OPC【4】:物理包
概述
- OPC遵循zip标准,因此可以使用python标准库zipfile对docx格式的物理文件进行读写操作。
- 在OPC中,物理包与抽象包是一对相对的概念,后续可以看到抽象包内的内容是将物理包内的信息进行编排形成地。简单点理解,物理包的作用在于数据持久化(写入)或者序列化(加载),而抽象包则是OPC的核心,用于管理part节点对象与关系信息。
- 本文源码引用自
python-docx==1.1.0,主要记录docx源码中docx.opc.phys_pkg, docx.opc.pkgreader, docx.opc.pkgwriter三个模块,前者主要描述OPC中的zip实现,后两者介绍了如何从物理文件中读取或者写入信息。
ZIP规范
- 本质使用标准库zipfile。
- office word编辑器中新建一个docx文件,本质是从一个docx模版文件开始的。
ZIP读取
ZIP读取的逻辑定义在docx.opc.phys_pkg模块中:
class _ZipPkgReader(PhysPkgReader):"""Implements |PhysPkgReader| interface for a zip file OPC package."""def __init__(self, pkg_file):super(_ZipPkgReader, self).__init__()self._zipf = ZipFile(pkg_file, "r")def blob_for(self, pack_uri):"""Return blob corresponding to `pack_uri`.Raises |ValueError| if no matching member is present in zip archive."""return self._zipf.read(pack_uri.membername)def close(self):"""Close the zip archive, releasing any resources it is using."""self._zipf.close()def rels_xml_for(self, source_uri):"""Return rels item XML for source with `source_uri` or None if no rels item ispresent."""try:rels_xml = self.blob_for(source_uri.rels_uri)except KeyError:rels_xml = Nonereturn rels_xml
- 从初始化方法中,可以看出本质是使用zipfile标准库打开一个包文件
- close方法本质是调用zipfile.ZipFile的close方法
- 获取包内某一子文件的数据,就是使用zipfile.ZipFile.read(membername),membername命名规范中,子文件夹内的文件名使用“slash”分隔
- 注意rels_xml_for方法,该方法返回给定packuri下包含关系集合的xml字符串。即如果实参为“/”,则
source_uri.rels_uri="_rels/.rels";如果实参为“/word/document.xml”, 则source_uri.rels_uri="word/_rels/document.xml.rels"
ZIP写入
源码如下:
class _ZipPkgWriter(PhysPkgWriter):"""Implements |PhysPkgWriter| interface for a zip file OPC package."""def __init__(self, pkg_file):super(_ZipPkgWriter, self).__init__()self._zipf = ZipFile(pkg_file, "w", compression=ZIP_DEFLATED)def close(self):"""Close the zip archive, flushing any pending physical writes and releasing anyresources it's using."""self._zipf.close()def write(self, pack_uri, blob):"""Write `blob` to this zip package with the membername corresponding to`pack_uri`."""self._zipf.writestr(pack_uri.membername, blob)
- 可以看到_ZipPkgWriter本质使用的是标准库zipfile内置的功能。
读取物理文件
读取docx物理文件涉及序列化part对象、序列化关系集合对象。
序列化part对象
包内文件“[Content_Types].xml”定义了包内子文件的默认、自定义类型。1由于实例化part对象必须指明part节点的类型,因此必须首先解析“[Content_Types].xml”文件。docx.opc.pkgreader模块中定义的content_types处理逻辑如下:
class _ContentTypeMap:"""Value type providing dictionary semantics for looking up content type by partname, e.g. ``content_type = cti['/ppt/presentation.xml']``."""def __init__(self):super(_ContentTypeMap, self).__init__()self._overrides = CaseInsensitiveDict()self._defaults = CaseInsensitiveDict()@staticmethoddef from_xml(content_types_xml):"""Return a new |_ContentTypeMap| instance populated with the contents of`content_types_xml`."""types_elm = parse_xml(content_types_xml)ct_map = _ContentTypeMap()for o in types_elm.overrides:ct_map._add_override(o.partname, o.content_type)for d in types_elm.defaults:ct_map._add_default(d.extension, d.content_type)return ct_map
- _ContentTypeMap的实例属性_overrides是一个类似字典对象,key为partname,值为part_content_type。实例属性_defaults也是一个类似字典的对象,key为partname后缀,如xml、rels、jpg等,值为part_content_type。
- from_xml实例方法中,content_type_xmls本质是“[Content_Types].xml”文件的内容——通过ZipFile打开docx物理文件,然后读取[Content_Types].xml内容。 parse_xml用于将xml字符串解析成元素树,注意parser_xml方法中使用的是docx自定义的解析器——该解析器设置并注册了xml命名空间。后续的逻辑则是迭代CT_Override与CT_Default元素。
获取了part的content_type与partname,序列化的part对象定义如下:
