UUID和雪花(Snowflake)算法该如何选择?

UUID和雪花(Snowflake)算法该如何选择?
UUID 和 Snowflake 都可以生成唯一标识,在分布式系统中可以说是必备利器,那么我们该如何对不同的场景进行不同算法的选择呢,UUID 简单无序十分适合生成 requestID, Snowflake 里面包含时间序列等,可以用于排序,效率都还可以,本文详细介绍了我们选择的使用不同算法的原因,两种算法不同维度的对比。
数据库的主键要如何选择?
数据库中的每一条记录都需要有一个唯一的标识,依据数据库的第二范式,数据库中每一个表中都需要有一个唯一的主键,其他数据元素和主键一一对应。 那么关于主键的选择就成为一个关键点了,一般来讲,你有两种选择方式:
- 使用业务字段作为主键,比如说对于用户表来说,可以使用手机号,
email或者身份证号作为主键。 - 使用生成的唯一
ID作为主键。
不过对于大部分场景来说,第一种选择并不适用,比如像评论表你就很难找到一个业务字段作为主键,因为在评论表中,你很难找到一个字段唯一标识一条评论。而对于用户表来说,我们需要考虑的是作为主键的业务字段是否能够唯一标识一个人,一个人可以有多个 email 和手机号,一旦出现变更 email 或者手机号的情况,就需要变更所有引用的外键信息,所以使用 email 或者手机作为主键是不合适的。
身份证号码确实是用户的唯一标识,但是由于它的隐私属性,并不是一个用户系统的必须属性,你想想,你的系统如果没有要求做实名认证,那么肯定不会要求用户填写身份证号码的。并且已有的身份证号码是会变更的,比如在 1999 年时身份证号码就从 15 位变更为 18 位,但是主键一旦变更,以这个主键为外键的表也都要随之变更,这个工作量是巨大的。
因此,我更倾向于使用生成的ID作为数据库的主键。不单单是因为它的唯一性,更是因为一旦生成就不会变更,可以随意引用。
在单库单表的场景下,我们可以使用数据库的自增字段作为 ID,因为这样最简单,对于开发人员来说也是透明的。但是当数据库分库分表后,使用自增字段就无法保证 ID的全局唯一性了。
想象一下,当我们分库分表之后,同一个逻辑表的数据被分布到多个库中,这时如果使用数据库自增字段作为主键,那么只能保证在这个库中是唯一的,无法保证全局的唯一性。那么假如你来设计用户系统的时候,使用自增 ID作为用户 ID,就可能出现两个用户有两个相同的 ID,这是不可接受的,那么你要怎么做呢?我建议你搭建发号器服务来生成全局唯一的 ID。
UUID与Snowflake对比
从我历年所经历的项目中,我主要使用的是变种的 Snowflake 算法来生成业务需要的 ID的,本讲的重点,也是运用它去解决 ID全局唯一性的问题。搞懂这个算法,知道它是怎么实现的,就足够你应用它来设计一套分布式发号器了,不过你可能会说了:“那你提全局唯一性,怎么不提 UUID 呢?”
