PySpark(三)RDD持久化、共享变量、Spark内核制度,Spark Shuffle、Spark执行流程
目录
RDD持久化
RDD 的数据是过程数据
RDD 缓存
RDD CheckPoint
共享变量
广播变量
累加器
Spark 内核调度
DAG
DAG 的宽窄依赖和阶段划分
内存迭代计算
Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用?
Spark为什么比MapReduce快?
Spark并行度
Spark Shuffle
Hash Shuffle
Sort Shuffle
Spark执行流程
RDD持久化
RDD 的数据是过程数据
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了
这个特性可以最大化的利用资源,老旧RDD没用了 就从内存中清理,给后续的计算腾出内存空间.
例如下面这个例子,生成rdd4的时候, rdd3已经被销毁了,然后下面rdd5需要调用rdd3的时候,只能从rdd->rdd2->rdd3再重新生成一次rdd3
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)rdd2 = rdd.map(lambda x:(x[0],x[1]+2))rdd3 = rdd2.distinct()rdd4 = rdd3.filter(lambda x:x[1]>5)print(rdd4.collect())# [('a', 8)]rdd5 = rdd3.glom()print(rdd5.collect())# [[('a', 5), ('a', 8)], [('a', 3), ('b', 4)], [('b', 3), ('c', 3)]]RDD 缓存
RDD的缓存技术:Spark提供了缓存AP1,可以让我们通过调用AP1,将指定的RDD数据保留在内存或者硬盘上缓存的API
最开始要引入:from pyspark.storagelevel import StorageLevel

缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上
但是,这个保存在设定上是认为不安全的,缓存的数据在设计上是 认为 有丢失风险的
所以,缓存有一个特点就是: 其保留RDD之间的血缘(依赖)关系
一旦缓存丢失可以基于血缘关系的记录重新计算这个RDD的数据
缓存如何丢失:
在内存中的缓存是不安全的,比如断电计算任务内存不足把缓存清理给计算让路硬盘中因为硬盘损坏也是可能丢失的
RDD缓存采用的是分散存储,也就是每一个executor都会将其处理的部分RDD存放在自己的内存或硬盘中
RDD CheckPoint
CheckPoint技术也是将RDD的数据保存起来,但是它仅支持硬盘存储
并且:它被设计认为是安全的,不保留 血缘关系
checkPoint存储RDD数据,是集中收集各个分区数据进行存储而缓存是分散存储,也就是说先将executor中的数据收集起来(比如收集到hdfs),然后再进行存储
缓存和CheckPoint的对比
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行HDFS是高可靠存储,checkPoint被认为是安全的.
- checkPoint不支持内存缓存可以缓存如果写内存性能比checkPoint要好一些
- CheckPoint因为设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留
sc.setCheckpointDir("hdfs://node1:8020/checkpoint")#设置存储位置rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)rdd2 = rdd.map(lambda x:(x[0],x[1]+2))rdd3 = rdd2.distinct()rdd3.checkpoint()共享变量
