Python爬虫快速入门
Python 爬虫Sutdy
1.基本类库
request(请求)
- 引入
from urllib import request
- 定义url路径
url="http://www.baidu.com"
- 进行请求,返回一个响应对象response
response=request.urlopen(url)
- 读取响应体read()以字节形式打印网页源码
response.read()
转码
编码 文本–byte encode
解码 byte–文本 decode
#将上方转为文本 text=response.read().decode("utf-8") # 打印为源码文本显示print(text)写入
语法:with open (‘文件名’,‘w’,设定编码格式) as fp: fp.write(文本) w代表写入
with open ('命名.html','w',encoding='utf-8') as fp:fp.write(text)读取
读取响应体内容并转为utf-8格式
response.read().decode("utf-8")- 读取状态
response.getcode()读取请求路径
response.geturl()
- 读取响应头
response.getheaders()
parse(url编码)
在开始网页请求之前需保证编码格式~
- 引入
from urllib import parse
使用测试
quote(编码)
#编码 result=parse.quote("小鲁班")unquote(解码)
#解码 result1=parse.unquote("%E9%E1%3E")
- 给多个参数编码方式1 变量名.format()
url2="http://www.baidu.com?name={}&pwd={}" url1=url2.format(parse.quote('用户名'),parse.quote('密码'))
- 给多个参数编码方式2 urlencode
obj={ "name":"肖", "password":"213123丽华", "age":"五十岁" } base_url="http://www.baidu.com/s?" params=parse.urlencode(obj) url=base_url+params
urlretrieve(便捷的下载方式)
request.urlretrieve('图片路径','保存路径')伪装成浏览器访问的样子
封装一个请求对象
请求对象可以携带除了url之外的一切服务器感兴趣的信息,例如cookie、UA等等…
url="http://www.baidu.com/" # 定义headers headers={'User-Agent':"Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36" } req=request.Request(url=url,headers=header)# 将请求对象传入 response=request.urlopen(req)
2.爬取各种常见的URL
如何找到正确的URL
- 直接获取浏览器的地址栏url
- 地址栏url不是固定,需要手动配置
- 有效地址不在地址栏中,而在Network(网络)中后台加载
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eAY6WTRm-1650877844184)(D:\StudyHard\assets\1650638350731.png)]
- 等等…
URL分为GET POST
返回值分为XML(HTML),JSON
处理post/get请求
案例:抓取百度翻译
找到URL
post_url="https://fanyi.baidu.com/sug"POST请求表单参数
data_dict={"kw":"sogreat" }请求前需要做一次url编码
data=parse.urlencode(data_dict)参数必须是bytes
data=data.encode("utf-8")封装请求对象
rq=erquset.Request(url=post_url,headers={},data=data)response=requset.urlopen(rq) text=response.read().decode('utf-8')最终结果是个符合JSON格式的字符串
- json格式字符串用json解析
- xml格式字符串用xml解析
进一步解析它转JSON
# 引入 import json json_obj=json.loads(text,encoding='utf-8') # 打印结果为json格式的数据 print(json_obj) # 并且可进行遍历 for...in for s in json_obj["data"] # data为json数据中的一个属性 print(s) #循环打印出data的每个值
案例:抓取KFC餐厅地址信息
找到请求地址与post请求参数
实现:
# 肯德基店铺位置 http://www.kfc.com.cn/kfccda/storelist/index.aspx #请求头优先级 UA-->cookie--->Refer--->其他 headers1={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44" } newaddr=input("请输入地址:") KFCurl="http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword" pageindex=1 # 使用循环查出所有的数据~ while True:datas={"cname":"","pid":"","pageIndex": pageindex,"pageSize": 10,"keyword": newaddr}#编译转码data=parse.urlencode(data)data=data.encode(encoding="utf-8")req1=request.Request(url=url,headers=headers,data=data)response1=request.urlopen(req1)address=response1.read().decode('utf-8')address1=json.loads(address) #转jsonif