【大数据】Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)
背景概述
单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈。因而提出了 namenode 水平扩展方案-- Federation。
Federation 中文意思为联邦,联盟,是 NameNode 的 Federation,也就是会有多个NameNode。多个 NameNode 的情况意味着有多个 namespace(命名空间),区别于 HA 模式下的多 NameNode,它们是拥有着同一个 namespace。

从上图中,我们可以很明显地看出现有的 HDFS 数据管理,数据存储 2 层分层的结构.也就是说,所有关于存储数据的信息和管理是放在 NameNode 这边,而真实数据的存储则是在各个 DataNode 下。而这些隶属于同一个 NameNode 所管理的数据都是在同一个命名空间下的。而一个 namespace 对应一个 block pool。Block Pool 是同一个 namespace 下的 block 的集合.当然这是我们最常见的单个 namespace 的情况,也就是一个 NameNode 管理集群中所有元数据信息的时候.如果我们遇到了之前提到的 NameNode 内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高 NameNode 的 jvm 大小绝对不是一个持久的办法.这时候就诞生了 HDFS Federation 的机制.
Federation 架构设计
HDFS Federation 是解决 namenode 内存瓶颈问题的水平横向扩展方案。
Federation 意味着在集群中将会有多个 namenode/namespace。这些 namenode 之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的 datanode 被用作通用的数据块存储存储设备。每个 datanode 要向集群中所有的namenode 注册,且周期性地向所有 namenode 发送心跳和块报告,并执行来自所有 namenode的命令。

Federation 一个典型的例子就是上面提到的 NameNode 内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理. 更重要的一点在于, 这些 NameNode是共享集群中所有的 e DataNode 的 , 它们还是在同一个集群内的 。
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的 datadir 所在目录里面查看 BP-xx.xx.xx.xx 打头的目录)。
多个 NN 共用一个集群里的存储资源,每个 NN 都可以单独对外提供服务。
每个 NN 都会定义一个存储池,有单独的 id,每个 DN 都为所有存储池提供存储。
DN 会按照存储池 id 向其对应的 NN 汇报块信息,同时,DN 会向所有 NN 汇报本地存储可用资源情况。

集群部署搭建
主机规划
公共组件
zk: 192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181
mysql: 192.168.1.32
HDFS-federation 规划
| cluster | hostname | ip | 机型 | 组件 |
|---|---|---|---|---|
| cluster-a | hadoop-31 | 192.168.1.31 | arm | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter |
| hadoop-32 | 192.168.1.32 | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter | ||
| hadoop-33 | 192.168.1.33 | DataNode/JournalNode | ||
| cluster-b | spark-34 | 192.168.1.34 | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter | |
| spark-35 | 192.168.1.35 | NameNode/DataNode/JournalNode/DFSZKFailoverController/DFSRouter | ||
| spark-36 | 192.168.1.36 | DataNode/JournalNode |
YARN-federation 规划
| cluster | hostname | ip | 机型 | 组件 |
|---|---|---|---|---|
| cluster-a | hadoop-31 | 192.168.1.31 | arm | ResourceManager/NodeManager/Router/ApplicationHistoryServer/JobHistoryServer/WebAppProxyServer |
| hadoop-32 | 192.168.1.32 | ResourceManager/NodeManager | ||
| hadoop-33 | 192.168.1.33 | NodeManager | ||
| spark-34 | 192.168.1.34 | NodeManager | ||
| cluster-b | spark-35 | 192.168.1.35 | ResourceManager/NodeManager/Router/ApplicationHistoryServer/JobHistoryServer/WebAppProxyServer | |
| spark-36 | 192.168.1.36 | ResourceManager/NodeManager |
环境变量配置
hadoop-env.sh 配置
export HADOOP_GC_DIR="/data/apps/hadoop-3.3.1/logs/gc"
if [ ! -d "${HADOOP_GC_DIR}" ];thenmkdir -p ${HADOOP_GC_DIR}
fi
export HADOOP_NAMENODE_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1234 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9211:/data/apps/hadoop-3.3.1/etc/hadoop/namenode.yaml"export HADOOP_DATANODE_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1244 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9212:/data/apps/hadoop-3.3.1/etc/hadoop/namenode.yaml"export HADOOP_ROOT_LOGGER=INFO,console,RFA
export SERVER_GC_OPTS="-XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=512M -XX:ErrorFile=/data/apps/hadoop-3.3.1/logs/hs_err_pid%p.log -XX:+PrintAdaptiveSizePolicy -XX:+PrintFlagsFinal -XX:MaxGCPauseMillis=100 -XX:+UnlockExperimentalVMOptions -XX:+ParallelRefProcEnabled -XX:ConcGCThreads=6 -XX:ParallelGCThreads=16 -XX:G1NewSizePercent=5 -XX:G1MaxNewSizePercent=60 -XX:MaxTenuringThreshold=1 -XX:G1HeapRegionSize=32m -XX:G1MixedGCCountTarget=8 -XX:InitiatingHeapOccupancyPercent=65 -XX:G1OldCSetRegionThresholdPercent=5"
export HDFS_NAMENODE_OPTS="-Xms4g -Xmx4g ${SERVER_GC_OPTS} -Xloggc:${HADOOP_GC_DIR}/namenode-gc-`date +'%Y%m%d%H%M'` ${HADOOP_NAMENODE_JMX_OPTS}"
export HDFS_DATANODE_OPTS="-Xms4g -Xmx4g ${SERVER_GC_OPTS} -Xloggc:${HADOOP_GC_DIR}/datanode-gc-`date +'%Y%m%d%H%M'` ${HADOOP_DATANODE_JMX_OPTS}"
export HDFS_ZKFC_OPTS="-Xms1g -Xmx1g ${SERVER_GC_OPTS} -Xloggc:${HADOOP_GC_DIR}/zkfc-gc-`date +'%Y%m%d%H%M'`"
export HDFS_DFSROUTER_OPTS="-Xms1g -Xmx1g ${SERVER_GC_OPTS} -Xloggc:${HADOOP_GC_DIR}/router-gc-`date +'%Y%m%d%H%M'`"
export HDFS_JOURNALNODE_OPTS="-Xms1g -Xmx1g ${SERVER_GC_OPTS} -Xloggc:${HADOOP_GC_DIR}/journalnode-gc-`date +'%Y%m%d%H%M'`"
export HADOOP_CONF_DIR=/data/apps/hadoop-3.3.1/etc/hadoop
yarn-env.sh 配置
export YARN_RESOURCEMANAGER_OPTS="$YARN_RESOURCEMANAGER_OPTS -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=2111 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9323:/data/apps/hadoop-3.3.1/etc/hadoop/yarn-rm.yaml"
export YARN_NODEMANAGER_OPTS="${YARN_NODEMANAGER_OPTS} -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=2112 -javaagent:/data/apps/hadoop-3.3.1/share/hadoop/jmx_prometheus_javaagent-0.17.2.jar=9324:/data/apps/hadoop-3.3.1/etc/hadoop/yarn-nm.yaml"
export YARN_ROUTER_OPTS="${YARN_ROUTER_OPTS}"
配置文件配置
HDFS的配置
cluster-a
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://cluster-a</value></property><property><name>ha.zookeeper.quorum</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>hadoop.zk.address</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>ha.zookeeper.parent-znode</name><value>/hadoop-ha-cluster-a</value></property><property><name>fs.trash.interval</name><value>360</value></property><property><name>fs.trash.checkpoint.interval</name><value>0</value></property><property><name>hadoop.proxyuser.hduser.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hduser.groups</name><value>*</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><property><name>hadoop.tmp.dir</name><value>/data/apps/hadoop-3.3.1/data</value></property><!--安全认证初始化的类--><property><name>hadoop.http.filter.initializers</name><value>org.apache.hadoop.security.HttpCrossOriginFilterInitializer</value></property><!