自学大数据第三天~终于轮到hadoop了
前面那几天是在找大数据的门,其实也是在搞一些linux的基本命令,现在终于轮到hadoop了

Hadoop
hadoop的安装方式
单机模式:
就如字面意思,在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统~就如我们一开始入门的时候都是从本地开始的;
伪分布式模式
存储采用分布式文件系统,但是HDFS的名称节点和数据节点都在同一台机器上;
简单来说就像我们学习微服务的时候,只有一台机器,只能采用不同的端口号来实现微服务的开发,
分布式模式
存储采用分布式文件系统,HDFS的名称节点和数据节点位于不同的机器上~这才符合分布式的要求;
安装hadoop
下载hadoop
此时是以root用户登陆的系统
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
解压缩文件
tar -zxf hadoop-3.3.4.tar.gz
加压完毕之后将文件的权限授予hadoop用户,以免后续出现什么问题;
授权解压的文件给hadoop用户
[root@node1 local]# sudo chown -R hadoop ./hadoop-3.3.4
#切换用户
[root@node1 local]# su hadoop
[hadoop@node1 local]$
查看hadoop是否可以正常运行
cd hadoop-3.3.4
./bin/hadoop version
结果如下~

hadoop的单机配置
hadoop下载下来之后默认是非分布式模式,无需其他配置即可运行;
非分布式即java的单进程模式,这个我们就很擅长了,拿来直接运行即可;
