【医学大模型 尘肺病】PneumoLLM:少样本大模型诊断尘肺病新方法
PneumoLLM:少样本大模型诊断尘肺病新方法
- 提出背景
- PneumoLLM 框架
- 效果
提出背景
论文:https://arxiv.org/pdf/2312.03490.pdf
代码:https://github.com/CodeMonsterPHD/PneumoLLM/tree/main
历史问题及其背景:
-
数据稀缺性问题:尘肺病的诊断数据不足,特别是在缺乏经济发展、医疗资源和专业医疗人员的地区。
- 背景:尘肺病多发生于长期暴露于含尘环境的个体,如建筑工地或煤矿,而这些地区往往医疗资源匮乏,数据收集困难。
-
传统预训练和微调策略的局限性:在数据稀缺的条件下,传统的预训练和微调方法效果不佳。
- 背景:预训练模型需要大量标记数据来优化权重分布,但尘肺病的有效诊断数据不足,限制了这种方法的应用。
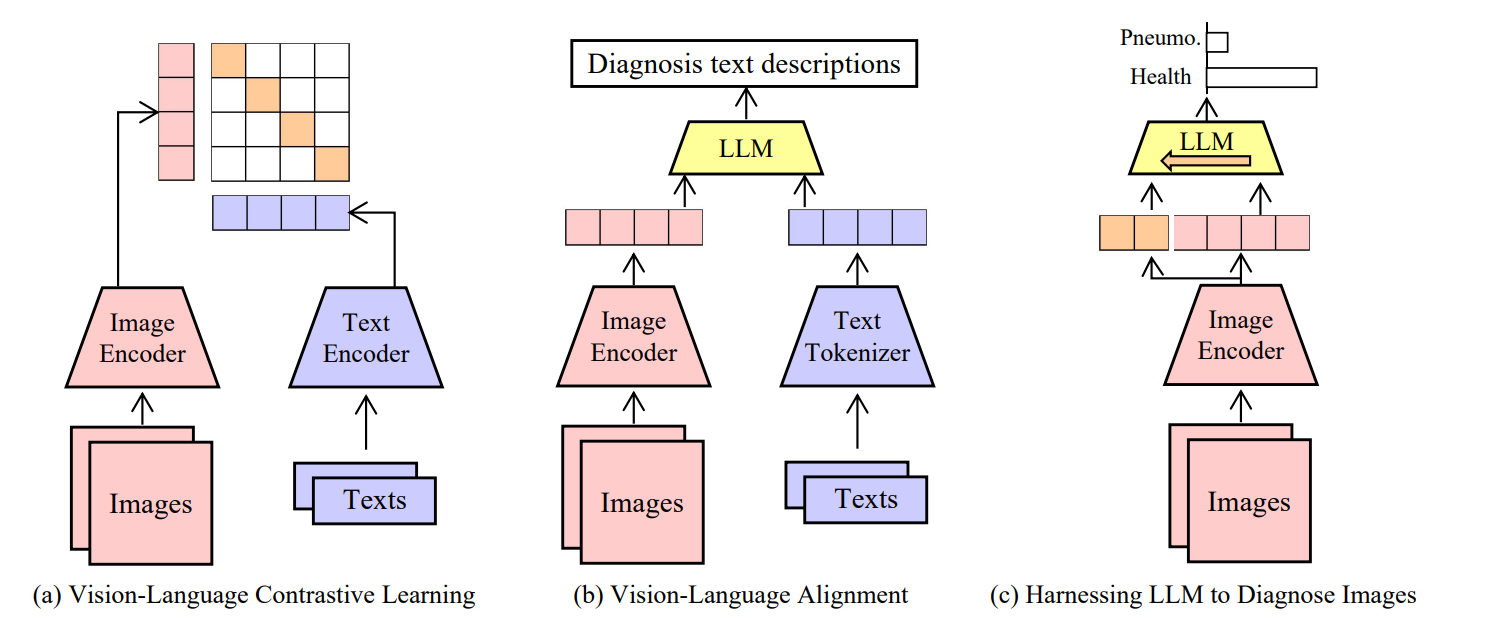
这张图展示了三种不同的方法来结合视觉(图像)和语言(文本)信息进行医学诊断。
这张图说明了从传统的视觉-语言对比学习到利用LLM进行直接图像诊断的进化路径。
最新的方法(c)简化了流程,省略了文本输入的步骤,直接利用图像数据,通过LLM进行医学诊断,形成了一个简单有效的诊断管道。
(a) 视觉-语言对比学习(Vision-Language Contrastive Learning):
- 这个方法使用图像编码器将图像转换为视觉表示,同时使用文本编码器将文本转换为语言表示。
- 然后,这些表示用于进行对比学习,目的是使模型学会将视觉信息和语言信息对齐,从而改善多模态表示。
比如诊断尘肺病,用一个图像编码器来分析X射线图像,并用文本编码器来理解医生的诊断报告。
然后,模型通过对比这两种信息来学习它们之间的关联。
(b) 视觉-语言对齐(Vision-Language Alignment):
- 在这种方法中,图像首先通过图像编码器处理,文本则通过文本分词器处理。
