[当人工智能遇上安全] 11.威胁情报实体识别 (2)基于BiGRU-CRF的中文实体识别万字详解
您或许知道,作者后续分享网络安全的文章会越来越少。但如果您想学习人工智能和安全结合的应用,您就有福利了,作者将重新打造一个《当人工智能遇上安全》系列博客,详细介绍人工智能与安全相关的论文、实践,并分享各种案例,涉及恶意代码检测、恶意请求识别、入侵检测、对抗样本等等。只想更好地帮助初学者,更加成体系的分享新知识。该系列文章会更加聚焦,更加学术,更加深入,也是作者的慢慢成长史。换专业确实挺难的,系统安全也是块硬骨头,但我也试试,看看自己未来四年究竟能将它学到什么程度,漫漫长征路,偏向虎山行。享受过程,一起加油~
前文讲解如何实现威胁情报实体识别,利用BiLSTM-CRF算法实现对ATT&CK相关的技战术实体进行提取,是安全知识图谱构建的重要支撑。这篇文章将以中文语料为主,介绍中文命名实体识别研究,并构建BiGRU-CRF模型实现。基础性文章,希望对您有帮助,如果存在错误或不足之处,还请海涵。且看且珍惜!
由于上一篇文章详细讲解ATT&CK威胁情报采集、预处理、BiLSTM-CRF实体识别内容,这篇文章不再详细介绍,本文将在上一篇文章基础上补充:
- 中文命名实体识别如何实现,以字符为主
- 以中文CSV文件为语料,介绍其处理过程,中文威胁情报类似
- 构建BiGRU-CRF模型实现中文实体识别
版本信息:
- keras-contrib V2.0.8
- keras V2.3.1
- tensorflow V2.2.0
常见框架如下图所示:
- https://aclanthology.org/2021.acl-short.4/


文章目录
- 一.ATT&CK数据采集
- 二.数据预处理
- 三.基于BiLSTM-CRF的实体识别
- 1.安装keras-contrib
- 2.安装Keras
- 3.中文实体识别
- 四.基于BiGRU-CRF的实体识别
- 五.总结
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习AI安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!
前文推荐:
- [当人工智能遇上安全] 1.人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [当人工智能遇上安全] 2.清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [当人工智能遇上安全] 3.安全领域中的机器学习及机器学习恶意请求识别案例分享
- [当人工智能遇上安全] 4.基于机器学习的恶意代码检测技术详解
- [当人工智能遇上安全] 5.基于机器学习算法的主机恶意代码识别研究
- [当人工智能遇上安全] 6.基于机器学习的入侵检测和攻击识别——以KDD CUP99数据集为例
- [当人工智能遇上安全] 7.基于机器学习的安全数据集总结
- [当人工智能遇上安全] 8.基于API序列和机器学习的恶意家族分类实例详解
- [当人工智能遇上安全] 9.基于API序列和深度学习的恶意家族分类实例详解
- [当人工智能遇上安全] 10.威胁情报实体识别之基于BiLSTM-CRF的实体识别万字详解
- [当人工智能遇上安全] 11.威胁情报实体识别 (2)基于BiGRU-CRF的中文实体识别万字详解
作者的github资源:
- https://github.com/eastmountyxz/When-AI-meet-Security
- https://github.com/eastmountyxz/AI-Security-Paper
一.ATT&CK数据采集
了解威胁情报的同学,应该都熟悉Mitre的ATT&CK网站,前文已介绍如何采集该网站APT组织的攻击技战术数据。网址如下:
- http://attack.mitre.org

第一步,通过ATT&CK网站源码分析定位APT组织名称,并进行系统采集。

安装BeautifulSoup扩展包,该部分代码如下所示:

01-get-aptentity.py
#encoding:utf-8
#By:Eastmount CSDN
import re
import requests
from lxml import etree
from bs4 import BeautifulSoup
import urllib.request#-------------------------------------------------------------------------------------------
#获取APT组织名称及链接#设置浏览器代理,它是一个字典
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
url = 'https://attack.mitre.org/groups/'#向服务器发出请求
r = requests.get(url = url, headers = headers).text#解析DOM树结构
html_etree = etree.HTML(r)
names = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/text()')
print (names)
print(len(names),names[0])
filename = []
for name in names:filename.append(name.strip())
print(filename)#链接
urls = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/@href')
print(urls)
print(len(urls), urls[0])
print("\n")
此时输出结果如下图所示,包括APT组织名称及对应的URL网址。

