AWS 专题学习 P10 (Databases、 Data Analytics)
文章目录
- 专题总览
- 1. Databases
- 1.1 选择合适的数据库
- 1.2 数据库类型
- 1.3 AWS 数据库服务概述
- Amazon RDS
- Amazon Aurora
- Amazon ElastiCache
- Amazon DynamoDB
- Amazon S3
- DocumentDB
- Amazon Neptune
- Amazon Keyspaces (for Apache Cassandra)
- Amazon QLDB
- Amazon Timestream
- 2. Data & Analytics
- 2.1 Amazon Athena
- Amazon Athena – 性能优化
- Amazon Athena – Federated Query (联合查询)
- 2.2 Redshift 概述
- Redshift 集群
- Redshift – 快照&灾难恢复
- Loading data into Redshift: Large inserts are MUCH better
- Redshift Spectrum
- 2.3 Amazon OpenSearch Service
- OpenSearch patterns - DynamoDB
- OpenSearch patterns - CloudWatch Logs
- OpenSearch patterns - Kinesis Data Streams & Kinesis Data Firehose
- 2.4 Amazon EMR
- Amazon EMR - 节点类型和购买方式
- 2.5 Amazon QuickSight
- QuickSight 集成
- QuickSight - 仪表板和分析
- 2.6 AWS Glue
- AWS Glue - 将数据转换为 Parquet 格式
- Glue 数据目录:数据集的目录
- Glue - 高层次概述
- 2.7 AWS Lake Formation
- Centralized Permissions Example
- 2.8 Kinesis Data Analytics 用于 SQL 应用程序
- Kinesis Data Analytics(SQL 应用程序)
- Kinesis Data Analytics 用于 Apache Flink
- 2.9 Amazon Managed Streaming for Apache Kafka(Amazon MSK)
- Apache Kafka 概述
- Kinesis Data Streams v.s. Amazon MSK
- Amazon MSK 消费者
- 大数据摄取流程
- 大数据摄取流程讨论
专题总览
包含专题内容总览和系列博客目录
https://blog.csdn.net/weixin_40815218/article/details/135590291
1. Databases
1.1 选择合适的数据库
- 在AWS上有很多托管的数据库可供选择
- 根据架构选择合适的数据库的问题:
- 读重、写重还是平衡工作负载?吞吐量需求?它会改变吗,在一天中需要进行扩展或波动吗?
- 存储多少数据以及存储多长时间?它会增长吗?平均对象大小?它们如何访问?
- 数据的持久性?数据的真实来源?
- 延迟要求?并发用户?
- 数据模型?如何查询数据?连接?结构化?半结构化?
- 强类型模式?更灵活?报告?搜索?关系型数据库/NoSQL?
- 许可证成本?切换到云原生数据库,如Aurora?
1.2 数据库类型
- 关系型数据库(SQL / OLTP):RDS,Aurora-适用于连接
- NoSQL数据库-无连接,无SQL:DynamoDB(~ JSON),ElastiCache(键/值对),Neptune(图形),DocumentDB(用于MongoDB),Keyspaces(用于Apache Cassandra)
- 对象存储:S3(用于大对象)/ Glacier(用于备份/存档)
- 数据仓库(SQL分析/ BI):Redshift(OLAP),Athena,EMR
- 搜索:OpenSearch(JSON)-全文搜索,非结构化搜索
- 图形:Amazon Neptune-显示数据之间的关系
- 分类帐:Amazon Quantum Ledger数据库
- 时间序列:Amazon Timestream
- 注意:某些数据库在数据和分析部分讨论
1.3 AWS 数据库服务概述
Amazon RDS
- 托管的 PostgreSQL / MySQL / Oracle / SQL Server / MariaDB /自定义
- 预置的 RDS 实例大小和EBS卷类型和大小
- 存储的自动扩展功能
- 支持读副本和多个可用区
- 通过 IAM,安全组,KMS,SSL 在传输中提供安全性
- 带有特定时间恢复功能(最多35天)的自动备份
- 长期恢复的手动数据库快照
- 托管和计划维护(有停机时间)
- 支持 IAM 身份验证,与 Secrets Manager 集成
- RDS Custom 用于访问和自定义基础实例(Oracle和SQL Server)
- 用例:存储关系数据集(RDBMS / OLTP),执行 SQL 查询,事务
Amazon Aurora
- 兼容 PostgreSQL / MySQL 的 API,存储和计算分离
- 存储:数据存储在6个副本中,跨3个可用区-高可用性,自愈,自动扩展
- 计算:多个可用区的 DB 实例群集,读取副本的自动扩展
- 群集:编写器和读取器 DB 实例的自定义端点
- 与 RDS 相同的安全性/监控/维护功能
- 了解 Aurora 的备份和恢复选项
- Aurora Serverless-用于不可预测/间歇工作负载,无需容量规划
- Aurora Multi-Master-用于连续写入故障转移(高写入可用性)
- Aurora Global:每个区域最多16个DB读取实例,<1秒存储复制
- Aurora Machine Learning:在 Aurora 上使用 SageMaker 和 Comprehend 执行 ML
- Aurora 数据库克隆:从现有数据库创建新集群,比恢复快照更快
- 用例:与 RDS 相同,但维护更少/更灵活/性能更好/功能更多
Amazon ElastiCache
- 托管的 Redis / Memcached(与 RDS 类似,但用于缓存)
- 内存数据存储,亚毫秒延迟
- 必须预置 EC2 实例类型
- 支持集群(Redis)和多 AZ、读副本(分片)
- 通过 IAM、安全组、KMS、Redis Auth 实现安全性
- 备份/快照/按时间点还原功能
- 托管和计划维护
- 需要对应用程序代码进行一些更改以发挥作用
- 用例:键值存储,频繁读取,较少写入,缓存数据库查询结果,存储网站的会话数据,不能使用 SQL。
Amazon DynamoDB
- AWS 的专有技术,托管的无服务器 NoSQL 数据库,毫秒级延迟
- 容量模式:预置容量可选择自动扩展或按需容量
- 可以替代 ElastiCache 作为键/值存储(例如存储会话数据,使用 TTL 功能)
- 高可用性,默认多 AZ,读写解耦,支持事务
- 用于读取缓存的 DAX 集群,微秒级读取延迟
- 安全性通过 IAM 进行身份验证和授权
- 事件处理:DynamoDB Streams 与 AWS Lambda 或 Kinesis 数据流集成
- 全局表功能:主动-主动设置
- 自动备份最长可保留 35 天,可进行 PITR(还原到新表)或按需备份
- 在 PITR 窗口内使用 S3 导出时无需使用 RCU,在 PITR 窗口内从 S3 导入时无需使用 WCU
- 非常适合快速演变的模式
- 用例:无服务器应用程序开发(小型文档 100 KB),分布式无服务器缓存,不具备 SQL 查询语言
Amazon S3
- S3 是一个…对象的键/值存储
- 适用于较大的对象,对于许多小对象效果不佳
- 无服务器,无限扩展,最大对象大小为 5 TB,支持版本控制
- 层级:S3 标准,S3 低频访问,S3 智能层,S3 Glacier + 生命周期策略
- 功能:版本控制,加密,复制,MFA-Delete,访问日志…
- 安全性:IAM,存储桶策略,ACL,访问点,对象/保险库锁定,CORS,对象/保险库锁定
- 加密:SSE-S3,SSE-KMS,SSE-C,客户端端加密,传输中的 TLS,默认加密
- 使用 S3 Batch 进行对象批量操作,使用 S3 Inventory 列出文件
- 性能:分块上传,S3 传输加速,S3 Select
- 自动化:S3 事件通知(SNS,SQS,Lambda,EventBridge)
- 用例:静态文件,大文件的键值存储,网站托管
DocumentDB
- Aurora 是 PostgreSQL / MySQL 的 “AWS 实现”…
- DocumentDB 是 MongoDB 的同类产品(一种 NoSQL 数据库)
- MongoDB 用于存储、查询和索引 JSON 数据
- 与 Aurora 类似的 “部署概念”
- 完全托管,高可用性,跨 3 个 AZ 复制
- DocumentDB 存储自动以 10GB 为增量增长,最高可达 64TB
- 可以自动扩展以处理每秒数百万个请求的工作负载
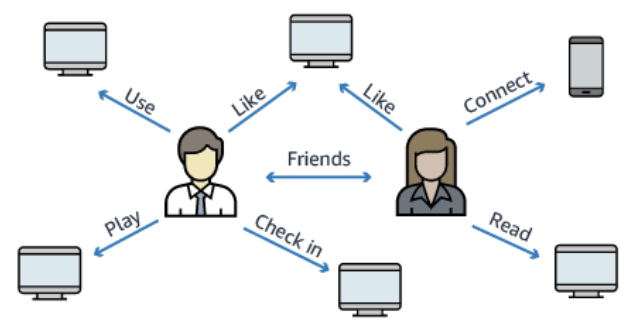
Amazon Neptune
- 完全托管的图数据库
- 一个受欢迎的图数据集可以是一个社交网络
- 用户有朋友
- 帖子有评论
- 评论有用户的点赞
- 用户分享和点赞帖子…
- 在 3 个 AZ 上高可用,并可拥有多达 15 个读副本
- 构建和运行处理高度连接数据集的应用程序-针对这些复杂且难以查询的优化
- 可以存储数十亿个关系并以毫秒级延迟查询图形
- 非常适合知识图谱(维基百科)、欺诈检测、推荐引擎、社交网络
Amazon Keyspaces (for Apache Cassandra)
- Apache Cassandra 是一个开源的分布式 NoSQL 数据库
- 一个托管的兼容 Apache Cassandra 的数据库服务
- 无服务器、可扩展、高可用、由 AWS 完全托管
- 根据应用程序的流量自动扩展表格的容量
- 表格在多个可用区内复制 3 次
- 使用 Cassandra 查询语言 (CQL)
- 无论规模如何,都可以实现单位数字毫秒级延迟,每秒处理数千个请求
- 容量:按需模式或预置模式与自动缩放
- 加密、备份、35 天的 PITR(时间点恢复)
- 用例:存储物联网设备信息、时间序列数据…
Amazon QLDB
-
QLDB 代表 “Quantum Ledger Database”(量子账本数据库)
-
账本是记录财务交易的账簿
-
完全托管、无服务器、高可用、在 3 个可用区中进行复制
-
用于查看应用程序数据随时间所有更改的历史记录
-
不可变系统:不能删除或修改任何条目,具有密码学验证!在这里插入图片描述
-
性能比常见的账本区块链框架提高 2-3 倍,使用 SQL 操作数据
-
与 Amazon Managed Blockchain 的区别:没有去中心化组件,符合金融监管规定
Amazon Timestream
- 完全托管、快速、可扩展、无服务器的时间序列数据库
- 自动调整容量进行扩缩
- 存储和分析每天的数万亿个事件
- 比关系型数据库快数千倍,成本只有其十分之一
- 定时查询、多度量记录、SQL 兼容
- 数据存储分层:近期数据存储在内存中,历史数据存储在成本优化的存储中
- 内置时间序列分析函数(帮助您在几乎实时中识别数据模式)
- 在传输和静止状态下进行加密
- 用例:物联网应用程序、运营应用程序、实时分析…