没错,UUID(Universally Unique Identifier,通用唯一标识码)不依赖于任何第三方系统,所以在性能和可用性上都比较好,我一般会使用它生成 Request ID 来标记单次请求,但是如果用它来作为数据库主键,它会存在以下几点问题。
排序
首先,生成的 ID做好具有单调递增性,也就是有序的,而 UUID 不具备这个特点。为什么 ID 要是有序的呢?因为在系统设计时,ID有可能成为排序的字段。我给你举个例子。
比如,你要实现一套评论的系统时,你一般会设计两个表,一张评论表,存储评论的详细信息,其中有 ID字段,有评论的内容,还有评论人 ID,被评论内容的 ID等等,以 ID字段作为分区键;另一个是评论列表,存储着内容 ID 和评论 ID的对应关系,以内容 ID为分区键。
我们在获取内容的评论列表时,需要按照时间序倒序排列,因为 ID是时间上有序的,所以我们就可以按照评论 ID的倒序排列。而如果评论 ID不是在时间上有序的话,我们就需要在评论列表中再存储一个多余的创建时间的列用作排序,假设内容 ID、评论 ID和时间都是使用 8 字节存储,我们就要多出 50% 的存储空间存储时间字段,造成了存储空间上的浪费。
有序ID会提升数据的写入性能
我们知道 MySQL InnoDB 存储引擎使用 B+ 树存储索引数据,而主键也是一种索引。索引数据在 B+ 树中是有序排列的,就像下面这张图一样,图中 2,10,26 都是记录的 ID,也是索引数据。
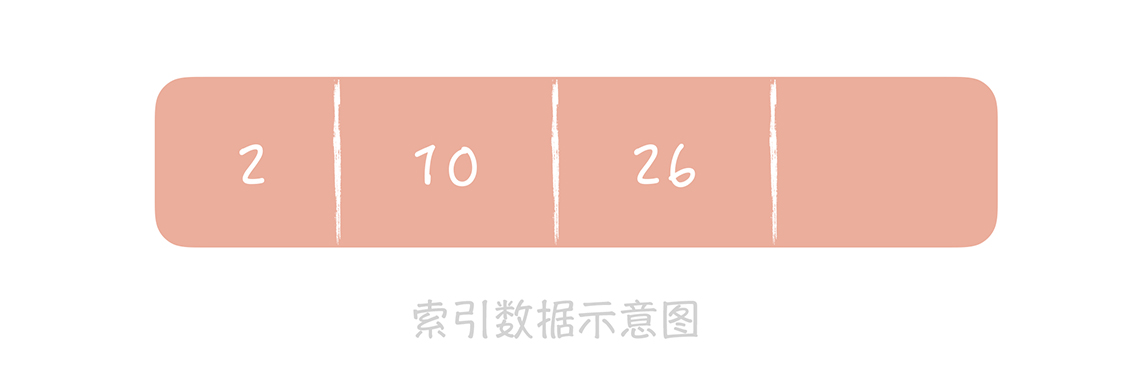
20201124094634
这时,当插入的下一条记录的 ID是递增的时候,比如插入 30 时,数据库只需要把它追加到后面就好了。但是如果插入的数据是无序的,比如 ID是 13,那么数据库就要查找 13 应该插入的位置,再挪动 13 后面的数据,这就造成了多余的数据移动的开销。
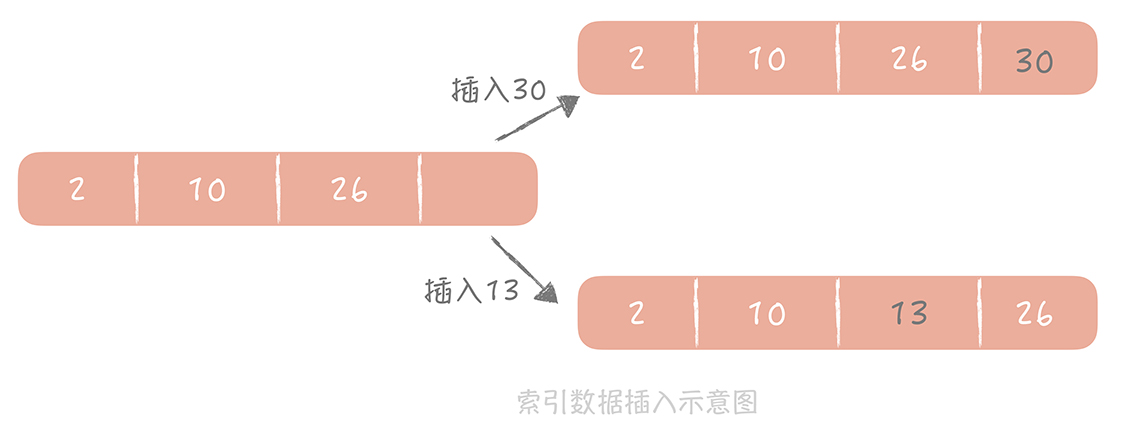
20201124094654
我们知道机械磁盘在完成随机的写时,需要先做 “寻道” 找到要写入的位置,也就是让磁头找到对应的磁道,这个过程是非常耗时的。而顺序写就不需要寻道,会大大提升索引的写入性能。
UUID不具备业务含义
