Java复习系列之阶段三:框架原理
1. Spring
1.1 核心功能
1. IOC容器
IOC,全称为控制反转(Inversion of Control),是一种软件设计原则,用于减少计算机代码之间的耦合度。控制反转的核心思想是将传统程序中对象的创建和绑定由程序代码直接控制转移到一个外部容器(如框架或库)来管理,从而实现模块间的解耦。
将对象的控制权,交给容器进行管理,只需要在使用时找容器要。
如何工作
在没有控制反转的传统程序设计中,程序的流程是由程序本身控制的。程序中的每个对象通常负责创建和管理它所依赖的其他对象。这导致了强耦合和难以维护的代码。
而在控制反转的情境中,这种创建和查找依赖对象的工作被委托给外部系统(如框架)。这个外部系统负责创建对象、解决它们的依赖关系以及管理它们的生命周期。
控制反转的好处
-
降低耦合度:通过将依赖关系的管理交给外部容器,可以减少代码间的直接依赖。
-
提高模块的可重用性:由于模块之间的耦合度降低,单个模块变得更容易重用。
-
增强代码的可测试性:控制反转使得模块间的耦合降低,从而使得单元测试更加容易实现。
-
增强代码的可维护性:代码变得更加模块化,易于理解和维护。
实现方式
控制反转通常通过以下方式实现:
-
依赖注入(Dependency Injection):是控制反转的一种形式,其中对象的依赖项(如服务、配置)不是由对象本身创建,而是在创建对象的时候由外部容器注入。
-
服务定位器(Service Locator):通过使用一个中心注册表,对象可以在运行时从中检索依赖项。
-
事件驱动:对象可以订阅和监听事件而不是直接调用特定的方法。
应用领域
控制反转广泛应用于现代软件开发中,尤其是在使用复杂框架和库的企业级应用程序中。许多流行的框架,如Spring(Java)、ASP.NET Core(.NET)等,都内置了控制反转机制。
IOC容器是如何降低代码耦合性的?
IOC(控制反转)容器通过接管对象的创建和生命周期管理,从而降低代码的耦合性。在没有IOC容器的情况下,对象之间的依赖关系通常是硬编码在对象内部的,这导致了高度的耦合。当使用IOC容器时,这种情况得到了改变:
-
分离对象创建和使用:在传统的程序设计中,一个对象负责创建和管理它依赖的其他对象。这种直接的依赖关系导致代码耦合。而IOC容器接管了对象的创建过程,对象只需要声明它们的依赖项,而不需要知道如何创建这些依赖项。这种方式使得对象之间的耦合度大大降低。
-
依赖注入:这是IOC的一种常见形式,其中IOC容器在运行时自动“注入”对象所需的依赖项。这意味着对象不再需要自己寻找或创建它们需要的依赖项。依赖注入可以是构造函数注入、属性注入或方法注入。
-
配置和代码的分离:在许多情况下,依赖关系可以通过外部配置(如XML文件、注解或特殊的配置类)来定义,而不是在代码中硬编码。这允许开发者在不改变代码的情况下更改依赖关系,从而提高了代码的灵活性和可维护性。
-
更容易的单元测试:由于对象不再直接创建它们的依赖项,所以在单元测试时更容易替换这些依赖项,比如使用Mock对象。这有助于写出更专注于单一功能的测试用例。
-
更好的管理和生命周期控制:IOC容器通常提供了对对象生命周期的管理功能,包括创建、初始化、使用和销毁等。这意味着对象的管理更加统一和集中,便于跟踪和控制。
通过这些方式,IOC容器减少了代码中的直接依赖关系,使得代码更加模块化,提高了可维护性和可扩展性。
总的来说,控制反转是一种有力的设计原则,用于构建松耦合、可维护和可测试的软件系统。
1.1.2 DI(依赖注入)
依赖注入(Dependency Injection,简称DI)是实现控制反转(Inversion of Control,IOC)的一种方法。在软件工程中,依赖注入指的是组件(如对象或函数)的依赖关系(即它所需要的其他组件)不是由组件本身在内部创建或查找,而是由外部实体(如框架、容器或另一个组件)提供。这种机制使得组件之间的耦合度降低,增加了代码的模块化和可测试性。
在Spring框架中,依赖注入(DI)是核心概念之一。它允许对象定义它们的依赖(即它们需要的其他对象),而不是自行创建它们。Spring容器负责创建对象、解决它们的依赖关系,并将所需的依赖注入到对象中。这一过程大大简化了代码的编写,使得开发者可以专注于业务逻辑,而不是对象的创建和管理。
Spring中的依赖注入的方式:
-
构造函数注入:通过构造函数将依赖注入到对象中。这种方法在对象创建时就提供了所有必需的依赖,确保了对象的不变性。
public class MyService {private final MyRepository repository;public MyService(MyRepository repository) {this.repository = repository;} } -
Setter注入:通过setter方法注入依赖。这种方法在对象创建后注入依赖,提供了更大的灵活性。
public class MyService {private MyRepository repository;public void setRepository(MyRepository repository) {this.repository = repository;} } -
字段注入:直接在字段上注入依赖。这是最简单的注入方式,但它也降低了类的测试性和封装性。
public class MyService {@Autowiredprivate MyRepository repository; }
Spring依赖注入的好处:
-
减少耦合:通过依赖注入,组件之间的耦合度降低,增强了模块的独立性。
-
增强测试性:依赖注入使得在单元测试时可以轻松地用mock对象替换真实依赖。
-
易于维护和扩展:由于依赖关系是由Spring容器管理的,修改和扩展应用程序变得更容易。
-
声明式配置:通过使用注解(如
@Autowired)或XML配置文件,可以在不修改代码的情况下改变依赖关系。
注意事项:
-
避免过度使用:依赖注入虽然方便,但过度使用(特别是自动装配)可能导致代码难以追踪和维护。
-
考虑使用构造函数注入:相比于字段注入和setter注入,构造函数注入通常被认为是更好的选择,因为它可以保证依赖的不变性和完整性。
-
合理管理作用域:在Spring中,对象(Bean)的作用域需要合理管理,以确保应用的性能和一致性。
Spring框架通过其强大的依赖注入功能,极大地促进了Java企业级应用的开发,使得应用程序更加模块化、易于测试和维护。
1.1.3 AOP
在Spring框架中,面向切面编程(Aspect-Oriented Programming,简称AOP)是一种编程范式,它允许开发者将横切关注点(cross-cutting concerns)从业务逻辑中分离出来。横切关注点是那些影响多个类的问题,例如日志记录、事务管理、安全性、缓存等。AOP通过提供一种分离和重用这些关注点的方式,增加了代码的模块化。
AOP的核心概念
-
切面(Aspect):一个模块化的横切关注点实现。切面可以包含通知和切点。
-
通知(Advice):在切面的特定连接点上采取的动作。通知类型包括“前置通知”(在方法执行之前运行)、“后置通知”(在方法成功完成后运行)、“环绕通知”(在方法运行前后都运行)、“异常通知”(在方法抛出异常时运行)和“最终通知”(无论方法如何结束都运行)。
-
连接点(Join Point):程序执行的某个特定位置,如类中的方法执行或异常处理。
-
切点(Pointcut):一组连接点,可以通过表达式定义来匹配方法签名。切点决定了通知应该在哪些连接点执行。
-
引入(Introduction):向现有类添加新方法或属性。
-
目标对象(Target Object):被一个或多个切面通知的对象。
-
代理(Proxy):为目标对象提供横切关注点的对象。在Spring AOP中,AOP代理通常是基于JDK动态代理或CGLIB代理。
AOP的使用
在Spring中,AOP通常用于以下用途:
- 日志记录:自动记录方法的执行情况。
- 事务管理:声明式地管理事务,使业务代码保持独立于事务代码。
- 性能监测:监测方法执行时间,以便优化性能。
- 安全控制:在方法执行前进行权限检查。
- 错误处理:为方法执行过程中的错误统一处理逻辑。
实现方式
在Spring框架中,AOP可以通过以下方式实现:
- 使用AspectJ注解:Spring支持使用AspectJ提供的注解(如
@Aspect、@Before、@After、@Around等)来定义切面、通知和切点。 - XML配置:在Spring的XML配置文件中定义切面和通知。
示例
一个简单的日志记录切面可能看起来像这样:
@Aspect
public class LoggingAspect {@Before("execution(* com.example.service.*.*(..))")public void logBeforeMethod(JoinPoint joinPoint) {System.out.println("Before method: " + joinPoint.getSignature().getName());}
}
这个例子中,LoggingAspect 类标记为一个切面(@Aspect),并且包含一个前置通知(@Before),它会在指定的方法(这里是com.example.service包下的所有方法)执行之前运行。
通俗理解AOP
让我尝试用一个更简单的比喻来解释Spring AOP(面向切面编程)的原理。
想象你去餐厅吃饭,你点了一些菜(这就像是程序中的一次方法调用)。在传统的程序设计中,你的订单直接进入厨房,并由厨师(目标对象)直接处理。
但在使用Spring AOP的情况下,情景就像是在你和厨师之间增加了一个服务员(代理对象)。这个服务员的工作不仅仅是传递你的订单给厨师,还包括了一些额外的任务,比如:
- 在将订单传递给厨师之前,他可能会记录下你的订单(前置通知,如日志记录)。
- 如果你要求特殊处理(如不要放辣),他会告知厨师这些特殊要求(方法拦截)。
- 当菜品做好后,他可能会检查菜品质量(后置通知)。
- 如果厨房出了问题(比如菜品做错了),他会向你报告(异常通知)。
在这个过程中,厨师(目标对象)只关心如何做菜,而所有额外的任务(日志记录、异常处理等横切关注点)都由服务员(代理对象)处理。这样,厨师的工作就被简化了,而且餐厅的管理(如日志、异常处理)变得更加灵活和有条理。
回到Spring AOP的世界,这就意味着:
- 目标对象(厨师)专注于它的主要职责(业务逻辑)。
- 代理对象(服务员)在目标对象处理请求(执行方法)之前后或期间,增加额外的处理步骤(AOP的通知)。
通过这种方式,Spring AOP允许我们将某些通用功能(如日志记录、安全检查)从业务逻辑中抽离出来,交由代理对象处理,从而使业务逻辑更加清晰和易于维护。
总的来说,Spring中的AOP提供了一种强大且灵活的方式来处理横切关注点,使得这些逻辑从业务代码中分离,从而提高了代码的可读性和可维护性。
1.1.4 事务
在Spring框架中,事务管理是一个核心功能,用于确保数据的一致性和完整性。Spring提供了一种声明式事务管理方式,这意味着你可以通过配置和注解来管理事务,而不是在代码中显式地控制事务的开始、提交和回滚。
Spring事务的核心概念:
-
声明式事务管理:通过使用注解或XML配置来管理事务,这使得事务管理与业务逻辑分离,降低了代码的耦合度。