第二步,访问APT组织对应的URL,采集详细信息(正文描述)。

第三步,采集对应的技战术TTPs信息,其源码定位如下图所示。

第四步,编写代码完成威胁情报数据采集。01-spider-mitre.py 完整代码如下:
#encoding:utf-8
#By:Eastmount CSDN
import re
import requests
from lxml import etree
from bs4 import BeautifulSoup
import urllib.request#-------------------------------------------------------------------------------------------
#获取APT组织名称及链接#设置浏览器代理,它是一个字典
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
url = 'https://attack.mitre.org/groups/'#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(r)
names = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/text()')
print (names)
print(len(names),names[0])
#链接
urls = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/@href')
print(urls)
print(len(urls), urls[0])
print("\n")#-------------------------------------------------------------------------------------------
#获取详细信息
k = 0
while k<len(names):filename = str(names[k]).strip() + ".txt"url = "https://attack.mitre.org" + urls[k]print(url)#获取正文信息page = urllib.request.Request(url, headers=headers)page = urllib.request.urlopen(page)contents = page.read()soup = BeautifulSoup(contents, "html.parser")#获取正文摘要信息content = ""for tag in soup.find_all(attrs={"class":"description-body"}):#contents = tag.find("p").get_text()contents = tag.find_all("p")for con in contents:content += con.get_text().strip() + "###\n" #标记句子结束(第二部分分句用)#print(content)#获取表格中的技术信息for tag in soup.find_all(attrs={"class":"table techniques-used table-bordered mt-2"}):contents = tag.find("tbody").find_all("tr")for con in contents:value = con.find("p").get_text() #存在4列或5列 故获取p值#print(value)content += value.strip() + "###\n" #标记句子结束(第二部分分句用)#删除内容中的参考文献括号 [n]result = re.sub(u"\\[.*?]", "", content)print(result)#文件写入filename = "Mitre//" + filenameprint(filename)f = open(filename, "w", encoding="utf-8")f.write(result)f.close() k += 1
输出结果如下图所示,共整理100个组织信息。


每个文件显示内容如下图所示:

数据标注采用暴力的方式进行,即定义不同类型的实体名称并利用BIO的方式进行标注。通过ATT&CK技战术方式进行标注,后续可以结合人工校正,同时可以定义更多类型的实体。
- BIO标注
| 实体名称 | 实体数量 | 示例 |
|---|---|---|
| APT攻击组织 | 128 | APT32、Lazarus Group |
| 攻击漏洞 | 56 | CVE-2009-0927 |
| 区域位置 | 72 | America、Europe |
| 攻击行业 | 34 | companies、finance |
| 攻击手法 | 65 | C&C、RAT、DDoS |
| 利用软件 | 48 | 7-Zip、Microsoft |
| 操作系统 | 10 | Linux、Windows |
更多标注和预处理请查看上一篇文章。
- [当人工智能遇上安全] 10.威胁情报实体识别之基于BiLSTM-CRF的实体识别万字详解
常见的数据标注工具:
- 图像标注:labelme,LabelImg,Labelbox,RectLabel,CVAT,VIA
- 半自动ocr标注:PPOCRLabel
- NLP标注工具:labelstudio
温馨提示:
由于网站的布局会不断变化和优化,因此读者需要掌握数据采集及语法树定位的基本方法,以不变应万变。此外,读者可以尝试采集所有锻炼甚至是URL跳转链接内容,请读者自行尝试和拓展!
二.数据预处理
假设存在已经采集和标注好的中文数据集,通常采用按字(Char)分隔,如下图所示,古籍为数据集,当然中文威胁情报也类似。

数据集划分为训练集和测试集。

接下来,我们需要读取CSV数据集,并构建汉字词典。关键函数:
- read_csv(filename):读取语料CSV文件
- count_vocab(words,labels):统计不重复词典
- build_vocab():构造词典
完整代码如下:
#encoding:utf-8
# By: Eastmount WuShuai 2024-02-05
import re
import os
import csv
import systrain_data_path = "data/train.csv"
test_data_path = "data/test.csv"
char_vocab_path = "char_vocabs.txt" #字典文件
special_words = ['<PAD>', '<UNK>'] #特殊词表示
final_words = [] #统计词典(不重复出现)
final_labels = [] #统计标记(不重复出现)#语料文件读取函数
def read_csv(filename):words = []labels = []with open(filename,encoding='utf-8') as csvfile:reader = csv.reader(csvfile)for row in reader:if len(row)>0: #存在空行报错越界word,label = row[0],row[1]words.append(word)labels.append(label)return words,labels#统计不重复词典
def count_vocab(words,labels):fp = open(char_vocab_path, 'a') #注意a为叠加(文件只能运行一次)k = 0while k<len(words):word = words[k]label = labels[k]if word not in final_words:final_words.append(word)fp.writelines(word + "\n")if label not in final_labels:final_labels.append(label)k += 1fp.close()#读取数据并构造原文字典(第一列)
def build_vocab():words,labels = read_csv(train_data_path)print(len(words),len(labels),words[:8],labels[:8])count_vocab(words,labels)print(len(final_words),len(final_labels))#测试集words,labels = read_csv(test_data_path)print(len(words),len(labels))count_vocab(words,labels)print(len(final_words),len(final_labels))print(final_labels)#labels生成字典label_dict = {}k = 0for value in final_labels:label_dict[value] = kk += 1print(label_dict)return label_dictif __name__ == '__main__':build_vocab()
输出结果如下,包括训练集数量,并输出前8行文字及标注,以及不重复的汉字个数,以及实体类别14个。
['晉', '樂', '王', '鮒', '曰', ':', '', '小']
['S-LOC', 'B-PER', 'I-PER', 'E-PER', 'O', 'O', '', 'O']
xxx 14
输出类别如下。
['S-LOC', 'B-PER', 'I-PER', 'E-PER', 'O', '', 'B-LOC', 'E-LOC', 'S-PER', 'S-TIM', 'B-TIM', 'E-TIM', 'I-TIM', 'I-LOC']
接着实体类别进行编码处理,输出结果如下:
{'S-LOC': 0, 'B-PER': 1, 'I-PER': 2, 'E-PER': 3, 'O': 4, '': 5, 'B-LOC': 6, 'E-LOC': 7, 'S-PER': 8, 'S-TIM': 9, 'B-TIM': 10, 'E-TIM': 11, 'I-TIM': 12, 'I-LOC': 13}
需要注意:在实体识别中,我们可以通过调用该函数获取识别的实体类别,关键代码如下。然而,由于真实分析中“O”通常建议编码为0,因此建议重新定义字典编码,更方便我们撰写代码,尤其是中文本遇到换句处理时,上述编码会乱序。
#原计划
from get_data import build_vocab #调取第一阶段函数
label2idx = build_vocab()#实际情况
label2idx = {'O': 0,'S-LOC': 1, 'B-LOC': 2, 'I-LOC': 3, 'E-LOC': 4,'S-PER': 5, 'B-PER': 6, 'I-PER': 7, 'E-PER': 8,'S-TIM': 9, 'B-TIM': 10, 'E-TIM': 11, 'I-TIM': 12}
....
sent_ids = [vocab2idx[char] if char in vocab2idx else vocab2idx['<UNK>'] for char in sent_]
tag_ids = [label2idx[label] if label in label2idx else 0 for label in tag_]
最终生成词典char_vocabs.txt。

