【昕宝爸爸小模块】HashMap用在并发场景存在的问题

HashMap用在并发场景存在的问题
- 一、✅典型解析
- 1.1 ✅JDK 1.8中
- 1.2 ✅JDK 1.7中
- 1.3 ✅如何避免这些问题
- 二、 ✅HashMap并发场景详解
- 2.1 ✅扩容过程
- 2.2 ✅ 并发现象
- 三、✅拓展知识仓
- 3.1 ✅1.7为什么要将rehash的节点作为新链表的根节点
- 3.2 ✅1.8是如何解决这个问题的
- 3.3 ✅除了并发死循环,HashMap在并发环境还有啥问题
这是一个非常典型的问题,但是只会出现在1.7及以前的版本,1.8之后就被修复了。
一、✅典型解析
1.1 ✅JDK 1.8中
虽然JDK 1.8修复了某些多线程对HashMap进行操作的问题,但在并发场景下,HashMap仍然存在一些问题。
如:虽然JDK 1.8修复了多线程同时对HashMap扩容时可能引起的链表死循环问题,但在JDK 1.8版本中多线程操作HashMap时仍然可能引起死循环,只是原因与JDK 1.7不同。此外,还存在数据丢失和容量不准确等问题。
在并发场景下,HashMap主要存在以下问题:
1. 死循环问题:在JDK 1.8中,引入了红黑树优化数组链表,同时改成了尾插,按理来说是不会有环了,但是还是会出现死循环的问题,在链表转换成红黑数的时候无法跳出等多个地方都会出现这个问题。
2. 数据丢失问题:在并发环境下,如果一个线程在获取头结点和hash桶时被挂起,而这个hash桶在它重新执行前已经被其他线程更改过,那么该线程会持有一个过期的桶和头结点,并且会覆盖之前其他线程的记录,从而造成数据丢失。
3. 容量不准问题:在多线程环境下,HashMap的容量可能不准确。这是因为在进行resize(调整table大小)的过程中,如果多个线程同时进行操作,可能会导致数组链表中的链表形成循环链表,使得get操作时e = e.next操作无限循环,从而无法准确计算出HashMap的容量。
在并发场景下使用HashMap需要注意其存在的问题,并采取相应的措施进行优化和改进。
1.2 ✅JDK 1.7中
在JDK 1.7中,HashMap在并发场景下存在问题。
首先,如果在并发环境中使用HashMap保存数据,有可能会产生死循环的问题,造成CPU的使用率飙升。这是因为HashMap中的扩容问题。当HashMap中保存的值超过阈值时,将会进行一次扩容操作。在并发环境下,如果一个线程发现HashMap容量不够需要扩容,而在这个过程中,另外一个线程也刚好进行扩容操作,就有可能造成死循环的问题。
其次,HashMap在JDK 1.7中并不是线程安全的,因此在多线程环境下使用HashMap需要额外的同步措施来保证并发安全性。否则,可能会导致数据不一致或者出现其他并发问题。
因此,在JDK 1.7中,HashMap在并发场景下也存在一些问题需要注意和解决。
1.3 ✅如何避免这些问题
为了避免在并发场景下使用HashMap时出现的问题,可以下几种方法:
- 使用线程安全的HashMap实现:Java提供了线程安全的HashMap实现,如ConcurrentHashMap。ConcurrentHashMap采用了分段锁的机制,可以保证在多线程环境下对HashMap的读写操作都是安全的。
- 手动同步:如果必须使用HashMap,可以在访问HashMap时进行手动同步。使用synchronized关键字将访问HashMap的代码块包装起来,保证同一时间只有一个线程可以访问HashMap,从而避免并发问题。
- 使用Java并发包中的数据结构:Java提供了一些并发包(java.util.concurrent),其中包含了一些线程安全的集合类,如ConcurrentHashMap、CopyOnWriteArrayList等。这些数据结构在内部已经进行了优化,可以保证在多线程环境下的安全性和性能。
避免在并发场景下使用HashMap时出现问题的关键是选择合适的线程安全的实现或手动进行同步操作,以确保数据的一致性和正确性。
看下面的这些Demo,解释了如何避免在并发场景下使用HashMap时出现的问题:
1. 使用线程安全的HashMap实现(ConcurrentHashMap):
import java.util.concurrent.ConcurrentHashMap;public class ConcurrentHashMapExample {public static void main(String[] args) {ConcurrentHashMap<String, String> concurrentHashMap = new ConcurrentHashMap<>();// 添加元素到ConcurrentHashMap中concurrentHashMap.put("key1", "value1");// 获取元素String value = concurrentHashMap.get("key1");System.out.println("Value for key1: " + value);}
}
2. 手动同步(使用synchronized关键字):
import java.util.HashMap;
import java.util.Map;public class SynchronizedHashMapExample {public static void main(String[] args) {Map<String, String> map = new HashMap<>();// 手动同步访问HashMapsynchronized (map) {// 添加元素到HashMap中map.put("key1", "value1");// 获取元素String value = map.get("key1");System.out.println("Value for key1: " + value);}}
}
3. 使用Java并发包中的数据结构(如 ConcurrentHashMap):
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;public class AtomicIntegerExample {public static void main(String[] args) {ConcurrentHashMap<String, AtomicInteger> concurrentHashMap = new ConcurrentHashMap<>();// 添加元素到ConcurrentHashMap中,使用AtomicInteger作为值,保证线程安全concurrentHashMap.put("key1", new AtomicInteger(1));// 获取并自增AtomicInteger的值,保持线程安全int newValue = concurrentHashMap.get("key1").incrementAndGet();System.out.println("New value for key1: " + newValue);}
}
二、 ✅HashMap并发场景详解
2.1 ✅扩容过程
HashMap在扩容的时候,会将元素插入链表头部,即头插法。如下图,原来是 A->B->C ,扩容后会变成 C->B->A 。
看一张图片:

