【EAI 005】EmbodiedGPT:通过具身思维链进行视觉语言预训练的具身智能大模型
论文描述:EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought
论文作者:Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, Ping Luo
作者单位:The University of Hong Kong, Shanghai AI Laboratory, Noah’s Ark Laboratory
论文原文:https://arxiv.org/abs/2305.15021
论文出处:NeurIPS 2023 spotlight
论文被引:42(01/05/2024)
项目主页:https://embodiedgpt.github.io/
论文代码:https://github.com/EmbodiedGPT/EmbodiedGPT_Pytorch
Abstract
具身人工智能(Embodied AI,EAI)是机器人技术的一个重要前沿领域,它能够为机器人规划和执行行动序列,以完成物理环境中的长周期(long-horizon)任务。本文提出了 EmbodiedGPT,它是一种端到端多模态具身人工智能基础模型,赋予具身Agent多模态理解和执行能力。为此:
- i)我们制作了一个大规模的具身规划数据集,称为 EgoCOT。该数据集包括从 Ego4D 数据集中精心挑选的视频以及相应的高质量语言指令。具体来说,我们利用思维链(Chain of Thoughts,CoT)模式生成一系列子目标,以实现有效的具身规划。
- ii)我们为 EmbodiedGPT 引入了一种高效的训练方法,通过前缀微调(Prefix Tuning)使 7B 大语言模型(LLM)适应 EgoCOT 数据集,从而生成高质量的规划。
- iii)我们引入了一种从 LLM 生成的规划查询中提取任务相关特征的范式,从而在高层次(High-Level)规划和低层次(Low-Level)控制之间形成闭环。
广泛的实验表明,EmbodiedGPT 在具身任务上非常有效,包括具身规划(embodied planning),具身控制(embodied control),视觉描述(visual captioning)和视觉问答(visual question answering)。EmbodiedGPT 通过提取更有效的特征,显著提高了具身控制任务的成功率。与使用 Ego4D 数据集进行微调的 BLIP-2 基准相比,EmbodiedGPT 在 Franka Kitchen 基准上的成功率提高了 1.6 倍,在 Meta-World 基准上的成功率提高了 1.3 倍。
1 Introduction
具身人工智能任务,如具身规划,具身 VQA 和具身控制,旨在赋予机器人在其环境中感知,推理和行动的能力,使其能够根据实时观察结果执行长周期(long-horizon)规划和自主行动(actions)。最近,GPT4 [1] 和 PaLM-E [2] 等大型语言模型(LLM)显示出了良好的语言理解,推理和思维链能力。这些进步为开发能够处理自然语言指令,执行多模态思维链,并在物理环境中规划行动的机器人提供了新的可能性。
大规模数据集在训练大型语言模型方面发挥着重要作用。例如,OpenCLIP 在 LAION-2B 数据集[3]上训练其 ViT-G/14 模型,该数据集包含 2B 个图像语言对。通用视觉语言任务可以从互联网上获取大量弱标签图像对,而具身人工智能任务则不同,它需要机器人领域的第一视角(Egocentric)数据。此外,精确规划需要结构化的语言指令,而这通常需要大量的人工努力和成本。这给收集高质量的多模态具身数据带来了挑战。一些研究人员[4, 5, 6, 7]探索利用模拟器创建大规模的具身数据集,但模拟与真实世界之间仍存在巨大差距。最近的研究[8, 9, 10]也在探索通过高效的微调策略(如 LoRA[11])将预先训练好的 LLMs 适应到新的领域。然而,仍有几个问题有待解决:
- 如何将 LLMs 应用于可能面临巨大领域差距的机器人领域
- 如何利用思维链能力进行结构化规划
- 如何以端到端的方式将输出语言规划用于下游操纵任务
为了解决上述难题,我们在这项工作中首先建立了一个大规模的具身规划数据集,称为 EgoCOT,其特征是思维链规划指令。它包含从 Ego4D 数据集[16]中精心挑选的第一视角的视频和相应的高质量分步语言指令,这些指令由机器生成,然后经过基于语义的过滤,最后由人工验证。此外,我们还创建了 EgoVQA 数据集,作为 Ego4D 数据集的扩展,重点关注第一视角的人-物交互视频问答任务,旨在提供更广泛的第一视角的多模态数据。

