【SparkML实践7】特征选择器FeatureSelector
本节介绍了用于处理特征的算法,大致可以分为以下几组:
- 提取(Extraction):从“原始”数据中提取特征。
- 转换(Transformation):缩放、转换或修改特征。
- 选择(Selection):从更大的特征集中选择一个子集。
- 局部敏感哈希(Locality Sensitive Hashing, LSH):这类算法结合了特征转换的方面与其他算法。
Feature Selectors
VectorSlicer
VectorSlicer 是一个转换器,它接受一个特征向量,并输出一个新的特征向量,该向量包含原始特征的子数组。它用于从向量列中提取特征。
VectorSlicer 接受一个带有指定索引的向量列,然后输出一个新的向量列,其值通过这些索引选择。有两种类型的索引:
- 整数索引,代表向量中的索引,使用 setIndices() 设置。
- 字符串索引,代表向量中的特征名称,使用 setNames() 设置。这要求向量列具有 AttributeGroup,因为实现是基于 Attribute 的 name 字段进行匹配的。
整数和字符串规格都是可以接受的。此外,您可以同时使用整数索引和字符串名称。至少必须选择一个特征。不允许有重复的特征,所以选定的索引和名称之间不能有重叠。请注意,如果选择了特征的名称,在遇到空的输入属性时会抛出异常。
输出向量将首先按照给定的顺序排列选定的索引特征,然后按照给定的顺序排列选定的名称特征。
Examples
Suppose that we have a DataFrame with the column userFeatures:
| userFeatures | x |
|---|---|
| [0.0, 10.0, 0.5] |
userFeatures 是一个向量列,包含三个用户特征。假设 userFeatures 的第一列全是零,因此我们想要移除它,只选择最后两列。VectorSlicer 通过 setIndices(1, 2) 选择最后两个元素,然后生成一个名为 features 的新向量列:
| userFeatures | features |
|---|---|
| [0.0, 10.0, 0.5] | [10.0, 0.5] |
假设我们还有 userFeatures 的潜在输入属性,即 [“f1”, “f2”, “f3”],那么我们可以使用 setNames(“f2”, “f3”) 来选择它们。
| userFeatures | features |
|---|---|
| [0.0, 10.0, 0.5] | [10.0, 0.5] |
| [“f1”, “f2”, “f3”] | [“f2”, “f3”] |
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Row, SparkSession}import java.util.Arraysobject VectorSlicerExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("VectorSlicerExample").getOrCreate()val data = Arrays.asList(Row(Vectors.sparse(3, Seq((0, -2.0), (1, 2.3)))),Row(Vectors.dense(-2.0, 2.3, 0.0)))val defaultAttr = NumericAttribute.defaultAttrval attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]])val dataset = spark.createDataFrame(data, StructType(Array(attrGroup.toStructField())))val slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")slicer.setIndices(Array(1)).setNames(Array("f3"))// or slicer.setIndices(Array(1, 2)), or slicer.setNames(Array("f2", "f3"))val output = slicer.transform(dataset)output.show(false)spark.stop()}
}
RFormula
- RFormula 通过指定 R 模型公式来选择列。目前我们支持 R 操作符的一个有限子集,包括 ‘~’、‘.’、‘:’、‘+’ 和 ‘-’。基本操作符有:
- 分隔目标和项
连接项,“+ 0” 表示去除截距
移除一个项,“- 1” 表示去除截距
: 交互作用(数值的乘积,或二值化的类别值)
. 所有列除了目标
假设 a 和 b 是双精度列,我们使用以下简单的例子来说明 RFormula 的效果:
y ~ a + b 表示模型 y ~ w0 + w1 * a + w2 * b,其中 w0 是截距,w1、w2 是系数。
y ~ a + b + a:b - 1 表示模型 y ~ w1 * a + w2 * b + w3 * a * b,其中 w1、w2、w3 是系数。
RFormula 生成一个特征向量列和一个双精度或字符串列的标签。就像在 R 中用于线性回归的公式一样,数值列将被转换为双精度数。至于字符串输入列,它们首先会通过 StringIndexer 转换,使用由 stringOrderType 确定的顺序,并且在排序后的最后一个类别会被丢弃,然后双精度数将被进行独热编码。
假设有一个包含值 {‘b’, ‘a’, ‘b’, ‘a’, ‘c’, ‘b’} 的字符串特征列,我们设置 stringOrderType 来控制编码:
ChiSqSelector
ChiSqSelector 代表卡方特征选择。它作用于带有类别特征的标记数据。ChiSqSelector 使用卡方独立性检验来决定选择哪些特征。它支持五种选择方法:numTopFeatures、percentile、fpr、fdr、fwe:
- numTopFeatures 根据卡方检验选择固定数量的顶级特征。这类似于选择具有最高预测能力的特征。
- percentile 与 numTopFeatures 类似,但它选择所有特征的一定比例,而不是固定数量。
- fpr 选择所有 p 值低于阈值的特征,从而控制选择的假阳性率。
- fdr 使用 Benjamini-Hochberg 程序选择所有假发现率低于阈值的特征。
- fwe 选择所有 p 值低于阈值的特征。阈值通过 1/numFeatures 缩放,从而控制选择的家族错误率。
- 默认情况下,选择方法为 numTopFeatures,且默认的顶级特征数量设置为 50。用户可以使用 setSelectorType 选择一个选择方法。
示例
假设我们有一个 DataFrame,它包含列 id、features 和 clicked,clicked 被用作我们要预测的目标:
| id | features | clicked |
|---|---|---|
| 7 | [0.0, 0.0, 18.0, 1.0] | 1.0 |
| 8 | [0.0, 1.0, 12.0, 0.0] | 0.0 |
| 9 | [1.0, 0.0, 15.0, 0.1] | 0.0 |
如果我们使用 ChiSqSelector 并设置 numTopFeatures = 1,那么根据我们的标签 clicked,我们特征中的最后一列将被选为最有用的特征:
| id | features | clicked | selectedFeatures |
|---|---|---|---|
| 7 | [0.0, 0.0, 18.0, 1.0] | 1.0 | [1.0] |
| 8 | [0.0, 1.0, 12.0, 0.0] | 0.0 | [0.0] |
| 9 | [1.0, 0.0, 15.0, 0.1] | 0.0 | [0.1] |