之所以选择使用头插法,是因为JDK的开发者认为,后插入的数据被使用到的概率更高,更容易成为热点数据,而通过头插法把它们放在队列头部,就可以使查询效率更高。
我们再来看一眼源码:
void transfer(Entry[] newTable) {Entry[] src = table;int newCapacity = newTable.length;for (int j = 9; j < src.length; j++) {Entry<K,V> e = src[j];if (e != null) {src[j] = null;do {Entry<K,V> next = e.next;int i = indexFor(e.hash, newCapacity);//节点直接作为新链表的根节点e.next = newTableli];newTable[i] = e;e = next;} while (e != null);}}
}
2.2 ✅ 并发现象
但是,正是由于直接把当前节点作为链表根节点的这种操作,导致了在多线程并发扩容的时候,产生了循环引用的问题。
假如说此时有两个线程进行扩容,thread-1 执行到 Entry<K,> next = e.next; 的时候被hang住,如下图所示:

此时 thread-2 开始执行,当 thread-2 扩容完成后,结果如下:

此时 thread-1 抢占到执行时间,开始执行e.next = newTable[i]; newTable[i] = e; e = next;后,会变成如下样式:

接着,进行下一次循环,继续执行 e.next = newTable[i]; newTable[i] = e; e = next; ,如下图所示:

因为此时 e != null,且 e.next = null,开始执行最后一次循环,结果如下:

可以看到,a和b已经形成环状,当下次get该桶的数据时候,如果get不到,则会一直在a和b直接循环遍历,导致CPU飙升到100%。
三、✅拓展知识仓
3.1 ✅1.7为什么要将rehash的节点作为新链表的根节点
在重新映射的过程中,如果不将 rehash 的节点作为新链表的根节点,而是使用普通的做法,遍历新链表中的每一个节点,然后将rehash的节点放到新链表的尾部,伪代码如下:
void transfer(Entry[] newTable) {for (int j = ; j < src.length; j++) {Entry<K,V> e = src[j];if (e != null) {src[j] = null;do {Entry<K,V> next = e.next;int i = indexFor(e.hash , newCapacity);//如果新桶中没有数值,则直接放进去if (newTable[i] == null) {newTable[i] = e;continue;}// 如果有,则遍历新桶的链表else {Entry<K,V> newTableEle = newTable[i];while(newTableEle != null) {Entry<K,V> newTableNext = newTableEle .next;//如果和新桶中链表中元素相同,则直接替换if(newTableEle.equals(e)) {newTableEle = e;break;}newTableEle = newTableNext ;}// 如果链表遍历完还没有相同的节点,则直接插入if(newTableEle == null) {newTableEle = e;}}} while (e != null);}}
}
通过上面的代码我们可以看到,这种做法不仅需要遍历老桶中的链表,还需要遍历新桶中的链表,时间复杂度是O(n^2),显然是不太符合预期的,所以需要将rehash的节点作为新桶中链表的根节点,这样就不需要二次遍历,时间复杂度就会降低到O(N)
3.2 ✅1.8是如何解决这个问题的
前面提到,之所以会发生这个死循环问题,是因为在JDK 1.8之前的版本中,HashMap是采用头插法进行扩容的,这个问题其实在JDK 1.8中已经被修复了,改用尾插法!JDK 1.8中的 resize 代码如下:
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == nul1) ? : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) {newThr = oldThr << 1; // double threshold}// initial capacity was placed in thresholdelse if (oldThr > 0) {newCap = oldThr;}// zero initial threshold signifies using defaultselse {newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)((TreeNode<K,V>)e).split(this,newTab,j,oldCap);// preserve orderelse {Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next ;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;else loTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
}
3.3 ✅除了并发死循环,HashMap在并发环境还有啥问题
1. 多线程put的时候,size的个数和真正的个数不一样
2. 多线程put的时候,可能会把上一个put的值覆盖掉
3. 和其他不支持并发的集合一样,HashMap也采用了fail-fast操作,当多个线程同时put和get的时候,会抛出并发异常
4. 当既有get操作,又有扩容操作的时候,有可能数据刚好被扩容换了桶,导致get不到数据
相关文章:
【昕宝爸爸小模块】HashMap用在并发场景存在的问题
HashMap用在并发场景存在的问题 一、✅典型解析1.1 ✅JDK 1.8中1.2 ✅JDK 1.7中1.3 ✅如何避免这些问题 二、 ✅HashMap并发场景详解2.1 ✅扩容过程2.2 ✅ 并发现象 三、✅拓展知识仓3.1 ✅1.7为什么要将rehash的节点作为新链表的根节点3.2 ✅1.8是如何解决这个问题的3.3 ✅除了…...

数据库索引
1、什么是索引?为什么要用索引? 1.1、索引的含义 数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询,更新数据库中表的数据。索引的实现通常使用B树和变种的B树(MySQL常用的索引就是B树&…...
开源知识库工具推荐:低成本搭建知识库
在信息爆炸的时代,企业和个体对知识的存储和管理需求日益增强。开源知识库工具因其开源、免费、高效的特性,成为了众多组织和个人的首选。如果你正在寻找一款优秀的开源知识库工具,本文将为你推荐三款性能优异的产品,感兴趣就往下…...

