如何训练和导出模型
介绍如何通过DI-engine使用DQN算法训练强化学习模型
一、什么是DQN算法
DQN算法,全称为Deep Q-Network算法,是一种结合了Q学习(一种价值基础的强化学习算法)和深度学习的算法。该算法是由DeepMind团队在2013年提出的,并在2015年通过在多款Atari 2600视频游戏上取得超越人类专家的表现而闻名。DQN算法是深度强化学习领域的一个里程碑,因为它展示了深度学习模型可以直接从原始输入(如像素)中学习控制策略。DQN 算法可以用来解决连续状态下离散动作的问题。
以图 中所示的所示的车杆(CartPole)环境为例,它的状态值就是连续的,动作值是离散的。

Q学习(Q-Learning)
在深入DQN之前,我们需要了解Q学习。Q学习是一种无模型(model-free)的强化学习算法,它学习在给定状态下采取各种行动的预期效用,即Q值(Q-value)。Q值函数Q(s, a)代表在状态s下采取行动a,并遵循最优策略所期望获得的累积回报。
Q学习的核心是Q表(Q-table),它存储了每个状态-动作对的Q值。然而,当状态空间或动作空间很大或连续时,Q表方法不再适用,因为它难以表示或更新这么大的表。这时候就需要DQN这类方法。
DQN的核心
DQN算法通过以下几个关键的技术改进来扩展Q学习的应用范围:
1.深度神经网络:
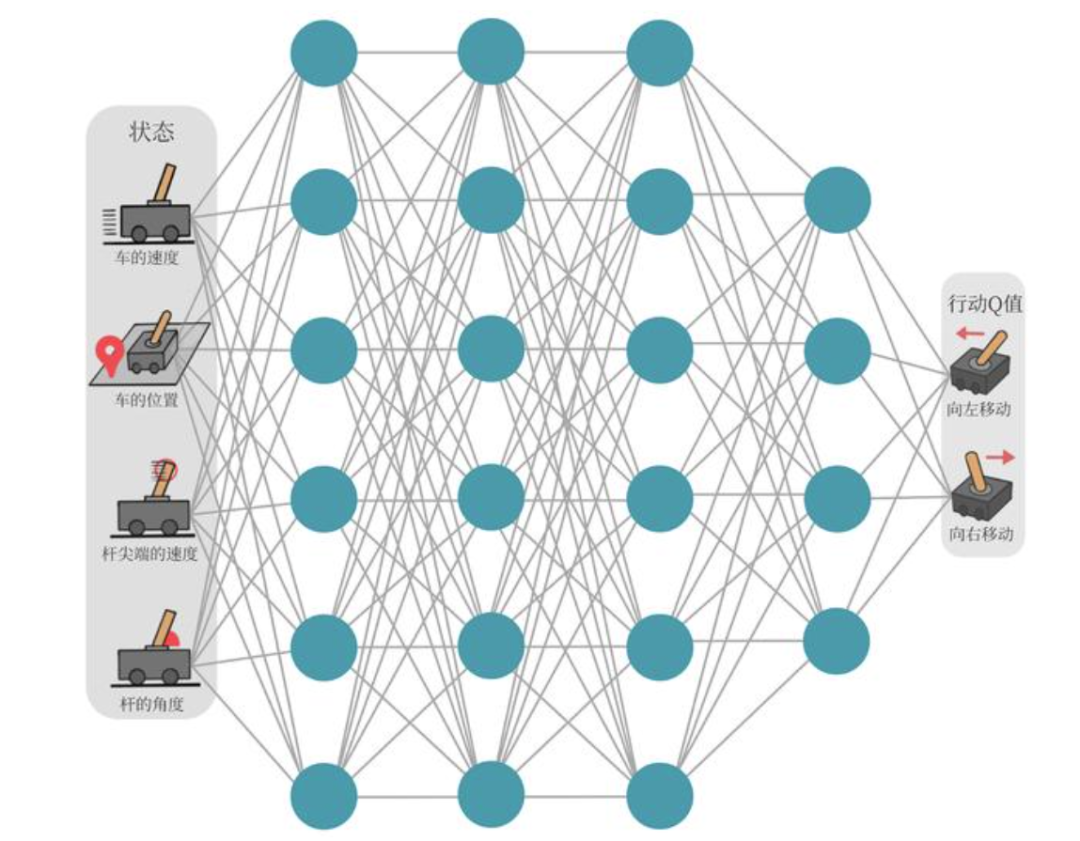
DQN使用深度神经网络来逼近Q值函数,而不是使用传统的Q表。这个网络称为Q网络,它的输入是状态,输出是每个可能动作的Q值。这使得算法可以应用于具有高维状态空间的问题,如直接从像素输入学习。
Q网络示意图:
1.经验回放(Experience Replay):
DQN存储代理的经验(状态,动作,奖励,新状态)在一个数据集中,称为回放缓冲区(replay buffer)。在训练过程中,会在此数据集中随机抽取一批经验来更新网络。这有助于打破样本间的时间相关性,提高了学习稳定性。
2.固定Q目标(Fixed Q-Targets):
在传统的Q学习中,Q表在每一步更新时都会用到,这会导致目标Q值和预测Q值在相同的过程中不断变化,从而可能导致学习过程不稳定。DQN引入了固定Q目标的概念,即在更新网络时,用于计算目标值的Q网络参数保持不变。具体来说,DQN会维护两个神经网络:一个在线网络(用于选择动作和学习)和一个目标网络(用于生成Q目标值)。目标网络的参数定期(或缓慢)地从在线网络复制过来。
DQN的更新规则
DQN的学习目标是最小化预测Q值和目标Q值之间的差异。目标Q值是通过使用贝尔曼方程(Bellman equation)计算得出的,即奖励加上下一个状态中最大Q值的折现值。更新规则可以通过以下损失函数来表达:

DQN的训练过程包括以下步骤:
1.初始化:
初始化在线网络和目标网络的参数。
在线网络和目标网络:在DQN(Deep Q-Network)算法中,”在线网络”和”目标网络”是两个并行使用的神经网络,它们有着相同的网络结构但是参数可能不同。这两个网络的引入旨在解决学习过程中可能出现的不稳定和发散问题。
在线网络,有时也被称为主网络(main network),是用来实际做决策和学习的网络。换句话说,它是与环境交互时用来评估当前状态并选择动作的网络。在每一步学习中,它也负责接收训练样本并通过梯度下降法更新自己的参数。在DQN中,在线网络输出给定状态下每个可能动作的预测Q值,然后根据这些Q值来选择动作(比如使用ε-贪婪策略)。在学习阶段,它还会根据从经验回放中抽取的样本来优化其参数,以减少预测Q值和目标Q值之间的误差。
目标网络是DQN算法中的关键创新之一。它的参数是在线网络参数的一个较为稳定的副本。目标网络不直接参与到决策或者收集经验的过程中,其主要作用是在计算目标Q值时提供一个稳定的目标。在DQN中,每隔一定的时间步,目标网络的参数会被更新为在线网络的参数,这样可以减少学习过程中的震荡和发散问题。在更新在线网络的参数时,使用目标网络的输出来计算目标Q值。具体而言,目标Q值是当前收到的奖励加上对下一个状态的最大Q值的折现。这里的最大Q值是由目标网络给出的,而不是在线网络。这种方法可以防止自我强化的反馈循环,因为目标网络的参数在优化过程中是固定的。在不断变化的数据(如强化学习中的状态和奖励)上训练一个网络时,如果使用即时更新的数据来计算目标值,会导致训练目标和网络参数之间的紧密耦合,这种耦合会使得学习过程变得非常不稳定。目标网络的使用就是为了解耦这两个元素,使得学习目标在短时间内保持稳定,从而有助于网络的稳定收敛。通过这种机制,目标网络在更新间隔期间保持不变,为在线网络提供一组稳定的目标来进行学习。这种做法类似于监督学习中的固定训练集,使得优化过程更加稳定和可靠。
1.数据收集:
通过与环境交互,按照ε-贪婪策略采取行动,并将经验(状态,动作,奖励,下一个状态)存储到回放缓冲区中。
ε-贪婪策略和回放缓冲区
ε-贪婪策略是一种在强化学习中用于控制探索和利用之间平衡的方法。在这种策略中:
_利用(Exploitation)_:代理选择它当前认为最优的动作,即根据Q值函数选择当前状态下Q值最高的动作。
_探索(Exploration)_:代理随机选择一个动作,与Q值无关,为了探索环境中尚未充分评估的状态或动作。
ε-贪婪策略通过一个参数ε(epsilon)来控制探索和利用的比例。ε通常设置为一个接近0但大于0的小数。在每个决策点:
以概率ε进行探索,即随机选择一个动作。
以概率1-ε进行利用,即选择Q值最高的动作。
随着学习的进行,ε的值通常会逐渐减小(例如,通过ε衰减),这意味着代理在学习初期会进行更多的探索,在学习后期则更倾向于利用其已学到的知识。
回放缓冲区(有时也称为经验回放),是用来存储代理与环境交互的经验的数据结构。