--是否启用跨域支持--><property><name>hadoop.http.cross-origin.enabled</name><value>true</value></property><property><name>hadoop.http.cross-origin.allowed-origins</name><value>*</value></property><property><name>hadoop.http.cross-origin.allowed-methods</name><value>GET, PUT, POST, OPTIONS, HEAD, DELETE</value></property><property><name>hadoop.http.cross-origin.allowed-headers</name><value>X-Requested-With, Content-Type, Accept, Origin, WWW-Authenticate, Accept-Encoding, Transfer-Encoding</value></property><property><name>hadoop.http.cross-origin.max-age</name><value>1800</value></property><property><name>hadoop.http.authentication.simple.anonymous.allowed</name><value>true</value></property><property><name>hadoop.http.authentication.type</name><value>simple</value></property><property><name>hadoop.security.authorization</name><value>false</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.SnappyCodec</value></property><property><name>io.serializations</name><value>org.apache.hadoop.io.serializer.WritableSerialization</value></property><property><name>ipc.client.connect.max.retries</name><value>50</value></property><property><name>ipc.client.connection.maxidletime</name><value>30000</value></property><property><name>ipc.client.idlethreshold</name><value>8000</value></property><property><name>ipc.server.tcpnodelay</name><value>true</value></property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.nameservices</name><value>cluster-a,cluster-b</value></property><property><name>dfs.ha.namenodes.cluster-a</name><value>nn1,nn2</value></property><property><name>dfs.ha.namenodes.cluster-b</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.cluster-a.nn1</name><value>192.168.1.31:8020</value></property><property><name>dfs.namenode.rpc-address.cluster-a.nn2</name><value>192.168.1.32:8020</value></property><property><name>dfs.namenode.http-address.cluster-a.nn1</name><value>192.168.1.31:9870</value></property><property><name>dfs.namenode.http-address.cluster-a.nn2</name><value>192.168.1.32:9870</value></property><property><name>dfs.namenode.rpc-address.cluster-b.nn1</name><value>192.168.1.34:8020</value></property><property><name>dfs.namenode.rpc-address.cluster-b.nn2</name><value>192.168.1.35:8020</value></property><property><name>dfs.namenode.http-address.cluster-b.nn1</name><value>192.168.1.34:9870</value></property><property><name>dfs.namenode.http-address.cluster-b.nn2</name><value>192.168.1.35:9870</value></property><property><name>dfs.namenode.name.dir</name><value>/data/apps/hadoop-3.3.1/data/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>/data/apps/hadoop-3.3.1/data/datanode</value></property><property><name>dfs.journalnode.edits.dir</name><value>/data/apps/hadoop-3.3.1/data/journal</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://192.168.1.31:8485;192.168.1.32:8485;192.168.1.33:8485/cluster-a</value></property><property><name>dfs.client.failover.proxy.provider.cluster-a</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.client.failover.proxy.provider.cluster-b</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.client.failover.random.order</name><value>true</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置隔离机制方法--><property><name>dfs.ha.zkfc.port</name><value>8019</value></property><property><name>dfs.ha.fencing.methods</name><value>shell(/bin/true)</value></property><property><name>dfs.ha.nn.not-become-active-in-safemode</name><value>true</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>fs.checkpoint.period</name><value>3600</value></property><property><name>fs.checkpoint.size</name><value>67108864</value></property><property><name>fs.checkpoint.dir</name><value>/data/apps/hadoop-3.3.1/data/checkpoint</value></property><property><name>dfs.datanode.hostname</name><value>192.168.1.31</value></property><property><name>dfs.namenode.handler.count</name><value>20</value></property><property><name>dfs.datanode.handler.count</name><value>100</value></property><property><name>dfs.datanode.max.transfer.threads</name><value>100</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.hosts.exclude</name><value>/data/apps/hadoop-3.3.1/etc/hadoop/exclude-hosts</value></property>
</configuration>
cluster-b
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://cluster-b</value></property><property><name>ha.zookeeper.quorum</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>hadoop.zk.address</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>ha.zookeeper.parent-znode</name><value>/hadoop-ha-cluster-b</value></property><property><name>fs.trash.interval</name><value>360</value></property><property><name>fs.trash.checkpoint.interval</name><value>0</value></property><property><name>hadoop.proxyuser.hduser.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hduser.groups</name><value>*</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><property><name>hadoop.tmp.dir</name><value>/data/apps/hadoop-3.3.1/data</value></property><!--安全认证初始化的类--><property><name>hadoop.http.filter.initializers</name><value>org.apache.hadoop.security.HttpCrossOriginFilterInitializer</value></property><!--是否启用跨域支持--><property><name>hadoop.http.cross-origin.enabled</name><value>true</value></property><property><name>hadoop.http.cross-origin.allowed-origins</name><value>*</value></property><property><name>hadoop.http.cross-origin.allowed-methods</name><value>GET, PUT, POST, OPTIONS, HEAD, DELETE</value></property><property><name>hadoop.http.cross-origin.allowed-headers</name><value>X-Requested-With, Content-Type, Accept, Origin, WWW-Authenticate, Accept-Encoding, Transfer-Encoding</value></property><property><name>hadoop.http.cross-origin.max-age</name><value>1800</value></property><property><name>hadoop.http.authentication.simple.anonymous.allowed</name><value>true</value></property><property><name>hadoop.http.authentication.type</name><value>simple</value></property><property><name>hadoop.security.authorization</name><value>false</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.SnappyCodec</value></property><property><name>io.serializations</name><value>org.apache.hadoop.io.serializer.WritableSerialization</value></property><property><name>ipc.client.connect.max.retries</name><value>50</value></property><property><name>ipc.client.connection.maxidletime</name><value>30000</value></property><property><name>ipc.client.idlethreshold</name><value>8000</value></property><property><name>ipc.server.tcpnodelay</name><value>true</value></property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.nameservices</name><value>cluster-a,cluster-b</value></property><property><name>dfs.ha.namenodes.cluster-a</name><value>nn1,nn2</value></property><property><name>dfs.ha.namenodes.cluster-b</name><value>nn1,nn2</value></property><property><name>dfs.namenode.rpc-address.cluster-a.nn1</name><value>192.168.1.31:8020</value></property><property><name>dfs.namenode.rpc-address.cluster-a.nn2</name><value>192.168.1.32:8020</value></property><property><name>dfs.namenode.http-address.cluster-a.nn1</name><value>192.168.1.31:9870</value></property><property><name>dfs.namenode.http-address.cluster-a.nn2</name><value>192.168.1.32:9870</value></property><property><name>dfs.namenode.rpc-address.cluster-b.nn1</name><value>192.168.1.34:8020</value></property><property><name>dfs.namenode.rpc-address.cluster-b.nn2</name><value>192.168.1.35:8020</value></property><property><name>dfs.namenode.http-address.cluster-b.nn1</name><value>192.168.1.34:9870</value></property><property><name>dfs.namenode.http-address.cluster-b.nn2</name><value>192.168.1.35:9870</value></property><property><name>dfs.namenode.name.dir</name><value>/data/apps/hadoop-3.3.1/data/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>/data/apps/hadoop-3.3.1/data/datanode</value></property><property><name>dfs.journalnode.edits.dir