len(address1['Table1']) == 0:break #表示没数据了for addr in address1['Table1']:print(addr)pageindex+=1优化:使用模块化管理 def 模块名(参数名): 可把它看作封装方法–相当于js的函数
#请求头优先级 UA-->cookie--->Refer--->其他 headers1={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44" } newaddr=input("请输入地址:") #url对象准备模块 def prepare_url(url,headers,data):#编译转码data=parse.urlencode(data)data=data.encode(encoding="utf-8")req1=request.Request(url=url,headers=headers,data=data)return req1 #请求数据模块 def request_with_url(reqs):response1=request.urlopen(reqs)address=response1.read().decode('utf-8')return address #对响应内容解析模块 def pare_data(text):address1=json.loads(text) #转jsonif len(address1['Table1']) == 0:return 'null' #表示没数据了for addr in address1['Table1']:print(addr) KFCurl="http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword" pageindex=1 # 使用循环查出所有的数据~ while True:datas={"cname":"","pid":"","pageIndex": pageindex,"pageSize": 10,"keyword": newaddr}reqs=prepare_url(KFCurl,headers1,datas)text=request_with_url(reqs)if(pare_data(text)=="null"):breakpageindex+=1
案例:抓取百度贴吧信息(get)
headers1={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44"
}
#第一页 https://tieba.baidu.com/f?kw=%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86&ie=utf-8&pn=0
#第二页 https://tieba.baidu.com/f?kw=%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86&ie=utf-8&pn=50
#第三页 https://tieba.baidu.com/f?kw=%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86&ie=utf-8&pn=100
#规律:pn=(page-1)*50
start_page=1
end_page=5
input_name="%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86"#斗罗大陆
for page in range(start_page,end_page+1):url="https://tieba.baidu.com/f?kw{}=&ie=utf-8&pn={}".format(input_name,(page-1)*50)request=urllib.request.Request(url=url,headers=headers1)response=urllib.request.urlopen(request)text=response.read().decode('utf-8')file_path="page{}.html".format(page)with open(file_path,'w',encoding="utf-8") as fp:fp.write(text)print(file_path,"下载完毕")
print("所有内容下载完毕")处理Ajax请求
案例:爬取豆瓣电影动画排行榜
# 定义headers headers={'User-Agent':"Mozilla/5.0 (Linux; Android 11; Pixel 5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.91 Mobile Safari/537.36" }# 1 0----2 20----3 40----得出:(p-1)*20# page=input("请输入你要查询动画类型的排行榜前几页") # print(page) base_url="https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start={}&genres=%E5%8A%A8%E7%94%BB" for p in range(0,4):total=p*20url=base_url.format(total)req=request.Request(url=url,headers=headers)response=request.urlopen(req)text=response.read().decode('utf-8')#转jsonjson_obj=json.loads(text)#只打印部分属性for val in json_obj['data']:title=val['title']rate=val['rate']print("title:{},rate:{}".format(title,rate))
相关文章:

Python爬虫快速入门
Python 爬虫Sutdy 1.基本类库 request(请求) 引入 from urllib import request定义url路径 url"http://www.baidu.com"进行请求,返回一个响应对象response responserequest.urlopen(url)读取响应体read()以字节形式打印网页源码 response.read()转码 编码 文本–by…...
部署MinIO
一、安装部署MINIO 1.1 下载 wget https://dl.min.io/server/minio/release/linux-arm64/minio chmod x minio mv minio /usr/local/bin/ # 控制台启动可参考如下命令, 守护进程启动请看下一个代码块 # ./minio server /data /data --console-address ":9001"1.2 配…...
RK3566环境搭建
环境:vmware16,ubuntu 18.04 安装依赖库: sudo apt-get install repo git ssh make gcc libssl-dev liblz4-tool expect g patchelf chrpath gawk texinfo chrpath diffstat binfmt-support qemu-user-static live-build bison flex fakero…...
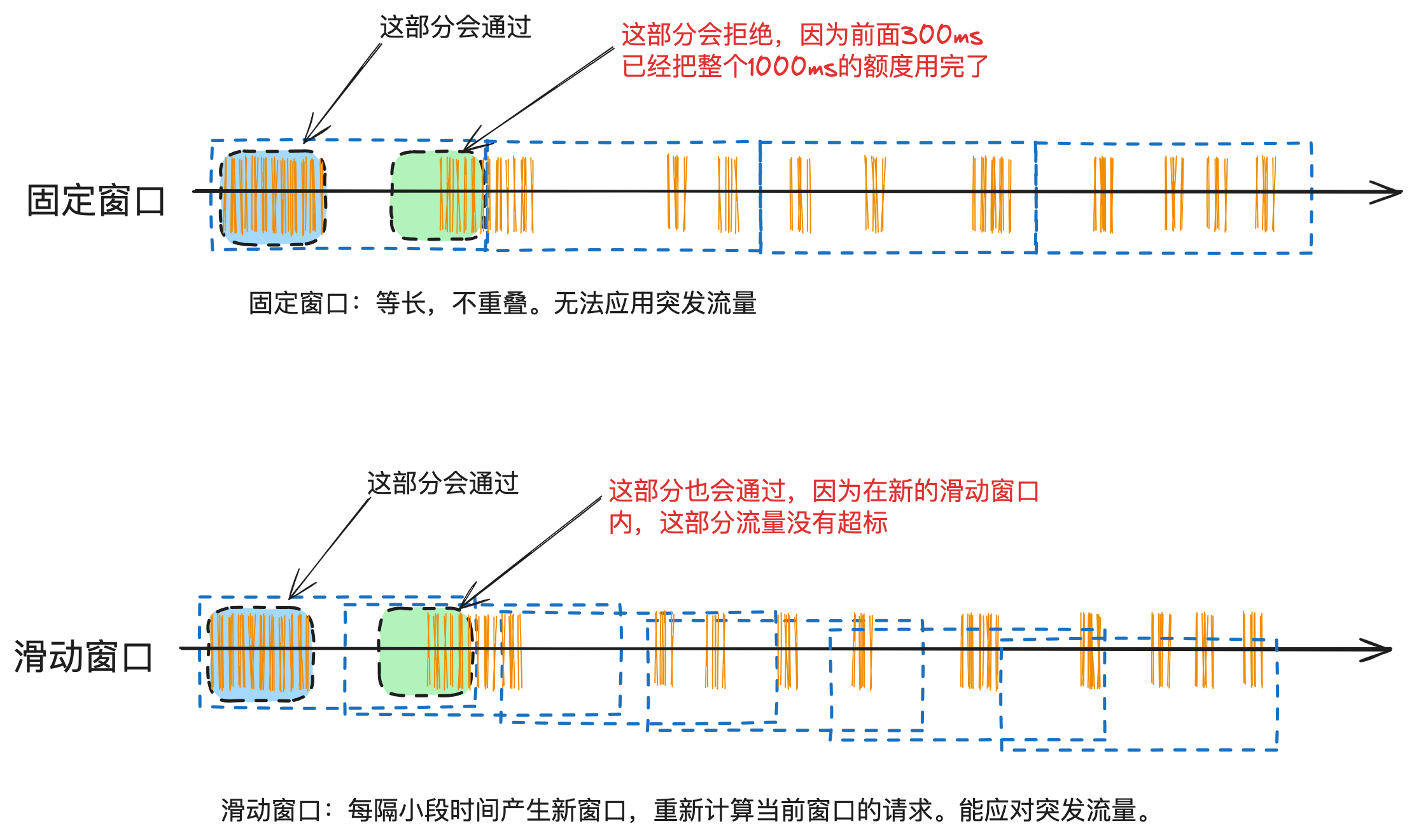
精确掌控并发:滑动时间窗口算法在分布式环境下并发流量控制的设计与实现
这是《百图解码支付系统设计与实现》专栏系列文章中的第(15)篇,也是流量控制系列的第(2)篇。点击上方关注,深入了解支付系统的方方面面。 上一篇介绍了固定时间窗口算法在支付渠道限流的应用以及使用redis…...

