HTAP(Hybrid Transactional/Analytical Processing)系统之统一存储的实时之道
文章目录
- HTAP与时俱进
- LASER中的存储
- 关键知识
- LSM(Log-Structured Merge Tree)
- SkipList(跳表)
- CDC(Changed Data Capture)
- SST(Sorted Sequence Table)
- 特性
- 列组(Column Group)
- 部分列更新
- LASER存储的实现
- 数据插入流程
- 部分列更新流程
- 初始化LEVELs
- 插入一条新记录并更新一条旧记录(合并L0和L1)
- 插入一条新记录并更新一条旧记录(不合并)
- 范围查询
- 部分列的Compaction
- LASER存储的性能
- 整体性能
- 插入性能
- 检索性能
- LASER存储的问题
- 写放大
- 点查放大
- 范围查询放大
- 更新放大
- 总结
- 思考
HTAP与时俱进
在线联机事务处理(OLTP)和在线联机分析处理(OLAP)这两类数据处理分析场景,是公司日常工作中不可不说的内容,尤其是在大数据时代的当下,说它们决定了公司的成败也不为过,因此诞生了各类成熟且高效地分布式计算、存储系统,如计算侧的MapReduce、Spark、Flink、Trino等,存储侧的Oracle、RocksDB、Clickhouse等。
但正是各类计算和存储系统的遍地开花,也导致了在实际中很难将不同的系统归一、数据统一,导致各类负担,尤其是流系统、批系统的天然隔阂,因此近年来大家都是力求找到或开发出一个系统,能够同时很好应付日常工作中的绝大部分OLTP/OLAP的业务就行了,就像Snowflake那样,实现一个相对完善的HTAP系统。
但要想做好一个HTAP系统,不可避免地需要要结合计算、存储这两个层面的特性来进行设计,虽然我们在实际的工作中经常强调要存算分离,保证集群系统能够至少满足BASE(Basically Available、Soft States、Eventually Consistent原则,也可以说是AP原则吧)原则,但这仅仅是强调使用上的注意事项,而要实现这样的系统,却不能分开计算而谈存储,反之亦然。
人都是“贪婪”的,一旦有了开发了一个工具,不管是使用者还是开发者,都希望随着技术的进步,这个工具能够变得更好,比如说时间,为别人/自己节省了多少时间,实时性达到秒级等,说到这里,这篇博客也就随着这篇论文Real-Time LSM-Trees for HTAP Workloads来看看学习和思考前人的成果,以帮助解决当下或未来的问题。
LASER中的存储
关键知识
LSM(Log-Structured Merge Tree)
很多文章都介绍这个概念了,大家可以自行查找一下,当然也有不少系统基于此原理实现了自己的存储,如Google LevelDB、Clickhouse、Flink Table Store等。
SkipList(跳表)
这个概念也有不少的大佬分析了其理论与实践,例如Redis中的应用,还有Real-Time LSM-Trees for HTAP Workloads论文中的提到的LASER系统。
CDC(Changed Data Capture)
实际上对应了数据库中的INSERT、DELETE、UPDATE操作,更细节知识自行查阅吧。
SST(Sorted Sequence Table)
可以认为就是持久化到磁盘上的数据文件,文件中的数据行都是按排序KEY有序的。
特性
列组(Column Group)
为了兼并行存和列存的优势,LASER在不同的存储等级(LEVEL)上定义不了同列组规则,一个列组就是一个数据行中的部分或全部字段,对应一个单独的存储文件,例如在下面的图中显示的,在Level 0层,文件是按行存储的,文件中的一行就对应了一条完整的Record;而在Leve 1层,会存储两个文件,分别保存(A, B)列以及(C, D)列;在Level 3层,一个列,就是一个单独的文件。(这里说一个文件并不准确,实际上应该是一类文件,毕竟文件一般会按大小被切分成多个)