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSessionobject ChiSqSelectorExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local").appName("ChiSqSelectorExample").getOrCreate()import spark.implicits._val data = Seq((7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0),(8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0),(9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0))val df = spark.createDataset(data).toDF("id", "features", "clicked")val selector = new ChiSqSelector().setNumTopFeatures(1).setFeaturesCol("features").setLabelCol("clicked").setOutputCol("selectedFeatures")val result = selector.fit(df).transform(df)println(s"ChiSqSelector output with top ${selector.getNumTopFeatures} features selected")result.show()spark.stop()}
}
UnivariateFeatureSelector
单变量特征选择器(UnivariateFeatureSelector)可以操作具有类别型/连续型标签的类别型/连续型特征。用户可以设置特征类型(featureType)和标签类型(labelType),Spark会根据指定的特征类型和标签类型选择使用的评分函数。
| 特征类型 | 标签类型 | 评分函数 |
|---|---|---|
| categorical(类别型) | categorical | chi-squared (chi2) |
| continuous | categorical | ANOVATest (f_classif) |
| continuous | continuous | F-value (f_regression) |
它支持五种选择模式:numTopFeatures、percentile、fpr、fdr、fwe:
- numTopFeatures 选择固定数量的最优特征。
- percentile 类似于numTopFeatures,但它选择所有特征的一定比例,而不是固定数量。
- fpr 选择所有p值低于阈值的特征,从而控制选择的假阳性率。
- fdr 使用Benjamini-Hochberg程序选择所有假发现率低于阈值的特征。
- fwe 选择所有p值低于阈值的特征。阈值通过1/numFeatures进行缩放,从而控制选择的家族误差率。
默认情况下,选择模式为numTopFeatures,且默认的selectionThreshold设置为50。
示例
假设我们有一个DataFrame,包含列id、features和label,label是我们预测的目标:
| id | features | label |
|---|---|---|
| 1 | [1.7, 4.4, 7.6, 5.8, 9.6, 2.3] | 3.0 |
| 2 | [8.8, 7.3, 5.7, 7.3, 2.2, 4.1] | 2.0 |
| 3 | [1.2, 9.5, 2.5, 3.1, 8.7, 2.5] | 3.0 |
| 4 | [3.7, 9.2, 6.1, 4.1, 7.5, 3.8] | 2.0 |
| 5 | [8.9, 5.2, 7.8, 8.3, 5.2, 3.0] | 4.0 |
| 6 | [7.9, 8.5, 9.2, 4.0, 9.4, 2.1] | 4.0 |
| 如果我们将特征类型设置为连续型,标签类型设置为类别型,且numTopFeatures = 1,则我们的特征中的最后一列被选为最有用的特征: |
| id | features | label | selectedFeatures |
|---|---|---|---|
| 1 | [1.7, 4.4, 7.6, 5.8, 9.6, 2.3] | 3.0 | [2.3] |
| 2 | [8.8, 7.3, 5.7, 7.3, 2.2, 4.1] | 2.0 | [4.1] |
| 3 | [1.2, 9.5, 2.5, 3.1, 8.7, 2.5] | 3.0 | [2.5] |
| 4 | [3.7, 9.2, 6.1, 4.1, 7.5, 3.8] | 2.0 | [3.8] |
| 5 | [8.9, 5.2, 7.8, 8.3, 5.2, 3.0] | 4.0 | [3.0] |
| 6 | [7.9, 8.5, 9.2, 4.0, 9.4, 2.1] | 4.0 | [2.1] |
import org.apache.spark.ml.feature.UnivariateFeatureSelector
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession/*** An example for UnivariateFeatureSelector.* Run with* {{{* bin/run-example ml.UnivariateFeatureSelectorExample* }}}*/
object UnivariateFeatureSelectorExample {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.appName("UnivariateFeatureSelectorExample").getOrCreate()import spark.implicits._val data = Seq((1, Vectors.dense(1.7, 4.4, 7.6, 5.8, 9.6, 2.3), 3.0),(2, Vectors.dense(8.8, 7.3, 5.7, 7.3, 2.2, 4.1), 2.0),(3, Vectors.dense(1.2, 9.5, 2.5, 3.1, 8.7, 2.5), 3.0),(4, Vectors.dense(3.7, 9.2, 6.1, 4.1, 7.5, 3.8), 2.0),(5, Vectors.dense(8.9, 5.2, 7.8, 8.3, 5.2, 3.0), 4.0),(6, Vectors.dense(7.9, 8.5, 9.2, 4.0, 9.4, 2.1), 4.0))val df = spark.createDataset(data).toDF("id", "features", "label")val selector = new UnivariateFeatureSelector().setFeatureType("continuous").setLabelType("categorical").setSelectionMode("numTopFeatures").setSelectionThreshold(1).setFeaturesCol("features").setLabelCol("label").setOutputCol("selectedFeatures")val result = selector.fit(df).transform(df)println(s"UnivariateFeatureSelector output with top ${selector.getSelectionThreshold}" +s" features selected using f_classif")result.show()spark.stop()}
}
VarianceThresholdSelector
VarianceThresholdSelector 是一个选择器,用于移除低方差特征。那些样本方差不大于 varianceThreshold 的特征将被移除。如果没有设置 varianceThreshold,默认值为 0,这意味着只有方差为 0 的特征(即在所有样本中具有相同值的特征)将被移除。
示例
假设我们有一个 DataFrame,它包含列 id 和 features,这些特征用作我们要预测的目标:
| id | features |
|---|---|
| 1 | [6.0, 7.0, 0.0, 7.0, 6.0, 0.0] |
| 2 | [0.0, 9.0, 6.0, 0.0, 5.0, 9.0] |
| 3 | [0.0, 9.0, 3.0, 0.0, 5.0, 5.0] |
| 4 | [0.0, 9.0, 8.0, 5.0, 6.0, 4.0] |
| 5 | [8.0, 9.0, 6.0, 5.0, 4.0, 4.0] |
| 6 | [8.0, 9.0, 6.0, 0.0, 0.0, 0.0] |
这6个特征的样本方差分别为16.67、0.67、8.17、10.17、5.07和11.47。如果我们使用VarianceThresholdSelector并设置varianceThreshold = 8.0,那么方差小于等于8.0的特征将被移除:
| id | features | selectedFeatures |
|---|---|---|
| 1 | [6.0, 7.0, 0.0, 7.0, 6.0, 0.0] | [6.0,0.0,7.0,0.0] |
| 2 | [0.0, 9.0, 6.0, 0.0, 5.0, 9.0] | [0.0,6.0,0.0,9.0] |
| 3 | [0.0, 9.0, 3.0, 0.0, 5.0, 5.0] | [0.0,3.0,0.0,5.0] |
| 4 | [0.0, 9.0, 8.0, 5.0, 6.0, 4.0] | [0.0,8.0,5.0,4.0] |
| 5 | [8.0, 9.0, 6.0, 5.0, 4.0, 4.0] | [8.0,6.0,5.0,4.0] |
| 6 | [8.0, 9.0, 6.0, 0.0, 0.0, 0.0] | [8.0,6.0,0.0,0.0] |
Locality Sensitive Hashing
局部敏感哈希(LSH)是一类重要的哈希技术,通常用于大数据集的聚类、近似最近邻搜索和异常值检测。
LSH的基本思想是使用一族函数(“LSH族”)将数据点哈希到桶中,使得彼此接近的数据点有很高的概率落在同一个桶里,而彼此距离较远的数据点则很可能落在不同的桶中。一个LSH族正式定义如下。
在一个度量空间(M, d)中,其中M是一个集合,d是M上的一个距离函数,一个LSH族是一族满足以下性质的函数h:
∀p,q∈M,
d(p,q)≤r1⇒Pr(h§=h(q))≥p1
d(p,q)≥r2⇒Pr(h§=h(q))≤p2
这样的LSH族称为(r1, r2, p1, p2)-敏感的。
在Spark中,不同的LSH族在不同的类中实现(例如,MinHash),并且每个类中都提供了特征转换、近似相似性连接和近似最近邻搜索的API。
在LSH中,我们定义一个假正例为一对距离较远的输入特征(满足d(p,q)≥r2)被哈希到同一个桶中,我们定义一个假反例为一对接近的特征(满足d(p,q)≤r1)被哈希到不同的桶中。
LSH Operations
我们描述了LSH可用于的主要操作类型。一个训练好的LSH模型具有这些操作的各自方法。
Feature Transformation
特征转换是添加哈希值作为新列的基本功能。这对于降维很有用。用户可以通过设置inputCol和outputCol来指定输入和输出列的名称。
LSH还支持多个LSH哈希表。用户可以通过设置numHashTables来指定哈希表的数量。这也用于近似相似性连接和近似最近邻搜索中的OR放大。增加哈希表的数量将提高精度,但也会增加通信成本和运行时间。
outputCol的类型是Seq[Vector],其中数组的维度等于numHashTables,向量的维度目前设置为1。在未来的版本中,我们将实现AND放大,以便用户可以指定这些向量的维度。
Approximate Similarity Join
近似相似性连接接受两个数据集,并近似返回数据集中距离小于用户定义阈值的行对。近似相似性连接支持连接两个不同的数据集和自连接。自连接会产生一些重复的对。
近似相似性连接接受转换过的和未转换过的数据集作为输入。如果使用未转换的数据集,它将自动被转换。在这种情况下,哈希签名将作为outputCol创建。
在连接的数据集中,可以在datasetA和datasetB中查询原始数据集。输出数据集中将添加一个距离列,以显示返回的每对行之间的真实距离。
Approximate Nearest Neighbor Search
近似最近邻搜索接受一个数据集(特征向量集)和一个键(单个特征向量),它近似返回数据集中最接近该向量的指定数量的行。
近似最近邻搜索接受转换过的和未转换过的数据集作为输入。如果使用未转换的数据集,它将自动被转换。在这种情况下,哈希签名将作为outputCol创建。
输出数据集中将添加一个距离列,以显示每个输出行与搜索键之间的真实距离。
注意:当哈希桶中没有足够的候选者时,近似最近邻搜索将返回少于k行。
LSH Algorithms
import org.apache.spark.ml.feature.BucketedRandomProjectionLSH
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.colval dfA = spark.createDataFrame(Seq((0, Vectors.dense(1.0, 1.0)),(1, Vectors.dense(1.0, -1.0)),(2, Vectors.dense(-1.0, -1.0)),(3, Vectors.dense(-1.0, 1.0))
)).toDF("id", "features")val dfB = spark.createDataFrame(Seq((4, Vectors.dense(1.0, 0.0)),(5, Vectors.dense(-1.0, 0.0)),(6, Vectors.dense(0.0, 1.0)),(7, Vectors.dense(0.0, -1.0))
)).toDF("id", "features")val key = Vectors.dense(1.0, 0.0)val brp = new BucketedRandomProjectionLSH().setBucketLength(2.0).setNumHashTables(3).setInputCol("features").setOutputCol("hashes")val model = brp.fit(dfA)// Feature Transformation
println("The hashed dataset where hashed values are stored in the column 'hashes':")
model.transform(dfA).show()// Compute the locality sensitive hashes for the input rows, then perform approximate
// similarity join.
// We could avoid computing hashes by passing in the already-transformed dataset, e.g.
// `model.approxSimilarityJoin(transformedA, transformedB, 1.5)`
println("Approximately joining dfA and dfB on Euclidean distance smaller than 1.5:")
model.approxSimilarityJoin(dfA, dfB, 1.5, "EuclideanDistance").select(col("datasetA.id").alias("idA"),col("datasetB.id").alias("idB"),col("EuclideanDistance")).show()// Compute the locality sensitive hashes for the input rows, then perform approximate nearest
// neighbor search.
// We could avoid computing hashes by passing in the already-transformed dataset, e.g.
