【初识爬虫+requests模块】
爬虫又称网络蜘蛛、网络机器人。本质就是程序模拟人使用浏览器访问网站,并将需要的数据抓取下来。爬虫不仅能够使用在搜索引擎领域,在数据分析、商业领域都得到了大规模的应用。
URL
每一个URL指向一个资源,可以是一个html页面,一个css文档,一个js文件,一张图片等等。
URL的格式:protocol://hostname[:port]/path[?query]
protocol:网络传输协议
hostname:存放资源的服务器的域名或IP地址
port:是一个可选的整数,取值范围是0-65535。如果被省略了,默认http端口为80,https的端口是443。
path:路由地址,一般用来表示主机上的一个目录或文件地址,由零个或多个/符号隔开的字符串,路由地址决定了服务端如何处理这个请求。
query:从?开始到它们之间的部分就是参数,又称搜索部分或者查询字符串。
HTTP协议
HTTP(超文本传输协议)主要作用是让服务端和客户端之间进行数据交互(相互传输数据)。
HTTPS(安全超文本传输协议)是HTTP协议的安全版,对传输数据进行加密。
HTTP请求
请求类别:HTTP协议中定义了八种请求方法。主要了解两种:get和post请求。
get请求:从服务器获取数据下来,并不会对服务器资源产生任何影响的时候使用get请求。
post请求:向服务端发送数据(登录)、上传文件等,会对服务器资源产生影响时使用post请求。
请求头
User-Agent:请求载体的身份标识。在请求一个网页的时候,服务器通过这个参数就可以知道这个请求是由那种浏览器发送的。如果我们是通过爬虫发送请求,那么我们的User-Agent就是Python。不过对于有反爬虫机制的网站来说,这样就可以轻易的判断这个请求时爬虫。因此,我们要设置这个值为一些浏览器的值,来伪装我们的爬虫。
Cookie:对应的是一个用户的信息,http协议是无状态的。也就是同一个人发送了两次请求,服务器没有能力知道这两个请求是否来自同一个人,因此这时候就用cookie来做标识。
请求体:提交的内容
HTTP响应
响应行:反馈基本的响应情况
常见的响应状态码:
200:请求正常,服务器正常的返回数据
302:临时重定向。比如在访问一个需要登录的页面的时,而此时没有登录,就会重定向到登陆页面。
400:请求的url在服务器上找不到。换句话说就是请求url错误。
403:服务器拒绝访问,权限不够。
500:服务器内部错误。
响应头:对响应内容的描述。
Content-Length:服务器通过这个头,告诉浏览器回送数据的长度。
Content-Type: 服务器通过这个头,告诉浏览器回送数据的类型。
编写爬虫的基础流程
1.确定你要获取的数据,确定需要爬取的URL地址。
网页上数据有的是通过js动态加载出来的。使用Ajax。
2.使用请求模块向URL地址发出请求,并得到响应内容。
通过代码去发送请求
3.从响应内容中提取所需数据。
4.存储
在python的html后缀名下的文件内中写:
<script>let xhr = new XMLHttpRequest()xhr.open('GET', 'http://yu.ming(全是数字的那一串)/curl/getIp')//发送请求xhr.send()xhr.onload = function(){//jsonlet data = JSON.parse(xhr.reponse)let span1 = document.createElement('span')let span2 = document.createElement('span')span1.innerHTML = 'ip:' + data.returnCitySN.ip + '<br>'span2.innerHTML = '地址' + data.returnCitySN.Country + '<br>'document.body.appendChild(span1)document.body.appendChild(span2)}
</script>requests模块
在cmd窗口下pip install requests来导入第三方模块,或者在pycharm内file的setting下Python Interpreter内进行下载。
requests模块的使用
1.requests.get():表示向网站发送GET请求,获取页面响应对象。
语法:
response=requests.get(url,headers=headers,params)
url:要抓取的url地址
headers:用于包装请求头信息
params:请求时携带的查询字符串参数
2.HttpResponse响应对象:我们使用requests模块向一个URL发起请求后会返回这样的对象。
响应对象属性:
text:获取相应内容字符串类型
content:获取响应内容bytes类型(抓取图片、音频、视频文件)
encoding:查看或指定响应字符编码
request.headers:查看响应对应的请求头
cookies:获取响应的cookie,经过set-cookie动作,返回coookieJar类型
json():将json字符串类型的响应内容转换为python对象
import requests
url = 'https://www.maoyan.com/board/6?timeStamp=1707033337406&channelId=40011&index=7&signKey=05c5030979de1a94fc40756853de3ca4&sVersion=1&webdriver=false&offset=0'# 使用requests 帮我们发送一个get请求
response = requests.get(url) # get函数内放置url参数,获取响应内容并用一个变量来接收
print(response.request.headers) # 获取请求头
print(response.text) # 获取响应内容(可能会被反爬虫阻拦获取不到。此时就需要伪装一下了)3.发送带header的请求
import requests
url = 'https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_0210197b670445ddbba4fb6fe8baceb0'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=header)
print(response.text)'''
正则的定义:按照一定的规则,在字符串里面匹配要找的内容
如何使用正则:导入re文件
'''
import re
# findall:找到所有满足条件的数据,得到一个列表
re.findall()# . 匹配一个任意字符 除了换行
# re.S 使. 可以匹配到换行符
re.findall('a.','aba\naa',re.S)# * 出现0次或多次
re.findall('a*','aba\naa')# .*贪婪匹配(尽量多匹配)
html = '<div></div>' print(re.findall('<.*>',html))
# 得到结果:['<div></div>']# .*?非贪婪匹配(尽量少匹配)
html = '<div></div>' print(re.findall('<.*?>',html))
# 得到结果:['<div>', '</div>']# 把想要的东西加括号,提取出来
html = '<div>XX</div>'
print(re.findall('<div>(.*?)</div>', html)) # ['XX']关于完整使用:
import requests
base_url = 'https://movie.douban.com/chart'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}def get_html(url):# 发送请求功能response = requests.get(url, headers=headers)return response.textdef parse_html(html):# 提取数据功能r_list = re.findall('<div class="pl2">.*?>\n(.*?)/.*?</a>.*?<span class="rating_nums">(.*?)</span>', html, re.S)return r_listdef save(data_list):# 存储数据功能for data in data_list:name = data[0].strip() # 去除两边空格num = data[1]print(name, num)print('-'*30)html = get_html(base_url)
# print(html)
data_list = parse_html(html)
save(data_list)结果:
怪物 8.6
------------------------------
荒野 5.7
------------------------------
涉过愤怒的海 7.2
------------------------------
枯叶 7.9
------------------------------
坠落的审判 8.5
------------------------------
爆裂点 5.7
------------------------------
再见,李可乐 6.3
------------------------------
杂种 8.2
------------------------------
刀尖 5.3
------------------------------
花月杀手 7.3
------------------------------将存储数据到mysql内
首先导入第三方模块pymysql
写法一:
import pymysql
# 导入模块
# 建立数据库的链接
db = pymysql.connect(host='127.0.0.1',port=3306,database='douban',user='root',password='123456',charset='utf8'
