【Deep Dive: AI Webinar】开放 ChatGPT - 人工智能开放性运作的案例研究

【深入探讨人工智能】网络研讨系列总共有 17 个视频。我们按照视频内容,大致上分成了 3 个大类:
1. 人工智能的开放、风险与挑战(4 篇)
2. 人工智能的治理(总共 12 篇),其中分成了几个子类:
a. 人工智能的治理框架(3 篇)
b. 人工智能的数据治理(4 篇)
c. 人工智能的许可证(4 篇)
d. 人工智能的法案(1 篇)
3. 炉边对谈-谁在构建开源人工智能?
今天发布的是第一个类别“人工智能的开放、风险与挑战”里的第三个视频:【开放 ChatGPT - 人工智能开放性运作的案例研究】。
我们期盼如此分类,对读者的易读性有帮助,也欢迎读者们的反馈和指正。
--- 开源社.国际接轨组 ---


欢迎来到另一个由开源促进会主办的深入探讨人工智能网络研讨会。我是 Stefano Maffulli 执行董事,我们将从 Andreas Liesenfeld 和 Mark Dingemanse 那里听到开放 ChatGPT:人工智能开放性运作的案例研究。希望你喜欢。最后我们会回答大家的问题。
我是 Andreas Liesenfeld,我将和 Mark Dingemanse 一起展示我们的合作作品。我们在荷兰拉德堡德大学的语言研究中心工作。今天我要讲的是开放 ChatGPT 项目 - 在人工智能中实现开放性的案例研究。这个想法源于我们作为欧洲学者的一个非常实际的担忧,欧洲学术界对开源软件的支持很大。例如,在德国,开源软件将成为公共机构的规范,也是国家数字化战略的基石。在法国,开源已被视为最近开源政策中科学研究的关键组成部分。在荷兰,国家数字化战略推行默认开源原则,敦促公务员尽可能地使用开源软件。
因此,当大型语言模型和文本生成器通过 ChatGPT 的发布而广为人知时,促使欧洲迫切需要确定一种这种类型且足够开放的技术,可以用于科学和教育。开放 ChatGPT 项目的第一个问题是,我们看到 “开源” 大型语言模型层出不穷,但它们到底有多开放?对于需要最大限度地开放和负责任的技术的用例来说,哪一个是正确的选择?在我们最近发表的论文中,我们提出了对指令调优文本生成器开放性的调查结果,发布了一个众包实时跟踪器,试图在这个快速发展的领域即时关注几乎每隔一天就会有新的所谓 ChatGPT 开放式替代品发布。
那么,您如何调查类似 ChatGPT 的文本生成器的开放性呢? 首先要注意的是,在复杂的 AI 系统中,开放性从来不是全有或全无。单是要对开放性做出判断,需要考虑的变化因素太多。我们需要将系统分解成各个部分,分解为最相关的构成要素,并首先将其分为三大领域,代码和数据的可用性,系统的文档化程度以及用户访问的选项。然后在这些区域内,我们进一步将系统分解为其元素。类似 ChatGPT 的文本生成器,至少包含以下 14 个特性。虽然这份不完全清单上的具体项目可能会引起争论或者可能取决于系统的具体配置。
无论如何,这样的列表都应该涵盖文本生成器的所有部分,在此,对开放性的循证判断是可行的。直接跳到结果。如果你拿这 14 个特征逐一检查每个系统,就会得到一张大表。目前这个数据库包含了大约 25 个系统的信息,包括 ChatGPT 本身,与类似的可用系统相比,它的开放性相当低。现在,我要从这个大表格中选取两个例子,然后和你谈谈它们在开放性方面的比较。
它们都声称是开源的,但根据我们基于证据的衡量标准,只有一个系统在我们的排名中名列前茅。第一个是 BLOOM,由法国政府支持的一项倡议。这个项目汇集了来自 100 多个机构的研究人员,历时一年创建一个非常大的语言模型。我们比较的另一个例子是最近也上了头条的模型: Meta 的 Llama2。Meta 自己将其介绍为 “我们的开源大型语言模型” 全球媒体的报道几乎无一例外,都接过了这一资格。正如我们将展示的那样,我们的方法提供了一种对 “免责声明” 的真实性和实用性进行循证判断的方法。以 BLOOM 和 Llama2 为例,介绍了这两个系统中开放性的相关维度。对于 BLOOM,我们特别关注模型的指令调优变体,称为 BLOOM(z)。
对于 Llama2,我们研究了三种类似的指令调优模型,称为 Llama2-7B, 13B, 70B 我们从开放代码开始,即传统意义上的开放源代码,我们问模型和训练流程的源代码是否可用? 可以检查吗? 我们能不能看看引擎盖下面的情况,或者甚至修补一下? 对 BLOOM 来说,情况就是这样。对于 Llama 没有可用的源代码,没有共享代码来重现数据管理、训练、微调或模型评估步骤。因此 Llama2 被标记为红色,表示不开放,BLOOM 被标记为绿色,表示开放。
