【Pytorch项目实战】之语义分割:U-Net、UNet++、U2Net
文章目录
- 博主精品专栏导航
- 一、前言
- 1.1、什么是图像分割?
- 1.2、语义分割与实例分割的区别
- 1.3、语义分割的上下文信息
- 1.4、语义分割的网络架构
- 二、网络 + 数据集
- 2.1、经典网络的发展史(模型详解)
- 2.2、分割数据集下载
- 三、算法详解
- 3.1、U-Net
- 3.1.1、网络框架(U形结构+跳跃连接结构)
- 3.1.2、镜像扩大(保留边缘信息)
- 3.1.3、数据增强(变形)
- 3.1.4、损失函数(交叉熵)
- 3.1.5、性能表现
- 3.2、UNet++
- 3.2.1、网络框架(U型结构+密集跳跃连接结构)
- 3.2.2、改进的跳跃连接结构(融合+拼接)
- 3.2.3、深度监督Deep supervision(剪枝)
- 3.2.4、损失函数
- 3.2.5、性能表现
- 3.3、U2-Net
- 3.3.1、网络框架(RSU结构+U型结构+跳跃连接结构)
- 3.3.2、残余U形块RSU
- 3.3.3、损失函数(交叉熵)
- 3.3.4、性能表现
- 四、项目实战
- 实战一:U-Net(不训练版)
- 实战二:U2-Net(不训练版)
- 实战三:基于U-Net实现目标检测(数据集:PASCAL VOC)
- 实战四:基于U2-Net的服装裤子分割(数据集:pants_data)
- 实战五:基于U2-Net的视网膜血管分割(数据集:DRIVE_data)
博主精品专栏导航
- 🍕 【Pytorch项目实战目录】算法详解 + 项目详解 + 数据集 + 完整源码
- 🍔 【sklearn】线性回归、最小二乘法、岭回归、Lasso回归
- 🥘 三万字硬核详解:yolov1、yolov2、yolov3、yolov4、yolov5、yolov7
- 🍰 卷积神经网络CNN的发展史
- 🍟 卷积神经网络CNN的实战知识
- 🍝 Pytorch基础(全)
- 🌭 Opencv图像处理(全)
- 🥙 Python常用内置函数(全)
一、前言
1.1、什么是图像分割?
对图像中属于特定类别的像素进行分类的过程,即逐像素分类。
- 图像分类:识别图像中存在的内容。
- 目标检测:识别图像中的内容和位置(通过边界框)。
- 语义分割:识别图像中存在的内容以及位置(通过查找属于它的所有像素)。
(1)传统的图像分割算法:灰度分割,条件随机场等。
(2)深度学习的图像分割算法:利用卷积神经网络,来理解图像中的每个像素所代表的真实世界物体。

1.2、语义分割与实例分割的区别
基于深度学习的图像分割技术主要分为两类:语义分割及实例分割。
语义分割(Semantic Segmentation):对图像中的每个像素点都进行分类预测,得到像素化的密集分类。然后提取具有感兴趣区域Mask。
- 特点:语义分割只能判断类别,无法区分个体。(只能将属于人的像素位置分割出来,但是无法分辨出图中有多少个人)

实例分割(Instance Segmentation):不需要对每个像素点进行标记,只需要找到感兴趣物体的边缘轮廓即可。
- 详细过程:即同时利用目标检测和语义分割的结果,通过目标检测提供的目标最高置信度类别的索引,将语义分割中目标对应的Mask抽取出来。
- 区别:目标检测输出目标的边界框和类别,实例分割输出的是目标的Mask和类别。
- 特点:可以区分个体。 (可以区分图像中有多少个人,不同人的轮廓都是不同颜色)

1.3、语义分割的上下文信息
- 上下文:指的是图像中的每一个像素点不可能是孤立的,一个像素一定和周围像素是有一定的关系的,大量像素的互相联系才产生了图像中的各种物体。
- 上下文特征:指像素以及周边像素的某种联系。 即在判断某一个位置上的像素属于哪种类别的时候,不仅考察到该像素的灰度值,还充分考虑和它临近的像素。
1.4、语义分割的网络架构
一个通用的语义分割网络结构可以被广泛认为是一个:编码器 - 解码器(Encoder-Decoder)。
- (1)编码器:负责特征提取,通常是一个预训练的分类网络(如:VGG、ResNet)。
- (2)解码器:将编码器学习到的可判别特征(低分辨率)从语义上投影到像素空间(高分辨率),以获得密集分类。
二、网络 + 数据集

2.1、经典网络的发展史(模型详解)
论文下载:史上最全语义分割综述(FCN、UNet、SegNet、Deeplab、ASPP…)
参考链接:经典网络 + 评价指标 + Loss损失(超详细介绍)

2.2、分割数据集下载
下载链接:【语义分割】FCN、UNet、SegNet、DeepLab
| 数据集 | 简介 |
|---|---|
| CamVid | 32个类别:367张训练图,101张验证图,233张测试图。 |
| PascalVOC 2012 | (1)支持 5 类任务:分类、分割、检测、姿势识别、人体。(2)对于分割任务,共支持 21 个类别,训练和验证各 1464 和 1449 张图 |
| NYUDv2 | 40个类别:795张训练图,645张测试图。 |
| Cityscapes | (1)50个不同城市的街景数据集,train/val/test的城市都不同。(2)包含:5k 精细标注数据,20k 粗糙标注数据。标注了 30 个类别。(3)5000张精细标注:2975张训练图,500张验证图,1525张测试图。(4)图像大小:1024x2048 |
| Sun-RGBD | 37个类别:10355张训练图,2860张测试图。 |
| MS COCO | 91个类别,328k 图像,2.5 million 带 label 的实例。 |
| ADE20K | 150个类别,20k张训练图,2k张验证图。 |
三、算法详解
3.1、U-Net
论文地址:U-Net:Convolutional Networks for Biomedical Image Segmentation
论文源码:论文源码已开源,可惜是基于MATLAB的Caffe版本。 U-Net的实验是一个比较简单的ISBI cell tracking数据集,由于本身的任务比较简单,U-Net紧紧通过30张图片并辅以数据扩充策略便达到非常低的错误率,拿了当届比赛的冠军。
Unet 发表于 2015 年,属于 FCN 的一种变体,是一个经典的全卷积神经网络(即没有全连接层)。采用编码器 - 解码器(下采样 - 上采样)的对称U形结构和跳跃连接结构。
- 全卷积神经网络(FCN)是图像分割的开天辟地之作。
- 为什么引入FCN:CNN浅层网络得到图像的纹理特征,深层得到轮廓特征等,但无法做到更精细的分割(像素级)。为了弥补这一缺陷,引入FCN。
- FCN与CNN的不同点:FCN将CNN最后的全连接层替换为卷积层,故FCN可以输入任意尺寸的图像。
- 而U-Net的初衷是为了解决生物医学图像问题。由于效果好,也被广泛的应用在卫星图像分割,工业瑕疵检测等。目前已有许多新的卷积神经网络设计方法,但仍延续了U-Net的核心思想。

3.1.1、网络框架(U形结构+跳跃连接结构)
具体过程:
- 输入图像大小为572 x 572。FCN可以输入任意尺寸的图像,且输出也是图像。
- (1)压缩路径(Contracting path):由4个block组成,每个block使用2个(conv 3x3,ReLU)和1个MaxPooling 2x2。
- 每次降采样之后的Feature Map的尺寸减半、数量翻倍。经过四次后,最终得到32x32的Feature Map。
- (2)扩展路径(Expansive path):由4个block组成,每个block使用2个(conv 3x3,ReLU)和1个反卷积(up-conv 2x2)。
- 11、每次上采样之后的Feature Map的尺寸翻倍、数量减半。
- 22、跳跃连接结构(skip connections):将左侧对称的压缩路径的Feature Map进行拼接(copy and crop)。由于左右两侧的Feature Map尺寸不同,将压缩路径的Feature Map裁剪到和扩展路径的Feature Map相同尺寸(左:虚线裁剪。右:白色块拼接)。
- 33、逐层上采样 :经过四次后,得到392X392的Feature Map。
- 44、卷积分类:再经过两次(conv 3x3,ReLU),一次(conv 1x1)。由于该任务是一个二分类任务,最后得到两张Feature Map(388x388x2)。

3.1.2、镜像扩大(保留边缘信息)
在不断的卷积过程中,图像会越来越小。为了避免数据丢失,在模型训练前,每一小块的四个边需要进行镜像扩大(不是直接补0扩大),以保留更多边缘信息。
由于当时计算机的内存较小,无法直接对整张图片进行处理(医学图像通常都很大),会采取把大图进行分块输入的训练方式,最后将结果一块块拼起来。

3.1.3、数据增强(变形)
医学影像数据普遍特点,就是样本量较少。当只有很少的训练样本可用时,数据增强对于教会网络所需的不变性和鲁棒性财产至关重要。
- 对于显微图像,主要需要平移和旋转不变性,以及对变形和灰度值变化的鲁棒性。特别是训练样本的随机弹性变形,是训练具有很少注释图像的关键。
- 在生物医学分割中,变形是组织中最常见的变化,并且可以有效地模拟真实的变形。
论文中的具体操作:使用粗糙的3乘3网格上的随机位移向量生成平滑变形。位移从具有10像素标准偏差的高斯分布中采样。然后使用双三次插值计算每个像素的位移。收缩路径末端的丢弃层执行进一步的隐式数据扩充。

