C语言 服务器编程-日志系统
日志系统的实现
- 引言
- 最简单的日志类 demo
- 按天日志分类和超行日志分类
- 日志信息分级
- 同步和异步两种写入方式
引言
日志系统是通过文件来记录项目的 调试信息,运行状态,访问记录,产生的警告和错误的一个系统,是项目中非常重要的一部分. 程序员可以通过日志文件观测项目的运行信息,方便及时对项目进行调整.
最简单的日志类 demo
日志类一般使用单例模式实现:
Log.h:
class Log
{
private:Log() {};~Log();
public:bool init(const char* file_name);void write_log(const char* str);static Log* getinstance();private:FILE* file;
};
Log.cpp:
Log::~Log()
{if (file != NULL){fflush(file);fclose(file);}
}Log* Log::getinstance()
{static Log instance;return &instance;
}bool Log::init(const char * file_name)
{file = fopen(file_name,"a");if (file == NULL){return false;}return true;
}void Log::write_log(const char* str)
{if (file == NULL)return;fputs(str, file);
}
main.cpp:
#include"Log.h"int main()
{Log::getinstance()->init("log.txt");Log::getinstance()->write_log("Hello World");
}
这个日志类实现了最简单的写日志的功能,但是实际应用时,需要在日志系统上开发出许多额外的功能来满足工作需要,有些时候还要进行日志的分类操作,因为你不能将所有的日志信息都塞到一个日志文件中,这样会大大降低可读性,接下来讲一下在这个最简单的日志类的基础上,怎么添加一些新功能.
按天日志分类和超行日志分类
先说两个比较简单的
按天分类和超行分类
按天分类:每一个日志按照天来分类(日志前加上当前的日期作为日志的前缀) 并且写日志前检查日志的创建时间,如果日志创建时间不是今天,那么就额外新创建一个日志,更新创建时间和行数,然后向新日志中写日志信息
超行分类:写日志前检查本次程序写入日志的行数,如果当前本次程序写入日志的行数已经到达上限,那么额外创建新的日志,更新创建时间,然后向新日志中写日志信息
为了实现这两个小功能,我们需要先向日志类中添加以下成员:
- 程序本次启动,写入日志文件的最大行数
- 程序本次启动,已经写入日志的行数
- 日志的创建时间
- 日志的路径名+文件名(创建新日志的时候,命名要跟之前的命名标准一样,最好是标准日志名+后缀的形式,这样便于标识)
更新后的日志类:
Log.h:
#pragma once
#include<stdio.h>
#include<string.h>
#include<string>
#include<time.h>
using namespace std;class Log
{
private:Log() ;~Log();public://初始化文件路径,文件最大行数bool init(const char* file_name,int split_lines= 5000000);void write_log(const char* str);static Log* getinstance();private:FILE* file;char dir_name[128];//路径名char log_name[128];//日志名int m_split_lines; //日志文件最大行数(之前的日志行数不计,只记录本次程序启动写入的行数)long long m_count; //已经写入日志的行数int m_today; //日志的创建时间
};
Log.cpp
#define _CRT_SECURE_NO_WARNINGS
#include"Log.h"Log::Log()
{m_count = 0;
}Log::~Log()
{if (file != NULL){fflush(file);fclose(file);}
}Log* Log::getinstance()
{static Log instance;return &instance;
}bool Log::init(const char * file_name,int split_lines)
{m_split_lines = split_lines; //设置最大行数time_t t = time(NULL);struct tm* sys_tm = localtime(&t);struct tm my_tm = *sys_tm; //获取当前的时间const char* p = strrchr(file_name, '/');//这里需要注意下,windows和linux的路径上的 斜杠符浩方向是不同的,windows是\,linux是 / ,而且因为转义符号的原因,必须是 \\char log_full_name[256] = { 0 };if (p == NULL) //判断是否输入了完整的路径+文件名,如果只输入了文件名{strcpy(log_name, file_name);snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);}else //如果输入了完整的路径名+文件名{strcpy(log_name, p + 1);strncpy(dir_name, file_name, p - file_name + 1);//规范化命名snprintf(log_full_name,255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);}m_today = my_tm.tm_mday; //更新时间file = fopen(log_full_name,"a"); //打开文件,打开方式:追加if (file == NULL){return false;}return true;
