简单易懂的PyTorch 损失函数:优化机器学习模型的关键
目录
torch.nn子模块Loss Functions详解
nn.L1Loss
用途
用法
使用技巧
注意事项
代码示例
nn.MSELoss
用途
用法
使用技巧
注意事项
代码示例
nn.CrossEntropyLoss
用途
用法
使用技巧
注意事项
代码示例
使用类别索引
使用类别概率
nn.CTCLoss
用途
用法
使用技巧
注意事项
代码示例
有填充的目标
未填充的目标
nn.NLLLoss
用途
用法
使用技巧
注意事项
代码示例
一维损失示例
二维损失示例(例如,用于图像)
nn.PoissonNLLLoss
用途
用法
使用技巧
注意事项
代码示例
nn.GaussianNLLLoss
用途
用法
使用技巧
注意事项
代码示例
异方差(Heteroscedastic)示例
同方差(Homoscedastic)示例
nn.KLDivLoss
用途
用法
使用技巧
注意事项
代码示例
nn.BCELoss
用途
用法
使用技巧
注意事项
代码示例
nn.BCEWithLogitsLoss
用途
用法
使用技巧
注意事项
代码示例
nn.MarginRankingLoss
用途
用法
使用技巧
注意事项
代码示例
nn.HingeEmbeddingLoss
用途
用法
使用技巧
注意事项
代码示例
nn.MultiLabelMarginLoss
用途
用法
使用技巧
注意事项
代码示例
nn.HuberLoss
用途
用法
使用技巧
注意事项
代码示例
nn.SmoothL1Loss
用途
用法
使用技巧
注意事项
代码示例
nn.SoftMarginLoss
用途
用法
使用技巧
注意事项
代码示例
nn.MultiLabelSoftMarginLoss
用途
用法
使用技巧
注意事项
代码示例
nn.CosineEmbeddingLoss
用途
用法
使用技巧
注意事项
代码示例
nn.MultiMarginLoss
用途
用法
使用技巧
注意事项
代码示例
nn.TripletMarginLoss
用途
用法
使用技巧
注意事项
代码示例
nn.TripletMarginWithDistanceLoss
用途
用法
使用技巧
注意事项
代码示例
总结
torch.nn子模块Loss Functions详解
nn.L1Loss
在 torch.nn 模块中,L1Loss 是一个非常重要的损失函数,主要用于衡量模型预测值和真实值之间的差异。这个函数计算的是预测值和目标值之间的平均绝对误差(Mean Absolute Error, MAE)。在深度学习和机器学习中,损失函数是衡量模型性能的关键指标,L1Loss 在回归问题中尤其有用。
用途
- 回归问题: 在处理回归问题时,
L1Loss能有效地量化预测值和实际值之间的差异。 - 异常值: 相比于平方误差损失(L2损失),
L1Loss对异常值更不敏感,因此在数据中有异常值时表现更好。
用法
- 参数配置:
size_average(已废弃): 是否对损失进行平均。reduce(已废弃): 是否应用缩减。reduction: 指定缩减方式,可以是'mean'(默认) 或'sum'。
- 输入:
input(预测值) 和target(目标值) 应为相同形状的张量。
使用技巧
- 选择适当的缩减方式: 默认情况下,
L1Loss使用均值。但在某些应用中,使用总和('sum')作为缩减方式可能更有意义。 - 复数支持:
L1Loss支持实数和复数输入。
注意事项
- 数据预处理: 由于
L1Loss对异常值不敏感,确保数据预处理阶段处理了异常值。 - 梯度下降: 与L2损失相比,L1损失在梯度下降时可能不那么平稳,因为它对误差的线性响应。
代码示例
下面是一个简单的使用 torch.nn.L1Loss 的例子:
import torch
import torch.nn as nn# 创建L1Loss损失函数实例
loss = nn.L1Loss()# 随机生成输入数据和目标数据
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)# 计算损失
output = loss(input, target)# 反向传播
output.backward()# 输出损失值
print(output)
在这个例子中,我们首先创建了一个 L1Loss 实例。然后生成了随机的输入和目标张量,计算了它们之间的 L1Loss,并通过 backward() 方法进行了反向传播。这样可以帮助我们理解 L1Loss 在实际中是如何工作的。
nn.MSELoss
torch.nn.MSELoss 是 PyTorch 中一个常用的损失函数,用于计算模型预测值和真实值之间的均方误差(Mean Squared Error, MSE)。这个损失函数在回归问题中特别有用,尤其是当我们希望强调较大误差的情况时(因为误差是平方的,所以大误差的影响更大)。
用途
- 回归问题:
MSELoss主要用于回归问题,其中目标是最小化预测值和实际值之间的差距。 - 强调大误差: 由于误差是平方的,所以
MSELoss对较大的误差更敏感,使得模型更加注重减少大的预测误差。
用法
- 参数配置:
size_average(已废弃): 是否对损失进行平均。reduce(已废弃): 是否应用缩减。reduction: 指定缩减方式,可以是'none','mean'(默认) 或'sum'。
- 输入:
input(预测值) 和target(目标值) 应为相同形状的张量。
使用技巧
- 选择适当的缩减方式: 根据具体的应用情况选择
'mean'或'sum'作为缩减方式。 - 异常值处理: 由于
MSELoss对大的误差更敏感,确保对数据中的异常值进行适当处理。
注意事项
- 梯度爆炸: 在使用
MSELoss时,由于误差平方的原因,可能会导致梯度爆炸的问题,特别是在误差较大时。需要适当调整学习率或使用梯度裁剪等技术来控制。
代码示例
下面是一个简单的使用 torch.nn.MSELoss 的例子:
import torch
import torch.nn as nn# 创建MSELoss损失函数实例
loss = nn.MSELoss()# 随机生成输入数据和目标数据
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)# 计算损失
output = loss(input, target)# 反向传播
output.backward()# 输出损失值
print(output)
在这个例子中,我们创建了一个 MSELoss 实例,随机生成了输入和目标张量,然后计算了它们之间的均方误差,并通过 backward() 方法进行了反向传播。这个过程帮助我们理解 MSELoss 如何在实际中工作,并对模型的训练过程产生影响。
nn.CrossEntropyLoss
torch.nn.CrossEntropyLoss 是 PyTorch 中用于分类问题的关键损失函数。它结合了 LogSoftmax 和 NLLLoss(Negative Log Likelihood Loss)的功能,通常用于多类分类问题中。这个损失函数计算输入的 logits(未经归一化的预测值)和目标类别之间的交叉熵损失。
用途
- 分类问题: 特别适用于具有多个类别的分类问题。
- 处理不平衡数据集: 可以通过
weight参数为各个类别指定不同的权重,这对于处理类别不平衡的数据集非常有用。
用法
- 参数:
weight(Tensor, 可选): 给每个类别指定的权重。ignore_index(int, 可选): 指定一个目标值,该值在计算损失时会被忽略。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。label_smoothing(float, 可选): 用于计算损失时的标签平滑,范围在 [0.0, 1.0]。
- 输入:
input应该包含每个类别的未经归一化的 logits。 - 目标:
target可以包含类别索引或类别概率。
使用技巧
- 权重调整: 对于不平衡的数据集,适当调整每个类别的权重可以提高模型的性能。
- 标签平滑: 用于避免模型对某些标签过于自信,有助于提高模型的泛化能力。
注意事项
- 输入和目标的一致性: 确保
input和target的维度一致,特别是在处理多维数据时(如图像)。 - 类别索引的有效范围: 当
target包含类别索引时,它们应该在[0, C)范围内,其中C是类别的数量。
代码示例
以下是使用 torch.nn.CrossEntropyLoss 的两个例子,分别展示了使用类别索引和类别概率作为目标的情况:
使用类别索引
import torch
import torch.nn as nn# 创建 CrossEntropyLoss 实例
loss = nn.CrossEntropyLoss()# 随机生成输入数据和目标类别索引
input = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)# 计算损失
output = loss(input, target)# 反向传播
output.backward()
使用类别概率
import torch
import torch.nn as nn# 创建 CrossEntropyLoss 实例
loss = nn.CrossEntropyLoss()# 随机生成输入数据和目标类别概率
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5).softmax(dim=1)# 计算损失
output = loss(input, target)# 反向传播
output.backward()
在这些例子中,我们创建了 CrossEntropyLoss 实例,随机生成了输入数据和目标(类别索引或类别概率),计算了损失,并执行了反向传播。这有助于我们理解 CrossEntropyLoss 在实际应用中的工作方式。
nn.CTCLoss
