Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器
本工作簿演示了 Elasticsearch 的自查询检索器将非结构化查询转换为结构化查询的示例,我们将其用于 BM25 示例。
在这个例子中:
- 我们将摄取 LangChain 之外的电影样本数据集
- 自定义 ElasticsearchStore 中的检索策略以仅使用 BM25
- 使用自查询检索将问题转换为结构化查询
- 使用文档和 RAG 策略来回答问题

安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考文章:
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请参考一下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:

Python 安装包
我们需要安装 Python 版本 3.6 及以上版本。我们还需要安装如下的 Python 安装包:
pip3 install lark elasticsearch langchain openai load_dotenv$ pip3 list | grep elasticsearch
elasticsearch 8.12.0
rag-elasticsearch 0.0.1 /Users/liuxg/python/rag-elasticsearch/my-app/packages/rag-elasticsearch环境变量
在启动 Jupyter 之前,我们设置如下的环境变量:
export ES_USER="elastic"
export ES_PASSWORD="xnLj56lTrH98Lf_6n76y"
export ES_ENDPOINT="localhost"
export OPENAI_API_KEY="YOUR_OPEN_AI_KEY"请在上面修改相应的变量的值。特别是你需要输入自己的 OPENAI_API_KEY。
拷贝 Elasticsearch 证书
我们把 Elasticsearch 的证书拷贝到当前的目录下:
$ pwd
/Users/liuxg/python/elser
$ cp ~/elastic/elasticsearch-8.12.0/config/certs/http_ca.crt .
$ ls http_ca.crt
http_ca.crt创建应用
我们在当前的目录下运行 jupyter notebook:
jupyter notebook连接到 Elasticsearch
from elasticsearch import Elasticsearch
from dotenv import load_dotenv
import os
from elasticsearch import Elasticsearchload_dotenv()openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)print(client.info())
准备示例数据集
docs = [{"text": "A bunch of scientists bring back dinosaurs and mayhem breaks loose","metadata": {"year": 1993, "rating": 7.7, "genre": "science fiction", "director": "Steven Spielberg", "title": "Jurassic Park"},},{"text": "Leo DiCaprio gets lost in a dream within a dream within a dream