图-1 列组的定义与组织
部分列更新
LASER存储的实现
数据插入流程
下图展示了LASER中的基本存储流程,图中也展示了一些配套的索引技术,如BLOOM FILTERS用于加速文件的查找、SkipList查找新记录的待插入位置。

一条新数据记录(Record)完整地经历CDC过程的简单描述如下:
- 决定Record的操作类型:Server接收到Record后,根据指定的
排序Key、唯一Key,在内存中的SKIPLIST以及磁盘中的LEVEL文件(这里指SST文件)查找,看是否存在相同的数据记录。如果存在则更新这条RECORD的操作类型为UPDATE,否则为INSERT。 - 插入到内存中的MUTABLE SKIPLIT:通过
跳表可以很快地确认这条新的数据记录的插入位置,因此就将其插入到内存。 - Flush到磁盘:如果新的数据记录插入后,到达了一定的阈值,则系统会尝试将
MUTABLE的数据刷新到磁盘,但在Flush之前,需要将新记录插入的内存数据表标记为IMMUTABLE,以保证数据写出时,不会发生 变更。 - 写出数据到Level0:
Level 0只定义了一个文件,因此会首先尝试将新的RECORD,按行格式,插入到此文件中。 - Compaction数据文件:如果新的RECORD插入Level 0后,导致文件的大小超过了阈值,则会触发Compaction行为,将Level 0的文件,下沉到更下层,达到优化存储的目的,因此这里会首先将
Level 0的文件,转存到Level 1。文件由Level 0插入到Level 1的过程,实际上是一个归并排序的过程,需要保证文件的有序性,因此这里可以采用二分查找来确认需要合并Level 1中的哪些文件,例如Level 0文件的SORT KEY值范围为[22, 66],那么需要与Level 1中的21-50和51-88的两个SST文件进行合并。 - 列组映射:上面的图只显示了文件的插入过程,但没有展示出列出的合并逻辑,这里简单说一下:
从
图-1可以知道每一个Level的列组划分是不同的,而Level 0中的文件中的一行可能包含了所有列值(如A、B、C、D四个列),而在Level 1中数据文件只有两类(A, B)和(C, D),因此需要将0层的文件中的数据行按列拆分成两个文件,分别以前两个列为一行和后两个列为一行,再分别进行合并,最终生成两类文件。
部分列更新流程
一般地,SQL中的UPDATE语句会更新部分列的历史值,因此LASER也需要有能力支持。
初始化LEVELs
Level 0:数据文件行式存储,因此文件中的一行,包含了全部列,A、B、C、D。
Level 1: 两个文件,即两人上Column Group,左边文件包含A、B列;右边文件包含C、D列
注意到每一行记录之前有一个特殊的整数,例如106: a6, b6, c6, d6中的106,表示的是数据记录排序键对应的值,可以看到在每一个文件中,所有的数据记录都是按此值有序。

插入一条新记录并更新一条旧记录(合并L0和L1)
插入一条新记录:
99: a9, b9, c9, d9
更新一条旧记录:107: -, -, c9, d9,其中-表示不更新,即保留A, B列的原有值
注意到,这里插入新记录后,导致LEVEL 0超过存储阈值,因此会触发L0的文件下沉到L1,因此下面的图展示的是合并后的结果。
在合并L0和L1的过程中,可以看到,原本在L0的行文件中的记录106: a6, b6, c6, d6,下沉到L1后,被纵向拆分到了两个Column Group文件中;而新的更新记录107: -, -, c9, d9最终只会在CG:<C, D>有值,而不会添加记录107: -, -到CG:<A, B>中,节约了存储空间。

插入一条新记录并更新一条旧记录(不合并)
插入一条新记录:
50: a0, b0, c0, d0
更新一条旧记录:108: a1, b1, -, -,其中-表示不更新,即保留C, D列的原有值
可以看到由于新插入的数据后,被首先Flush到Level 0,但Level 0的数据大小没有达到阈值,因此不会发生Compaction,新的数据就以行格式保留在L0中。

