py爬虫入门笔记(request.get的使用)
文章目录
- Day1
- 1. 了解浏览器开发者工具
- 2. Get请求http://baidu.com
- 3. Post请求https://fanyi.baidu.com/sug
- 4. 肯德基小作业
- Day2
- 1. 正则表达式
- 2. 使用re模块
- 3. 爬取豆瓣电影Top250的第一页
- 4. 爬取豆瓣电影Top250所有的250部电影信息
- Day3
- 1. xpath的使用
- 2. 认识下载照片+线程池的语法
- 题外话
我所参考的学习资料,该教程位于B站并可以通过 传送门访问。
没有完全照着视频敲,所以代码和视频的有些不一样,但是大体上的思路是一样的。下面的笔记供自己复习,简单的爬虫格式还是很固定的,爬点简单的东西拷贝过来直接用就行(虽然其实是我记不住接口😭😭😭)
Day1
1. 了解浏览器开发者工具
基本介绍浏览器开发工具的各个部分
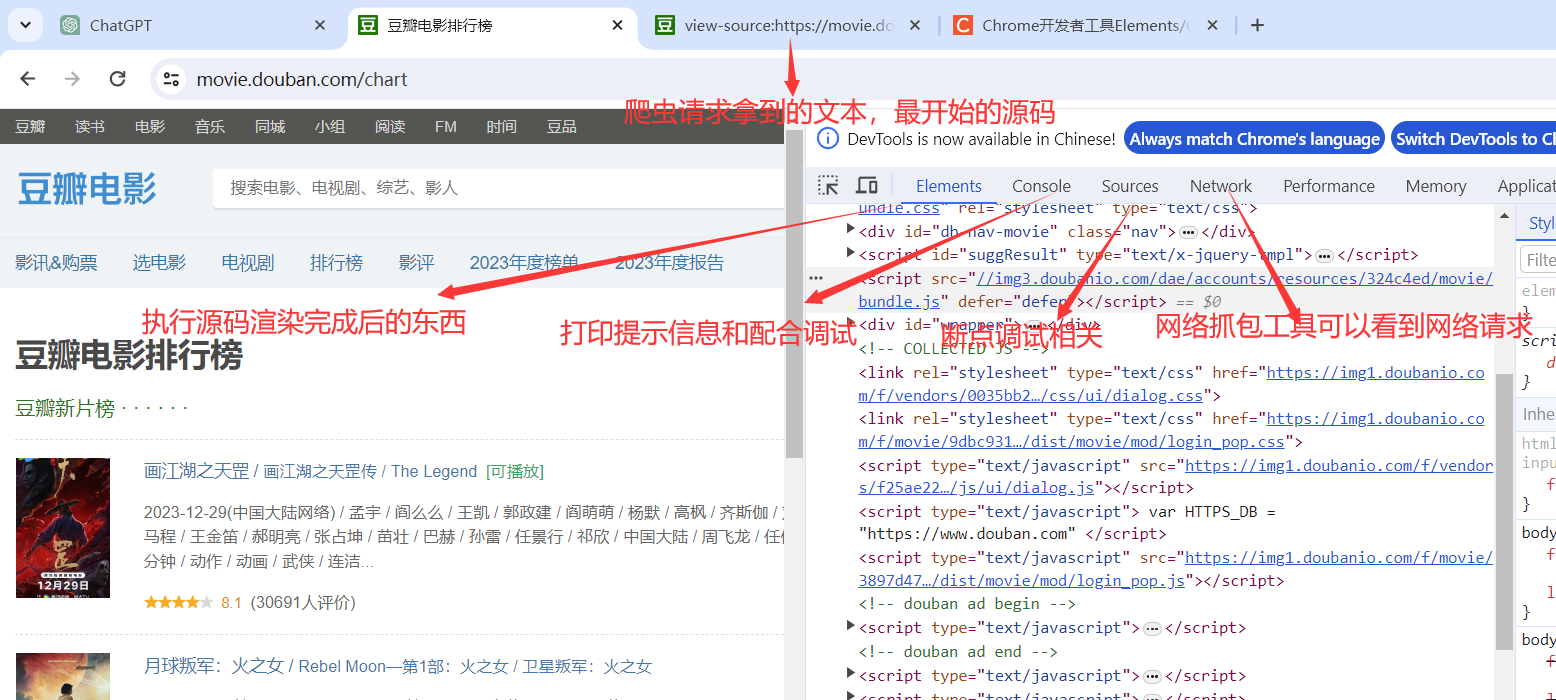
源码介绍
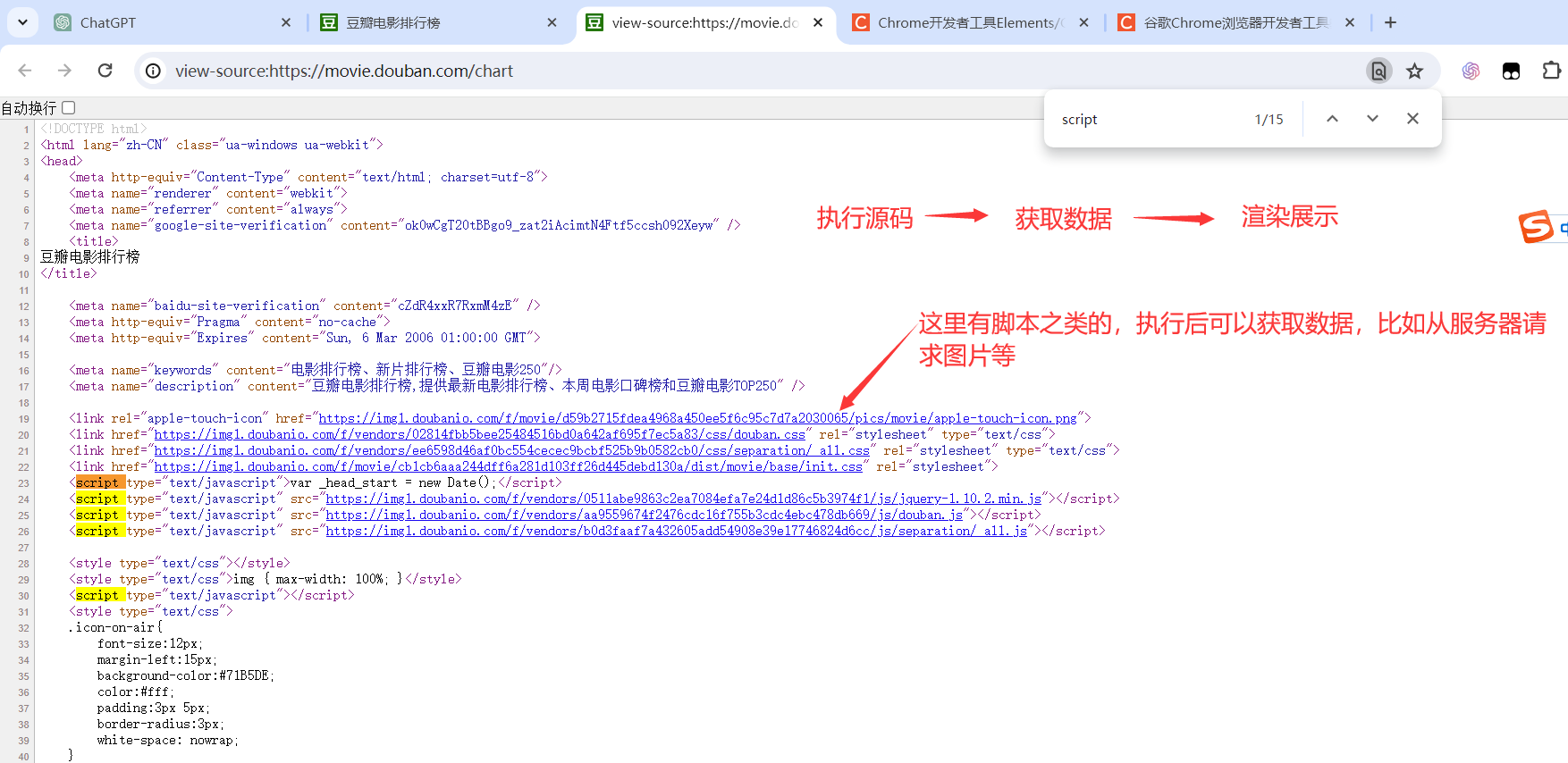
其余的相关字段
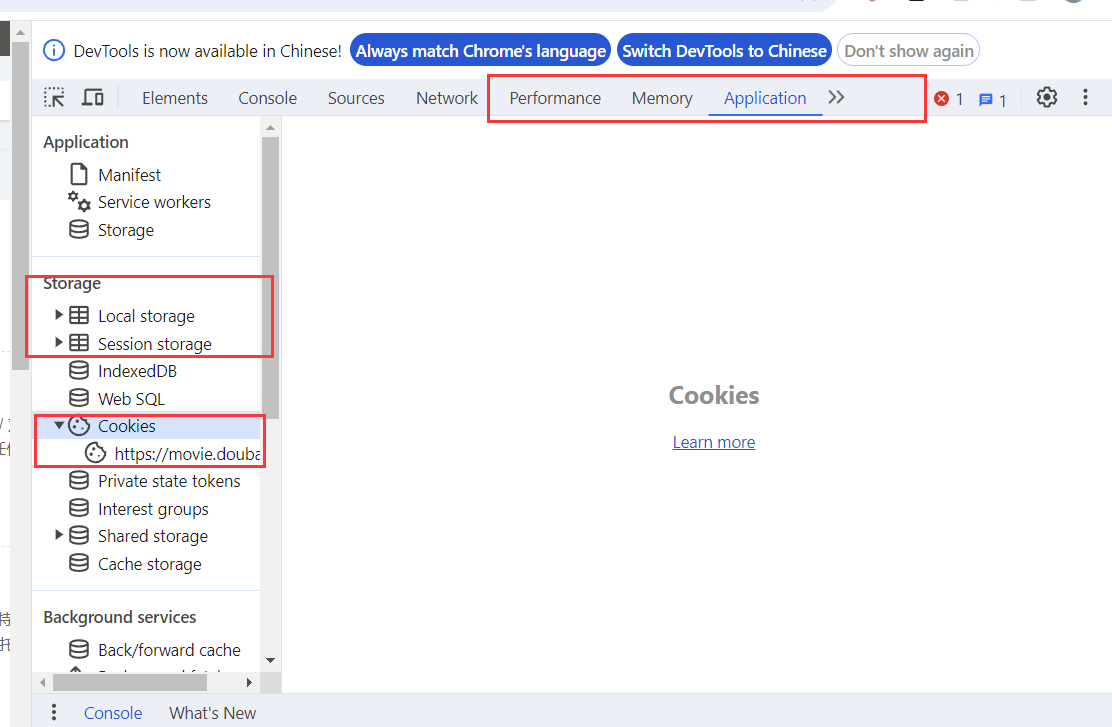
相对应的字段
来源:https://blog.csdn.net/maidu_xbd/article/details/94062690
爬虫拿到的不是Elements,拿到的是源码
2. Get请求http://baidu.com
装requests包,请求http://baidu.com再获取响应并且写入文件
import requestsurl='http://baidu.com'resp=requests.get(url) #请求百度,记住接受返回值,类型是Response类
print(type(resp)) #检查resp的类型# print(resp.text) #还可以打印状态码,报头等等with open("mybaidu.html",mode="w") as f:f.write(resp.text) #写入文件文件内容
<html> <meta http-equiv="refresh" content="0;url=http://www.baidu.com/"> </html>
pycharm有个小图标可以直接点开,也可以自己创建一个html文件复制进去。
content=“0;url=http://www.baidu.com/”:规定了刷新的时间间隔和目标 URL。这里的 0 表示立即刷新,url=http://www.baidu.com/ 是重定向的目标 URL。所以会展示出百度的页面
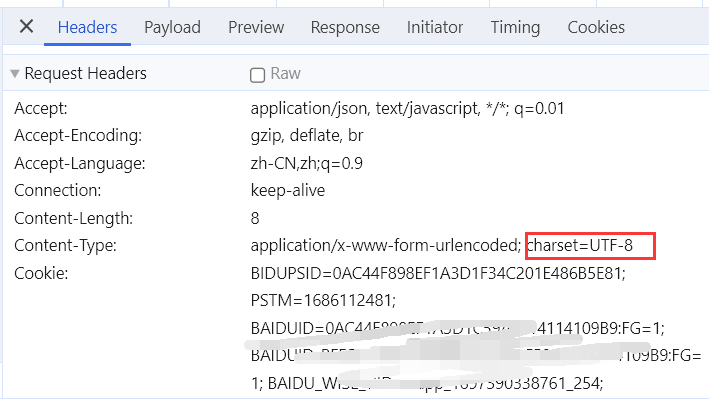
3. Post请求https://fanyi.baidu.com/sug
打开百度翻译,随便输入一个单词,打开Network->XHR->找到你输入的这个单词的请求->找到请求的类型和请求的url->发现携带了数据,在写代码时记得构建数据
注意会有多个请求,你输入一个单词就会造成一个请求,比如你输入apple,会出现 a ap app appl apple这么几个请求
如果收到的response是乱码的,可以检查request的编码,然后修改代码在发送的请求加上对应的编码
import requestsurl="https://fanyi.baidu.com/sug"
mydata={"kw":"apple"
}resp=requests.post(url,data=mydata)
resp.encoding="utf-8"
print(resp.status_code)
print(resp.text) #打出的字符含有\u是json的转义字符,使用json方法解析json数据返回的是一个字典
print(resp.json())
output:
200
{"errno":0,"data":[{"k":"Apple","v":"n. \u82f9\u679c\u516c\u53f8\uff0c\u539f\u79f0\u82f9\u679c\u7535\u8111\u516c\u53f8"},{"k":"apple","v":"n. \u82f9\u679c; \u82f9\u679c\u516c\u53f8; \u82f9\u679c\u6811"},{"k":"APPLE","v":"n. \u82f9\u679c"},{"k":"apples","v":"n. \u82f9\u679c\uff0c\u82f9\u679c\u6811( apple\u7684\u540d\u8bcd\u590d\u6570 ); [\u7f8e\u56fd\u53e3\u8bed]\u68d2\u7403; [\u7f8e\u56fd\u82f1\u8bed][\u4fdd\u9f84\u7403]\u574f\u7403; "},{"k":"Apples","v":"[\u5730\u540d] [\u745e\u58eb] \u963f\u666e\u52d2"}],"logid":2500940021}