Amazon Timestream – Architecture

2. Data & Analytics
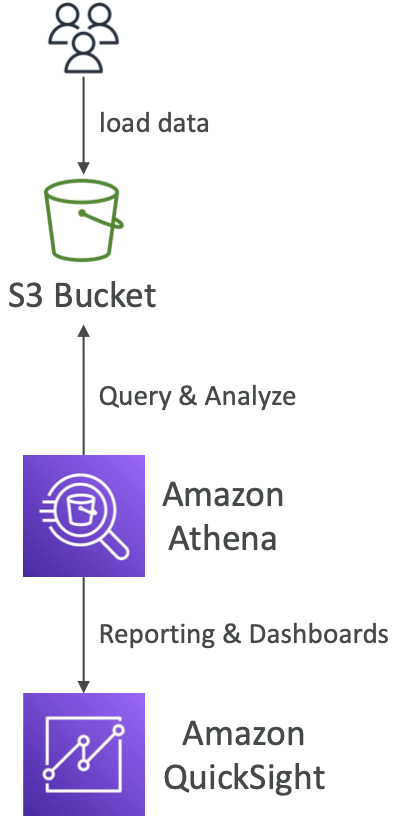
2.1 Amazon Athena
- 无服务器查询服务,用于分析存储在 Amazon S3 中的数据
- 使用标准SQL语言查询文件(基于 Presto 构建)
- 支持 CSV、JSON、ORC、Avro 和 Parquet 格式
- 定价:每TB数据扫描费用为$5.00
- 常与 Amazon Quicksight 一起用于报表/仪表盘
- 用例:商业智能/分析/报表,分析和查询 VPC 流日志、ELB 日志、CloudTrail 跟踪等…
- 考试提示:使用无服务器 SQL 分析 S3 中的数据,使用 Athena
Amazon Athena – 性能优化
- 使用列式数据以节省成本(减少扫描量)
- 推荐使用Apache Parquet或ORC
- 获得巨大的性能改进
- 使用Glue将数据转换为Parquet或ORC格式
- 压缩数据以便进行更小的检索(bzip2、gzip、lz4、snappy、zlip、zstd…)
- 在S3中对数据集进行分区,以便在虚拟列上进行轻松查询
- 示例:s3://athena-examples/flight/parquet/year=1991/month=1/day=1/
- 使用较大的文件(> 128 MB)以最小化开销
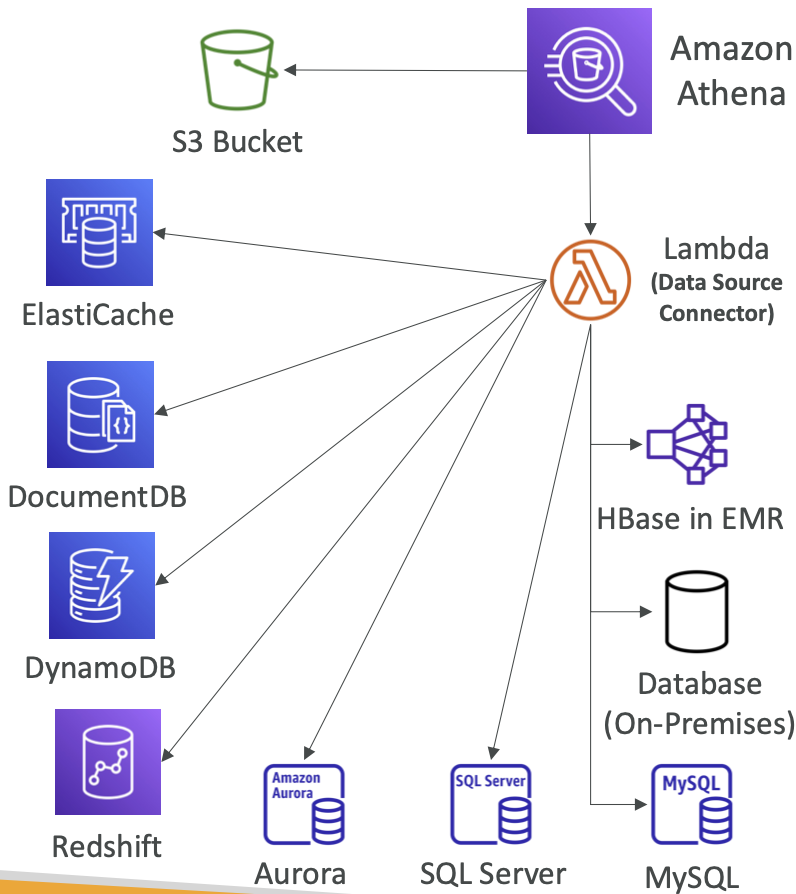
Amazon Athena – Federated Query (联合查询)
- 允许您在关系型、非关系型、对象和自定义数据源(AWS或本地)中运行SQL查询
- 使用在 AWS Lambda 上运行的数据源连接器来运行联合查询(例如CloudWatch Logs、DynamoDB、RDS…)
- 将结果存储回Amazon S3
2.2 Redshift 概述
- Redshift 基于 PostgreSQL,但不用于 OLTP
- 它是 OLAP-在线分析处理(分析和数据仓库)
- 性能比其他数据仓库提高10倍,可以扩展到PB级的数据
- 数据以列式存储(而不是基于行)和并行查询引擎
- 根据所预配的实例按量付费
- 具有用于执行查询的 SQL 接口
- BI 工具如 Amazon Quicksight 或 Tableau 与之集成
- 与 Athena 相比:由于索引,查询/连接/聚合更快
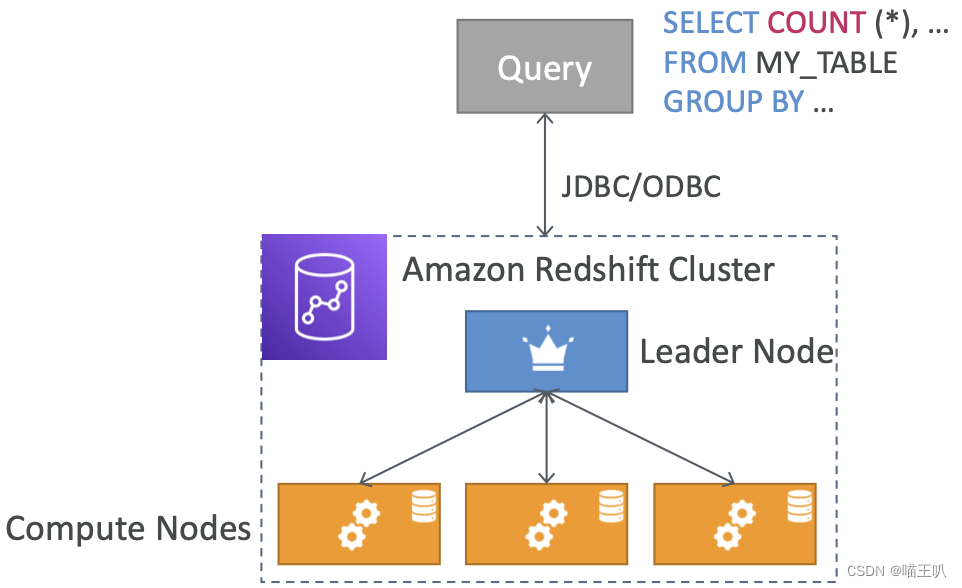
