PyTorch 各种池化层函数全览与用法演示
目录
torch.nn.functional子模块Pooling层详解
avg_pool1d
用法与用途
参数
注意事项
示例代码
avg_pool2d
用法与用途
参数
注意事项
示例代码
avg_pool3d
用法与用途
参数
注意事项
示例代码
max_pool1d
用法与用途
参数
注意事项
示例代码
max_pool2d
用法与用途
参数
注意事项
示例代码
max_pool3d
用法与用途
参数
注意事项
示例代码
max_unpool1d
用法与用途
参数
注意事项
示例代码
max_unpool2d
用法与用途
参数
注意事项
示例代码
max_unpool3d
用法与用途
参数
注意事项
示例代码
lp_pool1d
用法与用途
参数
注意事项
示例代码
lp_pool2d
用法与用途
参数
注意事项
示例代码
adaptive_max_pool1d
用法与用途
参数
注意事项
示例代码
adaptive_max_pool2d
用法与用途
参数
注意事项
示例代码
adaptive_max_pool3d
用法与用途
参数
注意事项
示例代码
adaptive_avg_pool1d
用法与用途
参数
注意事项
示例代码
adaptive_avg_pool2d
用法与用途
参数
注意事项
示例代码
adaptive_avg_pool3d
用法与用途
参数
注意事项
示例代码
fractional_max_pool2d
用法与用途
参数
注意事项
示例代码
fractional_max_pool3d
用法与用途
参数
注意事项
示例代码
总结
torch.nn.functional子模块Pooling层详解
avg_pool1d
torch.nn.functional.avg_pool1d 是 PyTorch 库中的一个函数,用于在一维输入信号上应用平均池化。平均池化是一种降低数据维度、提取特征的常用操作,特别适用于信号处理和时间序列数据。
用法与用途
- 用法:
avg_pool1d主要用于减小数据的尺寸,同时保留重要信息。通过在输入数据上滑动一个固定大小的窗口,并计算窗口内的平均值来实现。 - 用途: 在深度学习中,这个操作常用于降低特征图的维度,减少参数数量,从而减少计算量和防止过拟合。
参数
- input: 形状为
(minibatch, in_channels, iW)的输入张量。 - kernel_size: 窗口的大小,可以是单个数字或元组
(kW,)。 - stride: 窗口的步长,可以是单个数字或元组
(sW,)。默认值是kernel_size。 - padding: 输入两侧的隐式零填充数量,可以是单个数字或元组
(padW,)。默认值是 0。 - ceil_mode: 当为
True时,使用ceil而不是floor来计算输出形状。默认值是False。 - count_include_pad: 当为
True时,将零填充包括在平均计算中。默认值是True。
注意事项
- 确保输入数据的维度与函数要求相符。
- 调整
kernel_size和stride可以改变输出数据的大小和特征。 ceil_mode的选择会影响输出的尺寸,可能导致不同的结果。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个一维信号
input = torch.tensor([[[1, 2, 3, 4, 5, 6, 7]]], dtype=torch.float32)# 应用平均池化,窗口大小为3,步长为2
output = F.avg_pool1d(input, kernel_size=3, stride=2)print(output)
这段代码首先创建了一个一维的张量作为输入,然后应用了大小为3、步长为2的平均池化。输出结果将是每个窗口内元素的平均值。
avg_pool2d
torch.nn.functional.avg_pool2d 是 PyTorch 库中的一个函数,用于在二维输入信号上实施平均池化操作。这种操作广泛应用于图像处理和计算机视觉领域,特别是在卷积神经网络中,用于降低特征图的空间维度,同时保留关键信息。
用法与用途
- 用法:
avg_pool2d通过在输入数据上应用一个固定大小的窗口,并计算该窗口内所有元素的平均值,从而实现数据降维和特征提取。 - 用途: 在深度学习中,尤其是卷积神经网络中,
avg_pool2d用于减小特征图的空间尺寸,有助于减少模型参数和计算量,同时帮助防止过拟合。
参数
- input: 形状为
(minibatch, in_channels, iH, iW)的输入张量。 - kernel_size: 池化区域的大小,可以是单个数字或元组
(kH, kW)。 - stride: 池化操作的步长,可以是单个数字或元组
(sH, sW)。默认值是kernel_size。 - padding: 在输入的两侧添加的隐式零填充数量,可以是单个数字或元组
(padH, padW)。默认值是 0。 - ceil_mode: 当设置为
True时,计算输出形状时将使用ceil而非floor方法。默认值是False。 - count_include_pad: 当设置为
True时,平均计算中将包括零填充。默认值是True。 - divisor_override: 如果指定,将用作除数,否则将使用池化区域的大小。默认值是
None。
注意事项
- 确保输入张量的维度与函数要求相匹配。
- 通过调整
kernel_size和stride可以控制输出特征图的大小。 ceil_mode和count_include_pad的设置会影响池化操作的结果。divisor_override参数允许自定义池化过程中的除数,可以用于特殊的池化策略。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个二维信号(例如图像)
input = torch.tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]], dtype=torch.float32)# 应用平均池化,池化区域大小为2x2,步长为2
output = F.avg_pool2d(input, kernel_size=2, stride=2)print(output)
在这个例子中,我们创建了一个二维张量作为输入,然后应用了大小为2x2、步长为2的平均池化。输出结果将是每个池化区域内元素的平均值。
avg_pool3d
torch.nn.functional.avg_pool3d 是 PyTorch 中的一个函数,用于在三维输入信号上执行平均池化操作。这种操作在处理三维数据(如体积图像或视频序列)时非常有用,它可以减小数据的尺寸,同时保留关键信息。
用法与用途
- 用法:
avg_pool3d通过在输入数据上应用一个固定大小的三维窗口,并计算该窗口内所有元素的平均值来实现降维和特征提取。 - 用途: 在处理三维数据(如体积图像、视频序列或时间序列的多个通道)时,
