FlinkAPI开发之数据合流
案例用到的测试数据请参考文章:
Flink自定义Source模拟数据流
原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048
概述
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以Flink中合流的操作会更加普遍,对应的API也更加丰富。
联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)类似于SQL里面的union。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。
在代码中,我们只要基于DataStream直接调用.union()方法,传入其他DataStream作为参数,就可以实现流的联合了;得到的依然是一个DataStream:
stream1.union(stream2, stream3, ...)
案例:合并两个订单数据流
package com.zxl.flink;import com.zxl.bean.Orders;
import com.zxl.datas.OrdersData;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class DemoTest {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/7 为了效果更佳明显先分割成两条数据流DataStream<Orders> operator01 = ordersDataStreamSource.filter(orders -> orders.getOrder_amount() > 50);DataStream<Orders> operator02 = ordersDataStreamSource.filter(orders -> orders.getOrder_amount() < 50);// TODO: 2024/1/7 合流操作DataStream<Orders> stream = operator01.union(operator02);stream.print();environment.execute();}
}
连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink还提供了另外一种方便的合流操作——连接(connect),这个流的最终效果和SQLunion类似,只不过可以对每个流和输出的流数据进行处理更加灵活。
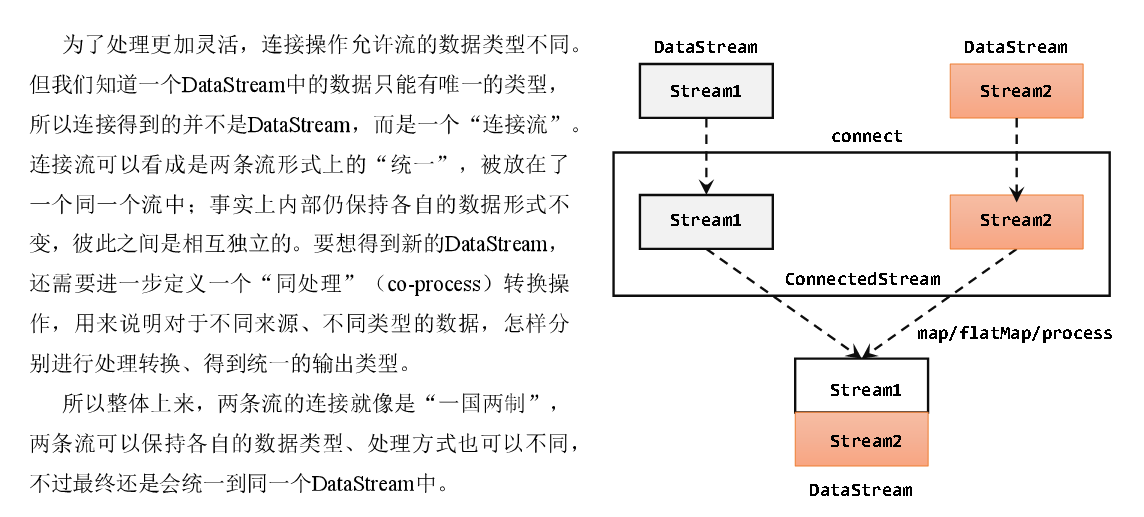
代码实现:需要分为两步:首先基于一条DataStream调用.connect()方法,传入另外一条DataStream作为参数,将两条流连接起来,得到一个ConnectedStreams;然后再调用同处理方法得到DataStream。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法
package com.zxl.flink;import com.zxl.bean.Orders;
import com.zxl.bean.Payments;
import com.zxl.datas.OrdersData;
import com.zxl.datas.PaymentData;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;public class DemoTest {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/6 支付数据DataStreamSource<Payments> paymentsDataStreamSource = environment.addSource(new PaymentData());// TODO: 2024/1/7 连接两条流ConnectedStreams<Orders, Payments> connectedStreams = ordersDataStreamSource.connect(paymentsDataStreamSource);// TODO: 2024/1/7 对连接的两条流和输出的流进行处理// TODO: 2024/1/7 通过Map进行处理SingleOutputStreamOperator<String> mapStream = connectedStreams.map(new CoMapFunction<Orders, Payments, String>() {@Overridepublic String map1(Orders orders) throws Exception {return orders.toString();}@Overridepublic String map2(Payments payments) throws Exception {return payments.toString();}});// TODO: 2024/1/7 通过flatMap进行处理SingleOutputStreamOperator<String> flatMaStream = connectedStreams.flatMap(new CoFlatMapFunction<Orders, Payments, String>() {@Overridepublic void flatMap1(Orders orders, Collector<String> collector) throws Exception {collector.collect(orders.toString());}@Overridepublic void