大数据学习之Flink算子、了解(Source)源算子(基础篇二)
Source源算子(基础篇二)
目录
Source源算子(基础篇二)
二、源算子(source)
1. 准备工作
2.从集合中读取数据
可以使用代码中的fromCollection()方法直接读取列表
也可以使用代码中的fromElements()方法直接列出数据获取
3. 从文件中读取数据
说明:
4. 从Socket读取数据
(1)编写StreamWordCount
(2)在 Linux 环境的主机bigdata1 上,执行下列命令,发送数据进行测试:
(3)启动 StreamWordCount 程序
(4)从 bigdata1 发送数据:
(5)看控制台的输出结果
5.从Kafka读取数据
6.自定义源算子(source)
7.Flink支持的数据类型
二、源算子(source)

Flink 可以从各种来源获取数据,然后构建 DataStream 进行转换处理。一般将数据的输入 来源称为数据源,而读取数据的算子就是源算子(Source)。所以,Source 就是我们整个处理 程序的输入端。
Flink 代码中通用的添加 Source 的方式,是调用执行环境的 addSource()方法:
//通过调用 addSource()方法可以获取 DataStream 对象
val stream = env.addSource(...)方法传入一个对象参数,需要实现 SourceFunction 接口,返回一个 DataStream。
1. 准备工作

case class Event(user: String, url: String, timestamp: Long)2.从集合中读取数据
- 最简单的读取数据的方式,就是在代码中直接创建一个集合,然后调用执行环境的 fromCollection 方法进行读取。
- 这相当于将数据临时存储到内存中,形成特殊的数据结构后, 作为数据源使用,一般用于测试。
import org.apache.flink.streaming.api.scala._case class Event(user: String, url: String, timestamp: Long)object SourceCollection {def main(args: Array[String]): Unit = {//获取流执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment//设置并行度(并行任务的数量)为1env.setParallelism(1)// 创建包含点击事件的列表// 点击操作中包含两个事件val clicks = List(Event("Mary", "/.home", 1000L), Event("Bob", "/.cart", 2000L))//将列表作为流输出//把clicks作为数据流val stream = env.fromCollection(clicks)//fromElements从给定的元素集合中创建一个DataStreamval stream1 = env.fromElements(Event("zhangsan","/.opt",1000L),Event("lisi","/.opt",2000L))stream.print("stream")stream1.print("stream1")env.execute()}
}可以使用代码中的fromCollection()方法直接读取列表
也可以使用代码中的fromElements()方法直接列出数据获取
3. 从文件中读取数据
真正的实际应用中,自然不会直接将数据写在代码中。通常情况下,我们会从存储介质中 获取数据,一个比较常见的方式就是读取日志文件。这也是批处理中最常见的读取方式。
val stream = env.readTextFile("input/words.txt")
说明:
-
参数可以是文件,可以是目录
-
可以是绝对路径,也可以是相对路径
-
相对路径是从系统属性 user.dir 获取路径:在 IDEA 下是 project 的根目录, standalone 模式下是集群节点根目录;
-
系统属性 user.dir:这是一个Java系统属性,它表示用户当前的工作目录。在很多应用中,它通常被用作参考路径。
-
IDEA下是project的根目录:当你在IDEA中打开一个项目时,项目的根目录通常是IDEA的工作目录。相对路径就是基于这个根目录来确定的。
-
standalone模式下是集群节点根目录:如Hadoop分布式计算系统中的独立模式(standalone mode)。在这种模式下,路径可能是相对于集群节点的根目录。
-
-
也可以从 HDFS 目录下读取, 使用路径 hdfs://...
-
前提要在pom文件中添加hadoop相关依赖
-
4. 从Socket读取数据
不论从集合还是文件,我们读取的其实都是有界数据。在流处理的场景中,数据往往是无 界的。一个简单的例子,就是我们之前用到的读取 socket 文本流。这种方式由于吞吐量小、 稳定性较差,一般也是用于测试。
//通过主机名和端口号读取socket文本流val linDs = env.socketTextStream("bigdata1",7777)具体实现案例:
(1)编写StreamWordCount
import org.apache.flink.streaming.api.scala._object StreamWordCount {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment//通过主机名和端口号读取socket文本流val linDs = env.socketTextStream("bigdata1",7777)//进行转换计算val result = linDs.flatMap(data => data.split(" ")) //用空格切分字符串.map((_,1)) //切分后的字符串转换为一个元组.keyBy(_._1) //使用元组的第一个字段进行分组.sum(1) //分组后的数据的第二个字段进行累加//打印计算结果result.print()env.execute()}
}(2)在 Linux 环境的主机bigdata1 上,执行下列命令,发送数据进行测试:
$ nc -lk 7777(3)启动 StreamWordCount 程序
我们会发现程序启动之后没有任何输出、也不会退出。这是正常的——因为 Flink 的流处 理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。
(4)从 bigdata1 发送数据:
hello flink
hello world
hello scala(5)看控制台的输出结果

