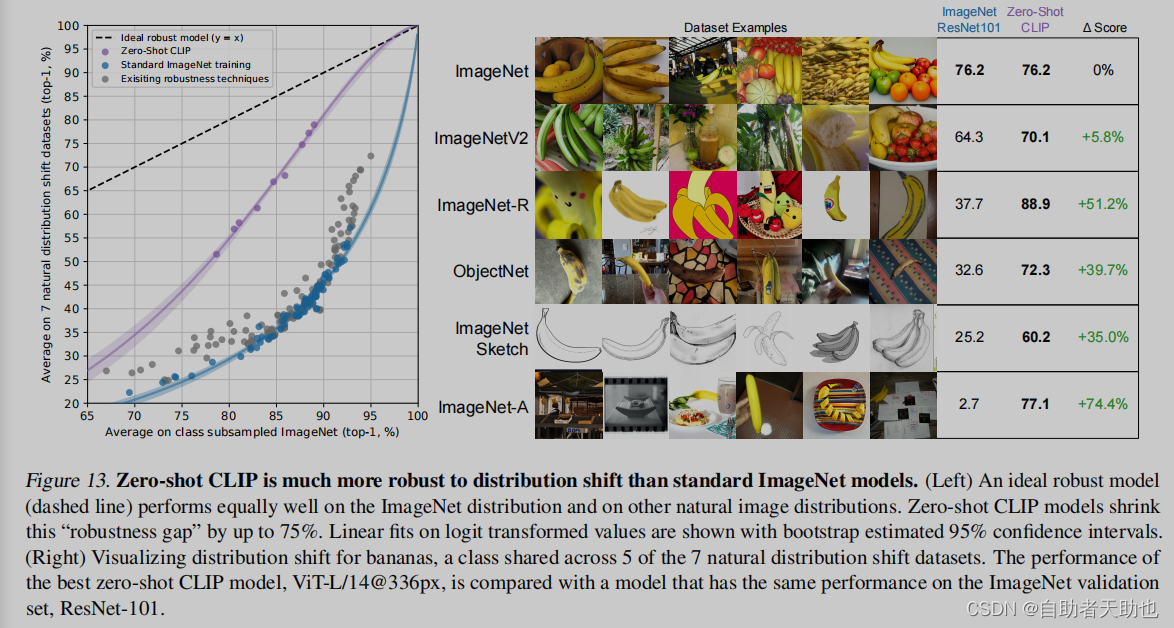
和人类进行比较,找了5个人来做实验
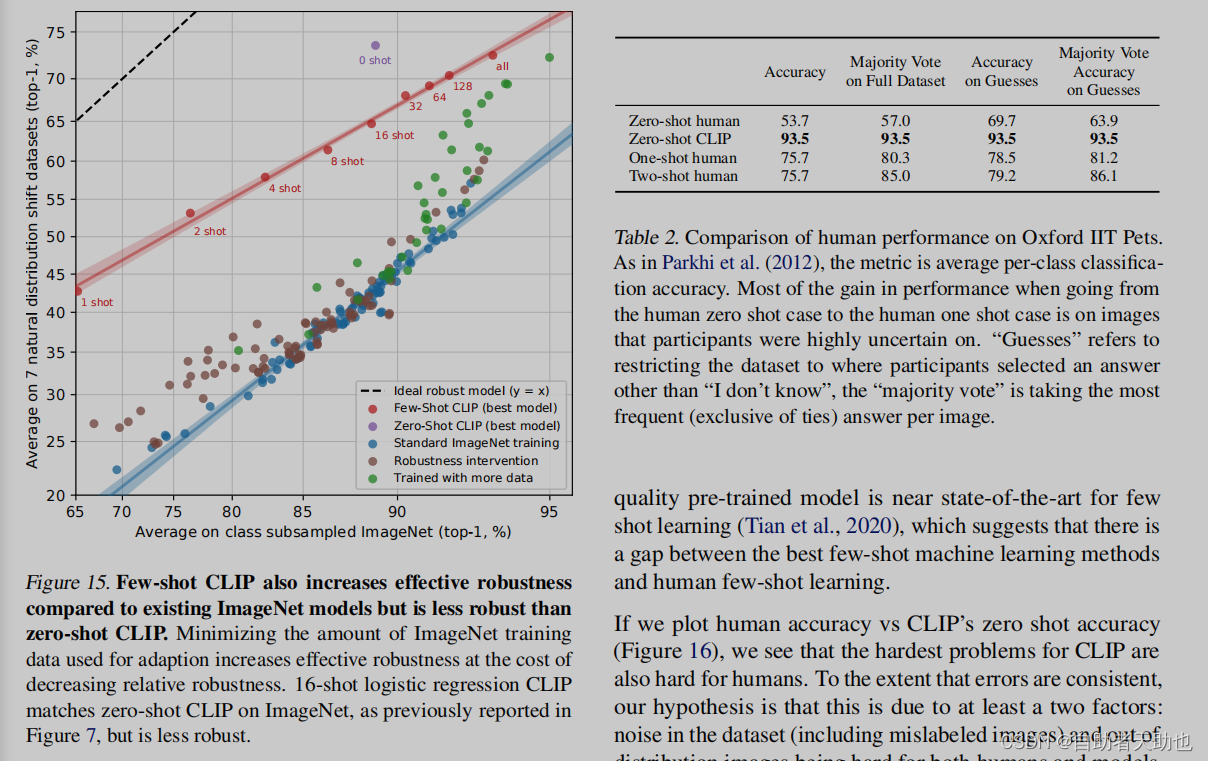
表格的体现出来的效果还是很好的
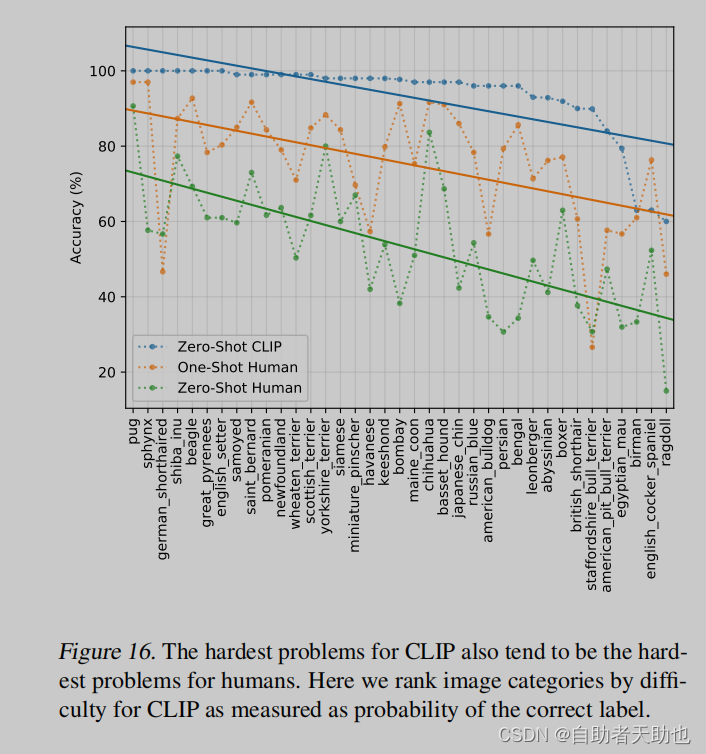
人类觉得难的,模型也觉得难
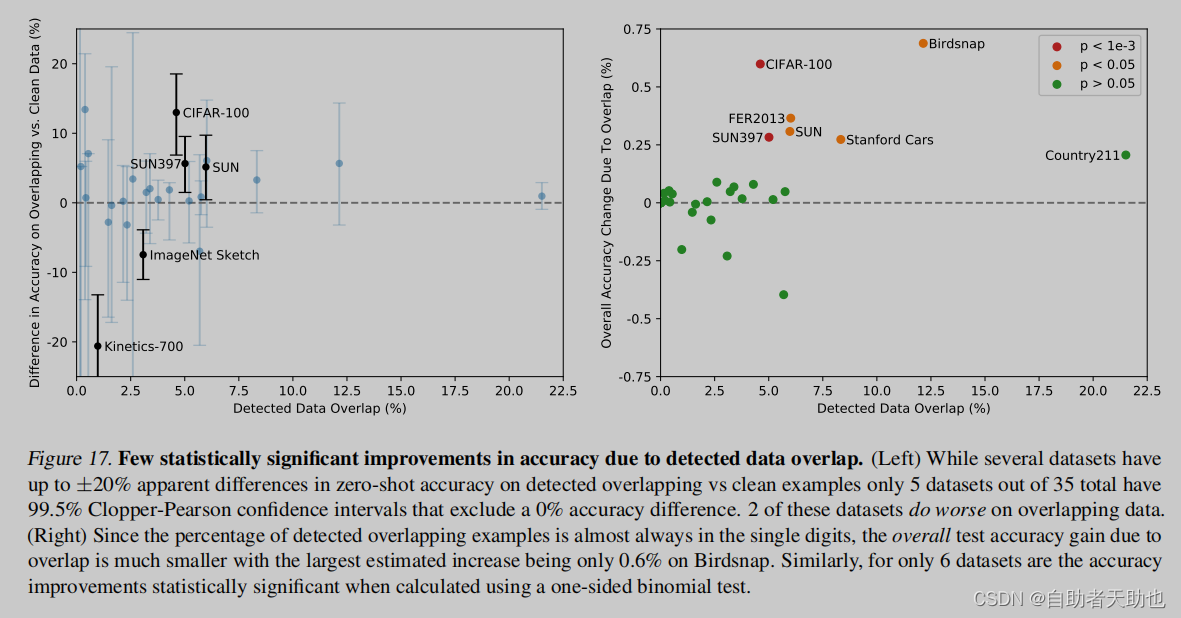
做了去重的实验,还是觉得clip的泛化性能好
1.5 局限性
Significant work is still needed to improve the task learning and transfer capabilities of CLIP. While scaling has so far steadily improved performance and suggests a route for continued improvement, we estimate around a 1000x increase in compute is required for zero-shot CLIP to reach overall state-of-the-art performance
扩大规模来弥补和stoa的差距不现实
CLIP also struggles with more abstract and systematic tasks such as counting the number of objects in an image. Finally for novel tasks which are unlikely to be included in CLIP’s pre-training dataset, such as classifying the distance to the nearest car in a photo, CLIP’s performance can be near random. We are confident that there are still many, many, tasks where CLIP’s zero-shot performance is near chance level.