接下来,我们问预训练数据集,用以训练基础大语言模型的数据集,是文档化和可用的吗?再一次,BLOOM 通过了检测,而 Llama2 没通过,看看语言模型权重。然后我们问训练好的模型是否公开可用? 我们发现 BLOOM 通过了检测,而对于 Llama2,需要一个注册步骤,所以它是黄色的,表示部分开放。然后我们看看系统的强化学习部分,我们询问指令调优步骤中使用的数据集是否有文档记录和可用。我们还询问了指令调优的模型权重是否可取得。所以就这项技术来说,这是最终用户将参与模型训练的最终产品。
然后我们看看这些模型发布时所用的许可证,这是传统的 OSI 领域,所以我们使用现有的 OSI 对开源的定义来区分许可证。Llama 有 Meta 的社区许可证,但其并非 OSI 曾批准过的许可证。BLOOM 有两个相关的许可证。源代码是 Apache 2.0 许可证,它是 OSI 批准过的开源许可证,但该模型本身是在 Responsible AI (RAIL) 许可证下发布的。让我们仔细看看这些许可证,RAIL 许可证对 OSI 来说不算开放,因为它施加了限制,但它是无限的,或者是发布技术的最好和最负责任的方式。
RAIL许可证是开发者认真思考责任和义务的一个有意思的案例。对于这种可能造成实际伤害的技术,谁有责任防止不良用途?所以特定的用例可能会受到限制,例如,不要使用该技术来利用特定群体的漏洞。这样的限制有助于防止有害的应用 BLOOM 和 Llama 在他们的许可证中都涉及了此类有害用例。这种防止伤害的责任具体是如何处理的呢?这里有两段来自许可证的引言:Llama2 规定 - 您不得表示 Llama2 的输出是人为生成的;而 RAIL 声明的限制要严格得多 - 您不得在未明确声明文本为机器生成的情况下生成内容。
因此,这两个组织选择了不同的途径来处理标注模型输出结果的责任。现在回到比较,接下来,我们看看代码文档的水平。这不是关于数据或代码是否可获得的问题,而是关于代码库是否有足够详细的文档。对于 BLOOM,我们有一个完整的代码库,有维护地很好,并且非常深入的文档。相反地,Llama2 只分享了一些最基本的例子。然后我们看看系统架构的文档,这包括从硬件需求、到模型如何训练、微调或评估的信息。
对于 BLOOM,这些都有详细的文档。至于 Llama2,一些内容已在一份公司预印本中披露了概述。说到预印本,开放的另一个重要方面是该系统的公共科学文献的范围。我们问是否有提供该系统科学而全面的文档预印本?我们也查找同行评议的论文,发现它们似乎在这个领域已经过时了。
接下来的两项是关于模型卡和数据表是否可用,这两种方法都是现有的标准化程序,可确保提供有关数据和模型设计的相关信息。最后,我们来看一下终端用户访问方法,并询问软件包是否被编入索引,并通过软件仓库来提供。我们要看是否有最大限度不受限制访问的应用程序接口 (API) 。像这样的详细比较表明,虽然两个系统都声称是开源的,但其实只有一个是开源的。通过深入研究细节,我们可以看到确切的差异。至关重要的是,基于证据的判断,有助于对在开发和发布此类人工智能技术时所采取的谨慎措施给予肯定,但也要戳穿企业的炒作,并指出对 “开源” 等术语的劫持。
在调查了大约 25 个这样的文本生成器后,我们发现在很多情况下,新系统要么从现有系统中继承数据,要么以复杂的方式组合现有数据集,这使得我们很难描述在哪里使用了什么数据集,这可能会导致数据集的许可证和一般使用方面的法律问题。
我们还发现人工合成数据呈上升趋势,这是从其他大型语言模型中获取的数据。目前,我们研究的系统中约有 40% 以某种形式使用合成数据,其法律和实际后果仍不得而知。另一个广受欢迎的做法是透过博客来发布,亦即组织在那里共享有关架构和性能的详细信息,只能通过帖子或预印本,但通常没有足够的细节。
另一方面,同行评议的论文也是非常罕见的,这类技术的一个更普遍的特点是:这些人工智能系统是复杂的、多元的,它们由多步骤训练流程组成,通常以步骤为特征。比如训练一个基础模型,可能是一个微调步骤,也可能是 RLHF 组件,比如在 ChatGPT 类型的系统中。而这些漫长的训练流程构成了使系统尽可能开放的挑战。因此,当涉及到回溯训练步骤或甚至逆向工程这样一个系统时,训练流程的后期步骤可能会阻碍对早期部分的访问。
至关重要的是,真正的开放只有在中间步骤被记录和开放的情况下才有可能。因此,真正的开放性,需要给训练过程中的每一个这样的障碍提供资源,以最大限度地保留逆向工程能力。
总之,我们评估开放性的方法是:首先,在各自的系统中分离出最相关的开放维度,然后在每个维度上提供基于证据的判断,并在公众场合进行这项工作,开放供大家参与审查。任何开放生成式 AI 系统的定义,需要将开放定义为复合的和分级的。没有放之四海而皆准的解决方案,因为需要领域知识来确定开放的相关维度。只有这样,我们相信逆向工程能力的精神才能延续到新一代的技术中。谢谢您的关注!
如有问题或意见,请在 opening-up-chatgpt.io 找到我们的联系方式。


