ES 分词器
概述
分词器的主要作用将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具
什么是分词器
顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES 中,Analysis
是通过分词器(Analyzer) 来实现的,可使用 ES 内置的分析器或者按需定制化分析器。
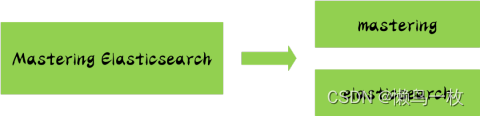
举一个分词简单的例子:比如你输入 Mastering Elasticsearch,会自动帮你分成两个单词,一个是 mastering,另一个是 elasticsearch,可以看出单词也被转化成了小写的。
分词器的构成
分词器是专门处理分词的组件,分词器由以下三部分组成:
character filter
接收原字符流,通过添加、删除或者替换操作改变原字符流
例如:去除文本中的html标签,或者将罗马数字转换成阿拉伯数字等。一个字符过滤器可以有零个或者多个
tokenizer
简单的说就是将一整段文本拆分成一个个的词。
例如拆分英文,通过空格能将句子拆分成一个个的词,但是对于中文来说,无法使用这种方式来实现。在一个分词器中,有且只有一个tokenizeer
token filters
将切分的单词添加、删除或者改变
例如将所有英文单词小写,或者将英文中的停词a删除等,在token filters中,不允许将token(分出的词)的position或者offset改变。同时,在一个分词器中,可以有零个或者多个token filters.
分词顺序
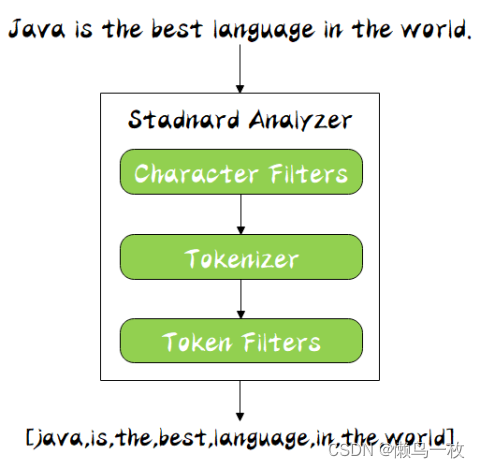
同时 Analyzer 三个部分也是有顺序的,从图中可以看出,从上到下依次经过 Character Filters,Tokenizer 以及 Token Filters,这个顺序比较好理解,一个文本进来肯定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
索引和搜索分词
文本分词会发生在两个地方:
- 创建索引:当索引文档字符类型为text时,在建立索引时将会对该字段进行分词。
- 搜索:当对一个text类型的字段进行全文检索时,会对用户输入的文本进行分词。
配置分词器
默认ES使用standard analyzer,如果默认的分词器无法符合你的要求,可以自己配置
分词器测试
可以通过_analyzerAPI来测试分词的效果。
COPY# 过滤html 标签
POST _analyze
{"tokenizer":"keyword", #原样输出"char_filter":["html_strip"], # 过滤html标签"text":"<b>hello world<b>" # 输入的文本
}
指定分词器
使用地方
分词器的使用地方有两个:
- 创建索引时
- 进行搜索时
创建索引时指定分词器
如果手动设置了分词器,ES将按照下面顺序来确定使用哪个分词器:
- 先判断字段是否有设置分词器,如果有,则使用字段属性上的分词器设置
- 如果设置了analysis.analyzer.default,则使用该设置的分词器
- 如果上面两个都未设置,则使用默认的standard分词器
字段指定分词器
为title属性指定分词器
PUT my_index
{"mappings": {"properties": {"title":{"type":"text","analyzer": "whitespace"}}}
}
指定默认default_seach
COPYPUT my_index
{"settings": {"analysis": {"analyzer": {"default":{"type":"simple"},"default_seach":{"type":"whitespace"}}}}
}
内置分词器
es在索引文档时,会通过各种类型 Analyzer 对text类型字段做分析,
不同的 Analyzer 会有不同的分词结果,内置的分词器有以下几种,基本上内置的 Analyzer 包括 Language Analyzers 在内,对中文的分词都不够友好,中文分词需要安装其它 Analyzer
| 分析器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
| standard | 标准分析器是默认的分析器,如果没有指定,则使用该分析器。它提供了基于文法的标记化(基于 Unicode 文本分割算法,如 Unicode 标准附件 # 29所规定) ,并且对大多数语言都有效。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ] |
| simple | 简单分析器将文本分解为任何非字母字符的标记,如数字、空格、连字符和撇号、放弃非字母字符,并将大写字母更改为小写字母。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| whitespace | 空格分析器在遇到空白字符时将文本分解为术语 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ] |
| stop | 停止分析器与简单分析器相同,但增加了删除停止字的支持。默认使用的是 english 停止词。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ quick, brown, foxes, jumped, over, lazy, dog, s, bone ] |
| keyword | 不分词,把整个字段当做一个整体返回 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.] |
