Python库学习(十四):ORM框架-SQLAlchemy
1.介绍
SQLAlchemy 是一个用于 Python 的 SQL 工具和对象关系映射(ORM)库。它允许开发者通过 Python 代码而不是 SQL查询语言来操作数据库。SQLAlchemy 提供了一种灵活且强大的方式来与关系型数据库交互,支持多种数据库后端,如 PostgreSQL、MySQL、SQLite 等。
本文使用的SQLAlchemy版本: 1.4.51
1.1 Core和Orm
当学习使用 SQLAlchemy 时,经常会听到两个核心概念:SQLAlchemy ORM 和 SQLAlchemy Core。它们分别是 SQLAlchemy 的两个主要组件,用于处理数据库操作的不同层次。
a.SQLAlchemy ORM:
-
提供了一种将数据库表映射到 Python对象的方式,通过定义Python类来表示数据库表。 -
对象关系映射允许开发者通过使用对象和类的方式进行数据库操作,而不必直接使用 SQL语句。 -
更适合那些希望以面向对象的方式与数据库交互、利用类和对象的优势的开发者。
b.SQLAlchemy Core:
-
以更灵活的方式构建 SQL查询,并允许直接执行原生SQL语句。 -
不涉及对象和类的概念,更注重于 SQL查询语句的构建和执行。 -
适合那些希望直接使用原生SQL的开发者。
c.SQLAlchemy核心组件图
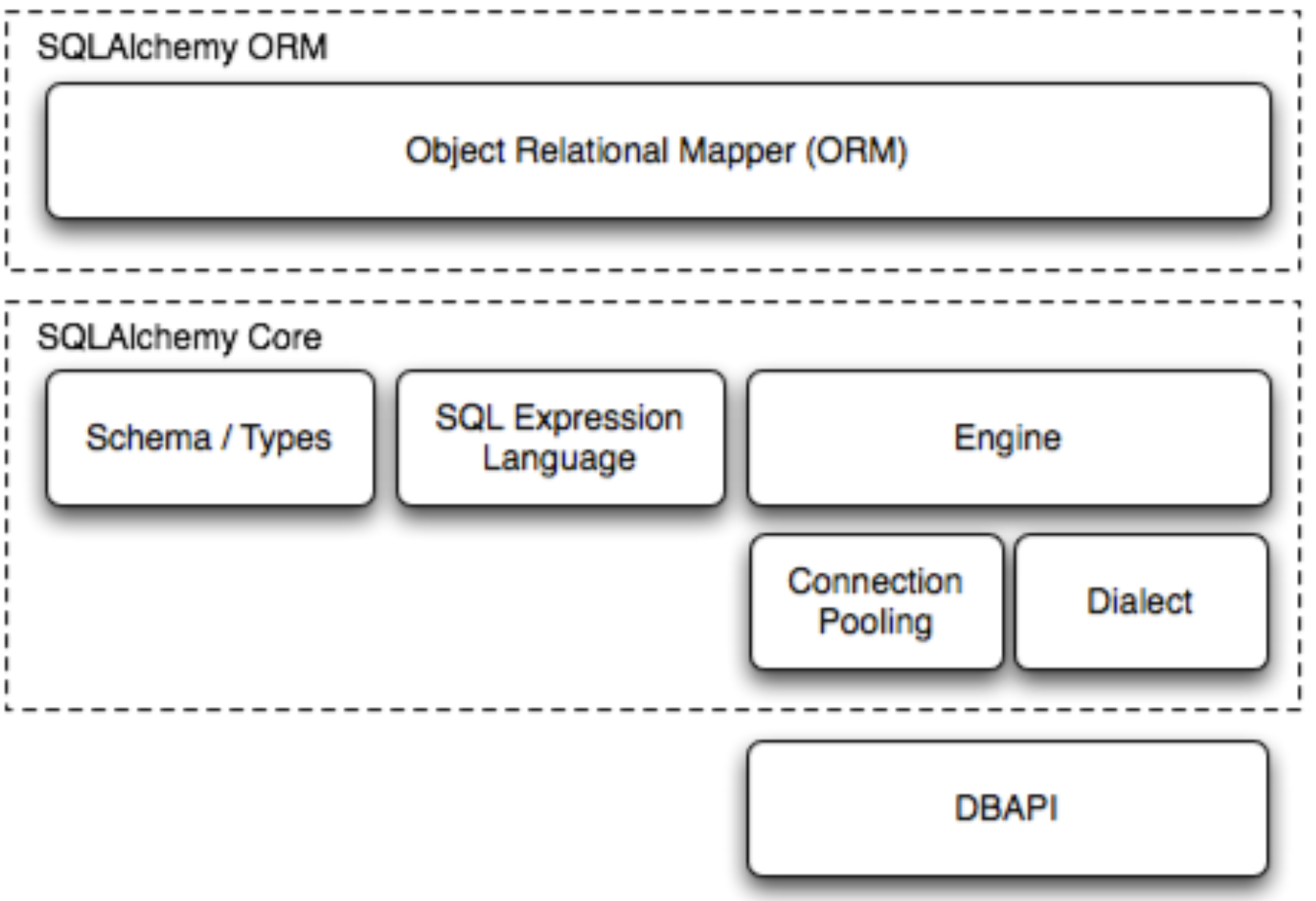
1.2 文档资料
-
SQLAlchemy 1.4 中文文档 -
SQLAlchemy 2.0 官方文档
2.使用准备
2.1 安装sqlalchemy
@注意: 虽然
sqlalchemy已经升级到2.0, 但发现自动生成模型工具sqlacodegen生成的代码还是基于1.4,加上2.0相关中文文档还不是很完善,所以这里仍然使用1.4版本 。
# 安装
$ python-learn pip install sqlalchemy==1.4.51
...
Installing collected packages: sqlalchemy
Successfully installed sqlalchemy-1.4.51
2.2 安装数据库依赖
sqlalchemy可以操作多种数据库,需要注意的是,不同的数据库的连接方式是不一样,依赖的库也不一样,这里列举一些常见数据依赖和连接格式:
2.2.1 关系型数据库
| 数据库 | 依赖 | 连接字符串 |
|---|---|---|
MySQL | pymysql | mysql+pymysql://username:password@localhost:3306/database_name |
PostgreSQL | psycopg2 | postgresql://username:password@localhost:5432/database_name |
SQLite | 不需要 | sqlite:///example.db |
Oracle | cx_Oracle | oracle://username:password@localhost:1521/orcl |
2.2.2 NoSQL数据库
| 数据库 | 依赖 | 连接字符串 |
|---|---|---|
MongoDB | pymongo | mongodb://username:password@localhost:27017/database_name |
CouchDB | couchdb | couchdb://username:password@localhost:5984/database_name |
Redis | redis | redis://localhost:6379/0 |
说明: 虽然SQLAlchemy支持两种方式操作数据库(Core和Orm),因为精力和文章篇幅问题,下面只学习ORM方式操作。
3.快速使用
3.1 使用流程
使用SQLAlchemy ORM的一般流程包括以下步骤:
-
定义模型类(ORM): 定义 Python类,其属性和数据表中的字段一一映射,一个模型类就是一个表。 -
创建引擎(Engine): 通俗的讲就是和数据库建立链接; -
创建会话(Session): 它提供了一种管理数据库事务和执行数据库操作的方式。会话允许你在应用程序中创建、更新、删除数据库中的数据,并提供了一系列方法来管理事务的提交和回滚。 -
执行数据库操作: 使用会话进行数据库操作,包括添加、修改、删除数据。
3.2 定义模型
from sqlalchemy import Column, String, TIMESTAMP
from sqlalchemy.dialects.mysql import BIGINT, TINYINT, VARCHAR
from sqlalchemy.ext.declarative import declarative_base
# 模型父类
Base = declarative_base()
# 用户模型和表一一对应
class YmUser(Base):