3.1.4、损失函数(交叉熵)
论文的相关配置:Caffe框架,SGD优化器,每个batch一张图片,动量=0.99,交叉熵损失函数。

3.1.5、性能表现
用DIC(微分干涉对比)显微镜记录玻璃上的HeLa细胞。
(a) 原始图像。
(b) 覆盖地面真实分割。不同的颜色表示HeLa细胞的不同实例。
(c) 生成的分割掩码(白色:前景,黑色:背景)。
(d) 使用像素级损失权重映射,以迫使网络学习边界像素。

3.2、UNet++
论文地址:UNet++:A Nested U-Net Architecture for Medical Image Segmentation
UNet++ 发表于 2018 年,基于U-Net,采用一系列嵌套的密集的跳跃连接结构,并通过深度监督进行剪枝。
- UNet++的初衷是为了解决 " U-Net对病变或异常的医学图像缺乏更高的精确性 " 问题。
3.2.1、网络框架(U型结构+密集跳跃连接结构)
黑、红、绿、蓝色的组件将UNet++与U-Net区分开来。【语义分割】UNet++
- 黑色:U-Net网络
- 红色:深度监督(deep supervision)。可以进行模型剪枝 (model pruning)
- 绿色:在跳跃连接(skip connections)设置卷积层,在 Encoder 和 Decoder 网络之间架起语义鸿沟。
- 蓝色:一系列嵌套的密集的跳跃连接,改善了梯度流动。

3.2.2、改进的跳跃连接结构(融合+拼接)
Encoder 网络通过下采样提取低级特征;Decoder 网络通过上采样提取高级特征。
- U-Net 网络:(作者认为会产生语义鸿沟)
- 特点:跳跃连接,又叫长连接或直接跳跃连接。将左右两边对称的特征图通过裁剪的方式进行拼接,有助于还原降采样所带来的信息损失(与残差块非常类似)。
- 缺点:裁剪将导致图像的深层细节丢失(如:人的毛发、小瘤附近的微刺等),影响细胞的微小特征(如:小瘤附近的微刺,可能预示着恶性瘤)。
- UNet++网络:
- 特点:一系列嵌套的,密集的跳跃连接。包括L1、L2、L3、L4四个U-Net网络,分别抓取浅层到深层特征。将左右两边对称的特征图先融合,再拼接,进而可以获取不同层次的特征。
【备注】不同大小的感受野,对不同大小的目标,其敏感度也不同,获取图像的特征也不同。浅层(小感受野)对小目标更敏感;深层(大感受野)对大目标更敏感。
3.2.3、深度监督Deep supervision(剪枝)
此概念在对 U-Net 改进的多篇论文中都有使用,并不是该论文首先提出。
在结构
后加上1x1卷积,相当于去监督每个分支的 U-Net 输出。在深度监督中,因为每个子网络的输出都是图像分割结果,所以通过剪枝使得网络有两种模式。
- (1)精确模式:对所有分割分支的输出求平均值
- (2)快速模式:从所有分割分支中选择一个分割图。剪枝越多参数越少,在不影响准确率的前提下,剪枝可以降低计算时间。

(1)为什么可以剪枝?
- 测试阶段:输入图像只有前向传播,剪掉部分对前面的输出完全没有影响;
- 训练阶段:输入图像既有前向,又有反向传播,剪掉部分对剩余部分有影响 (绿色方框为剪掉部分) ,会帮助其他部分做权重更新。
(2)为什么要在测试时剪枝,而不是直接拿剪完的L1、L2、L3训练?
- 剪掉的那部分对训练时的反向传播时时有贡献的,如果直接拿L1、L2、L3训练,就相当于只训练不同深度的U-NET,最后的结果会很差。
(3)如何进行剪枝?
- 将数据分为训练集、验证集和测试集。
训练集是需要训练的,测试集是不能碰的,所以根据选择的子网络在验证集的结果来决定剪多少。
3.2.4、损失函数

3.2.5、性能表现
如图显示:U-Net、宽U-Net和UNet++结果之间的定性比较。

如图显示:U-Net、宽U-Net和UNet++(在肺结节分割、结肠息肉分割、肝脏分割和细胞核分割任务中)的数量参数和分割精度。
- 结论:
(1)宽U-Net始终优于U-Net,除了两种架构表现相当的肝脏分割。这一改进归因于宽U-Net中的参数数量更大。
(2)在没有深度监督的情况下,UNet++比UNet和宽U-Net都取得了显著的性能提升,IoU平均提高了2.8和3.3个点。
(3)与没有深度监督的UNet++相比,具有深度监督的UNet++平均提高0.6分。

如图显示:在不同级别处修剪的UNet++分割性能。使用 UNet++ Li 表示在级别 i 处修剪的UNet++。
- 结论:UNet++ L3平均减少了32.2%的推断时间,同时仅将IoU降低了0.6个点。更积极的修剪进一步减少了推断时间,但代价是显著的精度降低。

3.3、U2-Net
论文地址:U2-Net:Going Deeper with Nested U-Structure for Salient Object Detection
代码下载:U2-Net-master
U2-Net 于 2020 年在CVPR上发表 ,主要针对显著性目标检测任务提出(Salient Object Detetion,SOD)。
显著性目标检测任务与语义分割任务非常相似,其是二分类任务,将图像中最吸引人的目标或区域分割出来,故只有前景和背景两类。
第一列为原始图像,第二列为GT,第三列为U2-net结果、第四列为轻量级U2-net结果,其他列为其他比较主流的显著性目标检测网络模型。
- 结论:无论是U2-net,还是轻量级U2-net,结果都比其他模型更出色。

U2-Net 基于 U-Net 提出了一种残余U形块(ReSidual U-blocks,RSU)结构。每个RSU就是一个缩版的 U-net,最后通过FPN的跳跃连接构建完整模型。
- U2-Net 中的每一个block里面也是 U-Net,故称为 U2-Net 结构
- 经过测试,对于分割物体前背景取得了惊人的效果。同样具有较好的实时性,经过测试在P100上前向时间仅为18ms(56fps)。
3.3.1、网络框架(RSU结构+U型结构+跳跃连接结构)
U2-Net包括6个编码器+5个解码器。除编码器En-6,其余的模型都是对称结构。通过跳跃连接结构进行特征拼接,并得到7个基于深度监督的损失值(Sup6-Sup0)。(6个block输出结果、1个特征融合后的结果)

3.3.2、残余U形块RSU
残余U形块RSU与现有卷积块的对比图:
(a)普通卷积块:PLN
(b)残余块:RES
(c)密集块:DSE
(d)初始块:INC
(e)残余U形块:RSU
- RSU:每通过一个block后,Eecoder都会通过最大池化层下采样2倍,Decoder都会采用双线性插值进行上采样。

残余U形块RSU与残差模块的对比图:
(1)残差模块的权重层替换为U形模块;
(2)原始特征替换为本地特征;

3.3.3、损失函数(交叉熵)
由于U2net分成了多个block,故每个block都将输出一个loss值。7个loss相加(6个block输出结果、1个特征融合后的结果)
- 公式(1):叠加损失值loss。l表示二值交叉熵损失函数,w表示每个损失的权重。
- 公式(2):采用二值交叉熵损失函数。
在训练过程中,使用类似于HED的深度监督[45]。其有效性已在HED和DSS中得到验证。U2-net网络详解

3.3.4、性能表现
U2-Net与其他最先进SOD模型的模型大小和性能比较。
- maxFβ测量值在数据集ECSSD[46]上计算。红星表示U2-Net(176.3 MB),蓝星表示轻量级U2-Net(4.7 MB)。CVPR2020 U2-Net:嵌套U-结构的更深层次的显著目标检测