}void Log::write_log(const char* str)
{if (file == NULL)return;time_t t = time(NULL); struct tm* sys_tm = localtime(&t); struct tm my_tm = *sys_tm; //获取当前的时间,用来后续跟日志的创建时间作对比m_count++; //日志行数+1if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //如果创建时间!=当前时间或者本次写入行数达到上限{ char new_log[256] = { 0 }; //新日志的文件名fflush(file);fclose(file);char time_now[16] = { 0 }; //格式化当前的时间snprintf(time_now, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);if (m_today != my_tm.tm_mday) //如果是创建时间!=今天{ //这里解释一下,m_today在init函数被调用的时候一定会被设置成当天的时间,只有init和write函数的调用不在同一天中,才会出现这种情况snprintf(new_log, 255, "%s%s%s", dir_name, time_now, log_name);m_today = my_tm.tm_mday; //更新创建时间m_count = 0; //更新日志的行数}else //如果是行数达到本次我们规定的写入上限{snprintf(new_log,255,"%s%s%lld_%s", dir_name, time_now, m_count / m_split_lines,log_name);//加上版本后缀}file = fopen(new_log, "a");}fputs(str, file);fputs("\n", file);
}
运行的结果:
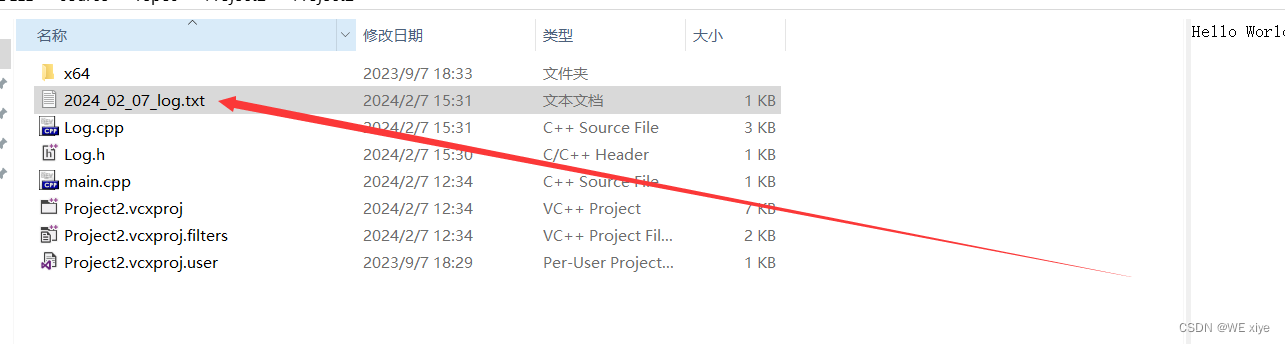
出现了一个以时间开头命名的日志,实现了按天分类
接下来我将一次性写入行数的上限调成5,看一下如果一次性写入超过了行数上限的运行结果是什么样:
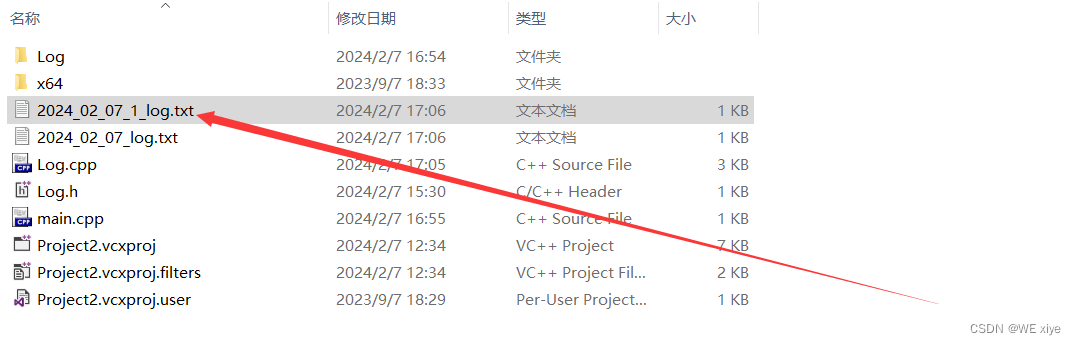
出现了一个后缀_1的新文件
PS:这里有一个小BUG:因为m_count是每次运行程序都会重置的一个变量,所以上一次运行时可能因为输出的行数过多,创建了好多新日志,但是下一次运行程序时,还是从第一个日志开始打印的. 而且规定行数上限并不是日志中文件行数的上限,而是每次运行程序写入日志文件的行数上限,所以这个功能并不完美甚至说非常鸡肋暂时还没优化好,在这里仅做一个小小的演示吧.
日志信息分级
我们应该将每一条日志信息进行分类,可以分为四大类:
Debug: 调试中产生的信息
WARN: 调试中产生的警告信息
INFO: 项目运行时的状态信息
ERROR: 系统的错误信息
然后我们可以在日志文件中,每一条日志信息的前面,加上这条信息被写入的时间和其所属的分级,这样会大大增加日志的可读性.
代码还是在上面代码的基础上继续改动
Log.h:
#pragma once
#include<stdio.h>
#include<string.h>
#include<string>
#include<time.h>
using namespace std;class Log
{
private:Log() ;~Log();public://初始化文件路径,日志缓冲区大小,文件最大行数bool init(const char* file_name, int log_buf_size = 8192, int split_lines= 5000000);//新增了一个日志分级void write_log(int level,const char* str);static Log* getinstance();private:FILE* file;char dir_name[128];//路径名char log_name[128];//日志名int m_split_lines; //日志文件最大行数long long m_count; //日志当前的行数int m_today; //日志创建的日期,记录是那一天int m_log_buf_size; //日志缓冲区的大小,用来存放日志信息字符串char* m_buf; //日志信息字符串;因为后续要把时间和日志分级也加进来,所以开一个新的char *
};
Log.cpp:
#define _CRT_SECURE_NO_WARNINGS
#include"Log.h"Log::Log()
{m_count = 0;
}Log::~Log()
{if (file != NULL){fflush(file);fclose(file);}if (m_buf != NULL){delete[] m_buf;m_buf = nullptr;}
}Log* Log::getinstance()
{static Log instance;return &instance;
}bool Log::init(const char * file_name, int log_buf_size , int split_lines)