within a ...","metadata": {"year": 2010, "director": "Christopher Nolan", "rating": 8.2, "title": "Inception"},},{"text": "A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea","metadata": {"year": 2006, "director": "Satoshi Kon", "rating": 8.6, "title": "Paprika"},},{"text":"A bunch of normal-sized women are supremely wholesome and some men pine after them","metadata":{"year": 2019, "director": "Greta Gerwig", "rating": 8.3, "title": "Little Women"},},{"text":"Toys come alive and have a blast doing so","metadata":{"year": 1995, "genre": "animated", "director": "John Lasseter", "rating": 8.3, "title": "Toy Story"},},{"text":"Three men walk into the Zone, three men walk out of the Zone","metadata":{"year": 1979,"rating": 9.9,"director": "Andrei Tarkovsky","genre": "science fiction","rating": 9.9,"title": "Stalker",}}
]索引数据到 Elasticsearch
我们选择对 Langchain 外部的数据进行索引,以演示如何将 Langchain 用于 RAG 并在任何 Elasticsearch 索引上使用自查询检索。
from elasticsearch import helpers# create the index
client.indices.create(index="movies_self_query")operations = [{"_index": "movies_self_query","_id": i,"text": doc["text"],"metadata": doc["metadata"]} for i, doc in enumerate(docs)
]# Add the documents to the index directly
response = helpers.bulk(client,operations,
)经过上面的操作后,我们可以在 Kibana 中进行查看:
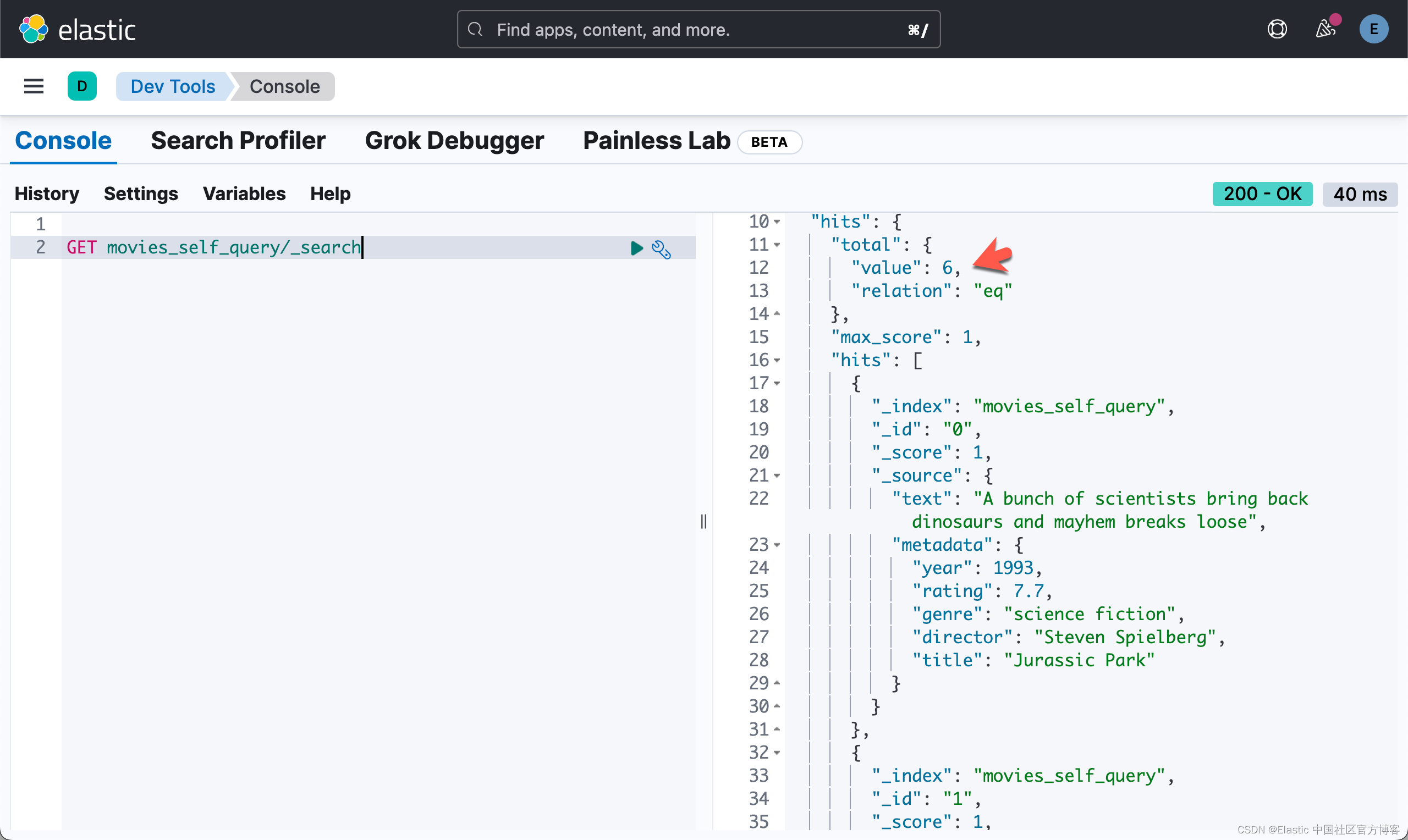
设置查询检索器
接下来,我们将通过提供有关文档属性的一些信息和有关文档的简短描述来实例化自查询检索器。
然后我们将使用 SelfQueryRetriever.from_llm 实例化检索器
from langchain.vectorstores.elasticsearch import ApproxRetrievalStrategy
from typing import List, Union
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.llms import OpenAI
from langchain.vectorstores.elasticsearch import ElasticsearchStore# Add details about metadata fields