flatMap2(Payments payments, Collector<String> collector) throws Exception {collector.collect(payments.toString());}});// TODO: 2024/1/7 收集订单金额和支付金额大于50元的数据SingleOutputStreamOperator<String> processStream = connectedStreams.process(new CoProcessFunction<Orders, Payments, String>() {@Overridepublic void processElement1(Orders orders, CoProcessFunction<Orders, Payments, String>.Context context, Collector<String> collector) throws Exception {if (orders.getOrder_amount() > 50) {collector.collect(orders.toString());}}@Overridepublic void processElement2(Payments payments, CoProcessFunction<Orders, Payments, String>.Context context, Collector<String> collector) throws Exception {if (payments.getPayment_amount() > 50) {collector.collect(payments.toString());}}});flatMaStream.print();environment.execute();}
}Map进行处理结果
flatMap进行处理结果
process进行处理的结果
窗口联结(Window Join)
Flink为基于一段时间的双流合并专门提供了一个窗口联结算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。
1)窗口联结的调用
窗口联结在代码中的实现,首先需要调用DataStream的.join()方法来合并两条流,得到一个JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的key;然后通过.window()开窗口,并调用.apply()传入联结窗口函数进行处理计算。通用调用形式如下:
stream1.join(stream2).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<JoinFunction>)
上面代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的key;而.equalTo()传入的KeySelector则指定了第二条流中的key。两者相同的元素,如果在同一窗口中,就可以匹配起来,并通过一个“联结函数”(JoinFunction)进行处理了。这里.window()传入的就是窗口分配器,之前讲到的三种时间窗口都可以用在这里:滚动窗(tumbling window)、滑动窗口(sliding window)和会话窗口(session window)。而后面调用.apply()可以看作实现了一个特殊的窗口函数。注意这里只能调用.apply(),没有其他替代的方法。传入的JoinFunction也是一个函数类接口,使用时需要实现内部的.join()方法。这个方法有两个参数,分别表示两条流中成对匹配的数据。其实仔细观察可以发现,窗口join的调用语法和我们熟悉的SQL中表的join非常相似:SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id; 这句SQL中where子句的表达,等价于inner join … on,所以本身表示的是两张表基于id的“内连接”(inner join)。而Flink中的window join,同样类似于inner join。也就是说,最后处理输出的,只有两条流中数据按key配对成功的那些;如果某个窗口中一条流的数据没有任何另一条流的数据匹配,那么就不会调用JoinFunction的.join()方法,也就没有任何输出了。
package com.zxl.flink;import com.zxl.bean.Orders;
import com.zxl.bean.Payments;
import com.zxl.datas.OrdersData;
import com.zxl.datas.PaymentData;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import scala.Tuple9;public class DemoTest {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/6 支付数据DataStreamSource<Payments> paymentsDataStreamSource = environment.addSource(new PaymentData());// TODO: 2024/1/7 配置订单数据水位线SingleOutputStreamOperator<Orders> ordersWater = ordersDataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy// TODO: 2024/1/7 指定watermark生成:升序的watermark,没有等待时间.