class _SerializedPart:"""Value object for an OPC package part.Provides access to the partname, content type, blob, and serialized relationshipsfor the part."""def __init__(self, partname, content_type, reltype, blob, srels):super(_SerializedPart, self).__init__()self._partname = partnameself._content_type = content_typeself._reltype = reltypeself._blob = blobself._srels = srels
- reltype特性存储CT_Relationshp元素Type属性值——每一part对象总是与package或者其它part对象关联。
- srels是指该part节点是否存在part_level级别的关系集合。通过关系可以引用包内其它子节点。
序列化关系对象
单条的序列化关系对象逻辑定义如下:
class _SerializedRelationship:"""Value object representing a serialized relationship in an OPC package.Serialized, in this case, means any target part is referred to via its partnamerather than a direct link to an in-memory |Part| object."""def __init__(self, baseURI, rel_elm):super(_SerializedRelationship, self).__init__()self._baseURI = baseURIself._rId = rel_elm.rIdself._reltype = rel_elm.reltypeself._target_mode = rel_elm.target_modeself._target_ref = rel_elm.target_ref@propertydef target_partname(self):"""|PackURI| instance containing partname targeted by this relationship.Raises ``ValueError`` on reference if target_mode is ``'External'``. Use:attr:`target_mode` to check before referencing."""if self.is_external:msg = ("target_partname attribute on Relationship is undefined w"'here TargetMode == "External"')raise ValueError(msg)# lazy-load _target_partname attributeif not hasattr(self, "_target_partname"):self._target_partname = PackURI.from_rel_ref(self._baseURI, self.target_ref)return self._target_partname
- 实例化方法中的baseURI用于target_partname特性。rel_ele是一个CT_Relationship元素。
- 单条关系只是rels文件中的一条记录,rels文件一般包含多条关系集合,该集合拥有同一个source
- baseURI一般是指包含rels文件的文件夹。
- CT_Relationship中的target_ref特性存储的是“CT_Relationship元素Target属性值”
序列化关系集合定义如下:
class _SerializedRelationships:"""Read-only sequence of |_SerializedRelationship| instances corresponding to therelationships item XML passed to constructor."""def __init__(self):super(_SerializedRelationships, self).__init__()self._srels = []@staticmethoddef load_from_xml(baseURI, rels_item_xml):"""Return |_SerializedRelationships| instance loaded with the relationshipscontained in `rels_item_xml`.Returns an empty collection if `rels_item_xml` is |None|."""srels = _SerializedRelationships()if rels_item_xml is not None:rels_elm = parse_xml(rels_item_xml)for rel_elm in rels_elm.Relationship_lst:srels._srels.append(_SerializedRelationship(baseURI, rel_elm))return srels
- rels_item_xml是指存储关系集合的rels文件的xml字符串
- parse_xml(rels_item_xml)返回CT_Relationships元素
【重要】PackageReader封装序列化关系及序列化part对象
到目前为止,我们还只获取到一个个零散的序列化part对象或者序列化关系集合,如何整合这些对象形成一个OPC标准的物理包——本质是一个图数据结构?从docx物理文件创建物理包对象的逻辑定义与PackageReader类:
class PackageReader:"""Provides access to the contents of a zip-format OPC package via its:attr:`serialized_parts` and :attr:`pkg_srels` attributes."""def __init__(self, content_types, pkg_srels, sparts):super(PackageReader, self).__init__()self._pkg_srels = pkg_srelsself._sparts = sparts@staticmethoddef from_file(pkg_file):"""Return a |PackageReader| instance loaded with contents of `pkg_file`."""phys_reader = PhysPkgReader(pkg_file)content_types = _ContentTypeMap.from_xml(phys_reader.content_types_xml)pkg_srels = PackageReader._srels_for(phys_reader, PACKAGE_URI)sparts = PackageReader._load_serialized_parts(phys_reader, pkg_srels, content_types)phys_reader.close()return PackageReader(content_types, pkg_srels, sparts)......