在DQN中,代理的每次动作、所观察到的下一个状态、获得的奖励以及是否达到终止状态等信息,都会作为一个元组(tuple)保存到回放缓冲区中。
存储这些经验的目的是:
打破样本间的时间相关性:强化学习中连续的状态转换和动作是高度相关的,这可能导致训练过程中的稳定性问题。通过从回放缓冲区中随机抽样,可以模
拟出一个更加独立同分布(i.i.d.)的数据集,从而提高学习算法的稳定性。
更高效地利用过去的经验:由于环境交互可能代价昂贵或时间消耗较大,通过重复使用历史数据来更新网络,可以更高效地利用这些数据,而不是使用一次
就丢弃。
2.学习更新:
从回放缓冲区中随机采样一批经验,计算损失函数并进行梯度下降更新在线网络参数。
损失函数:
损失函数(Loss Function),在机器学习和统计学中,是一种衡量模型预测值与真实值之间差异的函数。它是一个非负值的函数,当预测值与真实值完全一致时,损失函数的值最小(理想情况下为零)。损失函数对于训练机器学习模型至关重要,因为它提供了一个衡量标准,指导模型在学习过程中如何调整参数以提高预测的准确性。
3.同步目标网络:
每隔一定的步数,将在线网络的参数复制到目标网络。
4.重复以上步骤:
直到算法满足某种停止条件,比如达到一定的训练轮数或性能门槛。
DQN算法的主要优点是可以处理高维的状态空间,并且不需要环境的模型(即转移概率和奖励函数)。然而,DQN也有其局限性,如难以处理高维的动作空间、可能需要大量的数据来训练网络等。此外,DQN仅仅考虑了单步的最优化,没有像后续算法(如DDPG、TD3、SAC等)考虑多步或整个策略的最优化。尽管如此,DQN仍然是深度强化学习领域的基础算法之一,并为后续的许多研究提供了基础框架。
二、使用DI-engine实现DQN算法
DI-engine提供了完整的DQN实现模块与类:
DI-engine 为强化学习提供了一组模块化的工具和类,特别是对于实现和运行 DQN(Deep Q-Networks)算法。下面是这些与 DQN 相关的主要模块和类的详细解释:
DQNPolicy
DQNPolicy 是 DI-engine 中实现 DQN 算法的核心类。它包含了策略网络、目标网络、以及根据环境反馈进行学习和决策的逻辑。DQNPolicy 类通常会包含以下几个关键组件:
•神经网络模型:通常包括一个用于学习动作价值 (action-value) 函数的 Q 网络,以及一个目标网络,用于稳定学习过程。
•优化器:用于更新 Q 网络的参数。
•探索策略:比如 epsilon-greedy 策略,用于在学习的早期阶段平衡探索和利用。
•学习算法:定义了如何通过从经验回放缓冲区抽取样本,利用 Q-learning 更新网络参数的过程。
ReplayBuffer
ReplayBuffer 是一个用于存储交互经验的数据结构,它允许 DQN 算法在训练过程中重用这些经验。这种机制称为经验回放(Experience Replay),它可以提高样本的利用效率,降低样本之间的时间相关性,从而有助于学习过程的稳定性和效率。ReplayBuffer 通常提供以下功能:
•数据存储:能够存储代理与环境交互的数据,包括状态、动作、奖励和下一个状态。
•抽样机制:从缓冲区中随机抽取一批数据,用于训练更新网络。
SerialCollector
SerialCollector 是一个用于与环境交互并收集数据的模块。它按照顺序(串行)执行数据收集过程,将代理的动作应用到环境中,并收集结果状态、奖励等信息。收集到的数据将被存储在 ReplayBuffer 中供后续的训练过程使用。SerialCollector 的主要作用是:
•环境交互:执行代理的决策,并从环境中收集反馈。
•数据收集:将收集到的数据保存到经验回放缓冲区。
SerialEvaluator
SerialEvaluator 是用于评估已训练策略性能的模块。与 SerialCollector 类似,它也是按照顺序执行评估过程,但是不会将交互数据保存到 ReplayBuffer,因为评估过程不涉及学习。SerialEvaluator 主要负责:
•策略评估:运行代理在环境中的表现,通常不包含探索噪声,以准确评估策略的效果。
•性能统计:记录评估过程中的关键性能指标,如平均奖励、胜率等。
配置管理器
配置管理器不是一个类,而是一个用于管理和编译所有配置的系统。在 DI-engine 中,配置文件通常用 YAML 格式编写,包含了环境设置、策略超参数、训练和评估的配置等。配置管理器的功能包括:
•配置编译:根据用户的输入和配置文件,编译出一个完整的配置对象。
•配置管理:提供一个接口来管理和访问编译后的配置,确保代码中使用的参数和实际环境保持一致。
下面我们结合一些简化的伪代码来演示一下如何使用 DI-engine 中的 DQNPolicy, ReplayBuffer, SerialCollector, SerialEvaluator, 和配置管理器来实现一个基本的 DQN 训练循环。请注意,这些代码段是为了解释概念而简化的哦,并不是实际可运行的代码。
DQNPolicy
from ding.policy import DQNPolicy# 初始化 DQN 策略dqn_policy = DQNPolicy(model=your_model, # 你的 Q 网络模型gamma=0.99, # 折扣因子lr=1e-3 # 学习率)
ReplayBuffer
from ding.data.buffer import NaiveReplayBuffer# 初始化经验回放缓冲区buffer_size = 10000 # 定义缓冲区的大小replay_buffer = NaiveReplayBuffer(buffer_size)
SerialCollector