<Orders>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Orders>() {@Overridepublic long extractTimestamp(Orders orders, long l) {return orders.getOrder_date();}}));// TODO: 2024/1/7 配置支付数据水位线SingleOutputStreamOperator<Payments> paymentsWater = paymentsDataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy.<Payments>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Payments>() {@Overridepublic long extractTimestamp(Payments payments, long l) {return payments.getPayment_date();}}));// TODO window join// 1. 落在同一个时间窗口范围内才能匹配// 2. 根据keyby的key,来进行匹配关联// 3. 只能拿到匹配上的数据,类似有固定时间范围的inner joinDataStream<Tuple9> dataStream = ordersWater.join(paymentsWater).where(orders -> orders.getOrder_id()).equalTo(payments -> payments.getOrder_id()).window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<Orders, Payments, Tuple9>() {@Overridepublic Tuple9 join(Orders orders, Payments payments) throws Exception {Tuple9<Long, Long, Long, Integer, Integer, Long, Integer, Long, String> tuple9 = new Tuple9<>(orders.getOrder_id(), orders.getUser_id(), orders.getOrder_date(), orders.getOrder_amount(), orders.getProduct_id(), orders.getOrder_num(), payments.getPayment_amount(), payments.getPayment_date(), payments.getPayment_type());return tuple9;}});dataStream.print("join后的数据");environment.execute();}
}

间隔联结(Interval Join)
在有些场景下,我们要处理的时间间隔可能并不是固定的。这时显然不应该用滚动窗口或滑动窗口来处理——因为匹配的两个数据有可能刚好“卡在”窗口边缘两侧,于是窗口内就都没有匹配了;会话窗口虽然时间不固定,但也明显不适合这个场景。基于时间的窗口联结已经无能为力了。
为了应对这样的需求,Flink提供了一种叫作“间隔联结”(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
间隔联结的原理
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作A)中的任意一个数据元素a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以a的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫B)中的数据元素b,如果它的时间戳落在了这个区间范围内,a和b就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流A和B,也必须基于相同的key;下界lowerBound应该小于等于上界upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
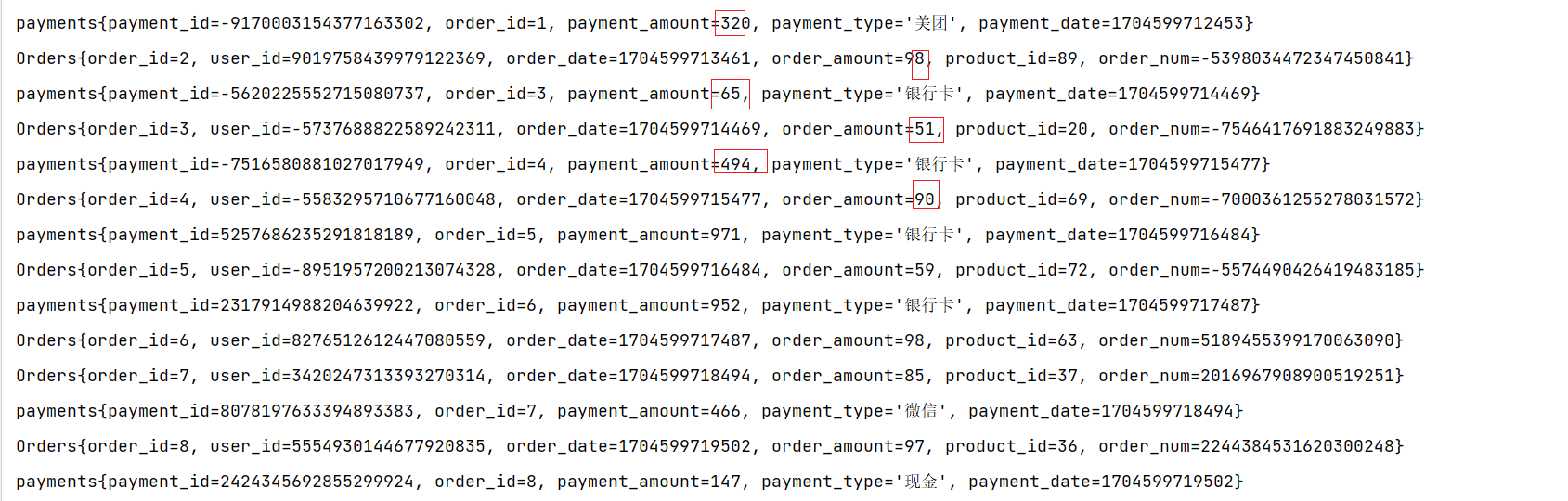
如下图所示,我们可以清楚地看到间隔联结的方式:
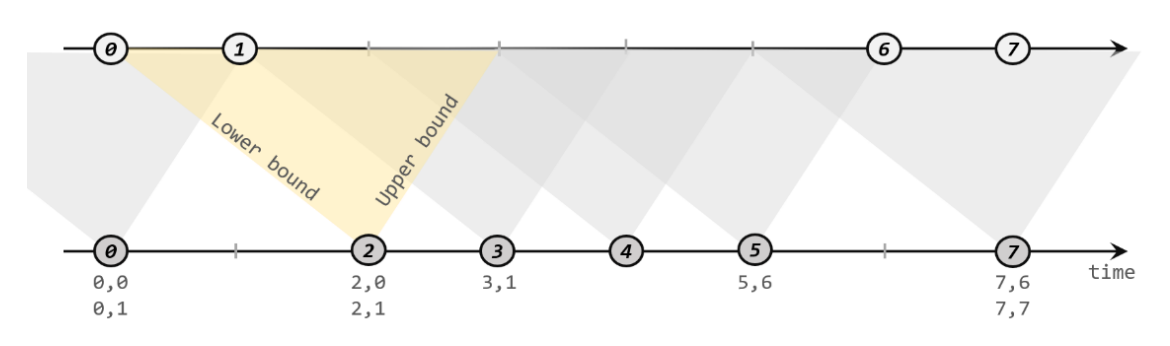
下方的流A去间隔联结上方的流B,所以基于A的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2毫秒,上界为1毫秒。于是对于时间戳为2的A中元素,它的可匹配区间就是[0, 3],流B中有时间戳为0、1的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A中时间戳为3的元素,可匹配区间为[1, 4],B中只有时间戳为1的一个数据可以匹配,于是得到匹配数据对(3, 1)。
所以我们可以看到,间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,interval join做匹配的时间段是基于流中数据的,所以并不确定;而且流B中的数据可以不只在一个区间内被匹配。
间隔联结的调用
间隔联结在代码中,是基于KeyedStream的联结(join)操作。DataStream在keyBy得到KeyedStream之后,可以调用.intervalJoin()来合并两条流,传入的参数同样是一个KeyedStream,两者的key类型应该一致;得到的是一个IntervalJoin类型。后续的操作同样是完全固定的:先通过.between()方法指定间隔的上下界,再调用.process()方法,定义对匹配数据对的处理操作。调用.process()需要传入一个处理函数,这是处理函数家族的最后一员:“处理联结函数”ProcessJoinFunction。