// `model.approxNearestNeighbors(transformedA, key, 2)`
println("Approximately searching dfA for 2 nearest neighbors of the key:")
model.approxNearestNeighbors(dfA, key, 2).show()
MinHash for Jaccard Distance
MinHash是一种用于Jaccard距离的LSH族,输入特征是自然数集合。两个集合的Jaccard距离由它们交集和并集的基数定义:
d(A, B) = 1 - |A ∩ B| / |A ∪ B|
MinHash对集合中的每个元素应用一个随机哈希函数g,并取所有哈希值的最小值:
h(A) = min_{a∈A}(g(a))
MinHash的输入集合表示为二进制向量,向量索引代表元素本身,向量中的非零值表示集合中该元素的存在。尽管支持密集和稀疏向量,但通常推荐使用稀疏向量以提高效率。例如,Vectors.sparse(10, Array[(2, 1.0), (3, 1.0), (5, 1.0)])表示空间中有10个元素。这个集合包含元素2、元素3和元素5。所有非零值都被视为二进制“1”值。
注意:空集不能通过MinHash转换,这意味着任何输入向量必须至少有一个非零条目。
import org.apache.spark.ml.feature.MinHashLSH
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.colval dfA = spark.createDataFrame(Seq((0, Vectors.sparse(6, Seq((0, 1.0), (1, 1.0), (2, 1.0)))),(1, Vectors.sparse(6, Seq((2, 1.0), (3, 1.0), (4, 1.0)))),(2, Vectors.sparse(6, Seq((0, 1.0), (2, 1.0), (4, 1.0))))
)).toDF("id", "features")val dfB = spark.createDataFrame(Seq((3, Vectors.sparse(6, Seq((1, 1.0), (3, 1.0), (5, 1.0)))),(4, Vectors.sparse(6, Seq((2, 1.0), (3, 1.0), (5, 1.0)))),(5, Vectors.sparse(6, Seq((1, 1.0), (2, 1.0), (4, 1.0))))
)).toDF("id", "features")val key = Vectors.sparse(6, Seq((1, 1.0), (3, 1.0)))val mh = new MinHashLSH().setNumHashTables(5).setInputCol("features").setOutputCol("hashes")val model = mh.fit(dfA)// Feature Transformation
println("The hashed dataset where hashed values are stored in the column 'hashes':")
