C++面试:跳表
目录
跳表介绍
跳表的特点:
跳表的应用场景:
C++ 代码示例:
跳表的特性
跳表示例
总结
跳表(Skip List)是一种支持快速搜索、插入和删除的数据结构,具有相对简单的实现和较高的查询性能。下面是跳表的详细介绍和一个简单的 C++ 代码示例:
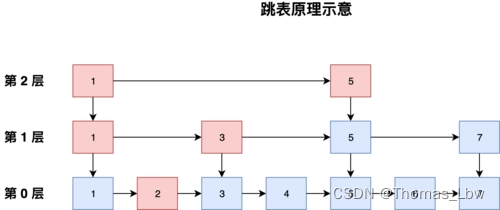
跳表介绍
跳表的特点:
- 有序结构: 跳表中的每个节点都包含一个元素,并且节点按照元素的大小有序排列。
- 多层索引: 跳表通过维护多层索引来实现快速搜索。每一层都是一个有序链表,最底层包含所有元素,而每上一层的节点是下一层节点的一部分。
- 跳跃式访问: 通过索引层,跳表允许在较高层直接跳过一些节点,从而提高搜索效率。
跳表的应用场景:
- 有序集合的实现: 用于需要频繁的插入、删除和搜索操作的有序数据集合,如 Redis 中的有序集合(Sorted Set)。
- 替代平衡树: 在某些场景下,跳表可以作为对平衡树的一种替代,具有更简单的实现和较好的性能。
C++ 代码示例:
#include <iostream>
#include <vector>
#include <cstdlib>const int MAX_LEVEL = 16; // 最大层数// 跳表节点定义
struct Node {int value;std::vector<Node*> forward; // 每层的指针数组Node(int val, int level) : value(val), forward(level, nullptr) {}
};// 跳表定义
class SkipList {
private:Node* header; // 头节点int level; // 当前跳表的最大层数public:SkipList() : level(1) {header = new Node(0, MAX_LEVEL);}// 随机生成一个层数int randomLevel() {int lvl = 1;while ((rand() % 2) && (lvl < MAX_LEVEL))lvl++;return lvl;}// 插入一个元素void insert(int val) {std::vector<Node*> update(MAX_LEVEL, nullptr);Node* current = header;// 从最高层到底层,找到每一层的插入位置for (int i = level - 1; i >= 0; i--) {while (current->forward[i] != nullptr && current->forward[i]->value < val) {current = current->forward[i];}update[i] = current;}// 随机生成一个层数int newLevel = randomLevel();// 如果新的层数比当前层数高,则更新 updateif (newLevel > level) {for (int i = level; i < newLevel; i++) {update[i] = header;}level = newLevel;}// 创建新节点Node* newNode = new Node(val, newLevel);// 更新每一层的指针for (int i = 0; i < newLevel; i++) {newNode->forward[i] = update[i]->forward[i];update[i]->forward[i] = newNode;}}// 搜索一个元素,返回是否存在bool search(int val) {Node* current = header;// 从最高层到底层,搜索每一层的节点for (int i = level - 1; i >= 0; i--) {while (current->forward[i] != nullptr && current->forward[i]->value < val) {current = current->forward[i];}}// 到达底层,判断是否找到目标元素if (current->forward[0] != nullptr && current->forward[0]->value == val) {return true;} else {return false;}}// 删除一个元素void remove(int val) {std::vector<Node*> update(MAX_LEVEL, nullptr);Node* current = header;// 从最高层到底层,找到每一层的删除位置for (int i = level - 1; i >= 0; i--) {while (current->forward[i] != nullptr && current->forward[i]->value < val) {current = current->forward[i];}update[i] = current;}// 到达底层,判断是否找到目标元素if (current->forward[0] != nullptr && current->forward[0]->value == val) {// 更新每一层的指针,删除目标节点for (int i = 0; i < level; i++) {if (update[i]->forward[i] != current->forward[i]) {break;}update[i]->forward[i] = current->forward[i]->forward[i];}// 如果删除的是最高层的节点,更新层数while (level > 1 && header->forward[level - 1] == nullptr) {level--;}// 释放节点内存delete current;}}// 打印跳表void printSkipList() {for (int i = level - 1; i >= 0; i--) {Node* current = header->forward[i];std::cout << "Level " << i << ": ";while (current != nullptr) {std::cout << current->value << " ";current = current->forward[i];}std::cout << std::endl;}std::cout << "-----------------------" << std::endl;}