在 EgoCOT 和 EgoVQA 的基础上,我们提出了一种端到端的多模态具身基础模型,称为 EmbodiedGPT,它能以更自然,更直观的方式与物理世界进行交互,并执行许多具身任务,如图 1 所示,例如具身规划,具身 VQA 和具身控制。EmbodiedGPT 包含四个共同工作的集成模块,其中包括:
- i) 一个用于编码当前观察视觉特征的冻结视觉模型;
- ii) 一个用于执行自然语言的冻结语言模型,以完成问答,图像描述和具身规划任务;
- iii) 一个带有语言映射层的 embodied-former,用于对齐视觉和体现指令,并利用生成的规划提取与任务相关的实例级特征,以便进行底层控制;
- iv)策略网络(policy network),负责根据任务相关特征生成底层动作,使 Agent 能够有效地与环境互动。
为了进一步提高 EmbodiedGPT 在生成包含子目标序列的可靠规划方面的性能,我们对冻结语言模型进行了前缀微调(Prefix Tuning),以鼓励生成更多可执行规划。
我们的方法具有以下核心优势:
- i) 生成的规划在物体部件级别(如机械臂的抓手或门的把手),表现出很强的可执行性和粒度性,并体现在子目标序列中;
- ii) EgoCOT 数据集基于开源的大规模数据集构建,与在专有机器人数据上训练的 PaLM-E [2] 模型相比,具有更强的可扩展性。EgoCOT数据集和EmbodiedGPT模型都将开源。
- iii) EmbodiedGPT 形成了从高层次规划到低层次控制的闭环,实现了高层次规划和低层次控制的无缝集成,提供了高效的任务性能和对各种任务的适应性。
为了实现这一目标,我们通过视觉观察和生成的具身规划之间的交叉关注,利用 embodied-former 来查询与任务相关的实例级特征。这使得策略网络只需不到 25 次演示(demonstrations)就能完成低层次(Low-Level)控制任务。
我们的贡献可归纳如下:
- i) 我们为具身人工智能建立了端到端的多模态基础模型 EmbodiedGPT,该模型具有 "思维链 "能力,使具身Agent能够以更自然,更直观的方式与物理世界交互。
- ii) 我们开发了两个数据集 EgoCOT 和 EgoVQA,其中包括来自 Ego4D 数据集的 2 亿个带注释的视频以及相应的详细规划指令和 VQA 数据。这些数据集首先由机器生成,然后基于语义进行过滤,最后由人工验证以进行质量控制。
- iii) 我们介绍了 EmbodiedGPT,这是一种经济高效的训练方法,也是从 LLM 生成的规划查询中提取任务相关特征的范例,从而在高层次规划和低层次控制之间形成闭环。
我们通过在多个具身任务(包括具身控制,具身规划,视频描述和视频问答)上取得最先进或相当的性能,证明了我们的方法的有效性。值得注意的是,与在Ego4D数据集上进行微调的BLIP-2[17]和专为操作任务设计的R3M[12]相比,EmbodiedGPT在Franka Kitchen[14]基准测试中的表现优于这两个模型,优势分别为22.1%和5.5%。同样,在 Meta-World [14] 基准上,EmbodiedGPT 分别以 22.5% 和 4.2% 的优势超过了这两个模型。
2 Related Work
2.1 Vision Language Pre-training with large scale foundation model
视觉语言预训练的重点是加强视觉观察与自然语言之间的联系。其目标是开发能够更好地理解和处理视觉内容的模型,例如识别物体和动作,以及生成描述性文本。随着模型变得越来越大,端到端预训练的计算费用也随之增加,因此需要模块化的视觉语言预训练方法。这些方法巧妙地使用预训练模型,在视觉语言预训练期间将其冻结,以节省计算成本。例如,Uniter [18],Oscar [19],VinVL [20] 和 LiT [21]等模型冻结了图像编码器,而 Frozen [22] 和 VGPT [23] 则冻结了语言模型。此外,Flamingo [24] 和 BLIP-2 [17] 同时使用冻结图像编码器和语言模型,在性能和计算效率之间取得了平衡。由于缺乏多模态具身规划的开源数据,以前的工作难以进行详细的任务分解,也缺乏生成精确和可执行规划的能力。为了解决这个问题,我们创建了 EgoCOT 数据集,并开发了一个具身思维链视觉语言预训练框架,以提高多模态模型在具身推理和规划方面的能力。
2.2 Egocentric Video Datasets.
第一视角的视频(Egocentric videos)是利用可穿戴式摄像头拍摄的,它提供了日常活动的自然视角,并提出了一些具有挑战性的研究问题 [25, 26, 27]。多年来,人们创建了多个第一视角的视频数据集,包括 [28, 29, 30]。然而,第一视角的视频收集成本高昂,而且以前的数据集往往规模较小,只针对特定领域。最近,一个大规模的第一视角视频数据集 Ego4D [16] 已经发布,并被用于具身表征学习。该数据集由来自 9 个国家 74 个地点的 931 人收集的 3,670 小时视频组成,视频配有旁白。对于具身人工智能任务而言,从大量,多样的第一视角的人类视频中学习,已成为一种很有前途的方法,可以获得用于控制此类任务的普遍有用的视觉表征。例如,
- R3M[12]通过结合时间对比学习和视频语言对齐,利用 Ego4D 人类视频数据集开发了一种稀疏而紧凑的视觉表征。
- VIP [31]利用 Ego4D 数据集学习目标条件机器人操纵的通用奖励函数。
2.3 Large Foundation Model Assistant System
大规模多模态语言模型(LLMs)的最新进展,如 GPT-3 [32] 和 GPT-4 [1],产生了各种能够理解多种信息模式的模型。该领域主要采用两种方法:
- 系统协作(systematic collaboration):系统协作方法涉及协调多个视觉模型或工具与语言模型,将视觉信息与文本描述结合起来。例如 Visual ChatGPT [33],MM-REACT [34] 和 HuggingGPT [35]。然而,这种方法受限于固定模块化模型的准确性和容量,可能导致错误累积。
- 端到端训练模型:旨在为多模态任务提供统一的模型。例如,
- Flamingo [24] 通过冻结预训练的视觉编码器和语言模型,将视觉和语言结合起来。
- BLIP-2 [13]引入了 Q-Former,将来自冻结视觉编码器的视觉特征与大型语言模型相统一。
- MiniGPT-4 [36] 和 LLaVA [37] 等模型将经过指令微调的语言模型与来自冻结视觉骨干的视觉特征相对齐。