C# Chart控件
// 定义图表区域 this.chart1.ChartAreas.Clear(); ChartArea chartArea1 new ChartArea("C1"); this.chart1.ChartAreas.Add(chartArea1); //定义存储和显示点的容器 this.chart1.Series.Clear(); Series series1 new Series("OK"); //series1.ChartAre…...
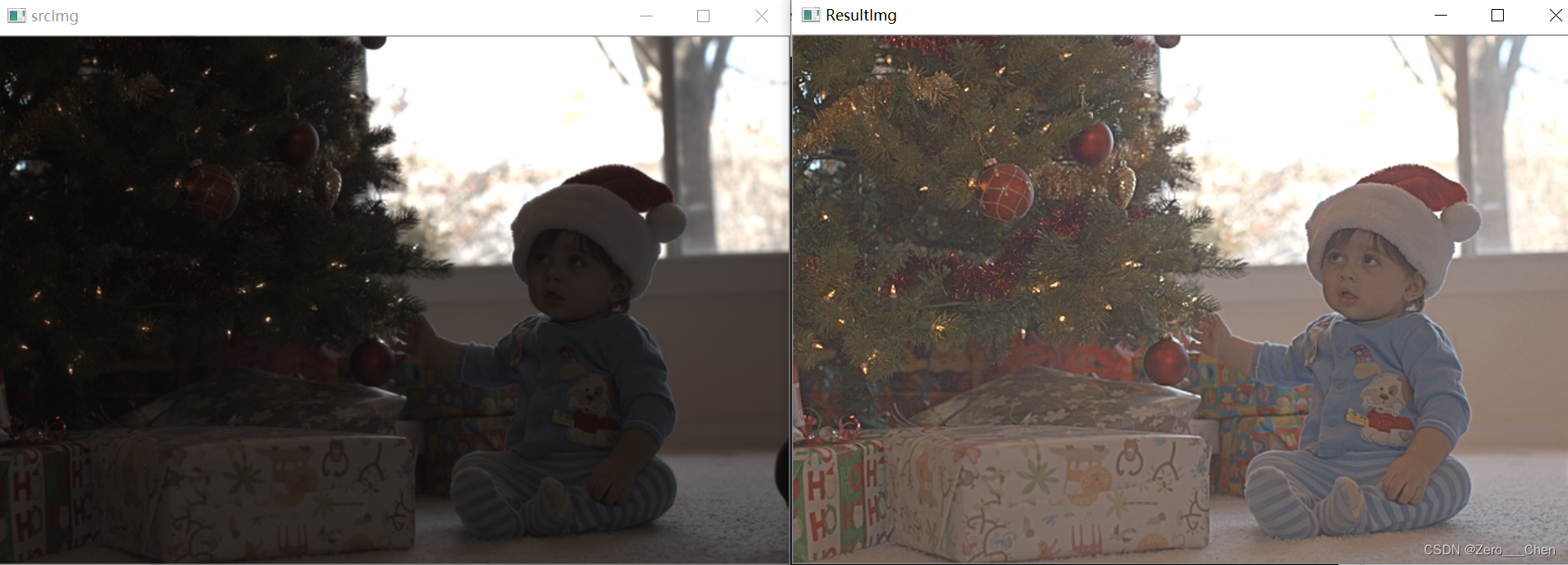
OpenCV C++ 图像处理实战 ——《多尺度自适应Gamma矫正的低照图像增强》
OpenCV C++ 图像处理实战 ——《多尺度自适应Gamma矫正的低照图像增强》 一、结果演示二、多尺度自适应Gamma矫正的低照度图像增强2.1HSI颜色空间2.1.1 功能源码2.2 自适应于直方图分布的 Gamma 矫正2.2.1 功能源码2.3 多尺度 Retinex 分解与明度增强2.3.1 功能源码三、源码测试…...

原型模式
为什么要使用原型模式 不用重新初始化对象,而是动态地获得对象运行时的状态。适用于当创建对象的成本较高时,如需进行复杂的数据库操作或复杂计算才能获得初始数据。 优点是可以隐藏对象创建的细节,减少重复的初始化代码;可以在…...