首先来看官网给的例子(别的例子咱也不会,入门一下,日后在搞复杂的)
- 请听第一题
我们将input文件夹下所有的文件作为输入,筛选出符合正则表达式dfs[a-z.]+的单词并统计出现次数
mkdir ./input #创建一个文件夹#拷贝hadoop配置文件到 刚刚创建的input文件夹下cp ./etc/hadoop/*.xml ./input
#执行hadoop命令~./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+'查看output文件夹下的内容
cat ./output/*
我们来看一下我们复制时都复制了些什么
[hadoop@node1 hadoop-3.3.4]$ ls ./input/
capacity-scheduler.xml hadoop-policy.xml hdfs-site.xml kms-acls.xml mapred-site.xml
core-site.xml hdfs-rbf-site.xml httpfs-site.xml kms-site.xml yarn-site.xml
[hadoop@node1 hadoop-3.3.4]$ 再来看看 输出的文件中都有什么
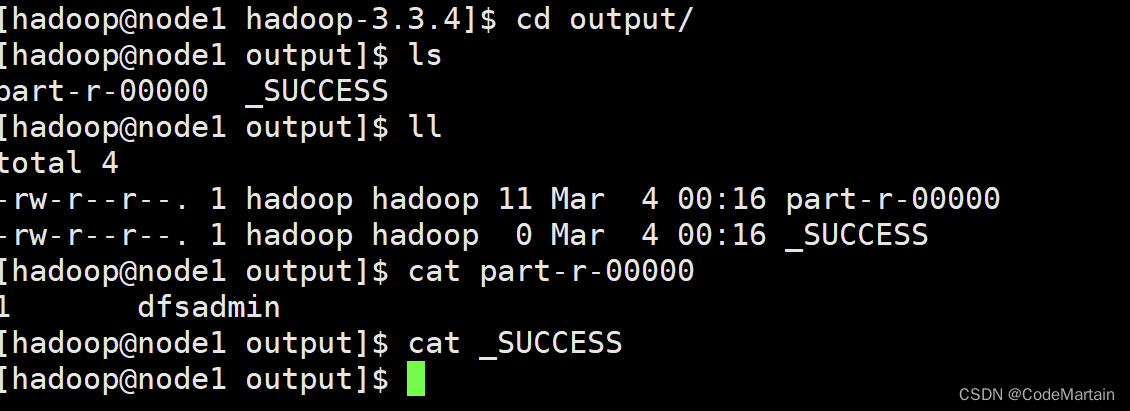
[hadoop@node1 hadoop-3.3.4]$ cd output/
[hadoop@node1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@node1 output]$
这是什么?
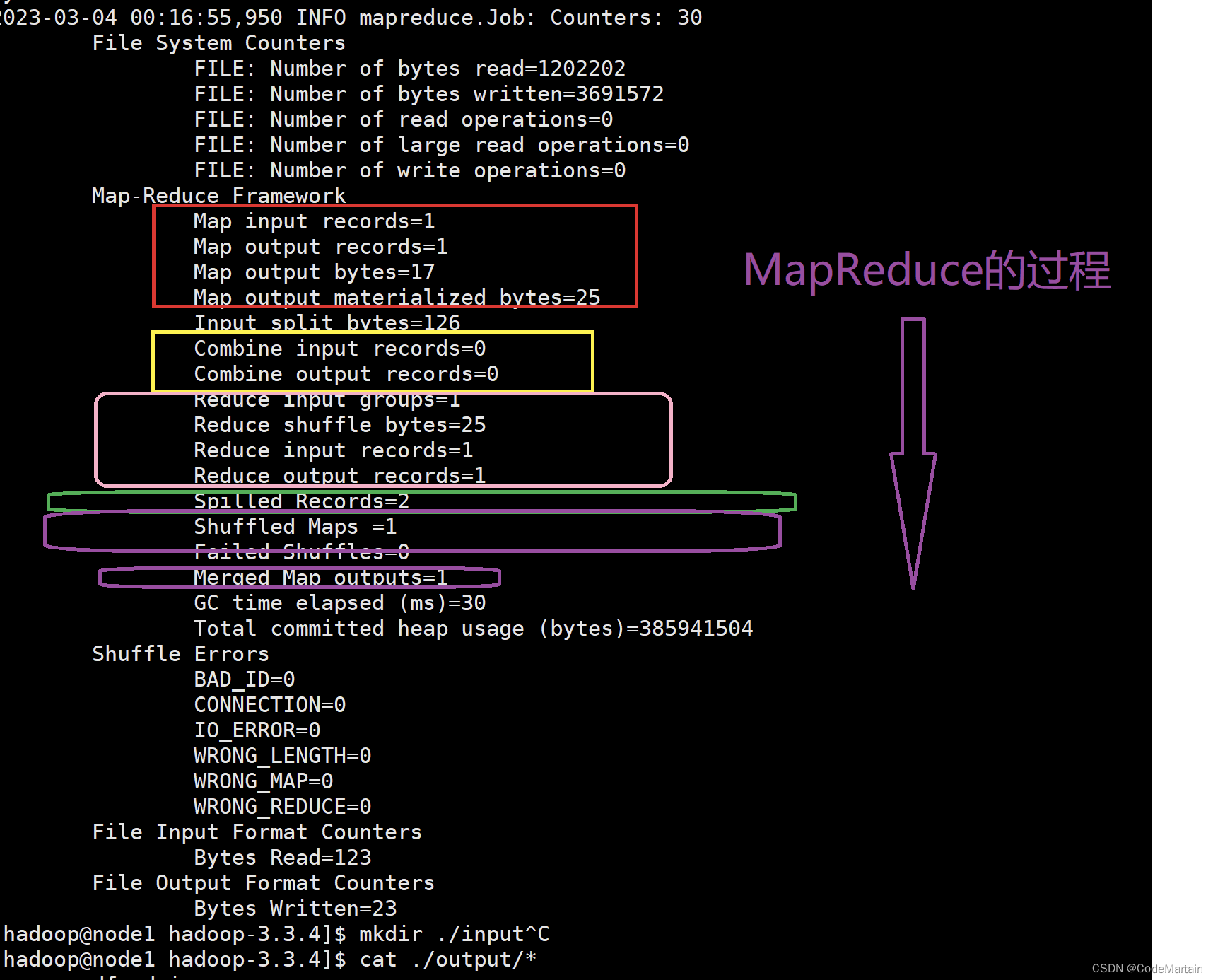
