DolphinScheduler + Amazon EMR Serverless 的集成实践

01
背景
Apache DolphinScheduler 是一个分布式的可视化 DAG 工作流任务调度开源系统,具有简单易用、高可靠、高扩展性、⽀持丰富的使用场景、提供多租户模式等特性。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
随着企业规模的扩大,业务数据的激增,以及 Apache DolphinScheduler 产品的完善、社区的日益火爆,越来越多的 EMR 客户,使用其进行集群任务的日常调度。相关安装、集成实践,本文不做详述,可以参考博客《使用 DolphinScheduler 进行 EMR 任务调度》。
使用 DolphinScheduler 进行 EMR 任务调度
https://aws.amazon.com/cn/blogs/china/emr-task-scheduling-with-dolphinscheduler/
Amazon EMR Serverless 是 EMR 中的无服务器选项,数据分析师和工程师可借助其轻松运行开源大数据分析框架(例如 Apache Spark 和 Apache Hive ),而无需配置、管理和扩展集群或服务器,使得数据工程师和分析师能够进一步聚焦业务价值的创造,最终实现降本增效。因此,越来越多的客户,开始尝试从 EMR on EC2 切换到 EMR Serverless,或者说从 DolphinScheduler + EMR 切换到 DolphinScheduler + EMR Serverless。
但在实践过程中,如下问题往往成为了拦路虎:
异步执行:在使用 EMR on Amazon EC2 + DolphinScheduler 时,很多客户选择 beeline、PyHive 或者 Spark-Submit 的方式,让任务提交后同步执行,以便调度引擎的正常工作与进度的监控。但 EMR Serverless 仅支持任务提交后的异步执行,这对于使用 DolphinScheduler 的客户来讲是很难接受的。
日志获取:切换到 EMR Serverless 后,获取任务日志的方式也发生了变化。由于任务的异步执行,导致在 DolphinScheduler 提交任务后,往往需要到 EMR Serverless 的 Job 列表页面查看日志,影响工作效率。
混合调度:很多客户经过实际评估后,往往需要将一部分任务放到 EMR on EC2 上运行,将另一部分任务放到 EMR Serverless,以达到最佳的性价比。但两类群集的任务执行与监控方式区别较大,将两种任务放到调度系统中混合调度的维护成本比较高。
任务形态:客户实际案例中,有的任务是执行一段 SQL 语句,有的任务是执行一个 Spark 脚本文件。但在 EMR Serverless 中默认仅支持提交脚本文件,无形中又给客户多设置了一道使用障碍。
02
解决方案
整体介绍与示例
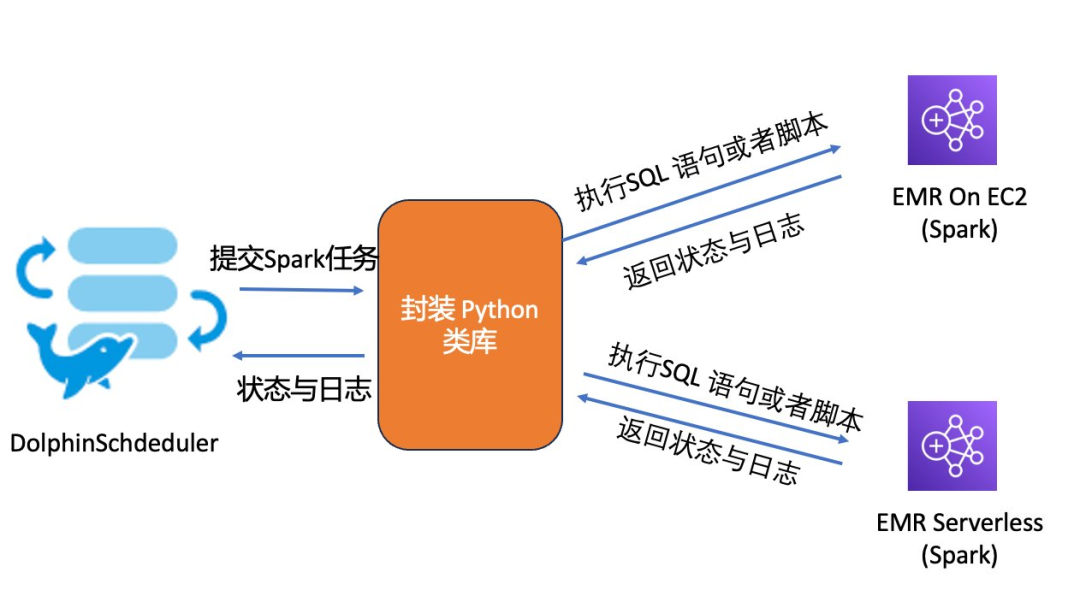
本文将以 Python 语言提交 Spark 任务为例,探索针对上述问题的解决方案。如下图所示,通过封装一个 Python 类库,将 EMR On EC2 与 EMR Serverless 两种形态下的 Spark 任务提交、执行与监控细节进行抽象,面向 DolphinScheduler 提供统一的接口来进行调用,简化用户使用 EMR Serverless 的门槛。
我们先通过代码演示如何使用封装的 Python 类库提交 Spark 任务,代码示例如下。其中 emr_common.Session 是抽象出来的 Python 类。
from emr_common import Session
#jobtype=0时,表示 EMR On EC2。可以手动设置集群 ID, 若不设置则默认会获取活动集群中的第 1 个。
session_emr=Session(jobtype=0)
#提交 SQL 语句,执行过程中,会持续打印状态并在任务完成时,打印日志
session_emr.submit_sql("sql-task","SELECT * FROM xxtable LIMIT 10"
#提交脚本文件,spark-test.py 是一个 pysark 或者 pyspark.sql 的程序脚本,执行过程中,会持续打印状态并在任务完成时,打印日志
session_emr.submit_file("script-task","spark-test.py")#jobtype=1 时,表示 EMR Serverless。可以手动设置应用 ID,若不设置则默认会获取 spark 应用程序中的第 1 个。
session_emrserverless=Session(jobtype=1,logs_s3_path='s3://xxx/xx')
#提交 SQL 语句,执行过程中,会持续打印状态并在任务完成时,打印日志
session_emrserverless.submit_sql("sql-task","SELECT * FROM xxtable LIMIT 10")
#提交脚本文件,spark-test.py 是一个 pysark 或者 pyspark.sql 的程序脚本,执行过程中,会持续打印状态并在任务完成时,打印日志
session_emrserverless.submit_file("script-task","spark-test.py")原理 & 细节阐述
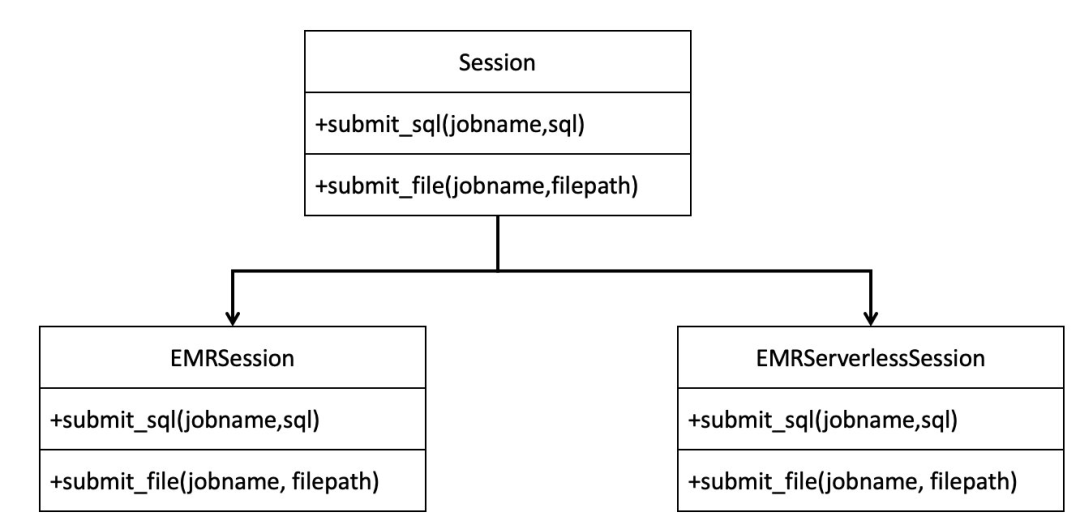
整体的类结构设计,采用的是面向对象的代理模式。面向客户使用的类是 Session 类,在 Session 类的构造函数中,会根据传入 jobtype 字段值来进一步构建内部类:EMRSession 或者 EMRServerlessSession。而真正的 Spark 任务提交、监控、日志查询逻辑则是封装在 EMRSession 或者 EMRServerlessSession 的对应方法中。
EMRSession 的实现逻辑
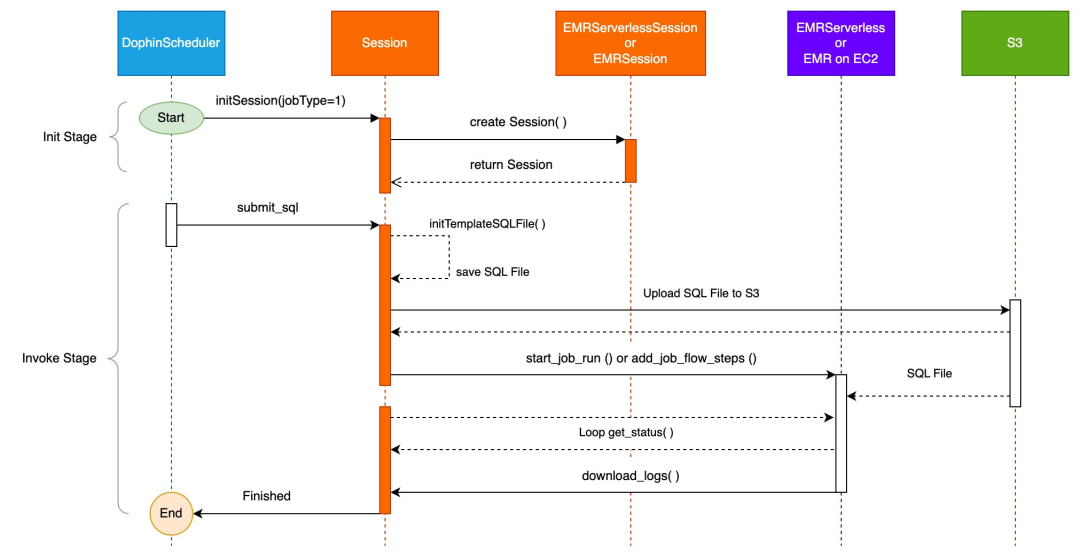
当调用 submit_sql(jobname,sql) 方法来提交任务,则会先读取 sql_template.py 文件,使用参数 sql 来替换文件中的${query}占位符,并生成一个临时文件上传至 Amazon S3;若是通过 submit_file(jobname,file) 方法来提交任务,则需要提前将脚本文件通过 DolphinScheduler 的资源中心进行上传,DolphinScheduler 后台会将文件上传至 S3 的指定目录。
当脚本文件上传至 S3 后,再通过 EMR Steps 中的 add_job_flow_steps 命令来远程提交 Spark 任务。这里有两点需要指出:若设置了 Python 虚拟环境,则在提交 Spark 任务时,会在 dd_job_flow_steps 命令的 spark-submit 配置部分设置相关参数来使用这个虚拟环境;同时也会使用默认的或者用户自定义的 spark_conf 参数来设置 spark 的 driver、executor 配置参数。