{m_log_buf_size = log_buf_size;m_buf = new char[m_log_buf_size];memset(m_buf,'\0', m_log_buf_size);// 开辟缓冲区,准备存放格式化的日志字符串m_split_lines = split_lines; //设置最大行数time_t t = time(NULL);struct tm* sys_tm = localtime(&t);struct tm my_tm = *sys_tm; //获取当前的时间const char* p = strrchr(file_name, '\\');char log_full_name[256] = { 0 };if (p == NULL){snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);strcpy(log_name, file_name);}else{strcpy(log_name, p + 1);strncpy(dir_name, file_name, p - file_name + 1);//规范化命名snprintf(log_full_name,255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);}m_today = my_tm.tm_mday; //更新日志的创建时间file = fopen(log_full_name,"a"); //打开文件,打开方式:追加if (file == NULL){return false;}return true;
}void Log::write_log(int level,const char* str)
{if (file == NULL)return;time_t t = time(NULL); struct tm* sys_tm = localtime(&t); struct tm my_tm = *sys_tm; //获取当前的时间,用来后续跟日志的创建时间作对比char level_s[16] = { 0 }; //日志分级switch (level){case 0:strcpy(level_s, "[debug]:");break;case 1:strcpy(level_s, "[info]:"); break;case 2:strcpy(level_s, "[warn]:"); break;case 3:strcpy(level_s, "[erro]:"); break;default:strcpy(level_s, "[info]:"); break;}m_count++; //日志行数+1if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //如果创建时间!=当前时间或者行数达到上限{char new_log[256] = { 0 }; //新日志的文件名fflush(file);fclose(file);char time_now[16] = { 0 }; //格式化当前的时间snprintf(time_now, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);if (m_today != my_tm.tm_mday) //如果是创建时间!=今天{snprintf(new_log, 255, "%s%s%s", dir_name, time_now, log_name);m_today = my_tm.tm_mday; //更新创建时间m_count = 0; //更新日志的行数}else //如果是行数达到文件上限{snprintf(new_log,255,"%s%s%lld_%s", dir_name, time_now, m_count / m_split_lines,log_name);//加上版本后缀}file = fopen(new_log, "a");}int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d %s",my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec,level_s); int m = snprintf(m_buf + n, m_log_buf_size-n-1,"%s",str);m_buf[n+m] = '\n';m_buf[n+m+1] = '\0';fputs(m_buf, file);}
main.cpp:
#include<iostream>
#include"Log.h"int main()
{Log::getinstance()->init("Log\\log.txt");Log::getinstance()->write_log(0,"Hello World");Log::getinstance()->write_log(1,"Hello World");Log::getinstance()->write_log(2,"Hello World");Log::getinstance()->write_log(3,"Hello World");
}
运行结果:
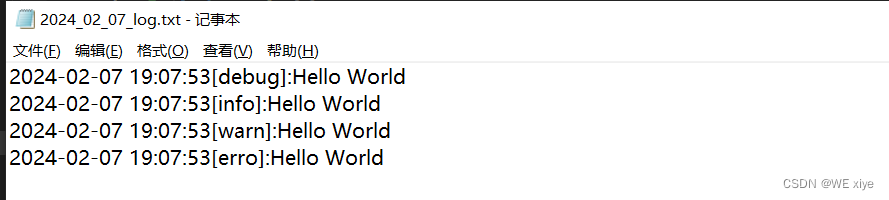
如图:日志信息前面已经加上了时间和类别分级,增加了可读性
同步和异步两种写入方式
同步写入和异步写入的逻辑:
图片来自公众号:两猿社
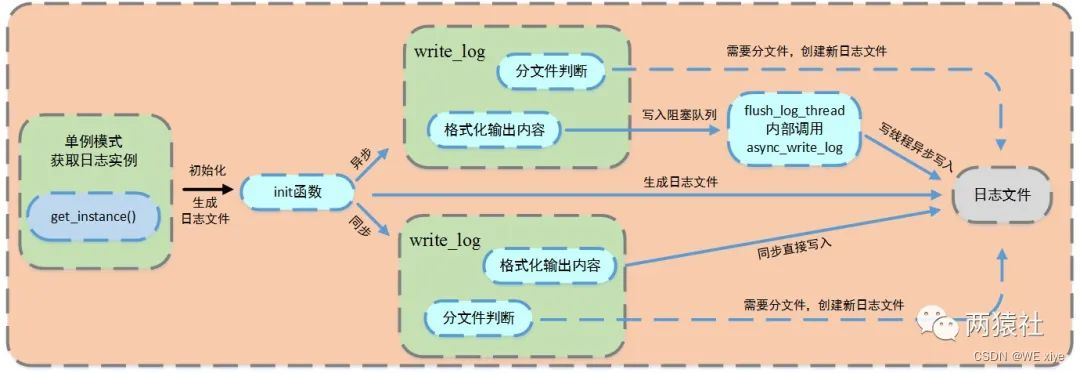
我先说明一下同步和异步的特点:
同步可以理解为顺序执行,而异步可以理解为并行执行
比如说吃饭和烧水两件事,如果先吃饭后烧水,这种是同步执行
如果说一边吃饭一边烧水,这种就是异步执行
那么同步执行和异步执行有什么优点,又使用在什么场景之下呢?
同步:
- 当对写入顺序和实时性要求很高时,例如需要确保按照特定顺序写入或写入即时生效的情况下,同步写入通常更合适。
- 在数据完整性和一致性很重要的情况下,同步写入能够提供更好的保证,避免数据丢失或不完整。
- 对于一些不频繁的、关键的写入操作,同步写入方式可能更容易确保操作的可靠性。
异步:
- 当写入频率很高或写入操作消耗较多时间时,使用异步写入可以显著提升系统性能和响应速度。
- 对于写入操作对主线程影响较大,容易阻塞主线程的情况下,通过异步写入可以将写入操作移到独立的线程中处理,减少主线程负担。
- 在需要降低I/O操作的影响、提高系统吞吐量和并发能力的场景下,异步写入方式更为适宜。
然后说一下如何实现同步和异步
同步只需要正常写入就行了
而异步我们可以借助生产者-消费者模型,由子线程执行写入操作.
