3.召回率-机器学习模型性能的常用的评估指标
在机器学习领域,召回率是一个关键的性能指标,用于评估模型在正样本中正确识别的能力。召回率的计算涉及到模型成功检测到的正样本数量与实际正样本的总数量之比。这个指标对于很多应用场景都至关重要,尤其是在那些要求较高的领域,比如医学诊断、欺诈检测等。
一.召回率(Recall)的定义
召回率是一个重要的评价指标,用于衡量模型对所有实际正样本的正确预测能力。具体来说,召回率计算的是模型预测为真阳性的实例与实际正样本总数的比率。这个指标回答了一个问题:“在所有实际为正样本的实例中,模型正确预测了多少?”
召回率的计算是基于模型对正例的识别能力,通过计算模型成功找到的正例占实际所有正例的比例,提供了一个关于模型“查全”的度量。高召回率意味着模型能够尽可能多地找到所有的正例,而低召回率则表示模型可能漏掉了一部分正例。
在二分类问题中,召回率是一个重要的性能指标,尤其在需要尽量避免漏诊的场景,如医学诊断、安全监控等。高召回率通常意味着模型在发现正例方面表现较好。
二.召回率的计算方法
召回率的计算非常直观,通过以下公式表示:
召回率 = T P / T P + F N 召回率=TP/TP+FN 召回率=TP/TP+FN
其中,TP 表示真正例(模型正确预测为正样本的实例数),FN 表示假负例(模型错误预测为负样本的实例数)。这个公式展示了在所有实际为正样本的实例中,有多少被模型成功检测到。因此,一个高召回率值表示模型在发现正样本方面更为强大。
与精确度不同,召回率关注的是模型对实际正样本的查全能力。即使模型对某个正样本的预测概率较低,只要该样本实际上是正样本,并且被模型正确预测为正样本,那么这个预测就会计入召回率的计算中。因此,召回率更关注模型是否能够找到尽可能多的正样本,而不仅仅是预测概率较高的那些。
三.召回率的直观解释
召回率回答了一个关键问题:在实际正样本中,模型有多大能力成功识别到这些正样本。一个高召回率的模型意味着在实际为正样本的情况下,它能够更可靠地做出正样本的预测。在某些任务中,如医学影像诊断,确保尽可能多的正样本被成功识别是至关重要的。
四.召回率的应用领域
-
医学诊断: 在医学影像诊断领域,召回率是至关重要的评价指标。考虑一个肿瘤检测的场景,如果模型不能成功识别所有的恶性肿瘤,可能导致漏诊,错过治疗的最佳时机,甚至危及患者的生命。因此,确保召回率尽可能高是医学影像诊断中的首要任务。因为漏诊的代价可能是巨大的,不仅在医学领域,还包括其他领域,如安全监控。在安全监控中,一个高召回率的模型能够更可靠地检测到潜在的危险情况,从而提高了整个系统的安全性。而一个低召回率的模型可能会导致漏掉一些潜在的威胁,造成严重的后果。
-
金融欺诈检测: 在金融欺诈检测中,召回率是一个至关重要的评价指标。欺诈检测的目标是尽早发现和阻止潜在的欺诈行为,以保护客户和金融机构的利益。召回率在这一领域的应用主要体现在以下几个方面:
2.1 早期发现欺诈行为: 金融欺诈通常涉及到异常或不寻常的交易模式,这可能表现为异常的交易金额、频繁的交易活动或异地交易。高召回率的模型能够更早地发现这些异常模式,从而提前预警潜在的欺诈行为。
2.2 减少漏报的风险: 欺诈检测中的一个关键挑战是尽量避免漏报,即确保模型尽可能找到所有的欺诈行为。高召回率意味着模型能够更全面地捕捉潜在的欺诈案例,降低了漏报的风险。
2.3 提高模型的实用性: 在金融领域,模型的实用性至关重要。高召回率的模型可以减少不必要的客户干预或阻止合法交易的风险,从而提高模型在实际业务中的可用性。
2.4 适应性欺诈检测: 金融欺诈形式多样,不断演变。高召回率的模型更具适应性,能够检测新型的欺诈手段,而不仅仅是依赖于已知的模式。
2.5 降低金融损失: 召回率的提高直接关系到金融机构能够尽早发现并阻止潜在的欺诈交易,从而降低金融损失。在金融领域,每一笔被漏掉的欺诈交易可能都导致巨大的经济损失,因此高召回率对于降低潜在损失至关重要。