四、项目实战
实战一:U-Net(不训练版)
由于模型未训练,故每次运行得到的结果都不同。原因:每次运行的初始化卷积核不同。代码剖析

import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from PIL import Image
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"class Encoder(nn.Module):def __init__(self, in_channels, out_channels):super(Encoder, self).__init__()self.block1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))self.block2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))self.pool = nn.MaxPool2d(kernel_size=2, stride=2)def forward(self, x):x = self.block1(x)x = self.block2(x)x_pooled = self.pool(x)return x, x_pooledclass Decoder(nn.Module):def __init__(self, in_channels, out_channels):super(Decoder, self).__init__()self.up_sample = nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2)self.block1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))self.block2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=0), nn.ReLU(inplace=True))def forward(self, x_prev, x):x = self.up_sample(x) # 上采样x_shape = x.shape[2:]x_prev_shape = x.shape[2:]h_diff = x_prev_shape[0] - x_shape[0]w_diff = x_prev_shape[1] - x_shape[1]x_tmp = torch.zeros(x_prev.shape).to(x.device)x_tmp[:, :, h_diff//2: h_diff+x_shape[0], w_diff//2: x_shape[1]] = xx = torch.cat([x_prev, x_tmp], dim=1) # 拼接x = self.block1(x) # 卷积+ReLUx = self.block2(x) # 卷积+ReLUreturn xclass UNet(nn.Module):def __init__(self, num_classes=2):super(UNet, self).__init__()"""padding=1。 输出图像大小=((572-3 + 2*1) / 1) + 1 = 572 # 卷积前后图像大小不变padding=0。 输出图像大小=((572-3) / 1) + 1 = 570 # 原论文每次卷积后,图像长宽各减2""" """编码器(4) —— 通道变化[3, 64, 128, 256, 512]"""self.down_sample1 = Encoder(in_channels=3, out_channels=64)self.down_sample2 = Encoder(in_channels=64, out_channels=128)self.down_sample3 = Encoder(in_channels=128, out_channels=256)self.down_sample4 = Encoder(in_channels=256, out_channels=512)"""中间过渡层 —— 通道变化512, 1024]"""self.mid1 = nn.Sequential(nn.Conv2d(512, 1024, 3, bias=False), nn.ReLU(inplace=True))self.mid2 = nn.Sequential(nn.Conv2d(1024, 1024, 3, bias=False), nn.ReLU(inplace=True))"""解码器(4) —— 通道变化[1024, 512, 256, 128, 64]"""self.up_sample1 = Decoder(in_channels=1024, out_channels=512)self.up_sample2 = Decoder(in_channels=512, out_channels=256)self.up_sample3 = Decoder(in_channels=256, out_channels=128)self.up_sample4 = Decoder(in_channels=128, out_channels=64)"""分类器 —— 通道变化[64, 类别数]"""self.classifier = nn.Conv2d(64, num_classes, 1)def forward(self, x):x1, x = self.down_sample1(x)x2, x = self.down_sample2(x)x3, x = self.down_sample3(x)x4, x = self.down_sample4(x)x = self.mid1(x)x = self.mid2(x)x = self.up_sample1(x4, x)x = self.up_sample2(x3, x)x = self.up_sample3(x2, x)x = self.up_sample4(x1, x)x = self.classifier(x)return xdef image_loader(image_path):"""模型训练前的格式转换:[3, 384, 384] -> [1, 3, 384, 384]"""image = Image.open(image_path) # 打开图像(numpy格式)loader = transforms.ToTensor() # 数据预处理(Tensor格式)image = loader(image).unsqueeze(0) # tensor.unsqueeze():增加一个维度,其值为1。return image.to(device, torch.float)def image_trans(tensor):"""绘制图像前的格式转换:[1, 3, 384, 384] -> [3, 384, 384]"""image = tensor.clone() # clone():复制image = torch.squeeze(image, 0) # tensor.squeeze():减少一个维度,其值为1。unloader = transforms.ToPILImage() # 数据预处理(PILImage格式)image = unloader(image) # 图像转换return imageif __name__ == '__main__':device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 可用设备raw_image = image_loader(r"大黄蜂.jpg") # 导入图像model = UNet(4) # 模型实例化new_image = model(raw_image) # 前向传播print("输入图像维度: ", raw_image.shape)print("输出图像维度: ", new_image.shape)raw_image = image_trans(raw_image)new_image = image_trans(new_image)# 由于模型未训练,故每次运行得到的结果都不同。原因:每次运行的初始化卷积核不同。plt.subplot(121), plt.imshow(raw_image, 'gray'), plt.title('raw_image')plt.subplot(122), plt.imshow(new_image, 'gray'), plt.title('new_image')plt.show()实战二:U2-Net(不训练版)
由于模型未训练,故每次运行得到的结果都不同。原因:每次运行的初始化卷积核不同。图像分割之U-Net、U2-Net及其Pytorch代码构建

import torch.nn.functional as F
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from PIL import Image
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"class ConvolutionLayer(nn.Module):def __init__(self, in_channels, out_channels, dilation=1):super(ConvolutionLayer, self).__init__()self.layer = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), padding=1 * dilation,dilation=(1 * dilation, 1 * dilation)), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True))self.conv_s1 = nn.Conv2d(in_channels, out_channels, kernel_size=(3, 3), padding=1 * dilation,dilation=(1 * dilation, 1 * dilation))self.bn_s1 = nn.BatchNorm2d(out_channels)self.relu_s1 = nn.ReLU(inplace=True)def forward(self, x):return self.layer(x)def upsample_like(src, tar):src = F.interpolate(src, size=tar.shape[2:], mode='bilinear')return srcclass DownSample(nn.Module):def __init__(self, ):super(DownSample, self).__init__()self.layer = nn.MaxPool2d(kernel_size=2, stride=2)def forward(self, x):return self.layer(x)class UNet1(nn.Module):def __init__(self, in_channels, mid_channels, out_channels):super(UNet1, self).__init__()self.conv0 = ConvolutionLayer(in_channels, out_channels, dilation=1)self.conv1 = ConvolutionLayer(out_channels, mid_channels, dilation=1)self.down1 = DownSample()self.conv2 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down2 = DownSample()self.conv3 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down3 = DownSample()self.conv4 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down4 = DownSample()self.conv5 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down5 = DownSample()self.conv6 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.conv7 = ConvolutionLayer(mid_channels, mid_channels, dilation=2)self.conv8 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv9 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv10 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv11 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv12 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv13 = ConvolutionLayer(mid_channels * 2, out_channels, dilation=1)def forward(self, x):x0 = self.conv0(x)x1 = self.conv1(x0)d1 = self.down1(x1)x2 = self.conv2(d1)d2 = self.down2(x2)x3 = self.conv3(d2)d3 = self.down3(x3)x4 = self.conv4(d3)d4 = self.down4(x4)x5 = self.conv5(d4)d5 = self.down5(x5)x6 = self.conv6(d5)x7 = self.conv7(x6)x8 = self.conv8(torch.cat((x7, x6), 1))up1 = upsample_like(x8, x5)x9 = self.conv9(torch.cat((up1, x5), 1))up2 = upsample_like(x9, x4)x10 = self.conv10(torch.cat((up2, x4), 1))up3 = upsample_like(x10, x3)x11 = self.conv11(torch.cat((up3, x3), 1))up4 = upsample_like(x11, x2)x12 = self.conv12(torch.cat((up4, x2), 1))up5 = upsample_like(x12, x1)x13 = self.conv13(torch.cat((up5, x1), 1))return x13 + x0class UNet2(nn.Module):def __init__(self, in_channels, mid_channels, out_channels):super(UNet2, self).