from ding.worker import Collector, SampleCollector# 初始化数据收集器collector = Collector(policy=dqn_policy, env=your_env)sample_collector = SampleCollector(collector, replay_buffer)# 收集数据new_data = sample_collector.collect(n_episode=1) # 收集一定数量的完整回合数据
SerialEvaluator
from ding.worker import Evaluator# 初始化评估器evaluator = Evaluator(policy=dqn_policy, env=your_env)# 进行评估evaluator.eval(n_episode=10) # 评估策略在10个回合中的表现
配置管理器
from ding.config import compile_config# 配置管理器通常在整个训练的开始阶段使用cfg = """base_config:env: your_env_namepolicy: dqnreplay_buffer_size: 10000"""# 编译配置compiled_cfg = compile_config(cfg)
整合这些模块的训练循环
# 假设所有的配置和初始化都已完成# 训练循环for epoch in range(num_epochs):# 数据收集new_data = sample_collector.collect(n_episode=collect_episodes_per_epoch)# 数据处理并存储到 ReplayBufferreplay_buffer.push(new_data)# 训练for _ in range(update_times_per_epoch):batch_data = replay_buffer.sample(batch_size) # 从缓冲区中抽取一批数据dqn_policy.learn(batch_data) # 使用抽取的数据更新策略# 定期评估模型性能if epoch % eval_interval == 0:eval_result = evaluator.eval(n_episode=eval_episodes)print(f"Evaluation result at epoch {epoch}: {eval_result}")
上一章模型训练程序分析:
import gymfrom ditk import loggingfrom ding.model import DQNfrom ding.policy import DQNPolicyfrom ding.envs import DingEnvWrapper, BaseEnvManagerV2, SubprocessEnvManagerV2from ding.data import DequeBufferfrom ding.config import compile_configfrom ding.framework import task, ding_initfrom ding.framework.context import OnlineRLContextfrom ding.framework.middleware import OffPolicyLearner, StepCollector, interaction_evaluator, data_pusher, \eps_greedy_handler, CkptSaver, online_logger, nstep_reward_enhancerfrom ding.utils import set_pkg_seedfrom dizoo.box2d.lunarlander.config.lunarlander_dqn_config import main_config, create_configdef main():# 设置日志记录级别logging.getLogger().setLevel(logging.INFO)# 编译配置文件,将用户定义的配置和系统默认配置合并cfg = compile_config(main_config, create_cfg=create_config, auto=True)# 初始化任务,包括日志、设备等环境设置ding_init(cfg)# 使用上下文管理器启动任务,这里的任务指强化学习的训练和评估流程with task.start(async_mode=False, ctx=OnlineRLContext()):# 创建环境管理器,用于并行管理多个环境实例collector_env = SubprocessEnvManagerV2(env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.collector_env_num)],cfg=cfg.env.manager)# 创建评估器环境管理器evaluator_env = SubprocessEnvManagerV2(env_fn=[lambda: DingEnvWrapper(gym.make(cfg.env.env_id)) for _ in range(cfg.env.evaluator_env_num)],cfg=cfg.env.manager)# 设置随机种子以获得可复现的结果set_pkg_seed(cfg.seed, use_cuda=cfg.policy.cuda)# 初始化DQN模型model = DQN(**cfg.policy.model)# 创建经验回放缓冲区buffer_ = DequeBuffer(size=cfg.policy.other.replay_buffer.replay_buffer_size)# 创建DQN策略policy = DQNPolicy(cfg.policy, model=model)# 使用中间件构建强化学习的各个组件task.use(interaction_evaluator(cfg, policy.eval_mode, evaluator_env))task.use(eps_greedy_handler(cfg))task.use(StepCollector(cfg, policy.collect_mode, collector_env))task.use(nstep_reward_enhancer(cfg))task.use(data_pusher(cfg, buffer_))task.use(OffPolicyLearner(cfg, policy.learn_mode, buffer_))task.use(online_logger(train_show_freq=10))task.use(CkptSaver(policy, cfg.exp_name, train_freq=100))# 运行任务,执行训练task.run()# 程序入口if __name__ == "__main__":main()
初始化和配置
在main函数的开头,我们首先设定日志记录等级为INFO,确保能够输出必要的运行信息:
logging.getLogger().setLevel(logging.INFO)紧接着,通过调用compile_config函数,我们合并了用户自定义的配置(main_config)和系统默认配置,并且可以通过create_config进一步定制化配置,这一步骤保证了参数的灵活性和可调整性:
cfg = compile_config(main_config, create_cfg=create_config, auto=True)环境设置
使用ding_init函数初始化任务,包括日志、设备等环境设置。这是准备强化学习实验所必要的步骤:
ding_init(cfg)环境管理器
在强化学习中,环境是与智能体进行交互的模拟器。在这个代码中,通过SubprocessEnvManagerV2创建了两个环境管理器,一个用于数据收集(collector_env),另一个用于评估(evaluator_env)。这两个环境管理器都通过DingEnvWrapper包装了Gym提供的环境:
collector_env = SubprocessEnvManagerV2(...)evaluator_env = SubprocessEnvManagerV2(...)
随机种子
为了结果的可复现性,使用set_pkg_seed设置了随机种子:
set_pkg_seed(cfg.seed, use_cuda=cfg.policy.cuda)DQN模型和策略
接下来,初始化了DQN模型,并根据配置文件中的参数创建了模型实例:
model = DQN(**cfg.policy.model)与此同时,创建了DQN策略,这个策略将指导智能体如何选择动作:
policy = DQNPolicy(cfg.policy, model=model)中间件和任务运行
中间件是Ding框架中用于构建复杂强化学习流程的关键组件。它们可以将数据收集、策略评估、经验回放等功能模块化,并串联成完整的学习过程。
在本代码中,使用了多个中间件组件:
interaction_evaluator负责策略评估。
eps_greedy_handler实现了ϵ-贪婪策略。
StepCollector负责收集环境交互数据。
nstep_reward_enhancer用于n步奖励计算。
data_pusher将收集的数据推送到经验回放缓冲区。
OffPolicyLearner负责学习过程。
online_logger提供训练过程中的日志信息。
CkptSaver定期保存训练的模型。
task.use(interaction_evaluator(...))task.use(eps_greedy_handler(...))...task.use(CkptSaver(...))
最终,通过task.run()执行任务,开始训练过程。
模型生成位置:
测试一下效果:

相关文章:
如何训练和导出模型
介绍如何通过DI-engine使用DQN算法训练强化学习模型 一、什么是DQN算法 DQN算法,全称为Deep Q-Network算法,是一种结合了Q学习(一种价值基础的强化学习算法)和深度学习的算法。该算法是由DeepMind团队在2013年提出的,…...

Springboot注解@Aspect(一)之@Aspect 作用和Aop关系详解
目录 Aspect的使用 配置 作用 通知相关的注解 例子 结果: Aspect作用和Spring Aop关系 示例 标签表达式 Aspect的使用 配置 要启用 Spring AOP 和 Aspect 注解,需要在 Spring 配置中启用 AspectJ 自动代理,但是在 Spring Boot 中&a…...

自动化防DDoS脚本
简介 DDoS (分布式拒绝服务攻击)是一种恶意的网络攻击,旨在通过占用目标系统的资源,使其无法提供正常的服务。在DDoS攻击中,攻击者通常控制大量的被感染的计算机或其他网络设备,同时将它们协调起来向目标系…...

ubuntu怎么查看有几个用户
在Ubuntu中,可以使用以下命令来查看系统中的用户数量: cat /etc/passwd | wc -l这个命令会读取 /etc/passwd 文件中的用户信息,并使用 wc -l 命令来计算行数,即用户数量。 另外,你也可以使用以下命令来查看当前登录到…...