- VideoChat[38],mPLUG-Owl[39]和 X-LLM[40]进一步扩大了对视频输入的支持。
- PaLM-E [41] 是第一个大型具身多模态模型,它直接结合了传感器模态的特征以提高真实世界的性能,并利用其大规模日常机器人数据进行了训练[42]。
与 PaLM-E 相比,EmbodiedGPT 更为紧凑,大小仅为 10B,并可额外支持视频描述,视频问答和根据演示视频进行规划。此外,我们还形成了一个从高层次(High-Level)规划到低层次(Low-Level)控制的闭环系统。
3 Method
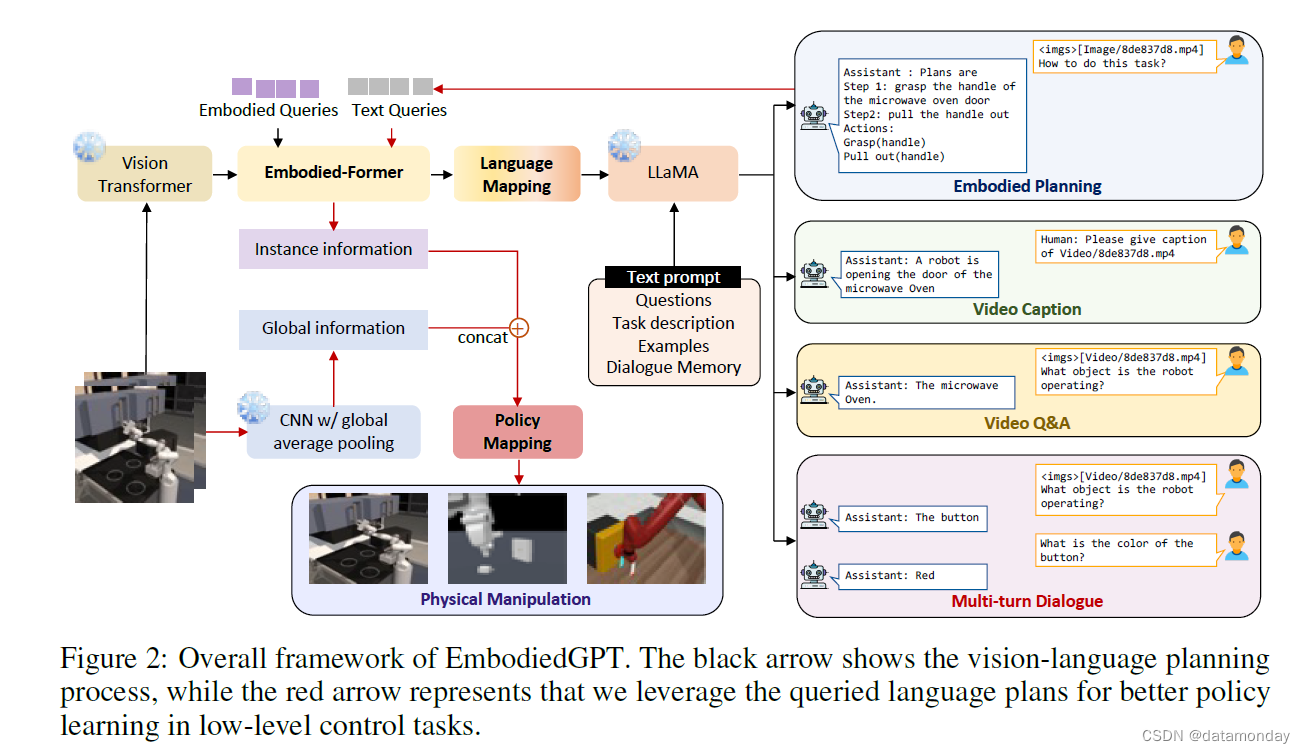
具身基础模型(embodied foundation model)的目标是通过准确感知环境,识别相关物体,分析其空间关系以及制定详细的任务规划,模仿人类的感知能力以及与环境的交互能力。为实现这一目标,EmbodiedGPT 采用了预先训练好的 vision transformer 作为视觉编码器,并采用预先训练好的 LLaMA [43] 模型作为语言模型。如图 2 所示,
- Embodied-former 是视觉域和语言域之间的桥梁,它首先通过涉及视觉标记,文本查询和可学习的具身查询的基于注意力的交互,从视觉模型的输出中提取紧凑的视觉特征,然后通过语言映射层将其映射到语言模态。这些嵌入会被发送到冻结的 LLaMA [43] 语言模型,用于视觉描述,视觉问答和具身规划。
- 然后,生成的规划将用于从由视觉模型通过 embodied-former 的一般视觉标记(tokens)中查询高度相关的特征。这些特征可用于生成低层次(Low-Level)控制指令,通过下游策略网络执行任务。
- 为了提高一系列具身任务的性能,我们引入了一种新颖的视频语言预训练范式,利用认知思维链从第一视角的视频输入中生成具身规划。我们将这一任务表述为标准的视觉问答(VQA)任务,以 “how to do the task that + original caption” 作为问题,以具身规划作为答案。这一框架丰富了具身规划和标准视觉问答任务的数据,鼓励 embodied-former 捕捉更适合具身控制任务的特定任务特征。
3.1 Framework
训练过程包括三个阶段,每个阶段都旨在逐步提升推理和规划能力。前两个阶段的重点是对基本认知和反应技能进行预训练,而第三阶段则是利用 EgoCOT 上第一视角的视频-文本数据训练具身AI任务。
-
第一阶段重点放在图像-文本对话对齐的预训练上,包括使用三个数据集:COCO Caption [44],来自 CC3M 的 59.5 万个经过精细过滤的图像-文本对[45],以及使用 BLIP-2 对 LAION-400M 进行 re-captioning 处理后获得的 49.1 万个经过过滤的图像-文本对[17]。这一阶段的主要目标是在保持视觉和语言模型参数冻结以节省计算资源的同时,预先训练 Embodied-former 和 language projection。
-
第二阶段的目标是增强模型理解和生成更复杂句子的能力,并提高其推理能力。为此,我们更新了language projection和prefix language adapter,并利用 LLaVA_Instruct_150K [46] 提供的 Complex_Reasoning_77k 和多回合对话数据集。
-
利用 EgoCOT 进行具身思维链训练:第三阶段首先使用 Conv3D [47] 将第二阶段预训练的视觉模型迁移到视频编码器,视频的时间偏移为 2,总帧数为 8。然后,我们引入思维链视觉语言预训练范式,即模型将视频的 8 个关键帧作为输入,同时输入任务描述,具身规划和结构化动名词对摘要(verb-noun pairs summary),以便根据提示(如清单 1)进行推理。为避免过拟合,我们提供了一个具有相同含义的不同指令的提示集(prompt set)。在这一阶段对 patch embedding,language projection layer,prefix language adapter 进行微调,以更好地捕捉时间信息。
3.2 Model Architecture
Embodied-former 用 E ( ⋅ ) \mathcal{E}(\cdot) E(⋅) 表示,它是视觉输入 xvis 和冻结语言模型之间的桥梁,是向语言模型提供最相关视觉数据的信息瓶颈(information bottleneck)。Embodied-former由两个子模块组成:
- 一个用于从图像输入中提取特征,记为 Evis : xvis → yvis
- 一个用于从文本输入中提取特征,记为 Etxt : xtxt → ytxt
我们使用 N N N 个可学习的具身查询嵌入 y q u e r y y_{query} yquery 作为 E \mathcal{E} E 的输入,通过交叉注意层与 xvis 交互,通过自注意层与 x t x t x_{txt} xtxt 交互。我们将输出查询表示记为 z ∈ R N × D z∈\mathbb{R}^{N ×D} z∈RN×D ,其中 D 是 embeddings 的维度。z 的维度明显小于视觉特征的维度。然后将输出查询嵌入转化为 z ′ ∈ R N × D ′ z^′∈ \mathbb{R}^{N ×D^′} z′∈RN×D′,其维度 D′与语言模态中 LLM 的文本嵌入维度相同。这种转换由一个映射函数来完成,该函数用 M 表示:z → z′,通过一个全连接(FC)层的线性投影来完成。投影嵌入的 z′ 可作为语言模型的软视觉提示,将整个交互解耦为视觉-查询交互和查询-文本交互。语言模型以 z′ 和文本提示(如 Listing 1 所示)为输入,推断出最终的具身规划。对于旨在产生与环境互动的行动的底层控制,具身规划 xplan 被用作 Embodied-former 的输入文本,以查询与任务相关的实例级特征 zinstance = E(xvis, xplan, yquery)。随后,Agent能够生成控制指令,如伺服器的转角,表示为 a = g(zinstance, zglobal)。该函数结合了特定实例信息 zinstance 和全局上下文信息 zglobal。全局上下文使用 ResNet50 模型[48]进行推断,该模型已在 ImageNet[49]上进行了预训练,并采用了全局平均池化技术。这里,g(-) 表示策略网络,它是一个多层感知器 (MLP) [50] 映射函数。策略网络的输出由具体的可执行动作组成,如笛卡尔坐标系中的位置和速度。更多实施细节见附录 A。