广播变量
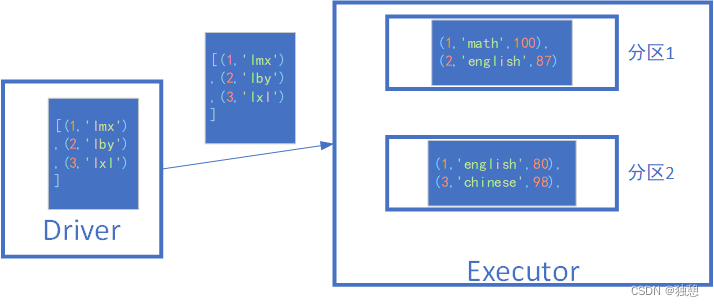
假如有下面一个场景,需要根据stu_ifo将score_ifo中的数字替换为名字,注意这里是本地数据stu_ifo与RDD数据联合处理
stu_ifo = [(1,'lmx'),(2,'lby'),(3,'lxl')]score_ifo = sc.parallelize([(1,'math',100),(2,'english',87),(1,'english',80),(3,'chinese',98),(2, 'chinese', 68),(1, 'chinese', 88)])def func(data):for i in stu_ifo:if data[0] == i[0]:return (i[1],data[1],data[2])get = score_ifo.map(func)print(get.collect())一般情况下, 如果一个executor里面有多个分区的情况,那么每个分区都要向driver申请一份本地数据,然而由于executor内部的数据是共享的,这样就会多申请了一份stu_ifo

只需要将stu_ifo标记为广播变量,就可以解决这个问题。只会向一个executor发送一次数据
只需要在之前声明:
stu_if_breadcast = sc.broadcast(stu_ifo)然后使用的时候:
stu_if_breadcast.value使用这个方法,可以节省IO次数以及executor内存
上述代码变为:
stu_ifo = [(1,'lmx'),(2,'lby'),(3,'lxl')]stu_if_breadcast = sc.broadcast(stu_ifo)score_ifo = sc.parallelize([(1,'math',100),(2,'english',87),(1,'english',80),(3,'chinese',98),(2, 'chinese', 68),(1, 'chinese', 88)])def func(data):for i in stu_if_breadcast.value:if data[0] == i[0]:return (i[1],data[1],data[2])get = score_ifo.map(func)print(get.collect())累加器
针对下面这种场景,我希望每map一次,我的num加1:
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],2)def countt(data):global numnum+=1print(num)return dataprint(rdd.map(countt).collect())print(num)# 1# 2# 3# 4# 5# 1# 2# 3# 4# 5# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# 0观察结果,由于分区的情况,在每个executor内num都加到了5,但是最后的num却还是0
因为加1操作只会发生在 executor 中,而最后打印的是driver中的num,所以还是0
这里可以使用spark的累加器变量:
num = sc.accumulator(0) #累加器rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],2)def countt(data):global numnum+=1return datardd.map(countt).collect()print(num)# 10Spark 内核调度