- 处理后的视觉和语言标记输入到大型语言模型(LLM)中,该模型根据输入的图像和文本生成诊断文本描述。
比如诊断尘肺病,使用一个文本分词器和图像编码器来处理数据,然后让LLM根据视觉标记和文本信息一起工作,生成更准确的诊断描述。
更准确的诊断描述,主要是因为它不仅仅看图像,还听文字。
想象一下,如果医生只看X光片,而不考虑患者的症状描述,那么有时候他可能会错过重要的线索。
但如果医生在看X光片的同时,还听了患者的症状讲述,那么他对患者的状况就会有更全面的了解,从而做出更准确的诊断。
© 利用LLM诊断图像(Harnessing LLM to Diagnose Images):
- 此方法直接使用图像编码器处理图像,不涉及文本输入。
- 编码后的图像被转换为视觉标记,并直接输入到LLM中。
- LLM基于视觉标记进行处理,最终直接输出诊断结果,比如判断图像是显示尘肺病(Pneumo.)还是健康(Health)。
比如诊断尘肺病,只使用图像编码器来处理X射线图像,并将编码后的视觉标记直接输入到LLM中。
LLM能够独立分析这些视觉标记,并直接给出一个二元诊断结果——表示图像是健康的还是表明有尘肺病。
这个方法不仅加快了诊断过程(因为它不再需要详细的文本报告),而且还允许团队快速筛选大量的X射线图像,识别出可能的尘肺病症状,这在资源有限的医疗环境中尤其有价值。
在方法©中,LLM通过大量的学习已经变得非常擅长识别图像中的病理特征,它不再需要依赖文本描述来辅助诊断。
它可以直接从图像中识别出健康和尘肺病的标志,然后给出诊断。
这就像是一个经验丰富的医生能够凭借专业的直觉快速诊断,而不需要每次都进行详尽的病史调查。
这种方法旨在减少对大量标记数据的依赖,同时提高诊断的准确性。
之所以用这个解法,是因为问题的那个特征:
- 直接利用LLMs处理图像的方法:避免传统的文本处理分支,直接通过LLMs处理图像来诊断尘肺病。
- 特征:LLMs在处理大量语料时学到的知识能够帮助筛选出图像中的关键视觉标记,提高医学图像诊断的准确性。
