MySQL核心SQL
一.结构化查询语言
SQL是结构化查询语言(Structure Query Language),它是关系型数据库的通用语言。
- DDL(Data Definition Languages)语句
数据定义语言,这些语句定义了不同的数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 create、drop、alter等。 - DML(Data Manipulation Language)语句
数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字,主要包括 insert、delete、update 和select 等。 - DCL(Data Control Language)语句
数据控制语句,用于控制不同的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户 的访问权限和安全级别。主要的语句关键字包括 grant、revoke 等。
二.库操作
show databases;
create database db01;
drop database db01;
use db01;
三.表操作
show tables;
create table user(
id int primary key auto_increment comment '主键',
nickname varchar(20) not null comment '昵称',
age int unsigned not null default 18 comment '年龄',
sex enum('男','女') default '男' comment '性别'
)engine=innodb default charset=utf8;
修改表名
alter table user rename to user1;
alter table user add password varchar(20);
删除字段
alter table user drop password;
改变字段的类型
alter table user modify password varchar(30);
desc user
show create table user;或者show create table user\G
drop table user;
四.CRUD操作
1.insert增加
INSERT INTO USER(nickname,age,sex) VALUES('张三',19,'男'),('李四',20,'女');
INSERT INTO USER(nickname,age,sex) VALUES('王五',26,'男');
这两条语句的区别:一条SQL语句执行一次三次握手和四次挥手
多条语句执行多次

2.update修改
UPDATE USER SET age=age+1;
UPDATE USER SET age=age+1 where id=1;
3.delete删除
delete from user where id=1;
delete from user;
delete from user where age between 1 and 2;
4.select查询
1.简单select查询
select * from user;
select id,nickname,age,sex from user;
select id,nickname,age,sex from user where sex='男';
2.去重distinct
select distinct age from user;
3.空值查询
select * from user where nickname is null;
4.union合并查询
select * from user where age>=20 union all select * from user where sex='男';
select * from user where age>=20 union select * from user where sex='男';
5.带in子查询
select * from user where age in(20,21);
6.分页查询
select * from user limit 3;
select * from user limit 1,3;
select * from user limit 3 offset 1;
select * from user where age>=20 limit 2 offset 1;
我们都知道有索引字段的情况下查询的条数都是一条,但是没有使用会发生什么情况,使用limit会不会提高查询的效率呢?
可以使用explain查询select查询的条数
EXPLAIN SELECT * FROM USER WHERE age>=20 LIMIT 1;
 可以看到还是要进行全表扫描的,但是实际执行过程中扫描到第一条符合条件的数据的时候就停止扫描了,在实际的环境中(对于大量的数据),使用limit查询的速度比不适用快很多
可以看到还是要进行全表扫描的,但是实际执行过程中扫描到第一条符合条件的数据的时候就停止扫描了,在实际的环境中(对于大量的数据),使用limit查询的速度比不适用快很多
向t_user表中插入2000000条数据的执行
delimiter $
Create Procedure add_t_user (IN n INT)
BEGIN
DECLARE i INT;
SET i=0;
WHILE i<n DO
INSERT INTO t_user VALUES(NULL,CONCAT(i+1,'@fixbug.com'),i+1);
SET i=i+1;
END WHILE;
END$
delimiter ;
call add_t_user(2000000);此时我们可以进行观察,速度明显是快很多的,自己可以尝试
因此当我们知道某个数据是唯一(或者需要查询执行数量的数据)时,并且字段没有建立索引,此时我们使用limit可以明显提高查询的效率.
实际生产项目中分页查询pagenum,pageno
select * from user limit (pageno-1)*pagenum,pagenum;
这种可以进行查询,但是效率很低,因为他首先需要从0->offset条数据,再将之后的数据取出来,0->offset条数据的时间
优化后的sql语句(id为主键,具体表的主键为准),因为主键建立了索引,我们只需要花常量的时间就可以定位到需要查询的位置
select * from user where id>(上一页最后一条数据的id) limit pagenum;
7.排序order by
select * from user order by age;(默认升序ASC)
select * from user order by age DESC;
select * from user order by age,nickname;
EXPLAIN SELECT * FROM USER ORDER BY nickname;
使用的是外排序
 EXPLAIN SELECT id,nickname FROM USER ORDER BY nickname;
EXPLAIN SELECT id,nickname FROM USER ORDER BY nickname;
使用的是索引
 是否使用的是索引与排序的字段是否添加索引和查询的字段是否有索引有关
是否使用的是索引与排序的字段是否添加索引和查询的字段是否有索引有关
8.分组group by
select age,count(age) as num from user group by age;
select age from user group by age having age>20;
select age,sex from user group by age,sex;
explain select age from user group by age;