__tablename__ = 'ym_user'
__table_args__ = {'comment': '用户表'}
id = Column(BIGINT, primary_key=True, comment='主键')
union_id = Column(String(64), comment='微信开放平台下的用户唯一标识')
open_id = Column(String(64), comment='微信openid')
nick_name = Column(String(32), index=True, comment='昵称')
password = Column(String(64), comment='密码')
avatar = Column(String(255),nullable=False, index=True, server_default=text("''"), comment='头像')
phone = Column(String(11), index=True, comment='手机号')
email = Column(String(50), comment='电子邮箱')
last_login = Column(String(20), comment='上次登录时间')
status = Column(TINYINT, server_default=text("'1'"), comment='状态;-1:黑名单 1:正常')
delete_at = Column(String(20), comment='删除时间')
created_at = Column(TIMESTAMP, comment='创建时间')
updated_at = Column(TIMESTAMP, comment='更新时间')
Column常用参数说明:
sqlalchemy 中的 Column 类有很多参数,以下是一些常用的参数:
-
name (str):列的名称。 -
type_ (TypeEngine):列的数据类型,例如String,Integer,DateTime等。 -
primary_key (bool):指定是否为主键列。 -
unique (bool):指定是否唯一。 -
nullable (bool):指定是否可以为空。 -
default:在插入新记录时,如果没有提供该列的值,则将使用默认值。 -
server_default:指定服务器端的默认值。 -
index (bool):指定是否创建索引。 -
autoincrement (bool):指定是否自增。 -
onupdate:在更新时设置的值。 -
server_onupdate:服务器端在更新时设置的值。 -
comment (str):列的注释。
3.3 创建引擎
from sqlalchemy import create_engine
dbHost = 'mysql+pymysql://root:root@127.0.0.1:3306/test'
engine = create_engine(
dbHost,
echo=True, # 是否打印SQL
pool_size=10, # 连接池的大小,指定同时在连接池中保持的数据库连接数,默认:5
max_overflow=20, # 超出连接池大小的连接数,超过这个数量的连接将被丢弃,默认: 5
)
@注意:
create_engine函数在调用时并不会立即与数据库建立真实的连接。相反,它仅是为了创建一个数据库引擎对象,该对象封装了连接到数据库的配置和行为,但直到实际执行数据库操作时才会尝试建立连接。
常见参数说明:
-
echo:True/False,是否打印执行的SQL,默认False; -
pool_size: 连接池的大小,指同时在连接池中保持的数据库连接数,默认为5; -
max_overflow: 溢出连接的最大数量。当连接池达到上限后,新的连接请求将被放置在溢出队列中。如果溢出队列满了,将引发异常,设置值需要>=pool_size; -
pool_recycle: 指定连接在连接池中保持的最长时间(以秒为单位)。当设置为非None时,连接将在此时间后被回收,避免数据库服务器断开空闲连接,默认为-1。
更多参数可查看文档: https://docs.sqlalchemy.org/en/14/core/engines.html
3.4 封装会话
from sqlalchemy.orm import sessionmaker
from contextlib import contextmanager
# 创建会话工厂
Session = sessionmaker(bind=engine)
@contextmanager
def getSession(autoCommitByExit=True):
"""使用上下文管理资源关闭"""
session = Session()
try:
yield session
# 退出时,是否自动提交
if autoCommitByExit:
session.commit()
except Exception as e:
session.rollback()
raise e
finally:
session.close()
3.5 使用示例
import json