范围查询
ColumnMergingIterators:用于合并ColumnGroup,一个Iterator实例只会
作用于同一个Level,因此不会真正的合并新旧数据,而是将要所有要检索的列(这里是A、B、C、D列)拼接在一起。
LevelMergingIterators:用于合并来自不同Level的数据,这些数据经过ColumnMergingIterators后返回了一个"临时表",包含了所有要检索的列,同时会进行新、旧列值的覆盖。
查询流程简述如下:

- SQL解析:接收
SELECT * FROM tbl WHERE sort_key >= 50 and sort_key <= 108,产生要返回的结果列的投影信息,即返回A、B、C、D。 - 确认数据所有层级:发现
sort_key的取值范围是[50, 108],在3个Level中都存在数据,因此需要遍历每一层的数据文件。 - 遍历每一层的数据文件:为每一个LEVEL创建
ColumnMergingIterators实例,遍历满足条件的数据文件,返回的结果是一个临时表且它们的Layout相同,均为A、B、C、D,例如对于sort_key = 107的数据记录,通过列拼接,最终得到在临时表中的对应行107: -, -, c9, d9。 - 合并每一层的临时表:通过
LevelMergingIterators实例,合并每一层的返回结果,同时进行数据记录的更新/删除动作,例如对于sort_key = 107的数据记录,发现它的旧值为107: a7, b7, c7, d7,新值为107: -, -, c9, d9,因此通过覆盖后的最终结果为107: a7, b7, c9, d9。 - 返回最终结果:最终结果集包含了所有要检索的列,以及包含了旧记录中的列的最新值。
部分列的Compaction
通过后台的Compaction线程,可以并行地在不同的
ColumnGroup上进行Compaction,因为在数据下沉的过程中,越往向,列组越小,并且互相不影响。
如下图所示,当前一共有两个Compaction任务在执行,第一个任务是合并L1和L2中的CG:<A, B>;第二个任务是合并L2和L3中的CG: <C>。

但这里有一个潜在的问题:为什么选择L1中的<A, B>下沉,以及L2中的<C>下沉?
简单来说,LASER为每一个Level配置了不同的Quota,例如为L1配置了上限记录数为2,而当前L1中一共存在3条记录,因此需要合并L1和L2;同时注意到CG: <A, B> 的占比最多,因此优先选择此CG下沉,故就对应了任务1,同理生成任务2。
最终,经过部分列上的下沉,可以避免对它列的影响,在一定程度上能够减缓由于数据下沉,导致在这些列上的检索时间变长的问题,当然也可以结合一些冷热策略可以更精细地控制正常过程。
LASER存储的性能
rocksdb:行存
rocksdb-col:列存
HTAP-simple:行、列混合存储,25%数据行存,其它列存。
Postgress:行存
MySQL:行存
MyRocks:行存
MonetDB:列存
Hyper:全内存列存
整体性能
如下图所示,在同时进行INSERT、UPDATE、SELECT操作时,LASER的整体性能是最好的,尤其是在设置了ColumnGroup的大小为6(6列)、15(15列)的场景下,而次强的则是HTAP-simple和rocksdb-col(它们完全是基于内存的)。