-
实例属性_pkg_srels表示package_level级别的关系集合,实例属性_sparts表示序列化的part对象集合。一般不直接创建PackageReader实例,而是通过from_file类方法创建实例。
-
from_file方法中,第一句本质是实例化_ZipPkgReader。
-
第二句是解析[Content_Types].xml
-
类方法_srels_for定义如下:
@staticmethoddef _srels_for(phys_reader, source_uri):"""Return |_SerializedRelationships| instance populated with relationships forsource identified by `source_uri`."""rels_xml = phys_reader.rels_xml_for(source_uri)return _SerializedRelationships.load_from_xml(source_uri.baseURI, rels_xml)- 结合定义,在第三句中,传入的第一个实参就是实例化的_ZipPkgReader;传入的第二个实参就是PACKAGR_URI——package_level级别的关系集合source对象就是package根节点。
- phys_reader.rels_xml_for(source_uri)就是获取"/_rel/.rels.xml"文件的xml字符串。
- 当“packuri”取值为“/”时,其baseURI依然为“/”——这是个特例,一般baseURI是packuri的目录部分。
-
类方法_load_serialized_parts的定义如下:
@staticmethoddef _load_serialized_parts(phys_reader, pkg_srels, content_types):"""Return a list of |_SerializedPart| instances corresponding to the parts in`phys_reader` accessible by walking the relationship graph starting with`pkg_srels`."""sparts = []part_walker = PackageReader._walk_phys_parts(phys_reader, pkg_srels)for partname, blob, reltype, srels in part_walker:content_type = content_types[partname]spart = _SerializedPart(partname, content_type, reltype, blob, srels)sparts.append(spart)return tuple(sparts)-
该方法从package_level级别的关系出发,根据深度优先的策略,返回序列化的part对象列表。
-
深度优先的实现定义在类方法_walk_phys_parts:
@staticmethoddef _walk_phys_parts(phys_reader, srels, visited_partnames=None):"""Generate a 4-tuple `(partname, blob, reltype, srels)` for each of the partsin `phys_reader` by walking the relationship graph rooted at srels."""if visited_partnames is None:visited_partnames = []for srel in srels:if srel.is_external:continuepartname = srel.target_partnameif partname in visited_partnames:continuevisited_partnames.append(partname)reltype = srel.reltypepart_srels = PackageReader._srels_for(phys_reader, partname)blob = phys_reader.blob_for(partname)yield (partname, blob, reltype, part_srels)next_walker = PackageReader._walk_phys_parts(phys_reader, part_srels, visited_partnames)for partname, blob, reltype, srels in next_walker:yield (partname, blob, reltype, srels)其中最核心的部分在:1)part_srels = PackageReader._srels_for(phys_reader, partname),用于加载part_level级别的关系集合;2)next_walker = PackageReader._walk_phys_parts(phys_reader, part_srels, visited_partnames),如果part_level级别的关系集合不为空,则将该part作为一个根节点,创建与其关联的其它序列化part对象。
-
写入物理文件
将OPC物理包封装的序列化part与关系持久化,相对读取过程较为容易。仍然需要先处理“[ContentType].xml”文件。处理“[ContentType].xml”文件的逻辑定义在_ContentTypesItem:
class _ContentTypesItem:"""Service class that composes a content types item ([Content_Types].xml) based on alist of parts.Not meant to be instantiated directly, its single interface method is xml_for(),e.g. ``_ContentTypesItem.xml_for(parts)``."""def __init__(self):self._defaults = CaseInsensitiveDict()self._overrides = {}def _add_content_type(self, partname, content_type):"""Add a content type for the part with `partname` and `content_type`, using adefault or override as appropriate."""ext = partname.extif (ext.lower(), content_type) in default_content_types:self._defaults[ext] = content_typeelse:self._overrides[partname] = content_type@classmethoddef from_parts(cls, parts):"""Return content types XML mapping each part in `parts` to the appropriatecontent type and suitable for storage as ``[Content_Types].xml`` in an OPCpackage."""cti = cls()cti._defaults["rels"] = CT.OPC_RELATIONSHIPScti._defaults["xml"] = CT.XMLfor part in parts:cti._add_content_type(part.partname, part.content_type)return cti