Mark Dingemanse
Associate Professor, Centre for Language Studies, Radboud University

Andreas Liesenfeld
Assistant Professor, Centre for Language Studies, Radboud University
作者丨Andreas Liesenfeld、Mark Dingemanse
翻译 | 李华根
审校 | 刘文涛
视频 | 陈玄
策划 | 李思颖、罗蕊艳
编辑丨王梦玉
相关阅读 | Related Reading
【Deep Dive: AI Webinar】自由与开源软件和人工智能的意识形态:“开放”对于平台和黑盒子系统意味着什么?
【Deep Dive: AI Webinar】预防生成式人工智能的风险
【深入探讨人工智能】网络研讨系列介绍
【探索 AI+开源的未来:Open Source Congress@日内瓦】
开源社简介
开源社(英文名称为“KAIYUANSHE”)成立于 2014 年,是由志愿贡献于开源事业的个人志愿者,依 “贡献、共识、共治” 原则所组成的开源社区。开源社始终维持 “厂商中立、公益、非营利” 的理念,以 “立足中国、贡献全球,推动开源成为新时代的生活方式” 为愿景,以 “开源治理、国际接轨、社区发展、项目孵化” 为使命,旨在共创健康可持续发展的开源生态体系。
开源社积极与支持开源的社区、高校、企业以及政府相关单位紧密合作,同时也是全球开源协议认证组织 - OSI 在中国的首个成员。
自2016年起连续举办中国开源年会(COSCon),持续发布《中国开源年度报告》,联合发起了“中国开源先锋榜”、“中国开源码力榜”等,在海内外产生了广泛的影响力。

相关文章:
【Deep Dive: AI Webinar】开放 ChatGPT - 人工智能开放性运作的案例研究
【深入探讨人工智能】网络研讨系列总共有 17 个视频。我们按照视频内容,大致上分成了 3 个大类: 1. 人工智能的开放、风险与挑战(4 篇) 2. 人工智能的治理(总共 12 篇),其中分成了几个子类&…...
)
Devops相关问题及答案(2024)
1、DevOps 的理念是什么? DevOps是一种组织文化、流程和工具的集合,旨在提高软件交付的速度和质量,通过自动化和持续改进的方法来促进开发(Dev)和运维(Ops)的协作。 DevOps的核心理念包括&…...

