飞桨自然语言处理框架 paddlenlp的 trainer
飞桨(PaddlePaddle)的NLP库PaddleNLP中的Trainer类是一个用于训练和评估模型的简单但功能完整的循环。它被优化用于与PaddleNLP一起使用。Trainer类简化了训练过程,提供了自动的批处理、模型保存、日志记录等特性。
以下是Trainer类的主要参数和功能:
- 模型:
model:可以是一个预训练的模型或一个自定义的paddle.nn.Layer。如果使用自定义模型,它需要与PaddleNLP提供的模型工作方式相同。
- criterion:
- 如果模型只输出logits,并且您想对模型的输出进行更多的计算,可以添加criterion层。
- args:
args:用于调整训练的参数。如果未提供,将默认使用一个具有output_dir设置为当前目录中名为tmp_trainer的目录的基本TrainingArguments实例。
- 数据整理器(DataCollator):
data_collator:用于从train_dataset或eval_dataset的列表中形成一批数据的功能。如果没有提供tokenizer,将默认使用default_data_collator;否则,将使用DataCollatorWithPadding的实例。
- 训练数据集和评估数据集:
train_dataset和eval_dataset:用于训练和评估的数据集。如果数据集是datasets.Dataset的实例,则不会接受model.forward()方法不接受的字段。
- 分词器(Tokenizer):
tokenizer:用于预处理数据的分词器。如果提供了,将在批量输入时自动将输入填充到最大长度,并在中断训练或重用模型时保存分词器。
- 计算指标(compute_metrics):
compute_metrics:用于在评估时计算指标的函数。它必须接受一个EvalPrediction对象并返回一个字典,字典中的字符串表示指标名称,对应的值表示指标值。
- 回调函数(callbacks):
callbacks:一个回调函数列表,用于自定义训练循环。可以将这些回调函数添加到默认回调函数列表中。如果想要移除默认使用的回调函数,可以使用Trainer.remove_callback方法。
- 优化器(optimizers):
optimizers:一个包含优化器和调度器的元组。如果没有提供,将默认使用AdamW优化器,并根据args使用get_linear_schedule_with_warmup调度器。
- 预处理logits用于指标(preprocess_logits_for_metrics):
preprocess_logits_for_metrics:一个函数,用于在每次评估步骤后预处理logits。它必须接受两个张量,即logits和labels,并返回处理后的logits。此函数的修改将在compute_metrics中反映在接收到的预测值上。
Trainer类简化了训练流程,让用户可以更加专注于模型的设计和训练策略,而不必担心底层的训练细节。通过提供这些参数和功能,用户可以轻松地训练、评估和部署模型。
paddlenlp/trainer/training_args.py
TrainingArguments 类是 PaddleNLP 中用于定义与训练循环相关的命令行参数的子集。这些参数用于配置训练过程的各种方面,例如输出目录、训练和评估的批处理大小、学习率、训练周期数等。通过 PdArgumentParser,可以将这个类转换为 argparse 参数,以便在命令行上指定。
以下是 TrainingArguments 类中一些关键参数的详细介绍:
- output_dir:模型预测和检查点的输出目录。
- overwrite_output_dir:如果为
True,将覆盖输出目录中的内容。 - do_train:是否运行训练。
- do_eval:是否在验证集上评估模型。
- do_predict:是否在测试集上进行预测。
- evaluation_strategy:训练期间采用的评估策略,可以是 “no”(不评估)、“steps”(每指定步数评估一次)或 “epoch”(每轮训练结束后评估)。
- per_device_train_batch_size:训练时的每个 GPU 核心/CPU 的批处理大小。
- per_device_eval_batch_size:评估时的每个 GPU 核心/CPU 的批处理大小。
- learning_rate:AdamW 优化器的初始学习率。
- num_train_epochs:要执行的总训练周期数。
- max_steps:要执行的总训练步数。
- log_on_each_node:在多节点分布式训练中,是否每个节点都进行日志记录。
- logging_dir:日志目录。
- logging_strategy:训练期间采用的日志策略,可以是 “no”(不记录日志)、“epoch”(每轮训练结束后记录日志)或 “steps”(每指定步数记录一次日志)。
- save_strategy:训练期间采用的检查点保存策略,可以是 “no”(不保存检查点)、“epoch”(每轮训练结束后保存检查点)或 “steps”(每指定步数保存一次检查点)。
这些参数可以在您的训练脚本中使用,以配置和控制训练过程。TrainingArguments类可以被转换为命令行参数,使用户能够轻松地在运行脚本时指定这些参数。
TrainingArguments类中的剩余参数用于进一步控制训练过程的高级特性,如混合精度训练、并行训练策略等。以下是对这些参数的详细介绍: - save_steps:如果
save_strategy="steps",则在达到指定的步数之前保存两次检查点。 - save_total_limit:如果指定了值,将限制保存的检查点总数,并在
output_dir中删除较旧的检查点。 - save_on_each_node:在多节点分布式训练中,是否在每个节点上保存模型和检查点。如果不同节点使用相同的存储,则不应激活此选项,因为文件名将相同。
- no_cuda:是否即使可用也禁用 CUDA。
- seed:训练开始时设置的随机种子,用于确保跨运行的可重复性。