model.transform(dfA).show()// Compute the locality sensitive hashes for the input rows, then perform approximate
// similarity join.
// We could avoid computing hashes by passing in the already-transformed dataset, e.g.
// `model.approxSimilarityJoin(transformedA, transformedB, 0.6)`
println("Approximately joining dfA and dfB on Jaccard distance smaller than 0.6:")
model.approxSimilarityJoin(dfA, dfB, 0.6, "JaccardDistance").select(col("datasetA.id").alias("idA"),col("datasetB.id").alias("idB"),col("JaccardDistance")).show()// Compute the locality sensitive hashes for the input rows, then perform approximate nearest
// neighbor search.
// We could avoid computing hashes by passing in the already-transformed dataset, e.g.
// `model.approxNearestNeighbors(transformedA, key, 2)`
// It may return less than 2 rows when not enough approximate near-neighbor candidates are
// found.
println("Approximately searching dfA for 2 nearest neighbors of the key:")
model.approxNearestNeighbors(dfA, key, 2).show()
相关文章:

【SparkML实践7】特征选择器FeatureSelector
本节介绍了用于处理特征的算法,大致可以分为以下几组: 提取(Extraction):从“原始”数据中提取特征。转换(Transformation):缩放、转换或修改特征。选择(Selection&…...

LeetCode983. Minimum Cost For Tickets——动态规划
文章目录 一、题目二、题解 一、题目 You have planned some train traveling one year in advance. The days of the year in which you will travel are given as an integer array days. Each day is an integer from 1 to 365. Train tickets are sold in three differen…...