插入性能
如下图所示,当仅执行INSERT操作时,LASER表现最好,尤其是设置CG的大小为2和3时,而HTAP-simple和rocksdb将之。

检索性能
𝑄1: INSERT INTO R VALUES (𝑎0, 𝑎1, …, 𝑎𝑐 )
𝑄2: SELECT 𝑎1, 𝑎2, …, 𝑎𝑘 FROM R WHERE 𝑎0 = 𝑣
𝑄3: UPDATE R SET 𝑎1 = 𝑣1, …, 𝑎𝑘 = 𝑣𝑘 WHERE 𝑎0 = 𝑣
𝑄4: SELECT 𝑎1 + 𝑎2 + … + 𝑎𝑘 FROM R WHERE 𝑎0 ∈ [𝑣𝑠 , 𝑣𝑒 )
𝑄5: SELECT 𝑀𝐴𝑋 (𝑎1), …, 𝑀𝐴𝑋 (𝑎𝑘) FROM RWHERE𝑎0 ∈ [𝑣𝑠 , 𝑣𝑒 )
如下图所示,分别执行不同Query时的延迟统计图,从中可以看到当前执行Q1、Q2、Q3时,LASER能够达到其它优势引擎的最好性能;而执行Q4的算术运算时,Hyper表现最好,比LASER快5倍(而MonetDB比LASER慢20倍);而执行Q5的聚合运算时,MonetDB和Hyper比LASER快5倍,这是由于Hyper和Monet存储的数据记录都是按列连续的,因此不需要像LASER那样需要先合并数据。

因此整体上看,在高负载,和能用场景下,LASER的表是所有列式引擎、行式引擎中综合表现最好的,也更加活动地通过CG的大小来适配不再的场景。
LASER存储的问题
下面提到的这些问题,都是论文中有提到的,同时也给出了估算公式,但是着实需要细致分析每一个算法才能更好地理解架构设计的精妙,这里就不展开分析了,也怕功力不够,引发解读错误,那就栽了!!!
写放大
不难想象,当我们更新更新或插入数据时,至少需要读取索引数据、旧的的数据记录,以确定当前数据行的操作类型;当发生数据合并(Compaction过程)时,需要将新旧数据写出到一个新的数据文件,同时保证旧的数据文件依然在此期间可以为查询作业提供服务,因此这么大的倍数与写入或更新的数据模型有关。
为了缓解此问题,可以基于ColumnGroup机制,同时为每一个Level制定不同的数据下沉策略。
点查放大
仅仅是等值查询,最坏情况下,需要在内存遍历,同时需要检查所有Level中的数据范围,以确定数据是否存在。
范围查询放大
比点查更坏,最坏情况下,要查询的数据在每一个Level中都存在,因此遍历记录每一层的数据文件的信息,来确定要读取的数据。
更新放大
在点查放大问题的基础之上,需要将新数据写出到Level 0,同时很可能会引发Compcation过程。
总结
Real-Time LSM-Trees for HTAP Workloads介绍了一个支持实现写入的、基于LSM的、支持HTAP场景的存储系统,LASER。论文提出了ColumnGroup存储规范,能在兼并行存、列存的优点,以相对最好的性能同时支持OLTP和OLAP事务,为打造流批一体计算&存储系统提供了借鉴,非学值得我们细细口味。
思考
- 使用什么的索引或算法,能够快速定位范围所包含的数据文件?
- 时间旅行?
- 并发写事务的支持?
- 如何支持插入入新的列?
- 。。。
相关文章:
HTAP(Hybrid Transactional/Analytical Processing)系统之统一存储的实时之道
文章目录 HTAP与时俱进LASER中的存储关键知识LSM(Log-Structured Merge Tree)SkipList(跳表)CDC(Changed Data Capture)SST(Sorted Sequence Table) 特性列组(Column Gro…...