from sqlalchemy import create_engine, and_, or_, update
def queryRows():
""" 查询示例 """
with getSession() as session:
query = session.query(YmUser).filter(
or_(
and_(
YmUser.id > 100,
YmUser.id < 200,
YmUser.nick_name.like("%飞%")
),
YmUser.phone.in_(["17408049453", "15795343139", "13189106944"])
)
)
result = query.all()
# 转成json
json_result = json.dumps([user.__dict__ for user in result], default=str)
print("json_result:", json_result)
for row in result:
print("id:{} nick_name:{} phone:{}".format(row.id, row.nick_name, row.phone))
return result
上述代码执行后生成SQL如下:
SELECT ... FROM ym_user
WHERE id > 100 AND id < 200
AND nick_name LIKE '%飞%'
OR phone IN ('17408049453','15795343139','13189106944')
4.新增数据
4.1 新增单条
def addOne():
""" 新增单条数据 """
row = YmUser(
union_id="ui_12344343434",
open_id="op_ksjdhjjkdhdjdhh",
nick_name="娃哈哈",
password="123456",
email="test@163.com",
phone="17600000000",
last_login=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
avatar="http://img-avatar.com/head-abc.jpg"
)
# 这里想获取新增后的id,需要refresh数据,就不能在上下文里提交
with getSession(False) as session:
session.add(row)
session.commit()
session.refresh(row)
print("添加成功,id:{}".format(row.id))
print("row:".format(row.__dict__))
"""
添加成功,id:10104
row: {'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x7fc78824f460>, 'nick_name': '娃哈哈', 'id': 10104, 'avatar': 'http://img-avatar.com/head-abc.jpg', 'email': 'test@163.com', 'status': 1, 'created_at': datetime.datetime(2024, 1, 4, 19, 29, 11), 'password': '123456', 'union_id': 'ui_12344343434', 'open_id': 'op_ksjdhjjkdhdjdhh', 'phone': '17600000000', 'last_login': '2024-01-04 19:29:11', 'delete_at': '', 'updated_at': datetime.datetime(2024, 1, 4, 19, 29, 11)}
"""
4.2 批量添加
def batchAdd():
""" 批量新增数据 """
rows = []
for n in range(3):
row = YmUser(
union_id="ui_12344343434",
open_id="op_ksjdhjjkdhdjdhh",
nick_name="娃哈哈" + str(n),
password="123456",
email="test@163.com",
phone="17600000000",
last_login=datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
avatar="http://img-avatar.com/head-abc.jpg"
)
rows.append(row)
# 这里设置不在上下文中提交,否则报错
with getSession() as session:
session.bulk_save_objects(rows)
5.更新数据
5.1 根据字典更新
def updateDictById(id: int, newVal: dict) -> int:
""" 根据id更新数据(值是字典) """