- fp16:是否使用 16 位(混合)精度训练而不是 32 位训练。
- fp16_opt_level:对于 16 位训练,选择的 AMP 优化级别。
- amp_custom_black_list:自定义黑名单,用于指定哪些操作不应转换为 16 位或 32 位。
- amp_custom_white_list:自定义白名单,用于指定哪些操作应转换为 16 位或 32 位。
- amp_master_grad:对于 AMP 优化级别
'O2',是否使用 float32 权重梯度进行计算。 - sharding:是否使用 Paddle Sharding Data Parallel 训练。
- sharding_parallel_degree:在特定卡组中的 Sharding 参数。
- tensor_parallel_degree:张量并行度,用于指定将 Transformer 层分割成多少部分。
- pipeline_parallel_degree:流水线并行度,用于指定将所有 Transformer 层分割成多少阶段。
- sep_parallel_degree:Paddle 序列并行策略,可以减少激活 GPU 内存。
- tensor_parallel_config:一些影响模型并行性能的额外配置。
- pipeline_parallel_config:一些影响流水线并行使用的额外配置。
- sharding_parallel_config:一些影响 Sharding 并行的额外配置。
- recompute:是否在训练过程中重新计算梯度。
- num_workers:数据加载过程中使用的线程数。
- max_predictions_per_batch:每个批处理中最大预测的数量。
- prediction_loss_only:在评估和生成预测时,是否只返回损失。
这些参数提供了对训练过程的细粒度控制,允许用户根据他们的需求和硬件配置来优化训练。在实际应用中,这些参数可能需要根据具体情况进行调整,以达到最佳的训练效果。
在您提供的TrainingArguments类的参数说明中,涵盖了训练循环中涉及的各种配置选项。以下是对这些参数的详细介绍: - per_device_train_batch_size:指定每个GPU核心/CPU在训练时使用的批处理大小。
- per_device_eval_batch_size:指定每个GPU核心/CPU在评估时使用的批处理大小。
- gradient_accumulation_steps:在执行反向传播和更新参数之前,累积梯度的步数。使用梯度累积时,一次步数对应一次反向传播。
- eval_accumulation_steps:在将预测结果移动到CPU之前,累积的预测步数。如果未设置,则整个预测结果将在GPU/TPU上累积后再移动到CPU。
- learning_rate:指定AdamW优化器的初始学习率。
- weight_decay:对AdamW优化器中的所有层(除偏置和LayerNorm层)应用的权重衰减。
- adam_beta1:AdamW优化器的beta1超参数。
- adam_beta2:AdamW优化器的beta2超参数。
- adam_epsilon:AdamW优化器的epsilon超参数。
- max_grad_norm:用于梯度裁剪的最大梯度范数。
- num_train_epochs:要执行的总训练周期数。
- max_steps:要执行的总训练步数。如果设置为正数,将覆盖
num_train_epochs。 - lr_scheduler_type:指定的学习率调度器类型。
- warmup_ratio:用于线性预热的总训练步数的比例。
- warmup_steps:用于从0到学习率进行线性预热的步数。
- num_cycles:余弦调度器中的波数。
- lr_end:多项式调度器中的结束学习率。
- power:多项式调度器中的幂因子。
在训练过程的其他方面,还提供了以下配置选项: - log_on_each_node:在多节点分布式训练中,是否每个节点都进行日志记录。
- logging_dir:日志目录。
- logging_strategy:训练期间采用的日志策略。
- logging_first_step:是否记录和评估第一个全局步骤。
- logging_steps:如果
logging_strategy="steps",则两次日志之间的更新步数。 - save_strategy:训练期间采用的检查点保存策略。
- save_steps:如果
save_strategy="steps",则在两次检查点保存之间的更新步数。 - save_total_limit:限制保存的检查点总数。
- save_on_each_node:在多节点分布式训练中,是否每个节点都保存模型和检查点。
- no_cuda:是否禁用CUDA。
- seed:训练开始时设置的随机种子。
- fp16:是否使用16位(混合)精度训练。
- fp16_opt_level:16位训练的AMP优化级别。
- amp_custom_black_list:自定义黑名单,用于指定哪些操作不应转换为16位或32位。
- amp_custom_white_list:自定义白名单,用于指定哪些操作应转换为16位或32位。
- amp_master_grad:是否使用float32权重梯度进行计算。
- sharding:是否使用Paddle Sharding Data Parallel训练。
- sharding_parallel_degree:Sharding参数,用于指定在特定卡组中的并行度。
- tensor_parallel_degree:张量并行度,用于指定将Transformer层分割成多少部分。
- pipeline_parallel_degree:流水线并行度,用于指定将所有Transformer层分割成多少阶段。
在您提供的TrainingArguments类的参数说明中,涵盖了训练循环中涉及的各种配置选项。以下是对这些参数的详细介绍:
- tensor_parallel_config:影响模型并行性能的一些额外配置,例如:
enable_mp_async_allreduce:支持在列并行线性反向传播期间的all_reduce(dx)与matmul(dw)重叠,可以加速模型并行性能。enable_mp_skip_c_identity:支持在列并行线性和行并行线性中跳过c_identity,当与mp_async_allreduce一起设置时,可以进一步加速模型并行。enable_mp_fused_linear_param_grad_add:支持在列并行线性中融合线性参数梯度添加,当与mp_async_allreduce一起设置时,可以进一步加速模型并行。enable_delay_scale_loss:在优化器步骤累积梯度,所有梯度除以累积步数,而不是直接在损失上除以累积步数。
- pipeline_parallel_config:影响流水线并行使用的额外配置,例如:
disable_p2p_cache_shape:如果您使用的最大序列长度变化,请设置此选项。disable_partial_send_recv:优化tensor并行的发送速度。enable_delay_scale_loss:在优化器步骤累积梯度,所有梯度除以内部流水线累积步数,而不是直接在损失上除以累积步数。enable_dp_comm_overlap:融合数据并行梯度通信。enable_sharding_comm_overlap:融合sharding stage 1并行梯度通信。enable_release_grads:在每次迭代后释放梯度,以减少峰值内存使用。梯度的创建将推迟到下一迭代的反向传播。
- sharding_parallel_config:影响Sharding并行的额外配置,例如:
enable_stage1_tensor_fusion:将小张量融合成大的张量块来加速通信,可能会增加内存占用。enable_stage1_overlap:在回传计算之前,将小张量融合成大的张量块来加速通信,可能会损害回传速度。enable_stage2_overlap:重叠stage2 NCCL通信与计算。重叠有一些约束,例如,对于广播重叠,logging_step应该大于1,在训练期间不应调用其他同步操作。
- recompute:是否重新计算前向传播以计算梯度。用于节省内存。仅支持具有transformer块的网络。
- scale_loss:fp16的初始scale_loss值。
- local_rank:分布式训练过程中的进程排名。
- dataloader_drop_last:是否丢弃最后一个不完整的批处理(如果数据集的长度不能被批处理大小整除)。
- eval_steps:如果
evaluation_strategy="steps",则两次评估之间的更新步数。 - max_evaluate_steps:要执行的总评估步数。
- dataloader_num_workers:数据加载过程中使用的子进程数。
- past_index:一些模型如TransformerXL或XLNet可以使用过去的隐状态为其预测。如果此参数设置为正整数,
Trainer将使用相应的输出(通常是索引2)作为过去状态,并在下一次训练步骤中将其提供给模型,作为关键字参数mems。 - run_name:运行的描述符。通常用于日志记录。
- disable_tqdm:是否禁用tqdm进度条和指标表。
- remove_unused_columns:如果使用
datasets.Dataset数据集,是否自动删除模型前向方法未使用的列。 - label_names:输入字典中对应于标签的键的列表。
- load_best_model_at_end:是否在训练结束时加载找到的最佳模型。
在您提供的TrainingArguments类的参数说明中,涵盖了训练循环中涉及的各种配置选项。以下是对这些参数的详细介绍: - metric_for_best_model:与
load_best_model_at_end配合使用,指定用于比较两个不同模型的度量。必须是评估返回的度量名称,可以是带前缀"eval_"或不带前缀。如果未指定且load_best_model_at_end=True,则默认为"loss"(使用评估损失)。 - greater_is_better:与
load_best_model_at_end和metric_for_best_model配合使用,指定更好的模型是否应该有更大的度量。默认为:- 如果
metric_for_best_model设置为不是"loss"或"eval_loss"的值,则默认为True。 - 如果
metric_for_best_model未设置,或设置为"loss"或"eval_loss",则默认为False。
- 如果
- ignore_data_skip:在继续训练时,是否跳过某些 epochs 和 batches 以确保数据加载与之前训练的数据加载阶段相同。如果设置为
True,训练将更快开始,但结果可能与中断的训练结果不同。 - optim:要使用的优化器:
adamw或adafactor。 - length_column_name:预计算长度的列名。如果该列存在,则按长度分组将使用这些值,而不是在训练启动时计算它们。除非
group_by_length为True且数据集是Dataset的实例。 - report_to:报告结果和日志的集成列表。支持的平台是
"visualdl"/"wandb"/"tensorboard"。"none"表示不使用任何集成。 - wandb_api_key:Weights & Biases (WandB) API 密钥,用于与 WandB 服务进行身份验证。
- resume_from_checkpoint:要从中恢复的模型检查点的路径。此参数不直接由
Trainer使用,而是由您的训练/评估脚本使用。 - flatten_param_grads:是否在优化器中使用
flatten_param_grads方法,仅用于 NPU 设备。默认为False。 - skip_profile_timer:是否跳过分析时间计时器,计时器将记录前向/反向/步等的时间使用情况。
- distributed_dataloader:是否使用分布式数据加载器。默认为
False。
这些参数提供了对训练过程的细粒度控制,允许用户根据他们的需求和硬件配置来优化训练。在实际应用中,这些参数可能需要根据具体情况进行调整,以达到最佳的训练效果。
相关文章:

飞桨自然语言处理框架 paddlenlp的 trainer
飞桨(PaddlePaddle)的NLP库PaddleNLP中的Trainer类是一个用于训练和评估模型的简单但功能完整的循环。它被优化用于与PaddleNLP一起使用。Trainer类简化了训练过程,提供了自动的批处理、模型保存、日志记录等特性。 以下是Trainer类的主要参数…...

SQL世界之命令语句Ⅲ
目录 一、SQL JOIN 1.JOIN 和 Key 2.使用 JOIN 3.不同的 SQL JOIN 二、SQL INNER JOIN 关键字 1.SQL INNER JOIN 关键字 2.INNER JOIN 关键字语法 3.内连接(INNER JOIN)实例 三、SQL LEFT JOIN 关键字 1.SQL LEFT JOIN 关键字 2.LEFT JOIN 关…...

Snoop Version 2 Packet Capture File Format
RFC1761 - Snoop Version 2 Packet Capture File Format, FEBRUARY 1995 本备忘录的状态 本备忘录为互联网社区提供帮助信息。 本备忘录不作为任何类型的互联网标准。 本备忘录的分发不受限制。 Status of this Memo This memo provides information for the Internet communit…...

扩展说明: 指令微调 Llama 2
这篇博客是一篇来自 Meta AI,关于指令微调 Llama 2 的扩展说明。旨在聚焦构建指令数据集,有了它,我们则可以使用自己的指令来微调 Llama 2 基础模型。 目标是构建一个能够基于输入内容来生成指令的模型。这么做背后的逻辑是,模型如…...

VUE 全局设置防重复点击
请求后端防止重复点击,用户点击加入遮罩层,请求完毕关闭遮罩层 我们利用请求拦截器,在用户点击的时候,弹出遮罩层 本文采用i18n国际化 element plus UI,提取你想要的,这里不做简化 完整代码如下…...
备战蓝桥杯---动态规划(基础1)
先看几道比较简单的题: 直接f[i][j]f[i-1][j]f[i][j-1]即可(注意有马的地方赋值为0) 下面是递推循环方式实现的AC代码: #include<bits/stdc.h> using namespace std; #define int long long int a[30][30]; int n,m,x,y; …...
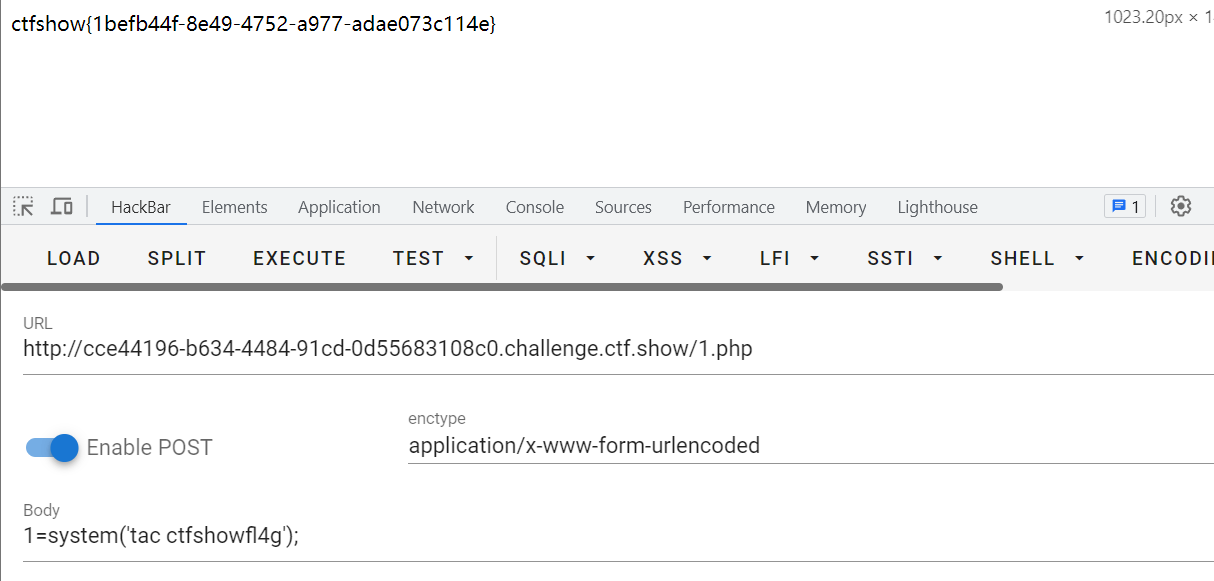
CVE-2018-19518 漏洞复现
CVE-2018-19518 漏洞介绍 IMAP协议(因特网消息访问协议)它的主要作用是邮件客户端可以通过这种协议从邮件服务器上获取邮件的信息,下载邮件等。它运行在TCP/IP协议之上,使用的端口是143。在php中调用的是imap_open函数。 PHP 的…...