</name><value>/data/apps/hadoop-3.3.1/data/journal</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://192.168.1.34:8485;192.168.1.35:8485;192.168.1.36:8485/cluster-b</value></property><property><name>dfs.client.failover.proxy.provider.cluster-a</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.client.failover.proxy.provider.cluster-b</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.client.failover.random.order</name><value>true</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置隔离机制方法--><property><name>dfs.ha.zkfc.port</name><value>8019</value></property><property><name>dfs.ha.fencing.methods</name><value>shell(/bin/true)</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><property><name>dfs.ha.nn.not-become-active-in-safemode</name><value>true</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>fs.checkpoint.period</name><value>3600</value></property><property><name>fs.checkpoint.size</name><value>67108864</value></property><property><name>fs.checkpoint.dir</name><value>/data/apps/hadoop-3.3.1/data/checkpoint</value></property><property><name>dfs.datanode.hostname</name><value>192.168.1.34</value></property><property><name>dfs.namenode.handler.count</name><value>20</value></property><property><name>dfs.datanode.handler.count</name><value>100</value></property><property><name>dfs.datanode.max.transfer.threads</name><value>100</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.hosts.exclude</name><value>/data/apps/hadoop-3.3.1/etc/hadoop/exclude-hosts</value></property>
</configuration>
YARN的配置
cluster-a
yarn-site.xml
<?xml version="1.0"?>
<configuration><!-- 重试次数 --><property><name>yarn.resourcemanager.am.max-attempts</name><value>2</value></property><!-- 开启 Federation --><property><name>yarn.federation.enabled</name><value>true</value></property><property><name>yarn.router.bind-host</name><value>192.168.1.31</value></property><property><name>yarn.router.hostname</name><value>192.168.1.31</value></property><property><name>yarn.router.webapp.address</name><value>192.168.1.31:8099</value></property><property><name>yarn.federation.state-store.class</name><value>org.apache.hadoop.yarn.server.federation.store.impl.ZookeeperFederationStateStore</value></property><property><name>yarn.nodemanager.amrmproxy.enabled</name><value>true</value></property><property><name>yarn.nodemanager.amrmproxy.ha.enable</name><value>true</value></property><!-- 开启RM高可用 --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定RM的cluster id --><property><name>yarn.resourcemanager.cluster-id</name><value>cluster-a</value></property><!-- 指定RM的名字 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 分别指定RM的地址 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>192.168.1.31</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>192.168.1.32</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>192.168.1.31:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>192.168.1.32:8088</value></property><!-- 指定zk集群地址 --><property><name>yarn.resourcemanager.zk-address</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>hadoop.zk.address</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>yarn.resourcemanager.work-preserving-recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.work-preserving-recovery.scheduling-wait-ms</name><value>10000</value></property><!--启动RM重启的功能,默认是false--><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value><description>Enable RM to recover state after starting. If true, thenyarn.resourcemanager.store.class must be specified</description></property><!--<property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value><description>The class to use as the persistent store.用于状态存储的类,默认是基于Hadoop 文件系统的实现(FileSystemStateStore)</description></property><property><name>yarn.resourcemanager.zk-address</name><value>192.168.1.31:2181,192.168.1.31:2181,192.168.1.32:2181</value><description>Comma separated list of Host:Port pairs. Each corresponds to a ZooKeeper server(e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002") to be used by the RM for storing RM state.This must be supplied when using org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStoreas the value for yarn.resourcemanager.store.class被RM用于状态存储的ZK服务器的主机:端口号,多个ZK之间使用逗号分离</description></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.LeveldbRMStateStore</value></property><property><name>yarn.resoucemanager.leveldb-state-store.path</name><value>${hadoop.tmp.dir}/yarn-rm-recovery/leveldb</value></property>--><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value></property><property><name>yarn.resourcemanager.fs.state-store.uri</name><value>hdfs://cluster-a/yarn/rmstore</value></property><property><name>yarn.resourcemanager.state-store.max-completed-applications</name><value>${yarn.resourcemanager.max-completed-applications}</value></property><!-- nodemanager --><property><name>yarn.nodemanager.address</name><value>192.168.1.31:45454</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>16384</value></property><property><name>yarn.nodemanager.container-executor.class</name><value>org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor</value></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/yarn/logs</value><description>on HDFS. store app stage info </description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/apps/hadoop-3.3.1/data/yarn/local</value></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/apps/hadoop-3.3.1/data/yarn/log</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.shuffleHandler</value></property><property><name>yarn.nodemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.nodemanager.recovery.dir</name><value>${hadoop.tmp.dir}/yarn-nm-recovery</value></property><property><name>yarn.nodemanager.recovery.supervised</name><value>true</value></property><!--<property><name>yarn.nodemanager.aux-services.timeline_collector.class</name><value>org.apache.hadoop.yarn.server.timelineservice.collector.PerNodeTimelineCollectorsAuxService</value></property>--><property><name>yarn.application.classpath</name><value>/data/apps/hadoop-3.3.1/etc/hadoop,/data/apps/hadoop-3.3.1/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/common/*,/data/apps/hadoop-3.3.1/share/hadoop/common/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/hdfs/*,/data/apps/hadoop-3.3.1/share/hadoop/hdfs/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/mapreduce/*,/data/apps/hadoop-3.3.1/share/hadoop/mapreduce/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/yarn/*,/data/apps/hadoop-3.3.1/share/hadoop/yarn/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/tools/*,/data/apps/hadoop-3.3.1/share/hadoop/tools/lib/*</value></property><!--需要执行如下命令,对应的参数才能生效yarn-daemon.sh start proxyserver然后就可以看到spark的任务监控了--><property><name>yarn.webapp.api-service.enable</name><value>true</value></property><property><name>yarn.webapp.ui2.enable</name><value>true</value></property><property><name>yarn.web-proxy.address</name><value>192.168.1.31:8089</value></property><!