avg_pool3d用于减少数据的空间或时间维度,有助于降低模型的参数数量和计算成本,并帮助防止过拟合。
参数
- input: 形状为
(minibatch, in_channels, iT, iH, iW)的输入张量。 - kernel_size: 池化区域的大小,可以是单个数字或三元组
(kT, kH, kW)。 - stride: 池化操作的步长,可以是单个数字或三元组
(sT, sH, sW)。默认值是kernel_size。 - padding: 在输入的所有方向上添加的隐式零填充数量,可以是单个数字或三元组
(padT, padH, padW)。默认值是 0。 - ceil_mode: 当设置为
True时,计算输出形状时将使用ceil而非floor方法。 - count_include_pad: 当设置为
True时,平均计算中将包括零填充。 - divisor_override: 如果指定,将用作除数,否则将使用池化区域的大小。默认值是
None。
注意事项
- 确保输入数据的维度与函数要求相符。
- 通过调整
kernel_size、stride和padding,可以控制输出数据的大小和特征。 ceil_mode、count_include_pad和divisor_override的设置会影响池化操作的结果。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个三维信号
input = torch.rand(1, 1, 10, 10, 10) # 随机生成的输入张量# 应用平均池化,池化区域大小为2x2x2,步长为2
output = F.avg_pool3d(input, kernel_size=2, stride=2)print(output)
这段代码创建了一个三维的随机张量作为输入,然后应用了大小为2x2x2、步长为2的平均池化。输出结果将是每个池化区域内元素的平均值。这种操作在处理具有时间维度的数据或更高维度的图像数据时特别有用。
max_pool1d
torch.nn.functional.max_pool1d 是 PyTorch 中用于一维输入信号的最大池化操作的函数。最大池化是一种常见的特征提取操作,它在处理时间序列数据或一维信号时非常有用。
用法与用途
- 用法:
max_pool1d通过在输入数据上应用一个固定大小的窗口,并从该窗口内选择最大值,从而实现特征降维和突出重要特征。 - 用途: 在信号处理和一维时间序列数据分析中,最大池化用于减少数据的尺寸,同时保留关键特征,例如在音频处理和自然语言处理中。
参数
- input: 形状为
(minibatch, in_channels, iW)的输入张量。minibatch维度是可选的。 - kernel_size: 滑动窗口的大小。可以是单个数字或元组
(kW,)。 - stride: 滑动窗口的步长。可以是单个数字或元组
(sW,)。默认值是kernel_size。 - padding: 在两边添加的隐含负无穷大的填充。其值必须在
0和kernel_size / 2之间。 - dilation: 滑动窗口内元素的步长。必须大于
0。 - ceil_mode: 如果为
True,将使用ceil而非floor来计算输出形状。这确保了输入张量的每个元素都被滑动窗口覆盖。 - return_indices: 如果为
True,将返回最大值的位置索引。这在以后使用torch.nn.functional.max_unpool1d时非常有用。
注意事项
- 确保输入数据的维度与函数要求相符。
- 适当选择
kernel_size和stride可以影响输出数据的尺寸和特征。 padding、dilation和ceil_mode的设置会影响池化操作的结果。return_indices选项可以用于在后续操作中恢复池化前的数据结构。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个一维信号
input = torch.tensor([[[1, 2, 3, 4, 5, 6, 7]]], dtype=torch.float32)# 应用最大池化,窗口大小为3,步长为2
output = F.max_pool1d(input, kernel_size=3, stride=2)print(output)
这段代码创建了一个一维的张量作为输入,然后应用了大小为3、步长为2的最大池化。输出结果将是每个窗口内的最大值。这种操作在提取时间序列数据的关键特征时特别有效。
max_pool2d
torch.nn.functional.max_pool2d 是 PyTorch 库中的一个函数,用于在二维输入信号上实施最大池化操作。最大池化是一种常用的特征提取操作,尤其在处理图像或二维数据时非常有用。
用法与用途
- 用法:
max_pool2d通过在输入数据上应用一个固定大小的二维窗口,并从该窗口内选择最大值,来实现特征降维和突出重要特征。 - 用途: 在图像处理和计算机视觉领域,最大池化用于减少数据的空间尺寸,同时保留重要特征,例如在卷积神经网络中用于特征图的降维。
参数
- input: 形状为
(minibatch, in_channels, iH, iW)的输入张量。minibatch维度是可选的。 - kernel_size: 池化区域的大小。可以是单个数字或元组
(kH, kW)。 - stride: 池化操作的步长。可以是单个数字或元组
(sH, sW)。默认值是kernel_size。 - padding: 在两边添加的隐含负无穷大的填充。其值必须在
0和kernel_size / 2之间。 - dilation: 滑动窗口内元素的步长。必须大于
0。 - ceil_mode: 如果为
True,将使用ceil而非floor来计算输出形状。这确保了输入张量的每个元素都被滑动窗口覆盖。 - return_indices: 如果为
True,将返回最大值的位置索引。这在以后使用torch.nn.functional.max_unpool2d时非常有用。
注意事项
- 确保输入数据的维度与函数要求相符。
- 适当选择
kernel_size和stride可以影响输出数据的尺寸和特征。 padding、dilation和ceil_mode的设置会影响池化操作的结果。return_indices选项可以用于在后续操作中恢复池化前的数据结构。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个二维信号(例如图像)
input = torch.tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]], dtype=torch.float32)# 应用最大池化,池化区域大小为2x2,步长为2
output = F.max_pool2d(input, kernel_size=2, stride=2)print(output)
这段代码创建了一个二维的张量作为输入,然后应用了大小为2x2、步长为2的最大池化。输出结果将是每个池化区域内的最大值。这种操作在提取图像中的关键特征时特别有效。