__init__()self.conv0 = ConvolutionLayer(in_channels, out_channels, dilation=1)self.conv1 = ConvolutionLayer(out_channels, mid_channels, dilation=1)self.down1 = DownSample()self.conv2 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down2 = DownSample()self.conv3 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down3 = DownSample()self.conv4 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down4 = DownSample()self.conv5 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.conv6 = ConvolutionLayer(mid_channels, mid_channels, dilation=2)self.conv7 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv8 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv9 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv10 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv11 = ConvolutionLayer(mid_channels * 2, out_channels, dilation=1)def forward(self, x):x0 = self.conv0(x)x1 = self.conv1(x0)d1 = self.down1(x1)x2 = self.conv2(d1)d2 = self.down2(x2)x3 = self.conv3(d2)d3 = self.down3(x3)x4 = self.conv4(d3)d4 = self.down4(x4)x5 = self.conv5(d4)x6 = self.conv6(x5)x7 = self.conv7(torch.cat((x6, x5), dim=1))up1 = upsample_like(x7, x4)x8 = self.conv8(torch.cat((up1, x4), dim=1))up2 = upsample_like(x8, x3)x9 = self.conv9(torch.cat((up2, x3), dim=1))up3 = upsample_like(x9, x2)x10 = self.conv10(torch.cat((up3, x2), dim=1))up4 = upsample_like(x10, x1)x11 = self.conv11(torch.cat((up4, x1), dim=1))return x11 + x0class UNet3(nn.Module):def __init__(self, in_channels, mid_channels, out_channels):super(UNet3, self).__init__()self.conv0 = ConvolutionLayer(in_channels, out_channels, dilation=1)self.conv1 = ConvolutionLayer(out_channels, mid_channels, dilation=1)self.down1 = DownSample()self.conv2 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down2 = DownSample()self.conv3 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down3 = DownSample()self.conv4 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.conv5 = ConvolutionLayer(mid_channels, mid_channels, dilation=2)self.conv6 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv7 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv8 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv9 = ConvolutionLayer(mid_channels * 2, out_channels, dilation=1)def forward(self, x):x0 = self.conv0(x)x1 = self.conv1(x0)d1 = self.down1(x1)x2 = self.conv2(d1)d2 = self.down2(x2)x3 = self.conv3(d2)d3 = self.down3(x3)x4 = self.conv4(d3)x5 = self.conv5(x4)x6 = self.conv6(torch.cat((x5, x4), 1))up1 = upsample_like(x6, x3)x7 = self.conv7(torch.cat((up1, x3), 1))up2 = upsample_like(x7, x2)x8 = self.conv8(torch.cat((up2, x2), 1))up3 = upsample_like(x8, x1)x9 = self.conv9(torch.cat((up3, x1), 1))return x9 + x0class UNet4(nn.Module):def __init__(self, in_channels, mid_channels, out_channels):super(UNet4, self).__init__()self.conv0 = ConvolutionLayer(in_channels, out_channels, dilation=1)self.conv1 = ConvolutionLayer(out_channels, mid_channels, dilation=1)self.down1 = DownSample()self.conv2 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.down2 = DownSample()self.conv3 = ConvolutionLayer(mid_channels, mid_channels, dilation=1)self.conv4 = ConvolutionLayer(mid_channels, mid_channels, dilation=2)self.conv5 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv6 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=1)self.conv7 = ConvolutionLayer(mid_channels * 2, out_channels, dilation=1)def forward(self, x):"""encode"""x0 = self.conv0(x)x1 = self.conv1(x0)d1 = self.down1(x1)x2 = self.conv2(d1)d2 = self.down2(x2)x3 = self.conv3(d2)x4 = self.conv4(x3)"""decode"""x5 = self.conv5(torch.cat((x4, x3), 1))up1 = upsample_like(x5, x2)x6 = self.conv6(torch.cat((up1, x2), 1))up2 = upsample_like(x6, x1)x7 = self.conv7(torch.cat((up2, x1), 1))return x7 + x0class UNet5(nn.Module):def __init__(self, in_channels, mid_channels, out_channels):super(UNet5, self).__init__()self.conv0 = ConvolutionLayer(in_channels, out_channels, dilation=1)self.conv1 = ConvolutionLayer(out_channels, mid_channels, dilation=1)self.conv2 = ConvolutionLayer(mid_channels, mid_channels, dilation=2)self.conv3 = ConvolutionLayer(mid_channels, mid_channels, dilation=4)self.conv4 = ConvolutionLayer(mid_channels, mid_channels, dilation=8)self.conv5 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=4)self.conv6 = ConvolutionLayer(mid_channels * 2, mid_channels, dilation=2)self.conv7 = ConvolutionLayer(mid_channels * 2, out_channels, dilation=1)def forward(self, x):x0 = self.conv0(x)x1 = self.conv1(x0)x2 = self.conv2(x1)x3 = self.conv3(x2)x4 = self.conv4(x3)x5 = self.conv5(torch.cat((x4, x3), 1))x6 = self.conv6(torch.cat((x5, x2), 1))x7 = self.conv7(torch.cat((x6, x1), 1))return x7 + x0class U2Net(nn.Module):def __init__(self, in_channels=3, out_channels=1):super(U2Net, self).__init__()self.en_1 = UNet1(in_channels, 32, 64)self.down1 = DownSample()self.en_2 = UNet2(64, 32, 128)self.down2 = DownSample()self.en_3 = UNet3(128, 64, 256)self.down3 = DownSample()self.en_4 = UNet4(256, 128, 512)self.down4 = DownSample()self.en_5 = UNet5(512, 256, 512)self.down5 = DownSample()self.en_6 = UNet5(512, 256, 512)# decoderself.de_5 = UNet5(1024, 256, 512)self.de_4 = UNet4(1024, 128, 256)self.de_3 = UNet3(512, 64, 128)self.de_2 = UNet2(256, 32, 64)self.de_1 = UNet1(128, 16, 64)self.side1 = nn.Conv2d(64, out_channels, kernel_size=(3, 3), padding=1)self.side2 = nn.Conv2d(64, out_channels, kernel_size=(3, 3), padding=1)self.side3 = nn.Conv2d(128, out_channels, kernel_size=(3, 3), padding=1)self.side4 = nn.Conv2d(256, out_channels, kernel_size=(3, 3), padding=1)self.side5 = nn.Conv2d(512, out_channels, kernel_size=(3, 3), padding=1)self.side6 = nn.Conv2d(512, out_channels, kernel_size=(3, 3), padding=1)self.out_conv = nn.Conv2d(6, out_channels, kernel_size=(1, 1))def forward(self, x):# ------encode ------x1 = self.en_1(x)d1 = self.down1(x1)x2 = self.en_2(d1)d2 = self.down2(x2)x3 = self.en_3(d2)d3 = self.down3(x3)x4 = self.en_4(d3)d4 = self.down4(x4)x5 = self.en_5(d4)d5 = self.down5(x5)x6 = self.en_6(d5)up1 = upsample_like(x6, x5)# ------decode ------x7 = self.de_5(torch.cat((up1, x5), dim=1))up2 = upsample_like(x7, x4)x8 = self.de_4(torch.cat((up2, x4), dim=1))up3 = upsample_like(x8, x3)x9 = self.de_3(torch.cat((up3, x3), dim=1))up4 = upsample_like(x9, x2)x10 = self.de_2(torch.cat((up4, x2), dim=1))up5 = upsample_like(x10, x1)x11 = self.de_1(torch.cat((up5, x1), dim=1))# side outputsup1 = self.side1(x11)sup2 = self.side2(x10)sup2 = upsample_like(sup2, sup1)sup3 = self.side3(x9)sup3 = upsample_like(sup3, sup1)sup4 = self.side4(x8)sup4 = upsample_like(sup4, sup1)sup5 = self.side5(x7)sup5 = upsample_like(sup5, sup1)sup6 = self.side6(x6)sup6 = upsample_like(sup6, sup1)sup0 = self.out_conv(torch.cat((sup1, sup2, sup3, sup4, sup5, sup6), 1))return torch.sigmoid(sup0)def image_loader(image_path):"""模型训练前的格式转换:[3, 384, 384] -> [1, 3, 384, 384]"""image = Image.open(image_path) # 打开图像(numpy格式)loader = transforms.ToTensor() # 数据预处理(Tensor格式)image = loader(image).unsqueeze(0) # tensor.unsqueeze():增加一个维度,其值为1。return image.to(device, torch.float)def image_trans(tensor):"""绘制图像前的格式转换:[1, 3, 384, 384] -> [3, 384, 384]"""image = tensor.clone() # clone():复制image = torch.squeeze(image, 0) # tensor.squeeze():减少一个维度,其值为1。unloader = transforms.ToPILImage() # 数据预处理(PILImage格式)image = unloader(image) # 图像转换return imageif __name__ == '__main__':device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 可用设备raw_image = image_loader(r"大黄蜂.jpg") # 导入图像model = U2Net(3, 1) # 模型实例化new_image = model(raw_image) # 前向传播print("输入图像维度: ", raw_image.shape)print("输出图像维度: ", new_image.shape)raw_image = image_trans(raw_image)new_image = image_trans(new_image)# 由于模型未训练,故每次运行得到的结果都不同。原因:每次运行的初始化卷积核不同。plt.subplot(121), plt.imshow(raw_image, 'gray'), plt.title('raw_image')plt.subplot(122), plt.imshow(new_image, 'gray'), plt.title('new_image')plt.show()实战三:基于U-Net实现目标检测(数据集:PASCAL VOC)
在GitCode上,基于Pascal VOC数据集的U-Net、PSP-Net、deeplabv3+三个网络模型的开源代码。
代码链接:基于Pytorch的目标分割:中文详细教程 + Pascal VOC数据集 + 完整代码

