Spring Data JPA入门到放弃
参考文档:SpringData JPA:一文带你搞懂 - 知乎 (zhihu.com)
一、 前言
1.1 概述
Java持久化技术是Java开发中的重要组成部分,它主要用于将对象数据持久化到数据库中,以及从数据库中查询和恢复对象数据。在Java持久化技术领域,Java Persistence API (JPA) 和 Spring Data JPA 是两个非常流行的框架。本文将对这两个框架进行简要介绍,以帮助您更好地理解它们的作用和使用方法。
1.2 JPA简介
Java Persistence API (JPA) 是一种基于 ORM (Object-Relational Mapping) 技术的 Java EE 规范(JPA是一种规范,而不是具体的框架)。它主要用于将 Java 对象映射到关系型数据库中,以便于对数据进行持久化操作。
JPA 主要由三个部分组成,分别是 Entity、EntityManager 和 Query。其中 Entity 用于描述 Java 对象和数据库表之间的映射关系;EntityManager 用于管理实体对象的生命周期和完成实体对象与数据库之间的操作;Query 用于查询数据。
JPA 支持多种底层实现,如 Hibernate、EclipseLink 等。在使用时,只需要引入相应的实现框架即可。 总结如下:
- JPA(Java Persistence API)是为Java EE平台设计的一种ORM解决方案。
- JPA提供了一些标准的API以及关系映射的元数据,使得Java开发人员可以在没有具体SQL编程经验的情况下,通过简单的注解配置实现对数据的访问和操作。
- JPA提供了对事务的支持,允许Java开发人员进行基于POJO的开发,在运行时将这些POJO映射成关系数据库表和列,最大限度地减少了Java开发者与数据库的交互。
1.3 Spring Data JPA简介
Spring Data JPA 是 Spring 框架下的一个模块,是基于 JPA 规范的上层封装,旨在简化 JPA 的使用。
Spring Data JPA 提供了一些常用的接口,如 JpaRepository、JpaSpecificationExecutor 等,这些接口包含了很多常用的 CRUD 操作方法,可直接继承使用。同时,Spring Data JPA 还提供了基于方法命名规范的查询方式,可以根据方法名自动生成相应的 SQL 语句,并执行查询操作。这种方式可以大大减少编写 SQL 语句的工作量。
除了基础的 CRUD 操作外,Spring Data JPA 还提供了一些高级功能,如分页、排序、动态查询等。同时,它也支持多种数据库,如 MySQL、PostgreSQL、Oracle 等。 总结如下:
- Spring Data JPA 是 Spring Data 项目家族中的一员,它为基于Spring框架应用程序提供了更加便捷和强大的数据操作方式。
- Spring Data JPA 支持多种数据存储技术,包括关系型数据库和非关系型数据库。
- Spring Data JPA 提供了简单、一致且易于使用的API来访问和操作数据存储,其中包括基本的CRUD操作、自定义查询方法、动态查询等功能。
- Spring Data JPA 也支持QueryDSL、Jinq、Kotlin Query等其他查询框架
二,快速开始
2.1 配置环境
- 使用 Spring Data JPA 需要在项目中配置相关依赖项和数据源。
- Spring Data JPA 支持的数据库类型包括 MySQL、PostgreSQL、Oracle、MongoDB 等。
2.2 添加依赖
- 在项目的 pom.xml 文件中添加如下 Spring Data JPA 相关依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId>
</dependency>- 如果使用其他数据库类型,可以替换
mysql-connector-java依赖,并相应地调整数据源配置。
2.3 创建实体类
- 在项目中创建实体类,用于映射数据库表和列。
- 实体类需要使用 @Entity 注解进行标记,并且需要指定主键和自动生成策略,@Table可以指定该实体对应生成数据表的名称
@Entity
@Table(name = "user")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;// ...// 省略 getter 和 setter 方法
}2.4 创建Repository接口
- 在项目中创建 Repository 接口,用于定义数据访问方法。
- Repository 接口需要继承自
JpaRepository接口,并且需要使用@Repositor注解进行标记,例如:
@Repository
public interface UserRepository extends JpaRepository<User, Long> {//自定义方法User findByName(String name);
}- 在示例中,我们定义了一个名为
UserRepository的接口,它继承自JpaRepository接口,泛型参数分别为实体类型和主键类型,并且新增了一个自定义查询方法findByName。 JpaRepository接口包含了基本的增删改查方法,且增和改都是调用save方法(通过已存在id来判断)