如果你想了解生产者-消费者模型,请点击链接
生产者-消费者模型
接下来给出带有同步和异步两种写入方式的日志实现,还是在之前代码的基础上改动
封装了生产者-消费者模型的阻塞队列类:
#ifndef BLOCK_QUEUE_H
#define BLOCK_QUEUE_H#include <iostream>
#include <stdlib.h>
#include <pthread.h>
#include <sys/time.h> //包含时间和定时器的头文件!
#include "../lock/locker.h"
using namespace std;template <class T>
class block_queue
{
public:block_queue(int max_size = 1000){if (max_size <= 0){exit(-1);}m_max_size = max_size;m_array = new T[max_size];m_size = 0;m_front = -1;m_back = -1;}void clear(){m_mutex.lock();m_size = 0;m_front = -1;m_back = -1;m_mutex.unlock();}~block_queue(){m_mutex.lock();if (m_array != NULL)delete [] m_array;m_mutex.unlock();}//判断队列是否满了bool full() {m_mutex.lock();if (m_size >= m_max_size){m_mutex.unlock();return true;}m_mutex.unlock();return false;}//判断队列是否为空bool empty() {m_mutex.lock();if (0 == m_size){m_mutex.unlock();return true;}m_mutex.unlock();return false;}//返回队首元素bool front(T &value) {m_mutex.lock();if (0 == m_size){m_mutex.unlock();return false;}value = m_array[m_front];m_mutex.unlock();return true;}//返回队尾元素bool back(T &value) {m_mutex.lock();if (0 == m_size){m_mutex.unlock();return false;}value = m_array[m_back];m_mutex.unlock();return true;}int size() {int tmp = 0;m_mutex.lock();tmp = m_size;m_mutex.unlock();return tmp;}int max_size(){int tmp = 0;m_mutex.lock();tmp = m_max_size;m_mutex.unlock();return tmp;}//往队列添加元素,需要将所有使用队列的线程先唤醒//当有元素push进队列,相当于生产者生产了一个元素//若当前没有线程等待条件变量,则唤醒无意义bool push(const T &item){m_mutex.lock();if (m_size >= m_max_size) //这里没考虑生产者必须在不空的情况下需要等待的问题{m_cond.broadcast();m_mutex.unlock();return false;}m_back = (m_back + 1) % m_max_size;m_array[m_back] = item;m_size++;m_cond.broadcast();m_mutex.unlock();return true;}//pop时,如果当前队列没有元素,将会等待条件变量bool pop(T &item){m_mutex.lock();while (m_size <= 0){if (!m_cond.wait(m_mutex.get())){m_mutex.unlock();return false;}}m_front = (m_front + 1) % m_max_size;item = m_array[m_front];m_size--;m_mutex.unlock();return true;}
private:locker m_mutex;cond m_cond;T *m_array;int m_size;int m_max_size;int m_front;int m_back;
};
#endif注意: 这个生产者消费者模型并没有考虑生产者必须要在不满的情况下才能生产这一情况,不过这样也能凑活用,先凑活看吧
Log.h:
#pragma once
#include<stdio.h>
#include<string.h>
#include<string>
#include<time.h>
using namespace std;class Log
{
private:Log() ;~Log();//异步写入方法:void* async_write_log(){string single_log;//要写入的日志while (m_log_queue->pop(single_log)){m_mutex.lock();//互斥锁上锁fputs(single_log.c_str(), file);m_mutex.unlock();//互斥锁解锁}}public://初始化文件路径,日志缓冲区大小,文件最大行数,阻塞队列长度(如果阻塞队列长度为正整数,表示使用异步写入,否则为同步写入)bool init(const char* file_name, int log_buf_size = 8192, int split_lines= 5000000,int max_queue_size=0);//新增了一个日志分级void write_log(int level,const char* str);//公有的异步写入函数,作为消费者线程的入口函数static void* flush_log_thread(void *args){Log::getinstance()->async_write_log();}static Log* getinstance();private:FILE* file;char dir_name[128];//路径名char log_name[128];//日志名int m_split_lines; //日志文件最大行数long long m_count; //日志当前的行数int m_today; //日志创建的日期,记录是那一天int m_log_buf_size; //日志缓冲区的大小,用来存放日志信息字符串char* m_buf; //日志信息字符串;因为后续要把时间和日志分级也加进来,所以开一个新的char *block_queue<string>* m_log_queue; //阻塞队列,封装生产者消费者模型bool m_is_async; //异步标记,如果为true,表示使用异步写入方式,否则是同步写入方式locker m_mutex; //互斥锁类,内部封装了互斥锁,用来解决多线程竞争资源问题
};
Log.cpp
#define _CRT_SECURE_NO_WARNINGS
#include"Log.h"
// pthread,mutex等需要在Linux下使用相关的头文件才能使用,因为我是windows环境就暂时不加了.Log::Log()
{m_count = 0;m_is_async = false;
}Log::~Log()
{if (file != NULL){fflush(file);fclose(file);}if (m_buf != NULL){delete[] m_buf;m_buf = nullptr;}
}Log* Log::getinstance()
{static Log instance;return &instance;