PASCAL VOC是由欧盟组织的世界级计算机视觉挑战赛。2005年举办第一场挑战赛,2012年停止举办。每年的内容都有所不同,从目标分类,到检测,分割,人体布局,动作识别等等,数据集的容量以及种类也在不断的增加和改善。
- PASCAL全称:Pattern Analysis,Statical Modeling and Computational Learning(模式分析,静态建模和计算学习)。
- VOC全称:Visual Object Classes(可视化对象类)。
- 近年来,目标检测或分割模型更倾向于使用MS COCO数据集Computer Vision Datasets。但PASCAL VOC数据集对于目标检测或分割类型具有先驱者地位PASCAL VOC Datasets。
- 最重要两个年份的数据集:PASCAL VOC 2007 与 PASCAL VOC 2012。PASCAL VOC Datasets的详细介绍
- 有兴趣的小伙伴还可以尝试自己制作训练集。语义分割:VOC数据集的制作教程
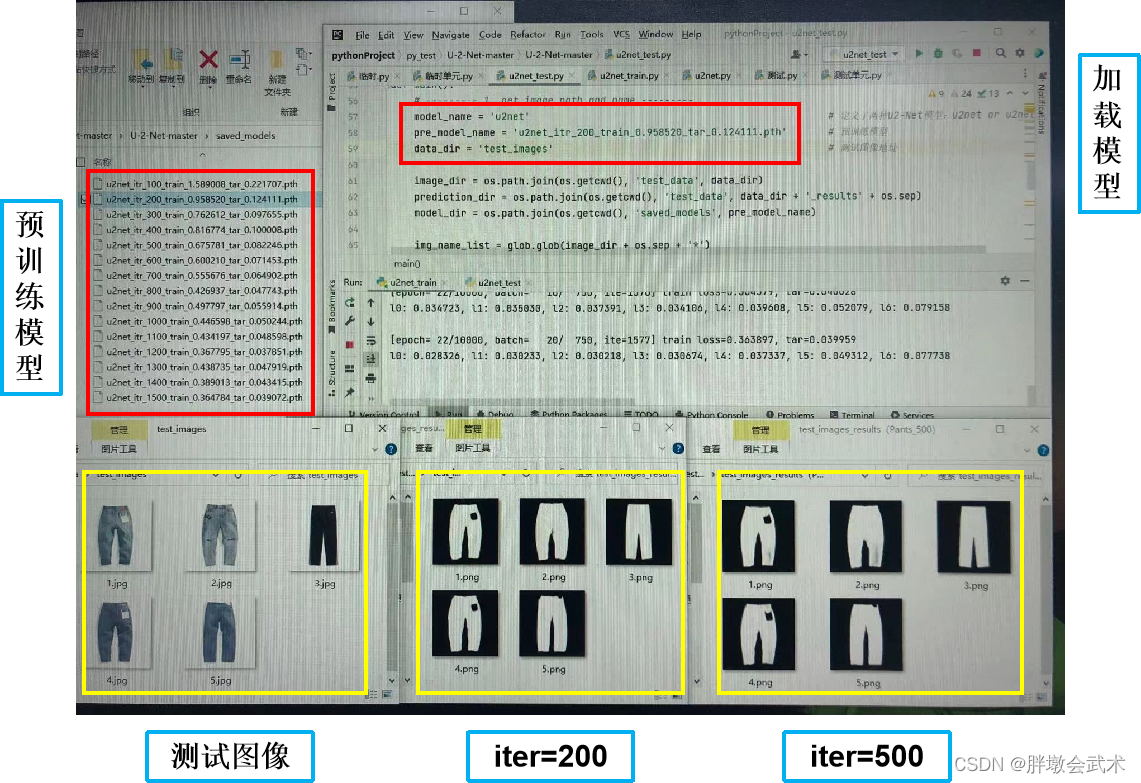
实战四:基于U2-Net的服装裤子分割(数据集:pants_data)
网盘链接:https://pan.baidu.com/s/1p32LsehWk8RmgvMOKxWsrw?pwd=2aem
提取码:2aem
U2-Net网络实现目标边缘检测(pants_data数据集)。
- 训练图像(服装裤子) —— 训练标签(服装裤子的轮廓图)
- 构建模型:将数据集与U2-Net官方开源代码进行整合,并对
u2net_train.py以及u2net_test.py进行了详细的整理与备注。
超参数设置:
epoch=10000,batch_size=10,iter=5000的演示图。
由于服装裤子的轮廓图相对简单,验证发现:iter = 200可以得到最优模型,而 iter = 500 生成的图1和图2裤脚有灰痕。
❤️ u2net_train.py
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as Ffrom torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch.optim as optim
import torchvision.transforms as standard_transformsimport numpy as np
import globfrom data_loader import Rescale
from data_loader import RescaleT
from data_loader import RandomCrop
from data_loader import ToTensor
from data_loader import ToTensorLab
from data_loader import SalObjDatasetfrom model import U2NET
from model import U2NETPimport os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"
########################################################################################################def muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v):"""损失函数"""bce_loss = nn.BCELoss(size_average=True)loss0 = bce_loss(d0, labels_v)loss1 = bce_loss(d1, labels_v)loss2 = bce_loss(d2, labels_v)loss3 = bce_loss(d3, labels_v)loss4 = bce_loss(d4, labels_v)loss5 = bce_loss(d5, labels_v)loss6 = bce_loss(d6, labels_v)loss = loss0 + loss1 + loss2 + loss3 + loss4 + loss5 + loss6print("l0: %3f, l1: %3f, l2: %3f, l3: %3f, l4: %3f, l5: %3f, l6: %3f\n"%(loss0.data.item(), loss1.data.item(), loss2.data.item(), loss3.data.item(),loss4.data.item(), loss5.data.item(), loss6.data.item()))return loss0, lossif __name__ == '__main__':######################################################################################################### (1)导入训练集data_dir = os.path.join(os.getcwd(), 'train_data' + os.sep) # 数据路径(train_data:存放图像+标签的文件夹)tra_image_dir = os.path.join('train_img' + os.sep) # 训练图像(train_img:存放图像的文件夹)tra_label_dir = os.path.join('train_label' + os.sep) # 训练标签(train_label:存放标签的文件夹)model_name = 'u2net' # 定义了两种模型:u2net、轻量级u2netpmodel_dir = os.path.join(os.getcwd(), 'saved_models' + os.sep) # 预训练模型(saved_models:存放预训练模型的文件夹)。os.sep不可删除image_ext = '.jpg' # 注意:图像与标签的后缀(tif、gif、jpg、png)label_ext = '.png' # 注意:图像与标签的文件名需一一对应tra_img_name_list = glob.glob(data_dir + tra_image_dir + '*' + image_ext) # 获取图像tra_lbl_name_list = []for img_path in tra_img_name_list:img_name = img_path.split(os.sep)[-1]aaa = img_name.split(".")bbb = aaa[0:-1]img_idx = bbb[0]for i in range(1, len(bbb)):img_idx = img_idx + "." + bbb[i]tra_lbl_name_list.append(data_dir + tra_label_dir + img_idx + label_ext) # 获取图像对应的标签print("train images: ", len(tra_img_name_list))print("train labels: ", len(tra_lbl_name_list))######################################################################################################### (2)超参数设置 ———— 图像增强 + 数据分配器epoch_num = 10batch_size = 10salobj_dataset = SalObjDataset(img_name_list=tra_img_name_list, lbl_name_list=tra_lbl_name_list,transform=transforms.Compose([RescaleT(320), RandomCrop(288), ToTensorLab(flag=0)]))salobj_dataloader = DataLoader(salobj_dataset, batch_size=batch_size, shuffle=True, num_workers=1)######################################################################################################### (3)模型选择if model_name == 'u2net':net = U2NET(3, 1)elif model_name == 'u2netp':net = U2NETP(3, 1)if torch.cuda.is_available():net.cuda()optimizer = optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)######################################################################################################### (4)开始训练print("start training", "..."*25)train_num = len(tra_img_name_list) # 训练图像的总数ite_num = 0 # 迭代次数ite_num4val = 0running_loss = 0.0 # 训练损失(总)running_tar_loss = 0.0 # 训练损失(loss0)save_frq = 100 # 每100次迭代训练,保存预训练模型for epoch in range(0, epoch_num):net.train() # 模型训练for i, data in enumerate(salobj_dataloader):ite_num = ite_num + 1ite_num4val = ite_num4val + 1inputs, labels = data['image'], data['label']inputs = inputs.type(torch.FloatTensor)labels = labels.type(torch.FloatTensor)if torch.cuda.is_available():inputs_v, labels_v = Variable(inputs.cuda(), requires_grad=False), Variable(labels.cuda(), requires_grad=False)else:inputs_v, labels_v = Variable(inputs, requires_grad=False), Variable(labels, requires_grad=False)optimizer.zero_grad() # 梯度清零d0, d1, d2, d3, d4, d5, d6 = net(inputs_v) # 前向传播loss2, loss = muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v) # 损失函数loss.backward() # 反向传播optimizer.step() # 梯度更新running_loss += loss.data.item() # 累加损失值(总)running_tar_loss += loss2.data.item() # 累加损失值(loss0)del d0, d1, d2, d3, d4, d5, d6, loss2, loss # 删除临时变量print("[epoch: %3d/%3d, batch: %5d/%5d, ite: %d] train loss: %3f, tar: %3f "% (epoch + 1, epoch_num, (i + 1) * batch_size, train_num, ite_num,running_loss / ite_num4val, running_tar_loss / ite_num4val))if ite_num % save_frq == 0:torch.save(net.state_dict(), model_dir + model_name + "_itr_%d_train_%3f_tar_%3f.pth"% (ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val))running_loss = 0.0running_tar_loss = 0.0net.train() # 继续训练ite_num4val = 0❤️ u2net_test.py
import os
from skimage import io, transform
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
# import torch.optim as optimimport numpy as np
from PIL import Image
import globfrom data_loader import RescaleT
from data_loader import ToTensor
from data_loader import ToTensorLab
from data_loader import SalObjDatasetfrom model import U2NET # full size version 173.6 MB
from model import U2NETP # small version u2net 4.7 MBdef normPRED(d):# normalize the predicted SOD probability mapma = torch.max(d)mi = torch.min(d)dn = (d-mi)/(ma-mi)return dndef save_output(image_name, pred, d_dir):predict = predpredict = predict.squeeze()predict_np = predict.cpu().data.numpy()im = Image.fromarray(predict_np*255).convert('RGB')img_name = image_name.split(os.sep)[-1]image = io.imread(image_name)imo = im.resize((image.shape[1], image.shape[0]), resample=Image.BILINEAR)pb_np = np.array(imo)aaa = img_name.split(".")bbb = aaa[0:-1]img_idx = bbb[0]for i in range(1, len(bbb)):img_idx = img_idx + "." + bbb[i]imo.save(d_dir + img_idx + '.png')def main():######################################################################################################### (1)导入测试集model_name = 'u2net' # 定义了两种模型:u2net、轻量级u2netppre_model_name = 'u2net_itr_4_train_6.046402_tar_0.528644.pth' # 预训练模型data_dir = 'test_images' # 存放测试图像的文件夹image_dir = os.path.join(os.getcwd(), 'test_data', data_dir) # 测试图像地址(test_data存放测试图像的上一级文件夹)prediction_dir = os.path.join(os.getcwd(), 'test_data', data_dir + '_results' + os.sep) # 结果存放地址(若无,则自动新建文件夹)model_dir = os.path.join(os.getcwd(), 'saved_models', pre_model_name) # 预训练模型地址(saved_models存放预训练模型的文件夹)img_name_list = glob.glob(image_dir + os.sep + '*') # 获取图像print(img_name_list)######################################################################################################### (2)超参数设置 ———— 图像增强 + 数据分配器test_salobj_dataset = SalObjDataset(img_name_list=img_name_list, lbl_name_list=[],transform=transforms.Compose([RescaleT(320), ToTensorLab(flag=0)]))test_salobj_dataloader = DataLoader(test_salobj_dataset, batch_size=1, shuffle=False, num_workers=1)######################################################################################################### (3)模型选择if model_name == 'u2net':print("load U2NET = 173.6 MB")net = U2NET(3, 1)elif model_name == 'u2netp':print("load U2NEP = 4.7 MB")net = U2NETP(3, 1)if torch.cuda.is_available():net.load_state_dict(torch.load(model_dir))net.cuda()else:net.load_state_dict(torch.load(model_dir, map_location='cpu'))######################################################################################################### (4)开始训练print("start testing", "..."*25)net.eval() # 测试模型for i_test, data_test in enumerate(test_salobj_dataloader):print("Extracting image:", img_name_list[i_test].split(os.sep)[-1]) # 提取图像(逐张)inputs_test = data_test['image']inputs_test = inputs_test.type(torch.FloatTensor)# 判断可用设备类型,并进行图像格式转换if torch.cuda.is_available():inputs_test = Variable(inputs_test.cuda())else:inputs_test = Variable(inputs_test)d1, d2, d3, d4, d5, d6, d7 = net(inputs_test) # 前向传播pred = d1[:, 0, :, :]pred = normPRED(pred) # 归一化# 判断文件夹是否存在,若不存在则新建if not os.path.exists(prediction_dir):os.makedirs(prediction_dir, exist_ok=True)save_output(img_name_list[i_test], pred, prediction_dir) # 保存预测图像del d1, d2, d3, d4, d5, d6, d7if __name__ == "__main__":main()实战五:基于U2-Net的视网膜血管分割(数据集:DRIVE_data)
网盘链接:https://pan.baidu.com/s/1q-vbgDFsDnabhOXQyqNYtw?pwd=znry
提取码:znry
DRIVE(Digital Retinal Images for Vessel Extraction)数据集来自于荷兰的糖尿病视网膜病变筛查计划,用于视网膜血管分割,进而研究病变原理。数据集于 2004 年由图像科学研究所发布,筛查人群为25-90岁的糖尿病受试者。共包括40张图像(训练集20、测试机20),33张未显示任何糖尿病视网膜病变迹象,7张显示轻度早期糖尿病视网膜病变迹象。