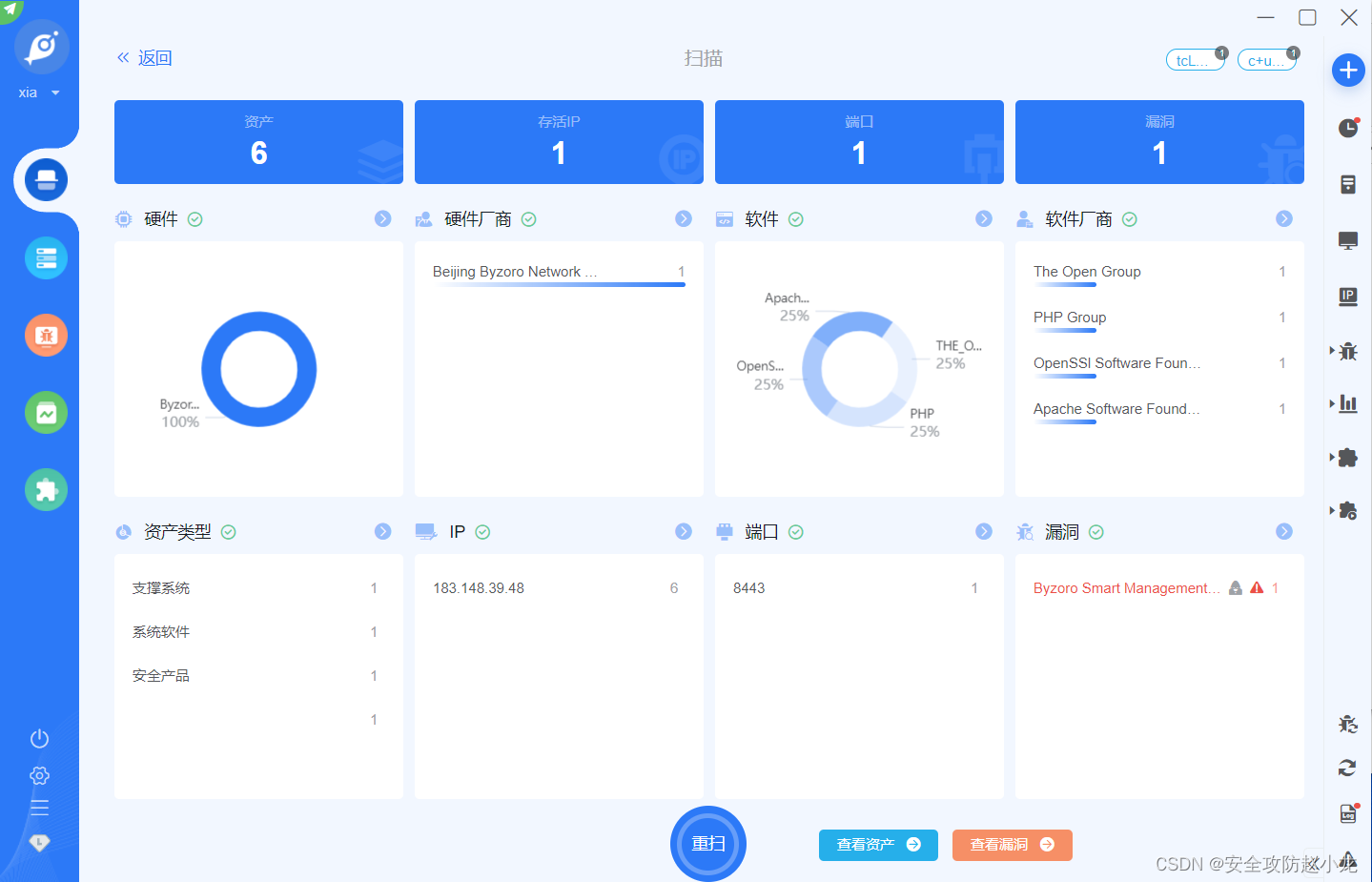
百卓Smart管理平台 uploadfile.php 文件上传漏洞【CVE-2024-0939】
百卓Smart管理平台 uploadfile.php 文件上传漏洞【CVE-2024-0939】 一、 产品简介二、 漏洞概述三、 影响范围四、 复现环境五、 漏洞复现手动复现小龙验证Goby验证 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工…...

项目中常用的一些数据库及缓存
1、常见的开发工具介绍 MySQL: MySQL是一种流行的开源关系型数据库管理系统(RDBMS),由瑞典MySQL AB公司开发,并在后来被Sun Microsystems收购,最终成为Oracle公司的一部分。MySQL广泛用于各种Web应用程序和大型企业应…...
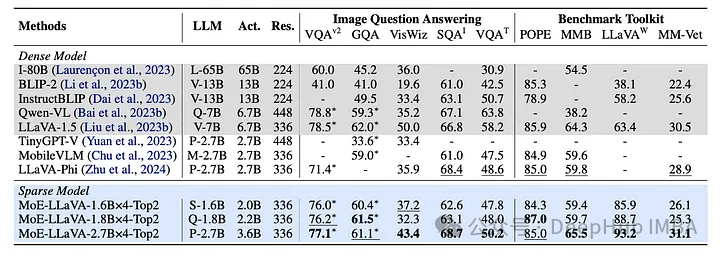
MoE-LLaVA:具有高效缩放和多模态专业知识的大型视觉语言模型
视觉和语言模型的交叉导致了人工智能的变革性进步,使应用程序能够以类似于人类感知的方式理解和解释世界。大型视觉语言模型(LVLMs)在图像识别、视觉问题回答和多模态交互方面提供了无与伦比的能力。 MoE-LLaVA利用了“专家混合”策略融合视觉和语言数据࿰…...

【Java】ArrayList和LinkedList的区别是什么
目录 1. 数据结构 2. 性能特点 3. 源码分析 4. 代码演示 5. 细节和使用场景 ArrayList 和 LinkedList 分别代表了两类不同的数据结构:动态数组和链表。它们都实现了 Java 的 List 接口,但是有着各自独特的特点和性能表现。 1. 数据结构 ArrayList…...
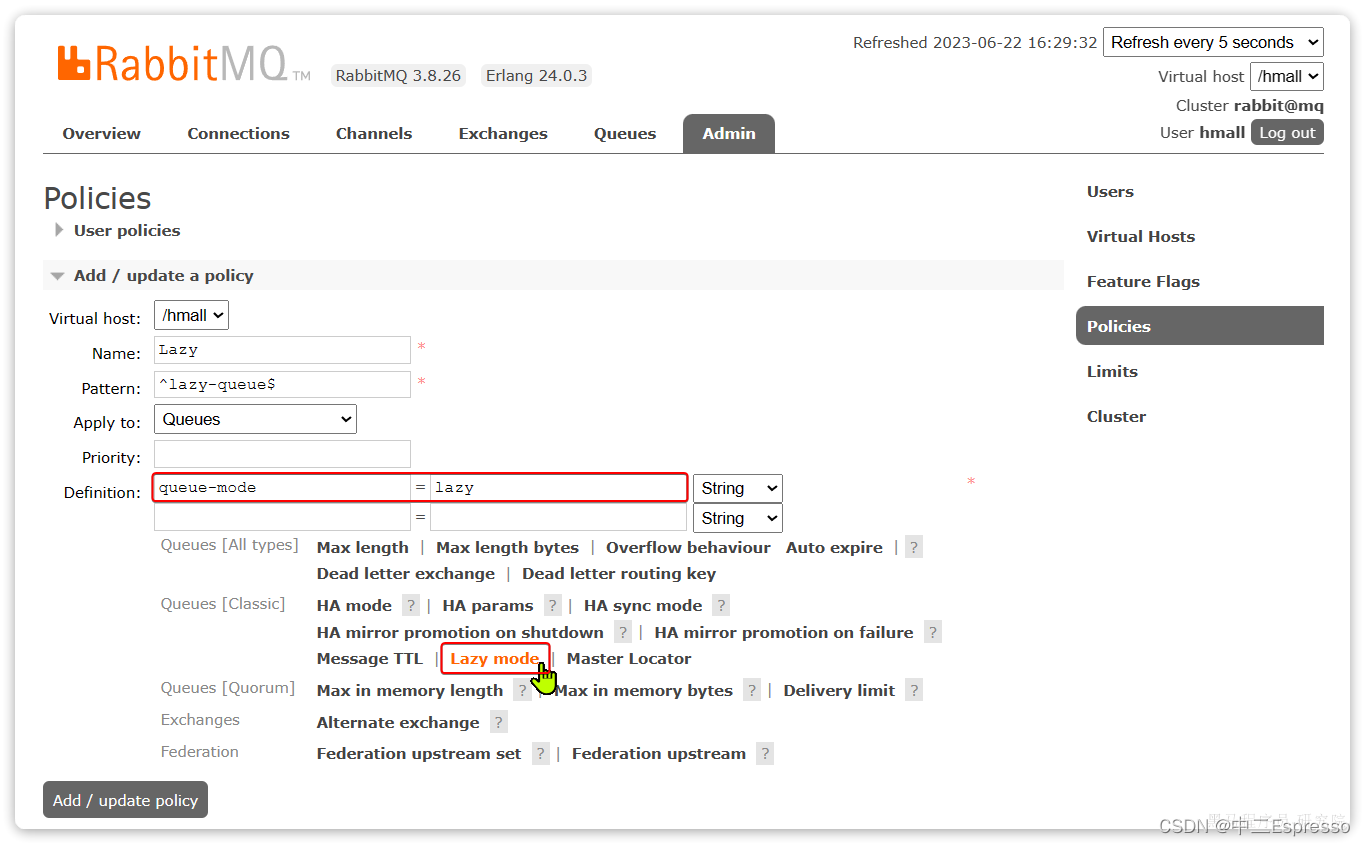
RabbitMQ-4.MQ的可靠性
MQ的可靠性 4.MQ的可靠性4.1.数据持久化4.1.1.交换机持久化4.1.2.队列持久化4.1.3.消息持久化 4.2.LazyQueue4.2.1.控制台配置Lazy模式4.2.2.代码配置Lazy模式4.2.3.更新已有队列为lazy模式 4.MQ的可靠性 消息到达MQ以后,如果MQ不能及时保存,也会导致消…...

编程相关的经典的网站和书籍
经典网站: Stack Overflow:作为全球最大的程序员问答社区,Stack Overflow 汇聚了大量的编程问题和解答,为程序员提供了极大的帮助。GitHub:全球最大的开源代码托管平台,程序员可以在上面共享自己的项目代码…...

Java代码实现基数排序算法(附带源码)
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。 1. 基数排序…...
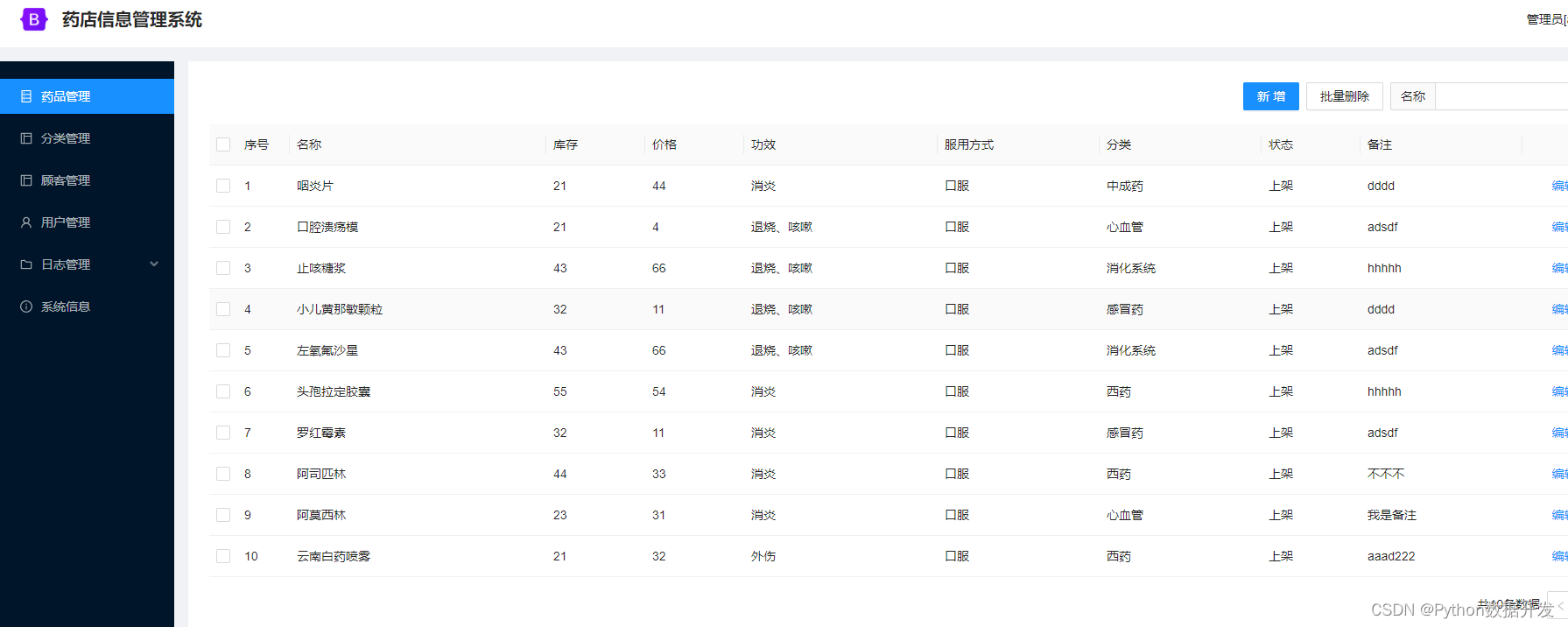
基于python+django,我开发了一款药店信息管理系统
功能介绍 平台采用B/S结构,后端采用主流的Python语言进行开发,前端采用主流的Vue.js进行开发。 功能包括:药品管理、分类管理、顾客管理、用户管理、日志管理、系统信息模块。 代码结构 server目录是后端代码web目录是前端代码 部署运行…...