- 不需要直接创建该实例,而是调用from_parts类方法创建实例
- from_parts大致就是迭代实参parts集合,根据part的文件后缀,将不同的content_type归类到defaults或者overrides集合。
处理完content_types,持久化序列化的关系与part节点的逻辑定义于PackageWriter:
class PackageWriter:"""Writes a zip-format OPC package to `pkg_file`, where `pkg_file` can be either apath to a zip file (a string) or a file-like object.Its single API method, :meth:`write`, is static, so this class is not intended to beinstantiated."""@staticmethoddef write(pkg_file, pkg_rels, parts):"""Write a physical package (.pptx file) to `pkg_file` containing `pkg_rels` and`parts` and a content types stream based on the content types of the parts."""phys_writer = PhysPkgWriter(pkg_file)PackageWriter._write_content_types_stream(phys_writer, parts)PackageWriter._write_pkg_rels(phys_writer, pkg_rels)PackageWriter._write_parts(phys_writer, parts)phys_writer.close()@staticmethoddef _write_content_types_stream(phys_writer, parts):"""Write ``[Content_Types].xml`` part to the physical package with anappropriate content type lookup target for each part in `parts`."""cti = _ContentTypesItem.from_parts(parts)phys_writer.write(CONTENT_TYPES_URI, cti.blob)@staticmethoddef _write_parts(phys_writer, parts):"""Write the blob of each part in `parts` to the package, along with a rels itemfor its relationships if and only if it has any."""for part in parts:phys_writer.write(part.partname, part.blob)if len(part._rels):phys_writer.write(part.partname.rels_uri, part._rels.xml)@staticmethoddef _write_pkg_rels(phys_writer, pkg_rels):"""Write the XML rels item for `pkg_rels` ('/_rels/.rels') to the package."""phys_writer.write(PACKAGE_URI.rels_uri, pkg_rels.xml)- write类方法中,第一句创建一个_ZipPkgWriter实例
- 第二句从parts实参收集content_types信息,并写入[ContentTypes].xml
- 第三句将package_level级别的关系写入’/_rels/.rels’
- 依次写入part节点文件及其关联的关系集合文件
- 关闭zip包
优化"There is no item named ‘word/NULL’ in the archive"异常
在执行docx.api.Document(filepath)时,如果抛出以上异常,通常原因是因为’word/_rels/document.xml.rels’文件中,某一CT_Relationship的Target属性值为“NULL”,因此可以重定义_SerializedRelationships的类方法load_from_xml,解决方案如下:
from docx.opc.oxml import parse_xmlfrom docx.opc.pkgreader import _SerializedRelationships, _SerializedRelationshipdef load_from_xml(baseURI, rels_item_xml):"""Return |_SerializedRelationships| instance loaded with the relationshipscontained in `rels_item_xml`.Returns an empty collection if `rels_item_xml` is |None|."""srels = _SerializedRelationships()if rels_item_xml is not None:rels_elm = parse_xml(rels_item_xml)for rel_elm in rels_elm.Relationship_lst:if rel_elm.get("Target") == "NULL":continue # 忽略此类part节点srels._srels.append(_SerializedRelationship(baseURI, rel_elm))return srels# 覆盖原定义setattr(_SerializedRelationships, "load_from_xml", load_from_xml)小结
本文结合OPC标准与docx三方库源码,对如何从docx格式文件中抽取物理包对象、以及将物理包对象写入docx格式文件的过程进行了记录。首先介绍了OPC遵循ZIP标准,其次对读取物理包进行分解——创建序列化关系及序列化parts集合,然后对写入物理包流程进行介绍,最后对一种docx抛出的常见异常给出了优化方法。通过本文可以加深对OPC物理包的认知、及为后续的OPC抽象包奠定基础。
OPC【3】:Part节点 ↩︎
相关文章:

OPC【4】:物理包
概述 OPC遵循zip标准,因此可以使用python标准库zipfile对docx格式的物理文件进行读写操作。在OPC中,物理包与抽象包是一对相对的概念,后续可以看到抽象包内的内容是将物理包内的信息进行编排形成地。简单点理解,物理包的作用在于…...