综合而言,召回率在金融欺诈检测中的应用是为了更好地平衡模型的准确性和全面性,确保模型能够及时准确地发现并应对潜在的欺诈威胁。这对于金融行业来说是非常重要的,因为金融交易的安全性和客户信任是金融机构的核心关注点。
-
安全监控: 在安全监控领域,召回率是一个关键的评价指标,用于衡量监控系统对于真实安全事件的检测能力。以下是召回率在安全监控中的应用简介:
3.1 提高真实事件的检测率: 安全监控系统的首要任务是检测真实的安全事件,如入侵、异常行为或其他潜在威胁。高召回率确保监控系统能够尽可能多地捕获到真实事件,降低漏报的风险,从而提高系统的实用性。
3.2 减少潜在风险: 安全监控的目标是尽早发现并应对潜在的威胁,以减少潜在的风险。高召回率意味着系统能够更全面地识别出可能的安全问题,帮助组织更早地采取措施,减小潜在的损失。
3.3 降低误报率: 监控系统在工作过程中可能会产生误报,即将正常行为错误地标记为异常或威胁。通过提高召回率,系统可以更精准地识别真实的威胁,减少对正常活动的误报,提高整体的精确性。
3.4 应对新型威胁: 安全威胁不断演变,新型威胁的出现对监控系统提出了挑战。高召回率的系统更具适应性,能够检测新型威胁的迹象,而不仅仅依赖于已知的模式。
3.5 加强应急响应: 在安全事件发生时,及时而准确的响应至关重要。高召回率确保监控系统及时发现真实事件,为应急响应提供更多的时间窗口,有助于有效化解潜在威胁。
总体而言,召回率在安全监控中的应用旨在提高系统的检测能力,降低风险,保障组织的安全。在当今复杂多变的网络环境中,高召回率的监控系统对于有效应对各种安全挑战至关重要。
-
搜索引擎: 在搜索引擎领域,召回率是一个关键的性能指标,用于评估搜索引擎检索结果中包含用户感兴趣信息的能力。以下是召回率在搜索引擎中的应用简介:
4.1 提高搜索结果的完整性: 搜索引擎的首要任务是提供用户与其查询相关的完整结果。高召回率确保搜索引擎能够涵盖与用户查询相关的尽可能多的页面,从而提供更全面的搜索结果。
4.2 降低漏检率: 用户对搜索引擎期望找到与其查询相关的所有重要信息。高召回率可以减少漏检,即确保搜索引擎尽可能多地检索到用户可能感兴趣的页面,避免遗漏重要信息。
4.3 提高用户满意度: 用户体验是搜索引擎成功的关键因素之一。高召回率意味着搜索引擎能够更好地满足用户的信息需求,为用户提供更多可能相关的搜索结果,从而提高用户满意度。
4.4 适应用户多样性需求: 不同用户对于相同查询可能有不同的偏好和需求。高召回率使得搜索引擎更能够适应用户的多样性需求,提供更丰富、多样化的搜索结果。
4.5 有效处理长尾查询: 长尾查询指的是相对不常见但总体数量庞大的查询。高召回率能够有效处理长尾查询,确保即使是不太常见的主题或关键词也能得到相关的搜索结果。
4.6 提高广告投放效果: 对于搜索引擎中的广告投放而言,高召回率可以确保广告能够更全面地覆盖潜在目标用户,提高广告的曝光和点击率。
总的来说,召回率在搜索引擎中的应用旨在提供更全面、多样化的搜索结果,以满足用户广泛的信息需求。这对于搜索引擎的竞争力和用户体验至关重要。
五.召回率的局限性
召回率作为一个重要的性能指标,在应用中存在一些局限性。以下是召回率的一些局限性:
5.1 忽略了准确性: 召回率主要关注模型成功检测到正样本的能力,而忽略了模型在负样本中的准确性。在某些场景下,对于负样本的准确性同样重要,而召回率无法提供这方面的信息。
5.2 不能区分错误类型: 召回率无法区分模型漏报和误报的具体情况。在实际应用中,了解模型产生错误的类型对于系统的改进和优化至关重要,而召回率无法提供这种详细信息。
5.3 受样本不平衡影响: 当正样本和负样本的比例极不平衡时,召回率可能不是一个全面的评价指标。模型只需倾向于预测为正样本,就能取得较高的召回率,但这并不代表模型的性能良好。
5.4 无法处理排序信息: 召回率通常用于二分类问题,而在实际搜索引擎等场景中,搜索结果的排序也是非常重要的。召回率不能很好地反映模型在排序方面的表现,而在一些应用中,用户更关心排名靠前的结果。