| pattern | 模式分析器使用正则表达式将文本拆分为术语。正则表达式应该匹配令牌分隔符,而不是令牌本身。正则表达式默认为 w+ (或所有非单词字符)。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| 多种西语系 arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english等等 | 一组旨在分析特定语言文本的分析程序。 |

分词器 _analyze 的使用
#standard
GET _analyze
{"analyzer": "standard","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#simpe
GET _analyze
{"analyzer": "simple","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}GET _analyze
{"analyzer": "stop","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#stop
GET _analyze
{"analyzer": "whitespace","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#keyword
GET _analyze
{"analyzer": "keyword","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}GET _analyze
{"analyzer": "pattern","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}#english
GET _analyze
{"analyzer": "english","text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}POST _analyze
{"analyzer": "icu_analyzer","text": "他说的确实在理”"
}POST _analyze
{"analyzer": "standard","text": "他说的确实在理”"
}POST _analyze
{"analyzer": "icu_analyzer","text": "这个苹果不大好吃"
}
可以看出是按照空格、非字母的方式对输入的文本进行了转换,比如对 Java 做了转小写,对一些停用词也没有去掉,比如 in,其中 token 为分词结果;start_offset 为起始偏移;end_offset 为结束偏移;position 为分词位置。
使用分析器进行分词
课程Demo
#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
#Stop Analyzer – 小写处理,停用词过滤(the,a,is)
#Whitespace Analyzer – 按照空格切分,不转小写
#Keyword Analyzer – 不分词,直接将输入当作输出
#Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
#Language – 提供了30多种常见语言的分词器
#2 running Quick brown-foxes leap over lazy dogs in the summer evening
其他常用分词器
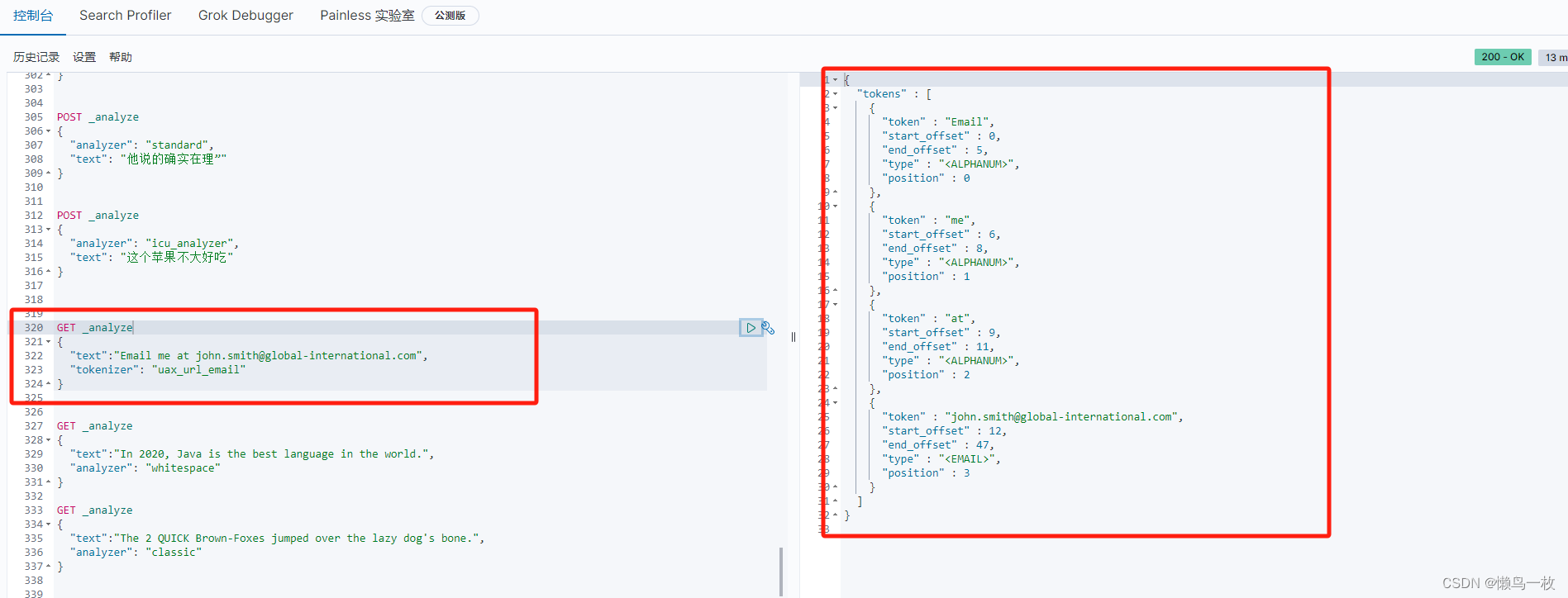
电子邮件分词器(UAX URL Email Tokenizer)
此分词器主要是针对email和url地址进行关键内容的标记。
GET _analyze
{"text":"Email me at john.smith@global-international.com","tokenizer": "uax_url_email"
}
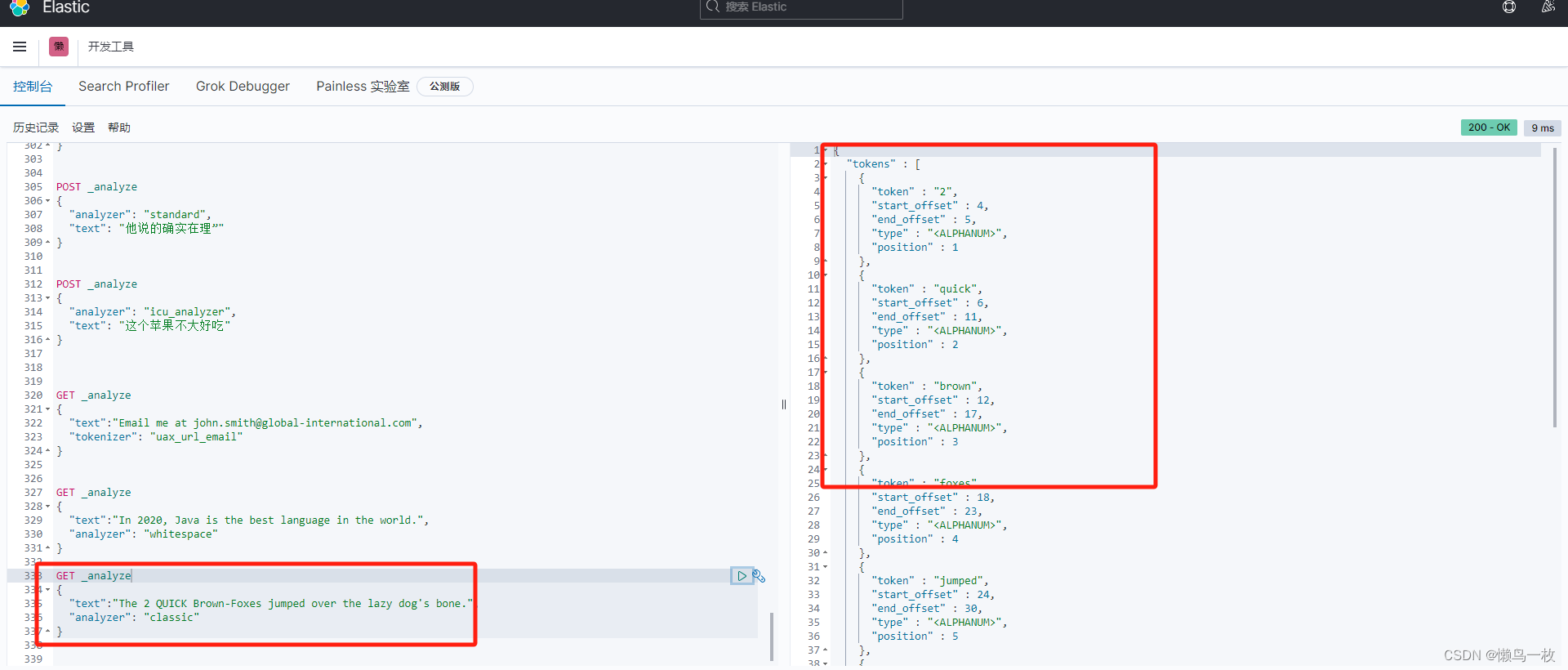
经典分词器(Classic Tokenizer)
可对首字母缩写词,公司名称,电子邮件地址和互联网主机名进行特殊处理,但是,这些规则并不总是有效,并且此关键词生成器不适用于英语以外的大多数其他语言
特点
- 它最多将标点符号拆分为单词,删除标点符号,但是,不带空格的点被认为是查询关键词的一部分
- 此分词器可以将邮件地址和URL地址识别为查询的term(词条)
GET _analyze
{"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.","analyzer": "classic"
}
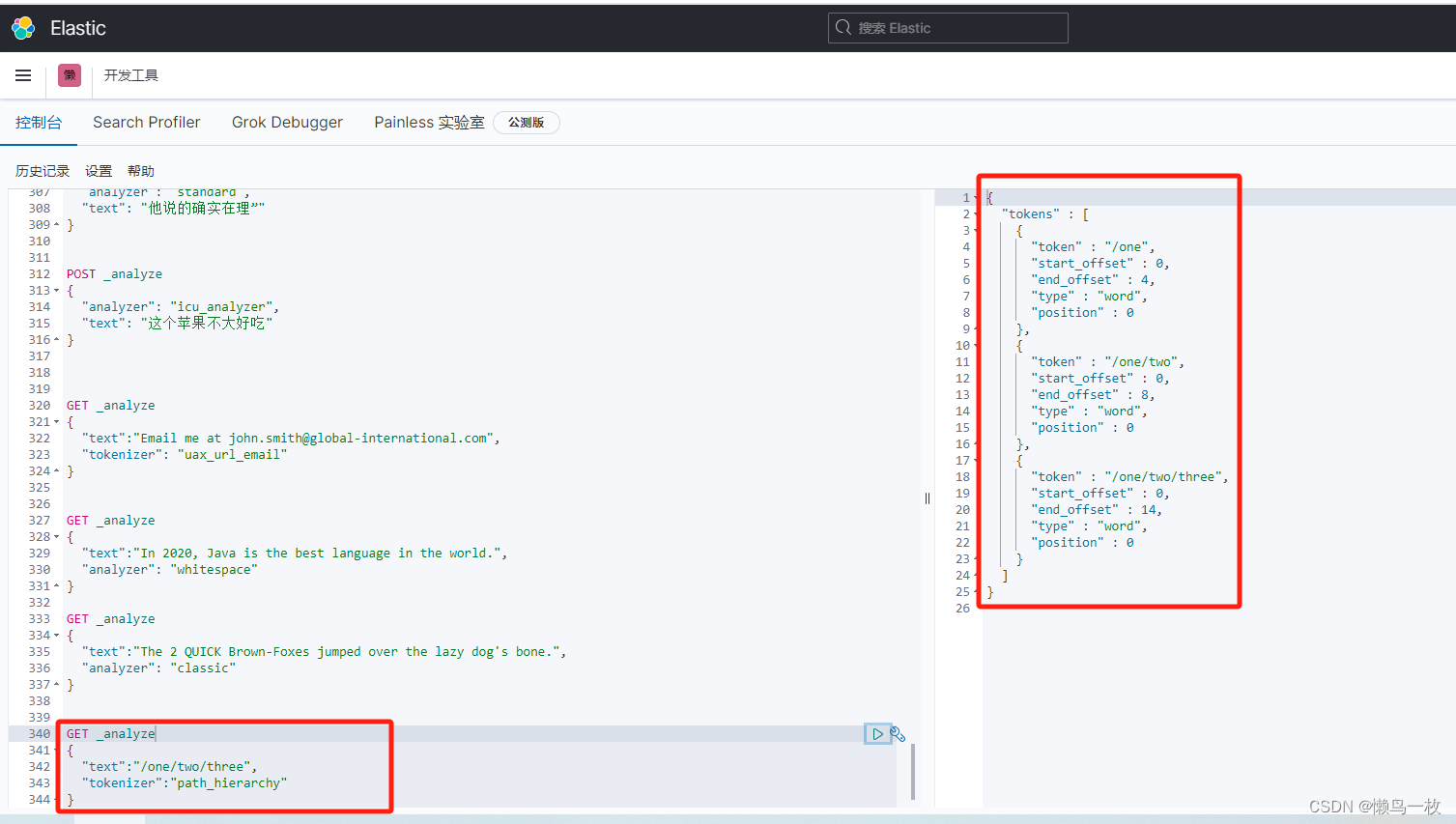
路径分词器(Path Tokenizer)
可以对文件系统的路径样式的请求进行拆分,返回被拆分各个层级内容。
GET _analyze
{"text":"/one/two/three","tokenizer":"path_hierarchy"
}
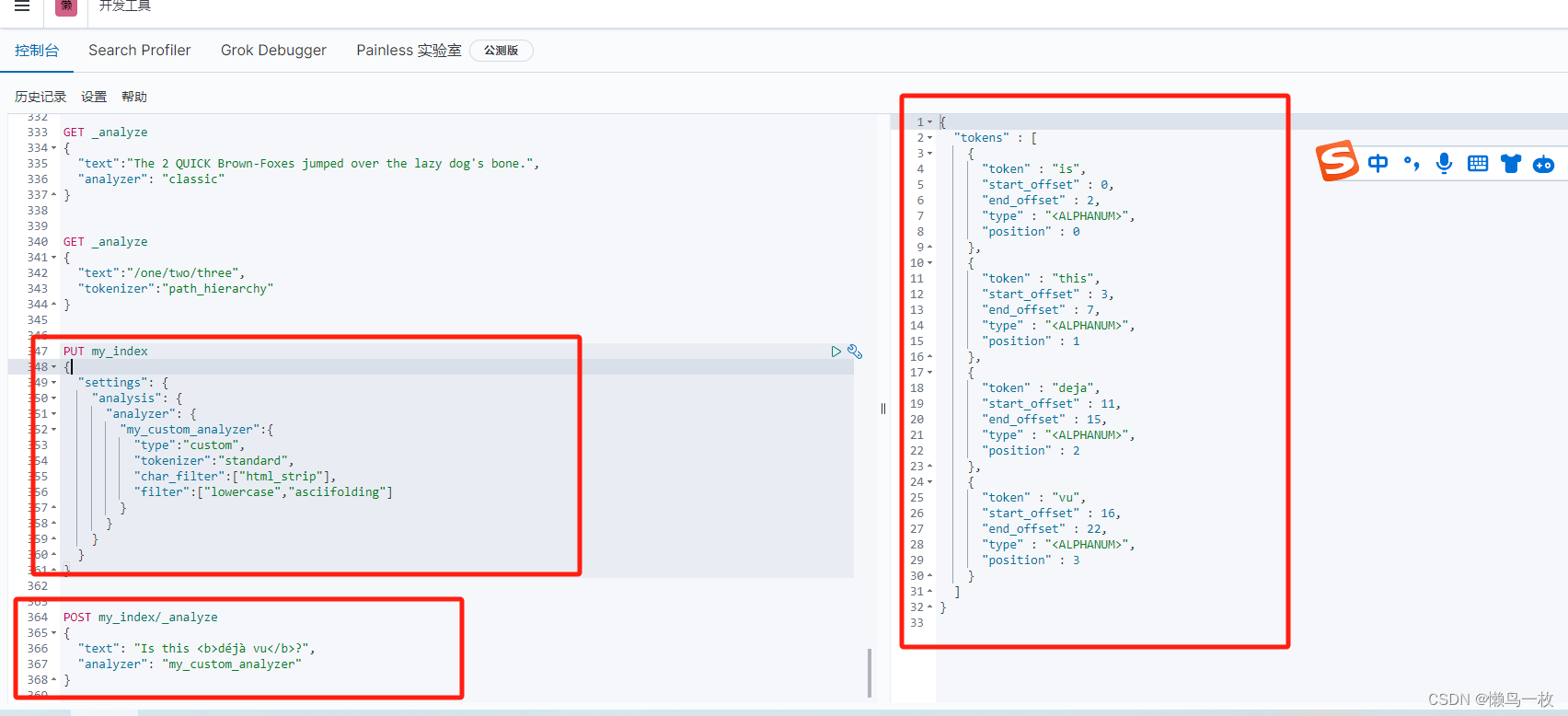
自定义分词器
当内置的分词器无法满足需求时,可以创建custom类型的分词器。
配置参数
| 参数 | 描述 |
|---|---|
| tokenizer | 内置或定制的tokenizer.(必须) |
| char_filter | 内置或定制的char_filter(非必须) |
| filter | 内置或定制的token filter(非必须) |
| position_increment_gap | 当值为文本数组时,设置改值会在文本的中间插入假空隙。设置该属性,对与后面的查询会有影响。默认该值为100. |
- 创建索引
上面的示例中定义了一个名为my_custom_analyzer的分词器
该分词器的type为custom,tokenizer为standard,char_filter为hmtl_strip,filter定义了两个分别为:lowercase和asciifolding
PUT my_index
