GPT-4模型中的token和Tokenization概念介绍
Token从字面意思上看是游戏代币,用在深度学习中的自然语言处理领域中时,代表着输入文字序列的“代币化”。那么海量语料中的文字序列,就可以转化为海量的代币,用来训练我们的模型。这样我们就能够理解“用于GPT-4训练的token数量大约为13万亿个”这句话的意思了。代币越多,训练次数越多,最终模型的质量一般也越好。13万亿个,这个数目是指在模型训练过程中所使用的数据集中的总token数,反映了模型在训练时接触到的数据规模之大。
1. GPT-4模型中的token和Tokenization
在GPT-4模型中,token指的是输入文本序列中的基本单元。每个token代表了文本的一个组成部分,可以是单个单词、子词(如BERT中的WordPiece分词)或者在视觉任务中可能是图像patch的编码表示。
Tokenization:
在深度学习的自然语言处理(NLP)中,代币化(Tokenization)是一个基本且关键的预处理步骤,它涉及将连续的文本序列分割成离散的、有意义的语言单元,这些单元通常被称为tokens。这个过程有助于计算机理解和处理人类自然语言。
具体来说:
-
词汇Tokenization:根据语法规则或词典,将文本划分为单词或术语。例如,“我爱自然语言处理”会被拆分成“我”、“爱”、“自然”和“语言处理”四个token。
-
字符Tokenization:将文本细粒度地分割为单个字符或子词。例如,上述句子在字符级别会被拆分成“我”、“爱”、“自”、“然”、“语”、“言”、“处”、“理”。
-
字节Pair Encoding(BPE)或Subword Tokenization:结合了词汇和字符级的优点,通过算法生成一种混合表示,包括常见单词和更复杂的结构,尤其是在处理罕见词汇时。
-
特殊Token:对于一些特定用途,模型可能还会引入特殊的tokens,如分隔符(用于标记句子边界)、填充符(用于保持序列长度一致)以及未知词符号(代表未见过的词汇)。
-
句法Tokenization:基于语法结构进行切分,比如短语或句子成分。
代币化后的tokens随后会经过嵌入层转换成向量表示,以便于输入到深度学习模型中进一步分析和建模。
具体到自然语言处理任务,当用户向GPT-4提供一个文本时,模型首先会使用Tokenizer将文本分割成一系列tokens。这些tokens随后被嵌入为连续向量,然后输入到Transformer模型进行自注意力计算和上下文理解。
Tokenizer:
当用户向GPT-4这样的先进自然语言处理模型提供文本输入时,确实首先会经过一个预处理步骤,其中的核心环节就是Tokenizer将文本进行代币化处理。GPT-4采用的Transformer架构要求输入数据以token的形式表示。
具体来说,GPT-4使用的Tokenizer(如Hugging Face Transformers库中的tokenizer)通常会执行以下操作:
-
分词:将连续的文本分割成单词或子词。
-
添加特殊tokens:
[CLS]用作整个句子的标记,有时用于分类任务的预测。[SEP]用在句子对之间或者序列结束处作为分隔符。<pad>或其他填充token,在需要填充到固定长度时使用。unk(未知词token),代表词汇表中未包含的词汇。
-
编码:将每个token映射到一个唯一的整数ID,形成一个可被模型理解的索引序列。
-
对于部分变体和优化,tokenizer可能还会应用Byte Pair Encoding (BPE) 或 WordPiece等算法来生成subword tokens,这样可以更有效地处理罕见词汇和OOV(Out Of Vocabulary)问题。
最终,得到的token序列会被转化为模型可以接受的嵌入向量形式,并输入到GPT-4模型中进行训练、推理或生成任务。
token序列的处理步骤:
当用户提供的文本经过Tokenizer处理后,得到的token序列会经历以下步骤:
-
Token Embedding: 每个token会被映射到一个高维向量空间中的特定点,这个过程称为token嵌入(或词嵌入)。GPT-4模型内已经预训练好了特定的embedding矩阵,用于将每个token ID转换为对应的固定维度的向量表示。
-
位置编码(Positional Encoding): 为了保留原始文本中单词的顺序信息,模型还会对每个token嵌入加上一个位置编码。这样,模型就可以理解tokens在句子中的相对或绝对位置关系。
-
Transformer层输入:经过嵌入和位置编码后的tokens,就作为连续向量被送入Transformer模型中。在GPT-4这样的自回归语言模型中,这些向量首先通过多层自注意力机制进行计算,每层自注意力允许模型根据上下文理解每个token的意义。
-
自注意力计算与上下文理解:Transformer模型利用自注意力机制来捕捉全局依赖性,即每个token都能够关注到其他所有token的信息,从而形成对整个输入序列的上下文理解。
-
解码与生成:在推理阶段,GPT-4模型基于前面计算出的上下文理解结果,逐个预测下一个token的概率分布,并以此循环生成后续的tokens,直至生成完整的输出文本或者达到终止条件为止。
GPT-4的语言能力出众
在GPT-4模型训练过程中,其处理的token总数非常庞大,达到13万亿个token级别,这意味着模型基于大量数据进行了充分学习,能够理解和生成复杂的语言结构及内容。
GPT-4模型训练所使用的数据规模极其庞大,处理的token总数达到13万亿级别。这意味着模型在训练过程中接触了各种各样的语言表达、上下文情境以及复杂的结构化和非结构化内容,从而具备了对大量领域知识的广泛理解能力和细致入微的语言生成能力。
通过学习这些海量的数据,GPT-4能够捕捉到人类语言中的细微差别,并在生成文本时实现高度连贯性和逻辑一致性。这样的大规模训练为模型提供了更强的一般性泛化能力,使其不仅能够在已知领域中表现优秀,还能在一定程度上适应未曾见过的新情境,生成高质量、自然流畅的文本输出。
GPT-4的“长篇大论”能力出众