深度学习框架Keras:基于U-Net的眼底图像血管分割实例(DRIVE数据集)
- 构建模型:博主将数据集与Pytorch下的U2-Net官方开源代码进行了整合,将
u2net_train.py以及u2net_test.py进行了详细的整理与备注。- 可以将眼部图像分别与眼部轮廓图像、手工标注血管图像进行训练,得到两个预训练模型,然后进行图像测试。
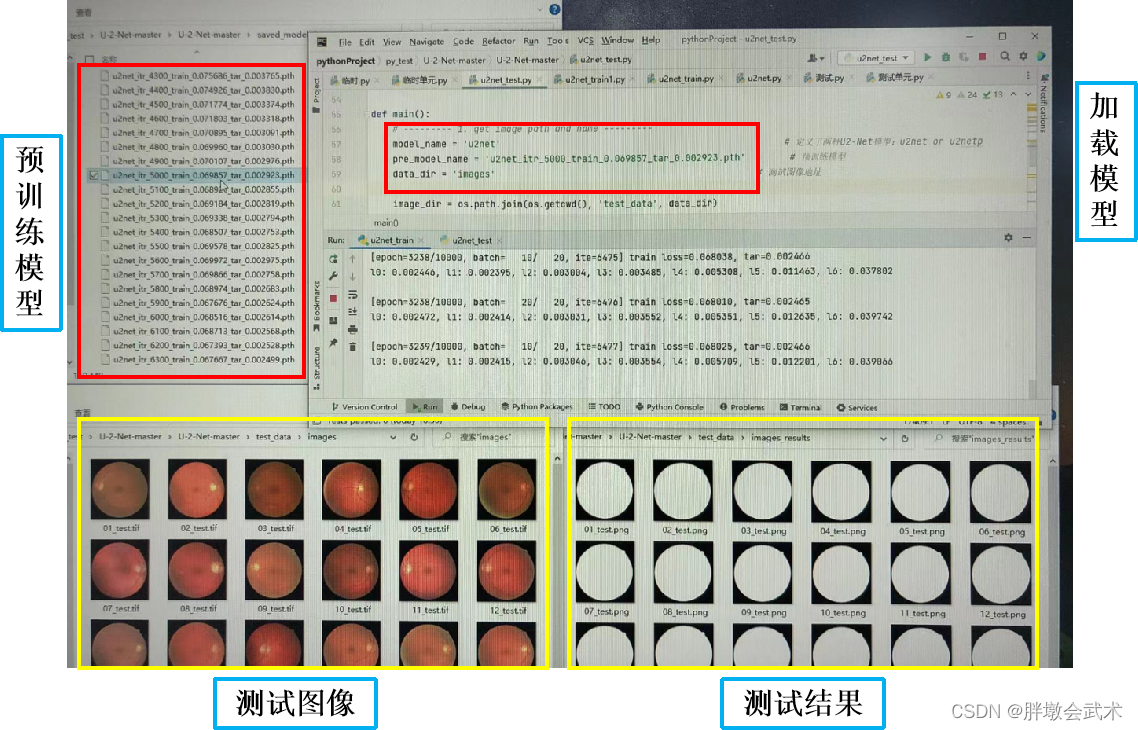
模型一:眼部图像作为训练集(Images)、手工标注血管图像作为训练掩膜(mask)
超参数设置:
epoch=10000,batch_size=10,iter=5000的演示图。
由于手工标注血管图像相对简单,验证发现,iter = 100 可以得到最优模型。
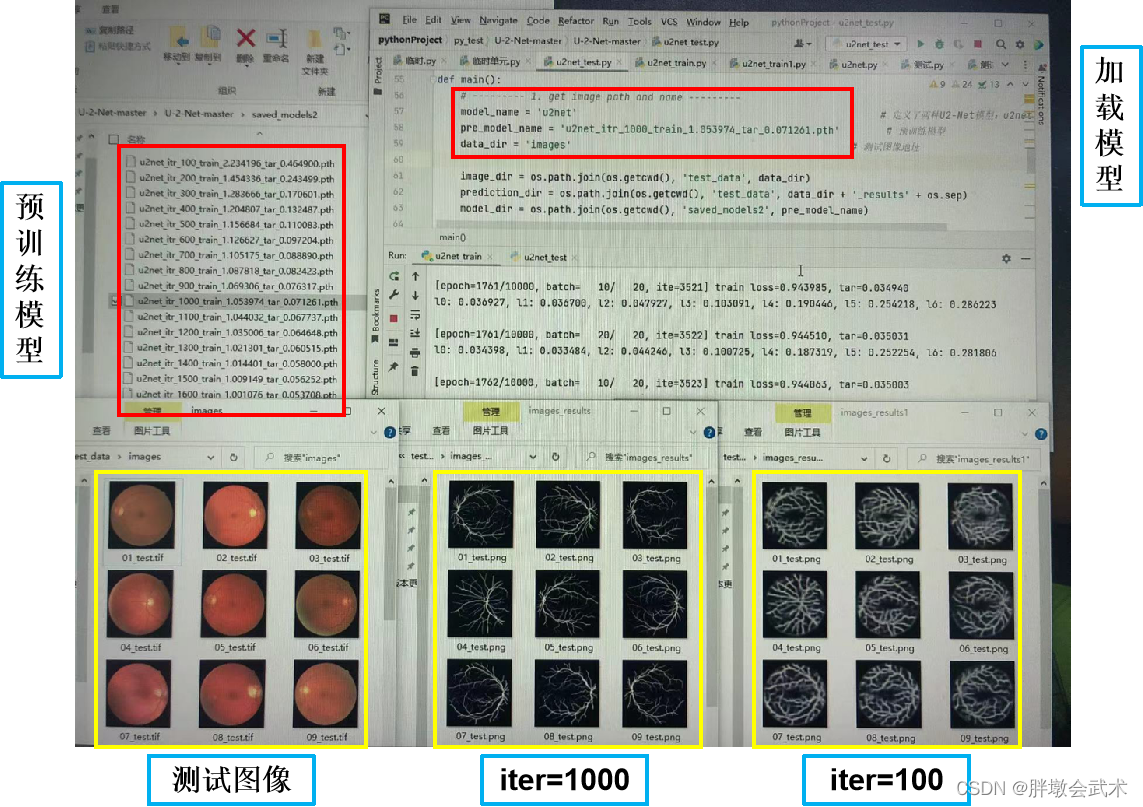
模型二:眼部图像作为训练集(Images)、眼部轮廓图像作为训练掩膜(manual)
超参数设置:
epoch=10000,batch_size=10,iter=5000的演示图。
由于眼部轮廓图像相对手工标注血管图像比较复杂,验证发现:iter = 1000可以得到最优模型,而 iter = 100 生成的结果会有点模糊。
❤️ u2net_train.py
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as Ffrom torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import torch.optim as optim
import torchvision.transforms as standard_transformsimport numpy as np
import globfrom data_loader import Rescale
from data_loader import RescaleT
from data_loader import RandomCrop
from data_loader import ToTensor
from data_loader import ToTensorLab
from data_loader import SalObjDatasetfrom model import U2NET
from model import U2NETPimport os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # "OMP: Error #15: Initializing libiomp5md.dll"
########################################################################################################def muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v):"""损失函数"""bce_loss = nn.BCELoss(size_average=True)loss0 = bce_loss(d0, labels_v)loss1 = bce_loss(d1, labels_v)loss2 = bce_loss(d2, labels_v)loss3 = bce_loss(d3, labels_v)loss4 = bce_loss(d4, labels_v)loss5 = bce_loss(d5, labels_v)loss6 = bce_loss(d6, labels_v)loss = loss0 + loss1 + loss2 + loss3 + loss4 + loss5 + loss6print("l0: %3f, l1: %3f, l2: %3f, l3: %3f, l4: %3f, l5: %3f, l6: %3f\n"% (loss0.data.item(), loss1.data.item(), loss2.data.item(), loss3.data.item(),loss4.data.item(), loss5.data.item(), loss6.data.item()))return loss0, lossif __name__ == '__main__':######################################################################################################### (1)导入训练集data_dir = os.path.join(os.getcwd(), 'train_data' + os.sep) # 数据路径(train_data:存放图像+标签的文件夹)tra_image_dir = os.path.join('images' + os.sep) # 训练图像(train_img:存放图像的文件夹)tra_label_dir = os.path.join('mask' + os.sep) # 训练标签(train_label:存放标签的文件夹)model_name = 'u2net' # 定义了两种模型:u2net、轻量级u2netpmodel_dir = os.path.join(os.getcwd(), 'saved_models' + os.sep) # 预训练模型(saved_models:存放预训练模型的文件夹)。os.sep不可删除image_ext = '.tif' # 注意:图像与标签的后缀(tif、gif、jpg、png)label_ext = '_mask.gif' # 注意:图像与标签的文件名需一一对应tra_img_name_list = glob.glob(data_dir + tra_image_dir + '*' + image_ext) # 获取图像tra_lbl_name_list = []for img_path in tra_img_name_list:img_name = img_path.split(os.sep)[-1]aaa = img_name.split(".")bbb = aaa[0:-1]img_idx = bbb[0]for i in range(1, len(bbb)):img_idx = img_idx + "." + bbb[i]tra_lbl_name_list.append(data_dir + tra_label_dir + img_idx + label_ext) # 获取图像对应的标签print("train images: ", len(tra_img_name_list))print("train labels: ", len(tra_lbl_name_list))######################################################################################################### (2)超参数设置 ———— 图像增强 + 数据分配器epoch_num = 10000batch_size = 10salobj_dataset = SalObjDataset(img_name_list=tra_img_name_list, lbl_name_list=tra_lbl_name_list,transform=transforms.Compose([RescaleT(320), RandomCrop(288), ToTensorLab(flag=0)]))salobj_dataloader = DataLoader(salobj_dataset, batch_size=batch_size, shuffle=True, num_workers=1)######################################################################################################### (3)模型选择if model_name == 'u2net':net = U2NET(3, 1)elif model_name == 'u2netp':net = U2NETP(3, 1)if torch.cuda.is_available():net.cuda()optimizer = optim.Adam(net.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)######################################################################################################### (4)开始训练print("start training", "..."*25)train_num = len(tra_img_name_list) # 训练图像的总数ite_num = 0 # 迭代次数ite_num4val = 0running_loss = 0.0 # 训练损失(总)running_tar_loss = 0.0 # 训练损失(loss0)save_frq = 100 # 每100次迭代训练,保存预训练模型for epoch in range(0, epoch_num):net.train() # 模型训练for i, data in enumerate(salobj_dataloader):ite_num = ite_num + 1ite_num4val = ite_num4val + 1inputs, labels = data['image'], data['label']inputs = inputs.type(torch.FloatTensor)labels = labels.type(torch.FloatTensor)if torch.cuda.is_available():inputs_v, labels_v = Variable(inputs.cuda(), requires_grad=False), Variable(labels.cuda(), requires_grad=False)else:inputs_v, labels_v = Variable(inputs, requires_grad=False), Variable(labels, requires_grad=False)optimizer.zero_grad() # 梯度清零d0, d1, d2, d3, d4, d5, d6 = net(inputs_v) # 前向传播loss2, loss = muti_bce_loss_fusion(d0, d1, d2, d3, d4, d5, d6, labels_v) # 损失函数loss.backward() # 反向传播optimizer.step() # 梯度更新running_loss += loss.data.item() # 累加损失值(总)running_tar_loss += loss2.data.item() # 累加损失值(loss0)del d0, d1, d2, d3, d4, d5, d6, loss2, loss # 删除临时变量print("[epoch: %3d/%3d, batch: %5d/%5d, ite: %d] train loss: %3f, tar: %3f "% (epoch + 1, epoch_num, (i + 1) * batch_size, train_num, ite_num,running_loss / ite_num4val, running_tar_loss / ite_num4val))if ite_num % save_frq == 0:torch.save(net.state_dict(), model_dir + model_name + "_itr_%d_train_%3f_tar_%3f.pth"% (ite_num, running_loss / ite_num4val, running_tar_loss / ite_num4val))running_loss = 0.0running_tar_loss = 0.0net.train() # 继续训练ite_num4val = 0❤️ u2net_test.py
import os
from skimage import io, transform
import torch
import torchvision
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
# import torch.optim as optimimport numpy as np
from PIL import Image
import globfrom data_loader import RescaleT
from data_loader import ToTensor
from data_loader import ToTensorLab
from data_loader import SalObjDatasetfrom model import U2NET # full size version 173.6 MB
from model import U2NETP # small version u2net 4.7 MBdef normPRED(d):# normalize the predicted SOD probability mapma = torch.max(d)mi = torch.min(d)dn = (d-mi)/(ma-mi)return dndef save_output(image_name, pred, d_dir):predict = predpredict = predict.squeeze()predict_np = predict.cpu().data.numpy()im = Image.fromarray(predict_np*255).convert('RGB')img_name = image_name.split(os.sep)[-1]image = io.imread(image_name)imo = im.resize((image.shape[1], image.shape[0]), resample=Image.BILINEAR)pb_np = np.array(imo)aaa = img_name.split(".")bbb = aaa[0:-1]img_idx = bbb[0]for i in range(1, len(bbb)):img_idx = img_idx + "." + bbb[i]imo.save(d_dir + img_idx + '.png')def main():######################################################################################################### (1)导入测试集model_name = 'u2net' # 定义了两种模型:u2net、轻量级u2netppre_model_name = 'u2net_itr_10_train_0.494240_tar_0.077563.pth' # 预训练模型data_dir = 'images' # 存放测试图像的文件夹image_dir = os.path.join(os.getcwd(), 'test_data', data_dir) # 测试图像地址(test_data存放测试图像的上一级文件夹)prediction_dir = os.path.join(os.getcwd(), 'test_data', data_dir + '_results' + os.sep) # 结果存放地址(若无,则自动新建文件夹)model_dir = os.path.join(os.getcwd(), 'saved_models', pre_model_name) # 预训练模型地址(saved_models存放预训练模型的文件夹)img_name_list = glob.glob(image_dir + os.sep + '*') # 获取图像print(img_name_list)######################################################################################################### (2)超参数设置 ———— 图像增强 + 数据分配器test_salobj_dataset = SalObjDataset(img_name_list=img_name_list, lbl_name_list=[],transform=transforms.Compose([RescaleT(320), ToTensorLab(flag=0)]))test_salobj_dataloader = DataLoader(test_salobj_dataset, batch_size=1, shuffle=False, num_workers=1)######################################################################################################### (3)模型选择if model_name == 'u2net':print("load U2NET = 173.6 MB")net = U2NET(3, 1)elif model_name == 'u2netp':print("load U2NEP = 4.7 MB")net = U2NETP(3, 1)if torch.cuda.is_available():net.load_state_dict(torch.load(model_dir))net.cuda()else:net.load_state_dict(torch.load(model_dir, map_location='cpu'))######################################################################################################### (4)开始训练print("start testing", "..."*25)net.eval() # 测试模型for i_test, data_test in enumerate(test_salobj_dataloader):print("Extracting image:", img_name_list[i_test].split(os.sep)[-1]) # 提取图像(逐张)inputs_test = data_test['image']inputs_test = inputs_test.type(torch.FloatTensor)# 判断可用设备类型,并进行图像格式转换if torch.cuda.is_available():inputs_test = Variable(inputs_test.cuda())else:inputs_test = Variable(inputs_test)d1, d2, d3, d4, d5, d6, d7 = net(inputs_test) # 前向传播pred = d1[:, 0, :, :]pred = normPRED(pred) # 归一化# 判断文件夹是否存在,若不存在则新建if not os.path.exists(prediction_dir):os.makedirs(prediction_dir, exist_ok=True)save_output(img_name_list[i_test], pred, prediction_dir) # 保存预测图像del d1, d2, d3, d4, d5, d6, d7if __name__ == "__main__":main()相关文章:
【Pytorch项目实战】之语义分割:U-Net、UNet++、U2Net
文章目录博主精品专栏导航一、前言1.1、什么是图像分割?1.2、语义分割与实例分割的区别1.3、语义分割的上下文信息1.4、语义分割的网络架构二、网络 数据集2.1、经典网络的发展史(模型详解)2.2、分割数据集下载三、算法详解3.1、U-Net3.1.1、…...