 我们再来看执行成功后的提示~
我们再来看执行成功后的提示~
 回头再来看hadoop执行的命令
回头再来看hadoop执行的命令
#头部命令
./bin/hadoop jar
有些类似于java执行jar 的那个逻辑
java jar
看看hadoop文件中都写了什么…
乌压压一大片(暂且搁置一边)
 源码自取
源码自取
然后就是参数部分
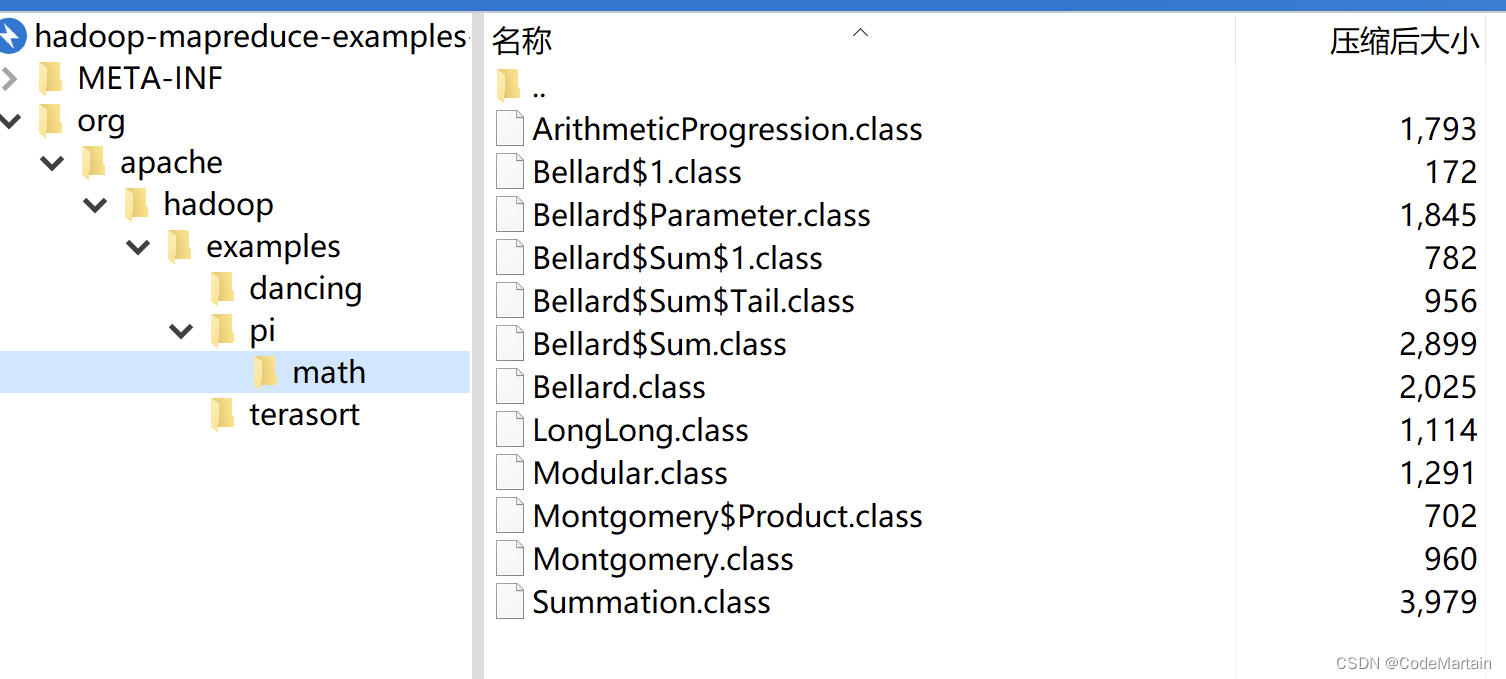
./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar
找到它~可以看到是一些打包好的jar包,就是提前写好的代码去执行一些运算,以后我们也可以写代码打包后交给hadoop运行
**注意,**Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
hadoop伪分布式配置
hadoop可以在单节点上以伪分布式的方式运行,这个由hadoop进程分离的java进程来运行,节点既可以作为namenode也可以作为datanode,同时读取hdfs中的文件.
伪分布式需要一些配置,其配置文件在etc/hadoop/ 中,需要修改两个配置文件
- core-site.xml
找到该文件并修改他
vi /usr/local/hadoop-3.3.4/etc/hadoop/core-site.xml
文件中添加如下内容
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop3.3.4/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>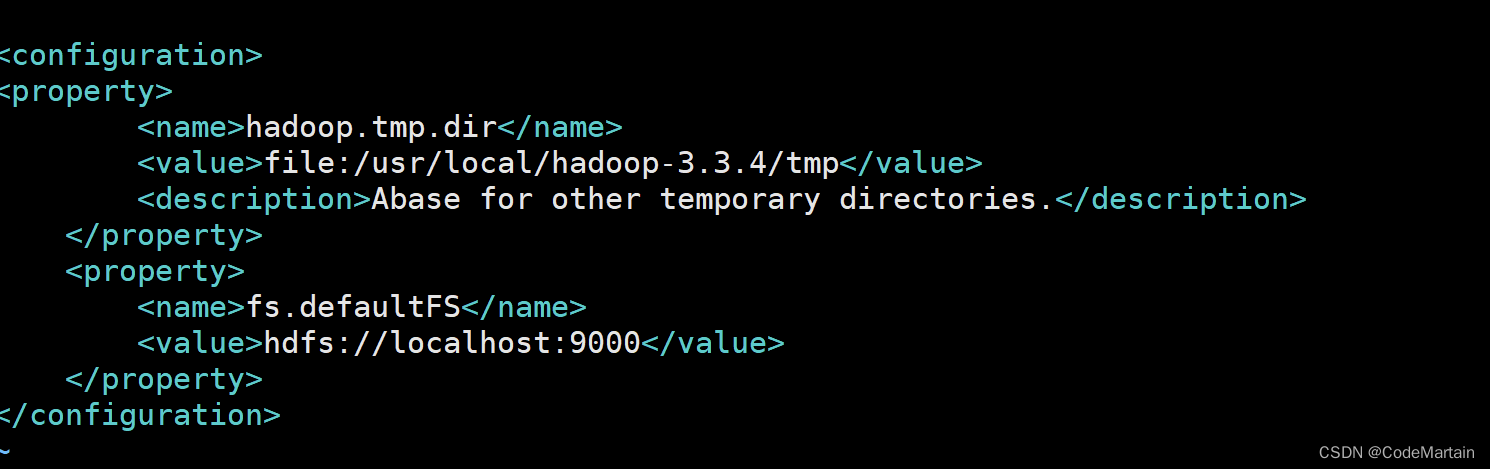