其实现实世界中使用的 ID中都包含有一些有意义的数据,这些数据会出现在 ID的固定的位置上。比如说我们使用的身份证的前六位是地区编号;7~14 位是身份证持有人的生日;不同城市电话号码的区号是不同的;你从手机号码的的前三位就可以看出这个手机号隶属于哪一个运营商。而如果生成的 ID可以被反解,那么从反解出来的信息中我们可以对 ID来做验证,我们可以从中知道这个 ID的生成时间,从哪个机房的发号器中生成的,为哪个业务服务的,对于问题的排查有一定的帮助。
最后,UUID 是由 32 个 16 进制数字组成的字符串,如果作为数据库主键使用比较耗费空间。
你能看到,UUID 方案有很大的局限性,也是我不建议你用它的原因,而 twitter 提出的 Snowflake 算法完全可以弥补 UUID 存在的不足,因为它不仅算法简单易实现,也满足 ID所需要的全局唯一性,单调递增性,还包含一定的业务上的意义。
Snowflake 的核心思想是将 64bit 的二进制数字分成若干部分,每一部分都存储有特定含义的数据,比如说时间戳、机器 ID、序列号等等,最终生成全局唯一的有序 ID。它的标准算法是这样的:

20201124094828
从上面这张图中我们可以看到,41 位的时间戳大概可以支撑 pow(2,41)/1000/60/60/24/365 年,约等于 69 年,对于一个系统是足够了。
如果你的系统部署在多个机房,那么 10 位的机器 ID可以继续划分为 2~3 位的 IDC 标示(可以支撑 4 个或者 8 个 IDC 机房)和 7~8 位的机器 ID(支持 128-256 台机器);12 位的序列号代表着每个节点每毫秒最多可以生成 4096 的 ID。
不同公司也会依据自身业务的特点对 Snowflake 算法做一些改造,比如说减少序列号的位数增加机器 ID的位数以支持单 IDC 更多的机器,也可以在其中加入业务 ID 字段来区分不同的业务。比方说我现在使用的发号器的组成规则就是:1 位兼容位恒为 0 + 41 位时间信息 + 6 位 IDC 信息(支持 64 个 IDC)+ 6 位业务信息(支持 64 个业务)+ 10 位自增信息(每毫秒支持 1024 个号)
我选择这个组成规则,主要是因为我在单机房只部署一个发号器的节点,并且使用 KeepAlive 保证可用性。业务信息指的是项目中哪个业务模块使用,比如用户模块生成的 ID,内容模块生成的 ID,把它加入进来,一是希望不同业务发出来的 ID可以不同,二是因为在出现问题时可以反解 ID,知道是哪一个业务发出来的 ID。
实现方式
那么了解了 Snowflake 算法的原理之后,我们如何把它工程化,来为业务生成全局唯一的 ID呢?