max_pool3d
torch.nn.functional.max_pool3d 是 PyTorch 库中的一个函数,用于对三维输入信号进行最大池化操作。这种操作在处理三维数据(如体积图像、视频序列)时非常有用,能够减小数据的尺寸,同时突出重要特征。
用法与用途
- 用法:
max_pool3d通过在输入数据上应用一个固定大小的三维窗口,并从该窗口内选择最大值,来实现特征降维和突出重要特征。 - 用途: 在处理三维数据,如体积图像、三维医学图像或视频序列时,最大池化用于减少数据的空间或时间维度,有助于降低模型的参数数量和计算成本,并帮助防止过拟合。
参数
- input: 形状为
(minibatch, in_channels, iD, iH, iW)的输入张量。minibatch维度是可选的。 - kernel_size: 池化区域的大小。可以是单个数字或元组
(kT, kH, kW)。 - stride: 池化操作的步长。可以是单个数字或元组
(sT, sH, sW)。默认值是kernel_size。 - padding: 在所有方向上添加的隐含负无穷大的填充。其值必须在
0和kernel_size / 2之间。 - dilation: 滑动窗口内元素的步长。必须大于
0。 - ceil_mode: 如果为
True,将使用ceil而非floor来计算输出形状。这确保了输入张量的每个元素都被滑动窗口覆盖。 - return_indices: 如果为
True,将返回最大值的位置索引。这在以后使用torch.nn.functional.max_unpool3d时非常有用。
注意事项
- 确保输入数据的维度与函数要求相符。
- 适当选择
kernel_size和stride可以影响输出数据的尺寸和特征。 padding、dilation和ceil_mode的设置会影响池化操作的结果。return_indices选项可以用于在后续操作中恢复池化前的数据结构。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个三维信号
input = torch.rand(1, 1, 10, 10, 10) # 随机生成的输入张量# 应用最大池化,池化区域大小为2x2x2,步长为2
output = F.max_pool3d(input, kernel_size=2, stride=2)print(output)
这段代码创建了一个三维的随机张量作为输入,然后应用了大小为2x2x2、步长为2的最大池化。输出结果将是每个池化区域内的最大值。这种操作在提取三维数据的关键特征时特别有效。
max_unpool1d
torch.nn.functional.max_unpool1d 是 PyTorch 库中用于计算 MaxPool1d 的部分逆操作的函数。这个函数主要用于将通过 MaxPool1d 操作减小的一维数据重新上采样(即还原)到接近原始尺寸的形状。
用法与用途
- 用法:
max_unpool1d通过使用MaxPool1d操作中保存的最大值的索引(indices),将数据“展开”回更接近原始尺寸的形状。这个过程常用于卷积神经网络(CNN)中的上采样阶段。 - 用途: 在卷积神经网络的可视化、深度学习模型的解码阶段或者在进行精确位置恢复的任务中,这个函数特别有用。
参数
- input: 经过
MaxPool1d操作后的输入张量。 - indices: 在
MaxPool1d操作中得到的最大值索引,用于指导上采样过程。 - kernel_size: 最初池化操作中使用的窗口大小。可以是单个数字或元组。
- stride: 最初池化操作中使用的步长。可以是单个数字或元组。如果未指定,则默认为
kernel_size。 - padding: 最初池化操作中使用的填充量。
- output_size: 期望的输出尺寸。如果未指定,则根据其他参数自动计算。
注意事项
- 确保
input和indices来自相同的MaxPool1d操作。 - 正确设置
kernel_size、stride和padding,以确保上采样结果的正确性。 - 如果指定了
output_size,需要确保它与期望的上采样结果尺寸相匹配。
示例代码
import torch
import torch.nn.functional as F# 示例输入和池化操作
input = torch.tensor([[[1, 2, 3, 4, 5, 6, 7]]], dtype=torch.float32)
input, indices = F.max_pool1d(input, kernel_size=2, stride=2, return_indices=True)# 应用 max_unpool1d 进行上采样
output = F.max_unpool1d(input, indices, kernel_size=2, stride=2)print(output)
在这个例子中,首先应用了 max_pool1d 来对输入数据进行下采样,并保存了最大值的索引。然后,使用 max_unpool1d 以及这些索引来上采样数据,尝试还原到接近其原始尺寸的形状。
max_unpool2d
torch.nn.functional.max_unpool2d 是 PyTorch 中的一个函数,它实现了 MaxPool2d 操作的部分逆过程。这种函数主要用于将经过 MaxPool2d 减小的二维数据重新上采样(即还原)到接近原始尺寸的形状。
用法与用途
- 用法:
max_unpool2d使用MaxPool2d操作时保留的最大值的索引(indices),将数据“展开”回更接近原始尺寸的形状。这个过程常用于卷积神经网络(CNN)中的上采样阶段。 - 用途: 在卷积神经网络的可视化、深度学习模型的解码阶段或者在进行精确位置恢复的任务中,这个函数特别有用。
参数
- input: 经过
MaxPool2d操作后的输入张量。 - indices: 在
MaxPool2d操作中得到的最大值索引,用于指导上采样过程。 - kernel_size: 最初池化操作中使用的窗口大小。可以是单个数字或元组。
- stride: 最初池化操作中使用的步长。可以是单个数字或元组。如果未指定,则默认为
kernel_size。 - padding: 最初池化操作中使用的填充量。
- output_size: 期望的输出尺寸。如果未指定,则根据其他参数自动计算。
注意事项
- 确保
input和indices来自相同的MaxPool2d操作。 - 正确设置
kernel_size、stride和padding,以确保上采样结果的正确性。 - 如果指定了
output_size,需要确保它与期望的上采样结果尺寸相匹配。
示例代码
import torch
import torch.nn.functional as F# 示例输入和池化操作
input = torch.tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]], dtype=torch.float32)