{'errno': 0, 'data': [{'k': 'Apple', 'v': 'n. 苹果公司,原称苹果电脑公司'}, {'k': 'apple', 'v': 'n. 苹果; 苹果公司; 苹果树'}, {'k': 'APPLE', 'v': 'n. 苹果'}, {'k': 'apples', 'v': 'n. 苹果,苹果树( apple的名词复数 ); [美国口语]棒球; [美国英语][保龄球]坏球; '}, {'k': 'Apples', 'v': '[地名] [瑞士] 阿普勒'}], 'logid': 2500940021}
4. 肯德基小作业
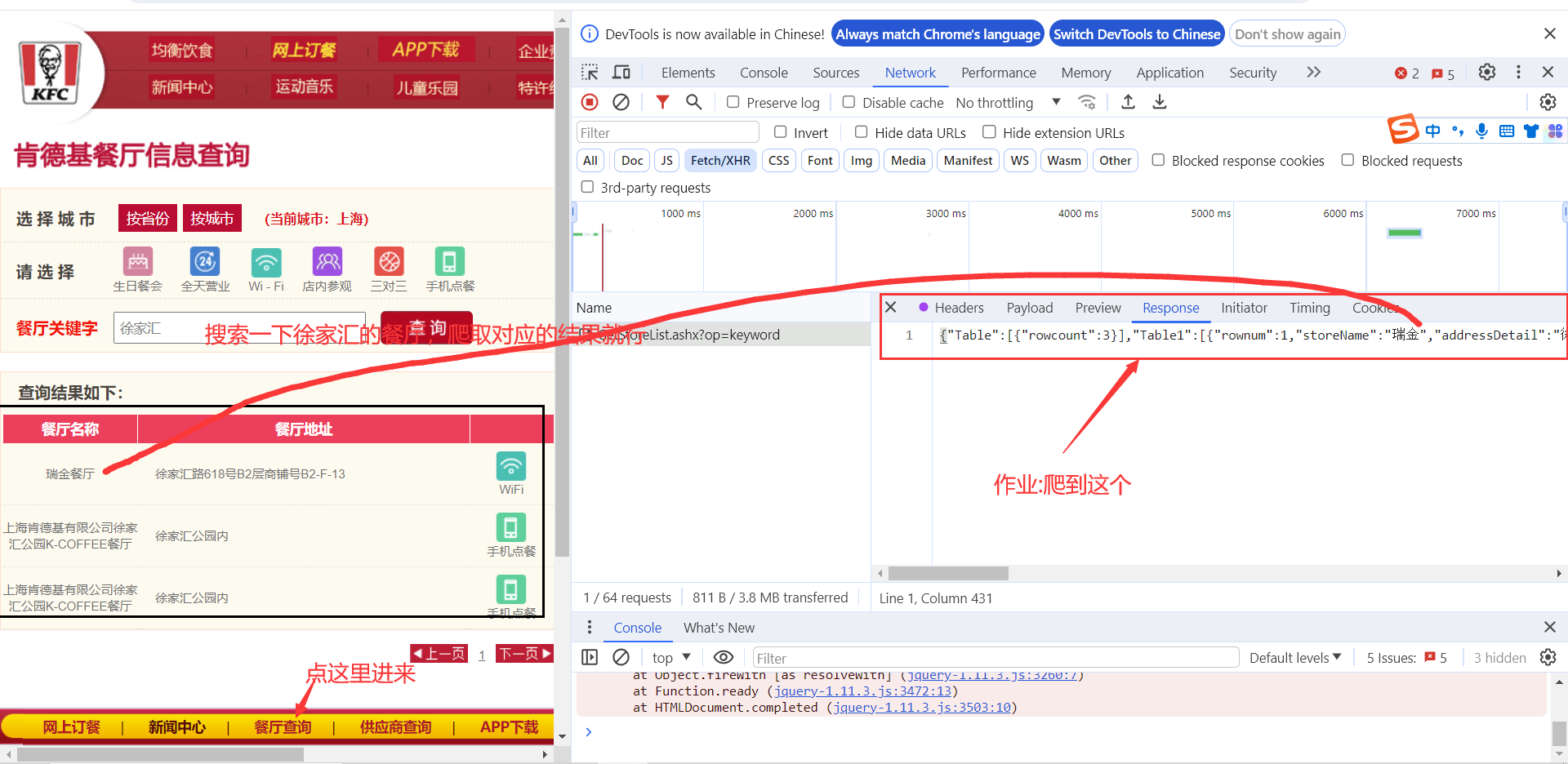
import requestsurl="https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"
mydata={
"cname":"",
"pid":"",
"keyword": "徐家汇",
"pageIndex": "1",
"pageSize": "10",
}resp=requests.post(url,data=mydata)
print(resp.status_code)
print(resp.json())
output:
200
{'Table': [{'rowcount': 3}], 'Table1': [{'rownum': 1, 'storeName': '瑞金', 'addressDetail': '徐家汇路618号B2层商铺号B2-F-13', 'pro': 'Wi-Fi,点唱机,礼品卡,溯源', 'provinceName': '上海市', 'cityName': '上海市'}, {'rownum': 2, 'storeName': '上海肯德基有限公司徐家汇公园K-COFFEE', 'addressDetail': '徐家汇公园内', 'pro': '高铁店,手机点餐', 'provinceName': '上海市', 'cityName': '上海市'}, {'rownum': 3, 'storeName': '上海肯德基有限公司徐家汇公园K-COFFEE', 'addressDetail': '徐家汇公园内', 'pro': '高铁店,手机点餐', 'provinceName': '上海市', 'cityName': '上海市'}]}进程已结束,退出代码0
Day2
1. 正则表达式
板书,直接搬过来了(正则不用去纠结很难的,一些简单的会写就行,严格的话比如检测用户名之类的都有现成的,比自己写得好还没啥漏洞)
![Y [ ] Y []_Y []YXU A Y P C I 5 B Q Q 67 ‘ M t m b ] ( h t t p s : / / p i c − 1304888003. c o s . a p − g u a n g z h o u . m y q c l o u d . c o m / i m g / Y AYPCI5BQQ67`M_tmb](https://pic-1304888003.cos.ap-guangzhou.myqcloud.com/img/Y AYPCI5BQQ67‘Mtmb](https://pic−1304888003.cos.ap−guangzhou.myqcloud.com/img/Y%5B%5D_Y X U XU XUAYPCI5BQQ67%60M_tmb.png)
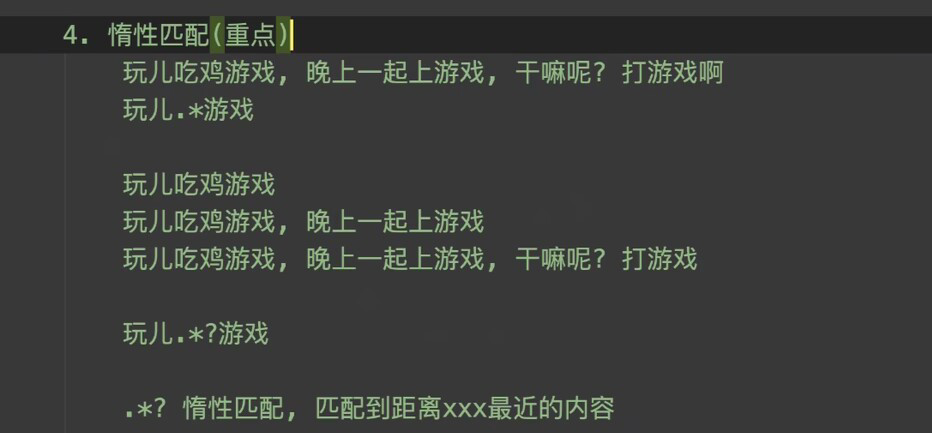
惰性匹配与贪婪匹配(惰性匹配有就匹配一次,贪婪匹配就是能匹配多少就匹配多少)
正则匹配网站:https://tool.oschina.net/regex?optionGlobl=global
手册:https://tool.oschina.net/uploads/apidocs/jquery/regexp.html
2. 使用re模块
导入re模块(内置的,不用pip)->练习findall search finditer方法
import reprint("findall")
result=re.findall(r"\d+","这是一个测试字符串,包含123和456。") #找到所有的数字,这里的r是为了避免处理转义字符,不加r字符串里的\默认转义
print(result) #返回的是一个列表
print()print("search")
result=re.search(r"\d+","这是一个测试字符串,包含123和456。")
print(result) #Match对象
print(result.group()) #使用group分组处理