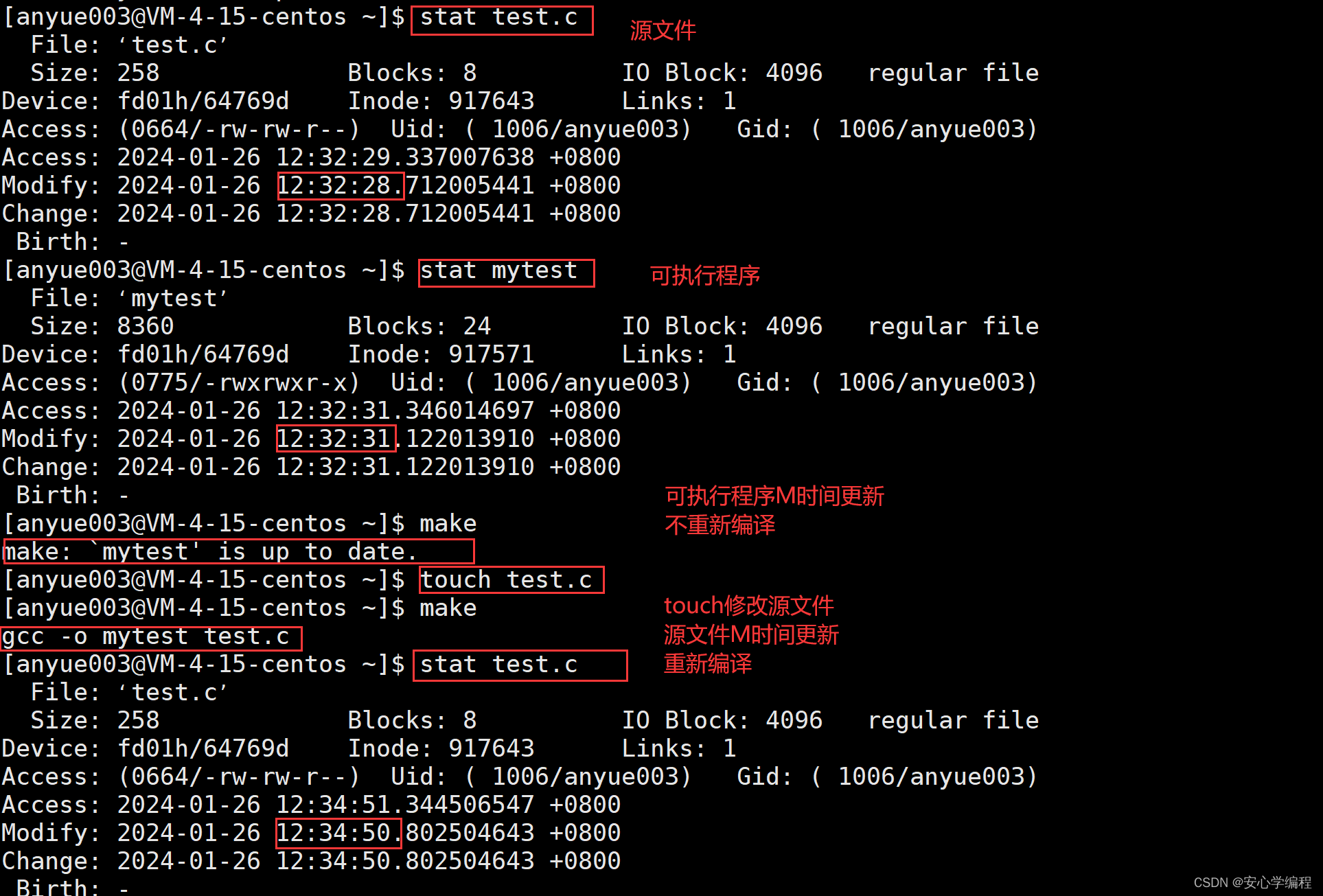
Linux | makefile简单教程 | Makefile的工作原理
前言 在学习完了Linux的基本操作之后,我们知道在linux中编写代码,编译代码都是要手动gcc命令,来执行这串代码的。 但是我们难道在以后运行代码的时候,难道都要自己敲gcc命令嘛?这是不是有点太烦了? 在vs中…...
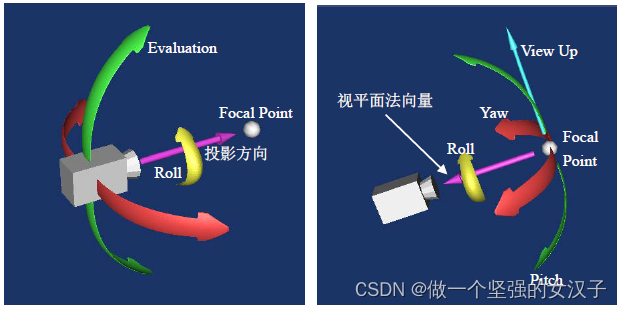
pcl+vtk(十四)vtkCamera相机简单介绍
一、vtkCamera相机 人眼相当于三维场景下的相机, VTK是用vtkCamera类来表示三维渲染场景中的相机。vtkCamera负责把三维场景投影到二维平面,如屏幕、图像等。 相机位置:即相机所在的位置,用方法vtkCamera::SetPosition()设置。 相…...

TS基础知识点快速回顾(上)
基础介绍 什么是 TypeScript? TypeScript,简称 ts,是微软开发的一种静态的编程语言,它是 JavaScript 的超集。 那么它有什么特别之处呢? js 有的 ts 都有,所有js 代码都可以在 ts 里面运行。ts 支持类型支持&#…...
无法使用)
hook(post-receive)无法使用
hook(post-receive)无法使用 为什么无法使用? 只有一个问题:权限不够,你想想,blog.git是一个中转站,咱们要把上传的东西转到blog下面,肯定要有写入操作呀,这个Git仓库的…...
qt学习:tcp区分保存多个客户端
在前面文掌的tcp客服端服务端进行更改 qt学习:Network网络类tcp客户端tcp服务端-CSDN博客https://blog.csdn.net/weixin_59669309/article/details/135842933?spm1001.2014.3001.5501前面的服务端每次有新的客户端连接,就会覆盖掉原来的指针࿰…...

ORM-08-EclipseLink 入门介绍
拓展阅读 The jdbc pool for java.(java 手写 jdbc 数据库连接池实现) The simple mybatis.(手写简易版 mybatis) 1. EclipseLink概述 本章介绍了EclipseLink及其关键特性:包括在EclipseLink中的组件、元数据、应用程序架构、映射和API。 本…...

数据结构之树和二叉树定义
数据结构之树和二叉树定义 1、树的定义2、树的基本概念3、二叉树的定义 数据结构是程序设计的重要基础,它所讨论的内容和技术对从事软件项目的开发有重要作用。学习数据结构要达到的目标是学会从问题出发,分析和研究计算机加工的数据的特性,以…...
