张量计算和操作
一、数据操作
1、基础
import torchx = torch.arange(12)
# x:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])x.shape
# torch.Size([12])x.numel()
# 12x = x.reshape(3, 4)
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])torch.zeros((2, 3, 4))
# tensor([[[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]],
# [[0., 0., 0., 0.],
# [0., 0., 0., 0.],
# [0., 0., 0., 0.]]])torch.ones((2, 3, 4))
# tensor([[[1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.]],
# [[1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.]]])# 从某个特定的概率分布中随机采样来得到张量中每个元素的值。
# 随机初始化参数的值。
torch.randn(3, 4)
# tensor([[-0.0135, 0.0665, 0.0912, 0.3212],
# [ 1.4653, 0.1843, -1.6995, -0.3036],
# [ 1.7646, 1.0450, 0.2457, -0.7732]])torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
# tensor([[2, 1, 4, 3],
# [1, 2, 3, 4],
# [4, 3, 2, 1]])2、运算符
在相同形状的两个张量上执行按元素操作
import torch+-*/**运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
#(tensor([ 3., 4., 6., 10.]),
# tensor([-1., 0., 2., 6.]),
# tensor([ 2., 4., 8., 16.]),
# tensor([0.5000, 1.0000, 2.0000, 4.0000]),
# tensor([ 1., 4., 16., 64.]))计算e^x
torch.exp(x)
#tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])张量连结,端对端地叠形成一个更大的张量
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])torch.cat((X, Y), dim=0)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [ 2., 1., 4., 3.],
# [ 1., 2., 3., 4.],
# [ 4., 3., 2., 1.]])torch.cat((X, Y), dim=1)
# tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
# [ 4., 5., 6., 7., 1., 2., 3., 4.],
# [ 8., 9., 10., 11., 4., 3., 2., 1.]])通过逻辑运算符构建二元张量
X == Y
# tensor([[False, True, False, True],
# [False, False, False, False],
# [False, False, False, False]])对张量中的所有元素进行求和,会产生一个单元素张量。
X.sum()
# tensor(66.)3、广播机制
在不同形状的两个张量上执行操作
1. 通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
2. 对生成的数组执行按元素操作。
import torcha = torch.arange(3)
#tensor([0, 1, 2])
a = torch.arange(3).reshape((3, 1))
#tensor([[0],
# [1],
# [2]])b = torch.arange(2)
#tensor([0, 1])
b = torch.arange(2).reshape((1, 2))
#tensor([[0, 1]])a和b分别是3×1和1×2矩阵,如果让它们相加,它们的形状不匹配,可以将两个矩阵广播为一个更大的3×2矩阵。
矩阵a将复制列,矩阵b将复制行(这个过程程序自动执行),然后再按元素相加。
a
# tensor([[0, 0],
# [1, 1],
# [2, 2]])
b
# tensor([[0, 1],
# [0, 1],
# [0, 1]])
a+b
# tensor([[0, 1],
# [1, 2],
# [2, 3]])4、索引和切片
张量中的元素可以通过索引访问
第一个元素 的索引是0,最后一个元素索引是‐1;
可以指定范围以包含第一个元素和最后一个之前的元素。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
print(X)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])print(X[-1])
# tensor([ 8., 9., 10., 11.])print(X[1:3])
# tensor([[ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])X[1, 2] = 9
print(X)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 9., 7.],
# [ 8., 9., 10., 11.]])X[0:2, :] = 12
print(X)
# tensor([[12., 12., 12., 12.],
# [12., 12., 12., 12.],
# [ 8., 9., 10., 11.]])5、节省内存
运行一些操作可能会导致为新结果分配内存。
例如,如果我们用Y = X + Y,我们将取消引用Y指向的张量, 而是指向新分配的内存处的张量。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])#Python的id()函数提供了内存中引用对象的确切地址。
before = id(Y)
Y = Y + Xprint(id(Y) == before)
# False这可能是不可取的,原因有两个:
(1)首先,我们不想总是不必要地分配内存。在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新所有参数。通常情况下,我们希望原地执行这些更新;
(2)如果我们不原地更新,其他引用仍然会指向旧的内存位置,这样我们的某些代码可能会无意中引用旧的参数。
执行原地操作非常简单,使用切片表示法将操作的结果分配给先前分配的数组。
例如Z[:] = <expression>
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
Z = torch.zeros_like(Y) #创建一个新的矩阵Z,其形状与X/Y相同print('id(Z):', id(Z))
# id(Z): 140070288237104Z[:] = X + Y
print('id(Z):', id(Z))
# id(Z): 140070288237104
如果在后续计算中没有重复使用X,可以使用X[:] = X + Y或X += Y来减少操作的内存开销。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])before = id(X)
X += Yprint(id(X) == before)
# True
6、转换为其他Python对象
张量tensor转换为数组张量numpy很容易,反之也同样容易。
torch张量和numpy数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量。
import torchX = torch.arange(12, dtype=torch.float32).reshape((3,4))
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])tensor转numpy
A = X.numpy()
# array([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]], dtype=float32)numpy转tensor
B = torch.tensor(A)
# tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])print(type(A))
# <class 'numpy.ndarray'>print(type(B))
# <class 'torch.Tensor'>两者之间的区别
- PyTorch Tensors:PyTorch 中的 tensor 是这个深度学习框架的基础数据结构,可以在GPU上运行以加速计算。
- NumPy Arrays:NumPy 的 ndarray 是 Python 中用于科学计算的一个基本库的核心组件。它们被广泛用于各种数值计算任务,并且通常在 CPU 上运行。
- PyTorch tensors 支持自动微分,这对于训练神经网络来说是非常重要的。而 NumPy arrays 没有内建的自动微分功能。
相关文章:

张量计算和操作
一、数据操作 1、基础 import torchx torch.arange(12) # x:tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])x.shape # torch.Size([12])x.numel() # 12x x.reshape(3, 4) # tensor([[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]])torch.zeros((2…...

【Spring Boot 3】【JPA】枚举类型持久化
【Spring Boot 3】【JPA】枚举类型持久化 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是要花…...
)
SVN 常用命令汇总(2024)
1、前言 1.1、如何检索本文档 使用CSDN自带的“目录”功能进行检索,会更容易查找到自己需要的命令。 1.2、svn常用命令查询:help —— 帮助 在使用过程中,可随时使用help命令查看各常用svn命令: svn help2、检出及更新 2.1、…...
K8S四层代理Service-02
Service的四种类型使用 ClusterIP使用示例Pod里使用service的服务名访问应用 NodePort使用示例 ExternalName使用示例 LoadBalancer K8S支持以下4种Service类型:ClusterIP、NodePort、ExternalName、LoadBalancer 以下是使用4种类型进行Service创建,应对…...

3、非数值型的分类变量
非数值型的分类变量 有很多非数字的数据,这里介绍如何使用它来进行机器学习。 在本教程中,您将了解什么是分类变量,以及处理此类数据的三种方法。 本课程所需数据集夸克网盘下载链接:https://pan.quark.cn/s/9b4e9a1246b2 提取码:uDzP 文章目录 1、简介2、三种方法的使用1…...

国内免费chartGPT网站汇总
https://s.suolj.com - (支持文心、科大讯飞、智谱等国内大语言模型,Midjourney绘画、语音对讲、聊天插件)国内可以直连,响应速度很快 很稳定 https://seboai.github.io - 国内可以直连,响应速度很快 很稳定 http://gp…...

【Alibaba工具型技术系列】「EasyExcel技术专题」实战研究一下 EasyExcel 如何从指定文件位置进行读取数据
实战研究一下 EasyExcel 如何从指定文件位置进行读取数据 EasyExcel的使用背景EasyExcel的时候痛点EasyExcel对比其他框架 EasyExcel的编程模式EasyExcel读取的指定位置导入数据的流程表头校验invokeHeadMap()方法 数据处理invoke()方法 执行中断hasNextdoAfterAllAnalysed()方…...

java.security.InvalidKeyException: Illegal key size错误
出现的问题 最近在对接第三方,涉及获取token鉴权。在本地调试能获取到token,但是在Linux环境上调用就报错:java.security.InvalidKeyException: Illegal key size 与三方沟通 ,排除了是传参和网络的原因;搜索资料发现…...