Python展示 RGB立方体的二维切面视图
代码实现 import numpy as np import matplotlib.pyplot as plt# 生成 24-bit 全彩 RGB 立方体 def generate_rgb_cube():# 初始化一个 256x256x256 的三维数组rgb_cube np.zeros((256, 256, 256, 3), dtypenp.uint8)# 填充立方体for r in range(256):for g in range(256):fo…...

03 顺序表
目录 线性表顺序表练习 线性表(Linear list)是n个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串。。。 线性表在逻辑上时线性结构,是连续的一条直线。但在物理结…...

2023年全球软件开发大会(QCon北京站2023)9月:核心内容与学习收获(附大会核心PPT下载)
随着科技的飞速发展,全球软件开发大会(QCon)作为行业领先的技术盛会,为世界各地的专业人士提供了交流与学习的平台。本次大会汇集了全球的软件开发者、架构师、项目经理等,共同探讨软件开发的最新趋势、技术与实践。本…...

ChatGPT 和 文心一言 的优缺点及需求和使用场景
ChatGPT和文心一言是两种不同的自然语言生成模型,它们有各自的优点和缺点。 ChatGPT(Generative Pre-trained Transformer)是由OpenAI开发的生成式AI模型,它在庞大的文本数据集上进行了预训练,并可以根据输入生成具有上…...
架构师之超时未支付的订单进行取消操作的几种解决方案
今天给大家上一盘硬菜,并且是支付中非常重要的一个技术解决方案,有这块业务的同学注意自己尝试一把哈! 一、需求如下: 生成订单30分钟未支付,自动取消 生成订单60秒后,给用户发短信 对上述的需求,我们给…...
【容器固化】 OS技术之OpenStack容器固化的实现原理及操作
1. Docker简介 要学习容器固化,那么必须要先了解下Docker容器技术。Docker是基于GO语言实现的云开源项目,通过对应用软件的封装、分发、部署、运行等生命周期的管理,达到应用组件级别的“一次封装,到处运行”。这里的应用软件&am…...

设置 SSH 通过密钥登录
我们一般使用 PuTTY 等 SSH 客户端来远程管理 Linux 服务器。但是,一般的密码方式登录,容易有密码被暴力破解的问题。所以,一般我们会将 SSH 的端口设置为默认的 22 以外的端口,或者禁用 root 账户登录。其实,有一个更…...