大模型学习与实践笔记(十三)
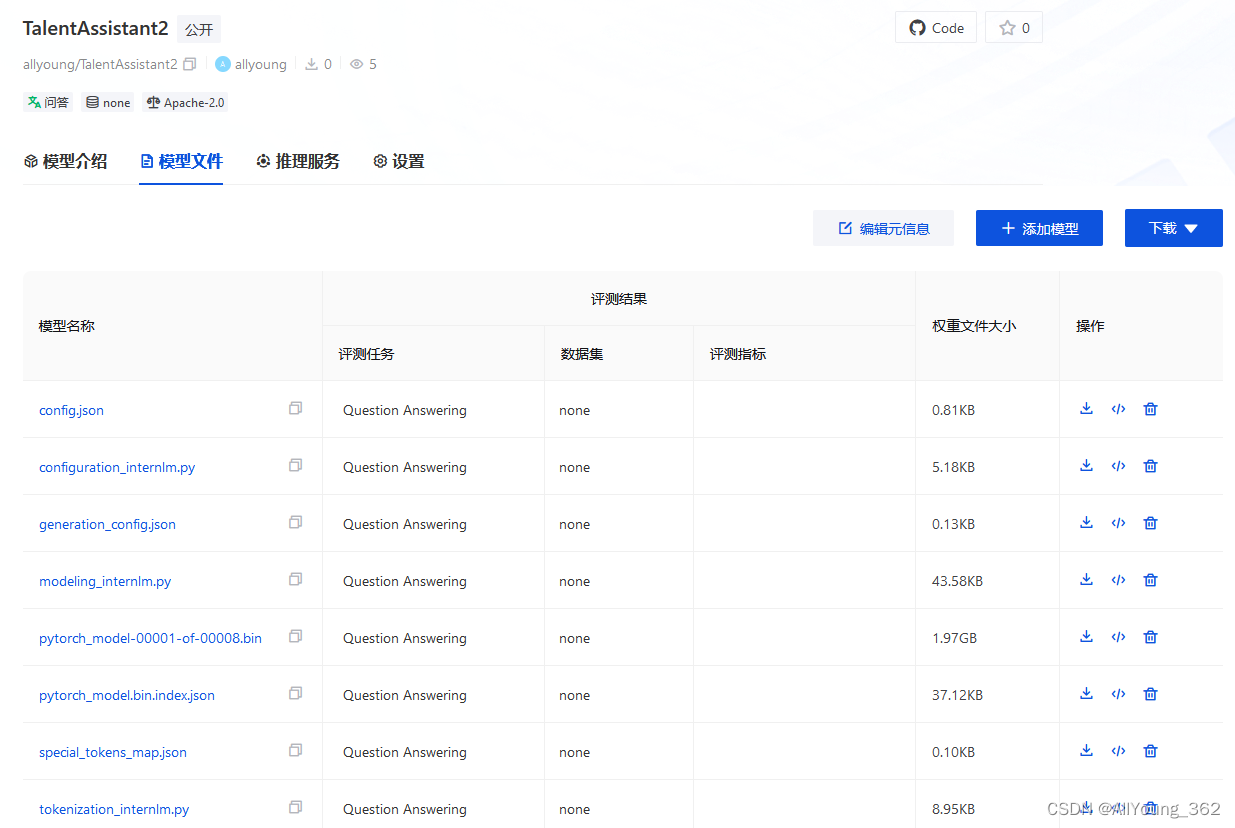
将训练好的模型权重上传到 OpenXLab 方式1: 先将Adapter 模型权重通过scp 传到本地,然后网页上传 步骤1. scp 到本地 命令为: scp -o StrictHostKeyCheckingno -r -P *** rootssh.intern-ai.org.cn:/root/data/ e/opencv/ 步骤2&#…...

计算机网络——网络层(1)
计算机网络——网络层(1) 小程一言专栏链接: [link](http://t.csdnimg.cn/ZUTXU) 网络层:数据平面网络层概述核心功能协议总结 路由器工作原理路由器的工作步骤总结 网际协议IPv4主要特点不足IPv6主要特点现状 通用转发和SDN通用转发SDN(软件…...

解释LoRA参数
目录 LoRA参数含义 LoRA在深度学习中的作用 示例代码中的LoRA应用 结论 LoRA参数含义 LoRA (lora_r): LoRA代表"Low-Rank Adaptation",是一种模型参数化技术,用于在不显著增加参数数量的情况下调整预训练模型。lora_r参数指的是LoRA中的秩&…...
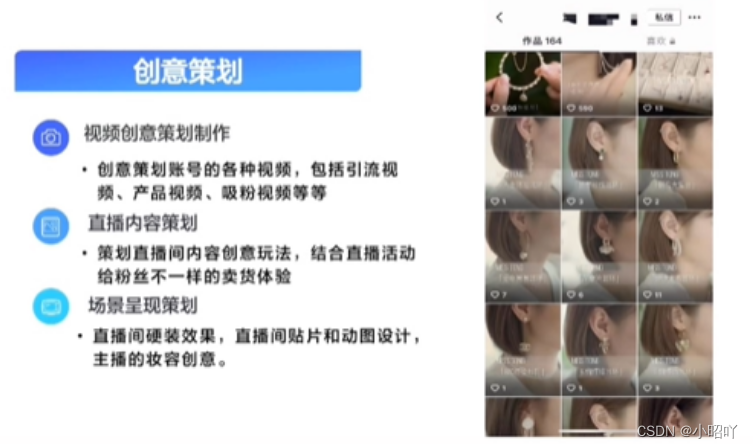
直播核心岗位基础内容
一.直播间核心岗位 1.直播间前端岗位 前端岗位分工 (1)主播岗位职责 (2)场控岗位职责 (3)助理岗位职责 中端岗位分工 (1)运营岗位职责 (2)中控岗位职责 …...