查询出来的数据其实是经过排序的,因此会出现filesort,因此group by之后的字段加索引是十分必要的
9.笔试实践题
| 字段名 | 描述 |
| serno | 流水号 |
| date | 交易日期 |
| accno | 账号 |
| name | 姓名 |
| amount | 金额 |
| brno | 缴费网点 |
select count( serno),sum( amount) from bank_bill;
select brno,date,sum(amount) as sum_account from bank_bill group by brno,date order by sum_account DESC;
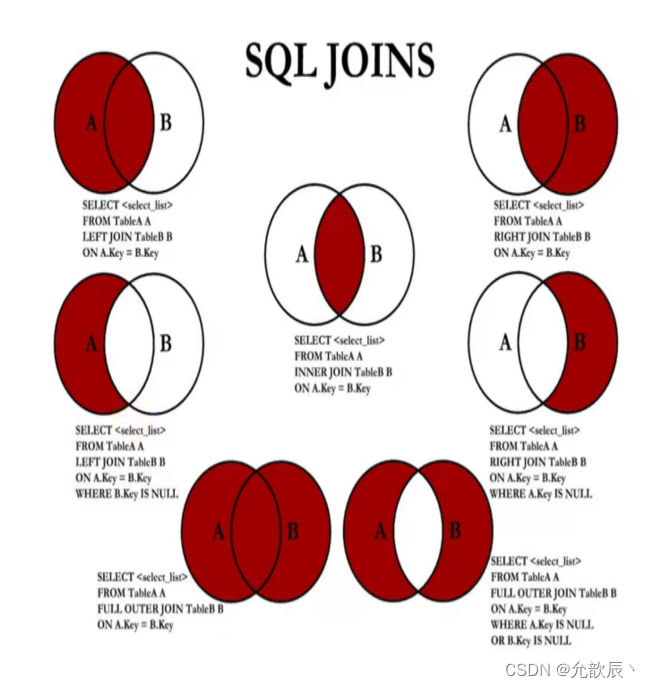
5.连接查询
连接查询主要分为以下的几个:
先来创建三个表
create table student(
uid int primary key auto_increment,
name varchar(20) not null,
age int not null,
sex enum('男','女') default '男' not null
);create table course(
cid int primary key auto_increment,
cname varchar(20) not null,
credit int not null
);create table exame(
uid int not null,
cid int not null,
time date not null,
score float not null,
primary key(uid,cid)
);
插入一些数据:
insert into student(name,age,sex)
values('zhangsan',18,'男'),('gaoyang',20,'女'),('chenwei',22,'男') ,('linfeng',21,'女'),('liuxiang',19,'女');
insert into course(cname, credit)
values('c++基础课程',5),('c++高级课程',10),('c++项目开发',8),('c++算法课程',12);
insert into exame(uid,cid,time,score)
values(1,2,'2021-04-10',80.0),(2,2,'2021-04-10',90.0),
(2,3,'2021-04-12',85.0),(3,1,'2021-04-09',56.0) ,
(3,2,'2021-04-10',93.0),(3,3,'2021-04-12',89.0),(3,4,'2021-04-11',100.0),
(4,4,'2021-04-11',99.0),(5,2,'2021-04-10',59.0),
(5,3,'2021-04-12',94.0),(5,4,'2021-04-11',95.0);
1.内连接查询
select t1.uid,t1.name,t1.age,t1.sex,t2.`score` from student t1 join exame t2 on t1.`uid`=t2.`uid`;