-- if not ha --><!--<property><name>yarn.resourcemanager.webapp.address</name><value>192.168.1.31:8088</value></property>--><property><name>yarn.resourcemanager.webapp.ui-actions.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.webapp.cross-origin.enabled</name><value>true</value></property><property><name>yarn.nodemanager.webapp.cross-origin.enabled</name><value>true</value></property><property><name>hadoop.http.cross-origin.allowed-origins</name><value>*</value></property><!-- 开启日志聚合 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log.server.url</name><value>http://192.168.1.31:19888/jobhistory/logs</value></property><property><name>yarn.log.server.web-service.url</name><value>http://192.168.1.31:8188/ws/v1/applicationhistory</value></property><!-- 以下是Timeline相关设置 --><!-- 设置是否开启/使用Yarn Timeline服务 --><!-- 默认值:false --><property><name>yarn.timeline-service.bind-host</name><value>192.168.1.31</value></property><property><name>yarn.timeline-service.enabled</name><value>true</value></property><property><name>yarn.timeline-service.hostname</name><value>192.168.1.31</value></property><property><name>yarn.timeline-service.address</name><value>192.168.1.31:10200</value></property><property><name>yarn.timeline-service.webapp.address</name><value>192.168.1.31:8188</value></property><property><name>yarn.timeline-service.http-cross-origin.enabled</name><value>true</value></property><property><name>yarn.timeline-service.webapp.https.address</name><value>192.168.1.31:8190</value></property><property><name>yarn.timeline-service.handler-thread-count</name><value>10</value></property><property><name>yarn.timeline-service.http-authentication.simple.anonymous.allowed</name><value>true</value></property><property><name>yarn.timeline-service.http-cross-origin.allowed-origins</name><value>*</value><description>Comma separated list of origins that are allowed for webservices needing cross-origin (CORS) support. Wildcards (*) and patternsallowed,#需要跨域源支持的web服务所允许的以逗号分隔的列表</description></property><property><name>yarn.timeline-service.http-cross-origin.allowed-methods</name><value>GET,POST,HEAD</value><description>Comma separated list of methods that are allowed for webservices needing cross-origin (CORS) support.,跨域所允许的请求操作</description></property><property><name>yarn.timeline-service.http-cross-origin.allowed-headers</name><value>X-Requested-With,Content-Type,Accept,Origin</value><description>Comma separated list of headers that are allowed for webservices needing cross-origin (CORS) support.允许用于web的标题的逗号分隔列表</description></property><property><name>yarn.timeline-service.http-cross-origin.max-age</name><value>1800</value><description>The number of seconds a pre-flighted request can be cachedfor web services needing cross-origin (CORS) support.可以缓存预先传送的请求的秒数</description></property><!-- 设置是否从Timeline history-service中获取常规信息,如果为否,则是通过RM获取 --><!-- 默认值:false --><property><name>yarn.timeline-service.generic-application-history.enabled</name><value>true</value><description>Indicate to clients whether to query generic applicationdata from timeline history-service or not. If not enabled then applicationdata is queried only from Resource Manager.向资源管理器和客户端指示是否历史记录-服务是否启用。如果启用,资源管理器将启动记录工时记录服务可以使用历史数据。同样,当应用程序如果启用此选项,请完成.</description></property><property><name>yarn.timeline-service.generic-application-history.store-class</name><value>org.apache.hadoop.yarn.server.applicationhistoryservice.FileSystemApplicationHistoryStore</value><description>Store class name for history store, defaulting to file system store</description></property><!-- 这个地址是HDFS上的地址 --><property><name>yarn.timeline-service.generic-application-history.fs-history-store.uri</name><value>/yarn/timeline/generic-history</value><description>URI pointing to the location of the FileSystem path where the history will be persisted.</description></property><property><name>yarn.timeline-service.store-class</name><value>org.apache.hadoop.yarn.server.timeline.LeveldbTimelineStore</value><description>Store class name for timeline store.</description></property><!-- leveldb是用于存放Timeline历史记录的数据库,此参数控制leveldb文件存放路径所在 --><!-- 默认值:${hadoop.tmp.dir}/yarn/timeline,其中hadoop.tmp.dir在core-site.xml中设置 --><property><name>yarn.timeline-service.leveldb-timeline-store.path</name><value>${hadoop.tmp.dir}/yarn/timeline/timeline</value><description>Store file name for leveldb timeline store.</description></property><!-- 设置leveldb中状态文件存放路径 --><!-- 默认值:${hadoop.tmp.dir}/yarn/timeline --><property><name>yarn.timeline-service.recovery.enabled</name><value>true</value></property><property><name>yarn.timeline-service.leveldb-state-store.path</name><value>${hadoop.tmp.dir}/yarn/timeline/state</value><description>Store file name for leveldb state store.</description></property><property><name>yarn.timeline-service.ttl-enable</name><value>true</value><description>Enable age off of timeline store data.</description></property><property><name>yarn.timeline-service.ttl-ms</name><value>6048000000</value><description>Time to live for timeline store data in milliseconds.</description></property><property><name>yarn.timeline-service.generic-application-history.max-applications</name><value>100000</value></property><!-- 设置RM是否发布信息到Timeline服务器 --><!-- 默认值:false --><property><name>yarn.resourcemanager.system-metrics-publisher.enabled</name><value>true</value><description>The setting that controls whether yarn system metrics is published on the timeline server or not byRM.</description></property><property><name>yarn.cluster.max-application-priority</name><value>5</value></property><property><name>hadoop.http.filter.initializers</name><value>org.apache.hadoop.security.HttpCrossOriginFilterInitializer,org.apache.hadoop.http.lib.StaticUserWebFilter</value></property>
</configuration>
cluster-b
yarn-site.xml
<?xml version="1.0"?>