我们直接将X射线图像输入到经过大规模语料库训练的LLM中。模型已经学习了大量的视觉和文本数据,使其能够理解和处理图像内容。
LLM识别出图像中的关键视觉标记,比如肺部的纤维化斑点,这些是尘肺病的典型迹象。通过分析这些视觉标记,模型直接提供了一个初步的尘肺病诊断结果,大大提高了诊断的准确性。
- 上下文多标记引擎:生成与图像标记条件相关的诊断标记,确保源图像标记保留所有相关的图像细节。
- 特征:这种方法能够在保留图像表示的同时,利用LLMs的诊断智能,达到保留图像细节与诊断智能之间的平衡。
尽管LLM已经提供了初步诊断,但为了进一步提高精度,需要确保模型能够充分理解和利用图像中的所有细节信息。
引入上下文多标记引擎,该引擎生成与图像标记条件相关的诊断标记。
这意味着模型不仅分析了肺部的纤维化斑点,还考虑了图像中的其他相关特征,如肺部阴影的分布和形状,以及与尘肺病相关的其他可视迹象。
通过这种方法,确保了从图像中提取的信息是全面而细致的,提高了模型对尘肺病的诊断能力,同时保持了对图像细节的高度敏感性。
- 信息发射模块:从源标记到诊断标记单向发射信息,引导学习过程朝向准确的诊断。
- 特征:通过精确控制信息的流动,这个模块帮助模型集中于对尘肺病的诊断,优化了学习轨迹。
有了全面的图像理解,下一步是确保这些信息能够有效地指导诊断过程。
信息发射模块被设计来从源标记(即图像的各个部分)向诊断标记单向发射信息。
这个过程涉及到从图像细节中抽象出诊断所需的关键信息,并将这些信息集中起来,形成一个明确的诊断结果。
这个模块的作用确保了诊断过程是有针对性的,能够忽略不相关的信息,专注于对尘肺病诊断有决定性意义的视觉标记。
最终,模型提供了一个准确和可靠的尘肺病诊断结果,优化了学习轨迹,提高了整体的诊断效率和准确性。
通过结合LLMs的强大图像处理能力和为尘肺病诊断专门设计的新型模块(上下文多标记引擎和信息发射模块),PneumoLLM框架能够有效地克服数据稀缺性问题和传统策略的局限性,为尘肺病等职业病的诊断提供了一个简化而高效的新途径。
总结:
-