input, indices = F.max_pool2d(input, kernel_size=2, stride=2, return_indices=True)# 应用 max_unpool2d 进行上采样
output = F.max_unpool2d(input, indices, kernel_size=2, stride=2)print(output)
在这个例子中,首先应用了 max_pool2d 来对输入数据进行下采样,并保存了最大值的索引。然后,使用 max_unpool2d 以及这些索引来上采样数据,尝试还原到接近其原始尺寸的形状。
max_unpool3d
torch.nn.functional.max_unpool3d 是 PyTorch 库中的一个函数,用于实现 MaxPool3d 操作的部分逆过程。这个函数主要应用于将经过 MaxPool3d 操作降维的三维数据重新上采样(即还原)到更接近原始尺寸的形状。
用法与用途
- 用法:
max_unpool3d利用在MaxPool3d操作中获得的最大值的索引(indices),将数据“展开”回原来更大的尺寸。这在卷积神经网络(CNN)的上采样阶段特别有用。 - 用途: 在深度学习模型的解码阶段、进行三维数据的重建或精确位置恢复任务中,
max_unpool3d非常有用。例如,在处理三维医学图像或视频数据时,它可以用于还原数据的空间结构。
参数
- input: 经过
MaxPool3d操作后的输入张量。 - indices: 在
MaxPool3d操作中得到的最大值索引,用于指导上采样过程。 - kernel_size: 最初池化操作中使用的窗口大小。可以是单个数字或元组。
- stride: 最初池化操作中使用的步长。可以是单个数字或元组。如果未指定,则默认为
kernel_size。 - padding: 最初池化操作中使用的填充量。
- output_size: 期望的输出尺寸。如果未指定,则根据其他参数自动计算。
注意事项
- 确保
input和indices来自相同的MaxPool3d操作。 - 正确设置
kernel_size、stride和padding,以确保上采样结果的正确性。 - 如果指定了
output_size,需要确保它与期望的上采样结果尺寸相匹配。
示例代码
import torch
import torch.nn.functional as F# 示例输入和池化操作
input = torch.rand(1, 1, 4, 4, 4) # 随机生成的输入张量
input, indices = F.max_pool3d(input, kernel_size=2, stride=2, return_indices=True)# 应用 max_unpool3d 进行上采样
output = F.max_unpool3d(input, indices, kernel_size=2, stride=2)print(output)
在这个例子中,首先应用了 max_pool3d 来对输入数据进行下采样,并保存了最大值的索引。然后,使用 max_unpool3d 以及这些索引来上采样数据,尝试还原到接近其原始尺寸的形状。这对于三维数据的处理尤其有用,例如在医学图像分析或视频处理中。
lp_pool1d
torch.nn.functional.lp_pool1d 是 PyTorch 中的一个函数,用于在一维输入信号上应用 Lp 池化(Lp-pooling)。Lp 池化是一种通用的池化操作,它包括平均池化和最大池化作为特例(分别对应于 L1 和 L∞ 池化)。
用法与用途
- 用法:
lp_pool1d通过计算输入信号中一定区域内的所有元素的 Lp 范数来实现池化。Lp 范数是一种度量向量元素绝对值的方法,其中 p 是一个正实数。 - 用途: Lp 池化在信号处理和一维时间序列数据分析中特别有用,它提供了一种比平均池化和最大池化更灵活的方法来提取特征。
参数
- input: 形状为
(minibatch, in_channels, iW)的输入张量。 - norm_type: Lp 范数的 p 值。常见的选择包括 1(L1 范数,相当于平均池化)和 ∞(L∞ 范数,相当于最大池化)。
- kernel_size: 池化窗口的大小。可以是单个数字。
- stride: 池化操作的步长。可以是单个数字。如果未指定,则默认为
kernel_size。 - ceil_mode: 如果为
True,将使用ceil而非floor来计算输出形状。
注意事项
- 确保
input的尺寸和类型符合预期。 - 选择合适的
norm_type可以根据具体的应用场景调整池化的行为。 - 正确设置
kernel_size和stride可以控制输出的尺寸。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个一维信号
input = torch.tensor([[[1, 2, 3, 4, 5, 6, 7]]], dtype=torch.float32)# 应用 Lp 池化,L2 范数,窗口大小为3,步长为2
output = F.lp_pool1d(input, norm_type=2, kernel_size=3, stride=2)print(output)
在这个例子中,我们应用了 L2 范数的 Lp 池化,其中窗口大小为 3,步长为 2。这种类型的池化有助于在保留重要信号特征的同时降低数据维度。
lp_pool2d
torch.nn.functional.lp_pool2d 是 PyTorch 中的一个函数,用于在二维输入信号上实施 Lp 池化(Lp-pooling)。Lp 池化是一种更通用的池化方法,它包括了平均池化和最大池化作为其特例。
用法与用途
- 用法:
lp_pool2d通过计算输入信号中的每个固定大小区域内所有元素的 Lp 范数来实现池化。这里的 Lp 范数是指向量元素绝对值的 p 次方和的 p 次方根。 - 用途: Lp 池化在图像处理和计算机视觉领域中非常有用,因为它提供了一种比平均池化和最大池化更灵活的方法来提取特征。
参数
- input: 形状为
(minibatch, in_channels, iH, iW)的输入张量。 - norm_type: Lp 范数的 p 值。常见选择包括 1(L1 范数,相当于平均池化)和 ∞(L∞ 范数,相当于最大池化)。
- kernel_size: 池化区域的大小。可以是单个数字或元组
(kH, kW)。 - stride: 池化操作的步长。可以是单个数字或元组
(sH, sW)。如果未指定,则默认为kernel_size。 - ceil_mode: 如果为
True,将使用ceil而非floor来计算输出形状。
注意事项
- 确保输入数据的尺寸和类型符合预期。
- 选择合适的
norm_type可以根据具体应用场景调整池化的行为。 - 正确设置