、Go 汇编及一些注意事项。)
关于 Go 协同程序(Coroutines 协程)、Go 汇编及一些注意事项。
参考: Go 汇编函数 - Go 语言高级编程 Go 嵌套汇编 - 掘金 (juejin.cn) 前言: Golang 适用 Go-Runtime(Go 运行时,嵌入在被编译的PE可执行文件之中)来管理调度协同程式的运行。 Go 语言没有多线程(MT&a…...

深入剖析BaseMapperPlus扩展接口及其在MyBatis-Plus中的实践价值
前言 BaseMapperPlus并非MyBatis-Plus(MP)官方提供的标准接口,而是社区开发者基于MP的BaseMapper接口进行二次封装和增强后创建的一个自定义接口。这个概念可能因不同项目或个人实践而有所差异,但其核心思想是为了解决特定场景下…...
Linux之安装配置VCentOS7+换源
目录 一、安装 二、配置 三、安装工具XSHELL 3.1 使用XSHELL连接Linux 四、换源 前言 首先需要安装VMware虚拟机,在虚拟机里进行安装Linux 简介 Linux,一般指GNU/Linux(单独的Linux内核并不可直接使用,一般搭配GNU套件&#…...
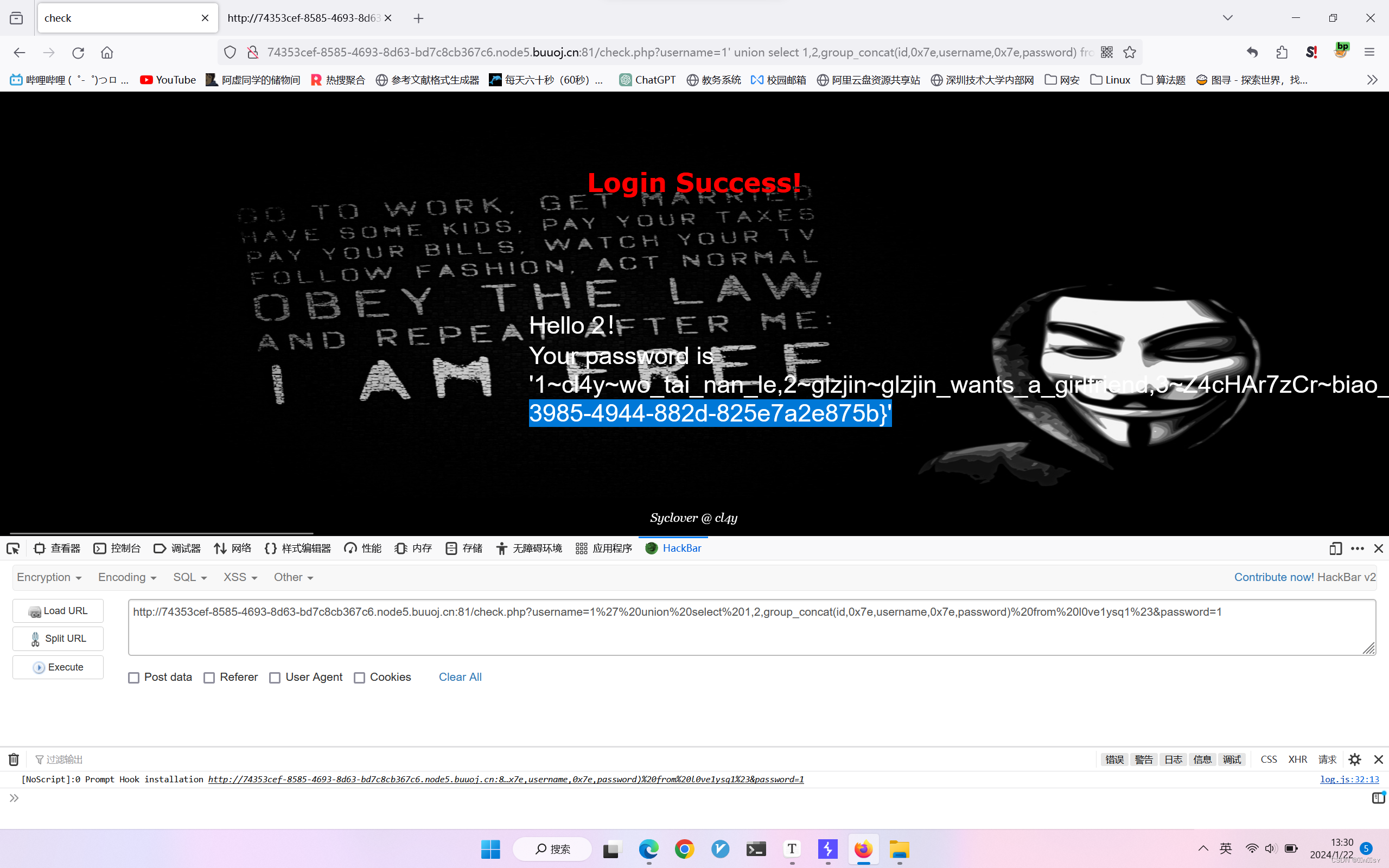
[极客大挑战 2019]LoveSQL1
万能密码测试,发现注入点 注意这里#要使用url编码才能正常注入 测试列数,得三列 查看table,一个是geekuser另一个是l0ve1ysq1 查看column,有id,username,password,全部打印出来,…...

网络安全的介绍
1.什么是网络安全 网络安全是一门关注保护计算机系统、网络基础设施和数据免受未经授权访问、破坏或窃取的学科。随着数字化时代的发展,网络安全变得尤为重要,因为大量的个人信息、商业机密和政府数据都储存在电子设备和云端系统中。以下是网络安全的概…...