嵌入到业务代码里,也就是分布在业务服务器中
这种方案的好处是业务代码在使用的时候不需要跨网络调用,性能上会好一些,但是就需要更多的机器 ID位数来支持更多的业务服务器。另外,由于业务服务器的数量很多,我们很难保证机器 ID的唯一性,所以就需要引入 ZooKeeper 等分布式一致性组件来保证每次机器重启时都能获得唯一的机器 ID。
作为独立的发号器服务部署
业务在使用发号器的时候就需要多一次的网络调用,但是内网的调用对于性能的损耗有限,却可以减少机器 ID的位数,如果发号器以主备方式部署,同时运行的只有一个发号器,那么机器 ID可以省略,这样可以留更多的位数给最后的自增信息位。即使需要机器 ID,因为发号器部署实例数有限,那么就可以把机器 ID写在发号器的配置文件里,这样即可以保证机器 ID唯一性,也无需引入第三方组件了。微博和美图都是使用独立服务的方式来部署发号器的,性能上单实例单 CPU 可以达到两万每秒。
Snowflake 算法设计的非常简单且巧妙,性能上也足够高效,同时也能够生成具有全局唯一性、单调递增性和有业务含义的 ID,但是它也有一些缺点,其中最大的缺点就是它依赖于系统的时间戳,一旦系统时间不准,就有可能生成重复的 ID。所以如果我们发现系统时钟不准,就可以让发号器暂时拒绝发号,直到时钟准确为止。
另外,如果请求发号器的 QPS 不高,比如说发号器每毫秒只发一个 ID,就会造成生成 ID的末位永远是 1,那么在分库分表时如果使用 ID作为分区键就会造成库表分配的不均匀。这一点,也是我在实际项目中踩过的坑,而解决办法主要有两个:
- 时间戳不记录毫秒而是记录秒,这样在一个时间区间里可以多发出几个号,避免出现分库分表时数据分配不均。
- 生成的序列号的起始号可以做一下随机,这一秒是
21,下一秒是30,这样就会尽量的均衡了。
我在开头提到,自己的实际项目中采用的是变种的 Snowflake 算法,也就是说对 Snowflake 算法进行了一定的改造,从上面的内容中你可以看出,这些改造:一是要让算法中的 ID 生成规则符合自己业务的特点;二是为了解决诸如时间回拨等问题。
其实,大厂除了采取 Snowflake 算法之外,还会选用一些其他的方案,比如滴滴和美团都有提出基于数据库生成 ID的方案。这些方法根植于公司的业务,同样能解决分布式环境下 ID全局唯一性的问题。对你而言,可以多角度了解不同的方法,这样能够寻找到更适合自己业务目前场景的解决方案,不过我想说的是,方案不在多,而在精,方案没有最好,只有最适合,真正弄懂方法背后的原理,并将它落地,才是你最佳的选择。
总结
Snowflake 的算法并不复杂,你在使用的时候可以不考虑独立部署的问题,先想清楚按照自身的业务场景,需要如何设计 Snowflake 算法中的每一部分占的二进制位数。比如你的业务会部署几个 IDC,应用服务器要部署多少台机器,每秒钟发号个数的要求是多少等等,然后在业务代码中实现一个简单的版本先使用,等到应用服务器数量达到一定规模,再考虑独立部署的问题就可以了。这样可以避免多维护一套发号器服务,减少了运维上的复杂度。
相关文章:
UUID和雪花(Snowflake)算法该如何选择?
UUID和雪花(Snowflake)算法该如何选择? UUID 和 Snowflake 都可以生成唯一标识,在分布式系统中可以说是必备利器,那么我们该如何对不同的场景进行不同算法的选择呢,UUID 简单无序十分适合生成 requestID, Snowflake 里…...

Jetpack Compose之进度条介绍(ProgressIndicator)
JetPack Compose系列(12)—进度条介绍 Compose自带进度条控件有两个,分别是:CircularProgressIndicator(圆形进度条)和LinearProgressIndicator(线性进度条)。 CircularProgressIn…...
【Qt基本功修炼】Qt线程的两种运行模式
1. 前言 QThread是Qt中的线程类,用于实现多线程运行。 QThread有两种工作模式,即 消息循环模式无消息循环模式 两种模式分别适用于不同的场景。下面我们将从多个方面,讲解QThread两种工作模式的区别。 2. 消息循环模式 2.1 实现原理 Q…...