逻辑起点是面对的主要挑战——数据稀缺性问题。
这个问题是由于尘肺病多发生在资源匮乏的地区,导致有效诊断数据难以收集,从而影响了疾病诊断的准确性和效率。
-
紧接着,传统方法——预训练和微调策略的局限性。
这些策略在数据丰富的条件下效果显著,但在数据稀缺的情况下效果大打折扣,因为它们依赖大量标记数据进行模型优化。
-
为了解决上述两个问题,提出了直接利用LLMs处理图像的新方法。
这种方法避免了传统文本处理分支的需求,能直接从图像中提取关键信息,以LLMs学到的知识为基础,提高了对尘肺病的诊断准确性。
-
进一步地,为了优化这一方法,引入了上下文多标记引擎和信息发射模块两个专门设计的模块。
这些模块的加入,不仅保持了图像细节的完整性,同时确保了模型能够更加专注和有效地学习对尘肺病的诊断,进一步提高了诊断的精确度和效率。
首先识别挑战,然后通过创新的方法和专门设计的模块来解决这些挑战,最终实现了一个既能克服数据稀缺性问题又能有效诊断尘肺病的新框架——PneumoLLM。
PneumoLLM 框架
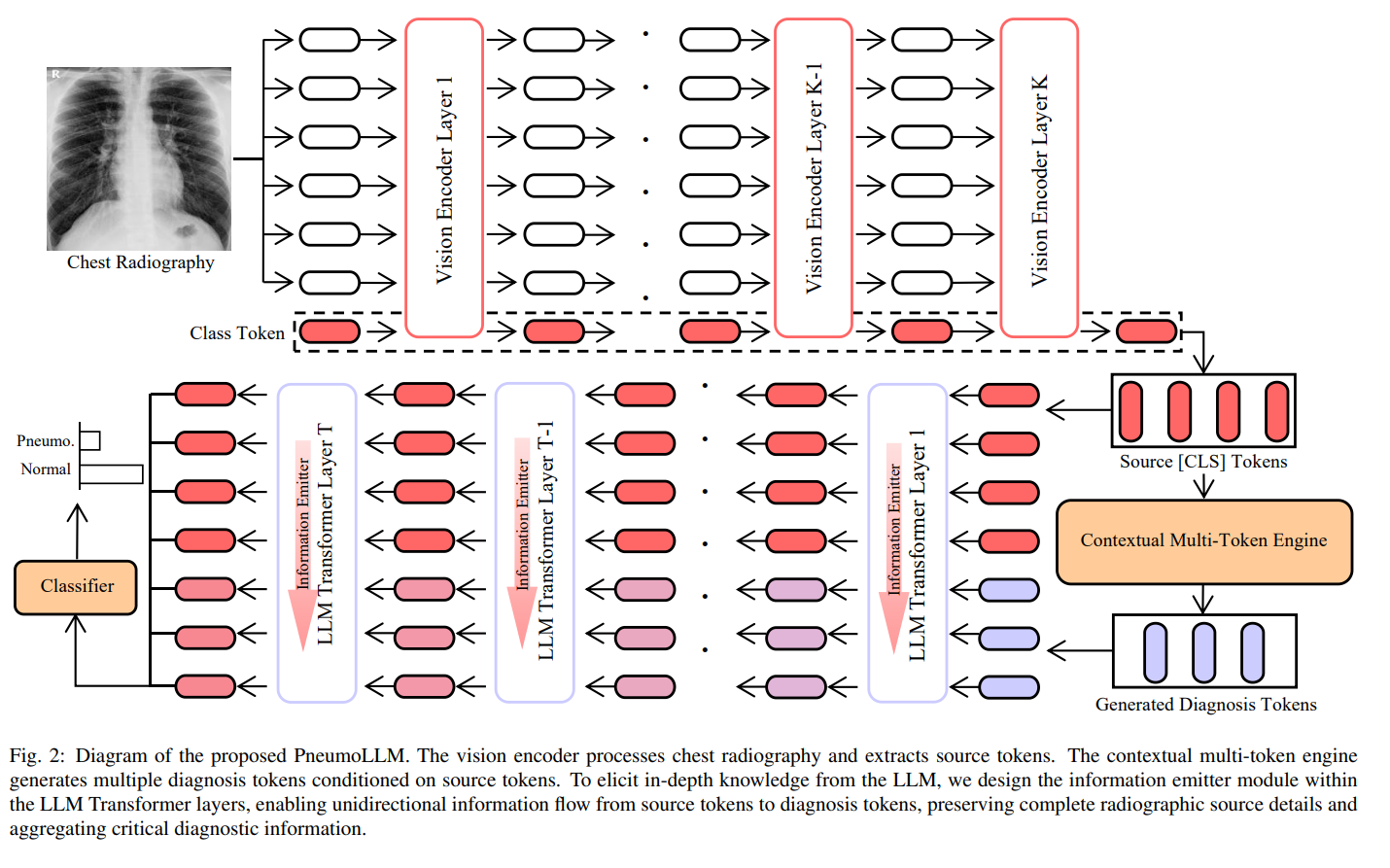
这幅图是PneumoLLM框架的图解,这是一个用于处理胸部X光图像并诊断尘肺病的系统。
整个流程分为几个关键步骤:
-
视觉编码器:首先,胸部X光图像经过视觉编码器处理。
这个编码器负责提取图像的特征,并将这些特征转换为一系列的“源标记”(Source Tokens),这些标记包括一个特殊的分类标记(Class Token),通常在自监督学习模型中用作整体图像的代表。
假设医院收到了一个矿工的胸部X光图像。
这张图像首先通过视觉编码器,该编码器识别图像中的关键特征,如肺部的阴影和纹理变化,并将这些特征转换成一组源标记,包括一个代表整体图像的分类标记。
-
LLM Transformer层:然后,这些源标记被传递到一系列的LLM Transformer层。
这些层通过自我注意力机制加深模型对图像特征的理解,能够捕捉不同部分之间的复杂关系。
接着,源标记输入到LLM Transformer层。