print()print("finditer")
result=re.finditer(r"\d+","这是一个测试字符串,包含123和456。")
print(result) #迭代器对象
for item in result:# print(item) #每个item都是Match对象,group处理print(item.group())
print()
output
findall
['123', '456']search
<re.Match object; span=(12, 15), match='123'>
123finditer
<callable_iterator object at 0x0000015AF5B88C70>
123
456进程已结束,退出代码0
finditer和findall的区别,如果大量数据处理可使用finditer节省内存,即不用一次性处理所有数据,迭代器结合循环就可以获取前一百个匹配啊之类的
使用compile预处理构造正则表达式对象,符合复用原则,也提高了代码的可读性
import re
obj=re.compile(r"\d+") #构建正则对象obj
result=obj.findall("这是一个测试字符串,包含123和456。")
print(result)
result=obj.search("这是一个测试字符串,包含123和456。")
print(result.group())
output
['123', '456']
123进程已结束,退出代码0
使用group进行分组提取出信息
import re
s="""
<div><a href="baidu.com">我是百度</a></div>
<div><a href="google.com">我是谷歌</a></div>
<div><a href="360.com">我是360</a></div>
"""
obj=re.compile(r'<div><a href="(?P<url>.*?)">(?P<name>.*?)</a></div>') #用.*?惰性匹配,?P<url>是进行分组,组名是url
result=obj.finditer(s)
for item in result:# print(item.groupdict()) #返回字典url=item.group("url")name=item.group("name")print(url,name)
output:
baidu.com 我是百度
google.com 我是谷歌
360.com 我是360进程已结束,退出代码0
3. 爬取豆瓣电影Top250的第一页
我们要获取电影的名字 年份 和平均得分
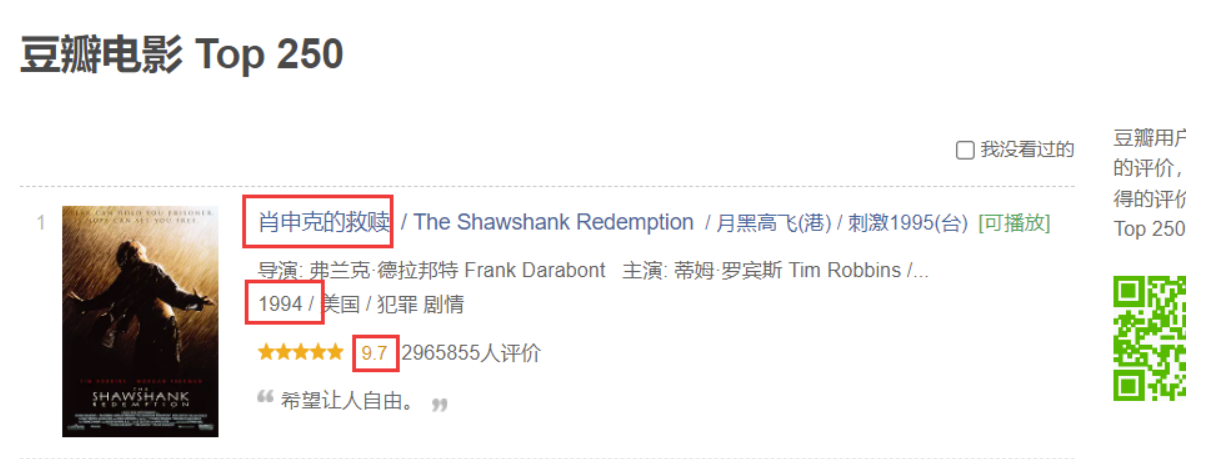
通过豆瓣电影Top250页面源码可知我们可以直接获得这些信息,所以爬取的基本流程就是获取源码->正则提取出需要的信息->分组打印即可
关键在于正则的编写
其中有一个关于反爬的机制,需要给我们的请求头部加一些特定的信息,比如
“User-Agent”:“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36”,
表示我们的请求不是由自动化程序发出的,如果不加伪装,默认情况下写的py爬虫的请求头部User-Agent的值会是
‘User-Agent’: ‘python-requests/2.28.1’
豆瓣那边发现是自动化程序发出的请求就不会给响应了(状态码也变成了418)
所以我们改一下头部信息再发过去(伪装成一个正常设备发过去的请求)
import re
import requestsurl="https://movie.douban.com/top250"
header={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
}
resp=requests.get(url,headers=header)
resp.encoding="utf-8"
print(resp.status_code) #观察状态码是不是200
# print(resp.text)obj=re.compile(r'<div class="item">.*?'r'<span class="title">(?P<name>.*?)</span>.*?'r'<br>(?P<year>.*?) .*?'r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>',re.S) #.*里的.默认匹配非换行符之外的所有字符,re.S选项表示换行符也参与匹配。因为请求到的源码里有很多换行符,所以必须加这个选项result=obj.finditer(resp.text)
for item in result:name=item.group('name')year=item.group('year')year=year.split()[0] #split返回的是列表,处理一下score=item.group('score')print(name,year,score)output