Redshift 集群
- Leader 节点:用于查询规划和结果聚合
- 计算节点:用于执行查询,将结果发送给 Leader
- 需要提前预配节点大小
- 可以使用预留实例以节省成本
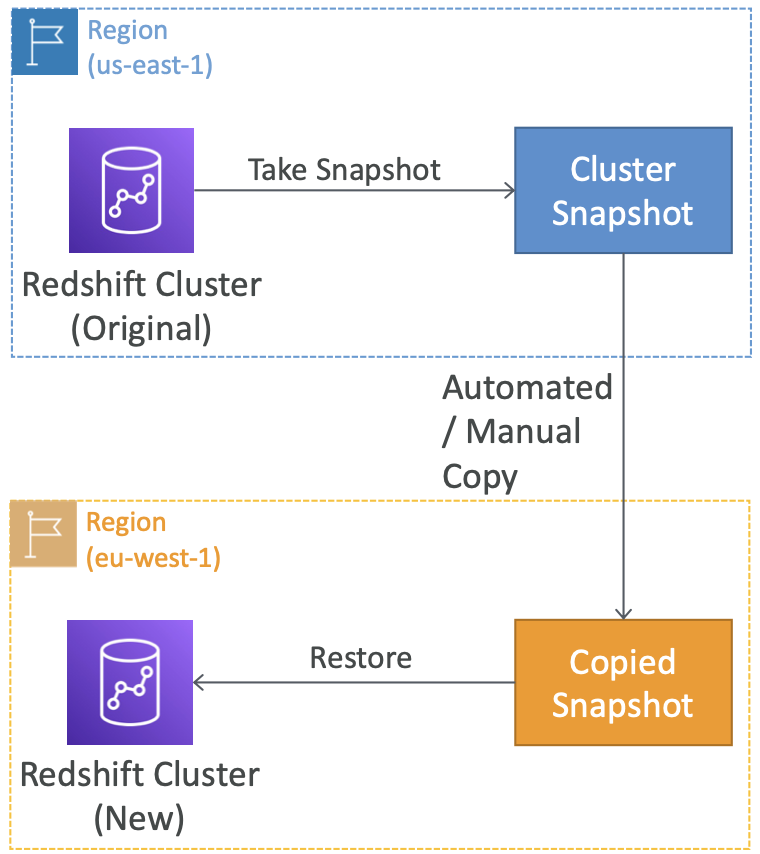
Redshift – 快照&灾难恢复
- Redshift 对某些集群具有“多-AZ”模式
- 快照是集群的时间点备份,存储在 S3 内部
- 快照是增量的(只保存改变的部分)
- 可以将快照还原到新的集群中
- 自动:每8小时、每5GB或按计划。设置保留期为1到35天
- 手动:快照保留直到删除
- 可以配置 Amazon Redshift 自动复制集群的快照(自动或手动)到另一个 AWS 区域
Loading data into Redshift: Large inserts are MUCH better
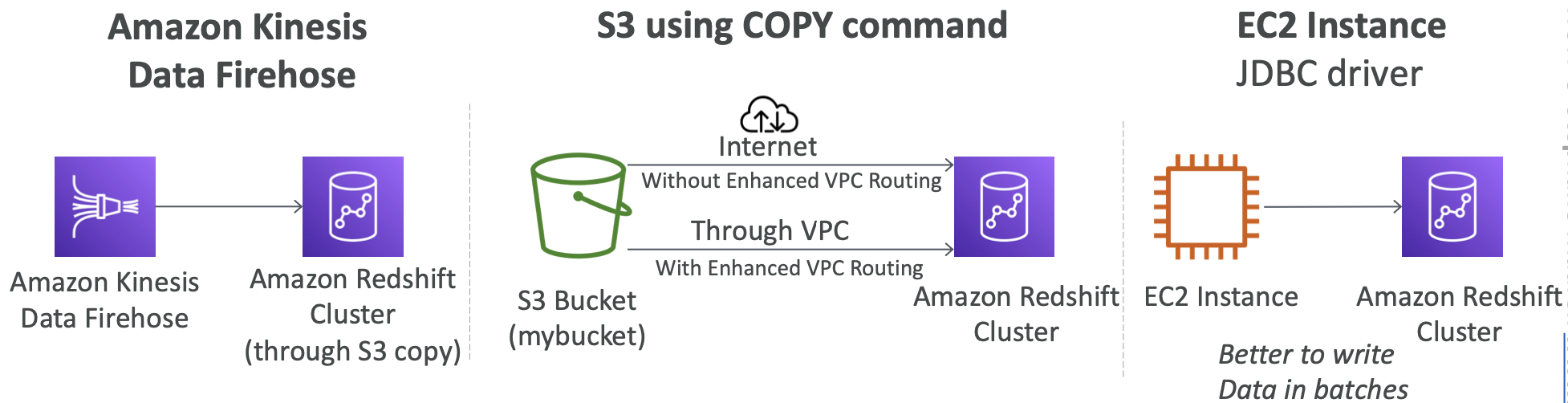
**copy customer
from ‘s3://mybucket/mydata’
iam_role ‘arn:aws:iam::0123456789012:role/MyRedshiftRole’; **
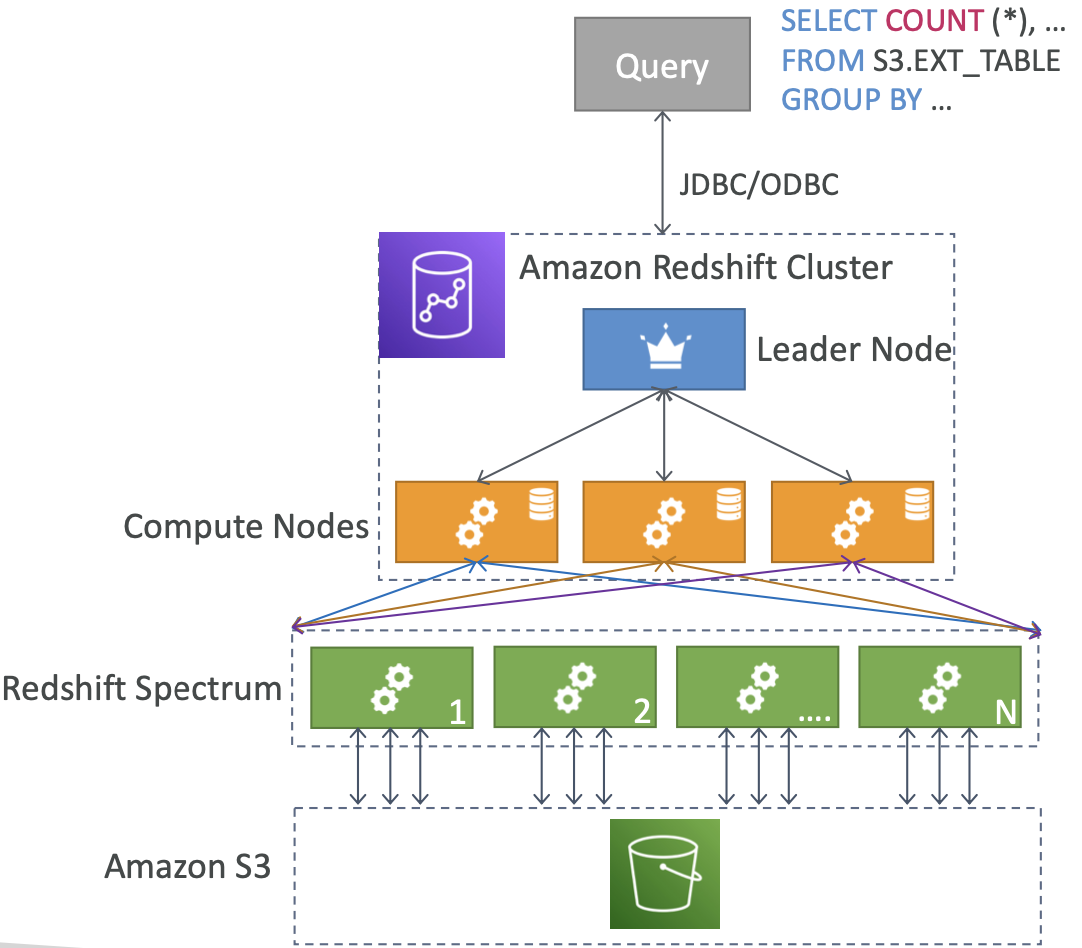
Redshift Spectrum
- 在不加载数据的情况下查询已经存在于S3中的数据
- 必须有可用的 Redshift 集群来启动查询
- 然后将查询提交给数千个 Redshift Spectrum 节点
2.3 Amazon OpenSearch Service
- Amazon OpenSearch 是 Amazon ElasticSearch 的后继者
- 在 DynamoDB 中,只能通过主键或索引进行查询…
- 使用 OpenSearch,您可以搜索任何字段,甚至是部分匹配
- 常常将 OpenSearch 用作其他数据库的补充
- OpenSearch 需要一组实例(而不是无服务器)
- 不支持 SQL(它有自己的查询语言)
- 从 Kinesis Data Firehose、AWS IoT 和 CloudWatch Logs 进行摄取
- 通过 Cognito 和 IAM、KMS 加密、TLS 实现安全性
- 配备 OpenSearch Dashboards(可视化)
OpenSearch patterns - DynamoDB
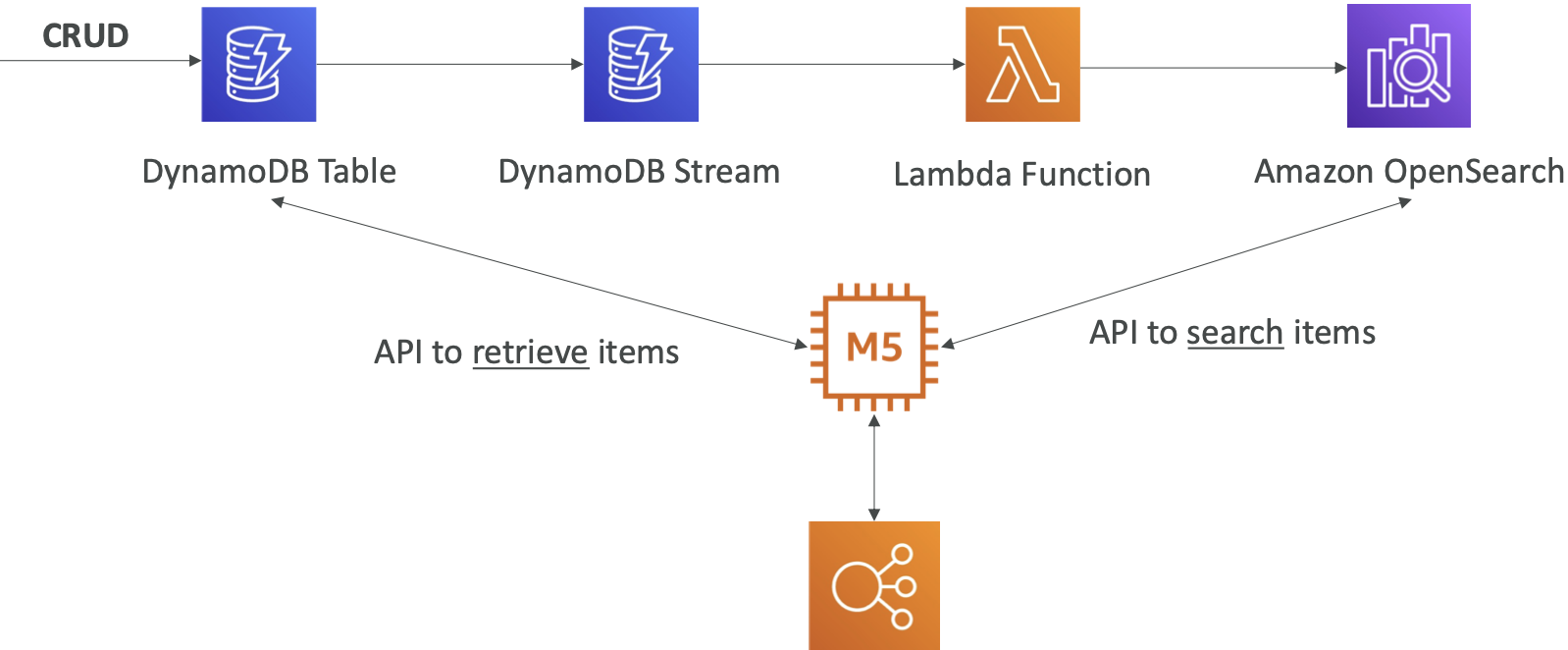
OpenSearch patterns - CloudWatch Logs