Python爬虫实战:抓取猫眼电影排行榜top100#4
爬虫专栏系列:http://t.csdnimg.cn/Oiun0 抓取猫眼电影排行 本节中,我们利用 requests 库和正则表达式来抓取猫眼电影 TOP100 的相关内容。requests 比 urllib 使用更加方便,而且目前我们还没有系统学习 HTML 解析库,所以这里就…...

Fiddler抓包工具之fiddler界面工具栏介绍
Fiddler界面工具栏介绍 (1)WinConfig:windows 使用了一种叫做“AppContainer”的隔离技术,使得一些流量无法正常捕获,在 fiddler中点击 WinConfig 按钮可以解除这个诅咒,这个与菜单栏 Tools→Win8 Loopback…...

LabVIEW工业监控系统
LabVIEW工业监控系统 介绍了一个基于LabVIEW软件开发的工业监控系统。系统通过虚拟测控技术和先进的数据处理能力,实现对工业过程的高效监控,提升系统的自动化和智能化水平,从而满足现代工业对高效率、高稳定性和低成本的需求。 随着工业自…...

Linux 文件连接:符号链接与硬链接
Linux 文件连接:符号链接与硬链接 介绍 在 Linux 系统中,文件连接是一个强大的概念,它允许我们在文件系统中创建引用,从而使得文件和目录之间产生联系。在本文中,我们将深入探讨两种主要类型的文件连接:符…...

数据分类分级
一段时间没写文章了,最近做政府数据治理方面的项目,数据治理一个重要的内容是数据安全,会涉及数据的分类分级,是数据治理的基础。 随着“十四五”规划推行,数据要素概念与意识全面铺开,国家、政府机构、企业…...

第三十天| 51. N皇后
Leetcode 51. N皇后 题目链接:51 N皇后 题干:按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整…...
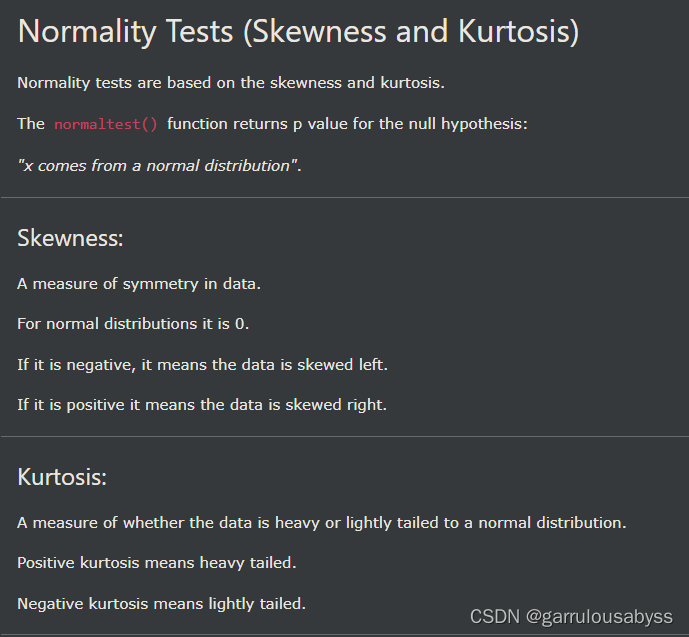
pythn-scipy 查漏补缺
1. 2. 3. 4. 5. 6. 7. 8. 9. 偏度 skewness,峰度 kurtosis...