3.3 Training Settings
我们采用了与 BLIP-2[17] 相同的预训练图像编码器。具体来说,我们使用 EVA-CLIP 中的 ViT-G/14 模型[51],并移除其最后一层,使用倒数第二层的输出特性。
对于冻结语言模型,我们采用了预先训练好的 LLaMA-7B 模型[43],并使用 ShareGPT 数据集和 GPT-4 生成的 52K 英语指令遵循数据集[52]对其进行了微调。然后,我们将经过微调的语言模型作为视觉语言预训练的冻结语言模型。
此外,在预训练过程中,我们还将冻结的 ViT [53] 和语言模型的参数数据类型转换为 FP16,以提高效率。
3.4 Creating EgoCOT and EgoVQA Dataset
对于我们的 EgoCOT 数据集,我们从 Ego4D 数据集[16]中获取了基本数据,其中包括 9,645 个未经修剪的视频,视频时长从 5 秒到 7 小时不等。为了准备好这些数据,我们进行了两个阶段的数据清理。
在第一阶段,我们过滤掉了缺少旁白或旁白很短的视频(分别占文本的 7.4% 和 0.9%),以及标签不确定的视频(占文本的 4.0%)。我们还排除了没有人与物体互动的视频,例如看电视或走路的视频。经过这一阶段后,我们得到了 290 万小时的视频,其中包含 385 万段叙述,这些叙述来自 129 个不同的场景,涵盖 2927 小时的视频。
为了生成成对的描述(captions),具身规划和相应的视频片段,我们使用了 EgoVLP 框架[54]来分割视频。旁白是由一系列句子 T0, … , Tn 组成的,并带有精确的时间戳 t0, … , tn,表示所描述事件发生的时间。对于每个带有时间戳 ti 的旁白 Ti,我们通过确定其开始和结束时间点,将其与片段 Vi 配对:
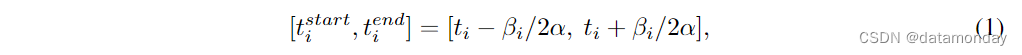
其中, β i = ∑ j = 0 n − 1 ( t j + 1 − t j ) / n β_i = \sum^{n-1}_{j=0} (t_{j+1} - t_j ) / n βi=∑j=0n−1(tj+1−tj)/n 是一个可调参数,等于给定视频中连续叙述之间的平均时间距离。相反,α 是一个比例因子,是根据 EgoCOT 数据集中所有视频中所有 βi 的平均值计算得出的(α = 4.9 秒)。对于每个视频片段,我们都会为 ChatGPT [55] 提供提示和相应的描述,以生成合理而详细的具身规划。描述通常是简短的介绍,如 “C opens a drawer.”。我们使用 ChatGPT 根据描述生成思维链,并将其整理成动名词对列表,如:
plans: grasp the handle with the gripper and pull the handle; actions: 1. grasp(handle, gripper) 2. pull(handle).
我们用来生成 EgoCOT 数据集的提示如 Listing 2 所示。为了提高生成的思维链的多样性,我们采用了 0.9 的 temperature 参数和 0.95 的 top-p 参数。对于每个提示,我们都进行了五次采样迭代。