三.基于BiLSTM-CRF的实体识别
1.安装keras-contrib
CRF模型作者安装的是 keras-contrib。
第一步,如果读者直接使用“pip install keras-contrib”可能会报错,远程下载也报错。
- pip install git+https://www.github.com/keras-team/keras-contrib.git
甚至会报错 ModuleNotFoundError: No module named ‘keras_contrib’。

第二步,作者从github中下载该资源,并在本地安装。
- https://github.com/keras-team/keras-contrib
- keras-contrib 版本:2.0.8
git clone https://www.github.com/keras-team/keras-contrib.git
cd keras-contrib
python setup.py install
安装成功如下图所示:

读者可以从我的资源中下载代码和扩展包。
- https://github.com/eastmountyxz/When-AI-meet-Security
2.安装Keras
同样需要安装keras和TensorFlow扩展包。

如果TensorFlow下载太慢,可以设置清华大学镜像,实际安装2.2版本。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow==2.2


3.中文实体识别
第一步,数据预处理,包括BIO标记及词典转换。
#encoding:utf-8
# By: Eastmount WuShuai 2024-02-05
# 参考:https://github.com/huanghao128/zh-nlp-demo
import re
import os
import csv
import sys
from get_data import build_vocab #调取第一阶段函数#------------------------------------------------------------------------
#第一步 数据预处理
#------------------------------------------------------------------------
train_data_path = "data/train.csv"
test_data_path = "data/test.csv"
val_data_path = "data/val.csv"
char_vocab_path = "char_vocabs.txt" #字典文件(防止多次写入仅读首次生成文件)
special_words = ['<PAD>', '<UNK>'] #特殊词表示
final_words = [] #统计词典(不重复出现)
final_labels = [] #统计标记(不重复出现)#BIO标记的标签 字母O初始标记为0
#label2idx = build_vocab()
label2idx = {'O': 0,'S-LOC': 1, 'B-LOC': 2, 'I-LOC': 3, 'E-LOC': 4,'S-PER': 5, 'B-PER': 6, 'I-PER': 7, 'E-PER': 8,'S-TIM': 9, 'B-TIM': 10, 'E-TIM': 11, 'I-TIM': 12}
print(label2idx)#索引和BIO标签对应
idx2label = {idx: label for label, idx in label2idx.items()}
print(idx2label)#读取字符词典文件
with open(char_vocab_path, "r") as fo:char_vocabs = [line.strip() for line in fo]
char_vocabs = special_words + char_vocabs
print(char_vocabs)#字符和索引编号对应
idx2vocab = {idx: char for idx, char in enumerate(char_vocabs)}
vocab2idx = {char: idx for idx, char in idx2vocab.items()}
print(idx2vocab)
print(vocab2idx)
输出结果如下所示:
{'O': 0, 'S-LOC': 1, 'B-LOC': 2, 'I-LOC': 3, 'E-LOC': 4, 'S-PER': 5, 'B-PER': 6, 'I-PER': 7, 'E-PER': 8, 'S-TIM': 9, 'B-TIM': 10, 'E-TIM': 11, 'I-TIM': 12}
{0: 'O', 1: 'S-LOC', 2: 'B-LOC', 3: 'I-LOC', 4: 'E-LOC', 5: 'S-PER', 6: 'B-PER', 7: 'I-PER', 8: 'E-PER', 9: 'S-TIM', 10: 'B-TIM', 11: 'E-TIM', 12: 'I-TIM'}['<PAD>', '<UNK>', '晉', '樂', '王', '鮒', '曰', ':', '', '小', '旻', ...]
{0: '<PAD>', 1: '<UNK>', 2: '晉', 3: '樂', 4: '王', 5: '鮒', 6: '曰', 7: ':', 8: '', 9: '小', 10: '旻', ... ]
{'<PAD>': 0, '<UNK>': 1, '晉': 2, '樂': 3, '王': 4, '鮒': 5, '曰': 6, ':': 7, '': 8, '小': 9, '旻': 10, ... ]
第二步,读取CSV数据,并获取汉字、标记对应的下标,以下标存储。
#------------------------------------------------------------------------
#第二步 数据读取
#------------------------------------------------------------------------
def read_corpus(corpus_path, vocab2idx, label2idx):datas, labels = [], []with open(corpus_path, encoding='utf-8') as csvfile:reader = csv.reader(csvfile)sent_, tag_ = [], []for row in reader:word,label = row[0],row[1]if word!="" and label!="": #断句sent_.append(word)tag_.append(label)"""print(sent_) #['晉', '樂', '王', '鮒', '曰', ':']print(tag_) #['S-LOC', 'B-PER', 'I-PER', 'E-PER', 'O', 'O']"""else: #vocab2idx[0] => <PAD>sent_ids = [vocab2idx[char] if char in vocab2idx else vocab2idx['<UNK>'] for char in sent_]tag_ids = [label2idx[label] if label in label2idx else 0 for label in tag_]"""print(sent_ids,tag_ids)for idx,idy in zip(sent_ids,tag_ids):print(idx2vocab[idx],idx2label[idy])#[2, 3, 4, 5, 6, 7] [1, 6, 7, 8, 0, 0]#晉 S-LOC 樂 B-PER 王 I-PER 鮒 E-PER 曰 O : O"""datas.append(sent_ids) #按句插入列表labels.append(tag_ids)sent_, tag_ = [], []return datas, labels#原始数据
train_datas_, train_labels_ = read_corpus(train_data_path, vocab2idx, label2idx)
test_datas_, test_labels_ = read_corpus(test_data_path, vocab2idx, label2idx)#输出测试结果 (第五句语料)
print(len(train_datas_),len(train_labels_),len(test_datas_),len(test_labels_))
print(train_datas_[5])
print([idx2vocab[idx] for idx in train_datas_[5]])
print(train_labels_[5])
print([idx2label[idx] for idx in train_labels_[5]])
输出结果如下,获取汉字和BIO标记的下标。
[2, 3, 4, 5, 6, 7] [1, 6, 7, 8, 0, 0]
晉 S-LOC 樂 B-PER 王 I-PER 鮒 E-PER 曰 O : O
其中,第5行数据示例如下:
[46, 47, 48, 47, 49, 50, 51, 52, 53, 54, 55, 56]
['齊', '、', '衛', '、', '陳', '大', '夫', '其', '不', '免', '乎', '!']
[1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0]
['S-LOC', 'O', 'S-LOC', 'O', 'S-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
对应语料如下:

第三步,数据填充和one-hot编码。
#------------------------------------------------------------------------
#第三步 数据填充 one-hot编码
#------------------------------------------------------------------------
import keras
from keras.preprocessing import sequenceMAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)#padding data
print('padding sequences')
train_datas = sequence.pad_sequences(train_datas_, maxlen=MAX_LEN)
train_labels = sequence.pad_sequences(train_labels_, maxlen=MAX_LEN)
test_datas = sequence.pad_sequences(test_datas_, maxlen=MAX_LEN)
test_labels = sequence.pad_sequences(test_labels_, maxlen=MAX_LEN)
print('x_train shape:', train_datas.shape)
print('x_test shape:', test_datas.shape)#encoder one-hot
train_labels = keras.utils.to_categorical(train_labels, CLASS_NUMS)
test_labels = keras.utils.to_categorical(test_labels, CLASS_NUMS)
print('trainlabels shape:', train_labels.shape)
print('testlabels shape:', test_labels.shape)
输出结果如下所示:
padding sequences
x_train shape: (xxx, 100)
x_test shape: (xxx, 100)
trainlabels shape: (xxx, 100, 13)
testlabels shape: (xxx, 100, 13)
编码示例如下:
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 2163 410 294980 18]
第四步,构建BiLSTM+CRF模型。
#------------------------------------------------------------------------
#第四步 构建BiLSTM+CRF模型
# pip install git+https://www.github.com/keras-team/keras-contrib.git
# 安装过程详见文件夹截图
# ModuleNotFoundError: No module named ‘keras_contrib’
#------------------------------------------------------------------------
import numpy as np
from keras.models import Sequential
from keras.models import Model
from keras.layers import Masking, Embedding, Bidirectional, LSTM, \Dense, Input, TimeDistributed, Activation
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_viterbi_accuracy
from keras import backend as K
from keras.models import load_model
from sklearn import metricsEPOCHS = 2
EMBED_DIM = 128
HIDDEN_SIZE = 64
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
K.clear_session()
print(VOCAB_SIZE, CLASS_NUMS) #3319 13#模型构建 BiLSTM-CRF
inputs = Input(shape=(MAX_LEN,), dtype='int32')
x = Masking(mask_value=0)(inputs)
x = Embedding(VOCAB_SIZE, EMBED_DIM, mask_zero=False)(x) #修改掩码False
x = Bidirectional(LSTM(HIDDEN_SIZE, return_sequences=True))(x)
x = TimeDistributed(Dense(CLASS_NUMS))(x)
outputs = CRF(CLASS_NUMS)(x)
model = Model(inputs=inputs, outputs=outputs)
model.summary()
输出结果如下图所示,显示该模型的结构。