)# 创建数据库 create database douban;(终端要输入的,否则会报错)
# 创建游标对象 通过游标对象去操作
cur = db.cursor()
# 执行操作
sql = 'insert into movie_info(name, num) values("%s", "%f")' % ('怪物', 8.6)
cur.execute(sql)
db.commit()
'''
创建表的语法:
create table movie_info(
id int primary key auto_increment,
name varchar(20),
num float(5)
);
'''
# 关闭游标对象
cur.close()
# 关闭连接
db.close()注意:
- 创建数据库和创建表的代码要在cmd的mysql内部进行。
- 在创建表之前先使用表:use douban;
- 小数记得用 %f 哦.

写法二:
全部写入进该表中:
import reimport requestsimport pymysql# 建立数据库的链接
db = pymysql.connect(host='127.0.0.1',port=3306,database='douban',user='root',password='123456',charset='utf8'
)cur = db.cursor()
sql = 'insert into movie_info(name, num) values("%s", "%s")'base_url = 'https://movie.douban.com/chart'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}def get_html(url):# 发送请求功能response = requests.get(url, headers=headers)return response.textdef parse_html(html):# 提取数据功能r_list = re.findall('<div class="pl2">.*?>\n(.*?)/.*?</a>.*?<span class="rating_nums">(.*?)</span>', html, re.S)return r_listdef save(data_list):# 存储数据功能for data in data_list:name = data[0].strip() # 去除两边空格num = data[1]print(name, num)li = [name, num]cur.execute(sql, li)db.commit()print('-'*30)html = get_html(base_url)
# print(html)
data_list = parse_html(html)
save(data_list)
# 关闭游标对象
cur.close()
# 关闭连接
db.close()注意:前面已经写入的内容要进行删除,不然会报错的(主键的唯一性)。
import reimport requestsimport pymysql# 建立数据库的链接
db = pymysql.connect(host='127.0.0.1',port=3306,database='douban',user='root',password='123456',charset='utf8'
)cur = db.cursor()
sql = 'insert into movie_info(name, num) values("%s", "%f")'base_url = 'https://movie.douban.com/top250?start={}&filter=' # {}切换页数
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
def get_html(url):# 发送请求功能response = requests.get(url, headers=headers)return response.textdef parse_html(html):# 提取数据功能r_list = re.findall('<div class="pl2">.*?>\n(.*?)/.*?</a>.*?<span class="rating_nums">(.*?)</span>', html, re.S)save(r_list)def save(data_list):# 存储数据功能for data in data_list:name = data[0].strip() # 去除两边空格num = data[1]print(name, num)li = [name, num]cur.execute(sql, li)db.commit()print('-'*30)# 对爬取的内容找规律
for start in range(0, 226, 25):url = base_url.format(start)print(url)html = get_html(url)parse_html(html)cur.close()
db.close()使用json来提取数据
import requests
import jsonurl = 'https://spa1.scrape.center/api/movie/?limit=10&offset=0'
response = requests.get(url)json_data = response.json() # 用json对象来进行接收
for data in json_data["results"]:print(data["name"])print(data["categories"])print('-'*30)换页提取:
第一种方式:
import reimport requestsbase_url = 'https://www.maoyan.com/board/4?offset={}'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}def get_html(url):'''通过requests模块发送get请求:param url: 给那个url发送请求:return: html代码'''response = requests.get(url, headers=headers)print(response.url)return response.textdef parse_html(html):'''提取数据的函数:param html: 在那个代码中寻找'''r_list = re.findall('<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', html, re.S)save(r_list)def save(data_list):for data in data_list:li = [data[0],data[1].split(':')[1].strip(),data[2].split(':')[1].strip(),]print(li)for offset in range(0, 91, 10):url = base_url.format(offset)html = get_html(url=url)parse_html(html)print('-'*100)第二种方式:
import reimport requestsbase_url = 'https://www.maoyan.com/board/4'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}params = {"offset": 0
}
def get_html(url):'''通过requests模块发送get请求:param url: 给那个url发送请求:return: html代码'''response = requests.get(url, headers=headers, params=params)print(response.url)return response.textdef parse_html(html):'''提取数据的函数:param html: 在那个代码中寻找'''r_list = re.findall('<div class="movie-item-info">.*?title="(.*?)".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', html, re.S)save(r_list)def save(data_list):for data in data_list:li = [data[0],data[1].split(':')[1].strip(),data[2].split(':')[1].strip(),]print(li)for offset in range(0, 91, 10):params['offset'] = offsethtml = get_html(url=base_url)parse_html(html)print('-'*100)https://curlconverter.com/#
代码复制copy的代码可自动生成
爬取音乐
import requestsresponse = requests.get('https://音乐所在网址')
print("请求成功")
song_data = response.content
with open('疑心病.mp3', 'wb')as f:f.write(song_data)会添加到pycharm内,拖拽到桌面上即可。
相关文章:
【初识爬虫+requests模块】
爬虫又称网络蜘蛛、网络机器人。本质就是程序模拟人使用浏览器访问网站,并将需要的数据抓取下来。爬虫不仅能够使用在搜索引擎领域,在数据分析、商业领域都得到了大规模的应用。 URL 每一个URL指向一个资源,可以是一个html页面,一…...