updateStmt = update(YmUser).where(YmUser.id == id).values(newVal)
with getSession() as session:
result = session.execute(updateStmt)
rowcount = result.rowcount
return rowcount
# 调用
updateVal = updateDictById(10, {
"nick_name": "猿码记",
"email": "猿码记@163.com",
"status": -1,
})
# 生成SQL
"""
UPDATE ym_user SET nick_name='猿码记', email='猿码记@163.com', status=-1 WHERE ym_user.id = 10
"""
5.2 根据模型更新
def updateModelById(id: int):
""" 根据id更新数据(值是model) """
with getSession() as session:
# 先查在更新
exist = session.query(YmUser).filter(YmUser.id == id).first()
if exist.id == 0:
return
exist.nick_name = "呵呵呵呵呵"
exist.email = "112233@qq.com"
# 调用
updateModelById(20)
# 生成SQL
"""
UPDATE ym_user SET nick_name='呵呵呵呵呵', email='112233@qq.com' WHERE ym_user.id = 20
"""
6.查询数据
6.1 常用方法列表
-
query.first(): 返回查询结果的第一条记录,如果没有结果则返回None。 -
query.one(): 返回查询结果的唯一一条记录,如果结果集为空或包含多条记录,则引发sqlalchemy.exc.NoResultFound或sqlalchemy.exc.MultipleResultsFound异常。 -
query.one_or_none(): 返回查询结果的唯一一条记录,如果结果集为空则返回None,如果包含多条记录则引发sqlalchemy.exc.MultipleResultsFound异常。 -
query.scalar(): 返回查询结果的第一列的第一个值,通常用于获取单个聚合函数的结果,如COUNT、SUM等。 -
query.filter(): 添加过滤条件到查询中,可以通过链式调用添加多个条件。 -
query.limit(10): 限制查询结果的数量。 -
query.join(*props, **kwargs): 执行连接操作,可以连接其他表进行复杂的查询。 -
query.outerjoin(*props, **kwargs): 执行外连接操作,返回左表中的所有记录以及右表中匹配的记录。 -
query.distinct(): 去除查询结果中的重复记录。 -
query.count(): 返回查询结果的记录数量,通常与 filter 结合使用以实现条件查询的数量统计。
6.2 常用筛选器运算符
# 等于
query.filter(User.name == '张三')
# 不等于
query.filter(User.name != '张三')
# like
query.filter(User.name.like('%张三%'))
# 不区分大小写like
query.filter(User.email.ilike('%163.com%'))
# in
query.filter(User.name.in_(['张三', '李四', '王麻子']))
# not in
query.filter(~User.name.in_(['张三', '李四', '王麻子']))
# AND查询
from sqlalchemy import and_
query.filter(and_(User.name == '张三', User.phone == '1760000000'))
# OR查询
from sqlalchemy import or_
query.filter(or_(User.name == '张三', User.phone == '1760000000'))
# order by查询 ORDER BY ym_user.id DESC, ym_user.phone DESC
query.order_by(desc(YmUser.id), desc(YmUser.phone))
# group by 查询
query.group_by(YmUser.phone)
6.3 分页查询示例
def queryByPage(page: int, pageSize: int, conditions: dict):
""" 分页查询 """
# 计算起始索引
offset = (page - 1) * pageSize
with getSession() as session:
query = session.query(YmUser)