在这里,模型使用注意力机制来探索不同标记之间的关系,理解哪些特征是诊断尘肺病的关键指标。
-
上下文多标记引擎:此外,图中展示了一个“上下文多标记引擎”(Contextual Multi-Token Engine)。
这个引擎接受源标记,并生成一系列的“诊断标记”(Generated Diagnosis Tokens),这些标记为诊断任务提供了更丰富的上下文信息和诊断线索。
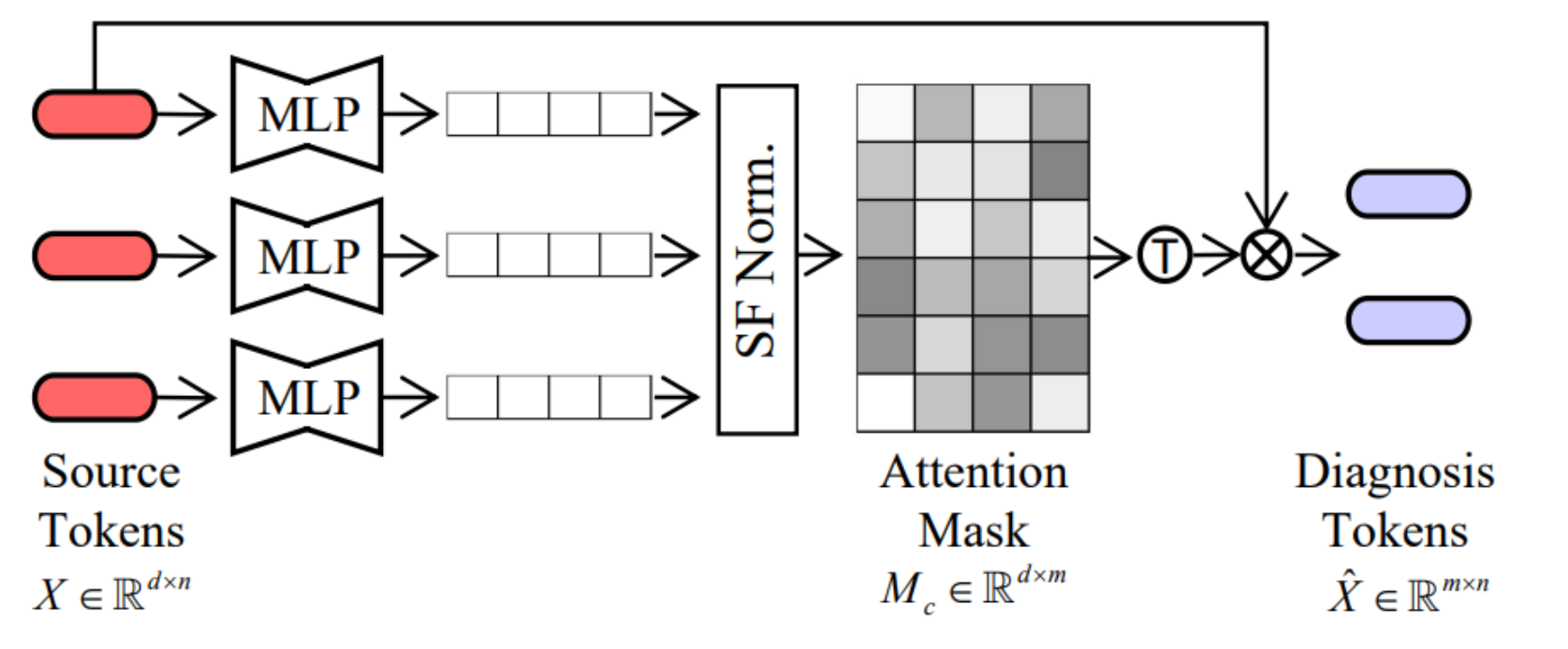
上图展示了如何生成额外的诊断标记,这些标记用于辅助尘肺病的诊断。
“源标记”通过多层感知机(MLP)处理,然后经过Softmax规范化生成“注意力掩码”。
注意力掩码用于加权源标记,通过一个矩阵转置操作生成“诊断标记”。
这个过程可以加强模型对诊断所需上下文的理解。
-
信息发射模块:在LLM Transformer层内,设计有一个“信息发射模块”(Information Emitter Module)。
这个模块确保从源标记到诊断标记的信息流是单向的,即信息只能从源标记流向诊断标记,这样做可以保留完整的放射学源细节,并汇总关键的诊断信息。
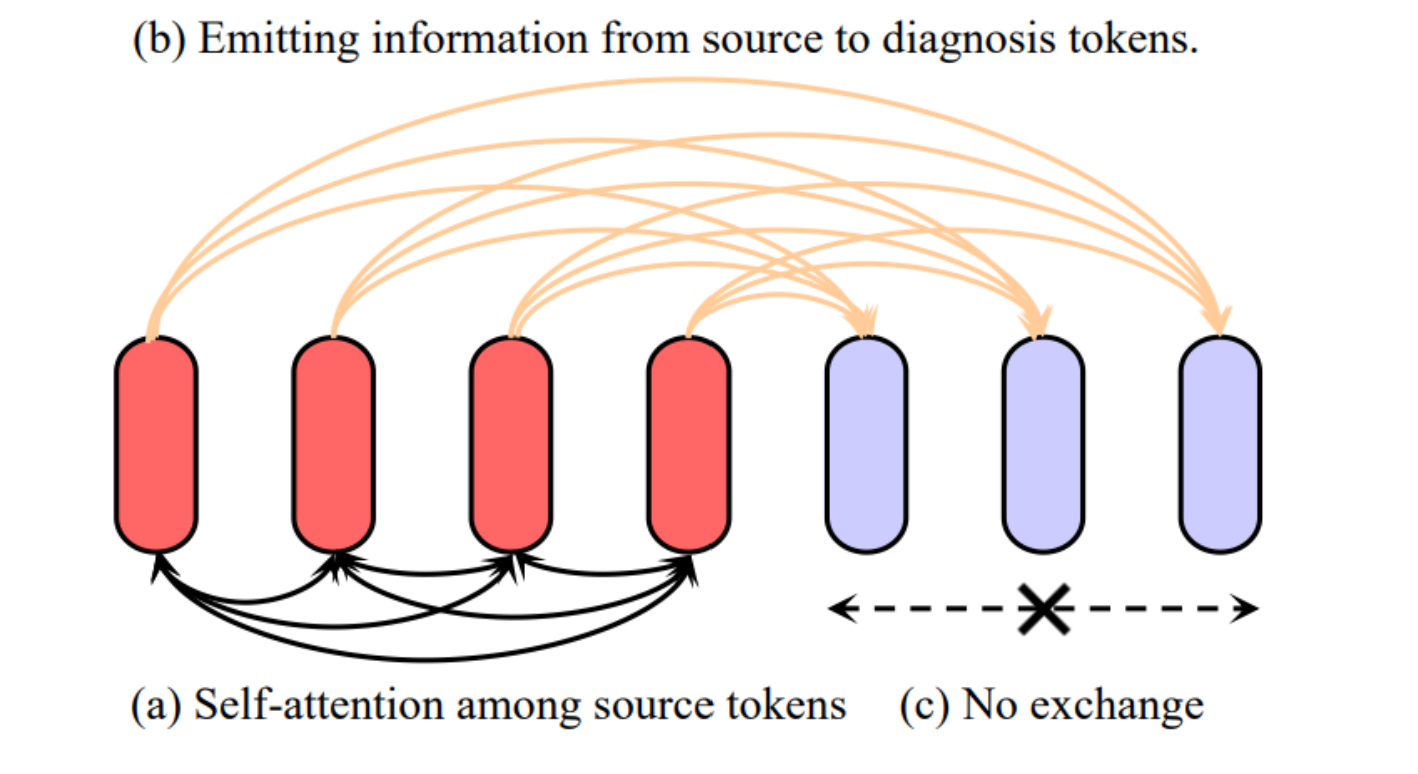
描述了如何将信息从源标记传递到诊断标记,同时保留源标记的完整性。
展示了源标记之间的自注意力机制(a),信息从源标记发射到诊断标记的过程(b),以及诊断标记之间没有信息交换©。
这种设计保持了源标记的一致性,同时允许新生成的诊断标记利用这些信息进行更精确的诊断推理。
- 分类器:最后,经过处理的诊断标记被送入分类器,该分类器基于累积的诊断信息来决定图像是表示尘肺病还是正常。
核心逻辑:
子解法1:PneumoLLM框架
- 特征:为了解决数据稀缺性的问题,PneumoLLM使用视觉编码器和LLM联合处理图像,抽取关键信息进行诊断。
子解法2:上下文多标记引擎和信息发射模块
- 特征:为了有效结合视觉编码器和LLM的知识,并产生上下文诊断标记,设计了上下文多标记引擎和信息发射模块。