torch.nn.CTCLoss 是 PyTorch 中用于处理序列学习任务的损失函数,特别是在不需要将输入数据分割成固定大小的场景中非常有用。这个损失函数通常与循环神经网络(RNNs)结合使用,用于任务如语音识别或手写识别,其中输入数据是连续的时间序列。
用途
- 序列学习任务: 特别适用于处理时间序列数据,如语音识别、手写识别等。
- 处理不对齐的数据:
CTCLoss能够处理输入序列和目标序列长度不一致的情况,这在许多序列到序列的学习任务中非常常见。
用法
- 参数:
blank(int, 可选): 指定空白标签的索引,默认为 0。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。zero_infinity(bool, 可选): 是否将无限损失置零及其相关的梯度,默认为 False。
- 输入:
log_probs应为 log softmax 后的概率分布。 - 目标:
targets包含目标序列的类别索引。
使用技巧
- 数据预处理: 确保输入数据经过适当的预处理和归一化。
- 长度控制: 输入序列和目标序列的长度需要正确地传递给损失函数。
注意事项
- 目标序列长度: 目标序列的长度必须小于或等于输入序列的长度。
- 空白标签处理: 确保在训练数据中正确地指定了空白标签。
代码示例
以下是使用 torch.nn.CTCLoss 的示例,展示了如何在有填充和未填充目标的情况下使用它:
有填充的目标
import torch
import torch.nn as nnT, C, N, S = 50, 20, 16, 30 # 定义输入序列长度、类别数、批量大小和目标序列长度# 初始化输入向量
input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()# 初始化目标
target = torch.randint(1, C, (N, S), dtype=torch.long)# 输入和目标的长度
input_lengths = torch.full((N,), T, dtype=torch.long)
target_lengths = torch.randint(10, S, (N,), dtype=torch.long)# CTCLoss
ctc_loss = nn.CTCLoss()
loss = ctc_loss(input, target, input_lengths, target_lengths)
loss.backward()
未填充的目标
import torch
import torch.nn as nnT, C, N = 50, 20, 16 # 定义输入序列长度、类别数、批量大小# 初始化输入向量
input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
input_lengths = torch.full((N,), T, dtype=torch.long)# 初始化目标
target_lengths = torch.randint(1, T, (N,), dtype=torch.long)
target = torch.randint(1, C, (sum(target_lengths),), dtype=torch.long)# CTCLoss
ctc_loss = nn.CTCLoss()
loss = ctc_loss(input, target, input_lengths, target_lengths)
loss.backward()
在这些例子中,我们首先初始化了输入数据和目标数据,其中输入数据通过 log softmax 转换成概率分布。然后定义了输入和目标的长度,并使用 CTCLoss 计算损失,最后执行了反向传播。这些步骤展示了 CTCLoss 在序列学习任务中的应用方式。
nn.NLLLoss
torch.nn.NLLLoss(Negative Log Likelihood Loss)是 PyTorch 中用于分类问题的一种损失函数,特别适用于具有 C 个类别的分类问题。它通常与 LogSoftmax 层一起使用,用于训练神经网络。
用途
- 分类问题: 用于训练具有固定类别数的分类模型。
- 不平衡数据集: 如果提供
weight参数,可以为每个类别指定不同的权重,这对于处理类别不平衡的数据集非常有用。
用法
- 参数:
weight(Tensor, 可选): 为每个类别分配的权重。ignore_index(int, 可选): 指定一个目标值,该值在计算损失时会被忽略。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input应包含每个类别的 log 概率。 - 目标:
target应为类别索引,范围在[0, C-1]。
使用技巧
- LogSoftmax 层: 在网络的最后一层添加 LogSoftmax 层以获得 log 概率。
- 交叉熵损失: 如果不想添加额外的 LogSoftmax 层,可以直接使用
CrossEntropyLoss,它结合了 LogSoftmax 和 NLLLoss。
注意事项
- 目标类别索引: 确保
target中的每个值都在[0, C-1]的范围内。 - 输入和目标的对齐: 输入和目标的尺寸应该匹配。
代码示例
以下是使用 torch.nn.NLLLoss 的两个例子,分别展示了一维和二维损失的使用:
一维损失示例
import torch
import torch.nn as nn
import torch.nn.functional as Fm = nn.LogSoftmax(dim=1)
loss = nn.NLLLoss()# 输入尺寸 N x C = 3 x 5
input = torch.randn(3, 5, requires_grad=True)# 目标类别索引
target = torch.tensor([1, 0, 4])# 计算损失
output = loss(m(input), target)
output.backward()
二维损失示例(例如,用于图像)
import torch
import torch.nn as nn
import torch.nn.functional as FN, C = 5, 4
loss = nn.NLLLoss()# 输入尺寸 N x C x height x width
data = torch.randn(N, 16, 10, 10)
conv = nn.Conv2d(16, C, (3, 3))
m = nn.LogSoftmax(dim=1)# 目标类别索引
target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C)# 计算损失
output = loss(m(conv(data)), target)
output.backward()
在这些例子中,我们首先使用 LogSoftmax 层将网络的输出转换为 log 概率,然后使用这些 log 概率和目标类别索引来计算 NLL 损失。最后,执行反向传播以更新模型的参数。这展示了 NLLLoss 在分类问题中的应用方式。
nn.PoissonNLLLoss
torch.nn.PoissonNLLLoss 是 PyTorch 中用于处理具有泊松分布目标的负对数似然损失函数。这个损失函数通常用于模型输出表示事件发生率的情况,如计数数据或事件频率的预测。
用途
- 计数数据或事件频率的预测: 特别适用于预测计数数据,如一段时间内某事件的发生次数。
- 泊松分布场景: 适用于目标数据符合泊松分布的情况。
用法
- 参数:
log_input(bool, 可选): 如果为 True,则输入被解释为 log 形式的事件率,否则直接解释为事件率。full(bool, 可选): 是否计算完整的损失,包括斯特林近似项。eps(float, 可选): 避免在log_input=False时计算 log(0) 的小值。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input应为预测的事件发生率(可以是 log 形式)。 - 目标:
target为实际观测到的事件次数。
使用技巧
- 选择正确的输入形式: 根据模型输出选择
log_input的正确值。 - 斯特林近似: 对于较大的目标值,使用斯特林近似可以提高损失计算的效率。
注意事项
- 输入和目标的对齐: 输入和目标的尺寸应该匹配。
- 参数的理解和使用: 正确理解每个参数的意义,并根据具体情况进行调整。
代码示例
以下是使用 torch.nn.PoissonNLLLoss 的示例:
import torch
import torch.nn as nn# 创建 PoissonNLLLoss 实例
loss = nn.PoissonNLLLoss()# 随机生成 log 输入和目标数据
log_input = torch.randn(5, 2, requires_grad=True)
target = torch.randn(5, 2)# 计算损失
output = loss(log_input, target)# 反向传播
output.backward()
在这个例子中,我们首先创建了一个 PoissonNLLLoss 实例。然后生成了随机的 log 输入和目标数据,计算了它们之间的泊松负对数似然损失,并通过 backward() 方法进行了反向传播。这有助于我们理解 PoissonNLLLoss 在实际中是如何工作的,特别是在处理事件频率或计数数据的预测时。
nn.GaussianNLLLoss
torch.nn.GaussianNLLLoss 是 PyTorch 中的一个损失函数,用于处理目标值被认为是由神经网络预测的期望值和方差参数化的高斯分布的情况。这种损失函数通常用于回归问题,其中模型的输出表示目标值的预测分布。
用途
- 预测分布的回归问题: 适用于目标值可以被视为具有由模型预测的期望和方差的高斯分布的场景。
用法
- 参数:
full(bool, 可选): 是否包含损失计算中的常数项,默认为 False。eps(float, 可选): 用于稳定性的小值,用于在计算中限制方差,默认为 1e-6。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input应为预测的期望值。 - 目标:
target为实际观测值。 - 方差:
var为预测的方差值。
使用技巧
- 方差的处理: 方差
var应保持为正值,通常通过模型输出非负值并加上一个小的eps值来实现。 - 广播规则: 方差
var可以与input具有相同的形状,或者有一维为 1 以实现广播。
注意事项
- 输入和目标的对齐: 确保输入、目标和方差的尺寸匹配。
- 参数理解和使用: 正确理解每个参数的意义,并根据具体情况进行调整。
代码示例
以下是使用 torch.nn.GaussianNLLLoss 的示例:
异方差(Heteroscedastic)示例
import torch
import torch.nn as nn# 创建 GaussianNLLLoss 实例
loss = nn.GaussianNLLLoss()# 随机生成输入、目标和方差数据
input = torch.randn(5, 2, requires_grad=True)
target = torch.randn(5, 2)
var = torch.ones(5, 2, requires_grad=True) # 异方差# 计算损失
output = loss(input, target, var)
output.backward()
同方差(Homoscedastic)示例
import torch
import torch.nn as nn# 创建 GaussianNLLLoss 实例
loss = nn.GaussianNLLLoss()# 随机生成输入、目标和方差数据
input = torch.randn(5, 2, requires_grad=True)
target = torch.randn(5, 2)
var = torch.ones(5, 1, requires_grad=True) # 同方差# 计算损失
output = loss(input, target, var)
output.backward()
在这些示例中,我们首先创建了一个 GaussianNLLLoss 实例。然后生成了输入(预测的期望)、目标和方差(预测的方差)数据,并计算了它们之间的高斯负对数似然损失。通过 backward() 方法进行反向传播有助于理解 GaussianNLLLoss 在实际应用中的工作方式,尤其是在处理预测分布的回归问题时。
nn.KLDivLoss
torch.nn.KLDivLoss 是 PyTorch 中用于计算两个概率分布之间的 Kullback-Leibler 散度(KL 散度)的损失函数。这个损失函数用于衡量模型预测的概率分布与目标概率分布之间的差异。
用途
- 概率分布的比较: 主要用于比较两个概率分布的相似性,例如在生成模型或者语言模型中。
- 模型优化: 用于优化模型以使其输出的概率分布更接近目标分布。
用法
- 参数:
reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'、'batchmean'或'sum'。log_target(bool, 可选): 指定目标是否在 log 空间,默认为 False。
- 输入:
input应为预测的 log 概率分布。 - 目标:
target为目标概率分布,可以是概率分布或其 log 形式(取决于log_target)。
使用技巧
- 输入格式: 确保输入是在 log 空间中,通常通过使用
log_softmax函数来实现。 - reduction 选择: 使用
'batchmean'作为reduction可以得到数学上更准确的 KL 散度值。
注意事项
- 输入和目标的对齐: 确保输入和目标的尺寸匹配。
- 概率分布的有效性: 确保输入和目标都是有效的概率分布。
代码示例
以下是使用 torch.nn.KLDivLoss 的示例:
import torch
import torch.nn as nn
import torch.nn.functional as F# 创建 KLDivLoss 实例
kl_loss = nn.KLDivLoss(reduction="batchmean")# 输入应为 log 概率分布
input = F.log_softmax(torch.randn(3, 5, requires_grad=True), dim=1)# 目标为概率分布
target = F.softmax(torch.rand(3, 5), dim=1)# 计算损失
output = kl_loss(input, target)# 使用 log 目标的示例
kl_loss = nn.KLDivLoss(reduction="batchmean", log_target=True)
log_target = F.log_softmax(torch.rand(3, 5), dim=1)
output = kl_loss(input, log_target)
在这些示例中,我们创建了 KLDivLoss 实例,然后为输入和目标生成了 log 概率分布和概率分布。接着,我们计算了它们之间的 KL 散度损失,并通过 backward() 方法进行反向传播。这些步骤展示了 KLDivLoss 在实际应用中如何用于衡量两个概率分布之间的差异。
nn.BCELoss
torch.nn.BCELoss(Binary Cross Entropy Loss)是 PyTorch 中用于衡量二元分类问题中目标值和输入概率之间的二元交叉熵的损失函数。这个损失函数常用于具有两个类别(如 0 和 1)的分类任务。
用途
- 二元分类问题: 在处理只有两个类别的分类任务时非常有效,例如判断图像是否包含某个对象。
- 自编码器: 在自编码器等重建任务中,用于衡量重建误差。
用法
- 参数:
weight(Tensor, 可选): 为每个批次元素的损失赋予的手动调整权重。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input应为预测的概率值,范围在 [0, 1]。 - 目标:
target为实际的标签值,也应在 [0, 1] 范围内。
使用技巧
- Sigmoid 激活: 在模型的最后一层通常使用 Sigmoid 激活函数来确保输出值在 [0, 1] 范围内。
- 数值稳定性: BCELoss 会对 log 函数的输出进行限制,以避免计算上的不稳定性。
注意事项
- 输入和目标的对齐: 确保输入和目标的尺寸匹配。
- 概率值范围: 输入和目标值应该是有效的概率值(即在 [0, 1] 范围内)。
代码示例
import torch
import torch.nn as nn# 创建 BCELoss 实例
loss = nn.BCELoss()# 使用 Sigmoid 函数将输入压缩到 [0, 1] 范围
m = nn.Sigmoid()
input = torch.randn(3, 2, requires_grad=True)# 目标值也在 [0, 1] 范围内
target = torch.rand(3, 2)# 计算损失
output = loss(m(input), target)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 BCELoss 实例。然后使用 Sigmoid 激活函数处理输入数据,以确保它们在 [0, 1] 的范围内。接着,我们计算了输入和目标之间的二元交叉熵损失,并执行了反向传播。这个过程展示了 BCELoss 在处理二元分类问题时的应用方式。
nn.BCEWithLogitsLoss
torch.nn.BCEWithLogitsLoss 是 PyTorch 中的一个损失函数,它结合了一个 Sigmoid 层和 BCELoss(二元交叉熵损失)到一个单独的类中。这种组合比单独使用 Sigmoid 激活后跟 BCELoss 更数值稳定,因为它利用了数值稳定性技巧(log-sum-exp)。
用途
- 二元分类问题: 适用于处理具有两个类别的分类任务,例如判断图像是否包含某个对象。
- 自编码器重建误差: 在例如自编码器的重建任务中用于衡量重建误差。
用法
- 参数:
pos_weight(Tensor, 可选): 正例的权重。这对于不平衡的数据集(例如,正例比反例少得多)非常有用。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input应为模型的原始输出(未经 Sigmoid 激活)。 - 目标:
target为实际的标签值,应在 [0, 1] 范围内。
使用技巧
- 避免数值不稳定: 使用 BCEWithLogitsLoss 而不是单独的 Sigmoid 激活和 BCELoss 可以减少数值不稳定性。
- 处理不平衡数据集: 通过
pos_weight参数调整正例和反例的权重,可以改善模型在不平衡数据集上的性能。
注意事项
- 输入和目标的对齐: 确保输入和目标的尺寸匹配。
- 概率值范围: 目标值应该是有效的概率值(即在 [0, 1] 范围内)。
代码示例
import torch
import torch.nn as nn# 创建 BCEWithLogitsLoss 实例
loss = nn.BCEWithLogitsLoss()# 输入为模型的原始输出
input = torch.randn(3, requires_grad=True)# 目标值在 [0, 1] 范围内
target = torch.empty(3).random_(2)# 计算损失
output = loss(input, target)# 反向传播
output.backward()
在这个示例中,我们创建了一个 BCEWithLogitsLoss 实例。然后为输入和目标生成了数据,其中输入是模型的原始输出(未经 Sigmoid 激活处理),目标是二元标签。接着,我们计算了输入和目标之间的损失,并执行了反向传播。这个过程展示了 BCEWithLogitsLoss 在处理二元分类问题时的应用方式。
nn.MarginRankingLoss