linux centos 账户管理命令
在CentOS或其他基于Linux的系统上,账户管理涉及到用户的创建、修改、删除以及密码的管理等任务。 linux Centos账户管理命令 1 创建用户: useradd username 这将创建一个新用户,但默认不会创建家目录。如果想要创建家目录,可以…...
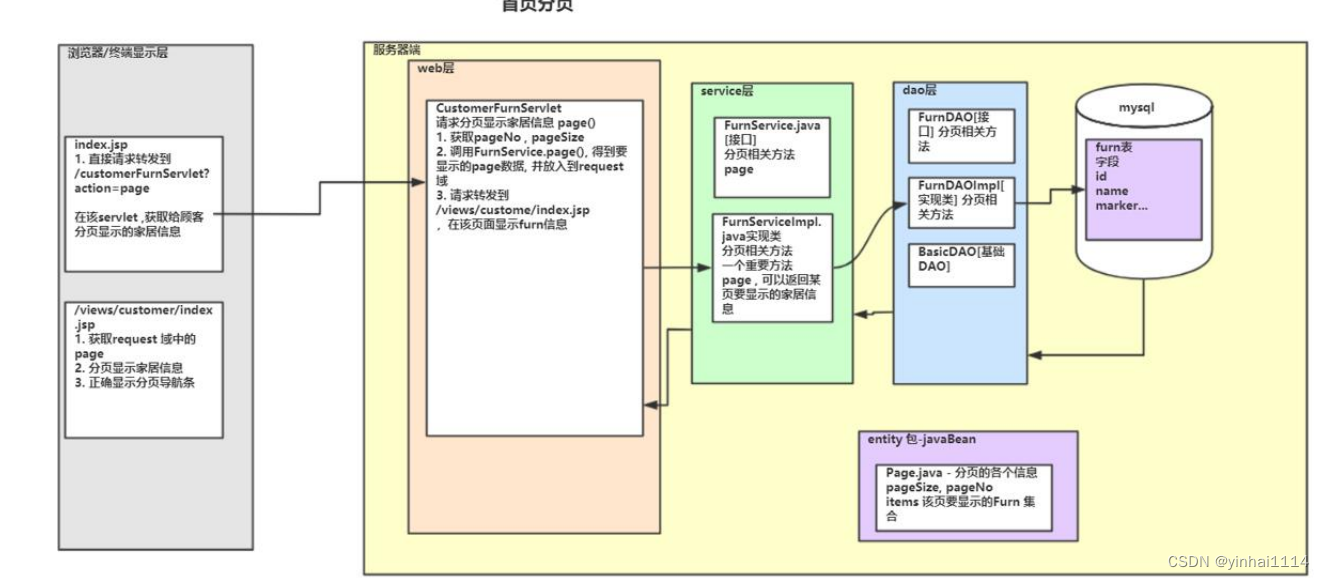
【JavaWeb学习笔记】19 - 网购家居项目开发(上)
一、项目开发流程 程序框架图 项目具体分层方案 MVC 1、说明是MVC MVC全称: Mode模型、View视图、Controller控制器。 MVC最早出现在JavaEE三层中的Web层,它可以有效的指导WEB层的代码如何有效分离,单独工作。 View视图:只负责数据和界面的显示&…...
强化学习的数学原理学习笔记 - RL基础知识
文章目录 Roadmap🟡基础概念贝尔曼方程(Bellman Equation)基本形式矩阵-向量形式迭代求解状态值 vs. 动作值 🟡贝尔曼最优方程(Bellman Optimality Equation,BOE)基本形式迭代求解 本系列文章介…...

winSCP是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?
WinSCP是一款免费的开源SFTP、SCP、FTP和WebDAV客户端,用于Windows操作系统。它提供了一个图形化界面,使用户可以方便地在本地计算机和远程计算机之间传输文件。 WinSCP支持SSH加密通信和多种认证方法,包括密码、公钥和键盘交互。它还支持自…...

SpringBoot的数据层解决方案
🙈作者简介:练习时长两年半的Java up主 🙉个人主页:程序员老茶 🙊 ps:点赞👍是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全栈,…...

极客时间-《如何成为学习高手》文章笔记 + 个人思考
极客时间-《如何成为学习高手》文章笔记 个人思考 底层思维高效学习05|教你全面提升专注力,学习时不再走神06|教你高效复习:巧用学习神器取得好成绩07|我考北大中文系时,15 天背下 10 门专业课的连点成线法…...

【前端】下载文件方法
1.window.open 我最初使用的方法就是这个,只要提供了文件的服务器地址,使用window.open也就是在新窗口打开,这时浏览器会自动执行下载。 2.a标签 其实window.open和a标签是一样的,只是a标签是要用户点击触发,而wind…...
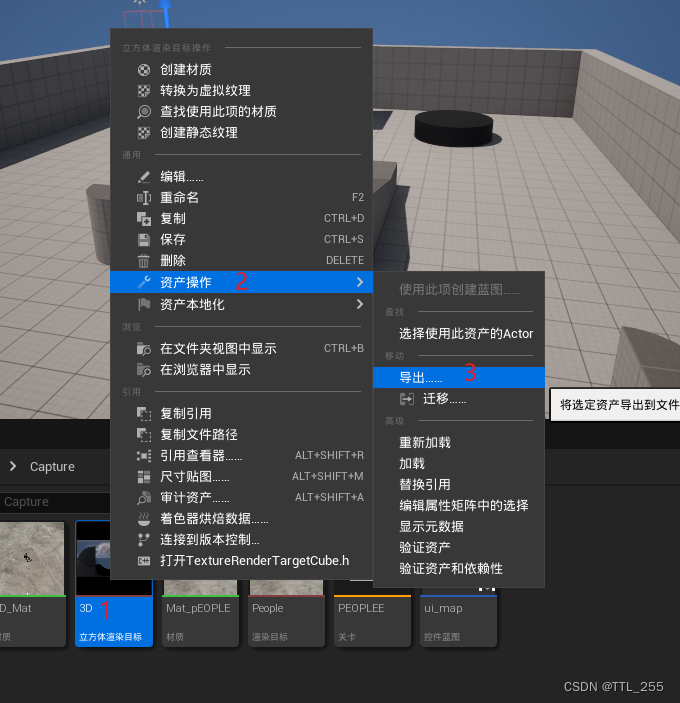
虚幻UE 材质-纹理 1
本篇笔记主要讲两个纹理内的内容:渲染目标和媒体纹理 媒体纹理可以参考之前的笔记:虚幻UE 媒体播放器-视频转成材质-播放视频 所以本篇主要讲两个组件:场景捕获2D、场景捕获立方体 两个纹理:渲染目标、立方体渲染目标 三个功能&am…...