2.5 运行示例应用程序
- 编写示例代码并运行应用程序,以验证 Spring Data JPA 的功能和使用方法。
- 示例代码可以是简单的控制台程序,也可以是 Web 应用程序。下面是一个基于 Spring Boot 的 Web 应用程序的示例代码:
@SpringBootApplication
public class Application implements CommandLineRunner {@Autowiredprivate UserRepository userRepository;public static void main(String[] args) {SpringApplication.run(Application.class, args);}@Overridepublic void run(String... args) throws Exception {User user = new User();user.setName("Alice");user.setEmail("alice@example.com");userRepository.save(user);User savedUser = userRepository.findByName("Alice");System.out.println(savedUser);}- 在示例代码中,我们使用
@SpringBootApplication注解标记了应用程序入口类,并且在main方法中启动了应用程序。 CommandLineRunner接口的run方法用于定义初始化逻辑,在示例中我们创建了一个名为Alice的用户,并将其保存到数据库中,随后使用findByName方法查询并输出该用户信息。
三、实体映射
在使用 Spring Data JPA 时,需要定义实体类和数据表之间的映射关系。下面介绍常用的实体映射注解。
3.1 Entity注解
@Entity 注解用于标记实体类,表示该类会被映射到数据库中的一个表。
示例代码:
@Entity
public class User {// 省略属性和方法
}3.2 Table注解
@Table 注解用于标注实体类与数据库表之间的映射关系,并可以指定表的名称、唯一约束等信息。
示例代码:
@Entity
@Table(name = "user")
public class User {// 省略属性和方法
}3.3 Column注解
@Column 注解用于标注实体类属性与数据表字段之间的映射关系,并可以指定字段名称、长度、精度等信息。(指定数据库列的长度和是否为null)
示例代码:
@Entity
@Table(name = "user")
public class User {@Idprivate Long id;@Column(name = "user_name", length = 20, nullable = false)private String userName;// 省略其他属性和方法
}3.4 Id注解
@Id 注解用于标注实体类属性作为主键,通常与 @GeneratedValue 注解一起使用指定主键生成策略。
示例代码:
@Entity
@Table(name = "user")
public class User {@Id@GeneratedValue(strategy = GenerationType.AUTO)private Long id;// 省略其他属性和方法
}3.5 GeneratedValue注解
@GeneratedValue 注解用于指定主键生成策略,通常与 @Id 注解一起使用。
示例代码:
@Entity
@Table(name = "user")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;// 省略其他属性和方法
}3.6 关系映射
关系映射通常包括一对一、一对多和多对多等关系。在 Spring Data JPA 中,可以使用 @OneToOne、@OneToMany 和 @ManyToMany 注解来标注关系映射。这些注解通常与 @JoinColumn 注解一起使用,用于指定关联的外键列。
示例代码:
@Entity
@Table(name = "user")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;//一(用户user)对多 (地址address)@OneToMany(mappedBy = "user", cascade = CascadeType.ALL)private List<Address> addresses;// 省略其他属性和方法
}@Entity
@Table(name = "address")
public class Address {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;//多 (地址address)对一(用户user)@ManyToOne@JoinColumn(name = "user_id")private User user;// 省略其他属性和方法
}在上例中,User 和 Address 之间是一对多的关系,所以在 User 实体类中使用了 @OneToMany 注解,在 Address 实体类中使用了 @ManyToOne 注解。mappedBy 属性用于指定关联的属性名称,这里是 user,表示 Address 实体类中的 user 属性与 User 实体类中的 addresses 属性相对应。cascade 属性表示级联操作,这里使用 CascadeType.ALL 表示在删除 User 实体时同时删除其关联的所有 Address 实体。@JoinColumn 注解用于指定外键名称,这里是 user_id,表示 Address 表中的 user_id 列与 User 表中的主键相对应。
四、Repository接口
Repository 接口是 Spring Data JPA 的核心接口之一,它提供了基本的增删改查方法和自定义查询方法,以及分页和排序等功能。在使用时需要继承 Repository 接口并指定对应的实体类和主键类型。
示例代码:
public interface UserRepository extends Repository<User, Long> {// 省略基本增删改查方法和自定义查询方法
}4.1 各类Repository接口
4.1.1 增删改查方法接口:Repository
在继承 Repository 接口后,会默认提供基本的增删改查方法,无需额外的代码实现即可使用。常用的方法如下:
| 方法名 | 描述 |
|---|---|
| T save(T entity) | 保存实体对象 |
| Iterable saveAll(Iterable entities) | 批量保存实体对象 |
| Optional findById(ID id) | 根据主键获取实体对象 |
| boolean existsById(ID id) | 判断是否存在特定主键的实体对象 |
| Iterable findAll() | 获取所有实体对象 |
| Iterable findAllById(Iterable ids) | 根据主键批量获取实体对象 |
| long count() | 获取实体对象的数量 |
| void deleteById(ID id) | 根据主键删除实体对象 |
| void delete(T entity) | 删除实体对象 |
| void deleteAll(Iterable<? extends T> entities) | 批量删除实体对象 |
示例代码:
public interface UserRepository extends Repository<User, Long> {// 保存用户User save(User user);// 根据主键获取用户Optional<User> findById(Long id);// 获取所有用户Iterable<User> findAll();// 根据主键删除用户void deleteById(Long id);
}4.1.2 分页和基本查询接口:JpaRepository
1,特点:
-
提供了基本的CRUD操作:JpaRepository接口继承自PagingAndSortingRepository和CrudRepository接口,因此提供了基本的CRUD操作,包括保存、更新、删除、查询等。
-
支持分页和排序:JpaRepository接口继承自PagingAndSortingRepository接口,因此支持分页和排序功能,可以方便地进行分页查询和结果排序。
-
自动生成查询方法:JpaRepository接口支持使用方法名来自动生成查询方法,无需手动编写SQL语句,可以根据方法名的规则来自动生成查询方法。
-
提供了一些其他便利方法:JpaRepository接口还提供了一些其他便利方法,如批量操作、统计记录数等。
2,父接口继承结构:

4.1.3 动态查询接口:JpaSpecificationExecutor
1,介绍
JpaSpecificationExecutor接口定义了一些方法,用于执行基于JPA规范的动态查询操作,包括:
-
<T> List<T> findAll(Specification<T> spec):根据给定的Specification对象进行查询,返回符合条件的实体对象列表。
-
<T> List<T> findAll(Specification<T> spec, Sort sort):根据给定的Specification对象进行查询,并按照指定的排序规则返回结果。
-
<T> Page<T> findAll(Specification<T> spec, Pageable pageable):根据给定的Specification对象进行分页查询,返回符合条件的实体对象分页结果。
JpaSpecificationExecutor接口相对于JpaRepository接口提供了更加灵活、动态的查询功能,适用于需要根据不同条件进行动态查询的场景。
2,接口方法:

3,使用示例代码:
//构造排序对象
Sort.Order showOrder = Sort.Order.asc("order");
Sort sort = Sort.by(showOrder);
String param = "something";
//拼接sql
PredicateBuilder<DocumentationCategory> predicateBuilder = Specifications.or();
for (int i = 0; i < parentIds.length; i++) {predicateBuilder = predicateBuilder.like("name", "%" + param + "%");
}
//创建查询条件对象
Specification<DocumentationCategory> specification = predicateBuilder.build();
//执行查询
List<DocumentationCategory> documentationCategoryList = documentationCategoryRepository.findAll(specification, sort);4.2 自定义查询方法
在 Repository 接口中可以定义自定义查询方法,实现按照指定规则查询数据。Spring Data JPA 支持三种方式定义自定义查询方法:方法名称查询、参数设置查询、使用 @Query 注解查询。
4.2.1 示例代码
1,文档表:
@Getter
@Setter
@NoArgsConstructor
@EqualsAndHashCode(callSuper = true)
public class Documentation extends AbstractBaseEntity {/*** 标题*/@Column(name = "title", length = 200, nullable = false)private String title;/*** 单位*/@Column(name = "unit", length = 200)private String unit;/*** 文档类型,DOCUMENTATION_TYPE*/@Column(name = "doc_type", length = 50)private String docType;/*** 年份*/@Column(name = "year", length = 4, nullable = false)private String year;/*** 排序*/@Column(name = "show_order")private Integer showOrder;/*** 是否置顶*/@Column(name = "top_able", columnDefinition = "boolean default false")private Boolean top;/*** 是否上屏*/@Column(name = "show_able", columnDefinition = "boolean default false")private Boolean show;/*** 文档资料目录*/@ManyToOne@JoinColumn(name = "document_category_id", nullable = false)private DocumentationCategory documentCategory;/*** 文号*/@Column(name = "document_number")private String documentNumber;/*** 文档来源*/@ManyToOne(targetEntity = Organization.class)@JoinColumn(name = "document_source_id")//指定document_source_id字段为外键列private Organization organization;
}对应的数据库:
CREATE TABLE `mt_rd_documentation` (`id` bigint(20) NOT NULL,`created_by` bigint(20) DEFAULT NULL,`created_time` datetime NOT NULL,`last_modified_by` bigint(20) DEFAULT NULL,`last_modified_time` datetime NOT NULL,`filter_path` varchar(380) DEFAULT NULL,`doc_type` varchar(50) DEFAULT NULL,`document_number` varchar(255) DEFAULT NULL,`is_html` bit(1) DEFAULT b'0',`show_able` bit(1) DEFAULT b'0',`show_order` int(11) DEFAULT NULL,`title` varchar(200) NOT NULL,`top_able` bit(1) DEFAULT b'0',`unit` varchar(200) DEFAULT NULL,`year` varchar(4) NOT NULL,`content` bigint(20) DEFAULT NULL,`document_category_id` bigint(20) NOT NULL,`document_source_id` bigint(20) DEFAULT NULL, #框架自动根据关系映射成bigint字段保存外键PRIMARY KEY (`id`),KEY `idx_rd_documentation` (`title`),KEY `FKb8ucjiqbadllcx19p889x7iy8` (`document_category_id`),KEY `FKhgiblpnx645pltghu1h5yy943` (`document_source_id`),CONSTRAINT `FKb8ucjiqbadllcx19p889x7iy8` FOREIGN KEY (`document_category_id`) REFERENCES `mt_rd_documentation_category` (`id`),CONSTRAINT `FKhgiblpnx645pltghu1h5yy943` FOREIGN KEY (`document_source_id`) REFERENCES `mt_sys_organization` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2,文件来源表(单位表):
public class Organization extends AbstractTreeEntity<Organization> {@ApiModelProperty(value = "主键,自动增长, 新建时为null",required = true)@ValueCopyIgnore@Id@GeneratedValue(generator = "snowflake")@GenericGenerator(name = "snowflake",strategy = "com.matech.framework.spring.jpa.SnowflakeIdGenerator")private Long id;@Column(name = "name",length = 100,nullable = false)private String name;@Column(name = "short_name",length = 100,nullable = false)private String shortName;@Column(name = "organization_type",nullable = false)@Enumerated(EnumType.STRING)private OrganizationType organizationType;@Column(name = "is_available",nullable = false)private Boolean available = true;@ManyToMany(mappedBy = "organizations",fetch = FetchType.LAZY)@OrderBy("showOrder asc")private Set<Employee> employees = new LinkedHashSet();@Transientprivate Unit unit;@Transientprivate Department department;@Transientprivate Position position;@Column(name = "is_interior",nullable = false)private Boolean interior = true;@ManyToMany(fetch = FetchType.LAZY)@JoinTable(name = "mt_sys_organization_role",joinColumns = {@JoinColumn(name = "organization_id"
)},inverseJoinColumns = {@JoinColumn(name = "role_id"
)})@OrderBy("name asc")private Set<Role> roles = new LinkedHashSet();@Transientprivate String fullName;
}3,Query语句:
下面Query中可以直接根据实体的对象成员的元素进行过滤,框架通过根据@JoinColumn配置的关系,自动进行联表查询,实现简化SQL开发的工作量,使得程序员有更多的余力致力于业务代码的开发(注意:这个不是普通的SQL语句(还需进过jpa框架解析的,所以可以用实体的字段名))