torch.nn.MarginRankingLoss 是 PyTorch 中用于衡量排名任务的损失函数。这个损失函数用于比较两组输入,并根据一个标签(1 或 -1)判断哪组输入应该有更高的排名。
用途
- 排名任务: 在需要比较两个输入的相对顺序或重要性时使用,例如在推荐系统或排序任务中。
- 成对比较: 用于比较一对样本,并决定哪个样本应该被排名更高。
用法
- 参数:
margin(float, 可选): 设定的间隔阈值,默认为 0。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input1和input2: 两组进行比较的输入。target: 包含 1 或 -1 的标签,指示哪组输入应该有更高的排名。
使用技巧
- 选择合适的间隔: 通过调整
margin参数来控制排名错误的惩罚程度。 - 数据预处理: 确保
input1、input2和target的尺寸匹配。
注意事项
- 标签的含义:
target中的 1 表示input1应该排名高于input2,-1 则相反。 - 输出解释: 损失值越低,表示模型在排名任务上的性能越好。
代码示例
import torch
import torch.nn as nn# 创建 MarginRankingLoss 实例
loss = nn.MarginRankingLoss()# 输入样本
input1 = torch.randn(3, requires_grad=True)
input2 = torch.randn(3, requires_grad=True)# 目标标签
target = torch.randn(3).sign() # 随机生成 1 或 -1# 计算损失
output = loss(input1, input2, target)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 MarginRankingLoss 实例。然后生成了两组输入样本和对应的目标标签。接着,我们计算了基于这些输入和标签的损失,并执行了反向传播。这个过程展示了 MarginRankingLoss 在比较两组输入的排名时的应用方式。
nn.HingeEmbeddingLoss
torch.nn.HingeEmbeddingLoss 是 PyTorch 中用于衡量输入张量 x 和标签张量 y(包含 1 或 -1)之间损失的函数。这通常用于测量两个输入是否相似或不相似,例如使用 L1 对成对距离作为 x,并且通常用于学习非线性嵌入或半监督学习。
用途
- 相似性/不相似性衡量: 在需要判断两个输入是相似还是不相似的任务中使用,如在一些嵌入学习或对比学习场景中。
- 非线性嵌入学习: 用于学习输入数据的非线性嵌入表示。
用法
- 参数:
margin(float, 可选): 间隔阈值,默认为 1。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input表示输入的特征。 - 目标:
target包含 1 或 -1,表示两个输入是相似(1)还是不相似(-1)。
使用技巧
- 选择合适的间隔: 通过调整
margin参数来控制相似和不相似的样本之间的差异。 - 目标值的处理: 确保目标张量
target中的值为 1 或 -1。
注意事项
- 输入和目标的对齐: 确保输入和目标的尺寸匹配。
- 损失函数解释: 损失值越低,表示模型在区分相似和不相似的样本上做得越好。
代码示例
import torch
import torch.nn as nn# 创建 HingeEmbeddingLoss 实例
loss = nn.HingeEmbeddingLoss()# 输入样本
input = torch.randn(3, requires_grad=True)# 目标标签
target = torch.tensor([1, -1, 1], dtype=torch.float) # 标签为 1 或 -1# 计算损失
output = loss(input, target)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 HingeEmbeddingLoss 实例。然后生成了输入样本和相应的目标标签。接着,我们计算了基于这些输入和标签的损失,并执行了反向传播。这个过程展示了 HingeEmbeddingLoss 在区分输入样本是否相似的任务中的应用方式。
nn.MultiLabelMarginLoss
torch.nn.MultiLabelMarginLoss 是 PyTorch 中用于多标签分类任务的损失函数。这个损失函数优化了多类别多分类的铰链损失(基于间隔的损失),适用于那些每个样本可能属于多个类别的情况。
用途
- 多标签分类: 在需要对每个样本预测多个目标类别的任务中使用,例如在图像中识别多个对象。
- 非排他性类别: 适用于样本可以同时属于多个类别的场景。
用法
- 参数:
reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input为模型的预测结果,尺寸为(N, C),其中N是批量大小,C是类别数。 - 目标:
target是目标类别的索引,同样尺寸为(N, C),但使用 -1 来填充不相关的类别。
使用技巧
- 正确设置目标: 目标张量
target中应包含每个样本的目标类别索引,非目标类别位置用 -1 填充。 - 理解损失计算: 损失是基于输入和目标类别之间的差距计算的,目标是减小正类别和负类别之间的间隔。
注意事项
- 输入和目标的对齐: 确保输入和目标的尺寸匹配。
- 目标类别的处理: 目标张量中的类别索引应正确设置,非目标类别用 -1 表示。
代码示例
import torch
import torch.nn as nn# 创建 MultiLabelMarginLoss 实例
loss = nn.MultiLabelMarginLoss()# 输入样本
x = torch.FloatTensor([[0.1, 0.2, 0.4, 0.8]])# 目标标签(3 和 0 是目标类别,-1 表示填充)
y = torch.LongTensor([[3, 0, -1, 1]])# 计算损失
output = loss(x, y)# 输出损失
print(output)
在这个示例中,我们首先创建了一个 MultiLabelMarginLoss 实例。然后定义了输入张量 x 和目标张量 y。目标张量中,3 和 0 是目标类别,其余位置用 -1 填充以表示这些位置不是目标类别。接着,我们计算了损失并打印了结果。这个过程展示了 MultiLabelMarginLoss 在多标签分类任务中的应用方式。
nn.HuberLoss
torch.nn.HuberLoss 是 PyTorch 中的一个损失函数,用于结合 L1 损失和 L2 损失的优点。这个损失函数在绝对元素误差低于某个阈值 delta 时使用平方项(类似于 L2 损失),而在误差高于 delta 时使用 delta 缩放的 L1 损失。这样的设计使得 Huber 损失对于离群值(outliers)的敏感性低于 L2 损失,同时在靠近零的区域相比 L1 损失提供了更平滑的梯度。
用途
- 回归问题: 特别适用于回归任务,尤其是当数据中包含离群值时。
- 离群值的处理: 相比于传统的 L2 损失,Huber 损失对离群值更加鲁棒。
用法
- 参数:
reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。delta(float, 可选): 在此阈值以下使用 L2 损失,在此阈值以上使用 L1 损失。默认值为 1.0。
- 输入:
input为模型的预测结果。 - 目标:
target为真实的目标值。
使用技巧
- 选择合适的
delta: 根据具体任务调整delta值,以平衡 L1 和 L2 损失之间的敏感性。 - 数据预处理: 确保输入和目标的尺寸匹配。
注意事项
- 输入和目标的对齐: 输入和目标必须有相同的形状。
- 损失函数解释: 在
delta附近,损失函数提供了平滑的梯度,远离delta时,则表现为 L1 损失,这有助于处理离群值。
代码示例
import torch
import torch.nn as nn# 创建 HuberLoss 实例
loss = nn.HuberLoss()# 输入样本和目标
input = torch.randn(3, requires_grad=True)
target = torch.randn(3)# 计算损失
output = loss(input, target)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 HuberLoss 实例。然后为输入和目标生成了随机数据。接着,我们计算了基于这些输入和目标的 Huber 损失,并执行了反向传播。这个过程展示了 HuberLoss 在处理回归任务时的应用方式,尤其是在数据中可能包含离群值的情况下。
nn.SmoothL1Loss
torch.nn.SmoothL1Loss 是 PyTorch 中的一个损失函数,用于计算输入和目标之间的平滑 L1 损失。它是 L1 损失和 L2 损失的结合体,当绝对误差小于某个阈值 beta 时使用平方项(类似于 L2 损失),而在误差大于 beta 时使用 L1 损失。这种设计使得 Smooth L1 损失对离群值不那么敏感,并且在靠近 0 的区域提供更平滑的梯度。
用途
- 回归问题: 特别适用于回归任务,尤其是当数据中可能包含离群值时。
- 防止梯度爆炸: 在某些情况下,例如 Fast R-CNN 中,可以防止梯度爆炸。
用法
- 参数:
beta(float, 可选): 在此阈值以下使用 L2 损失,在此阈值以上使用 L1 损失。默认值为 1.0。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input为模型的预测结果。 - 目标:
target为真实的目标值。
使用技巧
- 选择合适的