DAG
DAG:有向无环图
在spark中,每一个 action算子都会将前面的一串rdd依赖链条执行起来,这些执行链条其实就是DAG
有多少个action算子,就有多少个执行链条(JOB),就有多少个DAG
如果一个代码中,写了n个Action,那么这个代码运行起来产生n个JOB,每个JOB有自己的DAG个代码运行起来,在Spark中称之为: Application
spark中数据都是分区的,所以实际上每一个job都是带有分区关系的DAG
DAG 的宽窄依赖和阶段划分
RDD的前后关系分为 宽依赖和窄依赖
窄依赖:父RDD的一个分区,全部 将数据发给子RDD的一个分区
宽依赖:父RDD的一个分区将数据发给子RDD的多个分区
宽依赖还有一个别名: shuffle
对于Spark来说会根据DAG,按照宽依赖划分不同的DAG阶段
划分依据:从后向前,遇到宽依赖 就划分出一个阶段称之为stage
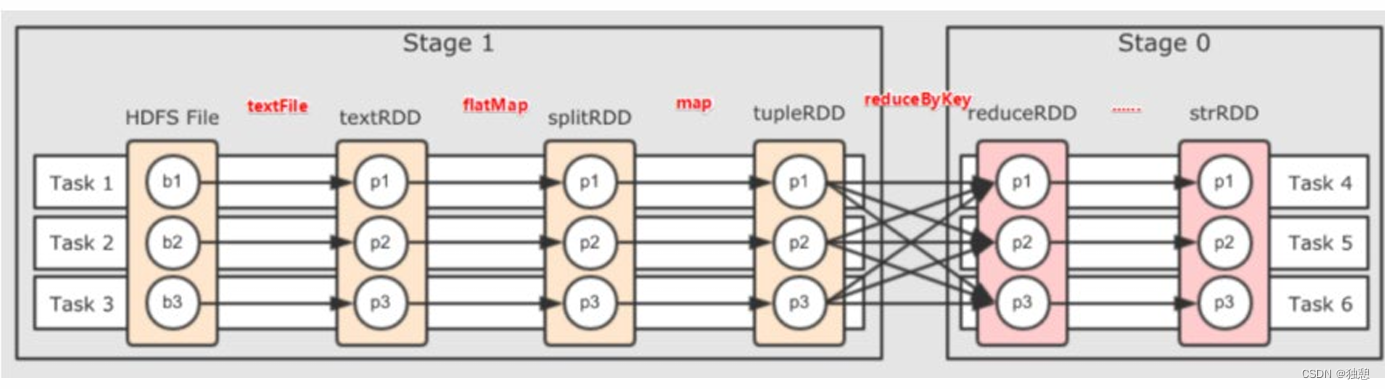 可以看到,在阶段内都是 窄依赖,这有助于构建内存迭代管道
可以看到,在阶段内都是 窄依赖,这有助于构建内存迭代管道
内存迭代计算
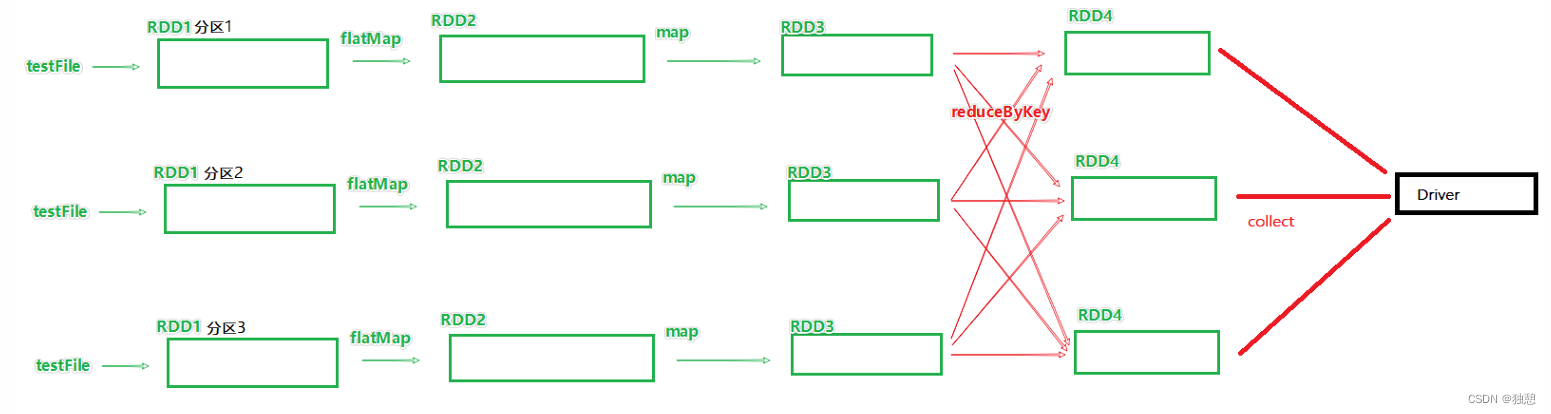
在执行上图的程序时,最优的方式肯定是task1,2,3,4,5,6都在独立且单独的线程中完成(还存在另外一种情况,比如b1->p1,p1->下一个p1是不同的线程,那可能会在线程中存在网络IO调用,影响性能)
task1 中rdd1rdd2 rdd3 的选代计算,都是由一个task(线程完成),这一阶段的这一条线,是纯内存计算.如上图,task1 task2 task3,就形成了三个并行的内存计算管道
Spark默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数如果全局并行度是3,其实大部分算子分区都是3
注意:Spark一般推荐只设置全局并行度,不要再算子上设置并行度除了一些排序算子外,计算算子就让他默认开分区就可以了.
Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用?
- Spark会产生DAG图
- DAG图会基于分区和宽窄依赖关系划分阶段
- 一个阶段的内部都是 窄依赖,窄依赖内,如果形成前后1:1的分区对应关系就可以产生许多内存选代计算的管道
- 这些内存迭代计算的管道,就是一个个具体的执行Task
- 一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了
Spark为什么比MapReduce快?
- Spark的算子丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR中处理复杂的任务.很多的复杂任务,是需要写多个MapReduce进行串联多个MR串联通过磁盘交互数据
- Spark可以执行内存迭代,算子之间形成DAG 基于依赖划分阶段后,在阶段内形成内存选代管道.但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的
Spark并行度
Spark的并行: 在同一时间内, 有多少个task在同时运行
并行度:并行能力的设置
比如设置并行度6,其实就是要6个task并行在跑在有了6个task并行的前提下,rdd的分区就被规划成6个分区了
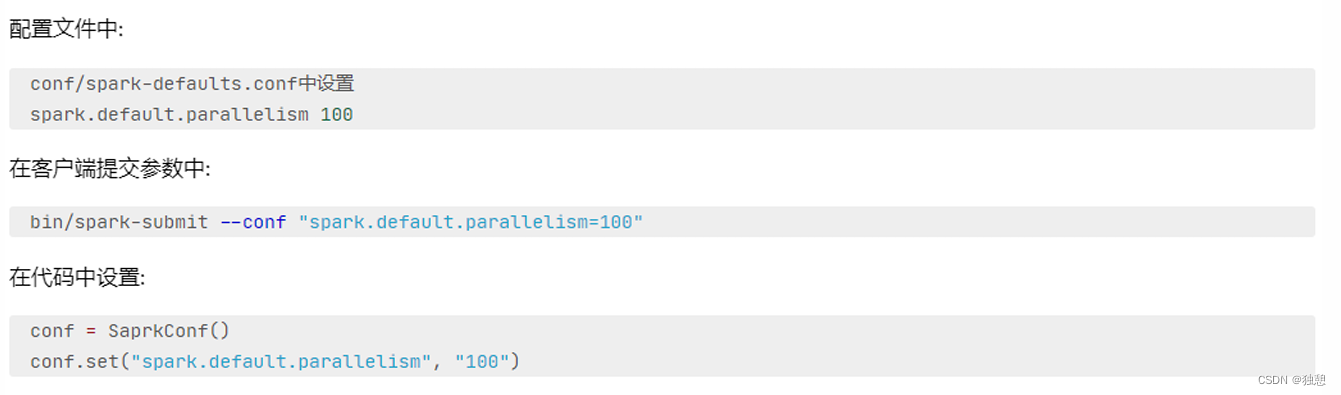
优先级从高到低:
代码中
客户端提交参数中
配置文件中
默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量来作为默认并行度)
 集群如何规划并行度?
集群如何规划并行度?
结论:设置为CPU总核心的2~10倍
为什么要设置最少2倍?