掌握Python设计模式,SQL Alchemy打破ORM与模型类的束缚
大家好,反转软件组件之间的依赖关系之所以重要,是因为它有助于降低耦合度和提高模块化程度,进而可以提高软件的可维护性、可扩展性和可测试性。 当组件之间紧密耦合时,对一个组件的更改可能会对其他组件产生意想不到的影响&#…...

性能分析与调优: Linux 磁盘I/O 观测工具
目录 一、实验 1.环境 2.iostat 3.sar 4.pidstat 5.perf 6. biolatency 7. biosnoop 8.iotop、biotop 9.blktrace 10.bpftrace 11.smartctl 二、问题 1.如何查看PSI数据 2.iotop如何安装 3.smartctl如何使用 一、实验 1.环境 (1)主机 …...

Could not erase files or folders:
IDEA删除 git 的 localChanges 内的文件时,提示Could not erase files or folders:。 确认下这个文件是否被打开,忘记关闭了;关闭后可以被删除。(文件被打开的情况下,用操作系统自带的删除,也无法删除成功…...

算法训练营第四十四天|动态规划:完全背包理论基础 518.零钱兑换II 377. 组合总和 Ⅳ
目录 动态规划:完全背包理论基础Leetcode518.零钱兑换IILeetcode377. 组合总和 Ⅳ 动态规划:完全背包理论基础 文章链接:代码随想录 题目链接:卡码网:52. 携带研究材料 思路:完全背包问题,物品可…...

探索计算机网络:应用层的魅力
在当今数字化时代,计算机网络已成为我们生活和工作中不可或缺的一部分。网络的每一层都扮演着独特而重要的角色,而应用层,作为网络模型中用户最直接接触的部分,其重要性不言而喻。这篇文章旨在深入探索应用层的核心概念、功能以及…...
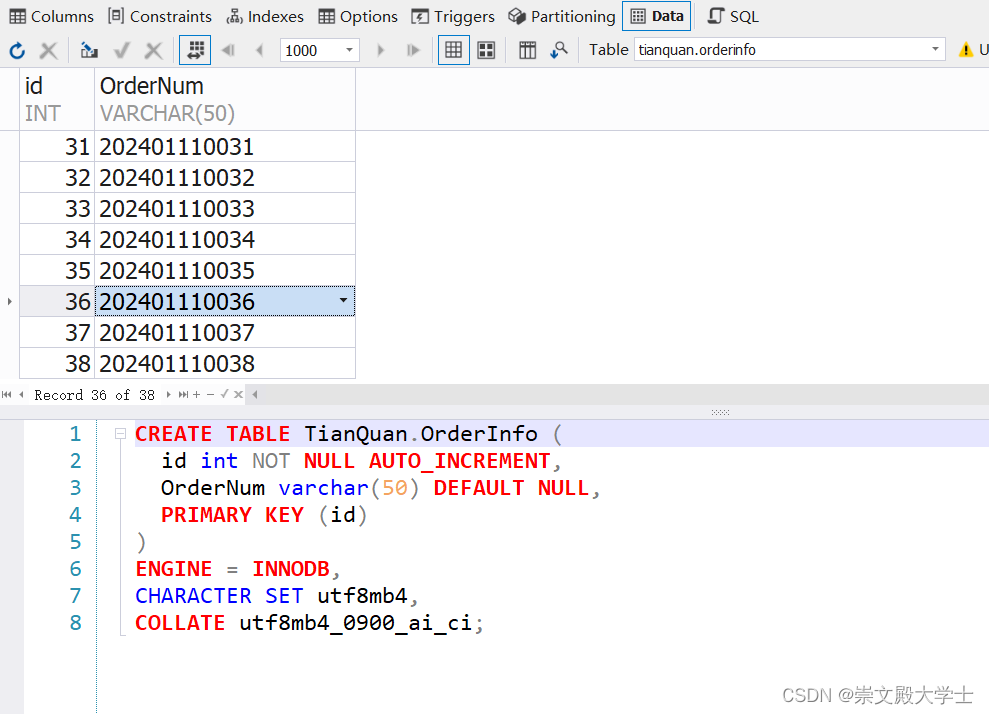
MySQL 按日期流水号 条码 分布式流水号
有这样一个场景,有多台终端,要获取唯一的流水号,流水号格式是 日期0001形式,使用MySQL的存储过程全局锁实现这个需求。 以下是代码示例。 注:所有的终端连接到MySQL服务器获取流水号,如果获取到的是 “-1”…...
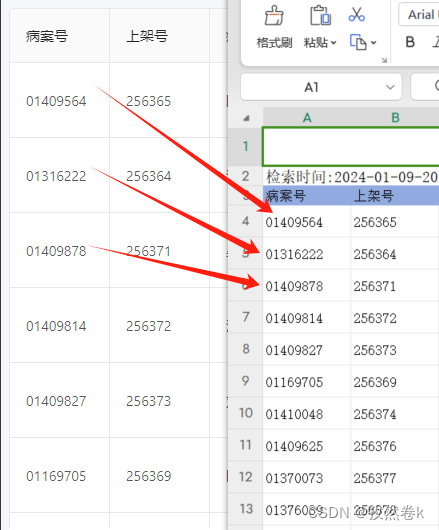
前端导出Excel文件,部分数字前面0消失处理办法
详细导出可以看之前的文章 js实现导出Excel文档_js 通过 接口 导出 xlsx 代码-CSDN博客 今天的问题是导出一些数据时,有些字段是前面带有0的字符串,而导出后再excel中就被识别成了数字 如图本来字符串前面的0 都没了 解决方案 1. 导出的时候在前面加单…...