beta: 根据具体任务调整beta值,以平衡 L1 和 L2 损失之间的敏感性。 - 数据预处理: 确保输入和目标的尺寸匹配。
注意事项
- 输入和目标的对齐: 输入和目标必须有相同的形状。
- 损失函数解释: 在
beta附近,损失函数提供了平滑的梯度,远离beta时,则表现为 L1 损失,这有助于处理离群值。
代码示例
import torch
import torch.nn as nn# 创建 SmoothL1Loss 实例
loss = nn.SmoothL1Loss()# 输入样本和目标
input = torch.randn(3, requires_grad=True)
target = torch.randn(3)# 计算损失
output = loss(input, target)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 SmoothL1Loss 实例。然后为输入和目标生成了随机数据。接着,我们计算了基于这些输入和目标的 Smooth L1 损失,并执行了反向传播。这个过程展示了 SmoothL1Loss 在处理回归任务时的应用方式,尤其是在数据中可能包含离群值的情况下。
nn.SoftMarginLoss
torch.nn.SoftMarginLoss 是 PyTorch 中用于二元分类问题的损失函数。它优化了输入张量 x 和目标张量 y(包含 1 或 -1)之间的逻辑损失(logistic loss)。
用途
- 二元分类问题: 适用于处理只有两个类别的分类任务,例如在情感分析或垃圾邮件检测中判断正类或负类。
- 逻辑损失: 提供一种平滑的二元分类损失函数,适用于非线性分类问题。
用法
- 参数:
reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input应为模型的预测结果。 - 目标:
target包含 1 或 -1,表示正类或负类。
使用技巧
- 数据预处理: 确保输入和目标的尺寸匹配,并且目标值为 1 或 -1。
- 理解损失计算: 损失是基于输入和目标之间的逻辑损失计算的,目标是最小化这个损失。
注意事项
- 输入和目标的对齐: 输入和目标必须有相同的形状。
- 损失函数解释: 损失函数的值越低,表示模型在二元分类任务上的性能越好。
代码示例
import torch
import torch.nn as nn# 创建 SoftMarginLoss 实例
loss = nn.SoftMarginLoss()# 输入样本
input = torch.randn(3, requires_grad=True)# 目标标签
target = torch.tensor([1, -1, 1], dtype=torch.float) # 标签为 1 或 -1# 计算损失
output = loss(input, target)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 SoftMarginLoss 实例。然后为输入和目标生成了数据,其中目标是二元标签(1 或 -1)。接着,我们计算了基于这些输入和目标的逻辑损失,并执行了反向传播。这个过程展示了 SoftMarginLoss 在处理二元分类问题时的应用方式。
nn.MultiLabelSoftMarginLoss
torch.nn.MultiLabelSoftMarginLoss 是 PyTorch 中用于多标签分类问题的损失函数。这个损失函数基于最大熵原理,优化了多标签一对多(one-versus-all)的损失,适用于每个样本可能属于多个类别的情况。
用途
- 多标签分类问题: 在需要对每个样本预测多个目标类别的任务中使用,例如图像中可能包含多个不同的物体。
- 一对多分类: 适用于一种情形,其中每个类别被视为独立的二元分类问题。
用法
- 参数:
weight(Tensor, 可选): 为每个类别分配的权重。如果给定,它必须是大小为 C 的张量。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input为模型的预测结果,尺寸为(N, C),其中N是批量大小,C是类别数。 - 目标:
target是目标类别的标签,同样尺寸为(N, C)。
使用技巧
- 正确设置目标: 目标张量
target中应包含每个样本的目标类别标签,其中每个位置上的值为 0 或 1。 - 权重的应用: 如果数据集中的类别不平衡,可以通过
weight参数调整每个类别的损失权重。
注意事项
- 输入和目标的对齐: 确保输入和目标的尺寸匹配。
- 损失函数解释: 损失值越低,表示模型在多标签分类任务上的性能越好。
代码示例
import torch
import torch.nn as nn# 创建 MultiLabelSoftMarginLoss 实例
loss = nn.MultiLabelSoftMarginLoss()# 输入样本
x = torch.FloatTensor([[0.1, 0.2, 0.4, 0.8]])# 目标标签
y = torch.FloatTensor([[0, 1, 0, 1]])# 计算损失
output = loss(x, y)# 输出损失
print(output)
在这个示例中,我们首先创建了一个 MultiLabelSoftMarginLoss 实例。然后定义了输入张量 x 和目标张量 y。目标张量中的每个位置代表一个类别,其中值为 1 表示该类别是目标类别,0 表示非目标类别。接着,我们计算了损失并打印了结果。这个过程展示了 MultiLabelSoftMarginLoss 在多标签分类任务中的应用方式。
nn.CosineEmbeddingLoss
torch.nn.CosineEmbeddingLoss 是 PyTorch 中用于衡量两个输入之间相似性或不相似性的损失函数。这个函数基于余弦相似度来测量输入之间的关系,通常用于学习非线性嵌入或半监督学习任务。
用途
- 相似性/不相似性度量: 在需要判断两个输入是否相似的任务中使用,如在嵌入学习或对比学习场景中。
- 非线性嵌入学习: 用于学习输入数据的非线性嵌入表示。
用法
- 参数:
margin(float, 可选): 间隔阈值,应在 -1 到 1 之间,通常建议在 0 到 0.5 之间。默认值为 0。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input1和input2为需要比较的两个输入张量。 - 目标:
target包含 1 或 -1,表示两个输入是相似(1)还是不相似(-1)。
使用技巧
- 选择合适的间隔: 通过调整
margin参数来控制相似和不相似样本之间的差异。 - 数据预处理: 确保
input1、input2和target的尺寸匹配。
注意事项
- 输入和目标的对齐: 输入和目标必须有相同的形状。
- 目标值的含义:
target中的 1 表示两个输入应该是相似的,而 -1 表示它们应该是不相似的。
代码示例
import torch
import torch.nn as nn# 创建 CosineEmbeddingLoss 实例
loss = nn.CosineEmbeddingLoss()# 输入样本
input1 = torch.randn(3, 5, requires_grad=True)
input2 = torch.randn(3, 5, requires_grad=True)# 目标标签
target = torch.tensor([1, -1, 1], dtype=torch.float) # 标签为 1 或 -1# 计算损失
output = loss(input1, input2, target)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 CosineEmbeddingLoss 实例。然后为两组输入生成了数据,以及相应的目标标签。接着,我们计算了基于这些输入和标签的余弦嵌入损失,并执行了反向传播。这个过程展示了 CosineEmbeddingLoss 在衡量两个输入是否相似的任务中的应用方式。
nn.MultiMarginLoss
torch.nn.MultiMarginLoss 是 PyTorch 中用于多类别分类的铰链损失(hinge loss)函数。这个损失函数是一种边际基损失(margin-based loss),用于优化多类别分类问题中的输入 x(一个二维的小批量张量)和输出 y(一个包含目标类别索引的一维张量)之间的关系。
用途
- 多类别分类问题: 在需要对每个样本进行多个类别之间的分类的任务中使用,例如在图像分类或文本分类中。
- 边际损失优化: 适用于那些需要增加分类决策边界的任务。
用法
- 参数:
p(int, 可选): 默认值为 1。1 和 2 是唯一支持的值。margin(float, 可选): 边际值,默认为 1。weight(Tensor, 可选): 给每个类别的损失赋予的手动调整权重。如果给定,它必须是大小为 C 的张量。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
input为模型的预测结果,尺寸为(N, C),其中N是批量大小,C是类别数。 - 目标:
target包含目标类别的索引,每个值应在0到C-1的范围内。
使用技巧
- 权重的应用: 如果数据集中的类别不平衡,可以通过
weight参数调整每个类别的损失权重。 - 选择合适的参数: 根据任务的具体需求选择合适的
p和margin。
注意事项
- 输入和目标的对齐: 确保输入和目标的尺寸匹配。
- 损失函数解释: 损失值越低,表示模型在多类别分类任务上的性能越好。
代码示例
import torch
import torch.nn as nn# 创建 MultiMarginLoss 实例
loss = nn.MultiMarginLoss()# 输入样本
x = torch.tensor([[0.1, 0.2, 0.4, 0.8]])# 目标标签
y = torch.tensor([3]) # 目标类别为 3# 计算损失