-
事务传播行为:Spring事务提供了多种事务传播行为,例如
REQUIRED(如果当前没有事务,就新建一个事务;如果已经存在事务,则加入这个事务)、REQUIRES_NEW(总是新建事务,如果已经存在事务,将它挂起)、SUPPORTS(如果存在事务,则加入事务;如果不存在事务,则以非事务方式运行)等。 -
事务隔离级别:事务隔离级别定义了一个事务可能受其他并发事务影响的程度。Spring支持数据库提供的所有事务隔离级别,如
READ_COMMITTED、REPEATABLE_READ等。 -
事务管理器:Spring支持多种类型的事务管理器,最常用的是针对JDBC的
DataSourceTransactionManager和针对JPA的JpaTransactionManager。
声明式事务的使用:
-
使用
@Transactional注解:在方法或类上添加@Transactional注解可以将其标记为事务性的。你可以在该注解中指定传播行为、隔离级别、超时时间等属性。@Service public class MyService {@Transactionalpublic void myTransactionalMethod() {// 业务逻辑} } -
配置事务管理器:在Spring配置文件中定义事务管理器。
<bean id="transactionManager"class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><property name="dataSource" ref="dataSource"/> </bean> -
启用事务注解:在Spring配置中启用事务注解的支持。
@Configuration @EnableTransactionManagement public class AppConfig {// ... }
注意事项:
- 确保事务方法的可见性为public。
- 注意事务的传播行为和隔离级别,以满足业务需求。
- 在异常处理中,只有来自事务方法的运行时异常(
RuntimeException)和错误(Error)默认会触发回滚。如果需要对检查型异常进行回滚,需要在@Transactional注解中显式指定。
Spring的声明式事务管理提供了一种灵活、强大且易于维护的方式来处理事务,这对于构建可靠和健壮的企业级应用至关重要。
事务的传播机制
事务的传播机制是Spring事务管理中的一个重要概念。它定义了业务方法之间交互时事务如何传播。例如,当一个事务方法被另一个事务方法调用时,是否应该加入到已有的事务中,还是应该开启一个新的事务。Spring提供了一系列事务传播行为,让开发者可以根据具体需求选择合适的策略。
以下是Spring支持的一些主要的事务传播行为:
-
REQUIRED(默认):如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
-
SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
-
MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
-
REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则将当前事务挂起。
-
NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,则将当前事务挂起。
-
NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
-
NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则其行为类似于REQUIRED。但它使用了一个单独的事务,这个事务是外部事务的一个子事务,如果嵌套事务失败,只会回滚这个子事务。
使用场景举例
-
REQUIRED:适用于大多数情况,尤其是当你希望在一个事务中完成多个操作时。
-
REQUIRES_NEW:适用于需要完全独立于当前事务的操作,例如,一个操作不应该回滚由于另一个操作引起的更改。
-
MANDATORY:适用于必须在事务中运行的操作,如果调用时没有事务环境,则应该是一个错误。
-
SUPPORTS:适用于既可以在事务中运行也可以不在事务中运行的操作,不会影响事务行为。
-
NEVER:适用于不应该在事务中运行的操作,确保没有事务环境。
-
NESTED:适用于需要独立于主事务进行单独回滚和提交的场景。
选择正确的事务传播行为对于保证事务的正确性和效率至关重要。错误的选择可能导致数据不一致,或者在不必要的情况下使用事务,影响性能。
导致Spring事务失效的情况有哪些?
Spring事务失效可能由多种原因造成,主要包括以下几个方面:
-
事务方法不是public:Spring事务使用动态代理实现,仅能拦截公共方法(public)。如果你在非公共方法上使用
@Transactional注解,事务是不会被应用的。 -
同一个类中方法互调:如果在同一个Spring Bean内部,一个非事务方法调用事务方法,事务是不会被应用的。因为事务是通过代理实现的,而内部方法调用不会通过代理。
-
事务传播行为不正确:如果事务方法的传播行为设置不合适,例如使用
PROPAGATION_NEVER或PROPAGATION_NOT_SUPPORTED,可能导致事务不被启动。 -
数据库不支持事务:如果你使用的数据库不支持事务或者配置的数据源不支持事务,那么Spring事务管理自然无法正常工作。
-
异常处理不当:默认情况下,Spring仅在遇到运行时异常(
RuntimeException)和错误(Error)时才回滚事务。如果你的方法抛出的是受检异常(checked exception),并且没有在@Transactional注解中显式指定回滚,事务不会回滚。 -
事务管理器配置错误:如果事务管理器没有正确配置或者没有将事务管理器与数据源关联,事务管理将无法正常工作。
-
使用JPA或Hibernate时清理模式配置错误:在使用JPA或Hibernate时,如果
spring.jpa.open-in-view是false,可能会导致事务在视图渲染之前就被提交。 -
不正确的事务隔离级别:如果事务的隔离级别设置不正确,可能会导致事务行为不符合预期。
-
多数据源问题:如果应用中配置了多个数据源而没有正确指定事务管理器,可能会导致事务不被应用到预期的数据库。
-
@Transactional注解用在非Spring管理的Bean上:
@Transactional只有在应用于Spring管理的Bean时才有效。如果注解用在Spring容器外的对象上,事务是不会被管理的。
为了确保Spring事务的正确性,开发者需要注意这些细节,并确保Spring配置和代码使用符合事务管理的要求。
事务的实现原理
Spring事务的实现原理主要基于Spring的AOP(面向切面编程)和代理机制。这个机制通过事务切面和事务管理器来管理事务的生命周期,包括事务的创建、提交和回滚。下面详细介绍这个过程:
1. AOP和代理机制
- 当在Spring配置中声明了
@Transactional注解时,Spring会通过AOP创建一个代理(Proxy),这个代理会环绕实际的方法。 - 如果使用的是基于接口的代理(默认情况下,如果目标类实现了接口),Spring使用JDK动态代理。如果目标类没有实现接口,Spring使用CGLIB来创建类代理。
2. 事务切面(Transaction Aspect)
- 事务切面是Spring事务实现的核心,它会拦截带有
@Transactional注解的方法。 - 这个切面通过
TransactionInterceptor(事务拦截器)来工作,它会在方法执行前后执行相应的事务管理逻辑。
3. 事务管理器(Transaction Manager)
- Spring为不同的数据访问技术提供了不同的事务管理器,如
DataSourceTransactionManager、HibernateTransactionManager等。 - 事务管理器负责实际的事务管理操作,如创建、提交或回滚事务。
4. 事务生命周期管理
- 开始事务:当执行到带有
@Transactional注解的方法时,事务管理器会根据事务属性(如传播行为、隔离级别等)来创建或加入一个现有事务。 - 进行业务逻辑:执行实际的业务方法。
- 事务结束:业务方法完成后,根据执行过程中是否发生异常来提交或回滚事务。默认情况下,只有在运行时异常(unchecked exception)发生时才回滚,但这是可配置的。
5. 异常处理和事务回滚
- 如果在事务方法中抛出了异常,
TransactionInterceptor会捕获这些异常,并根据配置决定是否回滚事务。 - 事务的回滚规则可以通过
@Transactional注解的rollbackFor和noRollbackFor属性来定制。
6. 使用代理的影响
- 由于Spring使用代理来管理事务,因此只有通过代理调用的方法才会受到事务管理的影响。这意味着,类内部的非代理方法调用将无法触发事务逻辑。
总结
Spring事务的实现原理是通过AOP和代理机制在运行时拦截方法调用,并根据@Transactional注解和配置的事务管理器来控制事务的边界和行为。这种方式提供了一种声明式的事务管理方法,使得开发者可以轻松地在业务代码中应用复杂的事务管理逻辑。
1.2 扩展功能
1.2.1 监听器
在Spring框架中,监听器(Listener)是一种用于监听和响应应用程序事件(如上下文事件、HTTP会话事件等)的组件。Spring提供了事件驱动模型来处理不同类型的应用程序事件。这种模型主要包括三个主要部分:事件(Events)、监听器(Listeners)和事件发布(Event Publishing)。
1. 事件(Events)
事件是应用程序的状态变化的一个封装。在Spring中,所有事件都是ApplicationEvent类的子类。Spring内置了许多标准事件,例如:
ContextRefreshedEvent:当ApplicationContext被初始化或刷新时发布。ContextStartedEvent:当ApplicationContext启动时发布。ContextStoppedEvent:当ApplicationContext停止时发布。ContextClosedEvent:当ApplicationContext关闭时发布。RequestHandledEvent:一个Web特定的事件,告知一个HTTP请求已经被服务。
2. 监听器(Listeners)
监听器是实现了ApplicationListener接口的任何Bean,用于处理特定的事件。监听器需要定义一个onApplicationEvent方法,该方法会在监听到相应的事件时被调用。例如,创建一个监听ContextRefreshedEvent的监听器:
import org.springframework.context.ApplicationListener;
import org.springframework.context.event.ContextRefreshedEvent;public class MyContextRefreshedListener implements ApplicationListener<ContextRefreshedEvent> {@Overridepublic void onApplicationEvent(ContextRefreshedEvent event) {// 执行当上下文刷新时的逻辑}