200
肖申克的救赎 1994 9.7
霸王别姬 1993 9.6
阿甘正传 1994 9.5
泰坦尼克号 1997 9.5
这个杀手不太冷 1994 9.4
千与千寻 2001 9.4
美丽人生 1997 9.5
星际穿越 2014 9.4
盗梦空间 2010 9.4
辛德勒的名单 1993 9.5
楚门的世界 1998 9.4
忠犬八公的故事 2009 9.4
海上钢琴师 1998 9.3
三傻大闹宝莱坞 2009 9.2
放牛班的春天 2004 9.3
机器人总动员 2008 9.3
疯狂动物城 2016 9.2
无间道 2002 9.3
控方证人 1957 9.6
大话西游之大圣娶亲 1995 9.2
熔炉 2011 9.4
教父 1972 9.3
触不可及 2011 9.3
当幸福来敲门 2006 9.2
寻梦环游记 2017 9.1进程已结束,退出代码0
数据拿到之后怎么处理就不是爬虫关心的事情了。
4. 爬取豆瓣电影Top250所有的250部电影信息
找到分页的规律构造每一页的url,构造好url后就转换成了爬取每一页的电影信息
找url的规律(点击分页按钮,发现start后面的数字呈规律性递增)
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
…
import re
import requests
def GetOnePage(url:str):#传入url爬取这一页的所有电影信息header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",}resp = requests.get(url, headers=header)# resp=requests.get(url)resp.encoding = "utf-8"# print(resp.request.headers)# print(resp.status_code)# print(resp.text)obj = re.compile(r'<div class="item">.*?'r'<span class="title">(?P<name>.*?)</span>.*?'r'<br>(?P<year>.*?) .*?'r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>', re.S)result = obj.finditer(resp.text)for item in result:name = item.group('name')year = item.group('year')year = year.split()[0]score = item.group('score')str=name+" "+year+" "+score+"\n" #构建表示信息的字符串# print(str)with open('info.txt',mode='a') as f:f.write(str)#创建文件如何写入电影信息# GetOnePage('https://movie.douban.com/top250') #测试函数
# https://movie.douban.com/top250?start=25&filter=
for i in range(0,10): #循环构造urlpage=i*25url=f"https://movie.douban.com/top250?start={page}&filter=" #f-string便于插入值,r-string取消转义,利用f-str构造urlGetOnePage(url)output:
写到了文件里面
Day3
1. xpath的使用
语法文档:https://docs.python.org/zh-cn/3/library/xml.etree.elementtree.html?highlight=xpath#elementtree-parsing-xml
熟悉xpath相关的一些语法
import requests
from lxml import etreeurl='http://www.baidu.com/' #这里没加请求头,baidu有反爬机制,加了请求头和不加得到的数据是不同的
#myhead={
# "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
#}
resp=requests.get(url)
resp.encoding='utf-8'
# print(resp.text) #打印响应的数据
et=etree.HTML(resp.text)
print(et) #印证确实是Element html对象result=et.xpath("/html/head/title/text()") #逐层往下找,text()表示标签之间的文本,如<p>123</p>