kernel_size和stride可以控制输出数据的尺寸。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个二维信号(例如图像)
input = torch.tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]], dtype=torch.float32)# 应用 Lp 池化,L2 范数,池化区域大小为2x2
output = F.lp_pool2d(input, norm_type=2, kernel_size=2)print(output)
在这个例子中,我们应用了 L2 范数的 Lp 池化,其中池化区域大小为 2x2。这种类型的池化有助于在保留重要图像特征的同时降低数据维度。
adaptive_max_pool1d
torch.nn.functional.adaptive_max_pool1d 是 PyTorch 中的一个函数,用于在一维输入信号上实施自适应最大池化操作。自适应池化是一种特殊类型的池化,它能够独立于输入尺寸,输出固定大小的特征图。
用法与用途
- 用法:
adaptive_max_pool1d通过调整池化窗口的大小来确保输出特征图具有指定的目标尺寸。这意味着它可以处理各种尺寸的输入,而输出始终保持一致的尺寸。 - 用途: 在处理不同长度的一维信号(如音频片段、时间序列数据)时,自适应最大池化特别有用,因为它允许神经网络在不同长度的输入上运行,而不需要对输入数据进行手动调整。
参数
- input: 形状为
(minibatch, in_channels, iW)的输入张量。 - output_size: 目标输出尺寸,是一个单独的整数。这个值指定了输出特征图的长度。
- return_indices: 是否返回池化过程中最大值的索引。默认值为
False。
注意事项
- 自适应池化不需要指定池化窗口的大小和步长,因为它会根据输入和目标输出尺寸自动确定这些参数。
- 如果设置
return_indices为True,函数将返回最大值的索引,这对于某些特殊应用(如上采样操作)可能很有用。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个一维信号
input = torch.tensor([[[1, 2, 3, 4, 5, 6, 7, 8, 9]]], dtype=torch.float32)# 应用自适应最大池化,目标输出长度为5
output = F.adaptive_max_pool1d(input, output_size=5)print(output)
在这个例子中,输入是一个长度为 9 的一维信号,而目标输出长度被设定为 5。adaptive_max_pool1d 会自动调整池化窗口的大小和步长,使得输出特征图的长度为 5。这对于需要固定尺寸输出的应用场景非常有用。
adaptive_max_pool2d
torch.nn.functional.adaptive_max_pool2d 是 PyTorch 库中的一个函数,用于在二维输入信号上执行自适应最大池化操作。这种池化操作可以适应不同大小的输入,输出固定大小的特征图。
用法与用途
- 用法:
adaptive_max_pool2d通过自动调整池化窗口的大小和步长,从而确保无论输入信号的尺寸如何,输出特征图都具有指定的目标尺寸。 - 用途: 在处理不同尺寸的图像或其他二维数据时,自适应最大池化特别有用。它允许神经网络在不同尺寸的输入上运行,而不需要手动调整输入数据的尺寸。
参数
- input: 形状为
(minibatch, in_channels, iH, iW)的输入张量。 - output_size: 目标输出尺寸。可以是单个整数(生成正方形的输出)或双整数元组
(oH, oW)。 - return_indices: 是否返回池化过程中最大值的索引。默认值为
False。
注意事项
- 自适应池化不需要显式指定池化窗口的大小和步长,因为它根据输入和目标输出尺寸自动确定这些参数。
- 如果设置
return_indices为True,函数将返回最大值的索引,这对于某些特殊应用(如上采样操作)可能很有用。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个二维信号(例如图像)
input = torch.rand(1, 1, 8, 8) # 随机生成一个 8x8 的输入张量# 应用自适应最大池化,目标输出尺寸为 (4, 4)
output = F.adaptive_max_pool2d(input, output_size=(4, 4))print(output)
在这个例子中,输入是一个 8x8 的二维信号,目标输出尺寸被设定为 4x4。adaptive_max_pool2d 会自动调整池化窗口的大小和步长,以确保输出特征图的尺寸为 4x4。这种方法在需要将不同尺寸的输入标准化到相同尺寸输出的场景中非常有用。
adaptive_max_pool3d
torch.nn.functional.adaptive_max_pool3d 是 PyTorch 库中的一个函数,用于在三维输入信号上进行自适应最大池化操作。这种池化技术可以适应不同大小的输入,生成固定大小的输出特征图。
用法与用途
- 用法:
adaptive_max_pool3d自动调整池化窗口的大小和步长,以确保输出特征图符合指定的目标尺寸,独立于输入信号的原始尺寸。 - 用途: 在处理三维数据(如体积图像、视频序列等)时,自适应最大池化尤其有用,因为它允许网络处理不同尺寸的输入数据,同时保证输出特征图的一致性。
参数
- input: 形状为
(minibatch, in_channels, iD, iH, iW)的输入张量。 - output_size: 目标输出尺寸。可以是单个整数(生成立方体形状的输出)或三整数元组
(oD, oH, oW)。 - return_indices: 是否返回池化过程中最大值的索引。默认值为
False。
注意事项
- 自适应池化不需要显式地指定池化窗口的大小和步长,因为这些参数会根据输入和目标输出尺寸自动确定。
- 如果设置
return_indices为True,函数会返回最大值的索引,这在某些特定应用中(例如在后续步骤中进行上采样操作)可能非常有用。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个三维信号
input = torch.rand(1, 1, 8, 8, 8) # 随机生成一个 8x8x8 的输入张量# 应用自适应最大池化,目标输出尺寸为 (4, 4, 4)
output = F.adaptive_max_pool3d(input, output_size=(4, 4, 4))print(output)
在这个例子中,输入是一个 8x8x8 的三维信号,目标输出尺寸被设定为 4x4x4。adaptive_max_pool3d 会自动调整池化窗口的大小和步长,以确保输出特征图的尺寸为 4x4x4。这种方法在需要将不同尺寸的输入标准化为相同尺寸输出的场景中非常有用。
adaptive_avg_pool1d