重点:on a.uid=c.uid区分大表和小表,按照数据量来区分,小表永远是整表扫描,然后去大表搜索从student小表中取出所有的a.uid,然后拿着这些uid去exame大表中搜索
对于inner join内连接,过滤条件写在where的后面和on连接条件里面,效果是一样的
select t1.uid,t1.name,t1.age,t1.sex,t2.`score`,t3.`cid`,t3.`cname`,t3.`credit` from student t1 join exame t2 on t1.`uid`=t2.`uid`
join course t3 on t3.`cid`=t2.`cid`;
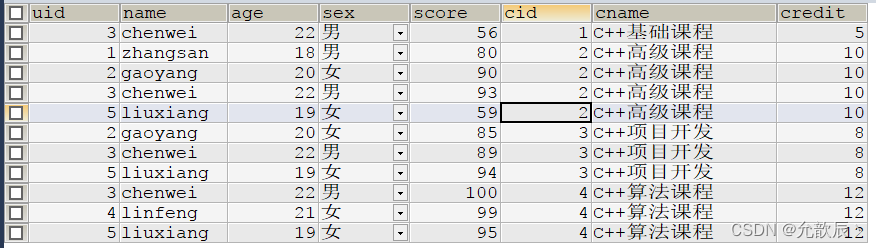
select b.cid,b.cname,b.credit,count(*) cnt
from exame c
inner join course b on c.cid=b.cid
where c.score>=90.0
group by c.cid
order by cnt;

内连接应用场景,前面t_user表可以通过id直接定位分页查询的位置,是因为加了索引,如果我们直接查询id,因为id加了索引,也可以减少查询的时间,但是我们需要的是查询全部的信息,怎么通过内连接可以减少查询的时间呢?
select id from t_user limit 100000,10
下面给出解决方案
select a.id,a.email,a.password from t_user a join (select id from t_user limit 100000,10) b
on a.id=b.id;
通过产生的id临时表,可以直接定位到查询的位置,也是因为id加了索引.
2.外连接查询
学生表中插入一条新的数据
insert into student(name,age,sex) values('weiwei',32,'男');
1.左连接查询
select a.*,b.* from student a left join exame b on a.`uid`=b.`uid`;
 把left这边的表所有的数据显示出来,在右表中不存在相应数据,则显示NULL
把left这边的表所有的数据显示出来,在右表中不存在相应数据,则显示NULL
使用explain查看可知是先查左表

2.右连接查询
select a.*,b.* from student a right join exame b on a.`uid`=b.`uid`;

select a.*,b.* from student a left join exame b on a.`uid`=b.`uid` where b.`cid`=2;select a.*,b.* from student a join exame b on a.`uid`=b.`uid` where b.`cid`=2;
此时上面的两条sql语句一个是内连接一个是外连接,两者按理来说应该是不一样的,但是实际显示的结果都是一致的

使用explain查看

可以看到都是先全表查询右表,然后再查询左表,这样与我们预期中的左连接查询结果是不一样的了,此时我们应该
select a.*,b.* from student a left join exame b on a.`uid`=b.`uid` and b.`cid`=2;
我们把查询的条件写在on的后面,此时查询的结果是我们想的左连接查询所预期的

使用explain查看也可以看到是先查询左表的.

外连接的连接条件不能像内连接一样写在on和where都行,如果想要产生符合预期的答案,应该要写在on后面
相关文章:
MySQL核心SQL
一.结构化查询语言 SQL是结构化查询语言(Structure Query Language),它是关系型数据库的通用语言。 SQL 主要可以划分为以下 3 个类别: DDL(Data Definition Languages)语句 数据定义语言,这…...

关于 setData 同步异步的问题
小程序官方文档中的回答解释: 所以大概意思就是: 1.setData在逻辑层的操作是同步,因此this.data中的相关数据会立即更新,比如下面的例子: const a 1 this.setData({b: a ? a : , }) console.log(that.data.b) // 1 2. setData在视图层的操作是异步,…...

Centos创建一个Python虚拟环境
在 CentOS 上创建一个 Python 虚拟环境,可以使用 virtualenv 工具。以下是创建和激活虚拟环境的基本步骤: 1.安装virtualenv 如果还没有安装 virtualenv,可以使用以下命令安装: sudo yum install python3-virtualenv请注意&…...