【linux】tcpdump 使用
tcpdump 是一个强大的网络分析工具,可以在 UNIX 和类 UNIX 系统上使用,用于捕获和分析网络流量。它允许用户截取和显示发送或接收过网络的 TCP/IP 和其他数据包。 一、安装 tcpdump 通常是默认安装在大多数 Linux 发行版中的。如果未安装,可…...
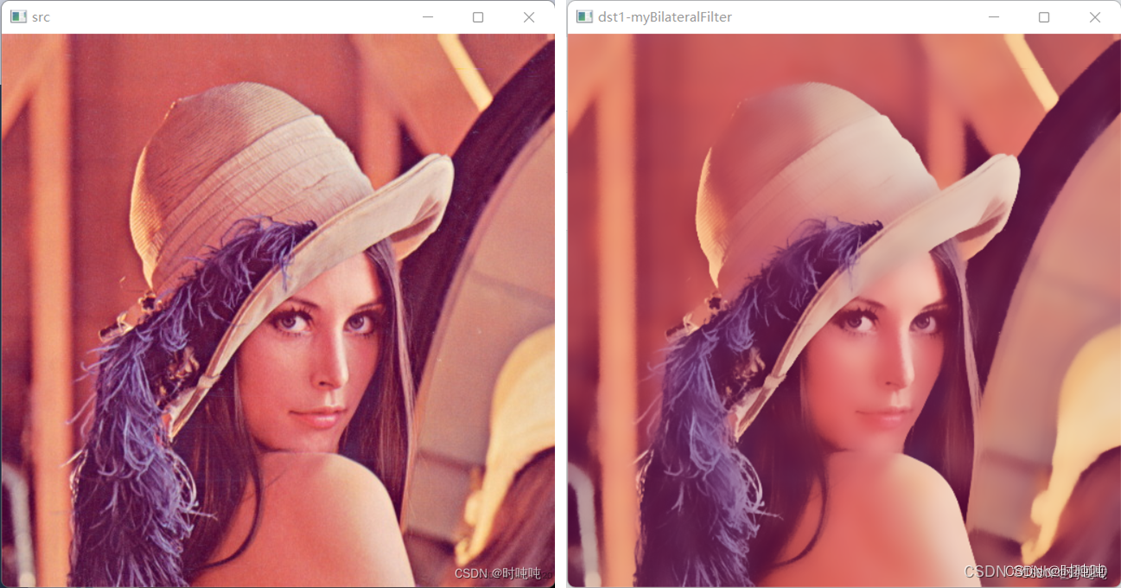
数字图像处理常用算法的原理和代码实现详解
本专栏详细地分析了常用图像处理算法的数学原理、实现步骤。配有matlab或C实现代码,并对代码进行了详细的注释。最后,对算法的效果进行了测试。相信通过这个专栏,你可以对这些算法的原理及实现有深入的理解! 如有疑问…...

Pandas实战100例 | 案例 26: 检测异常值
案例 26: 检测异常值 知识点讲解 在数据分析中,检测和处理异常值(或离群值)是一个重要的步骤。异常值可能会影响数据的整体分析。一种常用的方法是使用四分位数和四分位数间距(IQR)来识别异常值。 四分位数和 IQR: …...
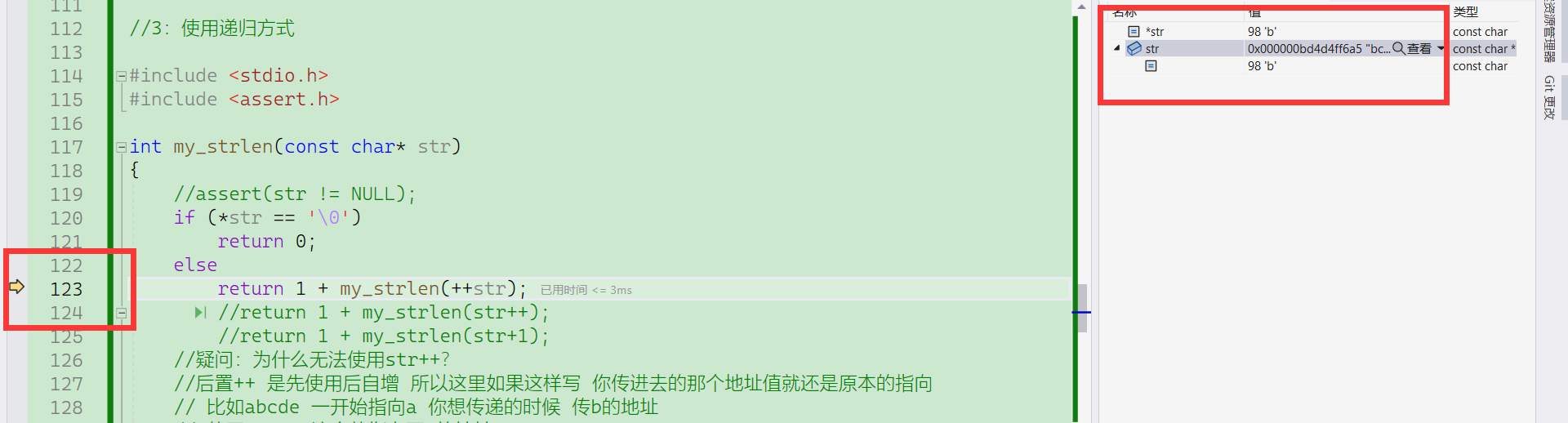
C语言学习NO.11-字符函数strlen,strlen函数的使用,与三种strlen函数的模拟实现
(一)strlen函数的使用 strlen函数的演示 #include <stdio.h> #include <string.h>int main() {char arr1[] "abcdef";char arr2[] "good";printf("arr1 %d,arr2 %d",strlen(arr1),strlen(arr2));return …...