torch.nn.functional.adaptive_avg_pool1d 是 PyTorch 库中的一个函数,用于对一维输入信号执行自适应平均池化操作。这种池化方法允许输入信号有不同的长度,但可以输出统一大小的特征表示。
用法与用途
- 用法:
adaptive_avg_pool1d通过自动调整池化窗口的大小来生成指定长度的输出,无论输入信号的原始长度如何。 - 用途: 在处理长度不一的一维信号时(如音频片段或时间序列数据),自适应平均池化特别有用。它使得神经网络可以接收不同长度的输入数据,同时生成固定大小的输出。
参数
- input: 形状为
(minibatch, in_channels, iW)的输入张量。 - output_size: 目标输出尺寸。这是一个整数,指定了输出特征表示的长度。
注意事项
- 自适应池化不需要指定池化窗口的具体大小和步长,因为它会根据输入尺寸和输出尺寸自动计算这些值。
- 这种方法非常适用于输入数据长度变化较大的场景,可以帮助标准化输出尺寸,便于后续处理。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个一维信号
input = torch.tensor([[[1, 2, 3, 4, 5, 6, 7, 8, 9]]], dtype=torch.float32)# 应用自适应平均池化,目标输出长度为5
output = F.adaptive_avg_pool1d(input, output_size=5)print(output)
在这个例子中,输入是一个长度为 9 的一维信号,而目标输出长度被设定为 5。adaptive_avg_pool1d 会自动调整池化窗口的大小,以确保输出特征图的长度为 5。这种方法在需要处理不同长度输入数据的应用场景中非常有用。
adaptive_avg_pool2d
torch.nn.functional.adaptive_avg_pool2d 是 PyTorch 库中用于执行二维自适应平均池化操作的函数。这个操作允许对具有不同尺寸的输入图像执行池化操作,同时生成具有固定尺寸的输出。
用法与用途
- 用法:
adaptive_avg_pool2d通过自动调整池化窗口的大小和步长,实现从不同尺寸的输入图像到固定尺寸输出的转换。 - 用途: 在处理尺寸不一的图像数据时,这种方法非常有用,例如在深度学习中处理不同尺寸的输入图像,而不需要预先调整其尺寸。
参数
- input: 形状为
(minibatch, in_channels, iH, iW)的输入张量。 - output_size: 目标输出尺寸。可以是单个整数(生成正方形的输出)或者双整数元组
(oH, oW)。
注意事项
- 当使用单个整数作为
output_size时,输出特征图将是一个正方形,其大小由该整数指定。 - 使用双整数元组时,可以更精确地控制输出特征图的高度和宽度。
- 自适应池化方法不需要手动指定池化窗口的大小和步长,因为它会根据输入和输出尺寸自动计算这些参数。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个二维信号(例如图像)
input = torch.rand(1, 1, 8, 8) # 随机生成一个 8x8 的输入张量# 应用自适应平均池化,目标输出尺寸为 (4, 4)
output = F.adaptive_avg_pool2d(input, output_size=(4, 4))print(output)
在这个例子中,输入是一个 8x8 的二维信号,目标输出尺寸被设定为 4x4。adaptive_avg_pool2d 会自动调整池化窗口的大小和步长,以确保输出特征图的尺寸为 4x4。这种方法在需要将不同尺寸的输入标准化为相同尺寸输出的场景中非常有用。
adaptive_avg_pool3d
torch.nn.functional.adaptive_avg_pool3d 是 PyTorch 库中的一个函数,用于对三维输入信号执行自适应平均池化操作。这种操作允许对具有不同尺寸的三维数据(如体积图像或视频序列)进行池化处理,同时生成具有固定尺寸的输出。
用法与用途
- 用法:
adaptive_avg_pool3d通过自动调整池化窗口的大小和步长,实现从不同尺寸的输入到固定尺寸输出的转换。 - 用途: 在处理体积图像、三维医学成像数据或视频序列等三维数据时,这种方法非常有用,因为它允许网络处理不同尺寸的输入数据,同时保证输出特征图的一致性。
参数
- input: 形状为
(minibatch, in_channels, iD, iH, iW)的输入张量。 - output_size: 目标输出尺寸。可以是单个整数(生成立方体形状的输出)或三整数元组
(oD, oH, oW)。
注意事项
- 当使用单个整数作为
output_size时,输出特征图将是一个立方体,其大小由该整数指定。 - 使用三整数元组时,可以更精确地控制输出特征图的深度、高度和宽度。
- 自适应池化方法不需要手动指定池化窗口的大小和步长,因为它会根据输入和输出尺寸自动计算这些参数。
示例代码
import torch
import torch.nn.functional as F# 示例输入,一个三维信号
input = torch.rand(1, 1, 8, 8, 8) # 随机生成一个 8x8x8 的输入张量# 应用自适应平均池化,目标输出尺寸为 (4, 4, 4)
output = F.adaptive_avg_pool3d(input, output_size=(4, 4, 4))print(output)
在这个例子中,输入是一个 8x8x8 的三维信号,目标输出尺寸被设定为 4x4x4。adaptive_avg_pool3d 会自动调整池化窗口的大小和步长,以确保输出特征图的尺寸为 4x4x4。这种方法在需要将不同尺寸的输入标准化为相同尺寸输出的场景中非常有用。
fractional_max_pool2d
torch.nn.functional.fractional_max_pool2d 是 PyTorch 库中的一个函数,用于对二维输入信号执行分数最大池化操作。这种池化操作与传统的最大池化不同,它允许使用随机或非整数步长,从而产生非标准尺寸的输出。
用法与用途
- 用法:
fractional_max_pool2d通过使用随机或分数步长在输入上进行池化,以生成目标输出尺寸或与输入尺寸成比例的输出。 - 用途: 在深度学习中,尤其是在图像处理和计算机视觉任务中,分数最大池化可以用于创建更加丰富和多样的特征表示,有助于提高模型的泛化能力。
参数
- input: 形状为
(minibatch, in_channels, iH, iW)的输入张量。 - kernel_size: 池化区域的大小。可以是单个整数(对于正方形的池化窗口)或元组
(kH, kW)。 - output_size: 目标输出尺寸,形式为
(oH, oW)。也可以是单个整数,用于创建正方形输出。 - output_ratio: 如果希望输出尺寸作为输入尺寸的比例,可以使用这个参数。它必须是范围在 (0, 1) 内的数字或元组。