5.从Kafka读取数据
Kafka 作为分布式消息传输队列,是一个高吞吐、易于扩展的消息系统。
而消息队列的传输方式,恰恰和流处理是完全一致的。
所以可以说 Kafka 和 Flink 天生一对,是当前处理流式数据的双子星。
在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算,这样的架构已经成为众多企业的首选
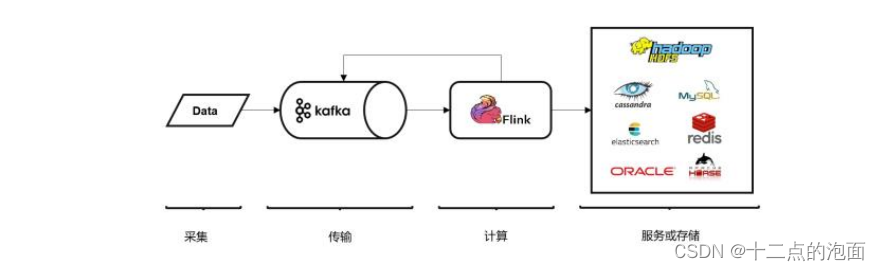
调用 env.addSource(),传入 FlinkKafkaConsumer 的对象实例就可以了。
创建 FlinkKafkaConsumer 时需要传入三个参数:
- 第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic 列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据 时,Kafka 连接器将会处理所有 topic 的分区,将这些分区的数据放到一条数据流中 去。
- 第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消 息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中 53 使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数 组简单地反序列化成字符串。DeserializationSchema 和 KeyedDeserializationSchema 是 公共接口,所以我们也可以自定义反序列化逻辑。
- 第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
更新中...6.自定义源算子(source)
接下来我们创建一个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法: run()和 cancel()。
- run()方法:使用运行时上下文对象(SourceContext)向下游发送数据;
- cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果。
7.Flink支持的数据类型
相关文章:
大数据学习之Flink算子、了解(Source)源算子(基础篇二)
Source源算子(基础篇二) 目录 Source源算子(基础篇二) 二、源算子(source) 1. 准备工作 2.从集合中读取数据 可以使用代码中的fromCollection()方法直接读取列表 也可以使用代码中的fromElements()方…...
抖去推短视频矩阵系统+实景无人直播系统技术源头开发
抖去推爆款视频生成器,通过短视频矩阵、无人直播,文案引流等,打造实体商家员工矩阵、用户矩阵、直播矩阵,辅助商家品牌曝光,团购转化等多功能赋能商家拓客引流。 短视频矩阵通俗来讲就是批量剪辑视频和批量发布视频&a…...