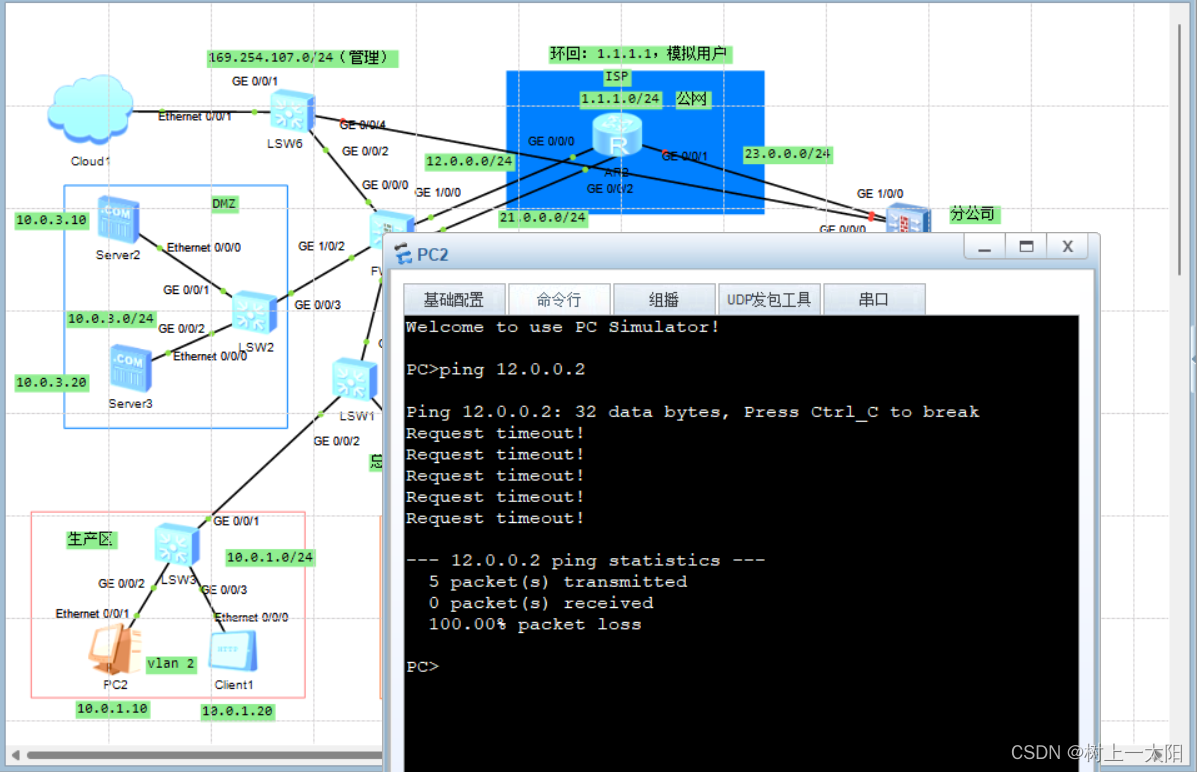
安全防御第三次作业
作业:拓扑图及要求如下图 注:server1是ftp服务器,server2是http服务器 lsw1: 其中g0/0/0口为trunk 实现 1,生产区在工作时间内可以访问服务器区,仅可以访问http服务器 验证: 2,办公…...
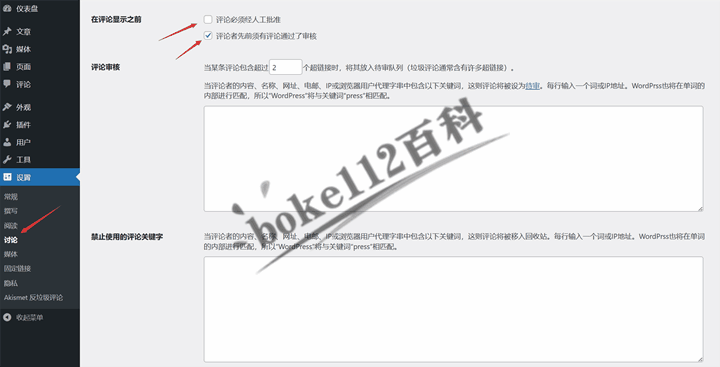
WordPress反垃圾评论插件Akismet有什么用?如何使用Akismet插件?
每次我们成功搭建好WordPress网站后,都可以在后台 >> 插件 >> 已安装的插件,在插件列表中可以看到有一个“Akismet反垃圾邮件:垃圾邮件保护”的插件(个人觉得是翻译错误,应该是反垃圾评论)。具…...

力扣80、删除有序数组中的重复项Ⅱ(中等)
1 题目描述 图1 题目描述 2 题目解读 对于有序数组nums,要求在不使用额外数组空间的条件下,删除数组nums中重复出现的元素,使得nums中出现次数超过两次的元素只出现两次。返回删除后数组的新长度。 3 解法一:双指针 双指针法可以…...

探索HTMLx:强大的HTML工具
1. HTMLX htmx 是一个轻量级的 JavaScript 库,它允许你直接在 HTML 中使用现代浏览器的功能,而不需要编写 JavaScript 代码。通过 htmx,你可以使用 HTML 属性执行 AJAX 请求,使用 CSS 过渡动画,利用 WebSocket 和服务…...