怎么使用好爬虫IP代理?爬虫代理IP有哪些使用技巧?
在互联网时代,爬虫技术被广泛应用于数据采集和处理。然而,在使用爬虫技术的过程中,经常会遇到IP被封禁的问题,这给数据采集工作带来了很大的困扰。因此,使用爬虫IP代理成为了解决这个问题的有效方法。本文将介绍如何使…...
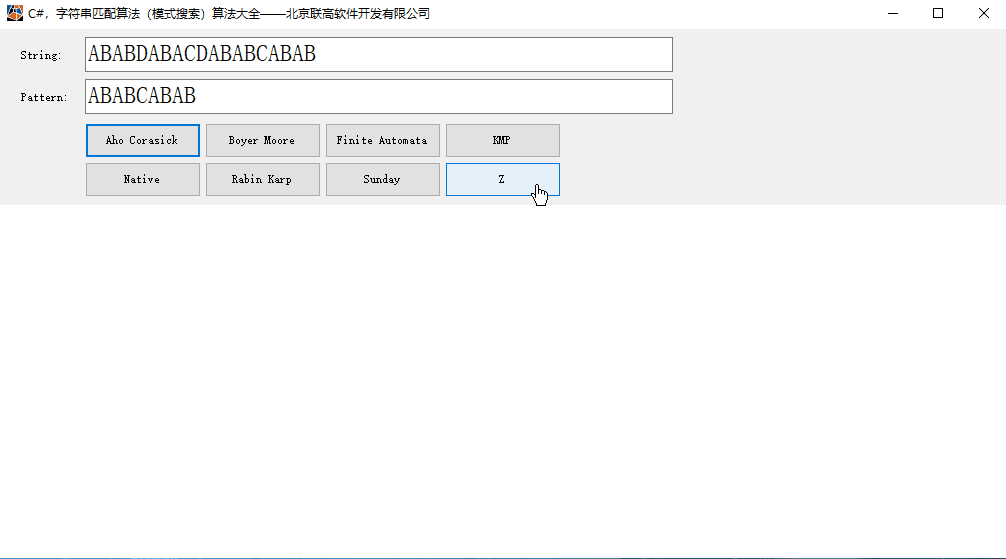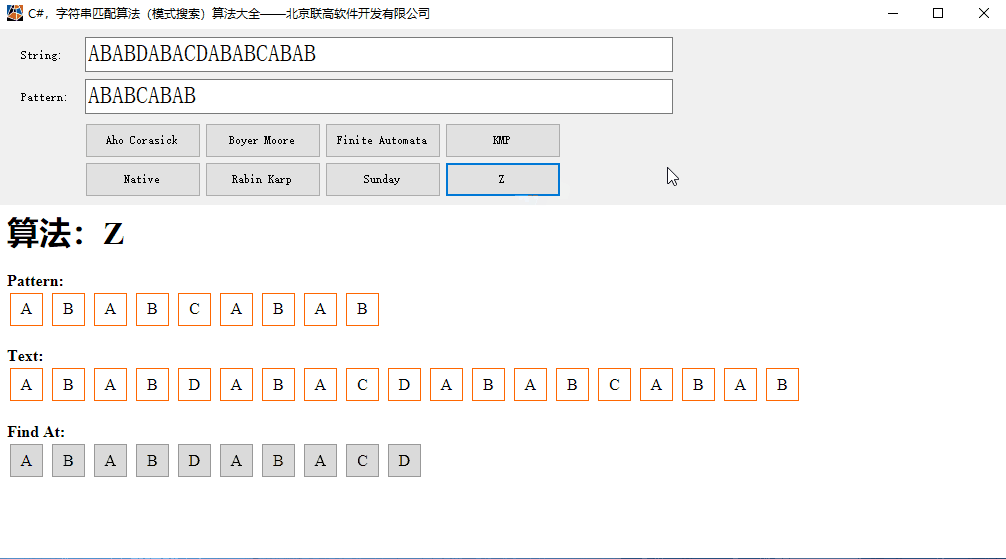