CPU的一个核心同一时间只能干一件事情所以,在100个核心的情况下,设置100个并行,就能让CPU 100%出力这种设置下如果task的压力不均衡,某个task先执行完了就导致某个CPU核心空闲
所以,我们将Task(并行)分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待.但是可以确保某个task运行完了.后续有task补上,不让cpu闲下来,最大程度利用集群的资源
Spark Shuffle
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上 还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及 到序列化反序列化、跨节点网络IO以及磁盘读写IO等。

Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是 Child Stage的第一步。
在Spark的中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。ShuffleManager随着 Spark的发展有两种实现的方式,分别为HashShuffleManager和SortShuffleManager,因此spark的Shuffle有Hash Shuffle和Sort Shuffle两种。
Hash Shuffle
未经优化的hashShuffleManager:
HashShuffle是根据task的计算结果的key值的hashcode%ReduceTask来决定放入哪一个区分,这样保证相同的数据 一定放入一个分区,根据下游的task决定生成几个文件,先生成缓冲区文件在写入磁盘文件,再将block文件进行合并。
一个task内部会根据hash分类,然后将不同类的数据放入不同的磁盘文件,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的,也就是下图所产生的的block file
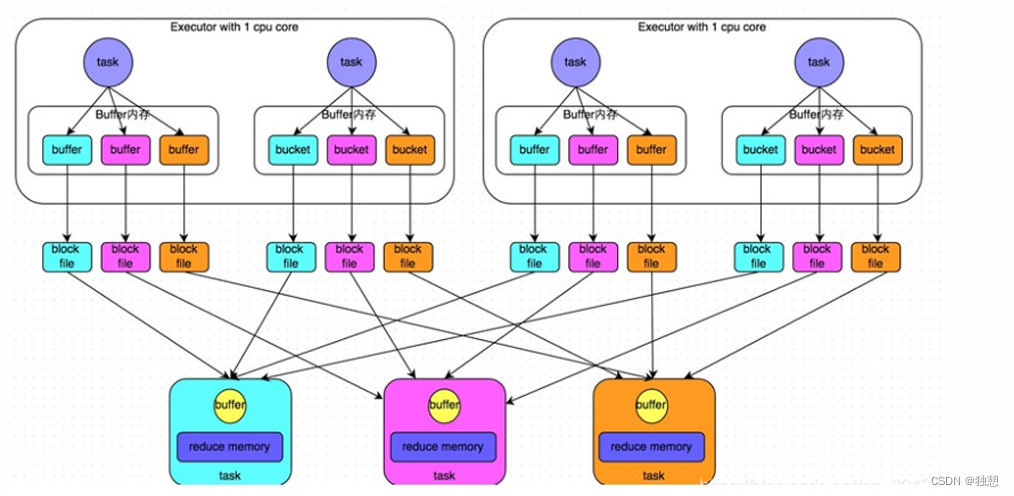
优化的hashShuffleManager:
在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概 念,每个shuffleFileGroup会对应一批磁盘文件,每一个Group磁盘文件的数量与下游stage的task数量是相同的。
其实说到底就是其在executor内部就会进行数据的汇合操作,大大减少了磁盘文件的生成

Sort Shuffle
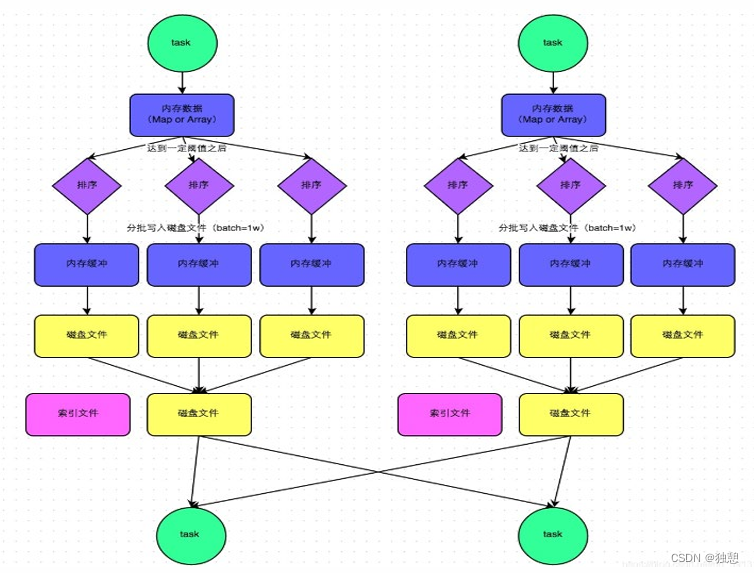
(1)该模式下,数据会先写入一个内存数据结构中(默认5M),此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内 存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。
(2)接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话 ,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
(3)排序 在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。 (4)溢写 排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数 据的形式分批写入磁盘文件。
(5)merge 一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之 前所有的临时磁盘文件都进行合并成1个磁盘文件,这就是merge过程。 由于一个task就只对应一个磁盘文件,也就意味着该task为Reduce端的stage的task准备的数据都在这一个文件中, 因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
说到底最大的区别就是,一个task只会生成一个磁盘文件和一个索引文件,大大降低了磁盘占有和网络IO数量
Sort Shuffle bypass机制
bypass运行机制的触发条件如下:
1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
2)不是map combine聚合的shuffle算子(比如reduceByKey有map combie)(这种算子不需要排序)
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash,然后根据key的hash值, 将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的 。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件, 只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作, 也就节省掉了这部分的性能开销。
Spark执行流程
在大方向上:
- 提交代码
- 生成Driver ,DAG Scheduler规划逻辑任务
- 生成Executor(被Driver生成)
- Driver内TaskScheduler去监控整个Spark程序的执行
在细节上,以YARN为例:
启动ApplicationMaster
AM启动Driver
- Driver构建DAG调度器规划任务
- Driver和AM通讯.AM得知要多少容器去申请
- Driver在申请的容器内部启动Executor
- Driver内的Task调度器,调度任务执行
相关文章:
PySpark(三)RDD持久化、共享变量、Spark内核制度,Spark Shuffle、Spark执行流程
目录 RDD持久化 RDD 的数据是过程数据 RDD 缓存 RDD CheckPoint 共享变量 广播变量 累加器 Spark 内核调度 DAG DAG 的宽窄依赖和阶段划分 内存迭代计算 Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用? Spark为什么比MapReduce快? Spa…...