- return_indices: 如果为
True,将返回池化过程中最大值的索引,可用于后续的max_unpool2d操作。
注意事项
- 分数最大池化的随机性可能导致不同的运行结果有所不同。
- 确保选择合适的
kernel_size、output_size或output_ratio,以达到期望的池化效果。 - 如果需要使用
max_unpool2d进行反池化操作,需要设置return_indices为True。
示例代码
import torch
import torch.nn.functional as F# 示例输入
input = torch.randn(20, 16, 50, 32)# 应用分数最大池化,窗口大小为3,目标输出尺寸为 13x12
output = F.fractional_max_pool2d(input, kernel_size=3, output_size=(13, 12))# 应用分数最大池化,窗口大小为3,输出尺寸为输入尺寸的一半
output_ratio = F.fractional_max_pool2d(input, kernel_size=3, output_ratio=(0.5, 0.5))
在这些示例中,输入是一个具有随机值的张量,我们应用了分数最大池化来减小其尺寸。第一个例子直接指定了输出尺寸,而第二个例子使用了输出比例来决定输出尺寸。这种方法为特征提取提供了更多的灵活性。
fractional_max_pool3d
torch.nn.functional.fractional_max_pool3d 是 PyTorch 库中的一个函数,用于在三维输入信号上实施分数最大池化操作。这种池化操作与传统的最大池化不同,它允许使用随机或非整数的步长,从而产生非标准尺寸的输出。
用法与用途
- 用法:
fractional_max_pool3d通过使用随机或分数步长在输入上进行池化,以生成目标输出尺寸或与输入尺寸成比例的输出。 - 用途: 在深度学习中,尤其是在三维数据处理(如体积图像或视频序列)中,分数最大池化可以用于创建更加丰富和多样化的特征表示,有助于提高模型的泛化能力。
参数
- input: 形状为
(N, C, T_in, H_in, W_in)或(C, T_in, H_in, W_in)的输入张量。 - kernel_size: 池化区域的大小。可以是单个整数(对于立方体的池化窗口)或元组
(kT, kH, kW)。 - output_size: 目标输出尺寸,形式为
(oT, oH, oW)。也可以是单个整数,用于创建立方体输出。 - output_ratio: 如果希望输出尺寸作为输入尺寸的比例,可以使用这个参数。它必须是范围在 (0, 1) 内的数字或元组。
- return_indices: 如果为
True,将返回池化过程中最大值的索引,可用于后续的max_unpool3d操作。
注意事项
- 分数最大池化的随机性可能导致不同的运行结果有所不同。
- 确保选择合适的
kernel_size、output_size或output_ratio,以达到期望的池化效果。 - 如果需要使用
max_unpool3d进行反池化操作,需要设置return_indices为True。
示例代码
import torch
import torch.nn.functional as F# 示例输入
input = torch.randn(20, 16, 50, 32, 16)# 应用分数最大池化,窗口大小为3,目标输出尺寸为 13x12x11
output = F.fractional_max_pool3d(input, kernel_size=3, output_size=(13, 12, 11))# 应用分数最大池化,窗口大小为3,输出尺寸为输入尺寸的一半
output_ratio = F.fractional_max_pool3d(input, kernel_size=3, output_ratio=(0.5, 0.5, 0.5))
在这些示例中,输入是一个具有随机值的张量,我们应用了分数最大池化来减小其尺寸。第一个例子直接指定了输出尺寸,而第二个例子使用了输出比例来决定输出尺寸。这种方法为特征提取提供了更多的灵活性。
总结
在 PyTorch 中,池化层函数是卷积神经网络(CNN)中的重要组成部分,用于降维、特征提取和防止过拟合。这些函数包括不同类型和维度的池化操作,如平均池化、最大池化和自适应池化,适用于处理一维、二维和三维数据。每种池化操作都有其特定的应用场景和参数设置,提供了灵活性以适应不同的深度学习需求。
相关文章:

PyTorch 各种池化层函数全览与用法演示
目录 torch.nn.functional子模块Pooling层详解 avg_pool1d 用法与用途 参数 注意事项 示例代码 avg_pool2d 用法与用途 参数 注意事项 示例代码 avg_pool3d 用法与用途 参数 注意事项 示例代码 max_pool1d 用法与用途 参数 注意事项 示例代码 max_pool2d…...
Redis:原理速成+项目实战——Redis实战7(优惠券秒杀+细节解决超卖、一人一单问题)
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:Redis:原理速成项目实战——Redis实战6(封装缓存工具(高级写法)&&缓存总…...

【刷题笔记3】
笔记3 输出小数位数控制。(自动四舍五入,不够就自动补0) double a123.456; cout<<fixed<<setprecision(2)<<a;递归题目的记录 (1):n*m的棋盘格子(n为横向的格子数…...

YOLOv8优化策略:轻量化改进 | 华为Ghostnet,超越谷歌MobileNet | CVPR2020
🚀🚀🚀本文改进:Ghost bottleneck为堆叠Ghost模块 ,与YOLOV8建立轻量C2f_GhostBottleneck 🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK 学姐带你学习YOLOv8,从入门到创新,轻轻松松搞定科研; 1.Ghostnet介绍 论文: https://arxiv.org/pdf/1911.11907.…...

格雷希尔G65系列快速接头满足汽车减震器的气压、油压测试要求
当汽车经过不平路面时,汽车减震器可以抑制弹簧吸震后因反弹带来的震荡和来自路面的冲击,为乘客带来平稳舒适的行车体验。减震器在出厂之前,需要模拟汽车的真实行驶环境,在模拟当中需要对它们进行气压和油压的轮番测试。 客户的测试…...

php中常用的几个安全函数
1. mysql_real_escape_string() 这个函数对于在PHP中防止SQL注入攻击很有帮助,它对特殊的字符,像单引号和双引号,加上了“反斜杠”,确保用户的输入在用它去查询以前已经是安全的了。但你要注意你是在连接着数据库的情况下使用这个…...