# 填充查询条件
if len(conditions) > 0:
query = query.filter_by(**conditions)
# 查询总条数
total = query.count()
# 排序分页
query = query.order_by(desc(YmUser.id)).offset(offset).limit(pageSize)
# 查询记录
result = query.all()
return total, result
# 调用
conditions = {
"status": 1,
}
queryByPage(1, 5, conditions)
# 生成SQL
"""
SELECT * FROM ym_user
WHERE ym_user.status = 1 ORDER BY ym_user.id DESC
LIMIT 0, 5
"""
6.4 使用文本SQL
def queryByTextSQL():
""" 使用文本SQL查询 """
with getSession() as session:
# 文本中直接带参数
query = session.query(YmUser).filter(text("id > 100 and id < 500"))
# 文本中,使用params绑定参数
query = query.filter(text("nick_name like :nick_name and last_login > :last_login")).params(
nick_name='%龙%',
last_login='2023-10-01 00:00:00'
)
# 排序
query = query.order_by(text("id desc"))
# 查询记录
result = query.all()
return result
# 调用
queryByTextSQL()
# 生成SQL
"""
SELECT * FROM ym_user
WHERE id > 100 and id < 500
AND nick_name like '%龙%' and last_login > '2023-10-01 00:00:00'
ORDER BY id desc
"""
6.5 连接查询
def queryByJoin():
""" 连接查询"""
with getSession() as session:
# -------方式一: 同时查询多张表 -------
query = session.query(YmUser, YmUserInfo).filter(YmUser.id == YmUserInfo.uid, YmUser.id < 50)
query = query.filter(YmUser.id == YmUserInfo.uid, YmUser.id < 50)
result = query.all()
for user, userInfo in result:
print("user:", user.__dict__)
print("userInfo:", userInfo.__dict__)
# -------方式二: 使用Join函数 -------
queryJoin = session.query(YmUser).join(YmUserInfo, YmUser.id == YmUserInfo.uid)
queryJoin = queryJoin.filter(YmUser.id < 50)
result2 = queryJoin.all()
# -------方式三: 使用outerjoin函数 -------
queryJoin2 = session.query(YmUser).outerjoin(YmUserInfo, YmUser.id == YmUserInfo.uid)
queryJoin2 = queryJoin2.filter(YmUser.id < 50)
result3 = queryJoin2.all()
return result, result2, result3
三种方式生成的SQL分别如下:
-- 方式一
SELECT ym_user.*,ym_user_info.*
FROM ym_user, ym_user_info
WHERE ym_user.id = ym_user_info.uid AND ym_user.id < 50
-- 方式二
SELECT ym_user.*,ym_user_info.*
FROM ym_user INNER JOIN ym_user_info ON ym_user.id = ym_user_info.uid
WHERE ym_user.id < 50
-- 方式三
SELECT ym_user.*,ym_user_info.*
FROM ym_user LEFT OUTER JOIN ym_user_info ON ym_user.id = ym_user_info.uid
WHERE ym_user.id < %(id_1)s
@注意: 只有方式一查询的结果是同时返回两个模型的数据
YmUser、YmUserInfo,其他方式返回的都是模型YmUser,返回几个模型取决于query()中的参数,是几个模型