第五步,模型训练和测试。flag标记变量分别设置为“train”和“test”。
flag = "train"
if flag=="train":#模型训练model.compile(loss=crf_loss, optimizer='adam', metrics=[crf_viterbi_accuracy])model.fit(train_datas, train_labels, epochs=EPOCHS, verbose=1, validation_split=0.1)score = model.evaluate(test_datas, test_labels, batch_size=256)print(model.metrics_names)print(score)model.save("bilstm_ner_model.h5")
elif flag=="test":#训练模型char_vocab_path = "char_vocabs_.txt" #字典文件model_path = "bilstm_ner_model.h5" #模型文件ner_labels = label2idxspecial_words = ['<PAD>', '<UNK>']MAX_LEN = 100#预测结果model = load_model(model_path, custom_objects={'CRF': CRF}, compile=False) y_pred = model.predict(test_datas)y_labels = np.argmax(y_pred, axis=2) #取最大值z_labels = np.argmax(test_labels, axis=2) #真实值word_labels = test_datas #真实值k = 0final_y = [] #预测结果对应的标签final_z = [] #真实结果对应的标签final_word = [] #对应的特征单词while k<len(y_labels):y = y_labels[k]for idx in y:final_y.append(idx2label[idx])#print("预测结果:", [idx2label[idx] for idx in y])z = z_labels[k]for idx in z: final_z.append(idx2label[idx])#print("真实结果:", [idx2label[idx] for idx in z])word = word_labels[k]for idx in word:final_word.append(idx2vocab[idx])k += 1print("最终结果大小:", len(final_y),len(final_z))n = 0numError = 0numRight = 0while n<len(final_y):if final_y[n]!=final_z[n] and final_z[n]!='O':numError += 1if final_y[n]==final_z[n] and final_z[n]!='O':numRight += 1n += 1print("预测错误数量:", numError)print("预测正确数量:", numRight)print("Acc:", numRight*1.0/(numError+numRight))print("预测单词:", [idx2vocab[idx] for idx in test_datas_[5]])print("真实结果:", [idx2label[idx] for idx in test_labels_[5]])print("预测结果:", [idx2label[idx] for idx in y_labels[5]][-len(test_datas_[5]):])
训练结果如下所示:
Epoch 1/232/8439 [..............................] - ETA: 6:51 - loss: 2.5549 - crf_viterbi_accuracy: 3.1250e-0464/8439 [..............................] - ETA: 3:45 - loss: 2.5242 - crf_viterbi_accuracy: 0.11428439/8439 [==============================] - 118s 14ms/step - loss: 0.1833 - crf_viterbi_accuracy: 0.9591 - val_loss: 0.0688 - val_crf_viterbi_accuracy: 0.9820
Epoch 2/1032/8439 [..............................] - ETA: 19s - loss: 0.0644 - crf_viterbi_accuracy: 0.982564/8439 [..............................] - ETA: 42s - loss: 0.0592 - crf_viterbi_accuracy: 0.9845...
['loss', 'crf_viterbi_accuracy']
[0.043232945389307574, 0.9868513941764832]
最终测试结果如下所示,由于作者数据集仅放了少量数据,且未进行调参比较,真实数据更多且效果会更好。
预测错误数量: 2183
预测正确数量: 2209
Acc: 0.5029599271402551预测单词: ['冬', ',', '楚', '公', '子', '罷', '如', '晉', '聘', ',', '且', '涖', '盟', '。']
真实结果: ['O', 'O', 'B-PER', 'I-PER', 'I-PER', 'E-PER', 'O', 'S-LOC', 'O', 'O', 'O', 'O', 'O', 'O']
预测结果: ['O', 'O', 'B-PER', 'E-PER', 'E-PER', 'E-PER', 'O', 'S-LOC', 'O', 'O', 'O', 'O', 'O', 'O']
四.基于BiGRU-CRF的实体识别
接下来构建BiGRU-CRF代码,以完整代码为例,并将预测结果存储在CSV文件上。
#encoding:utf-8
# By: Eastmount WuShuai 2024-02-05
import re
import os
import csv
import sys
from get_data import build_vocab #调取第一阶段函数#------------------------------------------------------------------------
#第一步 数据预处理
#------------------------------------------------------------------------
train_data_path = "data/train.csv"
test_data_path = "data/test.csv"
val_data_path = "data/val.csv"
char_vocab_path = "char_vocabs.txt" #字典文件(防止多次写入仅读首次生成文件)
special_words = ['<PAD>', '<UNK>'] #特殊词表示
final_words = [] #统计词典(不重复出现)
final_labels = [] #统计标记(不重复出现)#BIO标记的标签 字母O初始标记为0
#label2idx = build_vocab()
label2idx = {'O': 0,'S-LOC': 1, 'B-LOC': 2, 'I-LOC': 3, 'E-LOC': 4,'S-PER': 5, 'B-PER': 6, 'I-PER': 7, 'E-PER': 8,'S-TIM': 9, 'B-TIM': 10, 'E-TIM': 11, 'I-TIM': 12}#索引和BIO标签对应
idx2label = {idx: label for label, idx in label2idx.items()}#读取字符词典文件
with open(char_vocab_path, "r") as fo:char_vocabs = [line.strip() for line in fo]
char_vocabs = special_words + char_vocabs#字符和索引编号对应
idx2vocab = {idx: char for idx, char in enumerate(char_vocabs)}
vocab2idx = {char: idx for idx, char in idx2vocab.items()}#------------------------------------------------------------------------
#第二步 数据读取
#------------------------------------------------------------------------