微信小程序(三十八)滚动容器
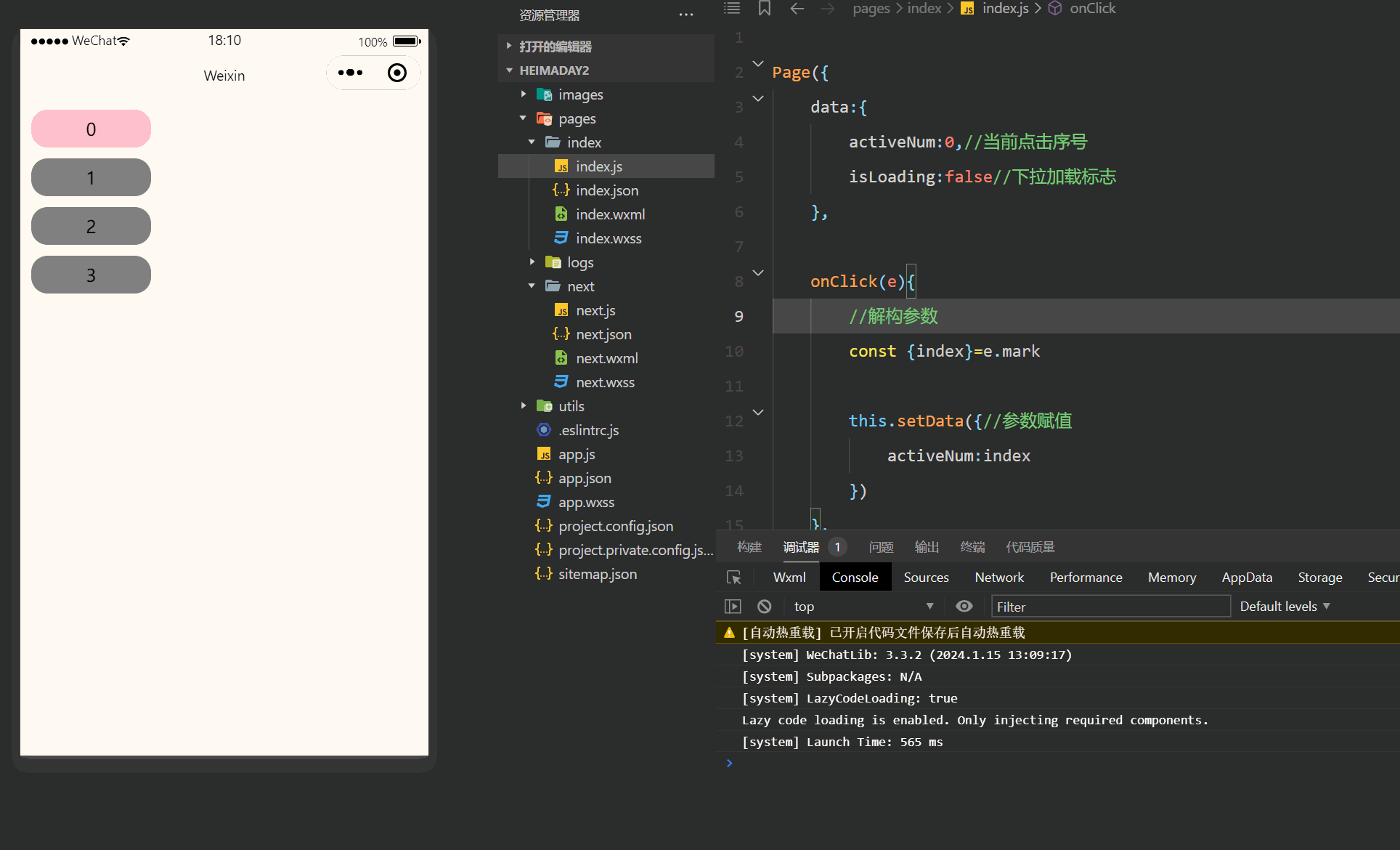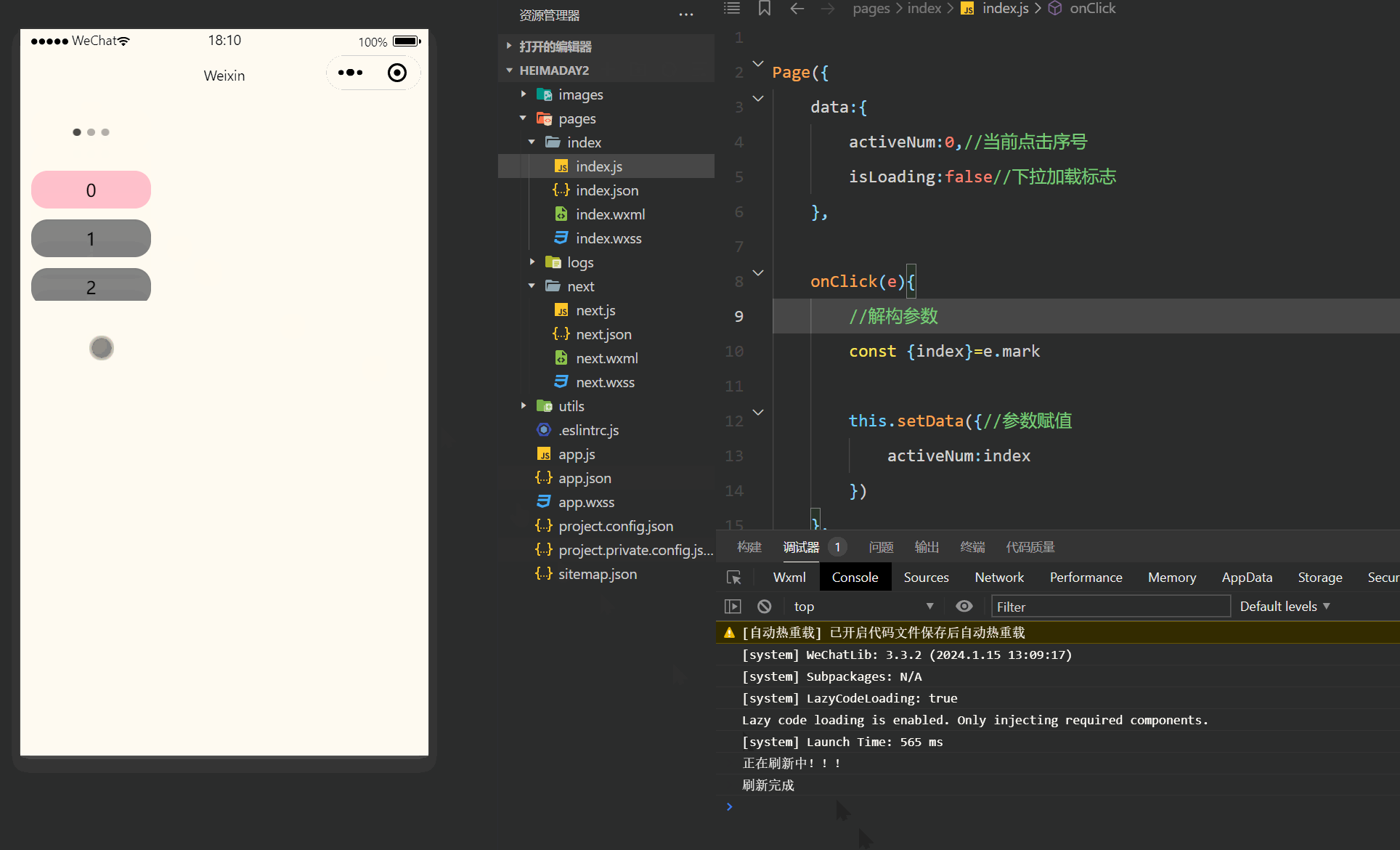