Netty应用(三) 之 NIO开发使用 网络编程 多路复用
目录
重要:logback日志的引入以及整合步骤
5.NIO的开发使用
5.1 文件操作
5.1.1 读取文件内容
5.1.2 写入文件内容
5.1.3 文件的复制
5.2 网络编程
5.2.1 accept,read阻塞的NIO编程
5.2.2 把accept,read设置成非阻塞的NIO编程
5.2.3 引入Selector监管者 【IO多路复用】
5.2.4 补充几个仍然存在的问题
5.2.5 引入服务器端的写操作
5.2.6 Selector多路复用的核心含义
重要:logback日志的引入以及整合步骤
sl4j是一个日志门面,它有两种具体的实现:
1.log4j2(年代久远,时间长,用的少)
2.logback(用的多,支持好)
而且最重要的一点就是:logback可以输出线程名,在多线程场景下这一点很重要。
- 引入依赖
<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.12</version>
</dependency>- 引入logback.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!-- 控制台输出 --><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern></encoder></appender><root level="DEBUG"><appender-ref ref="STDOUT"/></root></configuration>- 按照idea插件:log support
安装插件后,进行相关的配置:

- 测试相关的快捷键
引入idea插件后,就可以使用快捷键并且插件会帮你自动生成相关的类!

运行:
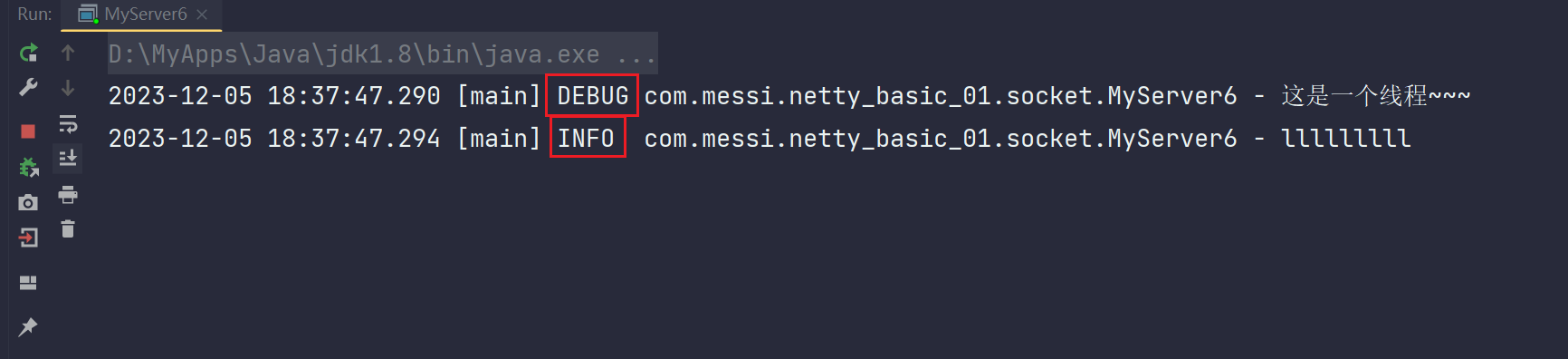
- 总结

- 补充
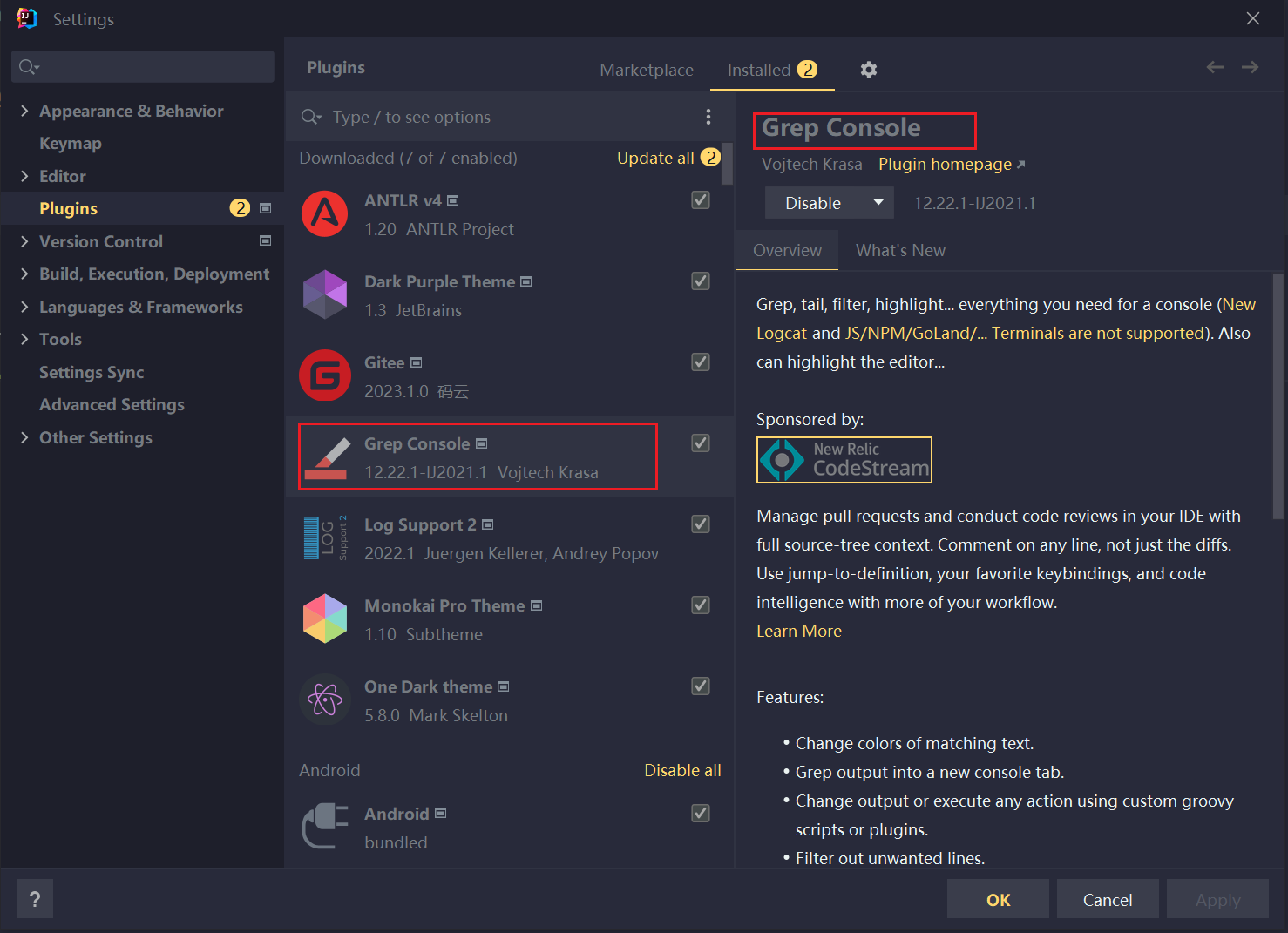
为了让控制台对不同日志级别进行不同颜色的甄别输出,再安装一个插件:Grep Console!
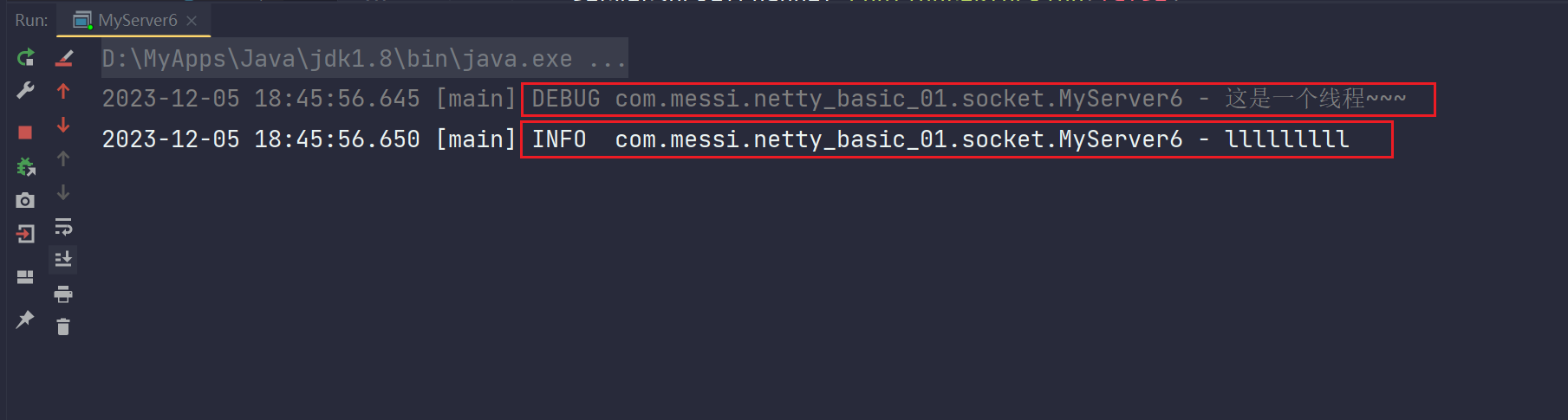
重启idea后,再一次进行测试展示具体效果:哈哈哈哈,颜色不一样了哦!
5.NIO的开发使用
5.1 文件操作
5.1.1 读取文件内容
第一个程序,就是读取文件内容的程序
public class TestNIO1 {public static void main(String[] args) throws Exception{//1.创建ChannelFileChannel channel = new FileInputStream("D:\\Daily_Code\\Netty_NEW\\data.txt").getChannel();//2.创建缓冲区ByteBuffer buffer = ByteBuffer.allocate(10) ;//因为可能缓冲区一次无法读取完文件的所有字节,所以要while循环读取,可能多次反复读取到申请的缓冲区中while (true) {//在创建完缓冲区后,默认是写模式//3.把通道内获取的文件数据,写入缓冲区int read = channel.read(buffer) ;//此时说明文件已读取完,循环应该退出if(read == -1) {break;}//4.程序读取buffer的内容数据,后续的操作,设置buffer为读模式buffer.flip();//5.循环读取缓冲区的数据while(buffer.hasRemaining()) {byte b = buffer.get();//把字节转换成可视化的字符//UTF-8编码中:一个字符占用1~4的字节大小。汉字,日文,韩文占用3个字节,ASCII表的字符占用1个字节,xxx字符占用2个字节,一些少数语言字符占用4个字节System.out.println("(char)b = " + (char) b);}//6.设置buffer为写模式,因为循环上去后需要写入缓冲区,所以需要重新设置为写模式buffer.clear();}}}5.1.2 写入文件内容
public class TestNIO11 {public static void main(String[] args) throws IOException {//1.获取Channel ,方法:1.FileOutputStream.getChannel() 2.RandomAccessFileFileChannel channel = new FileOutputStream("D:\\Daily_Code\\Netty_NEW\\data1").getChannel();//2.获取ByteBufferByteBuffer buffer = Charset.forName("UTF-8").encode("梅西");//3.write : 把ByteBuffer写入到data1这个文件channel.write(buffer);}}5.1.3 文件的复制
对于文件的复制来说:Channel管道对象的transferTo方法拷贝的性能要高于IO流的拷贝性能以及IOUtils.copy的性能。因为transferTo方法底层采用的是零拷贝技术,后面会详细总结。
public class TestNIO12 {public static void main(String[] args) throws Exception{//把data的数据拷贝到data2//方法1:使用IO流方式实现拷贝 效率较低
// FileInputStream inputStream = new FileInputStream("D:\\Daily_Code\\Netty_NEW\\data.txt");
// FileOutputStream fileOutputStream = new FileOutputStream("D:\\Daily_Code\\Netty_NEW\\data2.txt");
// byte[] byteBuffer = new byte[1024];
// while(true) {
// //把data文件的数据流读取到byteBuffer这个缓冲区
// int read = inputStream.read(byteBuffer);
// //读取完毕,退出
// if(read == -1) {
// break;
// }
// //把data文件的数据拷贝到fileOutputStream流对应的data1文件
// fileOutputStream.write(byteBuffer,0,read);
// }//方法2:使用commons-io这一工具类
// FileInputStream inputStream = new FileInputStream("D:\\Daily_Code\\Netty_NEW\\data.txt");
// FileOutputStream fileOutputStream = new FileOutputStream("D:\\Daily_Code\\Netty_NEW\\data2.txt");
// IOUtils.copy(inputStream,fileOutputStream) ;//方法3:使用NIO方式拷贝,底层是零拷贝,效率较高。但是一次最多拷贝2GB大小的数据,一旦超过2GB,则需要分段拷贝FileChannel from = new FileInputStream("D:\\Daily_Code\\Netty_NEW\\data.txt").getChannel();FileChannel to = new FileOutputStream("D:\\Daily_Code\\Netty_NEW\\data2.txt").getChannel();long left = from.size();while (left > 0) {//一旦拷贝数据超过2GB,则需要分段拷贝!left = left - from.transferTo(from.size()-left,left,to) ;}}}
transferTo方法:

5.2 网络编程
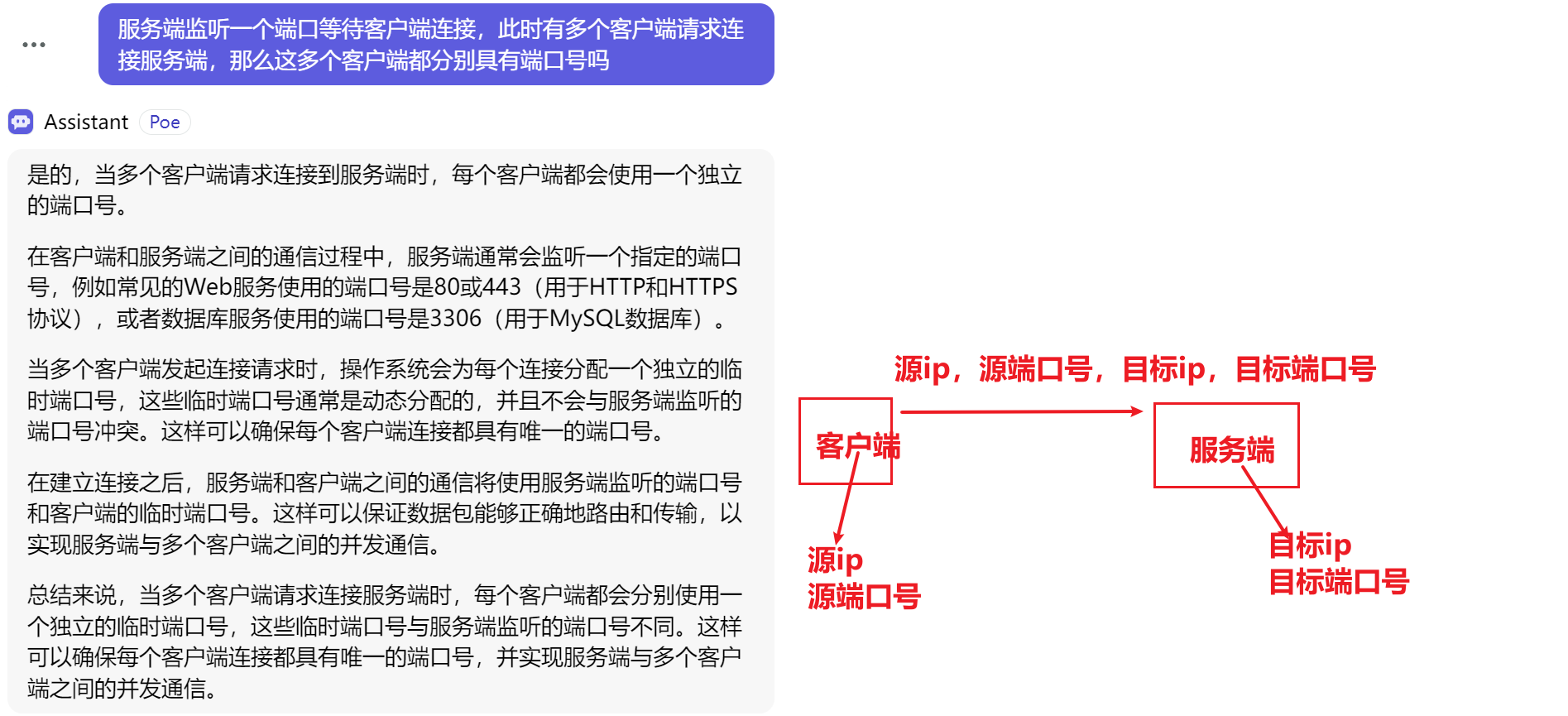
在日常开发中,通常都是多个客户端去连接并请求一个服务器端的,所以我们要把更多的关注点放在服务端如何处理这么多个客户端的请求压力(即:连接操作+读写操作的处理)
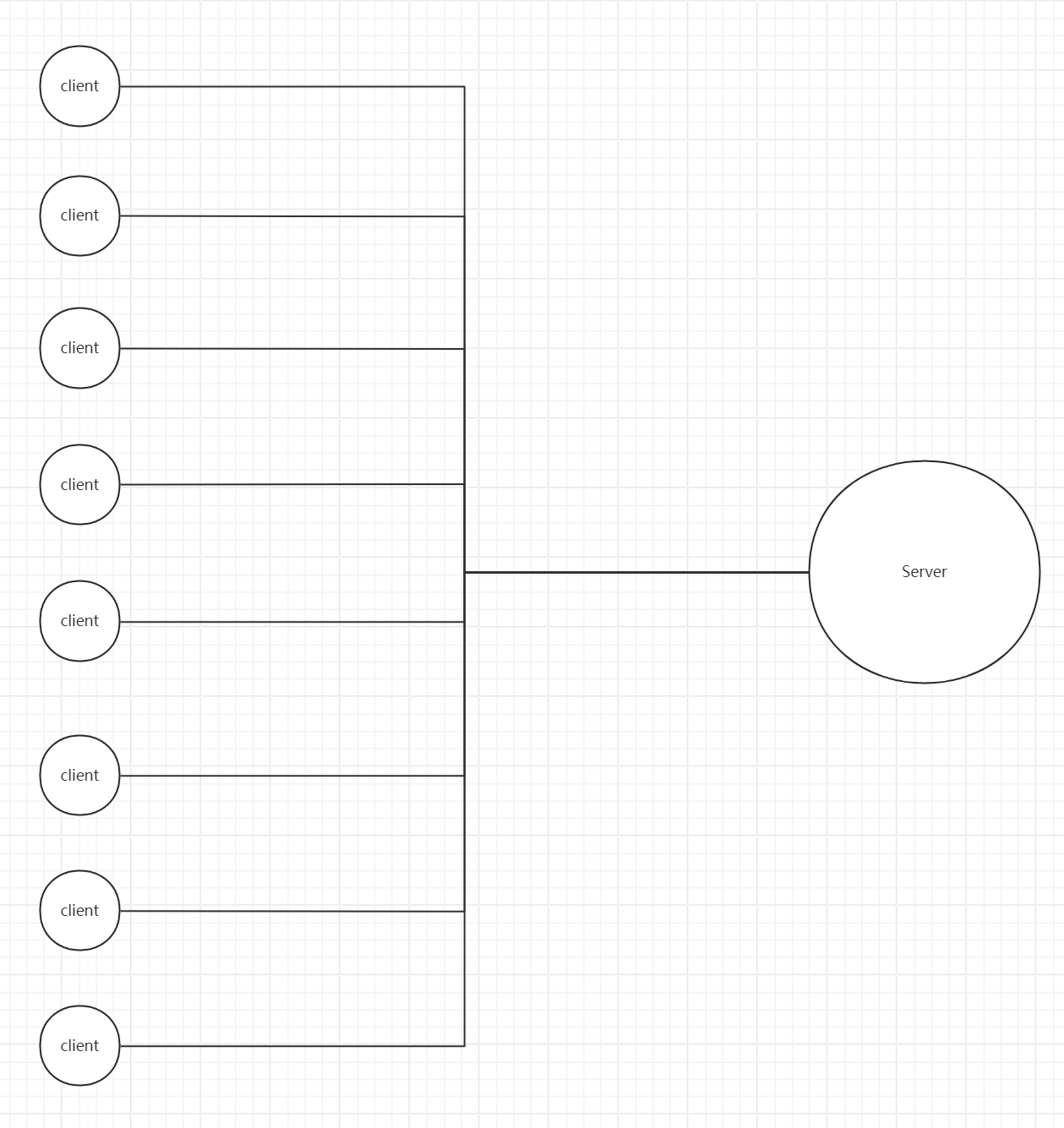
- 网络编程NIO的核心结构
1.Channel管道
服务端---》ServerSocketChannel (接受请求)
客户端---》SocketChannel (进行实际的通信)
2.Buffer缓冲区
无论什么类型,最终都要转换成字节类型,所以缓冲区使用的是ByteBuffer
- 端口号的意义
端口号:
端口号就是进行区分相同ip下的相同协议的不同程序的一种标识
5.2.1 accept,read阻塞的NIO编程
public class MyClient {public static void main(String[] args) throws Exception{SocketChannel socketChannel = SocketChannel.open();socketChannel.connect(new InetSocketAddress(8000)) ;System.out.println("-------------------------------");}}public class MyServer {public static void main(String[] args) throws Exception {//1.创建ServerSocketChannelServerSocketChannel serverSocketChannel = ServerSocketChannel.open();//2.设置服务端的监听端口serverSocketChannel.bind(new InetSocketAddress(8000)) ;//3.把建立连接成功的SocketChannel放入一个集合中List<SocketChannel> channelList = new ArrayList<>() ;//4.创建ByteBuffer缓冲区ByteBuffer buffer = ByteBuffer.allocate(20) ;while (true) {//5.阻塞时监听客户端的连接System.out.println("等待连接服务器...");SocketChannel socketChannel = serverSocketChannel.accept();System.out.println("服务器已经连接..."+socketChannel);//6.加入集合if(socketChannel != null) {channelList.add(socketChannel);}for(SocketChannel channel:channelList) {System.out.println("开始实际的数据通信....");//7.把客户端发送的数据写入到ByteBuffer缓冲区channel.read(buffer);//把buffer转换成读模式buffer.flip();//8.显示输出到控制台CharBuffer decode = Charset.forName("UTF-8").decode(buffer);System.out.println("decode.toString() = " + decode.toString());//把buffer转换成写模式buffer.clear();System.out.println("通信已经结束....");}}}}5.2.2 把accept,read设置成非阻塞的NIO编程
public class MyClient {public static void main(String[] args) throws Exception{SocketChannel socketChannel = SocketChannel.open();socketChannel.connect(new InetSocketAddress(8000)) ;System.out.println("-------------------------------");}}public class MyServer1 {public static void main(String[] args) throws Exception{ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.configureBlocking(false);serverSocketChannel.bind(new InetSocketAddress(8000));List<SocketChannel> channelList = new ArrayList<>() ;ByteBuffer buffer = ByteBuffer.allocate(20);while (true) {
// System.out.println("等待连接服务器.....");SocketChannel socketChannel = serverSocketChannel.accept();
// System.out.println("服务器已经连接...." + socketChannel) ;if(socketChannel != null) {socketChannel.configureBlocking(false);channelList.add(socketChannel) ;}for (SocketChannel channel : channelList) {int read = channel.read(buffer);if(read > 0) {System.out.println("开始实际的数据通信....");buffer.flip();CharBuffer decode = Charset.forName("UTF-8").decode(buffer);System.out.println("decode.toString() = " + decode.toString());buffer.clear();System.out.println("通信已经结束.......");}}}}}5.2.3 引入Selector监管者 【IO多路复用】
- 为什么要引入监管者Selector?
由于是非阻塞,所以会一直while循环。不断的while一直循环着十分影响性能问题,所以需要一个监管者来监管着事件状态的发生,而不要以whie死循环进行监管查看事件状态的发生

使用Selector充当监管者进行监管ServerSocketChannel和SocketChannel,但是Selector做了更加细粒度和高效的监管,Selector并不是像while循环一样无时无刻的监管着,而是Selector只在ServerSocketChannel触发ACCEPT状态事件的时候才会监管监控到,只在SocketChannel触发READ,WRITE状态事件的时候才会监管监控到。Selector就像一个警察,他不会无时无刻的监管人,只有当人触发了某些状态事件(如:抢劫,杀人等)时才会进行监控监管到人。Selector同理。这样可以极大的提高Selector监管监控的能力!也解决了while一直循环的问题。
- Selector的核心结构
Selector有两个核心结构:一个keys,一个SelectionKeys。都是HashSet。
当serverSocketChannel.register(selector, 0, null) 或 socketChannel.register(selector, 0, null) 调用时,是把serverSocketChannel或socketChannel注册存储到keys这个HashSet中
当SSC实际触发了Accept状态事件或SC实际触发了Read或Write状态事件后,会把触发事件的Channel注册存储到SelectionKeys这个HashSet中,但一旦处理完事件,就立马把该事件对应的Channel从SelectionKeys中删除。但是keys中一直存储着register注册的Channel。
- 为什么设置成非阻塞后,需要一直while循环?为什么引入Selector监管者后,性能就优化了?
深度分析一下吧。
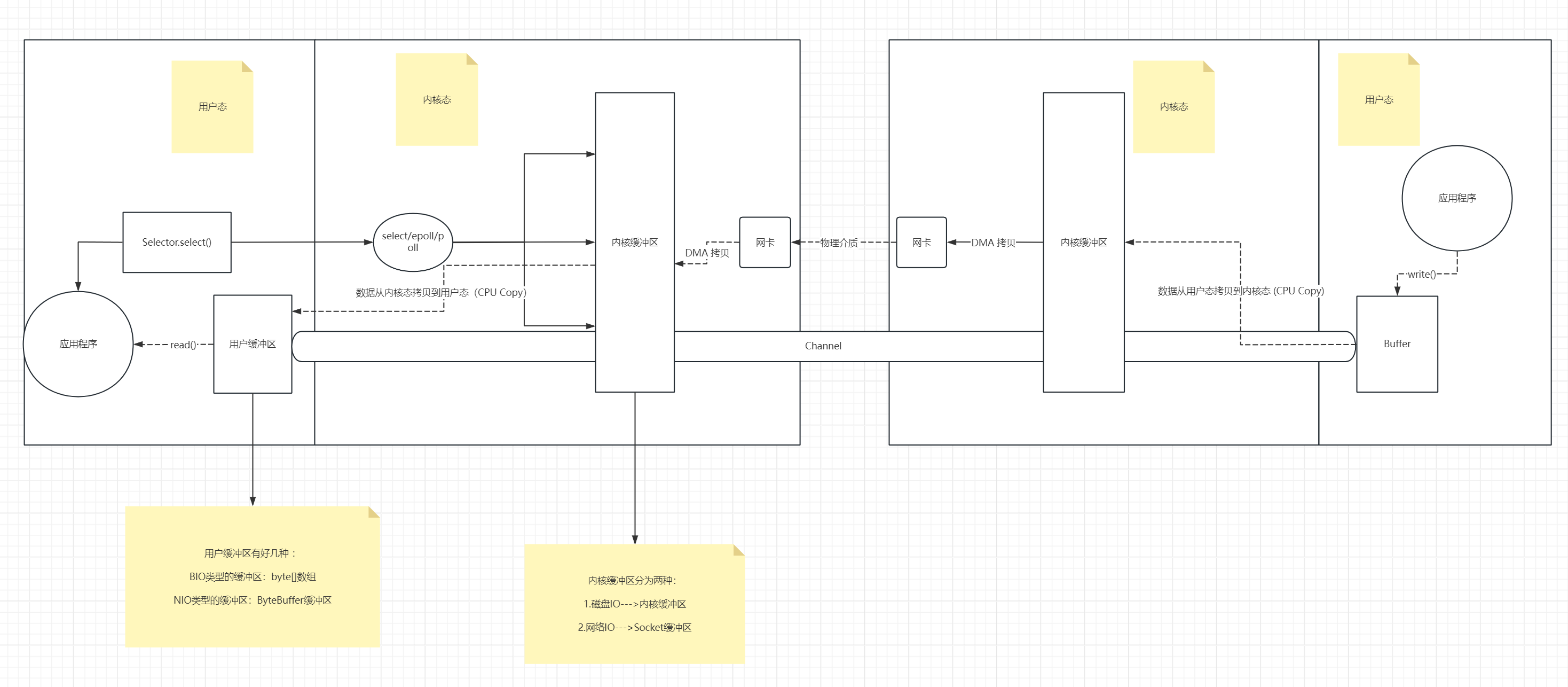
首先明白一个点:调用read或write或accept这些方法,实际上需要从用户态陷入内核态,在内核态中去调用系统函数才能真正的执行对应方法,然后再调相关的硬件驱动,最终才调用到具体的硬件。
可以简单的这样理解:用户态就是我们编写的java代码,内核态就是操作系统内核的代码。我们在用户态做while循环,就是不断的轮询陷入内核去询问内核的缓冲区 "你有read或write或accept事件触发了吗?",如果没有,那么也不阻塞。如果有,那么会拷贝内核缓冲区数据到用户态进行处理。
这就是同步非组塞,我们需要时刻轮询陷入内核询问是否处理完结果了,我们还需要去管理这个过程。
不断的while循环,实际上是不断的陷入内核,开销是极大的。
未引入Selector前,我们的性能消耗为:n次从用户态陷入内核态的切换消耗性能 + n次内核轮询询问是否有accept或read或write事件触发的性能消耗
所以要引入Selector监管者:就是selector.select()方法的调用监管
把所有的Channel,无论是ServerSocketChannel,还是SocketChannel都加入到Selector中。当调用selector.select()时,表示一次就把所有注册的SC或SSC都陷入内核,在内核中会不断的轮询监听SC或SSC,在内核中会不断的监听”注册到SSC或SC是否有accept或read或write事件的触发呢?“
如果没有事件发生,selector.select()会一直阻塞!但是selector.select()只是在用户态阻塞等待着的,而它在内核中还是会不断的去做轮询,不断的去询问内核缓存区 "注册在Selector上的SC或SSC是否有accept等事件的触发呢?",如果有,那么会把内核缓冲区的数据拷贝到用户态,然后进行用户态进行处理该拷贝的数据(插一嘴,如果一次拷贝不完,那么会再一次调用selector.select()去拷贝内核缓冲区的数据)。如果没有,那么继续轮询。
引入Selector前,我们的性能消耗为:1次从用户态陷入内核态的切换消耗性能 + n次内核轮询询问是否有accept或read或write事件触发的性能消耗
总结:
引入Selector这个监管者后,我们降低了(n-1)次从用户态陷入内核态的切换消耗性能
- 引入Selector后,Server服务器端代码的具体步骤如下:
具体步骤如下:
第一步:当SSC,SC注册到Selector对象后,SSC,SC对象都会被保存到keys中。
第二步:当selector.select()监控到SSC实际触发了Accept状态事件或SC实际触发了Read或Write状态事件后,会把这些实际触发了Accept状态事件的SSC对象 或 实际触发了Read或Write状态事件的SC对象保存到SelectionKeys中。为什么可以这样?因为SC或SSC事先已经在keys这个HashSet中完成了register存储!!selector.select()监控到事件发生后,只是把SSC或SC对象引用做了一个迁移存储。
第三步:后续我们迭代器遍历的就是SelectionKeys这个触发事件Channel集合。一旦事件处理完毕后,就应该把该事件对应的SSC或SC对象从SelectionKeys中删除掉
第四步:当再一次发生相同或不同类型事件时,selector.select()方法会再一次监控到事件的发生,再重新把SC或SSC的对象引用从keys这个HashSet迁移存储到SelectionKeys这个HashSet中!这样才是良性的循环。
补充说明:
1.等于说,无论是keys还是SelectionKeys,存储的都是SSC对象或SC对象。
2.还有一点需要注意:在keys中第一次存储SSC,SC对象时,是真正new创建出SSC,SC对象。但在SelectionKeys再进行存储时,其实就是把SSC,SC对象的引用复制到SelectionKeys中!
3.理论上:keys中存储的SSC或SC对象的数量是要大于等于selectionKeys中存储的SSC或SC的数量。因为有的SSC,SC没有触发事件状态,那么只会在keys中存储着,而不会移动迁移到selectionKeys中。
4.虽然客户端越来越多,注册的SocketChannel就会越来越多,但是注册的ServerSocketChannel一直只有一个
- 具体代码如下:
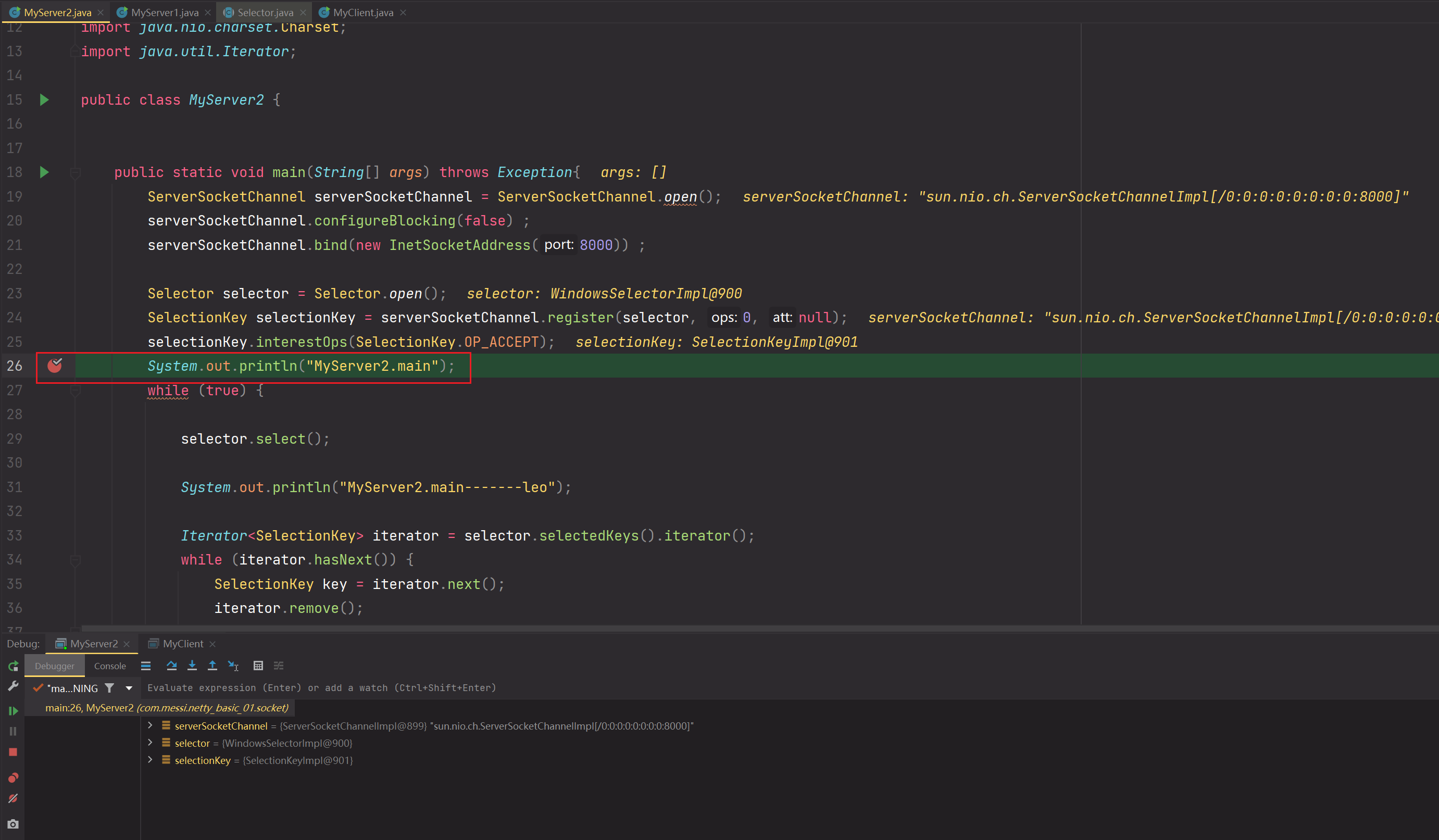
public class MyClient {public static void main(String[] args) throws Exception{SocketChannel socketChannel = SocketChannel.open();socketChannel.connect(new InetSocketAddress(8000)) ;System.out.println("-------------------------------");}}public class MyServer2 {public static void main(String[] args) throws Exception{//获取ServerSocketChannelServerSocketChannel serverSocketChannel = ServerSocketChannel.open();//监听绑定端口8000serverSocketChannel.bind(new InetSocketAddress(8000));//设置为非阻塞serverSocketChannel.configureBlocking(false);//获取Selector监管者Selector selector = Selector.open();//把ServerSocketChannel注册到Selector监管者上。实际上register注册存储到的是Selector的keys这个HashSet中SelectionKey selectionKey = serverSocketChannel.register(selector, 0, null);//添加感兴趣的事件:ACCEPTselectionKey.interestOps(SelectionKey.OP_ACCEPT) ;System.out.println("MyServer2.main");while (true) {//应用层阻塞等待监听Selector注册的所有Channel对应的所有事件状态,但是在内核层会不断的轮询询问是否事件触发开启//当内核层监听到有事件触发,那么应用层会停止等待,并且会把该触发事件对应的Channel存储到Selector对应的SelectionKeys这个HashSet中//如何存储到SelectionKeys中的?是从keys中拷贝对象引用到SelectionKeys中selector.select();System.out.println("-----------------MyServer2---------------------");//获取的是触发事件的所有Channel对象,即SelectionKeys这个HashSet中的所有Channel对象Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();//使用迭代器进行遍历,为了使用完毕后就把Channel从SelectionKeys中删除while (iterator.hasNext()) {SelectionKey key = iterator.next();//把使用完毕的触发事件Channel从SelectionKeys中删除,避免空指针异常//举个例子:如果不删除,第二次进入channel.accept()返回的是null,那么自然就会空指针异常!所以处理完事件后要把Channel从SelectionKeys中及时删除,但keys中一直保留着register注册的Channeliterator.remove();if(key.isAcceptable()) {ServerSocketChannel channel = (ServerSocketChannel) key.channel();//获取到连接的客户端ChannelSocketChannel sc = channel.accept();//设为非阻塞sc.configureBlocking(false);//实际上register注册存储到的是Selector的keys这个HashSet中SelectionKey scKey = sc.register(selector, 0, null);//添加感兴趣的事件scKey.interestOps(SelectionKey.OP_READ);} else if(key.isReadable()) {try {//此时为SocketChannel的读事件SocketChannel sc = (SocketChannel) key.channel();ByteBuffer buffer = ByteBuffer.allocate(5);//把Channel管道中的数据读取到Buffer缓冲区int read = sc.read(buffer);if(read == -1) {//当客户端调用socketChannel.close()请求与服务器断开时,会触发一个READ事件给服务器端的。但是这个READ事件比较特殊,服务器端处理后sc.read(buffer)==-1,此时必须cancel()一下//cancel()方法的调用表示服务器已经完成对客户端socketChannel.close()断开的处理。//如果不调用cancel,那么服务端会一直认为没有处理完该特殊的READ事件,会一直反复调用selector.select()方法key.cancel();} else {//转换成读模式buffer.flip();//解码buffer缓冲区中的数据成字符类型CharBuffer decode = Charset.forName("UTF-8").decode(buffer);//打印输出System.out.println("decode.toString() = " + decode.toString());}} catch (IOException e) {e.printStackTrace();//这里是做健壮性的处理//当出现异常时,客户端与服务器也是断开,此时服务器会接受到一个断开的READ事件。所以需要调用cancel方法处理该READ事件key.cancel();}}}}}}- debug测试
1.debug启动Server端
2.debug启动Client端