}bool Log::init(const char * file_name, int log_buf_size , int split_lines,int max_queue_size)
{if (max_queue_size >= 1){//设置写入方式flagm_is_async = true; //设置为异步写入方式//创建并设置阻塞队列长度m_log_queue = new block_queue<string>(max_queue_size);pthread_t tid;//flush_log_thread为回调函数,这里表示创建线程异步写日志pthread_create(&tid, NULL, flush_log_thread, NULL);}m_log_buf_size = log_buf_size;m_buf = new char[m_log_buf_size];memset(m_buf,'\0', m_log_buf_size);// 开辟缓冲区,准备存放格式化的日志字符串m_split_lines = split_lines; //设置最大行数time_t t = time(NULL);struct tm* sys_tm = localtime(&t);struct tm my_tm = *sys_tm; //获取当前的时间const char* p = strrchr(file_name, '\\');char log_full_name[256] = { 0 };if (p == NULL){snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);strcpy(log_name, file_name);}else{strcpy(log_name, p + 1);strncpy(dir_name, file_name, p - file_name + 1);//规范化命名snprintf(log_full_name,255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);}m_today = my_tm.tm_mday; //更新日志的创建时间file = fopen(log_full_name,"a"); //打开文件,打开方式:追加if (file == NULL){return false;}return true;
}void Log::write_log(int level,const char* str)
{if (file == NULL)return;time_t t = time(NULL); struct tm* sys_tm = localtime(&t); struct tm my_tm = *sys_tm; //获取当前的时间,用来后续跟日志的创建时间作对比char level_s[16] = { 0 }; //日志分级switch (level){case 0:strcpy(level_s, "[debug]:");break;case 1:strcpy(level_s, "[info]:"); break;case 2:strcpy(level_s, "[warn]:"); break;case 3:strcpy(level_s, "[erro]:"); break;default:strcpy(level_s, "[info]:"); break;}m_mutex.lock(); //互斥锁上锁m_count++; //日志行数+1if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //如果创建时间!=当前时间或者行数达到上限{char new_log[256] = { 0 }; //新日志的文件名fflush(file);fclose(file);char time_now[16] = { 0 }; //格式化当前的时间snprintf(time_now, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);if (m_today != my_tm.tm_mday) //如果是创建时间!=今天{snprintf(new_log, 255, "%s%s%s", dir_name, time_now, log_name);m_today = my_tm.tm_mday; //更新创建时间m_count = 0; //更新日志的行数}else //如果是行数达到文件上限{snprintf(new_log,255,"%s%s%lld_%s", dir_name, time_now, m_count / m_split_lines,log_name);//加上版本后缀}file = fopen(new_log, "a");}m_mutex.unlock(); //互斥锁解锁string log_str; m_mutex.lock();//格式化int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d %s",my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec,level_s); int m = snprintf(m_buf + n, m_log_buf_size-n-1,"%s",str);m_buf[n+m] = '\n';m_buf[n+m+1] = '\0';log_str = m_buf;m_mutex.unlock();//如果是异步的写入方式if (m_is_async && !m_log_queue->full()) {m_log_queue->push(log_str); }else//如果是同步的写入方式{m_mutex.lock(); fputs(log_str.c_str(), file);m_mutex.unlock(); }
}
日志系统先介绍到这里,我介绍的日志系统还是属于功能比较稀缺,实际使用上可能远远比这复杂,如果想使用日志系统,可以以文章介绍的为雏形继续添加新功能.
本文中代码非常可能有错误,如果发现有错误,烦请评论区指正,我会及时修改.
相关文章:
C语言 服务器编程-日志系统
日志系统的实现 引言最简单的日志类 demo按天日志分类和超行日志分类日志信息分级同步和异步两种写入方式 引言 日志系统是通过文件来记录项目的 调试信息,运行状态,访问记录,产生的警告和错误的一个系统,是项目中非常重要的一部…...

HarmonyOS 状态管理装饰器 Observed与ObjectLink 处理嵌套对象/对象数组 结构双向绑定
本文 我们还是来说 两个 harmonyos 状态管理的装饰器 Observed与ObjectLink 他们是用于 嵌套对象 或者 以对象类型为数组元素 的数据结构 做双向同步的 之前 我们说过的 state和link 都无法捕捉到 这两种数据内部结构的变化 这里 我们模拟一个类数据结构 class Person{name:…...

windows中的apache改成手动启动的操作步骤
使用cmd解决安装之后开机自启的问题 services.msc 0. 这个命令是打开本地服务找到apache的服务名称 2 .通过服务名称去查看服务的状态 sc query apacheapache3.附加上关掉和启动的命令(换成是你的服务名称) 关掉命令 sc stop apacheapache启动命令 …...
Intellij Idea的数据库工具 DataGrip
DataGrip DataGrip: IDEA自带,非常好用。智能提示很强大,快捷键跟IDEA自身一致。 如果下载不了 DataGrip,也可以直接用 IDEA 自带的。 常用的快捷键 alt8: 打开数据库Service ctrlshiftF10:打开常用的数…...
精品springboot疫苗发布和接种预约系统
《[含文档PPT源码等]精品基于springboot疫苗发布和接种预约系统[包运行成功]》该项目含有源码、文档、PPT、配套开发软件、软件安装教程、项目发布教程、包运行成功! 软件开发环境及开发工具: Java——涉及技术: 前端使用技术:…...