7.模型工具
这是个懒人神器,它可以自动生成 SQLAlchemy 模型类相关代码,不用我们挨个去写模型,它的实现原理:通过连接到数据库,然后分析数据库结构,最后生成对应的 SQLAlchemy 模型类的代码。
项目开源地址: https://github.com/agronholm/sqlacodegen
@说明: 本来一开始学习的
SQLAlchemy 2.0版本,因为这个工具生成的模型不能完全适配SQLAlchemy 2.0,后来就果断放弃,改用SQLAlchemy 1.4版本
7.1 安装
# 默认安装
$ pip install sqlacodegen
# 也可以指定版本安装,本人体验的是最新版本
$ pip install sqlacodegen==3.0.0rc3
7.2 生成模型
# 生成mysql相关表的模型
$ sqlacodegen mysql+pymysql://root:root@127.0.0.1:3306/test --outfile models.py
7.3 生成结果
from sqlalchemy import Column, Index, String, TIMESTAMP, text
from sqlalchemy.dialects.mysql import BIGINT, TINYINT, VARCHAR
from sqlalchemy.orm import declarative_base
Base = declarative_base()
class YmUser(Base):
__tablename__ = 'ym_user'
__table_args__ = (
Index('idx_nick_name', 'nick_name'),
Index('idx_phone', 'phone'),
{'comment': '用户表'}
)
id = Column(BIGINT, primary_key=True, comment='主键')
union_id = Column(String(64), nullable=False, server_default=text("''"), comment='微信开放平台下的用户唯一标识')
open_id = Column(String(64), nullable=False, server_default=text("''"), comment='微信openid')
nick_name = Column(String(32), nullable=False, server_default=text("''"), comment='昵称')
password = Column(String(64), nullable=False, server_default=text("''"), comment='密码')
avatar = Column(String(255), nullable=False, server_default=text("''"), comment='头像')
phone = Column(String(11), nullable=False, server_default=text("''"), comment='手机号')
email = Column(String(50), nullable=False, server_default=text("''"), comment='电子邮箱')
last_login = Column(String(20), nullable=False, server_default=text("''"), comment='上次登录时间')
status = Column(TINYINT, nullable=False, server_default=text("'1'"), comment='状态;-1:黑名单 1:正常')
delete_at = Column(String(20), nullable=False, server_default=text("''"), comment='删除时间')
created_at = Column(TIMESTAMP, nullable=False, server_default=text('CURRENT_TIMESTAMP'), comment='创建时间')
updated_at = Column(TIMESTAMP, nullable=False, server_default=text('CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP'),
comment='更新时间')
本文由 mdnice 多平台发布
相关文章:
Python库学习(十四):ORM框架-SQLAlchemy
1.介绍 SQLAlchemy 是一个用于 Python 的 SQL 工具和对象关系映射(ORM)库。它允许开发者通过 Python 代码而不是 SQL查询语言来操作数据库。SQLAlchemy 提供了一种灵活且强大的方式来与关系型数据库交互,支持多种数据库后端,如 P…...