PCIE Order Set
1 Training Sequence Training Sequence是由Order Set(OS) 组成,它们主要是用于bit aligment,symbol aligment,交换物理层的参数。当data_rate 2.5GT or 5GT 它们不会被扰码(scramble),当date_rate 8GT or higher 根据特殊的规则…...
)
nginx upstream server主动健康检测模块ngx_http_upstream_check_module 使用和源码分析(下)
目录 7. 实现一个UDP健康检测功能7.1 功能定义7.2 定义一个新的健康检测类型7.3 增加udp特定的健康检测需要的配置指令7.3.1 ngx_http_upstream_check_srv_conf_s结构体的扩展7.3.2 check_udp_send的实现7.3.3 check_udp_expect的实现7.3.4 16进制解码代码的实现7.4 ngx_http_u…...
基于SSM的网络在线考试系统(有报告)。Javaee项目。ssm项目。
演示视频: 基于SSM的网络在线考试系统(有报告)。Javaee项目。ssm项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,通过Spring …...
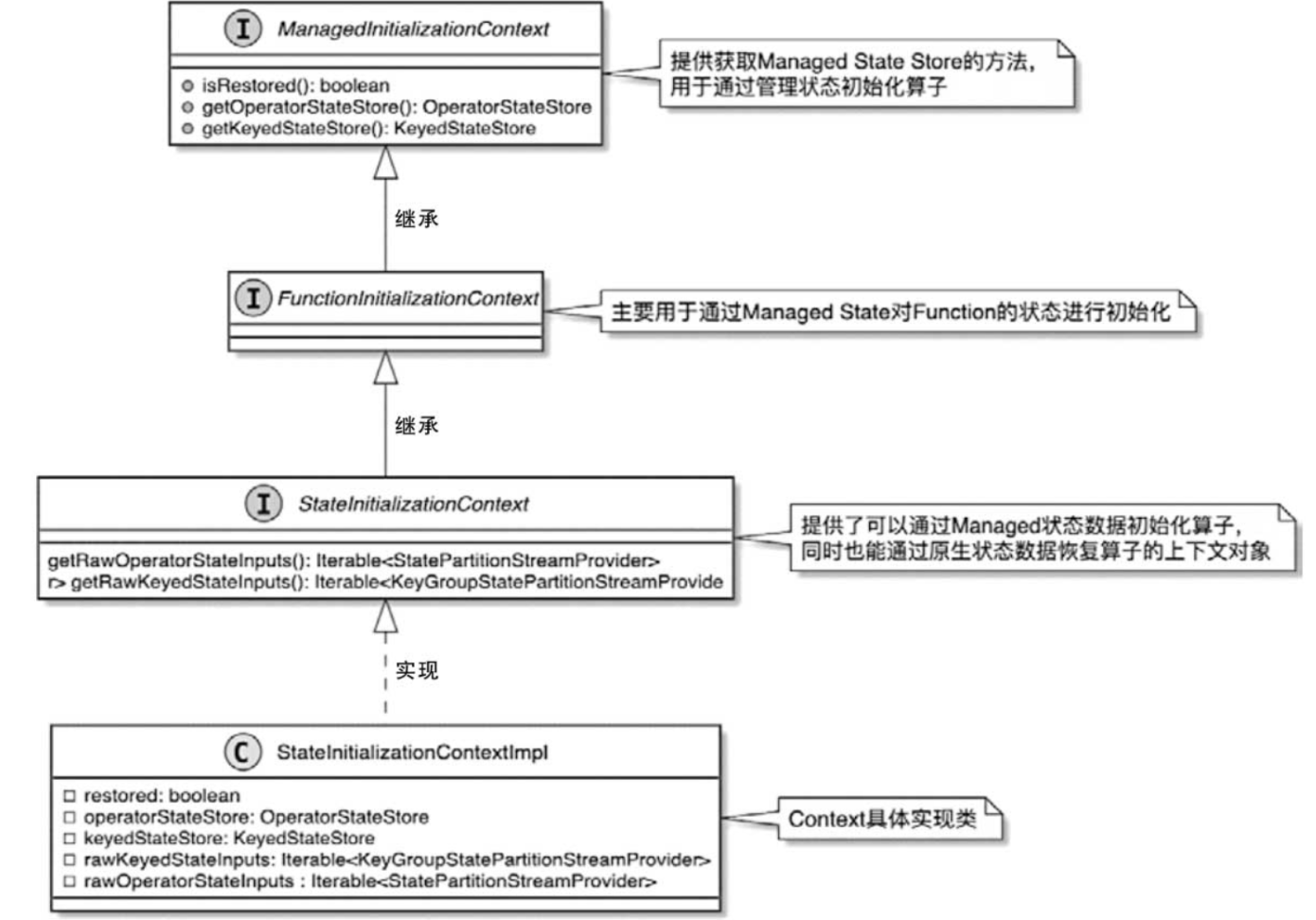
【Flink状态管理(二)各状态初始化入口】状态初始化流程详解与源码剖析