通用调用形式
stream1.keyBy(<KeySelector>).intervalJoin(stream2.keyBy(<KeySelector>)).between(Time.milliseconds(-2), Time.milliseconds(1)).process (new ProcessJoinFunction<Integer, Integer, String(){@Overridepublic void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {out.collect(left + "," + right);}});
可以看到,抽象类ProcessJoinFunction就像是ProcessFunction和JoinFunction的结合,内部同样有一个抽象方法.processElement()。与其他处理函数不同的是,它多了一个参数,这自然是因为有来自两条流的数据。参数中left指的就是第一条流中的数据,right则是第二条流中与它匹配的数据。每当检测到一组匹配,就会调用这里的.processElement()方法,经处理转换之后输出结果。
间隔联结实例
案例需求:在电商网站中,某些用户行为往往会有短时间内的强关联。我们这里举一个例子,我们有两条流,一条是下订单的流,一条是支付的流。我们可以针对同一个订单,来做这样一个联结。也就是一个订单的和这个订单的支付数据进行一个联结查询。
代码实现:正常使用
package com.zxl.flink;import com.zxl.bean.Orders;
import com.zxl.bean.Payments;
import com.zxl.datas.OrdersData;
import com.zxl.datas.PaymentData;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import scala.Tuple9;public class DemoTest {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/6 支付数据DataStreamSource<Payments> paymentsDataStreamSource = environment.addSource(new PaymentData());// TODO: 2024/1/7 配置订单数据水位线SingleOutputStreamOperator<Orders> ordersWater = ordersDataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy// TODO: 2024/1/7 指定watermark生成:升序的watermark,没有等待时间.<Orders>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Orders>() {@Overridepublic long extractTimestamp(Orders orders, long l) {return orders.getOrder_date();}}));// TODO: 2024/1/7 配置支付数据水位线SingleOutputStreamOperator<Payments> paymentsWater = paymentsDataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy.<Payments>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Payments>() {@Overridepublic long extractTimestamp(Payments payments, long l) {return payments.getPayment_date();}}));// TODO interval join//1. 分别做keyby,key其实就是关联条件KeyedStream<Orders, Long> ordersKeyedStream = ordersWater.keyBy(orders -> orders.getOrder_id());KeyedStream<Payments, Long> paymentsKeyedStream = paymentsWater.keyBy(payments -> payments.getOrder_id());//2. 调用 interval joinSingleOutputStreamOperator<Tuple9> process = ordersKeyedStream.intervalJoin(paymentsKeyedStream).between(Time.seconds(-10), Time.seconds(10)).process(new ProcessJoinFunction<Orders, Payments, Tuple9>() {/*** 两条流的数据匹配上,才会调用这个方法* @param left ks1的数据* @param right ks2的数据* @param ctx 上下文* @param out 采集器* @throws Exception*/@Overridepublic void processElement(Orders orders, Payments payments, ProcessJoinFunction<Orders, Payments, Tuple9>.Context