Post-procedure.
为确保生成的规划指令(planning instructions)的质量,我们进行了第二阶段的数据清洗。
- 我们使用 CLIP 模型[56]来评估视频和文本对之间的相似性。对于每段视频,我们将其与五个潜在的具身规划进行比较,并选择相似度最高的一个作为具身规划的相应标签。
- 然后,我们进一步进行数据清理,过滤掉相似度低于阈值的视频-描述-规划对(video-caption-planning pairs)。我们剔除了视频和描述之间以及视频和规划之间相似度较低的数据,以确保为 EgoCOT 数据集提供最高质量的数据。
对于视频片段的每个关键帧,我们使用 CLIP 模型将文本数据 T 和图像数据 I 都编码到一个共享的嵌入空间中。相似度使用余弦相似度函数计算,即 S(yT, yI ) = (yT · yI) / (∥yT∥yI∥),其中 S(yT, yI ) 表示文本和图像之间的相似度,yT 和 yI 是各自的嵌入空间。鉴于每个视频都包含多个关键帧,因此每个视频的相似性得分都是一个集合。这种集合策略有助于缓解单个帧之间的差异问题,并确保对整体相似性的测量更稳健,更有代表性。具有 n 个关键帧的视频 V 与文本数据 T 之间的集合相似性得分由以下公式给出:
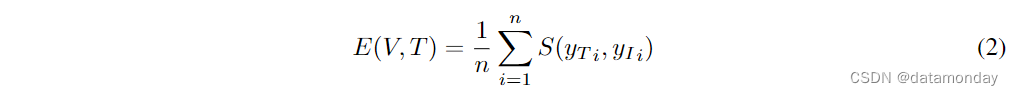
其中,E(V, T ) 是集合相似度得分,S(yT i, yI i) 是第 i 个关键帧的相似度得分,n 是关键帧的总数。我们还专门为第一视角的人-物互动视频问答任务创建了 EgoVQA 数据集,以丰富训练数据。对于 Ego4D 数据集中的每个描述,我们使用 ChatGPT 生成五个 QA 对。为确保相关性,我们通过设计 Listing 3 所示的提示来引导 ChatGPT 关注核心关键动词和名词。制作 EgoVQA 时的采样模式与 EgoCOT 相同。