更难的任务上确实不太行
However, CLIP only achieves 88% accuracy on the handwritten digits of MNIST
预训练的数据集和下游的数据分布如果是out of distribution也不太行
最好的是,直接生成图片的标题,这就是端到端的了,而不是给你一个自然语言的监督信号,做成一个生成式的模型。对比学习的函数和生成式的目标函数合在一起
对数据的利用并不高效。如何提高数据的利用效率,自监督的方式和伪标签的方式
做实验过程,总是以测试集为导向进行调参,而不是真正的zeroshot
这选中的27个数据集,也是有主观的偏见的,如果有一个数据集是专门来做zeroshot的那就太好了
数据都是网上爬的,没有经过过滤的,会带有社会的偏见
在一些很难用语言描述的任务过程中,如果你不提供训练样本的表现由于你few shot的效果
二、总结
We have investigated whether it is possible to transfer the success of task-agnostic web-scale pre-training in NLP to another domain. We find that adopting this formula results in similar behaviors emerging in the field of computer vision and discuss the social implications of this line of research. In order to optimize their training objective, CLIP models learn to perform a wide variety of tasks during pretraining. This task learning can then be leveraged via natural language prompting to enable zero-shot transfer to many existing datasets. At sufficient scale, the performance of this approach can be competitive with task-specific supervised models although there is still room for much improvement.
打破了固定标签的学习范式,无监督的方式进行学习,数据处理更方便,模型也是方便,推理更加方便。新意度100 有效性100 问题大小100分
相关文章:
Clip:学习笔记
Clip 文章目录Clip前言一、原理1.1 摘要1.2 引言1.3 方法1.4 实验1.4.1 zero-shot Transfer1.4.2 PROMPT ENGINEERING AND ENSEMBLING1.5 局限性二、总结前言 阅读论文: Learning Transferable Visual Models From Natural Language Supervision CLIP 论文逐段精读…...
STM32CubexMX与FreeRTOS学习
目录 LED与EXTI配置 基本定时器使用 软件定时器 在HAL库中实现printf 重点--记得自己添加头文件 队列实现 二值信号量实现 计数信号量实现 DMA实现 ADC配置 RTC配置 看门狗 窗口看门狗 FreeRTOS结合MX软件开发,基础配置直接生成,我们只…...

Master Slave 主从同步错误 Slave_IO_Running:NO/Slave_SQL_Running: No
Master Slave 主从同步错误 Slave_IO_Running:NO Slave_SQL_Running:Yes #在Slave库上查看状态 mysql> show slave status\G Slave_IO_Running: No Slave_SQL_Running: Yes #重启master库:service mysqld restart mysql> show master status; ------------…...