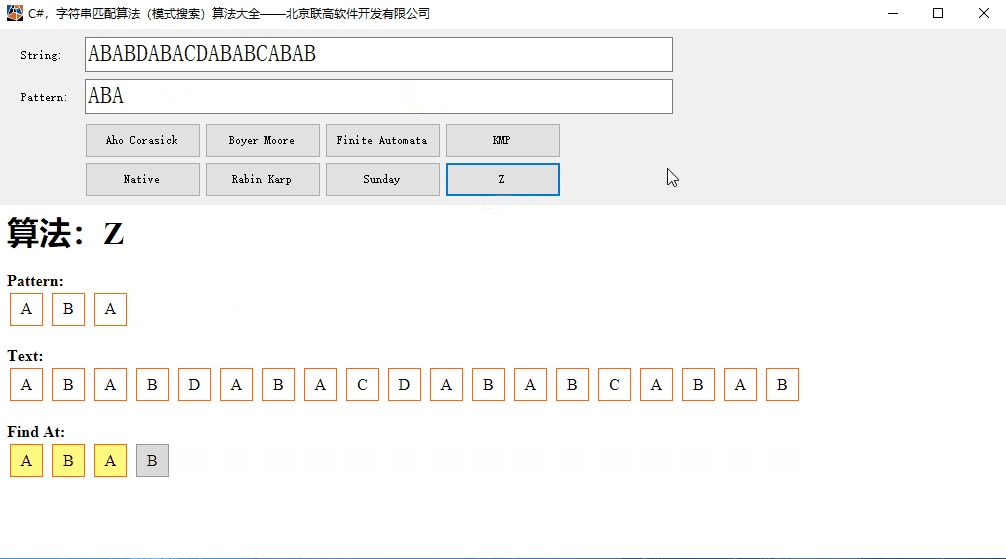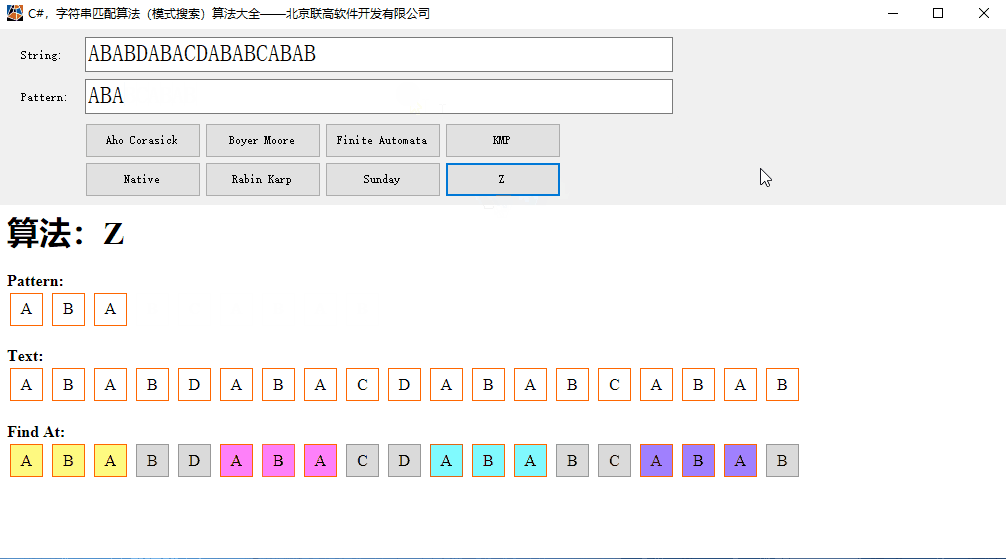
C#,字符串匹配算法(模式搜索)Z算法的源代码与数据可视化
Z算法也是模式搜索(Pattern Search Algorithm)的常用算法。 本文代码的运算效果: 一、Z 算法 线性时间模式搜索算法的Z算法,在线性时间内查找文本中模式的所有出现。 假设文本长度为 n,模式长度为 m,那么…...