4 Experiments
在本节中,我们将对多模态基础模型和 EmbodiedGPT 进行全面评估,包括视觉描述,具身规划和控制等各种任务。
Evaluation on image input tasks.
为了评估生成描述的质量和对给定图像的规划,我们对 30 名参与者进行了用户研究。该研究包括来自 MS-COCO 数据集[44]的 10 个图像描述任务案例,在不同具身人工智能模拟器中的 5 个具身规划场景,以及 5 个带有相应具身规划任务的真实世界场景。参与者被要求从五个维度对不同端到端模型生成的描述进行评分,评分标准从1到10不等,这五个维度分别是:
- 物体识别准确性
- 空间关系理解
- 答案冗余度
- 规划合理性
- 规划可执行性

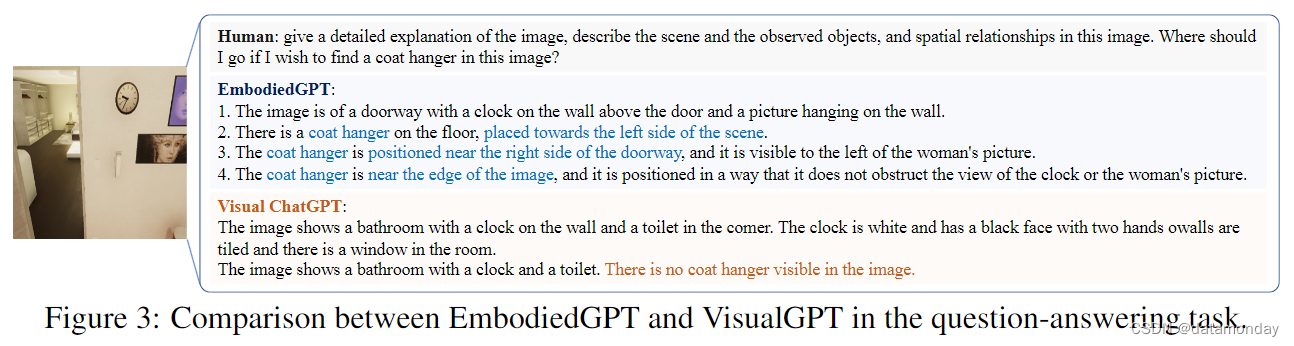
表 1 显示了所有参与者对不同模型的平均得分。结果表明,尽管语言模型中只有 7B 个参数,但 EmbodiedGPT 在物体识别和空间关系理解方面达到了与 LLaVA-13B 模型相当的水平。此外,EmbodiedGPT 生成的冗余内容较少,与给定的具身人工智能任务相关,并能生成最合理和可执行的规划输出。我们还将 EmbodiedGPT 的性能与 Visual ChatGPT [33] 进行了比较,后者采用分层方法,将多个预先训练好的视觉模型和语言模型结合起来回答问题。在虚拟家庭[57]基准测试中,Visual ChatGPT 使用视觉描述模型生成密集的描述,然后将其传入 ChatGPT 以得出解决方案。如图 3 所示,Visual ChatGPT 由于仅依赖描述模型提取视觉信息的局限性,未能找到衣架,导致与 EmbodiedGPT 等端到端模型相比性能较差。这些发现凸显了采用统一的端到端模型比依赖多个阶段的分层方法更有优势。
Evaluation on video input embodied AI tasks.
我们在标准具身人工智能基准 Franka Kitchen [14]和 Meta-World [15] 上评估了视频的识别能力和模型在具身控制任务中的规划能力。
- Meta-World 提供了一系列需要复杂物体操作技能的高难度任务,包括在钉子上组装一个戒指,在垃圾箱之间挑选并放置一个木块,按下按钮,打开抽屉和敲击钉子。
- Franka Kitchen 基准侧重于推开右门,打开橱柜,打开电灯,转动炉灶旋钮和打开微波炉等任务。如图 4 所示,给定演示视频后,EmbodiedGPT 可以准确解释具身控制任务,并提供分步规划。输出的规划被输入 EmbodiedGPT 的 Embodied-former 模块,以查询高度相关的特征,作为策略网络的输入,而底层动作则由策略网络生成,以与环境互动(更多可视化效果见附录 B)。
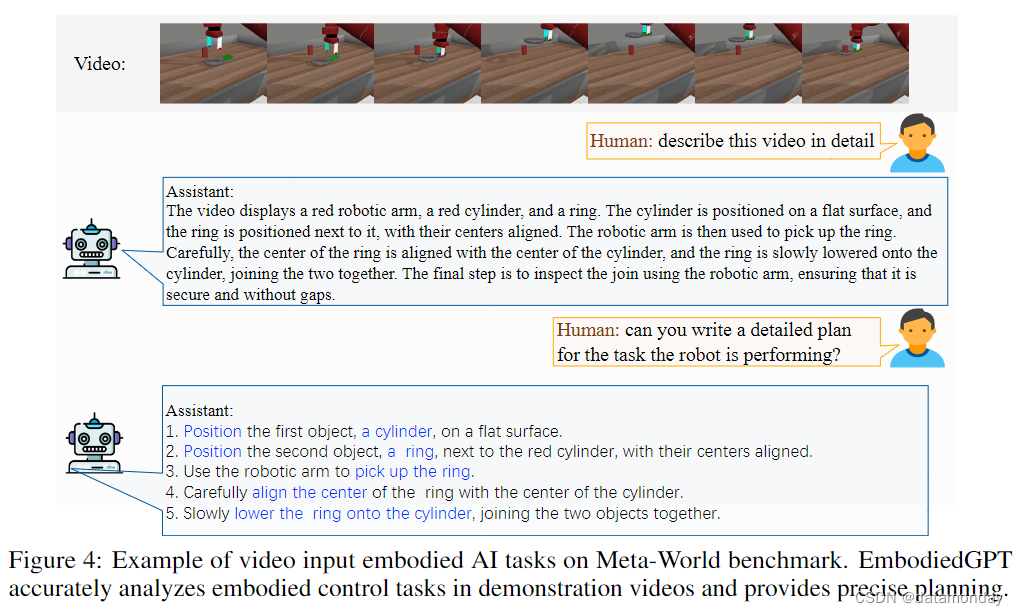
Evaluation on embodied control tasks.
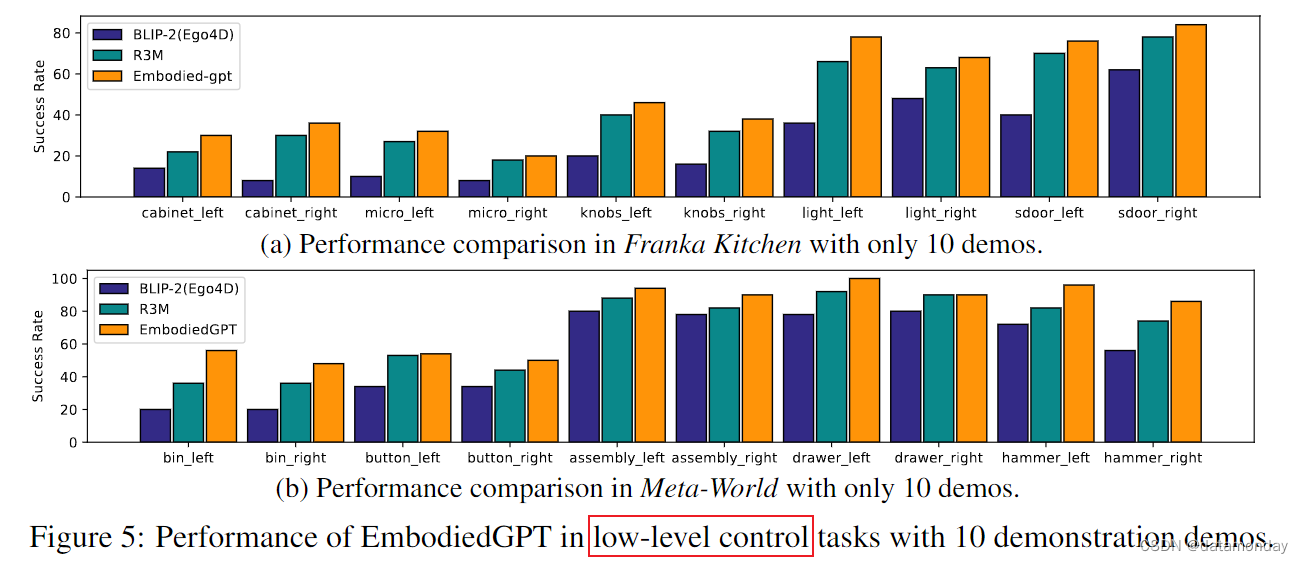
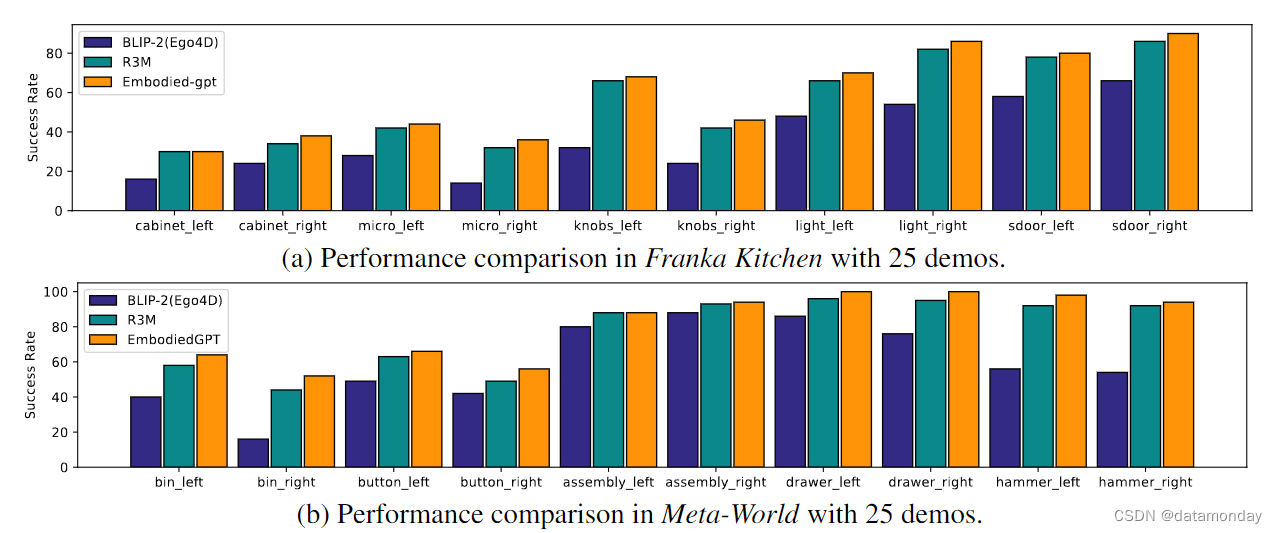
在具身控制任务方面,我们将我们的模型与 R3M[12] 进行了比较,R3M 是这两项基准测试中最先进的方法,我们还将其与一个名为 BLIP-2[Ego4D] 的消融版本进行了比较,BLIP-2[Ego4D]与 EmbodiedGPT 具有相同的结构和参数数量,但只在视频描述任务中使用 Ego4D 数据集进行了微调,而没有加入 EgoCOT。在所有实验中,策略网络都是通过对少量演示数据进行少量学习而获得的。有两种设置,一种是使用 10 个演示数据,另一种是使用 25 个演示数据。我们报告了在 100 次随机评估中的成功率,每个基准分别在 5 个种子和 2 个不同摄像头视角下的 5 个任务中仅进行视觉观察。如图 5 和图 6 所示,EmbodiedGPT 的表现优于基线方法,证明了使用 EgoCOT 学习的有效性。
Ablation study.
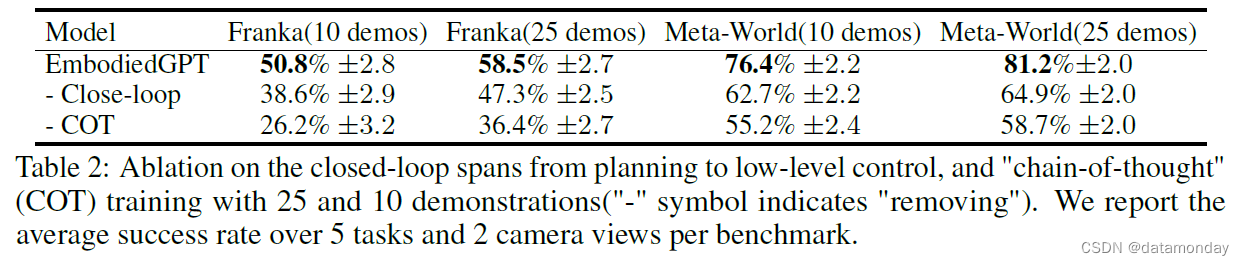
我们进行了消融研究,以分析思维链训练模式的有效性以及闭环控制设计的重要性。表 2 结果表明,使用 EgoCOT 方法与仅使用 EGO4D 描述任务进行训练相比,成功率有了显著提高。此外,闭环设计也是必要的,因为生成的规划包含具体而相关的子目标信息,而这些信息对于控制任务至关重要。
总之,EmbodiedGPT 在生成合理规划,从视觉输入中准确提取任务相关特征以及执行与环境交互的低层次(Low-Level)动作方面表现出了很强的能力。消融实验表明,基于 EgoCOT 的训练范式和从具身规划到低层次(Low-Level)控制的闭环设计都极大地促进了 EmbodiedGPT 性能的提高。
5 Conclusion
在本文中,我们介绍了 EmbodiedGPT,这是一种端到端的多模态具身人工智能基础模型,可使Agent执行逐步规划和低层次(Low-Level)命令。为此,我们创建了一个名为 EgoCOT 的大规模具身规划数据集,并开发了一种高效的训练方法,利用前缀微调(Prefix Tuning)生成具有思维链的高质量规划。此外,我们的具身控制范例还能无缝协调高层次(High-Level)规划和低层次(Low-Level)控制。广泛的实验证明,EmbodiedGPT 在不同的具身任务上都很有效,达到了最先进或相当的性能。我们相信,EmbodiedGPT 代表着向开发更智能的具身人工智能Agent迈出的重要一步。
Future works and limitations: 由于计算资源有限,EmbodiedGPT 冻结了视觉和语言模型的参数。所有模块的联合训练和探索其他模态(如语音)可能是未来的工作方向。目前,我们还没有预见到明显的不良伦理或社会影响。
A Implementation details
B More demos of EmbodiedGPT
B.1 Visual Captioning
B.2 Embodied Planning with image input
C Evaluation metric and scoring criteria for user study
D Insight about the prompt designing for multi-modal large model
相关文章:
【EAI 005】EmbodiedGPT:通过具身思维链进行视觉语言预训练的具身智能大模型
论文描述:EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought 论文作者:Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, Ping Luo 作者单位:The Universi…...