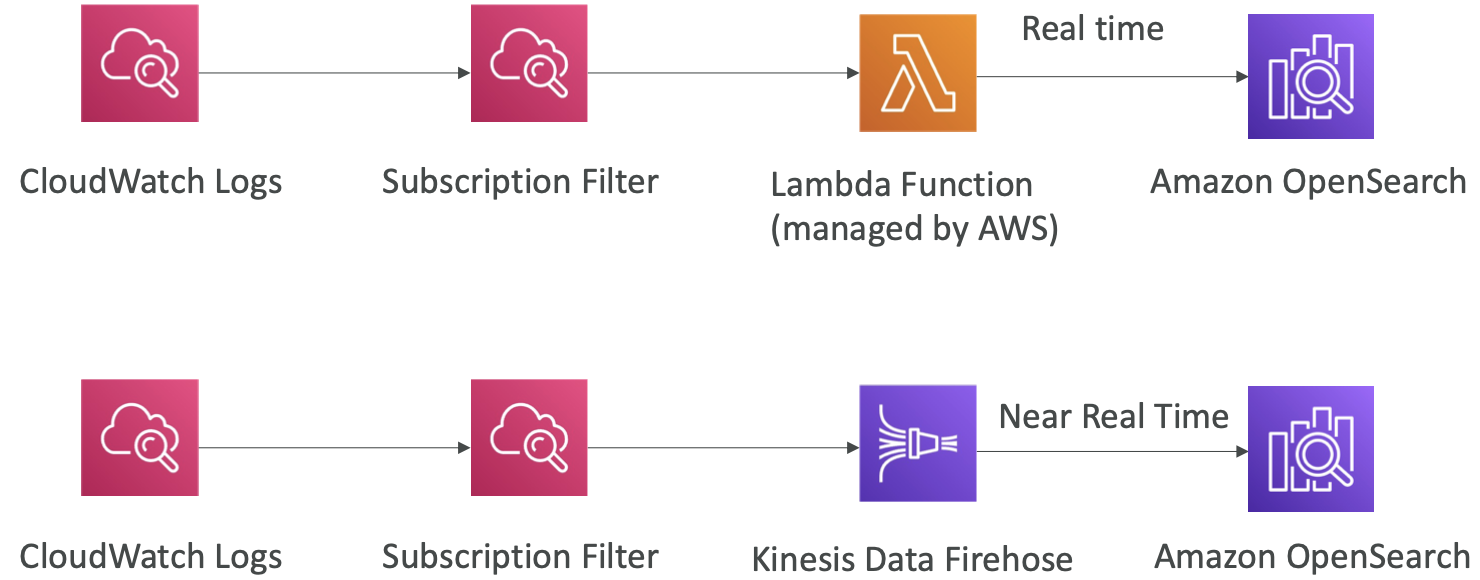
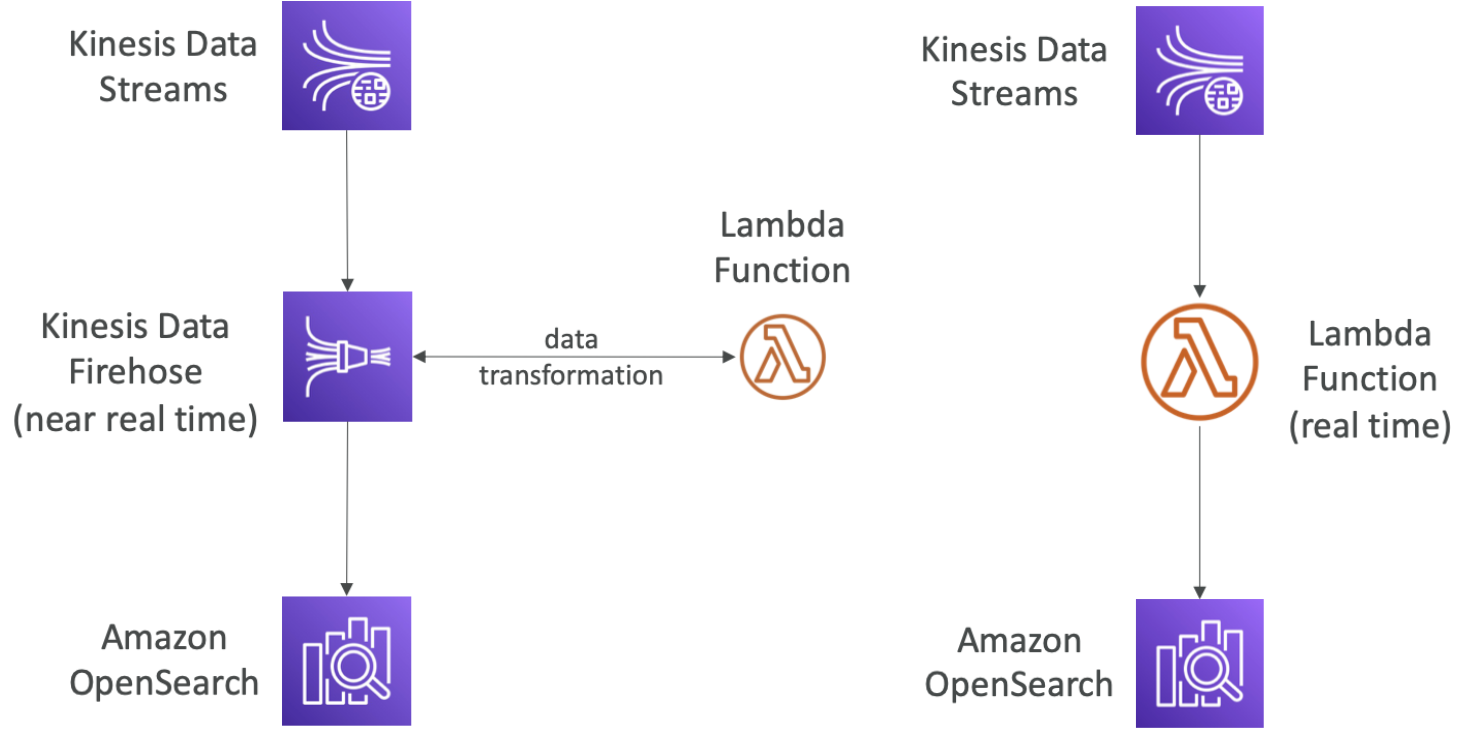
OpenSearch patterns - Kinesis Data Streams & Kinesis Data Firehose
2.4 Amazon EMR
- EMR 代表 “Elastic MapReduce”
- EMR 用于创建 Hadoop 集群(大数据),以分析和处理大量数据
- 集群可以由数百个 EC2 实例组成
- EMR 与 Apache Spark、HBase、Presto、Flink 等捆绑在一起
- EMR 负责所有供应和配置
- 支持自动扩展,并与 Spot 实例集成
- 用例:数据处理,机器学习,Web 索引,大数据…
Amazon EMR - 节点类型和购买方式
- 主节点:管理集群,协调,管理健康-长期运行
- 核心节点:运行任务和存储数据-长期运行
- 任务节点(可选):只是运行任务-通常是Spot实例
- 购买选项:
- 按需:可靠,可预测,不会被终止
- 预留实例(最低1年):成本节约(如果可用,EMR将自动使用)
- Spot实例:更便宜,可以终止,可靠性较低
- 可以有长期运行的集群或短暂(临时)集群
2.5 Amazon QuickSight
- 无服务器的机器学习驱动的业务智能服务,用于创建交互式仪表板
- 快速、自动可扩展、可嵌入、按会话定价
- 用例:
- 商业分析
- 构建可视化
- 执行即席分析
- 利用数据获得业务洞察
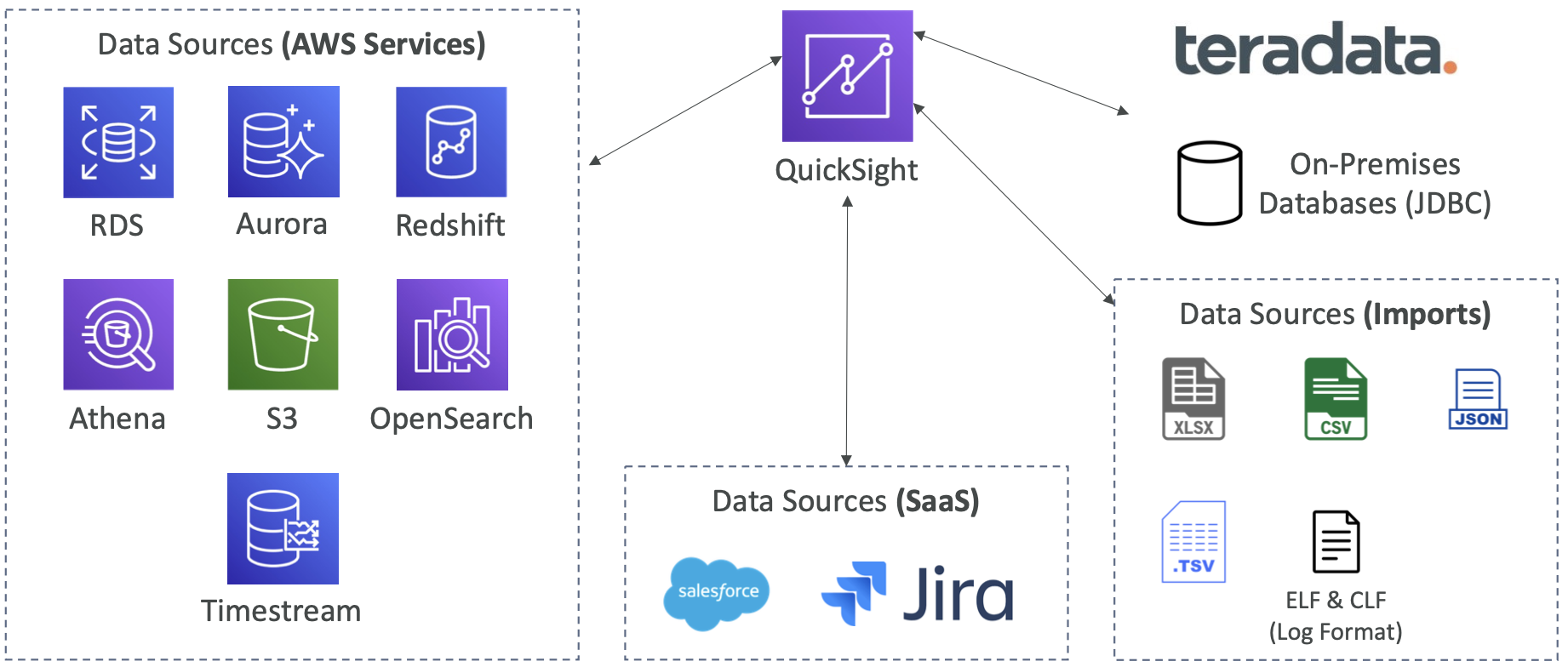
- 与RDS、Aurora、Athena、Redshift、S3等集成
- 如果数据导入到QuickSight中,使用SPICE引擎进行内存计算
- 企业版:可以设置列级安全性(CLS)
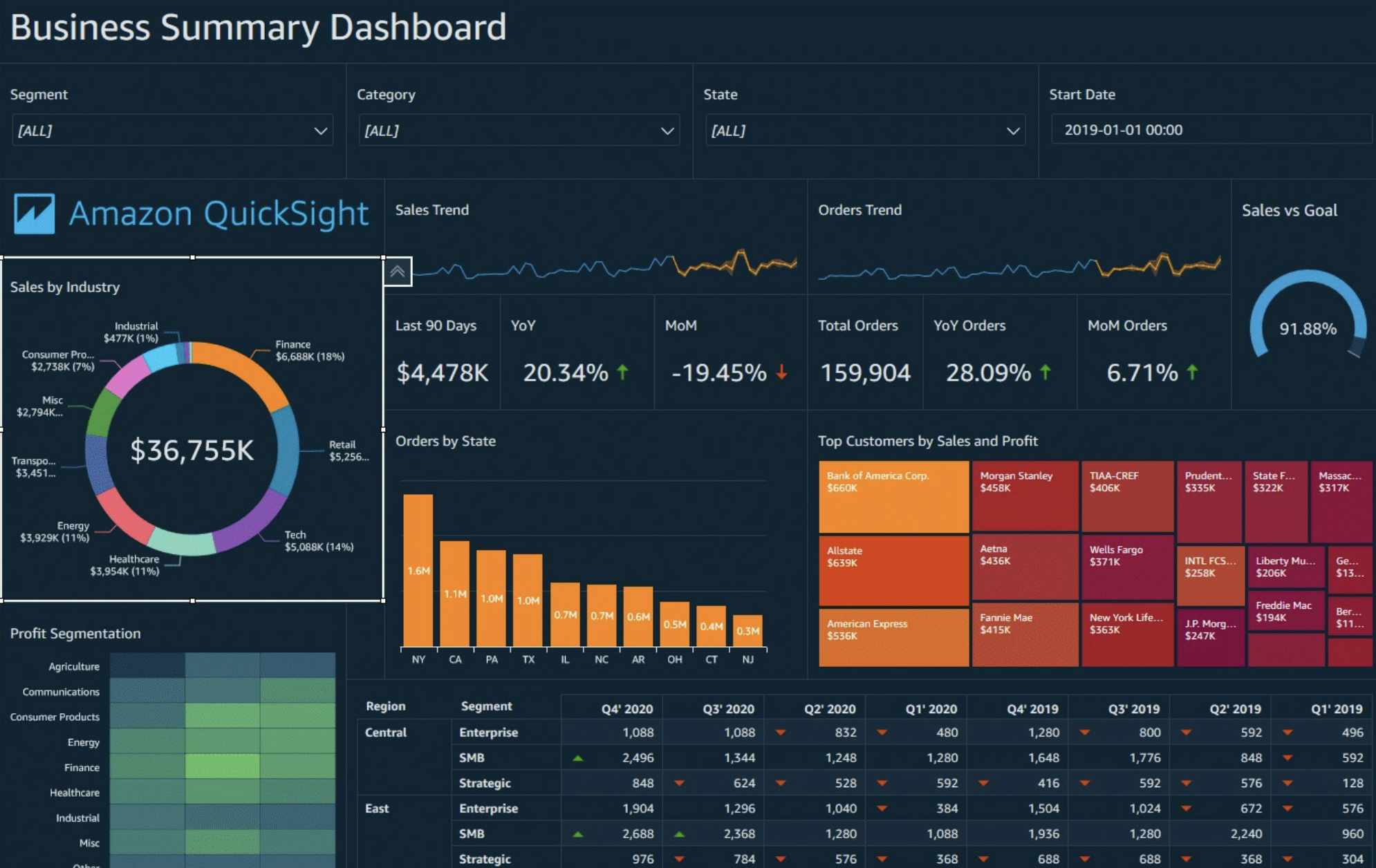
QuickSight 集成
QuickSight - 仪表板和分析
- 定义用户(标准版本)和组(企业版)
- 这些用户和组仅存在于QuickSight中,而不在IAM中!
- 仪表板…
- 是一个只读的分析快照,可以共享
- 保留分析的配置(过滤、参数、控件、排序)
- 您可以与用户或组分享分析或仪表板
- 要共享仪表板,必须首先发布它
- 看到仪表板的用户也可以看到底层数据
2.6 AWS Glue
- 托管的抽取、转换和加载(ETL)服务
- 用于准备和转换数据以供分析使用
- 完全无服务器的服务