context, Collector<Tuple9> collector) throws Exception {Tuple9<Long, Long, Long, Integer, Integer, Long, Integer, Long, String> tuple9 = new Tuple9<>(orders.getOrder_id(), orders.getUser_id(), orders.getOrder_date(), orders.getOrder_amount(), orders.getProduct_id(), orders.getOrder_num(), payments.getPayment_amount(), payments.getPayment_date(), payments.getPayment_type());collector.collect(tuple9);}});process.print();environment.execute();}
}

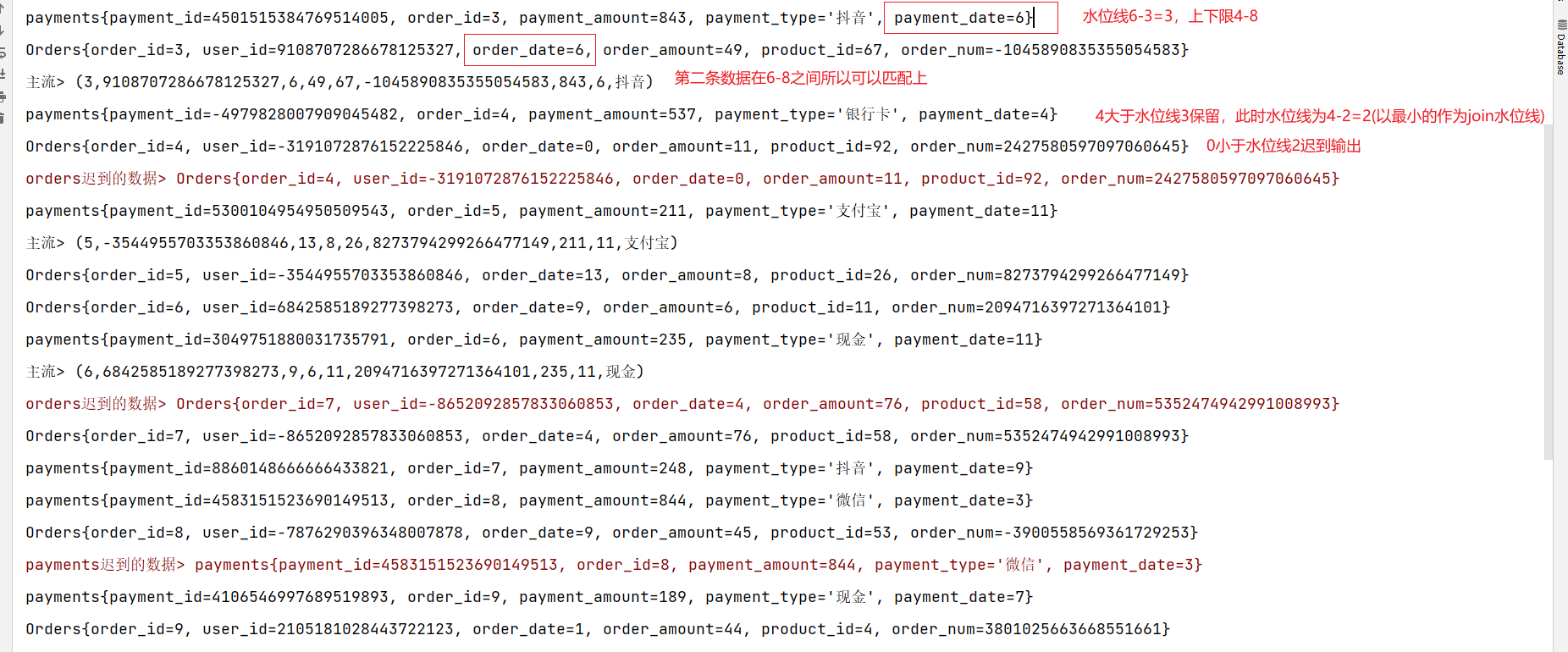
代码实现:处理迟到数据
package com.zxl.flink;import com.zxl.bean.Orders;
import com.zxl.bean.Payments;
import com.zxl.datas.OrdersData;
import com.zxl.datas.PaymentData;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import scala.Tuple9;import java.time.Duration;public class DemoTest {public static void main(String[] args) throws Exception {//创建Flink流处理执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置并行度为1environment.setParallelism(1);// TODO: 2024/1/7 定义时间语义environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);//调用Flink自定义Source// TODO: 2024/1/6 订单数据DataStreamSource<Orders> ordersDataStreamSource = environment.addSource(new OrdersData());// TODO: 2024/1/6 支付数据DataStreamSource<Payments> paymentsDataStreamSource = environment.addSource(new PaymentData());// TODO: 2024/1/7 配置订单数据水位线SingleOutputStreamOperator<Orders> ordersWater = ordersDataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy// TODO: 2024/1/7 指定watermark生成:升序的watermark,没有等待时间.<Orders>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(new SerializableTimestampAssigner<Orders>() {@Overridepublic long extractTimestamp(Orders orders, long l) {return orders.getOrder_date() * 1000;}}));// TODO: 2024/1/7 配置支付数据水位线SingleOutputStreamOperator<Payments> paymentsWater = paymentsDataStreamSource.assignTimestampsAndWatermarks(WatermarkStrategy.<Payments>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(new SerializableTimestampAssigner<Payments>() {@Overridepublic long extractTimestamp(Payments payments, long l) {return payments.getPayment_date() * 1000;}}));// TODO interval join//配置测输出流标签OutputTag<Orders> orders_tag = new OutputTag<Orders>("orders", Types.POJO(Orders.class));OutputTag<Payments> payments_tag = new OutputTag<Payments>("payments", Types.POJO(Payments.class));//1. 分别做keyby,key其实就是关联条件KeyedStream<Orders, Long> ordersKeyedStream = ordersWater.keyBy(orders -> orders.getOrder_id());KeyedStream<Payments, Long> paymentsKeyedStream = paymentsWater.keyBy(payments -> payments.getOrder_id());//2. 