{"settings": {"analysis": {"analyzer": {"my_custom_analyzer":{"type":"custom","tokenizer":"standard","char_filter":["html_strip"],"filter":["lowercase","asciifolding"]}}}}
}
- 测试使用自定义分词
POST my_index/_analyze
{"text": "Is this <b>déjà vu</b>?","analyzer": "my_custom_analyzer"
}
中文分词器
IKAnalyzer
IKAnalyzer是一个开源的,基于java的语言开发的轻量级的中文分词工具包
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本,在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
使用IK分词器
IK提供了两个分词算法:
- ik_smart:最少切分。
- ik_max_word:最细粒度划分。
ik_smart 分词算法
使用案例
原始内容
GET _analyze
{"analyzer": "ik_smart","text": "传智教育的教学质量是杠杠的"
}
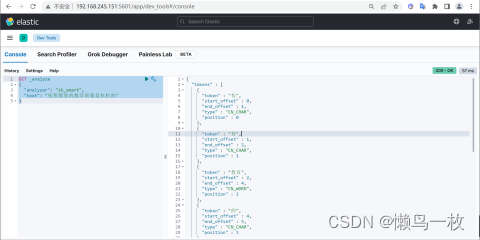
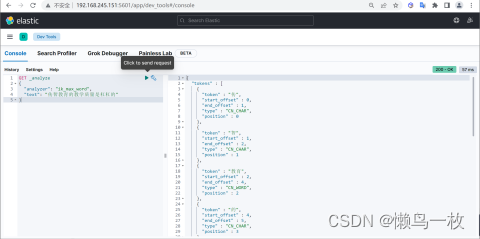
ik_max_word 分词算法
GET _analyze
{"analyzer": "ik_max_word","text": "传智教育的教学质量是杠杠的"
}
自定义词库
我们在使用IK分词器时会发现其实有时候分词的效果也并不是我们所期待的
问题描述
例如我们输入“传智教育的教学质量是杠杠的”,但是分词器会把“传智教育”进行拆开,分为了“传”,“智”,“教育”,但我们希望的是“传智教育”可以不被拆开。
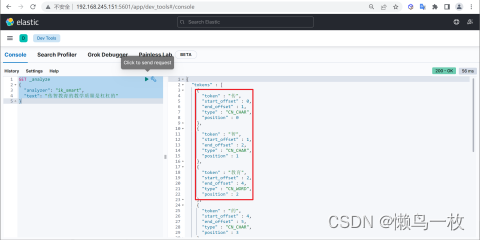
解决方案
对于以上的问题,我们只需要将自己要保留的词,加到我们的分词器的字典中即可
编辑字典内容
进入elasticsearch目录plugins/ik/config中,创建我们自己的字典文件yixin.dic,并添加内容:
cd plugins/ik/config
echo "传智教育" > custom.dic
扩展字典
进入我们的elasticsearch目录 :plugins/ik/config,打开IKAnalyzer.cfg.xml文件,进行如下配置:
vi IKAnalyzer.cfg.xml
#增加如下内容
<entry key="ext_dict">custom.dic</entry>
再次测试
重启ElasticSearch,再次使用kibana测试
GET _analyze
{"analyzer": "ik_max_word","text": "传智教育的教学质量是杠杠的"
}
可以发现,现在我们的词汇”传智教育”就不会被拆开了,达到我们想要的效果了