AWS Glue - 将数据转换为 Parquet 格式
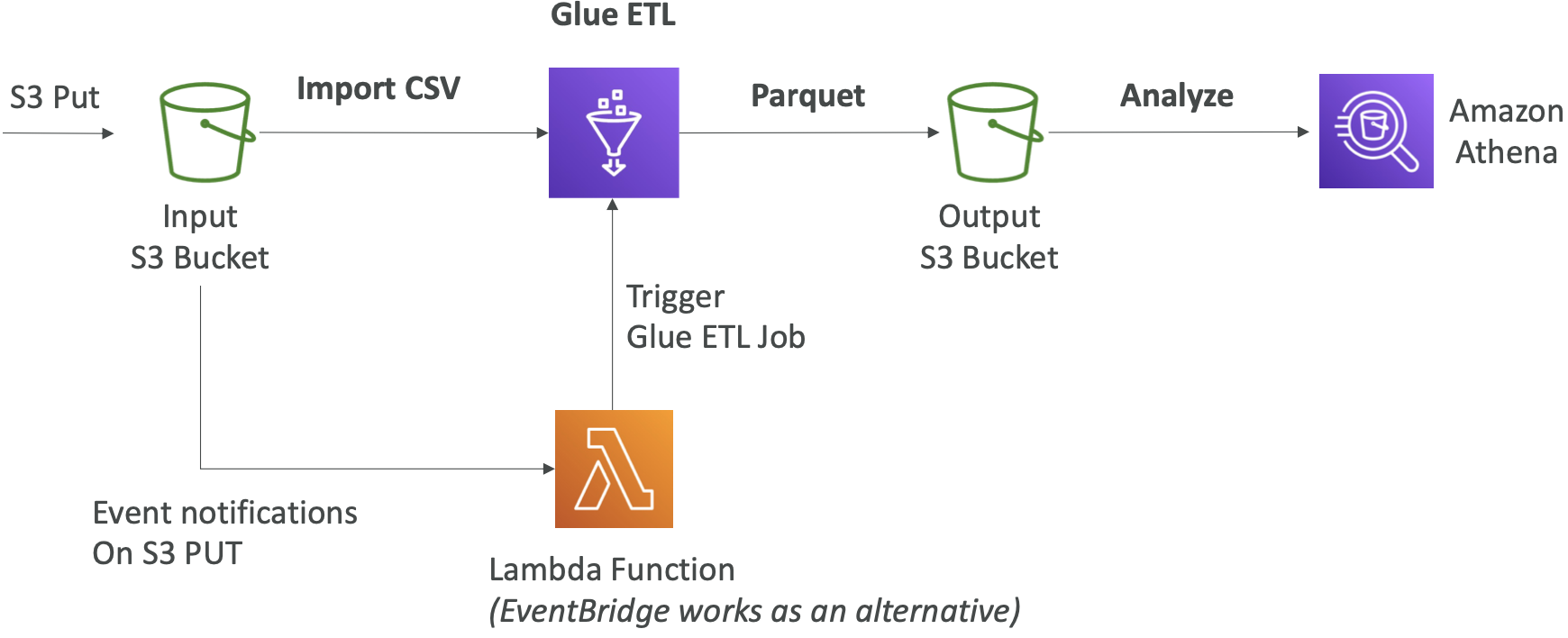
Glue 数据目录:数据集的目录
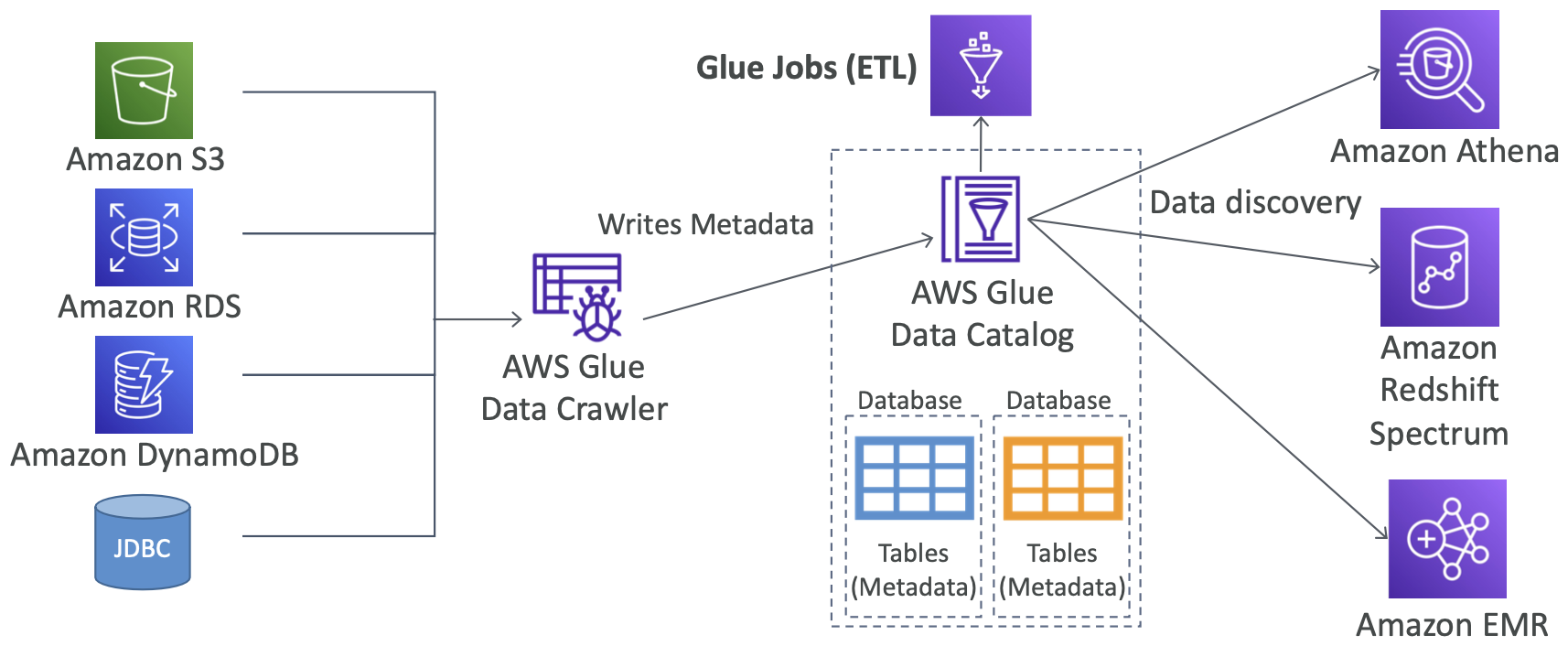
Glue - 高层次概述
- Glue 作业书签:防止重新处理旧数据
- Glue 弹性视图:
- 使用 SQL 在多个数据存储中组合和复制数据
- 无需自定义代码,Glue 监视源数据的更改,无服务器
- 利用“虚拟表”(物化视图)
- Glue DataBrew:使用预构建的转换清理和规范化数据
- Glue Studio:用于在 Glue 中创建、运行和监视 ETL 作业的新 GUI
- Glue 流式 ETL(基于 Apache Spark 结构化流):
- 兼容 Kinesis Data Streaming、Kafka、MSK(托管 Kafka)
2.7 AWS Lake Formation
- 数据湖 = 用于分析目的的数据的中心位置
- 完全托管的服务,可在几天内轻松设置数据湖
- 发现、清洗、转换和摄取数据到数据湖中
- 自动化许多复杂的手动步骤(收集、清洗、移动、编目数据等),并进行去重(使用 ML 转换)
- 在数据湖中结合结构化和非结构化数据
- 开箱即用的源蓝图:S3、RDS、关系型和 NoSQL 数据库等
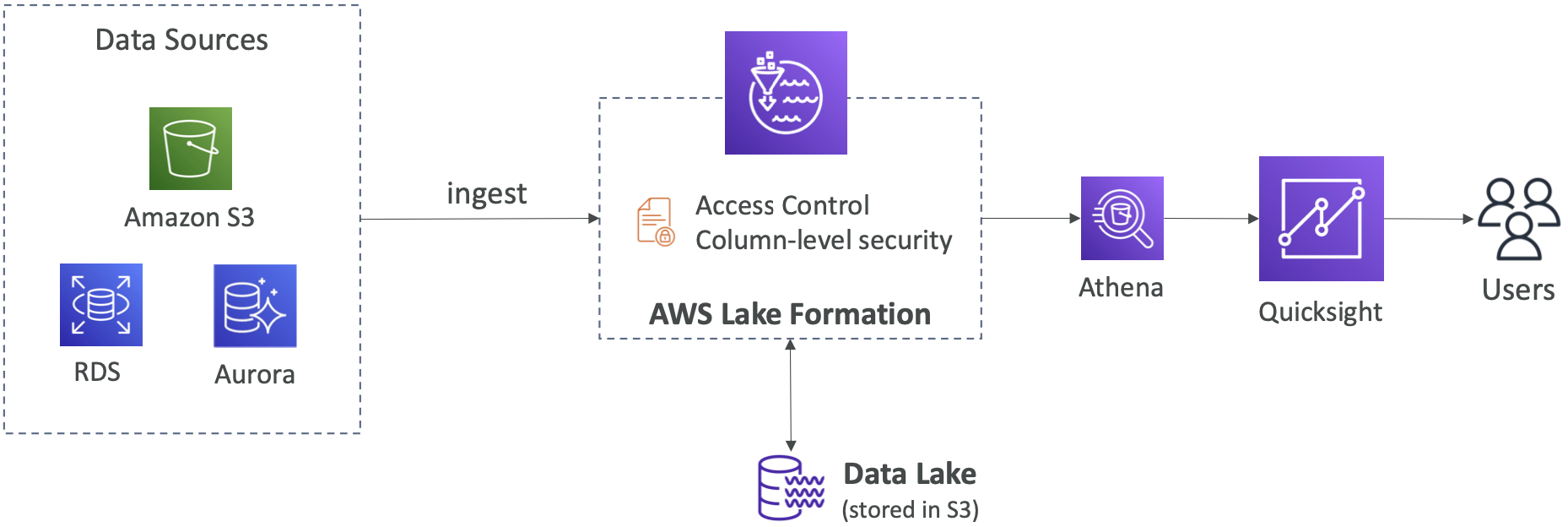
- 细粒度的应用程序访问控制(行级和列级)
- 建立在 AWS 全局之上
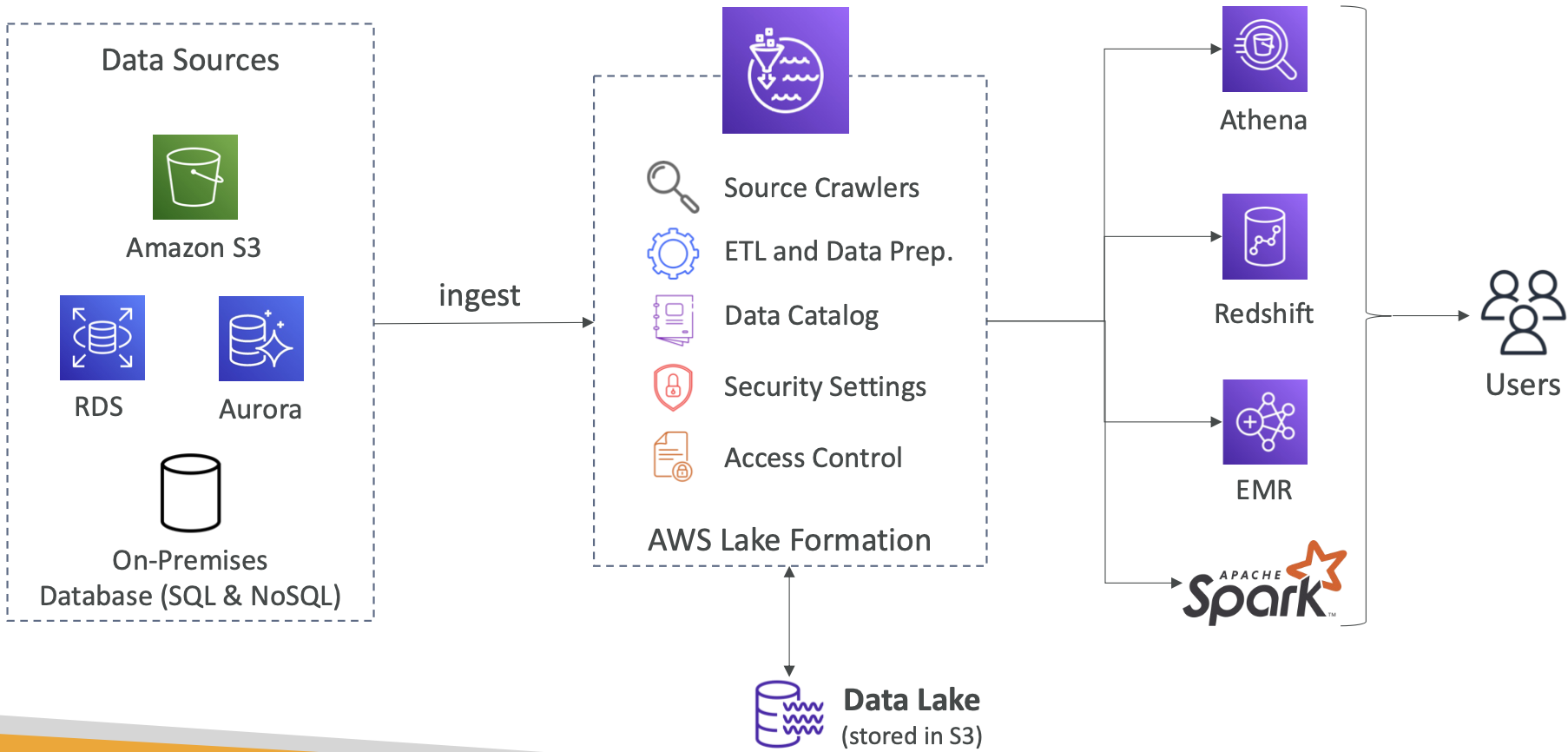
Centralized Permissions Example
2.8 Kinesis Data Analytics 用于 SQL 应用程序
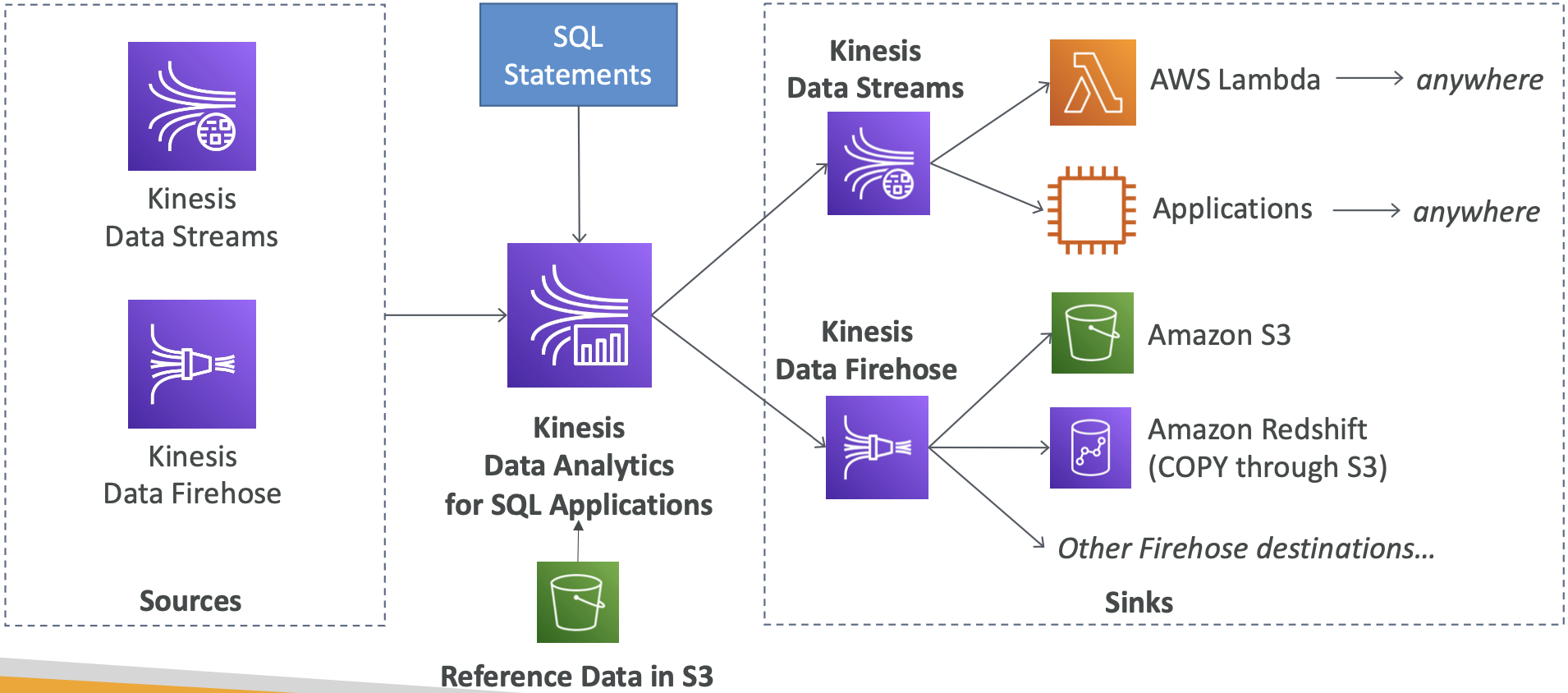
Kinesis Data Analytics(SQL 应用程序)
- 使用 SQL 在 Kinesis Data Streams 和 Firehose 上进行实时分析
- 添加 Amazon S3 的参考数据以丰富流式数据
- 完全托管,无需预配服务器
- 自动扩展
- 按实际消耗率付费
- 输出:
- Kinesis Data Streams:根据实时分析查询创建流
- Kinesis Data Firehose:将分析查询结果发送到目标位置
- 用例:
- 时间序列分析
- 实时仪表板
- 实时指标
Kinesis Data Analytics 用于 Apache Flink
- 使用 Flink(Java、Scala 或 SQL)处理和分析流式数据
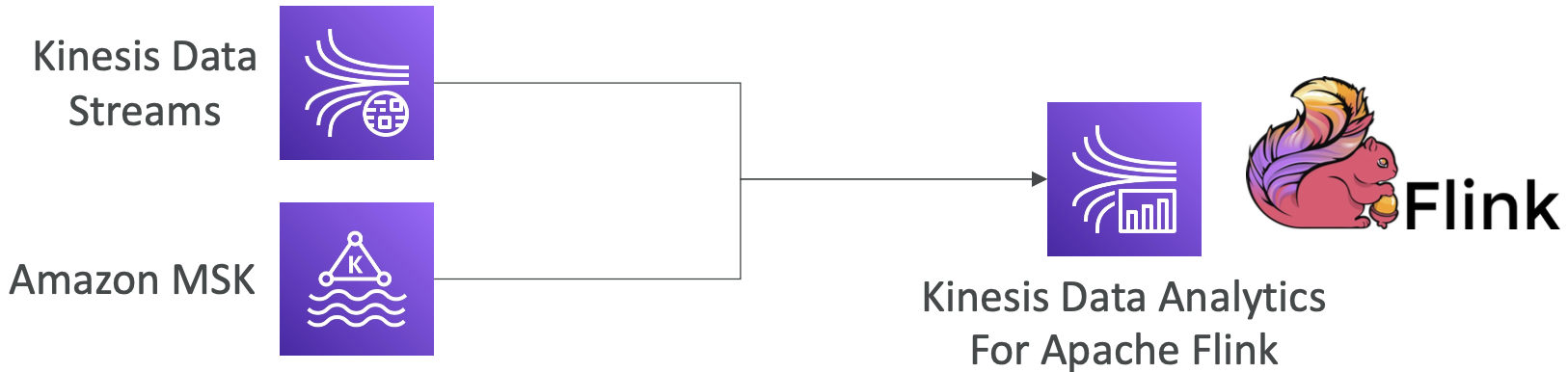
- 在 AWS 上的托管集群上运行任何 Apache Flink 应用程序
- 提供计算资源,支持并行计算,自动扩展
- 应用程序备份(实现为检查点和快照)
- 使用任何 Apache Flink 编程功能
- Flink 不从 Firehose 读取数据(请改用 Kinesis Analytics for SQL)
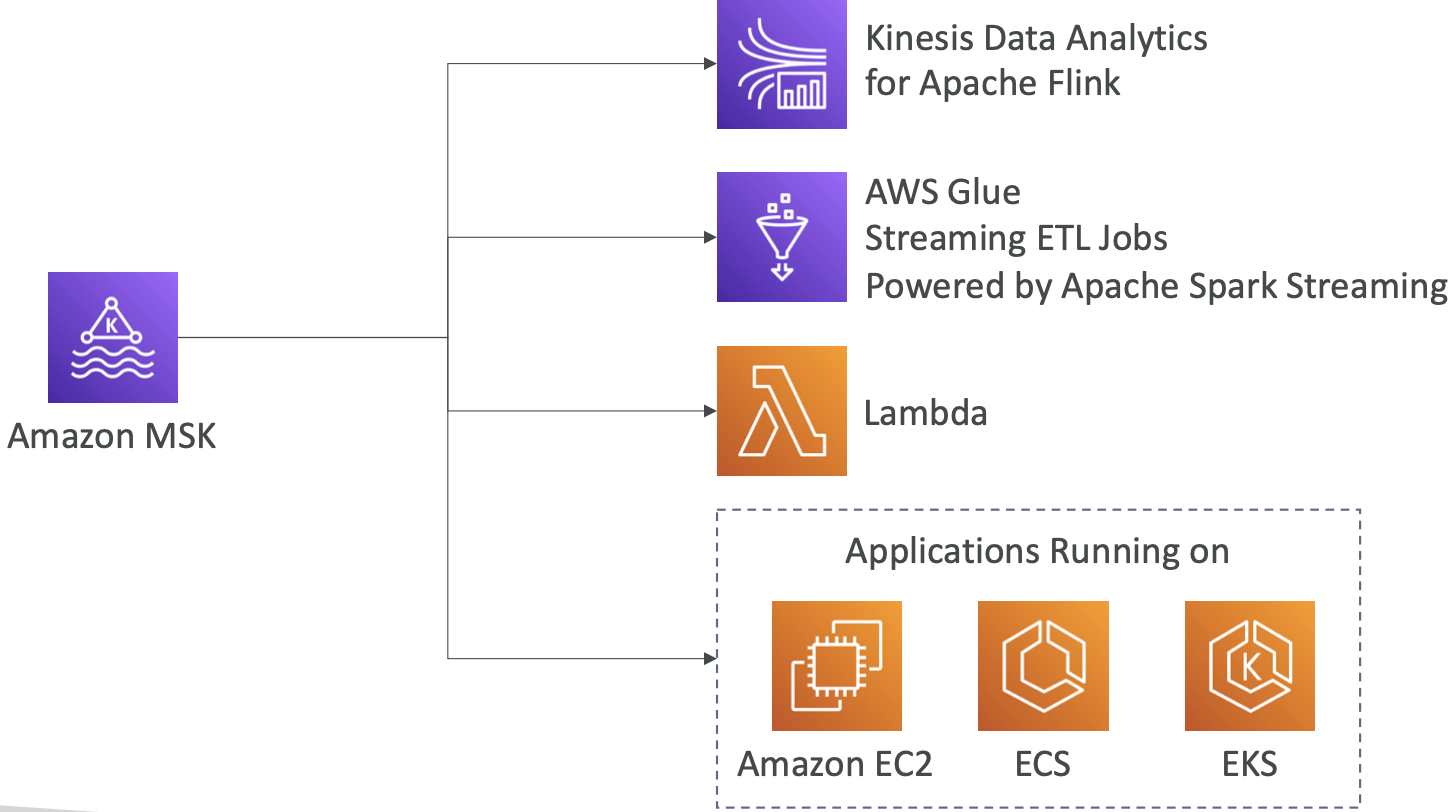
2.9 Amazon Managed Streaming for Apache Kafka(Amazon MSK)
- Amazon Managed Streaming for Apache Kafka(Amazon MSK)是 Amazon Kinesis 的替代品。
