阅读笔记lv.1
阅读笔记
- sql中各种 count
- 结论
- 不同存储引擎计算方式
- 区别
- count() 类型
- 责任链模式
- 常见场景
- 例子(闯关游戏)
sql中各种 count
结论
- innodb
count(*) ≈ count(1) > count(主键id) > count(普通索引列) > count(未加索引列)
-
myisam
有专门字段记录全表的行数,直接读这个字段就好了(innodb则需要一行行去算) -
如果确实需要获取行数,且可以接受不那么精确的行数(只需要判断大概的量级) 的话,那可以用explain里的rows,这可以满足大部分的监控场景,实现简单
-
如果要求行数准确 ,可以建个新表,里面专门放表行数的信息
-
如果对实时性要求比较高 的话,可以将更新行数的sql放入到对应事务里,这样既能满足事务隔离性,还能快速读取到行数信息
-
如果对实时性要求不高 ,接受一小时或者一天的更新频率,那既可以自己写脚本遍历全表后更新行数信息。也可以将通过监听binlog将数据导入hive,需要数据时直接通过hive计算得出
不同存储引擎计算方式
- count()方法的目的是计算当前sql语句查询得到的非NULL的行数
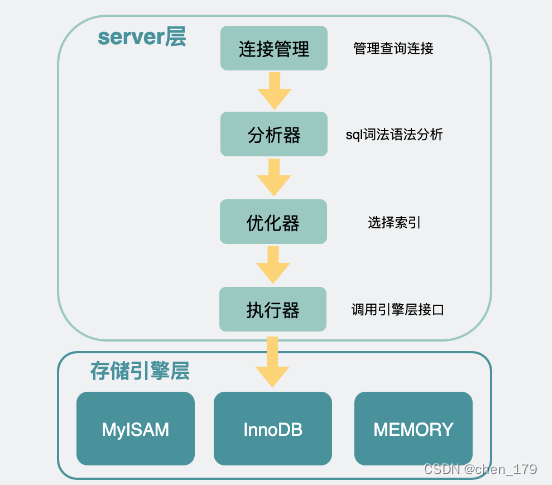
- 虽然在server层都叫count()方法,但在不同的存储引擎下,它们的实现方式是有区别的
-
- 比如同样是读全表数据
select count(*) from table (where *** );
当数据表小的时候,这是没问题的,但当数据量大的时候,比如未发送的短信到了百万量级 的时候,你就会发现,上面的sql查询时间会变得很长,最后timeout报错,查不出结果了 。
-
- 使用 myisam引擎 的数据表里有个记录当前表里有几行数据的字段,直接读这个字段返回就好了,因此速度快得飞起
-
- 使用innodb引擎 的数据表,则会选择体积最小的索引树 ,然后通过遍历叶子节点的个数挨个加起来,这样也能得到全表数据
区别
为什么innodb不能像myisam那样实现count()方法
-
最大的区别在于myisam不支持事务,而innodb支持事务
而事务,有四层隔离级别,其中默认隔离级别就是可重复读隔离级别(RR) -
- innodb引擎通过MVCC实现了可重复隔离级别 ,事务开启后,多次执行同样的select快照读 ,要能读到同样的数据。
-
- 对于两个事务A和B,一开始表假设就2条 数据,那事务A一开始确实是读到2条数据。事务B在这期间插入了1条数据,按道理数据库其实有3条数据了,但由于可重复读的隔离级别,事务A依然还是只能读到2条数据。
-
- 因此由于事务隔离级别的存在,不同的事务在同一时间下,看到的表内数据行数是不一致的 ,因此innodb,没办法,也没必要像myisam那样单纯的加个count字段信息在数据表上。
count() 类型
count方法的大原则是server层会从innodb存储引擎里读来一行行数据,并且只累计非null的值 。但这个过程,根据count()方法括号内的传参,有略有不同。
- count(*)
server层拿到innodb返回的行数据,不对里面的行数据做任何解析和判断 ,默认取出的值肯定都不是null,直接行数+1 - count(1)
server层拿到innodb返回的行数据,每行放个1进去,默认不可能为null,直接行数+1. -
- InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加
- count(字段)
count(字段)是不统计,字段值为null的值 -
- count(主键 id) 来说,InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加
-
-
count(字段),server要字段,就返回字段,如果字段为空,就不做统计,字段的值过大,都会造成效率低下
由于指明了要count某个字段,innodb在取数据的时候,会把这个字段解析出来 返回给server层,所以会比count(1)和count(*)多了个解析字段出来的流程
-

