爬虫工作量由小到大的思维转变---<第四十二章 Scrapy Redis 重试机制(ip相关)>
前言:
之前讲过一篇关于scrapy的重试机制的文章,那个是针对当时那哥们的代码讲的,但是,发现后面还是有很多问题; 本章节就着scrapy的重试机制来讲一下!!!
正文:
首先,要清楚一个概念,在scrapy的中间件中,默认会有一个scrapy重试中间件;只要你在settings.py设置中写上:
RETRY_TIMES=3 那么他就会自动重试!
即使你想拦截,例如在负责控制ip的中间件中拦截他,根本拦截不下来(只有最后一次才会拦截!)
那么这个retry_times 是怎么进行运算的呢?
q1:明明咱们设置的是3,怎么他重试了4次?
解释:第一次是原始请求,重试为0; 接着每一次都会+1,当达到3次重试时(已经发起了4次请求)的时候,就会进入报错机制!
q2:面对请求失败的时候,为什么def process_response拦截不了!?
解释:因为是ip或者超时引起的问题,不会走response返回体! 他直接进入报错--->解决办法:
def process_exception(self, request, exception, spider):if isinstance(exception, (ConnectError, ConnectionRefusedError, TCPTimedOutError)):current_retry_times = request.meta.get('retry_times', 0)if current_retry_times <=self.max_failures:# 记录失败的代理proxy = request.meta.get('proxy', '')self.remove_proxy(proxy, spider)print(f"代理 {proxy} 请求异常,尝试重试。当前重试次数:{current_retry_times}")# 更换新的代理IPnew_proxy = self.get_proxy(spider)if new_proxy:request.meta['proxy'] = new_proxy.decode('utf-8')request.meta['retry_times'] = current_retry_times+1return request.copy()else:print("超过重试次数")self.redis.sadd(self.fail_key,request.url)Q3:我在settings.py里面设置了重试次数为3,且每次请求都会从ip池中带一个ip; 为什么前面3次重试我都没办法拦截这个请求,他自动发起请求了?
解释:在中间件中,关闭那个scrapy默认的重试中间件! 这样,每次请求的重试他就不走他中间件了,而是走你设置的中间件!!!
DOWNLOADER_MIDDLEWARES = {
#把这个设置为NONE,关闭默认的重试中间件'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,# 添加代理ip的中间件'爬虫名.middlewares.RedisProxyMiddleware': 543,}查看翻译原重试中间件代码:
"""
一个用于重试可能由临时问题如连接超时或HTTP 500错误导致失败的请求的扩展。您可以通过修改抓取设置来改变此中间件的行为:
RETRY_TIMES - 重试失败页面的次数
RETRY_HTTP_CODES - 需要重试的HTTP响应代码失败的页面在抓取过程中被收集起来,并在爬虫完成抓取所有常规(非失败)页面后重新安排。
"""
from logging import Logger, getLogger
from typing import Optional, Unionfrom twisted.internet import defer
from twisted.internet.error import (ConnectError,ConnectionDone,ConnectionLost,ConnectionRefusedError,DNSLookupError,TCPTimedOutError,TimeoutError,
)
from twisted.web.client import ResponseFailedfrom scrapy.core.downloader.handlers.http11 import TunnelError
from scrapy.exceptions import NotConfigured
from scrapy.http.request import Request
from scrapy.spiders import Spider
from scrapy.utils.python import global_object_name
from scrapy.utils.response import response_status_messageretry_logger = getLogger(__name__)def get_retry_request(request: Request,*,spider: Spider,reason: Union[str, Exception] = "unspecified",max_retry_times: Optional[int] = None,priority_adjust: Optional[int] = None,logger: Logger = retry_logger,stats_base_key: str = "retry",