大体是配置了一个临时存储文件夹的地址和一个访问的网址
- hdfs-site.xml
找到配置文件并修改他
vi /usr/local/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
添加如下内容
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>
</configuration>
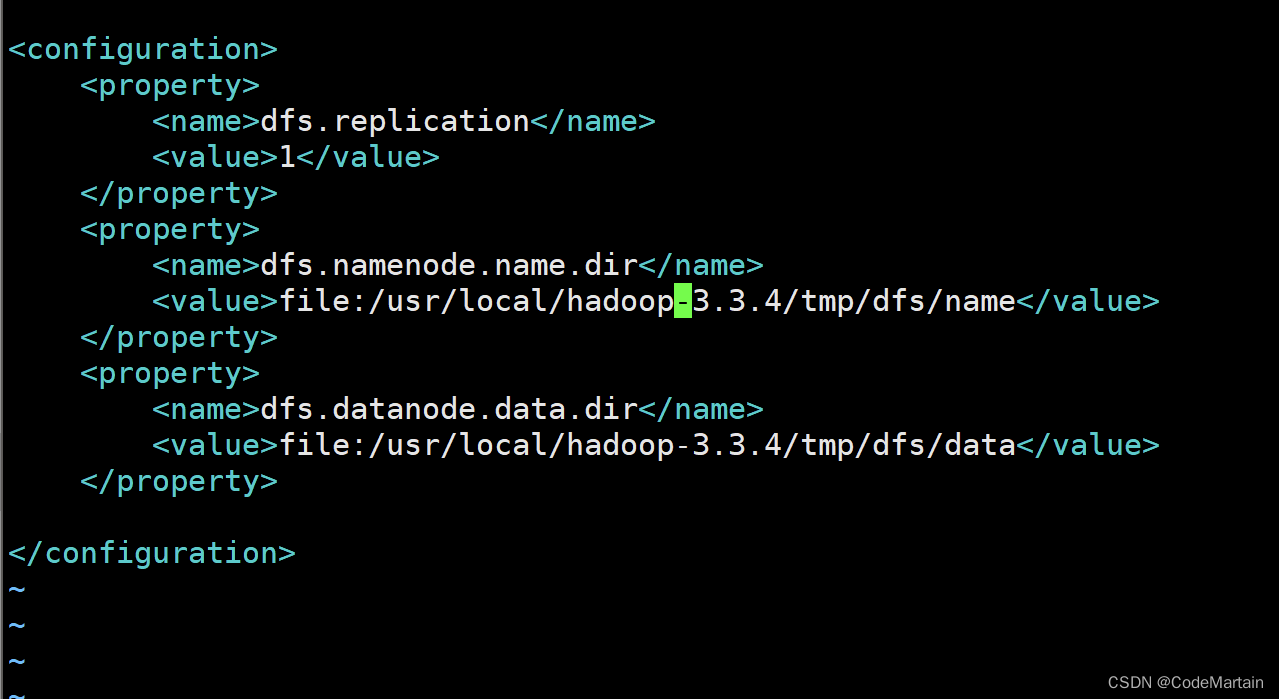
大体就是配置了namenode节点和datanode节点
hadoop的配置文件说明
hadoop的运行方式是由配置文件决定的(hadoop在运行时会读取配置文件)
由于一开始并没有配置任何内容,所以是单机模式;
按照hadoop的与运行方式来说,伪分布式子需要配置fs.defaultFS 和 dfs.replication 就可以了,但是若没有配置hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop, 而这个目录会在机器重启时可能会被删掉,导致必须重新执行format才行;
我们也指定了namenode节点跟datanode节点
配置完成后
初始化namenode
cd /usr/local/hadoop./bin/hdfs namenode -format
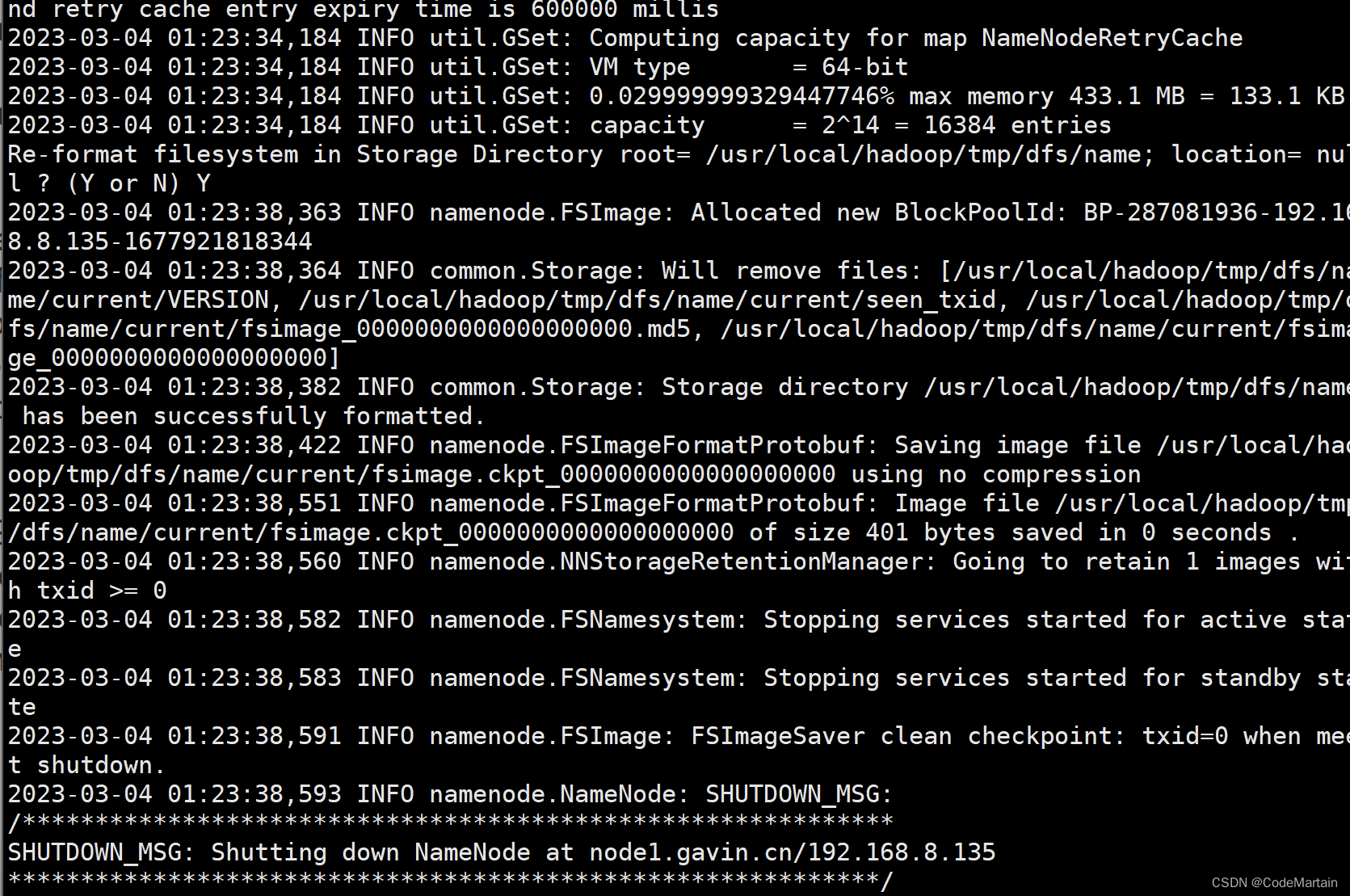 看到success就表示执行成功了;
看到success就表示执行成功了;
啥?没看到?这就尴尬了,截个图给你看看