print(result)
result=et.xpath("/html/head/link/@href") #匹配link标签的href属性
print(result)print()
keys=et.xpath("//div[@id='u1']/a/text()") #//div表示匹配HTML里所有的div,div[@id='u1']选择特定属性的div
# print(keys)
values=et.xpath("//div[@id='u1']/a/@href")
# print(values)
result=dict(zip(keys,values))
for item in result.items(): #一一对应输出print(item)output:
<Element html at 0x294a32b1000>
['百度一下,你就知道']
['http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css']('新闻', 'http://news.baidu.com')
('hao123', 'http://www.hao123.com')
('地图', 'http://map.baidu.com')
('视频', 'http://v.baidu.com')
('贴吧', 'http://tieba.baidu.com')
('更多产品', '//www.baidu.com/more/')进程已结束,退出代码0
2. 认识下载照片+线程池的语法
下载图片
import requestsurl='https://images.pexels.com/photos/2950499/pexels-photo-2950499.jpeg' #网上随便找了一张图片
resp=requests.get(url)
print(resp.status_code) #看一下请求是否成功#写入图片得使用content,返回的是二进制数据,所以得使用wb打开而不是w。不能使用text,text返回的是文本数据
with open('test.jpg',mode='wb') as f: f.write(resp.content)output:
运行成功后当前目录下多出一张test.jpg的图片
线程池
导包->创建线程池->确定线程池里最大线程的数量,提交任务
记得提交的任务要封装成一个函数
#导包,名字还挺长
from concurrent.futures import ThreadPoolExecutordef func():for i in range(0,10):print(f"子线程{i}")def main():with ThreadPoolExecutor(max_workers=10) as executor: #线程池同时最多执行十个线程executor.submit(func) #提交任务,func而不是func(),如果是func()会立即执行而不会放在线程池中跑for i in range(0, 10): #交替打印print(f"主线程{i}")# for i in range(0, 10): #线程池的任务完成了才会运行到这# print(f"主线程{i}")if __name__ == '__main__':main()
output:
可以明显看到交替打印的现象
子线程0主线程0
主线程1主线程2子线程1子线程2主线程3
主线程4
子线程3主线程5子线程4主线程6
主线程7子线程5
子线程6
主线程8
子线程7
主线程9子线程8
子线程9进程已结束,退出代码0
我没有做视频里的项目,但是我自己做了别的网站的,实现的效果差不多就是构建图库。
题外话
上面有错误的话敬请大佬斧正。
request.get的使用和加请求头之类的这些知识只是入门的,真正的爬虫和逆向紧密相关,所以会使用request.get不表示会爬虫🤡,要精通爬虫与多个方向都相关,比如加密算法,js逆向等,是一个很大的板块。但是学会上面的东西爬一些简单的不设防的网站没啥问题,比如构建自己的壁纸图库等。其实去年五月份就爬了ttok,按博主分类爬了几千个视频,但是调用别人的API终究不是自己写的,前两天想再运行的时候发现代码文件命名混乱和没写注释使得完全跑不了了,蚌。包括爬一些数据加密过的网站都是有难度的。
相关文章:
py爬虫入门笔记(request.get的使用)
文章目录 Day11. 了解浏览器开发者工具2. Get请求http://baidu.com3. Post请求https://fanyi.baidu.com/sug4. 肯德基小作业 Day21. 正则表达式2. 使用re模块3. 爬取豆瓣电影Top250的第一页4. 爬取豆瓣电影Top250所有的250部电影信息 Day31. xpath的使用2. 认识下载照片线程池的…...