文
责任链模式
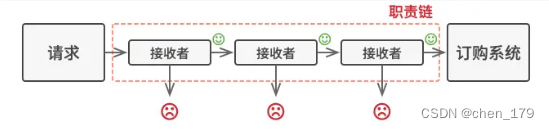
- 责任链模式是一种行为设计模式, 允许你将请求沿着处理者链进行发送。收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下个处理者。
常见场景
- 多条件的流程判断(如导入文件校验条件较多,且需逐层校验成功的;或类似闯关游戏,必须达到一定分数/条件才能开始下一关)
导入功能可能【模板方法】更适合
-
- 模板方法可以提供大部分相同的【模板】,根据不同的导入场景做小部分调整,实现各自独立的业务,大体上导入功能差不多
-
- 一次性实现一个算法的不变部分,并将可变的行为留给子类来实现
-
- 各子类中公共的行为被提取出来并集中到一个公共父类中,从而避免代码重复

- 各子类中公共的行为被提取出来并集中到一个公共父类中,从而避免代码重复
- ERP 系统流程审批:总经理、人事经理、项目经理
- Java 过滤器的底层实现 Filter
例子(闯关游戏)
-
假设现在有一个闯关游戏,进入下一关的条件是上一关的分数要高于 xx:
-
游戏一共 3 个关卡
进入第二关需要第一关的游戏得分大于等于 80
进入第三关需要第二关的游戏得分大于等于 90
简易版(多层 if 逐层判断是否满足条件)
//第一关
public class FirstPassHandler {public int handler(){System.out.println("第一关-->FirstPassHandler");return 80;}
}//第二关
public class SecondPassHandler {public int handler(){System.out.println("第二关-->SecondPassHandler");return 90;}
}//第三关
public class ThirdPassHandler {public int handler(){System.out.println("第三关-->ThirdPassHandler,这是最后一关啦");return 95;}
}//客户端
public class HandlerClient {public static void main(String[] args) {FirstPassHandler firstPassHandler = new FirstPassHandler();//第一关SecondPassHandler secondPassHandler = new SecondPassHandler();//第二关ThirdPassHandler thirdPassHandler = new ThirdPassHandler();//第三关int firstScore = firstPassHandler.handler();//第一关的分数大于等于80则进入第二关if(firstScore >= 80){int secondScore = secondPassHandler.handler();//第二关的分数大于等于90则进入第二关if(secondScore >= 90){thirdPassHandler.handler();}}}
}
- 实际上的 handle() 根据业务来传参及计算分数
- 缺点
当关数越多/条件越多时代码会变得很长,无限月读(if 嵌套)
if(第1关通过){// 第2关 游戏if(第2关通过){// 第3关 游戏if(第3关通过){// 第4关 游戏if(第4关通过){// 第5关 游戏if(第5关通过){// 第6关 游戏if(第6关通过){//...}}} }}
}
升级(责任链链表拼接每一关)
- 可以通过链表将每一关连接起来,形成责任链的方式,第一关通过后是第二关,第二关通过后是第三关… (减少客户端代码过多的 if 嵌套)
public class FirstPassHandler {/*** 第一关的下一关是 第二关*/private SecondPassHandler secondPassHandler;public void setSecondPassHandler(SecondPassHandler secondPassHandler) {this.secondPassHandler = secondPassHandler;}//本关卡游戏得分private int play(){return 80;}public int handler(){System.out.println("第一关-->FirstPassHandler");if(play() >= 80){//分数>=80 并且存在下一关才进入下一关if(this.secondPassHandler != null){return this.secondPassHandler.handler();}}return 80;}
}public class SecondPassHandler {/*** 第二关的下一关是 第三关*/private ThirdPassHandler thirdPassHandler;public void setThirdPassHandler(ThirdPassHandler thirdPassHandler) {this.thirdPassHandler = thirdPassHandler;}//本关卡游戏得分private int play(){return 90;}public int handler(){System.out.println("第二关-->SecondPassHandler");if(play() >= 90){//分数>=90 并且存在下一关才进入下一关if(this.thirdPassHandler != null){return this.thirdPassHandler.handler();}}return 90;}
}public class ThirdPassHandler {//本关卡游戏得分private int play(){return 95;}/*** 这是最后一关,因此没有下一关*/public int handler(){System.out.println("第三关-->ThirdPassHandler,这是最后一关啦");return play();}