一文读懂「Chain of Thought,CoT」思维链
前言: 思维链,在人工智能领域,是一个非常非常新的概念。强大的逻辑推理是大语言模型“智能涌现”出的核心能力之一,好像AI有了人的意识一样。而推理能力的关键在于——思维链(Chain of Thought,CoT)。 相关概念: 语言智能可以被理解为“使用基于自然语言的概念对经验事…...

杨中科 ASP.NET Core 中的依赖注入的使用
ASP.NET CORE中服务注入的地方 1、在ASP.NET Core项目中一般不需要自己创建ServiceCollection、IServiceProvider。在Program.cs的builder.Build()之前向builderServices中注入 2、在Controller中可以通过构造方法注入服 务。 3、演示 新建一个calculator类 注入 新建TestC…...

Spring Boot 和 Spring 有什么区别
Spring Boot 和 Spring 是两个不同的概念,它们服务于不同的目的,但它们之间有着紧密的联系。下面是它们之间的主要区别: 目的和定位: Spring:Spring 是一个开源的 Java 平台,它最初由 Rod Johnson 创建&am…...

Linux——以太网
一、Linux下的以太网架构 1、Linux 系统网络协议层架构 PHY 驱动的功能处于链路层: 2、以太网物理层与硬件连接 我们重点关注以下两点: (1)与 MAC 设备的接口,即是 gmii 还是 rgmii。 (2) Phy…...