在实际应用中,GPT-4可以处理的最大连续token数为32768个,这个长度使得模型在处理长文本或对话时具有更强的连贯性和上下文保持能力。
GPT-4模型在实际应用中可以处理的最大连续token数为32768个,这个显著增加的上下文窗口长度相较于前代模型是一个重大突破。这意味着对于长篇文章、文档、代码片段或者复杂的对话交互场景,GPT-4能够更好地理解和利用更长的历史信息流来进行推理和生成,从而增强了模型对文本连贯性和上下文依赖关系的把握能力。
由于能够记忆并考虑如此大跨度的上下文信息,GPT-4在完成如文本续写、文档总结、代码编写、多轮对话等任务时,能更准确地根据之前的输入内容进行响应,并保持前后一致性,极大地提高了模型的实用性与表现力。
2. Transformer架构中的Token
在Transformer架构中,Token 是对输入序列的基本单元的表示。对于文本数据,一个token可以是单个词、子词(如BERT中的WordPiece分词结果)、字符或者特定类型的标记(例如特殊符号用于指示句子开始或结束)。具体来说:
-
NLP中的Token处理:
- 输入文本首先通过分词器(Tokenizer)进行预处理,将原始文本切分成一系列tokens。
- 每个token会被转化为一个向量,这个过程通常包括查找表(Lookup Table),也就是嵌入层(Embedding Layer),它将每个token映射到一个固定的向量空间中。
-
视觉任务中的Token:
- 对于计算机视觉中的Transformer模型(如ViT,Vision Transformer),图像被分割成多个固定大小的patches(补丁)。
- 每个patch被视为一个token,并经过线性映射和位置编码转换为高维向量,这样原本的像素矩阵就转化为了一个可被Transformer模型理解的token序列。
-
特殊Token:
- 除了普通的文本或图像patch token之外,还存在特殊的token,如CLS(Classification)token,在某些模型中用于提供整个序列的汇总信息,常用于下游分类任务。
- SEP(Separator)token用来分隔不同的文本片段或序列。
- Padding token用于填充较短序列,使得所有输入保持相同的长度。
-
计算流程:
- 这些token的嵌入向量随后进入Transformer的自注意力层(Self-Attention Layer),在这些层中,模型学习并捕获不同token之间的依赖关系,生成上下文相关的token表示。
- 经过多层Transformer堆叠后,模型能够基于输入序列的整体上下文来预测下一个token或者做其他形式的任务,比如文本生成、机器翻译、文本分类等。
总结起来,token在Transformer中是构成输入序列的基本元素,它们经过一系列复杂的变换和计算,最终帮助模型理解和处理复杂的序列数据。
3. Token和self-attention
3.1 token和self-attention之间的联系
在Transformer模型中,token和self-attention之间有着紧密的联系:
-
Token:
- Token是输入数据的基本单元。在自然语言处理(NLP)中,token通常指代文本中的单词、子词或字符等,并通过嵌入层转化为固定维度的向量表示。
- 在计算机视觉(CV)任务中,如Vision Transformer (ViT),图像被分割成一系列patch,每个patch也被视为一个token。
-
Self-Attention:
- Self-Attention机制是一种计算方式,它允许模型同时考虑整个序列的信息来生成每个token的上下文感知的表示。
- 对于每个token(例如单词或图像patch),self-attention首先将其转换为Query、Key和Value矩阵,然后计算Query与所有Key之间的注意力权重(得分),并通过这些权重对所有Value进行加权求和,以获得该token的新表示。
-
关系阐述:
- 在Transformer架构中,每个token经过嵌入后进入自注意力层,self-attention在此阶段发挥核心作用。
- 每个token的Query向量会和其他所有token的Key向量进行交互,根据它们之间的相关性分配注意力权重,然后将这些权重应用于对应的Value向量上进行聚合。
- 这样,对于任意给定的token,其输出的上下文变量(Context Vector)就反映了整个序列信息对其的重要性,从而增强了模型理解和生成复杂依赖结构的能力。
总结来说,在Transformer模型中,token作为基本的数据元素参与self-attention计算过程,进而形成具有全局上下文信息的表示,这对于理解复杂的序列关系至关重要。
3.2 每个输入token的计算过程
在自注意力层中,每个输入token(无论是单词、子词或图像patch的嵌入向量)都会经历以下过程:
-
线性投影:首先,将每个token的嵌入向量通过三个不同的权重矩阵(W_Q, W_K, W_V)进行线性变换,分别得到Query(Q)、Key(K)和Value(V)矩阵。这些矩阵的维度通常是相同的,但它们代表了不同视角下的token信息。
- Query矩阵Q体现了当前token查询整个序列信息的需求。
- Key矩阵K是其他token如何响应查询的衡量标准。
- Value矩阵V包含了每个token的实际内容信息。
-
计算注意力得分:接下来,计算每个Query与所有Key之间的相似度得分,通常采用点积操作后除以一个缩放因子(sqrt(d_k)),其中d_k是Key向量的维度,目的是确保注意力分布的稳定性。然后将结果通过softmax函数归一化为概率分布。
-
加权求和获得上下文向量:最后,用上一步骤得到的每个Query对应的注意力分布权重去加权求和所有的Value向量,生成该Query token的新表示,即上下文相关的向量。
-
组合输出:每个原始token经过上述self-attention机制后得到了新的上下文感知向量,这些向量可以进一步经过残差连接和层归一化等操作,然后再进入下一层网络或者用于最终的预测任务。