信息学奥赛一本通1014:与圆相关的计算
1014:与圆相关的计算 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 167892 通过数: 85008 【题目描述】 给出圆的半径,求圆的直径、周长和面积。输入圆的半径实数r,输出圆的直径、周长、面积,每个数保留小数点后4…...
Vscode——通过SSH连接服务器
1、打开vscode —— 点击左下角 2、选择SSH 3、点击后会自动安装三个插件 4、点击左下角——连接服务器 5、再次点击左下角——连接服务器 6、登录成功后打开终端即可操作 快捷键:ctrl ~ 7、查看编辑服务器文件目录 点击文件——打开文件夹 8、确定后再次输入登录密…...

UE5 通过接口实现角色描边效果
接口不能够被实例化,不能够在内部书写函数的逻辑和设置属性,只能够被继承使用。它能够让不同的类实现有相同的函数,继承接口的类必须实现接口的函数。 并且,我们可以在不同的类里面的函数实现也不同,比如A类描边是红色…...

电脑提示dll丢失怎么办,教你一招将dll修复
使用电脑时,你的电脑是否出现关于dll文件丢失或找不到的问题,出现这种问题又该如何解决呢,dll文件问题会导致软件无法打开,或者会导致系统崩溃。今天就来教大家如何快速解决dll文件修复。 一.如何修复dll修复 方法一:…...

MATLAB mat 文件
1.mat文件格式 MATLAB(Matrix Laboratory)使用 .mat 文件格式来存储和加载数据。MAT 文件是一种二进制文件格式,能够保存 MATLAB 中的各种数据类型,包括矩阵、向量、结构体、元胞数组等。 特定和用途: 二进制格式&a…...
Linux du和df命令
目录 一. df二. du 一. df ⏹用于显示系统级别,磁盘分区上的可用和已用空间的信息 -h:以人类可读的格式显示文件系统大小 ⏹每秒钟监视当前磁盘的使用情况 watch 用于周期性的执行特定的命令-n 1 表示每一秒刷新一次命令执行的结果df -h ./ 表示周期性…...

Adobe Photoshop 快捷键
PS快捷键 图层 选择图层 Ctrl T:可以对图层的大小和位置进行调整 填充图层 MAC: AltBackspace (前景) or CtrlBackspace (背景) WINDOWS: AltDelete (前景) or CtrlDelete (背景) 快速将图层填充为前景色或背景色 平面化图层(盖印图层)…...
缓存代理服务器
1 缓存代理 1.1 缓存代理的概述 web代理的作用 缓存网页对象,减少重复请求 存储一些之前被访问的或且可能将要备再次访问的静态网页资源对象,使用户可以直接从缓存代理服务器获取资源,从而减少上游原始服务器的负载压力,加快整…...

四道面试题
一.网络的七层模型 网络的七层模型,也被称为OSI七层协议模型,是一种用于理解和描述网络通信过程的概念模型。这个模型将网络通信过程划分为七个层次,从低到高分别是:物理层、数据链路层、网络层、传输层、会话层、表示层和应用层…...

BRC20 技术分析
文章目录 什么是 BRC20 ?brc20 白皮书。重点基于链上数据解析获取交易详情返回值如何将 16 进制转换为 字符串没有节点,如何获取数据?见证隔离如何解析出 BRC20 数据?最后如何快速搭建节点BRC20 Indexer...