}public class HandlerClient {public static void main(String[] args) {FirstPassHandler firstPassHandler = new FirstPassHandler();//第一关SecondPassHandler secondPassHandler = new SecondPassHandler();//第二关ThirdPassHandler thirdPassHandler = new ThirdPassHandler();//第三关firstPassHandler.setSecondPassHandler(secondPassHandler);//第一关的下一关是第二关secondPassHandler.setThirdPassHandler(thirdPassHandler);//第二关的下一关是第三关//说明:因为第三关是最后一关,因此没有下一关//开始调用第一关 每一个关卡是否进入下一关卡 在每个关卡中判断firstPassHandler.handler();}
}
- 缺点
从代码中可以看到,每一关的处理逻辑中都有一个 set**PassHandler() 方法,只是参数类型不一样,但是作用其实是一样的,只是用来判断是否有下一关
每个关卡中都有下一关的成员变量并且是不一样的,形成链很不方便,代码扩展性不行
进化(责任链改造—抽象)
- 每个关卡中都有下一关的成员变量并且是不一样的,那么我们可以在关卡上抽象出一个父类或者接口,然后每个具体的关卡去继承或者实现,将参数合并成一个,不再需要在各自的 set**PassHandler 中传递不同的参数
- 责任链设计模式的基本组成
-
- 抽象处理者(Handler)角色: 定义一个处理请求的接口,包含抽象处理方法和一个后继连接
-
- 具体处理者(Concrete Handler)角色: 实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者
-
- 客户类(Client)角色: 创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程
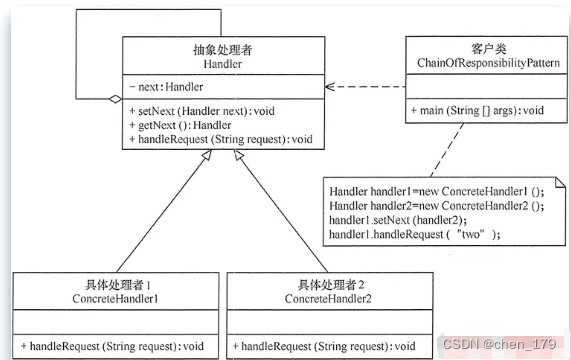
- 客户类(Client)角色: 创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程
public abstract class AbstractHandler {/*** 下一关用当前抽象类来接收*/protected AbstractHandler next;public void setNext(AbstractHandler next) {this.next = next;}public abstract int handler();
}public class FirstPassHandler extends AbstractHandler{private int play(){return 80;}@Overridepublic int handler(){System.out.println("第一关-->FirstPassHandler");int score = play();if(score >= 80){//分数>=80 并且存在下一关才进入下一关if(this.next != null){return this.next.handler();}}return score;}
}public class SecondPassHandler extends AbstractHandler{private int play(){return 90;}public int handler(){System.out.println("第二关-->SecondPassHandler");int score = play();if(score >= 90){//分数>=90 并且存在下一关才进入下一关if(this.next != null){return this.next.handler();}}return score;}
}public class ThirdPassHandler extends AbstractHandler{private int play(){return 95;}public int handler(){System.out.println("第三关-->ThirdPassHandler");int score = play();if(score >= 95){//分数>=95 并且存在下一关才进入下一关if(this.next != null){return this.next.handler();}}return score;}
}public class HandlerClient {public static void main(String[] args) {FirstPassHandler firstPassHandler = new FirstPassHandler();//第一关SecondPassHandler secondPassHandler = new SecondPassHandler();//第二关ThirdPassHandler thirdPassHandler = new ThirdPassHandler();//第三关// 和上面没有更改的客户端代码相比,只有这里的set方法发生变化,其他都是一样的firstPassHandler.setNext(secondPassHandler);//第一关的下一关是第二关secondPassHandler.setNext(thirdPassHandler);//第二关的下一关是第三关//说明:因为第三关是最后一关,因此没有下一关//从第一个关卡开始firstPassHandler.handler();}
}
- 从代码中可以看到,此次进化引入了一个 抽象处理者,让每一关的具体处理者都继承该类,后续在设置下一关对象的时候就不必各自编写各自的set**PassHandler() 方法,而是直接使用相同的处理方法,只需要编写各自的 handler() 得分方法,进一步简化了代码
终极进化(责任链工厂改造)
public enum GatewayEnum {// handlerId, 拦截者名称,全限定类名,preHandlerId,nextHandlerIdAPI_HANDLER(new GatewayEntity(1, "api接口限流", "cn.dgut.design.chain_of_responsibility.GateWay.impl.ApiLimitGatewayHandler", null, 2)),BLACKLIST_HANDLER(new GatewayEntity(2, "黑名单拦截", "cn.dgut.design.chain_of_responsibility.GateWay.impl.BlacklistGatewayHandler", 1, 3)),SESSION_HANDLER(new GatewayEntity(3, "用户会话拦截", "cn.dgut.design.chain_of_responsibility.GateWay.impl.SessionGatewayHandler", 2, null)),;GatewayEntity gatewayEntity;public GatewayEntity getGatewayEntity() {return gatewayEntity;}GatewayEnum(GatewayEntity gatewayEntity) {this.gatewayEntity = gatewayEntity;}