【JavaScript 漫游】【013】Date 对象知识点摘录
文章简介 本文为【JavaScript 漫游】专栏的第 013 篇文章,记录了 JS 语言中 Date 对象的重要知识点。 普通函数的用法构造函数的用法日期的运算静态方法,包括:Date.now()、Date.parse() 和 Date.UTC()实例方法,包括:…...

vue.config.js和webpack.config.js区别
webpack.config.js和vue.config.js的区别 webpack.config.js是webpack的配置文件,所有使用webpack作为打包工具的项目都可以使用,vue的项目可以使用,react的项目也可以使用。 vue.config.js是vue项目的配置文件,专用于vue项目。…...

H12-821_73
73.某台路由器Router LSA如图所示,下列说法中错误的是? A.本路由器的Router ID为10.0.12.1 B.本路由器为DR C.本路由器已建立邻接关系 D.本路由器支持外部路由引入 答案:B 注释: LSA中的链路信息Link ID,Data…...
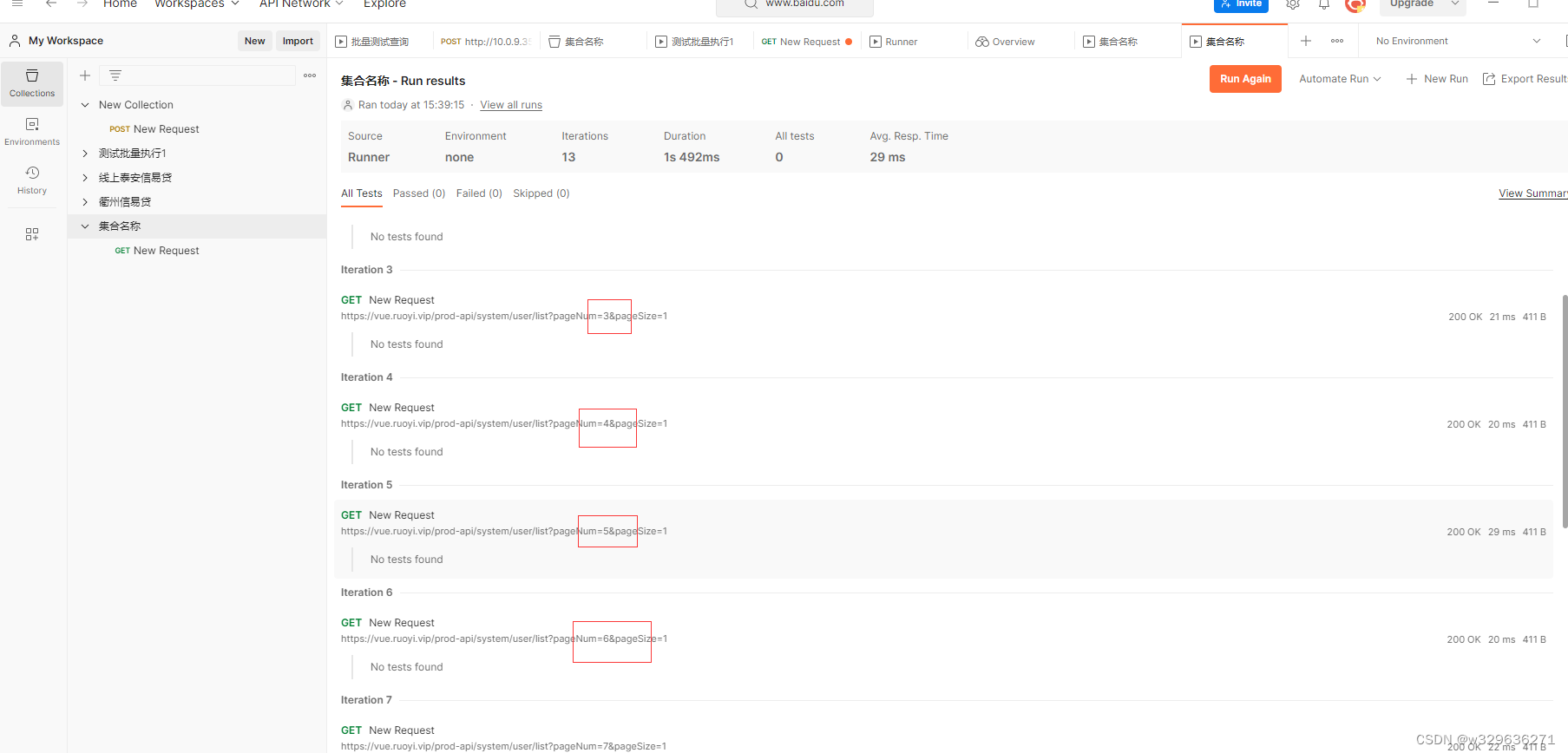
postman执行批量测试
1.背景 有许多的人常常需要使用第三方系统进行重复的数据查询,本文介绍使用PostMan的方式对数据进行批量的查询,减少重复的劳动。 2.工具下载 3.初入门 一、如图示进行点击,创建collection 二、输入对应的名称 三、创建Request并进行查…...