强化学习actor-critic
...

使用推测解码 (Speculative Decoding) 使 Whisper 实现 2 倍的推理加速
Open AI 推出的 Whisper 是一个通用语音转录模型,在各种基准和音频条件下都取得了非常棒的结果。最新的 large-v3 模型登顶了 OpenASR 排行榜,被评为最佳的开源英语语音转录模型。该模型在 Common Voice 15 数据集的 58 种语言中也展现出了强大的多语言性…...

pi gpio 内存映射
树霉pi gpio内存映射 #include <stdio.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> #include <stdlib.h>#define BCM2835_PERI_BASE 0x20000000 #define GPIO_BASE (BCM2835_PERI_BASE 0x200000) #define PAGE_SIZE…...
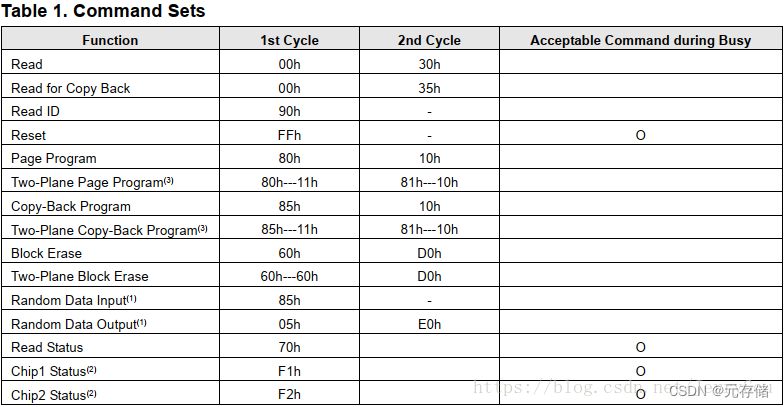
[NAND Flash 6.2] NAND 初始化常用命令:复位 (Reset) 和 Read ID 和 Read UID 操作和代码实现
依公知及经验整理,原创保护,禁止转载。 专栏 《深入理解NAND Flash》 <<<< 返回总目录 <<<< 把下文中的字母和数字用`包起来, 中文不变。 全文 4400 字,主要内容 复位的目的和作用? NAND Reset 种类:FFh, FCh, FAh, FDh 区别 Reset 操作步骤 和…...
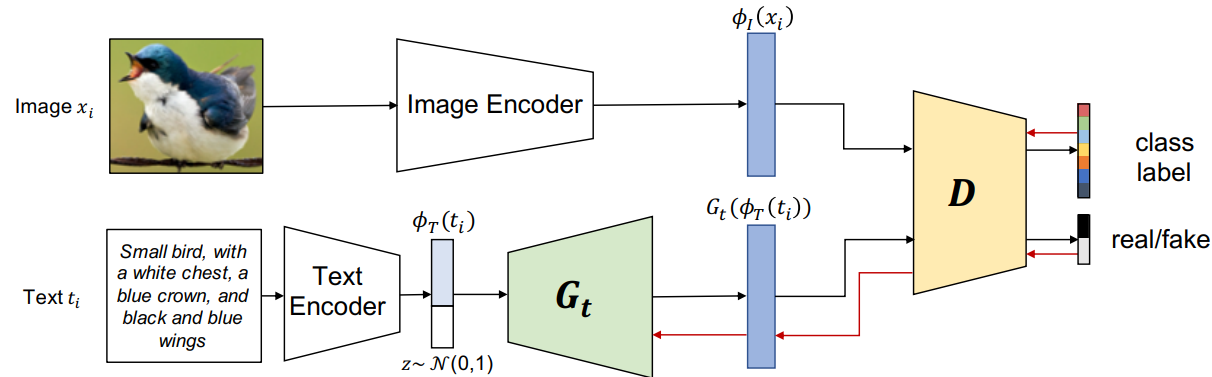
Multimodal Prototypical Networks for Few-shot Learning
tcGAN is provided with an embedding ϕ T \phi_T ϕT() of the textual description 辅助信息 作者未提供代码...

软件测试|Python requests库的安装和使用指南
简介 requests库是Python中一款流行的HTTP请求库,用于简化HTTP请求的发送和处理,也是我们在使用Python做接口自动化测试时,最常用的第三方库。本文将介绍如何安装和使用requests库,以及一些常见的用例示例。 安装requests库 首…...
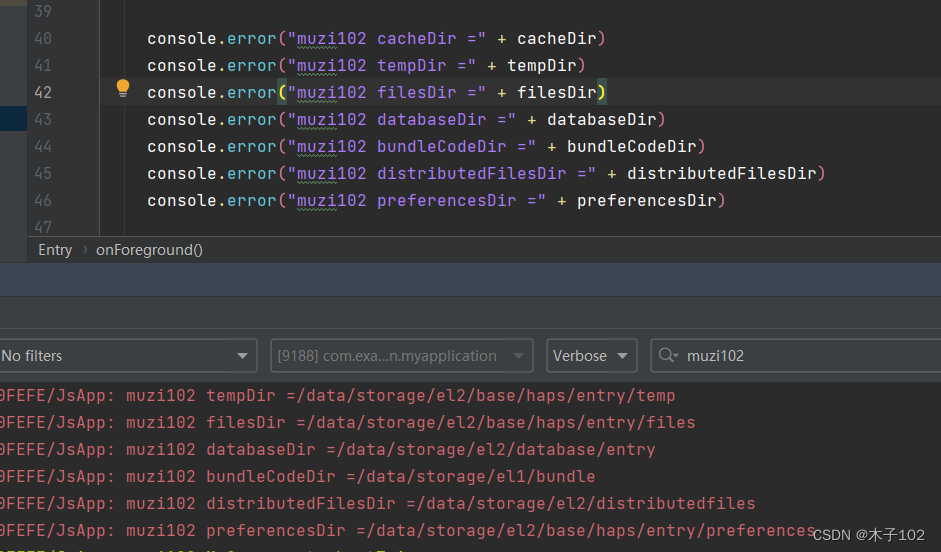
HarmonyOS应用开发学习笔记 应用上下文Context 获取文件夹路径
1、 HarmoryOS Ability页面的生命周期 2、 Component自定义组件 3、HarmonyOS 应用开发学习笔记 ets组件生命周期 4、HarmonyOS 应用开发学习笔记 ets组件样式定义 Styles装饰器:定义组件重用样式 Extend装饰器:定义扩展组件样式 5、HarmonyOS 应用开发…...