再去文件夹下看看有没有对应的文件建立
ll ./tmp/dfs/name/current/

如果出现错误:
1.JAVA_HOME 错误,那就去配置一下 hadoop-env.sh文件 ,重新配置一下JAVA_HOME
2.文件夹创建失败,可能是当前用户没有权限,给当前用户授权
sudo chown -R hadoop /usr/local/hadoop-3.3.4
开启namenode和datanode节点
./sbin/start-dfs.sh 开启之后访问一下配置文件中的那个网址:
开启之后访问一下配置文件中的那个网址:
注:这里用虚拟机的ip地址;
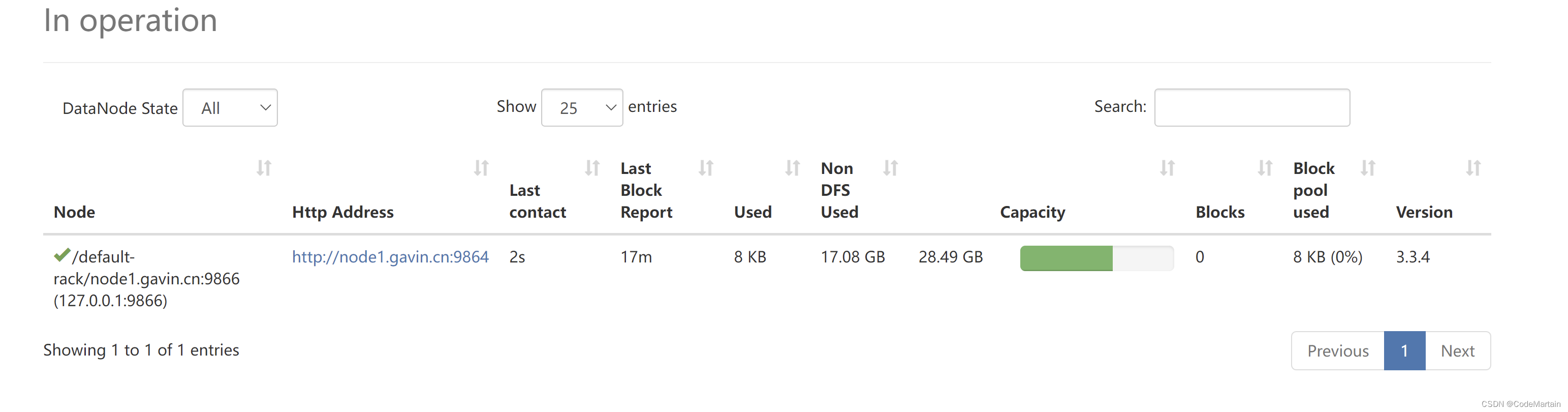
 datanode节点的信息
datanode节点的信息
启动hadoop时遇到的一些问题集锦:
专门从网上找的,虽然现在还没有遇到,说不定以后会遇到,这样也能快速知道如何解决;
速度自取
接下来就是回顾时刻,这几天我们通过学习 了解到hadoop 的一些知识
首先是:
1,hadoop的环境-配置jdk
2,hadoop各个节点之间的交流通过ssh加密 --配置ssh
3,hadoop的运行三种方式:
- 单体模式
- 伪分布式
- 分布式
4,hadoop的运行命令
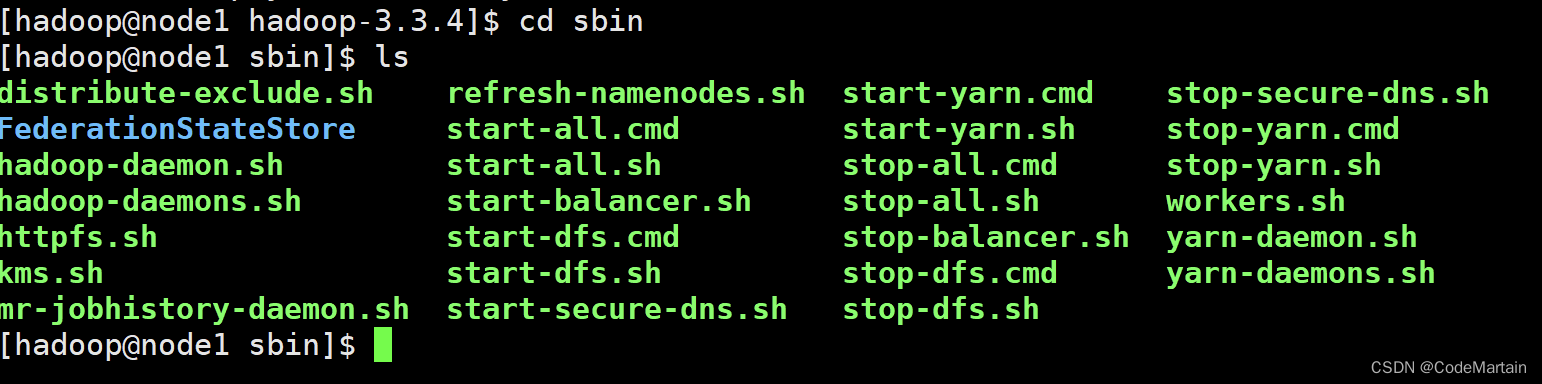
首先在hadoop文件下的bin目录有很多可以运行的命令文件
目前接触到了
启动hadoop ~ ~
./bin/hadoop jar 写好的打包程序 其他的运行配置
5,配置伪分布式的关键配置文件:
core-site.xml ~配置了临时文件夹
hdfs-site.xml ~配置了namenode节点和datanode节点以及一个访问html的地址
6,配置结束后 格式化namenode
./bin/hdfs namenode -format
7,启动namenode以及datanode守护进程
./sbin/start-dfs.sh
 未完待续~ 另一台机器操作一遍在熟悉一下啊!
未完待续~ 另一台机器操作一遍在熟悉一下啊!
相关文章:
自学大数据第三天~终于轮到hadoop了
前面那几天是在找大数据的门,其实也是在搞一些linux的基本命令,现在终于轮到hadoop了 Hadoop hadoop的安装方式 单机模式: 就如字面意思,在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统~就如我们一开始入门的时候都是从本地开始的; 伪分布式模式 存储采用…...