如果某些复杂的业务场景,需要写《原生的SQL语句》这就需要在@Query注解中指定nativeQuery = true 参数,该参数默认为false,表示不使用原生SQL。值得注意的是:采用原生SQL时,不能直接指定返回一个包含子对象成员的对象结果, 因为原生SQL不经过JPA框架处理,返回对象成员时,数据库保存的是该对象在数据库的id,而实体对象成员需要的是一个对象,会导致类型转换错误。但是某些场景可以直接返回,例如:返回对象成员都是基础数据类型等。
@Repository
public interface DocumentationRepository extends JpaRepository<Documentation, Long>, JpaSpecificationExecutor<Documentation> {@Query("select d.organization from Documentation d where d.organization.name = '研发部'")List<Organization> getAllOrg();@Query(value = "select org.id from mt_rd_documentation d inner JOIN" +" mt_sys_organization org on d.document_source_id = org.id where org.name = '研发部'", nativeQuery = true)List<Long> getAllOrg2();
}
4.2.1 方法名称查询
方法名称查询是 Spring Data JPA 中最简单的一种自定义查询方法,并且不需要额外的注解或 XML 配置。它通过方法名来推断出查询的条件,例如以 findBy 开头的方法表示按照某些条件查询,以 deleteBy 开头的方法表示按照某些条件删除数据。
示例代码:
public interface UserRepository extends Repository<User, Long> {// 根据用户名查询用户User findByUserName(String userName);// 根据年龄查询用户列表List<User> findByAge(Integer age);// 根据用户名和密码查询用户User findByUserNameAndPassword(String userName, String password);// 根据主键和用户名删除用户void deleteByIdAndUserName(Long id, String userName);
}4.2.2 查询参数设置
除了方法名称查询外,还可以使用参数设置方式进行自定义查询。它通过在方法上使用 @Query 注解来指定查询语句,然后使用 @Param 注解来指定方法参数与查询语句中的参数对应关系。
示例代码:
public interface UserRepository extends Repository<User, Long> {// 根据用户名查询用户@Query("SELECT u FROM User u WHERE u.userName = :userName")User findByUserName(@Param("userName") String userName);// 根据用户名和密码查询用户@Query("SELECT u FROM User u WHERE u.userName = :userName AND u.password = :password")User findByUserNameAndPassword(@Param("userName") String userName, @Param("password") String password);
}4.2.3 使用@Query注解
在自定义查询方法时,还可以使用 @Query 注解直接指定查询语句。@Query 注解的 value 属性表示查询语句,可以使用占位符 ?1、?2 等表示方法参数。
示例代码:
public interface UserRepository extends Repository<User, Long> {// 根据用户名查询用户@Query(value = "SELECT * FROM user WHERE user_name = ?1", nativeQuery = true)User findByUserName(String userName);// 根据用户名和密码查询用户@Query(value = "SELECT * FROM user WHERE user_name = ?1 AND password = ?2", nativeQuery = true)User findByUserNameAndPassword(String userName, String password);
}4.3 使用 Sort 和 Pageable 进行排序和分页
在查询数据时,经常需要对结果进行排序和分页操作。Spring Data JPA 提供了 Sort 和 Pageable 两个类来实现排序和分页功能。
Sort 类表示排序规则,可以使用 Sort.by() 静态方法创建实例,并指定排序属性和排序方向。常用方法如下:
| 方法名 | 描述 |
|---|---|
| static Sort by(Sort.Order... orders) | 根据排序规则创建 Sort 实例 |
| static Sort.Order by(String property) | 根据属性升序排序 |
| static Sort.Order by(String property, Sort.Direction direction) | 根据属性排序 |
示例代码:
public interface UserRepository extends Repository<User, Long> {// 根据年龄升序查询用户列表List<User> findByOrderByAgeAsc();// 根据年龄降序分页查询用户列表Page<User> findBy(Pageable pageable);
}Pageable 类表示分页信息,可以使用 PageRequest.of() 静态方法创建实例,并指定页码、每页数据量和排序规则。常用方法如下:
| 方法名 | 描述 |
|---|---|
| static PageRequest of(int page, int size, Sort sort) | 创建分页信息实例 |
| static PageRequest of(int page, int size, Sort.Direction direction, String... properties) | 创建分页信息实例 |
示例代码:
public interface UserRepository extends Repository<User, Long> {// 根据年龄降序分页查询用户列表Page<User> findBy(Pageable pageable);
}// 使用
Pageable pageable = PageRequest.of(0, 10, Sort.by("age").descending());
Page<User> page = userRepository.findBy(pageable);
List<User> userList = page.getContent();4.4 使用 @Modifying 注解进行修改
在 Spring Data JPA 中,使用 update 和 delete 语句需要使用 @Modifying 注解标注,并且需要添加 @Transactional 注解开启事务。需要注意的是,@Modifying 注解只支持 DML 语句。
示例代码:
public interface UserRepository extends Repository<User, Long> {// 更新用户密码@Modifying@Transactional@Query("UPDATE User u SET u.password = :password WHERE u.id = :id")void updatePasswordById(@Param("id") Long id, @Param("password") String password);// 删除年龄大于等于 age 的用户@Modifying@Transactional@Query("DELETE FROM User u WHERE u.age >= :age")void deleteByAgeGreaterThanEqual(@Param("age") Integer age);
}五、高级查询
5.1 使用 Specification 进行动态查询
在实际应用中,我们经常需要根据条件动态生成查询语句。Spring Data JPA 提供了 Specification 接口来支持动态查询,它可以通过使用匿名内部类或 Lambda 表达式来实现。
Specification 接口定义了 toPredicate() 方法,该方法接受一个 Root<T> 对象和一个 CriteriaQuery<?> 对象作为参数,并返回一个 Predicate 对象,表示查询条件。
在 toPredicate() 方法内部,可以通过 root.get() 方法获取实体属性,并使用 criteriaBuilder 构建查询条件。 1.例如,以下 Lambda 表达式表示查询 age 大于等于 18 的用户。
public interface UserRepository extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> {List<User> findAll(Specification<User> spec);
}// 使用
Specification<User> spec = (root, query, criteriaBuilder) -> criteriaBuilder.greaterThanOrEqualTo(root.get("age"), 18);
userRepostory.findAll(spec);2.假设我们有一个 User 实体类,该实体包含了 username、age 和 email 等属性。现在我们需要根据传入的参数动态生成查询条件并查询用户列表。