http状态码对照表
状态码含义100客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应。…...

金三银四-JVM核心知识高频面试题
又要快到一年一度的金三银四,开始复习啦~! 每天一点点。。 目录 一、JVM中的垃圾收集器有哪些,它们的工作原理是什么? 二、JVM中的类加载器有哪些,它们各自的作用是什么? 三、JVM中垃圾回收的…...
【GitHub项目推荐--谷歌大神又一开源代码调试神器】【转载】
如果调试是 Debug 的必经之路,那么编程应该将它考虑在内。今天我就和大家分享一个代码调试神器 - Cyberbrain。 Cyberbrain是一个免费开源的 Python 代码调试解决方案,它可视化程序执行以及每个变量的变化方式,让程序员免受调试之苦。主要具有…...

Ubuntu pip换源
在 Ubuntu 上使用 pip 更改软件包的下载源可以通过修改 pip.conf 文件来完成。 首先打开终端(Terminal)。 输入以下命令创建或编辑 pip.conf 文件: sudo nano /etc/pip.conf如果提示需要管理员密码,则输入密码并按 Enter 键确认。…...
解锁前端新潜能:如何使用 Rust 锈化前端工具链
前言 近年来,Rust的受欢迎程度不断上升。首先,在操作系统领域,Rust 已成为 Linux 内核官方认可的开发语言之一,Windows 也宣布将使用 Rust 来重写内核,并重写部分驱动程序。此外,国内手机厂商 Vivo 也宣布…...

vite前端工具链,为开发提供极速响应
一、概念 Vite是一个高性能的分布式智能合约平台。它使用了一种名为“异步架构”的设计,能够支持高吞吐量和低延迟的交易处理。Vite采用了基于DAG(有向无环图)的账本结构,可以实现并行处理多个交易,并且具有快速确认的…...