- 它是在AWS上完全托管的Apache Kafka服务。
- 允许您创建、更新和删除集群。
- MSK 为您创建和管理 Kafka broker 节点和 Zookeeper 节点。
- 在您的 VPC 中部署 MSK 集群,支持多可用区(高可用性最多3个)。
- 自动从常见的 Apache Kafka 故障中恢复。
- 数据存储在 EBS 卷上,持续时间由您决定。
- MSK 支持无服务器模式,无需管理容量。
- MSK 自动预配资源并扩展计算和存储。
Apache Kafka 概述
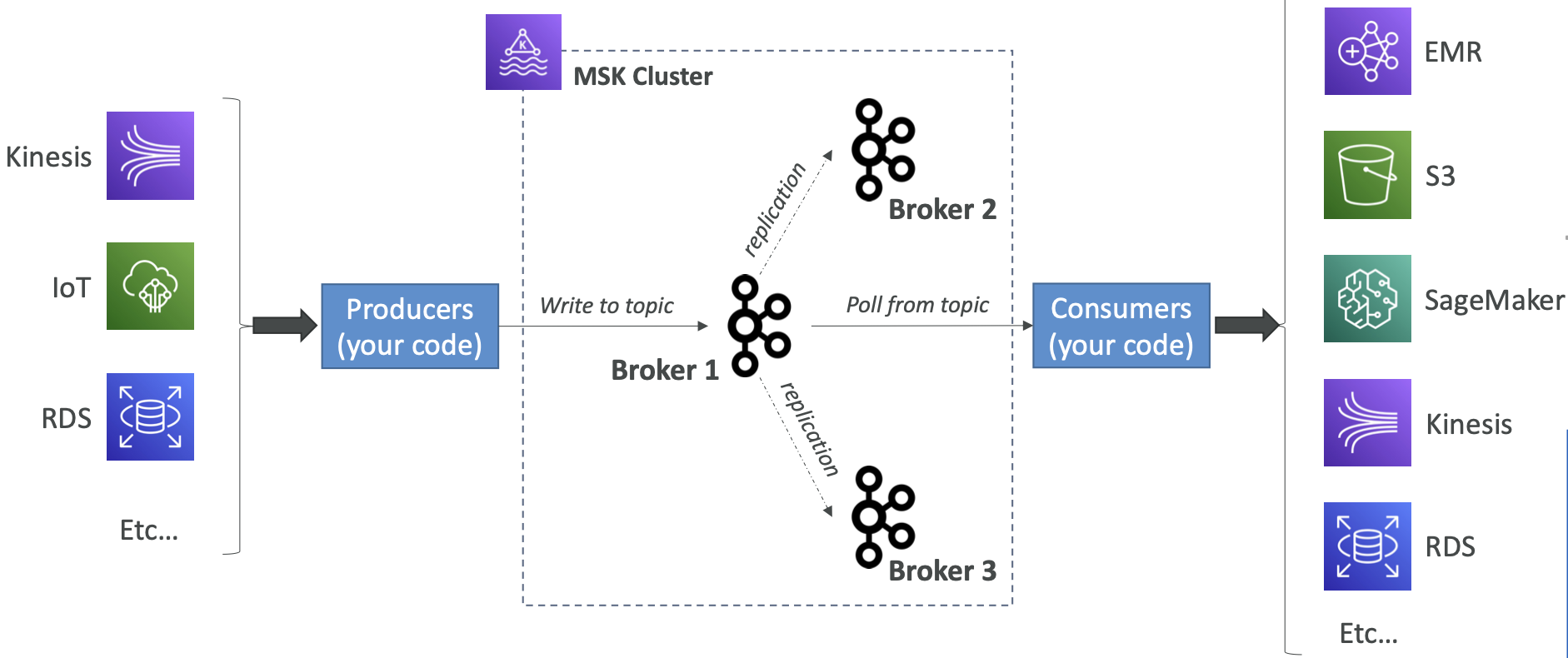
Kinesis Data Streams v.s. Amazon MSK
Kinesis Data Streams
- 1 MB的消息大小限制。
- 使用 Shards 进行数据流管理。
- 支持 Shard 的分裂和合并。
- 传输过程中使用 TLS 进行加密。
- 数据静态加密使用 KMS。
Amazon MSK
- 默认为1MB,可配置为更高(例如:10MB)。
- Kafka 主题使用分区进行管理。
- 只能向主题添加分区。
- 传输过程中支持明文或 TLS 加密。
- 数据静态加密使用 KMS。
Amazon MSK 消费者
大数据摄取流程
- 我们希望摄取流程是完全无服务器的。
- 我们希望实时收集数据。
- 我们希望对数据进行转换。
- 我们希望使用 SQL 查询转换后的数据。
- 使用查询创建的报表应该存储在 S3 中。
- 我们希望将数据加载到数据仓库中并创建仪表板。
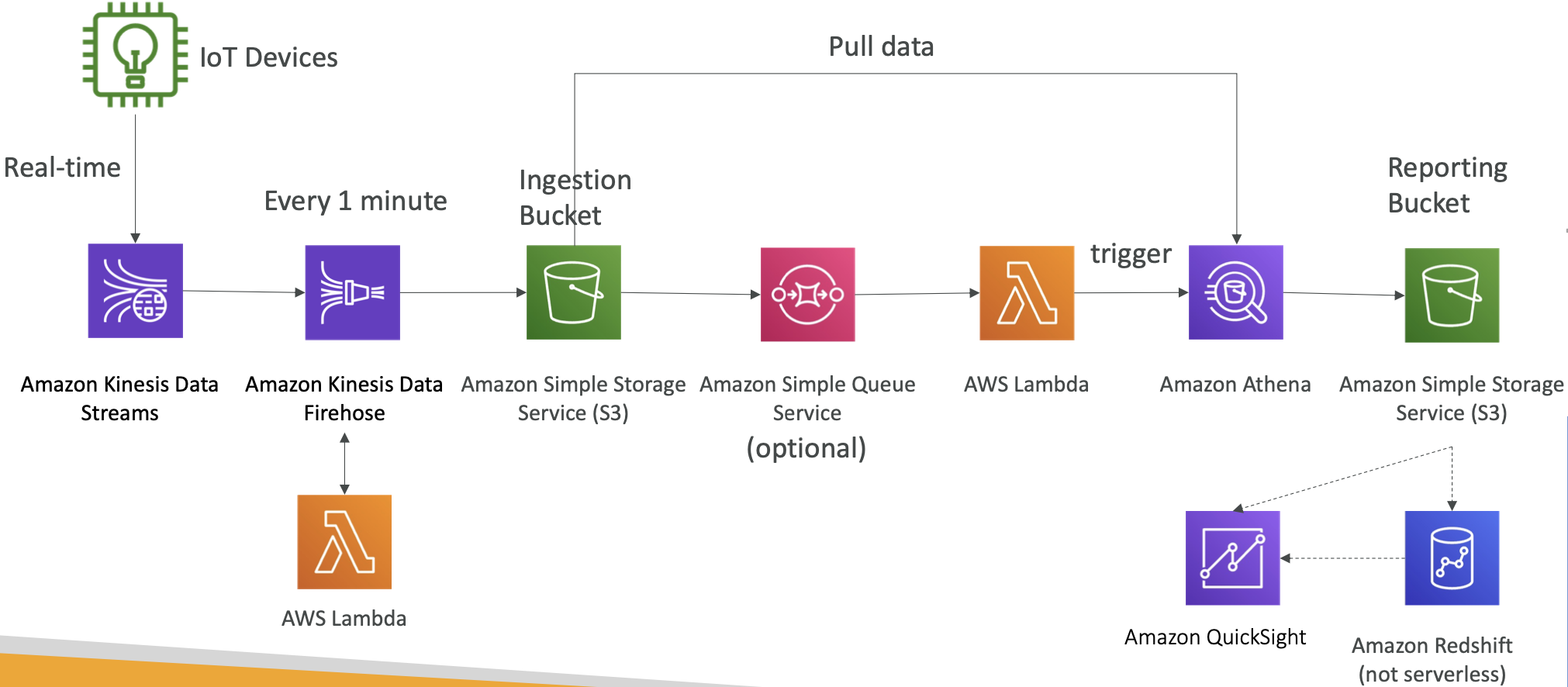
大数据摄取流程讨论
- IoT Core 允许您从物联网设备中获取数据。
- Kinesis 非常适合实时数据收集。
- Firehose 可以帮助将数据以近实时(1分钟)的方式交付给 S3。
- Lambda 可以帮助 Firehose 进行数据转换。
- Amazon S3 可以触发 SQS 的通知。
- Lambda 可以订阅 SQS(我们可以将 S3 连接到 Lambda)。
- Athena 是一种无服务器的 SQL 服务,查询结果存储在 S3 中。
- 报表存储桶包含经过分析的数据,可以被报表工具(如 AWS QuickSight、Redshift 等)使用。
相关文章:
AWS 专题学习 P10 (Databases、 Data Analytics)
文章目录 专题总览1. Databases1.1 选择合适的数据库1.2 数据库类型1.3 AWS 数据库服务概述Amazon RDSAmazon AuroraAmazon ElastiCacheAmazon DynamoDBAmazon S3DocumentDBAmazon NeptuneAmazon Keyspaces (for Apache Cassandra)Amazon QLDBAmazon Timestream 2. Data & …...
一键拥有你的GPT4
这几天我一直在帮朋友升级ChatGPT,现在已经可以闭眼操作了哈哈😝。我原本以为大家都已经用上GPT4,享受着它带来的巨大帮助时,但结果还挺让我吃惊的,还是有很多人仍苦于如何进行升级。所以就想着写篇教程来教会大家如何…...
幻兽帕鲁服务器数据备份
搭建幻兽帕鲁个人服务器,最近不少用户碰到内存不足、游戏坏档之类的问题。做好定时备份,才能轻松快速恢复游戏进度 这里讲一下如何定时将服务器数据备份到腾讯云轻量对象存储服务,以及如何在有需要的时候进行数据恢复。服务器中间的数据迁移…...