首先,我们需要在 UserRepository 接口中继承 JpaSpecificationExecutor 接口,示例代码如下:
@Repository
public interface UserRepository extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> {}然后,我们可以在 UserService 中定义一个方法来进行动态查询,示例代码如下:
@Service
public class UserServiceImpl implements UserService {@Autowiredprivate UserRepository userRepository;@Overridepublic List<User> findUsersByCondition(String username, String email, Integer age) {return userRepository.findAll((root, query, criteriaBuilder) -> {List<Predicate> list = new ArrayList<>();if (StringUtils.isNotBlank(username)) {list.add(criteriaBuilder.equal(root.get("username"), username));}if (StringUtils.isNotBlank(email)) {list.add(criteriaBuilder.like(root.get("email"), "%" + email + "%"));}if (age != null) {list.add(criteriaBuilder.greaterThanOrEqualTo(root.get("age"), age));}Predicate[] predicates = list.toArray(new Predicate[list.size()]);return criteriaBuilder.and(predicates);});}}在上述代码中,我们首先判断传入的 username、email、age 是否为空,然后通过 Lambda 表达式的方式构造查询条件,并将其作为参数传给 findAll 方法进行查询。在 Lambda 表达式中,我们使用 CriteriaBuilder 来构造查询条件,通过 root.get() 方法获取属性的值,然后使用 equal()、like() 或者其他方法创建 Predicate 对象。最后,我们将所有的 Predicate 组合起来,返回结果。
5.2 使用 QueryDSL 进行复杂查询
QueryDSL 是一种流行的 Java 查询框架,它以编程方式构建类型安全的查询。Spring Data JPA 支持 QueryDSL,可以使用 QueryDSL 提供的 API 构建复杂的查询语句。
使用 QueryDSL 前,需要添加依赖和配置。首先,我们需要在 pom.xml 文件中添加以下依赖:
<dependency><groupId>com.querydsl</groupId><artifactId>querydsl-jpa</artifactId><version>4.4.0</version>
</dependency><dependency><groupId>com.querydsl</groupId><artifactId>querydsl-apt</artifactId><version>4.4.0</version><scope>provided</scope>
</dependency>然后,我们需要添加一个 Q 实体类,该类将用于构建 QueryDSL 查询语句。可使用官方提供的 Maven 插件生成 Q 类代码,示例代码如下:
<build><plugins><plugin><groupId>com.mysema.maven</groupId><artifactId>apt-maven-plugin</artifactId><version>1.3.2</version><executions><execution><goals><goal>process</goal></goals><configuration><outputDirectory>target/generated-sources/java</outputDirectory><processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor></configuration></execution></executions></plugin></plugins>
</build>
@Entity
@Table(name = "user")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;@Column(name = "username")private String username;@Column(name = "age")private Integer age;@Column(name = "email")private String email;// 省略 getter 和 setter 方法
}
@Generated("com.querydsl.codegen.EntitySerializer")
public class QUser extends EntityPathBase<User> {private static final long serialVersionUID = -777444987L;public static final QUser user = new QUser("user");public final NumberPath<Integer> age = createNumber("age", Integer.class);public final StringPath email = createString("email");public final NumberPath<Long> id = createNumber("id", Long.class);public final StringPath username = createString("username");public QUser(String variable) {super(User.class, forVariable(variable));}public QUser(Path<? extends User> path) {super(path.getType(), path.getMetadata());}public QUser(PathMetadata metadata) {super(User.class, metadata);}}现在我们就可以使用 QueryDSL 进行复杂查询了。以下是一个示例代码,用于查询年龄大于等于20岁并且邮箱包含 "example.com" 的用户列表:
@Repository
public interface UserRepository extends JpaRepository<User, Long>, QuerydslPredicateExecutor<User> {}
@Service
public class UserServiceImpl implements UserService {@Autowiredprivate UserRepository userRepository;@Overridepublic List<User> findUsersByCondition(String email, Integer age) {QUser qUser = QUser.user;BooleanBuilder builder = new BooleanBuilder();if (StringUtils.isNotBlank(email)) {builder.and(qUser.email.endsWithIgnoreCase(email));}if (age != null) {builder.and(qUser.age.goe(age));}return (List<User>) userRepository.findAll(builder.getValue());}}在 UserServiceImpl 的 findUsersByCondition 方法中,我们首先创建了一个 QUser 对象,然后使用 BooleanBuilder 对象来构建查询条件,使用 endsWithIgnoreCase() 方法和 goe() 方法来构造查询条件。最后,我们将构建出来的查询条件传递给 findAll 方法进行查询。
5.3 使用 Native SQL 查询
在某些情况下,需要执行原生的 SQL 查询语句。Spring Data JPA 提供了 @Query 注解来支持使用原生 SQL 查询数据。在 @Query 注解中设置 nativeQuery=true 即可执行原生 SQL 语句。
以下示例代码演示了如何使用原生 SQL 查询 age 大于等于 18 的用户。
public interface UserRepository extends JpaRepository<User, Long> {@Query(value = "SELECT * FROM user WHERE age >= ?1", nativeQuery = true)List<User> findByAgeGreaterThanEqual(Integer age);
}// 使用
userRepository.findByAgeGreaterThanEqual(18);相关文章:
Spring Data JPA入门到放弃
参考文档:SpringData JPA:一文带你搞懂 - 知乎 (zhihu.com) 一、 前言 1.1 概述 Java持久化技术是Java开发中的重要组成部分,它主要用于将对象数据持久化到数据库中,以及从数据库中查询和恢复对象数据。在Java持久化技术领域&a…...