def read_corpus(corpus_path, vocab2idx, label2idx):datas, labels = [], []with open(corpus_path, encoding='utf-8') as csvfile:reader = csv.reader(csvfile)sent_, tag_ = [], []for row in reader:word,label = row[0],row[1]if word!="" and label!="": #断句sent_.append(word)tag_.append(label)else: #vocab2idx[0] => <PAD>sent_ids = [vocab2idx[char] if char in vocab2idx else vocab2idx['<UNK>'] for char in sent_]tag_ids = [label2idx[label] if label in label2idx else 0 for label in tag_]datas.append(sent_ids) #按句插入列表labels.append(tag_ids)sent_, tag_ = [], []return datas, labels#原始数据
train_datas_, train_labels_ = read_corpus(train_data_path, vocab2idx, label2idx)
test_datas_, test_labels_ = read_corpus(test_data_path, vocab2idx, label2idx)#------------------------------------------------------------------------
#第三步 数据填充 one-hot编码
#------------------------------------------------------------------------
import keras
from keras.preprocessing import sequenceMAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)#padding data
print('padding sequences')
train_datas = sequence.pad_sequences(train_datas_, maxlen=MAX_LEN)
train_labels = sequence.pad_sequences(train_labels_, maxlen=MAX_LEN)
test_datas = sequence.pad_sequences(test_datas_, maxlen=MAX_LEN)
test_labels = sequence.pad_sequences(test_labels_, maxlen=MAX_LEN)#encoder one-hot
train_labels = keras.utils.to_categorical(train_labels, CLASS_NUMS)
test_labels = keras.utils.to_categorical(test_labels, CLASS_NUMS)#------------------------------------------------------------------------
#第四步 构建BiGRU+CRF模型
#------------------------------------------------------------------------
import numpy as np
from keras.models import Sequential
from keras.models import Model
from keras.layers import Masking, Embedding, Bidirectional, LSTM, GRU, \Dense, Input, TimeDistributed, Activation
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_viterbi_accuracy
from keras import backend as K
from keras.models import load_model
from sklearn import metricsEPOCHS = 2
EMBED_DIM = 128
HIDDEN_SIZE = 64
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
K.clear_session()
print(VOCAB_SIZE, CLASS_NUMS)#模型构建 BiGRU-CRF
inputs = Input(shape=(MAX_LEN,), dtype='int32')
x = Masking(mask_value=0)(inputs)
x = Embedding(VOCAB_SIZE, EMBED_DIM, mask_zero=False)(x) #修改掩码False
x = Bidirectional(GRU(HIDDEN_SIZE, return_sequences=True))(x)
x = TimeDistributed(Dense(CLASS_NUMS))(x)
outputs = CRF(CLASS_NUMS)(x)
model = Model(inputs=inputs, outputs=outputs)
model.summary()flag = "test"
if flag=="train":#模型训练model.compile(loss=crf_loss, optimizer='adam', metrics=[crf_viterbi_accuracy])model.fit(train_datas, train_labels, epochs=EPOCHS, verbose=1, validation_split=0.1)score = model.evaluate(test_datas, test_labels, batch_size=256)print(model.metrics_names)print(score)model.save("bigru_ner_model.h5")
elif flag=="test":#训练模型char_vocab_path = "char_vocabs_.txt" #字典文件model_path = "bigru_ner_model.h5" #模型文件ner_labels = label2idxspecial_words = ['<PAD>', '<UNK>']MAX_LEN = 100#预测结果model = load_model(model_path, custom_objects={'CRF': CRF}, compile=False) y_pred = model.predict(test_datas)y_labels = np.argmax(y_pred, axis=2) #取最大值z_labels = np.argmax(test_labels, axis=2) #真实值word_labels = test_datas #真实值k = 0final_y = [] #预测结果对应的标签final_z = [] #真实结果对应的标签final_word = [] #对应的特征单词while k<len(y_labels):y = y_labels[k]for idx in y:final_y.append(idx2label[idx])z = z_labels[k]for idx in z: final_z.append(idx2label[idx])word = word_labels[k]for idx in word:final_word.append(idx2vocab[idx])k += 1n = 0numError = 0numRight = 0while n<len(final_y):if final_y[n]!=final_z[n] and final_z[n]!='O':numError += 1if final_y[n]==final_z[n] and final_z[n]!='O':numRight += 1n += 1print("预测错误数量:", numError)print("预测正确数量:", numRight)print("Acc:", numRight*1.0/(numError+numRight))print("预测单词:", [idx2vocab[idx] for idx in test_datas_[5]])print("真实结果:", [idx2label[idx] for idx in test_labels_[5]])print("预测结果:", [idx2label[idx] for idx in y_labels[5]][-len(test_datas_[5]):])#文件存储fw = open("Final_BiGRU_CRF_Result.csv", "w", encoding="utf8", newline='')fwrite = csv.writer(fw)fwrite.writerow(['pre_label','real_label', 'word'])n = 0while n<len(final_y):fwrite.writerow([final_y[n],final_z[n],final_word[n]])n += 1fw.close()
输出结果如下所示:
['loss', 'crf_viterbi_accuracy']
[0.03543611364953834, 0.9894005656242371]