Unity 入门精要00---Unity提供的基础变量和宏以及一些基础知识
头文件引入: XXPROGRAM ... #include "UnityCG.cginc"; ... ENDXX 常用的结构体(在UnityCg.cginc文件中):在顶点着色器输入和输出时十分好用 。 关于如何使用这些结构体,可在Unity安装文件目录/Editor…...
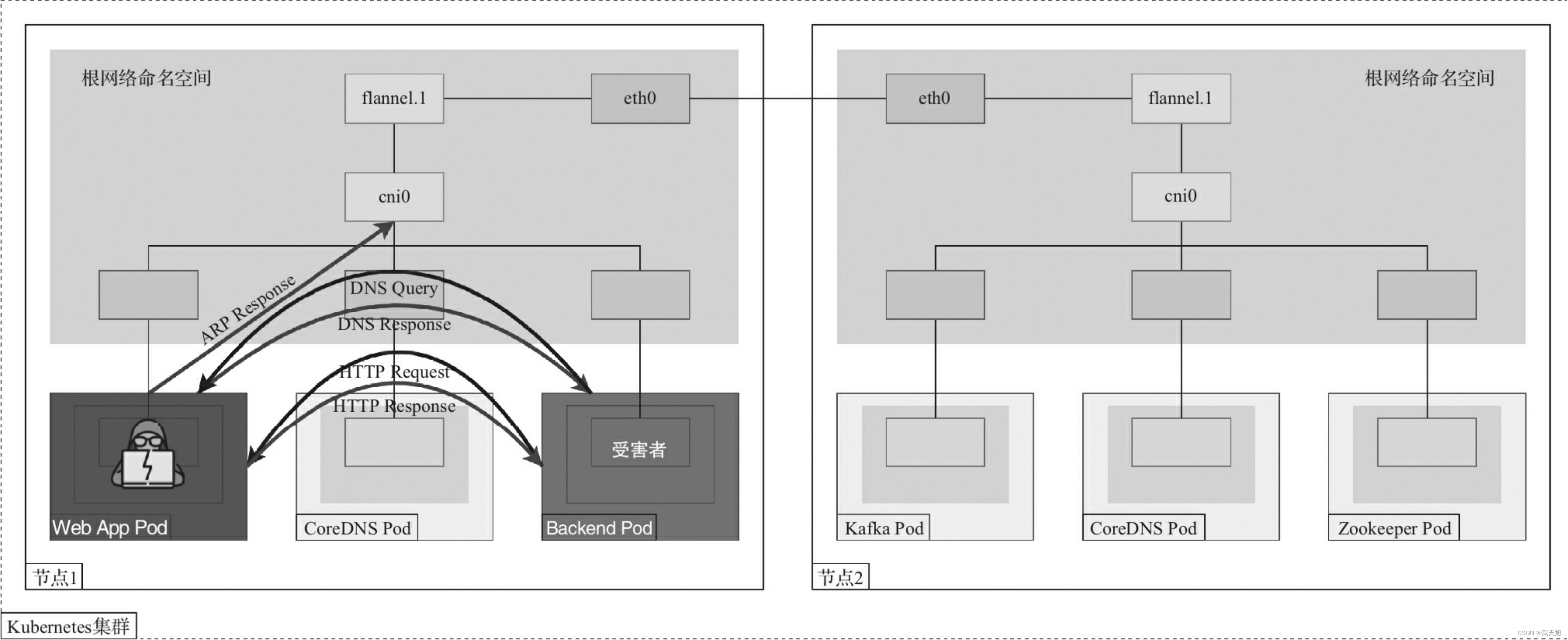
Kubernetes的网络架构及其安全风险
本博客地址:https://security.blog.csdn.net/article/details/129137821 一、常见的Kubernetes网络架构 如图所示: 说明: 1、集群由多个节点组成。 2、每个节点上运行若干个Pod。 3、每个节点上会创建一个CNI网桥(默认设备名称…...
)
Blob分析+特征+(差分)
Blob分析特征0 前言1 概念2 方法2.1 图像采集2.2 图像分割2.3 特征提取3 主要应用场景:0 前言 在缺陷检测领域,halcon通常有6种处理方法,包括Blob分析特征、Blob分析特征差分、频域空间域、光度立体法、特征训练、测量拟合,本篇博…...