}
3. 事件发布(Event Publishing)
事件可以通过实现ApplicationEventPublisherAware接口的Bean或者直接通过ApplicationContext发布。例如:
import org.springframework.context.ApplicationEventPublisher;
import org.springframework.context.ApplicationEventPublisherAware;
import org.springframework.context.ApplicationEvent;public class MyEventPublisherBean implements ApplicationEventPublisherAware {private ApplicationEventPublisher publisher;@Overridepublic void setApplicationEventPublisher(ApplicationEventPublisher applicationEventPublisher) {this.publisher = applicationEventPublisher;}public void publishEvent(ApplicationEvent event) {publisher.publishEvent(event);}
}
使用@EventListener注解
从Spring 4.2开始,可以使用@EventListener注解来简化事件监听器的创建。这允许在不实现ApplicationListener接口的情况下,直接在方法上定义监听逻辑:
import org.springframework.context.event.EventListener;
import org.springframework.context.event.ContextRefreshedEvent;public class MyBean {@EventListenerpublic void handleContextRefresh(ContextRefreshedEvent event) {// 处理上下文刷新事件}
}
事件和监听器的应用
事件和监听器在Spring中被广泛用于:
- 追踪应用程序的生命周期事件。
- 在不同组件之间解耦消息的发送和接收。
- 实现业务逻辑中的异步处理。
- 集成第三方服务,如消息队列、监控系统等。
总之,Spring的事件和监听器机制提供了一种强大的方式来处理应用程序中的各种事件,使得组件之间的通信更加清晰和解耦。
1.2.2 定时任务
Spring框架提供了一种简单而强大的方式来创建定时任务。这通常通过使用@Scheduled注解来实现,它允许你以声明式的方式定义定时任务。Spring的定时任务依赖于Spring的任务调度和执行框架。
使用@Scheduled注解
在Spring中,你可以通过在方法上添加@Scheduled注解来创建一个定时任务。这个注解提供了几种不同的方式来指定任务的执行计划:
-
固定延迟(fixedDelay):在上一个任务执行完毕后等待固定的时间。
@Scheduled(fixedDelay = 1000) public void taskWithFixedDelay() {// 任务逻辑 } -
固定速率(fixedRate):按照固定的速率执行任务,不考虑任务执行的时间。
@Scheduled(fixedRate = 1000) public void taskWithFixedRate() {// 任务逻辑 } -
Cron表达式(cron):通过Cron表达式定义更复杂的任务调度计划。
@Scheduled(cron = "0 * * * * ?") public void taskWithCronExpression() {// 任务逻辑 }
启用定时任务
为了使用@Scheduled注解,你需要在Spring配置中启用定时任务的支持。这通常通过在配置类上添加@EnableScheduling注解来实现:
@Configuration
@EnableScheduling
public class AppConfig {// 配置类的其它部分
}
注意事项
-
所有的定时任务默认在同一个线程池中执行,意味着任务之间可能会相互影响。可以配置自定义的
TaskScheduler来改变这种行为。 -
定时任务的执行时间受到系统时钟的影响,因此应该考虑系统时间的变化,比如夏令时的切换。
-
对于复杂的调度需求,可以考虑使用像Quartz这样的更强大的调度框架。
示例
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;@Component
public class MyScheduledTasks {@Scheduled(fixedRate = 5000)public void reportCurrentTime() {System.out.println("当前时间:" + System.currentTimeMillis());}
}
在这个示例中,reportCurrentTime方法每5秒执行一次,打印当前的时间戳。
Spring的定时任务功能提供了一种简便的方法来执行定时或周期性的任务,非常适合用于轻量级的后台任务调度。
1.2.3 Bean生命周期
当然,让我更清晰地解释Spring Bean的生命周期。Bean的生命周期可以分为几个关键阶段,这些阶段定义了Bean从创建到销毁的整个过程。这个过程涉及Spring框架如何创建、配置、初始化、使用以及销毁Bean。
1. 实例化(Instantiation)
- 创建Bean实例:首先,Spring容器使用构造器(或工厂方法)创建Bean的实例。此时,Bean尚未填充属性,也没有进行依赖注入。
2. 属性赋值(Populate Properties)
- 注入属性值:Spring容器注入配置的属性值或引用。这通常是通过XML配置文件、Java配置或注解来完成的。
3. BeanNameAware和BeanFactoryAware
- Aware接口实现:如果Bean实现了
BeanNameAware、BeanFactoryAware或其他以Aware结尾的接口,Spring容器将相应地调用这些接口的方法。例如,setBeanName方法会传递Bean的ID。
4. BeanPostProcessor(前置处理)
- 前置处理:
BeanPostProcessor的postProcessBeforeInitialization方法在Bean的初始化前被调用。这允许在Bean执行其初始化逻辑(如@PostConstruct注解的方法)之前执行一些自定义逻辑。
5. 初始化(Initialization)
- InitializingBean和@PostConstruct:如果Bean实现了
InitializingBean接口,afterPropertiesSet方法将被调用。同样,带有@PostConstruct注解的方法也会在此时执行。 - init-method:如果在Bean定义中指定了
init-method,该指定的方法也会被调用。
6. BeanPostProcessor(后置处理)
- 后置处理:
BeanPostProcessor的postProcessAfterInitialization方法在Bean的初始化后被调用。
7. 使用Bean
- Bean准备就绪:此时,Bean已完全初始化,可以用于应用程序中。
8. 销毁(Destruction)
- DisposableBean和@PreDestroy:当容器关闭,并且Bean的作用域不是原型时,如果Bean实现了
DisposableBean接口,destroy方法将被调用。带有@PreDestroy注解的方法也会在此时执行。 - destroy-method:如果在Bean定义中指定了
destroy-method,该指定的方法也会被调用。
总结
在整个生命周期中,你可以通过实现特定的接口或使用注解来插入自定义的行为。BeanPostProcessor允许你在初始化阶段前后添加自定义逻辑,而InitializingBean、DisposableBean和相应的注解允许你在Bean的初始化和销毁时添加自定义行为。这种灵活性是Spring框架的核心优势之一。
开始(getBean)->实例化->属性赋值->初始化->销毁
1.2.4 循环依赖
循环依赖是指两个或多个组件相互依赖对方,形成一个闭环的依赖关系。在Spring框架中,特别是在依赖注入(DI)中,循环依赖通常指的是两个或多个Bean互相引用,导致无法顺利完成创建和初始化过程。
Spring解决循环依赖的方法是三级缓存。
注意:Spring只支持解决单例bean的循环依赖。
后期Spring已经默认关闭了对循环依赖的支持,需要手动开启。
Spring通过三级缓存解决循环依赖的原理涉及对Bean创建过程的细致管理。在Spring中,创建一个Bean通常涉及到以下几个步骤:实例化、属性填充(依赖注入)和初始化。当两个或多个Bean互相依赖时,就可能发生循环依赖。Spring通过引入三级缓存机制解决了这个问题,特别是针对单例作用域的Bean。
这里是三级缓存如何工作的一个概览:
1. 第一级缓存:单例对象的高速缓存
- 用途:存储完全初始化好的Bean。
- 功能:当一个Bean完全初始化后(实例化、依赖注入、初始化方法调用完成),它被放入这个缓存中。之后,每次获取这个Bean时,都是从这个缓存中直接获取。
2. 第二级缓存:早期暴露对象的缓存
- 用途:存储还未完全初始化的Bean,即已经实例化但依赖注入还没有完全完成的Bean。
- 功能:这允许其他Bean引用还在创建过程中的Bean,从而解决循环依赖的问题。例如,如果Bean A需要注入Bean B,而Bean B又依赖于Bean A,当创建Bean B时,可以从这个缓存中获取对Bean A的引用。
3. 第三级缓存:Bean工厂的缓存
- 用途:存储能生成Bean的工厂对象。
- 功能:当Bean实例化时,会生成一个相应的工厂对象,该工厂对象负责完成Bean的剩余创建过程(如完成依赖注入)。如果在Bean的创建过程中需要引用该Bean,可以通过这个工厂对象来获取一个原始状态的Bean实例。
解决循环依赖的过程
-
实例化:Spring首先创建Bean的实例。
-
提前暴露引用:在Bean的属性注入之前,将Bean的原始状态通过工厂对象放入第三级缓存中。
-
属性填充:开始进行依赖注入。如果这个Bean依赖于另一个正在创建的Bean,它可以通过第三级缓存中的工厂对象来获取那个Bean的引用。
-
初始化:完成Bean的初始化(如调用初始化方法)。
-
缓存更新:当Bean完全初始化后,将其从第二级缓存移动到第一级缓存,并从第三级缓存中移除。
注意事项
- 这个机制只适用于单例作用域的Bean。
- 对于构造器注入的循环依赖,Spring无法解决,因为在调用构造器时Bean还没有被实例化,因此无法提前暴露引用。
- 通常建议避免循环依赖,如果可能,通过重构代码来消除它们。这样做可以提高代码的清晰度和可维护性。