metadata_field_info = [AttributeInfo(name="genre",description="The genre of the movie. Can be either 'science fiction' or 'animated'.",type="string or list[string]",),AttributeInfo(name="year",description="The year the movie was released",type="integer",),AttributeInfo(name="director",description="The name of the movie director",type="string",),AttributeInfo(name="rating", description="A 1-10 rating for the movie", type="float"),
]document_content_description = "Brief summary of a movie"# Set up openAI llm with sampling temperature 0
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)class BM25RetrievalStrategy(ApproxRetrievalStrategy):def __init__(self):passdef query(self,query: Union[str, None],filter: List[dict],**kwargs,):if query:query_clause = [{"multi_match": {"query": query,"fields": ["text"],"fuzziness": "AUTO",}}]else:query_clause = []bm25_query = {"query": {"bool": {"filter": filter,"must": query_clause}},}print("query", bm25_query)return bm25_queryvectorstore = ElasticsearchStore(index_name="movies_self_query",es_connection=client,strategy=BM25RetrievalStrategy()
)仅使用 BM25 的检索器
一种选择是自定义查询以仅使用 BM25 检索方法。 我们可以通过重写 custom_query 函数,指定查询仅使用 multi_match 来做到这一点。
在下面的示例中,自查询检索器使用 LLM 将问题转换为关键字和过滤器查询(query: dreams, filter: year range)。 然后使用自定义查询对关键字查询和过滤器查询执行基于 BM25 的查询。
这意味着如果你想在现有 Elasticsearch 索引上执行问题/答案用例,则不必对所有文档进行向量化。
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain.schema import format_documentretriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info, verbose=True
)LLM_CONTEXT_PROMPT = ChatPromptTemplate.from_template("""