):"""返回一个新的:class:`~scrapy.Request`对象来重试指定的请求,如果指定请求的重试次数已耗尽,则返回``None``。例如,在一个:class:`~scrapy.Spider`回调中,您可以如下使用它::def parse(self, response):if not response.text:new_request_or_none = get_retry_request(response.request,spider=self,reason='empty',)return new_request_or_none*spider* 是请求重试的:class:`~scrapy.Spider`实例。它用来访问:ref:`设置 <topics-settings>`和:ref:`统计 <topics-stats>`,以及提供额外的日志上下文(参考:func:`logging.debug`)。*reason* 是一个字符串或一个:class:`Exception`对象,表明为什么需要重试请求。它被用来命名重试统计信息。*max_retry_times* 是一个数字,决定了*request*可以被重试的最大次数。如果未指定或``None``,则从请求的: reqmeta:`max_retry_times`元键中读取。如果:reqmeta:`max_retry_times`元键未定义或``None``,则从: setting:`RETRY_TIMES`设置中读取。*priority_adjust* 是一个数字,决定了新请求的优先级如何相对于*request*进行调整。如果未指定,则从: setting:`RETRY_PRIORITY_ADJUST`设置中读取。*logger* 是用于记录消息的logging.Logger对象*stats_base_key* 是字符串,用作重试相关作业统计的基础键"""settings = spider.crawler.settingsstats = spider.crawler.statsretry_times = request.meta.get("retry_times", 0) + 1if max_retry_times is None:max_retry_times = request.meta.get("max_retry_times")if max_retry_times is None:max_retry_times = settings.getint("RETRY_TIMES")if retry_times <= max_retry_times:logger.debug("重试 %(request)s (失败 %(retry_times)d 次): %(reason)s",{"request": request, "retry_times": retry_times, "reason": reason},extra={"spider": spider},)new_request: Request = request.copy()new_request.meta["retry_times"] = retry_timesnew_request.dont_filter = Trueif priority_adjust is None:priority_adjust = settings.getint("RETRY_PRIORITY_ADJUST")new_request.priority = request.priority + priority_adjustif callable(reason):reason = reason()if isinstance(reason, Exception):reason = global_object_name(reason.__class__)stats.inc_value(f"{stats_base_key}/count")stats.inc_value(f"{stats_base_key}/reason_count/{reason}")return new_requeststats.inc_value(f"{stats_base_key}/max_reached")logger.error("放弃重试 %(request)s (失败 %(retry_times)d 次): %(reason)s",{"request": request, "retry_times": retry_times, "reason": reason},extra={"spider": spider},)return Noneclass RetryMiddleware:# IOError在尝试解压空响应时由HttpCompression中间件引发EXCEPTIONS_TO_RETRY = (defer.TimeoutError,TimeoutError,DNSLookupError,ConnectionRefusedError,ConnectionDone,ConnectError,ConnectionLost,TCPTimedOutError,ResponseFailed,IOError,TunnelError,)def __init__(self, settings):if not settings.getbool("RETRY_ENABLED"):raise NotConfiguredself.max_retry_times = settings.getint("RETRY_TIMES")self.retry_http_codes = set(int(x) for x in settings.getlist("RETRY_HTTP_CODES"))self.priority_adjust = settings.getint("RETRY_PRIORITY_ADJUST")@classmethoddef from_crawler(cls, crawler):return cls(crawler.settings)def process_response(self, request, response, spider):if request.meta.get("dont_retry", False):return responseif response.status in self.retry_http_codes:reason = response_status_message(response.status)return self._retry(request, reason, spider) or responsereturn responsedef process_exception(self, request, exception, spider):if isinstance(exception, self.EXCEPTIONS_TO_RETRY) and not request.meta.get("dont_retry", False):return self._retry(request, exception, spider)def _retry(self, request, reason, spider):max_retry_times = request.meta.get("max_retry_times", self.max_retry_times)priority_adjust = request.meta.get("priority_adjust", self.priority_adjust)return get_retry_request(request,reason=reason,spider=spider,max_retry_times=max_retry_times,priority_adjust=priority_adjust,)
这段代码是关于一个处理重试请求的Scrapy中间件的实现。主要解决因为暂时性问题(比如连接超时或者HTTP 500错误)导致的请求失败。下面是对每个方法的口语化中文解释:
get_retry_request
这个函数负责生成一个新的重试请求。如果一个请求因为某些临时性问题失败了,这个函数会根据设定的重试次数来决定是否生成一个新的请求来再次尝试。主要参数包括请求对象、蜘蛛实例、失败原因、最大重试次数和优先级调整等。如果达到了最大重试次数,就会返回None,表示不再重试。
简单来说,如果一个页面因为一些小问题加载失败了,这个函数就会帮你尝试重新加载一下,直到次数用尽或者加载成功为止。
RetryMiddleware
这个类是一个中间件,专门用来处理请求的重试逻辑。它继承自Scrapy的Middleware类,并根据Scrapy的全局设置来决定怎样处理失败的请求。
__init__
这个方法用来初始化RetryMiddleware类的实例。它会读取Scrapy的设置,比如是否启用重试、重试次数、需要重试的HTTP状态码和重试的优先级调整。如果没有启用重试,就会直接抛出NotConfigured异常,表示这个中间件不会被使用。
简而言之,就是根据你事先设定的规则,决定这个中间件开始工作时需要注意些什么。
from_crawler
这个类方法用于实例化中间件,它利用了Scrapy的crawler.settings来访问和使用配置文件中的设置。
换句话说,它是用来创建这个中间件实例,并确保它能按照你的设置来工作。
process_response
此方法处理每个请求的响应。如果一个响应的状态码位于需要重试的状态码列表之内,且该请求未被标记为不需要重试,则该方法会尝试重新调度请求。
这就像是,当你打开一网页失败时,浏览器会帮你刷新一下再试试。
process_exception
这个方法在请求过程中发生异常时被调用。如果遇到了定义在EXCEPTIONS_TO_RETRY中的异常,且该请求未被标记为不需要重试,此方法也会尝试重新调度该请求。
其实就是说,如果在尝试连接一个网站时遇到了问题(比如连接超时了),这个方法会让程序暂停一下,然后再试一次。
_retry
这个私有方法被process_response和process_exception调用,用来执行重试逻辑,判断一个请求是否应该重试,并据此生成一个新的重试请求或者放弃重试。
说白了,这个方法就是在决定,“这个请求是不是真的没救了?还是我们再给它一次机会?”。
整体来说,这段代码的作用是帮助你自动化地处理那些因为一些暂时问题失败的请求,让爬虫更加健壮、容错性更好。
相关文章:
>)
爬虫工作量由小到大的思维转变---<第四十二章 Scrapy Redis 重试机制(ip相关)>
前言: 之前讲过一篇关于scrapy的重试机制的文章,那个是针对当时那哥们的代码讲的,但是,发现后面还是有很多问题; 本章节就着scrapy的重试机制来讲一下!!! 正文: 首先,要清楚一个概念,在scrapy的中间件中,默认会有一个scrapy重试中间件;只要你在settings.py设置中写上: RETR…...

