5 scala的函数式编程简介
与Java一样,Scala 也是使用 Lambda 表达式实现函数式变成的。
1 遍历
除了使用 for 可以对数组、List、Set 进行遍历外,也可以使用 foreach 函数式编程进行遍历,使代码更为简洁。
foreach 的方法签名为:
foreach(f: (A) => Unit): Unit
- 参数:接受一个函数对象,函数的输入参数为集合的元素。
例如:
scala> List("C朗", "美斯", "云尼").foreach(p => println(p))
C朗
美斯
云尼
2 下划线简化函数定义
如果符合下面两个条件,则可以使用下划线 _ 代替 函数入参 简化函数定义:
(1) 函数的入参,只在函数体中出现一次。
(2) 函数体中没有嵌套调用。
例如,下面使用 _ 简化了函数体定义,使代码更加简洁:
scala> List("C朗", "美斯", "云尼").foreach(p => println(p))
C朗
美斯
云尼scala> List("C朗", "美斯", "云尼").foreach(println(_))
C朗
美斯
云尼
3 映射 map
如果要遍历集合中的每一个元素,并经过一个函数处理后生成新的元素,则可以使用集合的 map 方法。
map 方法签名为:
def map[元素类型](f: (I) => R): TraversableOnce[R]
下面例子中,定义一个 List 对象,并使每一个元素都加 1:
scala> val list = List(0,1,2,3)
val list: List[Int] = List(0, 1, 2, 3)scala> list.map(x=>x+1)
val res24: List[Int] = List(1, 2, 3, 4)
同样,可以使用下划线简化函数定义:
scala> val list = List(0,1,2,3)
val list: List[Int] = List(0, 1, 2, 3)scala> list.map(_+1)
val res25: List[Int] = List(1, 2, 3, 4)
4 扁平化映射
使用集合的 flatMap 方法实现扁平化映射。
可以把 flatMap 理解为先进行 map 操作,再进行 flatten 操作,即将列表中的元素转换成 List,然后再把 List类型的元素展开。
flatMap 的方法签名为:
def flatMap[元素类型](f: (I) => GenTraversableOnce[R]): TraversableOnce[R]
例如,一个 List 中每个元素为一行数据,每行数据内容为多个球员名字,每个球员名字用空格分隔,现在如果要统计这个 List 中一共有多少个球员,可使用 map + flatten 实现:
scala> var players = List("美斯 C朗", "C朗 姆总")
var players: List[String] = List(美斯 C朗, C朗 姆总)scala> players.map(_.split(" ")).flatten
val res27: List[String] = List(美斯, C朗, C朗, 姆总)scala> players.map(_.split(" ")).flatten.distinct
val res28: List[String] = List(美斯, C朗, 姆总)scala> players.map(_.split(" ")).flatten.distinct.length
val res29: Int = 3
也可以直接使用 flatMap 方法实现 map + flatten 的效果:
scala> var players = List("美斯 C朗", "C朗 姆总")
var players: List[String] = List(美斯 C朗, C朗 姆总)scala> players.flatMap(_.split(" "))
val res30: List[String] = List(美斯, C朗, C朗, 姆总)scala> players.flatMap(_.split(" ")).distinct
val res31: List[String] = List(美斯, C朗, 姆总)scala> players.flatMap(_.split(" ")).distinct.length
val res32: Int = 3
5 过滤
使用 filter 方法,可以过滤符合一定条件的元素,并返回元素 List。
filter 的方法签名为:
def filter(f: (I) => Boolean): TraversableOnce[I]
f: (I) => Boolean 传入集合的元素,返回布尔类型变量,如果满足条件则返回 true, 否则返回 false。
例如,一个保存数字的 List,只保留大于50的元素:
scala> List(90,88,33,44,50,55).filter(_ > 50)
val res33: List[Int] = List(90, 88, 55)
6 排序
Scala 的集合提供了 3 中排序方式:
- 默认排序
- 指定字段排序
- 自定义排序
6.1 默认排序
List 的 sorted 方法会对元素进行升序排列:
scala> List(90,88,33,44,50,55).sorted
val res35: List[Int] = List(33, 44, 50, 55, 88, 90)
6.2 指定字段排序
sortBy 方法,可以指定按特定的字段排序,将传入的函数转换后再进行排序。
sortBy 的方法签名为:
def sortBy[R](f: (I) => R): List(R)
例如,定义一个 List,里面包含了多个元组,元组第一个元素为 球员名称,第二个元素为球员身价,然后再通过身价对元素进行排序:
scala> val players = List(("C朗", 15000000), ("美斯", 21000000), ("姆总", 150000000), ("夏兰特", 180000000))
val players: List[(String, Int)] = List((C朗,15000000), (美斯,21000000), (姆总,150000000), (夏兰特,180000000))// 按名字排序
scala> players.sortBy(_._1)
val res36: List[(String, Int)] = List((C朗,15000000), (夏兰特,180000000), (姆总,150000000), (美斯,21000000))// 按身价排序
scala> players.sortBy(_._2)
val res37: List[(String, Int)] = List((C朗,15000000), (美斯,21000000), (姆总,150000000), (夏兰特,180000000))// 按身价倒序
scala> players.sortBy(0 - _._2)
val res38: List[(String, Int)] = List((夏兰特,180000000), (姆总,150000000), (美斯,21000000), (C朗,15000000))
6.3 自定义排序
使用 sortWith 方法,可以实现自定义排序,该方法的签名如下:
def sortWith(lt: (A, A) => Boolean): List[A]
函数有两个入参,第一个入参为 当前元素,第二个入参为 上一个元素。
下面的例子演示了按球员身价做顺序排序 和 倒序排序:
scala> val players = List(("C朗", 15000000), ("美斯", 21000000), ("姆总", 150000000), ("夏兰特", 180000000))
val players: List[(String, Int)] = List((C朗,15000000), (美斯,21000000), (姆总,150000000), (夏兰特,180000000))// 顺序排序
scala> players.sortWith(_._2 < _._2)
val res48: List[(String, Int)] = List((C朗,15000000), (美斯,21000000), (姆总,150000000), (夏兰特,180000000))// 倒序排序
scala> players.sortWith(_._2 > _._2)
val res47: List[(String, Int)] = List((夏兰特,180000000), (姆总,150000000), (美斯,21000000), (C朗,15000000))
7 分组
使用 groupBy 方法可以将数据分组后进行统计。
groupBy 的方法签名如下:
def groupBy[K](f: (I) => K): Map(K, List[I])
下面的例子,按国家队球员进行分组:
scala> val players = List("C朗 葡萄牙", "美斯 阿根廷", "B费 葡萄牙", "碧咸 英格兰", "普老师 英格兰")
val players: List[String] = List(C朗 葡萄牙, 美斯 阿根廷, B费 葡萄牙, 碧咸 英格兰, 普老师 英格兰)scala> players.groupBy(_.split(" ")(1))
val res49: Map[String, List[String]] = HashMap(阿根廷 -> List(美斯 阿根廷), 英格兰 -> List(碧咸 英格兰, 普老师 英格兰), 葡萄牙 -> List(C朗 葡萄牙, B费 葡萄牙))
8 聚合
reduce 提供了聚合功能。聚合就是将一个集合的数据合并为一个,在统计分析中经常使用。
reduce 的方法签名如下:
def reduce[A1 >: A](op: (A1, A1) => A1): A1
[A1 >: A]中(下界)A1必须是集合类型的子类op: (A1, A1) => A1用来不断进行聚合操作;第一个A1参数为当前聚合后的变量,第二个 A1 类型参数为当前要进行聚合的元素- 返回值 A1 是列表最终聚合成的值。
下面例子对一个 Int List 进行求和:
scala> val list = List(1,2,3,4,5,6,7,8,9,10)
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)scala> list.reduce(_+_)
val res51: Int = 55
还有指定了计算方向的聚合方法,reduceLeft 及 reduceRight
例如,对于数列 1,2,3,4,5,从左往右相减,结果为 1 - 2 - 3 - 4 - 5 = -13;如果从右往左相减,结果为 5 - 4 - 3 - 2 - 1 = -5:
scala> List(1,2,3,4,5).reduce(_-_)
val res52: Int = -13scala> List(1,2,3,4,5).reduceLeft(_-_)
val res53: Int = -13scala> List(1,2,3,4,5).reduceRight((e1,e2) => e2 - e1)
val res56: Int = -5
注意:
reduce跟reduceLeft是一样的,都是从左到右进行聚合,第一个参数为前值,第二个参数为当前值reduceRight是从右往左进行聚合,第一个参数为当前值,第二个参数为前值
相关文章:

5 scala的函数式编程简介
与Java一样,Scala 也是使用 Lambda 表达式实现函数式变成的。 1 遍历 除了使用 for 可以对数组、List、Set 进行遍历外,也可以使用 foreach 函数式编程进行遍历,使代码更为简洁。 foreach 的方法签名为: foreach(f: (A) > …...