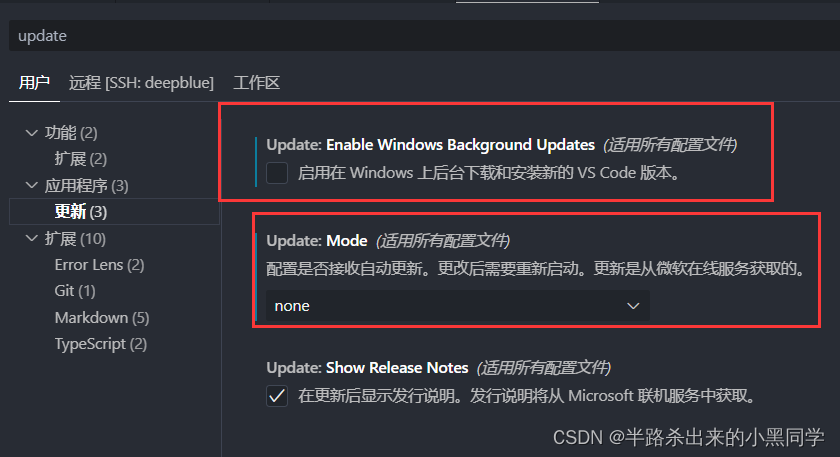
VSCODE使用ssh远程连接时启动服务器失败问题
错误情况 ping服务器的ip可通并且使用terminal可以ssh连接到远程服务器。但使用vscode的remote-ssh时,在「输出」栏出现了一直报 Waiting for server log… 的情况! 解决方法一 重置服务器设置,包括以下手段: 1.清理服务器端的…...

easyexcle 导出csv
导入jar <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.3.3</version></dependency>代码 private static List<List<String>> head() {List<List<String>&g…...
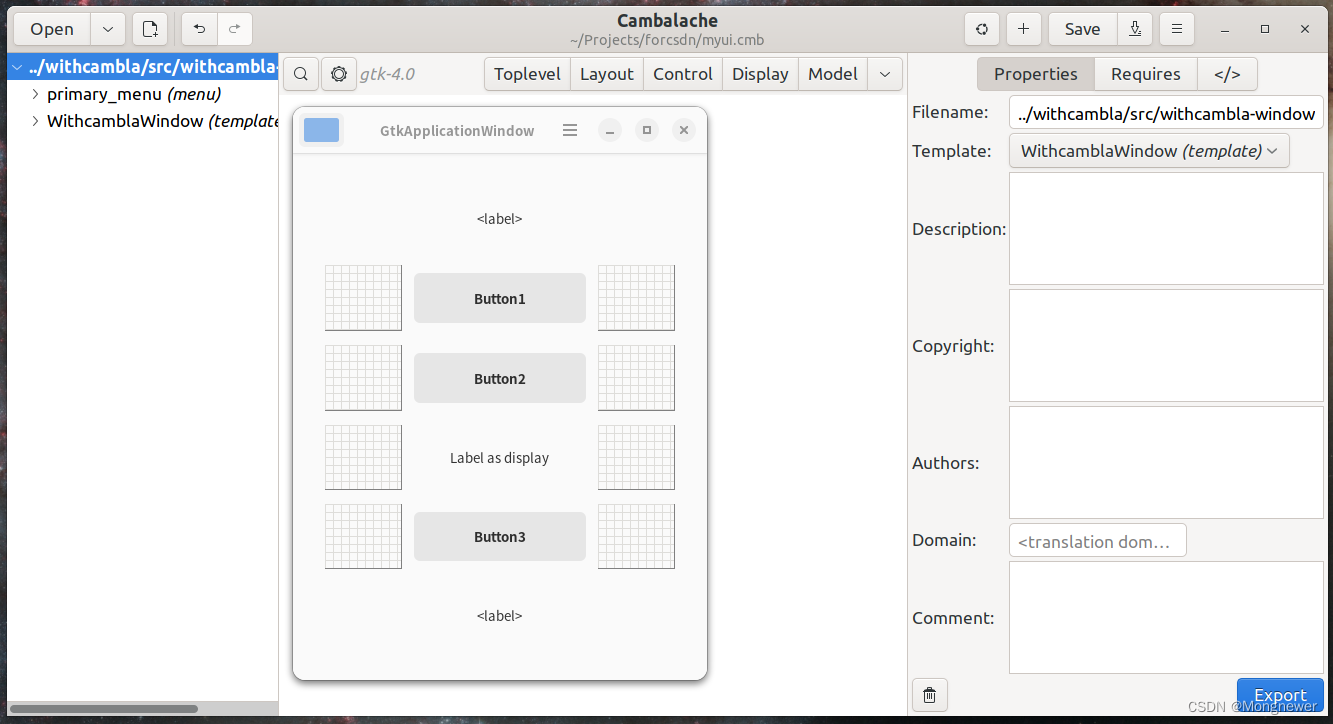
Ubuntu22.04 gnome-builder gnome C 应用程序习练笔记(一)
一、序言 gnome-builder构建器是gnome程序开发的集成环境,支持主力语言C, C, Vala, jscript, python等,界面以最新的 gtk 4.12 为主力,将其下版本的gtk直接压入了depreciated,但gtk4.12与普遍使用的gtk3有很大区别,原…...

ESP32QRCodeReader库使用,ESP32-CAM识别二维码并向自写接口发出请求确认身份。
#include <Arduino.h> #include <WiFi.h> #include <HTTPClient.h> #include <ESP32QRCodeReader.h>#define WIFI_SSID "username" #define WIFI_PASSWORD "password" // 连接电脑主机的IP地址的8088端口 #define WEBHOOK_URL &qu…...

什么是网络渗透,应当如何防护?
什么是网络渗透 网络渗透是攻击者常用的一种攻击手段,也是一种综合的高级攻击技术,同时网络渗透也是安全工作者所研究的一个课题,在他们口中通常被称为"渗透测试(Penetration Test)"。无论是网络渗透(Network Penetration)还是渗透…...

掌握C++中的动态数据:深入解析list的力量与灵活性
1. 引言 简介std::list和其在C中的角色 std::list是C标准模板库(STL)中提供的一个容器类,实现了双向链表的数据结构。与数组或向量等基于连续内存的容器不同,std::list允许非连续的内存分配,使得元素的插入和删除操作…...