零基础学Python网络爬虫案例实战 全流程详解 高级进阶篇
零基础学Python网络爬虫案例实战 全流程详解 入门与提高篇 零基础学Python网络爬虫案例实战 全流程详解 高级进阶篇 编辑推荐 本书讲解了Python爬虫技术的高级进阶知识,帮助有一定爬虫基础的读者进一步提高爬虫技术。本书详解了突破反爬机制的常用手段以及Scrapy和…...
(附MATLAB代码实现))
第十二届“中关村青联杯”全国研究生数学建模竞赛-A题:水面舰艇编队防空和信息化战争评估模型(续)(附MATLAB代码实现)
目录 5.3.3 问题三的总结 5.4 问题四的模型建立与求解 5.4.1 问题分析 5.4.2 计算方位角和航向角...

bmp图像文件格式超详解
0 BMP简介 BMP(Bitmap-File)图形文件,又叫位图文件,是Windows采用的图形文件格式,在Windows环境下运行的所有图像处理软件都支持BMP图像文件格式。Windows系统内部各图像绘制操作都是以BMP为基础的。一个BMP文件由四部分组成: B…...

Unity Meta Quest 一体机开发(十三):【手势追踪】自定义交互事件 EventWrapper
文章目录 📕教程说明📕交互事件概述📕自定义交互逻辑⭐方法一:Inspector 面板赋值⭐方法二:纯代码处理 此教程相关的详细教案,文档,思维导图和工程文件会放入 Spatial XR 社区。这是一个高质量…...

13、Redis高频面试题
1、项目中为什么用Redis 我们项目中之所以选择Redis,主要是因为Redis有下面这些优点: 操作速度快:Redis的数据都保存在内存中,相比于其它硬盘类的存储,速度要快很多数据类型丰富:Redis支持 string&#x…...

Koa学习笔记
1、npm 初始化 npm init -y生成 package.json 文件,记录项目的依赖2、git 初始化 git init生成 .git 隐藏文件夹,.git 的本地仓库创建 .gitignore 文件,添加不提交文件的名称3、创建 ReadMe.md 文件 记录项目笔记4、搭建项目 安装 Koa 框架npm install koa5、编写最基本的…...

HiDataPlus 3.3.2-005 搭建(个人的一点心得体会 x86 平台)
HDP 集群搭建 前置安装 yum -y install createrepo yum install -y lrzsz yum install -y wget yum install -y vim修改当前集群机器的主机名 hostnamectl set-hostname XXX 这里的 XXX 就是要设置的当前机器的主机名称。主机名称是集群唯一的,一定不要重复&am…...

【PHP】PHP实现与硬件串口交互,接收硬件发送的实时数据
一、前言 目的:借助虚拟串口软件(VSPD)模拟硬件串口发送数据,使用PHP语言实现接收硬件发送的数据。 我这里的需求是连接天平,把天平的称量数据实时的传送到PHP使用。 使用工具:vspd串口调试工具 使用语…...