【Unity】Timer计时器属性及使用
可以代替协程完成延时操作 可以不用Update进行计时 GitHub开源计时插件 网址:https://github.com/akbiggs/UnityTimer/tree/master 导入:URL:https://github.com/akbiggs/UnityTimer.git 基本功能: 创建计时器: Time…...

Salesforce lightning优势介绍
今天我要给大家说说,Salesforce的两个版本:第一代Classic UI,和13年以来为迎接移动化趋势而推出的新Lightning UI。Classic马上就要和我们说88了,那Lightning究竟有哪些大杀器让我们无法抗拒呢?让我们一探究竟吧。 首先…...
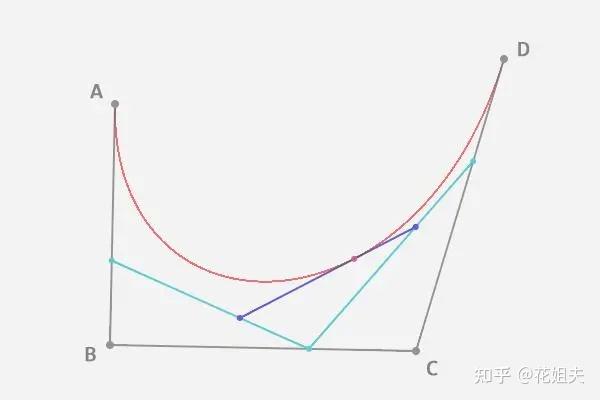
leaflet学习笔记-贝塞尔曲线绘制(八)
前言 两点之间的连线是很常见的,但是都是直直的一条线段,为了使连线更加平滑,我们可以使用曲线进行连线,本功能考虑使用贝塞尔曲线进行连线绘制,最后将线段的两端节点连接,返回一个polygon。 贝塞尔简介 …...

42-单双多路分支,嵌套分支,switch分支,for循环,for in,while,do while,break,continue
js流程控制,代码的执行机制:顺序控制,分支控制,循环控制 1.顺序控制:就是按照代码的书写顺序,自上而下执行 2.分支控制 2.1单路分支 // 单路分支// if(条件表达式){// 执行代码// }// 如果条件表达式满…...

CNCF之CoreDNS
目前我们学习云原生技术,就不得不去了解CNCF,即Cloud Native Computing Foundation,云原生计算基金会,它的宣言或理念是: The Cloud Native Computing Foundation (CNCF) hosts critical components of the global tec…...
MySQL一主一从读写分离
MySQL主从复制 一、主从复制概念 主从复制是指将主数据库的DDL和DML操作通过二进制日志传到从服务器中,然后在从服务器上对这些日志重新执行也叫重做,从而使得从数据库和主库的数据保持同步。 MySQL支持一台主库同时向多台从库进行赋值,从…...

【学术会议】第三届神经计算青年研讨会 学习笔记
第三届神经计算青年研讨会 学习笔记 会议时间:2024-1-6至2024-1-7 会议地点:电子科技大学 会议介绍: 为提升我国神经计算⻘年研究队伍的学术⽔平和国际影响⼒,研讨会主题涵盖:神经系统建模与模拟、脑机接⼝与类脑智能、…...

[C#]使用winform部署PP-MattingV2人像分割onnx模型
【官方框架地址】 https://github.com/PaddlePaddle/PaddleSeg 【算法介绍】 PP-MattingV2是一种先进的图像和视频抠图算法,由百度公司基于PaddlePaddle深度学习框架开发。它旨在提供更精准和高效的图像分割功能,特别是在处理图像中的细微部分…...
回顾2023,立2024flag
文章目录 回顾2023与CSDN相识专栏整理数据回顾 立2024flag 回顾2023 在过去的一年里,前端技术不断演进和创新。新技术、新框架层出不穷,给前端工程师提供了更多选择和挑战。2023年已经成为过去,回首这一年,我们也经历了许多挑战和…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...