三、设计模式相关理论总结
一、面向对象编程 1.1 概述 简称Object Oriented Program(OOP),指以类或对象作为基础组织单元,遵循封装、继承、多态以及抽象等特性,进行编程。其中面向对象不一定遵循封装、继承、封装和多态等特性,只是前人总结的套路规范&…...

鸿蒙 WiFi 连接 流程
那当界面上显示扫描到的所有Ap时,我们选择其中的一个Ap发起连接,看下代码流程是怎样的。 // applications/standard/settings/product/phone/src/main/ets/model/wifiImpl/WifiModel.tsconnectWiFi(password: string) {let apInfo this.userSelectedAp…...

golang 创建unix socket http服务端
服务端 package mainimport ("fmt""net""net/http""os" )func main() {http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {w.Write([]byte("hello"))})http.HandleFunc("/world", …...

annaconda如何切换当前python环境
annaconda默认的python环境是base: 把各种项目的依赖都安装到base环境中不是一个好的习惯,比如说我们做爬虫项目和做自动化测试项目等所需要的依赖是不一样的,我们可以将为每个项目创建自己的环境,在各自的环境中安装自己的依赖&…...
_)
gtkmm 与 Cambalache 与 Gtk::Builder (新手向)_
文章目录 前言Cambalache检查Xml.cpp文件如何写才能显示UI首先creat获取ui里的对象显示 前言 新手刚刚使用时的笔记 Cambalache检查Xml 窗口右键inspect UI Definition切换到Xml视图, 可以全选复制粘贴到你的ui文件里, Cambalache 只能保存为.cmb工程文件, 导出也不知道导出…...

uniapp小程序端使用计算属性动态绑定style样式踩坑
踩坑点: 使用uniapp编译小程序端动态绑定复杂style使用计算属性方式,return必须返回json字符串格式,不能返回object,否则会不起作用。 代码总览 视图层 逻辑层(注意这里是使用的计算属性哈) 这里我封装成了一个个性化…...