总结起来,Spring的三级缓存机制通过在Bean生命周期的不同阶段提供对Bean引用的访问,从而巧妙地解决了循环依赖的问题。
2. Spring Boot
2.1 优势
- 依赖版本管理,搭建项目更简单
- 简化配置。通过 Java Config 替代传统 xml 配置,以及引入自动配置机制
- 内嵌 Tomcat 简化项目部署
缺点:
约定优于配置虽然提高了开发效率,但是可能会导致意想不到的行为
冗余依赖
对于特定需求的限制
2.2 与传统 Web 项目的对比
项目结构
部署方式
2.3 常用注解
@SpringBootApplication
@ComponentScan(Spring框架的)
@EnableAutoConfiguration
@ConditionalOnXxx(Bean、class)
@ConditionalOnMissingXxx(Bean、class)
2.4 自动配置流程
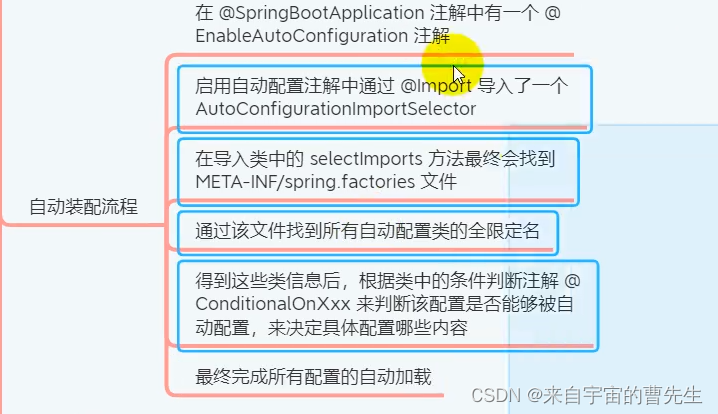
Spring Boot的自动配置是其核心功能之一,旨在减少显式配置的需求,简化Spring应用程序的开发过程。自动配置流程主要基于条件注解和@EnableAutoConfiguration注解来实现。下面是这个过程的大致步骤:
1. 启动类和@SpringBootApplication
- 当你启动一个Spring Boot应用时,通常会有一个带有
@SpringBootApplication注解的主类。这个注解实际上是一个方便的注解,它组合了@Configuration、@EnableAutoConfiguration和@ComponentScan。
2. @EnableAutoConfiguration注解
@EnableAutoConfiguration是自动配置的关键。它告诉Spring Boot根据类路径下的jar依赖、定义的Bean以及各种属性设置来开始自动配置过程。
3. 寻找自动配置类
- Spring Boot利用
spring.factories文件来加载自动配置类。这些配置文件通常位于自动配置库(比如spring-boot-autoconfigure)的META-INF目录下。 spring.factories文件包含了带有@Configuration注解的类的列表,这些类定义了如何配置Spring应用程序的各种部分。
4. 条件注解的评估
- 自动配置类使用条件注解(如
@ConditionalOnClass、@ConditionalOnMissingBean等)来控制配置的应用。这些注解确保只有在满足特定条件时,相关配置才会被应用。 - 例如,如果在类路径上有
JdbcTemplate类,那么与JDBC相关的自动配置就会被触发。
5. 自动配置的应用
- 在评估了所有条件之后,满足条件的自动配置类会被应用。这些配置类可以定义Bean、设置属性等,从而自动配置应用程序的不同部分。
- 自动配置尽可能智能,但也提供了适当的自定义选项。你可以通过在
application.properties或application.yml文件中设置属性来覆盖自动配置的默认值。
6. 自定义和覆盖
- 尽管自动配置提供了合理的默认设置,但你仍然可以通过定义自己的配置Bean来覆盖这些默认设置。如果你定义了某个自动配置类所期望的Bean,自动配置通常会退让,避免覆盖你的配置。
总结
Spring Boot的自动配置机制通过一系列的条件检查和配置类来自动配置Spring应用程序。这一过程极大地简化了配置工作,使开发者可以更专注于业务逻辑。同时,它也提供了足够的灵活性,允许开发者在必要时覆盖或自定义特定的配置。
2.5 启动流程
Spring Boot的启动流程涉及多个关键步骤,这些步骤共同工作,以初始化和配置Spring应用程序。下面是Spring Boot启动时的主要过程:
1. 运行主类
Spring Boot应用通常有一个包含main方法的主类,这个类上标注有@SpringBootApplication注解。当你运行这个主类时,Spring Boot的启动流程开始。
@SpringBootApplication
public class MyApp {public static void main(String[] args) {SpringApplication.run(MyApp.class, args);}
}
2. 创建SpringApplication对象
当调用SpringApplication.run()时,首先会创建一个SpringApplication对象。这个对象封装了应用的配置和环境。
3. 准备运行环境
SpringApplication对象准备运行环境。这包括配置Spring的profiles,读取配置文件(如application.properties或application.yml),以及初始化日志系统等。
4. 创建应用上下文
接着,Spring Boot创建一个合适的ApplicationContext实例。对于大多数web应用来说,这将是一个AnnotationConfigServletWebServerApplicationContext,它支持带注解的类。
5. 初始化应用上下文
一旦ApplicationContext被创建,Spring Boot开始初始化它。这包括注册Bean定义、加载配置类等。
6. 应用自动配置
这是Spring Boot的核心特性。基于@EnableAutoConfiguration注解,Spring Boot会自动配置应用程序。这涉及到扫描spring.factories文件中列出的配置类,并根据条件注解(如@ConditionalOnClass、@ConditionalOnMissingBean)应用它们。
7. 刷新应用上下文
一旦所有的Bean都被加载,所有的配置都被应用,ApplicationContext就会被刷新。这意味着所有的Bean实例化并调用它们的初始化方法。
8. 运行CommandLineRunner和ApplicationRunner
如果你的应用程序中有实现CommandLineRunner或ApplicationRunner接口的Bean,它们的run方法将在这个时候被调用。
9. 启动内嵌的Web服务器
对于web应用,Spring Boot会在这个阶段启动内嵌的web服务器(如Tomcat、Jetty或Undertow)。
10. 应用准备就绪
最后,应用完成启动并准备接受请求。
总结
Spring Boot的启动流程涵盖了从运行主类开始到应用准备就绪的一系列复杂步骤。这个过程自动化和简化了许多传统Spring应用程序所需的显式配置和引导过程。通过这种方式,Spring Boot使得创建和运行Spring应用变得更加快捷和容易。

3. Spring MVC
3.1 常用注解
@Controller @RestController
@RequestMapping
@GetMapping PostMapping PutMapping DeleteMapping
@RequestBody
@ResponseBody
3.2 请求处理流程
Spring MVC (Model-View-Controller) 的请求流程是 Spring 框架用于处理 web 请求的核心部分。它遵循典型的 MVC 设计模式。以下是 Spring MVC 处理请求的基本流程:
-
接收请求:用户的请求首先被前端控制器(Front Controller),即
DispatcherServlet接收。DispatcherServlet是 Spring MVC 的核心,它负责接收所有的请求并将它们转发到相应的处理器。 -
处理器映射(Handler Mapping):
DispatcherServlet调用HandlerMapping来确定每个请求的处理器(Controller)。基于请求的 URL、HTTP 方法等信息,HandlerMapping决定哪个 Controller 应该处理请求。 -
调用适当的控制器:一旦确定了处理器,
DispatcherServlet调用相应的 Controller。 -
业务逻辑处理:Controller 接收请求并处理业务逻辑。它可能会与后端服务交互,比如数据库或其他业务服务,来处理请求并准备数据。
-
模型和视图的选择:Controller 处理完业务逻辑后,它返回一个
ModelAndView对象,该对象包含模型数据和视图名称。模型(Model)包含要展示的数据,视图(View)是展示模型数据的模板。 -
视图解析(View Resolver):
DispatcherServlet使用ViewResolver来解析 Controller 返回的视图名称。ViewResolver根据视图名称确定具体的视图模板。 -
渲染视图:一旦确定了视图,
DispatcherServlet将模型数据传递给视图模板。视图模板使用这些数据来生成最终的 HTML、JSON 或其他格式的响应。 -
返回响应:生成的响应返回给
DispatcherServlet,然后由它返回给用户。
这个过程涉及许多 Spring MVC 的组件,例如 HandlerInterceptor(拦截器)、LocaleResolver(本地化解析器)、MultipartResolver(多部分解析器)等,可以进一步定制请求处理流程。通过这种方式,Spring MVC 提供了一个灵活、可扩展的架构来处理 Web 应用程序的请求。
3.3 扩展功能
3.3.1 统一异常处理
是Spring MVC提供的一个基于Controller实现的代理机制,利用AOP实现对所有的控制器进行代理,拦截所有从控制器跑出的异常,进行统一处理
步骤:
1. 创建一个统一异常处理类,标注@ControllerAdvice 或 @RestControllerAdvice 注解
2. 创建对应异常类型的处理方法,贴上@ExceptionHandler注解并制定要处理的异常类型
3. 在方法中实现该异常的处理方案,最终返回对应数据给前端
3.3.2 JSR303参数校验
JSR303 是Java规范的一项提议,主要是用于服务端参数校验
通过定义一套通用的注解规范,可以让服务端参数校验实现只加注解,就完成对参数检验的能力。

3.3.3 参数解析器
在 Spring MVC 中,参数解析器(Parameter Resolvers)是一种机制,用于处理传入的 HTTP 请求并将它们映射到控制器方法的参数。这个过程涉及到将请求数据(如路径变量、查询参数、请求体等)转换为适合控制器方法参数的格式。Spring 提供了多种内置的参数解析器,以及扩展点,允许开发者自定义参数解析器。以下是一些常见的内置参数解析器:
-
@RequestParam:- 用于获取请求参数(query parameters)。例如,
@RequestParam("id") String id会将请求中的id参数映射到方法的id参数上。
- 用于获取请求参数(query parameters)。例如,
-
@PathVariable:- 用于处理 URI 模板变量。例如,在请求路径中
/users/{userId},@PathVariable("userId")可以将userId的值提取出来。
- 用于处理 URI 模板变量。例如,在请求路径中
-
@RequestBody:- 用于处理 HTTP 请求的体部(body)。它通常用于处理 JSON 或 XML 数据,将其反序列化为 Java 对象。需要配合相应的消息转换器(如 Jackson)使用。