1.6 面试经典150题 - 买卖股票的最佳时机
买卖股票的最佳时机 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交易…...
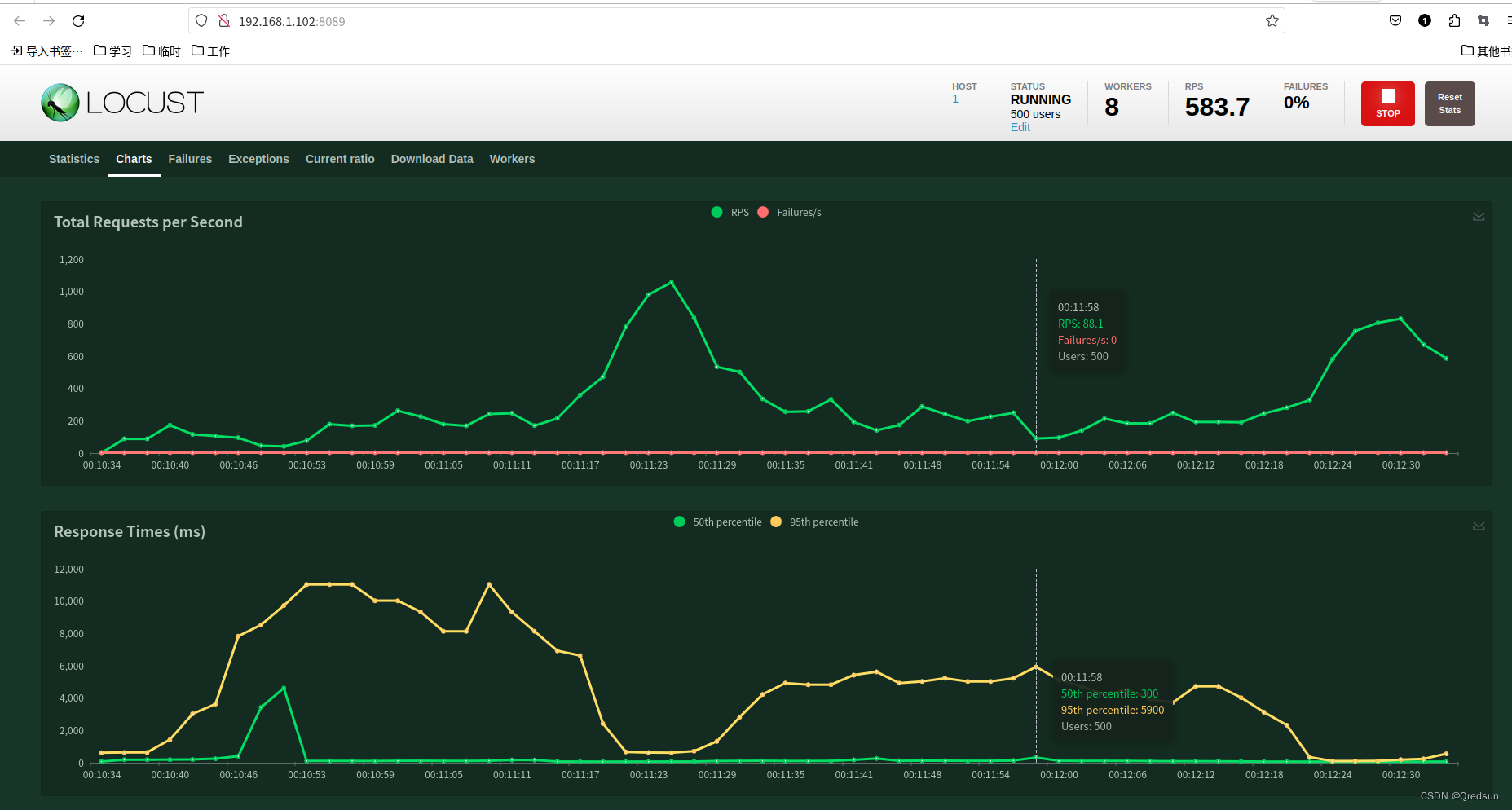
locust快速入门--使用分布式提高测试压力
背景: 使用默认的locust启动命令进行压测时,尽管已经将用户数设置大比较大(400),但是压测的时候RPS一直在100左右。需要增加压测的压力。 问题原因: 如果你是通过命令行启动的或者参考之前文章的启动方式…...
Pod资源——pod亲和性与反亲和性,pod重启策略)
K8s(三)Pod资源——pod亲和性与反亲和性,pod重启策略
目录 pod亲和性与反亲和性 pod亲和性 pod反亲和性 pod状态与重启策略 pod状态 pod重启策略 本文主要介绍了pod资源与pod相关的亲和性,以及pod的重启策略 pod亲和性与反亲和性 pod亲和性(podAffinity)有两种 1.podaffinity,…...

免费的域名要不要?
前言 eu.org的免费域名相比于其他免费域名注册服务,eu.org的域名后缀更加独特。同时,eu.org的域名注册也比较简单,只需要填写一些基本信息,就可以获得自己的免费域名。 博客地址 免费的域名要不要?-雪饼前言 eu.org…...

高通sm7250与765G芯片是什么关系?(一百八十一)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
[Python进阶] Python操作MySQL数据库:pymysql
7.7 操作MySQL数据库:pymysql 7.7.1 准备工作(创建mysql数据库) PHPStudy介绍: phpstudy是一款非常有用的PHP开发工具,旨在帮助开发者更加便捷地进行PHP程序的开发与调试。它提供了一个友好的图形用户界面,使得用户能够方便地进…...
)
Vue3实现带点击外部关闭对应弹出框(可共用一个变量)
首先,假设您在单文件组件(SFC)中使用了Vue3,并且有两个div元素分别通过v-if和v-else来切换显示一个带有.elpopver类的弹出组件。在这种情况下,每个弹出组件应当拥有独立的状态管理(例如:各自的isOpen变量)。…...
)
可视化试题(一)
1. 从可视化系统设计的角度出发,通常需要根据系统将要完成的任务的类型选择交互技术。按照任务类型分类可以将数据可视化中的交互技术分为选择、( 重新配置 )、重新编码、导航、关联、( 过滤 )、概览和细节等八…...
】)
RHCE 【在openEuler系统中搭建基本论坛(网站)】
目录 网站需求: 准备工作: 1.基于域名[www.openlab.com](http://www.openlab.com)可以访问网站内容为 welcome to openlab!!! 测试: 2.给该公司创建三个子界面分别显示学生信息,教学资料和缴费网站,基于[www.openla…...