Use the following context movies that matched the user question. Use the movies below only to answer the user's question.If you don't know the answer, just say that you don't know, don't try to make up an answer.----
{context}
----
Question: {question}
Answer:
""")DOCUMENT_PROMPT = PromptTemplate.from_template("""
---
title: {title}
year: {year}
director: {director}
---
""")def _combine_documents(docs, document_prompt=DOCUMENT_PROMPT, document_separator="\n\n"
):print("docs:", docs)doc_strings = [format_document(doc, document_prompt) for doc in docs]return document_separator.join(doc_strings)_context = RunnableParallel(context=retriever | _combine_documents,question=RunnablePassthrough(),
)chain = (_context | LLM_CONTEXT_PROMPT | llm)chain.invoke("Which director directed movies about dinosaurs that was released after the year 1992 but before 2007?")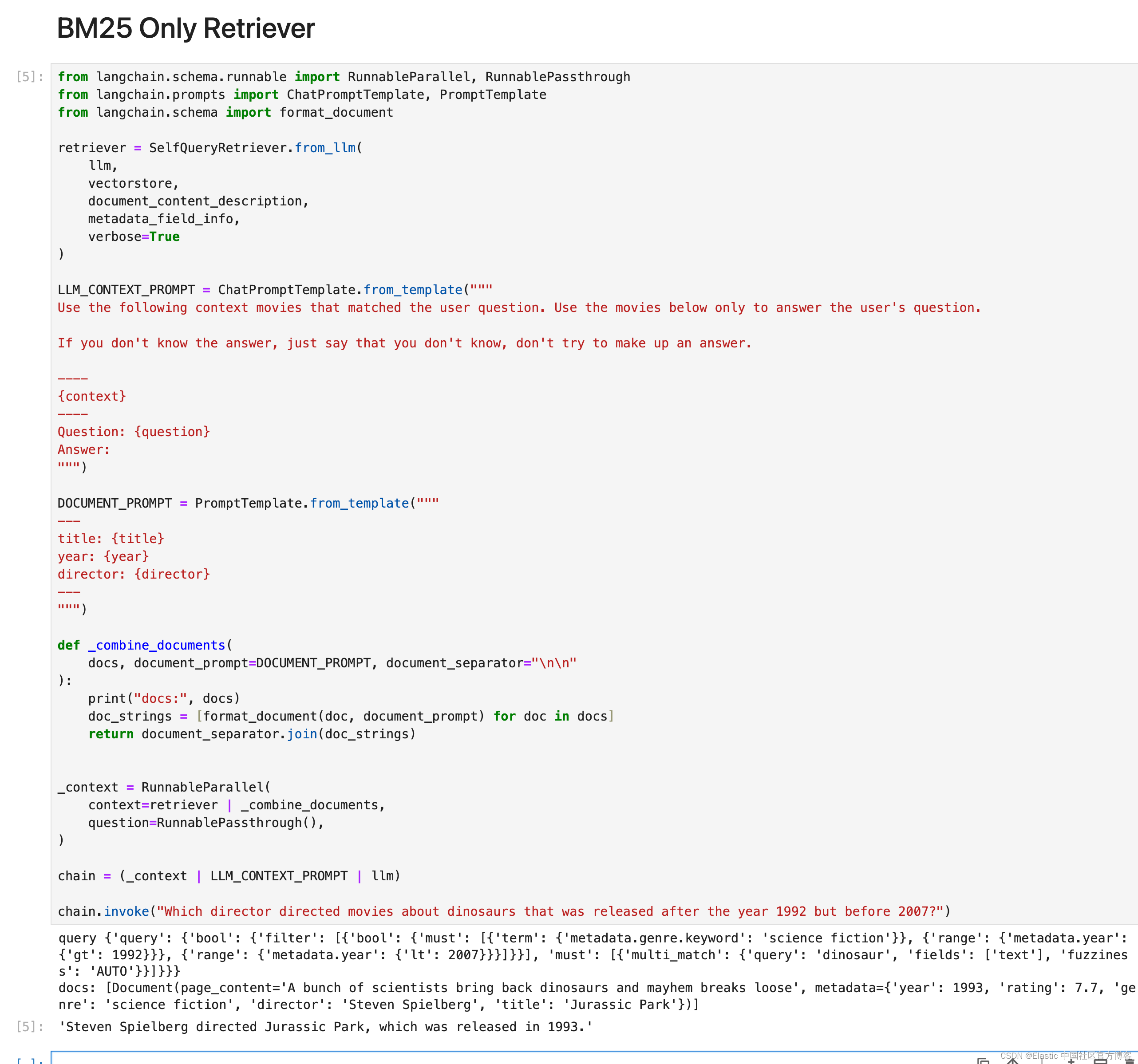
整个 notebook 的源码可以在地址下载:https://github.com/liu-xiao-guo/semantic_search_es/blob/main/chatbot-with-bm25-only-example.ipynb
相关文章:
Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器
本工作簿演示了 Elasticsearch 的自查询检索器将非结构化查询转换为结构化查询的示例,我们将其用于 BM25 示例。 在这个例子中: 我们将摄取 LangChain 之外的电影样本数据集自定义 ElasticsearchStore 中的检索策略以仅使用 BM25使用自查询检索将问题转…...

uniapp的api用法大全
页面生命周期API uniApp中的页面生命周期API可以帮助开发者在页面的不同生命周期中执行相应的操作。常用的页面生命周期API包括:onLoad、onShow、onReady、onHide、onUnload等。其中,onLoad在页面加载时触发,onShow在页面显示时触发…...

笔记——asp.net core 中的 REST
REST(reprentational state transfer,表层状态转移) REST原则:提倡按照HTTP的语义使用HTTP。 如果一个系统符合REST原则,我们就说这个系统是Restful风格的。 在RPC风格的Web API系统中,我们把服务端的代码…...

排序算法---堆排序
原创不易,转载请注明出处。欢迎点赞收藏~ 堆排序(Heap Sort)是一种基于二叉堆数据结构的排序算法。它将待排序的元素构建成一个最大堆(或最小堆),然后逐步将堆顶元素与堆的最后一个元素交换位置,…...