<configuration><!-- 重试次数 --><property><name>yarn.resourcemanager.am.max-attempts</name><value>2</value></property><!-- 开启 Federation --><property><name>yarn.federation.enabled</name><value>true</value></property><property><name>yarn.router.bind-host</name><value>192.168.1.35</value></property><property><name>yarn.router.hostname</name><value>192.168.1.35</value></property><property><name>yarn.router.webapp.address</name><value>192.168.1.35:8099</value></property><property><name>yarn.federation.state-store.class</name><value>org.apache.hadoop.yarn.server.federation.store.impl.ZookeeperFederationStateStore</value></property><property><name>yarn.nodemanager.amrmproxy.enabled</name><value>true</value></property><property><name>yarn.nodemanager.amrmproxy.ha.enable</name><value>true</value></property><!-- 开启RM高可用 --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定RM的cluster id --><property><name>yarn.resourcemanager.cluster-id</name><value>cluster-b</value></property><!-- 指定RM的名字 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 分别指定RM的地址 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>192.168.1.35</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>192.168.1.36</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>192.168.1.35:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>192.168.1.36:8088</value></property><!-- 指定zk集群地址 --><property><name>yarn.resourcemanager.zk-address</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>hadoop.zk.address</name><value>192.168.1.31:2181,192.168.1.32:2181,192.168.1.33:2181</value></property><property><name>yarn.resourcemanager.work-preserving-recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.work-preserving-recovery.scheduling-wait-ms</name><value>10000</value></property><!--启动RM重启的功能,默认是false--><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value><description>Enable RM to recover state after starting. If true, thenyarn.resourcemanager.store.class must be specified</description></property><!--<property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value><description>The class to use as the persistent store.用于状态存储的类,默认是基于Hadoop 文件系统的实现(FileSystemStateStore)</description></property><property><name>yarn.resourcemanager.zk-address</name><value>192.168.1.31:2181,192.168.1.31:2181,192.168.1.32:2181</value><description>Comma separated list of Host:Port pairs. Each corresponds to a ZooKeeper server(e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002") to be used by the RM for storing RM state.This must be supplied when using org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStoreas the value for yarn.resourcemanager.store.class被RM用于状态存储的ZK服务器的主机:端口号,多个ZK之间使用逗号分离</description></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.LeveldbRMStateStore</value></property><property><name>yarn.resoucemanager.leveldb-state-store.path</name><value>${hadoop.tmp.dir}/yarn-rm-recovery/leveldb</value></property>--><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value></property><property><name>yarn.resourcemanager.fs.state-store.uri</name><value>hdfs://cluster-b/yarn/rmstore</value></property><property><name>yarn.resourcemanager.state-store.max-completed-applications</name><value>${yarn.resourcemanager.max-completed-applications}</value></property><!-- nodemanager --><property><name>yarn.nodemanager.address</name><value>192.168.1.35:45454</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>16384</value></property><property><name>yarn.nodemanager.container-executor.class</name><value>org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor</value></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/yarn/logs</value><description>on HDFS. store app stage info </description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/apps/hadoop-3.3.1/data/yarn/local</value></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/apps/hadoop-3.3.1/data/yarn/log</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.shuffleHandler</value></property><property><name>yarn.nodemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.nodemanager.recovery.dir</name><value>${hadoop.tmp.dir}/yarn-nm-recovery</value></property><property><name>yarn.nodemanager.recovery.supervised</name><value>true</value></property><!--<property><name>yarn.nodemanager.aux-services.timeline_collector.class</name><value>org.apache.hadoop.yarn.server.timelineservice.collector.PerNodeTimelineCollectorsAuxService</value></property>--><property><name>yarn.application.classpath</name><value>/data/apps/hadoop-3.3.1/etc/hadoop,/data/apps/hadoop-3.3.1/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/common/*,/data/apps/hadoop-3.3.1/share/hadoop/common/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/hdfs/*,/data/apps/hadoop-3.3.1/share/hadoop/hdfs/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/mapreduce/*,/data/apps/hadoop-3.3.1/share/hadoop/mapreduce/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/yarn/*,/data/apps/hadoop-3.3.1/share/hadoop/yarn/lib/*,/data/apps/hadoop-3.3.1/share/hadoop/tools/*,/data/apps/hadoop-3.3.1/share/hadoop/tools/lib/*</value></property><!--需要执行如下命令,对应的参数才能生效yarn-daemon.sh start proxyserver然后就可以看到spark的任务监控了--><property><name>yarn.webapp.api-service.enable</name><value>true</value></property><property><name>yarn.webapp.ui2.enable</name><value>true</value></property><property><name>yarn.web-proxy.address</name><value>192.168.1.35:8089</value></property><!-- if not ha --><!--<property><name>yarn.resourcemanager.webapp.address</name><value>192.168.1.35:8088</value></property>--><property><name>yarn.resourcemanager.webapp.ui-actions.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.webapp.cross-origin.enabled</name><value>true</value></property><property><name>yarn.nodemanager.webapp.cross-origin.enabled</name><value>true</value></property><property><name>hadoop.http.cross-origin.allowed-origins</name><value>*</value></property><!-- 开启日志聚合 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log.server.url</name><value>http://192.168.1.35:19888/jobhistory/logs</value></property><property><name>yarn.log.server.web-service.url</name><value>http://192.168.1.35:8188/ws/v1/applicationhistory</value></property><!-- 以下是Timeline相关设置 --><!-- 设置是否开启/使用Yarn Timeline服务 --><!-- 默认值:false --><property><name>yarn.timeline-service.bind-host</name><value>192.168.1.35</value></property><property><name>yarn.timeline-service.enabled</name><value>true</value></property><property><name>yarn.timeline-service.hostname</name><value>192.168.1.35</value></property><property><name>yarn.timeline-service.address</name><value>192.168.1.35:10200</value></property><property><name>yarn.timeline-service.webapp.address</name><value>192.168.1.35:8188</value></property><property><name>yarn.timeline-service.http-cross-origin.enabled</name><value>true</value></property><property><name>yarn.timeline-service.webapp.https.address</name><value>192.168.1.35:8190</value></property><property><name>yarn.timeline-service.handler-thread-count</name><value>10</value></property><property><name>yarn.timeline-service.http-authentication.simple.anonymous.allowed</name><value>true</value></property><property><name>yarn.timeline-service.http-cross-origin.allowed-origins</name><value>*</value><description>Comma separated list of origins that are allowed for webservices needing cross-origin (CORS) support. Wildcards (*) and patternsallowed,#需要跨域源支持的web服务所允许的以逗号分隔的列表</description></property><property><name>yarn.timeline-service.http-cross-origin.allowed-methods</name><value>GET,POST,HEAD</value><description>Comma separated list of methods that are allowed for webservices needing cross-origin (CORS) support.,跨域所允许的请求操作</description></property><property><name>yarn.timeline-service.http-cross-origin.allowed-headers</name><value>X-Requested-With,Content-Type,Accept,Origin</value><description>Comma separated list of headers that are allowed for webservices needing cross-origin (CORS) support.