5.5 无法处理多类别问题: 召回率主要设计用于二分类问题,而在多类别问题中,对每个类别的召回率评估可能会更为复杂,需要综合考虑各个类别的性能。
5.6 不考虑概率信息: 召回率只关注样本是否被成功检测,而不关注模型对于样本的置信度或概率估计。在一些应用中,需要考虑模型对于不同样本的置信水平,而召回率无法提供这种信息。
总体而言,召回率作为一个单一的评价指标,需要与其他指标结合使用,以全面评估模型的性能。在具体应用中,根据任务的特点选择合适的评价指标是更为明智的做法。
六.召回率的未来发展方向
召回率的未来发展方向受到多个因素的影响,包括技术进步、应用需求和数据科学领域的不断演变。以下是召回率未来发展可能的方向:
6.1 结合多模态信息: 随着多模态数据处理技术的发展,未来召回率的研究可能会更加关注如何结合文本、图像、音频等多种模态信息来提高模型的召回性能。这对于一些需要综合不同数据源的任务如智能搜索和内容推荐是至关重要的。
6.2 考虑时序信息: 对于时序数据,特别是在事件预测和时间序列分析中,召回率可能需要更灵活地考虑时序信息。新的模型和算法可能会更好地适应不同时间点上的数据变化,提高时序数据的召回效果。
6.3 个性化召回: 随着个性化需求的增加,未来的召回算法可能会更加注重用户个性化的召回效果。这包括更好地理解用户兴趣、行为和偏好,从而提供更符合个体需求的推荐结果。
6.4 增强学习的应用: 强化学习技术的发展可能带来更灵活、自适应的召回模型。通过考虑模型在不同环境下的决策和反馈,增强学习可以在动态变化的场景中提供更好的召回效果。
6.5 大规模数据和分布式计算: 随着数据量的增大,未来的召回算法需要更好地处理大规模数据,并充分利用分布式计算资源。这涉及到更高效的算法设计和更强大的计算平台。
6.6 解释性和可解释性: 对于一些关键应用领域,如医疗和金融,模型的解释性和可解释性将变得尤为重要。未来的召回算法可能会更注重在提高模型解释性的同时保持高性能。
6.7 跨领域融合: 未来的召回研究可能更加跨领域,将计算机视觉、自然语言处理、推荐系统等不同领域的技术融合起来,以应对复杂多样的应用场景。
总体而言,召回率的未来发展将受益于多学科的融合、新技术的应用和对用户需求的更深入理解。这将推动召回率在各个领域的性能不断提升,并更好地适应不断变化的应用场景。
七.代码实现
召回率的计算通常涉及真正例(True Positives,TP)、假负例(False Negatives,FN)这两个关键指标。以下是召回率的简单代码实现:
def calculate_recall(true_positives, false_negatives):"""计算召回率Parameters:true_positives (int): 正确预测为正例的样本数false_negatives (int): 错误预测为负例的样本数Returns:recall (float): 召回率"""recall = true_positives / (true_positives + false_negatives + 1e-10) # 避免分母为零return recall# 示例数据
true_positives = 80
false_negatives = 20# 计算召回率
recall = calculate_recall(true_positives, false_negatives)# 打印结果
print(f"Recall: {recall}")
在上述代码中,true_positives 表示模型正确预测为正例的样本数量,false_negatives 表示模型错误预测为负例的样本数量。通过调用 calculate_recall 函数,可以得到召回率的计算结果。
在 scikit-learn 中,可以使用 recall_score 函数来计算召回率。以下是一个简单的示例代码:
from sklearn.metrics import recall_score
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression# 示例数据