4. Token
在自然语言处理(NLP)和计算机视觉(CV)等领域的Transformer模型中,token是一个非常基础且重要的概念:
-
在NLP中的Token:
- Token可以简单理解为文本数据的基本单元。对于英文文本来说,token通常指单个单词(如“the”、“cat”),但也可能是标点符号、数字或其他特殊字符。
- 在更细粒度的划分下,token还可以是子词或者字符级别的单位,例如BERT模型中的WordPiece分词方法会产生像"##ing"这样的子词token。
- NLP中的Transformer模型会使用特定的Tokenizer将输入的句子拆分成一系列tokens,并为每个token分配一个唯一的ID(索引)。这些ID随后被转换为嵌入向量作为模型的输入。
-
在CV中的Token:
- 在视觉Transformer(ViT)中,token的概念扩展到了图像领域。图像会被划分为多个不重叠的小块,每个小块被称为一个patch或token。
- 每个patch token通过线性变换(embedding层)转化为高维向量表示,这样原本连续的像素空间就被转换为了离散的序列形式,与NLP中的word embeddings类似。
- 此外,视觉Transformer中还引入了特殊的token,如Class token,用于对整个图像进行分类或总结全局信息。
总的来说,token是原始输入数据的一种抽象和离散化表示,在Transformer架构中,它们经过编码、注意力机制处理后,能够捕捉到数据内部复杂的上下文依赖关系,从而帮助模型完成各种复杂的任务。
在NLP中的Token:
在自然语言处理(NLP)中,“token”这个词有特定的含义:
定义:
- Token 是文本数据的基本单元,是将连续的自然语言文本分割成离散部分的过程中的产物。这个过程通常被称为词法分析或分词。每个token可以是一个单词、一个字符、一个符号、一个数字、标点符号等,具体取决于所使用的预处理策略和任务需求。
符号与表达:
- 在NLP中,tokens被用来表示原始文本中的有意义单位。例如,在英文文本中,token可能就是一个个单独的单词,如“the”,“dog”,“barked”。
- 对于其他语言,分词标准可能会有所不同。比如在中文里,由于没有空格作为单词分隔符,需要通过分词算法来确定token边界,得到的token可能是单个汉字或者词语组合。
计算方式:
- Tokenization(标记化)是NLP预处理的重要步骤之一。常见的tokenization方法包括:
- 基于空格分词:对于英语等空格分隔的语言,简单地按空格切割文本即可得到单词级别的tokens。
- 分词工具:对于像中文这样不以空格为分隔符的语言,需要使用专门的分词器进行分词,如jieba分词器对中文文本进行切分。
- 词干提取/词形还原:进一步的,token还可以经过词干提取(Stemming)或词形还原(Lemmatization),使得具有相同基本意义的不同形式的词汇归约为同一基础形态,便于后续处理。
- 进行完tokenization之后,这些tokens通常会被转换为数值型向量表示,以便计算机能够处理。这种转换通常采用**词嵌入(Word Embeddings)**技术,如Word2Vec、GloVe或者BERT模型生成的嵌入向量。词嵌入能捕获单词之间的语义和上下文信息,将每个token映射到一个固定维度的向量空间中。
总之,在NLP中,token作为自然语言处理的第一步,从原始文本中抽取出来,并通过各种方法将其转化为机器可理解的形式,从而参与到后续的文本分类、情感分析、命名实体识别等各种任务之中。
5. Tokenization(标记化)
Tokenization(标记化)是将文本数据分割成离散的符号或词汇单元的过程,这些单元被称为tokens。在NLP中,tokens并不直接具有维度大小的概念,因为它们最初只是文本中的基本单位,比如单词、字符或子词等。
然而,在后续处理中,当tokens被转换为数值表示时,就会涉及到维度大小的问题:
-
向量化表示:
- 对于词袋模型(Bag-of-Words)和TF-IDF等传统方法,每个token可以对应一个特征向量中的一个维度,该特征向量的维度大小等于词汇表的大小。
- 在词嵌入(Word Embeddings)如Word2Vec、GloVe等技术中,每个token会被映射到一个固定维度的向量空间,例如常见的维度大小有50维、100维、300维乃至更高,这个向量即代表了token的语义信息。
-
深度学习框架下的表示:
- 在BERT、Transformer等预训练模型中,每个token通过模型编码后会得到一个上下文相关的向量表示,其维度大小通常由模型参数决定,例如BERT-base模型中每个token的嵌入维度为768维。
至于“符号表示”,在tokenization阶段,tokens通常是原始文本中的字符串形式,例如英文中的"apple"、“the”等,或者中文中的"苹果"、“的”等。而转换成数值表示后,这些字符串就被编码成了数字索引(在独热编码或one-hot方式下)或浮点数向量(在词嵌入表示下)。
6. 如何理解Token
在自然语言处理(NLP)和计算机视觉等领域的Transformer模型中,token是一个基本的抽象概念,用于表示输入数据中的最小可处理单元。以下是对token理解的关键点:
-
文本处理中的Token:
在NLP中,token通常是指文本序列中的单个词、子词或字符。例如,在英文文本中,一个token可以是“cat”、“jumped”或单个字母“a”。对于分词更为细致的模型如BERT,可能会使用WordPiece算法将复杂的词汇拆分为多个子词tokens,如“playing”会被分成“play”和“##ing”。 -
图像处理中的Token:
在视觉Transformer(ViT)中,token代表了图像被分割成的小块或者patch。每个patch经过线性变换后得到一个向量,这个向量就成为了图像的一个token。 -