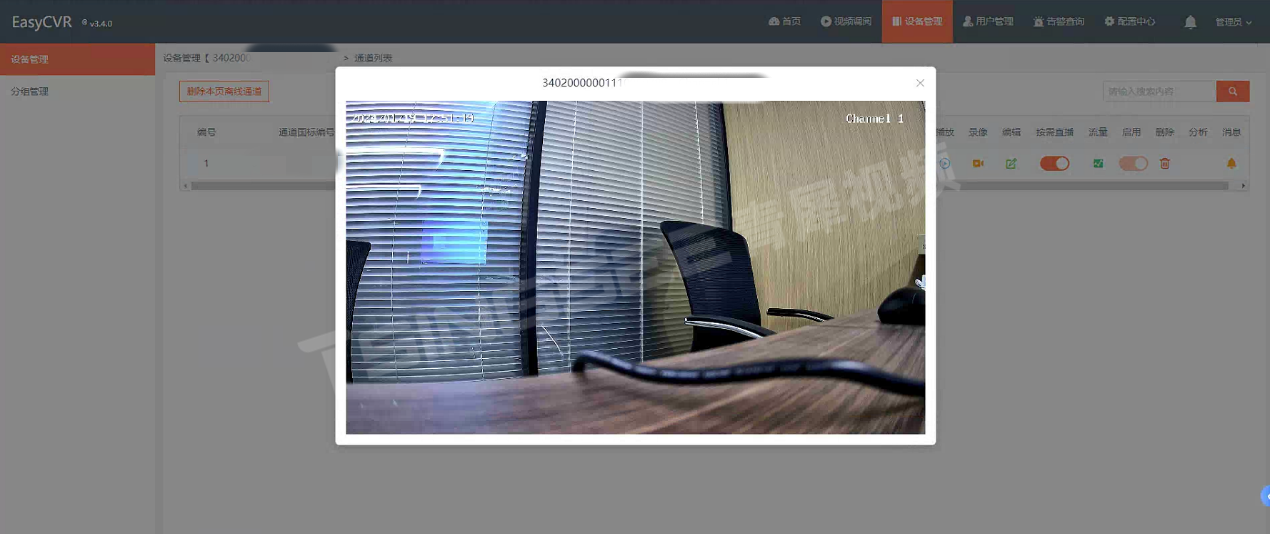
天地伟业接入视频汇聚/云存储平台EasyCVR详细步骤
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
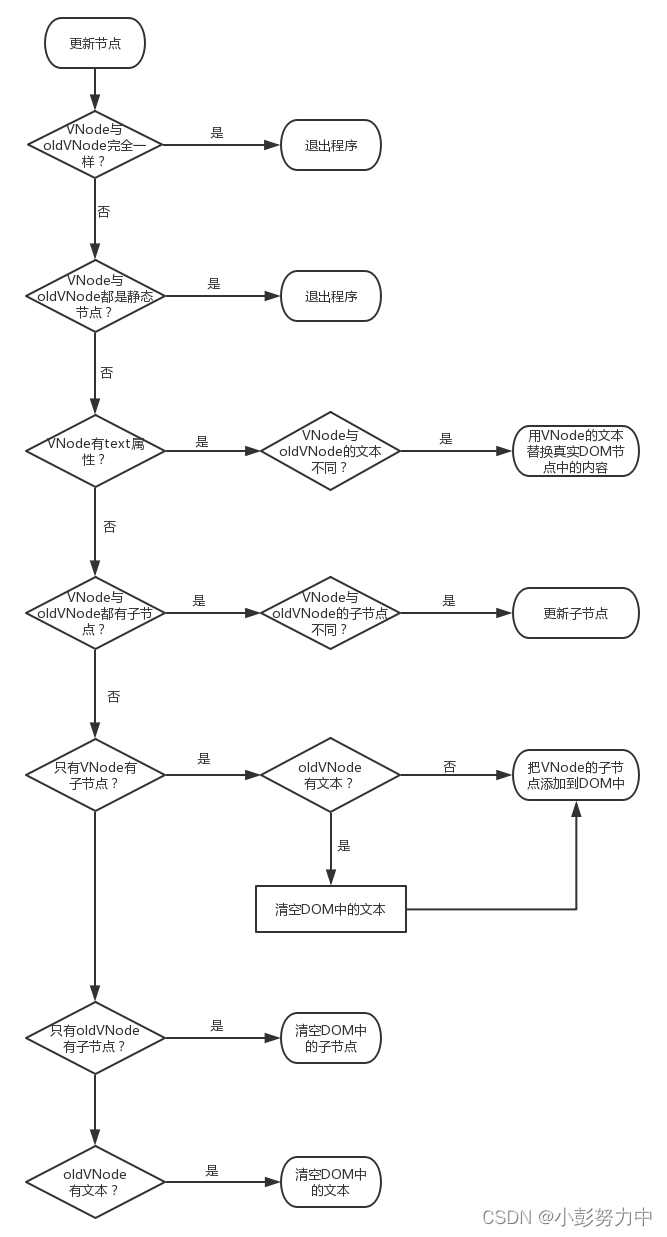
Vue源码系列讲解——虚拟DOM篇【二】(Vue中的DOM-Diff)
目录 1. 前言 2. patch 3. 创建节点 4. 删除节点 5. 更新节点 6. 总结 1. 前言 在上一篇文章介绍VNode的时候我们说了,VNode最大的用途就是在数据变化前后生成真实DOM对应的虚拟DOM节点,然后就可以对比新旧两份VNode,找出差异所在&…...
基于AST实现一键自动提取替换国际化文案
背景:在调研 formatjs/cli 使用(使用 formatjs/cli 进行国际化文案自动提取 )过程中,发现有以下需求formatjs/cli 无法满足: id 需要一定的语义化; defaultMessage和Id不能直接hash转换; 需要…...

嵌入式硬件工程师与嵌入式软件工程师
嵌入式硬件工程师与嵌入式软件工程师 纯硬件设备与嵌入式设备 纯硬件设备是指内部不包含微处理器,无需烧写软件就能够运行的电子设备。如天线、老式收音机、老式电视机、老式洗衣机等。这类设备通常功能简单,易于操作,用户通常只需要打开电…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...