django邮件通知功能-
需求: 1:下单人员下订单时需要向组长和投流手发送邮件通知 2:为何使用邮件通知功能?因为没钱去开通短信通知功能 设计 1:给用户信息表添加2个字段 第一个字段为:是否开通邮件通知的布尔值 第二个字段为: 用…...
C++ 类定义
C 类定义 定义一个类需要使用关键字 class,然后指定类的名称,并类的主体是包含在一对花括号中,主体包含类的成员变量和成员函数。 定义一个类,本质上是定义一个数据类型的蓝图,它定义了类的对象包括了什么࿰…...
IntelliJ IDE 插件开发 | (五)VFS 与编辑器
系列文章 IntelliJ IDE 插件开发 |(一)快速入门IntelliJ IDE 插件开发 |(二)UI 界面与数据持久化IntelliJ IDE 插件开发 |(三)消息通知与事件监听IntelliJ IDE 插件开发 |(四)来查收…...

金融OCR领域实习日志(一)
一、OCR基础 任务要求: 工作原理 OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相)检查纸上打印的字符,经过检测暗、亮的模式肯定其形状,而后用…...

CC++编译和链接介绍
介绍 C语言的编译和链接是将源代码转换为可执行文件的两个关键步骤。以下是详细的流程: 编译过程(Compilation) 预处理(Preprocessing): 编译器首先对源代码进行预处理,这个阶段处理#include包…...

Element-UI中的el-upload插件上传文件action和headers参数
官网给的例子action都是绝对地址,我现在需要上传到自己后台的地址,只有一个路由地址/task/upload 根据 config/index.js配置,那么action要写成/api/task/upload,另外也可以传入函数来返回地址:action"uploadUrl()"。 …...