子解法3:适配器层
- 特征:为了避免破坏LLM的稳健表示,引入了适配器层以适应视觉编码器和LLM模型,保持LLM原有结构的同时,提供了新的信息流。
举例:
-
视觉编码阶段:一个矿工的胸部X光图像被输入到系统中。视觉编码器处理图像并提取源标记,这是解决数据稀缺性问题的第一步。
-
上下文增强阶段:通过上下文多标记引擎生成额外的上下文诊断标记,并通过信息发射模块确保信息的单向流动。这是为了适应具体的诊断任务而设计的。
-
适配器转换阶段:使用适配器层将视觉特征转换为LLM兼容的维度,然后将这些特征输入到LLM中。这保持了LLM的原有结构,并且能够处理由于参数空间变化带来的挑战。
-
分类诊断阶段:最后,LLM处理并输出最终的分类分数,用于确定患者是否患有尘肺病。这是PneumoLLM框架的最终目标,通过交叉熵损失函数训练适配器层、多标记引擎和分类网络,保持其他参数固定。
效果
优于其他方法:
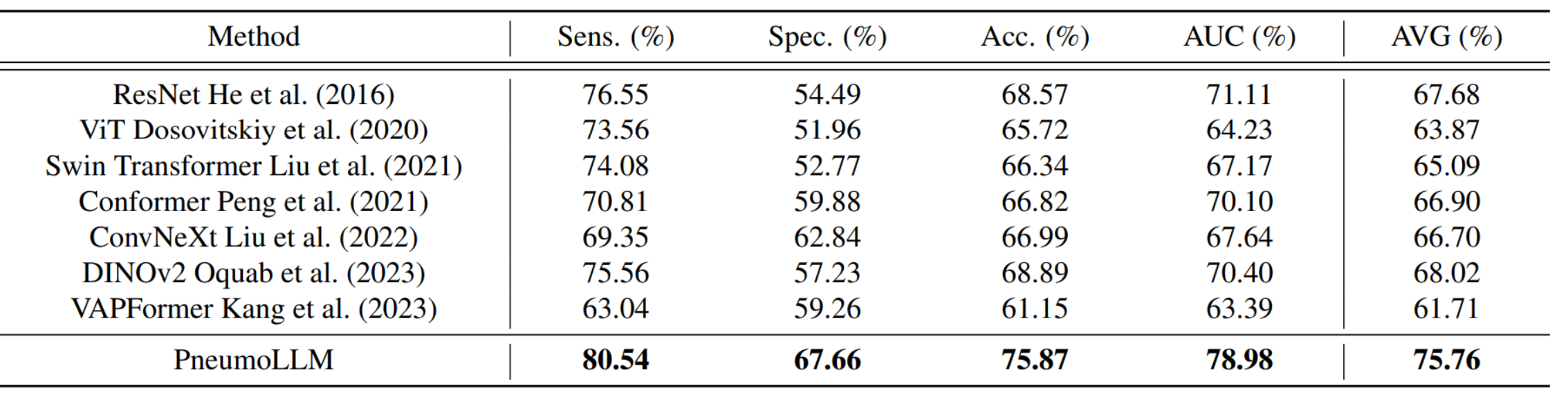
红色代表尘肺病,蓝色代表正常:
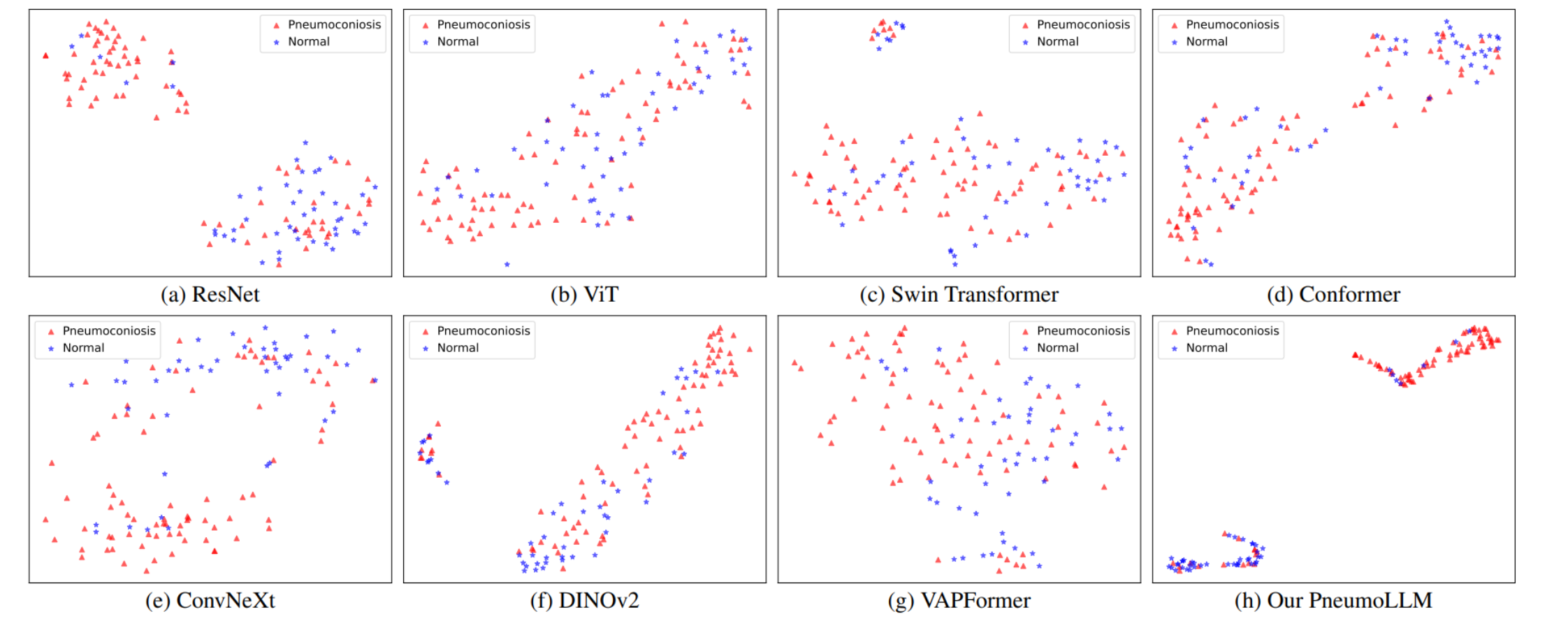
PneumoLLM 展示了较为紧密的同类点聚合和不同类别间的清晰分隔,这表明其具有较强的特征表示能力。
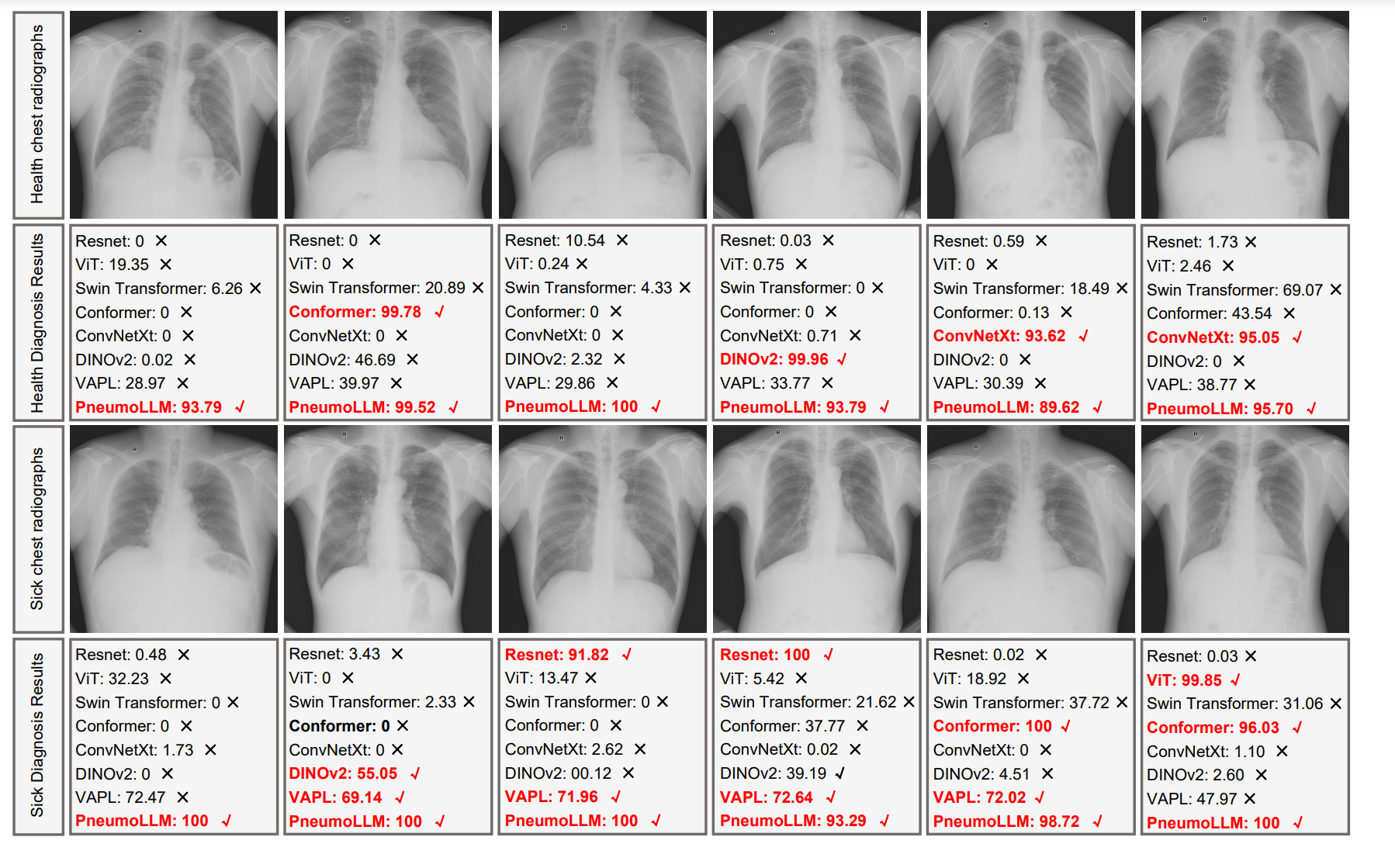
PneumoLLM在大多数情况下正确诊断出健康和疾病图像,相比其他方法具有更高的信心分数和准确率。
相关文章:
【医学大模型 尘肺病】PneumoLLM:少样本大模型诊断尘肺病新方法
PneumoLLM:少样本大模型诊断尘肺病新方法 提出背景PneumoLLM 框架效果 提出背景 论文:https://arxiv.org/pdf/2312.03490.pdf 代码:https://github.com/CodeMonsterPHD/PneumoLLM/tree/main 历史问题及其背景: 数据稀缺性问题&a…...