python脚本,实现监控系统的各项资源
今天的文章涉及到docker的操作和一个python脚本,实现监控网络的流量、CPU使用率、内存使用率和磁盘使用情况。一起先看看效果吧: 这是在控制台中出现的数据,可以很简单的看到我们想要的监控指标。如果实现定时任务和数据的存储、数据的展示&a…...
Flink处理函数(2)—— 按键分区处理函数
按键分区处理函数(KeyedProcessFunction):先进行分区,然后定义处理操作 1.定时器(Timer)和定时服务(TimerService) 定时器(timers)是处理函数中进行时间相关…...
服务器数据恢复—服务器进水导致阵列中磁盘同时掉线的数据恢复案例
服务器数据恢复环境: 数台服务器数台存储阵列柜,共上百块硬盘,划分了数十组lun。 服务器故障&检测: 外部因素导致服务器进水,进水服务器中一组阵列内的所有硬盘同时掉线。 北亚数据恢复工程师到达现场后发现机房内…...
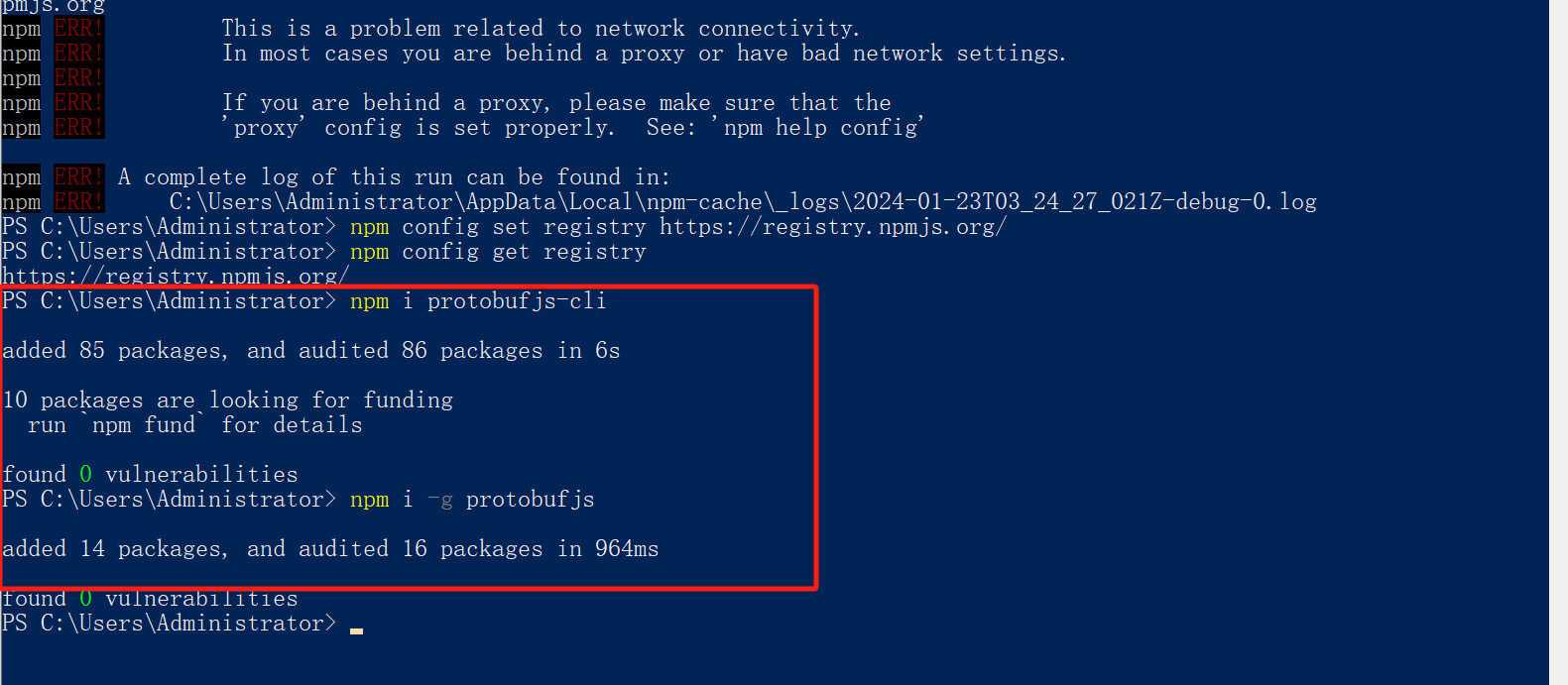
npm或者pnpm或者yarn安装依赖报错ENOTFOUND解决办法
如果报错说安装依赖报错,大概率是因为npm源没有设置对,比如我这里安装protobufjs的时候报错:ENOTFOUND npm ERR! code ENOTFOUND npm ERR! syscall getaddrinfo npm ERR! errno ENOTFOUND npm ERR! network request to https://registry.cnpm…...