在任务执行过程中,会每隔 10 秒获取一次任务状态,并打印至控制台。在失败状态时失败时,会到约定的 S3 路径上获取 Driver 的 stderr 与 stdout 日志文件。
EMRServerless 的实现逻辑
原理与 EMRSession 大同小异,只是各步骤具体的接口调用不同。
若调用 submit_sql(jobname,sql) 方法来提交任务,则会先读取 sql_template.py 文件,使用参数 sql 来替换文件中的${query}占位符,并生成一个临时文件上传至 S3;若是通过 submit_file(jobname,file) 方法来提交任务,则需要提前将脚本文件通过 DolphinScheduler 的资源中心进行上传,DolphinScheduler 后台会将文件上传至 S3 的指定目录。
当脚本文件上传至 S3 后,再通过 start_job_run 命令来远程提交 Spark 任务。这里有两点需要指出:若设置了 Python 虚拟环境,则在提交 Spark 任务时,会在 start_job_run 中 spark-submit 配置中设置相关参数来使用这个虚拟环境;同时也会使用默认的或者用户自定义的 spark_conf 参数来设置 Spark 的 driver、executor 配置参数。
在任务执行过程中,会每隔 10 秒获取一次任务状态,并打印至控制台。在失败状态时失败时,会到约定的 S3 路径上获取 Driver 的 stderr 与 stdout 日志文件。
接下来,我们通过时序图来表示 submit_sql(jobname,sql) 的调用逻辑,如下图所示:
完整代码
下面将展示完整的代码。其中,Session 类构造函数的参数,大多设置了默认值,以减少调用时的反复设置。在实际使用时,需根据真实场景来替换这些参数的默认值。接下来,将逐一解释 Session 类构造函数的每个参数。
application_id:若是 serverless,则设置应用程序的 ID; 若是 emr on ec2,则设置集群 ID;若不设置,则自动其第一个 active 的 app 或者 cluster 的 ID
jobtype:0: EMR on EC2;1: serverless;默认值为 0
job_role:EMR On EC2 的集群角色或者 EMRServerless 的 Job 角色。考虑到两者都需要 S3、Glue 等服务的访问权限,可以统一使用一个角色
dolphin_s3_path:DolphinScheduler 中配置的用于存储文件的 S3 路径。在 DolphinScheduler 中调度的 Python 任务代码中,可以直接通过相对路径引用其它 python 文件
logs_s3_path:对于 EMR on EC2 来说,就是集群级别的保存日志的 S3 路径;对于 EMR Serverless 来讲是 Job 级别的保存日志的 S3 路径,但通常可以统一使用一个路径
tempfile_s3_path:类库中会创建一些临时文件并保存在 S3 上
python_venv_s3_path:有的客户在编写 pyspark 时,还会引用一些其它的 Python 库。这时就需要准备一个 Python 虚拟环境,提前预置各类所需要的 Python 第三方库,并将虚拟环境打包并上传至 S3
spark_conf:这将会是一个常用的参数,用于设置 spark 的 driver 与 executor 的相关参数
import gzip
import os
from string import Template
import time
import boto3
from datetime import datetime
class EMRResult:def __init__(self,job_run_id,status):self.job_run_id=job_run_idself.status=status
class Session:def __init__(self,application_id='', #若是 serverless,则设置 应用的 ID; 若是emr on ec2,则设置集群 ID;若不设置,则自动其第一个active的 app 或者clusterjobtype=0, #0:EMR on EC2; 1: serverless job_role='arn:aws:iam::******:role/AmazonEMR-ExecutionRole-1694412227712',dolphin_s3_path='s3://*****/dolphinscheduler/ec2-user/resources/',logs_s3_path='s3://aws-logs-****-ap-southeast-1/elasticmapreduce/',tempfile_s3_path='s3://****/tmp/',python_venv_s3_path='s3://****/python/pyspark_venv.tar.gz',spark_conf='--conf spark.executor.cores=4 --conf spark.executor.memory=16g --conf spark.driver.cores=4 --conf spark.driver.memory=16g'):self.jobtype=jobtypeself.application_id = application_idself.region='ap-southeast-1'self.job_role = job_roleself.dolphin_s3_path = dolphin_s3_pathself.logs_s3_path=logs_s3_pathself.tempfile_s3_path=tempfile_s3_pathself.spark_conf=spark_confself.python_venv_s3_path=python_venv_s3_pathself.client = boto3.client('emr', region_name=self.region)self.client_serverless = boto3.client('emr-serverless', region_name=self.region)#如果未设置application_id,则查询当前第一个 active 的 EMR 集群/或者 EMR Serverless 应用的 IDif self.application_id == '':self.application_id=self.getDefaultApplicaitonId()if jobtype == 0 : #EMR on