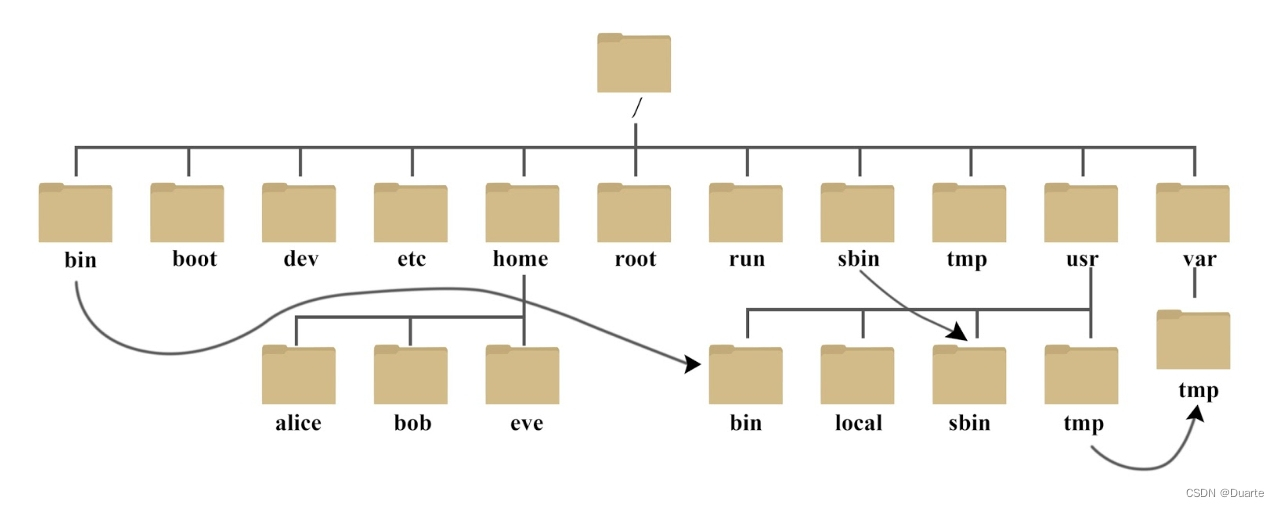
Linux快速入门
一. Linux的结构目录 1.1 Linux的目录结构 Linux为免费开源的系统,拥有众多发行版,为规范诸多的使用者对Linux系统目录的使用,Linux基金会发布了FHS标准(文件系统层次化标准)。多数的Linux发行版都遵循这一规范。 注&…...
【图形图像的C++ 实现 01/20】 2D 和 3D 贝塞尔曲线
目录 一、说明二、贝塞尔曲线特征三、模拟四、全部代码如下五、资源和下载 一、说明 以下文章介绍了用 C 计算和绘制的贝塞尔曲线(2D 和 3D)。 贝塞尔曲线具有出色的数学能力来计算路径(从起点到目的地点的曲线)。曲线的形…...
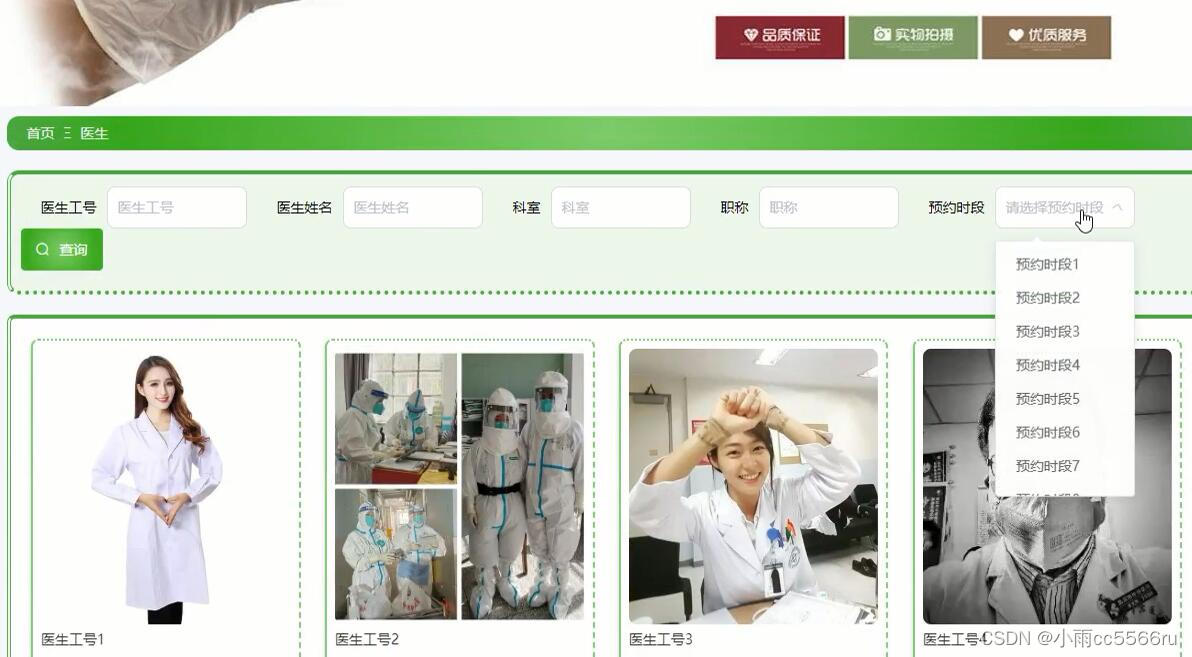
python+flask+django医院预约挂号病历分时段管理系统snsj0
技术栈 后端:python 前端:vue.jselementui 框架:django/flask Python版本:python3.7 数据库:mysql5.7 数据库工具:Navicat 开发软件:PyCharm . 第一,研究分析python技术,…...

《CSS 简易速速上手小册》第9章:CSS 最佳实践(2024 最新版)
文章目录 9.1 维护大型项目的 CSS9.1.1 基础知识9.1.2 重点案例:构建一个可复用的 UI 组件库9.1.3 拓展案例 1:优化现有项目的 CSS 结构9.1.4 拓展案例 2:实现主题切换功能 9.2 BEM、OOCSS 和 SMACSS 方法论9.2.1 基础知识9.2.2 重点案例&…...