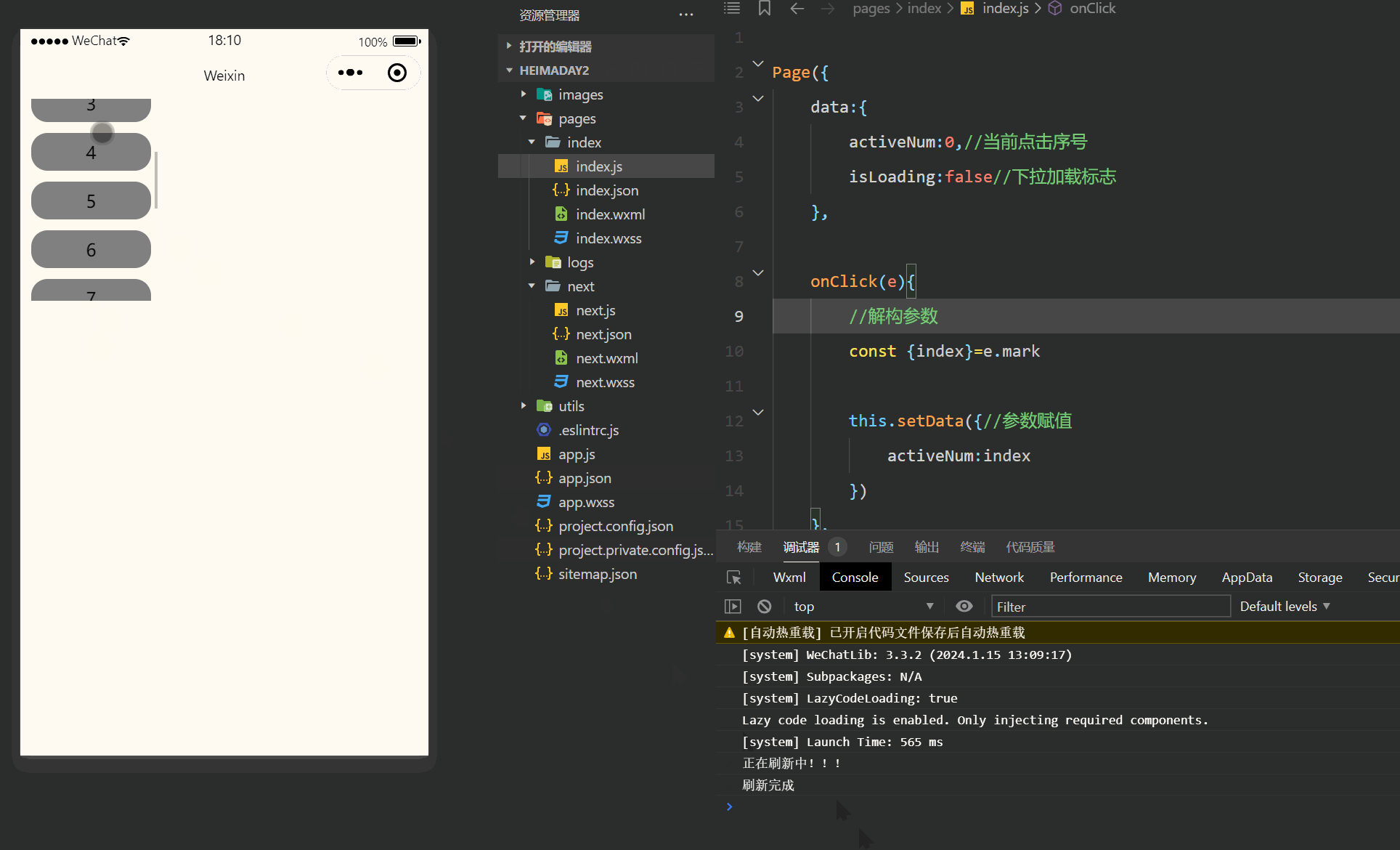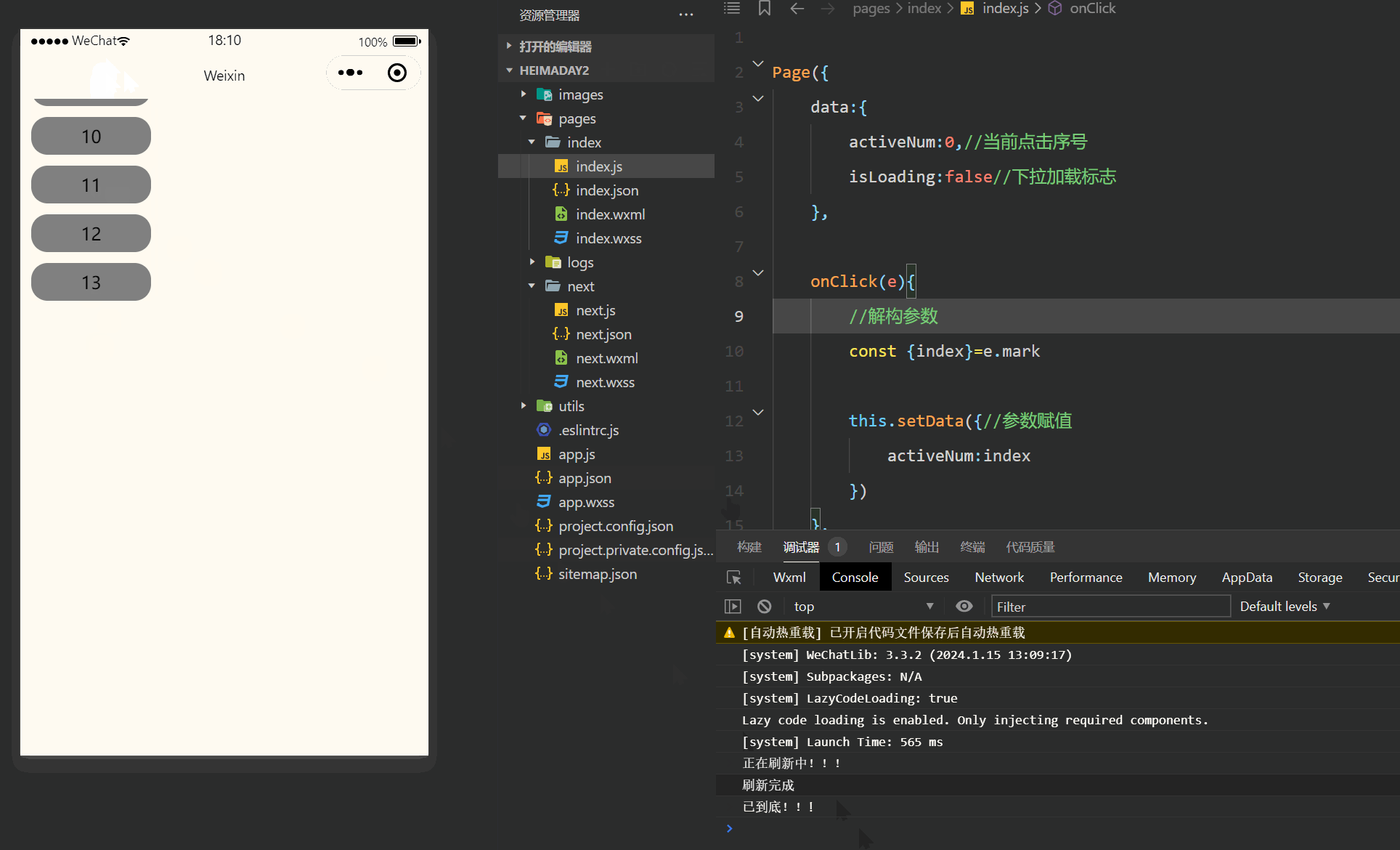
注释很详细,直接上代码 上一篇 新增内容: 1.滚动触底事件 2.下拉刷新事件 源码: index.wxml <view class"Area"> <!-- scroll-y 垂直滚动refresher-enabled 允许刷新bindrefresherrefresh 绑定刷新作用函数bindscrollto…...

