架构师之超时未支付的订单进行取消操作的几种解决方案
今天给大家上一盘硬菜,并且是支付中非常重要的一个技术解决方案,有这块业务的同学注意自己尝试一把哈!
一、需求如下:
-
生成订单30分钟未支付,自动取消
-
生成订单60秒后,给用户发短信
对上述的需求,我们给一个专业的名字来形容,那就是延时任务。你可能会问延时任务和定时任务有啥区别呢?
一共有以下几点区别
-
定时任务有明确的触发时间,延时任务没有
-
定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
-
定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
二、解决方案
(1)数据库轮询
该方案通常是在小型项目中使用,即通过一个线程定时的去扫描数据库,通过订单时间来判断是否有超时的订单,然后进行update或delete等操作
1)引入依赖
<dependency><groupId>org.quartz-scheduler</groupId><artifactId>quartz</artifactId><version>2.2.2</version>
</dependency>2)创建Demo类实现
public class MyJobDemo implements Job {public void execute(JobExecutionContext context)throws JobExecutionException {System.out.println("我去访问数据库啦。。。");}public static void main(String[] args) throws Exception {// 创建任务JobDetail jobDetail = JobBuilder.newJob(MyJobDemo.class).withIdentity("job1", "group1").build();// 创建触发器 每3秒钟执行一次Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "group3").withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3).repeatForever()).build();Scheduler scheduler = new StdSchedulerFactory().getScheduler();// 将任务及其触发器放入调度器scheduler.scheduleJob(jobDetail, trigger);// 调度器开始调度任务scheduler.start();}
}3)运行结果每3秒输出:
我去访问数据库啦。。。优点:简单易行,支持集群操作
缺点:
(1)对服务器内存消耗大
(2)存在延迟,比如你每隔3分钟扫描一次,那最坏的延迟时间就是3分钟
(3)假设你的订单有几千万条,每隔几分钟这样扫描一次,数据库损耗极大
(2)JDK的延迟队列
该方案是利用JDK自带的DelayQueue来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入DelayQueue中的对象,是必须实现Delayed接口的。
-
Poll():获取并移除队列的超时元素,没有则返回空
-
take():获取并移除队列的超时元素,如果没有则wait当前线程,直到有元素满足超时条件,返回结果。
1)定义一个类OrderDelay实现Delayed
public class OrderDelay implements Delayed {private String orderId;private long timeout;OrderDelay(String orderId, long timeout) {this.orderId = orderId;this.timeout = timeout + System.nanoTime();}public int compareTo(Delayed other) {if (other == this)return 0;OrderDelay t = (OrderDelay) other;long d = (getDelay(TimeUnit.NANOSECONDS) - t.getDelay(TimeUnit.NANOSECONDS));return (d == 0) ? 0 : ((d < 0) ? -1 : 1);}// 返回距离你自定义的超时时间差值public long getDelay(TimeUnit unit) {return unit.convert(timeout - System.nanoTime(),TimeUnit.NANOSECONDS);}void print() {System.out.println(orderId+"编号的订单即将删除啦。。。。");}