data = {'feature1': [1, 0, 1, 0, 1, 0, 1, 0],'feature2': [0, 1, 0, 1, 0, 1, 0, 1],'target': ['positive', 'negative', 'positive', 'negative', 'positive', 'negative', 'positive', 'negative']
}# 创建 DataFrame
import pandas as pd
df = pd.DataFrame(data)# 使用 LabelEncoder 对目标变量进行编码
le = LabelEncoder()
df['target'] = le.fit_transform(df['target'])# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[['feature1', 'feature2']], df['target'], test_size=0.2, random_state=42)# 构建模型(以逻辑回归为例)
model = LogisticRegression()
model.fit(X_train, y_train)# 模型预测
y_pred = model.predict(X_test)# 计算召回率
recall = recall_score(y_test, y_pred)# 打印结果
print(f"Recall: {recall}")八.结语
召回率作为机器学习中的重要评价指标,在许多应用场景中都扮演着关键的角色。通过衡量模型对正样本的识别能力,召回率提供了对模型性能的重要视角。在本次讨论中,我们深入探讨了召回率的定义、计算方法、应用领域以及一些相关的实际案例。
首先,我们了解了召回率的定义,它回答了一个关键问题,即在实际的正样本中,模型有多大能力成功识别到这些正样本。这对于许多任务,特别是那些需要高度敏感性的领域,如医学影像诊断和金融欺诈检测,至关重要。
我们讨论了召回率的计算方法,它通常被定义为模型成功预测的正样本数量与实际正样本总数的比例。这一度量为我们提供了对模型在真实情况下的表现有一个清晰的认识。
在应用领域方面,我们看到召回率在许多领域都有着广泛的应用。从安全监控到搜索引擎、金融欺诈检测,召回率都发挥着关键的作用。在这些场景中,确保尽可能多的正样本被成功识别对于任务的成功至关重要。
我们还讨论了召回率的局限性,包括在某些情况下可能导致误报率的上升。了解这些局限性有助于我们更全面地评估模型性能,同时在实际应用中做出更明智的决策。
最后,我们探讨了召回率的未来发展方向。随着技术的不断进步和应用需求的不断演变,召回率可能会在多模态信息融合、个性化召回、时序数据处理等方面取得更多突破。跨学科的研究和新技术的应用将推动召回率在各个领域的不断优化。
总的来说,召回率的重要性不可忽视,它在评估模型性能、指导决策和推动技术进步方面都发挥着重要作用。在未来,我们可以期待召回率在更多领域的深入应用和不断创新。
相关文章:

3.召回率-机器学习模型性能的常用的评估指标
在机器学习领域,召回率是一个关键的性能指标,用于评估模型在正样本中正确识别的能力。召回率的计算涉及到模型成功检测到的正样本数量与实际正样本的总数量之比。这个指标对于很多应用场景都至关重要,尤其是在那些要求较高的领域,…...
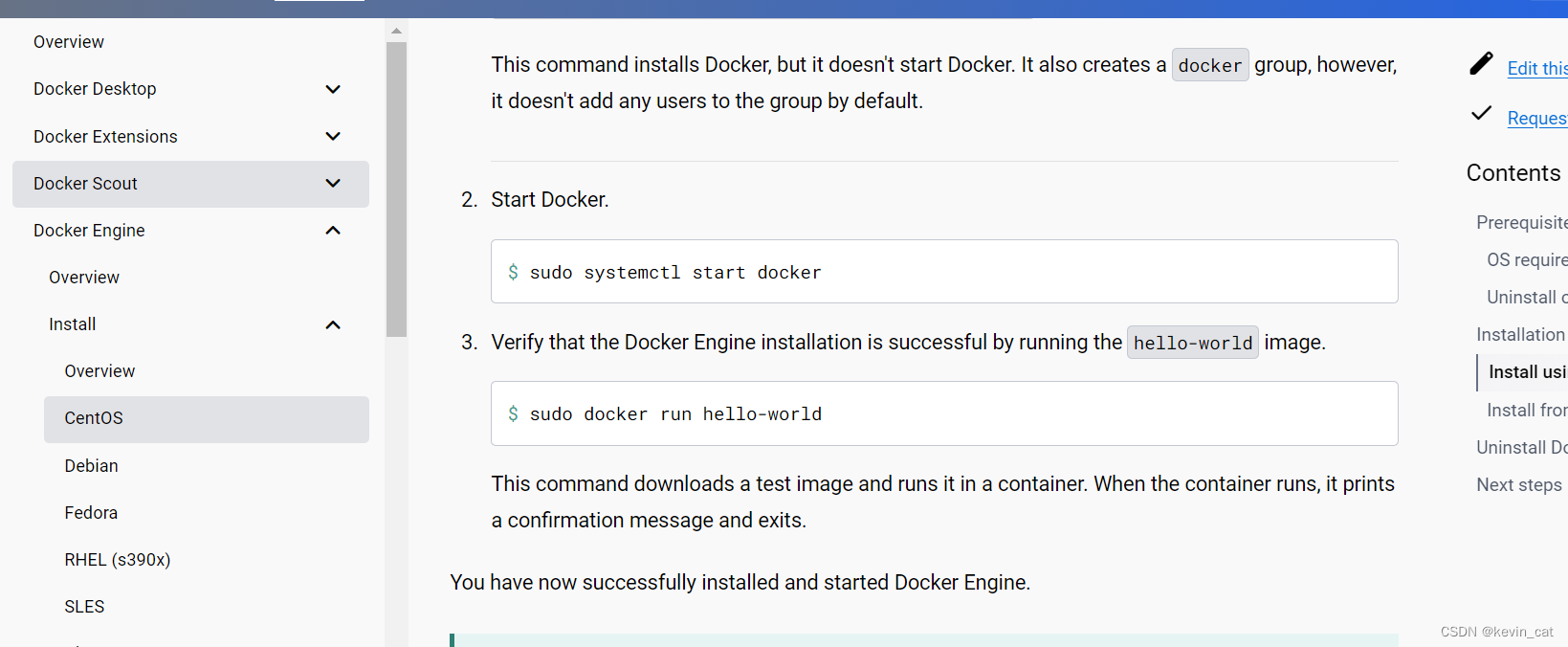
linux安装docker--更具官网教程
1.访问https://docs.docker.com/ 2.进入download 3输入cento 或者直接访问地址Install Docker Engine on CentOS | Docker Docs 4一步一步根据官网命令走 2安装 3 4 方式一: service docker start(开启) service docker status(…...