};int main() {// 创建跳表SkipList skipList;// 插入一些元素skipList.insert(3);skipList.insert(6);skipList.insert(7);skipList.insert(9);skipList.insert(12);// 打印跳表skipList.printSkipList();// 搜索元素int searchValue = 7;if (skipList.search(searchValue)) {std::cout << "Element " << searchValue << " found in the skip list." << std::endl;} else {std::cout << "Element " << searchValue << " not found in the skip list." << std::endl;}// 删除元素int removeValue = 6;skipList.remove(removeValue);// 打印删除后的跳表skipList.printSkipList();return 0;
}
这是一个简单的跳表实现,包括插入、搜索和删除操作。在实际应用中,跳表的层数、随机层数的方式以及其他细节可以根据具体需求进行调整。
跳表的特性
-
有序性: 跳表中的每个节点按照元素的大小有序排列。这使得在跳表中可以快速定位和搜索元素。
-
多层索引: 跳表通过维护多层索引来实现快速搜索。每一层都是一个有序链表,最底层包含所有元素,而每一层的节点是下一层节点的子集。这样的多层索引结构可以提高搜索效率。
-
跳跃式访问: 通过多层索引,跳表允许在较高层直接跳过一些节点,从而实现跳跃式的访问。这种设计类似于在二分查找中直接跳过一半的元素,从而提高了搜索的效率。
-
平衡性: 跳表的设计通过随机层数和灵活的插入策略,保持了跳表的平衡性。这有助于避免类似于二叉搜索树中的不平衡情况,使得操作的时间复杂度更加可控。
-
简单实现: 跳表相对于其他高效的数据结构,如平衡树,实现相对简单。它不需要像平衡树那样复杂的平衡维护,使得代码的实现和维护相对容易。
-
支持动态操作: 跳表天生适合动态操作,包括插入和删除。由于插入和删除操作只需要调整相邻节点的指针,而不需要进行全局的平衡调整,因此操作的效率较高。
-
适应范围广: 跳表可以应用于各种有序数据集合的场景,特别是在需要频繁插入、删除和搜索操作的场景中,其性能表现优异。
跳表的这些特性使得它在一些应用场景中具有明显的优势,尤其在无法提前知道数据分布情况的情形下,跳表能够以较简单的方式维护有序性和高效操作。
跳表示例
下面是一个使用 C++ 实现的跳表例子,包含插入、搜索、删除和打印操作。在这个例子中,我使用了模板类以支持不同类型的元素。
#include <iostream>
#include <vector>
#include <cstdlib>// 跳表节点定义
template <typename T>
struct Node {T value;std::vector<Node*> forward;Node(T val, int level) : value(val), forward(level, nullptr) {}
};// 跳表定义
template <typename T>
class SkipList {
private:Node<T>* header;int level;public:SkipList() : level(1) {header = new Node<T>(T(), MAX_LEVEL); // 初始值为 T() 的头节点}// 随机生成一个层数int randomLevel() {int lvl = 1;while ((rand() % 2) && (lvl < MAX_LEVEL))lvl++;return lvl;}// 插入一个元素void insert(const T& val) {std::vector<Node<T>*> update(MAX_LEVEL, nullptr);Node<T>* current = header;// 从最高层到底层,找到每一层的插入位置for (int i = level - 1; i >= 0; i--) {while (current->forward[i] != nullptr && current->forward[i]->value < val) {current = current->forward[i];}update[i] = current;}// 随机生成一个层数int newLevel = randomLevel();// 如果新的层数比当前层数高,则更新 updateif (newLevel > level) {for (int i = level; i < newLevel; i++) {update[i] = header;}level = newLevel;}// 创建新节点Node<T>* newNode = new Node<T>(val, newLevel);// 更新每一层的指针for (int i = 0; i < newLevel; i++) {newNode->forward[i] = update[i]->forward[i];update[i]->forward[i] = newNode;}}// 搜索一个元素,返回是否存在bool search(const T& val) const {Node<T>* current = header;// 从最高层到底层,搜索每一层的节点for (int i = level - 1; i >= 0; i--) {while (current->forward[i] != nullptr && current->forward[i]->value < val) {current = current->forward[i];}}// 到达底层,判断是否找到目标元素return (current->forward[0] != nullptr && current->forward[0]->value == val);}// 删除一个元素void remove(const T& val) {std::vector<Node<T>*> update(MAX_LEVEL, nullptr);Node<T>* current = header;// 从最高层到底层,找到每一层的删除位置for (int i = level - 1; i >= 0; i--) {while (current->forward[i] != nullptr && current->forward[i]->value < val) {current = current->forward[i];}update[i] = current;}// 到达底层,判断是否找到目标元素if (current->forward[0] != nullptr && current->forward[0]->value == val) {// 更新每一层的指针,删除目标节点for (int i = 0; i < level; i++) {if (update[i]->forward[i] != current->forward[i]) {break;}update[i]->forward[i] = current->forward[i]->forward[i];}// 如果删除的是最高层的节点,更新层数while (level > 1 && header->forward[level - 1] == nullptr) {level--;}// 释放节点内存delete current;}}// 打印跳表void printSkipList() const {for (int i = level - 1; i >= 0; i--) {Node<T>* current = header->forward[i];std::cout << "Level " << i << ": ";while (current != nullptr) {std::cout << current->value << " ";current = current->forward[i];}std::cout << std::endl;}std::cout << "-----------------------" << std::endl;}
};int main() {// 创建跳表SkipList<int> skipList;// 插入一些元素skipList.insert(3);skipList.insert(6);skipList.insert(7);skipList.insert(9);skipList.insert(12);// 打印跳表skipList.printSkipList();// 搜索元素int searchValue = 7;if (skipList.search(searchValue)) {std::cout << "Element " << searchValue << " found in the skip list." << std::endl;} else {std::cout << "Element " << searchValue << " not found in the skip list." << std::endl;}// 删除元素int removeValue = 6;skipList.remove(removeValue);// 打印删除后的跳表skipList.printSkipList();return 0;
}
在这个例子中,使用跳表有几个考虑因素:
-
高效的搜索操作: 跳表的搜索操作时间复杂度为 O(log n),其中 n 是跳表中的元素个数。相较于普通链表的线性搜索,跳表提供了更快的搜索速度。
-
支持动态操作: 跳表天生适合动态操作,包括插入和删除。由于插入和删除操作只需要调整相邻节点的指针,而不需要进行全局的平衡调整,因此在元素的动态更新场景下,跳表相对于其他数据结构更具有优势。
-
简单实现: 跳表的实现相对简单,不需要像平衡树那样复杂的平衡维护。这使得它在实际应用中更容易实现和维护。
-
对比其他数据结构: 在这个示例中,使用跳表的主要目的是演示跳表的基本原理和操作,并不代表它是绝对优于其他数据结构的选择。具体选择数据结构的决策取决于实际应用场景、数据分布情况以及对不同操作的需求。
总结
特性:
- 有序性: 跳表中的每个节点按照元素的大小有序排列,使得在跳表中可以快速定位和搜索元素。
- 多层索引: 跳表通过维护多层索引来实现快速搜索,每一层都是一个有序链表,最底层包含所有元素。
- 跳跃式访问: 通过多层索引,跳表允许在较高层直接跳过一些节点,实现跳跃式的访问,提高搜索效率。
- 平衡性: 通过随机层数和灵活的插入策略,保持了跳表的平衡性,避免了类似于二叉搜索树中的不平衡情况。
- 支持动态操作: 跳表天生适合动态操作,包括插入和删除,操作的时间复杂度较低。
应用场景:
- 有序集合的实现: 适用于需要频繁插入、删除和搜索操作的有序数据集合,例如在 Redis 中的有序集合(Sorted Set)实现中使用了跳表。
- 替代平衡树: 在某些场景下,跳表可以作为对平衡树的一种替代,相对简单的实现和较好的性能表现使得它成为一种备选选择。
- 动态数据库索引: 在数据库中,跳表可以用作动态索引结构,适用于动态更新和频繁搜索的情况。
- 高效的动态排序: 在需要频繁的动态排序操作的场景下,跳表的性能可能优于传统的排序算法。
总体评价:
- 优势: 跳表提供了一种在有序数据集合中实现高效的动态操作的方式,相较于平衡树结构实现较为简单,适用于需要频繁更新和搜索的场景。
- 劣势: 跳表相对于其他数据结构可能占用更多内存,对于某些内存敏感的场景,可能不是最优选择。在一些特定的搜索密集型场景中,红黑树等平衡树结构也具有竞争力。
总体而言,跳表在一些动态、搜索密集的应用场景中表现出色,但在具体选择时,需要综合考虑数据分布、内存使用、实现难度等因素。
相关文章:
C++面试:跳表
目录 跳表介绍 跳表的特点: 跳表的应用场景: C 代码示例: 跳表的特性 跳表示例 总结 跳表(Skip List)是一种支持快速搜索、插入和删除的数据结构,具有相对简单的实现和较高的查询性能。下面是跳表…...