}2)运行的测试Demo为,我们设定延迟时间为3秒
public class DelayQueueDemo {public static void main(String[] args) { List<String> list = new ArrayList<String>(); list.add("00000001"); list.add("00000002"); list.add("00000003"); list.add("00000004"); list.add("00000005"); DelayQueue<OrderDelay> queue = newDelayQueue<OrderDelay>(); long start = System.currentTimeMillis(); for(int i = 0;i<5;i++){ //延迟三秒取出queue.put(new OrderDelay(list.get(i), TimeUnit.NANOSECONDS.convert(3,TimeUnit.SECONDS))); try { queue.take().print(); System.out.println("After " + (System.currentTimeMillis()-start) + " MilliSeconds"); } catch (InterruptedException e) {} } }
}3)输出如下:
00000001编号的订单即将删除啦。。。。
After 3003 MilliSeconds
00000002编号的订单即将删除啦。。。。
After 6006 MilliSeconds
00000003编号的订单即将删除啦。。。。
After 9006 MilliSeconds
00000004编号的订单即将删除啦。。。。
After 12008 MilliSeconds
00000005编号的订单即将删除啦。。。。
After 15009 MilliSeconds优点:效率高,任务触发时间延迟低。
缺点:
(1)服务器重启后,数据全部消失,怕宕机
(2)集群扩展相当麻烦
(3)因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常
(4)代码复杂度较高
(3)时间轮算法

时间轮算法可以类比于时钟,如上图箭头(指针)按某一个方向按固定频率轮动,每一次跳动称为一个 tick。
这样可以看出定时轮由个3个重要的属性参数
-
ticksPerWheel(一轮的tick数)
-
tickDuration(一个tick的持续时间)
-
timeUnit(时间单位)
例如当ticksPerWheel=60,tickDuration=1,timeUnit=秒,这就和现实中的始终的秒针走动完全类似了。
如果当前指针指在1上面,我有一个任务需要4秒以后执行,那么这个执行的线程回调或者消息将会被放在5上。那如果需要在20秒之后执行怎么办,由于这个环形结构槽数只到8,如果要20秒,指针需要多转2圈。位置是在2圈之后的5上面(20 % 8 + 1)
具体实现(使用Netty的HashedWheelTimer来实现):
1)引依赖:
<dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.24.Final</version>
</dependency>2)创建HashedWheelTimerTest测试:
public class HashedWheelTimerTest {static class MyTimerTask implements TimerTask{boolean flag;public MyTimerTask(boolean flag){this.flag = flag;}public void run(Timeout timeout) throws Exception {System.out.println("我去数据库删除订单了。。。。");this.flag =false;}}public static void main(String[] argv) {MyTimerTask timerTask = new MyTimerTask(true);Timer timer = new HashedWheelTimer();timer.newTimeout(timerTask, 5, TimeUnit.SECONDS);int i = 1;while(timerTask.flag){try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("过去了"+i+"秒");i++;}}
}3)输出如下:
过去了1秒
过去了2秒
过去了3秒
过去了4秒
过去了5秒
我去数据库删除订单了。。。。
过去了6秒优点:效率高,任务触发时间延迟时间比delayQueue低,代码复杂度比delayQueue低。
缺点:
(1)服务器重启后,数据全部消失,怕宕机
(2)集群扩展相当麻烦
(3)因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常
(4)redis缓存
思路一
利用redis的zset,zset是一个有序集合,每一个元素(member)都关联了一个score,通过score排序来取集合中的值
相关的命令操作:
-
添加元素:ZADD key score member [[score member] [score member] …]
-
按顺序查询元素:ZRANGE key start stop [WITHSCORES]
-
查询元素score:ZSCORE key member
-
移除元素:ZREM key member [member …]
具体实现:我们将订单超时时间戳与订单号分别设置为score和member,系统扫描第一个元素判断是否超时,具体如下图所示
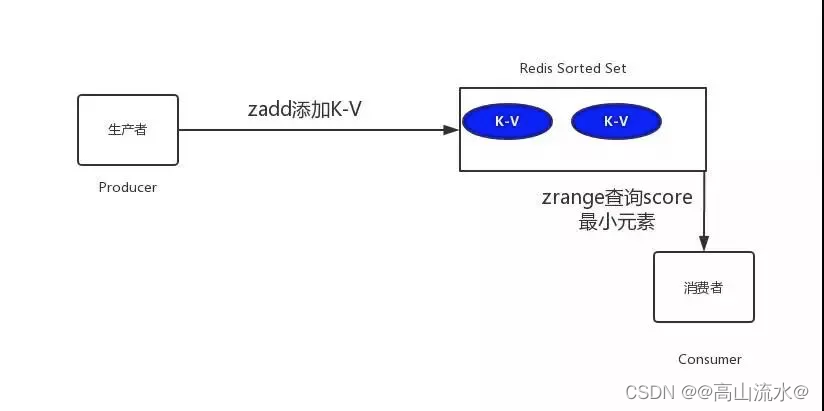
1)代码实现:
public class AppTest {private static final String ADDR = "127.0.0.1";private static final int PORT = 6379;private static JedisPool jedisPool = new JedisPool(ADDR, PORT);public static Jedis getJedis() {return jedisPool.getResource();}//生产者,生成5个订单放进去public void productionDelayMessage(){for(int i=0;i<5;i++){//延迟3秒Calendar cal1 = Calendar.getInstance();cal1.add(Calendar.SECOND, 3);int second3later = (int) (cal1.getTimeInMillis() / 1000);AppTest.getJedis().zadd("OrderId",second3later,"OID0000001"+i);System.out.println(System.currentTimeMillis()+"ms:redis生成了一个订单任务:订单ID为"+"OID0000001"+i);}}//消费者,取订单public void consumerDelayMessage(){Jedis jedis = AppTest.getJedis();while(true){Set<Tuple> items = jedis.zrangeWithScores("OrderId", 0, 1);if(items == null || items.isEmpty()){System.out.println("当前没有等待的任务");try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}continue;}int score = (int) ((Tuple)items.toArray()[0]).getScore();Calendar cal = Calendar.getInstance();int nowSecond = (int) (cal.getTimeInMillis() / 1000);if(nowSecond >= score){String orderId = ((Tuple)items.toArray()[0]).getElement();jedis.zrem("OrderId", orderId);System.out.println(System.currentTimeMillis() +"ms:redis消费了一个任务:消费的订单OrderId为"+orderId);}}}public static void main(String[] args) {AppTest appTest =new AppTest();appTest.productionDelayMessage();appTest.consumerDelayMessage();}
}2)输出的时候会看到,几乎都是3秒后进行订单的消费,然而它有一个致命的伤,高并发条件下,多消费者会取到同一个订单号,也就是我们常说的超卖问题,显然,出现了多个线程消费同一个资源的情况。
针对这个问题的解决方案是:
(1)用分布式锁,但是用分布式锁,性能下降了,该方案不细说。
(2)对ZREM的返回值进行判断,只有大于0的时候,才消费数据,于是consumerDelayMessage()方法里的
if(nowSecond >= score){String orderId = ((Tuple)items.toArray()[0]).getElement();jedis.zrem("OrderId", orderId);System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId);
}修改为:
if(nowSecond >= score){String orderId = ((Tuple)items.toArray()[0]).getElement();Long num = jedis.zrem("OrderId", orderId);if( num != null && num>0){System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId);}
}修改后代码输出即为正常。
思路二
该方案使用redis的Keyspace Notifications,利用该机制可以在key失效之后,提供一个回调,实际上是redis会给客户端发送一个消息。值得注意的是redis版本要在2.8以上。
具体实现:
1)向redis.conf中,加入一条配置
notify-keyspace-events Ex2)代码实现:
public class RedisTest {private static final String ADDR = "127.0.0.1";private static final int PORT = 6379;private static JedisPool jedis = new JedisPool(ADDR, PORT);private static RedisSub sub = new RedisSub();public static void init() {new Thread(new Runnable() {public void run() {jedis.getResource().subscribe(sub, "__keyevent@0__:expired");}}).start();}public static void main(String[] args) throws InterruptedException {init();for(int i =0;i<10;i++){String orderId = "OID000000"+i;jedis.getResource().setex(orderId, 3, orderId);System.out.println(System.currentTimeMillis()+"ms:"+orderId+"订单生成");}}static class RedisSub extends JedisPubSub {public void onMessage(String channel, String message) {System.out.println(System.currentTimeMillis()+"ms:"+message+"订单取消");}}
}3)输出体现3秒过后,订单取消了
redis的pub/sub机制存在一个硬伤,官网内容如下:
Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.直译过来的意思:
Redis的发布/订阅目前是即发即弃(fire and forget)模式的,因此无法实现事件的可靠通知。也就是说,如果发布/订阅的客户端断链之后又重连,则在客户端断链期间的所有事件都丢失了。
故,这个方案不太推荐使用。如你对可靠性要求不是很高时,可以使用。
优点:
(1)由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
(2)做集群扩展相当方便
(3)时间准确度高
缺点:
需要额外进行redis维护
(5)使用消息队列
可以采用RabbitMQ的延时队列。RabbitMQ具有以下两个特性,可以实现延迟队列
RabbitMQ可以针对Queue和Message设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为dead letter
lRabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了deadletter,则按照这两个参数重新路由。
优点:
高效,可以利用rabbitmq的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。
缺点:
本身的易用度要依赖于rabbitMq的运维.因为要引用rabbitMq,所以复杂度和成本变高
相关文章:
架构师之超时未支付的订单进行取消操作的几种解决方案
今天给大家上一盘硬菜,并且是支付中非常重要的一个技术解决方案,有这块业务的同学注意自己尝试一把哈! 一、需求如下: 生成订单30分钟未支付,自动取消 生成订单60秒后,给用户发短信 对上述的需求,我们给…...
【容器固化】 OS技术之OpenStack容器固化的实现原理及操作
1. Docker简介 要学习容器固化,那么必须要先了解下Docker容器技术。Docker是基于GO语言实现的云开源项目,通过对应用软件的封装、分发、部署、运行等生命周期的管理,达到应用组件级别的“一次封装,到处运行”。这里的应用软件&am…...

设置 SSH 通过密钥登录
我们一般使用 PuTTY 等 SSH 客户端来远程管理 Linux 服务器。但是,一般的密码方式登录,容易有密码被暴力破解的问题。所以,一般我们会将 SSH 的端口设置为默认的 22 以外的端口,或者禁用 root 账户登录。其实,有一个更…...

1.6 面试经典150题 - 买卖股票的最佳时机
买卖股票的最佳时机 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。 返回你可以从这笔交易…...
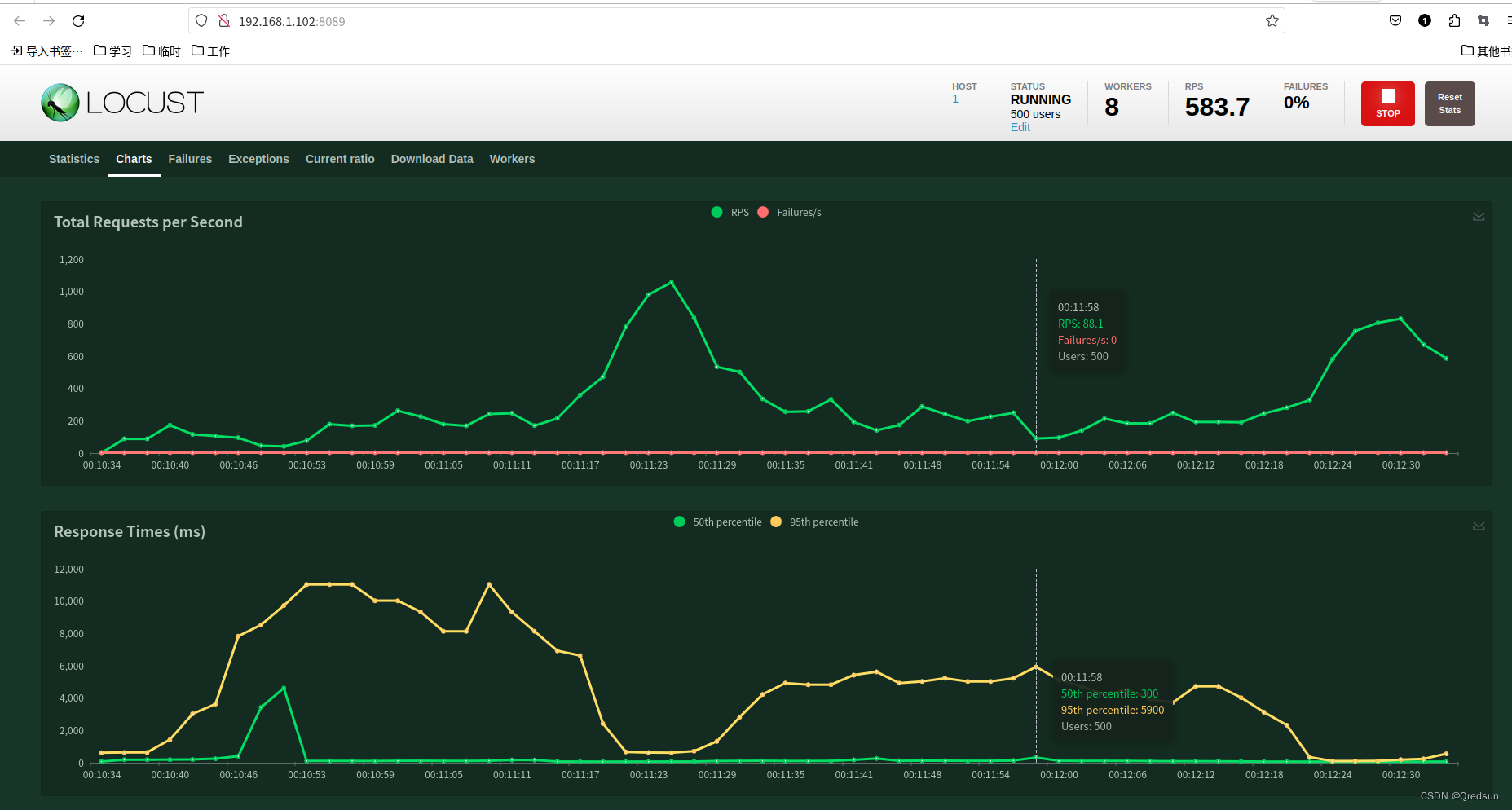
locust快速入门--使用分布式提高测试压力
背景: 使用默认的locust启动命令进行压测时,尽管已经将用户数设置大比较大(400),但是压测的时候RPS一直在100左右。需要增加压测的压力。 问题原因: 如果你是通过命令行启动的或者参考之前文章的启动方式…...
Pod资源——pod亲和性与反亲和性,pod重启策略)
K8s(三)Pod资源——pod亲和性与反亲和性,pod重启策略
目录 pod亲和性与反亲和性 pod亲和性 pod反亲和性 pod状态与重启策略 pod状态 pod重启策略 本文主要介绍了pod资源与pod相关的亲和性,以及pod的重启策略 pod亲和性与反亲和性 pod亲和性(podAffinity)有两种 1.podaffinity,…...

免费的域名要不要?
前言 eu.org的免费域名相比于其他免费域名注册服务,eu.org的域名后缀更加独特。同时,eu.org的域名注册也比较简单,只需要填写一些基本信息,就可以获得自己的免费域名。 博客地址 免费的域名要不要?-雪饼前言 eu.org…...

高通sm7250与765G芯片是什么关系?(一百八十一)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
[Python进阶] Python操作MySQL数据库:pymysql
7.7 操作MySQL数据库:pymysql 7.7.1 准备工作(创建mysql数据库) PHPStudy介绍: phpstudy是一款非常有用的PHP开发工具,旨在帮助开发者更加便捷地进行PHP程序的开发与调试。它提供了一个友好的图形用户界面,使得用户能够方便地进…...