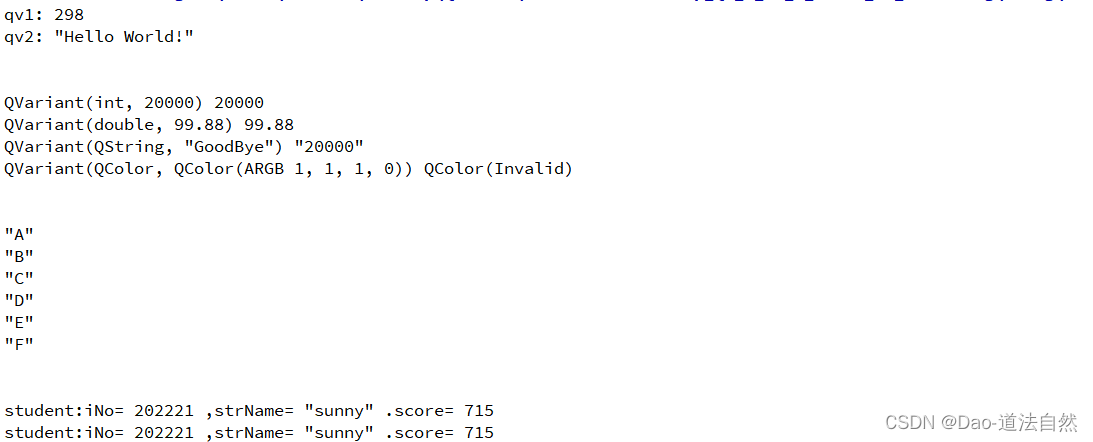
Qt QVariant类应用
QVariant类 QVariant类本质为C联合(Union)数据类型,它可以保存很多Qt类型的值,包括 QBrush,QColor,QString等等,也能存放Qt的容器类型的值。 QVariant::StringList 是 Qt 定义的一个 QVariant::type 枚举类型的变量&…...

不到1s生成mesh! 高效文生3D框架AToM
论文题目: AToM: Amortized Text-to-Mesh using 2D Diffusion 论文链接: https://arxiv.org/abs/2402.00867 项目主页: AToM: Amortized Text-to-Mesh using 2D Diffusion 随着AIGC的爆火,生成式人工智能在3D领域也实现了非常显著…...

Mac中管理多版本Jdk
1. 首先下载JDK,以jdk8和17为例 2. 打开.zprofile中添加如下内容 #java config export JAVA_8_HOME/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home export JAVA_17_HOME/Library/Java/JavaVirtualMachines/zulu-17.jdk/Contents/Home#default java …...
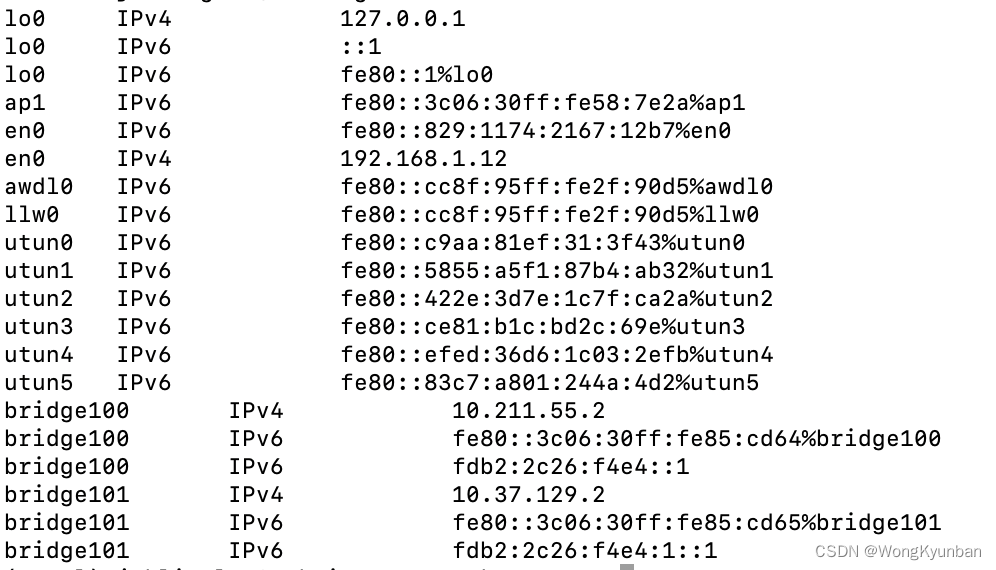
用C语言列出Linux或Unix上的网络适配器
上代码: 1. #include <sys/socket.h> 2. #include <stdio.h> 3. 4. #include <netdb.h> 5. #include <ifaddrs.h> 6. 7. int main() { 8. struct ifaddrs *addresses; 9. if(getifaddrs(&addresses) -1) { 10. printf("…...
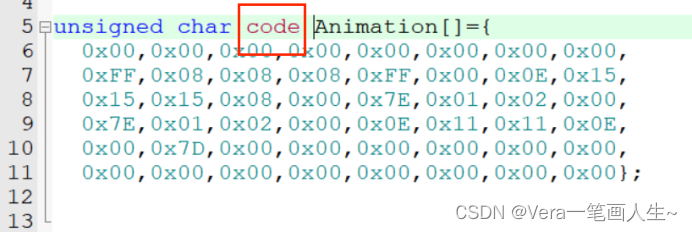
单片机学习笔记---LED点阵屏显示图形动画
目录 LED点阵屏显示图形 LED点阵屏显示动画 最后补充 上一节我们讲了点阵屏的工作原理,这节开始代码演示! 前面我们已经说了74HC595模块也提供了8个LED,当我们不使用点阵屏的时候也可以单独使用74HC595,这8个LED可以用来测试7…...