【SpringBootStarter】自定义全局加解密组件
【SpringBootStarter】 目的 了解SpringBoot Starter相关概念以及开发流程实现自定义SpringBoot Starter(全局加解密)了解测试流程优化 最终引用的效果: <dependency><groupId>com.xbhog</groupId><artifactId>globalValidation-spring…...

【射影几何15】python双曲几何工具geometry_tools
目录 一、说明二、环境问题:如何安装三、实现一个简单的例子四、绘制双曲组五、使用有限状态自动机加快速度六、资源和代码 一、说明 Geometry_tools 是一个 Python 包,旨在帮助您处理和可视化双曲空间和射影空间上的群动作。 该包主要构建在 numpy、…...

机器人抓取 [ 题目/摘要 ] 更新中..
题目:Robotic Grasping of Novel Objects using Visionl 链接:机器人抓取新物体 | IEEE Xplore(IEEE的Xplore) 【端到端】 摘要:我们考虑抓取新物体的问题,特别是第一次通过视觉看到的物体。抓取以前未知的…...
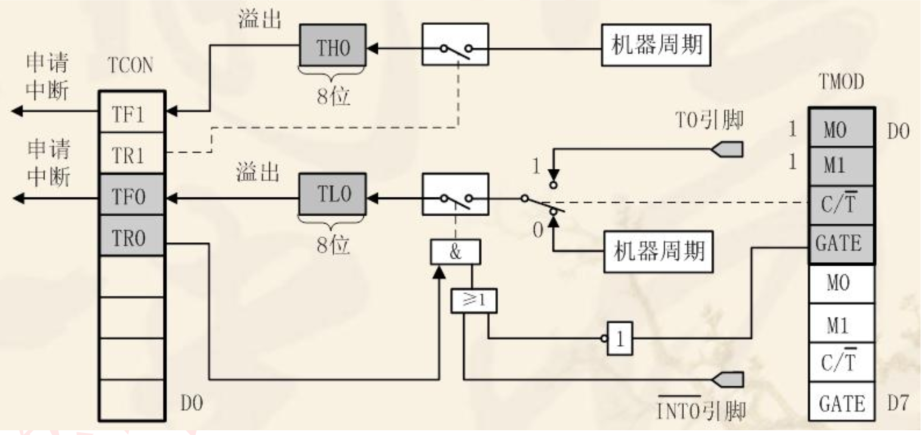
【51单片机】外部中断和定时器中断
目录 中断系统中断介绍中断概念 中断结构及相关寄存器中断结构中断相关寄存器 外部中断实验外部中断配置软件设计实验现象 定时器中断定时器介绍51 单片机定时器原理51 单片机定时/计数器结构51 单片机定时/计数器的工作方式 定时器配置硬件设计软件设计实验现象 中断系统 本章…...

零售行业供应商数据分发,怎样提高安全性和效率?
零售行业是我国经济发展的重要组成,零售行业包罗万象,如包括汽车零售、日化零售、快消品零售等,不同细分行业的运营模式各不相同,但大体来说,零售行业都具备最基础的供应商和零售商,供应商将商品或服务卖给…...
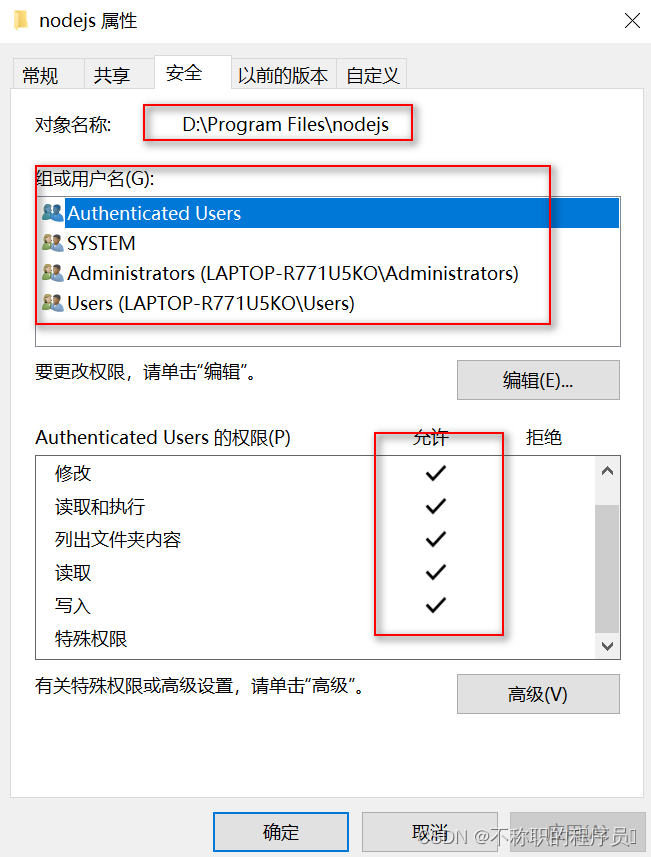
Windows下Node.js下载安装及环境变量配置教程
Windows下Node.js下载安装及环境变量配置教程 安装版本:node-v18.19.0-x64.msi 文章目录 Windows下Node.js下载安装及环境变量配置教程一、Node.js和NPM简介二、下载地址三、安装步骤四、环境配置五、安装淘宝镜像总结 一、Node.js和NPM简介 1、Node.js …...

广义表-C语言
广义表(Generalized List)是一种扩展了线性表的数据结构,它在线性表的基础上增加了元素可以是表的特点。在广义表中,元素不仅可以是单个的数据元素,还可以是一个子表,而子表中的元素也可以是数据元素或其他…...

uniapp+uView 【详解】录音,自制音频播放器
效果预览 代码实现 <template><view class"btnListBox"><view class"audioBox" v-if"audioLength"><u-row><u-col span"2"><u--text aligncenter :text"currentTime"></u--text>…...