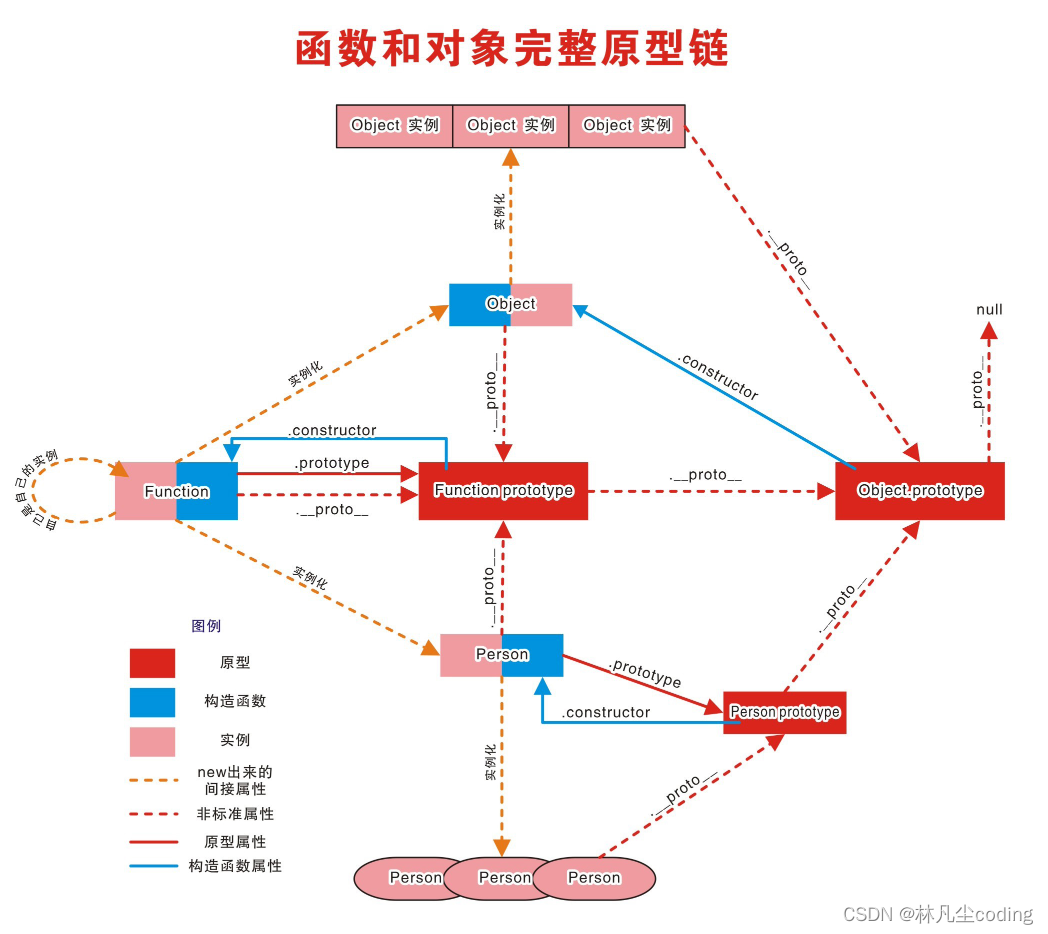
JavaScript函数之prototype原型和原型链
文章目录1. 原型2. 显式和隐式原型3. 原型链3.1 访问顺序4. instanceof4.1 如何判断1. 原型 函数的prototype属性 每个函数都有一个prototype属性,它默认指向一个Object空对象(即:原型对象)。原型对象中有一个属性constructor&a…...
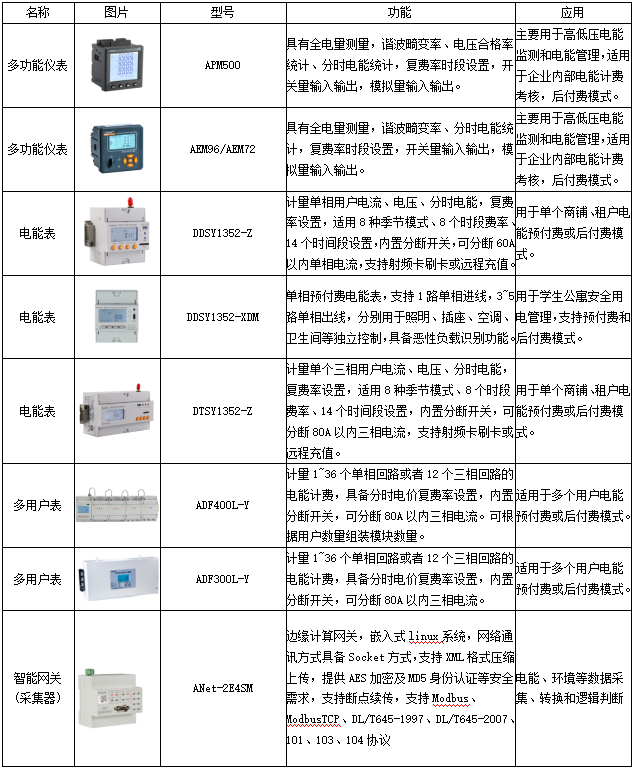
从上海分时电价机制调整看转供电用户电能计费
安科瑞 耿敏花2022年12月16日,上海市发改委发布《关于进一步完善我市分时电价机制有关事项的通知》(沪发改价管〔2022〕50号)。通知明确上海分时电价机制,一般工商业及其他两部制、大工业两部制用电夏季(7、8、9月)和冬季…...

TypeScript类型体操:获取数组中元素对象属性的值作为新类型
title: TypeScript类型体操:获取数组中元素对象属性的值作为新类型 date: 2023-03-03 20:58:24 categories: TypeScript类型体操 tags: TypeScript类型体操TypeScript 首先先说获取数组中元素对象属性的值作为新类型的解决方案 使用 as const 强调不可变数组使用 …...