蓝桥杯基础知识8 list
蓝桥杯基础知识8 list 01 list 的定义和结构 lits使用频率较低,是一种双向链表容器,是标准模板库(STL)提供的一种序列容器,lsit容器以节点(node)的形式存储元素,使用指针将这些节点链…...
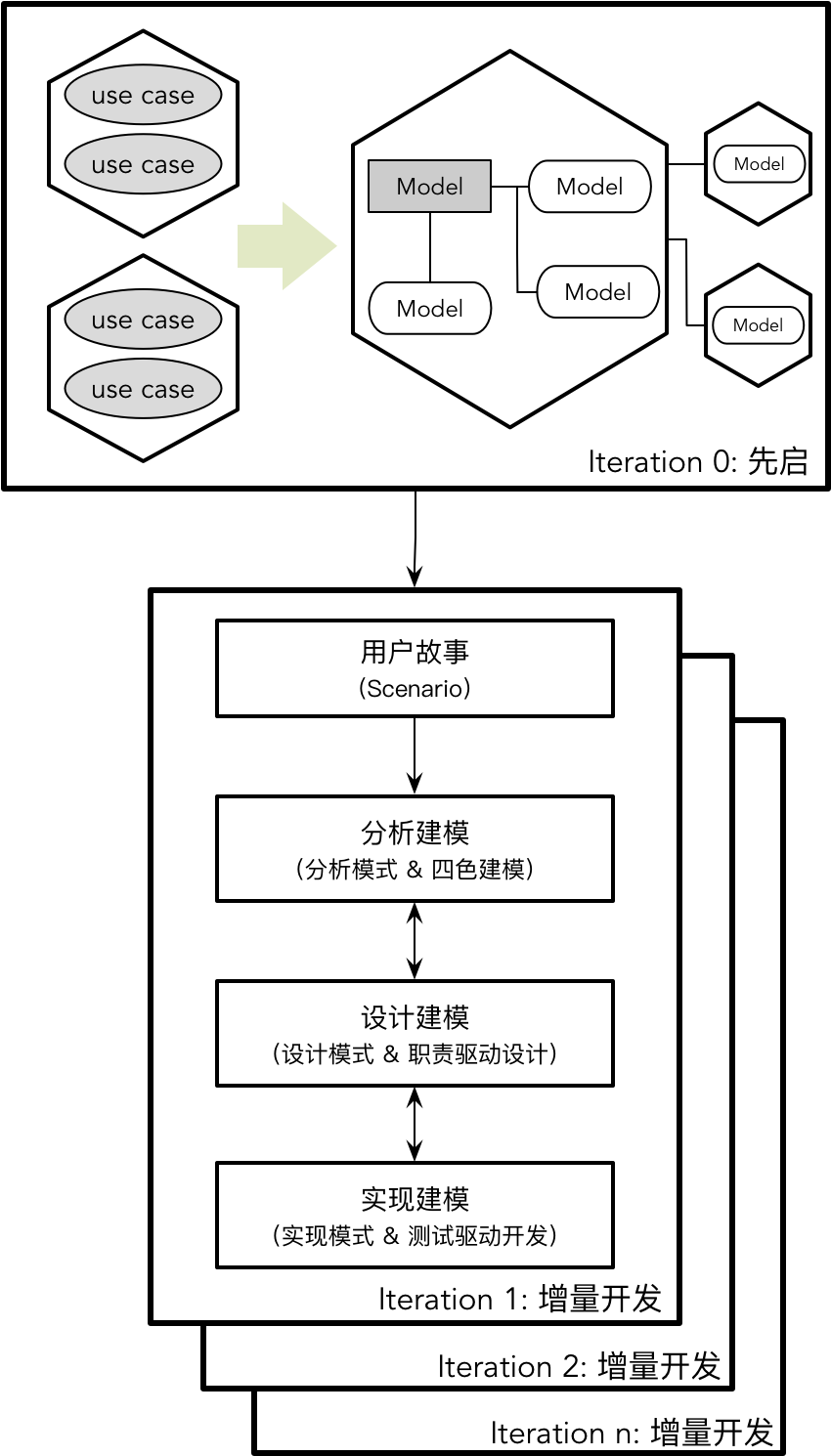
【DDD】学习笔记-理解领域模型
Eric Evans 的领域驱动设计是对软件设计领域的一次重新审视,是在面向对象语言大行其道时对数据建模的“拨乱反正”。Eric 强调了模型的重要性,例如他在书中总结了模型在领域驱动设计中的作用包括: 模型和设计的核心互相影响模型是团队所有成…...