MES系统数据采集的几种方式
生产制造执行MES系统具有能够帮助企业实现生产数据收集与分析、生产计划管理、生产过程监控等的功能板块,在这里小编就不一一介绍了,主要讲讲它的数据采集功能板块,可以说,数据采集是该系统进行数据统计与生产管理等后续工作的基础…...

铭文 LaunchPad 平台 Solmash 推出早鸟激励计划
为感谢用户对Solmash的支持,Solmash 特别推出“Solmash早鸟激励计划”,以回馈社区的早期参与者,这是专为已经参与Staking Pool或Honest Pool的用户推出的激励。 Solmash NFT激励 被列入早鸟计划的用户,可通过点击:sol…...

【前端规范】
1 前言 HTML 作为描述网页结构的超文本标记语言,一直有着广泛的应用。本文档的目标是使 HTML 代码风格保持一致,容易被理解和被维护。 2 代码风格 2.1 缩进与换行 [强制] 使用 4 个空格做为一个缩进层级,不允许使用 2 个空格 或 tab 字符…...

12、JVM高频面试题
1、JVM的主要组成部分有哪些 JVM主要分为下面几部分 类加载器:负责将字节码文件加载到内存中 运行时数据区:用于保存java程序运行过程中需要用到的数据和相关信息 执行引擎:字节码文件并不能直接交给底层操作系统去执行,因此需要…...

【Docker】Docker安装入门教程及基本使用
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《Docker实战》。🎯🎯 &…...

语义解析:如何基于SQL去实现自然语言与机器智能连接的桥梁
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:"没有罗马,那就自己创造罗马~" 目录 语义解析 定义 作用 语义解析的应用场景 场景一: 场景二: 总结语…...
Java项目:117SpringBoot动漫论坛网站
博主主页:Java旅途 简介:分享计算机知识、学习路线、系统源码及教程 文末获取源码 117SpringBoot动漫论坛网站 一、项目介绍 动漫论坛网站是由SpringBootMybatis开发的,旅游网站分为前台和后台,前台为用户浏览,后台进…...
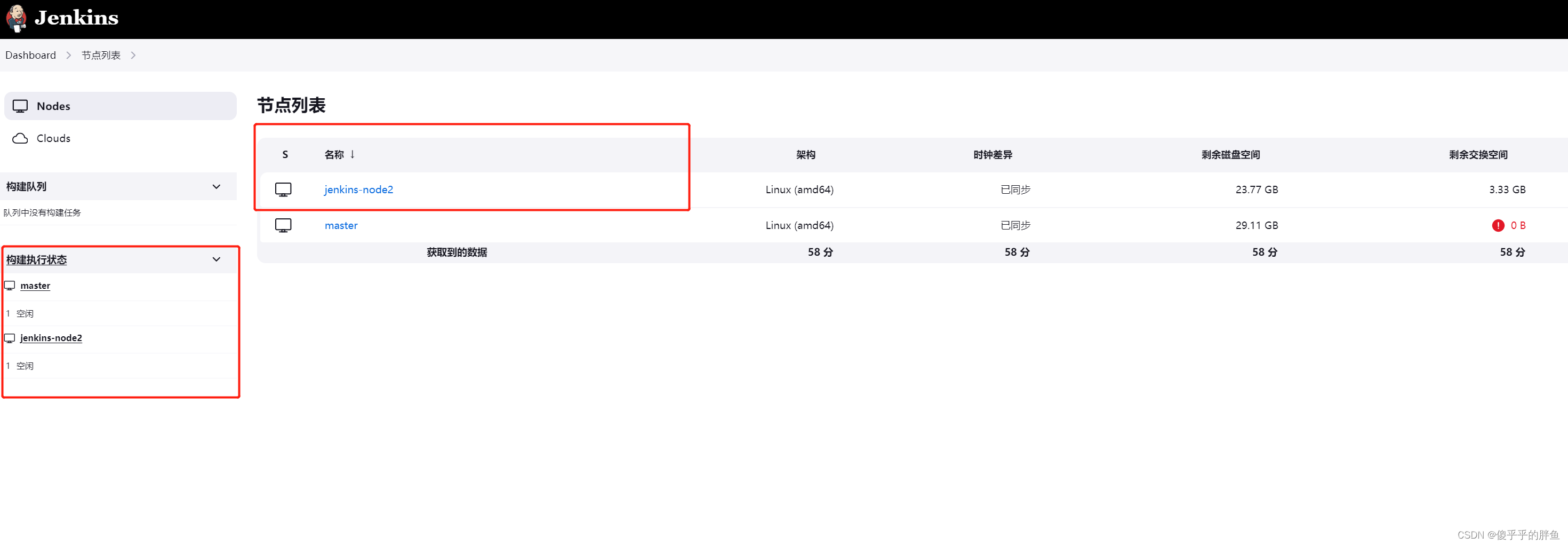
Jenkins基础篇--添加节点
节点介绍 Jenkins 拥有分布式构建(在 Jenkins 的配置中叫做节点),分布式构建能够让同一套代码在不同的环境(如:Windows 和 Linux 系统)中编译、测试等。 Jenkins 运行的主机在逻辑上是 master 节点,下图是主节点和从节点的关系。 添加节点 …...

【C++】手撕 list类(包含迭代器)
目录 1,list的介绍及使用 2,list_node 3,list_node() 3,list 4,list() 5,push_back(const T& x) 6,print() 7,_list_iterator 8,operator*() 9,…...

@Autowired 和 @Resource 的区别是什么?
Java面试题目录 Autowired 和 Resource 的区别是什么? Autowired 是 Spring 提供的注解。默认的注入方式为byType(根据类型进行匹配)。 Resource 是 JDK 提供的注解。默认注入方式为 byName(根据名称进行匹配)。 当一…...