七、插件机制
Interceptor MyBatis 插件模块中最核心的接口就是 Interceptor 接口,它是所有 MyBatis 插件必须要实现的接口,其核心定义如下: public interface Interceptor {// 插件实现类中需要实现的拦截逻辑Object intercept(Invocation invocation) …...
kmp算法
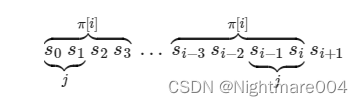
前缀函数 π[i]maxk0,⋯,i{k∣s[0,⋯,k−1]s[i−(k−1),⋯,i]}\pi\left[i\right] \max\limits_{k 0,\cdots, i}\left\{k|s\left[0,\cdots,k-1\right] s\left[i-\left(k-1\right) ,\cdots, i\right]\right\} π[i]k0,⋯,imax{k∣s[0,⋯,k−1]s[i−(k−1),⋯,i]} 简单来说…...

【Python】正则表达式简单教程
0x01 正则表达式概念及符号含义 掌握正则表达式,只需要记住不同符号所表示的含义,以及对目标对象模式(或规律)的正确概括。 1、基础内容 字符匹配 在正则表达式中,如果直接给出字符,就是精确匹配。\d 匹…...
SAP ABAP Odata
GetEntity和GetEntitys GetEntitys 创建Odata Project 导入结构 选择需要的字段 设定Key 勾选字段的creatable、updatable、sortable、nullable、filterable属性值。 再依上述步骤创建ZPOITEM结构和实体集 3. 创建ZPOHEADER和ZPOITEM的Association 两个实体集的关联字段&…...