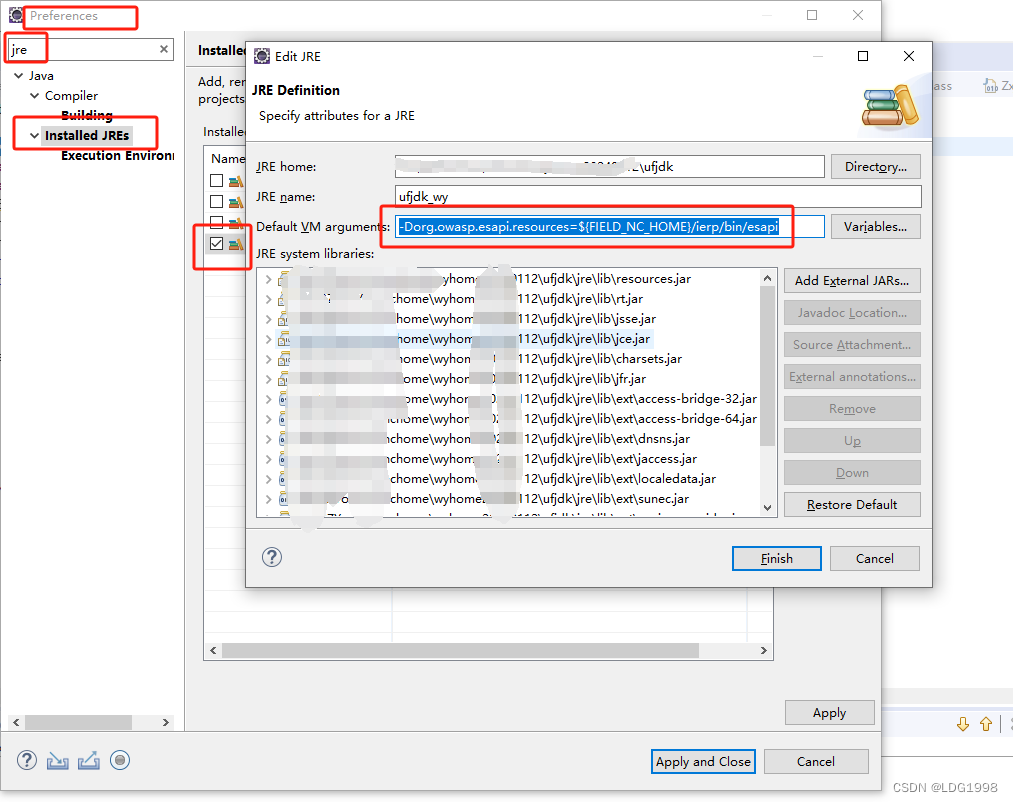
NC65中间件能启动,前端客户端启动失败,加载异常,卡住(org.owasp.esapi)
控制台输出错误 ESAPI.properties could not be loaded by any means. Fail.SecurityConfiguration class(org.owasp.esapi.reference.DefaultSecurityConfiguration) CTOR threw exception.效果图: 解决方案 添加如下参数: -Dorg.owasp.esapi.resou…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...
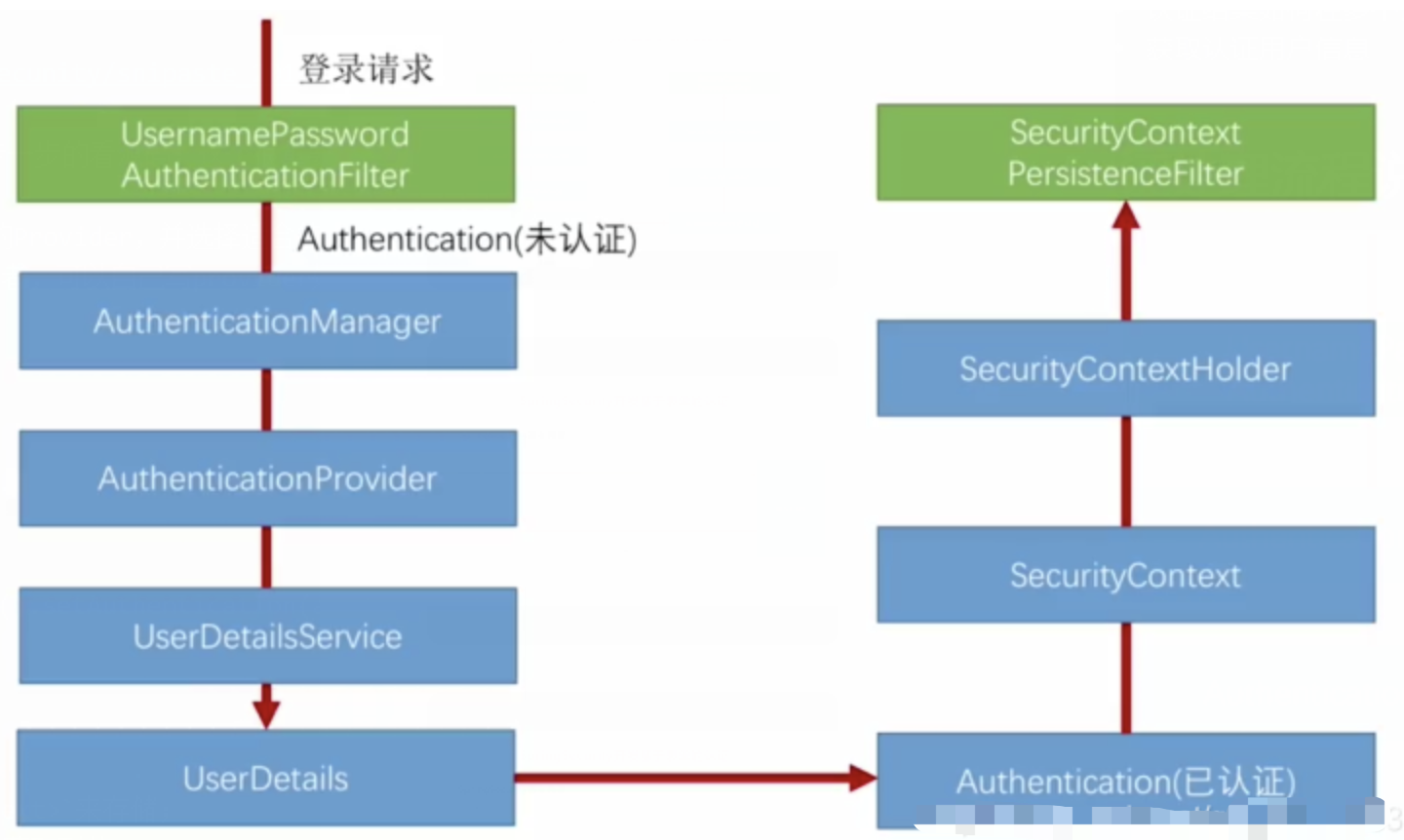
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...