Git分支常用指令
目录 1 git branch 2 git branch xx 3 git checkout xx 4 git checkout -b xx 5 git branch -d xx 6 git branch -D xx 7 git merge xx(含快进模式和冲突解决的讲解) 注意git-log: 1 git branch 作用:查看分支 示例: 2 git branch xx 作用&a…...

3.3 Binance_interface APP U本位合约行情-实时行情
Binance_interface APP U本位合约行情-实时行情 Github地址PyTed量化交易研究院 量化交易研究群(VX) py_ted目录 Binance_interface APP U本位合约行情-实时行情1. APP U本位合约行情-实时行情函数总览2. 模型实例化3. 获取一个产品的最优挂单 get_bookTicker4. 获取全部产品…...

机器学习——流形学习
流形学习是一种在机器学习领域中用于理解和分析数据的技术。它的核心思想是,尽管我们通常将数据表示为高维空间中的向量,但实际上数据可能具有较低维度的内在结构,这种结构被称为流形。流形学习的目标是发现并利用数据的这种潜在结构…...
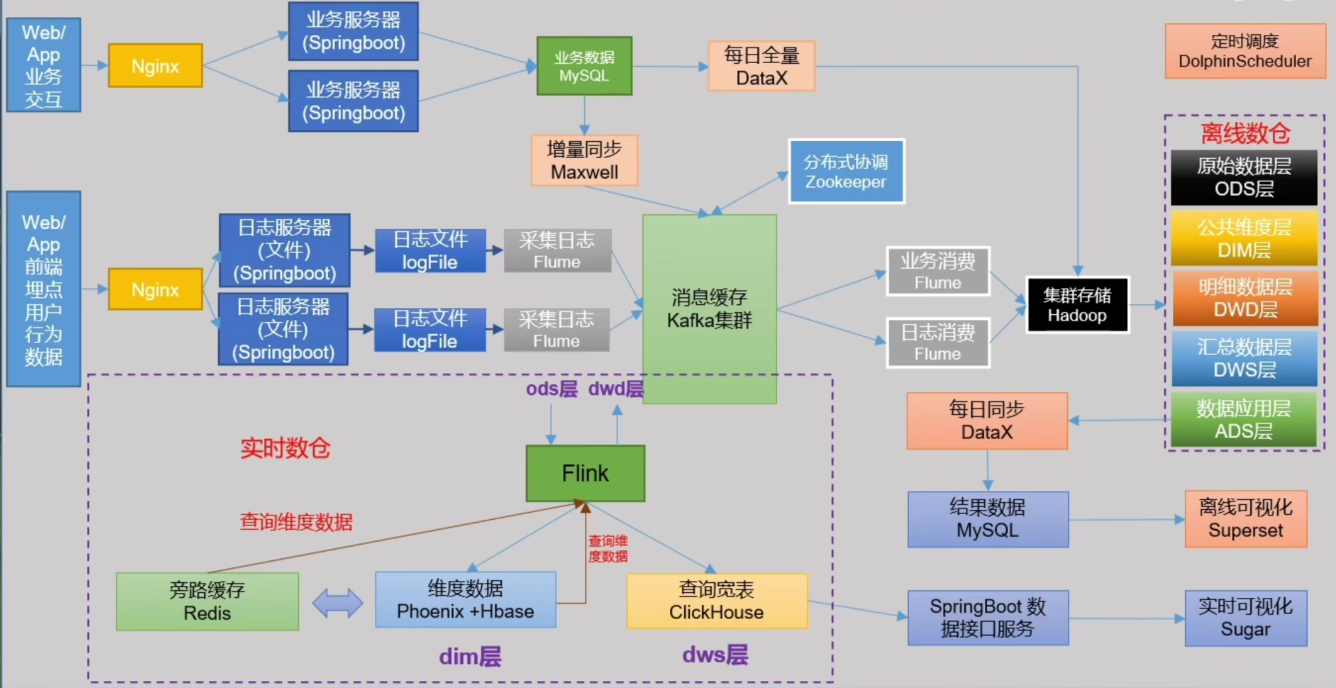
离线数仓(一)【数仓概念、需求架构】
前言 今天开始学习数仓的内容,之前花费一年半的时间已经学完了 Hadoop、Hive、Zookeeper、Spark、HBase、Flume、Sqoop、Kafka、Flink 等基础组件。把学过的内容用到实践这是最重要的,相信会有很大的收获。 1、数据仓库概念 1.1、概念 数据仓库&#x…...

物联网测试:2024 年的最佳实践和挑战
据 Transforma Insights 称,到 2030 年,全球广泛使用的物联网 (IoT) 设备预计将增加近一倍,从 151 亿台增至 290 亿台。这些设备以及智能汽车、智能手机等广泛应用于各种官僚机构。 健康视频监视器、闹钟以及咖啡机和冰箱等最受欢迎的家用电器…...

蓝桥杯Web应用开发-CSS3 新特性
CSS3 新特性 专栏持续更新中 在前面我们已经学习了元素选择器、id 选择器和类选择器,我们可以通过标签名、id 名、类名给指定元素设置样式。 现在我们继续选择器之旅,学习 CSS3 中新增的三类选择器,分别是: • 属性选择器 • 子…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...