python日志管理配置
日志基础配置文件 日志回转查看:参考:https://blog.csdn.net/B11050729/article/details/132353220 项目使用注解实现 """ settings.py logging配置 """ import osroot_dir os.path.normpath(os.path.join(os.path.ab…...

2024.1.28力扣每日一题——水壶问题
2024.1.28 题目来源我的题解方法一 深度搜索(DFS)/广度搜索(BFS)方法二 数学 题目来源 力扣每日一题;题序:365 我的题解 方法一 深度搜索(DFS)/广度搜索(BFSÿ…...

orin nx 安装paddlespeech记录
nx配置: 模块 版本说明 CPU 8核 内存 16G Cuda版本 11.4 Opencv版本 4.5.4 Tensorrt版本 5.1 Cudnn版本 8.6.0.166 Deepstream版本 6.2 Python版本 3.8 算力 100T 安装paddlepaddle: 去飞桨官网下载jetpack版本的:下…...

系统架构设计师-21年-上午答案
系统架构设计师-21年-上午答案 更多软考资料 https://ruankao.blog.csdn.net/ 1 ~ 10 1 前趋图(Precedence Graph)是一个有向无环图,记为:→{(Pi,Pj)|Pi must complete before Pj may strat},假设系统中进程P{P1,P2,P3…...

外包干了10个月,技术退步明显...
先说一下自己的情况,大专生,18年通过校招进入武汉某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落! 而我已经在一个企业干了四年的功能测…...
树莓派Pico入门
文章目录 1. Pico概述1.1 微处理器1.2 GPIO引脚1.3 MicroPython优点 2. 硬件准备2.1 购买清单2.2 软件需求 3. 安装MicroPython3.1下载固件3.2把固件安装到硬件里3.3补充 4. 第一个程序5. 验证运行效果6. 扩展应用 1. Pico概述 1.1 微处理器 ARM Cortex-M0 (频率 133MHz) 1.…...
yolov8使用旋转框自己做数据集检测
主要在数据集制作,训练的步骤和目标检测是一样的 1.数据集标注主要使用rolabelimg工具,这个工具不能在线安装 得下载源代码 然后运行 标注好数据保存会是一个xml文件 2.把xml文件转换成dota的xml文件,然后把dota的xml文件转换成dota的txt文件…...

docker重建镜像
DockerFile如下: FROM k8s-registry.qhtx.local/base/centos7-jdk8-haitong0704RUN yum -y update && yum install -y python3-devel && yum install -y python36 RUN mv /usr/bin/python /usr/bin/python_old RUN ln -s /usr/bin/python3 /usr/bi…...
【Linux】vim的基本操作与配置(上)
Hello everybody!今天我们要进入vim的讲解了。学会了vim,咱们就可以在Linux系统上做一些简单的编程啦! 那么废话不多说,咱们直接进入正题! 1.初识vim vim是一款多模式的文本编辑器,可以对一个文件进行编辑操作。 它一共有三个模…...