掌握C++20的革命性特性:Concepts
掌握C20的革命性特性:Concepts C20 的新特性 C20 引入了 Concepts,这是一种用于限制类和函数模板的模板类型和非类型参数的命名要求。Concepts 是作为编译时评估的谓词,用于验证传递给模板的模板参数。Concepts 的主要目的是使模板相关的编…...

win11开机后频繁刷新桌面,任务栏不显示,文件资源管理器explorer报错ntdll.dll
win11 开机后桌面频繁刷新,cpu 暴涨,任务栏不出现。 不知道是安装了什么软件还是系统升级造成的,好长时间不重启电脑了,然后重启了下电脑。 结果就是: 现象描述 重启后 输入密码进入后 变得巨慢。好久才进入的桌面。…...

解决Git添加.gitignore文件后不生效的问题
1. 问题描述 如上图所示,在已存在.gitignore文件且已经提交过的Git管理的项目中,其中.class、.jar文件以及.idea目录内的内容全部都还是被Git管理了,可见.gitignore文件并没有生效。 2. 原因发现 .gitignore文件只能作用于 Untracked Files…...

Shell Linux学习笔记
注意:该文章摘抄之百度,仅当做学习笔记供小白使用,若侵权请联系删除! 目录 什么是shell ? Linux正则匹配 grep tar与unzip echo history 重定向 shell 单双引号 位置参数 预定义变量 运算 正则表达式 字符截取命令 …...

kingbase常用SQL总结之锁等待信息
锁信息与等待事件 分析kingbase(pg)数据库锁等待、死锁时需要我们准确的定位等锁或者死锁相关的事务。关于获取锁等待信息或者死锁信息已有经典的SQL可以直接使用,但是需要我们先了解sql语句获取的每个字段的意义。 获取到锁等待事务不能完全…...

「优选算法刷题」:长度最小的子数组
一、题目 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。 示例 1: 输…...
RuoYi-Cloud本地部署--详细教程
文章目录 1、gitee项目地址2、RuoYi-Cloud架构3、本地部署3.1 下载项目3.2 idea打开项目3.3 启动nacos3.4 若依数据库准备3.5 启动redis3.6 修改nacos中的各个模块的配置文件3.7 启动ruoyi前端项目3.8 启动各个微服务模块 4、启动成功 1、gitee项目地址 https://gitee.com/y_p…...

如何优雅的发布一个 TypeScript 软件包?
向 NPM 发布软件包本身并不是一个特别困难的挑战。但是,配置你的 TypeScript 项目以取得成功可能是一个挑战。你的软件包能在大多数项目上运行吗?用户能否使用类型提示和自动完成功能?它能与 ES Modules (ESM) 和 CommonJS (CJS) 风格的导入一…...

总结的太到位:python 多线程系列详解
前言: 上vip课的时候每次讲到框架的执行,就会有好学的同学问用多线程怎么执行,然后我每次都会说在测开课程会详细讲解,这并不是套路,因为如果你不理解多线程,不清楚什么时候该用什么时候不该用,…...

惬意上手Python —— 装饰器和内置函数
1. Python装饰器 Python中的装饰器是一种特殊类型的函数,它允许用户在不修改原函数代码的情况下,增加或修改函数的行为。 具体来说,装饰器的工作原理基于Python的函数也是对象这一事实,可以被赋值给变量、作为参数传递给其他函数或者作为其他…...

python 调用dll
在Python中,可以使用ctypes库来调用DLL文件。ctypes库是一个标准库,用于在Python中加载共享库(例如DLL文件)并调用其中的函数。 以下是一个简单的示例,演示如何使用ctypes库调用DLL文件中的函数: import c…...
docker里Java服务执行ping命令模拟流式输出
文章目录 业务场景处理解决实现ping功能并实时返回输出实现长ping和中断请求docker容器找不到ping命令处理 业务场景 我们某市的客户,一直使用CS版本的信控平台,直接安装客户Windows server服务器上,主要对信号机设备进行在线管理、方案配时…...