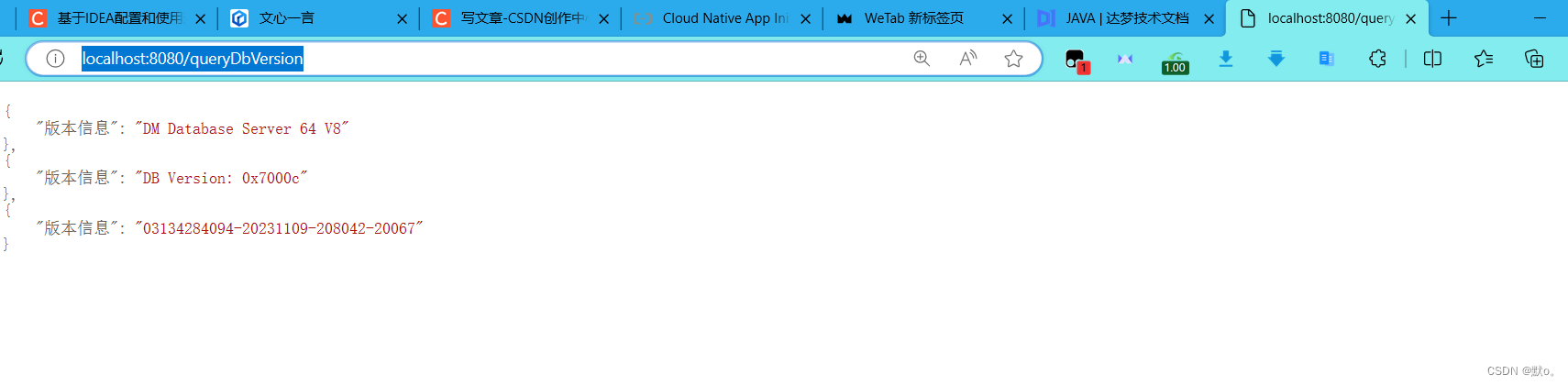
在IntelliJ IDEA中通过Spring Boot集成达梦数据库:从入门到精通
目录 博客前言 一.创建springboot项目 新建项目 选择创建类型编辑 测试 二.集成达梦数据库 添加达梦数据库部分依赖 添加数据库驱动包 配置数据库连接信息 编写测试代码 验证连接是否成功 博客前言 随着数字化时代的到来,数据库在应用程序中的地位越来…...
docker相关
下载Ubuntu18.04文件64位(32位安装不了MySQL) https://old-releases.ubuntu.com/releases/18.04.4/?_ga2.44113060.1243545826.1617173008-2055924693.1608557140 Linux ubuntu16.04打开控制台:到桌面,可以按快捷键ctrlaltt 查…...
生产力工具|卸载并重装Anaconda3
一、Anaconda3卸载 (一)官方方案一(Uninstall-Anaconda3-不能删除配置文件) 官方推荐的方案是两种,一种是直接在Anaconda的安装路径下,双击: (可以在搜索栏或者使用everything里面搜…...

大模型学习与实践笔记(十二)
使用RAG方式,构建opencv专业资料构建专业知识库,并搭建专业问答助手,并将模型部署到openxlab 平台 代码仓库:https://github.com/AllYoung/LLM4opencv 1:创建代码仓库 在 GitHub 中创建存放应用代码的仓库ÿ…...
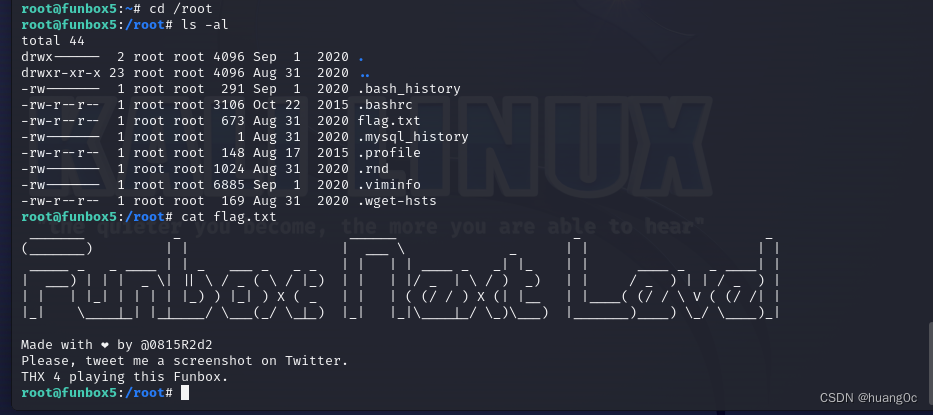
Vulnhub靶机:FunBox 5
一、介绍 运行环境:Virtualbox 攻击机:kali(10.0.2.15) 靶机:FunBox 5(10.0.2.30) 目标:获取靶机root权限和flag 靶机下载地址:https://www.vulnhub.com/entry/funb…...