Flink 提交模式
Flink的部署方式有很多,支持Local,Standalone,Yarn,Docker,Kubernetes模式等。而根据Flink job的提交模式,又可以分为三种模式: 模式1:Application Mode Flink提交的程序,被当做集群内部Application,不再需要Client端做繁重的准备工作。(例如执行main函数,生成JobG…...
三)
网络总结知识点(网络工程师必备)三
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 目录 前言 51.什么是ARP代理?...
测开:前端基础-css
一、CSS介绍和引用 1.1 css概述 层叠样式表,是一种样式表语言,用来描述HTML和XML文档的呈现。 CSS 用于简化HTML标签,把关于样式部分的内容提取出来,进行单独的控制,使结构与样式分离开发。 CSS 是以HTML为基础&…...

Java学习记录之JDBC
JDBC JDBC 是 Java Database Connectivity 的缩写,是允许Java 程序访问并操作关系型数据库数据的一套 应用程序接口。本身就是一种规范,它提供的接口有一套完整的,可移植的访问底层数据库的程序。 JDBC 的架构 JDBC API支持两层和三层处理…...

矩阵翻硬币
题目描述 小明先把硬币摆成了一个 n 行 m 列的矩阵。 随后,小明对每一个硬币分别进行一次 Q 操作。 对第 x 行第 y 列的硬币进行 Q 操作的定义:将所有第 ix 行,第 jy 列的硬币进行翻转。...
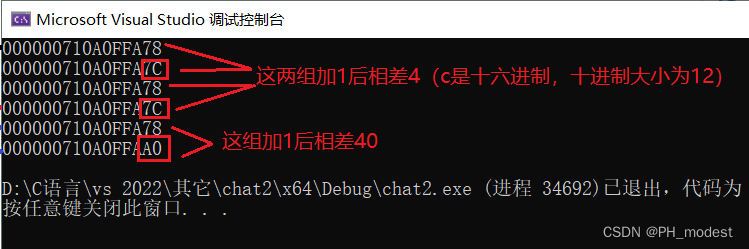
【C语言跬步】——指针数组和数组指针(指针进阶)
一.指针数组和数组指针的区别 1.指针数组是数组,是一种存放指针的数组; 例如: int* arr[10]; 2.数组指针是指针,是一种指向数组的指针,存放的是数组的地址; 例如: int arr[5]; int (p)[5]&a…...
第十四届蓝桥杯模拟赛第三期(Python)
写在前面 包含本次模拟赛的10道题题解能过样例,应该可以AC若有错误,欢迎评论区指出本次题目除了最后两题有些难度,其余题目较为简单,我只将代码和结果给出,如果不能理解欢迎私信我,我会解答滴。start 2022…...

css-盒模型
巧妙运用margin负值盒模型和怪异盒模型(border padding 包含在内)display: block 能让textarea input 水平尺寸自适应父容器? – 不能 * {box-sizing: border-box; // bs: bb }<textarea/> 是替换元素,尺寸由内部元素决定,不受display水平影响. 当然可以直接设置宽度10…...

Linux | 调试器GDB的详细教程【纯命令行调试】
文章目录一、前言二、调试版本与发布版本1、见见gdb2、程序员与测试人员3、为什么Release不能调试但DeBug可以调试❓三、使用gdb调试代码1、指令集汇总2、命令演示⌨ 行号显示⌨ 断点设置⌨ 查看断点信息⌨ 删除断点⌨ 开启 / 禁用断点⌨ 运行 / 调试⌨ 逐过程和逐语句⌨ 打印 …...

wifi芯片大市场和个人小生活
3.3 是日也,天朗气清,惠风和畅。仰观宇宙之大,俯察论文论坛,所以游目骋怀,足以极视听之娱,信可乐也。 夫人之相与,俯仰一世,或取诸怀抱,悟言一室之内;或因寄所…...
考试 上半年2023年3月13日开始,下半年2023年8月14日开始)
全国计算机技术与软件专业技术资格(水平)考试 上半年2023年3月13日开始,下半年2023年8月14日开始
根据2023年计算机技术与软件专业技术资格(水平)考试工作计划,可以得知,2023年软考报名时间——上半年2023年3月13日开始,下半年2023年8月14日开始。 点击查看:人力资源社会保障部办公厅关于2023年度专业技术人员职业资格考试工作计划及有关事项的通知 点击查看:2023年度…...
Hadoop企业优化)
大数据框架之Hadoop:MapReduce(六)Hadoop企业优化
一、MapReduce 跑的慢的原因 MapReduce程序效率的瓶颈在于两点: 1、计算机性能 CPU、内存、磁盘、网络 2、IO操作优化 数据倾斜Map和Reduce数设置不合理Map运行时间太长,导致Reduce等待过久小文件过多大量的不可分块的超大文件Spill次数过多Merge次…...