代码随想录算法训练营第十三天| 239. 滑动窗口最大值 、347.前 K 个高频元素
239. 滑动窗口最大值 思路: 用遍历区间的元素时,维护一个单调队列,从大到小排列。 要找到最大值,实际单调队列保存区间内最大值及最大值右侧的第二大值(用于当前最大值处于区间左端,在区间右移时更新临时最…...

旋转花键的使用寿命与机械原理分析
旋转花键是一种传动部件,广泛应用于各种机械设备中。对于厂商来说,如何保证使用寿命是重中之重,而旋转花键的使用寿命与其机械原理密切相关,了解其机械原理有助于更好地维护和使用旋转花键,从而提高其使用寿命。 旋转花…...
)
互联网摸鱼日报(2024-01-22)
互联网摸鱼日报(2024-01-22) 开源中国资讯 Stability AI 推出更小、更高效的 1.6B 语言模型 X 正面向 Android 推出音频和视频通话 Extism —— WebAssembly 插件实现框架 Gitee 推荐 | 龙蜥社区最佳安全加固实践指南 security-benchmark 每日一博 | 得物云原生容器技术探…...

CentOS 7 安装配置MySQL
目录 一、安装MySQL编辑编辑 1、检查MySQL是否安装及版本信息编辑 2、卸载 2.1 rpm格式安装的mysql卸载方式 2.2 二进制包格式安装的mysql卸载 3、安装 二、配置MySQL 1、修改MySQL临时密码 2、允许远程访问 2.1 修改MySQL允许任何人连接 2.2 防火墙的问题 2…...
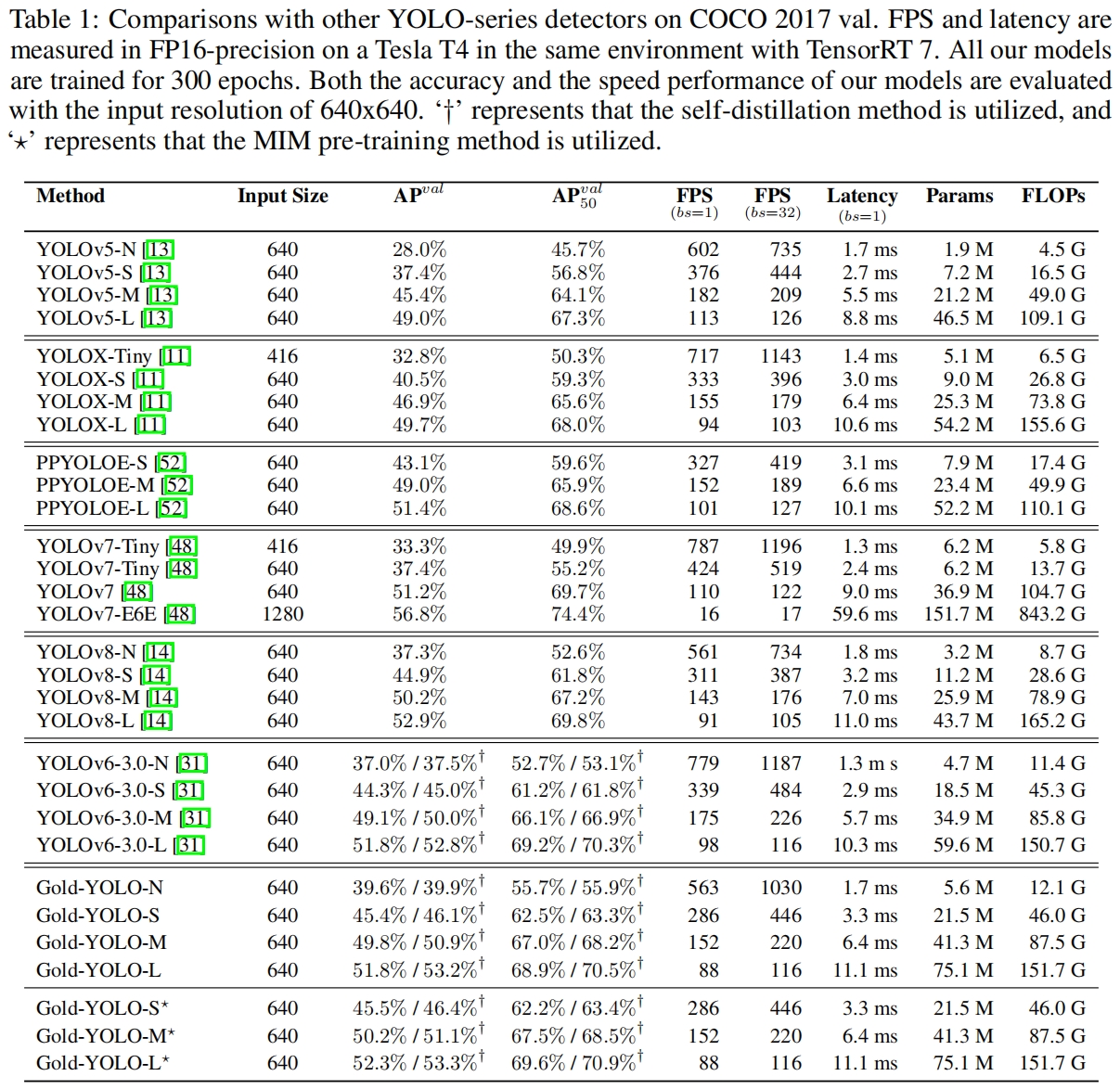
Gold-YOLO(NeurIPS 2023)论文与代码解析
paper:Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism official implementation:https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO 存在的问题 在过去几年里,YOLO系列已经…...