EC2self.session=EmrSession(region=self.region,application_id=self.application_id,job_role=self.job_role,dolphin_s3_path=self.dolphin_s3_path,logs_s3_path=self.logs_s3_path,tempfile_s3_path=self.tempfile_s3_path,python_venv_s3_path=self.python_venv_s3_path,spark_conf=self.spark_conf)elif jobtype ==1 : #EMR Serverlessself.session=EmrServerlessSession(region=self.region,application_id=self.application_id,job_role=self.job_role,dolphin_s3_path=self.dolphin_s3_path,logs_s3_path=self.logs_s3_path,tempfile_s3_path=self.tempfile_s3_path,python_venv_s3_path=self.python_venv_s3_path,spark_conf=self.spark_conf)else: #Pyhive ,used on-premiseself.session=PyHiveSession(host_ip="172.31.25.171",port=10000)self.initTemplateSQLFile()def submit_sql(self,jobname, sql):result= self.session.submit_sql(jobname,sql)if result.status == "FAILED" :raise Exception("ERROR:任务失败")def submit_file(self,jobname, filename):result= self.session.submit_file(jobname,filename)if result.status == "FAILED":raise Exception("ERROR:任务失败")def getDefaultApplicaitonId(self):if self.jobtype == 0: #EMR on EC2emr_clusters = self.client.list_clusters(ClusterStates=['STARTING', 'BOOTSTRAPPING', 'RUNNING', 'WAITING'])if emr_clusters['Clusters']:app_id= emr_clusters['Clusters'][0]['Id']print(f"选择默认的集群(或EMR Serverless 的应用程序)ID:{app_id}")return app_idelse:raise Exception("没有找到活跃的EMR集群")elif self.jobtype == 1: #EMR Serverlessemr_applications = self.client_serverless.list_applications()spark_applications = [app for app in emr_applications['applications'] if app['type'] == 'Spark']if spark_applications:app_id = spark_applications[0]['id']print(f"选择默认的应用ID:{app_id}")return app_idelse:raise Exception("没有找到活跃的 EMR Serverless 应用")def initTemplateSQLFile(self):with open('sql_template.py', 'w') as f:f.write('''
from pyspark.sql import SparkSessionspark = (SparkSession.builder.enableHiveSupport().appName("Python Spark SQL basic example").getOrCreate()
)df = spark.sql("$query")
df.show()''')
class EmrSession:def __init__(self,region,application_id, #若是EMR on EC2,则设置集群 ID;若不设置,则自动其第一个active的 app 或者clusterjob_role,dolphin_s3_path,logs_s3_path,tempfile_s3_path,python_venv_s3_path,spark_conf):self.s3_client = boto3.client("s3")self.region=regionself.client = boto3.client('emr', region_name=self.region)self.application_id = application_idself.job_role = job_roleself.dolphin_s3_path = dolphin_s3_pathself.logs_s3_path=logs_s3_pathself.tempfile_s3_path=tempfile_s3_pathself.python_venv_s3_path=python_venv_s3_pathself.spark_conf=spark_confself.client.modify_cluster(ClusterId=self.application_id,StepConcurrencyLevel=256)def submit_sql(self,jobname, sql):# temporary file for the sql parameterprint(f"RUN SQL:{sql}")self.python_venv_conf=''with open(os.path.join(os.path.dirname(os.path.abspath(__file__)), "sql_template.py")) as f:query_file = Template(f.read()).substitute(query=sql.replace('"', '\\"'))script_bucket = self.tempfile_s3_path.split('/')[2]script_key = '/'.join(self.tempfile_s3_path.split('/')[3:])current_time = datetime.now().strftime("%Y%m%d%H%M%S")script_key = script_key+"sql_template_"+current_time+".py"self.s3_client.put_object(Body=query_file, Bucket=script_bucket, Key=script_key)script_file=f"s3://{script_bucket}/{script_key}"result= self._submit_job_emr(jobname, script_file)self.s3_client.delete_object(Bucket=script_bucket, Key=script_key)return resultdef submit_file(self,jobname, filename):# temporary file for the sql parameterprint(f"Run File :{filename}")self.python_venv_conf=''if self.python_venv_s3_path and self.python_venv_s3_path != '':self.python_venv_conf = f"--conf spark.yarn.dist.archives={self.python_venv_s3_path}#environment --conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON=./environment/bin/python --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./environment/bin/python --conf spark.executorEnv.PYSPARK_PYTHON=./environment/bin/python"script_file=f"{self.dolphin_s3_path}{filename}"result= self._submit_job_emr(jobname, script_file)return resultdef _submit_job_emr(self, jobname, script_file):spark_conf_args = self.spark_conf.split()#设置虚拟环境的地址,用于支持 pyspark 以外的库python_venv_args=[]if self.python_venv_conf and self.python_venv_conf != '':python_venv_args=self.python_venv_conf.split()jobconfig=[{'Name': f"{jobname}",'ActionOnFailure': 'CONTINUE','HadoopJarStep': {'Jar': 'command-runner.jar','Args': ['spark-submit','--deploy-mode','cluster','--master','yarn','--conf','spark.yarn.submit.waitAppCompletion=true'] + spark_conf_args + python_venv_args + [script_file]}}]response = self.client.add_job_flow_steps(JobFlowId=self.application_id,Steps=jobconfig)print(jobconfig)if response['ResponseMetadata']['HTTPStatusCode'] != 200:print('task failed:')print(response)job_run_id = response['StepIds'][0]print(f"Submit job on EMR ,job id: {job_run_id}")job_done = Falsestatus='PENDING'while not job_done:status = self.get_job_run(job_run_id)print(f"current status:{status}")job_done = status in ["SUCCESS","FAILED","CANCELLING","CANCELLED","COMPLETED"]time.sleep(10)if status == "FAILED":self.print_driver_log(job_run_id,log_type="stderr")self.print_driver_log(job_run_id,log_type="stdout")return EMRResult(job_run_id,status)def get_job_run(self, job_run_id: str) -> dict:step_status = self.client.describe_step(ClusterId=self.application_id,StepId=job_run_id)['Step']['Status']['State']return step_status.upper()def print_driver_log(self, job_run_id: str, log_type: str = "stderr") -> str:print("starting download the driver logs")s3_client = boto3.client("s3")logs_location = f"{self.logs_s3_path}{self.application_id}/steps/{job_run_id}/{log_type}.gz"logs_bucket = logs_location.split('/')[2]logs_key = '/'.join(logs_location.split('/')[3:])print(f"Fetching {log_type} from {logs_location}")try:#日志生成需要一段时间,最长 100 秒for _ in range(10):try:s3_client.head_object(Bucket=logs_bucket, Key=logs_key)breakexcept Exception:print("等待日志生成中...")time.sleep(10)response = s3_client.get_object(Bucket=logs_bucket, Key=logs_key)file_content = gzip.decompress(response["Body"].read()).decode("utf-8")except s3_client.exceptions.NoSuchKey:file_content = ""print( f"等待超时,请稍后到 EMR 集群的步骤中查看错误日志或者手动前往: {logs_location} 