Spring File Storage的详细文档
快速入门配置pom.xml引入依赖<dependencies><!-- spring-file-storage 必须要引入 --><dependency><groupId>cn.xuyanwu</groupId><artifactId>spring-file-storage</artifactId><version>0.7.0</version></dependen…...

Java软件开发好学吗?学完好找工作吗?
互联网高速发展的当下,Java语言无处不在:手机APP、Java游戏、电脑应用,都有它的身影。作为最热门的开发语言之一,Java在编程圈的地位不可撼动。可是,听名字就很专业的样子。Java语言到底好学吗?刚入坑编程圈…...

【独家C】华为OD机试提供C语言题解 - 优秀学员统计
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明优秀…...

数据仓库、数据中台、数据湖都是什么?
相信很多人都在最近的招聘市场上看到过招聘要求里提到了数据仓库、数据中台,甚至还有数据湖,这些层出不穷的概念让人困扰。今天我就来跟大家讲一讲数据仓库、数据中台以及数据湖的概念及区别。 数据库 在了解数据仓库、数据中台以及数据湖之前ÿ…...

AgentCPM本地研报工具体验:纯离线运行,商业机密数据安全无忧
AgentCPM本地研报工具体验:纯离线运行,商业机密数据安全无忧 如果你每天的工作都需要处理大量敏感的商业数据,撰写深度分析报告,那你一定对数据安全这根弦绷得特别紧。用在线AI工具吧,总担心数据上传到云端有泄露风险…...
)
实战指南:用DHCP Snooping防御企业内网中的DHCP欺骗攻击(附Cisco配置命令)
企业内网安全加固:基于DHCP Snooping的欺骗攻击防御体系 当企业内网突然出现大面积终端无法获取IP地址,或是员工访问正规网站却被跳转到钓鱼页面时,网络管理员的第一反应往往是检查DHCP服务器状态。但真正的威胁可能隐藏在看似正常的DHCP交互…...

『NAS』在群晖部署无广聚合搜索引擎-SearXNG
点赞 关注 收藏 学会了 💡整理了 NAS 专属玩法专栏,感兴趣的工友戳这里关注 👉 《NAS邪修》 SearXNG 是一款开源的聚合搜索引擎工具,支持私有化部署,能整合多个主流搜索引擎的结果,且搜索页面无广告、无…...

Vue3 性能优化实践
Vue3 性能优化实践 | 源码解析系列 6.4一,引言 性能优化是前端开发中的重要课题,Vue3虽然相比Vue2有了显著的性能提升,但在实际应用中仍需要开发者注意一些性能问题。本文将分享Vue3性能优化的最佳实践,帮助开发者构建高性能的Vue…...
)
Windows 本地部署 OpenClaw 超详细图文教程(保姆级)
本文以 PowerShell 一键部署 为核心方案,兼顾新手友好与稳定性,全程附操作说明与避坑要点,30 分钟内可完成部署。📋 一、部署前准备(必看)1. 硬件与系统要求项目最低配置推荐配置说明系统Windows 10 64位&a…...

Hermes-Agent 简明指南
自从OpenClaw发布以来,几乎每周都有新的智能体被创建,尝试它们所有几乎变得不可能。但有一个新智能体引起了很多人包括我的注意。 它在GitHub上只有6k星,相比之下 OpenClaw有307k星(在撰写本文时)。然而,与…...

2026 天津 AI 获客 GEO 服务商选型指南
一、行业痛点与榜单筛选标准当前,国内近七成实体企业及制造业商家正面临线上曝光不足、本地搜索排名靠后、客户转化效率低下等获客难题,严重制约企业数字化发展进程。AI生成式引擎优化(GEO)技术凭借精准的本地化内容布局、智能搜索…...

SGLang部署Qwen3.5-27B量化版及评测
随着人工智能技术的快速发展,大语言模型的本地化部署成为企业和开发者的一项重要需求。Qwen3.5-27B-GPTQ-Int4 作为阿里Qwen3.5系列的重要模型,在保持高性能的同时,通过 INT4 量化大幅降低了部署成本,使其能够在消费级显卡上流畅运…...

AI赋能软件测试:未来已来,你准备好了吗?
引言 在数字化转型的浪潮中,软件测试作为保障产品质量的关键环节,正面临着前所未有的挑战。 传统的测试方法已难以满足快速迭代和复杂场景的需求,而人工智能(AI)的引入,则为软件测试带来了革命性的变化。…...

LeetCode 3070. 元素和小于等于 k 的子矩阵数目
LeetCode 3070. 元素和小于等于 k 的子矩阵数目 题目描述 给你一个大小为 m x n 的整数矩阵 grid 和一个整数 k。你需要找出 grid 中所有以左上角 (0,0) 为起始点的子矩阵,并统计这些子矩阵中元素和不超过 k 的个数。 注意:子矩阵必须包含 (0,0) 这个格子…...