HNU-数据库系统-作业
数据库系统-作业 计科210X 甘晴void 202108010XXX 第一章作业 10.09 1.(名词解释)试述数据、数据库、数据库管理系统、数据库系统的概念。 数据,是描述事物的符号记录。 数据库(DB),是长期存储在计算机内、有组织、可共享的大量…...

Python基础知识:整理10 异常相关知识
1 异常的捕获 1.1 基础写法 """基本语法:try:可能发生错误的代码except:如果出现异常,将执行的代码""" try:fr open("D:/abc.txt", "r", encoding"utf-8") except:print("出现异常…...
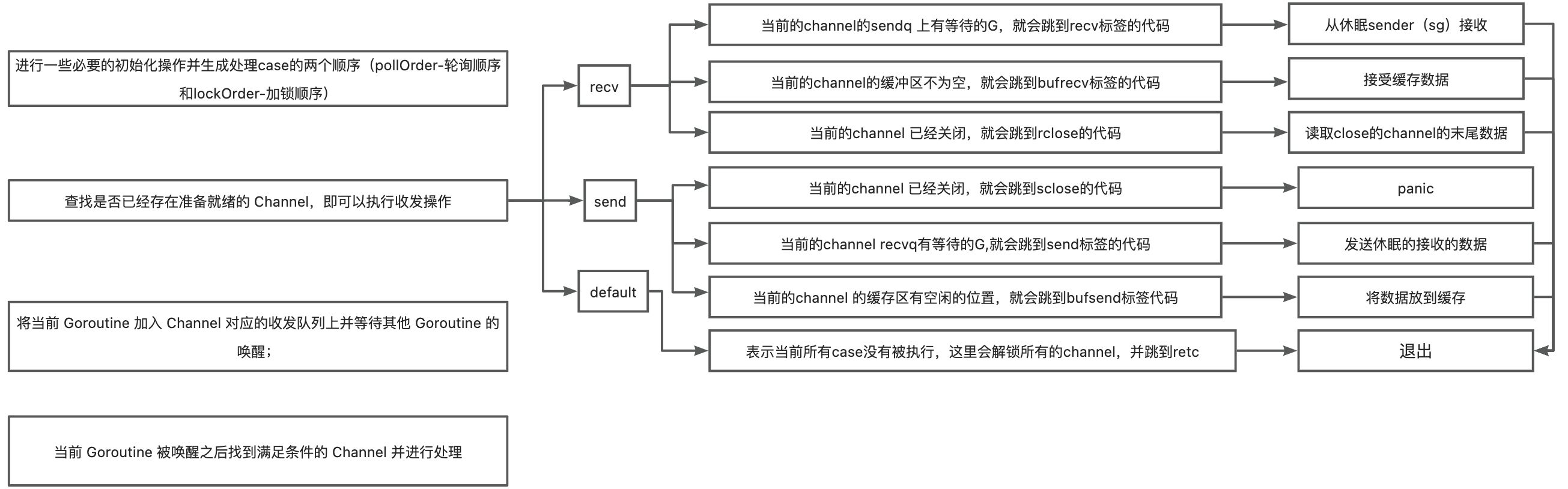
golang并发安全-select
前面说了golang的channel, 今天我们看看golang select 是怎么实现的。 数据结构 type scase struct {c *hchan // chanelem unsafe.Pointer // 数据 } select 非默认的case 中都是处理channel 的 接受和发送,所有scase 结构体中c是用来存储…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...
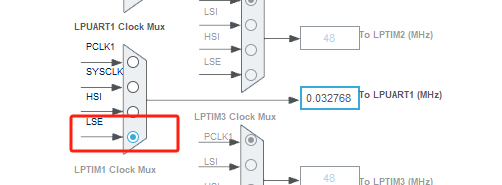
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

WEB3全栈开发——面试专业技能点P7前端与链上集成
一、Next.js技术栈 ✅ 概念介绍 Next.js 是一个基于 React 的 服务端渲染(SSR)与静态网站生成(SSG) 框架,由 Vercel 开发。它简化了构建生产级 React 应用的过程,并内置了很多特性: ✅ 文件系…...