下载")print(file_content)class EmrServerlessSession:def __init__(self,region,application_id, #若是 serverless, 则设置 应用的 ID;若不设置,则自动其第一个active的 app job_role,dolphin_s3_path,logs_s3_path,tempfile_s3_path,python_venv_s3_path,spark_conf):self.s3_client = boto3.client("s3")self.region=regionself.client = boto3.client('emr-serverless', region_name=self.region)self.application_id = application_idself.job_role = job_roleself.dolphin_s3_path = dolphin_s3_pathself.logs_s3_path=logs_s3_pathself.tempfile_s3_path=tempfile_s3_pathself.python_venv_s3_path=python_venv_s3_pathself.spark_conf=spark_confdef submit_sql(self,jobname, sql): #serverless# temporary file for the sql parameterprint(f"RUN SQL:{sql}")self.python_venv_conf=''with open(os.path.join(os.path.dirname(os.path.abspath(__file__)), "sql_template.py")) as f:query_file = Template(f.read()).substitute(query=sql.replace('"', '\\"'))script_bucket = self.tempfile_s3_path.split('/')[2]script_key = '/'.join(self.tempfile_s3_path.split('/')[3:])current_time = datetime.now().strftime("%Y%m%d%H%M%S")script_key = script_key+"sql_template_"+current_time+".py"self.s3_client.put_object(Body=query_file, Bucket=script_bucket, Key=script_key)script_file=f"s3://{script_bucket}/{script_key}"result= self._submit_job_emr(jobname, script_file)#delete the temp fileself.s3_client.delete_object(Bucket=script_bucket, Key=script_key)return resultdef submit_file(self,jobname, filename): #serverless# temporary file for the sql parameterprint(f"RUN Script :{filename}")self.python_venv_conf=''if self.python_venv_s3_path and self.python_venv_s3_path != '':self.python_venv_conf = f"--conf spark.archives={self.python_venv_s3_path}#environment --conf spark.emr-serverless.driverEnv.PYSPARK_DRIVER_PYTHON=./environment/bin/python --conf spark.emr-serverless.driverEnv.PYSPARK_PYTHON=./environment/bin/python --conf spark.executorEnv.PYSPARK_PYTHON=./environment/bin/python"script_file=f"{self.dolphin_s3_path}{filename}"result= self._submit_job_emr(jobname, script_file)return resultdef _submit_job_emr(self, name, script_file):#serverlessjob_driver = {"sparkSubmit": {"entryPoint": f"{script_file}","sparkSubmitParameters": f"{self.spark_conf} --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory {self.python_venv_conf}",}}print(f"job_driver:{job_driver}")response = self.client.start_job_run(applicationId=self.application_id,executionRoleArn=self.job_role,name=name,jobDriver=job_driver,configurationOverrides={"monitoringConfiguration": {"s3MonitoringConfiguration": {"logUri": self.logs_s3_path,}}},)job_run_id = response.get("jobRunId")print(f"Emr Serverless Job submitted, job id: {job_run_id}")job_done = Falsestatus="PENDING"while not job_done:status = self.get_job_run(job_run_id).get("state")print(f"current status:{status}")job_done = status in ["SUCCESS","FAILED","CANCELLING","CANCELLED",]time.sleep(10)if status == "FAILED":self.print_driver_log(job_run_id,log_type="stderr")self.print_driver_log(job_run_id,log_type="stdout")raise Exception(f"EMR Serverless job failed:{job_run_id}")return