栈和排序.
给你一个1->n的排列和一个栈,入栈顺序给定 你要在不打乱入栈顺序的情况下,对数组进行从大到小排序 当无法完全排序时,请输出字典序最大的出栈序列 输入 第一行一个数n 第二行n个数,表示入栈的顺序,用空格隔开&…...

springboot 多数据源怎么配置在控制台的sql打印日志
程序员的公众号:源1024,获取更多资料,无加密无套路! 最近整理了一波电子书籍资料,包含《Effective Java中文版 第2版》《深入JAVA虚拟机》,《重构改善既有代码设计》,《MySQL高性能-第3版》&…...

【WinForms 窗体】常见的“陷阱”
当涉及到 WinForms 窗体编程时,我们可能会遇到一些常见的问题。在本篇博客中,我将为你提供一些常见问题的解决方案。 跨线程访问控件 在 WinForms 中,当在非UI线程上执行操作并尝试访问 UI 控件时,会引发跨线程访问异常。为了解决…...
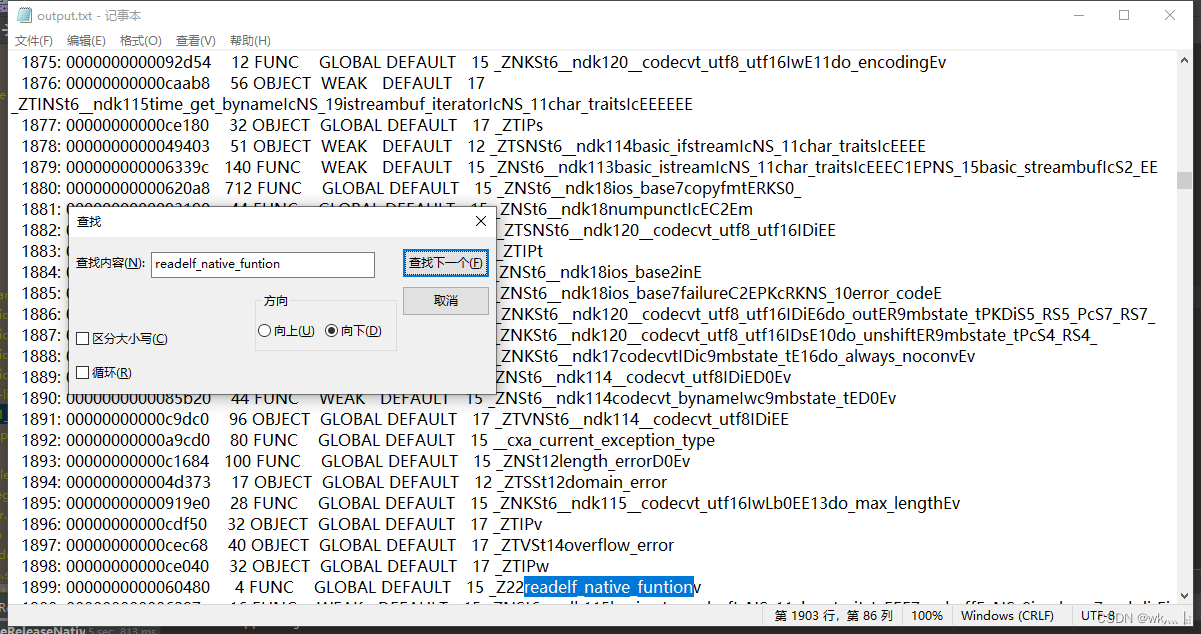
Android readelf 工具查找函数符号
ELF(Executable and Linkable Format)是一种执行文件和可链接文件的格式。它是一种通用的二进制文件格式,用于在各种操作系统中存储可执行程序、共享库和内核模块。 Android 开发当中的 so 库本质上就是一种特殊类型的 ELF 文件,…...