硅谷世纪审判:OpenAI总裁「认罪」,300亿股权纷争谁能笑到最后?
OpenAI总裁「认罪」,震惊法庭与网友就在刚刚,OpenAI总裁Greg Brockman当庭承认,自己从未投入一分钱,却套出了价值300亿美元的股权。此消息不仅惊呆了法庭上所有人,也让所有网友震惊。纽约大学学者马库斯判断࿰…...

动态高斯泼溅技术:突破视频帧率限制的清晰冻结帧
1. 项目概述:当视频按下暂停键时发生了什么在视频编辑软件里按下暂停键的瞬间,画面总会定格在某个模糊的帧——这是因为传统视频由离散的帧序列组成,每帧仅记录1/24秒的瞬间。动态高斯泼溅技术(Dynamic Gaussian Splatting&#x…...

Vue-Element-Admin中的Promise异步处理:终极请求封装与错误处理指南
Vue-Element-Admin中的Promise异步处理:终极请求封装与错误处理指南 【免费下载链接】vue-element-admin :tada: A magical vue admin https://panjiachen.github.io/vue-element-admin 项目地址: https://gitcode.com/gh_mirrors/vu/vue-element-admin Vue-…...

深度解析:如何用Python解决Minecraft存档损坏的5大技术方案
深度解析:如何用Python解决Minecraft存档损坏的5大技术方案 【免费下载链接】Minecraft-Region-Fixer Python script to fix some of the problems of the Minecraft save files (region files, *.mca). 项目地址: https://gitcode.com/gh_mirrors/mi/Minecraft-R…...

如何打造无缝移动体验:Hey社交应用的响应式设计与PWA技术实践
如何打造无缝移动体验:Hey社交应用的响应式设计与PWA技术实践 【免费下载链接】hey Hey is a decentralized and permissionless social media app built with Lens Protocol 🌿 项目地址: https://gitcode.com/gh_mirrors/hey/hey Hey作为基于Le…...

医学影像多模态学习:MedCLIPSeg技术解析与应用
1. 项目概述:当医学影像遇上多模态学习 去年在协助某三甲医院搭建胸片分析系统时,主治医师指着屏幕上的CT影像问我:"能不能让AI像人类医生一样,看到片子后不仅能识别病灶,还能用自然语言描述病变特征?…...

如何在15分钟内用ReplaceItems.jsx解决Illustrator批量替换难题?
如何在15分钟内用ReplaceItems.jsx解决Illustrator批量替换难题? 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中重复的替换操作消耗宝贵时间…...

Dism++终极指南:Windows系统优化与维护完整教程
Dism终极指南:Windows系统优化与维护完整教程 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language 还在为Windows系统运行缓慢、磁盘空间不足而烦恼吗&am…...

快速验证扑克玩法:用快马AI十分钟生成‘红桃38.49’游戏可运行原型
最近在和朋友玩扑克时接触到了"红桃38.49"这个有趣的玩法,突发奇想能不能快速做个线上版本。作为一个前端开发者,我决定尝试用InsCode(快马)平台来快速验证这个想法。没想到整个过程比想象中顺利很多,从零开始到可运行的原型只用了…...

终极NDI网络视频传输指南:5分钟掌握DistroAV完整教程
终极NDI网络视频传输指南:5分钟掌握DistroAV完整教程 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 想要在IP网络上实现专业级视频传输吗?Distro…...