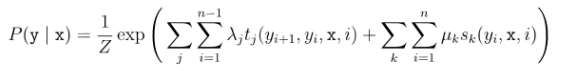
机器学习---概率图模型(隐马尔可夫模型、马尔可夫随机场、条件随机场)
1. 隐马尔可夫模型 机器学习最重要的任务是根据已观察到的证据(例如训练样本)对感兴趣的未知变量(例如类别标 记)进行估计和推测。概率模型(probabilistic model)提供了一种描述框架,将描述任…...

cool 框架 node 后端封装三方Api post请求函数
1.需求 现在一些数据源 ,需要从三方地址拿到一些数据 比如说电影列表 信息了 影院列表信息了 等一些展示的数据,但是人家这种东西 害需要使用 appkey appserect 这种验签 这种需求 你前端调用接口是直接调用不了的 因为需要用到验签 需要后端接口转接一…...

awd总结
总结: 由于是第一次参加AWD比赛,各方面经验都不足,在参赛的前几天也是疯狂搜集各种脚本、框架、工具等,同时也参考b站的视频进行学习,我发现就是还是实操才能更快的学习 我觉得就是我前期的准备工作不足,…...

【react】react+es6+antd5.13.2+ts,antd表格的操作如何在父组件写?
reactes6antd5.13.2ts,antd表格的操作如何在父组件写? 我的子组件columns.tsx,只加表头,操作放在父组件。 columns.tsx的代码: export const dataColumns [{title: 项目成员,dataIndex: name,key: name,},{title: 可选账号,alig…...

virtio笔记
最近在看虚拟化相关的东西,以virtio-console为例,记录下。 此文只是学习笔记,文中肯定有不少错误,不要参考 devicemd侧: virtio_console.c中,初始化会对port->cb赋值为 viritio_console_control_tx&am…...

初始web服务器(并基于idea来实现无需下载的tomcat)
前言 前面学习了对应的http协议,我们知道了他是在网络层进行数据传输的协议,负责相应数据以及接收数据的规则,但是在人员开发后端的时候不仅仅需要你写io流进行数据传输,还需要你进行对应的tcp协议来进行数据打包发送http协议-CSD…...
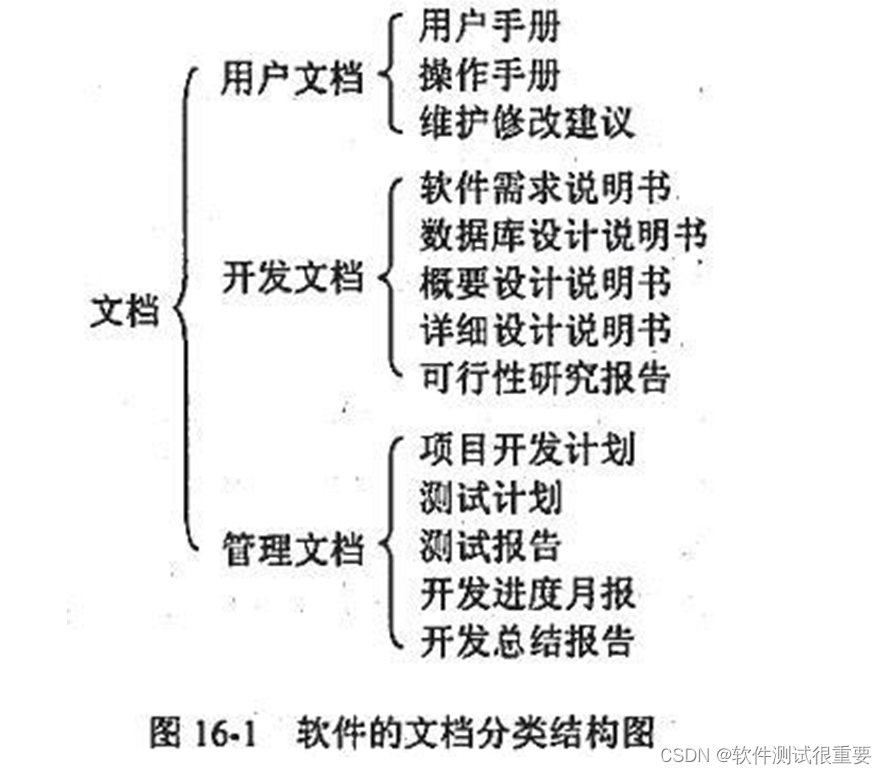
软件文档测试
1 文档测试的范围 软件产品由可运行的程序、数据和文档组成。文档是软件的一个重要组成部分。 在软件的整人生命周期中,会用到许多文档,在各个阶段中以文档作为前阶段工作成果的体现和后阶段工作的依据。 软件文档的分类结构图如下图所示: …...
从零开始手写mmo游戏从框架到爆炸(七)— 消息封装
导航:从零开始手写mmo游戏从框架到爆炸(零)—— 导航-CSDN博客 上一篇,我们初步把消息handler 注册到了服务中,在进行后续工作之前我们需要再做一些准备工作。 第一:把之前自己管理的bean放到spring中…...
)
从Unity到Three.js(画线组件line)
JavaScript 0基础,只是照着官方文档临摹了下,之后有时间再进行细节学习和功能封装。 import * as THREE from three; //引入threejsconst renderer new THREE.WebGLRenderer();//创建渲染器 //设置渲染范围,当前撑满全屏,屏幕左上角是&…...
)
LCP 30. 魔塔游戏 - 力扣(LeetCode)
题目描述 小扣当前位于魔塔游戏第一层,共有 N 个房间,编号为 0 ~ N-1。每个房间的补血道具/怪物对于血量影响记于数组 nums,其中正数表示道具补血数值,即血量增加对应数值;负数表示怪物造成伤害值,即血量减…...

数据结构——单向链表和双向链表的实现(C语言版)
目录 前言 1. 链表 1.1 链表的概念及结构 1.2 链表的分类 2. 单链表接口实现 2.1 数据结构设计与接口函数声明 2.2 创建结点,打印,查找 2.3 尾插,头插,尾删,头删 2.4 插入或删除 2.4.1在指定位置后 2.4.2在…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...