MySQL-索引回顾
索引是面试高频问答题,参考百度/CSDN/尚硅谷/黑马程序员/阿里云开发者社区,决定将索引知识回顾一下,忘记时,点开即可,时刻保持更新,事不宜迟,即刻享用。 索引概述 索引(index&#…...
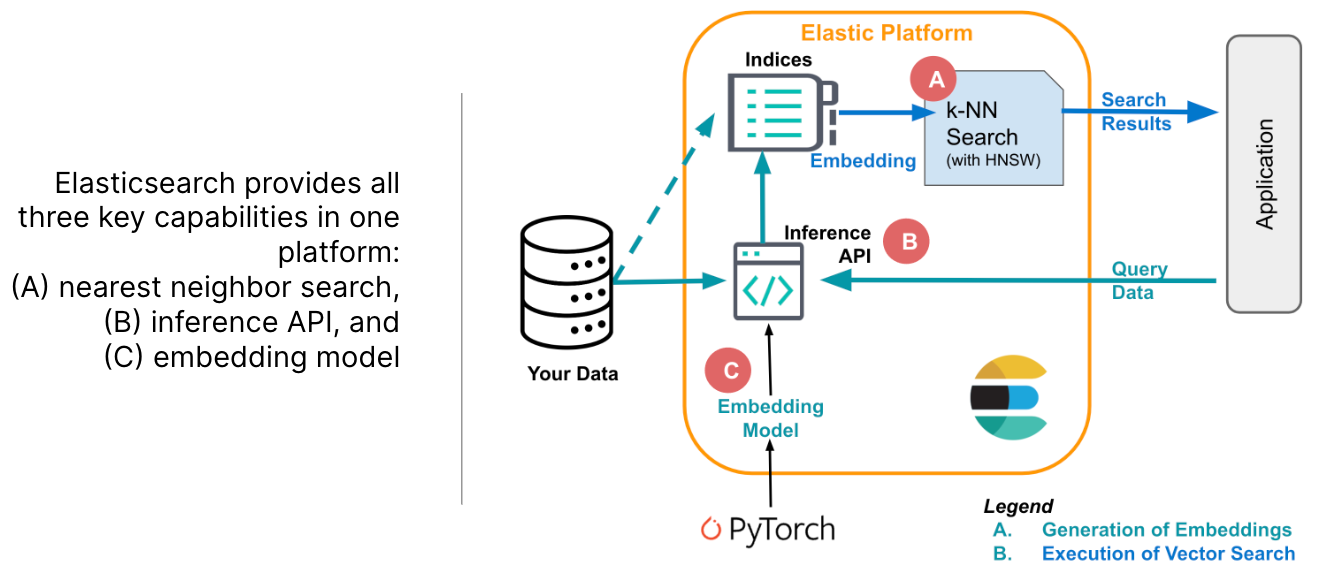
重新认识Elasticsearch-一体化矢量搜索引擎
前言 2023 哪个网络词最热?我投“生成式人工智能”一票。过去一年大家都在拥抱大模型,所有的行业都在做自己的大模型。就像冬日里不来件美拉德色系的服饰就会跟不上时代一样。这不前段时间接入JES,用上好久为碰的RestHighLevelClient包。心血…...
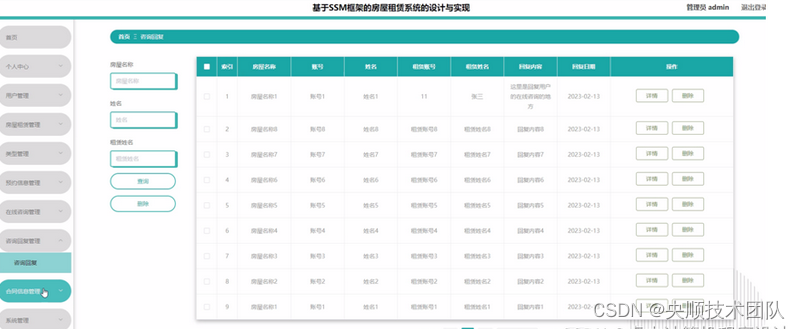
【附源码】基于SSM框架的房屋租赁系统的设计与实现
基于SSM框架的房屋租赁系统的设计与实现 🍅 作者主页 央顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 项目运行 环境配置: Jdk1.8 Tomcat7.0 Mysql HBuilderX&…...

[SpringBoot]如何在一个普通类中获取一个Bean
最近在项目中出现了一个这种情况:我一顿操作猛如虎的写了好几个设计模式,然后在设计模式中的类中想将数据插入数据库,因此调用Mapper持久层,但是数据怎么都写不进去,在我一顿操作猛如虎的查找下,发现在普通…...

[ERROR] 不再支持目标选项 5。请使用 7 或更高版本
在编译spirng boot 3.x版本时,出现了以下错误. 出现这个错误: [ERROR] COMPILATION ERROR : [INFO] -------------------------------------------- [ERROR] 不再支持源选项 5。请使用 7 或更高版本。 [ERROR] 不再支持目标选项 5。请使用 7 或更高版本。 要指定版本: 解决办…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...
AxureRP-Pro-Beta-Setup_114413.exe (6.0.0.2887)
Name:3ddown Serial:FiCGEezgdGoYILo8U/2MFyCWj0jZoJc/sziRRj2/ENvtEq7w1RH97k5MWctqVHA 注册用户名:Axure 序列号:8t3Yk/zu4cX601/seX6wBZgYRVj/lkC2PICCdO4sFKCCLx8mcCnccoylVb40lP...
如何做好一份技术文档?从规划到实践的完整指南
如何做好一份技术文档?从规划到实践的完整指南 🌟 嗨,我是IRpickstars! 🌌 总有一行代码,能点亮万千星辰。 🔍 在技术的宇宙中,我愿做永不停歇的探索者。 ✨ 用代码丈量世界&…...
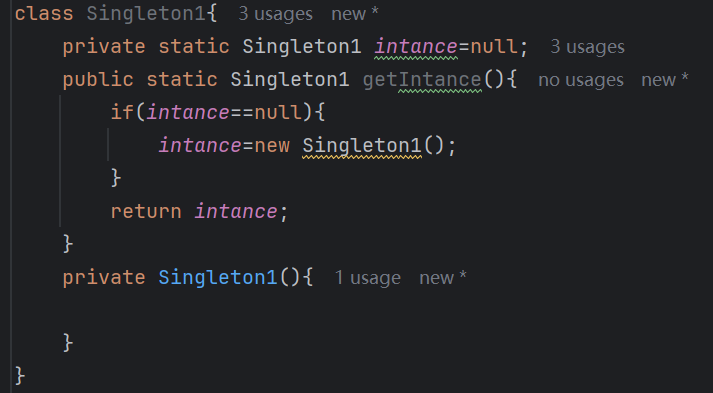
【Java多线程从青铜到王者】单例设计模式(八)
wait和sleep的区别 我们的wait也是提供了一个还有超时时间的版本,sleep也是可以指定时间的,也就是说时间一到就会解除阻塞,继续执行 wait和sleep都能被提前唤醒(虽然时间还没有到也可以提前唤醒),wait能被notify提前唤醒…...

第22节 Node.js JXcore 打包
Node.js是一个开放源代码、跨平台的、用于服务器端和网络应用的运行环境。 JXcore是一个支持多线程的 Node.js 发行版本,基本不需要对你现有的代码做任何改动就可以直接线程安全地以多线程运行。 本文主要介绍JXcore的打包功能。 JXcore 安装 下载JXcore安装包&a…...