【机器学习】一文读懂统计学与机器学习的区别。
统计学与机器学习的区别 1、机器学习2、统计学3、统计学与机器学习异同性3.1 差异性3.2 相似性 4、总结 1、机器学习 关于机器学习,我想大家都很熟悉,这里我再简单唠叨一些 机器学习是人工智能的一个子领域,主要关注如何通过算法使计算机系统…...
燃烧的指针(二)
🌈个人主页:小田爱学编程 🔥 系列专栏:c语言从基础到进阶 🏆🏆关注博主,随时获取更多关于c语言的优质内容!🏆🏆 😀欢迎来到小田代码世界~ &#x…...
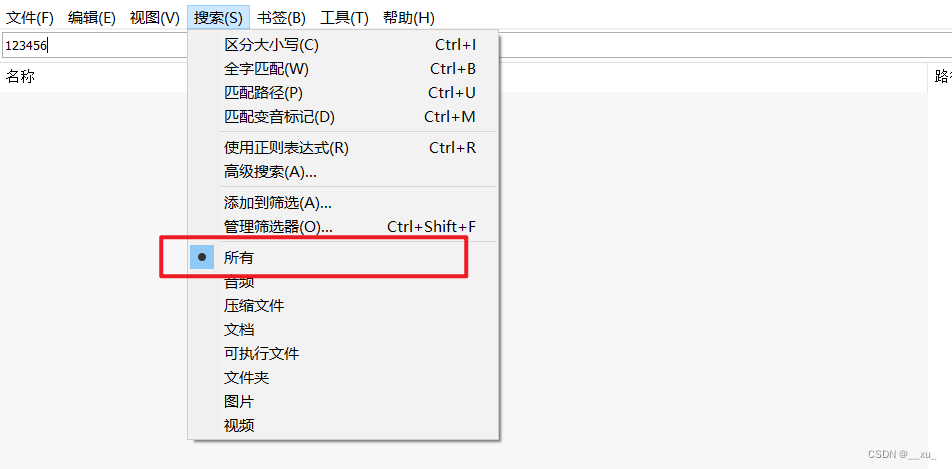
【工具使用-Everything】everything只能搜到文件夹,无法搜到文件
一,问题现象 everything搜索时,只能搜索到文件夹,无法搜索到文件夹下的文件。 二,问题原因 everything搜索设置问题,设置为"文件夹"导致 三,解决方法 将搜索选项设置为“所有”即可&#x…...

手写rpc和redis
rpc框架搭建 consumer 消费者应用 provider 提供的服务 Provider-common 公共类模块 rpc 架构 service-Registration 服务发现 nacos nacos配置中心 load-balancing 负载均衡 redis-trench 手写redis实现和链接 package com.trench.protocol;import com.trench.enumUtil.Redis…...
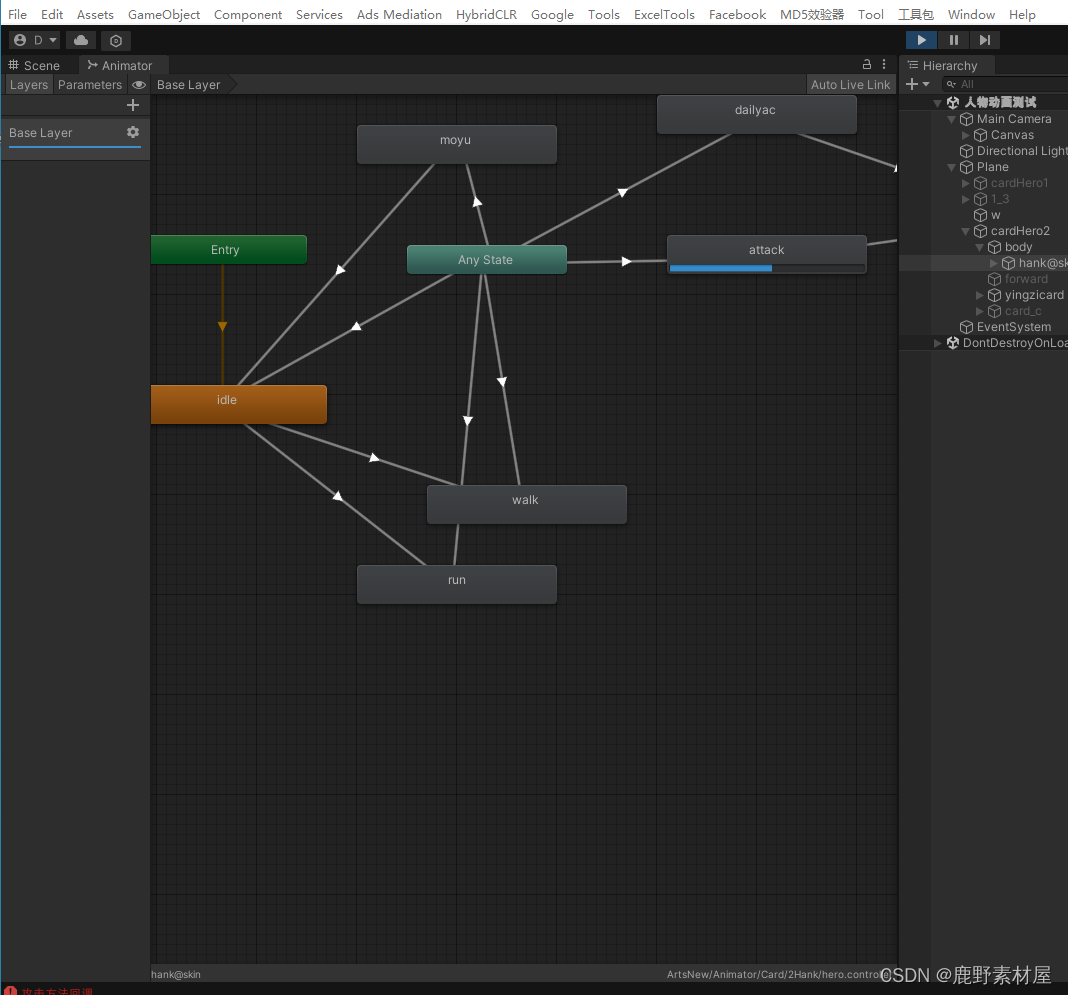
Unity动画桢事件
1,使用原因 在新项目内部审核的时候,说什么动画节奏不匹配,所以决定用动画桢事件来处理技能释放。当释放技能的时候,先播放技能动画,然后再动画桢所在的时间戳执行技能的逻辑。 2,具体实现 1,…...