)
Vue3实现带点击外部关闭对应弹出框(可共用一个变量)
首先,假设您在单文件组件(SFC)中使用了Vue3,并且有两个div元素分别通过v-if和v-else来切换显示一个带有.elpopver类的弹出组件。在这种情况下,每个弹出组件应当拥有独立的状态管理(例如:各自的isOpen变量)。…...
)
可视化试题(一)
1. 从可视化系统设计的角度出发,通常需要根据系统将要完成的任务的类型选择交互技术。按照任务类型分类可以将数据可视化中的交互技术分为选择、( 重新配置 )、重新编码、导航、关联、( 过滤 )、概览和细节等八…...
】)
RHCE 【在openEuler系统中搭建基本论坛(网站)】
目录 网站需求: 准备工作: 1.基于域名[www.openlab.com](http://www.openlab.com)可以访问网站内容为 welcome to openlab!!! 测试: 2.给该公司创建三个子界面分别显示学生信息,教学资料和缴费网站,基于[www.openla…...
20240112让移远mini-PCIE接口的4G模块EC20在Firefly的AIO-3399J开发板的Android11下跑通【DTS部分】
20240112让移远mini-PCIE接口的4G模块EC20在Firefly的AIO-3399J开发板的Android11下跑通【DTS部分】 2024/1/12 16:20 https://blog.csdn.net/u010164190/article/details/79096345 [Android6.0][RK3399] PCIe 接口 4G模块 EC20 调试记录 https://blog.csdn.net/hnjztyx/artic…...

日志采集传输框架之 Flume,将监听端口数据发送至Kafka
1、简介 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传 输的系统。Flume 基于流式架构,主要有以下几个部分组成。 主要组件介绍: 1)、Flume Agent 是一个 JVM 进程…...
关于Vue前端接口对接的思考
关于Vue前端接口对接的思考 目录概述需求: 设计思路实现思路分析1.vue 组件分类和获取数值的方式2.http 通信方式 分类 如何对接3.vue 组件分类和赋值方式, 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your p…...
跟多态有何区别?如何理解LSP中子类遵守父类的约定)
【设计模式之美】SOLID 原则之三:里式替换(LSP)跟多态有何区别?如何理解LSP中子类遵守父类的约定
文章目录 一. 如何理解“里式替换原则”?二. 哪些代码明显违背了 LSP?三. 回顾 一. 如何理解“里式替换原则”? 子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏。 里氏替换原则…...

代码随想录第六十三天——被围绕的区域,太平洋大西洋水流问题,最大人工岛
leetcode 130. 被围绕的区域 题目链接:被围绕的区域 步骤一:深搜或者广搜将地图周边的’O’全部改成’A’ 步骤二:遍历地图,将’O’全部改成’X’,将’A’改回’O’ class Solution { private:int dir[4][2] {-1, 0…...

Docker 项目如何使用 Dockerfile 构建镜像?
1、Docker 和 Dockerfile 的重要性 1.1、Docker 简介:讲述 Docker 的起源、它是如何革新现代软件开发的,以及它为开发者和运维团队带来的好处。重点强调 Docker 的轻量级特性和它在提高应用部署、扩展和隔离方面的优势。 本文已收录于,我的…...
实践学习PaddleScience飞桨科学工具包
实践学习PaddleScience飞桨科学工具包 动手实践,在实践中学习!本项目可以在AIStudio平台一键运行!地址:https://aistudio.baidu.com/projectdetail/4278591 本项目第一次执行会报错,再执行一次即可。若碰到莫名其妙的…...
Vue 中修改 Element 组件的 下拉菜单(Dropdown) 的样式
Vue 中修改 Element 组件的 下拉菜单(Dropdown) 的样式 今天在项目中碰到一个 UI 改造的需求,需要根据设计图把页面升级成 UI 设计师提供的设计图样式。 到最后页面改造完了,但是 UI 提供的下拉菜单样式全部是黑色半透明的,只能硬着头皮改了。…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...