允许用于web的标题的逗号分隔列表</description></property><property><name>yarn.timeline-service.http-cross-origin.max-age</name><value>1800</value><description>The number of seconds a pre-flighted request can be cachedfor web services needing cross-origin (CORS) support.可以缓存预先传送的请求的秒数</description></property><!-- 设置是否从Timeline history-service中获取常规信息,如果为否,则是通过RM获取 --><!-- 默认值:false --><property><name>yarn.timeline-service.generic-application-history.enabled</name><value>true</value><description>Indicate to clients whether to query generic applicationdata from timeline history-service or not. If not enabled then applicationdata is queried only from Resource Manager.向资源管理器和客户端指示是否历史记录-服务是否启用。如果启用,资源管理器将启动记录工时记录服务可以使用历史数据。同样,当应用程序如果启用此选项,请完成.</description></property><property><name>yarn.timeline-service.generic-application-history.store-class</name><value>org.apache.hadoop.yarn.server.applicationhistoryservice.FileSystemApplicationHistoryStore</value><description>Store class name for history store, defaulting to file system store</description></property><!-- 这个地址是HDFS上的地址 --><property><name>yarn.timeline-service.generic-application-history.fs-history-store.uri</name><value>/yarn/timeline/generic-history</value><description>URI pointing to the location of the FileSystem path where the history will be persisted.</description></property><property><name>yarn.timeline-service.store-class</name><value>org.apache.hadoop.yarn.server.timeline.LeveldbTimelineStore</value><description>Store class name for timeline store.</description></property><!-- leveldb是用于存放Timeline历史记录的数据库,此参数控制leveldb文件存放路径所在 --><!-- 默认值:${hadoop.tmp.dir}/yarn/timeline,其中hadoop.tmp.dir在core-site.xml中设置 --><property><name>yarn.timeline-service.leveldb-timeline-store.path</name><value>${hadoop.tmp.dir}/yarn/timeline/timeline</value><description>Store file name for leveldb timeline store.</description></property><!-- 设置leveldb中状态文件存放路径 --><!-- 默认值:${hadoop.tmp.dir}/yarn/timeline --><property><name>yarn.timeline-service.recovery.enabled</name><value>true</value></property><property><name>yarn.timeline-service.leveldb-state-store.path</name><value>${hadoop.tmp.dir}/yarn/timeline/state</value><description>Store file name for leveldb state store.</description></property><property><name>yarn.timeline-service.ttl-enable</name><value>true</value><description>Enable age off of timeline store data.</description></property><property><name>yarn.timeline-service.ttl-ms</name><value>6048000000</value><description>Time to live for timeline store data in milliseconds.</description></property><property><name>yarn.timeline-service.generic-application-history.max-applications</name><value>100000</value></property><!-- 设置RM是否发布信息到Timeline服务器 --><!-- 默认值:false --><property><name>yarn.resourcemanager.system-metrics-publisher.enabled</name><value>true</value><description>The setting that controls whether yarn system metrics is published on the timeline server or not byRM.</description></property><property><name>yarn.cluster.max-application-priority</name><value>5</value></property><property><name>hadoop.http.filter.initializers</name><value>org.apache.hadoop.security.HttpCrossOriginFilterInitializer,org.apache.hadoop.http.lib.StaticUserWebFilter</value></property>
</configuration>
HDFS启动命令
启动journalnode
在规划的journalnode上启动journalnode组件(必须先启动 journalnode, 否则namenode启动时,无法连接)
bin/hdfs --daemon start journalnode
# 进程为
JournalNode
主:格式化namenode(限首次)
bin/hdfs namenode -format -clusterId CID-55a8ca40-4cfa-478f-a93d-3238b8b50e86 -nonInteractive {{ $cluster }}
主:启动namenode
bin/hdfs --daemon start namenode
# 进程为
NameNode
主:格式化zkfc(限首次)
bin/hdfs zkfc -formatZK
主:启动zkfc
bin/hdfs --daemon start zkfc
# 进程为
DFSZKFailoverController
主:启动router(限RBF模式)
bin/hdfs --daemon start dfsrouter
# 进程为
DFSRouter
从:同步namenode元数据(限首次)
bin/hdfs namenode -bootstrapStandby
从:启动namenode
bin/hdfs --daemon start namenode
# 进程为
NameNode
从:启动zkfc
bin/hdfs --daemon start zkfc
# 进程为
DFSZKFailoverController
从:启动router(限RBF模式)
bin/hdfs --daemon start dfsrouter
# 进程为
DFSRouter
启动datanode
所有的dn节点执行如下命令:
bin/hdfs --daemon start datanode
# 进程为
DataNode
停止组件命令
# 简便的
kill -9 `jps -m | egrep -iw 'journalnode|NameNode|DataNode|DFSZKFailoverController|DFSRouter' | awk '{print $1}'`kill -9 `jps -m | egrep -iw 'ResourceManager|NodeManager|Router' | awk '{print $1}'`rm -rf /data/apps/hadoop-3.3.1/data/* /data/apps/hadoop-3.3.1/logs/*[root@hadoop-31 zookeeper-3.8.0]# bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[federationstore, hadoop-ha-cluster-a, hadoop-ha-cluster-b, hdfs-federation, yarn-leader-election, zookeeper]
[zk: localhost:2181(CONNECTED) 1] deleteall /federationstore
[zk: localhost:2181(CONNECTED) 2] deleteall /hadoop-ha-cluster-a
[zk: localhost:2181(CONNECTED) 3] deleteall /hadoop-ha-cluster-b
[zk: localhost:2181(CONNECTED) 4] deleteall /hdfs-federation
[zk: localhost:2181(CONNECTED) 5] deleteall /yarn-leader-election# 优雅的
bin/hdfs --daemon stop datanode
bin/hdfs --daemon stop dfsrouter
bin/hdfs --daemon stop zkfc
bin/hdfs --daemon stop namenode
bin/hdfs --daemon stop journalnodeYARN启动命令
主: 启动ResourceManager
bin/yarn --daemon start resourcemanager
# 进程为
ResourceManager
从: 启动ResourceManager
bin/yarn --daemon start resourcemanager
# 进程为
ResourceManager
启动nodemanager
bin/yarn --daemon start nodemanager
# 进程为
NodeManager
启动timelineserver
bin/yarn --daemon start timelineserver# 进程为
ApplicationHistoryServer
启动proxyserver
bin/yarn --daemon start proxyserver# 进程为
WebAppProxyServer
启动historyserver (MR)
bin/mapred --daemon start historyserver# 进程为
JobHistoryServer
主:启动router(限Federation模式)
bin/yarn --daemon start router
# 进程为
Router
主从切换命令
# 将 nn1 切换成主节点
bin/hdfs haadmin -ns cluster-a -transitionToActive --forceactive --forcemanual nn1# 将 nn2 切换成主节点
bin/hdfs haadmin -ns cluster-a -failover nn1 nn2
相关文章:
【大数据】Hadoop-HA-Federation-3.3.1集群高可用联邦安装部署文档(建议收藏哦)
背景概述 单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈。因而提出了 namenode 水平扩展方案-- Federation。 Federation 中…...

【设计模式之美 设计原则与思想:面向对象】14 | 实战二(下):如何利用面向对象设计和编程开发接口鉴权功能?
在上一节课中,针对接口鉴权功能的开发,我们讲了如何进行面向对象分析(OOA),也就是需求分析。实际上,需求定义清楚之后,这个问题就已经解决了一大半,这也是为什么我花了那么多篇幅来讲…...

工作技术小结
2023/1/31 关于后端接口编写小结 1,了解小程序原型图流程和细节性的东西 2,数据库关联结构仔细分析,找到最容易查询的关键字段,标语表之间靠什么关联 2023/2/10 在web抓包过程中,如果要实现批量抓取,必须解…...
无重复字符的最长子串-力扣3-java
一、题目描述给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。示例 1:输入: s "abcabcbb"输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:输入: s "bbbbb"输出: 1解释: 因为…...
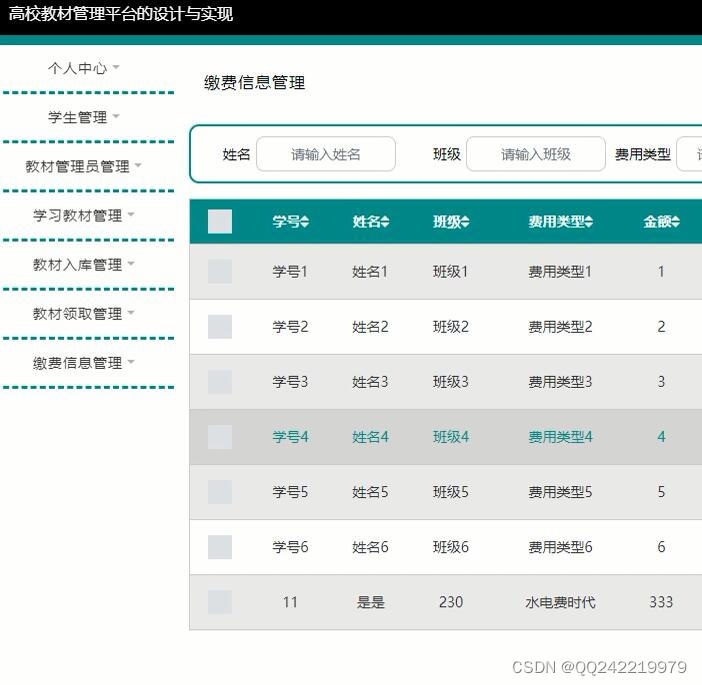
java ssm高校教材管理平台 idea maven
设计并且实现一个基于JSP技术的高校教材管理平台的设计与实现。采用MYSQL为数据库开发平台,SSM框架,Tomcat网络信息服务作为应用服务器。高校教材管理平台的设计与实现的功能已基本实现,主要学生、教材管理、学习教材、教材入库、教材领取、缴…...