云原生安全:风险挑战与安全架构设计策略
概述 数字化转型已经成为当今最流行的话题之一,大部分企业已经开启自身的数字化转型之旅,在未来企业只有数字化企业和非数字化企业之分。通过数字经济的加速发展,可以有效推动企业数字化转型的步伐。云计算作为数字化转型的底座和重要的载体…...

c语言-文件的读写操作
文章目录 前言一、文件基础1.1 文件的分类1.2 文件路径和文件名 二、文件的打开和关闭2.1 文件指针2.2 文件的打开和关闭 总结 前言 本篇文章介绍c语言的文件读写操作。 一、文件基础 1.1 文件的分类 在c语言中,从文件的功能角度来看,文件可分为以下两…...

Python处理日期和时间库之arrow使用详解
概要 日期和时间处理是许多应用程序中的常见任务,但在 Python 中,标准库中的 datetime 模块有时可能会让这些任务变得复杂和繁琐。幸运的是,有一个名为 Arrow 的第三方库,它提供了简化日期和时间处理的功能,使其更加直…...
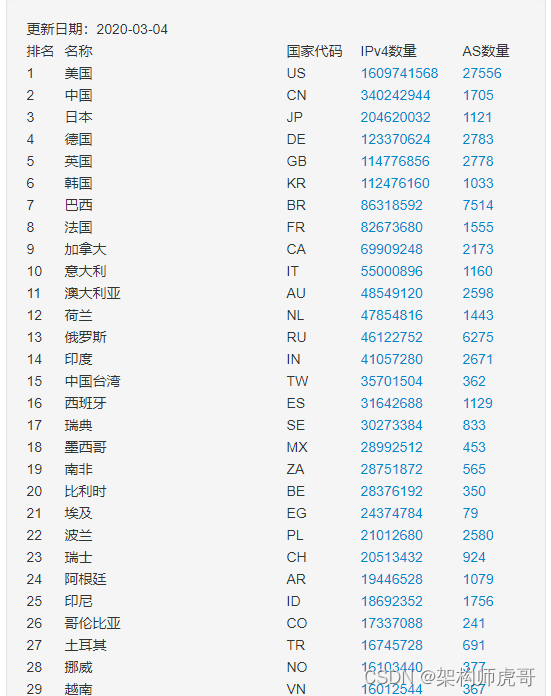
架构师之路(十四)计算机网络(网络层)
前置知识(了解):计算机基础。 作为架构师,我们所设计的系统很少为单机系统,因此有必要了解计算机和计算机之间是怎么联系的。局域网的集群和混合云的网络有啥区别。系统交互的时候网络会存在什么瓶颈。 网络层提供主机…...

Spring Boot开发Spring Security
这里我对springboot不做过多描述,因为我觉得学这个的肯定掌握了springboot这些基础 导入核心依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring‐boot‐starter‐security</artifactId> </depen…...
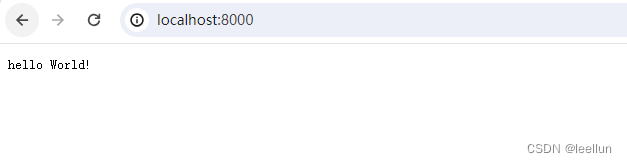
gin介绍及helloworld
1. 介绍 Gin是一个golang的微框架,封装比较优雅,API友好,源码注释比较明确,具有快速灵活,容错方便等特点 对于golang而言,web框架的依赖要远比Python,Java之类的要小。自身的net/http足够简单&…...