生成文件如下图所示:

五.总结
写到这里这篇文章就结束,希望对您有所帮助,后续将结合经典的Bert进行分享。忙碌的2024,真的很忙,项目本子论文毕业工作,等忙完后好好写几篇安全博客,感谢支持和陪伴,尤其是家人的鼓励和支持, 继续加油!
- 一.ATT&CK数据采集
- 二.数据预处理
- 三.基于BiLSTM-CRF的实体识别
1.安装keras-contrib
2.安装Keras
3.中文实体识别 - 四.基于BiGRU-CRF的实体识别
- 五.总结
人生路是一个个十字路口,一次次博弈,一次次纠结和得失组成。得失得失,有得有失,不同的选择,不一样的精彩。虽然累和忙,但看到小珞珞还是挺满足的,感谢家人的陪伴。望小珞能开心健康成长,爱你们喔,继续干活,加油!
(By:Eastmount 2024-02-07 夜于贵阳 http://blog.csdn.net/eastmount/ )
相关文章:

[当人工智能遇上安全] 11.威胁情报实体识别 (2)基于BiGRU-CRF的中文实体识别万字详解
您或许知道,作者后续分享网络安全的文章会越来越少。但如果您想学习人工智能和安全结合的应用,您就有福利了,作者将重新打造一个《当人工智能遇上安全》系列博客,详细介绍人工智能与安全相关的论文、实践,并分享各种案…...
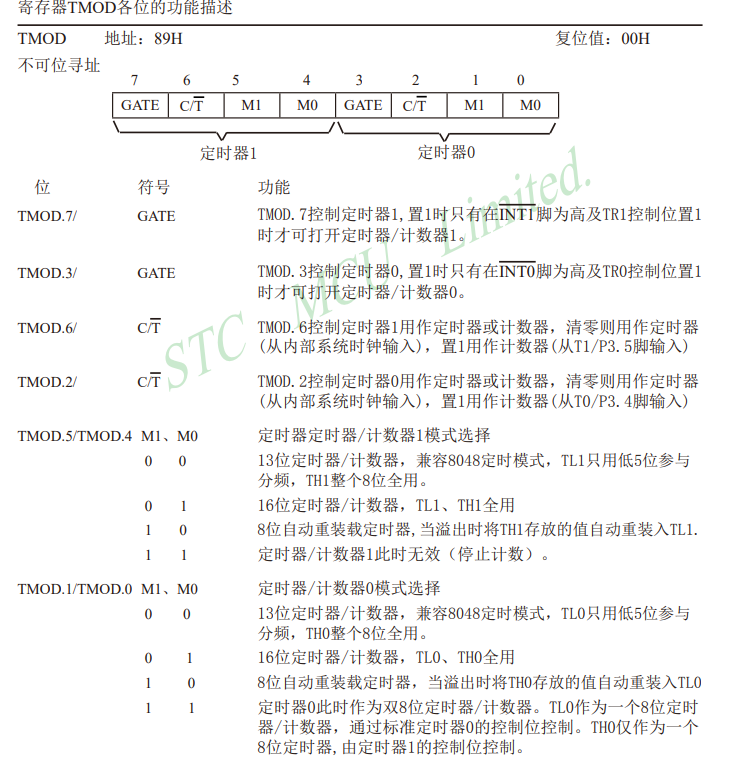
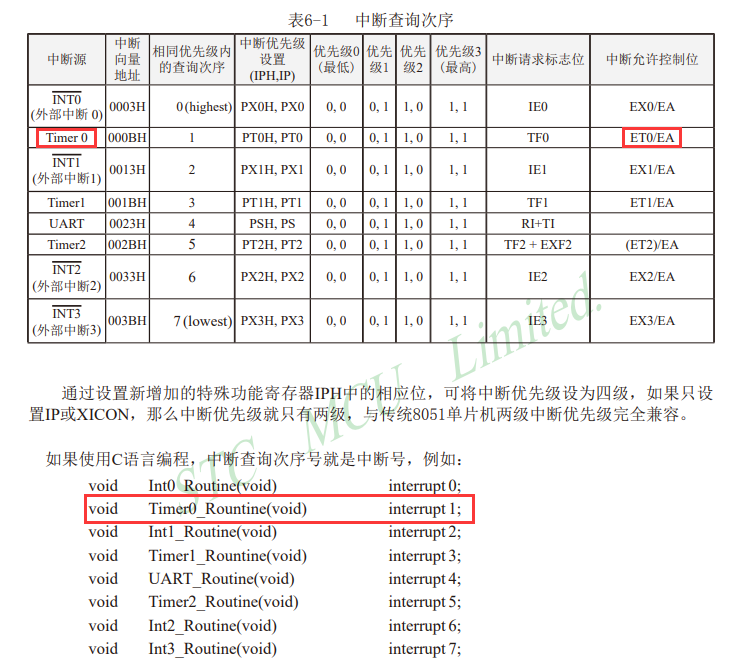
16:定时器和计数器
定时器和计数器 1、定时器和计数器的介绍2、定时器是如何工作3、寄存器4、51单片机定时器简介(数据手册)5、定时器中的寄存器(数据手册)5.1、TCON(定时器控制寄存器)5.2、TMOD(工作模式寄存器&a…...

c#通过ExpressionTree 表达式树实现对象关系映射
//反射expression实现对象自动映射 void Main() {Person p1new(){Id1,Name"abc"};var persondto p1.MapTo<Person, PersonDto>();Console.WriteLine($"id:{persondto.Id}-name:{persondto.Name}"); }public static class AutoMapperExs { public s…...