搭建Redis集群
一 应用场景 为什么需要redis集群? 当主备复制场景,无法满足主机的单点故障时,需要引入集群配置。 一般数据库要处理的读请求远大于写请求 ,针对这种情况,我们优化数据库可以采用读写分离的策略。我们可以部 署一台…...

C语言sizeof 不是函数吗?
一、问题 sizeof 怎么⽤,它不是函数吗? 二、解答 sizeof 在 C 和 C 中不是一个函数,而是一个运算符。它在编译时计算其操作数所占用的内存大小,并返回一个大小(字节数),这个结果是类型或表达式…...

Mybatis的XML配置
MyBatis 是一个持久层框架,通过 XML 配置文件来定义 SQL 映射和结果的映射规则。以下是关于 MyBatis XML 配置文件的详细说明: 基本结构: XML 配置文件通常包含 <mapper>、<resultMap>、<typeAliases> 等元素。 2. mappe…...

Oracle报错:ORA-08002: sequence CURRVAL is not yet defined in this session
问题 直接查询序列的当前值,然后报了这个错误。 SELECT HR.EMPLOYEES_SEQ.CURRVAL; ORA-08002: sequence CURRVAL is not yet defined in this session解决 ORA-08002错误是Oracle数据库中的一个常见错误,它表示在当前会话中未定义序列的CURRVAL值。这…...
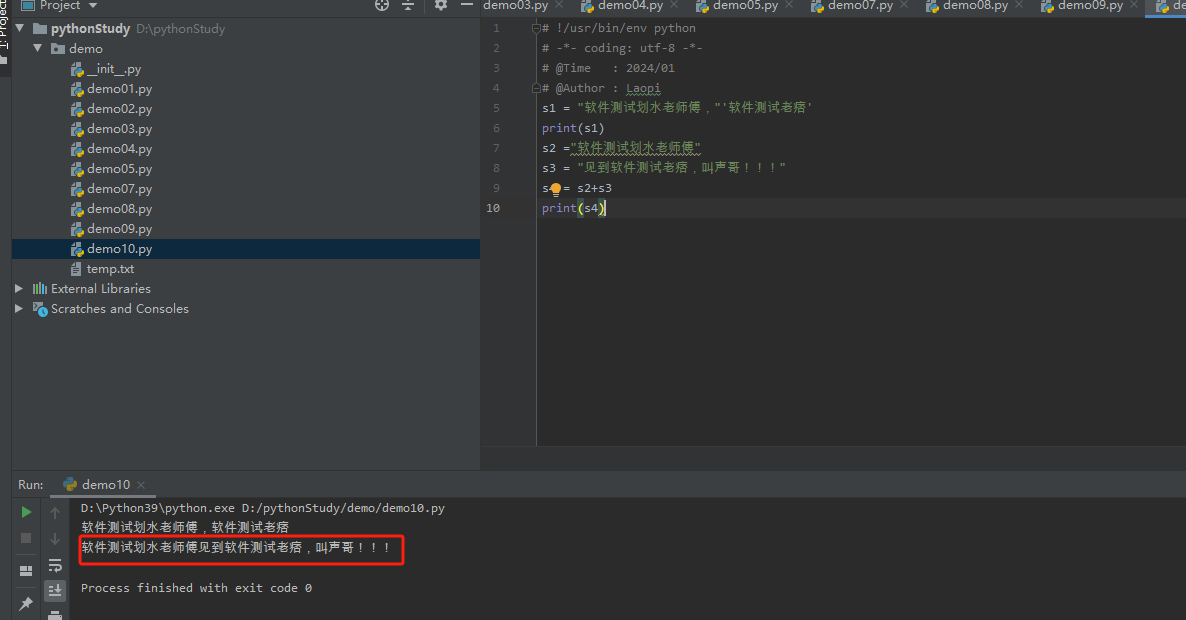
python10-Python的字符串之拼接字符串
如果直接将两个字符串紧挨着写在一起,Python就会自动拼接它们,例如如下代码。 s1 "软件测试划水老师傅,"软件测试老痞print(s1) 上面代码将会输出: 软件测试划水老师傅,软件测试老痞 上面这种写法只是书写字符串的一…...