Python学习之路-Tornado基础:数据库
Python学习之路-Tornado基础:数据库 简介 与Django框架相比,Tornado没有自带ORM,对于数据库需要自己去适配。我们使用MySQL数据库。 在Tornado3.0版本以前提供tornado.database模块用来操作MySQL数据库,而从3.0版本开始,此模块…...
Golang的for循环变量和goroutine的陷阱,1.22版本的更新
先来看一段golang 1.22版本之前的for循环的代码 package mainimport "fmt"func main() {done : make(chan bool)values : []string{"chen", "hai", "feng"}for _, v : range values {fmt.Println("start")go func() {fmt.P…...

List 差集
文章目录 基本类型对象类型 基本类型 ListUtils.subtract 方法用于计算两个集合的差集,即返回 list1 中有但 list2 中没有的元素。 其中,list1 指向第一个集合,list2 指向第二个集合。该方法返回一个新的 List 对象,它包含所有在…...
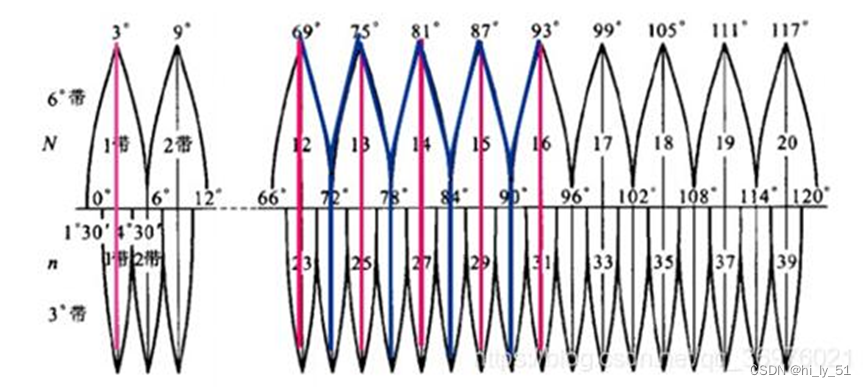
ArcGIS的UTM与高斯-克吕格投影分带要点总结
UTM(通用横轴墨卡托投影、等角横轴割椭圆柱投影)投影分带投影要点: 1)UTM投影采用6度分带 2)可根据公式计算,带数(经度整数位/6)的整数部分31 3)北半球地区࿰…...
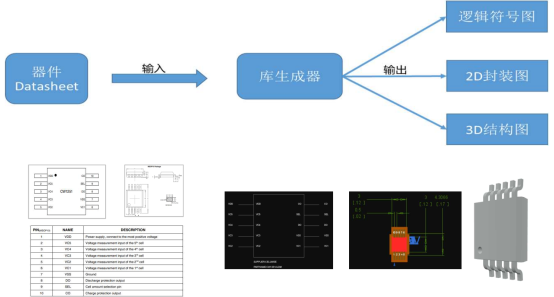
华为第二批难题一:基于预训练AI模型的元件库生成
我的理解:华为的这个难道应该是想通过大模型技术,识别元件手册上的图文内容,与现有建库工具结合,有潜力按标准生成各种库模型。 正好,我们正在研究,利用知识图谱技术快速生成装配模型,其中也涉…...
Android AOSP源码研究之万事开头难----经验教训记录
文章目录 1.概述2.Android源下载1.配置环境变量2.安装curl3.下载repo并授权4.创建一个文件夹保存源码5.设置repo的地址并配置为清华源6.初始化仓库7.指定我们需要下载的源码分支并初始化 2.1 使用移动硬盘存放Android源码的坑2.2 解决方法 3.Android源码编译4.Android源烧录 1.…...

动态数据源
一、部署 1、导入依赖 <dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.1.0</version></dependency>2、编写yml 配置文件 spring:datasource:dyna…...

2024.1.29力扣每日一题——自由之路
2024.1.29 题目来源我的题解方法一 动态规划 题目来源 力扣每日一题;题序:514 我的题解 方法一 动态规划 定义 dp[i][j] 表示从前往后拼写出 key的第 i个字符, ring 的第 j个字符与 12:00 方向对齐的最少步数(下标均从 0 开始&…...

Qt应用软件【协议篇】UDP示例
UDP协议简介 UDP(用户数据报协议)是一种无连接的网络协议,提供了简单但是不可靠的消息传输服务。与TCP不同,UDP不保证数据包的顺序、重复性或者可达性,但它在速度和效率上具有优势,特别适合那些对实时性要求高的应用,如视频流、在线游戏等。 Qt中的UDP编程 在Qt中,U…...