Android native ASAN 排查内存泄漏
一、概述 android 对native - c/c 的调试和排查是比较难受的一件事。我看周遭做window , linux 甚至ios的调试排查起c的代码都比较方便。习惯了app开发去熟悉native是各种痛苦,最主要是排查问题上。后续有时间打算整理下native 的错误排查使用ÿ…...
Django项目开发
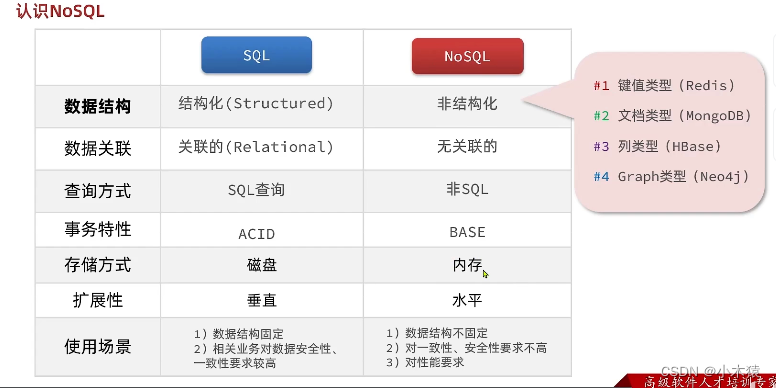
一.认识NoSQL 1.SQL 关系型数据库 结构化: 定义主键,无符号型数据等关联的:结构化表和表之间的关系通过外键进行关联,节省存储空间SQL查询:语法固定 SELECT id,name,age FROM tb_user WHERE id1 ACID 2.NoSQL 非关系型数据库 Re…...

Debezium系列之:深入理解Debezium Server和Debezium Server实际应用案例详解
Debezium系列之:深入理解Debezium Server和Debezium Server实际应用案例详解 一、认识Debezium Server二、下载Debezium Server三、解压Debezium Server四、查看Debezium Server目录五、Debezium Server配置六、Debezium Server启动输出样式七、源配置八、格式配置九、Transfo…...
IDE2022源码编译tomcat
因为学习需要,我需要源码编译运行tomcat对其源码进行一个简单的追踪分析。由于先前并未接触过java相关的知识,安装阻力巨大。最后请教我的开发朋友才解决了最后的问题。将其整理出来,让大家能够快速完成相关的部署。本文仅解决tomcat-8.5.46版…...

214 情人节来袭,电视剧 《点燃我温暖你》李峋同款 Python爱心表白代码,赶紧拿去用吧
大家好,我是徐公,六年大厂程序员经验,今天为大家带来的是动态心形代码,电视剧 《点燃我温暖你》同款的,大家赶紧看看,拿去向你心仪的对象表白吧,下面说一下灵感来源。 灵感来源 今天ÿ…...

数据库范式
基本概念 函数依赖 x→yx\rightarrow yx→y,当确定xxx的时候,yyy也可以确定 例: 学号→\rightarrow→姓名,当知道了学号,就知道了学生姓名 学号,课程号→\rightarrow→成绩,当知道了学号和课程号ÿ…...
CUDA中的底层驱动API
文章目录CUDA底层驱动API1. Context2. Module3. Kernel Execution4. Interoperability between Runtime and Driver APIs5. Driver Entry Point Access5.1. Introduction5.2. Driver Function Typedefs5.3. Driver Function Retrieval5.3.1. Using the driver API5.3.2. Using …...

【博客616】prometheus staleness对PromQL查询的影响
prometheus staleness对PromQL查询的影响 1、prometheus staleness 官方文档的解释: 概括: 运行查询时,将独立于实际的当前时间序列数据选择采样数据的时间戳。这主要是为了支持聚合(sum、avg 等)等情况,…...

多传感器融合定位十三-基于图优化的建图方法其二
多传感器融合定位十二-基于图优化的建图方法其二3.4 预积分方差计算3.4.1 核心思路3.4.2 连续时间下的微分方程3.4.3 离散时间下的传递方程3.5 预积分更新4. 典型方案介绍4.1 LIO-SAM介绍5. 融合编码器的优化方案5.1 整体思路介绍5.2 预积分模型设计Reference: 深蓝学院-多传感…...
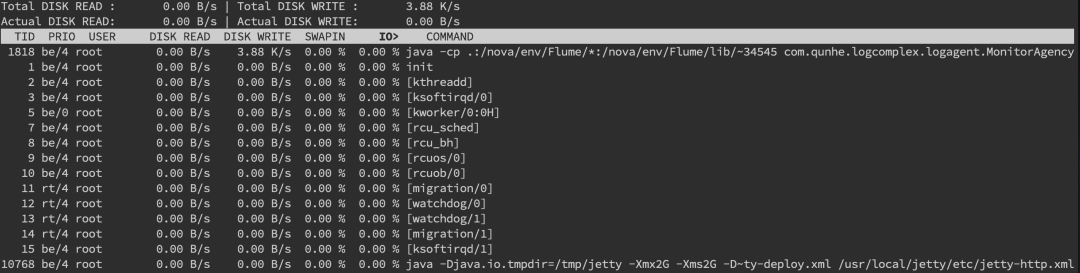
linux 服务器线上问题故障排查
一 线上故障排查概述 1.1 概述 线上故障排查一般从cpu,磁盘,内存,网络这4个方面入手; 二 磁盘的排查 2.1 磁盘排查 1.使用 df -hl 命令来查看磁盘使用情况 2.从读写性能排查:iostat -d -k -x命令来进行分析 最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及…...

Sandman:一款基于NTP协议的红队后门研究工具
关于Sandman Sandman是一款基于NTP的强大后门工具,该工具可以帮助广大研究人员在一个安全增强型网络系统中执行红队任务。 Sandman可以充当Stager使用,该工具利用了NTP(一个用于计算机时间/日期同步协议)从预定义的服务器获取并…...
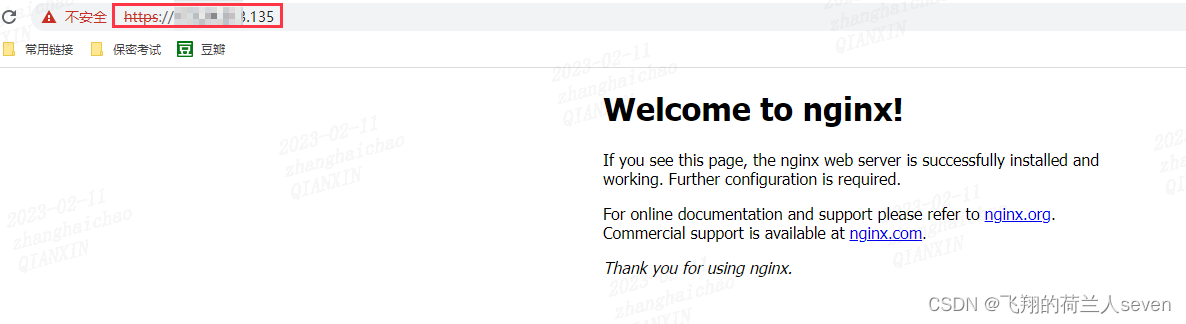
【SSL/TLS】准备工作:HTTPS服务器部署:Nginx部署
HTTPS服务器部署:Nginx部署1. 准备工作2. Nginx服务器YUM部署2.1 直接安装2.2 验证3. Nginx服务器源码部署3.1 下载源码包3.2 部署过程4. Nginx基本操作4.1 nginx常用命令行4.2 nginx重要目录1. 准备工作 1. Linux版本 [rootlocalhost ~]# cat /proc/version Li…...
微搭低代码从入门到精通11-数据模型
学习微搭低代码,先学习基本操作,然后学习组件的基本使用。解决了前端的问题,我们就需要深入学习后端的功能。后端一般包括两部分,第一部分是常规的数据库的操作,包括增删改查。第二部分是业务逻辑的编写,在…...

【算法基础】前缀和与差分
😽PREFACE🎁欢迎各位→点赞👍 收藏⭐ 评论📝📢系列专栏:算法💪种一棵树最好是十年前其次是现在1.什么是前缀和前缀和指一个数组的某下标之前的所有数组元素的和(包含其自身&#x…...
LTD212次升级 | 官网社区支持PC端展示 • 官网新增证件查询应用,支持条形码扫码查询
1、新增证件查询应用,支持条形码扫码查询; 2、新增用户社区PC端功能; 01证件查询应用 1、新增证件查询应用功能 支持证件信息录入、打印功能,支持条形码扫码识别。 后台管理操作路径:官微中心 - 应用 - 证件查询 …...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...