openssl3.2 - 官方demo学习 - encode - rsa_encode.c
文章目录 openssl3.2 - 官方demo学习 - encode - rsa_encode.c概述笔记END openssl3.2 - 官方demo学习 - encode - rsa_encode.c 概述 命令行参数 server_priv_key.pem client_priv_key.pem 这2个证书是前面certs目录里面做的 官方这个程序有bug, 给出2个证书, 还要从屏幕上输…...
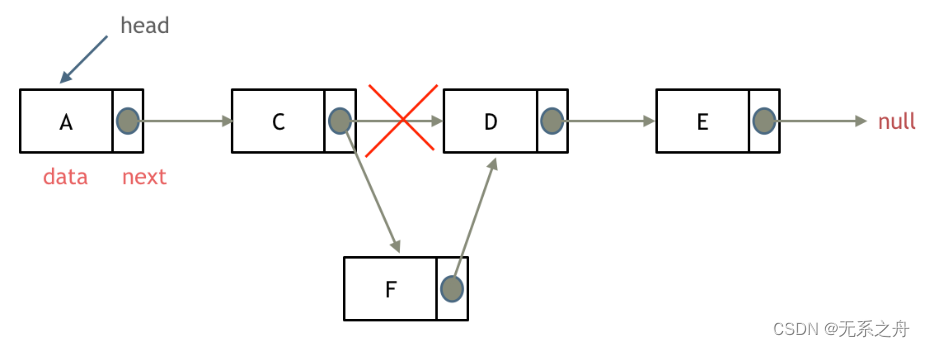
Day03
今日任务 链表理论基础203.移除链表元素707.设计链表206.反转链表 链表理论基础 1)单链表 单链表中的指针域只能指向节点的下一个节点 2)双链表 双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个…...

adb 常用命令汇总
目录 adb 常用命令 1、显示已连接的设备列表 2、进入设备 3、安装 APK 文件到设备 4、卸载指定包名的应用 5、从设备中复制文件到本地 6、将本地文件复制到设备 7、查看设备日志信息 8、重启设备 9、截取设备屏幕截图 10、屏幕分辨率 11、屏幕密度 12、显示设备的…...
ubuntu 2022.04 安装vcs2018和verdi2018
主要参考网站朋友们的作业。 安装时参考: ubuntu18.04安装vcs、verdi2018_ubuntu安装vcs-CSDN博客https://blog.csdn.net/qq_24287711/article/details/130017583 编译时参考: 【ASIC】VCS报Error-[VCS_COM_UNE] Cannot find VCS compiler解决方法_e…...

品牌推广与情绪价值的深度结合:市场大局下的新趋势与“准”原则
随着社会经济的快速发展和消费者心理的复杂化,品牌推广已经不再是单一的信息传递,而是一个与消费者建立情感连接、传达品牌价值的过程。在这个过程中,情绪价值起到了至关重要的作用。它不仅影响着消费者的购买决策,更是品牌与消费…...

React16源码: React中的不同的expirationTime的源码实现
不同的 expirationTime 1 )概述 在React中不仅仅有异步任务大部分情况下都是同步的任务,所以会有不同 expirationTime 的存在 2 )种类 A. Sync 模式,优先级最高 任务创建完成之后,立马更新到真正的dom里面是一个创建…...
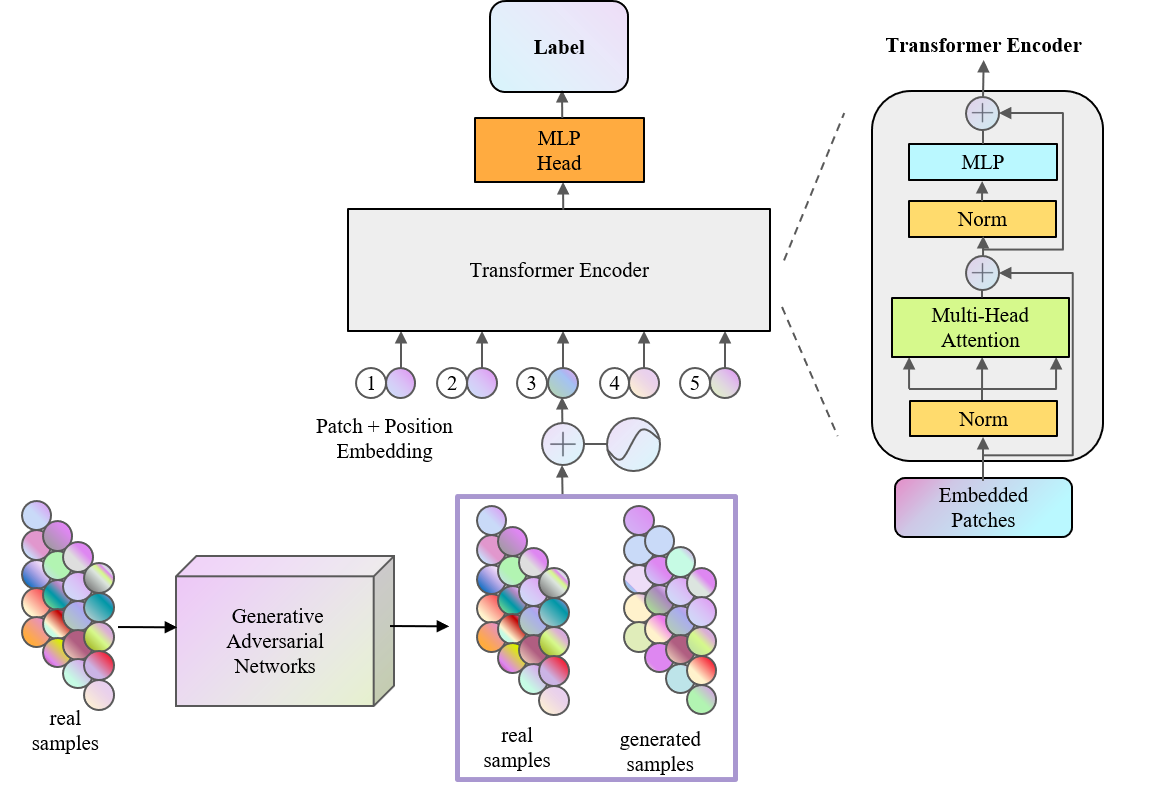
TRB 2024论文分享:基于生成对抗网络和Transformer模型的交通事件检测混合模型
TRB(Transportation Research Board,美国交通研究委员会,简称TRB)会议是交通研究领域知名度最高学术会议之一,近年来的参会人数已经超过了2万名,是参与人数和国家最多的学术盛会。TRB会议几乎涵盖了交通领域…...