npm,yarn和pnpm
npm扁平的node_modules结构比如项目依赖了A 和 C,而 A 和 C 依赖了不同版本的 B1.0 和 B2.0,D也依赖B1.0, node_modules 结构如下:node_modules ├── A1.0.0 ├── B1.0.0 └── C1.0.0└── node_modules└── B2.0.0C依赖的B2.0因为版…...
)
【算法】【数组与矩阵模块】在排好序的矩阵中找数,时间复杂度O(M+N)
目录前言问题介绍解决方案代码编写java语言版本c语言版本c语言版本思考感悟写在最后前言 当前所有算法都使用测试用例运行过,但是不保证100%的测试用例,如果存在问题务必联系批评指正~ 在此感谢左大神让我对算法有了新的感悟认识! 问题介绍 …...

【Java|基础篇】计算机中数据的存储规则
文章目录前言:1.计算机中的数据2.二进制的介绍二进制的运算规则常见的进制3.字符的存储4.汉字的存储5.图片的存储6.音频的存储总结:前言: 本篇文章只是为了科普 计算机中数据的存储规则 1.计算机中的数据 计算机的数据大致分为三类:文本数据,图片和音频 注:视频是图片和音频…...
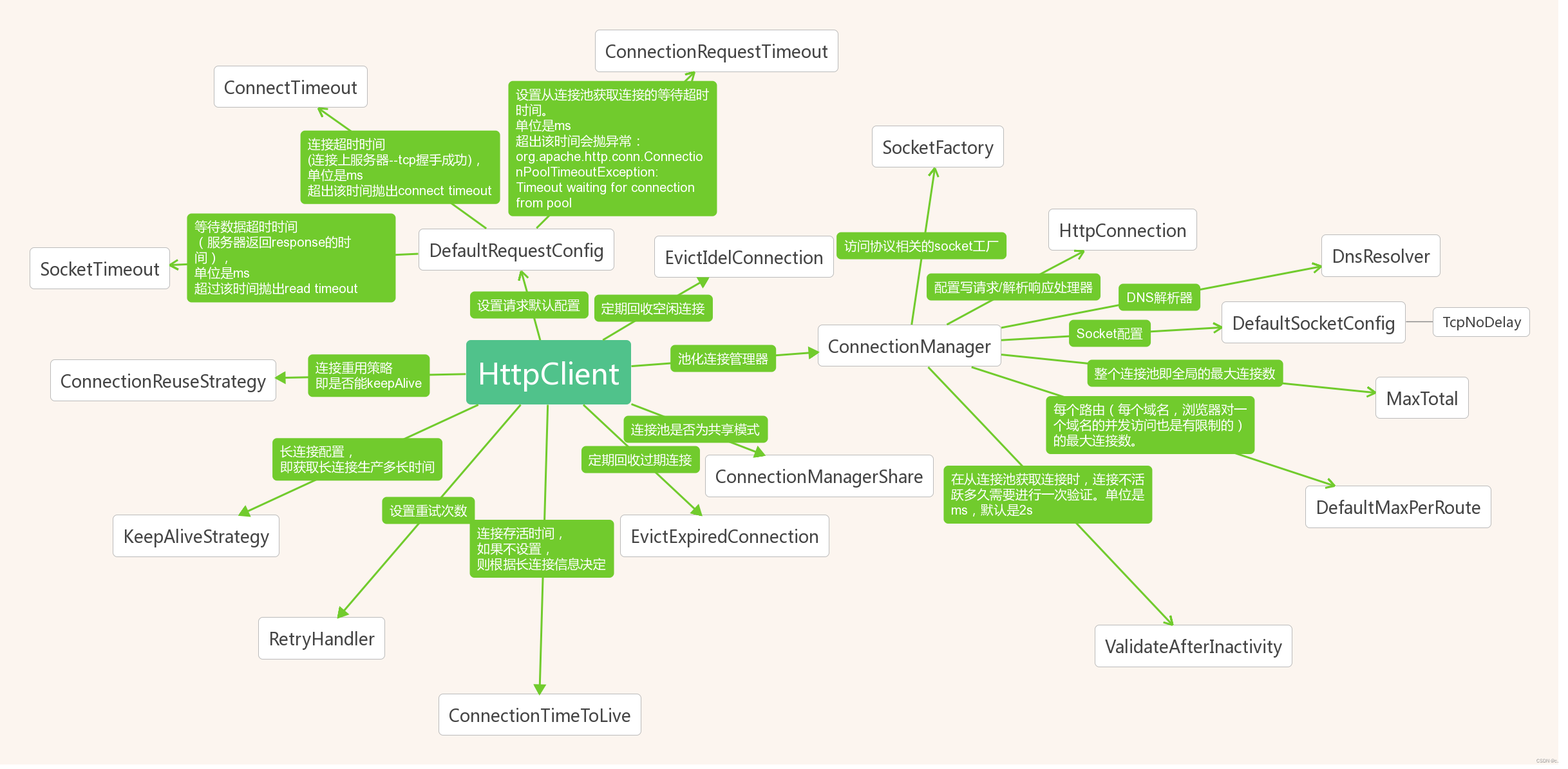
RestTemplate使用HttpClient连接池
文章目录RestTemplate使用HttpClient连接池ClientHttpRequestFactorySimpleClientHttpRequestFactorySimpleClientHttpRequestFactory 设置超时时间HttpURLConnection的缺点HttpComponentsClientHttpRequestFactoryPoolingHttpClientConnectionManager配置连接池HttpClient总结…...