学会使用ubuntu——ubuntu22.04使用Google、git的魔法操作
ubuntu22.04使用Google、git的魔法操作 转战知乎写作 https://zhuanlan.zhihu.com/p/679332988...

【机组】计算机组成原理实验指导书.
🌈个人主页:Sarapines Programmer🔥 系列专栏:《机组 | 模块单元实验》⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。 目录 第一章 性能特点 1.1 系…...

解决Sublime Text V3.2.2中文乱码问题
目录 中文乱码出现情形通过安装插件来解决乱码问题 中文乱码出现情形 打开一个中文txt文件,显示乱码,在File->Reopen With Encoding里面找不到支持简体中文正常显示的编码选项。 通过安装插件来解决乱码问题 安装Package Control插件 打开Tool->…...

Oracle 12CR2 RAC部署翻车,bug避坑经历
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

情绪共享机器:潜力与挑战
在设想的未来科技世界中,有一种神奇的机器,它能够让我们戴上后即刻感知并体验他人当下的情绪。这种情绪共享机器无疑将深刻地改变我们对人际关系、社会交互乃至人性本质的理解。然而,这一科技创新所带来的影响并非全然积极,也伴随…...

docker 安装python3.8环境镜像并导入局域网
一、安装docker yum -y install docker docker version #显示 Docker 版本信息 可以看到已经下载下来了 拉取镜像python3镜像 二、安装docker 中python3环境 运行本地镜像,并进入镜像环境 docker run -itd python-38 /bin/bash docker run -itd pyth…...

修复“电脑引用的账户当前已锁定”问题的几个方法,看下有没有能帮助到你的
面对“电脑引用的账户当前已锁定,且可能无法登录”可能会让你感到焦虑。这是重复输入错误密码后出现的登录错误。当帐户锁定阈值策略配置为限制未经授权的访问时,就会发生这种情况。 但是,如果你在等待半小时后输入正确的密码,你可以重新访问你的帐户。同样,如果你有一个…...
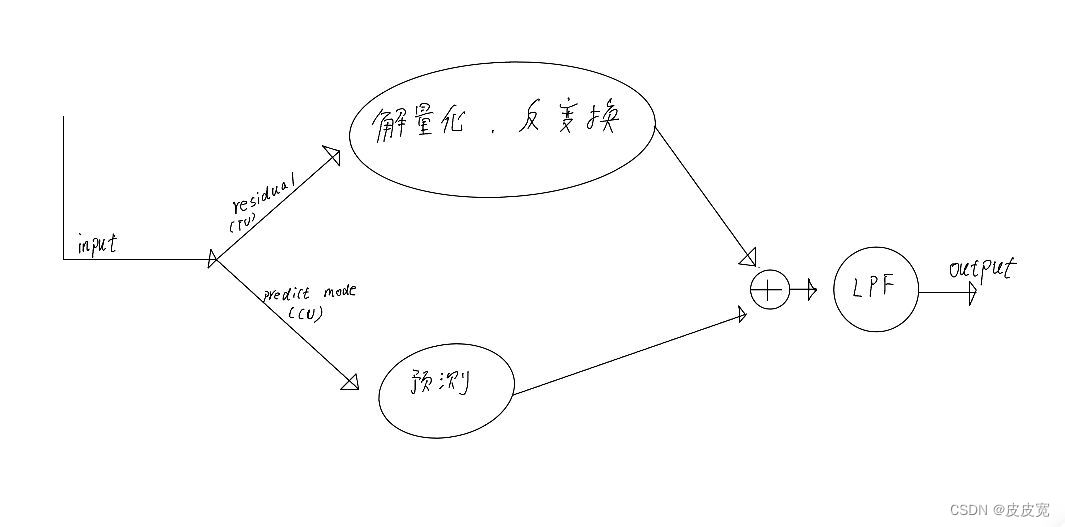
vp9协议笔记
vp9协议笔记📒 本文主要是对vp9协议的梳理,协议的细节参考官方文档:VP9协议链接(需要加速器) vp9协议笔记 vp9协议笔记📒1. 视频编码概述2. 超级帧superframe(sz):2. fr…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...