Token Embedding:
无论是在文本还是图像中,每个token都会通过嵌入层转换为一个固定维度的向量,这被称为token embedding。这种embedding包含了token的基本语义信息,并且通常是连续实数向量,便于神经网络进行后续的数学运算。 -
Token在Transformer中的作用:
Transformer模型处理这些token时,利用self-attention机制来捕获它们之间的上下文依赖关系。每个token通过自注意力模块生成新的上下文相关的表示,这些表示综合了整个序列的信息。 -
特殊Token:
在一些特定情况下,还会引入特殊的tokens,比如CLS (Classification) token用于分类任务,SEP (Separator) token用于区分句子或段落,以及Padding token用于填充较短序列以达到统一长度。
总之,token是Transformer模型理解和处理复杂序列数据的基础单位,它通过嵌入及自注意力机制使得模型能够学习到序列内部丰富的结构和语义信息。
7. 上下文变量(Context Variables)与Token
在Transformer模型中,Token 是对输入序列中的基本单元(如自然语言处理中的单词或子词)的表示。对于视觉任务而言,token可以是图像patch的嵌入表示。每个token通过嵌入层(通常是一个线性变换)转换为一个固定维度的向量,这个向量包含了该token的语义信息。
上下文变量(Context Variables) 在Transformer中指的是经过自注意力机制计算后得到的新表示,它综合了整个序列中所有token的信息。Transformer通过Self-Attention模块来实现这一点:
-
定义:
- Query (Q)、Key (K) 和 Value (V):输入序列中的每个token首先分别通过不同的权重矩阵映射成对应的查询向量、键向量和值向量。
- 位置编码 (Positional Encoding):为了保留序列顺序信息,模型还会给每个token加上一个基于其位置的位置编码。
-
计算:
- Attention Score:计算query与所有key之间的点积,并除以sqrt(d_k)进行缩放(其中d_k是key向量的维度),然后使用softmax函数归一化生成注意力权重分布。
- 上下文向量:将得到的注意力权重分布与所有的value向量做加权求和,从而得出每个token在考虑了整个序列上下文后的新的表示,即上下文变量。
-
实现(简化版示例):
Python1class MultiHeadAttention(nn.Module): 2 def __init__(self, d_model, num_heads): 3 super(MultiHeadAttention, self).__init__() 4 self.num_heads = num_heads 5 self.d_k = d_model // num_heads 6 self.linear_layers = nn.ModuleList([ 7 nn.Linear(d_model, d_model) for _ in range(3) # 分别用于Q, K, V 8 ]) 9 self.output_linear = nn.Linear(d_model, d_model) 10 11 def forward(self, Q, K, V, attn_mask=None): 12 batch_size, seq_length, d_model = Q.size() 13 Q = self.linear_layers[0](Q) 14 K = self.linear_layers[1](K) 15 V = self.linear_layers[2](V) 16 17 # reshape for multi-head attention 18 Q = Q.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2) 19 K = K.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2) 20 V = V.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2) 21 22 # scaled dot-product attention 23 scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k) 24 if attn_mask is not None: 25 scores.masked_fill_(attn_mask == 0, -float('inf')) 26 attn_weights = torch.softmax(scores, dim=-1) 27 28 # context vectors 29 context = torch.matmul(attn_weights, V).transpose(1, 2).contiguous().view(batch_size, seq_length, d_model) 30 31 # final linear projection 32 output = self.output_linear(context) 33 34 return output, attn_weights
请注意,上述代码实现了多头注意力机制的一个简化版本,实际应用中还需要考虑其他细节,比如残差连接、LayerNorm等组件。同时,位置编码部分也需要在输入序列嵌入之前添加。
附:
讲讲GPT-4模型中13万亿个token的故事:
理解GPT-4模型的能力水平,可以换一种理解方式。打个比方,假如你在街机游戏厅打游戏,突然间,老板给了你13万亿个游戏币,这些游戏币打完以后,想想你的水平会咋样?这就是GPT-4模型的语言能力水平体现。当然,实际中不推荐过度玩游戏哈。
相关文章:

GPT-4模型中的token和Tokenization概念介绍
Token从字面意思上看是游戏代币,用在深度学习中的自然语言处理领域中时,代表着输入文字序列的“代币化”。那么海量语料中的文字序列,就可以转化为海量的代币,用来训练我们的模型。这样我们就能够理解“用于GPT-4训练的token数量大…...

宽字节注入漏洞原理以及修复方法
漏洞名称:宽字节注入 漏洞描述: 宽字节注入是相对于单字节注入而言的,该注入跟HTML页面编码无关,宽字节注入常见于mysql中,GB2312、GBK、GB18030、BIG5、Shift_JIS等这些都是常说的宽字节,实际上只有两字节。宽字节带来的安全问…...

【Linux】SystemV IPC
进程间通信 一、SystemV 共享内存1. 共享内存原理2. 系统调用接口(1)创建共享内存(2)形成 key(3)测试接口(4)关联进程(5)取消关联(6)释…...

iview 页面中判断溢出才使用Tooltip组件
使用方法 <TextTooltip :content"contentValue"></TextTooltip> 给Tooltip再包装一下 <template><Tooltip transfer :content"content" :theme"theme" :disabled"!showTooltip" :max-width"300" :p…...
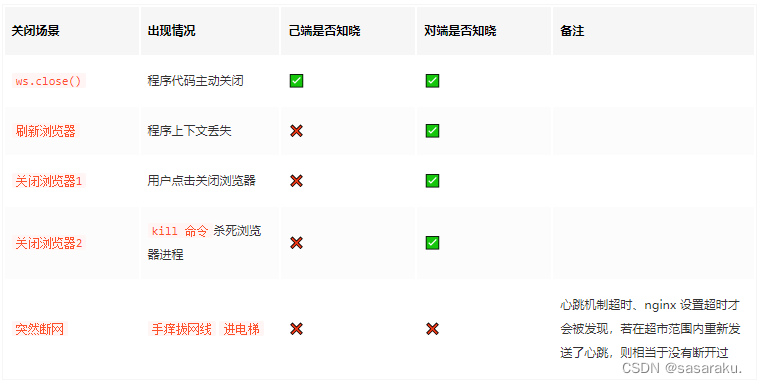
如何使用websocket
如何使用websocket 之前看到过一个面试题:吃饭点餐的小程序里,同一桌的用户点餐菜单如何做到的实时同步? 答案就是:使用websocket使数据变动时服务端实时推送消息给其他用户。 最近在我们自己的项目中我也遇到了类似问题…...
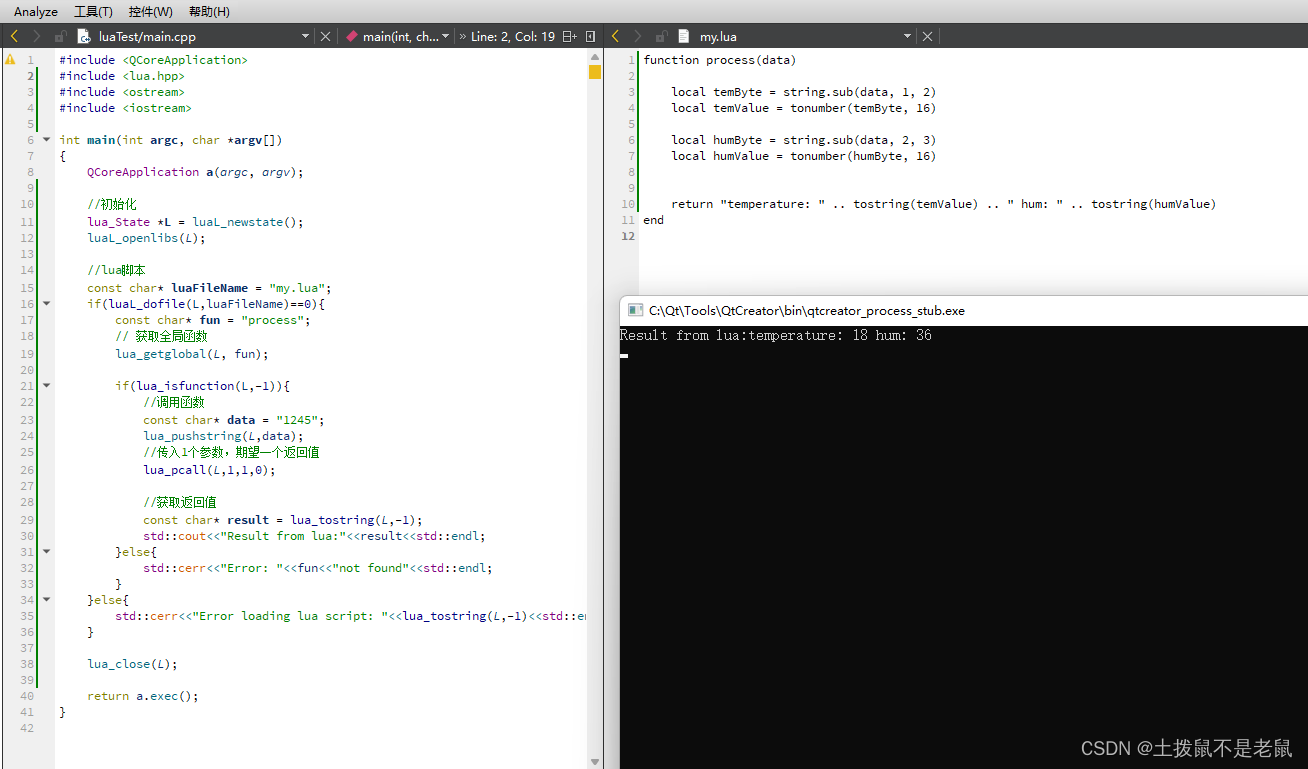
C++ 调用lua 脚本
需求: 使用Qt/C 调用 lua 脚本 扩展原有功能。 步骤: 1,工程中引入 头文件,库文件。lua二进制下载地址(Lua Binaries) 2, 调用脚本内函数。 这里调用lua 脚本中的process函数,并…...
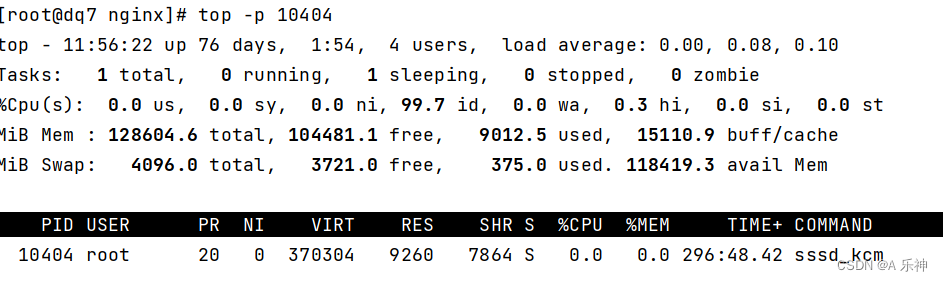
Centos 内存和硬盘占用情况以及top作用
目录 只查看内存使用情况: 内存使用排序取前5个: 硬盘占用情况 定位占用空间最大目录 top查看cpu及内存使用信息 前言-与正文无关 生活远不止眼前的苦劳与奔波,它还充满了无数值得我们去体验和珍惜的美好事物。在这个快节奏的世界中&…...

【数据结构】堆(创建,调整,插入,删除,运用)
目录 堆的概念: 堆的性质: 堆的存储方式: 堆的创建 : 堆的调整: 向下调整: 向上调整: 堆的创建: 建堆的时间复杂度: 向下调整: 向上调整ÿ…...
v-if 和v-for的联合规则及示例
第073个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 提供vue2的一些基本操作:安装、引用,模板使用,computed&a…...