回归预测 | Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变量回归预测
回归预测 | Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变量回归预测 目录 回归预测 | Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变…...

【AWS系列】巧用 G5g 畅游Android流媒体游戏
序言 Amazon EC2 G5g 实例由 AWS Graviton2 处理器提供支持,并配备 NVIDIA T4G Tensor Core GPU,可为 Android 游戏流媒体等图形工作负载提供 Amazon EC2 中最佳的性价比。它们是第一个具有 GPU 加速功能的基于 Arm 的实例。 借助 G5g 实例,游…...
)
GNSS数据及产品下载地址(FTP/HTTP)
GNSS数据/产品下载地址 天线改正文件(atx)下载Index of /pub/station/general 通用广播星历(brdc/brdm):ftp://cddis.gsfc.nasa.gov/pub/gps/data/daily/YYYY/brdcftp://cddis.gsfc.nasa.gov/pub/gps/data/campaign/mgex/daily/rinex3/YYYY/brdmftp://epncb.oma.b…...

【STM32】STM32学习笔记-DMA数据转运+AD多通道(24)
00. 目录 文章目录 00. 目录01. DMA简介02. DMA相关API2.1 DMA_Init2.2 DMA_InitTypeDef2.3 DMA_Cmd2.4 DMA_SetCurrDataCounter2.5 DMA_GetFlagStatus2.6 DMA_ClearFlag 03. DMA数据单通道接线图04. DMA数据单通道示例05. DMA数据多通道接线图06. DMA数据多通道示例一07. DMA数…...
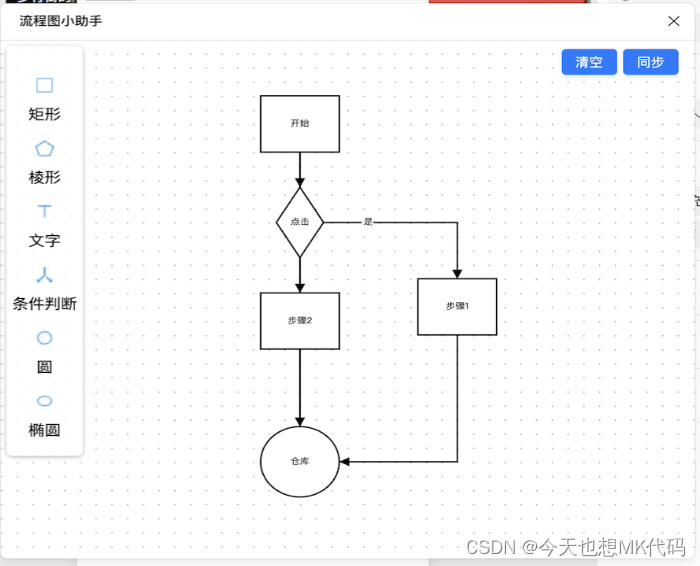
即时设计:设计流程图,让您的设计稿更具条理和逻辑
流程图小助手 更多内容 在设计工作中,流程图是一种重要的工具,它可以帮助设计师清晰地展示设计思路和流程,提升设计的条理性和逻辑性。今天,我们要向您推荐一款强大的设计工具,它可以帮助您轻松为设计稿设计流程图&a…...

单个独立按键控制直流电机开关
/*----------------------------------------------- 内容:对应的电机接口需用杜邦线连接到uln2003电机控制端 使用5V-12V 小功率电机皆可 ------------------------------------------------*/ #include<reg52.h> //包含头文件,一般情况…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...