Python 操作Redis
在 Python中我们使用 redis库来操作 Redis数据库。Redis数据库的使用命令这里就不介绍了。 需要安装 redis库。检查是否安装redis: pip redis 如果未安装,使用 pip命令安装 redis。 pip install redis #安装最新版本 一、Redis连接 Redis提供两个类 Re…...

CEC2020:鱼鹰优化算法(Osprey optimization algorithm,OOA)求解CEC2020(提供MATLAB代码
一、鱼鹰优化算法简介 鱼鹰优化算法(Osprey optimization algorithm,OOA)由Mohammad Dehghani 和 Pavel Trojovsk于2023年提出,其模拟鱼鹰的捕食行为。 鱼鹰是鹰形目、鹗科、鹗属的仅有的一种中型猛禽。雌雄相似。体长51-64厘米…...

词对齐 - MGIZA++
文章目录关于 MGIZAgiza-py安装 MGIZA命令说明mkclsd4normhmmnormplain2sntsnt2coocsnt2coocrmpsnt2plainsymalmgizageneral parameters:No. of iterations:parameter for various heuristics in GIZA for efficient training:parameters for describing the type and amount o…...
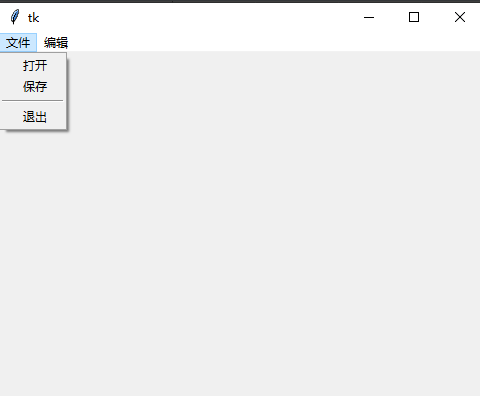
GUI 之 Tkinter编程
GUI 图形界面,Tkinter 是 Python 内置的 GUI 库,IDLE 就是 Tkinter 设计的。 1. Tkinter 之初体验 import tkinter as tkroot tk.Tk() # 创建一个窗口root.title(窗口标题)# 添加 label 组件 theLabel tk.Label(root, text文本内容) theLabel.p…...