文章目录 1. 状态初始化总流程梳理2.创建StreamOperatorStateContext3. StateInitializationContext的接口设计。4. 状态初始化举例:UDF状态初始化 在TaskManager中启动Task线程后,会调用StreamTask.invoke()方法触发当前Task中算子的执行,在…...

python+flask人口普查数据的应用研究及实现django
作为一款人口普查数据的应用研究及实现,面向的是大多数学者,软件的界面设计简洁清晰,用户可轻松掌握使用技巧。在调查之后,获得用户以下需求: (1)用户注册登录后,可进入系统解锁更多…...

C语言:函数
C语言:函数 函数的概念库函数自定义函数实参与形参return语句数组做参数声明与定义externstatic 嵌套调用 函数的概念 在C语言中,存在一个函数的概念,有人也将其翻译为子程序。 在数学中,函数是一个完成特定功能的公式࿰…...

jmeter-问题一:关于线程组,线程数,用户数详解
文章目录 jmeter参数介绍1.线程数2.准备时长(Ramp-up)3.循环次数4.same user on each iteratio5.调度器 场景一:当你的线程组中线程数为1,循环为1场景二:当你的线程组中线程数为2,循环为1场景三:当你的线程组中线程数为1ÿ…...

golang 通过 cgo 调用 C++ 库
思路 将 C 库包装成 C 库 -> golang 通过 cgo 调用 C 库 C 相关文件 目录列表 include/ some.h C 库头文件some_wrapper.h < 用于将 C 库包装成 C 库的头文件 lib/ libsome.a C 库 src/ some_wrapper.cpp < 用于将 C 库包装成 C 库的源码文件 源码示例 some.h…...