MyBatis之动态代理实现增删改查以及MyBatis-config.xml中读取DB信息文件和SQL中JavaBean别名配置
MyBatis之环境搭建以及实现增删改查 前言实现步骤1. 编写MyBatis-config.xml配置文件2. 编写Mapper.xml文件(增删改查SQL文)3. 定义PeronMapper接口4. 编写测试类1. 执行步骤2. 代码实例3. 运行log 开发环境构造图总结 前言 上一篇文章,我们…...

百面嵌入式专栏(面试题)内存管理相关面试题1.0
沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇我们将介绍内存管理相关面试题 。 一、内存管理相关面试题 page数据结构中的_refcount和_mapcount有什么区别?匿名页面和高速缓存页面有什么区别?page数据结构中有一个锁,我们称为页锁,请问trylock_page()和loc…...

SpringMVC 1.请求参数检查 2.全局异常处理 3.请求参数封装为Pojo
ErrorEnum.java // 枚举所有的错误 package com.example.demo.enums;import lombok.Getter;public enum ErrorEnum {SYSTEM_ERROR(-1, "系统错误"),PARAM_ERROR(-2, "参数错误"),OK(0, "成功"),;Getterprivate final int code;Getterprivate fi…...

7机器人位姿的数学描述与坐标变
由上次刚体的空间转动直接切换为机器人相关术语。 1.机器人位姿的数学描述与坐标变换 1.1位姿描述 {B}相对于{A}的姿态描述用3x3矩阵表示为: 式中为三个单位正交主矢量,分别表示刚体坐标系{B}的三个坐标轴XBYBZB在参考系{A}中的方位,∠XBXA表…...
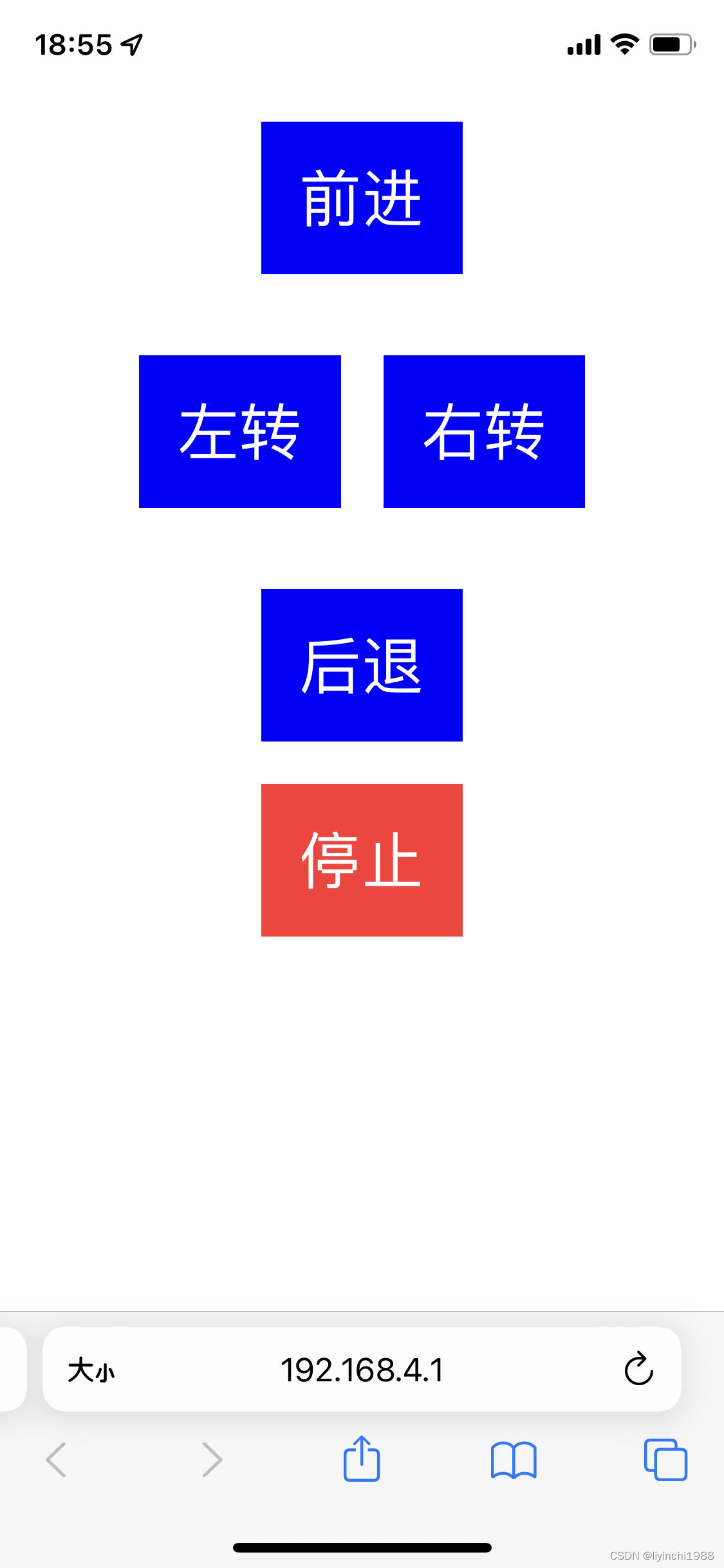
基于ESP8266 开发板(MCU)遥控小车
遥控小车 遥控界面 【项目源码】 第一版ESP8266 https://github.com/liyinchigithub/esp8266_car_webServerhttps://github.com/liyinchigithub/esp8266_car_webServer 第二版ESP32 GitHub - liyinchigithub/esp32-wroom-car: 嵌入式单片机 ESP32 Arduino 遥控小车&a…...