Vue3+ts获取props的值并且定义props值的类型的方法。
1.引入withDefaults模块,给defineProps绑定默认值。 import { withDefaults } from vue2.定义Props传输值的类型。 interface Props {// 类型type: string;name: string;id: number; }3.给props的值设置默认值。 const props withDefaults(defineProps<Prop…...

EasyExcel 不使用科学计数发并以千分位展示
EasyExcel 不使用科学计数发并以千分位展示 不使用科学计数法 不使用科学计数法 BigDecimalStringConverter 将 BigDecimal 类型的数值转换为字符串类型,并将其导出到 Excel 文件中。在 convertToExcelData 方法中,我们将 BigDecimal 转换为字符串&…...

【Python机器学习】SVM——调参
下面是支持向量机一个二维二分类数据集的训练结果: import mglearn import matplotlib.pyplot as plt from sklearn.svm import SVCplt.rcParams[font.sans-serif] [SimHei] plt.rcParams[axes.unicode_minus] False X,ymglearn.tools.make_handcrafted_dataset()…...
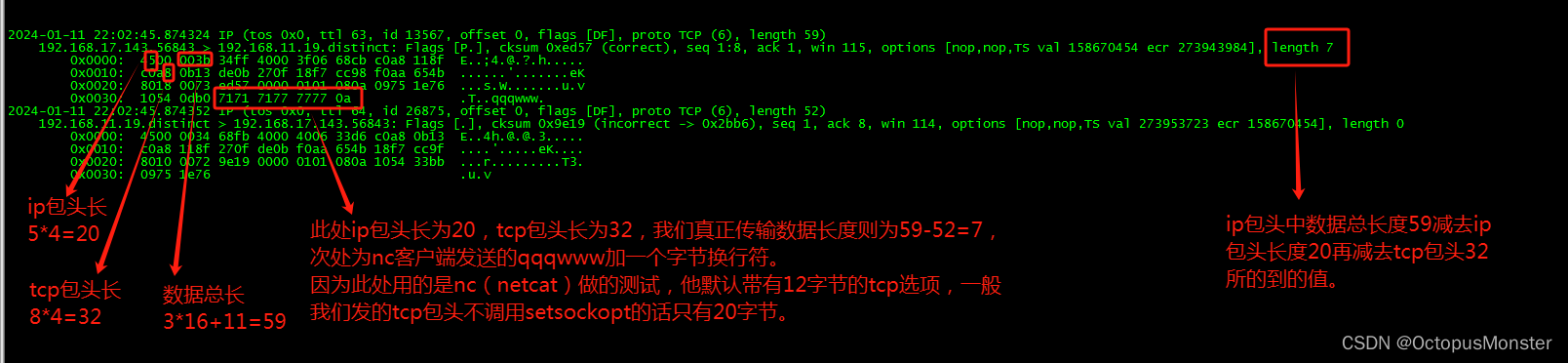
网络传输(TCP)
前言 我们tcpdump抓包时会看到除报文数据外,前面还有一段其他的数据,这段数据分为两部分,ip包头(一般20字节)和tcp包头(一般20字节),一般这两个头长度和为40,我们直接跳…...