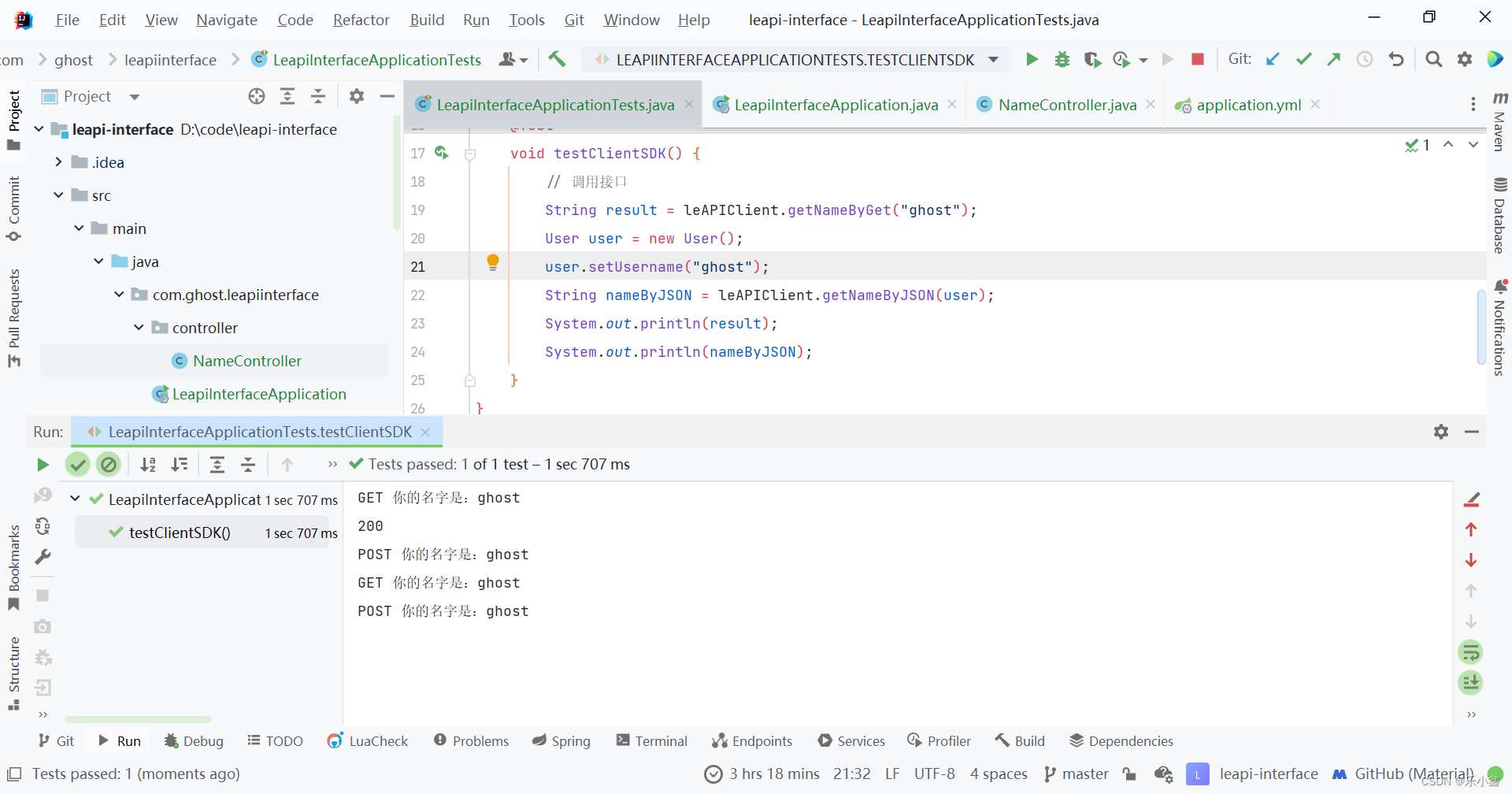
使用 IDEA 开发一个简单易用的 SDK
目录 一、什么是 SDK 二、为什么要开发 SDK 三、开发 SDK 的详细步骤 四、导入 SDK 进行测试 附:ConfigurationProperties 注解的介绍及使用 一、什么是 SDK 1. 定义:软件开发工具包 Software Development Kit 2. 用于开发特定软件或应用程序的工…...
CSS transition(过渡效果)详解
CSS过渡效果(Transition)是一种在CSS3中引入的动画效果,它允许开发者在元素状态变化时(如鼠标悬停、类更改等)平滑地改变CSS属性值,从而创建出平滑的动画效果。过渡效果可以应用于多种CSS属性,如…...
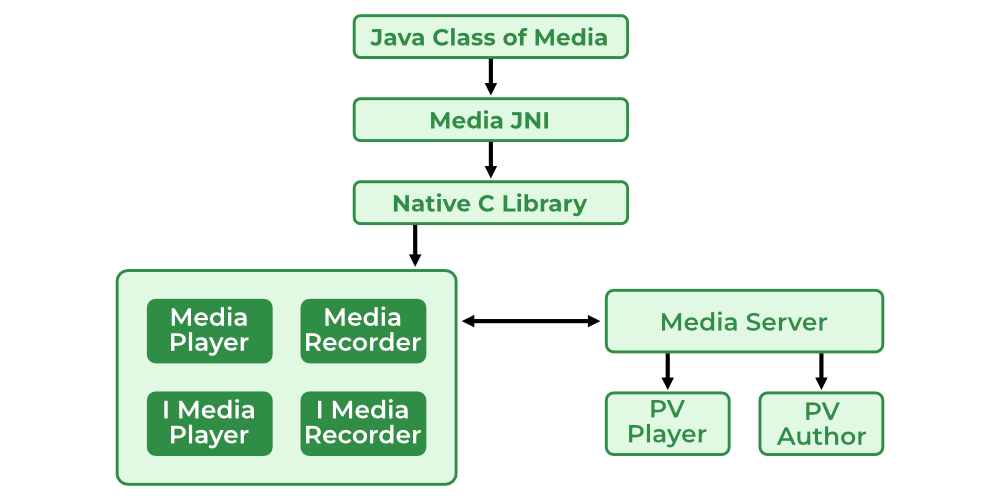
Android13多媒体框架概览
Android13多媒体框架概览 Android 多媒体框架 Android 多媒体框架旨在为 Java 服务提供可靠的接口。它是一个系统,包括多媒体应用程序、框架、OpenCore 引擎、音频/视频/输入的硬件设备,输出设备以及一些核心动态库,比如 libmedia、libmedi…...
一文读懂:MybatisPlus从入门到进阶
快速入门 简介 在项目开发中,Mybatis已经为我们简化了代码编写。 但是我们仍需要编写很多单表CURD语句,MybatisPlus可以进一步简化Mybatis。 MybatisPlus官方文档:https://www.baomidou.com/,感谢苞米豆和黑马程序员。 Mybat…...