output = loss(x, y)# 输出损失
print(output)
在这个示例中,我们首先创建了一个 MultiMarginLoss 实例。然后定义了输入张量 x 和目标张量 y。目标张量中的值表示目标类别的索引。接着,我们计算了损失并打印了结果。这个过程展示了 MultiMarginLoss 在多类别分类任务中的应用方式。
nn.TripletMarginLoss
torch.nn.TripletMarginLoss 是 PyTorch 中的一个损失函数,用于衡量给定的三元组输入张量之间的相对相似性。这个函数常用于度量样本间的相对相似性,例如在人脸识别或其他形式的度量学习中。三元组由锚点(anchor)、正样本(positive examples)和负样本(negative examples)组成。所有输入张量的形状应为 (N, D),其中 N 是批量大小,D 是向量维度。
用途
- 度量学习: 在需要学习数据点之间相对距离的任务中使用,例如人脸识别、图像检索等。
- 相对相似性度量: 用于确定一个样本(锚点)与正样本的相似度是否显著高于与负样本的相似度。
用法
- 参数:
margin(float, 可选): 边界值,默认为 1.0。p(int, 可选): 用于计算成对距离的范数度,默认为 2。eps(float, 可选): 数值稳定性常数,默认为 1e-6。swap(bool, 可选): 是否使用距离交换,默认为 False。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
anchor,positive,negative分别为锚点、正样本和负样本张量。
使用技巧
- 合理设置参数: 根据具体任务调整
margin、p和eps参数。 - 正确构造三元组: 确保锚点、正样本和负样本正确构造。
注意事项
- 输入张量的形状: 所有输入张量的形状必须相同。
- 损失函数解释: 损失值越低,表示锚点与正样本的相似度越高,与负样本的相似度越低。
代码示例
import torch
import torch.nn as nn# 创建 TripletMarginLoss 实例
triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2, eps=1e-7)# 输入样本
anchor = torch.randn(100, 128, requires_grad=True)
positive = torch.randn(100, 128, requires_grad=True)
negative = torch.randn(100, 128, requires_grad=True)# 计算损失
output = triplet_loss(anchor, positive, negative)# 反向传播
output.backward()
在这个示例中,我们首先创建了一个 TripletMarginLoss 实例。然后定义了锚点、正样本和负样本张量。接着,我们计算了这些输入基于三元组损失的输出,并执行了反向传播。这个过程展示了 TripletMarginLoss 在度量学习和相对相似性度量任务中的应用方式。
nn.TripletMarginWithDistanceLoss
torch.nn.TripletMarginWithDistanceLoss 是 PyTorch 中的一个损失函数,它用于度量三个输入张量(表示为锚点(anchor)、正样本(positive)和负样本(negative))之间的三元组损失,并且允许使用自定义的距离函数来计算锚点与正负样本之间的距离。
用途
- 度量学习: 常用于需要学习数据点之间相对距离的任务,如人脸识别、图像检索等。
- 自定义距离函数: 允许使用自定义的距离函数,使得这个损失函数可以灵活地应用于不同的场景和需求。
用法
- 参数:
distance_function(Callable, 可选): 用于量化两个张量之间接近程度的非负实值函数。margin(float, 可选): 边界值,用于确定正负样本距离差异的最小值。swap(bool, 可选): 是否使用距离交换策略。reduction(str, 可选): 指定损失的缩减方式,可以是'none'、'mean'或'sum'。
- 输入:
anchor,positive,negative分别为锚点、正样本和负样本张量。
使用技巧
- 选择合适的距离函数: 根据任务特性选择或定义合适的距离函数。
- 合理设置参数: 调整
margin和swap参数以满足特定任务的需求。
注意事项
- 输入张量的形状: 所有输入张量的形状必须相同。
- 损失函数解释: 损失值越低,表示锚点与正样本的距离越近,与负样本的距离越远。
代码示例
import torch
import torch.nn as nn
import torch.nn.functional as F# 初始化嵌入
embedding = nn.Embedding(1000, 128)
anchor_ids = torch.randint(0, 1000, (1,))
positive_ids = torch.randint(0, 1000, (1,))
negative_ids = torch.randint(0, 1000, (1,))
anchor = embedding(anchor_ids)
positive = embedding(positive_ids)
negative = embedding(negative_ids)# 使用内置距离函数
triplet_loss = nn.TripletMarginWithDistanceLoss(distance_function=nn.PairwiseDistance())
output = triplet_loss(anchor, positive, negative)
output.backward()# 使用自定义距离函数
def l_infinity(x1, x2):return torch.max(torch.abs(x1 - x2), dim=1).valuestriplet_loss = nn.TripletMarginWithDistanceLoss(distance_function=l_infinity, margin=1.5)
output = triplet_loss(anchor, positive, negative)
output.backward()# 使用 Lambda 自定义距离函数
triplet_loss = nn.TripletMarginWithDistanceLoss(distance_function=lambda x, y: 1.0 - F.cosine_similarity(x, y))
output = triplet_loss(anchor, positive, negative)
output.backward()
在这个示例中,我们演示了如何使用 TripletMarginWithDistanceLoss 损失函数,并展示了如何使用内置的距离函数以及如何定义和使用自定义的距离函数。这个过程展示了 TripletMarginWithDistanceLoss 在度量学习任务中的应用方式。
总结
这篇博客探讨了 PyTorch 中的各种损失函数,包括 L1Loss、MSELoss、CrossEntropyLoss、CTCLoss、NLLLoss、PoissonNLLLoss、GaussianNLLLoss、KLDivLoss、BCELoss、BCEWithLogitsLoss、MarginRankingLoss、HingeEmbeddingLoss、MultiLabelMarginLoss、HuberLoss、SmoothL1Loss、SoftMarginLoss、MultiLabelSoftMarginLoss、CosineEmbeddingLoss、MultiMarginLoss、TripletMarginLoss 和 TripletMarginWithDistanceLoss。每种损失函数都详细描述了其用途、实现方式、使用技巧和注意事项,并提供了实际代码示例,使读者能够更好地理解和应用这些损失函数于各种机器学习和深度学习场景。
相关文章:

简单易懂的PyTorch 损失函数:优化机器学习模型的关键
目录 torch.nn子模块Loss Functions详解 nn.L1Loss 用途 用法 使用技巧 注意事项 代码示例 nn.MSELoss 用途 用法 使用技巧 注意事项 代码示例 nn.CrossEntropyLoss 用途 用法 使用技巧 注意事项 代码示例 使用类别索引 使用类别概率 nn.CTCLoss 用途 …...

Kubernetes/k8s的存储卷/数据卷
k8s的存储卷/数据卷 容器内的目录和宿主机的目录挂载 容器在系统上的生命周期是短暂的,delete,k8s用控制创建的pod,delete相当于重启,容器的状态也会回复到初始状态 一旦回到初始状态,所有的后天编辑的文件都会消失…...
【漏洞复现】锐捷RG-UAC统一上网行为管理系统信息泄露漏洞
Nx01 产品简介 锐捷网络成立于2000年1月,原名实达网络,2003年更名,自成立以来,一直扎根行业,深入场景进行解决方案设计和创新,并利用云计算、SDN、移动互联、大数据、物联网、AI等新技术为各行业用户提供场…...
)
Android - 串口通讯(SerialPort)
最早的博客Android 模拟串口通信过程_launch virtual serial port driver pro-CSDN博客里就是用过 Google 提供的 demo,最近想再写个其他的demo发现用起来有点麻烦,还需要导入其他 module,因此在网上找到了Android-SerialPort-API: https://g…...

如何使用設置靜態住宅IP
靜態住宅IP就是一種靜態的、分配給住宅用戶的IP地址。與動態IP地址不同,靜態住宅IP一旦分配給用戶,就會一直保持不變,除非ISP(Internet Service Provider,互聯網服務提供商)進行手動更改。那麼,…...