-
@RequestHeader:- 用于获取 HTTP 请求头的值。例如,
@RequestHeader("User-Agent") String userAgent会提取请求中的User-Agent头信息。
- 用于获取 HTTP 请求头的值。例如,
-
@CookieValue:- 用于从 HTTP 请求中提取 cookie 值。
-
@ModelAttribute:- 通常用于将请求参数(包括 URL 参数和表单参数)绑定到 Java 对象上。它也可以用于将模型属性暴露给视图。
-
@SessionAttribute和@RequestAttribute:- 用于访问存储在会话(Session)或请求(Request)中的属性。
-
HttpServletResponse和HttpServletRequest:- 可以直接在方法参数中使用
HttpServletRequest或HttpServletResponse来访问底层的请求和响应对象。
- 可以直接在方法参数中使用
-
Principal:- 用于访问当前认证的用户的主体信息。
除了这些内置的参数解析器,Spring 还允许开发者通过实现 HandlerMethodArgumentResolver 接口来创建自定义的参数解析器。这为开发人员提供了极大的灵活性,以适应各种复杂的应用场景。在自定义解析器中,开发者可以定义如何解析请求数据,并将其转换为控制器方法所需的参数类型。
创建一个自定义的参数解析器(HandlerMethodArgumentResolver)在Spring MVC中是一种高级用法,允许你对如何从HTTP请求映射数据到控制器方法的参数进行精细控制。下面是创建一个自定义参数解析器的具体流程:
-
定义解析器类:
- 创建一个类,实现
HandlerMethodArgumentResolver接口。这个接口要求实现两个方法:supportsParameter和resolveArgument。
- 创建一个类,实现
-
实现
supportsParameter方法:- 这个方法决定了你的解析器是否应该用于特定的控制器方法参数。它接收一个
MethodParameter对象,你可以检查这个参数的类型、注解等,然后返回true或false来表明是否支持该参数。
- 这个方法决定了你的解析器是否应该用于特定的控制器方法参数。它接收一个
-
实现
resolveArgument方法:- 这个方法负责实际解析参数。它接收
MethodParameter、ModelAndViewContainer和NativeWebRequest对象作为输入,并应返回一个对象,该对象将被用作控制器方法的参数值。在这个方法里,你可以访问请求的内容,然后基于这些信息构建和返回适当的对象。
- 这个方法负责实际解析参数。它接收
-
注册解析器:
- 一旦你的解析器类实现完成,你需要将其注册到Spring MVC配置中。这通常是在一个配置类中通过扩展
WebMvcConfigurer并重写addArgumentResolvers方法来完成的。在这个方法中,将你的自定义解析器添加到给定的ArgumentResolvers列表中。
- 一旦你的解析器类实现完成,你需要将其注册到Spring MVC配置中。这通常是在一个配置类中通过扩展
-
使用自定义解析器:
- 一旦注册,当Spring MVC发现控制器方法的参数被你的解析器支持时(根据
supportsParameter方法),它将使用你的解析器来解析这些参数。
- 一旦注册,当Spring MVC发现控制器方法的参数被你的解析器支持时(根据
以下是一个简化的示例来说明这个过程:
import org.springframework.core.MethodParameter;
import org.springframework.web.context.request.NativeWebRequest;
import org.springframework.web.method.support.HandlerMethodArgumentResolver;
import org.springframework.web.method.support.ModelAndViewContainer;public class MyCustomArgumentResolver implements HandlerMethodArgumentResolver {@Overridepublic boolean supportsParameter(MethodParameter parameter) {return parameter.getParameterType().equals(MyCustomType.class);}@Overridepublic Object resolveArgument(MethodParameter parameter, ModelAndViewContainer mavContainer,NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception {// 实现参数解析逻辑return new MyCustomType(/* 参数构造 */);}
}// 在Spring配置中注册解析器
@Configuration
public class WebConfig implements WebMvcConfigurer {@Overridepublic void addArgumentResolvers(List<HandlerMethodArgumentResolver> resolvers) {resolvers.add(new MyCustomArgumentResolver());}
}
在这个例子中,MyCustomArgumentResolver 是一个自定义的解析器,用于处理 MyCustomType 类型的参数。这个解析器被注册到Spring MVC配置中,之后就可以在控制器方法中使用 MyCustomType 类型的参数了。
3.3.4 拦截器与过滤器的区别
拦截器(Interceptors)和过滤器(Filters)在Java Web应用程序中都用于处理请求和响应的预处理和后处理,但它们在实现方式和使用场景上有一些关键区别:
拦截器 (Interceptors)
-
定义与框架相关:拦截器是Spring框架的一部分,特别是在Spring MVC中使用。它们与Spring的上下文紧密集成。
-
处理范围:拦截器只拦截通过Spring的DispatcherServlet的请求。这意味着它们主要用于拦截控制器(Controller)的动作。
-
灵活性与功能:拦截器提供了更多的灵活性,可以访问Spring的上下文、控制器和处理器方法的信息。拦截器可以在请求处理之前、之后以及渲染视图之后进行工作。
-
配置与实现:拦截器是通过实现Spring的
HandlerInterceptor接口或者继承HandlerInterceptorAdapter类来创建的,并在Spring的配置文件中配置。 -
用途:常用于处理跨切面的关注点,例如日志记录、权限验证、事务处理等。
过滤器 (Filters)
-
定义与框架无关:过滤器是Servlet规范的一部分,它不依赖于Spring或任何特定的框架,因此更为通用。
-
处理范围:过滤器可以拦截几乎所有的请求,包括静态资源的请求,如图片、CSS和JavaScript文件。
-
功能:过滤器主要用于在Servlet级别处理请求和响应,比如修改请求头和响应头、编码请求体和响应体等。
-
配置与实现:过滤器是通过实现
javax.servlet.Filter接口来创建的,并在web.xml文件或通过使用Java配置进行配置。 -
用途:常用于请求的预处理,比如编码处理、安全过滤、图像/数据压缩等。
总结
- 依赖范围:拦截器依赖于Spring MVC,而过滤器依赖于Servlet容器。
- 处理层级:拦截器更靠近应用程序层(控制器),过滤器更靠近Web服务器层。
- 功能:拦截器通常用于处理与业务逻辑相关的问题,而过滤器更多用于处理通用的HTTP层面的问题。
- 灵活性:拦截器通常比过滤器提供更多的灵活性和更精细的控制,因为它们可以访问Spring MVC的内部工作机制。
在实际应用中,根据需求选择使用拦截器还是过滤器是非常重要的。有时,它们也会一起使用以提供全面的请求处理。
4. MyBatis
4.1 特点
是一个半自动化的 ORM 框架,更多是对 JDBC 的封装,提供了许多动态拼接SQL的功能,让程序员来关注SQL的编写。
4.2 与Hibernate的区别
MyBatis 和 Hibernate 都是在 Java 生态系统中广泛使用的持久层框架,但它们在哲学、设计和使用方式上有显著的区别。以下是一些主要的区别点:
1. 数据访问方式:
-
MyBatis:
- 是一个半自动化的ORM(对象关系映射)框架。它允许开发者编写SQL语句并手动映射到Java对象。
- 主要通过XML或注解的方式配置SQL语句。
- 提供了更多的控制权在SQL级别,适合需要精细调整SQL性能和行为的场景。
-
Hibernate:
- 是一个完全自动化的ORM框架,隐藏了大部分的数据库交互。
- 使用HQL(Hibernate Query Language)或JPQL(Java Persistence Query Language),以及Criteria API来构建查询,这些都是更接近于面向对象的方式。
- 自动管理SQL语句的生成,将数据库操作更多地映射为对象和类的操作。
2. 学习曲线和易用性:
-
MyBatis:
- 相对容易学习,特别是对于那些已经熟悉SQL的开发者。
- 提供了更接近数据库的操作方式,对于数据库设计和SQL优化有更多的控制。
-
Hibernate:
- 学习曲线较陡峭,特别是对于Hibernate的缓存机制、实体生命周期、会话管理等高级特性。
- 抽象级别更高,对于不需要深入了解数据库细节的应用来说更方便。
3. 性能:
-
MyBatis:
- 性能通常较好,因为它允许开发者编写直接的SQL语句,更容易进行性能优化。
- 提供了更精确的控制,但这也意味着开发者需要花更多时间来优化SQL语句。
-
Hibernate:
- 由于其自动生成SQL的特性,可能会在某些复杂场景下产生不太高效的SQL。
- 提供了强大的缓存机制,可以显著提高应用性能,但需要正确配置和使用。
4. 缓存机制:
-
MyBatis:
- 提供一级(本地)和二级(跨会话)缓存,但相比于Hibernate,其缓存机制较为简单。
-
Hibernate:
- 提供更复杂的缓存机制,包括一级缓存(会话缓存)和二级缓存(跨会话缓存),以及查询缓存。
5. 集成和兼容性:
-
MyBatis:
- 更容易与现有的数据库和SQL代码集成,特别是在已有数据库和复杂SQL的项目中。
-
Hibernate:
- 强大的JPA(Java Persistence API)提供者,支持与JPA标准的兼容,使得它在Java EE环境中集成更加自然。
总的来说,选择MyBatis或Hibernate取决于项目的需求、团队的熟悉程度以及对数据库控制的需求。MyBatis适合那些需要精细控制SQL和数据库交互的场景,而Hibernate适合那些需要快速开发且数据库交互不是主要瓶颈的应用。
4.3 # 与 $ 符号的区别