EMRResult(job_run_id,status)def get_job_run(self, job_run_id: str) -> dict:response = self.client.get_job_run(applicationId=self.application_id, jobRunId=job_run_id)return response.get("jobRun")def print_driver_log(self, job_run_id: str, log_type: str = "stderr") -> str:s3_client = boto3.client("s3")logs_location = f"{self.logs_s3_path}applications/{self.application_id}/jobs/{job_run_id}/SPARK_DRIVER/{log_type}.gz"logs_bucket = logs_location.split('/')[2]logs_key = '/'.join(logs_location.split('/')[3:])print(f"Fetching {log_type} from {logs_location}")try:response = s3_client.get_object(Bucket=logs_bucket, Key=logs_key)file_content = gzip.decompress(response["Body"].read()).decode("utf-8")except Exception:file_content = ""print(file_content)在 DolphinScheduler 上的应用
经过以上类库抽象与封装后,在 DolphinScheduler 上使用该类库,可以简单且灵活的向 EMR on EC2 和 EMR Serverless 提交 Spark 任务。
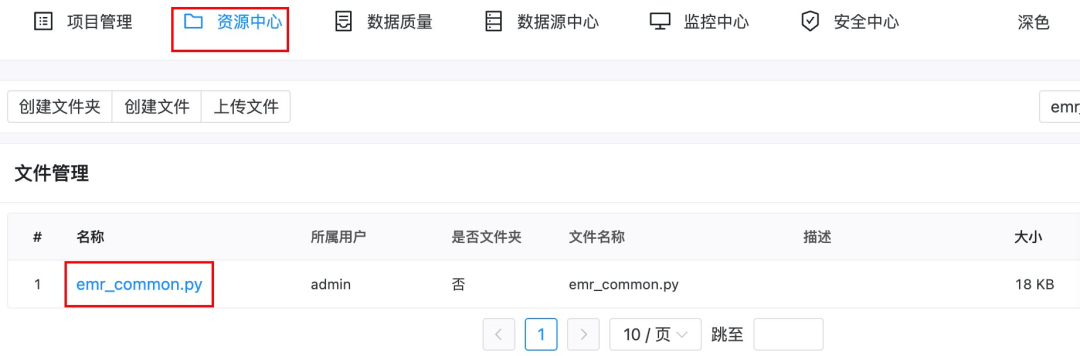
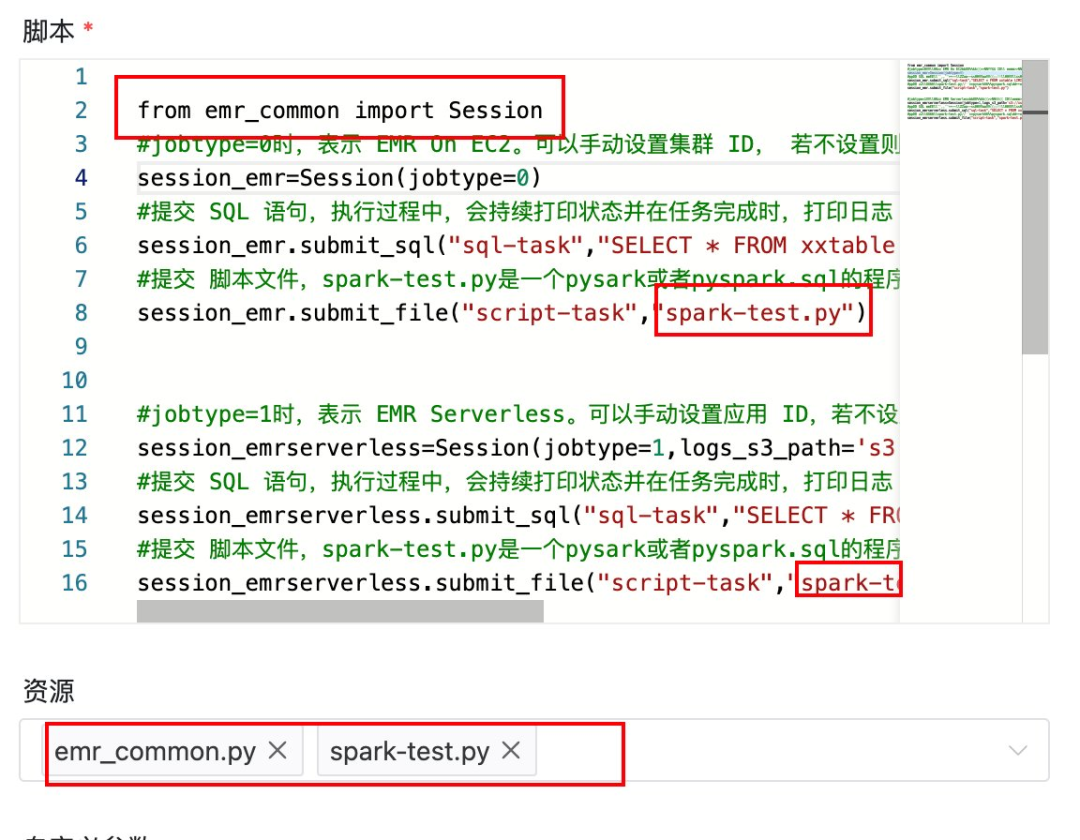
首先,将上述代码上传至 DolphinScheduler 的资源中心,文件名为 “emr_common.py”,如下图所示。
然后在工作流程中插入 Python节点,按照 Demo 代码示例,提交 Spark 任务。通过 Session 的构造函数参数 jobtype 来控制,是向 EMR on EC2 提交 Spark 任务,还是向 EMR Serverless 提交 Spark 任务。需要注意的是,填写完 Python 代码后,为了让节点中的 Python 代码能正确地引用类库 “emr_common.py”,一定要在节点的资源设置中添加 “emr_common.py”,如下两图所示(注:需要提前在 DolphinScheduler 的节点上安装 emr_common.py 所引用的第三方 Python 库)。
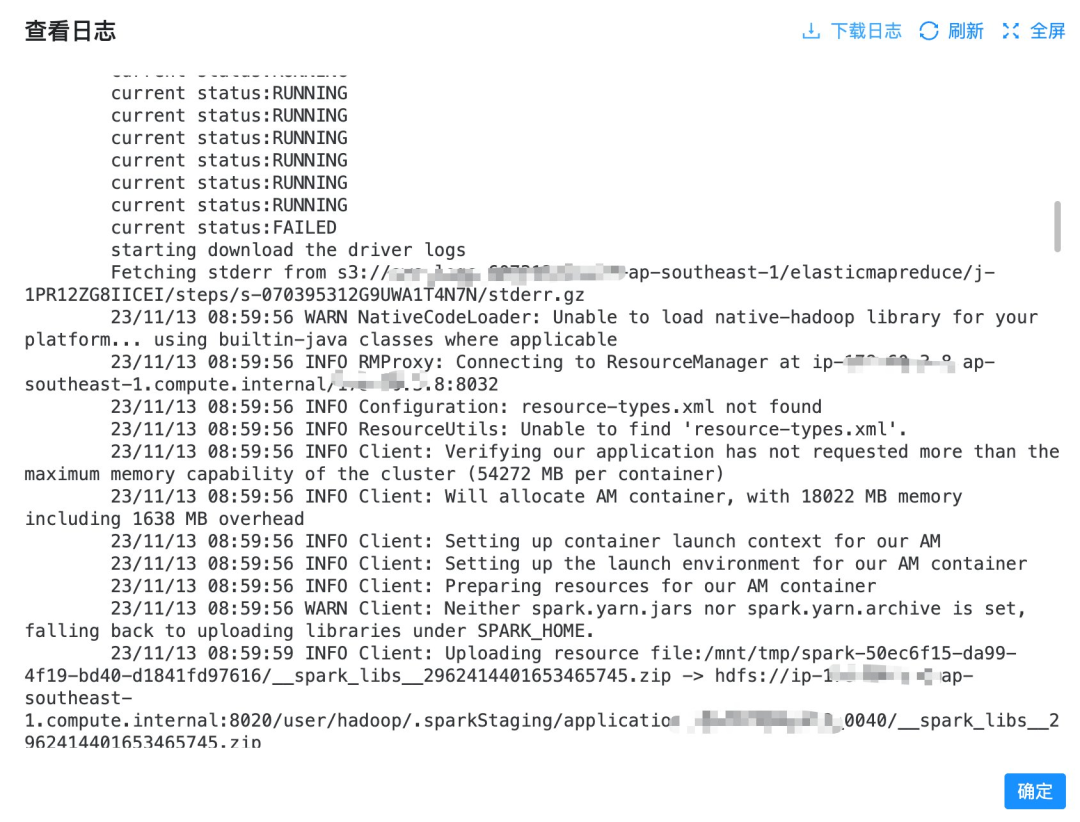
当任务执行结束后,如果出现错误,就可以在 DolphinScheduler 中直接查看日志,无需到 Yarn、Spark UI 或者 EMRServerless 的 Job 页面去下载与查看日志了,如下图所示。
03
总结
本文通过对 EMR on EC2 与 EMRServerless 中 Spark 任务的提交、监控、下载日志过程进行抽象并封装成 Python 类库,极大的简化了使用 Spark 的门槛,以及从 EMR on EC2 切换至 EMRServerless 的改造成本,优化了 EMRServerless+DolphinScheduler 的集成实践,消除了客户对于使用 EMRServerless 的一些疑惑以及担忧。最终帮助客户逐渐从集群运维的工作负担中解脱出来,更加专注于应用逻辑的开发与业务价值的创造。
本篇作者

张盼富
亚马逊云科技解决方案架构师,从业十三年,先后经过历云计算、供应链金融、电商等多个行业,担任过高级开发、架构师、产品经理、开发总监等多种角色,有丰富的大数据应用与数据治理经验。加入亚马逊云科技后,致力于通过大数据+AI 技术,帮助企业加速数字化转型。

刘元元
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案架构设计、咨询、实施等工作。曾担任研发经理、架构师的岗位并拥有多年的互联网系统的架构设计、系统开发的经验,覆盖金融、文旅、交通等行业,在 SaaS 系统和 Serverless 领域有着丰富的经验。

庄颖勤
亚马逊云科技解决方案架构师,负责基于亚马逊云科技的云计算方案架构设计、咨询、实施等工作。在 DevOps、CI/CD 和容器等领域拥有丰富的技术和支持经验,致力于帮助客户实现技术创新和业务发展。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
DolphinScheduler + Amazon EMR Serverless 的集成实践
01 背景 Apache DolphinScheduler 是一个分布式的可视化 DAG 工作流任务调度开源系统,具有简单易用、高可靠、高扩展性、⽀持丰富的使用场景、提供多租户模式等特性。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方…...

【服务器APP】利用HBuilder X把网页打包成APP
目录 🌺1. 概述 🌼1.1 新建项目 🌼1.2 基础配置 🌼1.3 图标配置 🌼1.4 启动界面配置 🌼1.5 模块配置 🌼1.6 打包成APP 🌺1. 概述 探讨如何将网页转化为APP,这似乎…...

vue3 组合式API获取子组件的属性和方法
在vue2中,获取子组件实例的方法或者属性时,父组件直接通过ref即可直接获取子组件的属性和方法,如下: // father.vue <child ref"instanceRef" /> this.$ref[instanceRef].testVal this.$ref[instanceRef].testFun…...

[数据结构+算法] 给一棵树和一个sum,判断是否存在从root到叶子结点的path之和等于sum?
[数据结构算法] 给一棵树和一个sum,判断是否存在从root到叶子结点的path之和等于sum? 可以使用两种方法求解 递归 CheckTreeSumRecursive 问题转换为递归判断左右子树是否满足路径和等于sum减去当前节点的值。 迭代 CheckTreeSumNonRecursive 使用两个…...
非阿里云注册域名如何在云解析DNS设置解析?
概述 非阿里云注册域名使用云解析DNS,按照如下步骤: 添加域名。 添加解析记录。 修改DNS服务器。 DNS服务器变更全球同步,等待48小时。 添加解析记录 登录云解析DNS产品控制台。 在 域名解析 页面中,单击 添加域名 。 在 …...