Golang 打包
构建/打包 使用 Go 的构建命令: go build在包含 main 函数的包的目录下执行,它会生成一个可执行文件。文件名默认与包所在的目录名相同,但也可以使用 -o 选项来指定输出的文件名 交叉编译 Windows 环境下进行交叉编译以构建其他平台的可执…...

力扣每日一练(24-1-14)
做过类似的题,一眼就是双指针,刚好也就是题解。 if not nums:return 0p1 0 for p2 in range(1, len(nums)):if nums[p2] ! nums[p1]:p1 1nums[p1] nums[p2]return p1 1 根据规律,重复的数字必定相连,那么只要下一个数字与上一…...
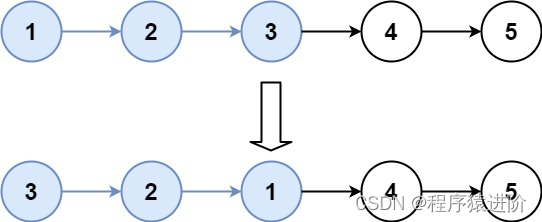
K 个一组翻转链表(链表反转,固定长度反转)(困难)
优质博文:IT-BLOG-CN 一、题目 给你链表的头节点head,每k个节点一组进行翻转,请你返回修改后的链表。 k是一个正整数,它的值小于或等于链表的长度。如果节点总数不是k的整数倍,那么请将最后剩余的节点保持原有顺序。…...
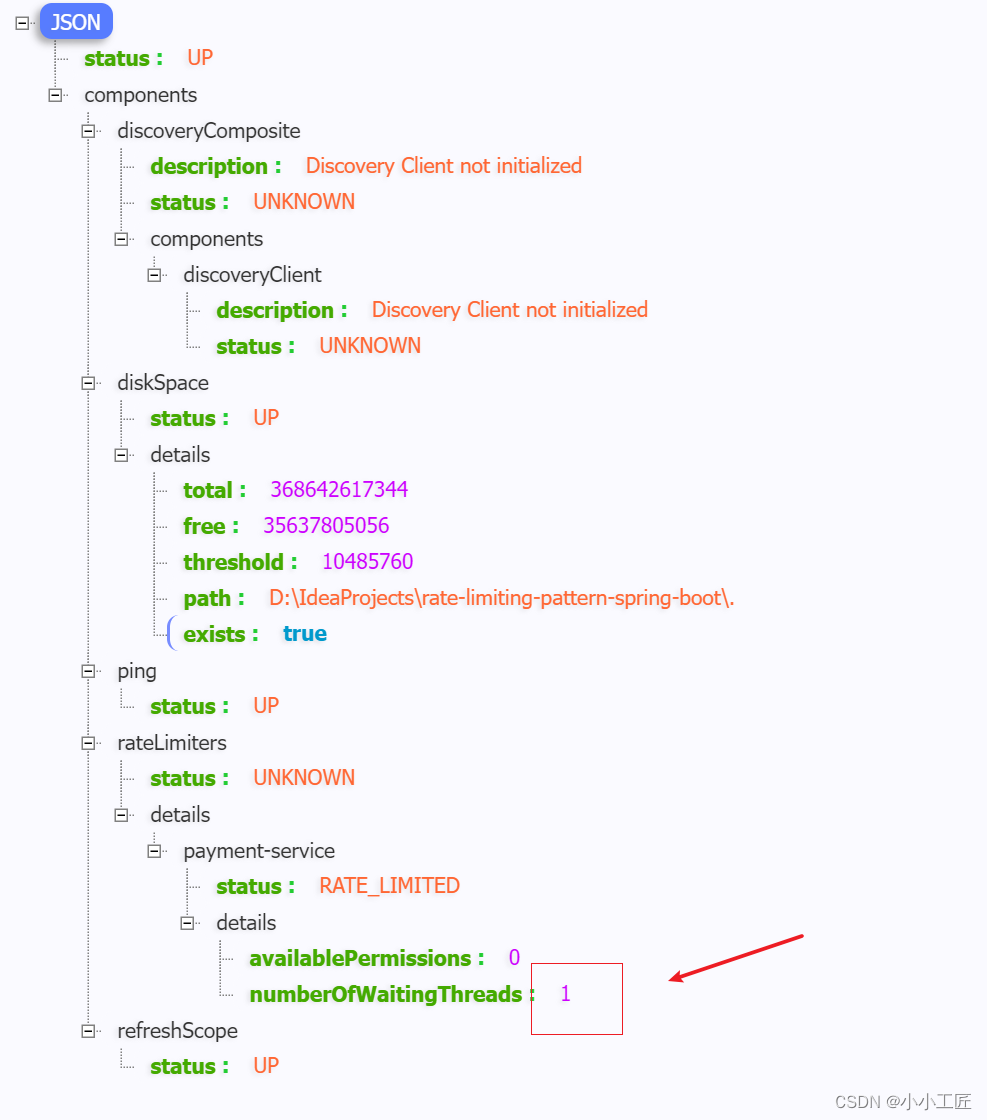
Spring Boot - 利用Resilience4j-RateLimiter进行流量控制和服务降级
文章目录 Resilience4j概述Resilience4j官方地址Resilience4j-RateLimiter微服务演示Payment processorPOM配置文件ServiceController Payment servicePOMModelServiceRestConfigController配置验证 探究 Rate Limiting请求三次 ,观察等待15秒连续访问6次 Resilienc…...