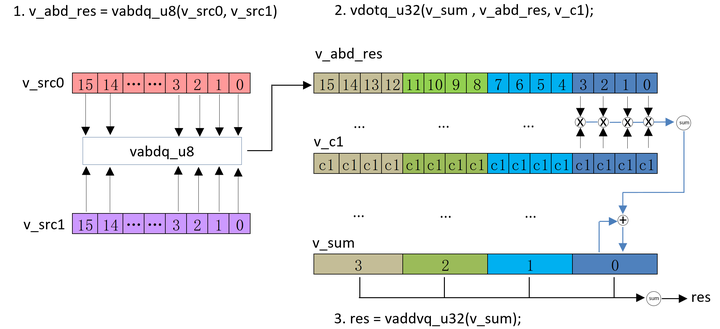
性能优化(CPU优化技术)-NEON指令介绍
「发表于知乎专栏《移动端算法优化》」 本文主要介绍了 NEON 指令相关的知识,首先通过讲解 arm 指令集的分类,NEON寄存器的类型,树立基本概念。然后进一步梳理了 NEON 汇编以及 intrinsics 指令的格式。最后结合指令的分类,使用例…...
【极数系列】Flink环境搭建(02)
【极数系列】Flink环境搭建(02) 引言 1.linux 直接在linux上使用jdk11flink1.18.0版本部署 2.docker 使用容器部署比较方便,一键启动停止,方便参数调整 3.windows 搭建Flink 1.18.0版本需要使用Cygwin或wsl工具模拟unix环境…...
仓储管理系统——软件工程报告(需求分析)②
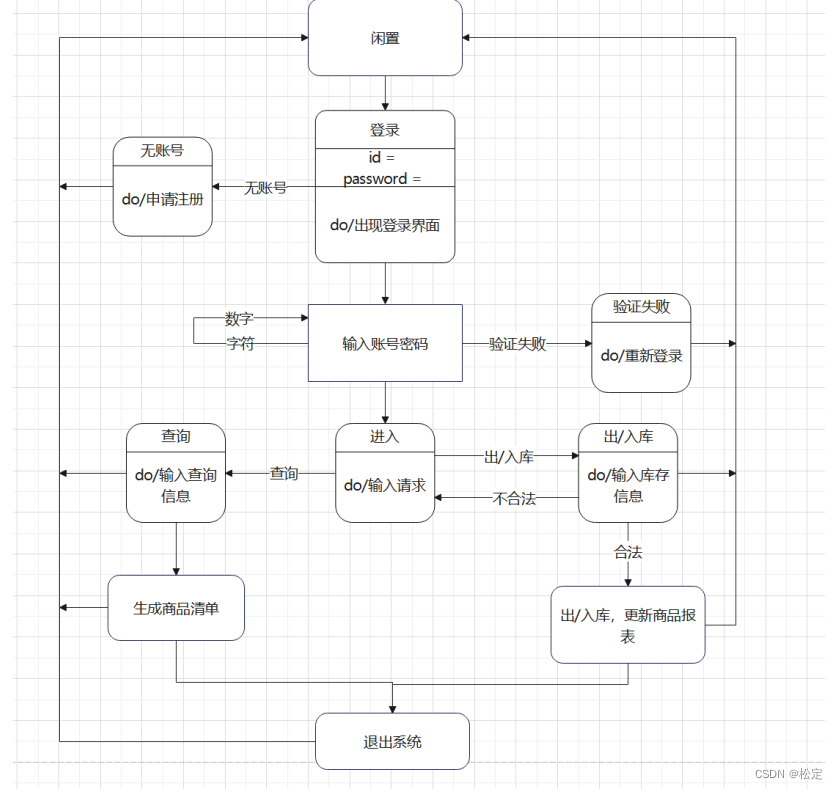
需求分析 一、系统概况 仓库管理系统是一种基于互联网对实际仓库的管理平台,旨在提供一个方便、快捷、安全的存取货物和查询商品信息平台。该系统通过在线用户登录查询,可以线上操作线下具体出/入库操作、查询仓库商品信息、提高仓库运作效率ÿ…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...