陪护系统|陪护小程序提升长者护理服务质量的关键
在如今逐渐老龄化的社会中,老年人对更好的护理服务需求不断增加。科技的进步使得陪护小程序系统源码成为提供优质服务的重要途径之一。本文将从运营角度探讨如何优化陪护小程序系统源码,提升长者护理服务的质量。 首先,我们需要对软件的设计和…...
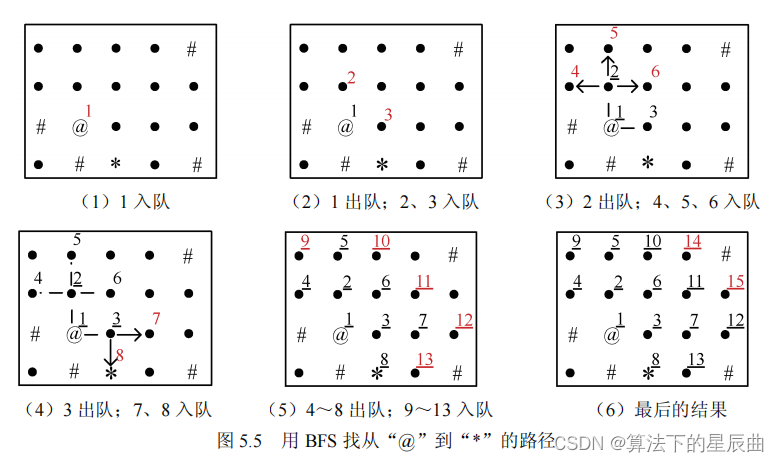
C++算法之双指针、BFS和图论
一、双指针 1.AcWing 1238.日志统计 分析思路 前一区间和后一区间有大部分是存在重复的 我们要做的就是利用这部分 来缩短我们查询的时间 并且在使用双指针时要注意对所有的博客记录按时间从小到大先排好顺序 因为在有序的区间内才能使用双指针记录两个区间相差 相当于把一个…...
自然语言处理)
【大厂AI课学习笔记】1.5 AI技术领域(3)自然语言处理
今天来梳理自然语言处理的相关内容。 自然语言处理:定义、关键技术、技术发展、应用场景与商业化成功 一、自然语言处理的定义 自然语言处理(NLP)是人工智能(AI)领域的一个重要分支,它研究的是如何让计算…...
【数字电子技术课程设计】多功能数字电子钟的设计
目录 摘要 1 设计任务要求 2 设计方案及论证 2.1 任务分析 2.1.1 晶体振荡器电路 2.1.2 分频器电路 2.1.3 时间计数器电路 2.1.4 译码驱动电路 2.1.5 校时电路 2.1.6 整点报时/闹钟电路 2.2 方案比较 2.3 系统结构设计 2.4 具体电路设计 3 电路仿真测试及结…...
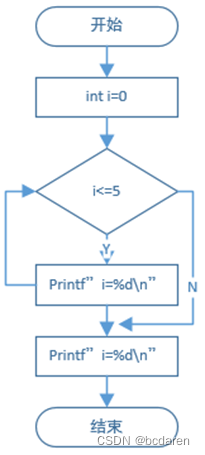
【新书推荐】7.3 for语句
本节必须掌握的知识点: 示例二十四 代码分析 汇编解析 for循环嵌套语句 示例二十五 7.3.1 示例二十四 ■for语句语法形式: for(表达式1;表达式2;表达式3) { 语句块; } ●语法解析: 第一步:执行表达式1,表达式1…...

爬山算法优化遗传算法优化极限学习机的多分类预测,p-ga-elm多分类预测
目录 背影 极限学习机 爬山算法优化遗传算法优化极限学习机的多分类预测,p-ga-elm多分类预测 主要参数 MATLAB代码 效果图 结果分析 展望 完整代码下载链接:爬山算法优化遗传算法优化极限学习机的多分类预测,p-ga-elm多分类预测(代码完整,数据)资源-CSDN文库 https://d…...