3.测试客户端连接服务端,服务端selector.select()监听到
客户端连接上服务器后,selector.select()方法就会监听到该连接事件,后续就会把该连接事件对应的Channel对象存储到SelectionKeys

4.测试客户端write写,服务端selector.select()监听到READ事件的产生,后续会把该READ事件对应的Channel存储到SelectionKeys中,使用channel.read(buffer),一次处理不完的话会多次调用selector.select()
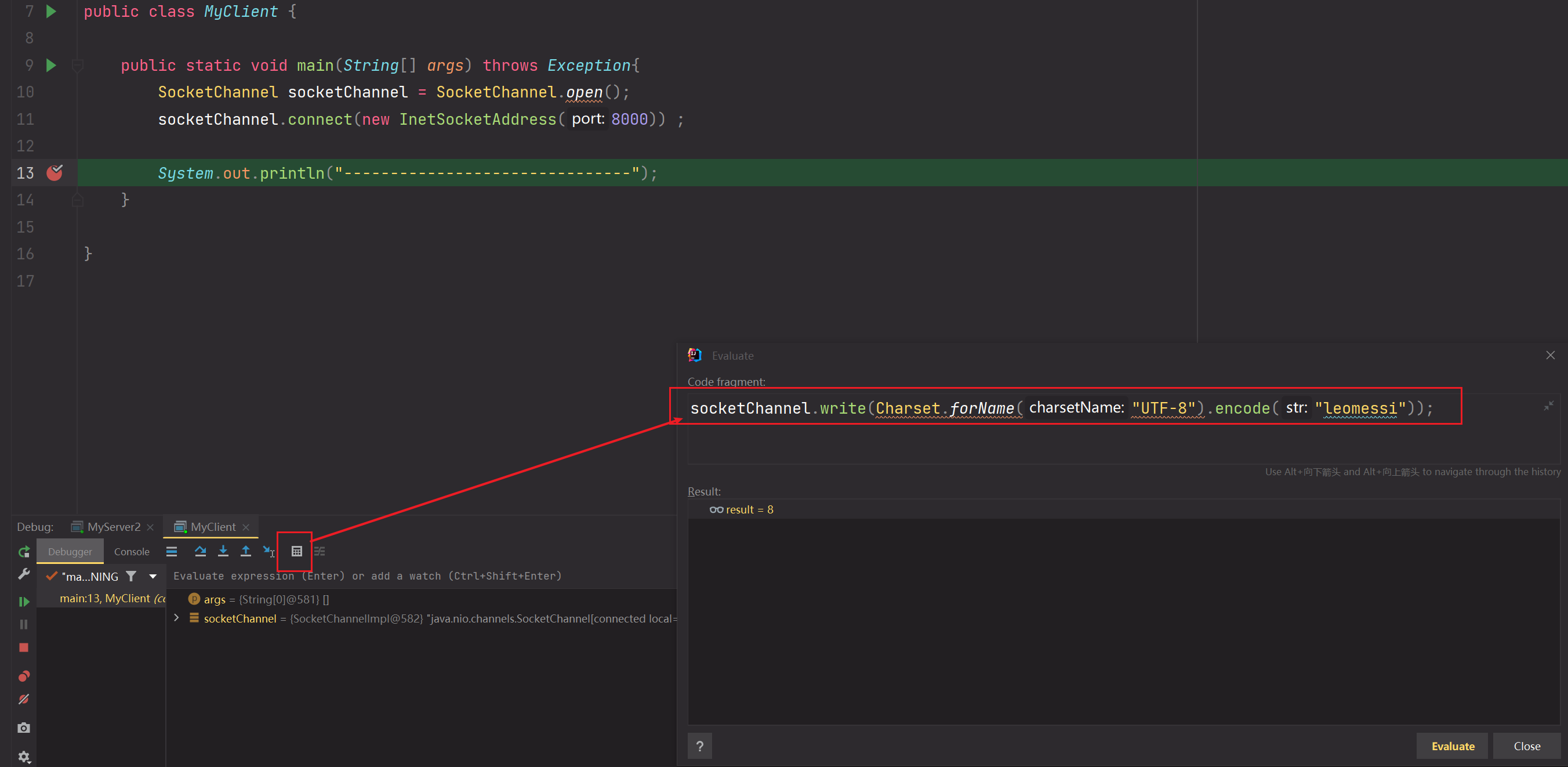
Server端:
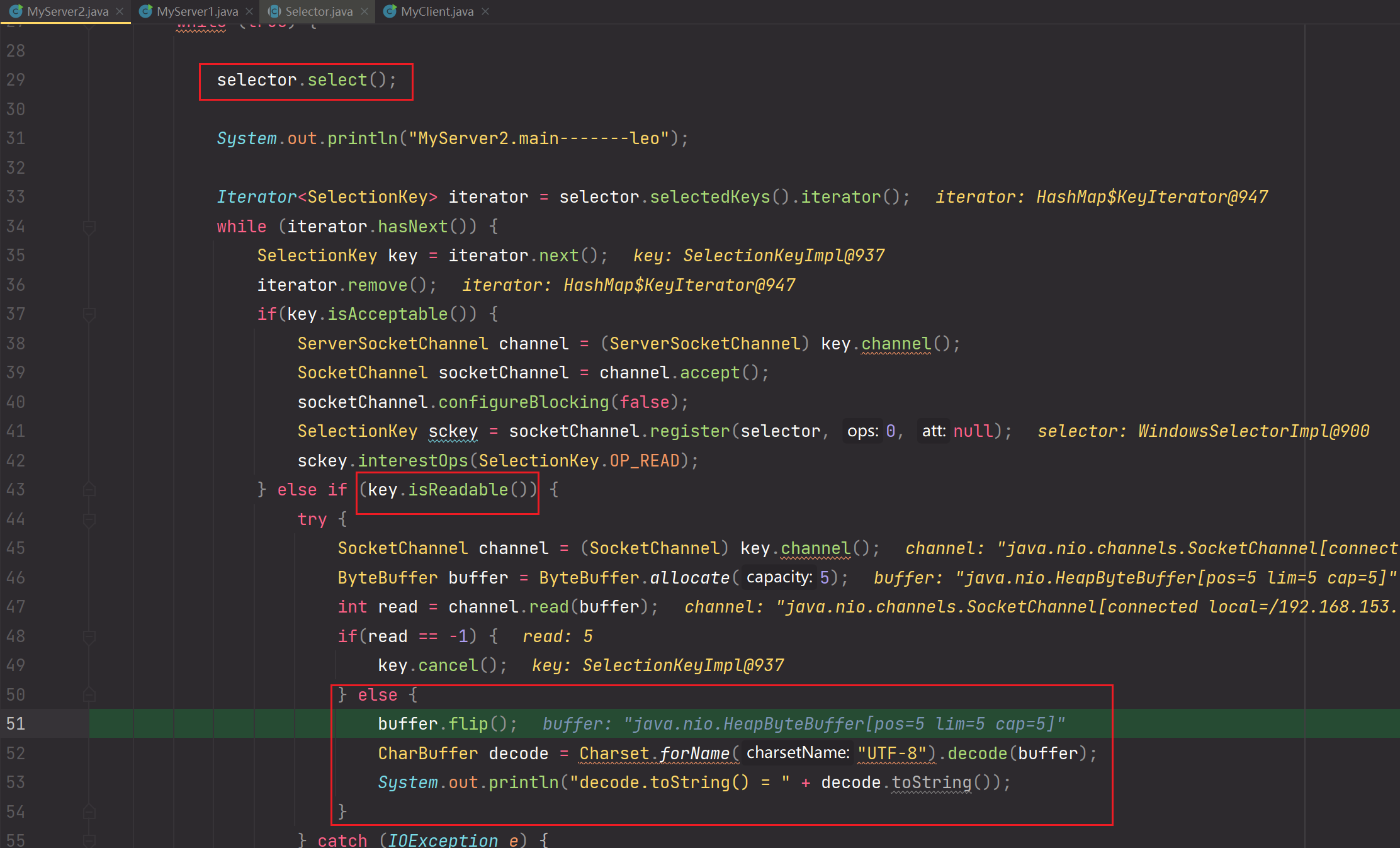
5.测试客户端socketChannel.close(),服务端selector.select()监听到该特殊的READ事件的产生,后续会把该特殊READ事件对应的Channel存储到SelectionKeys中,使用key.cancel()处理。如果不使用key.cancel()进行处理的话,会一直调用selector.select()

Server端:

- 细节分析1:
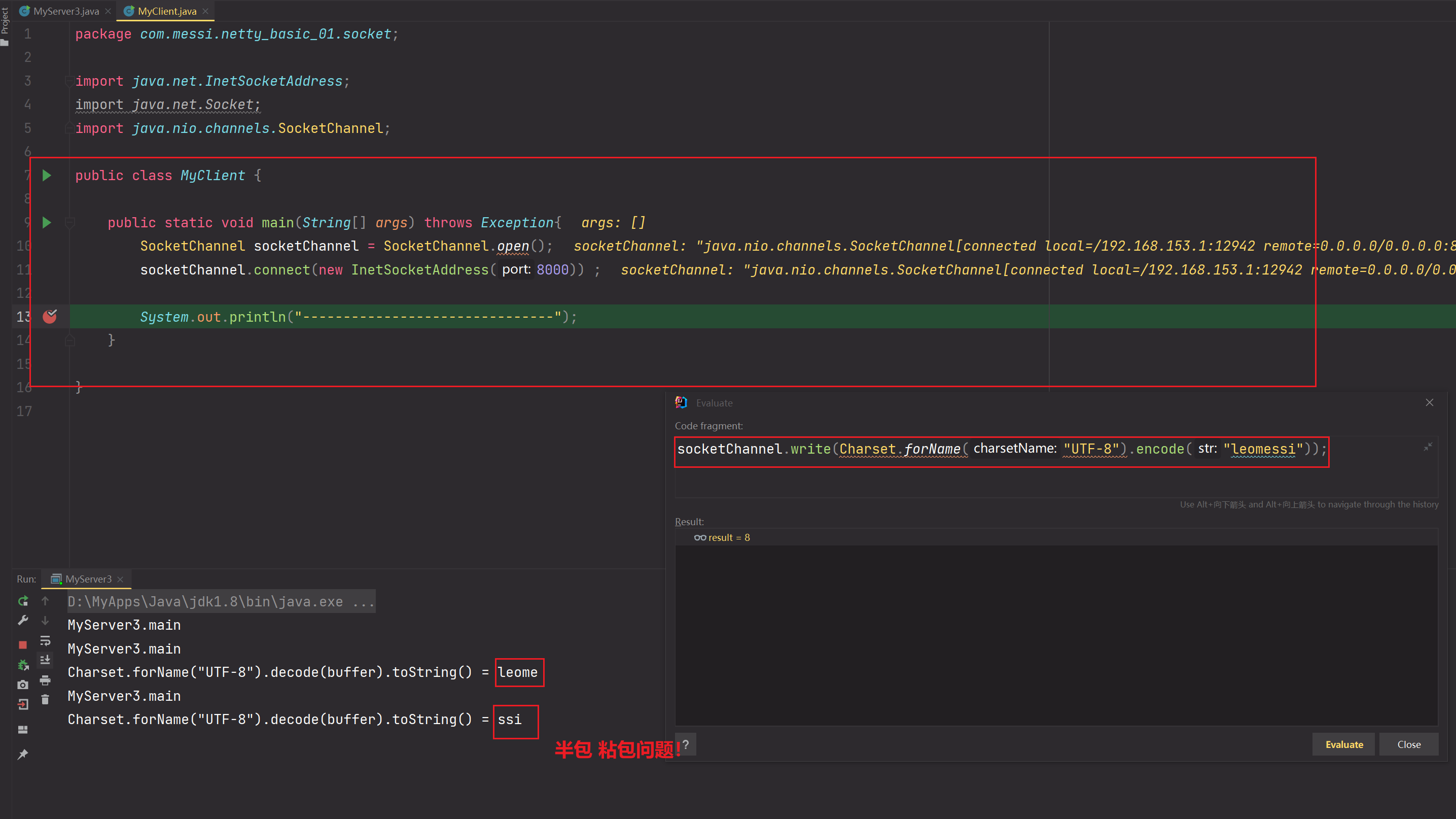
客户端一次发送数据"leomessi",如果缓冲区ByteBuffer大小为5,那么一次读取不完客户端发送的数据,会分批处理客户端发送的数据,直到处理完毕,那么会while true循环2次selector.select(),服务端第一次调用selector.select()处理的是leome,第二次调用select执行的是ssi。
结论:
1.当client客户端连接服务器发起操作后,服务器必须全部处理完成后整个交互才算结束,如果没有全部处理完成,select方法就会被一直调用
上述的案例中,由于leomessi这个数据一次没有处理完,所以才会被调用多次了
2.在某些特殊的操作下,服务器端无法处理,那么select方法就会被频繁的调用 (如:socketChannel.close()的调用,服务端不可以通过channel.read(buffer)简单的进行处理,需要调用cancle()处理该断开的READ事件)
- 细节分析2:针对于细节分析1中结论第二点,会需要cancle方法的引入
为什么引入cancle方法?
客户端与服务器端建立连接后,过一段时间后,SocketChannel调用close方法与服务端断开。此时相当于客户端发送了一个READ事件给到服务端,只不过这个READ事件十分特殊,它是一个告知服务端我要断开的READ事件,服务端需要进行特殊处理,而不是简单的调用read(buffer)!针对于这种特殊的READ事件,在处理时需要调用cancle方法。如果不这样处理,会给服务端一种错觉,总感觉还有数据没有处理完成,会导致selector.select()一直轮询访问内核,性能消耗极大。
- 解决半包粘包 并且 引入attatchment附件机制
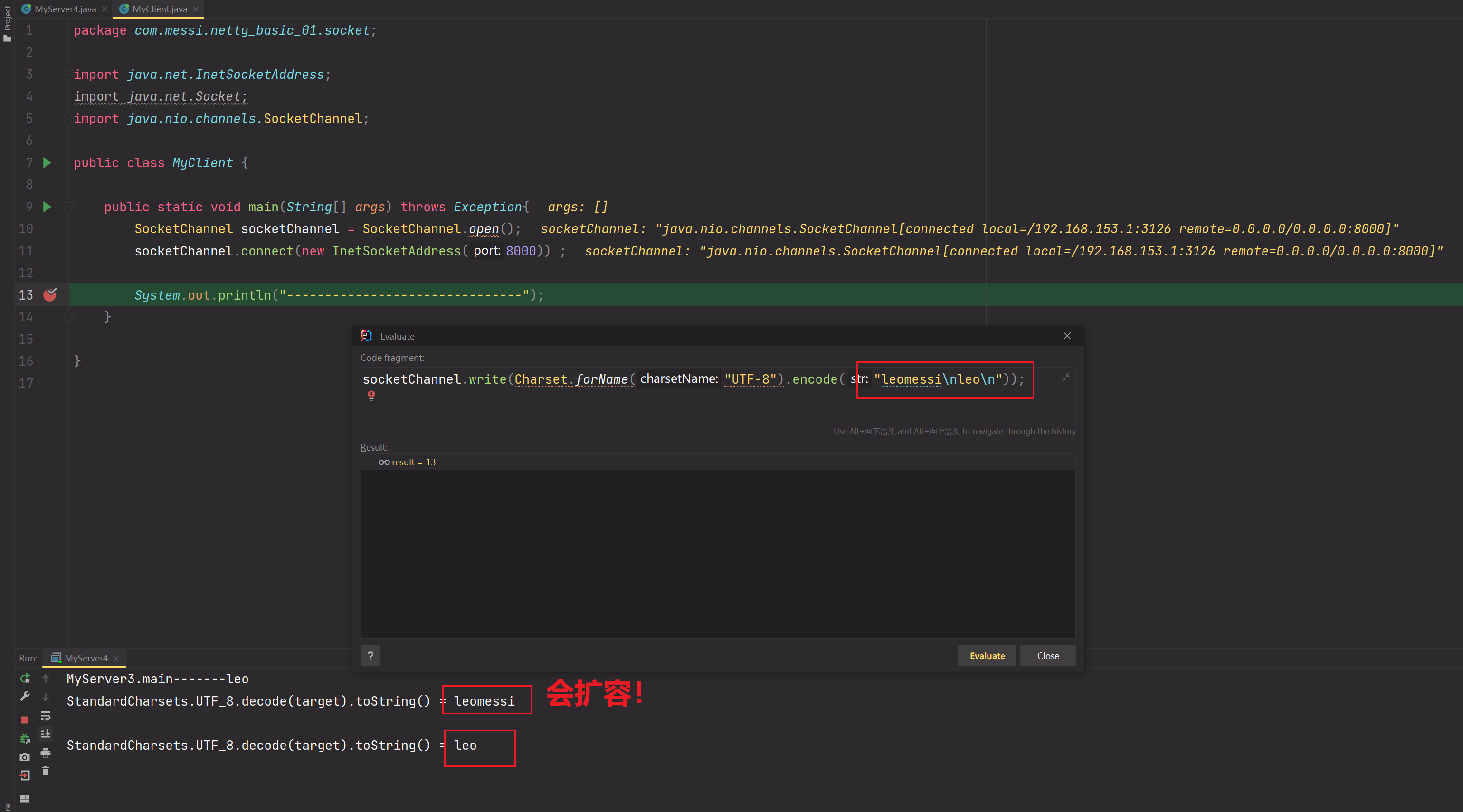
先说半包粘包问题:
当发送数据"leomessi",如果对方ByteBuffer缓冲区大小只有5,那么第一次接收到的为 leome,第二次接收到的为ssi。其实这就是半包粘包的现象,原本服务端想以完整leomessi进行接收的
为解决该问题,引入相关方法,但是又出现了一个新问题:
如果发送的数据为"leo\nmessi"在解决半包粘包过程中,由于ByteBuffer缓冲区为7,那么第一次读取到的是leo\nmes,通过解决半包粘包方法可知,compact会让mes迁移到最前面等待下一次,但是由于每一次我们都创建的是新ByteBuffer缓冲区,所以mes丢失!所以最终输出的是leo 和 si。
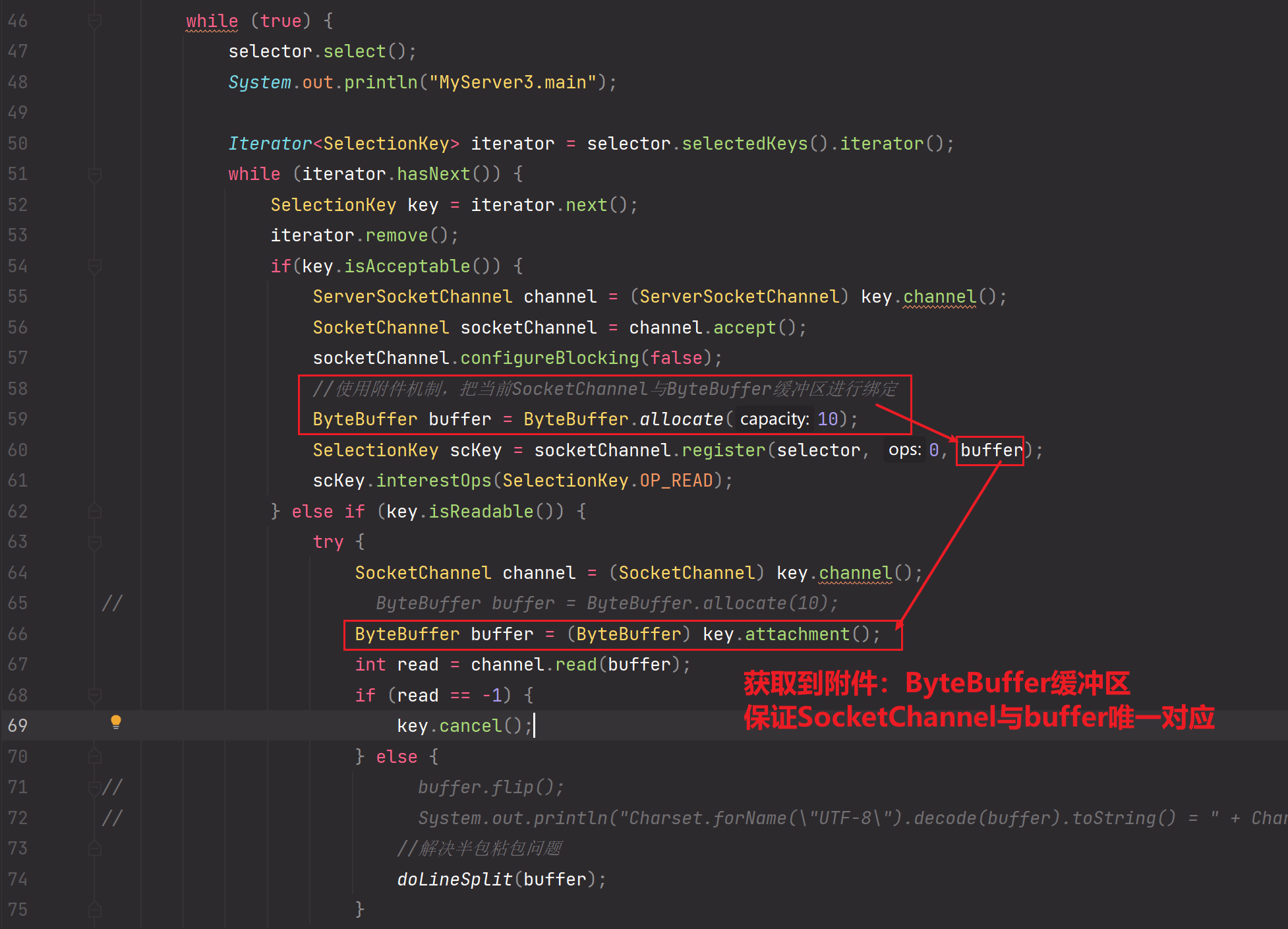
为解决该问题,引入attatchment机制,把Channel与ByteBuffer绑定!具体操作就是在Channel.register的时候,把ByteBuffer作为附件注册给该Channel,之后直接通过Channel获取附件即可拿到对应唯一的ByteBuffer缓冲区,只要缓冲区保持唯一,那么就不会出现compact后数据丢失的情况
首先演示半包粘包的问题:
public class MyServer3 {public static void main(String[] args) throws Exception{ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.bind(new InetSocketAddress(8000));serverSocketChannel.configureBlocking(false);Selector selector = Selector.open();SelectionKey selectionKey = serverSocketChannel.register(selector, 0, null);selectionKey.interestOps(SelectionKey.OP_ACCEPT);while (true) {selector.select();System.out.println("MyServer3.main");Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();while (iterator.hasNext()) {SelectionKey key = iterator.next();iterator.remove();if(key.isAcceptable()) {ServerSocketChannel channel = (ServerSocketChannel) key.channel();SocketChannel socketChannel = channel.accept();socketChannel.configureBlocking(false);SelectionKey scKey = socketChannel.register(selector, 0, null);scKey.interestOps(SelectionKey.OP_READ);} else if (key.isReadable()) {try {SocketChannel channel = (SocketChannel) key.channel();ByteBuffer buffer = ByteBuffer.allocate(5);int read = channel.read(buffer);if (read == -1) {key.cancel();} else {buffer.flip();System.out.println("Charset.forName(\"UTF-8\").decode(buffer).toString() = " + Charset.forName("UTF-8").decode(buffer).toString());}} catch (IOException e) {e.printStackTrace();key.cancel();}}}}}}
服务端:启动

客户端:
向服务端发送数据leomessi,由于服务端ByteBuffer过小,导致半包粘包问题
解决方法:
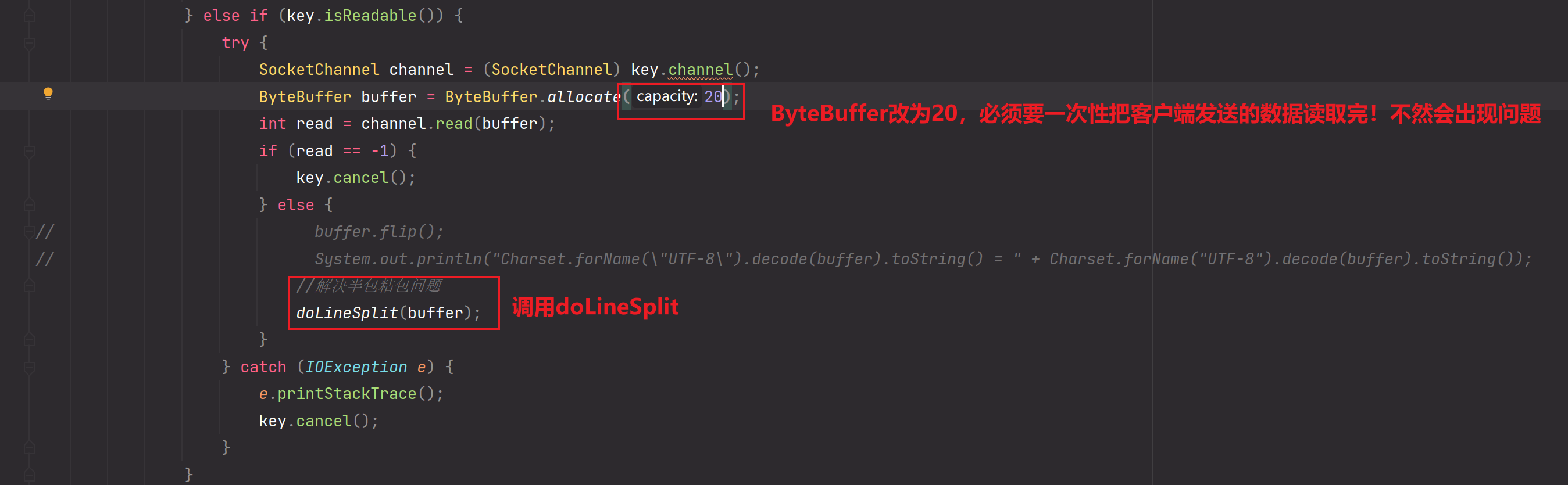
再测试:解决半包粘包问题
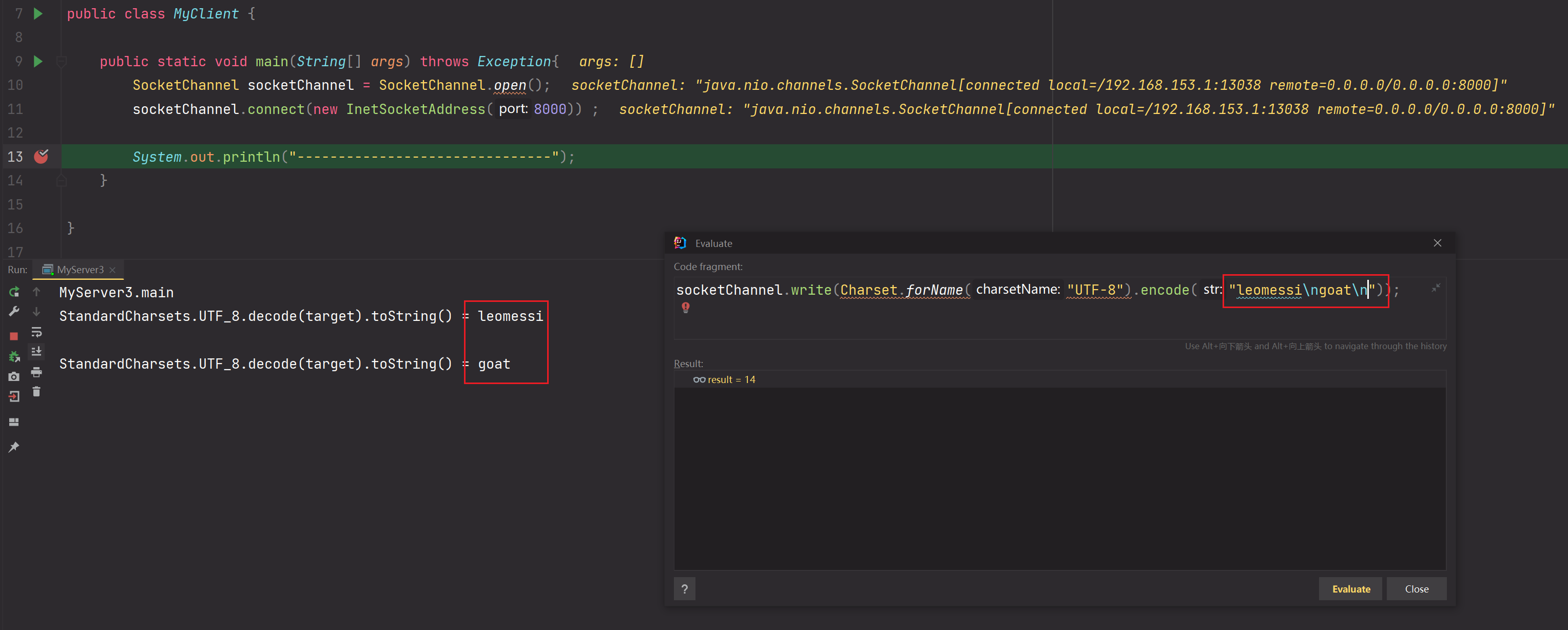
但是出现新问题!通过上面解决问题步骤可知,我们必须要把ByteBuffer缓冲区设为"一次可以读取完客户端发送的数据的大小",如果不这样设置,会出现问题!演示如下:

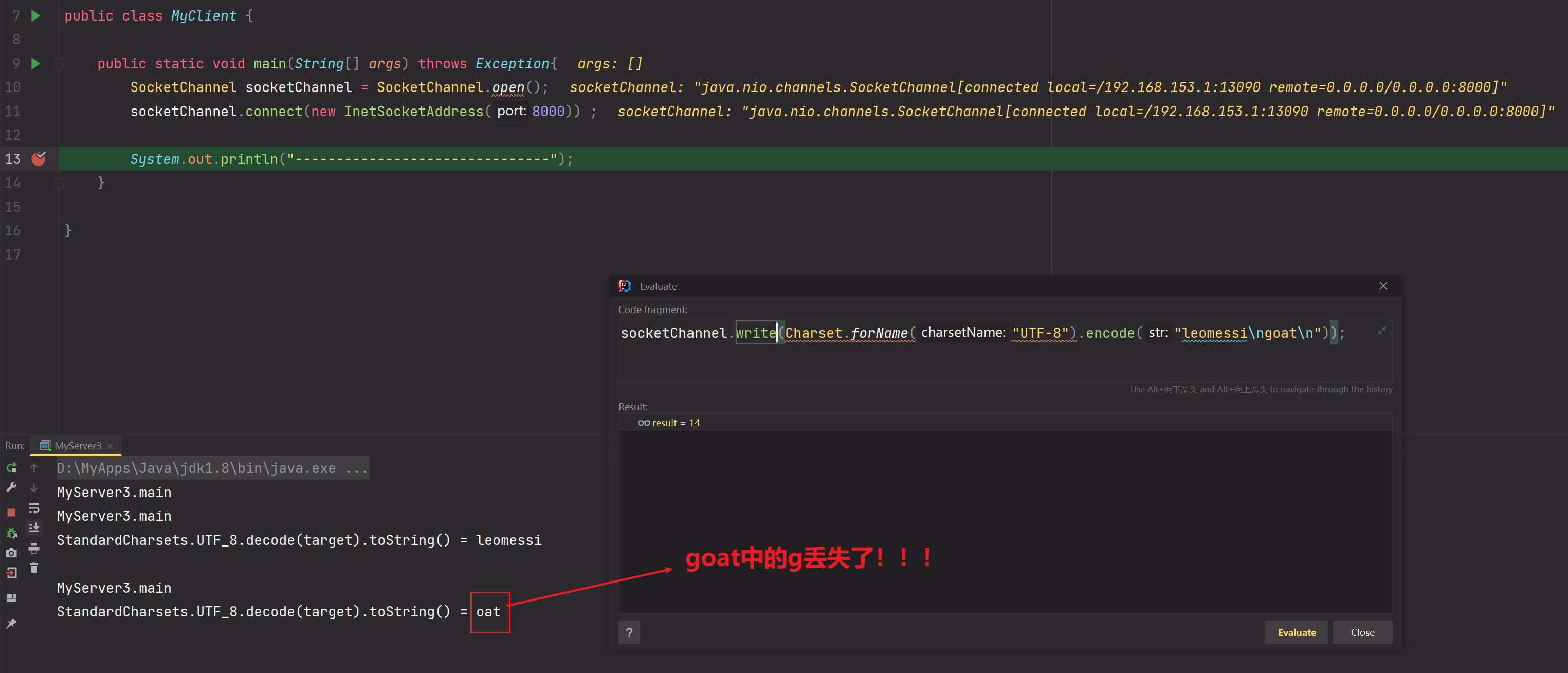
为什么会出现这种问题?
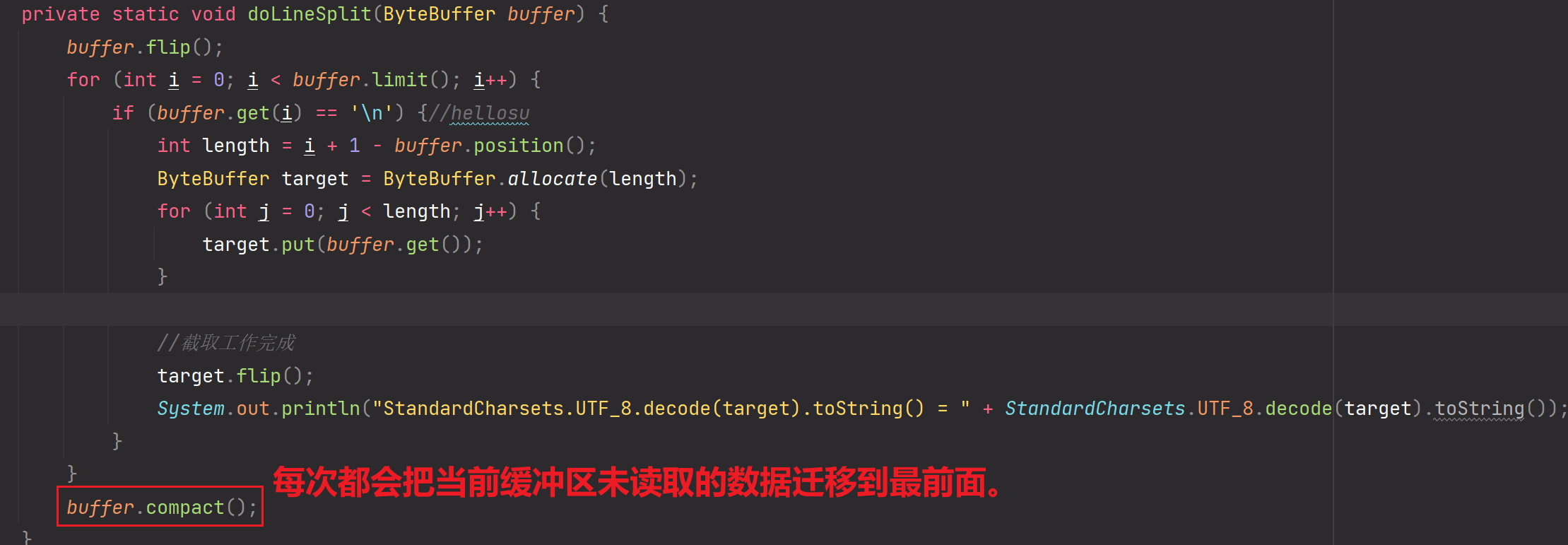

解决方法,把Channel与Buffer进行绑定,使用附件机制进行绑定!!!
测试:
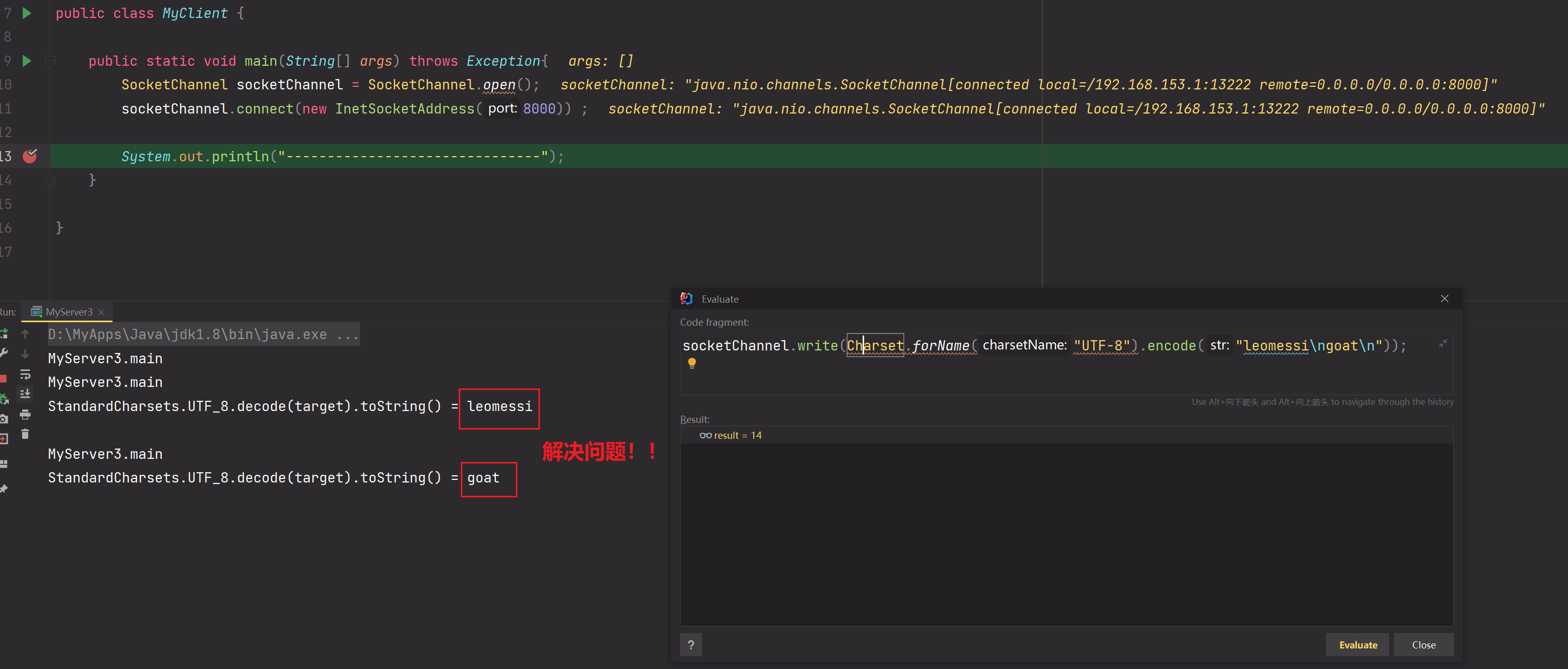
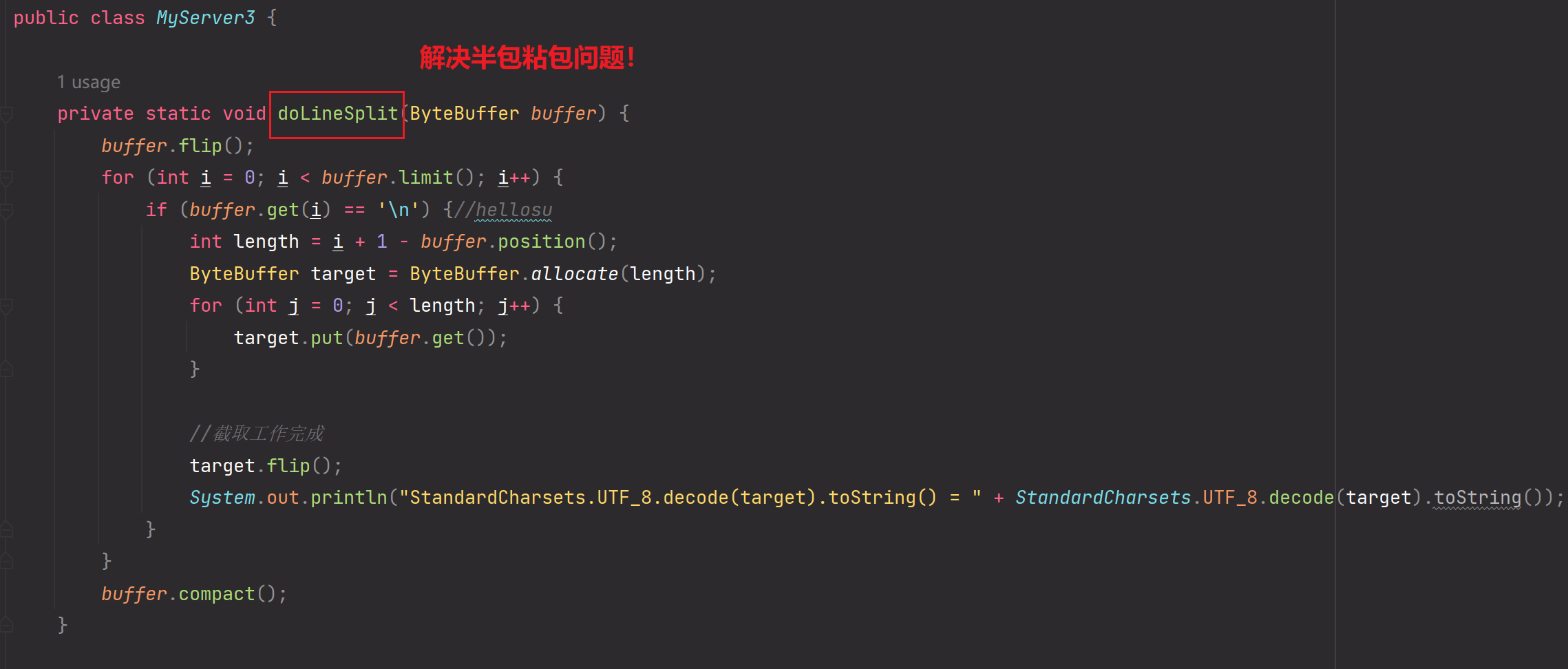
解决半包粘包过程中,由于ByteBuffer不断重新创建导致数据丢失的问题:
public class MyServer3 {private static void doLineSplit(ByteBuffer buffer) {buffer.flip();for (int i = 0; i < buffer.limit(); i++) {if (buffer.get(i) == '\n') {//hellosuint length = i + 1 - buffer.position();ByteBuffer target = ByteBuffer.allocate(length);for (int j = 0; j < length; j++) {target.put(buffer.get());}//截取工作完成target.flip();System.out.println("StandardCharsets.UTF_8.decode(target).toString() = " + StandardCharsets.UTF_8.decode(target).toString());}}buffer.compact();}public static void main(String[] args) throws Exception{ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.bind(new InetSocketAddress(8000));serverSocketChannel.configureBlocking(false);Selector selector = Selector.open();SelectionKey selectionKey = serverSocketChannel.register(selector, 0, null);selectionKey.interestOps(SelectionKey.OP_ACCEPT);while (true) {selector.select();System.out.println("MyServer3.main");Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();while (iterator.hasNext()) {SelectionKey key = iterator.next();iterator.remove();if(key.isAcceptable()) {ServerSocketChannel channel = (ServerSocketChannel) key.channel();SocketChannel socketChannel = channel.accept();socketChannel.configureBlocking(false);//使用附件机制,把当前SocketChannel与ByteBuffer缓冲区进行绑定ByteBuffer buffer = ByteBuffer.allocate(10);SelectionKey scKey = socketChannel.register(selector, 0, buffer);scKey.interestOps(SelectionKey.OP_READ);} else if (key.isReadable()) {try {SocketChannel channel = (SocketChannel) key.channel();
// ByteBuffer buffer = ByteBuffer.allocate(10);ByteBuffer buffer = (ByteBuffer) key.attachment();int read = channel.read(buffer);if (read == -1) {key.cancel();} else {
// buffer.flip();
// System.out.println("Charset.forName(\"UTF-8\").decode(buffer).toString() = " + Charset.forName("UTF-8").decode(buffer).toString());//解决半包粘包问题doLineSplit(buffer);}} catch (IOException e) {e.printStackTrace();key.cancel();}}}}}}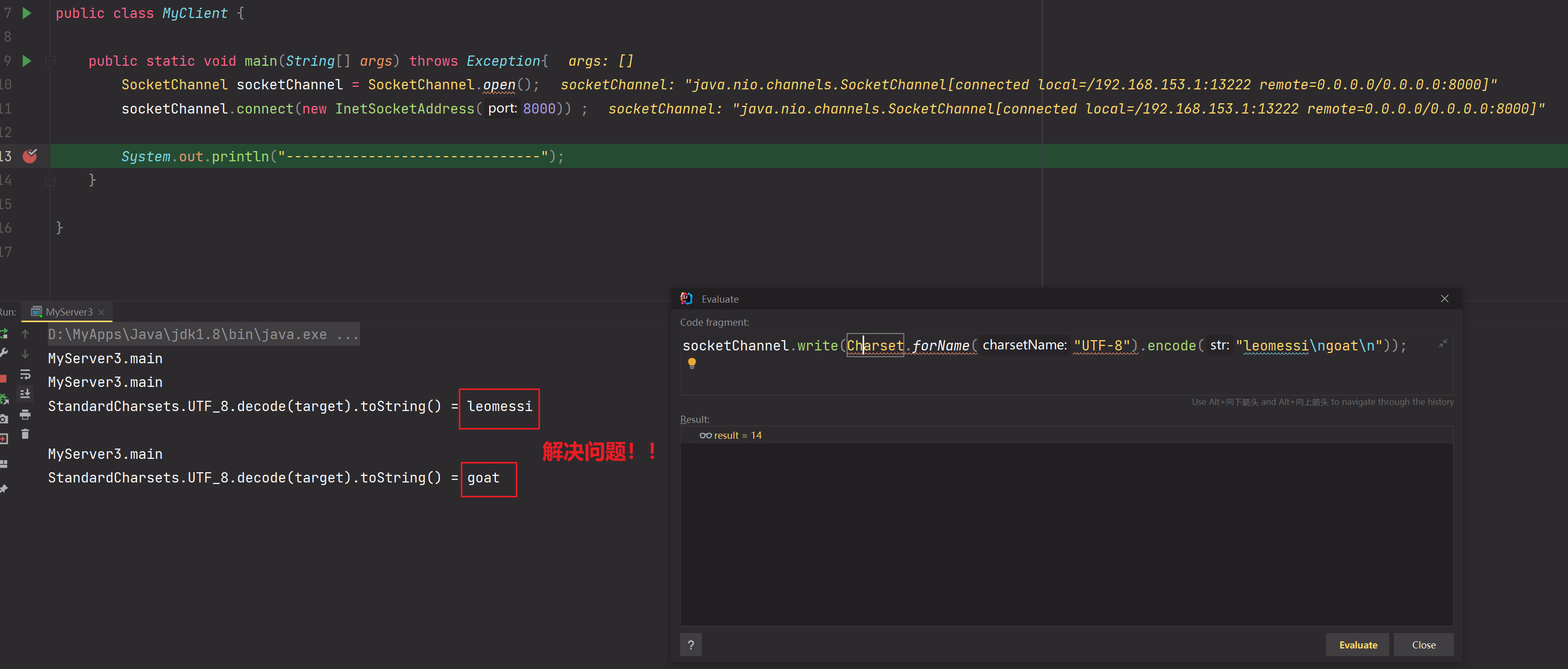
补充:

假如说:我们不仅想要把ByteBuffer缓冲区作为附件,还想要其他的数据作为附件,该咋怎么办???
方法1:封装多个attatchment元素成一个集合然后register。优点:不存在僵化,后续如果有新的attatchment元素增加,只需要add到集合中即可。缺点:不具有业务含义
方法2:封装多个attatchment元素成一个类然后register。优点:具有业务含义。缺点:存在僵化,如果后续有新的attatchment元素增加,那就无法再增加。当然:类里面可以添加一个集合属性!这样就完美解决了类的缺点
为什么封装成一个类后才能具有业务含义?一个属性name="小明",如果单看name这个属性,你知道name代表的是一个狗的名字还是人的名字,只有把name封装到一个类中,比如 public class User {private String name="小明"}后才可以体现该name代表的是一个人名
- 解决缓冲区大小不够导致频繁循环。需要扩容解决该问题
客户端发送数据'leomessi\nleo'给服务器,但是Buffer缓冲区大小只有5字节,所以第一次只能接收到leome,由于在接收的数据中查询不到\n,所以不会读取任何字节,所以buffer.compact()调用时,会把未读取的leome迁移到最前面,如下:

演示问题如下:
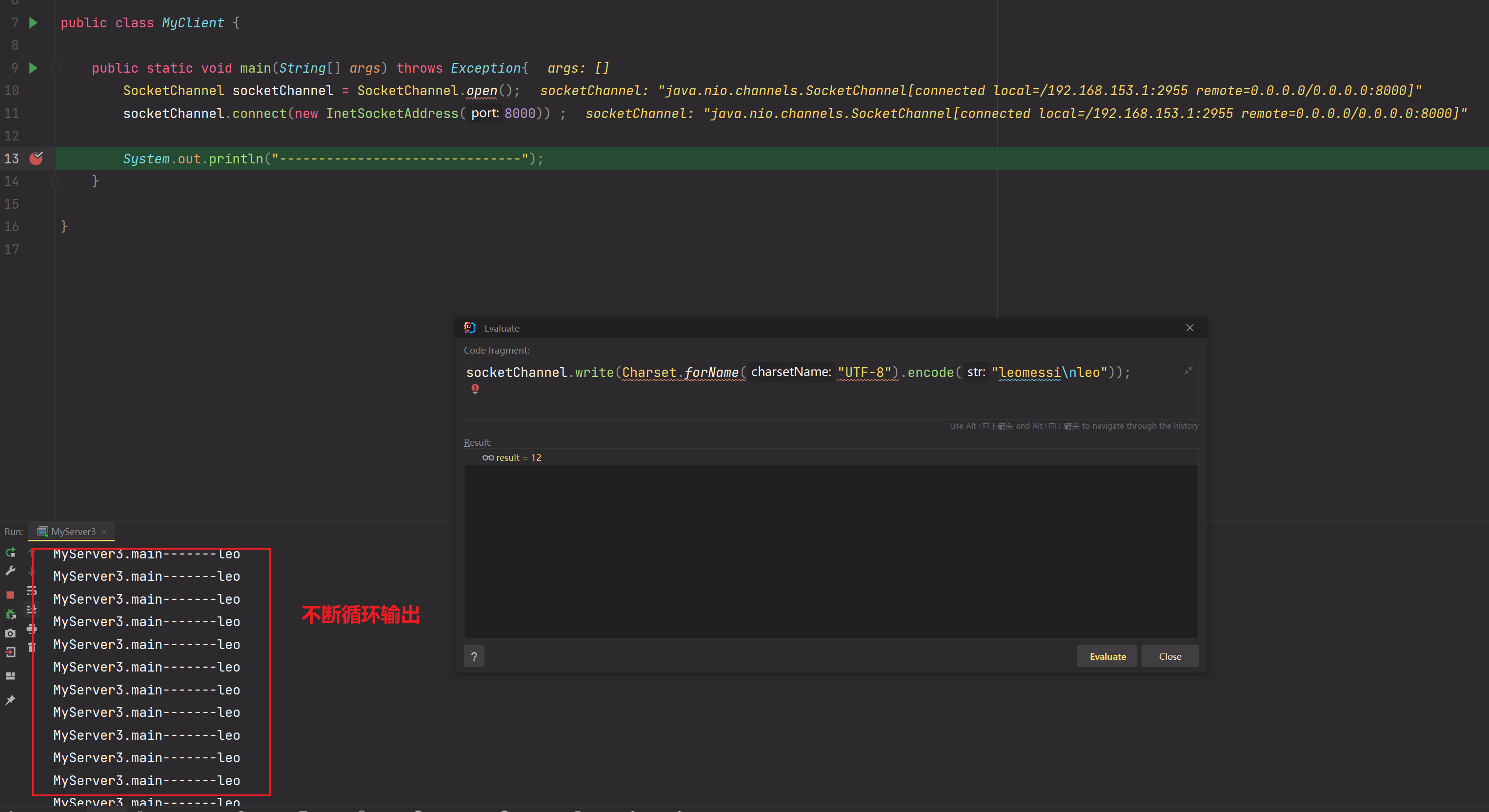
分析:


解决方法:
扩容,每次按照2倍扩容。
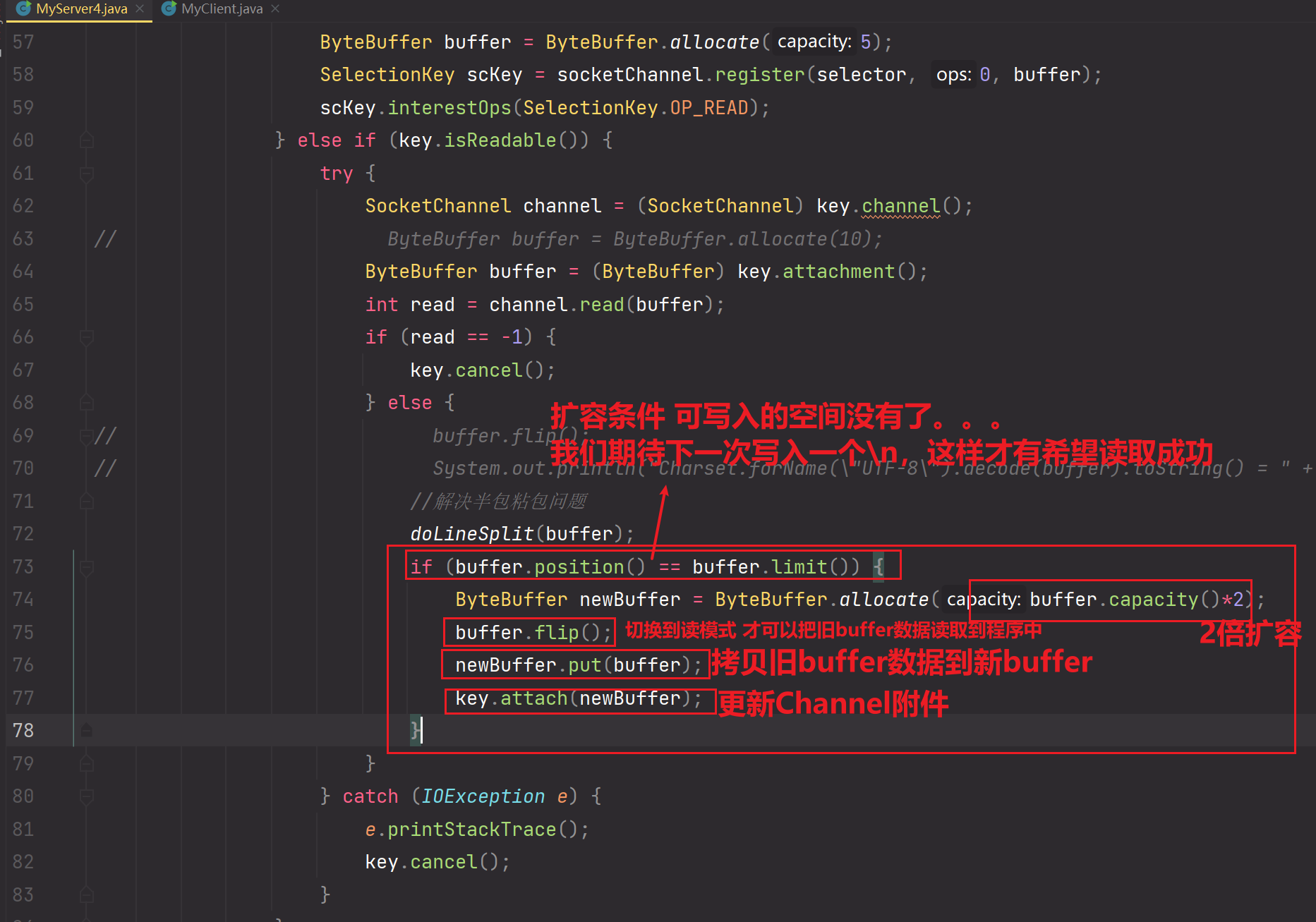
演示:
5.2.4 补充几个仍然存在的问题
1.
除了扩容需要我们清楚,我们依然要考虑缩容的问题:
为什么要缩容?
在第一段时间操作时,由于ByteBuffer缓冲区太小(也可能是客户端发送的数据过大导致后续不断扩容),我们不断的进行扩容操作。但是过了一段时间后,客户端发送的消息数据相对当前缓冲区太小,那么我们应该不断的缩小缓冲区大小,也就是缩容。如果不考虑缩容的话,那么在多线程并发的场景下,每过来一个客户端,我们都需要建立一个SocketChannel,都需要与SocketChannel对应建立一个ByteBuffer缓冲区。假设有10万个客户端与服务端连接,需要建立10万个ByteBuffer。如果ByteBuffer不在客户端发送相对小的消息数据进行合理缩容,由于ByteBuffer是占用内存的!!所以会造成极大的内存浪费!
无论是是扩容还是缩容,后续netty帮我们做的很好了。。。
2.
我们无论是进行扩容还是缩容时,需要把老ByteBuffer缓冲区的数据拷贝到新ByteBuffer缓冲区。ByteBuffer底层就是数组,需要一个个的去拷贝,效率特别低,为了优化,需要引入零拷贝机制。
3.
在网络通信过程中,如何处理解决半包粘包的问题?其实就两种方式,如下:
方法1.使用 \n 区分不同的信息数据,保证了消息的完整性。但是这种挨个字节进行检索\n的方式,效率较低。(使用\n+compact方式进行解决半包粘包问题)
方法2.使用头体分离的方式。在'头'中记录元数据,所谓元数据就是真实数据的各种信息,但是不包括真实数据本身。如:记录真实数据的大小,真实数据的类型。在'体'中记录的才是真实数据本身。
使用头体分离的话,我们就可以通过'头'中元数据中记录的真实数据的大小,然后按这个大小去读取'体'中真实数据。这样也解决了半包粘包的问题。这种方式在当前是流行的。效率较高。
如:HTTP协议,在该协议中响应头中有一个Content-Length,根据这个大小我们再去响应体中去读取Content-Length大小的真实数据!
- 补充网络知识:分包与流量控制
分包:
要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生分包。
待发送数据大于MSS(最大报文长度),TCP在传输前将进行分包。
流量控制:

5.2.5 引入服务器端的写操作
- 第一版代码
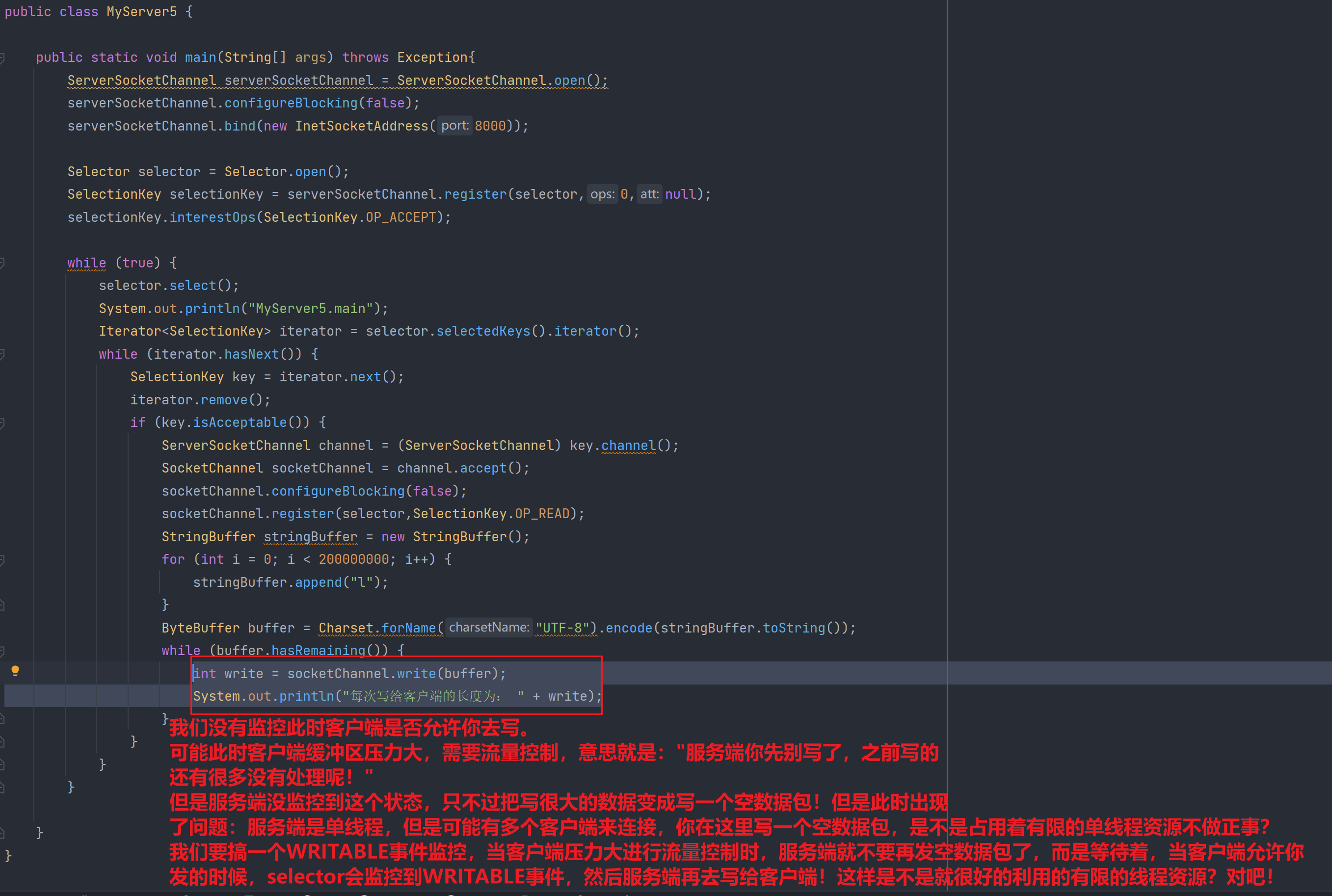
public class MyServer5 {public static void main(String[] args) throws Exception{ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.configureBlocking(false);serverSocketChannel.bind(new InetSocketAddress(8000));Selector selector = Selector.open();SelectionKey selectionKey = serverSocketChannel.register(selector,0,null);selectionKey.interestOps(SelectionKey.OP_ACCEPT);while (true) {selector.select();System.out.println("MyServer5.main");Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();while (iterator.hasNext()) {SelectionKey key = iterator.next();iterator.remove();if (key.isAcceptable()) {ServerSocketChannel channel = (ServerSocketChannel) key.channel();SocketChannel socketChannel = channel.accept();socketChannel.configureBlocking(false);socketChannel.register(selector,SelectionKey.OP_READ);StringBuffer stringBuffer = new StringBuffer();for (int i = 0; i < 200000000; i++) {stringBuffer.append("l");}ByteBuffer buffer = Charset.forName("UTF-8").encode(stringBuffer.toString());while (buffer.hasRemaining()) {int write = socketChannel.write(buffer);System.out.println("每次写给客户端的长度为: " + write);}}}}}
}public class MyClient1 {public static void main(String[] args) throws Exception{SocketChannel socketChannel = SocketChannel.open();socketChannel.connect(new InetSocketAddress(8000));int read = 0;while (true) {ByteBuffer buffer = ByteBuffer.allocate(1024 * 1024);read += socketChannel.read(buffer);System.out.println("本次读取的大小为: " + read);buffer.clear();}}}测试:
Server:

Client:
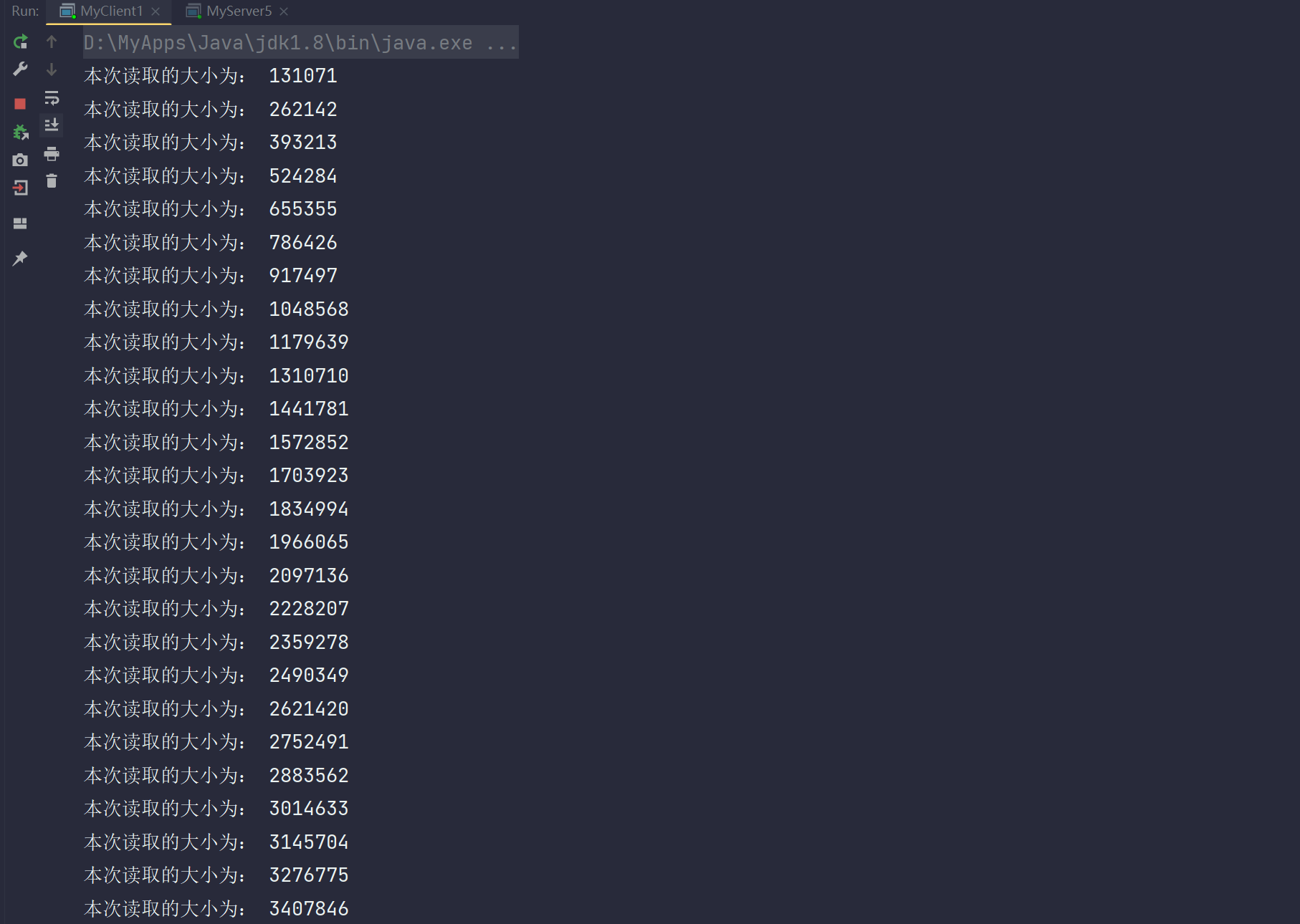
- 分析第一版存在的问题
- 解决第一版存在的问题,引出第二版代码
代码思路如图所示:

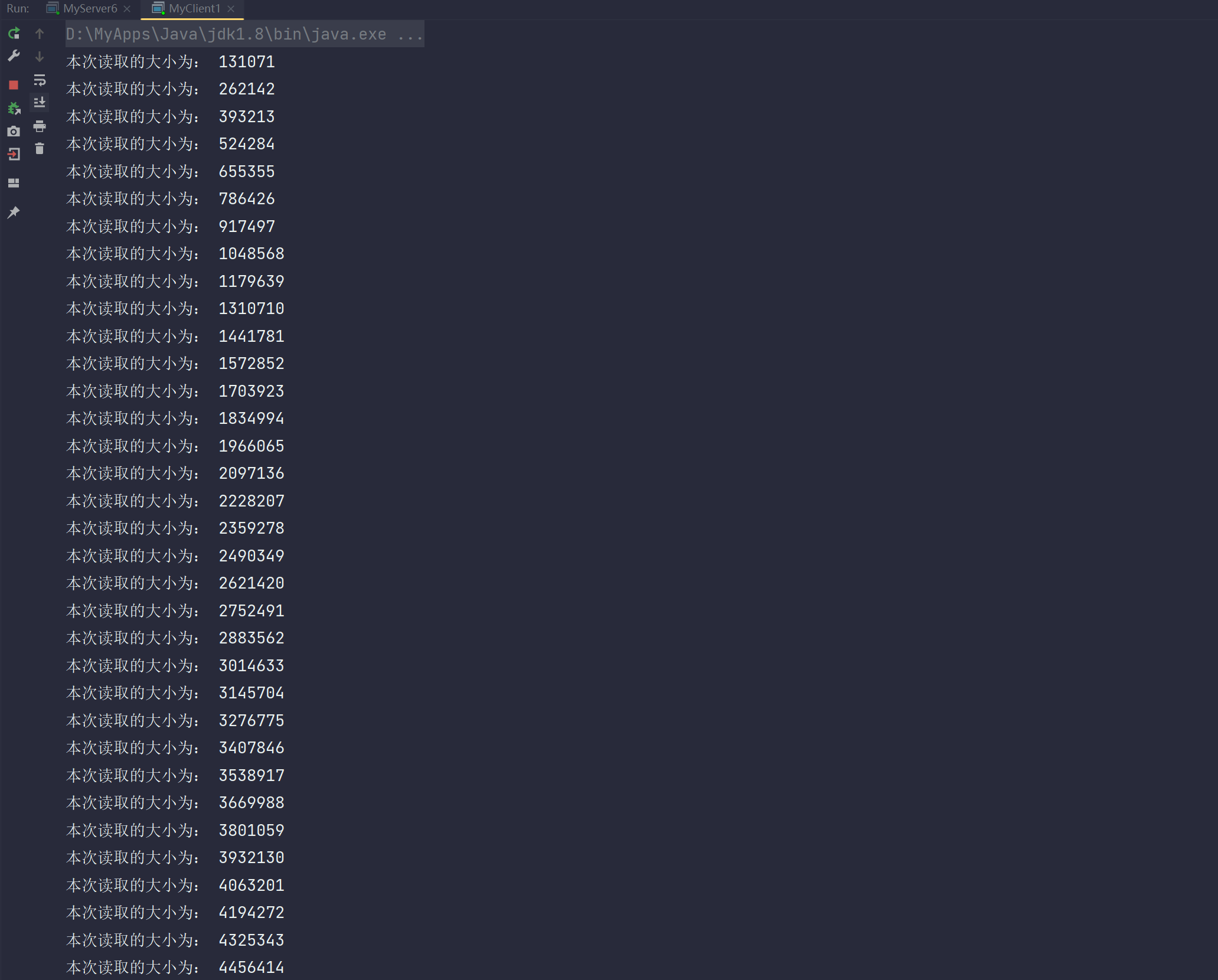
public class MyServer6 {public static void main(String[] args) throws Exception{//ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.configureBlocking(false);//服务端监听端口8000serverSocketChannel.bind(new InetSocketAddress(8000));//创建监管者Selector selector = Selector.open();//注册ServerSocketChannel到Selector监管者上。具体表现为:把该Channel存储到keys这一HashSet中serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);while (true) {//监管者调用select()在操作系统内核轮询询问文件描述符是否就绪(是否触发事件?)【应用层等待阻塞,但是在内核层一直轮询询问是否有事件触发!】// 一旦触发某一事件,则把该触发事件的Channel的引用从keys中复制copy到SelectionKeys这一HashSet中selector.select();System.out.println("MyServer6.main");//获取注册在Selector中的SelectionKeys集合Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();//遍历while (iterator.hasNext()) {SelectionKey key = iterator.next();//一旦处理完该事件,那么就要把该事件对应的Channel从SelectionKeys中删除 避免重复处理该事件iterator.remove();//连接事件if (key.isAcceptable()) {//拿到ServerSocketChannelServerSocketChannel channel = (ServerSocketChannel) key.channel();//accept监听获取到对应连接上的SocketChannelSocketChannel socketChannel = channel.accept();//设为非阻塞socketChannel.configureBlocking(false);//注册READ事件SelectionKey scKey = socketChannel.register(selector, SelectionKey.OP_READ);//拼接StringBuffer sb = new StringBuffer();for (int i = 0; i < 200000000; i++) {sb.append("s");}//创建缓冲区,默认为写模式ByteBuffer buffer = Charset.forName("UTF-8").encode(sb.toString());//把该Buffer缓冲区的数据通过SocketChannel写给client客户端int write = socketChannel.write(buffer);System.out.println("第一次写出的数据大小:" + write);//如果Buffer一次没有写完,那么需要增加WRITE事件,并且把Buffer缓冲区传递下去(共享但要保证线程安全,所以采取附件的方式)//为什么不能把Buffer设为全局变量进行共享?因为在多线程情况下,共享全局变量,产生并发安全问题。局部变量一般都是线程安全的,因为每一个线程都会在自己的栈帧中保持自己独立的局部变量//为什么要增加WRITE事件?触发WRITE事件的条件:客户端此时处理的及,允许你服务端发数据。//啥时候不能触发WRITE事件?客户端处理不过来,压力大,不允许服务端再发。如果不使用WRITE事件方式,则服务端在不能发数据的情况下,也会发空数据包给客户端。这样是不是导致浪费了服务端有限的线程资源?所以需要WRITE事件!if (buffer.hasRemaining()) {scKey.interestOps(scKey.interestOps()+SelectionKey.OP_WRITE);scKey.attach(buffer);}} else if (key.isWritable()) {//写事件//获取发送数据的ChannelSocketChannel channel = (SocketChannel) key.channel();//获取附件,目的是接着第一次写之后继续写,保证Buffer唯一传递ByteBuffer attachment = (ByteBuffer) key.attachment();//写!但是不循环写,本次写完后,如果客户端还让继续写,那么Selector.select()会再一次监听到WRITABLE事件,那么可以再一次到这里写!int write = channel.write(attachment);System.out.println("本次写出的数据大小为: " + write);//如果Buffer写完了,那么需要把附件置空,并且清空WRITE事件if (!attachment.hasRemaining()) {key.attach(null);key.interestOps(key.interestOps()-SelectionKey.OP_WRITE);}}}}}}public class MyClient1 {public static void main(String[] args) throws Exception{SocketChannel socketChannel = SocketChannel.open();socketChannel.connect(new InetSocketAddress(8000));int read = 0;while (true) {ByteBuffer buffer = ByteBuffer.allocate(1024 * 1024);read += socketChannel.read(buffer);System.out.println("本次读取的大小为: " + read);buffer.clear();}}}测试:
Server端
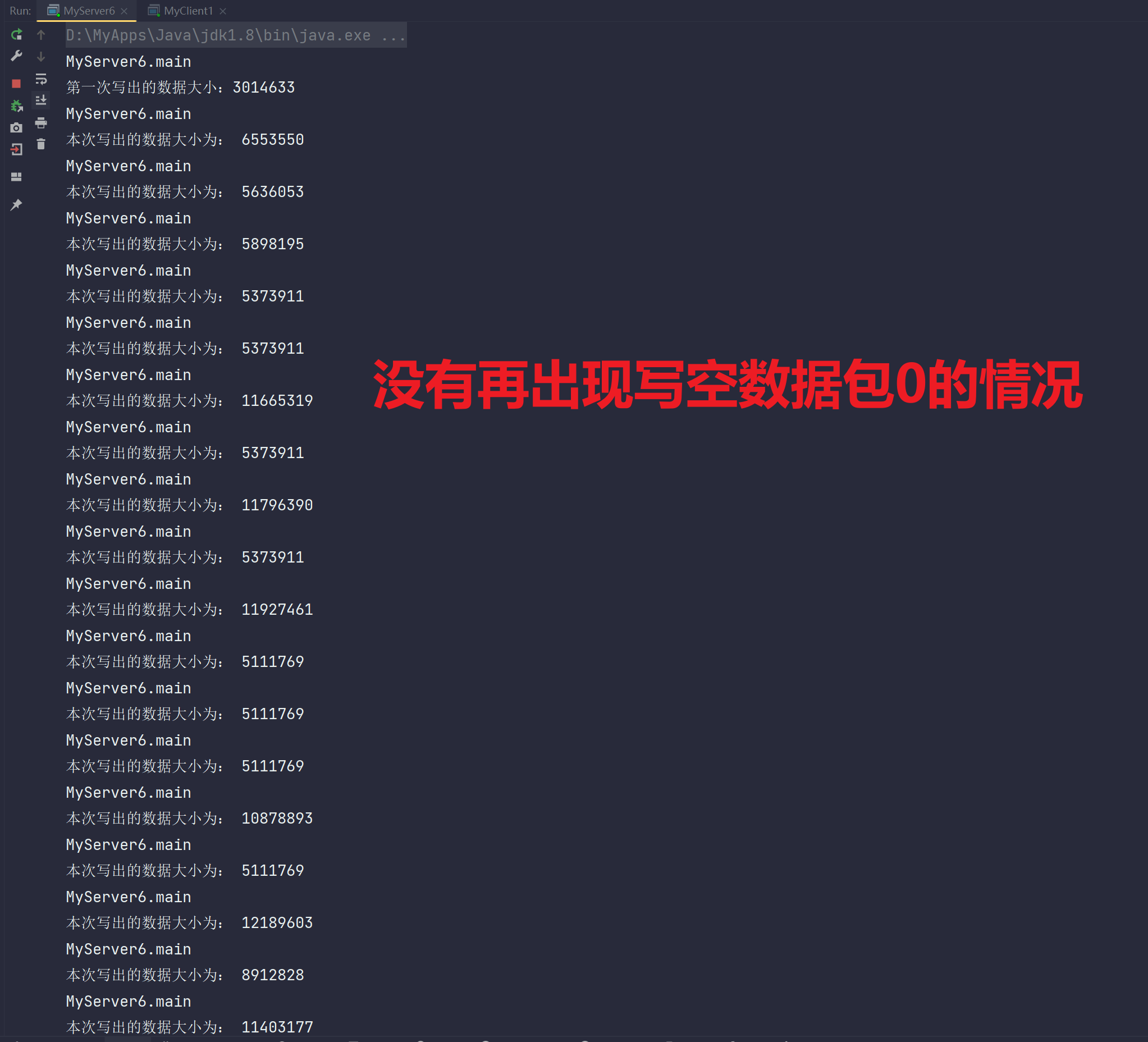
Client端:
5.2.6 Selector多路复用的核心含义
把多个客户端(SocketChannel)和服务端(ServerSocketChannel)都注册到一个Selector上,Selector监听内核缓冲区,当允许触发READ或WRITE的时候,才会让当前线程去执行该就绪事件的操作。这样就更加高效的利用了当前线程的资源性能。也使得单线程的资源利用率发挥的很好。
linux操作系统 默认可以允许客户端连接的socket数量不够多,我们需要在合适的事件增加修改这个socket数量。啥时候修改呢?当并发上来后,CPU和内存相比之前没什么太大变化,说明此时socket连接数量不够了,客户端再来请求连接时,服务端(linux)直接给拒绝了,所以CPU和内存不受这次并发流量大的影响。此时我们应该提升linux服务器对应的socket数量。
相关文章:
Netty应用(三) 之 NIO开发使用 网络编程 多路复用
目录 重要:logback日志的引入以及整合步骤 5.NIO的开发使用 5.1 文件操作 5.1.1 读取文件内容 5.1.2 写入文件内容 5.1.3 文件的复制 5.2 网络编程 5.2.1 accept,read阻塞的NIO编程 5.2.2 把accept,read设置成非阻塞的NIO编程 5.2.3…...