linux系统nginx做负载均衡
负载均衡 作用upstream配置负载均衡算法配置分类热备轮询加权轮询ip_hash 负载均衡配置状态参数nginx配置7层协议及4层协议七层协议做负载均衡四层协议做负载均衡 会话保持ip_hashsticky_cookie_insertjvm_route 作用 负载均衡(Load Balance,简称 LB&am…...
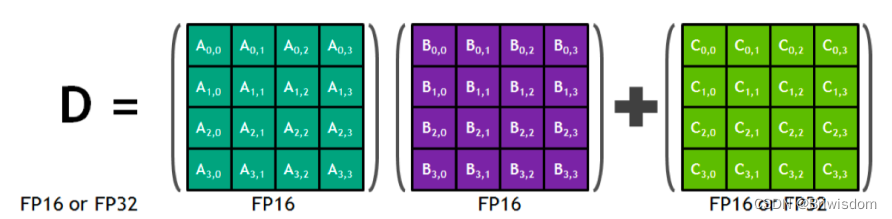
Tensor Core的一些概念理解
英伟达的GPU产品架构发展如下图,Tensor Core是从2017年的Volta架构开始演变的针对AI模型大量乘加运算的特殊处理单元。本文主要梳理一些关于Tensor Core的一些基础概念知识。 什么是混合精度? 混合精度在底层硬件算子层面,使用半精度…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...
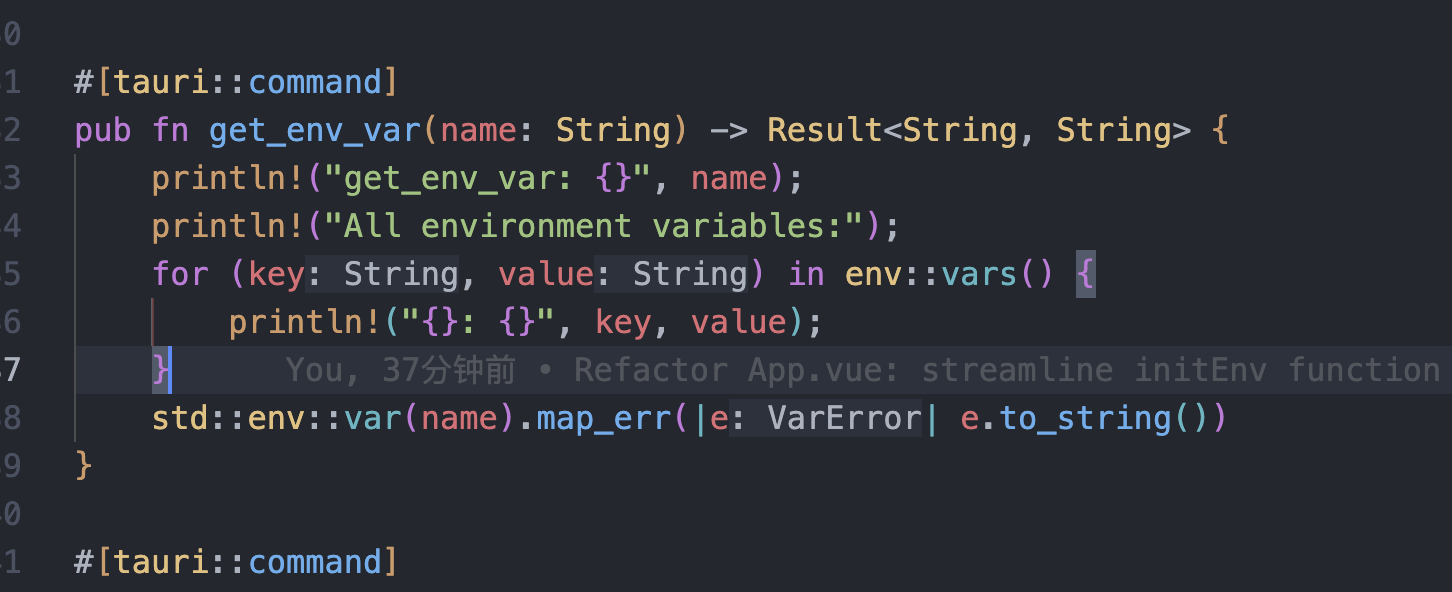
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...
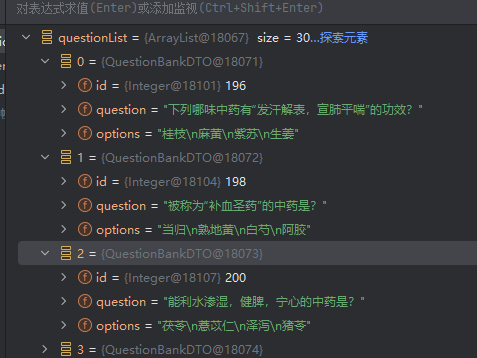
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...
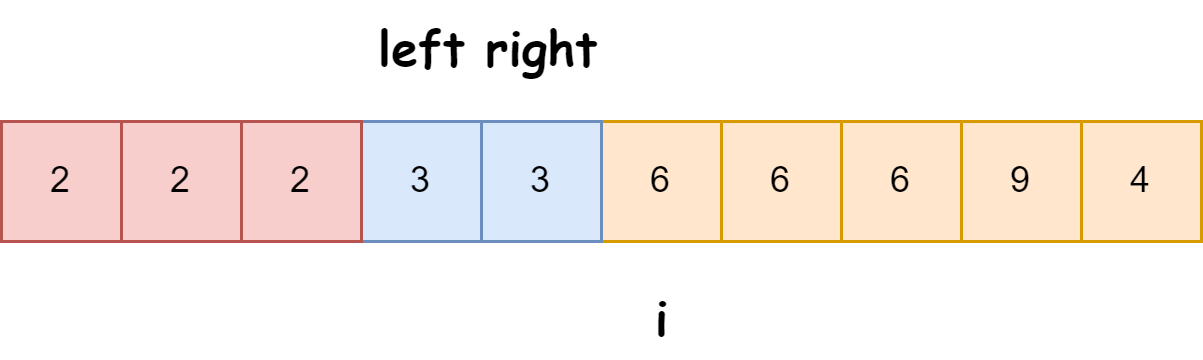
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...