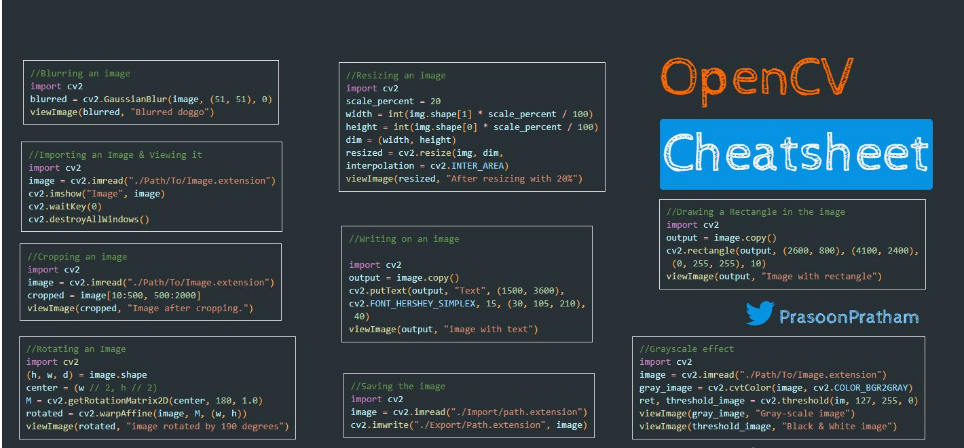
挑战杯 opencv 图像识别 指纹识别 - python
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于机器视觉的指纹识别系统 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 该项目较为新颖,适…...
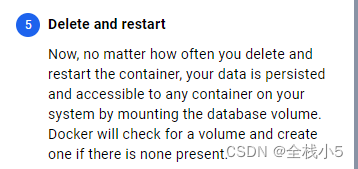
【Docker】了解Docker Desktop桌面应用程序,TA是如何管理和运行Docker容器(2)
欢迎来到《小5讲堂》,大家好,我是全栈小5。 这是《Docker容器》系列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对…...

PHP、Python、Java 和 Go语言对比
PHP、Python、Java 和 Go 都是流行的编程语言,每种语言都有其独特的优势和适用场景。下面是对这些语言的一些基本对比: 一:PHP 适用场景:主要用于Web开发,特别是服务器端脚本。 特点:语法简单易懂&#…...

算法题目题单+题解——图论
简介 本文为自己做的一部分图论题目,作为题单列出,持续更新。 题单由题目链接和题解两部分组成,题解部分提供简洁题意,代码仓库:Kaiser-Yang/OJProblems。 对于同一个一级标题下的题目,题目难度尽可能做…...
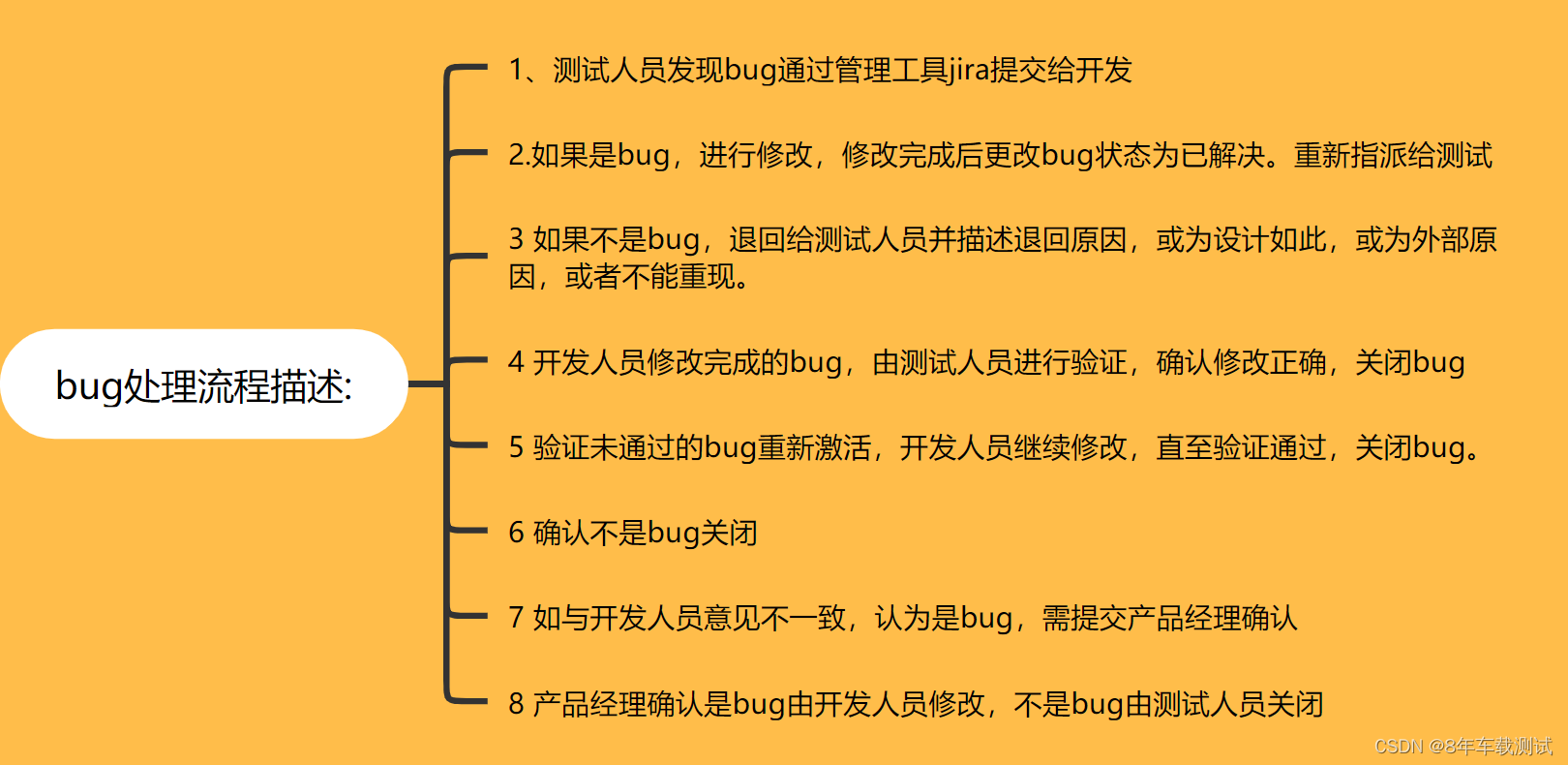
车载测试中:如何处理 bug
一:Jira 提交 bug 包含那些内容 二:如何处理现上 bug 三:车载相关的 bug 如何定位 四:遇到 bug ,复现不出来怎么办 五:bug 的处理流程 一:Jira 提交 bug 包含那些内容二:如何处理现上…...
亲测解决vscode的debug用不了、点了没反应
这个问题在小虎登录vscode同步了设置后出现,原因是launch文件被修改或删除。解决方法是重新添加launch。 坏境配置 win11 + vscode 解决方法 Ctrl + shift + P,搜索debug添加配置: 选择python debugger。 结果生成了一个文件在当前路径: launch内容: {// Use Int…...

立足智能存取解决方案|HEGERLS智能托盘四向车储存制动能量 实现能源回收
对于商业配送和工业生产的企业而言,如何能高效率、低成本进行低分拣、运输、码垛、入库,用以提升仓库空间的利用效率,是现在大多企业急需要解决的行业痛点。对此,为了解决上述痛点,近年来,物流仓储集成商、…...