多个coco数据标注文件合并
一、coco数据集是什么? COCO(Common Objects in Context)是一个用于目标检测和图像分割任务的标注格式。如果你有多个COCO格式的JSON文件,你可能需要将它们合并成一个文件,以便更方便地处理和管理数据。在这篇博客中&…...

Kubernetes(K8S)拉取本地镜像部署Pod 实现类似函数/微服务功能(可设置参数并实时调用)
以两数相加求和为例,在kubernetes集群拉取本地的镜像,实现如下效果: 1.实现两数相加求和 2.可以通过curl实时调用,参数以GET方式提供,并得到结果。(类似调用函数) 一、实现思路 需要准备如下的…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

es6+和css3新增的特性有哪些
一:ECMAScript 新特性(ES6) ES6 (2015) - 革命性更新 1,记住的方法,从一个方法里面用到了哪些技术 1,let /const块级作用域声明2,**默认参数**:函数参数可以设置默认值。3&#x…...
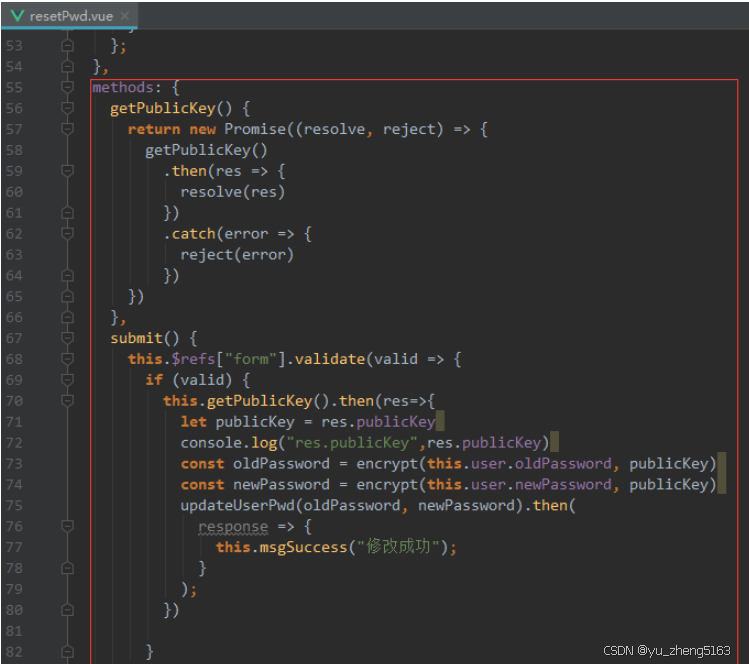
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...