幻兽帕鲁怎么样?好玩? Mac版的玩《幻兽帕鲁》也很简单,只需三个步骤
幻兽帕鲁怎么样 幻兽帕鲁是一款集合了多种游戏元素的游戏,它巧妙地融合了《方舟:生存进化》的野外生存挑战、《荒野之息》的开放世界探索、《魔兽世界》的多元角色互动以及宝可梦的精灵捕捉与培养等经典游戏元素。游戏的核心系统是「帕鲁」捕获,你可以让…...
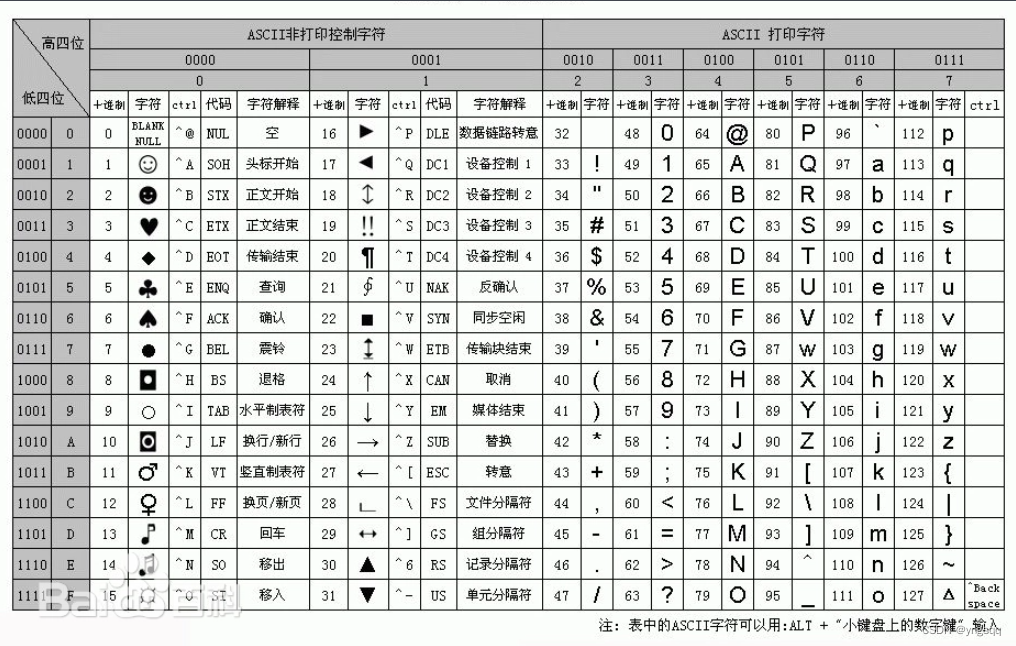
002集——统一码(Unicode)及ASCII码详解
统一码(Unicode),它也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以…...
下载、安装Jenkins
进入官网 下载Jenkins https://www.jenkins.io 直接点击Download 一般是下长期支持版 因为它是java写的,你要运行它(Jenkins.war)肯定要有java环境 有两种方式去运行它,一种是下载Tomcat(是很经典的java容器或者jav…...
python flask 魔术方法
魔术方法作用_init_对象的初始化方法_class_返回对象所属的类_module_返回类所在的模块_mro_返回类的调用顺序,可以找到其父类(用于找父类)_base_获取类的直接父类(用于找父类)_bases_获取父类的元组,按它们…...

2024清洁能源、环境与智慧城市国际研讨会(ISCEESC2024)
2024清洁能源、环境与智慧城市国际研讨会(ISCEESC2024) 会议简介 2024年清洁能源、环境与智慧城市国际研讨会(ISCEESC2024)将在中国丽江举行。本次会议主要围绕清洁能源、环境和智慧城市等研究领域,旨在为该研究领域的专家学者提供一个国际…...
Postgres与DynamoDB:选择哪个数据库
启动新项目时需要做出的决定之一是使用哪个数据库。如果您使用的是Django这样的包含电池的框架,那么没有理由再三考虑。选择一个受支持的数据库引擎,就可以了。另一方面,如果你使用像FastAPI或Flask这样的微框架,你需要自己做出这…...

【ELK】logstash快速入门
1.概述 1.1.什么是logstash? 之前我们聊了es,并且用docker搭建了一个eskibana的环境。es目前最普遍的用法是用来存储日志的,然后结合kibana对日志做一些可视化的工作。既然要收集日志,就面临着一个问题: 各个系统的…...
SQL sever2008中创建用户并赋权
一、创建数据库dream CREATE DATABASE dream; 二、创建登录用户XZS 法一:使用SSMS创建 通过查询 sys.syslogins 系统视图来确定当前登录是否具有系统管理员权限。执行以下查询语句: SELECT name, isntname FROM sys.syslogins WHERE sysadmin 1;选…...

SpringBoot2-Jwt
1.官网 jwt.io/libraries 2.选jose4j pom <dependency><groupId>org.bitbucket.b_c</groupId><artifactId>jose4j</artifactId><version>0.9.4</version> </dependency> 3.创建jwt工具 public class JwtUtil {private stat…...
2、安全开发-Python-Socket编程端口探针域名爆破反弹Shell编码免杀
用途:个人学习笔记,欢迎指正! 目录 主要内容: 一、端口扫描(未开防火墙情况) 1、Python关键代码: 2、完整代码:多线程配合Queue进行全端口扫描 二、子域名扫描 三、客户端,服务端Socket编程通信cmd命…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...