- #取值:通过预编译语句拼接SQL,避免SQL注入问题;支持获取简单类型(String Date Long)的值;
- $取值:通过直接拼接SQL语句,可能产生SQL注入;不支持获取简单类型(String Date Long)的值;
4.4 缓存
4.4.1 一级缓存
默认开启,作用域仅为SqlSession 级别,只要当前SqlSesison关闭,缓存失效
规则为SQL+参数完全相同,才会命中缓存,该缓存的数据被缓存在内存中
由于缓存的规则其只在SqlSession级别生效,一个请求->一个SqlSession 所以一级缓存没有太大用
4.4.2 二级缓存
二级缓存是Mybatis提供的一个扩展缓存的机制,在一级缓存的基础上,二级缓存的作用域是命名空间级别的,只要这个命名空间不被销毁,缓存数据不会被销毁的。
缓存规则同样是SQL+参数完全相同,默认是关闭的,可以结合第三方库杨家,实现内存或分布式缓存的实现。
执行查询时,会以查询语句的SQL+参数作为key,查询得到的值为value
当执行了增删改操作时,自动删除缓存,保证数据的一致性
缺点:由于缓存是命名空间级别的,因此只有在该命名空间下进行的表结构操作,缓存的管理才有效
员工mapper 部门mapper
4.5 分页拦截器实现原理
MyBatis的分页拦截器是基于拦截器(Interceptor)机制实现的,这是MyBatis提供的一个强大功能,允许在特定的时刻插入自定义行为,例如,在执行查询之前或之后。分页拦截器主要用于实现分页查询的功能,而不必修改实际的查询语句。下面是分页拦截器的基本实现原理:
1. 拦截器机制
- MyBatis的拦截器基于Java的动态代理机制。
- 开发者可以创建一个实现了MyBatis
Interceptor接口的类,其中的intercept方法就是拦截器的核心。 - 在这个方法中,可以拦截执行的SQL语句和查询参数。
2. 分页拦截的流程
-
拦截查询操作:当执行查询操作时,分页拦截器会拦截这个操作。这通常发生在
Executor.query()方法被调用时。 -
检测并修改SQL:拦截器会检查当前执行的SQL是否需要分页。如果需要,它会重写SQL语句,加入数据库特定的分页命令,如
LIMIT子句(在MySQL中)。 -
参数处理:同时,拦截器也会处理与分页相关的参数,例如当前页码和每页显示的记录数。
-
执行修改后的查询:然后,拦截器会执行修改后的SQL语句。
-
返回分页结果:最后,拦截器将查询结果封装成分页信息(如总记录数、总页数、当前页的数据等)并返回。
3. 示例
假设原始的SQL语句是:
SELECT * FROM users;
如果要对这个查询进行分页,假设每页显示10条记录,查询第2页,那么分页拦截器会修改这个SQL为:
SELECT * FROM users LIMIT 10 OFFSET 10;
这个修改后的SQL语句将只返回第11到第20条记录。
4. 配置
在MyBatis配置文件中,需要将这个分页拦截器注册为一个插件。
5. 优点与局限
- 优点:分页拦截器可以让分页逻辑与业务逻辑解耦,使得开发者无需在每个分页查询中手动编写分页逻辑。
- 局限:它依赖于数据库的分页语法,可能需要根据不同的数据库进行调整。此外,如果查询逻辑非常复杂,自动化的分页改写可能不够高效或者不适用。
总的来说,MyBatis的分页拦截器是一种方便且强大的工具,能够有效地实现分页功能,但在特定情况下可能需要针对具体的数据库和查询进行调整。
5. Spring Security
5.1 简介
Spring Security是一个功能强大且高度可定制的认证和访问控制框架,是Spring生态系统中用于保护基于Spring的应用程序的标准选择。它提供了全面的安全性解决方案,旨在解决企业级应用程序中的安全性问题。以下是Spring Security的一些关键特点和组件:
核心特点
-
全面的认证和授权支持:Spring Security支持多种认证机制,包括表单登录、HTTP Basic、OAuth2、LDAP等,并提供了强大的授权规则配置。
-
防范攻击:它提供了防止跨站请求伪造(CSRF)、会话固定攻击、点击劫持等安全威胁的机制。
-
与Spring生态系统集成:与Spring Framework紧密集成,可以轻松与Spring MVC、Spring Data等其他Spring项目结合使用。
-
灵活的配置:提供基于Java配置和XML配置的方式,允许开发者根据需求定制安全策略。
-
扩展性:通过实现自定义的认证提供者、决策管理器等组件,可以扩展和定制其默认行为。
关键组件
-
SecurityContextHolder和SecurityContext:用于存储当前安全上下文的细节,包括当前用户的细节。
-
Authentication:代表用户的认证信息,如用户名和密码。
-
GrantedAuthority:表示授权信息,通常以角色的形式出现。
-
UserDetails:提供必要的信息来构建
Authentication对象。 -
UserDetailsService:用于根据用户名检索用户的详细信息。
-
PasswordEncoder:用于密码的加密和匹配。
-
FilterChain:Spring Security使用一系列过滤器来提供安全性,例如
UsernamePasswordAuthenticationFilter用于处理表单登录。
使用流程
-
客户端请求:用户发出请求(例如,登录请求)。
-
过滤器链处理:请求通过一系列Spring Security过滤器,处理诸如认证、授权等安全相关的事项。
-
认证和授权:根据配置的认证提供者进行认证,并根据配置的权限规则进行授权。
-
成功或失败的处理:根据认证和授权的结果,进行相应的处理,如重定向到不同的页面或返回错误信息。
使用场景
- 保护Web应用程序,限制对URL的访问。
- 方法级别的安全性,例如使用注解保护特定的服务方法。
- 集成OAuth2以提供单点登录(SSO)和资源服务器保护。
- 实现LDAP认证、数据库认证等。
5.2 原理
Spring Security的原理基于一系列的过滤器(Filters)和拦截器(Interceptors),它们协同工作以提供认证和授权功能。这个框架遵循“默认拒绝访问”的原则,即在没有明确授权的情况下,用户不被允许访问任何资源。下面是Spring Security工作原理的一个概览:
1. 过滤器链 (Filter Chain)
- Spring Security使用Servlet过滤器来拦截请求。
- 请求首先经过一系列Spring Security定义的过滤器,这个过滤器链负责执行各种安全检查。
2. 认证 (Authentication)
- 认证入口点:当用户尝试访问受保护的资源但未经认证时,系统将用户重定向到认证入口点(例如登录页面)。
- 认证过滤器:如
UsernamePasswordAuthenticationFilter,用于处理登录表单提交的数据。 - 认证管理器:
AuthenticationManager调用AuthenticationProvider,后者负责与数据库或其他服务交互以验证用户凭据。
3. 授权 (Authorization)
- 在认证成功后,请求再次通过过滤器链。
- 安全拦截器:如
FilterSecurityInterceptor,检查用户是否有权访问当前请求的资源。 - 访问决策管理器:
AccessDecisionManager评估用户的GrantedAuthority(权限)与资源所需的权限。
4. 异常处理
- 认证异常:如果认证失败(如用户名/密码不正确),则抛出认证异常。
- 授权异常:如果用户尝试访问无权访问的资源,抛出授权异常。
- 异常处理:异常被
AuthenticationEntryPoint或AccessDeniedHandler捕获,并根据配置进行处理,如重定向到错误页面。
5. 会话管理
- Spring Security还管理用户会话,包括会话固定保护、并发会话控制等。
6. 过滤器的例子
- UsernamePasswordAuthenticationFilter:处理表单登录。
- BasicAuthenticationFilter:处理HTTP基本认证。
- CsrfFilter:处理跨站请求伪造(CSRF)保护。
- LogoutFilter:处理用户注销。
7. 安全上下文 (Security Context)
- 在整个请求处理过程中,用户的认证信息存储在
SecurityContextHolder中的SecurityContext中,可用于在应用程序的任何位置获取当前用户信息。
总之,Spring Security的原理涉及到一系列精心设计的组件和机制,它们共同协作,为Spring应用程序提供了全面的安全性保障。这种设计允许灵活地配置和扩展,以适应不同应用程序的安全需求。
总的来说,Spring Security是一个非常强大的工具,它不仅提供了认证和授权的标准机制,还提供了防范常见安全威胁的能力,是构建安全Spring应用程序的关键组件。
6. Activiti7
Activiti7 是一个轻量级、高性能的工作流和业务流程管理 (BPM) 平台,主要用于管理、执行和优化业务流程。Activiti 是一个基于 Java 的工作流引擎,最初由 Alfresco Software 开发,并且是 Apache 2.0 许可的开源项目。Activiti7 是 Activiti 项目的最新版本,提供了一系列更新和改进。
主要特点
-
BPMN 2.0 支持:Activiti7 完全支持业务流程模型和标记语言(BPMN 2.0),这是一种为工作流和业务流程图定义标准的 XML 格式。
-
灵活性和可扩展性:Activiti7 设计灵活,易于与其他应用程序和系统集成。它提供了丰富的 API,使开发者能够轻松地将工作流功能集成到各种应用程序中。
-
轻量级和高性能:Activiti7 的设计重点在于轻量级和性能,使其适合于各种规模的项目,从小型应用到大型企业系统。
-
云原生支持:Activiti7 专为云环境优化,支持在云环境中运行,与微服务架构兼容。
-
Spring Boot 集成:Activiti7 可以很好地与 Spring Boot 集成,提供了便捷的方式来部署和管理业务流程。
应用场景
Activiti7 可用于多种业务场景,包括但不限于:
- 自动化流程:自动化企业内的标准业务流程,如员工请假流程、财务审批流程等。
- 文档管理:在文档审批和管理过程中执行业务逻辑。
- 任务分配:在团队或部门之间自动分配和管理任务。
- 业务规则集成:与业务规则引擎集成,提供决策支持。
技术栈
Activiti7 使用 Java 作为主要开发语言,但它的 REST API 允许通过网络与使用其他编程语言编写的系统交互。它通常与关系数据库一起使用,以持久化流程实例、任务和其他相关数据。
总的来说,Activiti7 是一个强大、灵活的工作流和 BPM 解决方案,适用于需要自动化和优化其业务流程的组织和开发者。通过支持 BPMN 2.0、提供灵活的集成选项,并专为云环境优化,它成为了企业流程管理的流行选择。
相关文章:
Java复习系列之阶段三:框架原理
1. Spring 1.1 核心功能 1. IOC容器 IOC,全称为控制反转(Inversion of Control),是一种软件设计原则,用于减少计算机代码之间的耦合度。控制反转的核心思想是将传统程序中对象的创建和绑定由程序代码直接控制转移到…...