通用排序)
Java字符串(包含字母和数字)通用排序
说明:本文章是之前查到的一篇安卓版的,具体原文路径忘记了。稍微改了一点,挺符合业务使用的! 一、看代码 /*** 包含数字的字符串进行比较(按照从小到大排序)*/private static Integer compareString(Stri…...

【Spring】springmvc如何处理接受http请求
目录 编辑 1. 背景 2. web项目和非web项目 3. 环境准备 4. 分析链路 5. 总结 1. 背景 今天开了一篇文章“SpringMVC是如何将不同的Request路由到不同Controller中的?”;看完之后突然想到,在请求走到mvc 之前服务是怎么知道有请求进来…...

2024年安全员-B证证模拟考试题库及安全员-B证理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年安全员-B证证模拟考试题库及安全员-B证理论考试试题是由安全生产模拟考试一点通提供,安全员-B证证模拟考试题库是根据安全员-B证最新版教材,安全员-B证大纲整理而成(含2024年…...

redis过期淘汰策略、数据过期策略与持久化方式
redis的过期淘汰策略 redis过期淘汰策略有很多,默认是no-eviction 不删除任何数据,内存不足存入会直接报错,可以在redis配置文件中进行设置,其中有两个非常重要的概念,LRU与LFU LRU表示最近最少使用,LFU为最少频率使用 又按照volatile已设置过期时间的数据集和allkeys所有数…...
Oracle Vagrant Box 扩展根文件系统
需求 默认的Oracle Database 19c Vagrant Box的磁盘为34GB。 最近在做数据库升级实验,加之导入AWR dump数据,导致空间不够。 因此需要对磁盘进行扩容。 扩容方法1:预先扩容 此方法参考文档Vagrant, how to specify the disk size?。 指…...
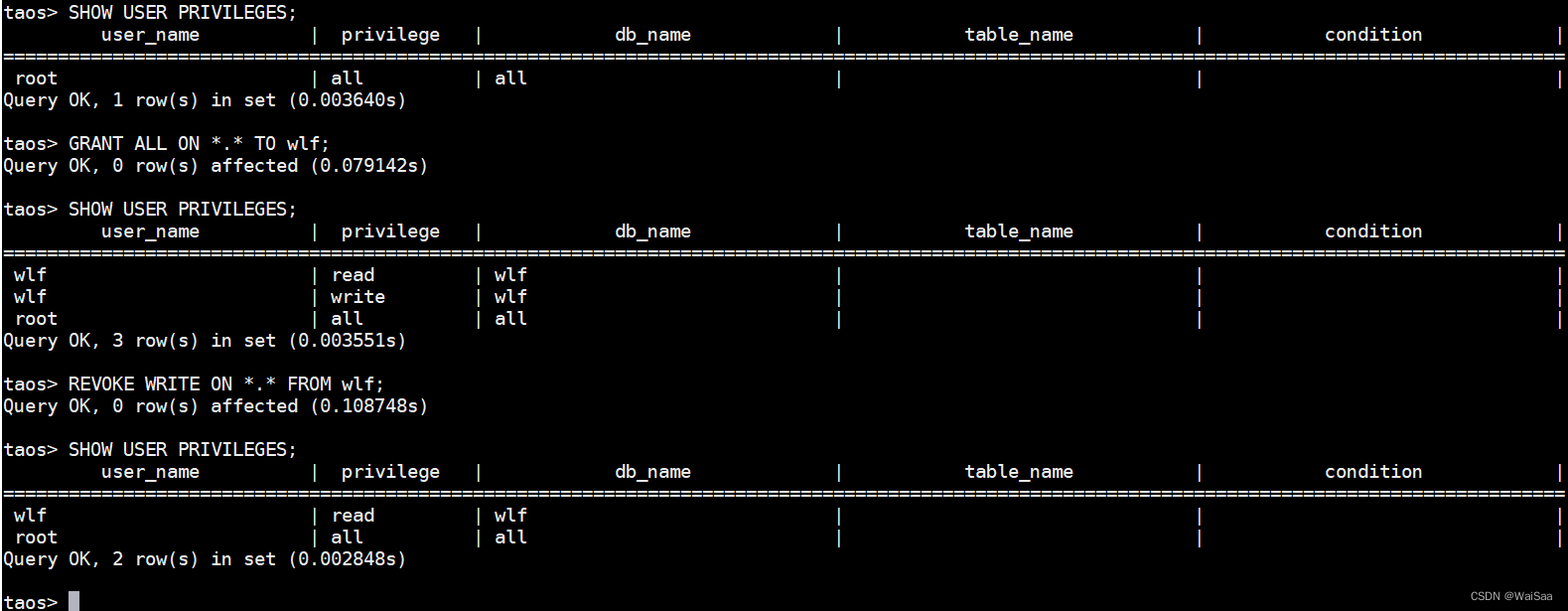
TDengine用户权限管理
Background 官方文档关于用户管理没有很详细的介绍,只有零碎的几条,这里记录下方便后面使用。官方文档:https://docs.taosdata.com/taos-sql/show/#show-users 1、查看用户 show users;super 1,表示超级用户权限 0,表…...