调用 interval joinSingleOutputStreamOperator<Tuple9> process = ordersKeyedStream.intervalJoin(paymentsKeyedStream).between(Time.seconds(-2), Time.seconds(2)).sideOutputLeftLateData(orders_tag).sideOutputRightLateData(payments_tag).process(new ProcessJoinFunction<Orders, Payments, Tuple9>() {/*** 两条流的数据匹配上,才会调用这个方法* @param left ks1的数据* @param right ks2的数据* @param ctx 上下文* @param out 采集器* @throws Exception*/@Overridepublic void processElement(Orders orders, Payments payments, ProcessJoinFunction<Orders, Payments, Tuple9>.Context context, Collector<Tuple9> collector) throws Exception {Tuple9<Long, Long, Long, Integer, Integer, Long, Integer, Long, String> tuple9 = new Tuple9<>(orders.getOrder_id(), orders.getUser_id(), orders.getOrder_date(), orders.getOrder_amount(), orders.getProduct_id(), orders.getOrder_num(), payments.getPayment_amount(), payments.getPayment_date(), payments.getPayment_type());collector.collect(tuple9);}});ordersKeyedStream.print();paymentsKeyedStream.print();process.print("主流");process.getSideOutput(orders_tag).printToErr("orders迟到的数据");process.getSideOutput(payments_tag).printToErr("payments迟到的数据");environment.execute();}
}
相关文章:
FlinkAPI开发之数据合流
案例用到的测试数据请参考文章: Flink自定义Source模拟数据流 原文链接:https://blog.csdn.net/m0_52606060/article/details/135436048 概述 在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以…...
11 个 Python全栈开发工具集
前言 以下是专注于全栈开发不同方面的 Python 库;有些专注于 Web 应用程序开发,有些专注于后端,而另一些则两者兼而有之。 1. Taipy Taipy 是一个开源的 Python 库,用于构建生产就绪的应用程序前端和后端。 它旨在加快应用程序开发…...
【GDAL】Windows下VS+GDAL开发环境搭建
Step.0 环境说明(vs版本,CMake版本) 本地的IDE环境是vs2022,安装的CMake版本是3.25.1。 Step.1 下载GDAL和依赖的组件 编译gdal之前需要安装gdal依赖的组件,gdal所依赖的组件可以在官网文档找到,可以根据…...

基于sumo实现交通灯控制算法的模板
基于sumo实现交通灯控制算法的模板 目录 在windows安装run hello world networkroutesviewsettings & configurationsimulation 交通灯控制系统 介绍文件生成器类(FileGenerator)道路网络(Network)辅助函数生成道路网络&am…...

设计模式之单例模式的懒饿汉
懒汉式 说白了就是你不叫我我不动,你叫我我才动。 类初始化模式,也叫延迟占位模式。在单例类的内部由一个私有静态内部类来持有这个单例类的实例。因为在 JVM 中,对类的加载和类初始化,由虚拟机保证线程安全。 public class Singl…...

多平台多账号一站式短视频管理矩阵营销系统下载
矩阵营销系统多平台多账号一站式管理,一键发布作品。智能标题,关键词优化,排名查询,混剪生成原创视频,账号分组,意向客户自动采集,智能回复,多账号评论聚合回复,免切换&a…...

go work
vscode gopls插件工具依赖go work,否则会报错 https://github.com/golang/tools/blob/master/gopls/doc/workspace.md Go 1.18 新特性多模块工作区教程-让多模块开发变得简单 - Go语言中文网 - Golang中文社区...
基于JavaWeb+BS架构+SpringBoot+Vue智能菜谱推荐系统的设计和实现
基于JavaWebBS架构SpringBootVue智能菜谱推荐系统的设计和实现 文末获取源码Lun文目录前言主要技术系统设计功能截图订阅经典源码专栏Java项目精品实战案例《500套》 源码获取 文末获取源码 Lun文目录 目 录 目 录 III 第一章 概述 1 1.1 研究背景 1 1.2研究目的及意义 1 1.3…...
SpringSecurity集成JWT实现后端认证授权保姆级教程-授权配置篇
🍁 作者:知识浅谈,CSDN签约讲师,CSDN博客专家,华为云云享专家,阿里云专家博主 📌 擅长领域:全栈工程师、爬虫、ACM算法 💒 公众号:知识浅谈 🔥网站…...