【Python】01快速上手爬虫案例一:搞定豆瓣读书
文章目录 前言一、VSCodePython环境搭建二、爬虫案例一1、爬取第一页数据2、爬取所有页数据3、格式化html数据4、导出excel文件 前言 实战是最好的老师,直接案例操作,快速上手。 案例一,爬取数据,最终效果图: 一、VS…...

JavaEE 网络编程
JavaEE 网络编程 文章目录 JavaEE 网络编程引子1. 网络编程-相关概念1.1 基本概念1.2 发送端和接收端1.3 请求和响应1.4 客户端和服务端 2. Socket 套接字2.1 数据包套接字通信模型2.2 流套接字通信模型2.3 Socket编程注意事项 3. UDP数据报套接字编程3.1 DatagramSocket3.2 Da…...
)
5.rk3588用cv读取图片(C++)
rk3588自带了cv,不需要重新安装,执行以下操作即可: 一、读取图片 1.读取某张图片 #define HAVE_OPENCV_VIDEO #define HAVE_OPENCV_VIDEOIO#include <opencv2/opencv.hpp> #include <iostream> #include <opencv2/opencv.h…...
Github 无法正常访问?一招解决
查询IP网址: https://ip.chinaz.com/ 主页如下: 分别查询以下三个网址的IP: github.com github.global.ssl.fastly.net assets-cdn.github.com 修改 hosts 文件: 将 /etc/hosts 复制到 home 下 sudo cp /etc/hosts ./ gedit hosts 在底下…...
架构师的36项修炼-08系统的安全架构设计
本课时讲解系统的安全架构。 本节课主要讲 Web 的攻击与防护、信息的加解密与反垃圾。其中 Web 攻击方式包括 XSS 跨站点脚本攻击、SQL 注入攻击和 CSRF 跨站点请求伪造攻击;防护手段主要有消毒过滤、SQL 参数绑定、验证码和防火墙;加密手段,…...
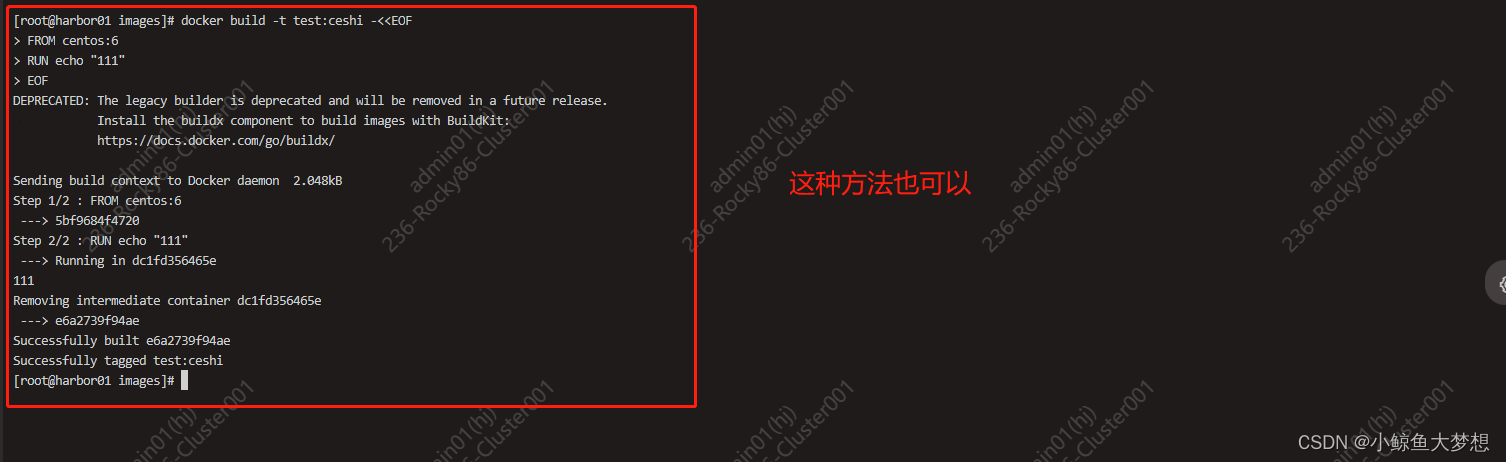
docker 构建应用
docker 应用程序开发手册 开发 docker 镜像 Dockerfile 非常容易定义镜像内容由一系列指令和参数构成的脚本文件每一条指令构建一层一个 Dockerfile 文件包含了构建镜像的一套完整指令指令不区分大小写,但是一般建议都是大写从头到尾按顺序执行指令必须以 FROM 指…...

Go语言grpc服务开发——Protocol Buffer
文章目录 一、Protocol Buffer简介二、Protocol Buffer编译器安装三、proto3语言指南四、序列化与反序列化五、引入grpc-gateway1、插件安装2、定义proto文件3、生成go文件4、实现Service服务5、gRPC服务启动方法6、gateway服务启动方法7、main函数启动8、验证 相关参考链接&am…...

【开源】基于JAVA语言的实验室耗材管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 耗材档案模块2.2 耗材入库模块2.3 耗材出库模块2.4 耗材申请模块2.5 耗材审核模块 三、系统展示四、核心代码4.1 查询耗材品类4.2 查询资产出库清单4.3 资产出库4.4 查询入库单4.5 资产入库 五、免责说明 一、摘要 1.1…...
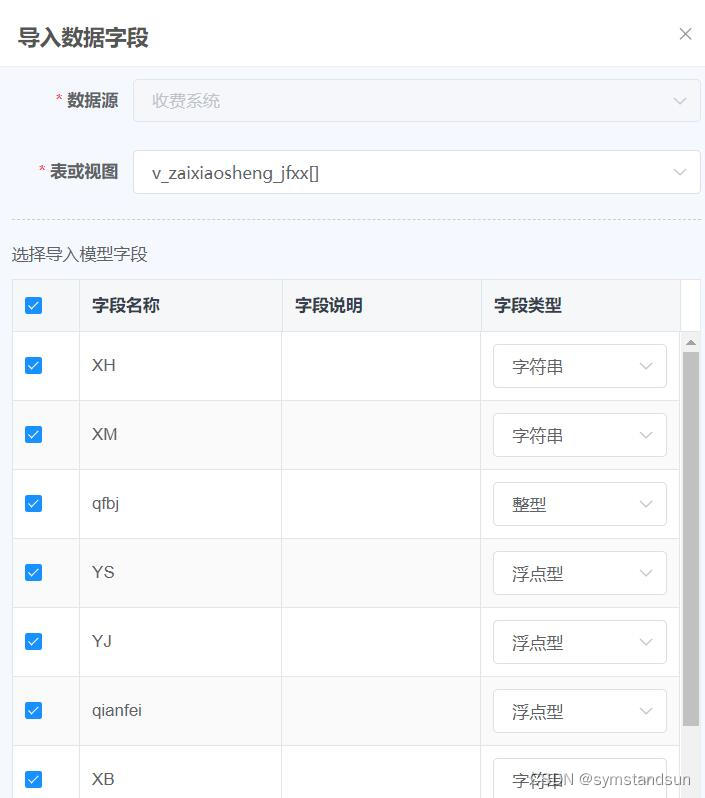
金智易表通构建学生缴费数据查询+帆软构建缴费大数据报表并整合到微服务
使用金智易表通挂接外部数据,快速建设查询类服务,本次构建学生欠费数据查询,共有3块设计,规划如下: 1、欠费明细查询:学校领导和财务处等部门可查询全校欠费学生明细数据;各二级学院教职工可查询本二级学院欠费学生明细数据。 2、大数据统计报表:从应收总额、欠费总额…...

MySQL复合索引
复合索引是指在数据库表上同时包含两个或更多列的索引。它们对于优化涉及这些列的查询非常有效,特别是当这些列常常在查询条件(如WHERE子句)、排序(ORDER BY子句)和连接(JOIN条件)中使用时。 复…...

Web3 游戏开发者的数据分析指南
作者:lesleyfootprint.network 在竞争激烈的 Web3 游戏行业中,成功不仅仅取决于游戏的发布,还需要在游戏运营过程中有高度的敏锐性,以应对下一次牛市的来临。 人们对 2024 年的游戏行业充满信心。A16Z GAMES 和 GAMES FUND ONE …...
temu跨境电商怎么样?做temu蓝海项目有哪些优势?