vue3 自动引入 ref reactive...
npm i unplugin-auto-import -D vite.config.js import { defineConfig } from vite; import vue from vitejs/plugin-vue; import AutoImport from unplugin-auto-import/vite;export default defineConfig({plugins: [vue(),AutoImport({// 自动导入 Vue 相关函数࿰…...
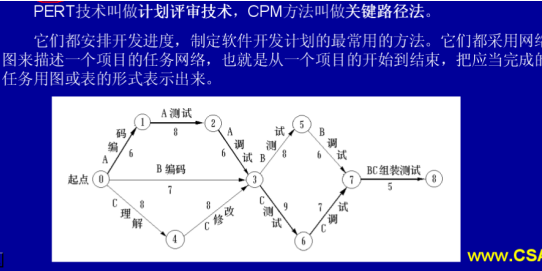
软考复习之软件工程篇
软件生命周期 问题定义:要示系统分析员与用户进行交流,弄清”用户需要计算机解决什么问题”然后提出关于“系统目标与范围的说明”,提交用户审查和确认 可行性研究:一方面在于把待开发的系统的目标以明确的语言描述出来…...
MySQL和Oracle、PostgreSQL的区别)
MySQL(七)MySQL和Oracle、PostgreSQL的区别
文章目录 一、MySQL和Oracle1.1 基本差别1.2 使用区别 二、MySQL和PostgreSQL2.1 基本差别2.2 使用差别 本系列文章: MySQL(一)SQL语法、数据类型、常用函数、事务 MySQL(二)MySQL SQL练习题 MySQL(三&…...
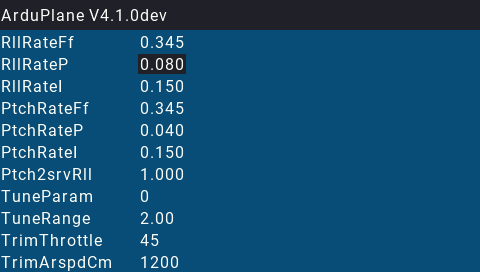
(2)(2.4) CRSF/ELRS Telemetry
文章目录 前言 1 ArduPilot 参数编辑器 前言 !Note ELRS(ExpressLRS)遥控系统使用穿越火线协议,连接方式类似。不过,它不像穿越火线那样提供双向遥测。 TBS CRSF 接收机与 ArduPilot 的接口中包含遥测和遥控信息。…...

服务器发送http请求
1、发送GET请求 curl localhost:9009/setCreateDataItem?a1&bnihao 2、发送POST请求 curl -X POST -d a1&bnihao localhost:9009/setCreateDataItem 3、发送json格式请求: curl -H "Content-Type: application/json" -X POST -d {"abc…...

Effective Objective-C 学习第二周
理解“属性”这一概念 “属性”(property)是 Objective-C 的一项特性,用于封装对象中的数据。Objective-C 对象通常会把其所需的数据保存为各种实例变量。实例变量一般通过“存取方法”来访问。其中,“获取方法”(get…...

JS进阶-深入对象(二)
拓展:深入对象主要介绍的是Js的构造函数,实例成员,静态成员,其中构造函数和Java种的构造函数用法相似,思想是一样的,但静态成员和实例成员和java种的有比较大的差别,需要认真理解 • 创建对象三…...

【Gene Expression Prediction】Part2 Enchancer discovery
文章目录 5. 第一个讲座:Enchancer discovery5.1 STARR-seq5.2 Enchancer detection with weakly supervised learning5.3 Model performance 来自Manolis Kellis教授(MIT计算生物学主任)的课 YouTube:(Gene Expression Predictio…...

【UEFI基础】EDK网络框架(UDP4)
UDP4 UDP4协议说明 UDP的全称是User Datagram Protocol,它不提供复杂的控制机制,仅利用IP提供面向无连接的通信服务。它将上层应用程序发来的数据在收到的那一刻,立即按照原样发送到网络。 UDP报文格式: 各个参数说明如下&…...