}public class GatewayEntity {private String name;private String conference;private Integer handlerId;private Integer preHandlerId;private Integer nextHandlerId;
}public interface GatewayDao {/*** 根据 handlerId 获取配置项* @param handlerId* @return*/GatewayEntity getGatewayEntity(Integer handlerId);/*** 获取第一个处理者* @return*/GatewayEntity getFirstGatewayEntity();
}public class GatewayImpl implements GatewayDao {/*** 初始化,将枚举中配置的handler初始化到map中,方便获取*/private static Map<Integer, GatewayEntity> gatewayEntityMap = new HashMap<>();static {GatewayEnum[] values = GatewayEnum.values();for (GatewayEnum value : values) {GatewayEntity gatewayEntity = value.getGatewayEntity();gatewayEntityMap.put(gatewayEntity.getHandlerId(), gatewayEntity);}}@Overridepublic GatewayEntity getGatewayEntity(Integer handlerId) {return gatewayEntityMap.get(handlerId);}@Overridepublic GatewayEntity getFirstGatewayEntity() {for (Map.Entry<Integer, GatewayEntity> entry : gatewayEntityMap.entrySet()) {GatewayEntity value = entry.getValue();// 没有上一个handler的就是第一个if (value.getPreHandlerId() == null) {return value;}}return null;}
}public class GatewayHandlerEnumFactory {private static GatewayDao gatewayDao = new GatewayImpl();// 提供静态方法,获取第一个handlerpublic static GatewayHandler getFirstGatewayHandler() {GatewayEntity firstGatewayEntity = gatewayDao.getFirstGatewayEntity();GatewayHandler firstGatewayHandler = newGatewayHandler(firstGatewayEntity);if (firstGatewayHandler == null) {return null;}GatewayEntity tempGatewayEntity = firstGatewayEntity;Integer nextHandlerId = null;GatewayHandler tempGatewayHandler = firstGatewayHandler;// 迭代遍历所有handler,以及将它们链接起来while ((nextHandlerId = tempGatewayEntity.getNextHandlerId()) != null) {GatewayEntity gatewayEntity = gatewayDao.getGatewayEntity(nextHandlerId);GatewayHandler gatewayHandler = newGatewayHandler(gatewayEntity);tempGatewayHandler.setNext(gatewayHandler);tempGatewayHandler = gatewayHandler;tempGatewayEntity = gatewayEntity;}// 返回第一个handlerreturn firstGatewayHandler;}/*** 反射实体化具体的处理者* @param firstGatewayEntity* @return*/private static GatewayHandler newGatewayHandler(GatewayEntity firstGatewayEntity) {// 获取全限定类名String className = firstGatewayEntity.getConference(); try {// 根据全限定类名,加载并初始化该类,即会初始化该类的静态段Class<?> clazz = Class.forName(className);return (GatewayHandler) clazz.newInstance();} catch (ClassNotFoundException | IllegalAccessException | InstantiationException e) {e.printStackTrace();}return null;}}public class GetewayClient {public static void main(String[] args) {GetewayHandler firstGetewayHandler = GetewayHandlerEnumFactory.getFirstGetewayHandler();firstGetewayHandler.service();}
}
- 待深究
文
相关文章:
阅读笔记lv.1
阅读笔记 sql中各种 count结论不同存储引擎计算方式区别count() 类型 责任链模式常见场景例子(闯关游戏) sql中各种 count 结论 innodb count(*) ≈ count(1) > count(主键id) > count(普通索引列) > count(未加索引列)myisam 有专门字段记录…...