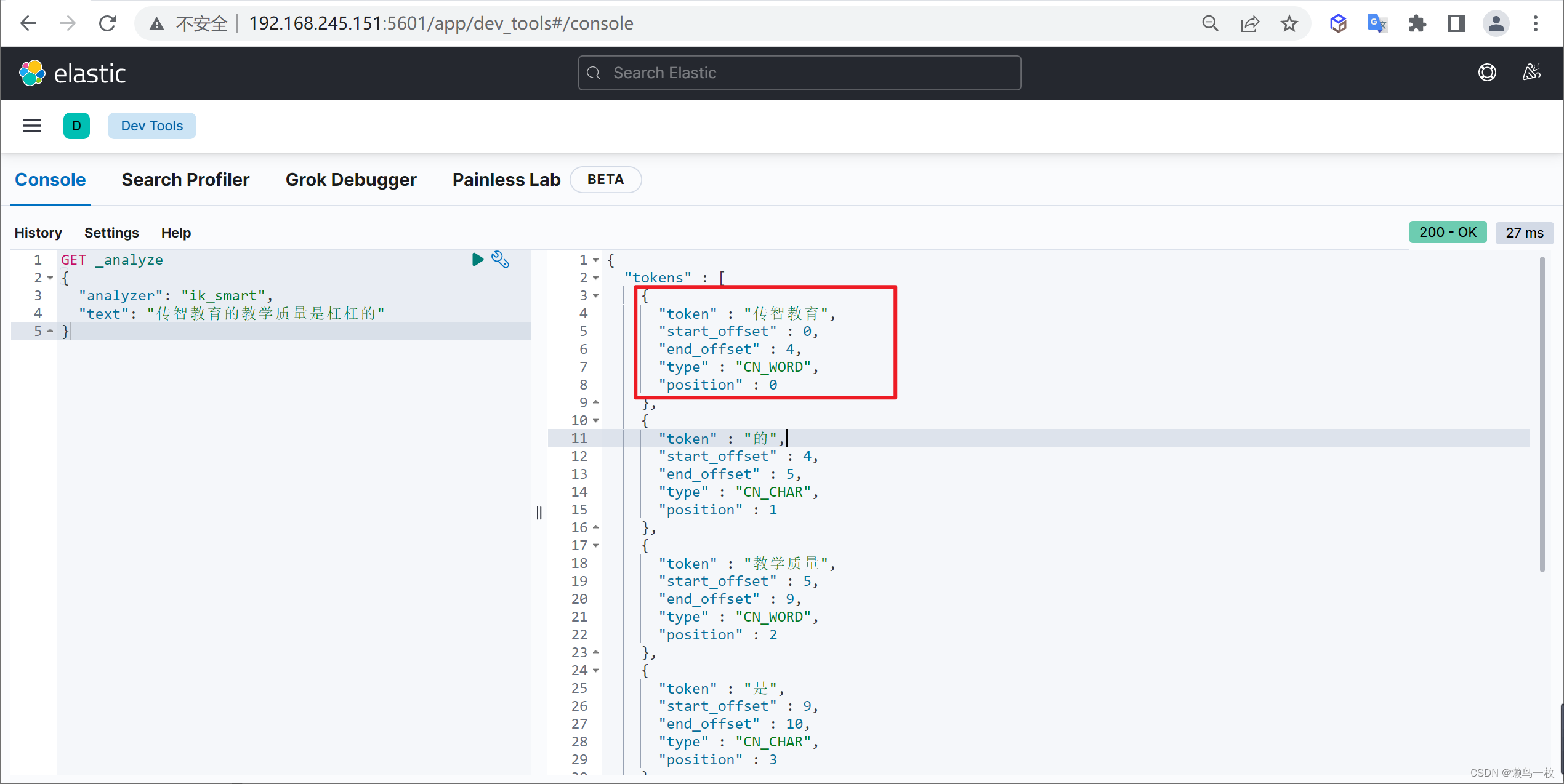
分词的可配置项
standard 分词器可配置项
| 选项 | 描述 |
|---|---|
| max_token_length | 最大令牌长度。如果看到令牌超过此长度,则将其max_token_length间隔分割。默认为255。 |
| stopwords | 预定义的停用词列表,例如english或包含停用词列表的数组。默认为none。 |
| stopwords_path | 包含停用词的文件的路径。 |
COPY{"settings": {"analysis": {"analyzer": {"my_english_analyzer": {"type": "standard","max_token_length": 5,"stopwords": "_english_"}}}}
}
正则分词器(Pattern Tokenizer) 可配置选项
可配置项
正则分词器有以下的选项
| 选项 | 描述 |
|---|
|pattern |正则表达式|
|flags |正则表达式标识|
|lowercase| 是否使用小写词汇|
|stopwords |停止词的列表。|
|stopwords_path |定义停止词文件的路径。|
COPY{"settings": {"analysis": {"analyzer": {"my_email_analyzer": {"type": "pattern","pattern": "\\W|_","lowercase": true}}}}
}
路径分词器(Path Tokenizer)可配置选项
| 选项 | 描述 |
|---|---|
| delimiter | 用作路径分隔符的字符 |
| replacement | 用于定界符的可选替换字符 |
| buffer_size | 单次读取到术语缓冲区中的字符数。默认为1024。术语缓冲区将以该大小增长,直到所有文本都被消耗完为止。建议不要更改此设置。 |
| reverse | 正向还是反向获取关键词 |
| skip | 要忽略的内容 |
COPY{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "my_tokenizer"}},"tokenizer": {"my_tokenizer": {"type": "path_hierarchy","delimiter": "-","replacement": "/","skip": 2}}}}
}
语言分词(Language Analyzer)
ES 为不同国家语言的输入提供了 Language Analyzer 分词器,在里面可以指定不同的语言
相关文章:
ES 分词器
概述 分词器的主要作用将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具 什么是分词器 顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES 中,Ana…...