融资项目——配置redis
一、 在maven中导入相关依赖。在springboot框架中,我们使用spring data redis <!-- spring boot redis缓存引入 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifa…...

npm修改镜像源
背景:切换npm镜像源是经常遇到的事,下面记录下具体操作命令 1. 打开终端运行"npm config get registry"命令来查看当前配置的镜像源 npm config get registry2. 修改成淘宝镜像源"https://registry.npmjs.org/" npm config set re…...

K8S系列文章之 [基于 Alpine 使用 kubeadm 搭建 k8s]
先部署基础环境,然后根据官方文档 K8s - Alpine Linux,进行操作。 将官方文档整理为脚本 整理脚本时,有部分调整 #!/bin/shset -x # 添加源,安装时已经配置 #cat >> /etc/apk/repositories <<"EOF" #htt…...
JVM相关-JVM模型、垃圾回收、JVM调优
一、JVM模型 JVM内部体型划分 JVM的内部体系结构分为三部分,分别是:类加载器(ClassLoader)子系统、运行时数据区(内存)和执行引擎 1、类加载器 概念 每个JVM都有一个类加载器子系统(class l…...

提升图像分割精度:学习UNet++算法
文章目录 一、UNet 算法简介1.1 什么是 UNet 算法1.2 UNet 的优缺点1.3 UNet 在图像分割领域的应用 二、准备工作2.1 Python 环境配置2.2 相关库的安装 三、数据处理3.1 数据的获取与预处理3.2 数据的可视化与分析 四、网络结构4.1 UNet 的网络结构4.2 UNet 各层的作用 五、训练…...
排序算法---冒泡排序
原创不易,转载请注明出处。欢迎点赞收藏~ 冒泡排序是一种简单的排序算法,其原理是重复地比较相邻的两个元素,并将顺序不正确的元素进行交换,使得每次遍历都能将一个最大(或最小)的元素放到末尾。通过多次遍…...

基于数据挖掘的微博事件分析与可视化大屏分析系统
设计原理,是指一个系统的设计由来,其将需求合理拆解成功能,抽象的描述系统的模块,以模块下的功能。功能模块化后,变成可组合、可拆解的单元,在设计时,会将所有信息分解存储在各个表中࿰…...
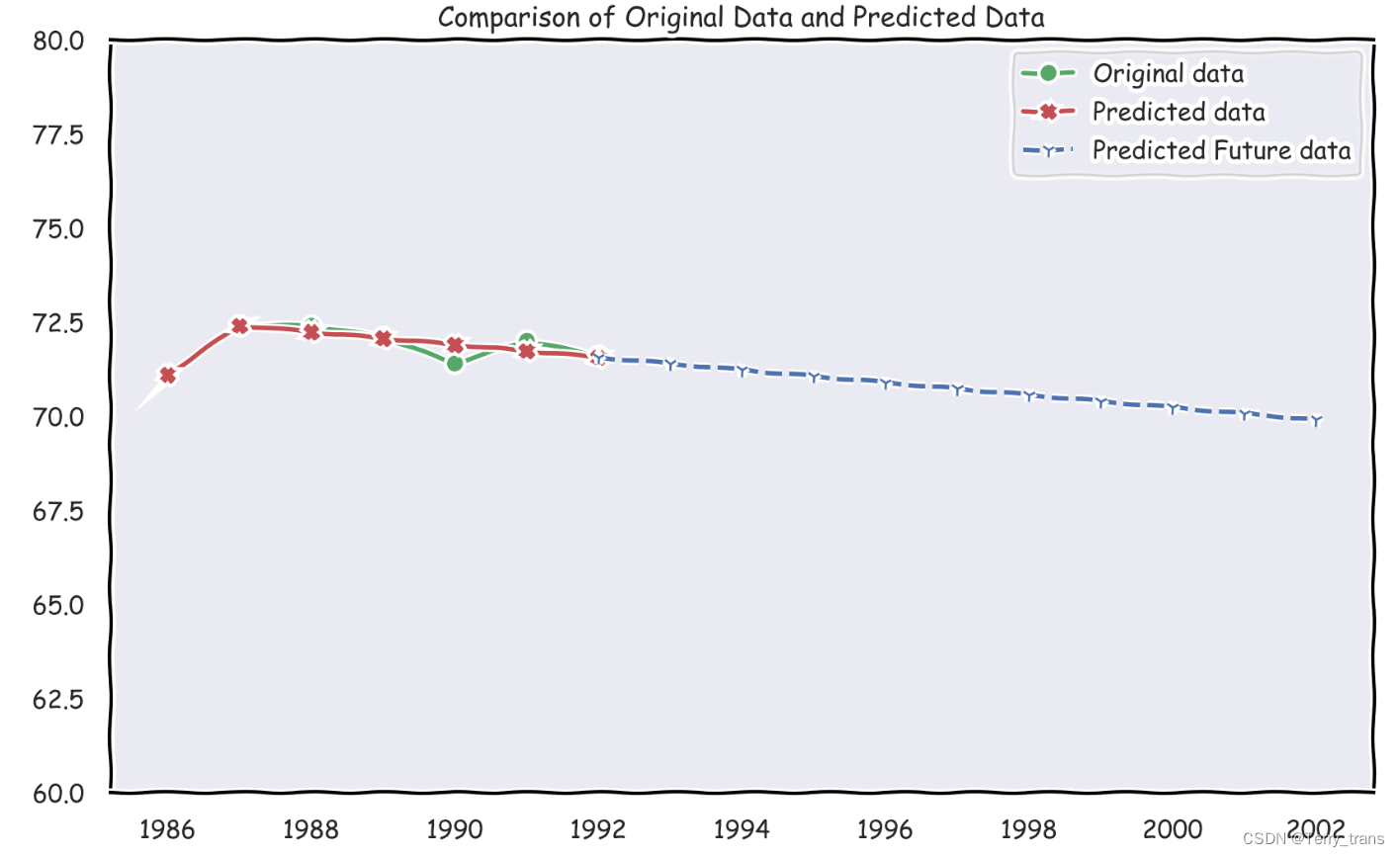
数学建模-灰色预测最强讲义 GM(1,1)原理及Python实现
目录 一、GM(1,1)模型预测原理 二、GM(1,1)模型预测步骤 2.1 数据的检验与处理 2.2 建立模型 2.3 检验预测值 三、案例 灰色预测应用场景:时间序列预测 灰色预测的主要特点是模型使用的…...
智慧自助餐饮系统(SpringBoot+MP+Vue+微信小程序+JNI+ncnn+YOLOX-Nano)
一、项目简介 本项目是配合智慧自助餐厅下的一套综合系统,该系统分为安卓端、微信小程序用户端以及后台管理系统。安卓端利用图像识别技术进行识别多种不同菜品,识别成功后安卓端显示该订单菜品以及价格并且生成进入小程序的二维码,用户扫描…...
零基础学编程从入门到精通,系统化的编程视频教程上线,中文编程开发语言工具构件之缩放控制面板构件用法
一、前言 零基础学编程从入门到精通,系统化的编程视频教程上线,中文编程开发语言工具构件之缩放控制面板构件用法 编程入门视频教程链接 https://edu.csdn.net/course/detail/39036 编程工具及实例源码文件下载可以点击最下方官网卡片——软件下载—…...
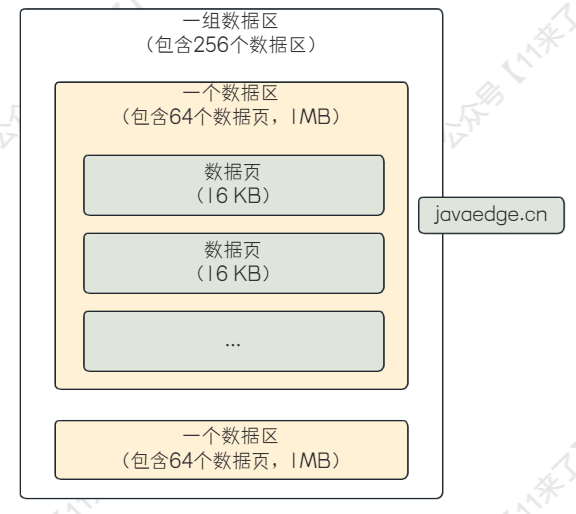
【MySQL进阶之路】MySQL 中表空间和数据区的概念以及预读机制
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送! 在我后台回复 「资料」 可领取编程高频电子书! 在我后台回复「面试」可领取硬核面试笔记! 文章导读地址…...
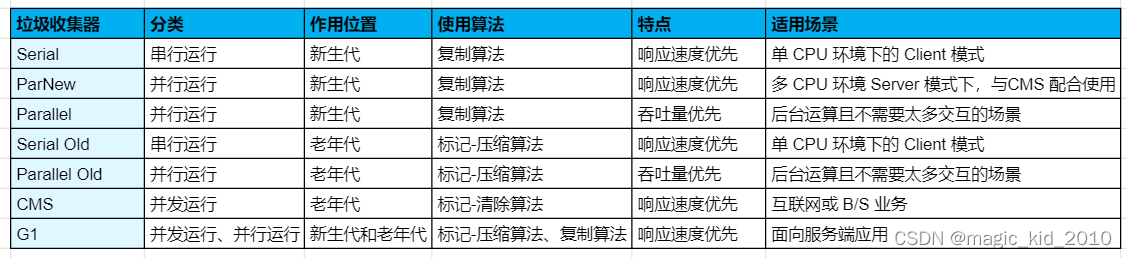
JVM 性能调优 - 常用的垃圾回收器(6)
垃圾收集器 在 JVM(Java虚拟机)中,垃圾收集器(Garbage Collector)是负责自动管理内存的组件。它的主要任务是在程序运行过程中,自动回收不再使用的对象所占用的内存空间,以便为新的对象提供足够的内存。 JVM中的垃圾收集器使用不同的算法和策略来实现垃圾收集过程,以…...

【java】Hibernate访问数据库
一、Hibernate访问数据库案例 Hibernate 是一个在 Java 社区广泛使用的对象关系映射(ORM)工具。它简化了 Java 应用程序中数据库操作的复杂性,并提供了一个框架,用于将对象模型数据映射到传统的关系型数据库。下面是一个简单的使…...
— byte数组传输)
从零开始手写mmo游戏从框架到爆炸(八)— byte数组传输
导航:从零开始手写mmo游戏从框架到爆炸(零)—— 导航-CSDN博客 Netty帧解码器 Netty中,提供了几个重要的可以直接使用的帧解码器。 LineBasedFrameDecoder 行分割帧解码器。适用场景:每个上层数据包,使…...
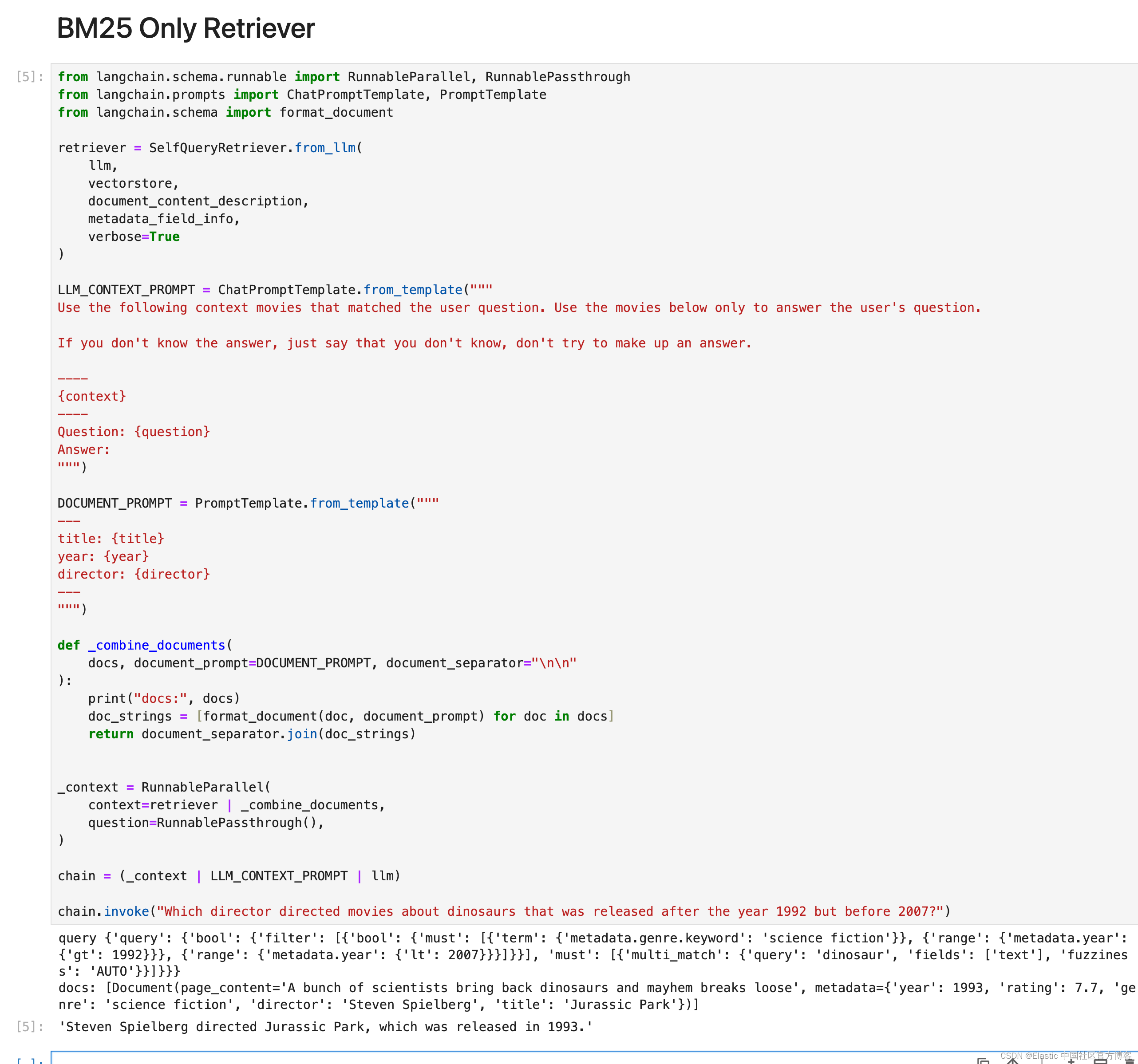
Elasticsearch:BM25 及 使用 Elasticsearch 和 LangChain 的自查询检索器
本工作簿演示了 Elasticsearch 的自查询检索器将非结构化查询转换为结构化查询的示例,我们将其用于 BM25 示例。 在这个例子中: 我们将摄取 LangChain 之外的电影样本数据集自定义 ElasticsearchStore 中的检索策略以仅使用 BM25使用自查询检索将问题转…...

uniapp的api用法大全
页面生命周期API uniApp中的页面生命周期API可以帮助开发者在页面的不同生命周期中执行相应的操作。常用的页面生命周期API包括:onLoad、onShow、onReady、onHide、onUnload等。其中,onLoad在页面加载时触发,onShow在页面显示时触发…...

笔记——asp.net core 中的 REST
REST(reprentational state transfer,表层状态转移) REST原则:提倡按照HTTP的语义使用HTTP。 如果一个系统符合REST原则,我们就说这个系统是Restful风格的。 在RPC风格的Web API系统中,我们把服务端的代码…...

排序算法---堆排序
原创不易,转载请注明出处。欢迎点赞收藏~ 堆排序(Heap Sort)是一种基于二叉堆数据结构的排序算法。它将待排序的元素构建成一个最大堆(或最小堆),然后逐步将堆顶元素与堆的最后一个元素交换位置,…...
通用排序)
Java字符串(包含字母和数字)通用排序
说明:本文章是之前查到的一篇安卓版的,具体原文路径忘记了。稍微改了一点,挺符合业务使用的! 一、看代码 /*** 包含数字的字符串进行比较(按照从小到大排序)*/private static Integer compareString(Stri…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...