【软件测试】性能测试面试题都问什么?面试官想要什么?回答惊险避坑......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 1、你认为不同角色关…...

后端开发基础能力以及就Java的主流开发框架介绍
前言:java语言开发转后端,必须了解后端主流的一些东西,共勉。 后端开发需要具备以下基础能力: 1.编程语言:熟练掌握至少一门编程语言,如Java、Python、Ruby、PHP、C#等。 2.数据结构和算法:具…...
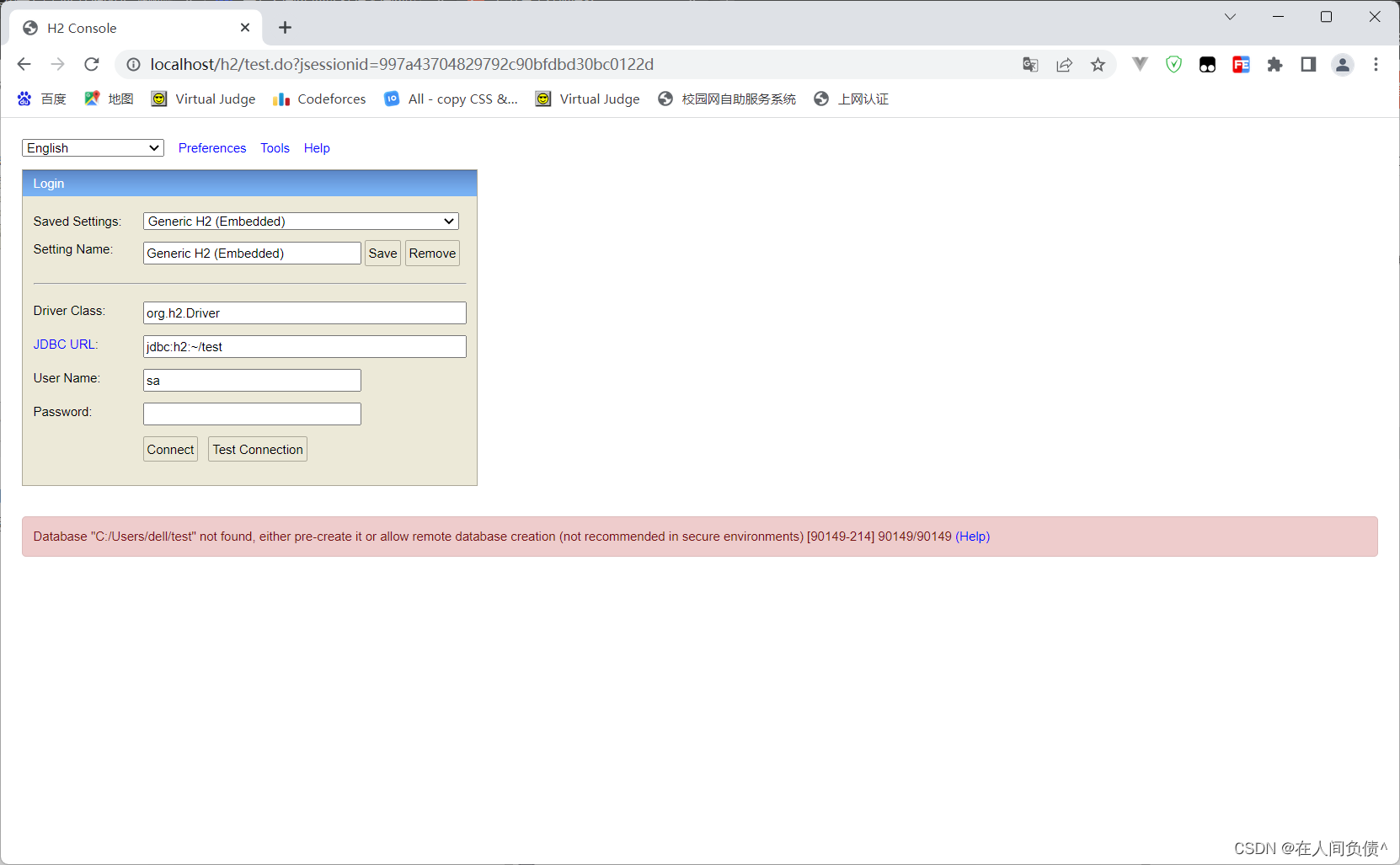
H2数据库连接时用户密码错误:Wrong user name or password [28000-214] 28000/28000 (Help)
H2数据库连接时用户密码错误: 2023-03-03 08:25:07 database: wrong user or password; user: "SA" org.h2.message.DbException: Wrong user name or password [28000-214]出现的问题配置信息原因解决办法org.h2.message.DbException: Wrong user name or password …...

青岛诺凯达机械盛装亮相2023济南生物发酵展,3月与您相约
BIO CHINA生物发酵展,作为生物发酵产业一年一度行业盛会,由中国生物发酵产业协会主办,上海信世展览服务有限公司承办,2023第10届国际生物发酵展(济南)于2023年3月30-4月1日在山东国际会展中心(济…...
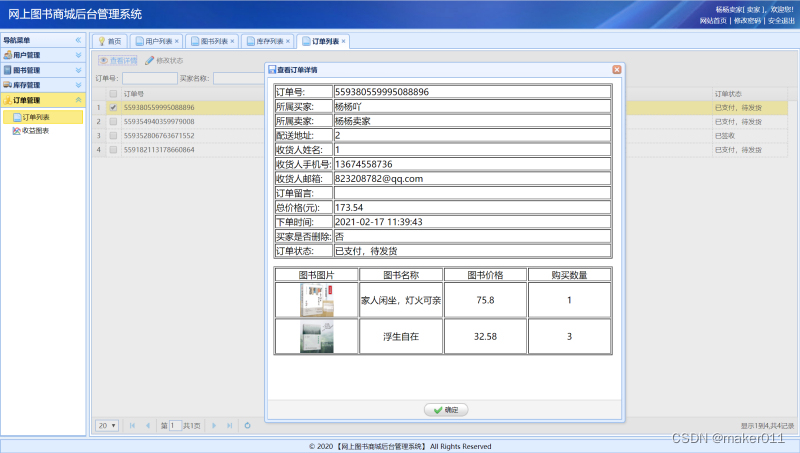
【JAVA程序设计】【C00111】基于SSM的网上图书商城管理系统——有文档
基于SSM的网上图书商城管理系统——有文档项目简介项目获取开发环境项目技术运行截图项目简介 基于ssm框架开发的网上在线图书售卖商城项目,本项目分为三种权限:系统管理员、卖家、买家 管理员角色包含以下功能: 用户信息管理、权限管理、订…...