【K8S 云原生】Kurbernets集群的调度策略
目录 一、Kubernetes的list-watch机制 1、List-watch 2、创建pod的过程: 二、scheduler调度的过程和策略: 1、简介 2、预算策略:predicate 3、优先策略: 3.1、leastrequestedpriority: 3.2、balanceresourceal…...
预览的vue组件库)
vue-office 支持多种文件(docx、excel、pdf)预览的vue组件库
一、文档链接 https://gitcode.com/mirrors/501351981/vue-office/overview?utm_sourcecsdn_github_accelerator&isLogin1 二、安装 #docx文档预览组件 npm install vue-office/docx vue-demi0.13.11#excel文档预览组件 npm install vue-office/excel vue-demi0.13.11#…...

如何使用GaussDB创建脱敏策略(MASKING POLICY)
目录 一、前言 二、GaussDB中的脱敏策略 1、数据脱敏的定义 2、创建脱敏策略的语法说明 三、在GaussDB中如何创建数据脱敏策略(示例) 1、创建脱敏策略的一般步骤 2、GaussDB数据库中创建脱敏策略的完整示例 1)开启安全策略开关,以初识用户omm登录…...

【Golang map并发报错】panic: assignment to entry in nil map
go并发写map[string]interface{}数据的时候,报错:panic: assignment to entry in nil map 多个key同时操作一个map时,如: test[key1] 1 test[key2] "a" test[key3] true 就会遇到并发nil值报错,什么…...
【GO语言依赖】Go语言依赖管理简述
在运行环境中,遭遇报错,显示找不到函数 经过研究后发现需要进行依赖管理,进行如下操作后解决: 起源 最早的时候,Go所依赖的所有的第三方库都放在GOPATH这个目录下面。这就导致了同一个库只能保存一个版本的代码。如…...

论文阅读记录SuMa SuMa++
首先是关于SuMa的阅读,SuMa是一个完整的激光SLAM框架,核心在于“基于面元(surfel)”的过程,利用3d点云转换出来的深度图和法向量图来作为输入进行SLAM的过程,此外还改进了后端回环检测的过程,利用提出的面元的概念和使…...
性能分析与调优: Linux 内存观测工具
目录 一、实验 1.环境 2.vmstat 3.PSI 4.swapon 5.sar 6.slabtop 7.numstat 8.ps 9.top 10.pmap 11.perf 12.bpftrace 二、问题 1.接口读写报错 2.slabtop如何安装 3.numactl如何安装 4.numad启动服务与关闭NUMA 5. perf如何安装 6. kernel-lt-doc与kern…...

【ARM 嵌入式 编译系列 3.4 -- 查看所依赖库文件的路径 详细介绍】
文章目录 问题背景库文件路径查看库文件路径信息打印显示连接标准库不使用标准库 libgcc.a问题背景 在自己构建的 Makefle系统中对 cortex-m33 代码编译时,在链接阶段总是报出下面问题 ... arm-none-eabi-ld: cannot find libgcc.a: No such file or directory arm-none-eab…...
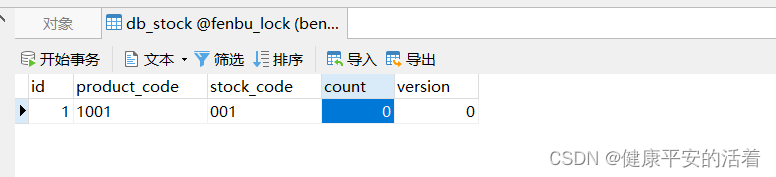
分布式锁3: zk实现分布式锁3 使用临时顺序节点+watch监听实现阻塞锁
一 zk实现分布式锁 1.1 使用临时顺序节点 的问题 接上一篇文章,每个请求要想正常的执行完成,最终都是要创建节点,如果能够避免争抢必然可以提高性能。这里借助于zk的临时序列化节点,实现分布式锁 1. 主要修改了构造方法和lock方…...

google drive api
1.创建oauth2 json 文件 https://developers.google.com/drive/api/quickstart/pythoncchttps://developers.google.com/drive/api/quickstart/python这里要注意quickstart的code会经常更新,有可能之前的版本不能用了 比方说下面这个包 from google.oauth2.crede…...
)
3_代理模式(动态代理JDK原生和CGLib)
一.代理模式 1.概念 代理模式(Proxy Pattern )是指为其他对象提供一种代理,以控制对这个对象的访问,属于结构型模式。 在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的…...
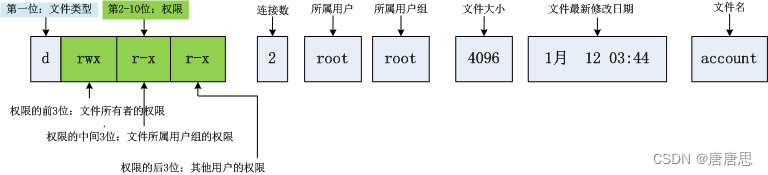
Linux的权限(1)
目录 操作系统的"外壳"程序 外壳程序是什么? 为什么存在外壳程序? 外壳程序怎么运行操作? 权限 什么是权限? 权限的本质? Linux中的(人)用户权限? su和su -的区别…...

数据安全保障的具体措施有哪些
随着信息化时代的到来,数据已经成为企业和社会发展的重要资产。然而,数据安全问题也日益突出,如何保障数据的安全性、完整性和可用性成为了亟待解决的问题。以下将详细探讨数据安全保障的各个方面,以期为企业和社会提供更好的数据…...

浅谈标签及应用场景
一、标签的定义 标签是根据业务场景的需求,通过对目标对象(包含静态、动态特性),运用抽象、归纳、推理等算法得到的高度精炼的特征标识,用于差异化管理与决策。标签由标签名称和标签值组成,打在目标对象上…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

vue3 daterange正则踩坑
<el-form-item label"空置时间" prop"vacantTime"> <el-date-picker v-model"form.vacantTime" type"daterange" start-placeholder"开始日期" end-placeholder"结束日期" clearable :editable"fal…...