【Digester解析XML文件的三种方式】
Digester解析XML文件的三种方式 1. Digester解析XML文件的三种方式1.1 作用及依赖jar包 2. 重点和难点3. XML文件4. 通过不同的方式解析这个xml文件4.1 通过java编码方式解析(javabean存储)4.2 通过java编码方式解析(list和map存储࿰…...
MATLAB curve fitting toolbox没有怎么办?
版本:MATLAB R2023b 如果在安装MATLAB时仅仅选择了安装MATLAB,而并未选择其他选项,则在进入MATLAB后会发现顶部的APP栏中无法找到曲线拟合工具箱。 本人跟随MATLAB中的教程进行下载时,出现了如下报错: 最终解决方案&a…...

Linux之快速入门(CentOS 7)
文章目录 一、Linux目录结构二、常用命令2.1 切换用户2.2查看ip地址2.3 cd2.4 目录查看2.5 查看文件内容2.6 创建目录及文件2.7 复制和移动2.8 其他2.9 tar3.0 which3.1 whereis3.2 find(这个命令尽量在少量用户使用此软件时运行,因为此命令是真的读磁盘…...

Spring框架中的设计模式
🎉欢迎来到Spring专栏:Spring框架中的设计模式 📜其他专栏:java面试 数据结构 源码解读 故障分析 🎬作者简介:大家好,我是小徐🥇☁️博客首页:CSDN主页小徐的博客&#x…...

Java数据结构与算法:邻接矩阵和邻接表
Java数据结构与算法:邻接矩阵和邻接表 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 什么是邻接矩阵和邻接表? 在图的表示中,…...