推荐一款开源的跨平台划词翻译和OCR翻译软件:Pot
Pot简介 一款开源的跨平台划词翻译和OCR翻译软件 下载安装指南 根据你的机器型号下载对应版本,下载完成后双击安装即可。 使用教程 Pot具体功能如下: 划词翻译输入翻译外部调用鼠标选中需要翻译的文本,按下设置的划词翻译快捷键即可按下输…...
spring boot学习第十一篇:发邮件
1、pom.xml文件内容如下(是我所有学习内容需要的,不再单独分出来,包不会冲突): <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"…...
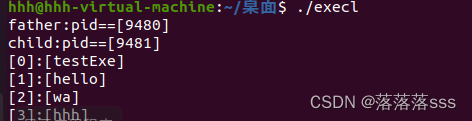
Linux中ps/kill/execl的使用
ps命令: ps -aus或者ps -ajx或者 ps -ef可以查看有哪些进程。加上 | grep "xxx" 可以查看名为”xxx"的进程。 ps -aus | grep "xxx" kill命令: kill -9 pid 杀死某个进程 kill -l 查看系统有哪些信号 execl函数&#…...
【web前端开发】HTML及CSS简单页面布局练习
案例一 网页课程 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthdevice-wi…...

2.7日学习打卡----初学RabbitMQ(二)
2.7日学习打卡 JMS 由于MQ产品很多,操作方式各有不同,于是JAVA提供了一套规则 ——JMS,用于操作消息中间件。JMS即Java消息服务 (JavaMessage Service)应用程序接口,是一个Java平台中关于面 向消息中间件的…...
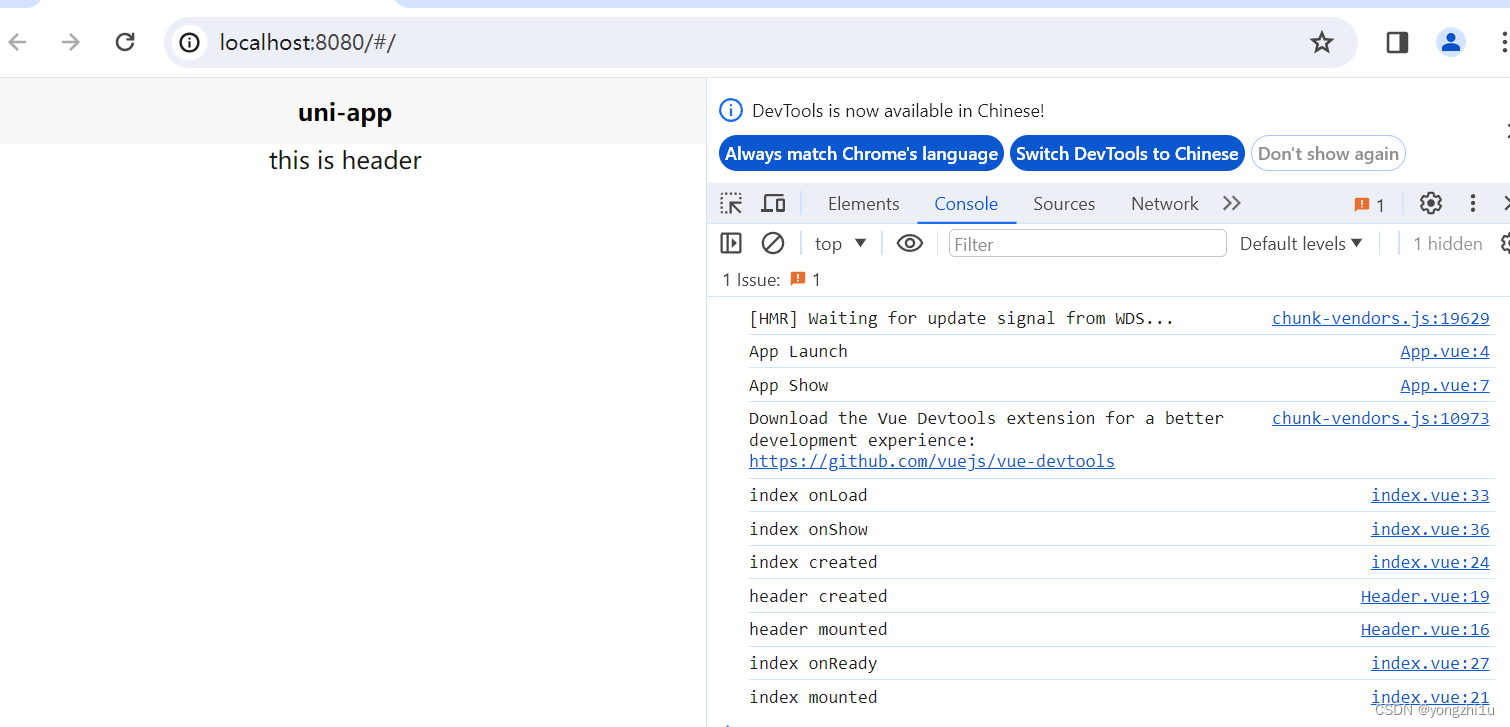
【工作学习 day04】 9. uniapp 页面和组件的生命周期
问题描述 uniapp常用的有:页面和组件,并且页面和组件各自有各自的生命周期函数,那么在页面/组件请求数据时,是用created呢,还是用onLoad呢? 先说结论: 组件使用组件的生命周期,页面使用页面的…...