MFC模拟消息发送,自定义以及系统消息
在MFC框架下,有很多系统已经定义好的消息,例如ON_WM_LBUTTONDOWN()、ON_WM_MBUTTONDOWN()等等。我们在使用的时候只需要声明并调用就可以了,最简单的用法。 提升了一点难度的用法就是自己设置自定义消息,再提升一点难度的就是如何…...

并发,并行,线程与UI操作
并行和并发是计算机领域中两个相关但不同的概念。 并行(Parallel)指的是同时执行多个任务或操作,它依赖于具有多个处理单元的系统。在并行计算中,任务被分成多个子任务,并且这些子任务可以同时在不同的处理单元上执行…...

react 6种方式编写样式
在React中,编写样式主要有以下几种方式: 1. 内联样式: 直接在React组件中使用style属性来定义样式。这种方式比较适合定义动态的样式,因为它允许你将JavaScript表达式作为样式的值。 2. 外部样式表 :通过创建外部的…...
计算机找不到msvcr100.dll的多种解决方法分享,轻松解决dll问题
msvcr100.dll作为系统运行过程中不可或缺的一部分,它的主要功能在于提供必要的运行时支持,确保相关应用程序能够顺利完成编译和执行。因此,当操作系统或应用程序在运行阶段搜索不到该文件时,自然会导致各类依赖于它的代码无法正常…...

系分笔记数据库反规范化、SQL语句和大数据
文章目录 1、概要2、反规范化3、大数据4、SQL语句5、总结 1、概要 数据库设计是考试重点,常考和必考内容,本篇主要记录了知识点:反规范化、SQL语句及大数据。 2、反规范化 数据库遵循范式的设计,使得多表查询和连接表查询较多的时…...

php实现支付宝商户转账
目录 一:背景介绍 一:准备工作 三:代码实现 一:背景介绍 最近工作中,要用到支付宝的商家转账功能,用php代码实现,网上找的内容,有些是老版本的实现,有些是调用sdk&am…...
)
并发编程(十一)
性能测试的常用命令 1、Netstat是在内核中访问网络连接状态及其相关信息的程序,它能够显示协议统计和当前TCP/IP的网络连接。 Netstat命令的常用格式如下: netstat -a:显示所有网络连接和侦听端口。 netstat -b:显示在创建网络…...

vue3 指令详解
系列文章目录 TypeScript 从入门到进阶专栏 文章目录 系列文章目录前言一、v-model (双向绑定功能)二、v-bind(用于将一个或多个属性绑定到元素的属性或组件的 prop)三、v-if、v-else、v-else-if(用于根据条件选择性地渲染元素)四、v-show(根…...
数据科学竞赛平台推荐
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

安全防御之安全审计技术
安全防御中的安全审计技术是保障信息系统安全的重要手段之一。其主要目标是对信息系统及其活动进行记录、审查和评估,以确保系统符合安全策略、法规要求,并能够及时发现潜在的安全风险和异常行为。通过安全审计,可以对系统中的各种活动进行记…...

C#多窗口那些事儿
目录 1、调用窗体与被调用窗体 2、窗体的本质 3、调用窗体访问被调用窗体内部对象 4、被调用窗体访问调用窗体 (1)被动方式,也就是调用窗体主动给被调用窗体一个“接口” i.调用窗体定义“静态”变量,并将开放的变量复制 ii.在被调用窗体中,使用:调用窗体名.静态变…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 )
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...