小鼠的滚动疲劳仪-转棒实验|ZL-200C小鼠转棒疲劳仪
转棒实验|ZL-200C小鼠转棒疲劳仪用于检测啮齿类动物的运动功能。通过测量动物在滚筒上行走的持续时间,来评定**神经系统*病或损坏以及药物对运动协调功能和疲劳的影响。 疲劳实验中,让小鼠在不停转动的棒上运动,肌肉会很快进入疲劳状态&#…...
平衡搜索二叉树(AVL树)
目录 前言 一、AVL树的概念 二、AVL树的定义 三、AVL树的插入 四、AVL树的旋转 4.1、右单旋 4.2、左单旋 4.3、左右双旋 4.4、右左双旋 五、AVL树的验证 5.1、 验证其为二叉搜索树 5.2、 验证其为平衡树 六、AVL树的性能 前言 二叉搜索树虽可以缩短查找的效率&…...

2024年1月12日学习总结
学习目标 完成集中学习的readme 完成联邦学习的代码编写 边学习边总结 学习内容 Introduction to Early Stopping 1、Overfitting 过拟合是所有机器学习,深度学习中可能出现的一个比较严重的问题。具体表现就是:你的模型在训练集上处理的效果非常好&…...

PCL 使用克拉默法则进行四点定球(C++详细过程版)
目录 一、算法原理二、代码实现三、计算结果本文由CSDN点云侠原创,PCL 使用克拉默法则进行四点定球(C++详细过程版),爬虫自重。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT生成的文章。 一、算法原理 已知空间内不共面的四个点,设其坐标为 A (…...

前端导致浏览器奔溃原因分析
内存泄漏 内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。(程序某个未使用的变量或者方法,长期占…...
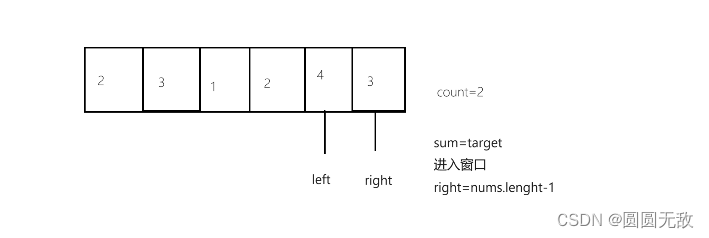
力扣:209.长度最小的子数组
1.题目分析: 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。 示例 …...

常见类型的yaml文件如何编写?--kind: Service
基本说明 在 Kubernetes 中,Service 是一种抽象的方式,用于定义一组 Pod 的访问方式和网络服务。Service 提供了一个稳定的网络端点(Endpoint),使得其他服务或外部用户可以通过 Service 来访问被管理的 Pod。 负载均…...

linux环境下安装postgresql
PostgreSQL: Linux downloads (Red Hat family)postgresql官网 PostgreSQL: Linux downloads (Red Hat family) 环境: centos7 postgresql14 选择版本 执行启动命令 配置远程连接文件 vi /var/lib/pqsql/14/data/postgresql.conf 这里将listen_addresses值由lo…...