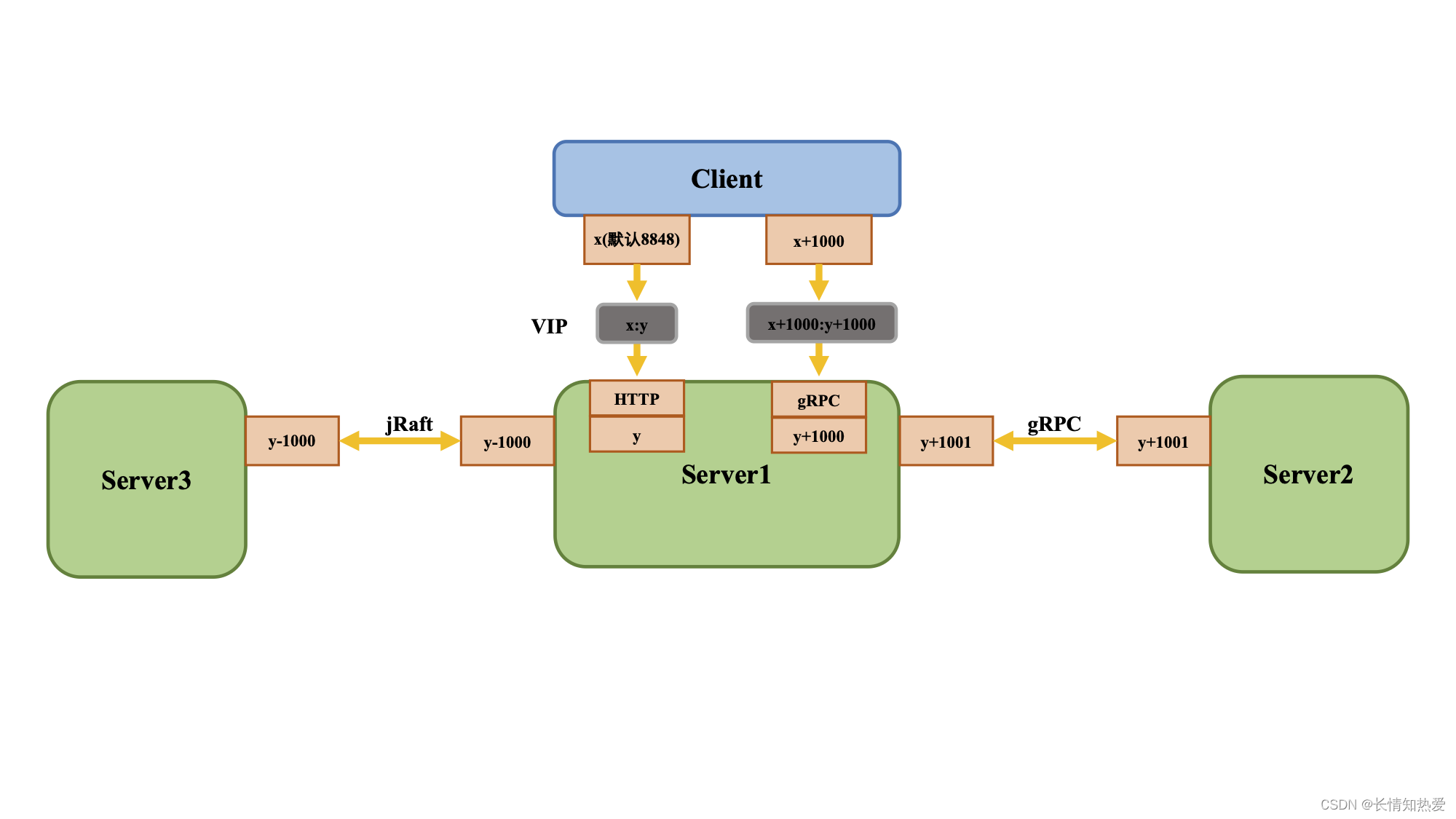
微服务-微服务Alibaba-Nacos注册中心实现
1. 系统架构的演变 俗话说, 没有最好的架构,只有最合适的架构。 微服务架构也是随着信息产业的发展而出现的最有普 遍适用性的一套架构模式。通常来说,我们认为架构发展历史经历了这样一个过程:单体架构——> 垂直架构 ——&g…...

多符号表达式的共同子表达式提取教程
生成的符号表达式,可能会存在过于冗长的问题,且多个符号表达式中,有可能存在相同的计算部分,如果不进行处理,计算过程中会导致某些算式计算多次,从而影响计算效率。 那么多个符号表达式生成函数时…...
Java 反射获取属性名、属性类型、属性值、判断属性类型
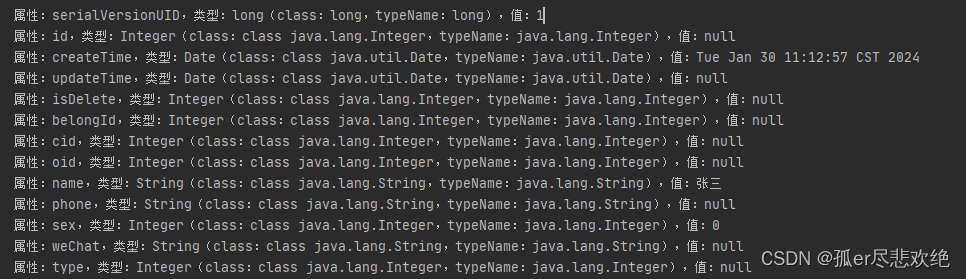
1.代码 /*** 通过反射获取对象属性名、属性类型、属性值** param t 需要反射的对象* author hcx*/public static <T> void reflect(T t){// 获取所有属性// getDeclaredFields 不包含父类,包含私有属性// getFields 包含父类属性Field[] fields t.getClass(…...

Docker私有仓库搭建
目录 1.registry私有仓库 拉取registry镜像 修改docker配置文件并重启 运行registry容器 修改想要上传的镜像的标签并上传验证 再另一台主机上获取此镜像 浏览器验证 2.Docker--harbor私有仓库部署与管理 什么是Harbor Harbor的特性 Harbor的构成 Harbor部署 准备…...
C语言第十三弹---VS使用调试技巧
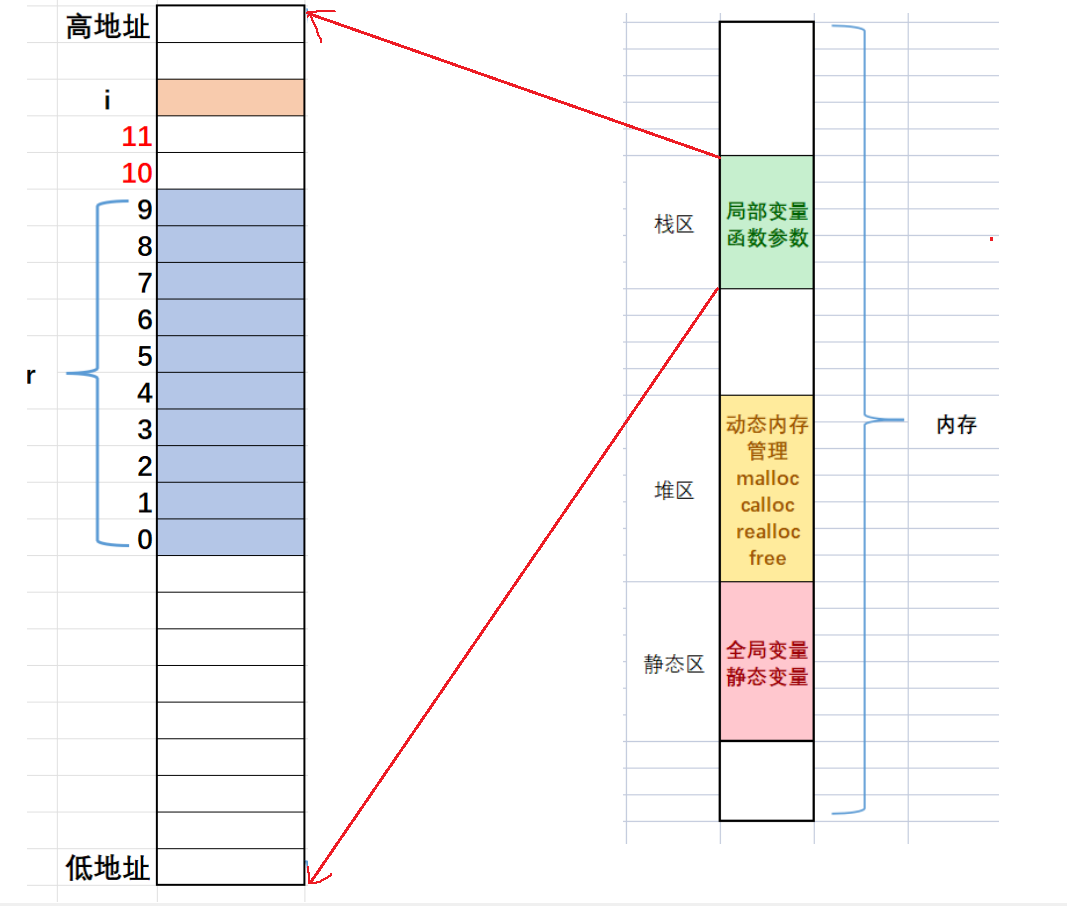
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 VS调试技巧 1、什么是bug 2、什么是调试(debug)? 3、Debug和Release编辑 4、VS调试快捷键 4.1、环境准备 4.2、调试…...