关系型非关系型数据库区别,以MongoDB为例在express中连接MongoDB示例
目录 关系型数据库 关系型数据库常见的类型有: 关系型数据库的优点包括: 非关系型数据库 非关系型数据库常见的类型有: 非关系型数据库的特点包括: 关系型数据库和非关系型数据库区别 MongoDB是什么 MongoDB优势ÿ…...
Java版商城:Spring Cloud+SpringBoot b2b2c实现多商家入驻直播带货及 免 费 小程序商城搭建的完整指南
随着互联网的快速发展,越来越多的企业开始注重数字化转型,以提升自身的竞争力和运营效率。在这个背景下,鸿鹄云商SAAS云产品应运而生,为企业提供了一种简单、高效、安全的数字化解决方案。 鸿鹄云商SAAS云产品是一种基于云计算的软…...
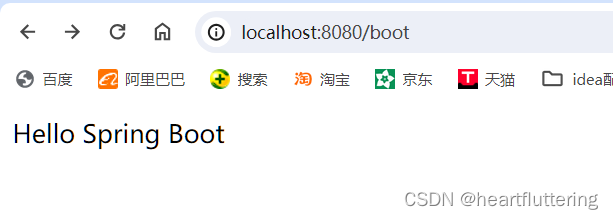
【Spring Boot】SpringBoot maven 项目创建图文教程
创建一个Spring Boot项目并使用Maven进行构建是一项相对简单的任务。以下是使用IntelliJ IDEA创建Spring Boot Maven项目的详细教程: 步骤 1:安装 IntelliJ IDEA 确保你已经安装了最新版本的 IntelliJ IDEA。你可以从官方网站下载并安装。 步骤 2&am…...
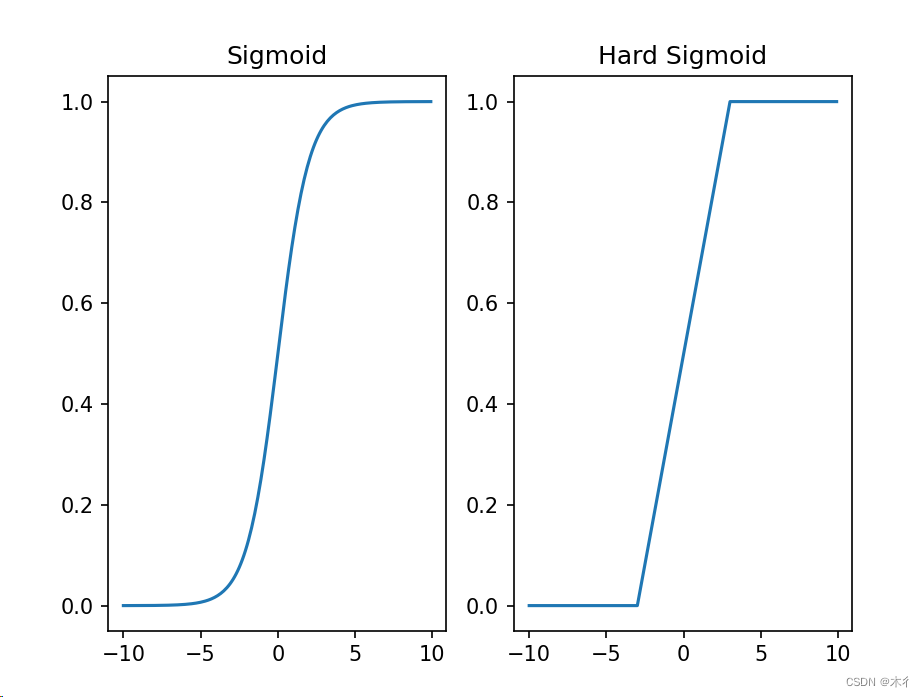
【Python】Sigmoid和Hard Sigmoid激活函数对比总结及示例
Sigmoid和Hard Sigmoid是两种常用的激活函数,它们在神经网络中起到非线性变换的作用。以下是它们之间的对比和优缺点总结: Sigmoid激活函数: 优点: 输出范围是0到1之间,可以用于二分类问题。函数形状相对平滑&#…...

ajax+axios——统一设置请求头参数——添加请求头入参——基础积累
最近在写后台管理系统(我怎么一直都只写管理系统啊啊啊啊啊啊啊),遇到一个需求,就是要在原有系统的基础上,添加一个仓库的切换,并且需要把选中仓库对应的id以请求头参数的形式传递到每一个接口当中。。。 …...