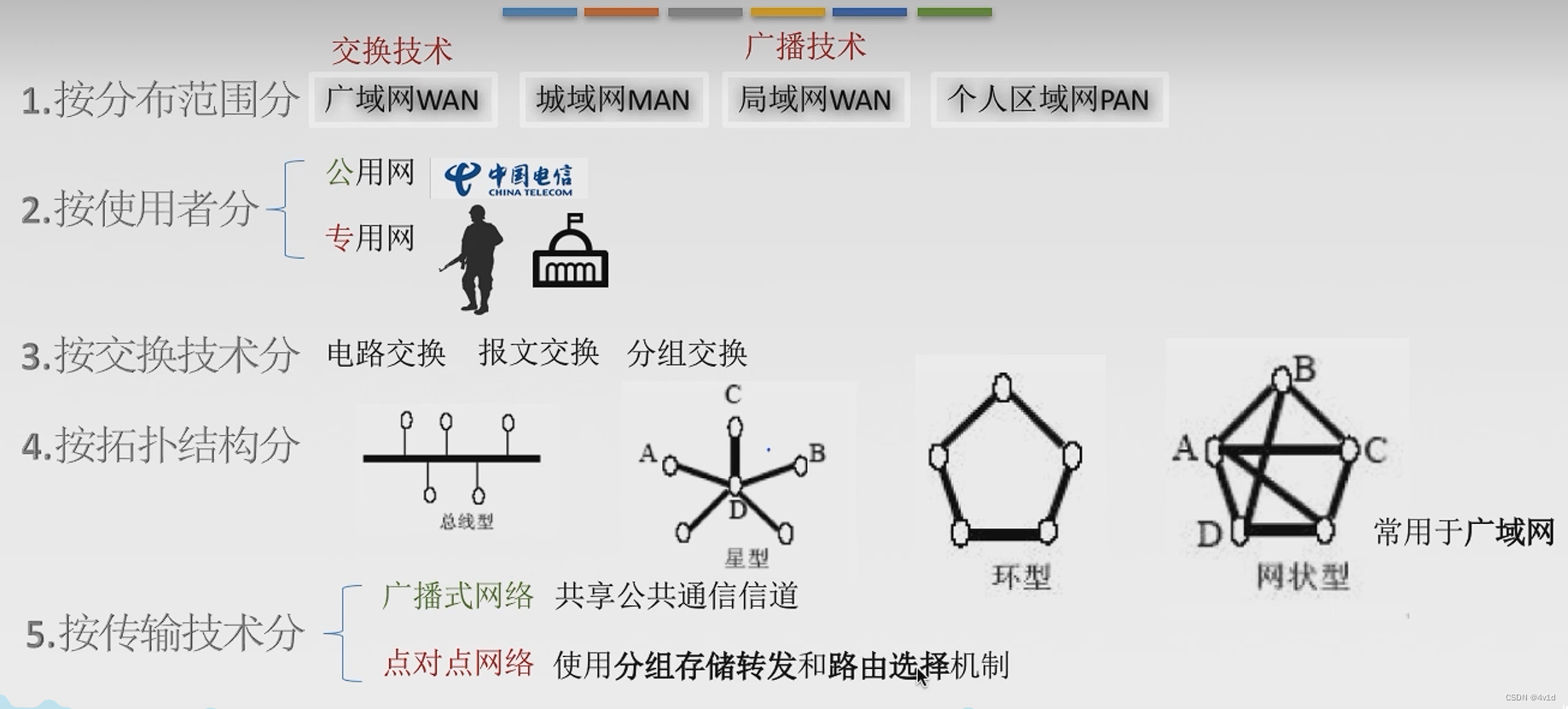
计算机网络概念、组成、功能和分类
文章目录 概要1.怎么学习计算机网络2.概念3.功能、组成4.工作方式、功能组成5.分类 概要 概念、组成、功能和分类 1.怎么学习计算机网络 2.概念 通信设备:比如路由器、路由器 线路:将系统和通信设备两者联系的介质之类的 计算机网络是互连的、自治的的计…...
MyBatisPlus基础操作之增删改查
目录 一、基本使用 1.1 插入数据 1.2 删除操作 1.3 更新操作 二、条件构造器Wrapper 2.1 常用AbstractWrapper方法 2.1.1 示例一 2.2.2 示例二 2.2.3 示例三 2.2 常用QueryWrapper方法 2.2.1 示例一 2.2.2 示例二 2.2.3 示例三(常用) 2.3 常…...

视频处理学习笔记1:YUYV422、NV12和h264
最近因为工作关系在恶补视频相关知识点,在此做一记录便于日后复习。 以下均是个人学习经验总结,可能存在错误和坑,欢迎大佬指教。 工作中用到的是YUYV422存储格式。存储的就是裸流YUYV422格式文件。 YUYV422是两个像素点共用一个UV分量&am…...

CTFshow web(命令执行29-36)
?ceval($_GET[shy]);­passthru(cat flag.php); #逃逸过滤 ?cinclude%09$_GET[shy]?>­php://filter/readconvert.base64-encode/resourceflag.php #文件包含 ?cinclude%0a$_GET[cmd]?>&cmdphp://filter/readconvert.base64-encode/…...

PyTorch深度学习实战(23)——从零开始实现SSD目标检测
PyTorch深度学习实战(23)——从零开始实现SSD目标检测 0. 前言1. SSD 目标检测模型1.1 SSD 网络架构1.2 利用不同网络层执行边界框和类别预测1.3 不同网络层中默认框的尺寸和宽高比1.4 数据准备1.5 模型训练 2. 实现 SSD 目标检测2.1 SSD300 架构2.2 Mul…...