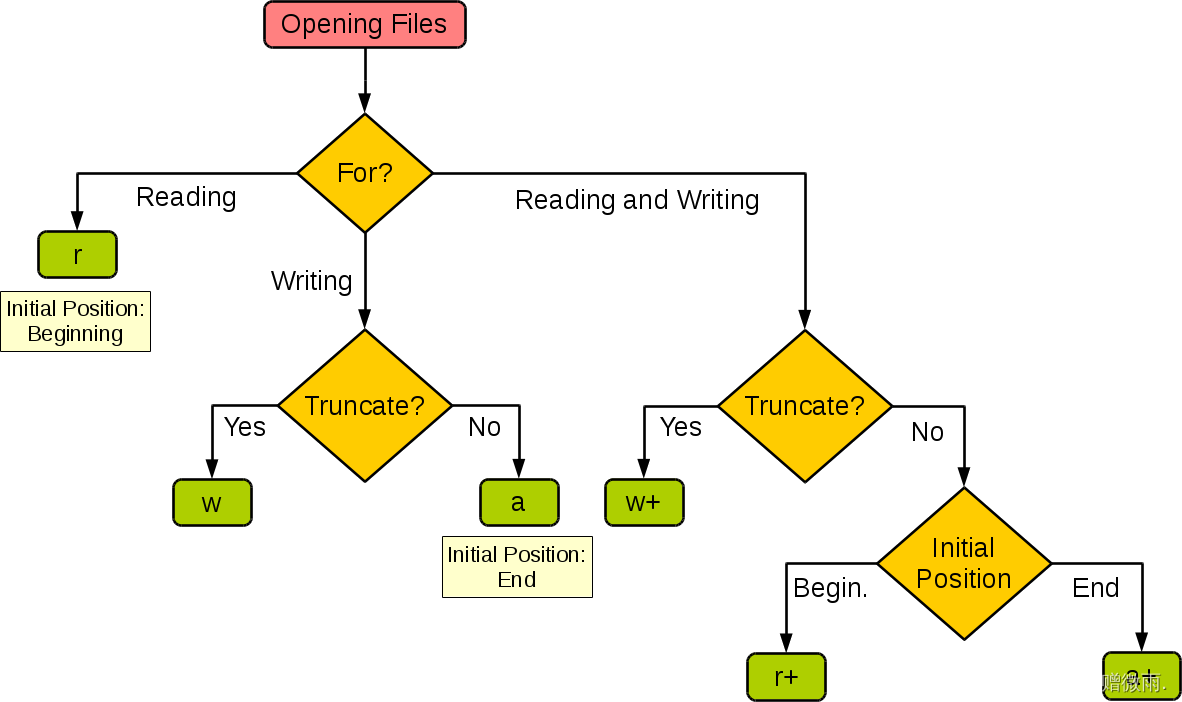
【Python学习笔记】25.Python3 输入和输出(1)
前言 在前面几个章节中,我们其实已经接触了 Python 的输入输出的功能。本章节我们将具体介绍 Python 的输入输出。 输出格式美化 Python两种输出值的方式: 表达式语句和 print() 函数。 第三种方式是使用文件对象的 write() 方法,标准输出文件可以用…...
C++复习笔记8
泛型编程:编写的是与类型无关的通用代码,是代码复用的一种手段,模板是泛型编程的基础。 1.函数模板:类型参数化,增加代码复用性。例如对于swap函数,不同类型之间进行交换都需要进行重载,但是函数…...

RabbitMQ入门
目录1. 搭建示例工程1.1. 创建工程1.2. 添加依赖2. 编写生产者3. 编写消费者4. 小结需求 官网: https://www.rabbitmq.com/ 需求:使用简单模式完成消息传递 步骤: ① 创建工程(生成者、消费者) ② 分别添加依赖 ③ 编…...
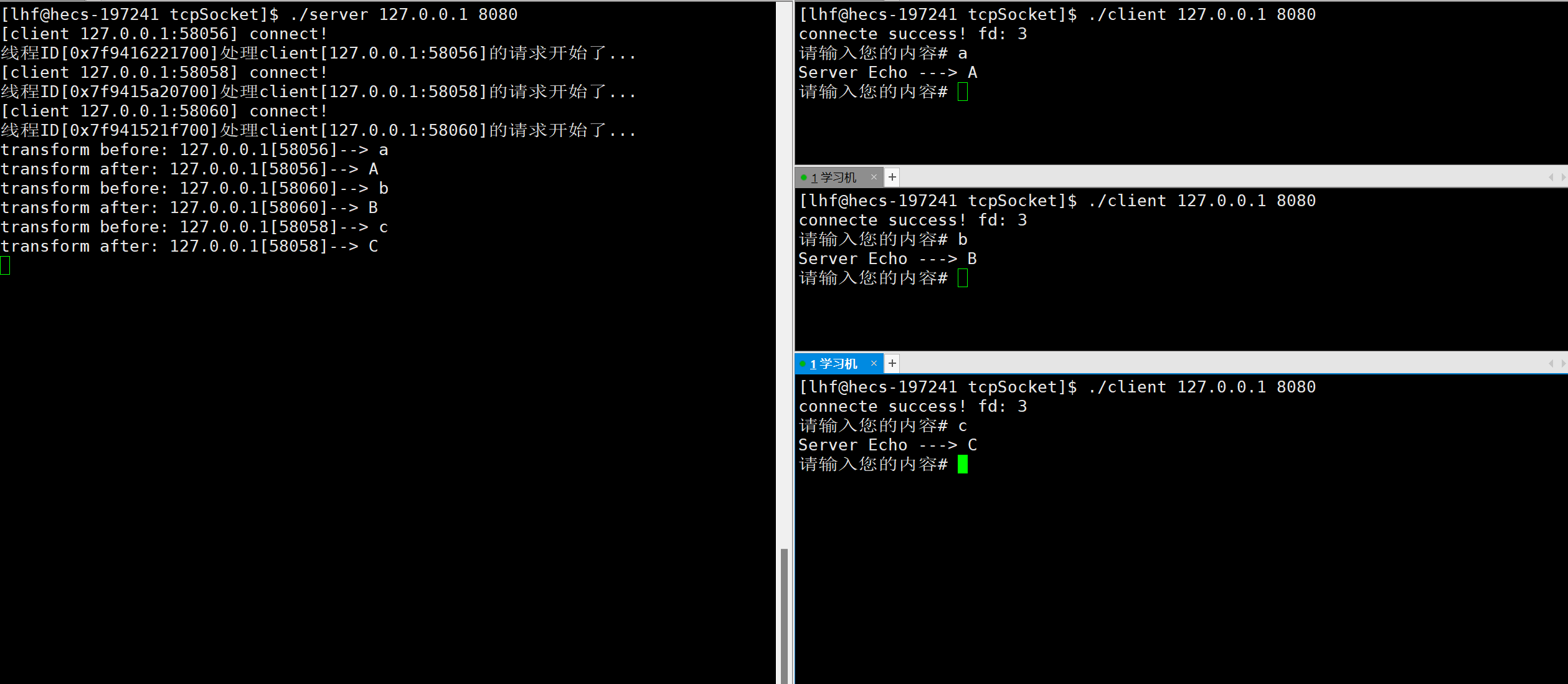
【计算机网络】Linux环境中的TCP网络编程
文章目录前言一、TCP Socket API1. socket2. bind3. listen4. accept5. connect二、封装TCPSocket三、服务端的实现1. 封装TCP通用服务器2. 封装任务对象3. 实现转换功能的服务器四、客户端的实现1. 封装TCP通用客户端2. 实现转换功能的客户端五、结果演示六、多进程版服务器七…...
idekCTF 2022 比赛复现
Readme 首先 []byte 是 go 语言里面的一个索引,比如: package mainimport "fmt"func main() {var str string "hello"var randomData []byte []byte(str)fmt.Println(randomData[0:]) //[104 101 108 108 111] }上面这串代码会从…...

jvm的类加载过程
加载 通过一个类的全限定名获取定义此类的二进制字节流将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口链接 验证 验证内容的合法性准备 把方法区的静态变量初…...