各互联网企业测绘资质调研
公司子公司产品产品介绍资质获得资质时间阿里巴巴高德高德地图作为阿里的全资子公司,中国领先的数字地图内容、导航和位置服务解决方案提供商,互联网地图行业龙头,2021年4月高德实现全月平均日活跃用户数超过1亿的重要里程碑,稳居…...
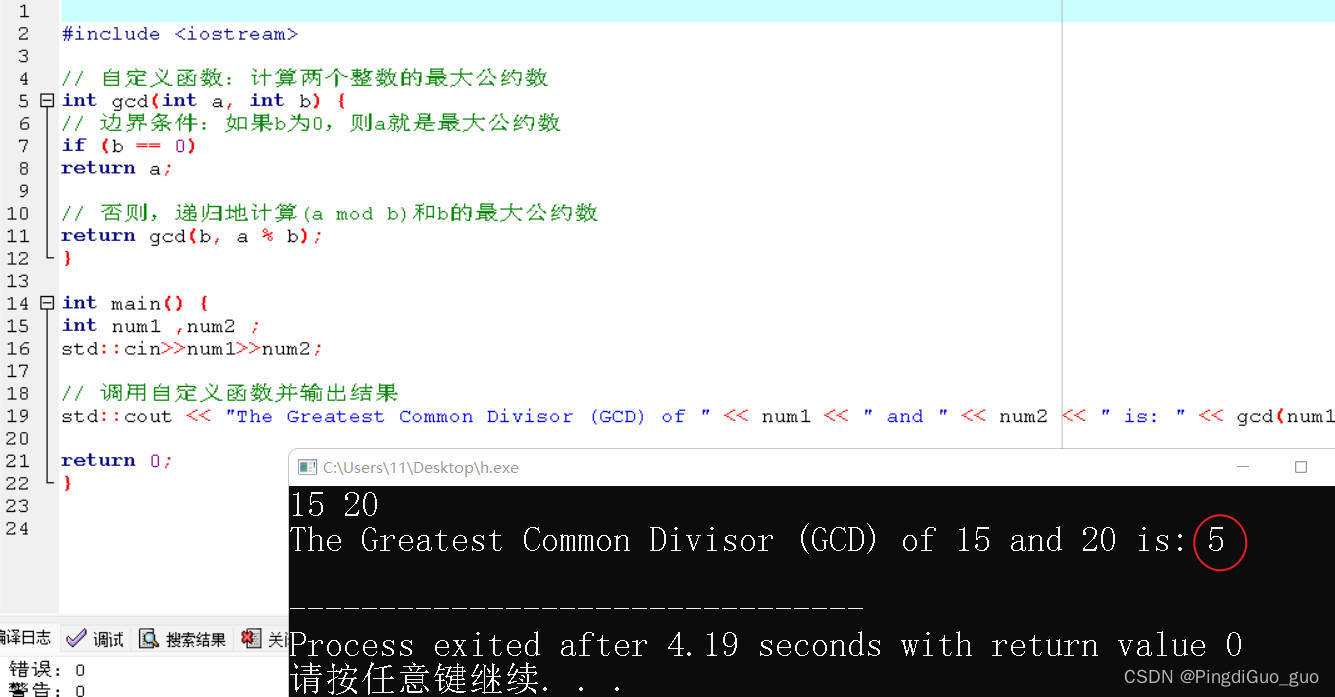
C++自定义函数详解
个人主页:PingdiGuo_guo 收录专栏:C干货专栏 铁汁们新年好呀,今天我们来了解自定义函数。 文章目录 1.数学中的函数 2.什么是自定义函数 3.自定义函数如何使用? 4.值传递和引用传递(形参和实参区分) …...
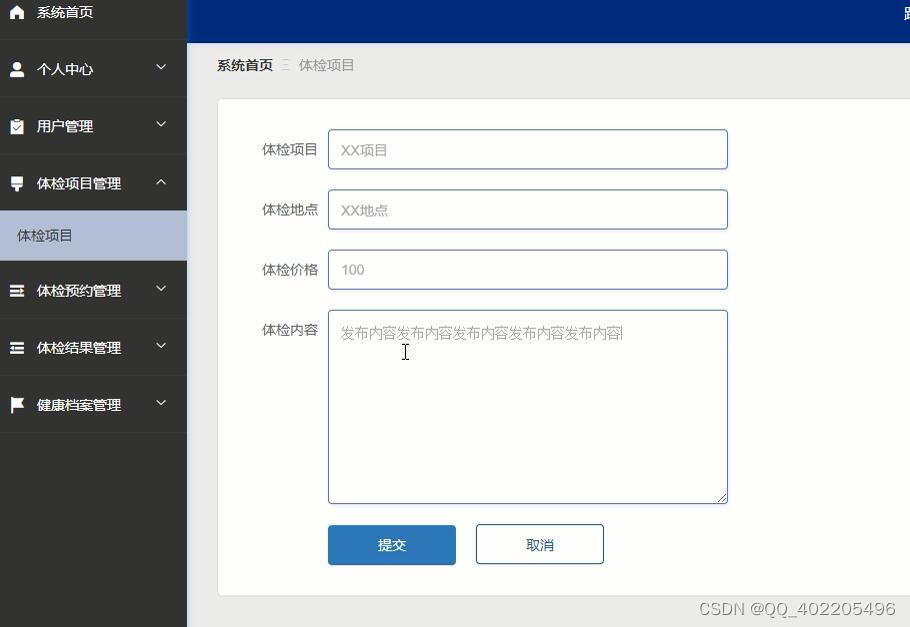
flask+vue+python跨区通勤人员健康体检预约管理系统
跨区通勤人员健康管理系统设计的目的是为用户提供体检项目等功能。 与其它应用程序相比,跨区通勤人员健康的设计主要面向于跨区通勤人员,旨在为管理员和用户提供一个跨区通勤人员健康管理系统。用户可以通过系统及时查看体检预约等。 跨区通勤人员健康管…...

Spring Boot动态加载Jar包与动态配置技术探究
Spring Boot动态加载Jar包与动态配置技术探究 1. 引言 在当今快节奏的软件开发领域,高效的开发框架是保持竞争力的关键。Spring Boot作为一款快速开发框架,以其简化配置、内嵌Web服务器、强大的开发工具等特性,成为众多开发者的首选。其背后…...

Lua metatable metamethod
示例代码 《programming in lua》里有一个案例很详细,就是写一个集合类的table,其负责筛选出table中不重复的元素并组合成一个新的table。本人按照自己的方式默写了一次,结果发现大差不差,代码如下: Set {} --集合--…...
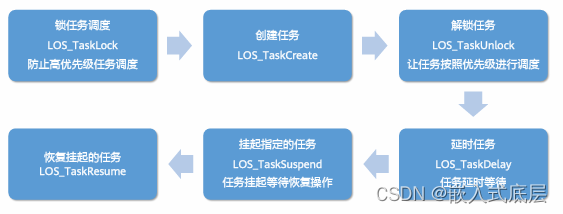
HCIA-HarmonyOS设备开发认证V2.0-3.2.轻量系统内核基础-任务管理
目录 一、任务管理1.1、任务状态1.2、任务基本概念1.3、任务管理使用说明1.4、任务开发流程1.5、任务管理接口 一、任务管理 从系统角度看,任务是竞争系统资源的最小运行单元。任务可以使用或等待CPU、使用内存空间等系统资源,并独立于其它任务运行。 O…...