Mysql-数据库优化-客户端连接参数
客户端参数 原文地址 # 连接池配置 # 初始化连接数 spring.datasource.druid.initial-size1 # 最小空闲连接数,一般设置和initial-size一致 spring.datasource.druid.min-idle1 # 最大活动连接数,一个数据库能够支撑最大的连接数是多少呢? …...
【十二】【C++】vector用法的探究
vector类创建对象 /*vector类创建对象*/ #if 1 #define _CRT_SECURE_NO_WARNINGS#include <iostream> using namespace std; #include <vector> #include <algorithm> #include <crtdbg.h>class Date {public:Date(int year 1900, int month 1, int …...

Docker 基本介绍
Docker 基本介绍 镜像 Docker镜像就是一个只读的模板。 例如:一个镜像可以包含一个完整的ubuntu操作系统环境,里面仅安装了Apache或用户需要的其它应用 程序。 镜像可以用来创建Docker容器。Docker提供了一个很简单的机制来创建镜像或者更新现有的镜…...

CentOS 7 安装 install abiword
安装 1.下载noarch安装包 wget http://repo.iotti.biz/CentOS/7/noarch/lux-release-7-1.noarch.rpm 2.安装noarch rpm -Uvh lux-release-7-1.noarch.rpm 3.安装abiword yum -y install abiword...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...