华为三层交换机之基本操作
Telnet简介 Telnet是一个应用层协议,可以在Internet上或局域网上使用。它提供了基于文本的远程终端接口,允许用户在本地计算机上登录到远程计算机,然后像在本地计算机上一样使用远程计算机的资源。Telnet客户端和服务器之间的通信是通过Telnet协议进行的…...
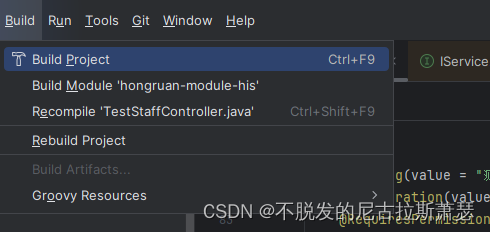
IntelliJ IDEA 快捷键大全
IntelliJ IDEA 快捷键大全 一、文本编辑二、构建、编译项目 一、文本编辑 CtrlN 查找类 CtrlN 查找文件 CtrlF 查找文本 可以根据需求去选择红框内的选项 CtrlX 剪切 剪切选中文本,如果未选中则剪切当前行CtrlC 复制 复制选中文本,如果未选中则复制当前…...

scrapy的概念作用和工作流程
1. scrapy的概念 Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。 Scrapy 使用了Twisted[twɪstɪd]异步网络框架,可以加快我们的下载速度。 Scrapy文档地址:http://scrapy-chs.readthedocs.io/zh_…...