专业课145+合肥工业大学833信号分析与处理考研经验合工大电子信息通信
今年专业课145也是考研科目中最满意的一门,其他基本相对平平,所以这里我总结一下自己的专业课合肥工业大学833信号分析与处理的复习经验。 我所用的教材是郑君里的《信号与系统》(第三版)和高西全、丁玉美的《数字信号处理》&…...
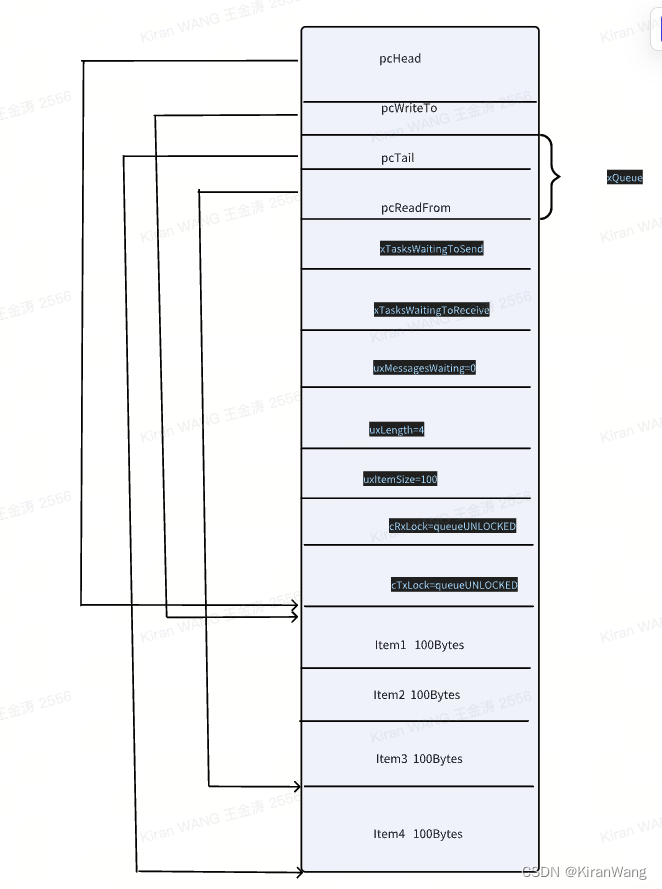
FreeRtos Queue (一)
本篇主要讲队列的数据结构和初始化 一、队列的数据结构 二、队列初始化完是什么样子的 队列初始化的函数调用关系:xQueueGenericCreate->prvInitialiseNewQueue->xQueueGenericReset 所以,最终初始化完的队列是这样的 假设申请了4个消息体&…...
深入理解 Hadoop (五)YARN核心工作机制浅析
概述 YARN 的核心设计理念是 服务化(Service) 和 事件驱动(Event EventHandler)。服务化 和 事件驱动 软件设计思想的引入,使得 YARN 具有低耦合、高内聚的特点,各个模块只需完成各自功能,而模…...

优化 - 重构一次Mysql导致服务器的OOM
概述 优化了一次前后端处理不当导致的CPU的一次爆机行为,当然,这和服务器的配置低也有着密不可分的关系,简单的逻辑学告诉我们,要找到真正的问题,进行解决,CPU爆机的关键点在于前后端两个方面,…...

【光波电子学】基于MATLAB的多模光纤模场分布的仿真分析
基于MATLAB的多模光纤模场分布的仿真分析 一、引言 (1)多模光纤的概念 多模光纤(MMF)是一种具有较大纤芯直径的光纤结构,其核心直径通常在10-50微米范围内。与单模光纤(SMF)相比,…...