《动手学深度学习(PyTorch版)》笔记7.2
注:书中对代码的讲解并不详细,本文对很多细节做了详细注释。另外,书上的源代码是在Jupyter Notebook上运行的,较为分散,本文将代码集中起来,并加以完善,全部用vscode在python 3.9.18下测试通过&…...
【MySQL进阶之路】BufferPool 生产环境优化经验
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送! 在我后台回复 「资料」 可领取编程高频电子书! 在我后台回复「面试」可领取硬核面试笔记! 文章导读地址…...
Vim工具使用全攻略:从入门到精通
引言 在软件开发的世界里,Vim不仅仅是一个文本编辑器,它是一个让你的编程效率倍增的神器。然而,对于新手来说,Vim的学习曲线似乎有些陡峭。本文将手把手教你如何从Vim的新手逐渐变为高手,深入理解Vim的操作模式&#…...

Chapter 8 - 7. Congestion Management in TCP Storage Networks
TCP Flow Monitoring versus I/O Flow Monitoring TCP flow monitoring shouldn’t be confused with I/O flow monitoring because of the following reasons: TCP 流量监控不应与 I/O 流量监控混淆,原因如下: 1. TCP belongs to the transport layer (layer 4) of the OS…...

带你快速入门js高级-基础
1.作用域 全局 scriptxx.js 局部 函数作用域{} 块作用域 const let 2.闭包 函数外有权访问函数内的变量, 闭包可以延长变量生命周期 function 函数名 () {return function () {// 这里的变量不会立刻释放} }3.垃圾回收 不在使用(引用的变量), 防止占用内存,需要…...

数据结构与算法-链表(力扣附链接)
之前我们对C语言进行了一定的学习,有了一些基础之后,我们就可以学习一些比较基础的数据结构算法题了。这部分的知识对于我们编程的深入学习非常有用,对于一些基本的算法,我们学习之后,就可以参加一些编程比赛了&#x…...
多线程JUC:等待唤醒机制(生产者消费者模式)
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:多线程&JUC:解决线程安全问题——synchronized同步代码块、Lock锁 📚订阅专栏:多线程&am…...

无人机动力系统高倍率锂聚合物电池介绍,无人机锂电池使用与保养,无人机飞行控制动力源详解
无人机电池使用及保养 电池是无人机飞行的动力来源,也是一个消耗品,对电池充分了解,采取正确的使用方法,妥善进行维护保养将有助于提高飞行的安全性、延长电池的使用寿命。以下将详细对电池的使用和管理进行讲解。 高倍率锂聚合物电池的含义…...

[BeginCTF]真龙之力
安装程序 双击安装 出现了安装失败的标签,开发者不允许测试。 查看Mainfest入口文件 <?xml version"1.0" encoding"utf-8"?> <manifest xmlns:android"http://schemas.android.com/apk/res/android" android:versionCo…...

手写分布式存储系统v0.3版本
引言 承接 手写分布式存储系统v0.2版本 ,今天开始新的迭代开发。主要实现 服务发现功能 一、什么是服务发现 由于咱们的服务是分布式的,那从服务管理的角度来看肯定是要有一个机制来知道具体都有哪些实例可以提供服务。举个例子就是,张三家…...

除夕快乐!
打印的简单实现,祝大家新的一年万事顺意! 龙年大吉! #include <stdio.h> #include <windows.h> #include <string.h>int main() {const char* message "除夕快乐!";int i;for (i 0; i < strlen(message);…...
17:定时器编程实战
1、实验目的 (1)使用定时器来完成LED闪烁 (2)原来实现闪烁时中间的延迟是用delay函数实现的,在delay的过程中CPU要一直耗在这里不能去做别的事情。这是之前的缺点 (3)本节用定时器来定一个时间(譬如0.3s),在这个定时器定时时间内…...
Fink CDC数据同步(五)Kafka数据同步Hive
6、Kafka同步到Hive 6.1 建映射表 通过flink sql client 建Kafka topic的映射表 CREATE TABLE kafka_user_topic(id int,name string,birth string,gender string ) WITH (connector kafka,topic flink-cdc-user,properties.bootstrap.servers 192.168.0.4:6668…...

ubuntu原始套接字多线程负载均衡
原始套接字多线程负载均衡是一种在网络编程中常见的技术,特别是在高性能网络应用或网络安全工具中。这种技术允许应用程序在多个线程之间有效地分配和处理网络流量,提高系统的并发性能。以下是关于原始套接字多线程负载均衡技术的一些介绍: …...

leetcode (算法)66.加一(python版)
需求 给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。 你可以假设除了整数 0 之外,这个整数不会以零开头。 示例 1: 输入:digi…...

DataX源码分析 TaskGroupContainer
系列文章目录 一、DataX详解和架构介绍 二、DataX源码分析 JobContainer 三、DataX源码分析 TaskGroupContainer 四、DataX源码分析 TaskExecutor 五、DataX源码分析 reader 六、DataX源码分析 writer 七、DataX源码分析 Channel 文章目录 系列文章目录TaskGroupContainer初始…...
)
2024年华为OD机试真题-螺旋数字矩阵-Java-OD统一考试(C卷)
题目描述: 疫情期间,小明隔离在家,百无聊赖,在纸上写数字玩。他发明了一种写法: 给出数字个数n和行数m(0 < n ≤ 999,0 < m ≤ 999),从左上角的1开始,按照顺时针螺旋向内写方式,依次写出2,3...n,最终形成一个m行矩阵。 小明对这个矩阵有些要求: 1.每行数字的…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...