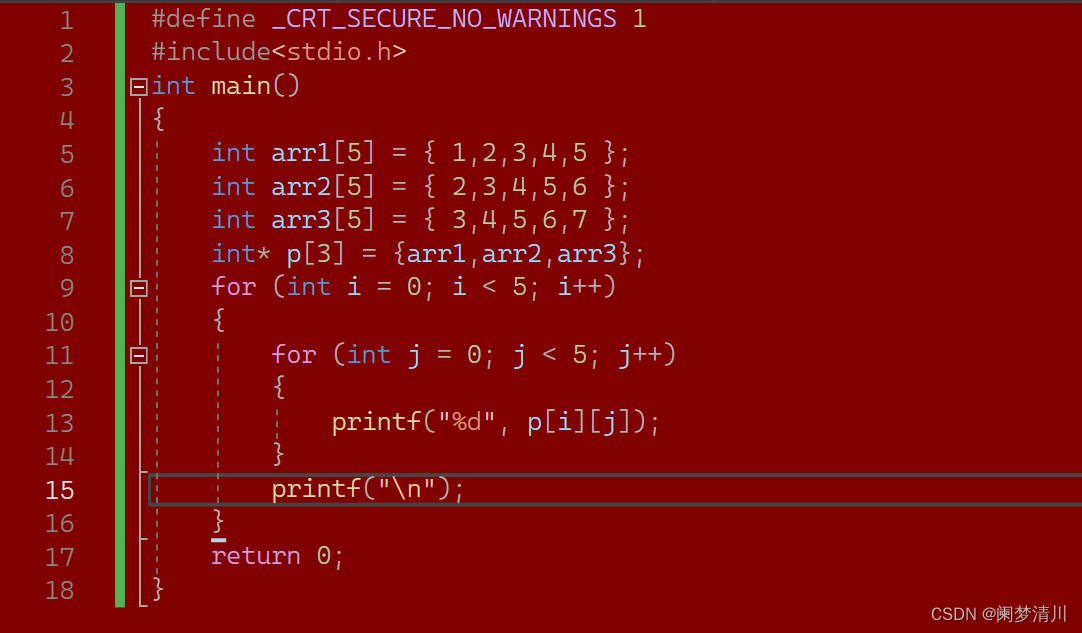
C语言--------指针(1)
0.指针&指针变量 32位平台,指针变量是4个字节(32bit/84)--------x86 64位平台,指针变量是8个字节(64bit/88)--------x64 编号指针地址;我们平常讲的p是指针就是说p是一个指针变量; ************只要…...

Vite 下一代的前端工具链,前端开发与构建工具
一、Vite 简介 官方中文网站:Vite | 下一代的前端工具链 官方定义: Vite,下一代的前端工具链,为开发提供极速响应。 Vue3.4版本,Vue新版本使用Vite构建、开发、调试、编译。 Vite的优势 极速的服务启动 使用原生…...
【SpringBoot】FreeMarker视图渲染
目录 一、FreeMarker 简介 1.1 什么是FreeMarker? 1.2 Freemarker模板组成部分 1.3 为什么要使用FreeMarker 二、Springboot集成FreeMarker 2.1 配置 2.2 数据类型 2.2.1 字符串 2.2.2 数值 2.2.3 布尔值 2.2.4 日期 2.3 常见指令 2.3.2 assign 2.3…...

巴尔加瓦算法图解:算法运用。
树 如果能将用户名插入到数组的正确位置就好了,这样就无需在插入后再排序。为此,有人设计了一种名为二叉查找树(binary search tree)的数据结构。 每个node的children 都不大于两个。对于其中的每个节点,左子节点的值都比它小,…...
Docker的镜像和容器的区别
1 Docker镜像 假设Linux内核是第0层,那么无论怎么运行Docker,它都是运行于内核层之上的。这个Docker镜像,是一个只读的镜像,位于第1层,它不能被修改或不能保存状态。 一个Docker镜像可以构建于另一个Docker镜像之上&…...

忘记 RAG:拥抱Agent设计,让 ChatGPT 更智能更贴近实际
RAG(检索增强生成)设计模式通常用于开发特定数据领域的基于实际情况的ChatGPT。 然而,重点主要是改进检索工具的效率,如嵌入式搜索、混合搜索和微调嵌入,而不是智能搜索。 这篇文章介绍了一种新的方法,灵感…...

利用路由懒加载和CDN分发策略,对Vue项目进行性能优化
目录 一、Vue项目 二、路由懒加载 三、CDN分发策略 四、如何对Vue项目进行性能优化 一、Vue项目 Vue是一种用于构建用户界面的JavaScript框架,它是一种渐进式框架,可以用于构建单页应用(SPA)和多页应用。Vue具有简单易学、灵…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...