Nanbeige 4.1-3B在Java面试准备中的应用:高频考点解析
Nanbeige 4.1-3B在Java面试准备中的应用:高频考点解析 还在为Java面试熬夜刷题、背八股文而头疼吗?试试用AI来帮你高效备考吧 最近帮几个准备跳槽的朋友做面试辅导,发现大家普遍面临同样的困境:Java知识点太多太杂,八股…...

FaceFusion局域网设置全攻略:告别只能本机使用的烦恼
FaceFusion局域网设置全攻略:告别只能本机使用的烦恼 1. 为什么需要局域网访问FaceFusion? FaceFusion作为新一代AI换脸工具,凭借其强大的去遮挡、高清化和卡通脸替换功能,已经成为许多创作者和开发者的首选工具。但在实际使用中…...

Qwen3-Reranker效果可视化:柱状图+表格双视图展示重排序得分分布
Qwen3-Reranker效果可视化:柱状图表格双视图展示重排序得分分布 1. 理解语义重排序的核心价值 在信息检索和问答系统中,我们经常遇到这样的问题:搜索引擎返回了一大堆结果,但真正相关的答案可能排在了后面。传统的关键词匹配方法…...

Qwen3.5-9B创新落地:盲文图像识别+语音描述实时生成
Qwen3.5-9B创新落地:盲文图像识别语音描述实时生成 1. 技术背景与模型特性 Qwen3.5-9B作为新一代多模态大模型,在视觉-语言融合领域实现了重大突破。该模型通过创新的架构设计,在保持高效推理的同时,显著提升了跨模态理解与生成…...

【Dify企业级异步架构避坑手册】:92%开发者踩过的3类状态不一致陷阱,含完整时序图与补偿代码模板
第一章:Dify企业级异步架构避坑手册导论在构建高并发、可扩展的AI应用平台时,Dify 的异步任务调度机制是核心能力之一,但其默认配置与生产环境之间存在显著鸿沟。企业级部署中,常见问题包括 Celery worker 消息积压、Redis 连接泄…...
)
VSCode终端不显示conda环境名?别慌,Windows下这3步搞定(附PowerShell管理员权限设置)
VSCode终端不显示conda环境名?Windows下3步精准排查与修复 刚在VSCode里敲完conda activate my_env,终端却静悄悄没任何反应——这场景像极了对着麦克风说话却发现设备根本没开。作为每天与Python环境打交道的开发者,我完全理解这种不安&…...

YDB-100A传动轴专用平衡机
YDB-100A传动轴专用平衡机一、用途特点:该系列为硬支承卧式动平衡机,采用滚轮支承,圈带拖动,普通型为双速电机驱动,“A"型为变频电机加变频器调速,由工业控制计算机进行数据处理,彩色屏幕实…...

MiniCPM-o-4.5-nvidia-FlagOS模型管理:利用GitHub进行版本控制与协作
MiniCPM-o-4.5-nvidia-FlagOS模型管理:利用GitHub进行版本控制与协作 你是不是也遇到过这种情况:和同事一起调一个模型应用,改了几版代码,结果发现谁也说不清哪个版本效果最好;或者自己鼓捣了半天,想回退到…...

影墨·今颜小红书模型ComfyUI可视化工作流搭建:零代码玩转AI内容生成
影墨今颜小红书模型ComfyUI可视化工作流搭建:零代码玩转AI内容生成 你是不是也见过那些用AI生成的精美小红书风格图片,自己也想试试,但一看到复杂的代码和命令行就头疼?别担心,今天咱们就来点不一样的。不用写一行代码…...

jar包反编译教程
下载 cfr-0.152.jar 包 1. 官方 GitHub 发布地址(最权威) 链接:https://github.com/leibnitz27/cfr/releases/download/0.152/cfr-0.152.jar说明:这是项目官方发布的版本,安全可靠,直接点击即可下载。 2…...