HTTP 代理原理及实现(二)
在上篇《HTTP 代理原理及实现(一)》里,我介绍了 HTTP 代理的两种形式,并用 Node.js 实现了一个可用的普通 / 隧道代理。普通代理可以用来承载 HTTP 流量;隧道代理可以用来承载任何 TCP 流量,包括 HTTP 和 H…...

JavaScript 地址信息与页面跳转
在JavaScript中,你可以使用各种方法来处理地址信息并进行页面跳转。以下是一些常见的方法: 1.使用window.location对象: window.location对象包含了当前窗口的URL信息,并且可以用来进行页面跳转。 * 获取URL的某一部分…...
第383题赎金信(Python))
力扣(leetcode)第383题赎金信(Python)
383.赎金信 题目链接:383.赎金信 给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。 如果可以,返回 true ;否则返回 false 。 magazine 中的每个字符只能在 ransomNote…...

提升网络安全重要要素IP地址
在数字化时代,网络安全已经成为人们关注的焦点。本文将深入探讨网络安全与IP地址之间的紧密联系,以及IP地址在构建数字世界的前沿堡垒中的关键作用。 网络安全是当今数字社会中不可忽视的挑战之一。而IP地址,作为互联网通信的基础协议&#…...
解析c++空指针解引用奔溃
空指针解引用引起程序奔溃是c/c中最常见的稳定性错误之一。 显然并非所有使用空指针的语句都会导致奔溃,那什么情况下使用空指针才会引起程序奔溃呢?有一个判断标准:判断空指针是否会导致访问非法内存的情况,如果会导致访问非法内…...

Oracle START WITH 递归语句的使用方法及示例
Oracle数据库中的START WITH语句经常与CONNECT BY子句一起使用,以实现对层次型数据的查询。这种查询模式非常适用于处理具有父子关系的数据,如组织结构、分类信息等。 理解START WITH和CONNECT BY 在层次型查询中,START WITH定义了层次结构…...
使用Windbg动态调试目标进程的一般步骤详解
目录 1、概述 2、将Windbg附加到已经启动起来的目标进程上,或者用Windbg启动目标程序 2.1、将Windbg附加到已经启动起来的目标进程上 2.2、用Windbg启动目标程序 2.3、Windbg关联到目标进程上会中断下来,输入g命令将该中断跳过去 3、分析实例说明 …...
Linux驱动学习—输入子系统
1、什么是输入子系统? 输入子系统是Linux专门做的一套框架来处理输入事件的,像鼠标,键盘,触摸屏这些都是输入设备,但是这邪恶输入设备的类型又都不是一样的,所以为了统一这些输入设备驱动标准应运而生的。…...
计算机网络(2)
计算机网络(2) 小程一言专栏链接: [link](http://t.csdnimg.cn/ZUTXU) 计算机网络和因特网(2)分组交换网中的时延、丢包和吞吐量时延丢包吞吐量总结 协议层次及其服务模型模型类型OSI模型分析TCP/IP模型分析 追溯历史 小程一言 我…...
什么是预训练Pre-training—— AIGC必备知识点,您get了吗?
Look!👀我们的大模型商业化落地产品📖更多AI资讯请👉🏾关注Free三天集训营助教在线为您火热答疑👩🏼🏫 随着人工智能(AI)不断重塑我们的世界,其发展的一个关键方面已经…...

bat脚本sqlserver 不同数据库同步
如果你想使用批处理脚本(.bat)在 SQL Server 中同步不同数据库的数据,你可以考虑以下步骤: 设置环境变量: 确保你的系统环境变量中已经设置了 SQLCMD 和 BCP 的路径。 编写批处理脚本: 使用 sqlcmd 来执行…...
阶段十-分布式-Redis02
第一章 Redis 事务 1.1 节 数据库事务复习 数据库事务的四大特性 A:Atomic ,原子性,将所以SQL作为原子工作单元执行,要么全部执行,要么全部不执行;C:Consistent,一致性࿰…...

微信小程序实战-02翻页时钟-2
微信小程序实战系列 《微信小程序实战-01翻页时钟-1》 文章目录 微信小程序实战系列前言计时功能实现clock.wxmlclock.wxssclock.js 运行效果总结 前言 接着《微信小程序实战-01翻页时钟-1》,继续完成“6个页面的静态渲染和计时”功能。 计时功能实现 clock.wxm…...

每天刷两道题——第十一天
1.1滑动窗口最大值 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。返回滑动窗口中的最大值 。 输入:nums [1,3,-1,-3,5,3,6,7], k 3 输出&…...

Git提交规范
一. 修改类型 每个类型值都表示了不同的含义,类型值必须是以下的其中一个: feat:提交新功能fix:修复了bugdocs:只修改了文档style:调整代码格式,未修改代码逻辑(比如修改空格、格式…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...
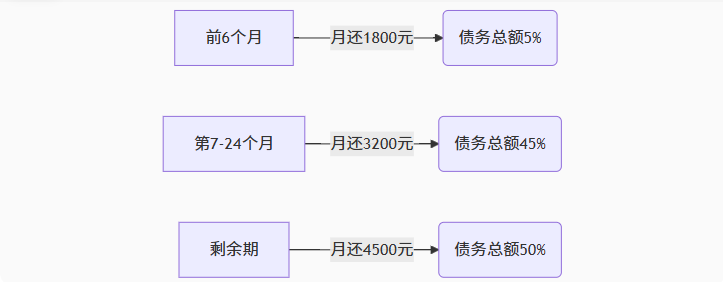
【无标题】湖北理元理律师事务所:债务优化中的生活保障与法律平衡之道
文/法律实务观察组 在债务重组领域,专业机构的核心价值不仅在于减轻债务数字,更在于帮助债务人在履行义务的同时维持基本生活尊严。湖北理元理律师事务所的服务实践表明,合法债务优化需同步实现三重平衡: 法律刚性(债…...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...