中小型网络系统总体规划与设计方法
目录 1.基于网络的信息系统基本结构 2.网络需求调研与系统设计原则 3.网络用户调查 4.网络节点地理位置分布情况 5.网络需求详细分析 6.应用概要分析 7.网络工程设计总体目标与设计原则 8.网络结构与拓扑构型设计方法 9.核心层网络结构设计 10.接入核心路由器 11.汇聚…...
以管理员权限删除某文件夹
到开始菜单中找到—命令提示符—右击以管理员运行 使用:del /f /s /q “文件夹位置” 例:del /f /s /q "C:\Program Files (x86)\my_code\.git"...
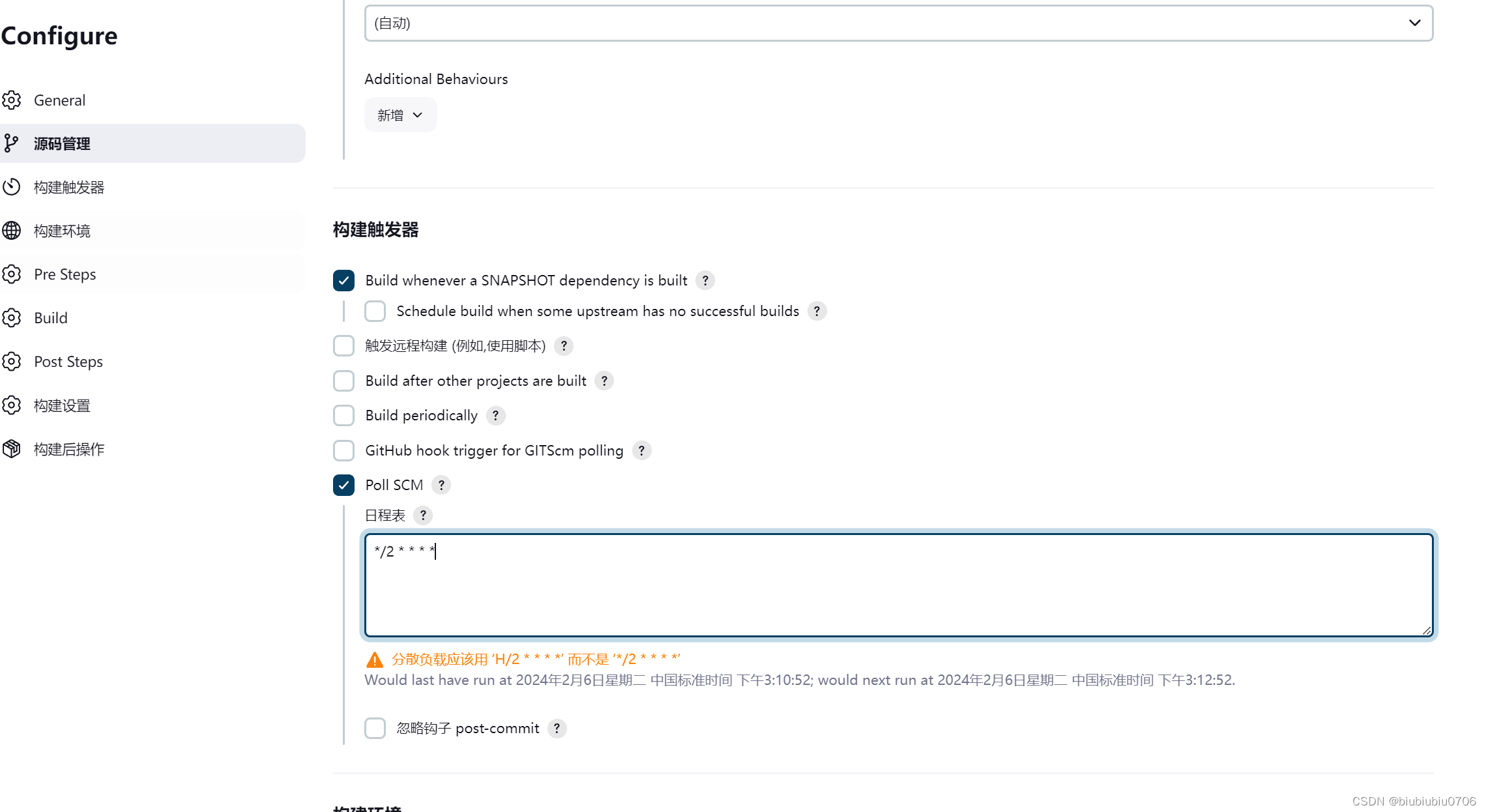
JenkinsGitLab完成自动化构建部署
关于GitLab安装:GitLab安装-CSDN博客 Docker中安装GitLab:Docker下安装GitLab-CSDN博客 安装JenKins Jenkins官网:Jenkins 中文版:Jenkins 安装时候中文页面的war包下不来 在英文页面 记得装JDK8以上 JenKins使用java写的 运行JenKins需要JDK环境 我这里已经装好了 将下…...