【温故而知新】JavaScript类、类继承、静态方法
文章目录 前言一、类二、类继承三、静态方法四、热门文章 前言 JavaScript是一种广泛使用的编程语言,主要用于Web开发。它是一种脚本语言,这意味着它不需要像编译语言那样预先编译,而是在运行时解释和执行。JavaScript可以直接在浏览器中运行…...

小黑艰难的前端啃bug之路:内联元素之间的间隙问题
今天开始学习前端项目,遇到了一个Bug调了好久,即使margin为0,但还是有空格。 小黑整理,用四种方法解决了空白问题 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></tit…...

Ubuntu 申请 SSL证书并搭建邮件服务器
文章目录 Log 一、域名连接到泰坦(Titan)电子邮件二、NameSilo Hosting 避坑三、Ubuntu 搭建邮件服务器1. 环境准备2. 域名配置3. 配置 Postfix 和 Dovecot① 安装 Nginx② 安装 Tomcat③ 申请 SSL 证书(Lets Encrypt)④ 配置 pos…...
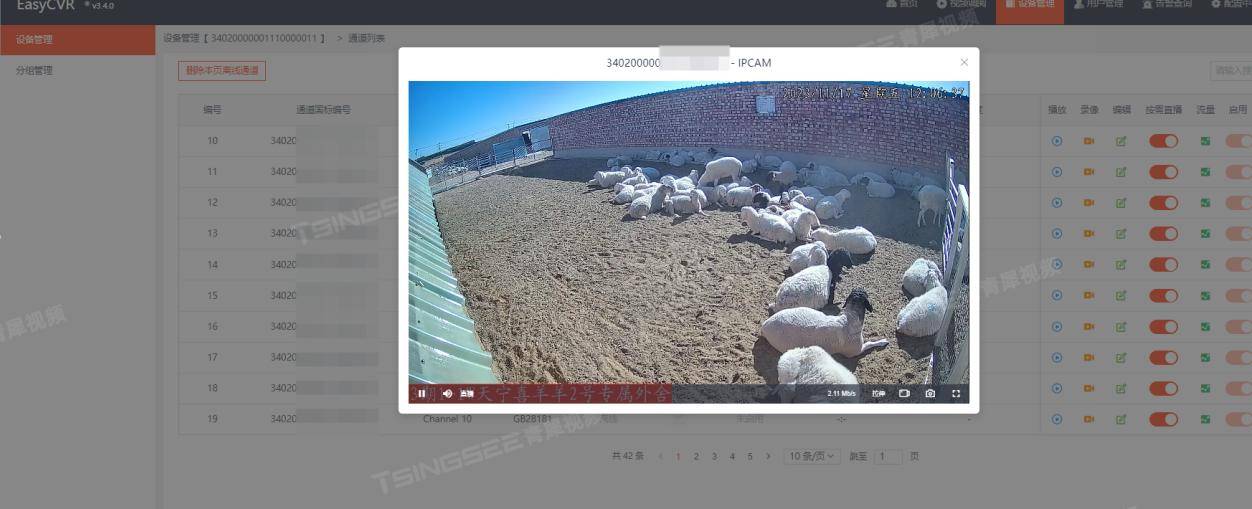
视频监控方案设计:EasyCVR视频智能监管系统方案技术特点与应用
随着科技的发展,视频监控平台在各个领域的应用越来越广泛。然而,当前的视频监控平台仍存在一些问题,如视频质量不高、监控范围有限、智能化程度不够等。这些问题不仅影响了监控效果,也制约了视频监控平台的发展。 为了解决这些问…...

pyspark.sql.types 中的类型有哪些
对 pyspark.sql.types 中的类型做个记录 1、首先正常使用的时候,我们需要引用他们: from pyspark.sql.types import MapType,StringType # 或者 from pyspark.sql.types import *PySpark SQL TYPES是PySpark模型中的一个类,用于定义PySpark数…...
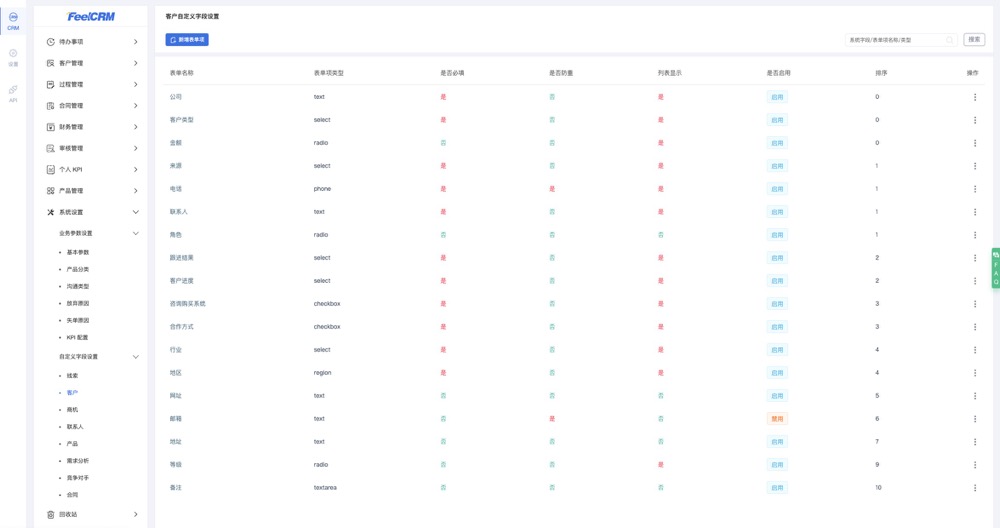
开源CRM客户管理系统-FeelCRM
FeelCRM客户管理系统 开源项目介绍 FeelCRM客户管理系统,符合中小企业业务流程;支持线索管理、客户管理、商机管理、合同管理、审核管理等多个模块;希望能为广大中小企业以及开发者们提供一个更多的可能性;本版本是我公司跨语言…...

Linux创建新分区挂载后普通用户没有读写权限
Linux创建新分区挂载后普通用户没有读写权限 为了使用更大的空间,楼主按照 ubuntu 16.04 硬盘分区,挂载,硬盘分区方案 这个教程新建硬盘分区给普通用户挂载后,发现普通用户没有权限对挂载的文件夹进行读写。 导致无论是创建文…...

清越 peropure·AI 国内版ChatGP新功能介绍
当OpenAI发布ChatGPT的时候,没有人会意识到,新一代人工智能浪潮将给人类社会带来一场眩晕式变革。其中以ChatGPT为代表的AIGC技术加速成为AI领域的热门发展方向,推动着AI时代的前行发展。面对技术浪潮,清越科技(PeroPure)立足多样化生活场景、精准把握用户实际需求,持续精确Fin…...

力扣1027. 最长等差数列
动态规划 思路: 可以参考力扣1218. 最长定差子序列目前不清楚公差,可以将序列最大最小值找到,公差的范围是 [-(max - min), (max - min)],按公差递增迭代遍历求出最长等差数列; class Solution { public:int longest…...
)
GraphicsMagick 的 OpenCL 开发记录(二十三)
文章目录 ImageMagick和GraphicsMagick函数及宏对照表 <2022-04-14 周四> ImageMagick和GraphicsMagick函数及宏对照表 在开发过程中收集了这两个项目中的一些相同或相似功能的函数或者宏定义,希望对大家有所帮助,如下: TypeImageMa…...
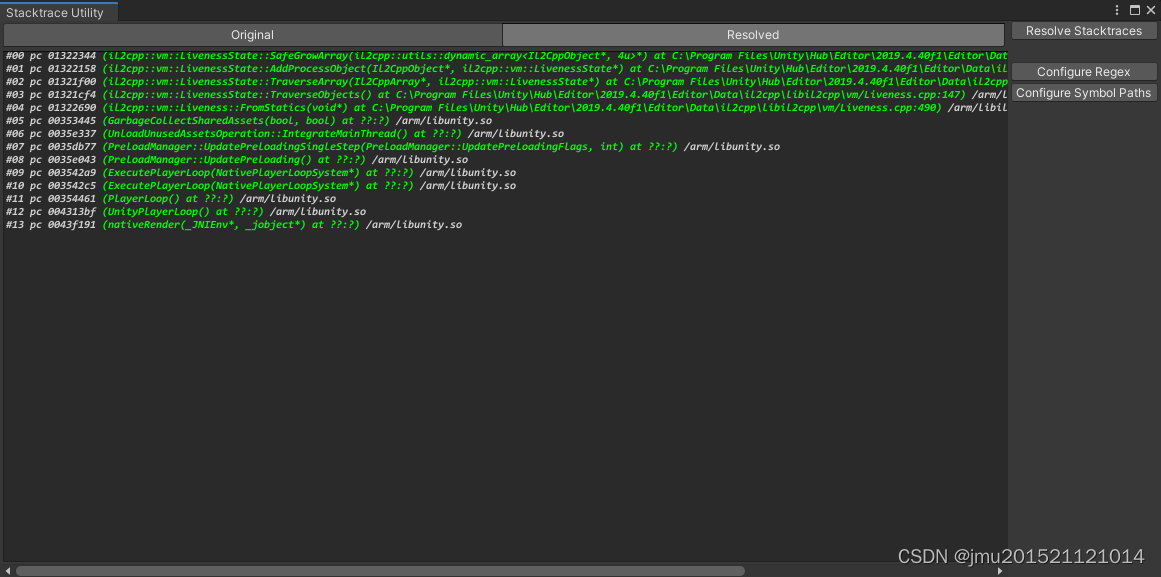
通过Android Logcat分析firebase崩溃
参考:UnityIL2CPP包Crash闪退利用Android Logcat还原符号表堆栈日志 - 简书 一、安装Android Logcat插件 1、新建空白unity工程,打开PackageManager窗口,菜单栏Window/PackageManager 2、PackageManager中安装Android Logcat日志工具 3、安…...

【AI大模型】WikiChat超越GPT-4:在模拟对话中事实准确率提升55%终极秘密
WikiChat,这个名字仿佛蕴含了无尽的智慧和奥秘。它不仅是一个基于人工智能和自然语言处理技术的聊天机器人,更是一个能够与用户进行深度交流的智能伙伴。它的五个突出特点:高度准确、减少幻觉、对话性强、适应性强和高效性能,使得…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...
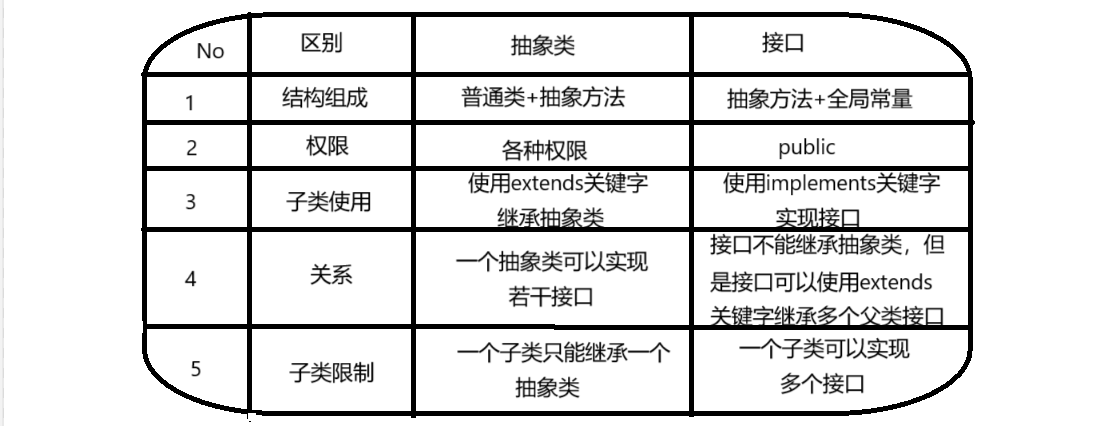
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...