在学习爬虫前的准备
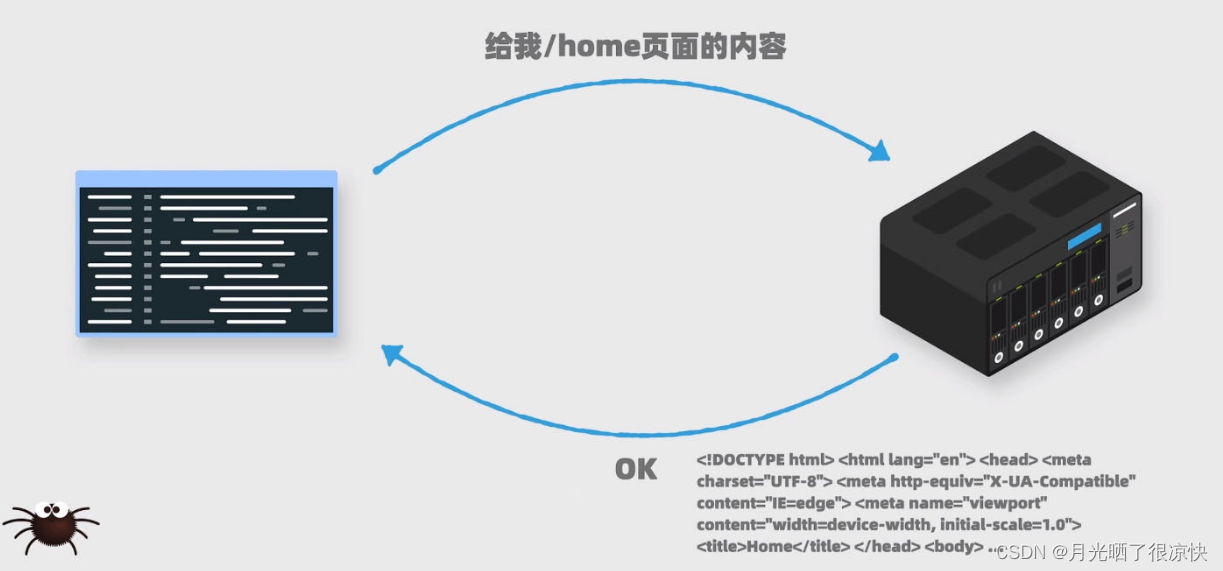
1. 写一个爬虫程序需要分几步 获取网页内容。 我们会通过代码给一个网站服务器发送请求,它会返回给我们网页上的内容。 在我们平时使用浏览器访问服务器内容是,本质上也是向服务器发送一个请求,然后服务器返回网页上的内容。只不过浏览器还会…...
windows下安装oracle-win-64-11g超详细图文步骤
官方下载地址:点这里 1.根据自己电脑情况,解压64或者32位客户端,以及database压缩包 2.解压后双击执行database文件夹下的setup.exe 3.详细的安装步骤 (1)数据库安装 一、配置安全更新 电子邮件可写可不写…...

Go模板后端渲染时vue单页面冲突处理
go后端模版语法是通过 {{}} ,vue也是通过双花括号来渲染的,如果使用go渲染vue的html页面的时候就会报错,因为分别不出来哪个是vue的,哪个是go的,既可以修改go的模板语法 template.New("output").Delims(&qu…...

笔记本摄像头模拟监控推送RTSP流
使用笔记本摄像头模拟监控推送RTSP流 一、基础安装软件准备 本文使用软件下载链接:下载地址 FFmpeg软件: Download ffmpeg 选择Windows builds by BtbN 一个完整的跨平台解决方案,用于录制、转换和流式传输音频和视频。 EasyDarwin软件:Download Easy…...

鸿蒙开发已解决-ArkTS编译时遇到arkts-no-obj-literals-as-types错误
文章目录 项目场景:问题描述原因分析:解决方案:解决方案1解决方案2此Bug解决方案总结项目场景: 在开发鸿蒙项目过程中,遇到了arkts-no-obj-literals-as-types,总结了自己和网上人的解决方案,故写下这篇文章。 遇到问题: rkTS编译时遇到arkts-no-obj-literals-as-type…...
实现目标检测中的数据格式自由(labelme json、voc、coco、yolo格式的相互转换)
在进行目标检测任务中,存在labelme json、voc、coco、yolo等格式。labelme json是由anylabeling、labelme等软件生成的标注格式、voc是通用目标检测框(mmdetection、paddledetection)所支持的格式,coco是通用目标检测框࿰…...

一文读懂JVS逻辑引擎如何调用规则引擎:含详细步骤与场景示例
在当今的数字化时代,业务逻辑和规则的复杂性不断增加,这使得逻辑引擎和规则引擎在处理业务需求时显得尤为重要。逻辑引擎和规则引擎通过定义、解析和管理业务逻辑和规则,能够帮助企业提高工作效率、降低运营成本,并增强决策的科学…...

苹果应用上架是否需要软件著作权?
苹果应用上架是否需要软件著作权? 摘要 随着移动互联网的发展,苹果应用在市场上占据了很大份额。但是,很多开发者在上传苹果应用到App Store时,都会遇到一个问题,即是否需要进行软著申请?本文将深入探讨这…...
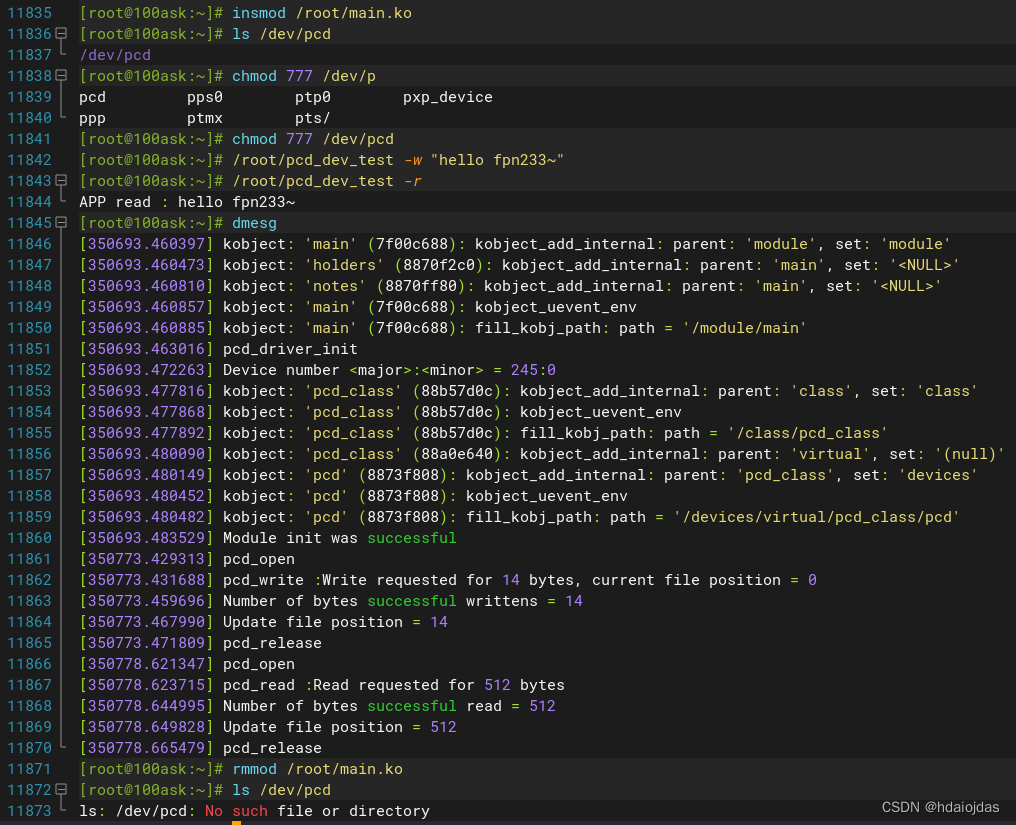
LDD学习笔记 -- Linux字符设备驱动
LDD学习笔记 -- Linux字符设备驱动 虚拟文件系统 VFS设备号相关Kernel APIs动态申请设备号动态创建设备文件内核空间和用户空间的数据交换系统调用方法readwritelseek 写一个伪字符设备驱动在主机上测试pcd(HOST)在目标板上测试pcd(TARGET) 字符驱动程序用于与Linux内核中的设备…...

杰理AC63串口收发实例
在event.h文件中预定义串口消息 #define DEVICE_EVENT_FROM_MY_UART ((M << 24) | (Y << 16) | (U << 8) | \0)在app_spp_and_le.c文件里对SYS_DEVICE_EVENT做处理,添加收到DEVICE_EVENT_FROM_MY_UART消息时的处理函数my_rx_handler(); cas…...