0104 AJAX介绍
Ajax 的全称是 Asynchronous Javascript And XML (异步 JavaScript 和 XML )。 通俗的理解:在网页中利用 XMLHttpRequest 对象和服务器进行数据交互的方式,就是 Ajax Ajax 能让我们轻松实现网页与服务器之间的数据交互。 浏览器…...
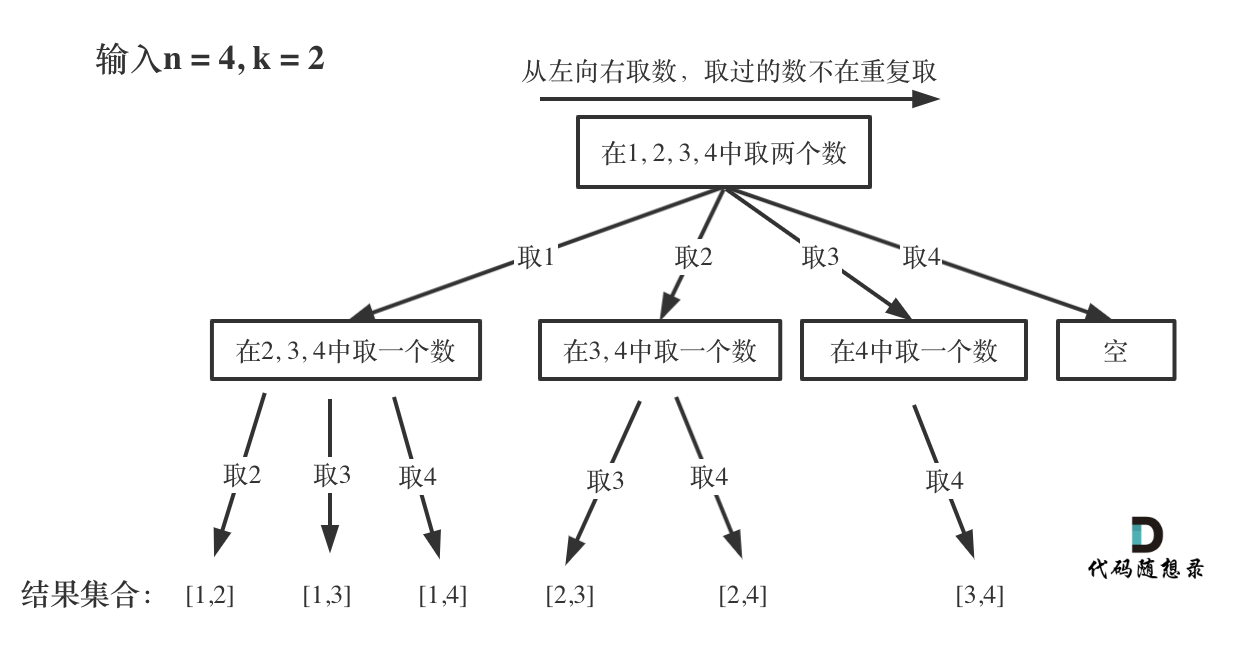
代码随想录算法训练营第24天 | 理论基础 77. 组合
目录 理论基础 什么是回溯法 回溯法的效率 回溯法解决的问题 如何理解回溯法 回溯法模板 77. 组合 💡解题思路 💻实现代码 理论基础 什么是回溯法 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。 回溯法的效率 虽然回溯法很难ÿ…...

【深度学习环境搭建】Windows搭建Anaconda3、已经Pytorch的GPU版本
目录 搭建Anaconda3搭建GPU版本的Pytorch你的pip也要换源,推荐阿里源打开conda的PowerShell验证 搭建Anaconda3 无脑下载安装包安装(自行百度) 注意点: 1、用户目录下的.condarc需要配置(自定义环境的地址(…...

基于WebFlux的Websocket的实现,高级实现自定义功能拓展
基于WebFlux的Websocket 一、导入XML依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId> </dependency><!-- 或者引入jackson --> <dependency><group…...

使用 LLVM clang C/C++ 编译器编译 OpenSSL 3.X库
1、下载 OpenSSL 3.X 库的源代码放到待编译目录 2、解压并接入 OpenSSL 3.X 库源码的根目录 3、复制 ./Configure 一个取名为 ./Configure-clang 4、修改 ./Configure-clang 找到配置段: CC CXX CPP LD 把它们改成 CC > "/usr/bin/clang-…...

【信息安全】hydra爆破工具的使用方法
hydra简介 hydra又名九头蛇,与burp常规的爆破模块不同,hydra爆破的范围更加广泛,可以爆破远程桌面连接,数据库这类的密码。他在kali系统中自带。 参数说明 -l 指定用户名 -L 指定用户名字典文件 -p 指定密码 -P 指…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...
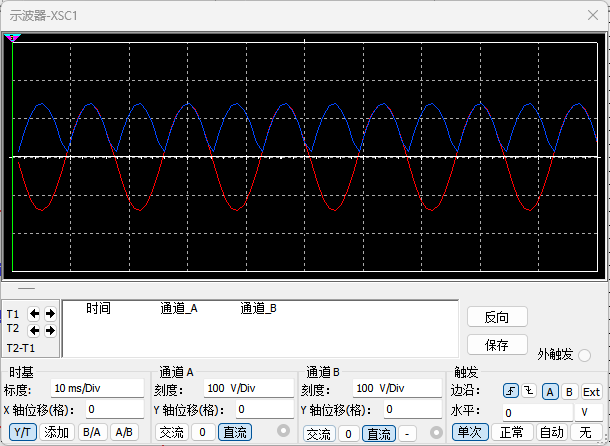
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...

【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构C.1 指令微调阶段C.2 排名与生成的总和指令微调阶段C.3 RankRAG推理:检索-重排-生成 D 实验设计E 个人总结 A 论文出处 论文题目:RankRAG:Unifying Context Ranking…...