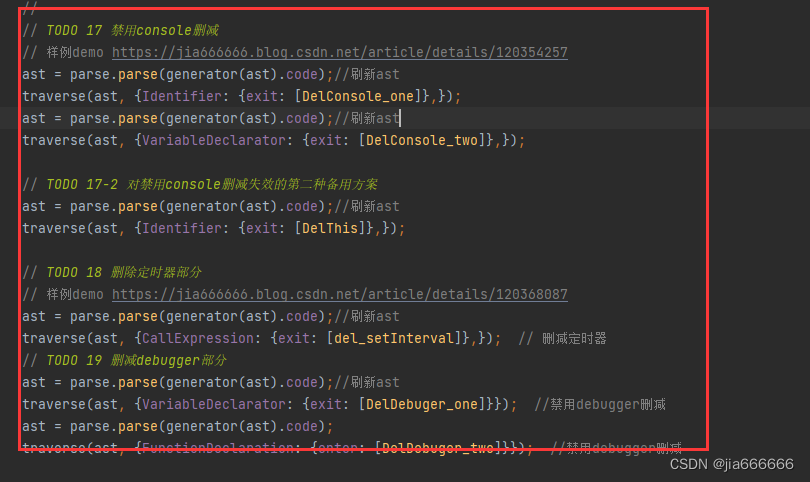
AST反混淆实战-jsjiamiv7最高配置
js加密混淆网站 https://www.jsjiami.com/一、混淆demo生成 01 打开目标网址 https://www.jsjiami.com/ 02 按照顺序加密混淆二、混淆前后demo 混淆前的源码 (function(w, d) { w.update "2023年01月17日05:34:29更新"; d.info "本站历时1年半研发的新版本V7…...

colorThief+vite+react使用方法
官网: Color Thief npm i --save colorthief 第一种,import载入图片 经过尝试,在vite中,要引入.mjs版本 import ColorThief from colorthief/dist/color-thief.mjs 第一种,通过import载入图片 import aa from /assets/123.jpgconst [resultColor,setResultColor]useState() …...
Hive(15)中使用sum() over()实现累积求和和滑动求和
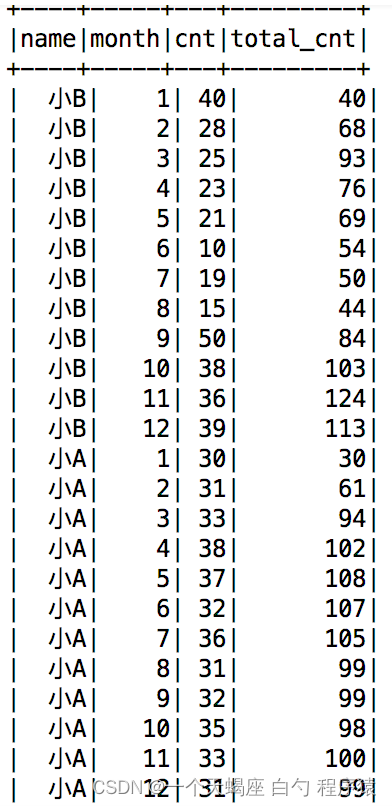
目的: 三个常用的排序函数row_number(),rank()和dense_rank()。这三个函数需要配合开窗函数over()来实现排序功能。但over()的用法远不止于此,本文咱们来介绍如何实现累计求和和滑动求和。 1、数据介绍 三列数据,分别是员工的姓名、月份和…...

2024年Java搭建面试题
2024年Java实战面试题(北京)_java 5 年 面试-CSDN博客 1、搭建docker容器 # 安装依赖的环境 yum -y install yum-utils device-mapper-persistent-data lvm2 # 设置镜像源为阿里 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/lin…...
二维数组的学习
前言 在前面我们学习了一维数组,但是有的问题需要用二位数组来解决。 二维数组常称为矩阵,把二维数组写成行和列的排列形式,可以有助于形象化的理解二维数组的逻辑结构。 一、二维数组的定义 二维数组定义的一般格式: 数据类型 数…...
)
Java集合(List集合)
什么是集合? 什么是集合?集合就是“由若干个确定的元素所构成的整体”,在程序中,一般代表保存 若干个元素(数据)的某种容器类。 在Java中,如果一个Java对象可以在内部持有(保存&…...

7、Json文件的操作总结【robot framework】
1、JSONLibrary简介 Robot Framework 是一种通用的自动化测试框架,它支持使用关键字驱动的测试,并且易于学习和使用。Robot Framework 提供了丰富的标准库,而 JSONLibrary 就是其中之一,用于处理 JSON 数据。 安装 JSONLibrary 在…...

python 循环解压 解压多重压缩包
在实际数据中,经常会有压缩包套压缩包的情况,并且有可能出现“zip”压缩包下面套“tar”的可能。 你可以运行后面的代码,来完成自动解压。代码会不断检查folder_a_path 文件夹下是否还有压缩包。目前支持zip、rar、tar、7z等四种格式的压缩文…...
基于C#制作一个连连看小游戏
基于C#制作一个连连看小游戏,实现:难易度选择、关卡选择、倒计时进度条、得分计算、音效播放等功能。 目录 引言游戏规则开发环境准备游戏界面设计游戏逻辑实现图片加载与显示鼠标事件处理游戏优化与扩展添加关卡与难度选择说明</...

Android-System 根据包名查找已安装应用apk方法
1、根据包名查找应用的安装路径 dumpsys package packageName | grep Path 例如: kona:/ # dumpsys package com.yw_pt.oshnoh | grep PathcodePath/data/app/com.yw_pt.oshnoh-N4rPqGh58weRjMpA1q3evwresourcePath/data/app/com.yw_pt.oshnoh-N4rPqGh58weRjMpA1q3…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...