JVM 性能调优 - 参数基础(2)
查看 JDK 版本 $ java -version java version "1.8.0_151" Java(TM) SE Runtime Environment (build 1.8.0_151-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode) 查看 Java 帮助文档 $ java -help 用法: java [-options] class [args...] …...
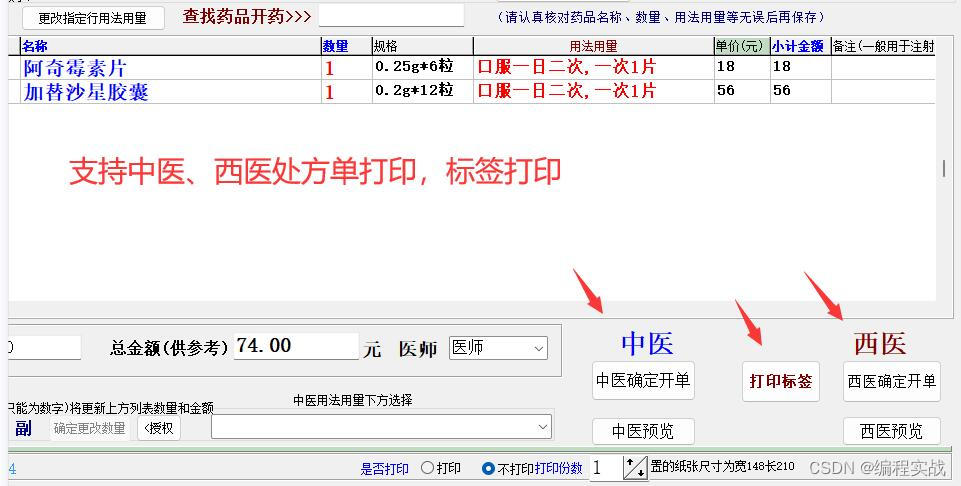
大型软件编程实例分享,诊所门诊处方笺管理系统多台电脑同时使用的软件教程
大型软件编程实例分享,诊所门诊处方笺管理系统多台电脑同时使用的软件教程 一、前言 以下教程以 佳易王诊所门诊电子处方管理系统V17.2 为例说明 软件资源可以点击最下方官网卡片了解详情 软件左侧为导航栏 1、系统参数设置:可以设置打印等参数 2、…...

Kook Zimage真实幻想Turbo部署避坑指南:24G显存流畅运行1024x1024
Kook Zimage真实幻想Turbo部署避坑指南:24G显存流畅运行1024x1024 1. 项目背景与核心优势 如果你正在寻找一款能在消费级显卡上流畅运行的高质量幻想风格文生图工具,Kook Zimage真实幻想Turbo值得重点关注。这个项目巧妙结合了Z-Image-Turbo底座的极速…...

Spring Boot整合ClickHouse避坑指南:当Java遇上列式数据库
Spring Boot整合ClickHouse避坑指南:当Java遇上列式数据库 列式数据库正在重塑大数据处理格局,而ClickHouse凭借其惊人的查询速度成为这一领域的明星。作为Java开发者,我们该如何在Spring Boot生态中高效驾驭这款OLAP利器?本文将带…...

计算机毕设 java 辽宁工大毕业论文管理系统 Java 高校毕业论文全流程管理平台开发 基于 SpringBoot 的毕业论文选题与答辩管理系统实现
计算机毕设 java 辽宁工大毕业论文管理系统 655cp9(配套有源码 程序 mysql 数据库 论文)本套源码可以先看具体功能演示视频领取,文末有联 xi 可分享随着高等教育规模的扩大和信息化技术的发展,高校毕业论文管理工作面临着流程繁琐…...

模拟ic设计,集成电路,运算放大器 [1]各种运放现成电路大合集,适合新手 单极放大器 五管运...
模拟ic设计,集成电路,运算放大器 [1]各种运放现成电路大合集,适合新手 单极放大器 五管运放 套筒运放 折叠运放 各种比较器 轨到轨运放 全差分放大器 CMFB共模反馈 [2]工艺库tsmc180nm,比较基础,入门合适,有…...
的智能追踪艺术)
Unity:Cinemachine Virtual Camera(虚拟摄像机)的智能追踪艺术
1. Cinemachine Virtual Camera的核心价值 第一次接触Cinemachine时,我完全被它的智能程度震惊了。记得当时在做一个篮球游戏demo,需要摄像机跟随球员运球突破。传统方法要写一堆代码处理镜头平滑移动、边界限制、动态缩放,而Cinemachine Vir…...
)
AutoGen Manager-Broadcast机制详解:手把手教你配置多代理聊天组(含Python代码示例)
AutoGen Manager-Broadcast机制深度解析:构建高效多代理协作系统的实践指南 在当今AI技术快速发展的背景下,多代理协作系统正成为解决复杂问题的关键架构。微软推出的AutoGen框架为开发者提供了一套强大的工具集,其中Manager-Broadcast机制是…...
)
保姆级教程:手把手复现攻防世界shrine靶场(Flask+Jinja2 SSTI)
从零构建Flask SSTI靶场:绕过黑名单获取FLAG的实战指南 第一次接触CTF中的SSTI漏洞时,我完全被那些奇怪的{{}}符号和魔术方法搞晕了。直到亲手搭建环境复现漏洞,才真正理解模板注入的精妙之处。本文将带你从零开始,完整复现攻防世…...

Laravel 10.x重磅升级:五大核心特性解析
Laravel 10.x 作为 PHP 流行框架的重要版本,引入了多项增强功能:一、路由改进路由参数类型声明支持在闭包路由中声明参数类型:Route::get(/user/{id}, function (int $id) {return User::find($id); });路由缓存优化路由缓存生成效率提升约 3…...

毕业季“求生”指南:如何用AI工具高效攻克论文重难点?
面对查重、格式、答辩的多重压力,一个智能工具箱正在重新定义论文写作的流程与体验。 深夜,实验室的灯还亮着,屏幕上闪烁的光标仿佛在嘲笑你的疲惫。文档里那30%的重复率标红格外刺眼,导师的批注“逻辑不清,AI痕迹明显…...

告别C++:用Python pysoem库玩转EtherCAT,实现多轴电机协同运动控制Demo
Python与EtherCAT的工业控制革命:多轴协同运动控制实战 在工业自动化领域,EtherCAT(以太网控制自动化技术)凭借其高实时性和分布式时钟同步机制,已成为运动控制系统的首选总线协议。传统上,这类系统开发多采…...