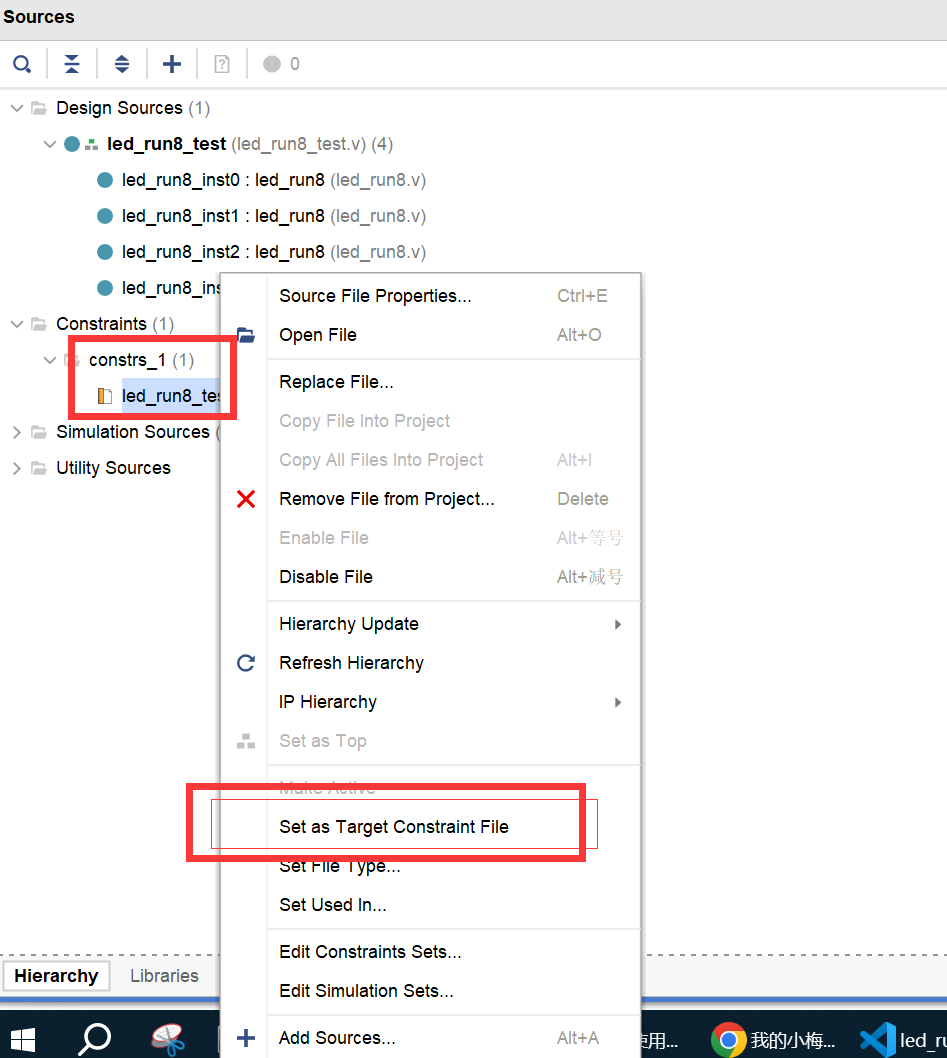
vivado使用注意事项
记得给constrs(.xdc)限制文件设置为目标文件(set as Target Consraint File)...
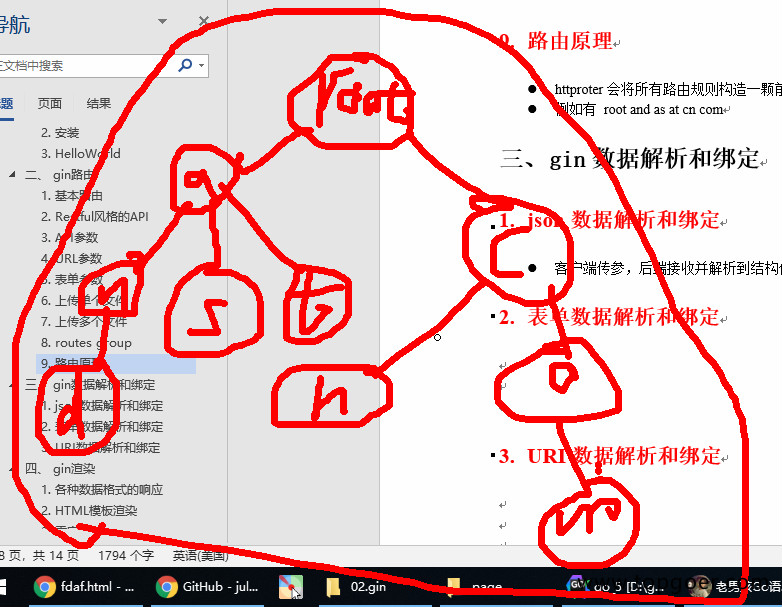
gin路由篇
1. 基本路由 gin 框架中采用的路由库是基于httprouter做的 import ("net/http""github.com/gin-gonic/gin" )func main() {// 1.创建路由r : gin.Default()// 2.绑定路由规则,执行的函数// gin.Context,封装了request和responser.…...