基于卷积神经网络CNN的三相故障识别
目录 背影 卷积神经网络CNN的原理 卷积神经网络CNN的定义 卷积神经网络CNN的神经元 卷积神经网络CNN的激活函数 卷积神经网络CNN的传递函数 卷积神经网络CNN手写体识别 基本结构 主要参数 MATALB代码 结果图 展望 背影 现在生活,为节能减排,减少电能损…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...
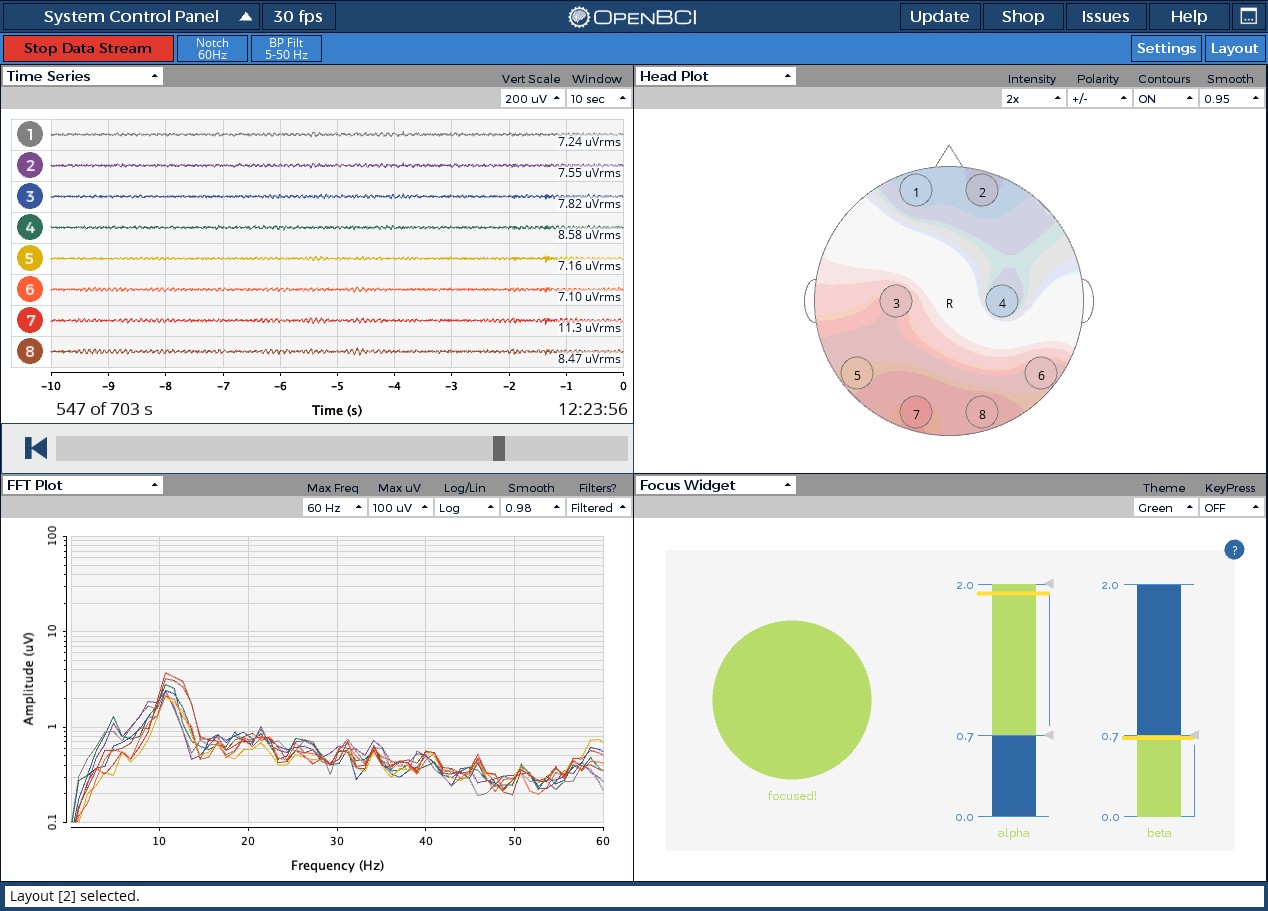
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...
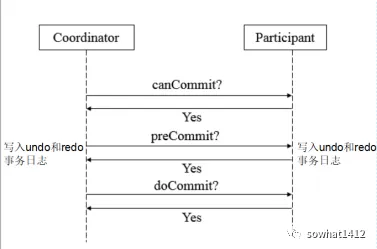
解析两阶段提交与三阶段提交的核心差异及MySQL实现方案
引言 在分布式系统的事务处理中,如何保障跨节点数据操作的一致性始终是核心挑战。经典的两阶段提交协议(2PC)通过准备阶段与提交阶段的协调机制,以同步决策模式确保事务原子性。其改进版本三阶段提交协议(3PC…...