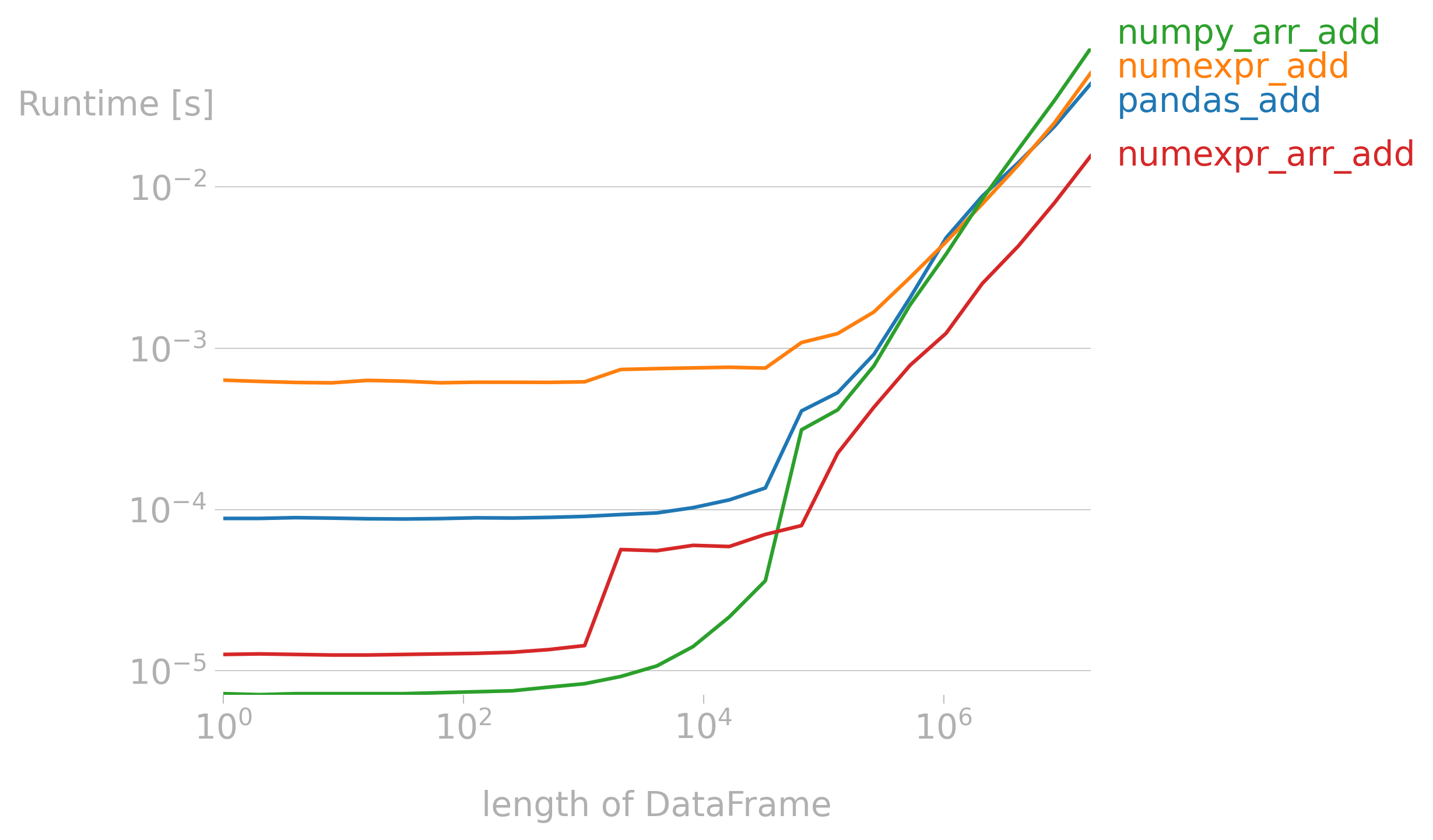
【附代码】NumPy加速库NumExpr(大数据)
文章目录 相关文献测试电脑配置数组加减乘除数组乘方Pandas加减乘除总结 作者:小猪快跑 基础数学&计算数学,从事优化领域5年,主要研究方向:MIP求解器、整数规划、随机规划、智能优化算法 如有错误,欢迎指正。如有…...