C++逆向分析--继承的本质
一.一些思考 继承是面向对象的三个特性之一。这篇文章我们从底层的角度去理解什么是继承。他的作用是什么。首先继承的出现是更好的避免代码的重复冗余。要理解一件事很重要,C其实是C的延申。那么C的出现是为了解决C语言上C祖师爷认为不友好的事情,也为…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...
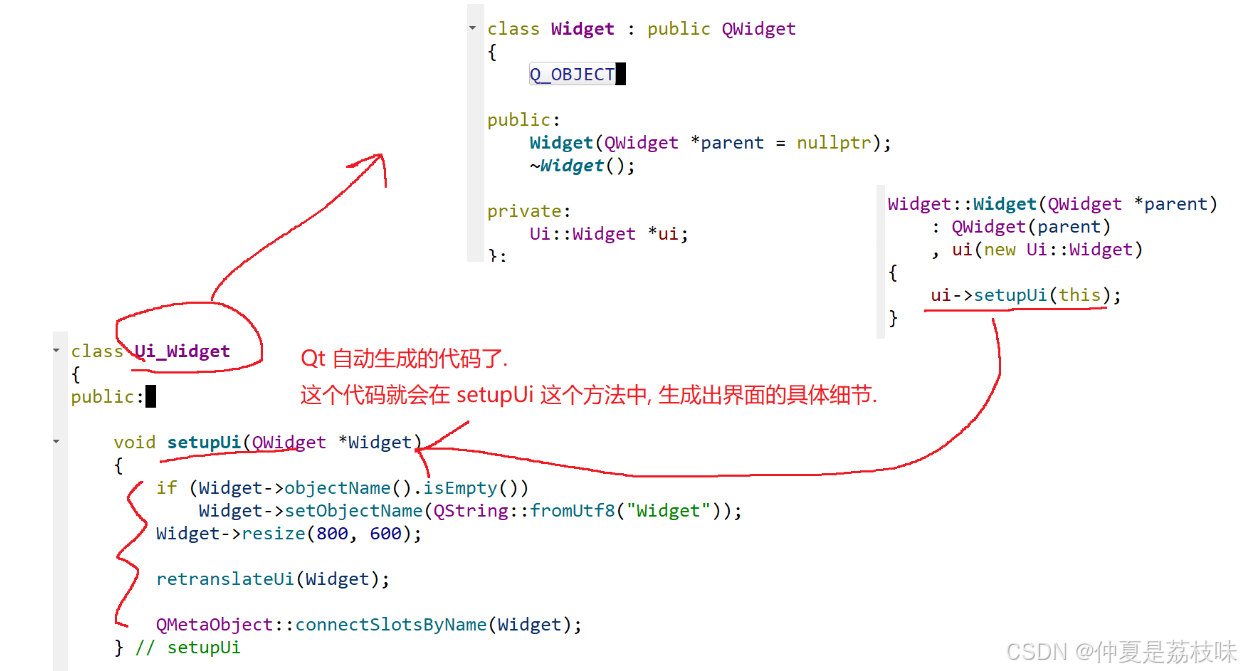
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...
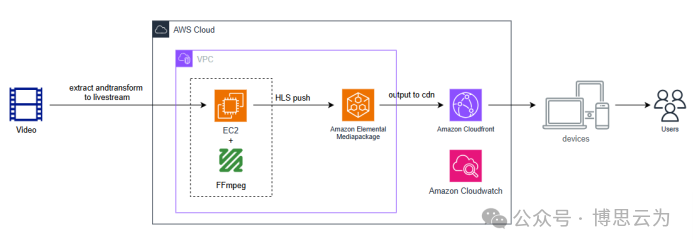
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...

接口 RESTful 中的超媒体:REST 架构的灵魂驱动
在 RESTful 架构中,** 超媒体(Hypermedia)** 是一个核心概念,它体现了 REST 的 “表述性状态转移(Representational State Transfer)” 的本质,也是区分 “真 RESTful API” 与 “伪 RESTful AP…...