从0开始搭建若依微服务项目 RuoYi-Cloud(保姆式教程完结)
文章接上一章: 从0开始搭建若依微服务项目 RuoYi-Cloud(保姆式教程 一)-CSDN博客 四. 项目配置与启动 当上面环境全部准备好之后,接下来就是项目配置。需要将项目相关配置修改成当前相关环境。 数据库配置 新建数据库ÿ…...
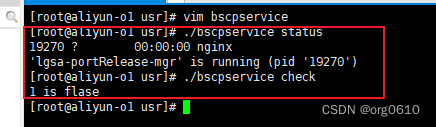
Linux true/false区分
bash的数值代表和其它代表相反:0表示true;非0代表false。 #!/bin/sh PIDFILE"pid"# truenginx进程运行 falsenginx进程未运行 checkRunning(){# -f true表示普通文件if [ -f "$PIDFILE" ]; then# -z 字符串长度为0trueif [ -z &qu…...

一些著名的软件都用什么语言编写?
1、操作系统 Microsoft Windows :汇编 -> C -> C 备注:曾经在智能手机的操作系统(Windows Mobile)考虑掺点C#写的程序,比如软键盘,结果因为写出来的程序太慢,实在无法和别的模块合并&…...

外卖跑腿系统开发:构建高效、安全的服务平台
在当今快节奏的生活中,外卖跑腿系统的开发已成为技术领域的一个重要课题。本文将介绍如何使用一些常见的编程语言和技术框架,构建一个高效、安全的外卖跑腿系统。 1. 技术选择 在开始开发之前,我们需要选择适合的技术栈。常用的技术包括&a…...

【MQ02】基础简单消息队列应用
基础简单消息队列应用 在上一课中,我们已经学习到了什么是消息队列,有哪些消息队列,以及我们会用到哪个消息队列。今天,就直接进入主题,学习第一种,最简单,但也是最常用,最好用的消息…...
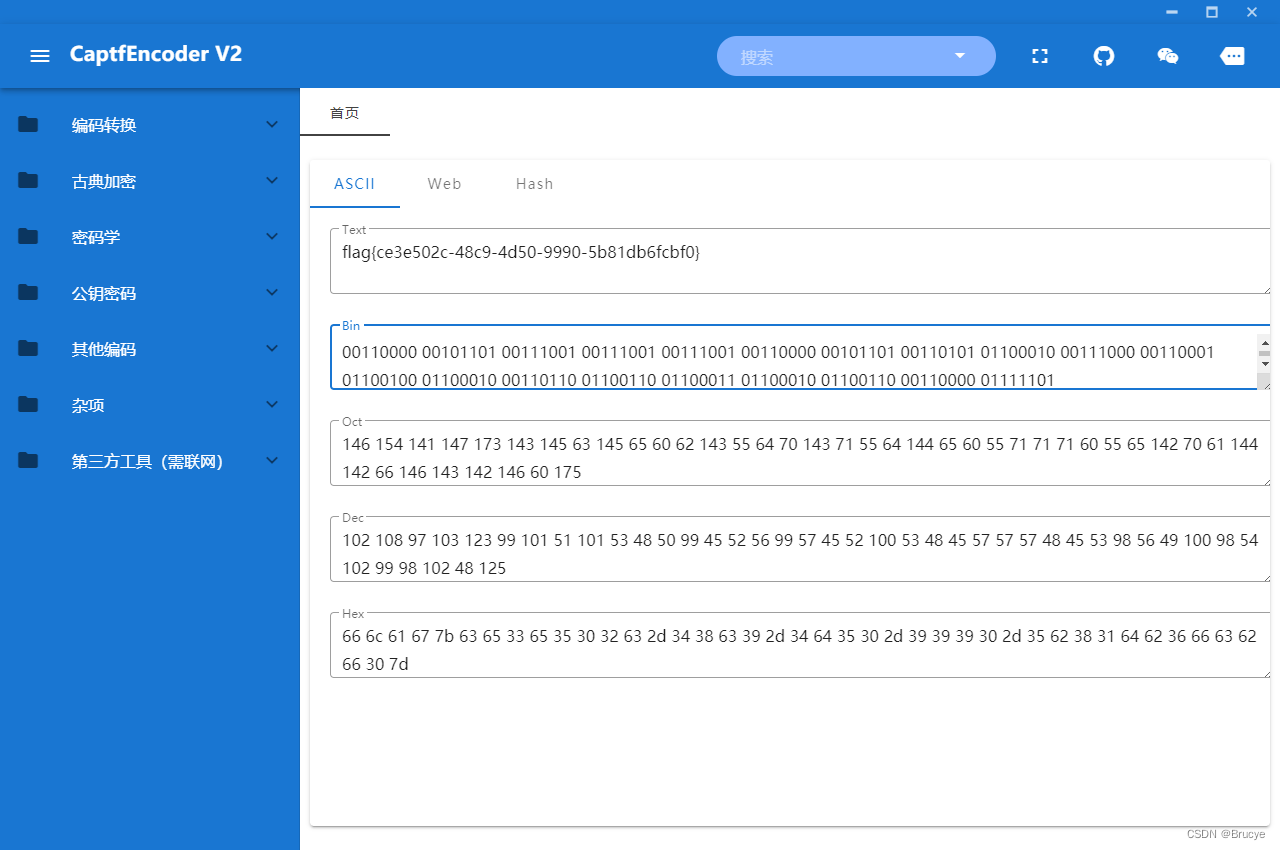
CTF CRYPTO 密码学-7
题目名称:敲击 题目描述: 让我们回到最开始的地方 0110011001101100011000010110011101111011011000110110010100110011011001010011010100110000001100100110001100101101001101000011100001100011001110010010110100110100011001000011010100110000…...