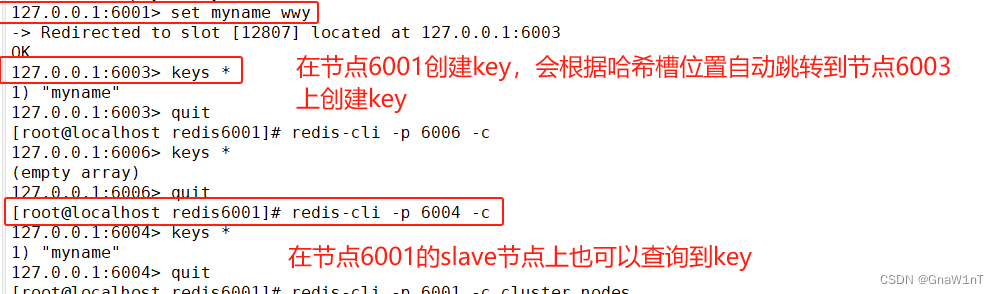
Redis高可用(主从复制、哨兵模式和Cluster集群)
目录 前瞻 主从复制 哨兵 集群 主从复制 主从复制的作用 主从复制流程 搭建Redis主从复制 实验准备 实验流程 修改 Redis 配置文件(Master节点操作) 修改 Redis 配置文件(Slave节点操作) 验证主从效果 哨兵模式 哨兵…...

【Web】CTFSHOW PHP命令执行刷题记录(全)
目录 web29 web30 web31 web32 web33 web34 web35 web36 web37-39 web40 web41 (y4✌脚本) web42 -44 web45 web46 -49 web50 web51 web52 web53 web54 web55-56 web57 web58 web59 web60 web61 web62 web63-65 web66-67 w…...

鸿蒙开发已解决-Failed to connect to gitee.com port 443: Time out 连接超时提示
文章目录 项目场景:问题描述原因分析:解决方案:解决方案1解决方案2:解决方案3:此Bug解决方案总结解决方案总结**心得体会:解决连接超时问题的三种方案**项目场景: 导入Sample时遇到导入失败的情况,并提示“Failed to connect to gitee.com port 443: Time out”连接超…...

使用cURL命令在Linux中测试HTTP服务器的性能
cURL是一个强大的命令行工具,用于从或向服务器传输数据。它支持多种协议,包括HTTP、HTTPS、FTP等。在Linux系统中,cURL可以用于测试和评估HTTP服务器的性能。下面是一些使用cURL命令测试HTTP服务器性能的示例和说明。 1. 基本请求 要向指定…...

机器学习 -- 余弦相似度
场景 我有一个 页面如下(随便找的): 我的需求是拿到所有回答的链接, 再或者我在找房子网上,爬到所有的房产信息,我们并不想做过多的处理,我只要告诉程序,请帮我爬一个类似 xxx 相似…...
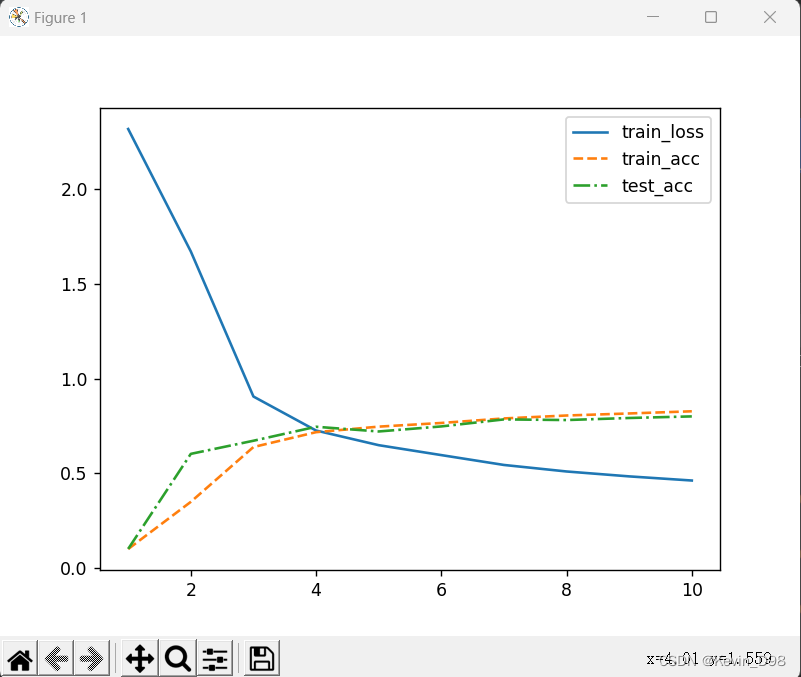
LeNet-5(fashion-mnist)
文章目录 前言LeNet模型训练 前言 LeNet是最早发布的卷积神经网络之一。该模型被提出用于识别图像中的手写数字。 LeNet LeNet-5由以下两个部分组成 卷积编码器(2)全连接层(3) 卷积块由一个卷积层、一个sigmoid激活函数和一个…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...