)
2024.2.8日总结(小程序开发5)
对上拉触底事件进行节流处理 在data中定义isloading节流阀 false表示当前没有进行任何数据请求true表示当前正在进行数据请求 在getColors()方法中修改isloading节流阀的值 在刚调用getColors时将节流阀设置true在网络请求的complete回调函数中,将节流阀重置为f…...

Spring Boot配置文件优先级
1、bat文件启动java程序 java -Dmmmqqq -Dfile.encodingUTF-8 -jar ruoyi-admin.jar --mmmiii --llllll 2、配置类型 程序参数Program arguments : --mmmiii 单个属性值,可以从String[] args读取到,放在jar包命令后面 VM参数VM options :一般以-D …...

Rust 初体验1
Rust 初体验 安装 打开官网,下载 rustup-init.exe, 选择缺省模式(1)安装。 国内源设置 在 .Cargo 目录下新建 config 文件,添加如下内容: [source.crates-io] registry "https://github.com/rus…...

【深度学习】实验7布置,图像超分辨
清华大学驭风计划 因为篇幅原因实验答案分开上传, 实验答案链接http://t.csdnimg.cn/P1yJF 如果需要更详细的实验报告或者代码可以私聊博主 有任何疑问或者问题,也欢迎私信博主,大家可以相互讨论交流哟~~ 深度学习训练营 案例 7 ࿱…...
【八大排序】归并排序 | 计数排序 + 图文详解!!
📷 江池俊: 个人主页 🔥个人专栏: ✅数据结构冒险记 ✅C语言进阶之路 🌅 有航道的人,再渺小也不会迷途。 文章目录 一、归并排序1.1 基本思想 动图演示2.2 递归版本代码实现 算法步骤2.3 非递归版本代…...
Netty应用(三) 之 NIO开发使用 网络编程 多路复用
目录 重要:logback日志的引入以及整合步骤 5.NIO的开发使用 5.1 文件操作 5.1.1 读取文件内容 5.1.2 写入文件内容 5.1.3 文件的复制 5.2 网络编程 5.2.1 accept,read阻塞的NIO编程 5.2.2 把accept,read设置成非阻塞的NIO编程 5.2.3…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...