【C生万物】C语言数据类型、变量和运算符
📚博客主页:爱敲代码的小杨. ✨专栏:《Java SE语法》 | 《数据结构与算法》 | 《C生万物》 ❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️ 🙏小杨水平有…...
CTF--Web安全--SQL注入之‘绕过方法’
一、什么是绕过注入 众所周知,SQL注入是利用源码中的漏洞进行注入的,但是有攻击手段,就会有防御手段。很多题目和网站会在源码中设置反SQL注入的机制。SQL注入中常用的命令,符号,甚至空格,会在反SQL机制中…...

线程池常用的阻塞队列
新任务来的时候,会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。 不同的线程池会选用不同的阻塞队列,我们可以结合内置线程池来分析。 ● 容量为 Integer.MAX_VALUE 的 LinkedBlockingQue…...
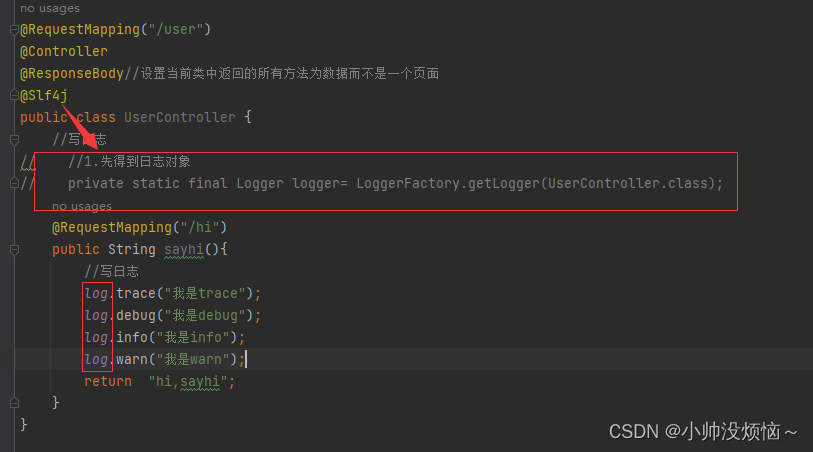
【Java EE】----SpringBoot的日志文件
1.SpringBoot使用日志 先得到日志对象通过日志对象提供的方法进行打印 2.打印日志的信息 3.日志级别 作用: 可以筛选出重要的信息不同环境实现不同日志级别的需求 ⽇志的级别分为:(1-6级别从低到高) trace:微量&#…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...
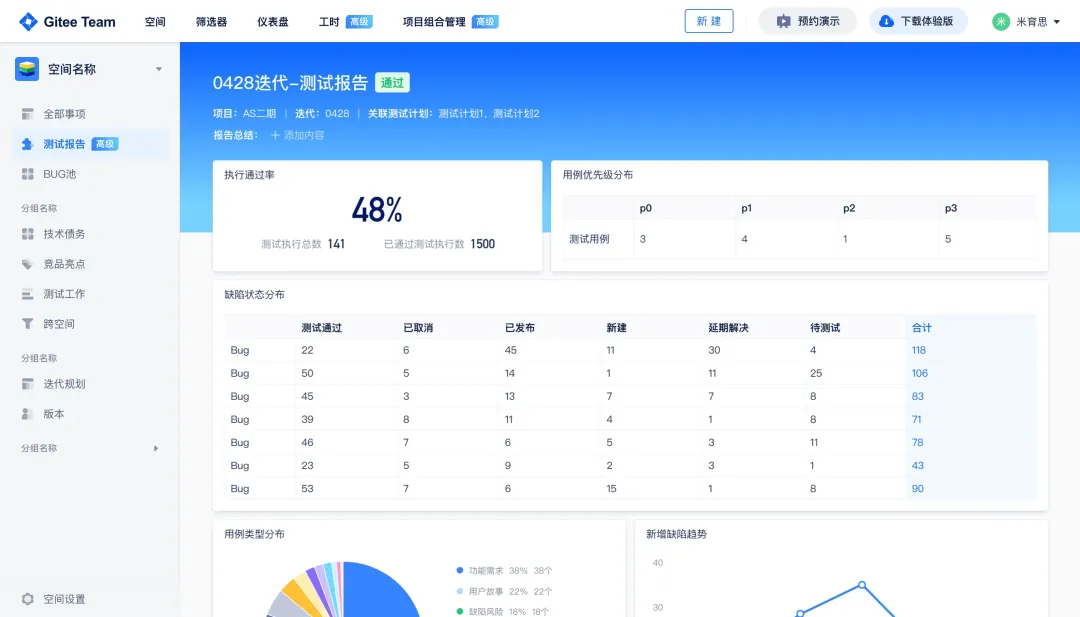
从“安全密码”到测试体系:Gitee Test 赋能关键领域软件质量保障
关键领域软件测试的"安全密码":Gitee Test如何破解行业痛点 在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的"神经中枢"。从国防军工到能源电力,从金融交易到交通管控,这些关乎国计民生的关键领域…...