首页热卖推荐商品显示axios异步请求数据动态渲染实现
flex-wrap属性: 默认情况下,项目都排在一条线(又称“轴线”)上。flex- wrap属性定义,如果一条轴线 排不下,如何换行? flex-wrap:wrap 该样式用于设置 换行。 .product_name{white-space: nowrap…...
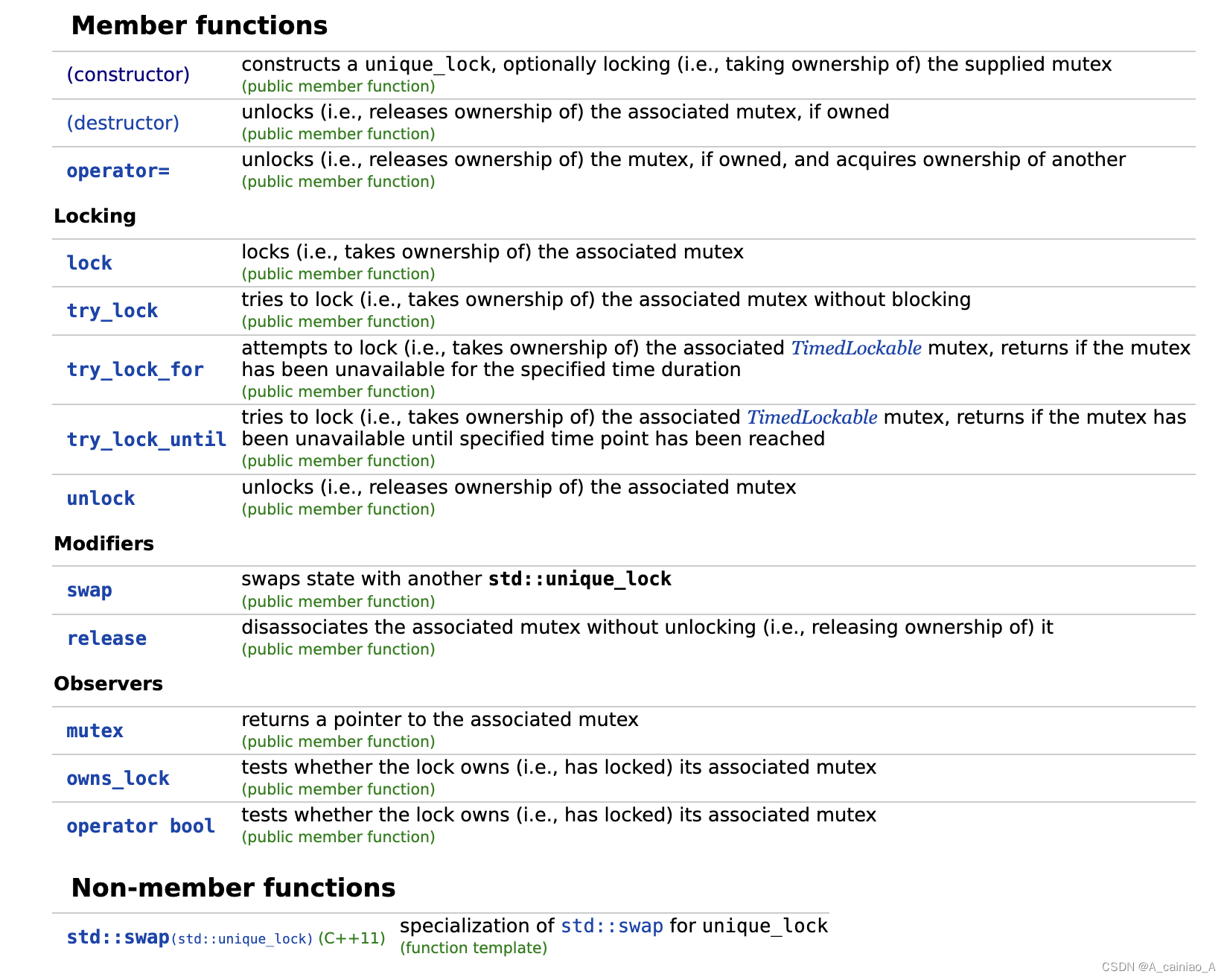
【C++11并发】mutex 笔记
简介 在多线程中往往需要访问临界资源,C11为我们提供了mutex等相关类来保护临界资源,保证某一时刻只有一个线程可以访问临界资源。主要包括各种mutex,他们的命名大都是xx_mutex。以及RAII风格的wrapper类,RAII就是一般在构造的时…...

洛谷 P5635 【CSGRound1】天下第一
原址链接 P5635 【CSGRound1】天下第一 先看标签 搜索?模拟?用不着这么复杂 创建函数a(int x,int y,int p) a(int x,int y,int p){if(x<0){return 1;}x (xy)%p;if(y<0){return 2;}y (xy)%p;return a(x,y,p); }写入主函数 #include<iostrea…...

如何通过Navicat远程访问宝塔面板安装的MySQL数据库
Navicat报错信息: 错误代码 1045 Access denied for user ‘root’’219.144.205.81’ (using password:YES) —— 没有权限的访问的报错 1.宝塔面板 > 放行端口:3306 2.阿里云安全组 > 放行端口:3306 3.配置mysql3306端口 4.使用Xshell 链接服务器 m…...
)
【硅谷甄选】导航守卫(进度条,网页标题,路由鉴权)
import setting from /setting import router from /router // 任意路由切换实现进度条业务: nprogress插件 import nprogress from nprogress // js插件在ts中的报错 // 引入进度条样式 import nprogress/nprogress.css // 表示在加载进度条时不显示加载小图标 np…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...