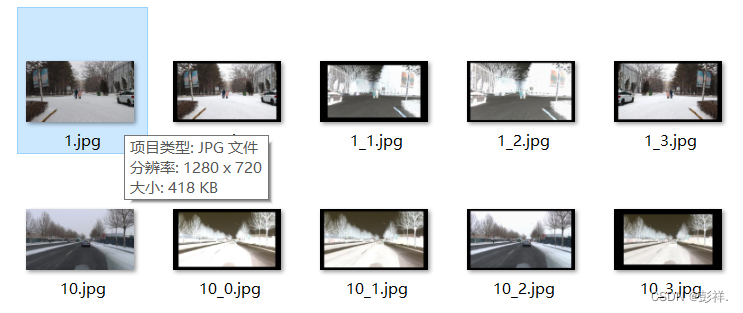
VOC数据增强与调整大小
数据增强是针对数据集图像数量太少所采取的一种方法。 博主在实验过程中,使用自己的数据集时发现其数据量过少,只有280张,因此便想到使用数据增强的方式来获取更多的图像信息。对于图像数据,我们可以采用旋转等操作来获取更多的图…...

Linux 安装jenkins和jdk11
Linux 安装jenkins和jdk111. Install Jdk112. Jenkins Install2.1 Install Jenkins2.2 Start2.3 Error3.Awakening1.1 Big Data -- Postgres4. Awakening1. Install Jdk11 安装jdk11 sudo yum install fontconfig java-11-openjdk 2. Jenkins Install 2.1 Install Jenkins 下…...
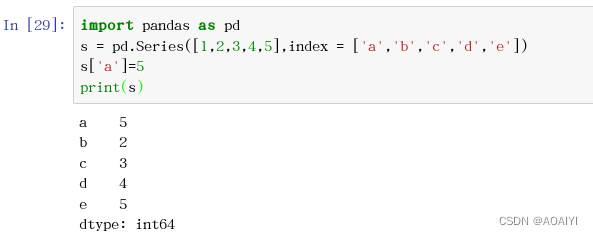
Pandas——Series操作【建议收藏】
pandas——Series操作 作者:AOAIYI 创作不易,觉得文章不错或能帮助到你学习,可以点赞收藏评论哦 文章目录pandas——Series操作一、实验目的二、实验原理三、实验环境四、实验内容五、实验步骤1.创建Series2.从具体位置的Series中访问数据3.使…...
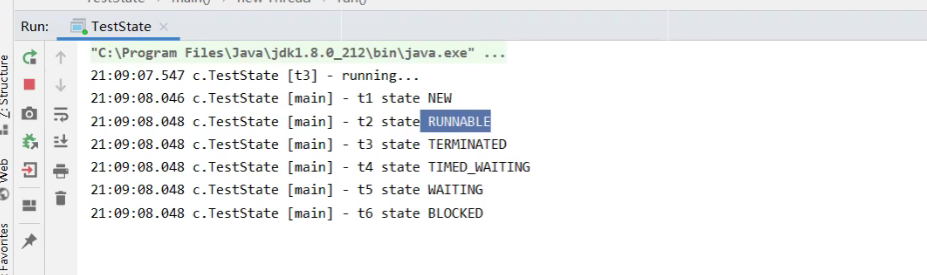
JUC并发编程Ⅰ -- Java中的线程
文章目录线程与进程并行与并发进程与线程应用应用之异步调用应用之提高效率线程的创建方法一:通过继承Thread类创建方法二:使用Runnable配合Thread方法三:使用FutureTask与Thread结合创建查看进程和线程的方法线程运行的原理栈与栈帧线程上下…...
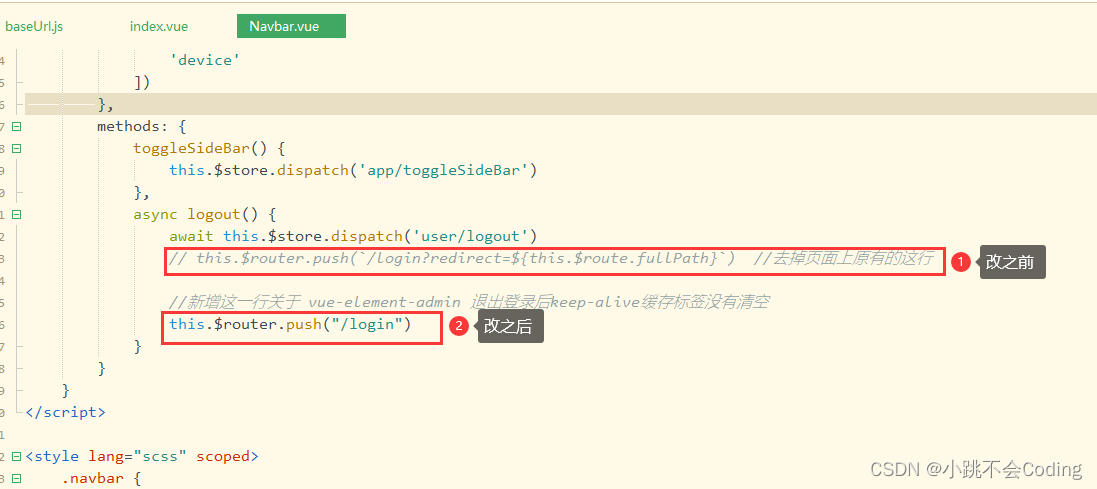
基于vue-admin-element开发后台管理系统【技术点整理】
一、Vue点击跳转外部链接 点击重新打开一个页面窗口,不覆盖当前的页面 window.open(https://www.baidu.com,"_blank")"_blank" 新打开一个窗口"_self" 覆盖当前的窗口例如:导入用户模板下载 templateDownload() {wi…...
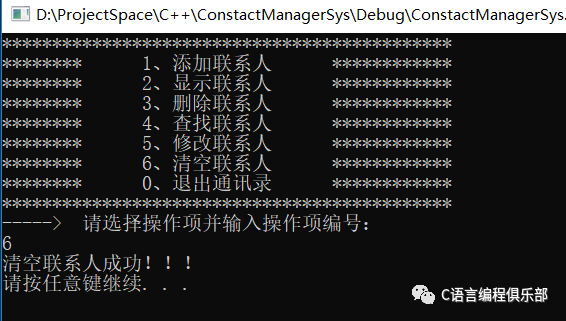
【C语言学习笔记】:通讯录管理系统
系统中需要实现的功能如下: ✿ 添加联系人:向通讯录中添加新人,信息包括(姓名、性别、年龄、联系电话、家庭住址)最多记录1000人 ✿ 显示联系人:显示通讯录中所有的联系人信息 ✿ 删除联系人:按…...
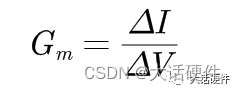
开关电源环路稳定性分析(10)——OPA和OTA型补偿器传递函数
大家好,这里是大话硬件。 在前面9讲的内容中将开关电源环路分析进行了梳理,我相信很多人即使都看完了,应该还是不会设计,而且还存在几个疑问。比如我随便举几个: 开关电源的带宽怎么设定?开关电源精度和什…...
)
2.11知识点整理(关于pycharm,python,pytorch,conda)
pycharm 设置anaconda环境: File -> Settings->选择左侧的project xxx再选择打开Project Interpreter页->选择add添加解释器->添加Anaconda中Python解释器(Anaconda安装目录下的python.exe) (选择existing environment ÿ…...
Linux服务器开发-2. Linux多进程开发
文章目录1. 进程概述1.1 程序概览1.2 进程概念1.3 单道、多道程序设计1.4 时间片1.5 并行与并发1.6 进程控制块(PCB)2. 进程的状态转换2.1 进程的状态2.2 进程相关命令查看进程实时显示进程动态杀死进程进程号和相关函数3. 进程的创建-fork函数3.1 进程创…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...