概率论与数理统计————1.随机事件与概率
一、随机事件 随机试验:满足三个特点 (1)可重复性:可在相同的条件下重复进行 (2)可预知性:每次试验的可能不止一个,事先知道试验的所有可能结果 (3)不确定…...
【生存技能】git操作
先下载git https://git-scm.com/downloads 我这里是win64,下载了相应的直接安装版本 64-bit Git for Windows Setup 打开git bash 设置用户名和邮箱 查看设置的配置信息 获取本地仓库 在git bash或powershell执行git init,初始化当前目录成为git仓库…...

docker 将镜像打包为 tar 包
目录 1 实现 1 实现 要将镜像导出为.tar包,可以使用Docker命令行工具进行操作。下面是导出镜像的步骤: 首先,使用以下命令列出当前系统上的镜像,并找到要导出的镜像的ID或名称: docker images使用以下命令将镜像导出为…...
)
341. 最优贸易(dp思想运用,spfa,最短路)
341. 最优贸易 - AcWing题库 C 国有 n 个大城市和 m 条道路,每条道路连接这 n 个城市中的某两个城市。 任意两个城市之间最多只有一条道路直接相连。 这 m 条道路中有一部分为单向通行的道路,一部分为双向通行的道路,双向通行的道路在统计…...
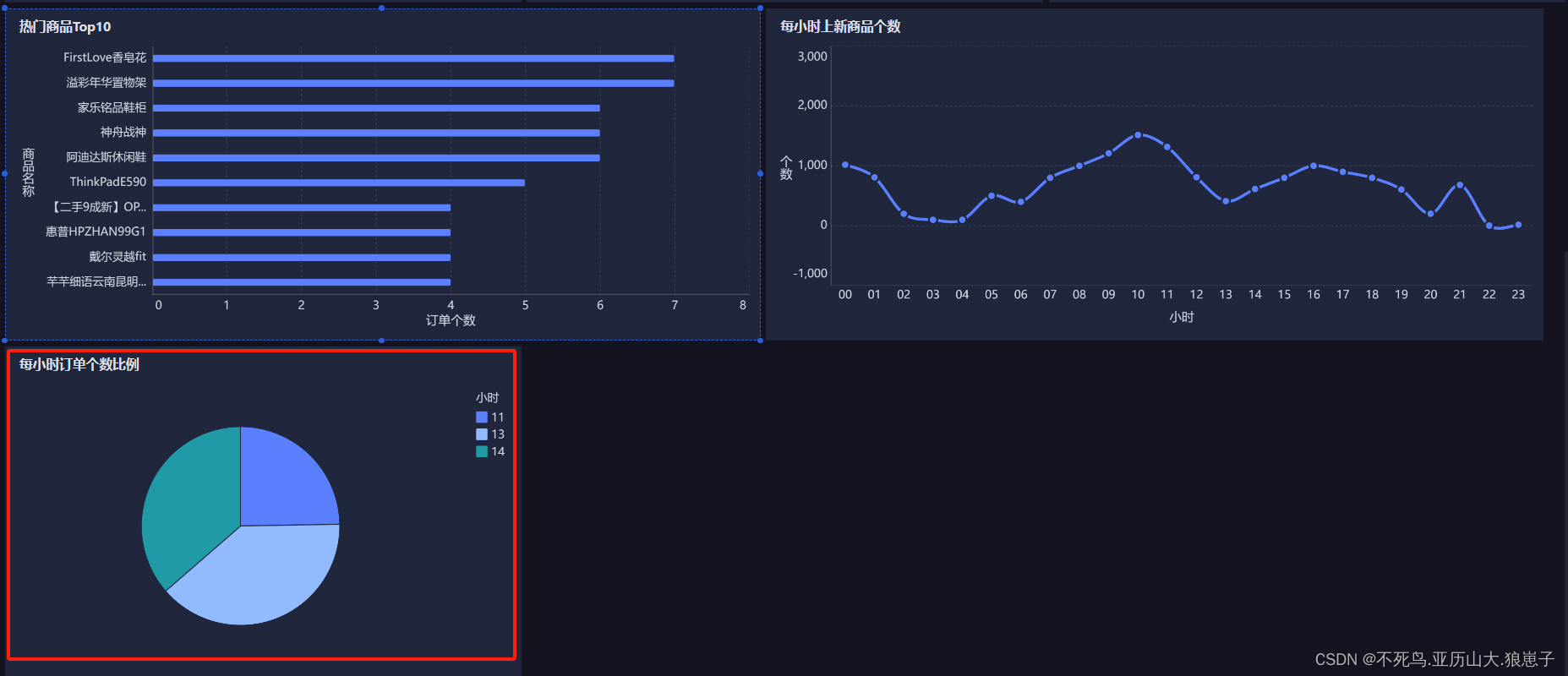
FineBI实战项目一(19):每小时订单笔数分析开发
点击新建组件,创建下每小时订单笔数组件。 选择饼图,拖拽cnt(总数)到角度,拖拽hourstr到颜色,调节内径。 修改现在的文字 拖拽组件到仪表盘。 效果如下:...

What is `@RequestBody ` does?
RequestBody 是SpringMVC框架中的注解,通常与POST、PUT等方法配合使用。当客户端发送包含JSON或XML格式数据的请求时,可以通过该注解将请求体内容绑定到Controller方法参数上 作用 自动反序列化: SpringMVC会根据RequestBody注解的参数类型&…...

Windows安装Rust环境(详细教程)
一、 安装mingw64(C语言环境) Rust默认使用的C语言依赖Visual Studio,但该工具占用空间大安装也较为麻烦,可以选用轻便的mingw64包。 1.1 安装地址 (1) 下载地址1-GitHub:Releases niXman/mingw-builds-binaries GitHub (2) 下载地址2-W…...

Marin说PCB之传输线损耗---趋肤效应和导体损耗01
大家在做RF上的PCB走线或者是车载相机的上走线的时候经常会听那些硬件工程师们说你这个走线一定要保证50欧姆的阻抗匹配啊,还有就是记得加粗走做隔层参考。 有的公司的EE硬件同事会很贴心的把RF走线的注意事项给你备注在原理图上或者是layoutguide上,遇到…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...