随机森林和决策树区别
随机森林(Random Forest)和决策树(Decision Tree)是两种不同的机器学习算法,其中随机森林是基于决策树构建的一种集成学习方法。以下是它们之间的主要区别: 决策树: 单一模型: 决策树是一种单一模型&#…...

新建VM虚拟机-安装centOS7-连接finalshell调试
原文 这里有问题 首先进入/etc/sysconfig/network-scripts/目录 cd /etc/sysconfig/network-scripts/ 然后编辑文件 ifcfg-ens33 vi ifcfg-ens33...

936. 戳印序列
Problem: 936. 戳印序列 文章目录 思路解题方法复杂度Code 思路 这道题目要求我们通过使用印章来印刷目标字符串,使得目标字符串最终变成全为’?‘的字符串。我们可以使用贪心的思想来解决这个问题。 首先,我们需要找到所有可以匹配印章的位置ÿ…...
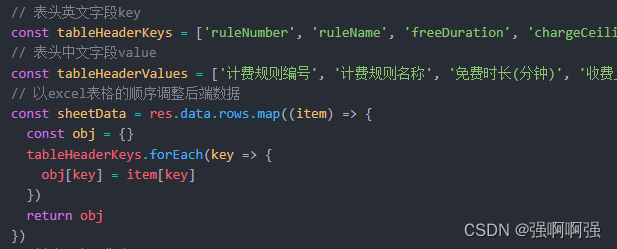
20240129收获
今天终于发现《八部金刚功》第五部我一直做的是错的,嗨。这里这个写法非常聪明,创立的数组,以及用obj[key] item[key]这样的写法,这个写法充分展示了js常规写法中只有等号右边会去参与运算,等号左边就是普通的键的写法…...

【虚拟机数据恢复】异常断电导致虚拟机无法启动的数据恢复案例
虚拟机数据恢复环境: 某品牌R710服务器MD3200存储,上层是ESXI虚拟机和虚拟机文件,虚拟机中存放有SQL Server数据库。 虚拟机故障: 机房非正常断电导致虚拟机无法启动。服务器管理员检查后发现虚拟机配置文件丢失,所幸…...

vue3 + antd 封装动态表单组件(三)
传送带: vue3 antd 封装动态表单组件(一) vue3 antd 封装动态表单组件(二) 前置条件: vue版本 v3.3.11 ant-design-vue版本 v4.1.1 我们发现ant-design-vue Input组件和FormItem组件某些属性支持slot插…...
【算法专题】贪心算法
贪心算法 贪心算法介绍1. 柠檬水找零2. 将数组和减半的最少操作次数3. 最大数4. 摆动序列(贪心思路)5. 最长递增子序列(贪心算法)6. 递增的三元子序列7. 最长连续递增序列8. 买卖股票的最佳时机9. 买卖股票的最佳时机Ⅱ(贪心算法)10. K 次取反后最大化的数组和11. 按身高排序12…...

x-cmd pkg | sqlite3 - 轻量级的嵌入式关系型数据库
目录 简介首次用户 技术特点竞品和相关产品sqlite 与 x-cmd进一步阅读 简介 sqlite3 是一个轻量级的文件数据库,体积非常小,提供简单优雅而功能强大的 sql 化的数据查询。 通常情况下,sqlite 指的是 SQLite 2.x 版本,而 sqlite3 …...

LeetCode —— 43. 字符串相乘
😶🌫️😶🌫️😶🌫️😶🌫️Take your time ! 😶🌫️😶🌫️😶🌫️😶🌫️…...

PalWorld/幻兽帕鲁Ubuntu 22.04 LTS 一键部署脚本
上去就是干! 创建install.sh文件 #!/bin/bashsteam_usersteam log_path/tmp/pal_server.logif getent passwd "$steam_user" >/dev/null 2>&1; thenecho "User $steam_user exists." elseecho "User $steam_user does not exi…...

【Vue】Vue3.0样式隔离
在这里记录一下Vue3.0里面的样式隔离特性,在项目开发过程当中,有时候将样式单独提到了一个文件当中再引入到单组件文件当中,会导致没有样式隔离。 这里阅读Vue官方文档找到了解决办法。 一、scoped 我们了解到的最常见就是scopedÿ…...
Git初识
📙 作者简介 :RO-BERRY 📗 学习方向:致力于C、C、数据结构、TCP/IP、数据库等等一系列知识 📒 日后方向 : 偏向于CPP开发以及大数据方向,欢迎各位关注,谢谢各位的支持 在学习Git之前我们先引入一…...
)
OpenHarmony隐藏应用(应用不在桌面显示,隐藏应用图标)
注意:此种方式是在OpenHarmony系统中生效 目录 一.找到UnsgnedReleasedProfileTemplate.json文件 二.修改 UnsgnedReleasedProfileTemplate.json文件 三.重新签名 一.找到UnsgnedReleasedProfileTemplate.json文件 什么是U...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...