麦芯(MachCore)开发教程1 --- 设备软件中间件
黄国强 2024/1/10 acloud163.com 对任何公司来说,在短时间内开发一款高质量设备专用软件,是一件不太容易做到的事情。麦芯是笔者发明的一款设备软件中间件产品。麦芯致力于给设备厂商提供一个开发工具和平台,让客户快速高效的开发自己的设备专…...

reset命令
作用:将当前 HEAD 重置为指定状态 Git 的四个区域 Workspace:工作区,就是你平时存放项目代码的地方;Index / Stage:暂存区,用于临时存放你的改动,事实上它只是一个文件,保存即将提交到文件列表…...
LinuxIO基础知识与概念)
Linux内核--进程管理(十二)LinuxIO基础知识与概念
目录 一、引言 二、IO基本概念 ------>2.1、内存空间划分 ------>2.2、读写操作 ------>2.3、用户态切换到内核态的3种方式 三、PIO&DMA ------>3.1、PIO 工作原理 ------>3.2、DMA 工作原理 四、缓冲IO和直接IO ------>4.1、缓冲 IO ------&…...
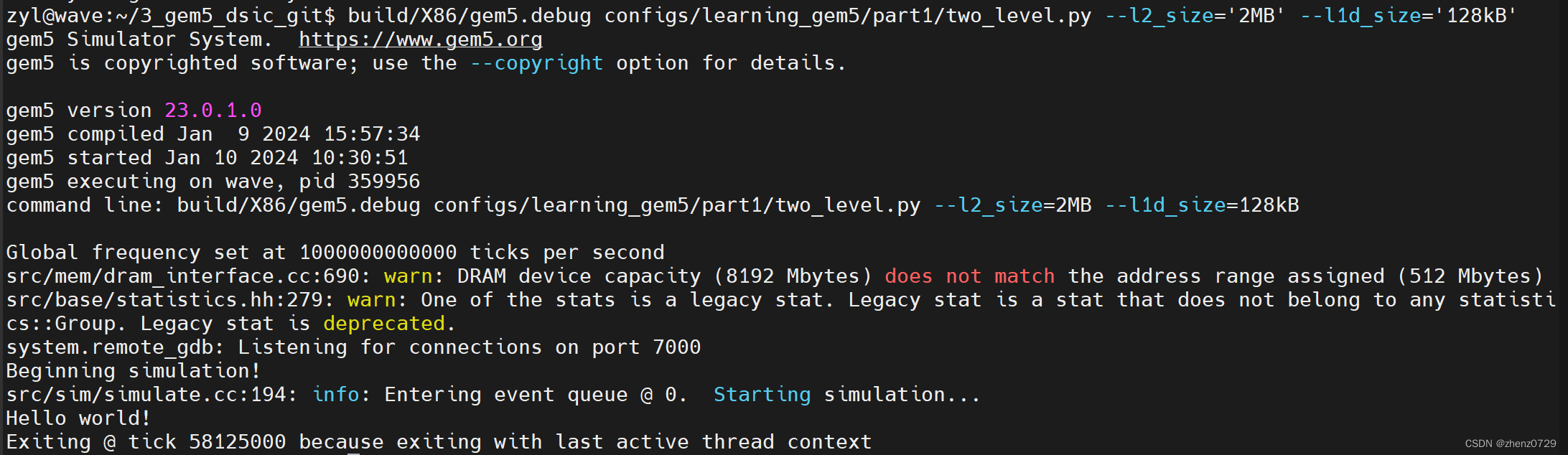
gem5学习(11):将缓存添加到配置脚本中——Adding cache to the configuration script
目录 一、Creating cache objects 1、Classic caches and Ruby 二、Cache 1、导入SimObject(s) 2、创建L1Cache 3、创建L1Cache子类 4、创建L2Cache 5、L1Cache添加连接函数 6、为L1ICache和L1DCache添加连接函数 7、为L2Cache添加内存侧和CPU侧的连接函数 完整代码…...

上海雏鸟科技无人机灯光秀跨年表演点亮三国五地夜空
2023年12月31日晚,五场别开生面的无人机灯光秀跨年表演在新加坡圣淘沙、印尼雅加达、中国江苏无锡、浙江衢州、陕西西安等五地同步举行。据悉,这5场表演背后均出自上海的一家无人机企业之手——上海雏鸟科技。 在新加坡圣淘沙西乐索海滩,500架…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...
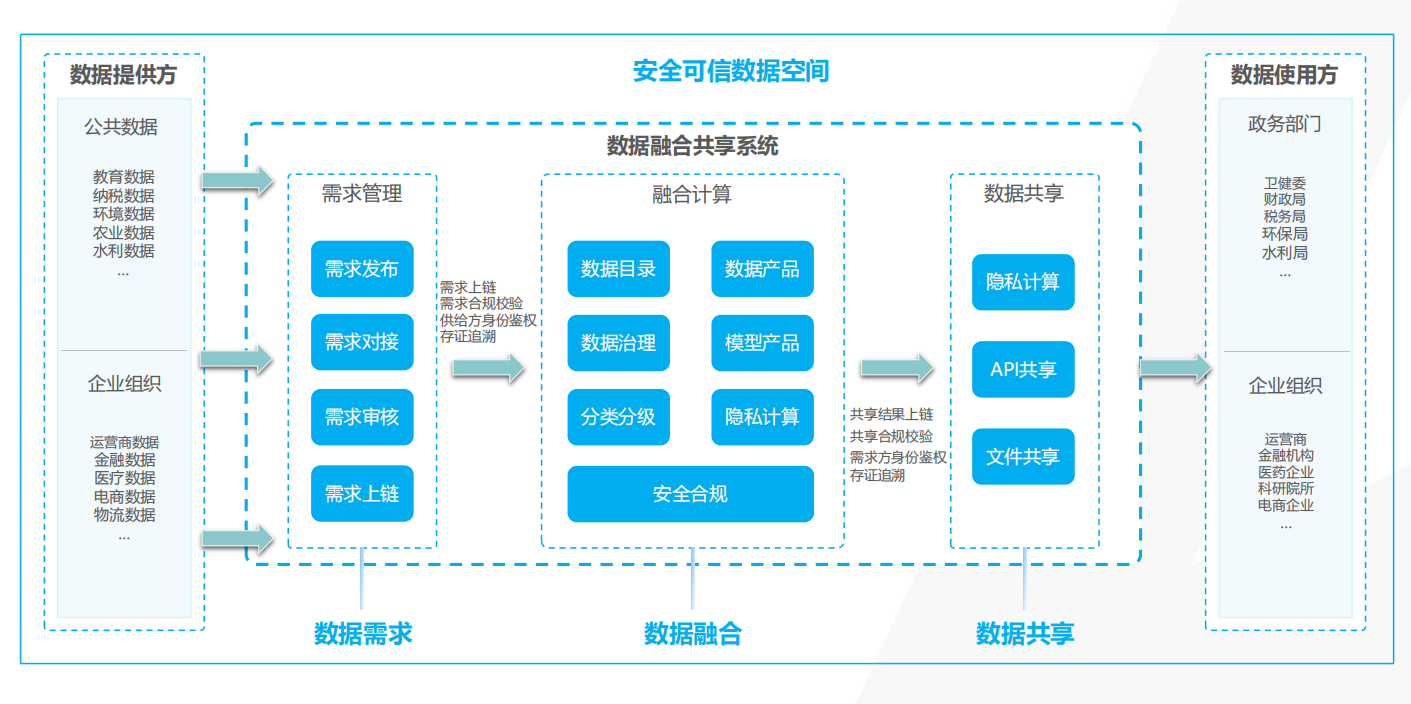
热烈祝贺埃文科技正式加入可信数据空间发展联盟
2025年4月29日,在福州举办的第八届数字中国建设峰会“可信数据空间分论坛”上,可信数据空间发展联盟正式宣告成立。国家数据局党组书记、局长刘烈宏出席并致辞,强调该联盟是推进全国一体化数据市场建设的关键抓手。 郑州埃文科技有限公司&am…...