在全球电商市场激烈的竞争中,Temu跨境电商平台以其独特的优势和策略,逐渐崭露头角。对于许多想要拓展海外市场的商家来说,Temu的蓝海项目提供了一个充满机遇的新平台。本文将深入探讨Temu跨境电商的优势以及在蓝海市场中的发展前景。 全球化市…...
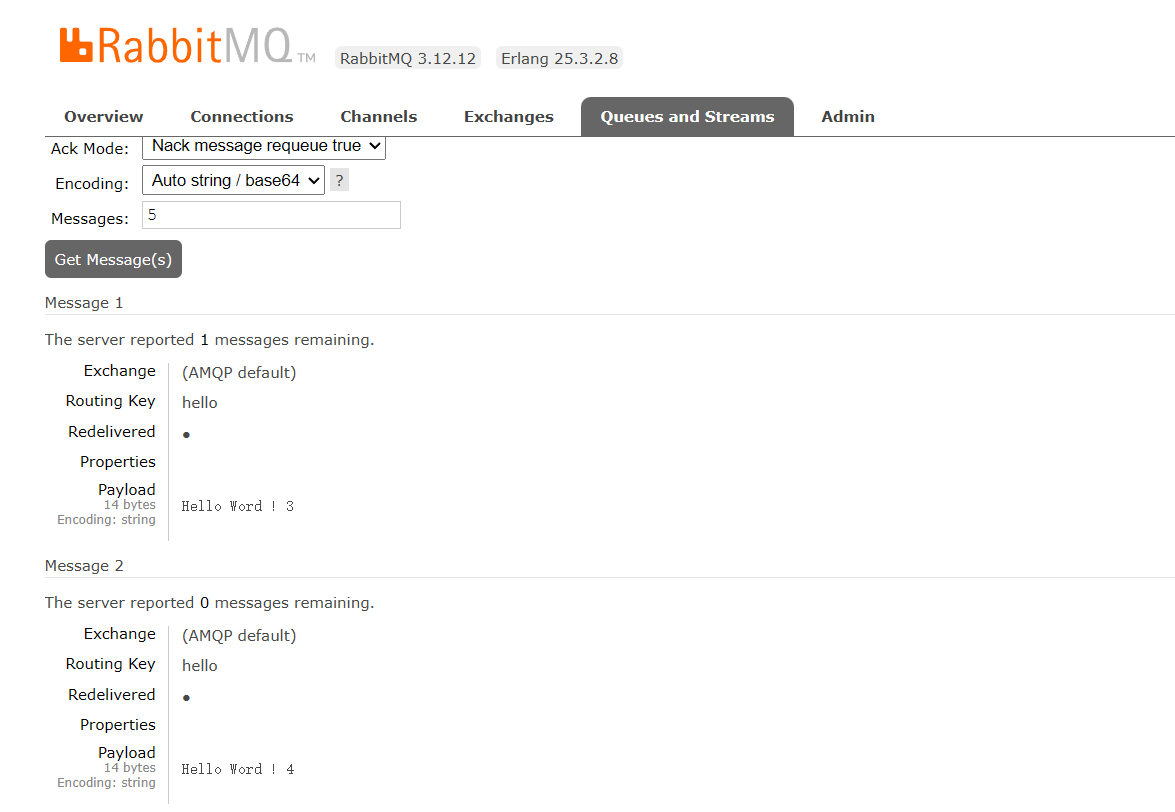
C#使用RabbitMQ-1_Docker部署并在c#中实现简单模式消息代理
介绍 RabbitMQ是一个开源的消息队列系统,实现了高级消息队列协议(AMQP)。 🍀RabbitMQ起源于金融系统,现在广泛应用于各种分布式系统中。它的主要功能是在应用程序之间提供异步消息传递,实现系统间的解耦和…...

EasyExcel中自定义拦截器的运用
在EasyExcel中自定义拦截器不仅可以帮助我们不止步于数据的填充,而且可以对样式、单元格合并等带来便捷的功能。下面直接开始 我们定义一个MergeWriteHandler的类继承AbstractMergeStrategy实现CellWriteHandler public class MergeLastWriteHandler extends Abst…...
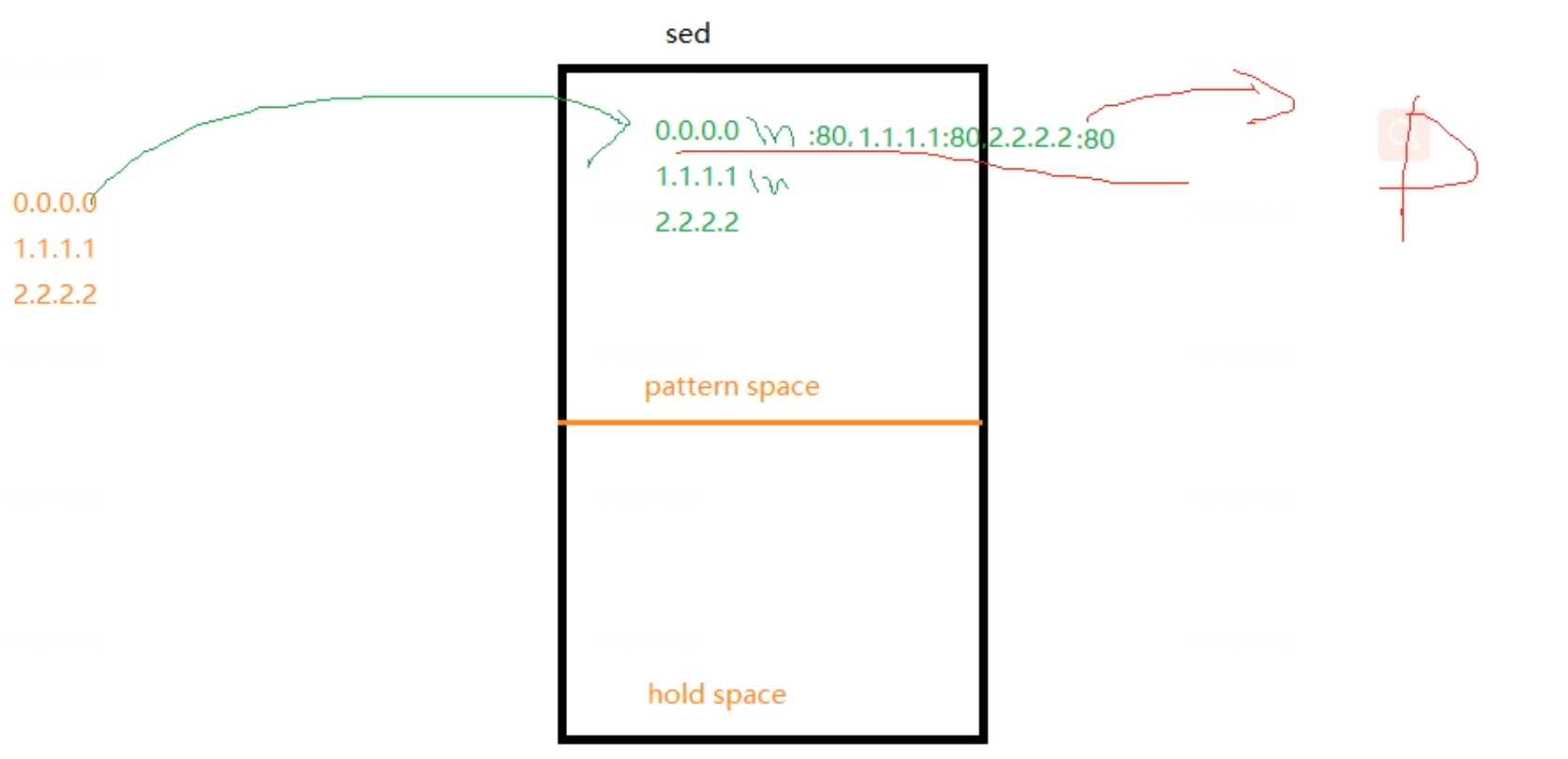
shell编程-7
shell学习第7天 sed的学习1.sed是什么2.sed有两个空间pattern hold3.sed的语法4. sed里单引号和双引号的区别:5.sed的查找方式6.sed的命令sed的标签用法sed的a命令:追加sed的i命令:根据行号插入sed的c命令:整行替换sed的r命令sed的s命令:替换sed的d命令:删除sed中的&符号 7…...

工业智能网关储能物联网应用实现能源的高效利用及远程管理
储能电力物联网是指利用物联网技术和储能技术相结合,实现对电力系统中各种储能设备的智能管理和优化控制。随着可再生能源的不断发展和应用,电力系统面临着越来越大的电力调度和储能需求而储能电力物联网的出现可以有效解决这一问题,提高电力…...

虹科数字化与AR部门升级为安宝特AR子公司
致关心虹科AR的朋友们: 感谢您一直以来对虹科数字化与AR的支持和信任,为了更好地满足市场需求和公司发展的需要,虹科数字化与AR部门现已升级为虹科旗下独立子公司,并正式更名为“安宝特AR”。 ”虹科数字化与AR“自成立以来&…...

服务器是什么?(四种服务器类型)
服务器 服务器定义广义: 专门给其他机器提供服务的计算机。狭义:一台高性能的计算机,通过网络提供外部计算机一些业务服务 个人PC内存大概8G,服务器内存128G起步 服务器是什么 服务器指的是 网络中能对其他机器提供某些服务的计算机系统 ,相对…...
09-微服务Sentinel整合GateWay
一、概述 在微服务系统中,网关提供了微服务系统的统一入口,所以我们在做限流的时候,肯定是要在网关层面做一个流量的控制,Sentinel 支持对 Spring Cloud Gateway、Zuul 等主流的 API Gateway 进行限流。 1.1 总览 Sentinel 1.6.…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...