4、安全开发-Python-蓝队项目流量攻击分析文件动态监控图片隐写技术
用途:个人学习笔记,有所借鉴,欢迎指正! 总结: (1)使用python脚本Scapy库实现指定网卡的流量抓包分析 (2)使用python脚本Watchdog实现指定目录文件行为监控 (…...
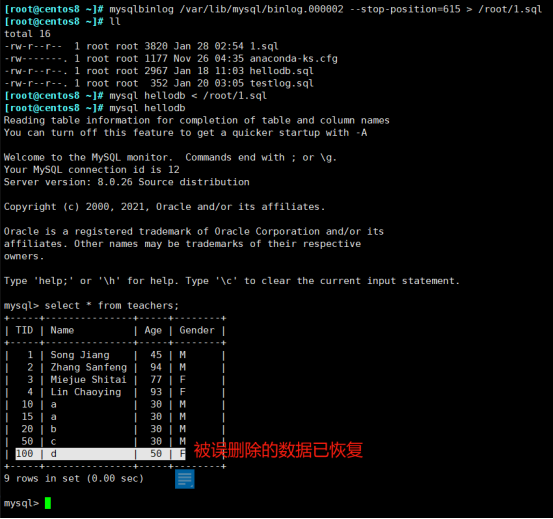
MySQL 日志管理
4.6)日志管理 MySQL 支持丰富的日志类型,如下: 事务日志:transaction log 事务日志的写入类型为 "追加",因此其操作为 "顺序IO"; 通常也被称为:预写式日志 write ahead…...
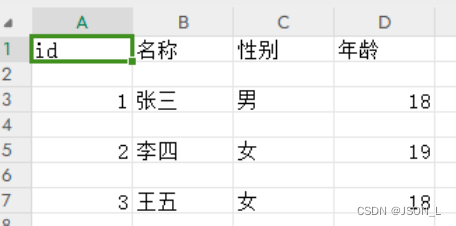
Python CSV文件读取和写入
本文主要为Python 实现CSV文件读取和写入操作。 CSV文件写入和读取 因为没有现成的csv文件,所以csv的顺序为先写入后读取。 写入 创建csv文件并把数据写入,有两种实现方式:直接插入所有行和插入单行。 示例如下: import csv i…...
如何使用C#调用LabVIEW算法
新建一个工程 这是必须的; 创建项目 项目 点击完成; 将项目另存为;方便后续的使用; 创建 一个测试VI 功能很简单,用的一个加法;将加数A,B设置为输入,和C设置为输出,…...

调用百度文心AI作画API实现中文-图像跨模态生成
作者介绍 乔冠华,女,西安工程大学电子信息学院,2020级硕士研究生,张宏伟人工智能课题组。 研究方向:机器视觉与人工智能。 电子邮件:1078914066qq.com 一.文心AI作画API介绍 1. 文心AI作画 文…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...

高效的后台管理系统——可进行二次开发
随着互联网技术的迅猛发展,企业的数字化管理变得愈加重要。后台管理系统作为数据存储与业务管理的核心,成为了现代企业不可或缺的一部分。今天我们要介绍的是一款名为 若依后台管理框架 的系统,它不仅支持跨平台应用,还能提供丰富…...

嵌入式面试常问问题
以下内容面向嵌入式/系统方向的初学者与面试备考者,全面梳理了以下几大板块,并在每个板块末尾列出常见的面试问答思路,帮助你既能夯实基础,又能应对面试挑战。 一、TCP/IP 协议 1.1 TCP/IP 五层模型概述 链路层(Link Layer) 包括网卡驱动、以太网、Wi‑Fi、PPP 等。负责…...